Neural Network Inference on Mobile SoCs
The ever-increasing demand from mobile Machine Learning (ML) applications calls for evermore powerful on-chip computing resources. Mobile devices are empowered with heterogeneous multi-processor Systems-on-Chips (SoCs) to process ML workloads such as…
Authors: Siqi Wang, Anuj Pathania, Tulika Mitra
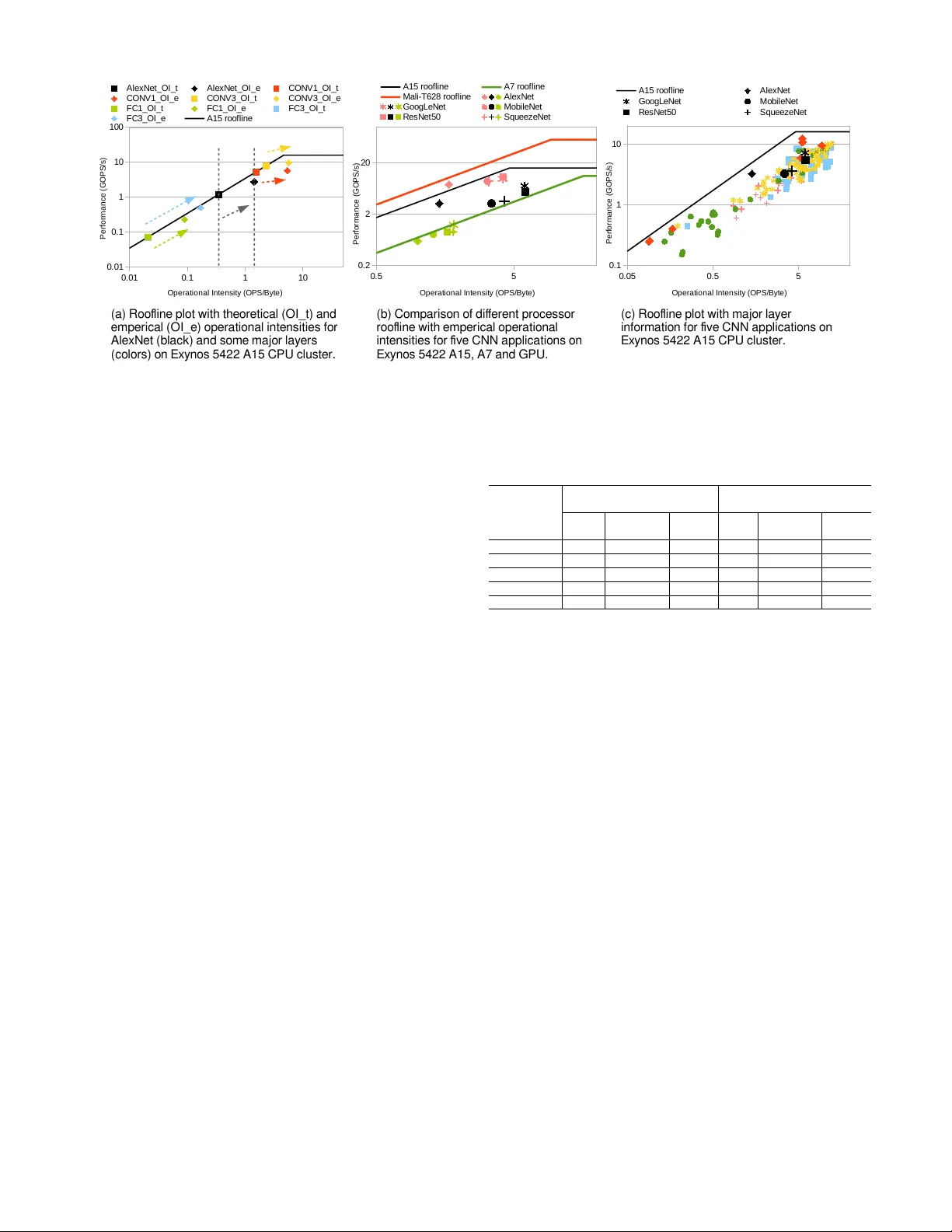
Neural Network Inference on Mobile SoCs Siqi W ang, Anuj Pathania, T ulika Mitra Abstract —The ever -increasing demand fr om mobile Machine Learning (ML) applications calls for evermor e powerful on-chip computing resour ces. Mobile devices are empower ed with hetero- geneous multi-processor Systems-on-Chips (SoCs) to process ML workloads such as Con volutional Neural Network (CNN) infer- ence. Mobile SoCs house several different types of ML capable components on-die, such as CPU , GPU , and accelerators. These different components are capable of independently performing inference but with very different power -performance character - istics. In this article, we pro vide a quantitative e valuation of the inference capabilities of the different components on mobile SoCs. W e also present insights behind their respectiv e po wer- performance behavior . Finally , we explore the performance limit of the mobile SoCs by synergistically engaging all the components concurrently . W e observe that a mobile SoC provides up to 2x impro vement with parallel inference when all its components are engaged, as opposed to engaging only one component. Index T erms —Deep learning, conv olutional neural networks, heterogeneous computing, embedded multiprocessor SoCs I . I N T RO D U C T I O N The tremendous popularity of Neural-Network (NN) based machine learning applications in recent years has been fuelled partly by the increased capability of the compute engines, in particular , the GPUs. T raditionally , both the network training and inference were performed on the cloud with mobile devices only acting as user interfaces. Howe ver , enriched user experience and pri vac y concerns now demand inference to be performed on the mobile devices themselves with high accuracy and throughput. In this article, we look at NN-enabled vision applica- tions on mobile devices. These applications extract high- lev el semantic information from real-time video streams and predominately use Con volutional Neural Netw orks (CNNs). They are important in many domains, such as Advanced Driv er-Assistance Systems (AD AS), V irtual Reality (VR), and Augmented Reality (AR). Enabling these applications in the power -constrained mobile devices is challenging due to the enormous computational and memory requirements. Heterogeneous multi-processor SoC enables the current state-of-the-art mobile devices. Howe ver , the presence of multiple vendors fragments the mobile SoCs. Accelerators (including GPU, FPGA, and dedicated neural accelerators) demonstrate great performance for inference. Howe ver , these high-performance components are present in only a small fraction of the mobile devices. Moreov er, due to market fragmentation, it is impossible to develop a mobile application S. W ang, A. Pathania and T . Mitra are with the Department of Com- puter Science, School of Computing, National University of Singapore. E- mail: ((wangsq, pathania, tulika)@comp.nus.edu.sg). Address: COM1, 13 Computing Drive, S117417. (Corresponding author: T ulika Mitra) Core Core Core Core L2 Cache Core Core Core Core L2 Cache GPU NPU CCI Bus DRAM D VFS D VFS D VFS Big CPU Small CPU Fig. 1: An abstract block diagram of a mobile SoC with an asymmetric multi-core CPU, GPU, and NPU. with accelerators that can run across multiple devices. Instead, the CPUs remain the common denominator among mobile SoCs and is the fav ored choice for inference [1]. W e embark on an exploration to quantitatively characterize and understand the inferencing capabilities of the mobile SoCs giv en the di verse landscape. W e portray the power- performance gap between the ubiquitous CPUs and the high- performance accelerators in high-end devices and uncover the reasons behind the gap through the roofline models. Finally , we propose simultaneous engagement of all the SoC compo- nents to greatly expand the promise of functional deployment of vision applications on mobile devices. I I . I N F E R E N C E O N M O B I L E S O C S A. Heter ogeneous Multi-pr ocessor SoCs There are over two thousand unique mobile SoCs in the mobile devices market. The di versity comes from the choice of different CPUs, GPUs, caches, memory controllers, and other application-specific accelerators. This fragmentation of the SoC market makes standard optimizations impossible. Howe ver , the similarity among these SoCs lies in the choice of one or more CPU core clusters. 1) ARM big .LITTLE: Multi-cores enable the state-of-the- art Mobile SoCs. 99.9% of the Andr oid devices in the market in 2019 have multiple cores [1]. Among these, about half of the SoCs implement performance heterogeneity with at least two CPU clusters: a high-performance and an energy- efficient core cluster . ARM big.LITTLE architecture, one of the most popular architectures implementing this heterogeneity , is present in Hi-Silicon Kirin , Samsung Exynos , and Qualcomm Snapdragon series SoCs. The heterogeneous cores differ in power -performance-area characteristics but share the same Instruction Set Architecture (ISA). Figure 1 sho ws an abstract block diagram of this architecture. The general availability of CPUs make them a fav orable choice for mobile inference and make device-agnostic optimizations feasible. 2) Accelerators: Existing architectures, including GPU and FPGA, have prov en to be advantageous for ML workloads and are thus commonly used for deployment on certain devices. Both academic and commercial dedicated accelerators ( Goo gle Edge TPU , Intel Nervana NNP , Huawei NPU , Apple Neural Engine ) offer e xceptional runtime and energy-efficienc y . There are no standard neural accelerators for mobile SoCs, making horizontal application integration difficult. Limited av ailability ev en constraints the use of GPUs. B. Mobile ML F rame work and Optimizations T ensorflow , PyT or ch , and MXNet are some of the common ML dev elopment frameworks for all scenarios. T ensorflow Lite like frameworks facilitates the compression of huge models to fit into resource-constrained mobile devices. Efficient libraries and APIs bridge the gap between the frameworks and the underlying hardware, examples of which are Nvidia cuDNN for GPUs, ARM NN po wered by Compute Library (ARM- CL) for ARM CPUs and GPUs, F acebook NNP ACK , and QNNP A CK for mobile CPUs. These libraries usually optimize with detailed architectural information. ARM-CL supports ac- celeration through ARM NEON vectorization and provides NEON assembly implementation for the most computation- ally intensiv e conv olution kernels. Algorithmic optimizations (W inograd transform, FFT , sparsity e xploration) lower the computational complexity of con volution computations. Fur- thermore, quantization and network pruning are common techniques that bring down the processing requirement with the sacrifice of accuracy [2]. Even though most mobile inference w orkloads run on CPUs, optimizations of ML workloads with accelerators hordes most of the attention. There is a lot of room for optimizations on mobile CPUs to enable ML applications across different mobile platforms. I I I . C H A R AC T E R I Z I N G I N F E R E N C I N G O N M O B I L E S O C W e perform experiments across different technology nodes using two commonly used mobile SoCs: 28 nm Exynos 5422 within Odr oid XU3 dev elopment platform and 10 nm Kirin 970 within Hike y 970 development platform. Released in 2014 and 2017 respectively , these two SoCs show us the progress of mobile SoCs development over the years. Furthermore, these two SoCs roughly approximate the mid- and high-end mobile SoCs today . In the experiments, both SoCs are using ARM-CL 18.05v . Kirin 970 NPU is supported by HiAI DDK (v100) for network deployment. For Exynos5422 , in-built power sensors, running at 200 Hz, measure the power of each component. For Kirin 970 , because of the absence of any integrated on-chip po wer sensors, we approximate the power consumption by measuring the socket po wer with the help of a power measurement unit [3] running at 100 Hz. T ABLE I: Throughput of different networks on different mobile SoCs components running at their peak frequencies. Network Exynos 5422 Throughput (Imgs/s) Kirin 970 Throughput (Imgs/s) A7 A15 T628 A53 A73 G72 NPU AlexNet 1.1 3.1 7.8 2.2 7.6 32.5 32.5 GoogLeNet 0.9 3.4 5.2 3.0 7.1 19.9 34.4 MobileNet 1.5 5.7 8.5 6.5 17.7 29.1 Not Supported ResNet50 0.2 1.3 2.1 1.5 2.8 8.4 21.9 SqueezeNet 1.5 5.0 8.0 6.8 15.7 43.0 49.3 A. Experimental Set-up 1) CPU: Both SoCs include ARM big.LITTLE based asym- metric multi-core CPU. Kirin 970 CPU adopts ARMv8-A architecture. It consists of a high-performance high-power out-of-order four-core Cortex-A73 cluster (2.36 GHz) and a low-performance low-po wer four-core in-order Cortex- A53 (1.8 GHz). Exynos 5422 has a similar design but uses an older ARMv7-A architecture with Cortex-A15 (2 GHz) and Cortex-A7 (1.4 GHz) cores. All CPU cores support NEON advanced Single Instruction Multiple Data (SIMD) operations, which allo ws for four 32-bit floating-point operations per cycle. 2) GPU: Kirin 970 adopts ARM Mali G72 MP12 GPU (850 MHz), implementing the second generation Bifr ost ar - chitecture. It has twelve shader cores with three execution engines each. Each engine is capable of eight FP32 oper- ations per cycle, giving a total peak compute capability of 244.8 GFLOPS/s for G72 . Exynos 5422 includes an ARM Mali T628 MP6 GPU (600 MHz). It adopts an older Midgard architecture with six shader cores implementing T ripipe design with two arithmetic pipelines. Each pipeline is capable of eight FP32 operations per cycle, pro viding a total peak compute capability of 57.6 GFLOPS/s for T628 . 3) NPU: Kirin 970 includes a Huawei NPU purpose- built for ML. It has a peak performance of 1.92 TFLOPS/s with FP16. The accompanying HiAi DDK API enables the deployment of networks on NPU b ut only works with Andr oid . Exynos 5422 does not hav e any ML accelerator . 4) Network Structur e: W e e xperiment with se veral popular networks introduced in recent years – Ale xNet [4], GoogleNet [5], MobileNet [6], ResNet50 [7], and SqueezeNet [8]. B. Individual Heter ogeneous Components W e first study each component in isolation by running infer- encing of multiple images in a stream on a single component. Both Big and Small clusters are self-suf ficient for inferencing. GPU and NPU require the support of a Small cluster for inferencing. 1) Thr oughput: T able I shows the throughput of each com- ponent on both our SoCs. All components in Kirin 970 outper- form their respectiv e counterparts in older Exynos 5422 . Big A73 cluster, Small A53 cluster, and G72 GPU outperform Big A15 cluster , Small A7 cluster , and T628 GPU on average by a factor of 4.4x, 2.6x, and 4.2x, respectiv ely . The performance gap between the Big and Small cluster has reduced from 4x to Fig. 2: Energy efficiency of different components while run- ning at their peak frequencies. 2.5x with a decrease in Big to Small po wer consumption ratio from 10x to 4x. Furthermore, the performance gap between GPU and CPU clusters is only about 2x to 3x for both SoCs. For NPU, we were unable to deploy MobileNet due to incompatible operators. On average, NPU is only 1.6x better than the high-end G72 GPU. On the other hand, the portability of applications across dif ferent platforms remains a challenge for dedicated accelerators. The proprietary dev elopment kit makes the general optimization a difficult endeavor . 2) Energy Ef ficiency: W e measure the average acti ve power consumption of inferencing on different components and cal- culate the energy efficienc y , as shown in Figure 2. For Exynos 5422 , power sensors for individual components measure the power consumption of each component separately . For Kirin 970 , we calculate activ e power values by subtracting the idle power (measured when no workload is running) from socket power measurement taken during inferencing. Therefore, the power measurements for Kirin are slightly higher , as memory power cannot be separated. NPU is the most ener gy-efficient among all components, which we expect, giv en its custom design for inference. GPUs are the second-most ener gy-efficient component. Small clusters also show good energy-ef ficiency . Howe ver , T able I shows their performance in terms of absolute throughput is too low to be ever useful alone. Comparing across two platforms, the energy efficiency of each component has improved for the newer SoC. Howe ver , the improvement is minimal and ev en negativ e for the Small CPU cluster . Compared to its predecessor A7, A53 is more complex and area hungry with 64-bit, complex branch predic- tion, and larger TLB. It achieves greater performance but at the cost of ev en greater power consumption. 3) Impact of T echnolo gy Scaling V ersus Arc hitectural In- novations: Exynos 5422 and Kirin 970 use the 28 nm and 10 nm technology nodes, respectiv ely . In moving from 28 nm Exynos 5422 to 10 nm Kirin 970 , the maximum frequency of the Big cluster has only changed from 2 GHz ( A15 ) to 2.36 GHz ( A73 ), while the Small cluster changes from 1.4 GHz ( A7 ) to 1.8 GHz ( A53 ). So the frequency scaling is 1.18x for the big cluster and 1.29x for the Small cluster for these two platforms. On the other hand, we get 4.4x and 2.6x throughput improv ement across technology generations (T able I) for Big cluster and Small cluster, respectiv ely . This improvement in performance is achiev ed through smart designs such as micro- architectural improvements (improved branch predictor, cache data prefetchers, etc.), larger caches, and 64-bit support lead- ing to improved NEON processing, among others. Howe ver , in the case of the small cluster , with an increased area, the micro-architectural changes giv e an increase in power that cannot be offset by technology scaling. Indeed, the small A53 cluster consumes roughly twice the power of the small A7 cluster . Thus, the energy-ef ficiency improvement is limited for the small cluster for some networks as we move from A7 to A53 . In contrast, between the two big clusters, A73 is more power -efficient compared to A15 ; the energy-ef ficiency improv es from A15 to A73 cluster . As mentioned earlier , the power measurements for A7 and A15 are quite accurate, while the measured power for A53 and A73 are higher as it includes the memory power that could not be separated. 4) Insights: W e observe that NPU provides unmatched energy-ef ficiency for inferences. It is the optimal choice to perform network inferences on the platforms with such ded- icated accelerators. Ho wever , a developer needs to put in substantial ef fort to port their application with proprietary API to execute on NPU, and the effort would not bear any fruits on mobile devices lacking this very-specific NPU. NPU, as a black-box, also causes inflexibility in development and optimizations. Furthermore, NPU is compatible with only a limited set of network designs. These extra requirements could make it quickly obsolete for future networks. On the other hand, high-end GPUs can provide performance comparable to NPU at satisfactory energy-ef ficiency . GPUs are capable of running General-Purpose (GPGPU) applications written in OpenCL , which is easily portable to a large variety of GPUs and even CPUs supporting OpenCL . This generality makes it a good candidate to use when high performance is a major consideration. CPUs provide both the worst energy-efficienc y as well as the w orst throughput among all components. Still, they are critical for inferencing because they are commonly present across all mobile devices. Lo w-end mobile SoCs would lack accelerators like NPU. They may contain a low-end GPU, but maybe missing OpenCL support and thereby lack any inferencing capability . Network inference on CPU is inevitable and demands optimization considerations. Our analysis shows that any component alone on both platforms can barely support the increasing performance re- quirement for network inferencing. Section V -A presents the co-ex ecution methodology that can mitigate the performance issue to some extent. Still, we must continue to look into the networks themselves in search of further optimization opportunities. I V . R O O FL I N E A N A L Y S I S T o understand the execution behaviors of the networks on each SoC components, we perform a roofline analysis. Roofline analysis [9] is a widely applied methodology that can classify an application as memory- or compute-bound on giv en hardware. It gi ves insights to dev elopers for improving their application design to cater to the computation and memory capability of the underlying processing devices. The horizontal “Ceiling” and the “Roof ” constructs a “Roofline” that bounds the maximum performance of an application (measured in GOPS/s) under a hardware-determined compute- or memory- bound, respecti vely . Operational Intensity (OI) of applica- tion (measured in FLOPS/byte) determines whether its peak performance is bounded by the memory bandwidth (measured in GB/s) or compute capability (measured in GOP/s) of the hardware. Both Exynos 5422 and Kirin 970 sho w similar behavior for the CPU core clusters and GPU. Therefore, we only present here the analysis for Exynos 5422 . A. Construction of a Roofline Model Hardware specifications provide the peak pure compute performance. Micro-benchmarking [10] provides the peak (sustainable) memory bandwidth. Specifications claim peak memory bandwidth of the memory bus to be 14.9 GB/s. How- ev er , we observe the actual component-wise peak bandwidth to be 3.44 GB/s, 0.49 GB/s, and 6.15 GB/s for A15 cluster , A7 cluster , and T628 GPU, respectively . Many variations of the roofline model are constructed to adapt to different use-cases. In this analysis, we defined two operational intensities, that are, theoretical OI ( O I t ) and empirical OI ( O I e ), defined in Eqn (1) and (2). O I t = GO P S/ M em Access (1) O I e = GO P S/DRAM Access (2) W e calculate O I t by analyzing the code. The memory accesses include all the data required in the computation. During actual executions, multiple le vels of caches within components improv e the memory access performance. The caches make it difficult for O I t to correlate with the actual performance on the components. Therefore, we introduce empirical operational intensity O I e . W e calculate OI e using the actual DRAM accesses on the bus, which models the presence of multi-lev el memory hierarchy . It is more informati ve and has a better correlation with the actual performance on the component than O I t . W e use application-specific performance counters obtained from ARM Str eamline DS5 at run-time for calculation of O I e (CPU: L2 data r efill , GPU: Mali L2 cache external r ead/write bytes ). Fig. 3(a) show the roofline points of major layers in AlexNet on A15 cluster for both O I t and O I e . B. Theoretical and Empirical OI Figure 3(a) plots the O I t (squares) and O I e (diamonds) values of sev eral AlexNet major layers, marked with dif ferent colors. Black marks the whole network O I t and O I e of AlexNet. The intersection points of the O I t values with the “Roofline” represent the theoretical maximum performance for the code-based theoretical operational intensities, which fall in the memory-bound region on the “Roof ”. The corresponding points for O I e are actual achiev ed performance in GOPS/s, which are always below the “Roofline”. The presence of cache reduces the memory accesses going to the DRAM during ex ecution, and thus increases the opera- tional intensity . Therefore, for all layers, O I e points are on the right of O I t points, indicating higher performance. For layers with low O I t (fully connected, FC), the points move along the “Roofline”, achieving the theoretical maximum performance. For layers with higher O I t (con volutional, CONV), the points cross the boundary of memory-bound and become compute- bound. The performance gain is not as significant, and we explain this with the underutilization due to insufficient or imperfect parallelization. Overall, O I e is a better indicator of real-world performance. Therefore, we only plot values of OI e going forward. C. Acr oss Differ ent Components Figure 3(b) shows the performance of different networks on different components on Exynos 5422 . The color of the points corresponds to the respectiv e component. W e can observe that memory sev erely bottlenecks the performance of both A7 cluster and T628 GPU. Performance of A15 cluster falls in both compute- and memory-bound regions depending upon the network. The O I e values are different because of the dif ferent mem- ory hierarchies for different components. The Big core cluster with a larger cache size (L2: 2MB) deriv es higher benefits from memory hierarchy than GPU (L2: 128KB). Ho wever , AlexNet that is notorious for huge parameter sizes caches will get flushed regardless of the cache sizes resulting in a smaller benefit from the memory hierarchy . On the other hand, small filter sizes lead to sub-optimal parallelization (under - utilization). This observ ation holds more starkly for newer networks with smaller filter size than older networks. The observation explains the significant deviation in the empir- ical performance of networks on the components from the “Roofline”. D. Major Layers in Inference W e do a deeper layer-le vel analysis to explain the behavior of the networks. Both con volutional and fully-connected layers dominate the total ex ecution time of networks, and thus both are considered as major layers worthy of examination. W e limit our analysis to Big cluster because networks there show both memory- and compute-bound beha vior . Figure 3(c) sho ws that different layers in AlexNet (and also other networks to a lesser extent) exhibits different empirical OIs. Con volutional layers at the start of AlexNet perform compute-intensive con- volution on large inputs and thereby ha ve relati vely higher OIs. On the other hand, fully-connected layers perform memory- intensiv e operations on large size parameters and thereby hav e relativ ely lower OIs. Con volutional and fully-connected layers of Ale xNet fall in the compute- and memory-bound region of the roofline model, respecti vely . Overall, AlexNet falls somewhere in the middle of both. 0 . 0 1 0 . 1 1 1 0 0 . 0 1 0 . 1 1 1 0 1 0 0 A l e x N e t _ O I _ t A l e x N e t _ O I _ e C O N V 1 _ O I _ t C O N V 1 _ O I _ e C O N V 3 _ O I _ t C O N V 3 _ O I _ e F C 1 _ O I _ t F C 1 _ O I _ e F C 3 _ O I _ t F C 3 _ O I _ e A 1 5 r o o f l i n e O p e r a t i o n a l I n t e n si t y (O PS/ B y t e ) P e r f o r m a n c e ( G O P S / s ) 0 . 0 5 0 . 5 5 0 . 1 1 1 0 A 1 5 r o o f l i n e A l e x N e t G o o g L e N e t M o b i l e N e t R e s N e t 5 0 S q u e e z e N e t O p e ra t i o n a l I n t e n si t y (O PS/ B yt e ) P e r f o r m a n c e ( G O P S / s ) 0 . 5 5 0 . 2 2 2 0 A 1 5 r o o f l i n e A 7 r o o f l i n e M a l i - T 6 2 8 r o o f l i n e A l e x N e t G o o g L e N e t M o b i l e N e t R e s N e t 5 0 S q u e e z e N e t O p e ra t i o n a l I n t e n si t y (O PS/ B yt e ) P e r f o r m a n c e ( G O P S / s ) ( a ) R o o i n e p lo t w i t h t h e o r e t i ca l ( O I _t ) an d e m p e r i ca l ( O I_e ) o p e r a t i o n al i n t e n s i t i e s f o r A le x N e t ( b la ck) a n d so m e m ajo r la ye r s ( co lo r s ) o n E x yn o s 5422 A 1 5 C PU clu s t e r . ( b ) C o m p a r i s o n o f d i * e r e n t p r o ce s so r r o o i n e w i t h e m p e r i ca l o p e r a t i o n al i n t e n s i t i e s f o r + v e C N N a p p li ca t i o n s o n E x yn o s 54 22 A 15, A 7 an d G PU. ( c) R o o i n e p lo t w i t h m a j o r la ye r i n f o r m a t i o n f o r + v e C N N a p p li ca t i o n s o n E x yn o s 5 422 A 15 C P U clu st e r . Fig. 3: Roofline plot for inference workloads and major layer information on multiple processors in Exynos 5422 . In general, we observe that layers of a network are scattered in both compute- or memory-bound region. This difference comes from the choice of the size of the input tensors and filters. The vast differences in O I e for different layers within a network moti vates layer-le vel optimizations such as per-layer Dynamic V oltage and Frequency Scaling (DVFS) for power management. Furthermore, the variation within a network motiv ates fine-grain layer level co-executions, which improve the overall chip utilization [11]. E. Effect of Quantization Quantization is a commonly applied technique that reduces the memory and computation requirement of a network while reducing accuracy . Ho wever , the quality of its implemen- tation primarily determines the benefits it provides. In the implementation of quantized MobileNet in ARM-CL (18.05v), QASYMM8 model with 8-bit weights is used. This implemen- tation fails to improve the ov erall performance of the network. Deeper analysis reveals that the latencies of con volutional layers are indeed reduced, but the overheads from extensiv e de-quantization and re-quantization overshado w any benefit. Quantization reduces the total operations and memory access required near-proportionally . Reduction in memory accesses results in a slightly higher empirical operational intensity O I e . Therefore, the roofline analysis of a quantized network nearly o verlaps with that of its non-quantized counter- part, and quantization does not improve the memory behavior of the layers. Lo wer operation requirements under quantization predominately contribute to the reduction in execution time of the conv olutional layers. F . Glimpse of NPU NPU, due to its nov elty and dedicated machine learning processing design, garners a lot of attention. Howe ver , most of the details are kept confidential. W e are unaware of its architectural and integration details. Therefore, we can only attempt to rev erse engineer its behavior to gain some insights. T ABLE II: Throughput improvement on Exynos 5422 and Hike y 970 by co-ex ecution o ver the best throughput with a single component ( T628 and G72 GPU). Network Exynos 5422 Throughput (Imgs/s) Kirin 970 Throughput (Imgs/s) T628 Co- execution Gain G72 Co- execution Gain AlexNet 7.8 10.3 32.4% 32.5 33.4 2.8% GoogLeNet 5.2 8.7 66.3% 19.9 28.4 42.8% MobileNet 8.5 14.9 76.7% 29.1 51.5 77.1% ResNet50 2.1 2.9 38.6% 8.4 12.3 46.3% SqueezeNet 8.0 13.8 73.9% 43.0 54.5 26.7% W e implement a kernel module that enables counting of traffic on the CCI b us. W e attribute the traffic on the CCI bus that goes to DRAM during the engagement of NPU to the main memory activity of NPU. The maximum observed memory bandwidth of e xecuting se veral networks and the peak performance of 1.92 TOPS from the specification construct the “Roof ” and “Ceiling” of the NPU roofline. W e observe that the performance of NPU is significantly bounded by the memory for the networks tested. This observation shows a significant scope for optimization to achiev e the full processing potential of NPU. V . I M P R OV I N G T H E P E R F O R M A N C E A. Co-Execution of Multiple Components Stream processing, depending on the application, requires 10 to 40 images/second throughput. Some applications ev en require multiple inferences to run at the same time. T able I shows that the high-end Kirin 970 SoC can barely sustain such requirement while the mid-end Exynos 5422 cannot. W e previously observed that peak bandwidth consumed by any indi vidual component is far below the total bandwidth supported by the bus. This observation supports the claim that inferencing through multiple components together will not make individual components more memory-constrained com- pared to their isolated inferencing. Therefore, we use ARM- T ABLE III: Throughput improv ement on Kirin 970 by co- ex ecution over the best throughput with a single compo- nent (NPU). Network Throughput (Images/s) Gain (%) Image Frames Composition (%) NPU Co- execution A73 A53 G72 NPU AlexNet 32.5 63.7 96.0 1.90 0.95 47.47 49.68 GoogleNet 34.4 59.3 72.4 3.06 1.70 33.33 61.90 ResNet50 21.9 30.9 40.9 2.63 1.32 26.97 69.08 SqueezeNet 49.3 95.1 92.9 3.18 1.69 43.43 51.69 Fig. 4: Energy efficiency of co-execution on Exynos 5422 with all components, on Kirin 970 with CPU and GPU (excluding NPU) and all components (including NPU). CL to create an infrastructure, wherein multiple components process images from a single unified stream in parallel using a work-stealing mechanism. The infrastructure uses a buf fer to reorder the out-of-sync output from different components. Co-ex ecution obtains significantly higher throughput than the highest throughput component in isolated ex ecution. T able II shows the peak co-execution throughput on both mobile SoCs with the ARM big.LITTLE CPU core cluster and GPU. W e include the best individual component executions, which are GPU for both platforms, for comparison. On av- erage, the co-execution gi ves 50% throughput improv ement ov er GPU only execution. Furthermore, T able II shows Exynos 5422 ’ s obsolescence. Ev en with the co-ex ecution, Exynos 5422 shows very low absolute throughput. B. Co-execution with NPU The performance of NPU is unbeatable. T able III shows that Kirin 970 , with co-execution of all on-chip components, giv es exceptionally high throughput. In practice, we can ex ecute NPU and GPU in parallel to wards one application that demands very high performance or to perform multiple inferences simultaneously with multiple applications. C. Co-Execution Ener gy Efficiency Synergistic co-execution engages multiple components si- multaneously to improve performance at the cost of higher power consumption. Therefore, the ener gy ef ficiency of the co-ex ecution is the av erage energy efficienc y of engaged components. Figure 4 shows the energy ef ficiency of the ex ecution that engages all the components on Exynos 5422 , the CPU clusters and GPU on Kirin 970 (exclude NPU), and all the components on Kirin 970 (include NPU). Overall, the co-ex ecution energy efficienc y is always better than the Big CPU cluster . In Kirin 970 SoC, as GPU is much more energy- efficient than the CPU clusters, the co-ex ecution provides better energy efficiency than the po wer-ef ficient Small CPU cluster . V I . S U M M A RY Mobile inferencing is now ubiquitous. In this work, we examine the power-performance characteristics of inferenc- ing through se veral prominent neural networks on dif ferent components av ailable within a mobile SoC. W e also perform roofline analysis of networks on components to un veil the further optimization scope. W e show that network throughput can increase by up to 2x using co-execution that engages all the components in inferencing simultaneously . Siqi W ang is currently a research assistant and is working toward the Ph.D. degree at School of Computing, National Univ ersity of Singapore. Her current research interests include performance optimization, task scheduling, general purpose GPUs and deep learning on heterogeneous multi-processor systems. Anuj Pathania is currently working as a research fello w at School of Computing, National Univ ersity of Singapore. He receiv ed his Ph.D. degree from Karlsruhe Institute of T echnology (KIT), Germany in 2018. His research focuses on resource management algorithms with emphasis on performance-, power - and thermal-efficienc y in embedded systems. T ulika Mitra is a Professor of Computer Science at School of Computing, National University of Singapore. She received her PhD degrees in computer science from the State Univ ersity of New Y ork Stony Brook in 2000. Her research interests span various aspects of the design automation of embedded real-time systems, cyber-physical systems, and Internet of Things. R E F E R E N C E S [1] C.-J. W u, D. Brooks, K. Chen, D. Chen, S. Choudhury , M. Dukhan, K. Hazelwood, E. Isaac, Y . Jia, B. Jia et al. , “Machine learning at facebook: Understanding inference at the edge, ” in 2019 IEEE Interna- tional Symposium on High P erformance Computer Architectur e (HPCA) . IEEE, 2019, pp. 331–344. [2] M. W ess, S. M. P . Dinakarrao, and A. Jantsch, “W eighted quantization- regularization in dnns for weight memory minimization toward hw implementation, ” IEEE Tr ansactions on Computer-Aided Design of Inte grated Circuits and Systems , vol. 37, no. 11, pp. 2929–2939, 2018. [3] “Keysight T echnologies B2900 Series Precision Source/Measure Unit, ” https://goo.gl/U4HMbu. [4] A. Krizhevsky , I. Sutske ver, and G. E. Hinton, “Imagenet classification with deep con volutional neural networks, ” in Advances in neural infor- mation pr ocessing systems , 2012, pp. 1097–1105. [5] C. Szegedy , W . Liu, Y . Jia, P . Sermanet, S. Reed, D. Anguelov , D. Erhan, V . V anhoucke, and A. Rabinovich, “Going deeper with con volutions, ” in Proceedings of the IEEE conference on computer vision and pattern r ecognition , 2015, pp. 1–9. [6] A. G. Ho ward, M. Zhu, B. Chen, D. Kalenichenk o, W . W ang, T . W eyand, M. Andreetto, and H. Adam, “Mobilenets: Efficient con volutional neural networks for mobile vision applications, ” arXiv preprint:1704.04861 , 2017. [7] K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition, ” in Pr oceedings of the IEEE conference on computer vision and pattern recognition , 2016, pp. 770–778. [8] F . N. Iandola, S. Han, M. W . Moskewicz, K. Ashraf, W . J. Dally , and K. Keutzer , “SqueezeNet: AlexNet-le vel accuracy with 50x fewer parameters and 0.5 MB model size, ” arXiv preprint :1602.07360 , 2016. [9] S. Williams, A. W aterman, and D. Patterson, “Roofline: An insightful visual performance model for floating-point programs and multicore architectures, ” Lawrence Berkeley National Lab .(LBNL), Berkeley , CA (United States), T ech. Rep., 2009. [10] S. Siamashka, “Tin ymembench, ” https://github.com/ssvb/tin ymembench. [11] S. W ang, G. Ananthanarayanan, Y . Zeng, N. Goel, A. Pathania, and T . Mitra, “High-throughput cnn inference on embedded arm big.little multi-core processors, ” IEEE T ransactions on Computer-Aided Design of Inte grated Cir cuits and Systems , 2019. [Online]. A vailable: http://dx.doi.org/10.1109/TCAD.2019.2944584
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment