Reinforcement Learning with Convex Constraints
In standard reinforcement learning (RL), a learning agent seeks to optimize the overall reward. However, many key aspects of a desired behavior are more naturally expressed as constraints. For instance, the designer may want to limit the use of unsaf…
Authors: Sobhan Miryoosefi, Kiante Brantley, Hal Daume III
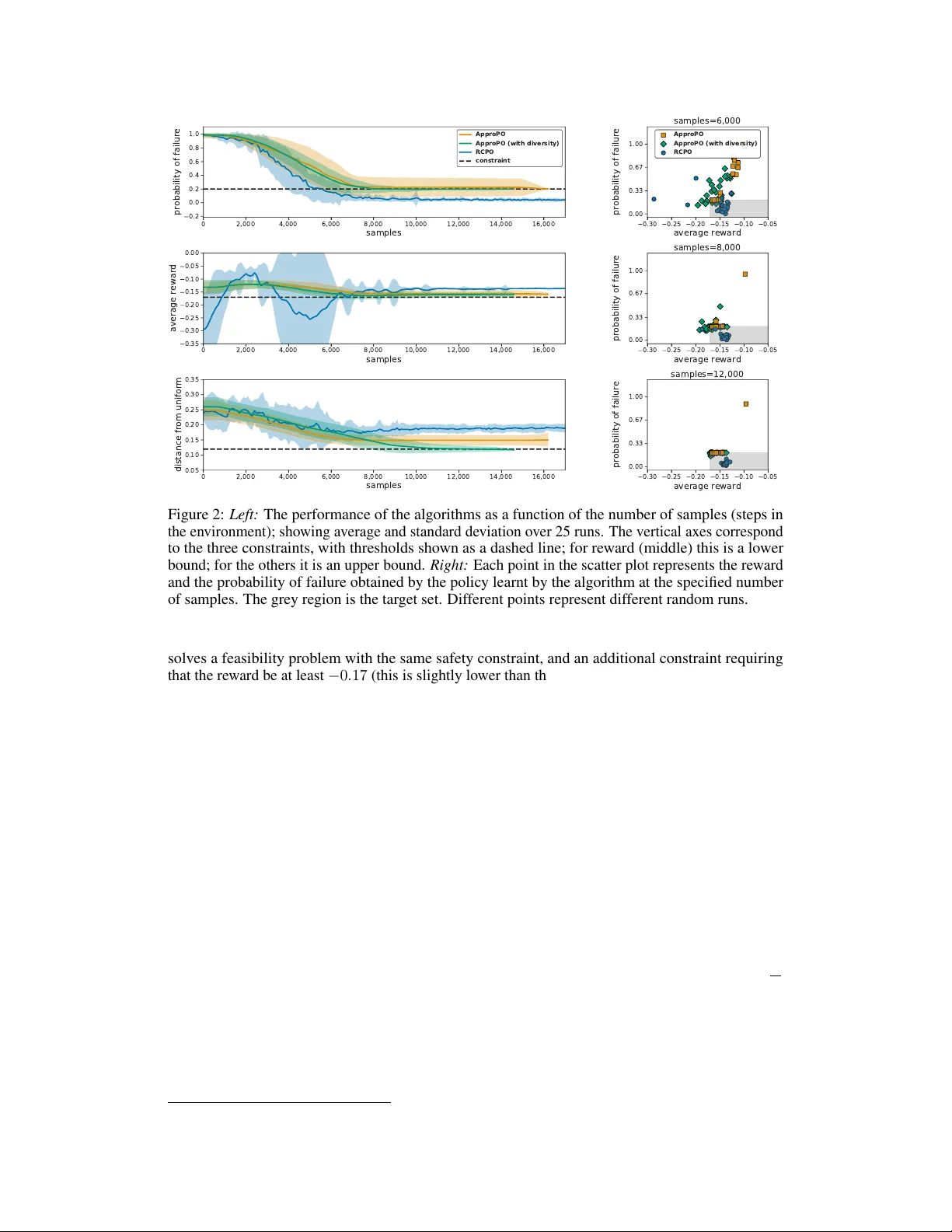
Reinf or cement Learning with Con vex Constraints Sobhan Miryoosefi Princeton Univ ersity miryoosefi@cs.princeton.edu Kianté Brantley Univ ersity of Maryland kdbrant@cs.umd.edu Hal Daumé III Microsoft Research Univ ersity of Maryland me@hal3.name Mirosla v Dudík Microsoft Research mdudik@microsoft.com Robert E. Schapire Microsoft Research schapire@microsoft.com Abstract In standard reinforcement learning (RL), a learning agent seeks to optimize the ov erall reward. Howe ver , many key aspects of a desired beha vior are more natu- rally expressed as constraints. For instance, the designer may want to limit the use of unsafe actions, increase the diversity of trajectories to enable exploration, or approximate expert trajectories when re wards are sparse. In this paper , we propose an algorithmic scheme that can handle a wide class of constraints in RL tasks, specifically , any constraints that require expected v alues of some vector measure- ments (such as the use of an action) to lie in a conv ex set. This captures previously studied constraints (such as safety and proximity to an expert), but also enables new classes of constraints (such as di versity). Our approach comes with rigorous theoretical guarantees and only relies on the ability to approximately solve standard RL tasks. As a result, it can be easily adapted to work with any model-free or model-based RL algorithm. In our experiments, we show that it matches pre vious algorithms that enforce safety via constraints, but can also enforce ne w properties that these algorithms cannot incorporate, such as div ersity . 1 Introduction Reinforcement learning (RL) typically considers the problem of learning to optimize the behavior of an agent in an unkno wn en vironment against a single scalar re ward function. For simple tasks, this can be suf ficient, but for complex tasks, boiling do wn the learning goal into a single scalar re ward can be challenging. Moreover , a scalar re ward might not be a natural formalism for stating certain learning objectiv es, such as safety desires (“avoid dangerous situations”) or e xploration suggestions (“maintain a distribution o ver visited states that is as close to uniform as possible”). In these settings, it is much more natural to define the learning goal in terms of a vector of measur ements over the behavior of the agent, and to learn a polic y whose measurement vector is inside a target set ( §2 ). W e derive an algorithm, approac hability-based policy optimization ( A P P R O P O , pronounced like “apropos”), for solving such problems ( § 3 ). Giv en a Markov decision process with vector -valued measurements ( §2 ), and a target constraint set, A P P RO P O learns a stochastic policy whose expected measurements f all in that target set (akin to Blackwell approachability in single-turn games, Blackwell , 1956 ). W e derive our algorithm from a game-theoretic perspecti ve, lev eraging recent results in online con ve x optimization. A P P R O P O is implemented as a r eduction to any of f-the-shelf reinforcement learning algorithm that can return an approximately optimal polic y , and so can be used in conjunction with the algorithms that are the most appropriate for any gi ven domain. Preprint. Under revie w . Our approach builds on prior work for reinforcement learning under constraints, such as the formalism of constrained Marko v decision processes (CMDPs) introduced by Altman ( 1999 ). In CMDPs, the agent’ s goal is to maximize rew ard while satisfying some linear constraints over auxiliary costs (akin to our measurements). Altman ( 1999 ) gav e an LP-based approach when the CMDP is fully known, and more recently , model-free approaches hav e been dev eloped for CMDPs in high-dimensional settings. For instance, Achiam et al.’ s ( 2017 ) constrained policy optimization (CPO) focuses on safe e xploration and seeks to ensure approximate constraint satisfaction during the learning process. T essler et al.’ s ( 2019 ) re ward constrained policy optimization (RCPO) follo ws a two-timescale primal-dual approach, giving guarantees for the con ver gence to a fix ed point. Le et al. ( 2019 ) describe a batch of f-policy algorithm with P A C-style guarantees for CMDPs using a similar game-theoretic formulation to ours. While all of these works are only applicable to orthant constraints, our algorithm can work with arbitrary con vex constraints. This enables A P P R O P O to incorporate previously studied constraint types, such as inequality constraints that represent safety or that keep the polic y’ s behavior close to that of an e xpert ( Syed and Schapire , 2008 ), as well as constraints like the aforementioned e xploration suggestion, implemented as an entropy constraint on the policy’ s state visitation vector . The entropy of the visitation vector was recently studied as the objectiv e by Hazan et al. ( 2018 ), who gav e an algorithm capable of maximizing a concave function (e.g., entropy) over such vectors. Howe ver , it is not clear whether their approach can be adapted to the con ve x constraints setting studied here. Our main contributions are: (1) a new algorithm, A P P R O P O , for solving reinforcement learning problems with arbitrary con vex constraints; (2) a rigorous theoretical analysis that demonstrates that it can achiev e sublinear regret under mild assumptions ( § 3 ); and (3) a preliminary experimental comparison with RCPO ( T essler et al. , 2019 ), showing that our algorithm is competiti ve with RCPO on orthant constraints, while also handling a div ersity constraint ( §4 ). 2 Setup and preliminaries: Defining the feasibility problem W e begin with a description of our learning setting. A vector-valued Markov decision pr ocess is a tuple M = ( S , A , β , P s , P z ) , where S is the set of states, A is the set of actions and β is the initial-state distribution. Each episode starts by drawing an initial state s 0 from the distribution β . Then in each step i = 1 , 2 , . . . , the agent observes its current state s i and takes action a i ∈ A causing the environment to move to the next state s i +1 ∼ P s ( ·| s i , a i ) . The episode ends after a certain number of steps (called the horizon) or when a terminal state is reached. Howe ver , in our setting, instead of recei ving a scalar re ward, the agent observes a d -dimensional measur ement vector z i ∈ R d , which, like s i +1 , is dependent on both the current state s i and the action a i , that is, z i ∼ P z ( ·| s i , a i ) . (Although not explicit in our setting, re ward could be incorporated in the measurement vector .) T ypically , actions are selected according to a (stationary) policy π so that a i ∼ π ( s i ) , where π maps states to distrib utions over actions. W e assume we are working with policies from some candidate space Π . For simplicity of presentation, we assume this space is finite, though possibly extremely large. For instance, if S and A are finite, then Π might consist of all deterministic policies. (Our results hold also when Π is infinite with minor technical adjustments.) Our aim is to control the MDP so that measurements satisfy some constraints. For an y policy π , we define the long-term measur ement z ( π ) as the expected sum of discounted measurements: z ( π ) , E " ∞ X i =0 γ i z i π # (1) for some discount factor γ ∈ [0 , 1) , and where expectation is over the random process described abov e (including randomness inherent in π ). Later , we will also find it useful to consider mixed policies µ , which are distributions ov er finitely many stationary policies. The space of all such mixed policies ov er Π is denoted ∆(Π) . T o execute a mixed polic y µ , before taking an y actions, a single policy π is randomly selected according to µ ; then all actions henceforth are chosen from π , for the entire episode. The long-term measurement of a mixed polic y z ( µ ) is defined accordingly: z ( µ ) , E π ∼ µ [ z ( π )] = X π µ ( π ) z ( π ) . (2) 2 Our learning problem, called the feasibility pr oblem , is specified by a con ve x tar get set C . The goal is to find a mixed polic y µ whose long-term measurements lie in the set C : Feasibility Problem: Find µ ∈ ∆(Π) such that z ( µ ) ∈ C . (3) For instance, in our experiments ( §4 ) we consider a grid-world en vironment where the measurements include the distance tra veled, an indicator of hitting a rock, and indicators of visiting v arious locations on the grid. The feasibility goal is to achieve at most a certain trajectory length while keeping the probability of hitting the rock belo w a threshold for safety reasons, and maintaining a distribution ov er visited states close to the uniform distribution to enable exploration. W e can potentially also handle settings where the goal is to maximize one measurement (e.g., “re ward”) subject to others by performing a binary search ov er the maximum attainable value of the re ward (see §3.4 ). 3 A pproach, algorithm, and analysis Before gi ving details of our approach, we overvie w the main ideas, which, to a lar ge degree, follo w the work of Abernethy et al. ( 2011 ), who considered the problem of solving two-player g ames; we extend these results to solv e our feasibility problem ( 3 ). Although feasibility is our main focus, we actually solve the stronger problem of finding a mixed policy µ that minimizes the Euclidean distance between z ( µ ) and C , meaning the Euclidean distance between z ( µ ) and its closest point in C . That is, we want to solv e min µ ∈ ∆(Π) dist( z ( µ ) , C ) (4) where dist denotes the Euclidean distance between a point and a set. Our main idea is to take a game-theoretic approach, formulating this problem as a game and solving it. Specifically , suppose we can express the distance function in Eq. ( 4 ) as a maximization of the form dist( z ( µ ) , C ) = max λ ∈ Λ λ · z ( µ ) (5) for some con ve x, compact set Λ . 1 Then Eq. ( 4 ) becomes min µ ∈ ∆(Π) max λ ∈ Λ λ · z ( µ ) . (6) This min-max form immediately ev okes interpretation as a two-person zero-sum game: the first player chooses a mixed policy µ , the second player responds with a vector λ , and λ · z ( µ ) is the amount that the first player is then required to pay to the second player . Assuming this game satisfies certain conditions, the final payout under the optimal play , called the value of the game, is the same ev en when the order of the players is rev ersed: max λ ∈ Λ min µ ∈ ∆(Π) λ · z ( µ ) . (7) Note that the policy µ we are seeking is the solution of this game, that is, the policy realizing the minimum in Eq. ( 6 ). Therefore, to find that policy , we can apply general techniques for solving a game, namely , to let a no-regret learning algorithm play the game repeatedly against a best-response player . When played in this way , it can be shown that the averages of their plays conv erge to the solution of the game (details in §3.1 ). In our case, we can use a no-regret algorithm for the λ -player , and best response for the µ -player . Importantly , in our context, computing best response turns out to be an especially con venient task. Giv en λ , best response means finding the mix ed policy µ minimizing λ · z ( µ ) . As we sho w below , this can be solv ed by treating the problem as a standard reinforcement learning task where in each step i , the agent accrues a scalar rew ard r i = − λ · z i . W e refer to any algorithm for solving the problem of scalar reward maximization as the best-r esponse oracle . During the run of our algorithm, we in voke this oracle for dif ferent vectors λ corresponding to different definitions of a scalar re ward. 1 Note that the distance between a point and a set is defined as a minimization of the distance function over all points in the set C , but here we require that it be rewritten as a maximization of a linear function o ver some other set Λ . W e will show ho w to achiev e this in §3.2 . 3 Algorithm 1 Solving a game with repeated play 1: input concave-con ve x function g : Λ × U → R , online learning algorithm L E A R N E R 2: for t = 1 to T do 3: L E A R N E R makes a decision λ t ∈ Λ 4: u t ← argmin u ∈U g ( λ t , u ) 5: L E A R N E R observes loss function ` t ( λ ) = − g ( λ , u t ) 6: end for 7: return λ = 1 T P T t =1 λ t and u = 1 T P T t =1 u t Although the oracle is only capable of solving RL tasks with a scalar rew ard, our algorithm can lev erage this capability to solve the multi-dimensional feasibility (or distance minimization) problem. In the remainder of this section, we pro vide the details of our approach, leading to our main algorithm and its analysis, and conclude with a discussion of steps for making a practical implementation. W e begin by discussing game-playing techniques in general, which we then apply to our setting. 3.1 Solving zero-sum games using online lear ning At the core of our approach, we use the general technique of Freund and Schapire ( 1999 ) for solving a game by repeatedly playing a no-regret online learning algorithm against best response. For this purpose, we first briefly revie w the framew ork of online conv ex optimization, which we will soon use for one of the players: At time t = 1 , . . . , T , the learner makes a decision λ t ∈ Λ , the en vironment re veals a con ve x loss function ` t : Λ → R , and the learner incurs loss ` t ( λ t ) . The learner seeks to achiev e small r e gret , the g ap between its loss and the best in hindsight: Regret T , " T X t =1 ` t ( λ t ) # − min λ ∈ Λ " T X t =1 ` t ( λ ) # . (8) An online learning algorithm is no-r e gr et if Regret T = o ( T ) , meaning its a verage loss approaches the best in hindsight. An example of such an algorithm is online gradient descent (OGD) of Zink evich ( 2003 ) (see Appendix A ). If the Euclidean diameter of Λ is at most D , and k∇ ` t ( λ ) k ≤ G for any t and λ ∈ Λ , then the regret of OGD is at most DG √ T . Now consider a two-player zero-sum game in which two players select, respectively , λ ∈ Λ and u ∈ U , resulting in a payout of g ( λ , u ) from the u -player to the λ -player . The λ -player wants to maximize this quantity and the u -player wants to minimize it. Assuming g is concav e in λ and con ve x in u , if both spaces Λ and U are con vex and compact, then the minimax theorem ( von Neumann , 1928 ; Sion , 1958 ) implies that max λ ∈ Λ min u ∈U g ( λ , u ) = min u ∈U max λ ∈ Λ g ( λ , u ) . (9) This means that the λ -player has an “optimal” strategy which realizes the maximum on the left and guarantees payoff of at least the value of the game, i.e., the v alue giv en by this expression; a similar statement holds for the u -player . W e can solve this game (find these optimal strate gies) by playing it repeatedly . W e use a no-regret online learner as the λ -player . At each time t = 1 , . . . , T , the learner chooses λ t ∈ Λ . In response, the u -player , who in this setting is permitted knowledge of λ t , selects u t to minimize the payout, that is, u t = argmin u ∈U g ( λ t , u ) . This is called best r esponse . The online learning algorithm is then updated by setting its loss function to be ` t ( λ ) = − g ( λ , u t ) . (See Algorithm 1 .) As stated in Theorem 3.1 , λ and u , the averages of the players’ decisions, con ver ge to the solution of the game (see Appendix B for the proof). Theorem 3.1. Let v be the value of the game in Eq. ( 9 ) and let Regret T be the r e gr et of the λ -player . Then for λ and u we have min u ∈U g ( λ , u ) ≥ v − δ and max λ ∈ Λ g ( λ , u ) ≤ v + δ, wher e δ = 1 T Regret T . (10) 4 3.2 Algorithm and main result W e can now apply this game-playing framew ork to the approach outlined at the beginning of this section. First, we show ho w to write distance as a maximization, as in Eq. ( 5 ). For no w , we assume that our target set C is a conve x cone , that is, closed under summation and also multiplication by non-negati ve scalars (we will remo ve this assumption in §3.3 ). With this assumption, we can apply the following lemma (Lemma 13 of Abernethy et al. , 2011 ), in which distance to a conv ex cone C ⊆ R d is written as a maximization ov er a dual con vex cone C ◦ called the polar cone : C ◦ , { λ : λ · x ≤ 0 for all x ∈ C } . (11) Lemma 3.2. F or a conve x cone C ⊆ R d and any point x ∈ R d dist( x , C ) = max λ ∈C ◦ ∩B λ · x , (12) wher e B , { x : k x k ≤ 1 } is the Euclidean ball of radius 1 at the origin. Thus, Eq. ( 5 ) is immediately achie ved by setting Λ = C ◦ ∩ B , so the distance minimization problem ( 4 ) can be cast as the min-max problem ( 6 ). This is a special case of the zero-sum game ( 9 ), with U = { z ( µ ) : µ ∈ ∆(Π) } and g ( λ , u ) = λ · u , which can be solved with Algorithm 1 . Note that the set U is con vex and compact, because it is a linear transformation of a con ve x and compact set ∆(Π) . W e will see below that the best responses u t in Algorithm 1 can be expressed as z ( π t ) for some π t ∈ Π , and so Algorithm 1 returns u = 1 T T X t =1 z ( π t ) = z 1 T T X t =1 π t ! , which is exactly the long-term measurement vector of the mixed policy ¯ µ = 1 T P T t =1 π t . For this mixed polic y , Theorem 3.1 immediately implies dist( z ( ¯ µ ) , C ) ≤ min µ ∈ ∆(Π) dist( z ( µ ) , C ) + 1 T Regret T . (13) If the problem is feasible, then min µ ∈ ∆(Π) dist( z ( µ ) , C ) = 0 , and since Regret T = o ( T ) , our long-term measurement z ( ¯ µ ) con ver ges to the target set and solves the feasibility problem ( 3 ). It remains to specify how to implement the no-regret learner for the λ -player and best response for the u -player . W e discuss these next, beginning with the latter . The best-response player , for a gi ven λ , aims to minimize λ · z ( µ ) ov er mixed policies µ , but since this objectiv e is linear in the mixture weights µ ( π ) (see Eq. 2 ), it suf fices to minimize λ · z ( π ) ov er stationary policies π ∈ Π . The ke y point, as already mentioned, is that this is the same as finding a policy that maximizes long-term re ward in a standard reinforcement learning task if we define the scalar rew ard to be r i = − λ · z i . This is because the rew ard of a policy π is giv en by R ( π ) , E " ∞ X i =0 γ i r i π # = E " ∞ X i =0 γ i ( − λ · z i ) π # = − λ · E " ∞ X i =0 γ i z i π # = − λ · z ( π ) . (14) Therefore, maximizing R ( π ) , as in standard RL, is equiv alent to minimizing λ · z ( π ) . Thus, best response can be implemented using any one of the many well-studied RL algorithms that maximize a scalar rew ard. W e refer to such an RL algorithm as the best-response or acle . For robustness, we allo w this oracle to return an approximately optimal policy . Best-response oracle: B E S T R E S P O N S E ( λ ) . Giv en λ ∈ R d , return a policy π ∈ Π that satisfies R ( π ) ≥ max π 0 ∈ Π R ( π 0 ) − 0 , where R ( π ) is the long-term re ward of policy π with scalar reward defined as r = − λ · z . For the λ -player , we do our analysis using online gradient descent ( Zinke vich , 2003 ), an ef fectiv e no-regret learner . For its update, OGD needs the gradient of the l oss functions ` t ( λ ) = − λ · z ( π t ) , which is just − z ( π t ) . W ith access to the MDP , z ( π ) can be estimated simply by generating multiple trajectories using π and av eraging the observed measurements. W e formalize this by assuming access to an estimation oracle for estimating z ( π ) . 5 Algorithm 2 A P P R O P O 1: input projection oracle Γ C ( · ) for target set C which is a con vex cone, best-response oracle B E S T R E S P O N S E ( · ) , estimation oracle E S T ( · ) , step size η , number of iterations T 2: define Λ , C ◦ ∩ B , and its projection operator Γ Λ ( x ) , ( x − Γ C ( x )) / max { 1 , k x − Γ C ( x ) k} 3: initialize λ 1 arbitrarily in Λ 4: for t = 1 to T do 5: Compute an approximately optimal polic y for standard RL with scalar rew ard r = − λ t · z : π t ← B E S T R E S P O N S E ( λ t ) 6: Call the estimation oracle to approximate long-term measurement for π t : ˆ z t ← E S T ( π t ) 7: Update λ t using online gradient descent with the loss function ` t ( λ ) = − λ · ˆ z t : λ t +1 ← Γ Λ λ t + η ˆ z t 8: end for 9: return ¯ µ , a uniform mixture o ver π 1 , . . . , π T Estimation oracle: E S T ( π ) . Giv en policy π , return ˆ z satisfying k ˆ z − z ( π ) k ≤ 1 . OGD also requires projection to the set Λ = C ◦ ∩ B . In fact, if we can simply project onto the target set C , which is more natural, then it is possible to also project onto Λ . Consider an arbitrary x and denote its projection onto C as Γ C ( x ) . Then the projection of x onto the polar cone C ◦ is Γ C ◦ ( x ) = x − Γ C ( x ) ( Ingram and Marsh , 1991 ). Giv en the projection Γ C ◦ ( x ) and further projecting onto B , we obtain Γ Λ ( x ) = ( x − Γ C ( x )) / max { 1 , k x − Γ C ( x ) k} (because Dykstra’ s projection algorithm con ver ges to this point after two steps, Boyle and Dykstra , 1986 ). Therefore, it suf fices to require access to a pr ojection oracle for C : Projection oracle: Γ C ( x ) = argmin x 0 ∈C k x − x 0 k . Pulling these ideas together and plugging into Algorithm 1 , we obtain our main algorithm, called A P P R O P O (Algorithm 2 ), for appr oachability-based policy optimization . The algorithm prov ably yields a mixed polic y that approximately minimizes distance to the set C , as sho wn in Theorem 3.3 (prov ed in Appendix C ). Theorem 3.3. Assume that C is a con vex cone and for all measurements we have k z k ≤ B . Suppose we run Algorithm 2 for T rounds with η = B 1 − γ + 1 − 1 T − 1 / 2 . Then dist( z ( ¯ µ ) , C ) ≤ min µ ∈ ∆(Π) dist( z ( µ ) , C ) + B 1 − γ + 1 T − 1 / 2 + 0 + 2 1 , (15) wher e ¯ µ is the mixed policy returned by the algorithm. When the goal is to solve the feasibility problem ( 3 ) rather than the stronger distance minimization ( 4 ), we can make use of a weaker reinforcement learning oracle, which only needs to find a policy that is “good enough” in the sense of providing long-term re ward abov e some threshold: Positi ve-response oracle: P O S R E S P O N S E ( λ ) . Gi ven λ ∈ R d , return π ∈ Π that satisfies R ( π ) ≥ − 0 if max π 0 ∈ Π R ( π 0 ) ≥ 0 (and arbitrary π otherwise), where R ( π ) is the long-term re ward of π with scalar rew ard r = − λ · z . When the problem is feasible, it can be shown that there must exist π ∈ Π with R ( π ) ≥ 0 , and furthermore, that ` t ( λ t ) ≥ − ( 0 + 1 ) (from Lemma C.1 in Appendix C ). This means, if the goal is feasibility , we can modify Algorithm 2 , replacing B E S T R E S P O N S E with P O S R E S P O N S E , and adding a test at the end of each iteration to report infeasibility if ` t ( λ t ) < − ( 0 + 1 ) . The pseudocode is provided in Algorithm 4 in Appendix D along with the proof of the follo wing con ver gence bound: Theorem 3.4. Assume that C is a con vex cone and for all measurements we have k z k ≤ B . Suppose we run Algorithm 4 for T r ounds with η = B 1 − γ + 1 − 1 T − 1 / 2 . Then either the algorithm r eports infeasibility or r eturns ¯ µ such that dist( z ( ¯ µ ) , C ) ≤ B 1 − γ + 1 T − 1 / 2 + 0 + 2 1 . (16) 6 3.3 Removing the cone assumption Our results so far hav e assumed the target set C is a con vex cone. If instead C is an arbitrary con vex, compact set, we can use the technique of Abernethy et al. ( 2011 ) and apply our algorithm to a specific con ve x cone ˜ C constructed from C to obtain a solution with prov able guarantees. In more detail, giv en a compact, conv ex target set C ⊆ R d , we augment ev ery vector in C with a new coordinate held fixed to some v alue κ > 0 , and then let ˜ C be its conic hull. Thus, ˜ C = cone( C × { κ } ) , where cone( X ) = { α x | x ∈ X , α ≥ 0 } . (17) Giv en our original vector-v alued MDP M = ( S , A , β , P s , P z ) , we define a new MDP M 0 = ( S , A , β , P s , P 0 z 0 ) with ( d + 1) -dimensional measurement z 0 ∈ R d +1 , defined (and generated) by z 0 i = z i ⊕ h (1 − γ ) κ i , z i ∼ P z ( · | s i , a i ) (18) where ⊕ denotes vector concatenation. Writing long-term measurement for M and M 0 as z and z 0 respectiv ely , z 0 ( π ) = z ( π ) ⊕ h κ i , for any polic y π ∈ Π , and similarly for any mixed policy µ . The main idea is to apply the algorithms described abo ve to the modified MDP M 0 using the cone ˜ C as target set. For an appropriate choice of κ > 0 , we show that the resulting mixed policy will approximately minimize distance to C for the original MDP M . This is a consequence of the following lemma, an extension of Lemma 14 of Abernethy et al. ( 2011 ), which shows that distances are largely preserved in a controllable way under this construction. The proof is in Appendix E . Lemma 3.5. Consider a compact, conve x set C in R d and x ∈ R d . F or any δ > 0 , let ˜ C = cone( C × { κ } ) , wher e κ = max x ∈C k x k √ 2 δ . Then dist( x , C ) ≤ (1 + δ )dist( x ⊕ h κ i , ˜ C ) . Corollary 3.6. Assume that C is a con vex, compact set and for all measur ements we have k z k ≤ B . Then by putting η = B + κ 1 − γ + 1 − 1 T − 1 / 2 and running Algorithm 2 for T r ounds with M 0 as the MDP and ˜ C as the tar get set, the mixed policy ¯ µ returned by the algorithm satisfies dist( z ( ¯ µ ) , C ) ≤ (1 + δ ) min µ ∈ ∆(Π) dist( z ( µ ) , C ) + B + κ 1 − γ + 1 T − 1 / 2 + 0 + 2 1 , (19) wher e κ = max x ∈C k x k √ 2 δ for an arbitrary δ > 0 . Similarly for Algorithm 4 , we either have dist( z ( ¯ µ ) , C ) ≤ (1 + δ ) B + κ 1 − γ + 1 T − 1 / 2 + 0 + 2 1 (20) or the algorithm r eports infeasibility . 3.4 Practical implementation of the positive r esponse and estimation oracles W e next briefly describe a fe w techniques for the practical implementation of our algorithm. As discussed in §3.2 , when our aim is to solv e a feasibility problem, we only need access to a positi ve response oracle. In episodic en vironments, it is straightforward to use any standard iterativ e RL approach as a positiv e response oracle: As the RL algorithm runs, we track its accrued rewards, and when the trailing av erage of the last n trajectory-le vel re wards goes abo ve some le vel − , we return the current policy (possibly specified implicitly as a Q -function). 2 Furthermore, the av erage of the mea- surement vectors z collected ov er the last n trajectories can serve as the estimate ˆ z t of the long-term measurement required by the algorithm, side-stepping the need for an additional estimation oracle. The hyperparameters and n influence the oracle quality; specifically , assuming that the re wards are bounded and the overall number of trajectories until the oracle terminates is at most polynomial in n , we hav e 0 = − O ( p (log n ) /n ) and 1 = O ( p (log n ) /n ) . In principle, we could use Theorem 3.4 to select a v alue T at which to stop; in practice, we run until the running a verage of the measurements ˆ z t gets within a small distance of the target set C . If the RL algorithm runs for too long without achie v- ing non-negati ve re wards, we stop and declare that the underlying problem is “empirically infeasible. ” (Actual infeasibility would hold if it is truly not possible to reach non-neg ativ e expected rew ard.) 2 This assumes that the last n trajectories accurately estimate the performance of the final iterate. If that is not the case, the oracle can instead return the mixture of the policies corresponding to the last n iterates. 7 G R R R R R R R R G R R R R R R R R G R R R R R R R R 0.01 0.02 0.03 0.04 0.05 Figure 1: Left: The Mars rover en vironment. The agent starts in top-left and needs to reach the goal in bottom-right while av oiding rocks. Middle, Right: V isitation probabilities of A P P RO P O (middle) and A P P R O P O with a diversity constraints (right) at 12k samples. Both plots based on a single run. An important mechanism to further speed up our algorithm is to maintain a “cache” of all the policies returned by the positive response oracle so far . Each of the cached policies π is stored with the estimate of its e xpected measurement vector ˆ z ( π ) ≈ ¯ z ( π ) , based on its last n iterations (as abov e). In each outer-loop iteration of our algorithm, we first check if the cache contains a policy that already achiev es a re ward at least − under the ne w λ ; this can be determined from the cached ˆ z ( π ) since the rew ard is just a linear function of the measurement vector . If such a policy is found, we return it, alongside ˆ z ( π ) , instead of calling the oracle. Otherwise, we pick the policy from the cache with the largest re ward (belo w − by assumption) and use it to warm-start the RL algorithm implementing the oracle. The cache can be initialized with a few random policies (as we do in our experiments), effecti vely implementing randomized weight initialization. The cache interacts well with a straightforward binary-search scheme that can be used when the goal is to maximize some reward (possibly subject to additional constraints), rather than only satisfy a set of constraints. The feasibility problems corresponding to iterates of binary search only differ in the constraint values, b ut use the same measurements, so the same cache can be reused across all iterations. Running time. Note that A P P R O P O spends the bulk of its running time executing the best-response oracle. It additionally performs updates of λ , but these tend to be orders of magnitude cheaper than any per -episode (or per-transition) updates within the oracle. For example, in our e xperiments ( §4 ), the dimension of λ is either 2 or 66 (without or with the div ersity constraint, respectiv ely), whereas the policies π trained by the oracle are two-layer netw orks described by 8,704 floating-point numbers. 4 Experiments W e next ev aluate the performance of A P P R O P O and demonstrate its ability to handle a variety of constraints. For simplicity , we focus on the feasibility version (Algorithm 4 in Appendix D ). W e compare A P P R O P O with the RCPO approach of T essler et al. ( 2019 ), which adapts policy gradient, specifically , asynchronous actor-critic (A2C) ( Mnih et al. , 2016 ), to find a fixed point of the Lagrangian of the constrained polic y optimization problem. RCPO maintains and updates a vector of Lagrange multipliers, which is then used to deriv e a reward for A2C. The vector of Lagrange multipliers serves a similar role as our λ , and the overall structure of RCPO is similar to A P P RO P O , so RCPO is a natural baseline for a comparison. Unlike A P P R O P O , RCPO only allows orthant constraints and it seeks to maximize rew ard, whereas A P P R O P O solves the feasibility problem. For a fair comparison, A P P RO P O uses A2C as a positiv e-response oracle, with the same hyperpa- rameters as used in RCPO. Online learning in the outer loop of A P P R O P O was implemented via online gradient descent with momentum. Both RCPO and A P P RO P O have an outer -loop learning rate parameter , which we tuned ov er a grid of values 10 − i with integer i (see Appendix F for the details). Here, we report the results with the best learning rate for each method. W e ran our experiments on a small v ersion of the Mar s r over grid-w orld en vironment, used pre viously for the ev aluation of RCPO ( T essler et al. , 2019 ). In this environment, depicted in Figure 1 (left), the agent must mov e from the starting position to the goal without crashing into rocks. The episode terminates when a rock or the goal is reached, or after 300 steps. The environment is stochastic: with probability δ = 0 . 05 the agent’ s action is perturbed to a random action. The agent receives small negati ve re ward each time step and zero for terminating, with γ = 0 . 99 . W e used the same safety constraint as T essler et al. ( 2019 ): ensure that the (discounted) probability of hitting a rock is at most a fixed threshold (set to 0 . 2 ). RCPO seeks to maximize reward subject to this constraint. A P P RO P O 8 0 2,000 4,000 6,000 8,000 10,000 12,000 14,000 16,000 samples 0.2 0.0 0.2 0.4 0.6 0.8 1.0 probability of failure ApproPO ApproPO (with diversity) RCPO constraint 0 2,000 4,000 6,000 8,000 10,000 12,000 14,000 16,000 samples 0.35 0.30 0.25 0.20 0.15 0.10 0.05 0.00 average reward 0 2,000 4,000 6,000 8,000 10,000 12,000 14,000 16,000 samples 0.05 0.10 0.15 0.20 0.25 0.30 0.35 distance from uniform 0.30 0.25 0.20 0.15 0.10 0.05 average reward 1.00 0.67 0.33 0.00 probability of failure samples=6,000 ApproPO ApproPO (with diversity) RCPO 0.30 0.25 0.20 0.15 0.10 0.05 average reward 1.00 0.67 0.33 0.00 probability of failure samples=8,000 0.30 0.25 0.20 0.15 0.10 0.05 average reward 1.00 0.67 0.33 0.00 probability of failure samples=12,000 Figure 2: Left: The performance of the algorithms as a function of the number of samples (steps in the en vironment); sho wing average and standard de viation over 25 runs. The vertical axes correspond to the three constraints, with thresholds sho wn as a dashed line; for re ward (middle) this is a lo wer bound; for the others it is an upper bound. Right: Each point in the scatter plot represents the reward and the probability of failure obtained by the polic y learnt by the algorithm at the specified number of samples. The grey re gion is the target set. Different points represent dif ferent random runs. solves a feasibility problem with the same safety constraint, and an additional constraint requiring that the rew ard be at least − 0 . 17 (this is slightly lower than the final re ward achiev ed by RCPO). W e also experimented with including the e xploration suggestion as a “diversity constraint, ” requiring that the Euclidean distance between our visitation probability vector (across the cells of the grid) and the uniform distribution o ver the upper-right triangle cells of the grid (excluding rocks) be at most 0 . 12 . 3 In Figure 2 (left), we show ho w the probability of failure, the av erage reward, and the distance to the uniform distribution ov er upper triangle vary as a function of the number of samples seen by each algorithm. Both variants of our algorithm are able to satisfy the safety constraints and reach similar rew ard as RCPO with a similar number of samples (around 8k samples). Furthermore, including the div ersity constraint, which RCPO is not capable of enforcing, allo wed our method to reach a more div erse policy as depicted in both Figure 2 (bottom-left) and Figure 1 (right). 5 Conclusion In this paper , we introduced A P P RO P O , an algorithm for solving reinforcement learning problems with arbitrary con vex constraints. A P P RO P O can combine any no-regret online learner with any standard RL algorithm that optimizes a scalar reward. Theoretically , we sho wed that for the specific case of online gradient descent, A P P R O P O learns to approach the constraint set at a rate of 1 / √ T , with an additi ve non-v anishing term that measures the optimality g ap of the reinforcement learner . Experimentally , we demonstrated that A P P R O P O can be applied with well-known RL algorithms for discrete domains (like actor-critic), and achie ves similar performance as RCPO ( T essler et al. , 2019 ), while being able to satisfy additional types of constraints. In sum, this yields a theoretically justified, practical algorithm for solving the approachability problem in reinforcement learning. 3 This number ensures that A P P R O P O without the diversity constraint does not satisfy it automatically . 9 References Abernethy , J., Bartlett, P . L., and Hazan, E. (2011). Blackwell approachability and no-regret learning are equiv alent. In Pr oceedings of the 24th Annual Conference on Learning Theory , pages 27–46. Achiam, J., Held, D., T amar , A., and Abbeel, P . (2017). Constrained policy optimization. In Pr oceedings of the 34th International Confer ence on Machine Learning , volume 70 of Pr oceedings of Machine Learning Resear ch , pages 22–31. Altman, E. (1999). Constrained Markov decision pr ocesses , volume 7. CRC Press. Blackwell, D. (1956). An analog of the minimax theorem for vector payoffs. P acific Journal of Mathematics , 6(1):1–8. Boyle, J. P . and Dykstra, R. L. (1986). A method for finding projections onto the intersection of con ve x sets in hilbert spaces. In Advances in order r estricted statistical infer ence , pages 28–47. Springer . Freund, Y . and Schapire, R. E. (1999). Adaptiv e game playing using multiplicative weights. Games and Economic Behavior , 29(1-2):79–103. Hazan, E., Kakade, S. M., Singh, K., and V an Soest, A. (2018). Prov ably efficient maximum entrop y exploration. arXiv pr eprint arXiv:1812.02690 . Ingram, J. M. and Marsh, M. (1991). Projections onto conv ex cones in hilbert space. Journal of appr oximation theory , 64(3):343–350. Le, H. M., V oloshin, C., and Y ue, Y . (2019). Batch policy learning under constraints. arXiv pr eprint arXiv:1903.08738 . Mnih, V ., Badia, A. P ., Mirza, M., Gra ves, A., Lillicrap, T ., Harley , T ., Silver , D., and Kavukcuoglu, K. (2016). Asynchronous methods for deep reinforcement learning. In International Confer ence on Machine Learning , pages 1928–1937. Sion, M. (1958). On general minimax theorems. P acific Journal of mathematics , 8(1):171–176. Syed, U. and Schapire, R. E. (2008). A game-theoretic approach to apprenticeship learning. In Advances in Neural Information Pr ocessing Systems (NeurIPS) . T essler, C., Manko witz, D. J., and Mannor , S. (2019). Reward constrained polic y optimization. In International Confer ence on Learning Repr esentations . von Neumann, J. (1928). Zur theorie der gesellschaftsspiele. Mathematische Annalen , 100:295–320. Zinke vich, M. (2003). Online con vex programming and generalized infinitesimal gradient ascent. In Pr oceedings of the International Confer ence on Machine Learning (ICML) . 10 Supplementary Material For: Reinforcement Learning with Con v ex Constraints A Online gradient descent (OGD) Algorithm 3 Online gradient descent (OGD) 1: input : projection oracle Γ Λ { Γ Λ ( λ ) = argmin λ 0 ∈ Λ λ − λ 0 } 2: init : λ 1 arbitrarily 3: parameters : step size η t 4: for t = 1 to T do 5: observ e con vex loss function ` t : Λ → R 6: λ 0 t +1 = λ t − η t ∇ ` t ( λ t ) 7: λ t +1 = Γ Λ ( λ 0 t + 1 ) 8: end for Theorem A.1. ( Zinkevic h , 2003 ) Assume that for any λ , λ 0 ∈ Λ we have λ − λ 0 ≤ D and also k∇ ` t ( λ ) k ≤ G . Let η t = η = D G √ T . Then the r e gret of OGD is Regret T ( OGD ) = T X t =1 ` t ( λ t ) − min λ T X t =1 ` t ( λ ) ≤ D G √ T . B Proof of Theor em 3.1 W e hav e that 1 T T X t =1 g ( λ t , u t ) = 1 T T X t =1 min u ∈U g ( λ t , u ) (21) ≤ 1 T min u ∈U T X t =1 g ( λ t , u ) (22) ≤ min u ∈U g 1 T T X t =1 λ t , u ! (23) ≤ max λ ∈ Λ min u ∈U g ( λ , u ) . (24) Eq. ( 21 ) is because the u -player is playing best response so that u t = argmin u ∈U g ( λ t , u ) . Eq. ( 22 ) is because taking the minimum of each term of a sum cannot exceed the minimum of the sum as a whole. Eqs. ( 23 ) and ( 24 ) use the concavity of g with respect to λ , and the definition of max , respectiv ely . By letting δ = 1 T Regret T , writing the definition of regret for the λ -player , and using ` t ( λ ) = − g ( λ , u t ) , we hav e 1 T T X t =1 g ( λ t , u t ) + δ = 1 T max λ ∈ Λ T X t =1 g ( λ , u t ) ≥ max λ ∈ Λ g λ , 1 T T X t =1 u t ! ≥ min u ∈U max λ ∈ Λ g ( λ , u ) , where the second and third inequalities use con vexity of g with respect to u and definition of min , respectiv ely . Combining yields min u ∈U g 1 T T X t =1 λ t , u ! ≥ min u ∈U max λ ∈ Λ g ( λ , u ) − δ, and also max λ ∈ Λ g λ , 1 T T X t =1 u t ! ≤ max λ ∈ Λ min u ∈U g ( λ , u ) + δ, completing the proof. 11 C Proof of Theor em 3.3 Let v be the value of the game in Eq. ( 7 ): v = min µ ∈ ∆(Π) dist( z ( µ ) , C ) , (25) and let ` t ( λ ) = − λ · ˆ z t (i.e., the loss function that OGD observes). Lemma C.1. F or t = 1 , 2 , . . . , T we have ` t ( λ t ) = − λ t · ˆ z t ≥ − v − ( 0 + 1 ) . Pr oof. By Eq. ( 5 ) (which must hold by Lemma 3.2 ), and by Eq. ( 25 ), there e xists µ ∗ ∈ ∆(Π) such that v = dist( z ( µ ∗ ) , C ) = max λ ∈ Λ λ · z ( µ ∗ ) . Thus, λ t · z ( µ ∗ ) ≤ v since λ t ∈ Λ for all t . By our assumed guarantee for the policy π t returned by the planning oracle, we hav e − λ t · z ( π t ) ≥ − λ t · z ( µ ∗ ) − 0 ≥ − v − 0 . Now using the error bound of the estimation oracle, k z ( π t ) − ˆ z t k ≤ 1 , (26) and the fact that k λ t k ≤ 1 , we hav e ( − λ t · ˆ z t ) + 1 ≥ − λ t · z ( π t ) . Combining completes the proof. Now we are ready to prove Theorem 3.3 . Using the definition of mixed policy ¯ µ returned by the algorithm we hav e dist( z ( ¯ µ ) , C ) = dist 1 T T X t =1 z ( π t ) , C ! = max λ ∈ Λ λ · 1 T T X t =1 z ( π t ) ! (27) = 1 T max λ ∈ Λ T X t =1 λ · z ( π t ) ≤ 1 T max λ ∈ Λ T X t =1 λ · ˆ z t + 1 (28) = − 1 T min λ ∈ Λ T X t =1 ` t ( λ ) + 1 (29) ≤ − 1 T min λ ∈ Λ T X t =1 ` t ( λ ) + 1 + 1 T T X t =1 ( ` t ( λ t ) + 1 + 0 + v ) (30) = v + − 1 T min λ ∈ Λ T X t =1 ` t ( λ ) + 1 T T X t =1 ` t ( λ t ) ! + 2 1 + 0 = v + Regret T (OGD) T + 2 1 + 0 . Here, Eq. ( 27 ) is by Eq. ( 5 ). Eq. ( 28 ) uses Eq. ( 26 ) and the fact that k λ k ≤ 1 . Eq. ( 31 ) uses Lemma C.1 . The diameter of decision set Λ = C ◦ ∩ B is at most 1 . The gradient of the loss function ∇ ( ` t ( λ )) = − ˆ z t has norm at most k z ( π t ) k + 1 ≤ B 1 − γ + 1 . Therefore, setting η = ( B 1 − γ + 1 ) √ T − 1 based on Theorem A.1 , we get Regret T (OGD) T ≤ B 1 − γ + 1 T − 1 / 2 12 D A P P R O P O for feasibility Algorithm 4 A P P R O P O – Feasibility 1: input projection oracle Γ C ( · ) for target set C which is a con vex cone, positiv e response oracle PosPlan( · ) , estimation oracle Est( · ) , step size η , number of iterations T 2: define Λ , C ◦ ∩ B , and its projection operator Γ Λ ( x ) , ( x − Γ C ( x )) / max { 1 , k x − Γ C ( x ) k} 3: initialize λ 1 arbitrarily in Λ 4: for t = 1 to T do 5: Call positi ve response oracle for the standard RL with scalar re ward r = − λ t · z : π t ← P osPlan( λ t ) 6: Call the estimation oracle to approximate long-term measurement for π t : ˆ z t ← Est( π t ) 7: Update using online gradient descent with the loss function ` t ( λ ) = − λ · ˆ z t : λ t +1 ← Γ Λ λ t + η ˆ z t 8: if ` t ( λ t ) < − ( 0 + 1 ) then 9: retur n pr oblem is infeasible 10: end if 11: end for 12: return ¯ µ , a uniform mixture o ver π 1 , . . . , π T D.1 Pr oof of Theorem 3.4 Lemma D.1. If the pr oblem is feasible, then for t = 1 , 2 , . . . , T we have ` t ( λ t ) = − λ t · ˆ z t ≥ − ( 0 + 1 ) . Pr oof. If the problem is feasible, then there exists µ ∗ such that z ( µ ∗ ) ∈ C . Since all λ t ∈ C ◦ , they all hav e non-positive inner product with e very point in C including z ( µ ∗ ) . Since − λ t · z ( µ ∗ ) ≥ 0 , we can conclude that max π ∈ Π R ( π ) = max π ∈ Π − λ t · z ( π ) ≥ 0 . Therefore, by our guarantee for the positiv e response oracle, R ( π t ) = − λ t · z ( π ) ≥ − 0 . Now using Eq. ( 26 ) and the f act that k λ t k ≤ 1 , we hav e ( − λ t · ˆ z t ) + 1 ≥ − λ t · z ( π t ) . Combining completes the proof. The proof of Theorem 3.4 is similar to that of Theorem 3.3 . If the algorithm reports infeasibility then the problem is infeasible as a result of Lemma D.1 . Otherwise, we hav e 1 T T X t =1 ( ` t ( λ t ) + 1 + 0 ) ≥ 0 , which can be combined with Eq. ( 29 ) as before. Continuing this argument as before yields dist( z ( µ ) , C ) ≤ B 1 − γ + 1 T − 1 / 2 + 2 1 + 0 , completing the proof. E Proof of Lemma 3.5 Let C 0 = C × { κ } and q be the projection of ˜ x = x ⊕ h κ i onto ˜ C = cone( C 0 ) , i.e., q = arg min y ∈ ˜ C k ˜ x − y k . Let r be the last coordinate of q . W e prove the lemma in cases based on the value of r (which cannot be negati ve by construction). 13 (a) r > κ (b) 0 < r < κ (c) r = 0 Figure 3: Geometric Interpretation of the proof of Lemma 3.5 Case 1 ( r > κ ): Since q ∈ cone( C 0 ) with r > 0 , there exists α > 0 and q 0 ∈ C 0 so that q = α q 0 . See Figure 3a . Consider the plane defined by the three points ˜ x , q , q 0 . Since the origin 0 is on the line passing through q and q 0 , it must also be in this plane. Now consider the line that passes through ˜ x and q 0 . Note that all points on this line have last coordinate equal to κ , and they are all also in the aforementioned plane. Let v ⊕ h κ i be the projection of 0 onto this line ( v ∈ R d ). 14 Note that the two triangles ∆( ˜ x , q , q 0 ) and ∆( 0 , v ⊕ h κ i , q 0 ) are similar since the y are right triangles with opposite angles at q 0 . Therefore, by triangle similarity , k q 0 k k v ⊕ h κ ik = k ˜ x − q 0 k k ˜ x − q k ≥ dist( ˜ x , C 0 ) dist( ˜ x , ˜ C ) = dist( x , C ) dist( ˜ x , ˜ C ) . Since q 0 ∈ C 0 , we hav e k q 0 k ≤ p (max x ∈C k x k ) 2 + κ 2 , resulting in k q 0 k k v ⊕ h κ ik ≤ p (max x ∈C k x k ) 2 + κ 2 κ = √ 1 + 2 δ ≤ 1 + δ by the choice of κ giv en in the lemma. Combining completes the proof for this case. Case 2 ( r = κ ): Since q ∈ cone( C 0 ) with κ as last coordinate, we hav e q ∈ C 0 . Thus, dist( x , C ) = dist( ˜ x , C 0 ) ≤ k ˜ x − q k = dist( ˜ x , ˜ C ) which completes the proof for this case. Case 3 ( 0 < r < κ ): The proof for this case is formally identical to that of Case 1, except that, in this case, the two triangles ∆( ˜ x , q , q 0 ) and ∆( 0 , v ⊕ h κ i , q 0 ) are now similar as a result of being right triangles with a shared angle at q 0 . See Figure 3b . Case 4 ( r = 0 ): Since q ∈ cone( C 0 ) , q must hav e been generated by multiplying some α ≥ 0 by some point in C 0 . Since all points in C 0 hav e last coordinate equal to κ > 0 , and since r = 0 , it must be the case that α = 0 , and thus, q = 0 . Let q 0 be the projection of ˜ x onto C 0 . See Figure 3c . Consider the plane defined by the three points ˜ x , q = 0 , q 0 . Let q 00 be the projection of ˜ x onto the line passing through q and q 0 . Then k ˜ x − q 00 k ≤ k ˜ x k = dist( ˜ x , ˜ C ) . Now consider the line passing through ˜ x and q 0 . Note that all points on this line hav e last coordinate equal to κ and are also in the aforementioned plane. Let v ⊕ h κ i be the projection of 0 onto this line ( v ∈ R d ). Note that the two triangles ∆( ˜ x , q 00 , q 0 ) and ∆( 0 , v ⊕ h κ i , q 0 ) are similar since they are right triangles with a shared angle at q 0 . Therefore, by triangle similarity , k q 0 k k v ⊕ h κ ik = k ˜ x − q 0 k k ˜ x − q 00 k ≥ dist( ˜ x , C 0 ) dist( ˜ x , ˜ C ) = dist( x , C ) dist( ˜ x , ˜ C ) . The rest of the proof for this case is exactly as in Case 1. F Additional experimental details All the models were trained using the following hyperparameters: policy network consists of 2 -layer fully-connected MLP with ReLU acti vation and 128 hidden units and a A2C learning rate of 10 − 2 . For A P P RO P O , the constant κ ( §3.3 ) is set to be 20 . In the following figures, the performance of the algorithms has been depicted using dif ferent hyperparamters; sho wing av erage and standard de viation ov er 25 runs,. 15 0 2000 4000 6000 8000 10000 12000 14000 16000 samples 0.2 0.4 0.6 0.8 1.0 probability of failure 0 2000 4000 6000 8000 10000 12000 14000 16000 samples 0.35 0.30 0.25 0.20 0.15 0.10 0.05 0.00 average reward 0 2000 4000 6000 8000 10000 12000 14000 16000 samples 0.05 0.10 0.15 0.20 0.25 0.30 0.35 distance from uniform ApproPO eta=1e1, n=10 ApproPO eta=1e0, n=10 ApproPO eta=1e-1, n=10 ApproPO eta=1e-2, n=10 Constraint (a) n = 10 0 2000 4000 6000 8000 10000 12000 14000 16000 samples 0.2 0.4 0.6 0.8 1.0 probability of failure 0 2000 4000 6000 8000 10000 12000 14000 16000 samples 0.35 0.30 0.25 0.20 0.15 0.10 0.05 0.00 average reward 0 2000 4000 6000 8000 10000 12000 14000 16000 samples 0.05 0.10 0.15 0.20 0.25 0.30 0.35 distance from uniform ApproPO eta=1e1, n=20 ApproPO eta=1e0, n=20 ApproPO eta=1e-1, n=20 ApproPO eta=1e-2, n=20 Constraint (b) n = 20 Figure 4: Performance of A P P RO P O using different hyperparameters. The two numbers are learning rate for the online learning algorithm and n ( §3.4 ) respecti vely . In all figures, the x-axis is number samples. The vertical ax es correspond to the three constraints, with thresholds sho wn as a dashed line; for rew ard (middle) this is a lower bound; for the others it is an upper bound. 16 0 2000 4000 6000 8000 10000 12000 14000 16000 samples 0.2 0.4 0.6 0.8 1.0 probability of failure 0 2000 4000 6000 8000 10000 12000 14000 16000 samples 0.35 0.30 0.25 0.20 0.15 0.10 0.05 0.00 average reward 0 2000 4000 6000 8000 10000 12000 14000 16000 samples 0.05 0.10 0.15 0.20 0.25 0.30 0.35 distance from uniform ApproPO (with diversity) eta=1e0, n=10 ApproPO (with diversity) eta=1e-1, n=10 ApproPO (with diversity) eta=1e-2, n=10 Constraint (a) n = 10 0 2000 4000 6000 8000 10000 12000 14000 16000 samples 0.2 0.4 0.6 0.8 1.0 probability of failure 0 2000 4000 6000 8000 10000 12000 14000 16000 samples 0.35 0.30 0.25 0.20 0.15 0.10 0.05 0.00 average reward 0 2000 4000 6000 8000 10000 12000 14000 16000 samples 0.05 0.10 0.15 0.20 0.25 0.30 0.35 distance from uniform ApproPO (with diversity) eta=1e0, n=20 ApproPO (with diversity) eta=1e-1, n=20 ApproPO (with diversity) eta=1e-2, n=20 Constraint (b) n = 20 Figure 5: Performance of A P P R O P O with div ersity constraints using different hyperparameters. The two numbers are learning rate for the online learning algorithm and n ( § 3.4 ) respectively . In all figures, the x-axis is number samples. The vertical axes correspond to the three constraints, with thresholds sho wn as a dashed line; for re ward (middle) this is a lo wer bound; for the others it is an upper bound. 17 0 2000 4000 6000 8000 10000 12000 14000 16000 samples 0.2 0.0 0.2 0.4 0.6 0.8 1.0 1.2 probability of failure 0 2000 4000 6000 8000 10000 12000 14000 16000 samples 0.35 0.30 0.25 0.20 0.15 0.10 0.05 0.00 average reward 0 2000 4000 6000 8000 10000 12000 14000 16000 samples 0.05 0.10 0.15 0.20 0.25 0.30 0.35 distance from uniform RCPO lr_lambda =1e-2 RCPO lr_lambda =1e-3 RCPO lr_lambda =1e-4 Constraint Figure 6: Performance of RCPO using different learning rates for Lagrange multiplier . In all figures, the x-axis is number samples. The vertical ax es correspond to the three constraints, with thresholds shown as a dashed line; for rew ard (middle) this is a lower bound; for the others it is an upper bound. 18
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment