피드포워드 학습을 위한 고정 랜덤 목표 투사
본 논문은 지도학습에서 원-핫 레이블을 고정된 랜덤 매트릭스로 투사하여, 역전파의 가중치 전송과 업데이트 락을 제거하고, 레이어별로 순전파만으로 가중치를 갱신할 수 있는 Direct Random Target Projection(DRTP) 알고리즘을 제안한다. 실험 결과 DRTP가 기존 Feedback Alignment(FA)·Direct Feedback Alignment(DF‑A)보다 메모리·연산 비용이 낮으며, MNIST·CIFAR‑10 수준…
저자: Charlotte Frenkel, Martin Lefebvre, David Bol
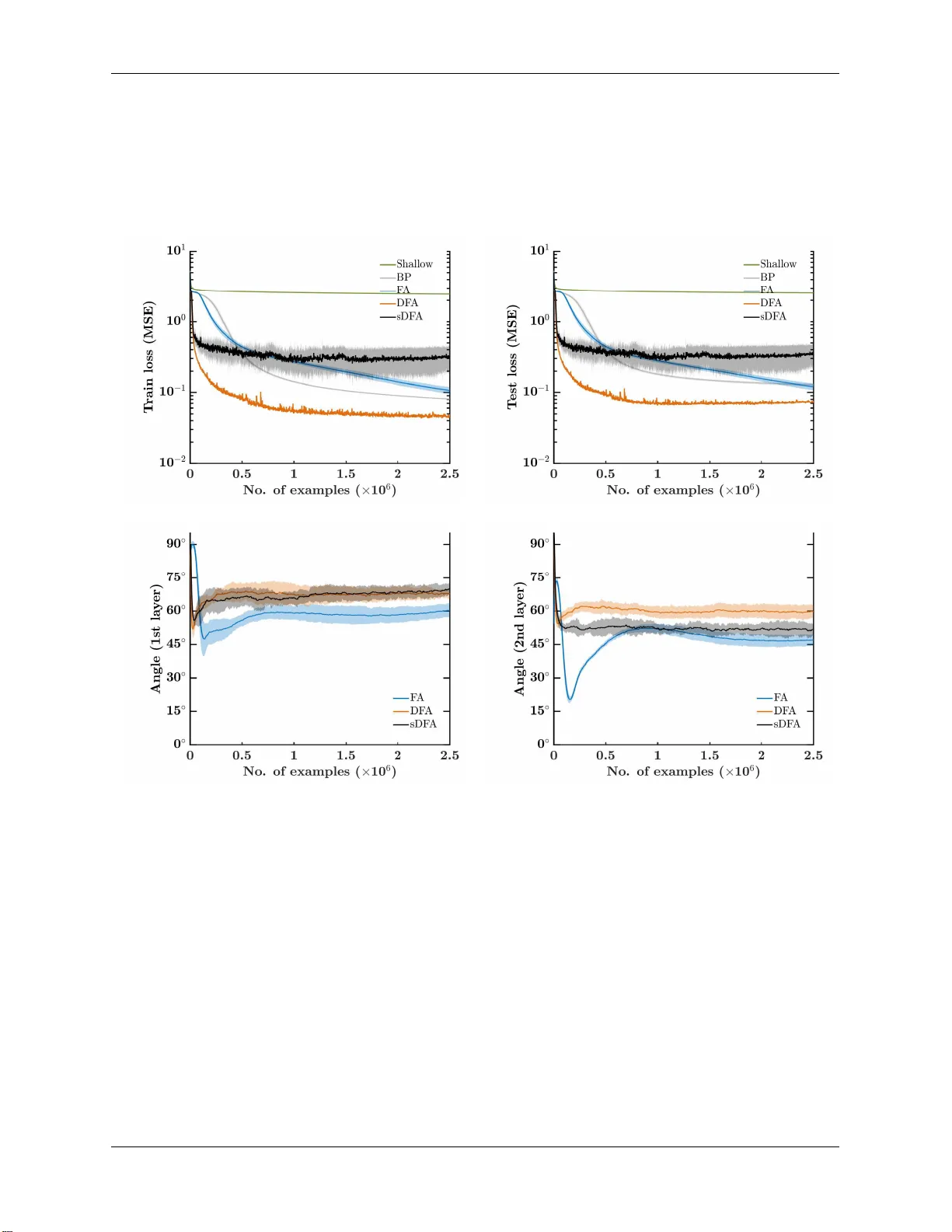
본 논문은 딥 뉴럴 네트워크 학습에 필수적인 역전파(back‑propagation, BP)의 두 가지 근본적인 한계—가중치 전송(weight‑transport) 문제와 업데이트 락(update‑locking) 문제—를 동시에 해결하고자 한다. 기존 연구에서는 무작위 고정 가중치를 이용한 Feedback Alignment(FA)와 Direct Feedback Alignment(DF‑A) 등이 가중치 전송 문제를 완화했지만, 여전히 역전파 단계에서 전체 네트워크를 순전파한 뒤에야 가중치를 업데이트할 수 있어 메모리 버퍼링이 필요했다.
저자들은 지도 학습에서 레이블이 원‑핫 인코딩된 벡터라는 점에 주목한다. 이 레이블은 실제 오류(예측값‑레이블)의 부호와 동일한 정보를 담고 있기 때문에, 레이블 자체를 “오류 부호”의 대체물로 사용할 수 있다. 이를 바탕으로, 레이블 y*를 고정된 랜덤 매트릭스 Bₖ에 투사하고, 그 부호(sign)만을 각 은닉층 k에 전달한다. 이 과정을 Direct Random Target Projection(DRTP)이라 명명한다.
수식적으로는 다음과 같다.
- 입력 x가 첫 번째 은닉층에 들어가면 z₁ = W₁x + b₁, y₁ = f₁(z₁)
- 각 은닉층 k에 대해 모듈레이션 신호 δyₖ = sign(y*·Bₖ) 를 계산한다.
- 가중치 업데이트는 ΔWₖ = −η · δyₖ · yₖ₋₁ᵀ 로, 순전파 직후 바로 수행된다.
이때 δyₖ는 BP가 제공하는 정확한 그래디언트 δzₖ와 90° 이내의 각을 유지한다는 것이 실험적으로 확인되었다. 즉, 오류 부호만으로도 충분히 “정렬(alignment)”된 신호를 제공해 학습이 가능하다.
실험은 두 가지 과제로 구성된다.
1) **회귀**: 256‑차원 입력을 받아 10개의 비선형 코사인 함수를 근사하는 256‑100‑100‑3 네트워크. 여기서는 BP, FA, DF‑A, sDF‑A(오류 부호만 사용)와 비교했으며, sDF‑A가 초기 수렴이 빠르고, 모든 알고리즘이 90° 이내의 정렬을 유지함을 확인했다.
2) **분류**: 16×16 픽셀 이미지 10 클래스를 구분하는 256‑500‑500‑10 네트워크. DF‑A가 가장 낮은 오류(0.05%)와 빠른 수렴을 보였지만, DRTP는 메모리·연산 비용이 현저히 낮음에도 불구하고 BP와 FA에 근접한 정확도(≈1.8% 오류)를 달성했다. 또한 테스트 정확도에서도 과도한 오버피팅 없이 안정적인 성능을 유지했다.
하드웨어 측면에서 DRTP는 다음과 같은 장점을 제공한다.
- **가중치 전송 제거**: 고정 랜덤 매트릭스 Bₖ는 학습 중 변하지 않으므로, 전방 가중치와 역방향 가중치를 동일하게 유지할 필요가 없다.
- **업데이트 락 해소**: 각 층은 순전파가 끝나는 즉시 가중치를 업데이트할 수 있어, 전체 네트워크를 버퍼링할 필요가 없으며 메모리 요구량이 크게 감소한다.
- **연산 단순화**: 오류 부호는 부호 연산만 필요하고, 랜덤 매트릭스와의 곱셈은 사전 계산된 고정값이므로, 저전력 마이크로컨트롤러나 이벤트‑드리븐 ASIC에 적합하다.
저자들은 이러한 특성을 활용해, DRTP 기반의 이벤트‑드리븐 컨볼루션 프로세서를 설계했으며, 기존 대비 16.8% 전력·11.8% 실리콘 면적 절감 효과를 입증했다. 이는 DRTP가 실제 임베디드·뉴로모픽 시스템에 적용 가능함을 실증한다.
또한, DRTP는 세 가지 요인 학습 규칙(three‑factor learning rule)과도 일맥상통한다. 전역적인 “오류 부호”가 전역 모듈레이터 역할을 하고, 로컬 프리‑포스트 시냅스 활동과 결합해 가중치를 조정한다는 점에서 생물학적 plausibility를 갖는다.
결론적으로, DRTP는 (1) 가중치 전송 문제 완전 해소, (2) 레이어별 업데이트 락 제거, (3) 오류 부호만으로 충분한 학습 신호 제공, (4) 저전력·저메모리 엣지 디바이스에 최적화된 구조라는 네 가지 핵심 기여를 한다. 향후 연구에서는 더 복잡한 데이터셋(ImageNet)이나 스파이킹 뉴럴 네트워크에 적용해 성능 한계를 탐색하고, 하드웨어 구현을 통한 실시간 학습 시스템 구축이 기대된다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기