강화학습을 위한 볼록 제약조건 처리 방법
본 논문은 기대값이 볼록 집합에 속하도록 하는 다양한 제약을 강화학습에 적용할 수 있는 알고리즘 APPROPO를 제안한다. 제약을 게임 이론적 프레임워크로 변환하고, λ‑플레이어에 온라인 경사 하강법, μ‑플레이어에 기존 스칼라 보상 RL 오라클을 이용해 서브선형 레그레트를 보장한다. 실험에서는 안전 제약과 다양성 제약을 동시에 만족시키는 것을 확인하였다.
저자: Sobhan Miryoosefi, Kiante Brantley, Hal Daume III
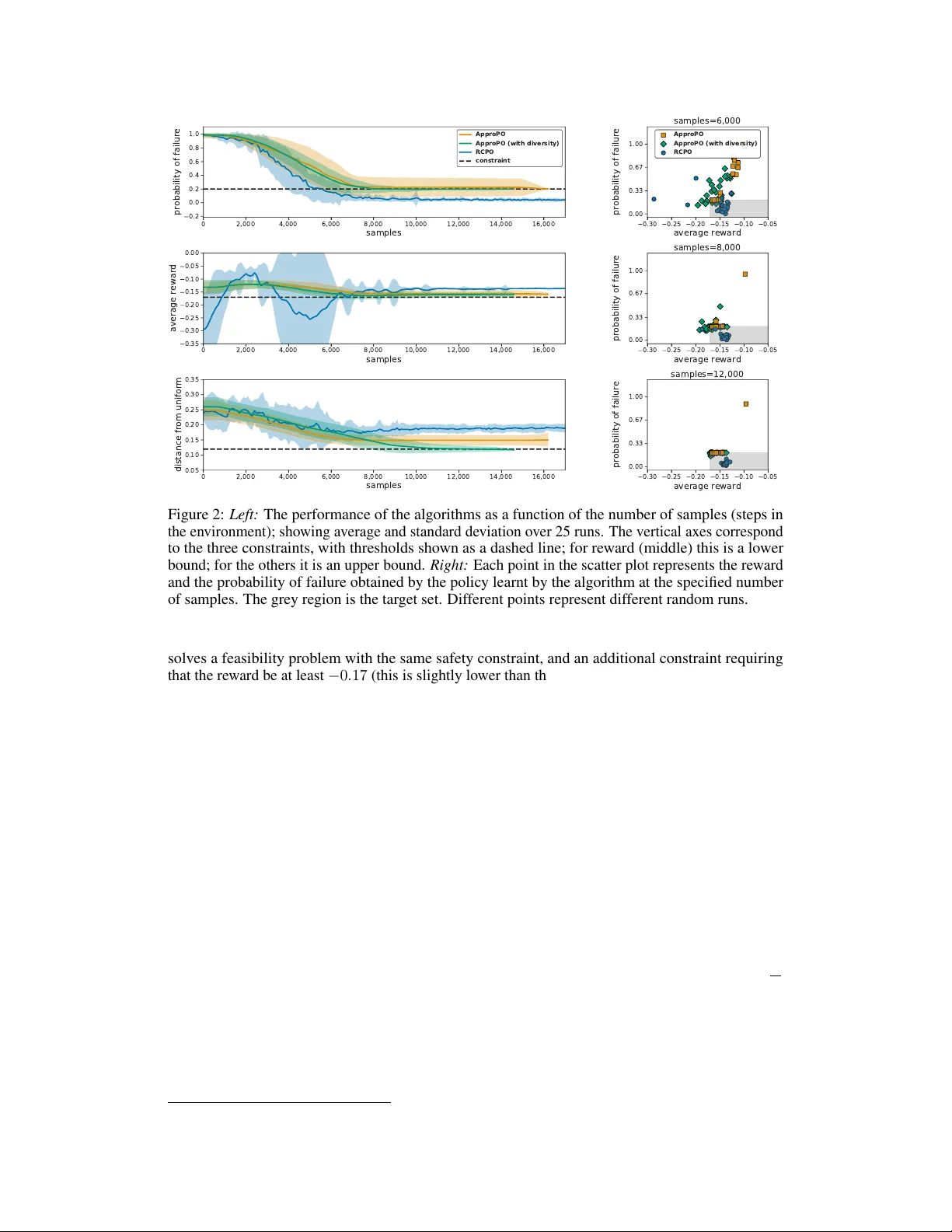
논문은 강화학습(RL)에서 에이전트가 달성해야 할 목표를 단일 스칼라 보상이 아니라 다차원 측정 벡터의 기대값이 특정 볼록 집합 C 안에 들어가도록 하는 제약 형태로 일반화한다. 이러한 제약은 안전성(위험 행동 제한), 전문가 행동 근접성, 탐색 다양성 등 다양한 실제 요구사항을 포괄한다. 기존의 CMDP는 선형 제약에 국한되었지만, 본 연구는 임의의 볼록 제약을 다룰 수 있는 새로운 알고리즘 APPROPO를 제시한다.
먼저, 측정 벡터 z_i∈ℝ^d 를 정의하고, 정책 π에 대한 장기 기대값 z(π)=E
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기