Learning without feedback: Fixed random learning signals allow for feedforward training of deep neural networks
While the backpropagation of error algorithm enables deep neural network training, it implies (i) bidirectional synaptic weight transport and (ii) update locking until the forward and backward passes are completed. Not only do these constraints precl…
Authors: Charlotte Frenkel, Martin Lefebvre, David Bol
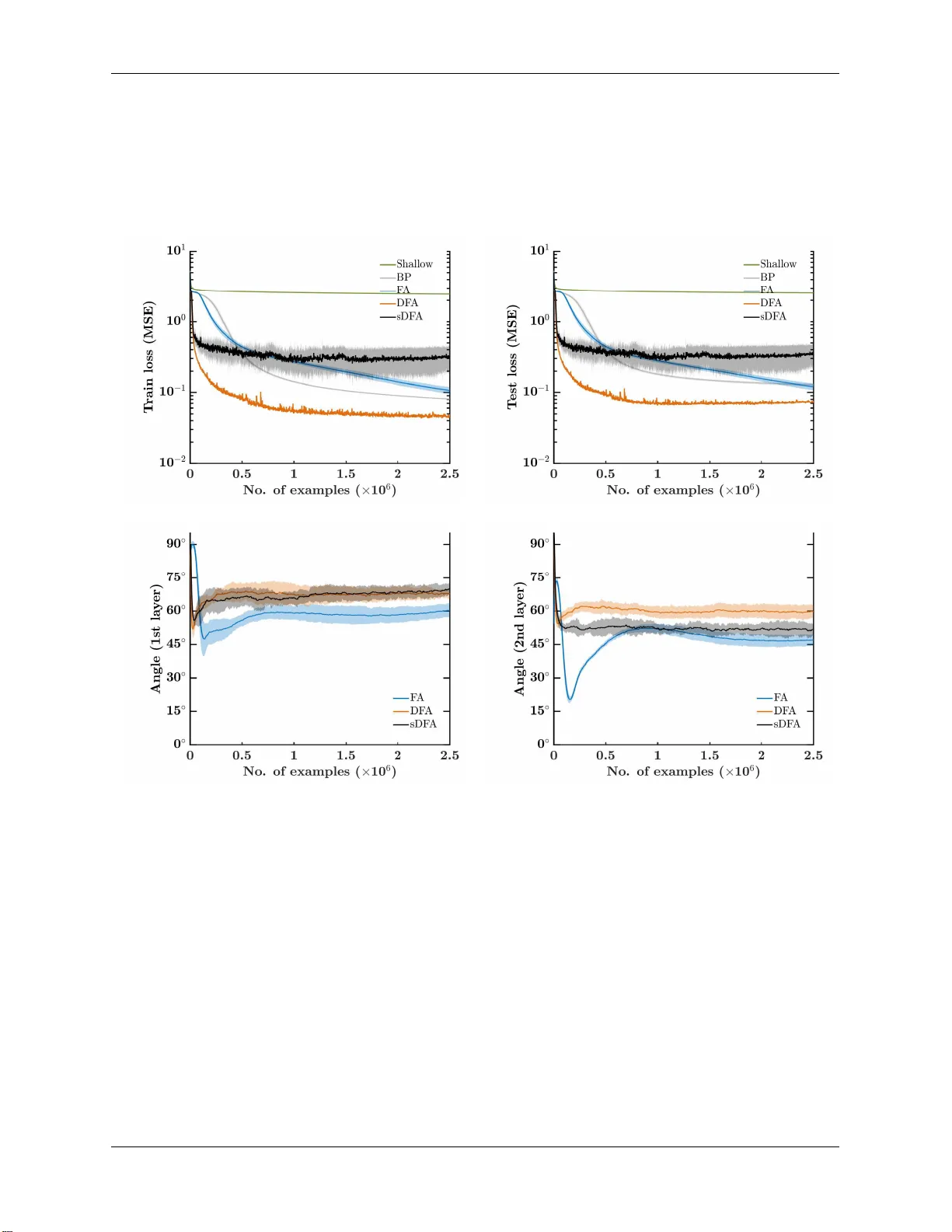
This paper has been accepte d for publication in the F r ontiers in Neur oscience jour n al. The fully-e dited paper is a vailable at https: //www. frontiersin.org/articles/10.3389/fnins.2021.629892 , with DOI 10.33 89/fnins.2 021.629892. L E A R N I N G W I T H O U T F E E D B A C K : F I X E D R A N D O M L E A R N I N G S I G N A L S A L L O W F O R F E E D F O RW A R D T R A I N I N G O F D E E P N E U R A L N E T W O R K S Charlotte Frenkel ∗† ICTEAM Institute Université catholique de Lou vain Louvain-la-Neuve BE-1348 , Belgium charl otte@i ni.uzh.ch Martin Lefebvre ∗ ICTEAM Institute Université catholique de Lou vain Louvain-la-Neuve BE-1348 , Belgium marti n.lefe bvre@uclouvain.be David Bol ICTEAM Institute Université catholique de Lou vain Louvain-la-Neuve BE-1348 , Belg ium david .bol@u clouvain.be A B S T R AC T While the backprop agation o f error algorithm enables deep neural network training, it imp lies (i) bidirection al synaptic weight transport and (ii) update lo cking until the forward an d ba ckward passes are completed . Not only do th e se c o nstraints preclud e biolog ic a l plausib ility , but they also hinder the development o f low-cost ad aptiv e smart sensors at the edge, as they severely constrain m emory accesses and entail buf ferin g ov erh ead. In this work, we show that the one-ho t-encoded labels provided in supervised classification pr oblems, denoted as targets, can be viewed as a proxy for the error sign. Therefo re, their fixed random projection s enable a layerwise feedfo r ward training of the hid den laye r s, thus solving the weight transport and upd ate loc king p r oblems wh ile relaxing the compu tational and memory requirem ents. Based o n these obser vations, we p ropose the direct random target pr ojection (DR TP) algor ithm and d emonstrate that it provid es a tradeo ff between accuracy an d compu tatio nal cost that is suitable for adaptive edg e co mputing d evices. Index terms – Backpropag ation, deep n eural networks, weight transport, update loc k ing, edge co m puting, bio lo gically- plausible learnin g. 1. Intr oduction Artificial neural ne tworks (ANNs) wer e propo sed as a first step tow ard bio-inspire d computation by emu la tin g th e way the brain p rocesses information with densely-inter connected neu rons and synapses as comp utational and m emory elements, re spectiv ely [1, 2]. In order to train ANNs, it is nece ssary to identif y how much each neu ron contributed to the output err o r , a problem re f erred to as the cr edit a ssignment [3]. The back propag ation o f er ror (BP) algorithm [4] allowed solvin g the cr e d it assignment pro blem f or multi-laye r ANNs, thus enabling the dev elop ment of d eep networks for applications rangin g from comp uter vision [5, 6, 7] to n atural language processing [8, 9]. Howev er, two critical issues preclud e BP f rom being biologically plausible. ∗ These authors contributed equally . † C. Frenkel was with Univ ersité catholique de L ouv ain as a Research Fel l o w f rom the National Foundation for Scientific Research (FNRS) of Belg ium. She is no w with the Institute of Neuroinformatics, Uni versity of Zürich an d ET H Zürich, Switzerland. Learning without feedb ack: Direct random target p rojection C. Frenkel, M. Lefebvre and D. Bol First, BP requires symm etry between th e forward and backward w e ights, which is kn own as th e weight tr an sport pr ob- lem [10]. Beyond imply ing a p erfect and instantaneous commun ication of para m eters b e tween th e feedforward and feedback pathways, erro r b ackprop agation requires each layer to have full knowledge of all the weights in the down- stream layers, m aking BP a non-lo cal algorith m for both weigh t an d er ror information . From a hardware ef ficien cy point of v iew , th e weight sym metry requirem ent also severely constrain s memory access p a tter ns [11]. Therefo re, there is an increasin g interest in developing training alg orithms that relea se this constraint, as it has been shown th a t weight symmetry is not m andatory to re ach near-BP pe rforman ce [ 1 2]. T he f eedback align ment (F A) algo rithm [13], also called rando m b ackprop agation [14], demonstrates th at using fixed random weigh ts in th e feed back pathway al- lows con veying useful erro r gradient inform a tion: the network learns to alig n the for ward weig hts with the bac kward ones. Direct fe e d back a lig nment (DF A) [15] builds on these results an d directly pr opagates the error between the network pr edictions and the tar gets (i.e. one-h ot-encod ed labels) to each hidden layer thro ugh fixed random con nec- ti vity matrices. DF A demonstrates a limited accuracy penalty compared to BP on the MNIST [16] and CIF AR-10 [17] datasets, w h ile using the o u tput error as a global modulator and keepin g weig ht informa tio n local. Th erefore, DF A bears imp ortant structur a l similar ity with learning r u les that are believed to take place in the brain [1 8, 19], known as three-factor synaptic plasticity rules, which rely on local pr e- an d post-synap tic spike-based activity tog ether with a global modulatio n [ 2 0]. Finally , an other ap proach fo r solv ing the weigh t tran sp ort pro blem con sists in com puting targets for eac h lay e r instead o f gr adients. T he target values can either be comp uted based o n au to-encod ers at e a ch layer [21] or genera te d by ma king use of the p re-activ ation of the current lay er and the error o f the next layer, pro p- agated thro ugh a d edicated trainable feed back pathway [22]. The BP , F A and DF A algo rithms are summa r ized in Figures 1A–1C, respectively . The second issue of BP is its requiremen t for a full f orward pass befo re param eters can be u pdated during the back- ward pass, a pheno menon ref erred to as up date locking [ 23, 24]. Beyond making BP biolo gically implausible, upd ate locking has c ritical implications fo r BP implemen tation as it requir es buffering all th e layer in p uts and activ ations during th e forward and back ward p asses in o r der to compu te the weight updates, leading to a high m emory overhead. As the previously-describ ed F A and DF A so lutions to the weight tr ansport pro blem only tackle the weight locality as- pect, specific tech niques enab ling local error handling or gradient ap p roximatio n are requir ed to tack le u p date loc k ing. On the one hand, the err or loca lity appr oach relies o n layerwise loss fun ctions [25, 26, 2 7, 28], it enables tr aining layers indepe n dently a n d without requirin g a forward pa ss in the en tire network. The genera tion o f local errors can be achieved with auxiliar y fixed ran dom classifiers, allowing for near-BP perfo rmance on the MNIST and CIF AR-10 datasets [ 25]. T h is strategy has also been po rted to a biologically- p lausible spike-based th ree-factor synap tic p lasticity rule [26]. Scaling to Image Net [2 9] re q uires either the use of two combined layerwise loss functions [27] or a parallel optimization of a greedy objective using deep er au xiliary classifiers [28]. Howe ver, the error locality appr oach still suffers from u pdate lockin g at the lay er scale as layerwise f orward and b ackward passes ar e re q uired. Beyond imply- ing a com putational overhead, the auxiliary classifiers also suffer f rom the weight transpo rt pr oblem, a r equiremen t that can on ly be partially relaxed: in order to maintain p erform a nce, it is necessary to keep at least the weig ht sign informa tio n during the lay erwise back ward p asses [25]. On the other hand, th e synthetic g radients appr oa ch [23, 24] relies o n lay erwise pred ictors of subsequent network com putation. Howe ver , training local gr a d ient pre d ictors still requires backpr opagating gra d ient information f rom deeper layers. In order to fully solve both th e weigh t transpor t and the upda te locking pro blems, we pro pose the direct rand om tar- get pro jection (DR TP) algo rithm (Fig. 1D). Co m pared to DF A, the targets are used in place of the o utput erro r and projected onto the hid den layers. W e demon strate b oth theoretica lly and experimentally that, in the framework of classification problems, the error sign inform a tion co ntained in the targets is sufficient to maintain feedb ack alignmen t with th e loss g radients δ z k for th e weigh ted sum of inp uts in laye r k , d enoted as the mod ulatory sign als in the subse- quent text, and allows training m ulti-layer networks, leading to thr ee key advantages. First, DR TP solves the weight transport pro b lem by entirely rem ovin g the need fo r d edicated f eedback pathways. Second , layers can be upd ated indepen d ently and witho ut u p date lock ing as a full forward pass is n ot r e quired, thu s redu cing memor y requ irements by releasing the need to buffer inpu ts and ac ti vations of eac h layer . Third , DR T P is a purely f eedforward an d lo w-cost algorithm whose updates rely on layerwise info rmation that is imm ediately available upo n comp utation o f the lay er outputs. Estimating the lay erwise loss gradients δ y k only req uires a label- d ependen t r andom vector selection, contrast- ing with the error locality a nd synthetic gra dients ap proache s that requir e the addition of side networks for erro r o r gradient prediction. DR TP ev en compares fa vorably to DF A, as the latter still requires a m ultiplication between the output error and a fixed rand om matr ix. Therefo re, DR TP allows re la x ing struc tu ral, mem o ry and comp utational requirem ents, yet we demonstrate th a t, co m- pared to BP , F A and DF A, DR TP is id eal fo r im plementation in ed ge-comp uting devices, thus enablin g adap tation to uncon tr olled en vir onments wh ile meeting stringen t power a n d resource constrain ts. Suitable applica tio ns fo r DR TP range from distributed smart sensor networks for th e Internet-o f-Thing s (IoT) [30] to em bedded systems and cog ni- ti ve rob otic ag ents [31]. The MNIST and CIF AR-10 da ta sets hav e thus been selected fo r benchma rking a s they are 2 Learning without feedb ack: Direct random target p rojection C. Frenkel, M. Lefebvre and D. Bol W 3 BP F A DF A DRTP B k e T x y 1 y * e = W k+1 z k+1 T J y k A B C D B k z k+1 T B k y * T y k W eight-transpor t-free Update-unlocked ✓ ✕ ✓ ✓ ✓ ✕ ✕ ✕ y 3 y 2 z k = W k y k-1 + b k y k = f k ( z k ) z k = y k ⊙ f k ( z k ) ' Lay er equations x x x y * y * y * y 2 y 3 y 1 y 1 y 1 y 2 y 2 y 2 y 3 y 3 y 3 e e e y 1 y 3 y 3 y 3 y 2 y 1 y 2 y 1 y 2 y 1 W 2 W 1 W 3 T W 2 T W 1 W 2 W 3 W 3 W 3 W 2 W 2 W 1 W 1 B 2 T B 1 T B 2 T B 1 T B 2 T B 1 T Figure 1: The proposed direct random ta rget projection a lg orithm builds o n feedback-alig nment- based alg o- rithms to tackle the weight transport problem while further releasing update locking. Black arrows indicate the feedfor ward pathways an d orang e arrows the feedback pathways. In the k -th layer, the weighted sum o f inputs y k − 1 is denoted as z k , th e bias as b k , th e acti vation function as f k ( · ) and its der i vati ve as f ′ k ( · ) , with k ∈ [1 , K ] , k ∈ N , and K the n u mber of layers. Trainable forward weigh t matrices ar e de noted as W k and fixed random co nnectivity matrices as B k . The input vector is den oted as x , the target vector as y ∗ and the loss f unction as J ( · ) . Th e estimated loss gr a dients for the o utputs of th e k -th hidden lay er , deno ted as δ y k , ar e provided f o r ea ch training alg orithm. The layer equatio ns fo r z k , y k and δ z k , d efined as the modulator y sign als, ar e p rovided in the upper left co rner, with ⊙ denoting the elem e ntwise mu ltiplication o perator . (A) Backprop agation of er ror (BP) alg orithm [4]. (B) Feedback alignment (F A) algorith m [13]. (C) Direct feedb ack alignmen t ( DF A) algo rithm [15]. (D) Pr o posed direct random target p rojection (DR TP) alg orithm. Adapted from [15] and [24]. representative of the complexity level requ ir ed in auto n omous always-on adaptive edge computing , which is not the case of larger and mor e challen ging datasets such as Image Net. This fu rthermor e h ig hlights that edg e co mputing is an ideal use case for bio logically-mo ti vated algorithms, as an out-of-th e-box application of feedback-a lignment- and target-prop a gation-based algorithm s curren tly does not scale to complex d atasets (see [32] for a recent r evie w). W e demonstra te this claim in [33] with the d e sign of an event-driven con volutional processor that req uires o nly 16.8- % power an d 1 1 .8-% silicon area overheads f or o n-chip o nline learnin g, a recor d-low overhead that is specifically enabled by DR TP , thus highligh tin g its low co st for edge computin g devices. Finally , as DR T P ca n also be fo rmulated as a th ree- factor learning rule for biologically-pla u sible learning, it is suitable for embedded neurom orphic comp u ting, in which high-d ensity synap tic p lasticity can curr e ntly no t be achiev ed without comp romising learn ing performan ce [34, 35]. 2. Results 2.1. W eight updates based only o n the error sign provide learning to multi-layer networks. W e demon strate with two experimen ts, respectively on a r egre ssion task an d a classification problem, that modulato ry signals b ased only on the err or sign are within 90 ◦ of those prescrib ed b y BP , thus providing learning in multi-lay er networks. T o do so, we use an error-sign-based version of DF A, su bsequently denoted as sDF A, in which the err or vector is replaced by the error sign in th e global feedback pathway . 2.1.1. Regression This first experiment aims at d emonstrating that the error sign provid es usefu l modu latory sign a ls to multi-layer net- works by com paring training algorithm s on a regression task. The ob jecti ve is to appr o ximate 10 no nlinear func tions T j ( x ) = co s ( x + φ j ) , wh ere φ j = − π / 2 + j π / 9 f or j ∈ [0 , 9 ] , j ∈ N 0 and x denote s the mean o f x , a 256-d imensional vector wh ose entr ies ar e drawn f rom a no rmal distribution with a mean lying in [ − π , π ] (see Section 4). A 256 -100- 100- 3 Learning without feedb ack: Direct random target p rojection C. Frenkel, M. Lefebvre and D. Bol A B C D Figure 2: Error -sign-ba sed dir ect f e edback alignment ( sDF A) provides useful modulat ory signals in regression tasks. A 256- 100-10 0-10 network with tanh hidden and o utput units is tr ained to learn cosine f unctions with five training algorithms: shallow learning , BP , F A, DF A an d sDF A. W ith this simple setup, BP and F A suffer from the vanishing gradients pr oblem, which would be alleviated by usin g ReLU-ba sed networks with batch norma liza tio n. The sco p e of th e figu re is to high light that sDF A provides usef ul modulato ry signals for r egression tasks, withou t any additional tech nique. As fo r other feedback -alignmen t- based algorithms, sDF A upd ates are within 90 ◦ of th e backpr o pagation upda tes. The train and test losses and the alignment angles are monitored every 1k sam p les, er ror bars are on e stan dard deviation over 10 ru ns. Angles have been smoo thed by an exponentially - weighted moving av erag e filter with a momentu m coefficient of 0.95. ( A) M e a n squ ared error loss o n th e 5k -example training set. (B) Mean squ ared error lo ss on the 1k -example test set. ( C) Angle between the mo dulatory signals δ z k prescribed b y BP and b y feedback - alignment- b ased alg orithms in the first hidd en layer . (D ) Angle between the mo dulatory signals δ z k prescribed by BP an d by fe edback-alig nment-b a sed algorithm s in the secon d hidden layer . 4 Learning without feedb ack: Direct random target p rojection C. Frenkel, M. Lefebvre and D. Bol 10 fu lly-conn ected network is tr a ined to app roximate T ( · ) with five training algorithm s: shallow lear n ing (i.e. froz en random hidden layers and a train ed output layer), BP , F A, DF A and sDF A. The mean squared error (M SE ) lo ss on the training set is sh own in Figu re 2A. While shallow learnin g fails to learn a meaningf ul appro x imation of T ( · ) , sDF A an d DF A show the fastest initial conver gen ce due to the separate direct f eed- back pathway p recluding g radients from vanishing, wh ich is cle a r ly an issue for BP and F A. Altho ugh th is would be alleviated b y using ReLU-based networks with batch norm alization [ 36], it highligh ts that direct-feedb ack-alignm e nt- based me th ods do n ot n eed further tech niques such as batch no r malization to a d dress this issue, ultimately lea ding to reduced hard ware requ irements. While DF A de m onstrates the hig h est per formanc e on this task, sDF A comes ea r lier to stag nation as it does not account fo r the outp u t error m agnitude red uction as training prog resses, thus pr e venting a reduction of th e effecti ve lea rning rate in the hidden laye rs as the output error decreases. sDF A cou ld there fore bene fit from the use of a learnin g rate sch e duler . Sim ilar co nclusions h old fo r th e loss o n th e test set ( Figure 2B). Th e an gle between the modu latory sign a ls pr escribed by BP an d by feedback-alig nment-ba sed algorith ms is shown in Figures 2C and 2D for the first a n d second h idden layers, respectively . While all feedba ck-alignme n t-based algorithms lie clo se to each other with in 90 ◦ of the BP mod ulatory sig n als, F A h as a clear advantage du ring the first 100 epoch s o n the 5k-example training set. sDF A p erforms on p ar with DF A in th e first hid den layer, while it surprisingly provides a better alignmen t th an DF A in the secon d hidden layer , tho u gh n ot fully leveraged due to the absence of mod ulation in the magnitud e of the update s from the outp u t er ror . 2.1.2. Classification W ith this seco nd experiment, we demon strate that, in addition to pr oviding useful modulatory sig n als for regression problem s, the err or sign info rmation allows tr a ining multi-layer networks to solve classification problem s. T he task consists in training a 256- 500-5 0 0-10 network to solve a synthetic classification problem with 16 × 1 6-pixel images and 10 classes; the data to c la ssify is generated automatically with th e Python sklea rn library [37] (see Section 4). As for regression, the network is trained with shallow learning, BP , F A, DF A an d sDF A. Figure 3A shows that, af ter 5 00 epochs with a 25k-examp le train ing set, DF A p rovides the fastest and most ac c u rate training with a classification error of 0.05%, followed by BP , F A an d sDF A with 0 .19%, 0. 6 4% an d 1.54%, respectively . Shallow learnin g lags almost an order of m a g nitude beh ind with 8.95 %. Howe ver , Figu re 3B shows that DF A also ha s a hig her overfitting and lies close to sDF A on th e test set, with 3.48 % and 4.0 7%, r e spectiv ely . The lowest classification errors are of 1.85% f or BP and 1 .81% fo r F A, wh ile shallow lea r ning lag s b ehind at 9. 57%. The angle between the modulato ry sign als prescrib e d by BP and by fee d back-align ment-based algorith ms is shown in Figures 3C and 3D, for the fir st an d seco nd hidd en layer s, re spectiv ely . As for th e regression task, all feedback- alignment-b ased algorithms exhibit alignmen ts close to each other , while the co n vergence of BP and F A is slowed down by the vanishing grad ients problem . Here, alignmen ts tend to level off after 5 0 e pochs, with th e lowest an g le provided by F A, fo llowed by DF A and sDF A. As sDF A is always within 90 ◦ of the BP modu latory signals, it is able to train multi-lay e r n etworks. 2.2. For classification, a fe e dback pathway is no longer required as t he error sign is known in advance In the framework of classification p roblems, training examples ( x , c ∗ ) con sist of an inp ut data sample to classify , denoted as x , and a lab e l c ∗ denoting th e class x belon gs to, amon g C possible classes. The target vector, denoted as y ∗ , co rrespond s to the o ne-hot- e ncoded class label c ∗ . Th e ou tput layer non lin earity mu st b e chosen as a sigmoid or a sof tmax functio n , yielding ou tput values that ar e strictly boun ded between 0 and 1 . Deno ting the outpu t vector o f a K -layer network as y K , the erro r vector is defined as e = y ∗ − y K . Under the aforementio ned cond itions, it results that the c -th entry o f the C -dimensional error vector e , denoted e c , is defined as e c = 1 − y K c if c = c ∗ , − y K c otherwise. As the entries of y K are strictly boun ded b e twe en 0 and 1, the error sign is g i ven by sign ( e c ) = 1 if c = c ∗ , − 1 otherwise. Due to the no nlinearity in the o utput lay er forcing the outp ut values to r emain strictly boun ded between 0 and 1 , the error sign is class-depend ent and known in advance as training examples ( x , c ∗ ) a lready p rovide the erro r sign informa tio n with th e label c ∗ . A feed back pathway is thus no lon ger requir e d as we h ave shown that the error sign allows provid ing useful modulato ry signals to train mu lti-layer n etworks. Therefo re, beyond bein g free fr o m the weight transport pr oblem as DF A, sDF A also allows re leasing update locking and the associated memory overhead in classification problem s. 5 Learning without feedb ack: Direct random target p rojection C. Frenkel, M. Lefebvre and D. Bol A B C D Figure 3: Error-sign-based direct feedback alignment (sDF A) provides useful modulatory signals in classifica- tion t asks. A 256 -500- 5 00-10 network with tanh hidd en u nits an d sigmoid outp ut units is tra in ed to classify a synthetic dataset of 16 × 16-pixel imag e s into 10 classes with fi ve training algor ithms: shallow learn ing, BP , F A, DF A and sDF A. W ith this simple setu p, BP and F A suffer from the vanishing gradien ts pro blem, which would be alleviated by using ReLU-based networks with batch no rmalization. Th e scope of the figur e is to high light that sDF A p rovides u seful mod- ulatory signals for classification tasks, witho ut any additional technique. The update directions of th e sDF A alg orithm are within 90 ◦ of the backpropag ation up dates and are comparable to o ther feedb ack-alignm ent-based algor ithms. The train and test losses an d the alignment ang les are monito red every 2.5k samples, err or bars are one standard deviation over 10 runs. Angles have been sm o othed by an exponen tially-weighted moving average filter with a momentum co - efficient of 0.9 5. (A) Error o n the 25k -example tr aining set, reach ing on average 0.19 % for BP , 0.6 4% for F A, 0 .05% for DF A, 1. 5 4% for sDF A and 8.9 5% for shallow le a r ning after 500 epochs. ( B) Er r or on the test set, rea c hing on av- erage 1.85% for BP , 1.81 % for F A, 3.48 % for DF A, 4.07% f or sDF A an d 9.5 7% f or shallow le a r ning after 5 0 0 epo chs. (C) Angle between the mo dulatory sign als δ z k prescribed b y BP an d b y f eedback- alignment-b ased algorithm s in the first hidden la y er . (D) Angle betwee n the mod ulatory signals δ z k prescribed by BP and by fe e dback-alig nment-ba sed algorithm s in the second h id den layer . 6 Learning without feedb ack: Direct random target p rojection C. Frenkel, M. Lefebvre and D. Bol Algorithm 1 Pseudoco de for the direct random target projection (DR TP) algo rithm. k ∈ [1 , K ] , k ∈ N , d e- notes the lay er index and W k , b k , B k and f k ( · ) denote th e train able for ward weights an d biases, the fixed rando m connectivity matrices and the acti vation f u nction of th e k -th hidden lay er , respecti vely . The weighted sum of inputs or pre-activation is d e n oted as z k and the layer output o r post-activation is d enoted as y k , with y 0 correspo n ding to the input x . The o ne-hot-e n coding of la b els am ong C o utput classes is denoted as y ∗ and the learning rate as η . The up date for the weights an d b iases in the outpu t layer are computed f or sigmoid/softmax o utput units with a binary/catego r ical cross-entro py loss. for ( k = 1; k ≤ K ; k = k + 1) do z k ← W k y k − 1 + b k y k ← f k ( z k ) if k < K then W k ← W k + η B T k y ∗ ⊙ f ′ k ( z k ) y T k − 1 b k ← b k + η B T k y ∗ ⊙ f ′ k ( z k ) else W K ← W K + η C ( y ∗ − y K ) y T k − 1 b K ← b K + η C ( y ∗ − y K ) end if end for 2.3. Direct ra ndom target pr o j ection deliv ers useful modulat o ry signals for cla ssification This section provides the g round s to show why the prop o sed d ir ect rando m target projectio n (DR T P) algo rithm delivers useful mod u latory sign als to multi-laye r networks in the fr amew or k of classification p roblems. First, we show how DR TP can be viewed as a simplified version of sDF A in wh ich the target vector y ∗ is used as a surrog ate f or the err or sign. Next, we demon strate m athematically th at, in a mu lti- la y er network comp osed of linear hidden layer s and a nonlinear o utput lay er , th e mo dulatory sign als pr e scr ibed by DR T P and BP ar e always within 9 0 ◦ of each other, thus providing lea rning in multi-la y er network s. DR TP is a simplified version of error-sign-based DF A. As we have shown that sDF A solves bo th th e weight transport an d the u pdate locking problem s in classification tasks, we propo se the direct r a n dom target p rojection (DR TP) algorith m, illustrated in Fig. 1 D and written in pseud ocode in Algorithm 1, as a simplified version of sDF A that enhances both perform ance an d com putational efficiency . In sDF A, the feed back signal rando mly p rojected to the hidden layers is the sign of the error vecto r e = y ∗ − y K , while in DR TP , this fe edback signal is replac e d by the target vector y ∗ . Being a one-h ot encod ing of c ∗ , y ∗ has a single positive entry cor respondin g to the co rrect class and ze r o entries elsewhere: y ∗ c = 1 + sign ( e c ) 2 = 1 if c = c ∗ , 0 other wise. Thus, y ∗ correspo n ds to a surr ogate f or the error sign vector used in sDF A, wher e shift an d rescaling o p erations have been app lied to sign ( e ) . As the co nnectivity matrices B k in the DR T P gradients δ y k = B T k y ∗ are fixed and random (Figu r e 1D), they can be v iewed as co mprising the rescalin g operation . On ly the shift o peration applied to sign ( e ) makes a critical difference between DR TP and sDF A, wh ich is fav orable to DR TP fo r two reasons. First, DR TP is compu tationally ch eaper than sDF A. Ind eed, projectin g the target vector y ∗ to the hidden layers th rough fixed random connectivity m atrices is eq uiv alent to a label-d ependen t selection o f a layerwise r a ndom vector . On the contrary , sDF A requires m ultiplying the erro r sign vector with th e fixed rando m connectivity matrices for each training example, as all e n tries of the error sign vector ar e non- zero. Second, experiments on the MNI ST and CIF AR- 10 datasets show th at DR TP systematically outp erforms sDF A (Supplem entary Figur es S1A and S2 A, Supplemen ta r y T ables S1 and S2). Indee d, when the feedback infor mation on ly relies o n the er ror sign and no long er on its magnitude, the weight up d ates becom e less selecti ve to the useful information : as all entries o f th e er r or sign vector have unit norm, th e C − 1 entries co rrespond ing to incorrect classes outweigh the single entry associated to the correct class and degrade the alignment (Supplemen tary Figures S1B an d S2B). 7 Learning without feedb ack: Direct random target p rojection C. Frenkel, M. Lefebvre and D. Bol W k W k+1 W k-1 y k y k-1 y * B k-1 T B k T La yer k-1 La yer k Figure 4: Network o f DR TP-updat ed linear hidden layers co nsidered in the cont ext of the mat hematical proof of alignment between the DRTP a nd BP modulatory signals. The same co n ventions as in Figure 1 are used. The directions of the DRT P a nd BP modulatory signals are within 90 ◦ of each other . W e provid e a mathematical proof of alignmen t be twe en the DR TP and BP mod ulatory signals. The structu r e of our p roof is insp ir ed from the F A proof of a lig nment in [13], which we expand in two ways. First, we exten d this pr o of for the c a se of DR TP . Second , while [13] demo nstrate the align ment with th e BP modu la to ry sig nals for a network consisting of a single linear h idden layer, a linear output laye r an d a mean squared er ror loss, we demo nstrate that alignm ent can be achieved for an ar bi- trary nu m ber of linear hid d en layers, a nonlinea r outpu t lay er with sigmo id/softmax ac ti vation and a binary/categorical cross-entro py loss f or classification proble m s. Both pro ofs are restricted to the case of a single train ing example. Un- der these conditions, it is possible to guaran tee that the DR T P mod ulatory signals are aligned with those o f BP . This comes f r om the fact that the prescribed weig h t upd ates lead to a soft alignment between the p roduct o f forward we ig ht matrices and the fixed random con nectivity m a tr ices. The mathem atical d e tails, inclu ding th e lemma and theor e m proof s, have be en abstracted out to Supplem entary N o te Supplementa r y Note 1. In the case of the multi-layer neural n etwork co mposed of line a r hidden layers shown in Figure 4, the ou tp ut of the k -th hidde n lay er is gi ven by y k = z k = W k y k − 1 for k ∈ [1 , K − 1] , where K is th e number of lay ers, y 0 = x is the inpu t vector, an d the b ia s vector b k is om itted without loss of genera lity . The outpu t lay er is described by z K = W K y K − 1 , y K = σ ( z K ) , where σ ( · ) is either th e sigmoid o r the softmax activation fun ction. T he loss function J ( · ) is either the b inary cro ss- entropy (BCE) loss fo r sigmo id output units or the categorical cross-en tropy (CCE) loss f or softm ax ou tput units, computed over the C outpu t classes: J BCE ( y K , y ∗ ) = − 1 C C X c =1 y ∗ c log ( y K c ) + (1 − y ∗ c ) log (1 − y K c ) , J CCE ( y K , y ∗ ) = − 1 C C X c =1 y ∗ c log ( y K c ) . Lemma. In the case of zero-initialized weights, i.e. W 0 k = 0 fo r k ∈ [1 , K ] , k ∈ N , and hen ce of zero- initialized hidden layer outp uts, i.e. y 0 k = 0 for k ∈ [1 , K − 1] and z 0 K = 0 , co nsidering a DR TP-ba sed train in g performed recursively with a single elemen t of th e training set ( x, c ∗ ) and y ∗ denoting the on e-hot enco ding of c ∗ , at every discrete update step t , there are non-negative scalars s t y k and s t W k for k ∈ [1 , K − 1] and a C - dimensional vector s t W K such that y t k = − s t y k B T k y ∗ for k ∈ [1 , K − 1] W t 1 = − s t W 1 B T 1 y ∗ x T W t k = s t W k B T k y ∗ B T k − 1 y ∗ T for k ∈ [2 , K − 1] W t K = − s t W K B T K − 1 y ∗ T . 8 Learning without feedb ack: Direct random target p rojection C. Frenkel, M. Lefebvre and D. Bol Theorem. Un der the same conditions a s in the lemm a an d for th e linear-hidde n-layer network dynamics d escribed above, th e k -th layer mo dulatory signals prescr ib ed by DR TP ar e always a negativ e scalar multiple of th e Moor e- Penrose pseud o-inv erse of the pr oduct of forward matrices of laye rs k + 1 to K , locate d in the feedb ack path way between the ou tp ut layer an d the k -th hidd en layer , multiplied by the error . That is, for k ∈ [1 , K − 1] an d t > 0 , − 1 s t k k +1 Y i = K W t i ! + e = B T k y ∗ with s t k > 0 . Alignment. In the fr amew ork o f c lassification p roblems, as the coefficients s t k are strictly positive scalars fo r t > 0 , it results from the the orem that the dot prod uct between the BP and DR TP modulato ry signals is strictly p ositi ve, i.e. − e T K Y i = k +1 W T i ! T B T k y ∗ > 0 e T K Y i = k +1 W T i ! T k +1 Y i = K W i ! + | {z } I e s t k > 0 e T e s t k > 0 . The BP an d D R TP mod ulatory signals are thus within 90 ◦ of each other . 2.4. DR TP learns to classify MNIST and CIF AR-10 images without fee dba ck In this section , we comp are DR TP with BP and o ther feedb ack-alignm ent-based algorithms, namely F A an d DF A, on the MNIST and CIF AR-10 datasets. Both datasets h ave 10 output classes, they respe cti vely c o nsist in classifying 28 × 28 grayscale im ages of handwritten digits for MNIST and 32 × 32 RGB images of vehicles and anima ls fo r CIF AR- 10. T h e n etwork topo lo gies conside r ed in o ur experim ents are, o n th e o n e h and, fully-c o nnected (FC) networks with one or two hidd en lay ers, r espectiv ely denote d a s FC1 a n d FC2, each h idden la y er being constituted o f eith er 500 or 1000 tanh units. On the oth er hand , con volutional (CONV) network s are used with either fixed r andom or trainable kernels. The CONV network for MNIST consists of one conv olutional layer followed by a m ax-poo lin g lay er and one f ully-con n ected hid den layer , while fo r CIF AR-10 it consists of two conv olutiona l layers, ea c h followed by a max-po oling layer, and two fully - connected hidden layers (see Section 4). 2.4.1. MNIST The resu lts o n the MNIST da taset are summarized in T ab le 1. In FC networks, BP , F A an d DF A perf orm similarly , the accuracy degrad ation of F A and DF A is ma rgin al. While th e re is a highe r accuracy d egradation for DR TP , it compare s fa vorably to shallow learning, which su ffers from a hig h accuracy p enalty . It shows th at DR TP allows training hid den lay ers to lear n MNIST digit classification withou t fe edback. Th e CONV network top ology lead s to the lowest error, h ighlighting that extracting spatial in formation , e ven with rand om kern els, is sufficient to so lve the MNIST task. The accuracy slightly degrades along the F A, DF A and DR TP algorith ms, with a higher gap for shallow lea r ning. Whe n kernels are trained, BP provides the hig hest improvemen t compared to the erro r obtained with random kernels, followed by DR TP , while no significan t ch a nge can be ob served for F A and DF A. Th is is likely d ue to the fact tha t the r e is not enough parameter redundan cy in conv olutio nal lay e r s to allo w for an efficient trainin g with feedback -alignmen t-based algorith ms, which is common ly re f erred to as a bottleneck effect (see Section 3). In d eed, the angle betwee n the BP loss gra d ients and the feed back-align ment-based ones is ro ughly 90 ◦ , leadin g to r andom updates (Supplem entary Figure S3 ). This imp roved performa n ce o f DR TP with trained kernels is thus unexpected. Regarding drop out, a positive impact is shown on BP , F A and DF A: a mo d erate dropo ut p robability is beneficial for FC1 networks, wh ile increasing it to 0.25 can be used for FC2 n etworks. Dr opout has n o p ositi ve impact for CONV networks, while it degrades the accuracy o btained with DR TP an d shallow learn ing in all cases. 9 Learning without feedb ack: Direct random target p rojection C. Frenkel, M. Lefebvre and D. Bol T able 1 : Mean and standard deviation of the te st e r ror on the MNIST dataset over 10 trials. DO stand s for dropo ut and in dicates the dr opout pr obability used in the fully-conne cted layers of both FC and CONV networks. The FC networks consist of one ( FC1) o r tw o (FC2) hidd en layers comprising 5 00 or 1000 tanh units, with a n ou tp ut fully - connected layer of 10 sigmoid un its. The CONV network topo lo gy is as follows: a convolutional layer with 32 5 × 5 kernels, a stride of 1 and a padd in g of 2, a ma x -poolin g lay er with 2 × 2 kernels and a strid e of 2 , a fully- c onnected layer of 100 0 tanh u nits and an outpu t fu lly-conn ected layer of 10 sigmo id u nits. Network BP F A DF A DR TP Shallow FC1-500 DO 0.0 1.65 ± 0.06% 1.71 ± 0.05% 1.76 ± 0.05 % 4.61 ± 0.13% 8.25 ± 0.09% DO 0.1 1.59 ± 0.03% 1 . 63 ± 0.0 5% 1.68 ± 0.03% 4.92 ± 0.13 % 9.17 ± 0.11 % DO 0.25 1.7 6 ± 0.05 % 1.74 ± 0.04% 1 .86 ± 0. 03% 5.7 5 ± 0.09 % 10.15 ± 0.1 1% FC1-1000 DO 0.0 1.57 ± 0.04% 1 . 62 ± 0.0 5% 1.67 ± 0.03% 4.10 ± 0.07 % 7.92 ± 0.10 % DO 0.1 1.48 ± 0.03% 1 . 55 ± 0.0 5% 1.58 ± 0.05% 4.31 ± 0.06 % 9.29 ± 0.12 % DO 0.25 1.5 4 ± 0.04 % 1.56 ± 0.02% 1 .63 ± 0. 03% 4.9 4 ± 0.06 % 10.01 ± 0.1 7% FC2-500 DO 0.0 1.46 ± 0.08% 1 . 72 ± 0.0 4% 1.69 ± 0.06% 4.58 ± 0.09 % 8.25 ± 0.10 % DO 0.1 1.46 ± 0.04% 1 . 51 ± 0.0 4% 1.57 ± 0.06% 5.00 ± 0.07 % 9.33 ± 0.09 % DO 0.25 1.3 8 ± 0.04 % 1.69 ± 0.02% 1 .52 ± 0. 03% 5.9 4 ± 0.06 % 11.01 ± 0.1 2% FC2-1000 DO 0.0 1.50 ± 0.09% 1 . 57 ± 0.0 6% 1.65 ± 0.07% 4.00 ± 0.10 % 7.85 ± 0.09 % DO 0.1 1.46 ± 0.02% 1 . 46 ± 0.0 3% 1.57 ± 0.03% 4.25 ± 0.06 % 8.73 ± 0.08 % DO 0.25 1.3 8 ± 0.03 % 1.50 ± 0.05% 1 .45 ± 0. 03% 5.0 5 ± 0.09 % 9.84 ± 0.05% CONV (rando m) DO 0.0 1.21 ± 0.05% 1 . 30 ± 0.0 6% 1.25 ± 0.08% 1.82 ± 0.11 % 2.83 ± 0.19 % DO 0.1 1.25 ± 0.03% 1 . 33 ± 0.0 6% 1.30 ± 0.06% 2.06 ± 0.08 % 4.74 ± 0.30 % DO 0.25 1.2 9 ± 0.04 % 1.32 ± 0.06% 1 .33 ± 0. 05% 2.6 0 ± 0.14 % 6.49 ± 0.35% CONV (trained) DO 0.0 0.93 ± 0.04% 1 . 22 ± 0.0 6% 1.31 ± 0.06% 1.48 ± 0.15 % DO 0.1 1.03 ± 0.04% 1 . 27 ± 0.0 6% 1.34 ± 0.06% 1.50 ± 0.17 % – DO 0.25 1.0 0 ± 0.03 % 1.29 ± 0.04% 1 .40 ± 0. 06% 1.8 1 ± 0.20 % 2.4.2. CIF AR- 10 The r e sults on the CIF AR-1 0 dataset are summarized in T able 2, high lighting co nclusions similar to th ose alread y drawn for the MNI ST dataset. Compa red to BP , accu r acy d egrades along the F A, DF A and DR TP algo rithms. Th e gap is higher for DR T P , y et it again compares fav or ably to shallow learning , demonstrating th a t DR TP also allows training hidden laye rs to learn CIF AR-10 im a g e classification without feedback . For CONV networks, if kernels are trained, only BP is able to p rovide a significan t advantage. Due to th e b ottleneck effect, F A only pr ovides a slight improvement, while DF A an d DR TP are n egati vely impacted. Regarding drop out, a moderate probability o f 0 .1 works fairly well for BP , F A, DF A a nd DR TP , while a higher probability of 0 .25 r arely p r ovides any ad vantage. Dropo ut always leads to an accuracy r eduction fo r shallo w learning. Finally , data aug mentation (DA) improves the accuracy of all algo rithms and is more effecti ve than dropo u t. 3. Discussion While the backpro pagation of error alg orithm allo wed taking artificial neural networks to ou tp erform h umans o n com- plex datasets su c h as ImageNet [38], the key p roblems of weight transport and u p date locking highligh t how a iming at breaking accuracy records on standard d atasets has diverted attention fro m hardware e fficiency considerations. While accuracy is the ke y driver for applications that can be backed by significant GPU and CPU r e sources, th e development of decentralized adaptive smart senso r s calls f or keeping hard ware requir ements of learnin g algo rithms to a minim um. Moreover , it has b een shown th at w e ig ht transpor t and u pdate locking are not b iologically p lausible [10, 14], following from the non- lo cality in b oth weigh t and g radient infor mation. Theref ore, there is curren tly an increasing inter est in releasing these constraints in order to achieve h igher hard ware efficiency an d to understand the mechanisms that could underlie biolog ical syn aptic plasticity . The pr oposed DR TP algorith m successfully a d dresses both the weight tran sport an d the update lock ing p roblems, which has on ly b een partially d emonstrated in previously-prop osed app roaches. Indeed, the F A and DF A algorith ms 10 Learning without feedb ack: Direct random target p rojection C. Frenkel, M. Lefebvre and D. Bol T able 2: Mean and standar d deviation of t he test error on the CIF AR-1 0 da taset over 10 trials. DO stands for dropo ut and indicates the dr opout probability u sed in th e fully-con nected layers of both FC and CONV networks. D A stands f or data au g mentation, wh ich consists in ho rizontally flippin g the training images. No drop out is used for D A. The FC network s consist of one (FC1) or two (FC2) hidd en layers com prising 500 o r 100 0 tanh u nits, with an o u tput fully-co n nected layer of 1 0 sigmo id u nits. The CONV n etwork topolog y is as follows: two conv olution al layers w ith respectively 64 and 2 56 3 × 3 kernels, a stride and a p a dding of 1, both fo llowed by a max-poo ling lay er with 2 × 2 kernels and a stride of 2, then two fully - connected layer s of 1000 tanh units and an outp u t f u lly-conn ected layer of 10 sigmoid units. Network BP F A DF A DR TP Shallow FC1-500 DO 0.0 48.45 ± 0.38% 49. 38 ± 0.2 2% 49.6 2 ± 0.29 % 53.92 ± 0 .23% 58 .83 ± 0. 2 7% DO 0.1 47.48 ± 0.39% 48. 94 ± 0.2 2% 48.8 5 ± 0.23 % 53.77 ± 0 .17% 59 .33 ± 0. 1 7% DO 0.25 47 . 80 ± 0.2 1% 48.62 ± 0.23% 4 8.65 ± 0 .29% 54.26 ± 0.16 % 60.44 ± 0.1 4% D A 45.87 ± 0.22% 47. 11 ± 0.3 4% 47.3 4 ± 0.26 % 52.73 ± 0 .31% 58 .60 ± 0. 2 0% FC1-1000 DO 0.0 47.52 ± 0.30% 48. 47 ± 0.1 8% 48.4 4 ± 0.34 % 53.34 ± 0 .10% 57 .91 ± 0. 1 7% DO 0.1 46.42 ± 0.28% 47. 72 ± 0.1 9% 47.7 9 ± 0.31 % 53.15 ± 0 .15% 58 .35 ± 0. 2 4% DO 0.25 46 . 21 ± 0.1 6% 47.11 ± 0.18% 4 7.11 ± 0 .25% 53.39 ± 0.15 % 59.20 ± 0.1 8% D A 45.01 ± 0.33% 46. 15 ± 0.3 6% 46.2 4 ± 0.32 % 51.87 ± 0 .32% 57 .40 ± 0. 2 4% FC2-500 DO 0.0 49.03 ± 0.22% 50. 66 ± 0.2 4% 50.4 5 ± 0.36 % 53.41 ± 0 .35% 59 .62 ± 0. 3 4% DO 0.1 48.32 ± 0.16% 49. 64 ± 0.2 3% 49.5 8 ± 0.30 % 54.06 ± 0 .46% 60 .34 ± 0. 2 4% DO 0.25 49 . 96 ± 0.1 8% 50.80 ± 0.16% 5 0.00 ± 0 .13% 54.57 ± 0.33 % 61.77 ± 0.1 8% D A 46.62 ± 0.10% 48. 55 ± 0.2 5% 48.7 5 ± 0.28 % 52.54 ± 0 .34% 58 .99 ± 0. 2 0% FC2-1000 DO 0.0 48.81 ± 0.22% 49. 87 ± 0.1 8% 50.0 5 ± 0.21 % 52.68 ± 0 .25% 58 .59 ± 0. 1 4% DO 0.1 46.58 ± 0.24% 47. 97 ± 0.1 8% 48.6 8 ± 0.34 % 52.45 ± 0 .15% 59 .12 ± 0. 1 3% DO 0.25 47 . 65 ± 0.1 6% 48.82 ± 0.15% 4 8.08 ± 0 .14% 53.29 ± 0.31 % 60.52 ± 0.1 4% D A 46.05 ± 0.14% 47. 41 ± 0.2 7% 47.9 0 ± 0.19 % 51.27 ± 0 .21% 57 .90 ± 0. 2 3% CONV (rando m) DO 0.0 29.83 ± 0.25% 30. 27 ± 0.4 5% 29.9 8 ± 0.30 % 32.65 ± 0 .38% 44 .89 ± 0. 6 7% DO 0.1 29.49 ± 0.36% 29. 58 ± 0.3 3% 29.4 4 ± 0.31 % 32.57 ± 0 .34% 48 .38 ± 0. 3 3% DO 0.25 30 . 39 ± 0.3 2% 30.55 ± 0.28% 3 0.31 ± 0 .35% 33.90 ± 0.53 % 52.27 ± 0.3 4% D A 27.87 ± 0.25% 28. 52 ± 0.4 0% 28.4 6 ± 0.43 % 31.04 ± 0 .45% 44 .23 ± 0. 4 2% CONV (trained) DO 0.0 25.31 ± 0.25% 29. 92 ± 0.2 6% 31.3 8 ± 0.38 % 35.82 ± 0 .59% – DO 0.1 27.12 ± 0.23% 28. 98 ± 0.3 6% 30.5 6 ± 0.41 % 35.17 ± 0 .91% DO 0.25 25 . 61 ± 0.2 3% 28.95 ± 0.17% 3 1.23 ± 0 .38% 35.51 ± 0.61 % D A 25.27 ± 0.26% 28. 16 ± 0.4 5% 29.4 9 ± 0.49 % 34.39 ± 0 .64% only add r ess the weight transpo rt p roblem [13, 15]. The error locality app roach still suffers from the weigh t transport problem in the lo cal classifiers [25, 26, 2 7], while the synthe tic g r adients approach requir es ba c k propag ating gradient informa tio n fro m deeper layer s in order to train the lay erwise grad ient predictors [23, 24]. Both the error loc ality and the synthetic grad ients ap proach e s also incur com p utational overhead b y requirin g the addition of side local network s for error or g radient pre d iction. On the co ntrary , DR TP is a strikin gly simp le rule that alleviates the two key BP issues by enab ling each lay er to be updated with local infor mation as the forward evaluation proceeds. In order to estimate th e lay erwise loss gradients δ y k for ea c h layer, the only operation re q uired by DR TP is a labe l-depend e nt random vector selectio n (Figure 1 D ). Despite the absence of ded icated f eedback pathways, we demonstrated on the MNIST an d CIF AR-10 datasets that DR TP allows train ing hidden layers at low co mputation al and mem o ry costs, thus highlig hting its suitability for d eployment in ada p ti ve sma r t sensors at the edge and for em bedded system s in general. In term s of floating- point operations (FLOPs), the overhead of DR TP weigh t updates is ap p roximately equal to th e cost o f the forward pass, assuming that (i) th e numb e r o f classes o f the p roblem is negligible comp a red to the number of units in the hidden lay ers, which is ty pical of edge com p uting tasks, an d (ii) th e learning rate is emb edded in th e ma gnitude of the random c o nnectivity matrices B T k . Doub lin g the computation al c o st of shallow-learning networks (i.e. doubling the n umbers of hidden units o r hidd e n layers) does n ot allow recovering th eir perform ance gap co mpared to DR TP-u pdated networks (T ables 1 an d 2). Even more im portantly wh e n conside r ing dedicated hardware im p lementations fo r edge compu ting, the memo r y requirem ents should b e min imized so as to fit the who le network topolo gy into on-chip memo ry resources. Indeed , accesses to off-chip DRAM memory are th ree orders of 11 Learning without feedb ack: Direct random target p rojection C. Frenkel, M. Lefebvre and D. Bol magnitud e more expensi ve en ergy-wise th an a 32-bit FLOP [ 3 9]. Therefor e, as op posed to inc r easing the resou rces of shallow-trained n e tworks, DR TP offers a low-ov erh ead train ing algor ithm operating o n sma ll network to pologies, ideally suitin g edg e-compu ting h ardware require ments. These claim s are p roven in silico in [33], where implementing DR TP in an event-driven conv olution al proce ssor requir es only 16.8- % power and 11. 8-% silicon area overheads and allows dem o nstrating a fa vorable accuracy-power-area tradeo ff co mpared to both on-ch ip online- and off-chip offline- trained conv entio nal machine learning accelera tors o n the MNIST dataset. By solving the weig ht tr ansport and up date lo cking problems, DR TP also releases key biological implausibility is- sues. Ne u rons in th e b rain sepa r ate for ward and backward inform ation in so matic a nd de ndritic co mpartmen ts, a proper ty th at is highligh te d in the form ulation of th r ee-factor synaptic plasticity rules [20]: pre-syna p tic an d post- synaptic activities ar e m odulated by a third factor correspon ding to a lo c al dendritic voltage. [13] build on the idea that a separate dendr itic compar tment integrates higher-order feed back an d g enerates local teaching signals, whe re the erro rs could be viewed as a mismatch b etween expected and actual percep tions or action s. T his aspect is fu rther emphasized in the subsequen t work o f [18] wh en framing DF A as a spike-based three- factor learnin g r ule. In the case of DR TP , compar ed to DF A, th e er r or signal is r eplaced b y th e targets, wh ich c o uld co r respond to a modu la tio n that bypasses the actual perc eptions o r r ealized actions, relying only on pred ictions or in tentions. Furthermo r e, DR TP could come in line with recent findings in c o rtical areas that reveal the existence of o utput-ind ependen t target signa ls in th e den dritic instruc tive pathways of intermed iate-layer n eurons [ 40]. Und erstanding the mechanisms of synap tic plasticity is critical in the field of neuromo rphic en gineering , which aim s a t p o rting b io logical com putational princi- ples to ha r dware toward h igher energy efficiency [41, 42]. Howe ver , even simple local bio-in spired learn ing rules such as spike-timing-de p endent plasticity (STDP) [43] can lead to non-trivial hard ware requirem ents, which currently hinders adaptive neurom orphic systems from reaching high-de nsity large-scale in tegration [3 4]. While ad aptations of STDP , suc h as spike-depen dent synaptic plasticity (SDSP) [44], release most of the STDP hard ware constraints, their tra in ing perfo rmance is c u rrently no t sufficient to support dep loyability o f neu r omorp h ic hardware fo r real-world scenarios [34, 35]. A thre e-factor formu lation of DR TP would re lease the update locking p roblem in th e spike-b ased three-factor form ulations of DF A [18, 19], which cur rently imply memo ry and co ntrol overhead in their h ardware implementatio ns [45, 46]. Porting DR TP to ne u romor p hic hardware is thus a natural next step. While DR TP r elaxes structural, memo ry and com putational requirem ents tow ard de centralized hard ware de p loyment, the accu r acy degradation over DF A comes fro m the fact that only the error sign is taken in to accoun t, not its class- depend ent mag nitude. This co uld be mitigated b y keeping tr a ck o f the error m agnitude over the last samples in order to mod ulate the layer wise learn ing rates, at the expen se of releasing the purely f eedforward natu re of DR TP . A learning rate scheduler could a lso be used. The DR TP algo rithm was d eriv ed spec ifica lly f o r classification p roblems with sigm oid/softmax o u tput un its and a binary/categorical cro ss-entropy loss, yet hidden lay er activ ation s also play a key role in the learning dynamics of DR TP . As the estimated loss grad ients δ y k computed from the targets have a constant sign an d mag nitude, the weights updates o n ly chan ge due to the previous layer outputs an d the deriv ative of the activation fu nction, as tra in ing pr o gresses. When using activ ation functions such as tanh in th e hidden layers, the network sto ps learning thanks to the acti vation function deriv ative, whose value vanishes as its input argument moves away fro m zero. This mech anism specific to DR TP is highligh ted in Supp lementary Figures S4-S6 and could be exploited to generate networks who se activ ation s can be binarized during inference, which we will investigate in future work. In retu rn, only activ ation fun ctions presen ting this saturation pr operty are expected to le a d to satisfying perfor mance when u sed in c o njunction with DR TP , which for example excludes ReLU a c ti vations. Finally , as fo r all othe r feedb ack-alignm e nt-based algor ithms, DR T P on ly sligh tly impr oves o r even degrade s the accuracy when ap plied to con volutional layers. Con volutional layers do not pr ovide the par ameter redun dancy that can be fo und in fully-co n nected layers, a bottleneck effect that was first hig hlighted for F A [13] and has r ecently been studied for DF A [47]. Nevertheless, o th er tr aining algorith ms based eith er o n a gr eedy layerwise learnin g [ 2 8] or on the alignmen t with local targets [22] have p roven to be successful in training con volutional layer s a t the expense of only partially solv ing the up date lo cking p roblem. Indeed, the training algorithm propo sed in [ 28] still suffers from update lock ing in the lay erwise auxiliary network s while th e one pr oposed in [2 2] r elies on th e backp ropagatio n of the outp ut error to comp ute the layerwise targets. If fixed random convolutional layers do not me e t the perfo rmance requirem ents of the target ap p lication, a com bination o f DR TP for fully - connected layers together with error locality or synthetic g radients app r oaches for conv olu tio nal lay e rs can be consider ed. This granularity in th e selection of learnin g mechanisms, trading off accu racy and hardware efficiency , co mes in accordan ce with the wide spec tr um of pla sticity mechanisms that are be lieved to o perate in the brain [48]. 12 Learning without feedb ack: Direct random target p rojection C. Frenkel, M. Lefebvre and D. Bol 4. Materials and Methods The training on both the synthetic regression a nd classification tasks and th e MNIST and CIF AR-10 datasets has been carried ou t with PyT orch [4 9], on e of the nu m erous Python f ramew o r ks su p porting deep learning . I n all experiments, the rep o rted update angles betwee n feed back-align ment-based algor ithms a nd BP were genera ted at each update step, where the BP update v alue s were co m puted solely to assess the ev olution of the alignment angle over the update steps carried out by F A, DF A, sDF A or DR TP . Regression. The examples in the train ing an d test sets are d enoted as ( x, y ∗ ) . The 10- dimensional target vectors y ∗ are generated using y ∗ j = T j ( x ) = cos ( x + φ j ) , wher e φ j = − π / 2 + j π / 9 for j ∈ [0 , 9] and j ∈ N 0 . x denotes the mean o f x , a 2 56-dim e nsional vector whose entr ies are initialized from a norm al d istribution with a mean sampled from a unifo rm distribution between − π and π and with a un it variance. The tra in ing a n d test sets re spectiv ely contain 5k an d 1 k exam ples. The traine d n etwork has a 256-10 0-100 - 10 topo lo gy with tanh h idden an d output units, whose f o rward weights are drawn from a He un iform distribution [3 8] and are zero- initialized for feedback-a lig nment- based algorithms. The random con nectivity matrices of f eedback- a lignment-b ased algorith ms are also drawn fro m He unifor m distributions. The weig hts a r e updated after each min ibatch of 5 0 examples, an d the network is trained fo r 50 0 epochs with a fixed lea r ning rate η = 5 × 10 − 4 for a ll training alg orithms. Th e loss functio n is the mean squared error . The lo sses on the training and test sets and th e alignm e nt ang les with BP upd ates ar e mon itored ev ery 1 k sample s. The experiment is rep eated 1 0 tim es for each tra in ing algorithm, with d if fe r ent network initializations for each experiment run. Synthetic data classification. The examples in the training and test sets are gener ated using the make_ classi fication function fro m the Python lib rary sk learn [37]. The main inpu ts requ ired by this fu nction are the numb er of samp les to be generated, the number of features n in the inpu t vector s x , the num ber o f in formative features n inf among th e inpu t vectors, the number of c lasses, th e num ber of clusters per class and a factor class_se p which condition s the class separation. In this work, we have u sed n = 25 6 and n inf = 128, ten classes, five clusters per class an d c lass_s ep = 4 . 5 . Using this set of parameters, the make_ classi fication function then generates examples by cre a ting for eac h c la ss clusters of points norm ally distributed ab o ut the vertice s of an n inf -dimension al hyperc u be. The remain ing features are filled with n ormally-d istributed r andom no ise. The ge n erated examples ar e then separated into training and test sets of 25k and 5k examp les, respectiv ely . Th e trained network has a 25 6-500 - 500-1 0 top ology with tanh hid den units and sigmoid output units. The forward a nd ba c k ward weights initializatio n, as well as th e fo rward weig ht u pdates, are per formed as f or regression. As this is a classification task, the loss function is the bin a ry cro ss-en tropy loss. The network is tr ained fo r 500 epoch s with a fixed learning rate η = 5 × 10 − 4 . The losses on the training a n d te st sets and the alignm ent angles with BP updates are monito r ed every 2.5 k samples. For each training algor ithm, the exper iment is repeated 10 times with different network initializations. MNIST a nd CIF AR-10 images classificatio n. A fixed learn ing rate is selected ba sed on a grid search f or each training algo rithm, d a ta set and network type ( T able 3). For both the MNIST and CIF AR-10 expe r iments, the chosen optimizer is Adam with default parameters. A sigmoid output lay er and a binary cross-entro py loss are used for all training algorithm s. The entries o f th e forward weig ht m atrices W k are initialized with a He unifo rm distribution, as well as the en tr ies of the fixed r andom connectivity m atrices B k of feedback- alignment-b ased alg orithms. When used, dropo ut is applied with the same probab ility to all fully -connected layers. For MNIST , the networks are trained fo r 100 e pochs with a m inibatch size of 6 0. The CONV n etwork topo logy consists of a conv olution al lay er with 3 2 5 × 5 kernels, a stride of 1 and a pad ding of 2, a m ax-poolin g lay er with 2 × 2 kernels and a stride of 2, a fully- connected layer of 1000 tanh u nits and an o utput f ully-conn ected lay er of 1 0 u nits. For CIF AR-1 0, a minibatch size of 100 is used and early stop ping is ap plied, with a maxim um o f 200 epochs. The CONV n etwork topolog y co nsists of two c o n volutional layers with respe c tively 64 an d 2 56 3 × 3 kernels, a stride an d a padd in g of 1, both followed by a max-po o ling laye r with 2 × 2 kernels and a stride of 2, then two f ully-conn ected layers o f 1000 tanh units and an output fully-co nnected layer of 10 units. For all exp e riments, th e test error is averaged over the last 10 ep ochs of training. Th e r esults repor ted in T ables 1, 2, S1 and S2 are the mean and stan d ard deviation over 1 0 trials. Code A v ail ability The PyT orch code allowing to reprod uce all results in th is study is av ailab le o p en source under th e Ap ache 2.0 license at http s://gi thub.com/ChFrenkel/DirectRandomTargetProjection . 13 Learning without feedb ack: Direct random target p rojection C. Frenkel, M. Lefebvre and D. Bol T able 3 : The lea rning rate values for the MNIST and CIF AR - 10 dat asets are selected based on a grid search. A different lea rning rate is selected for each trainin g a lg orithm, dataset and network type. Dataset Network BP F A DF A sDF A DR TP Shallow MNIST FC1 1.5 × 1 0 − 4 5 × 10 − 4 1.5 × 1 0 − 4 5 × 10 − 4 1.5 × 1 0 − 4 1.5 × 1 0 − 2 FC2 5 × 10 − 4 1.5 × 1 0 − 4 5 × 10 − 4 5 × 10 − 4 1.5 × 1 0 − 4 5 × 10 − 3 CONV (rand .) 5 × 10 − 5 1 . 5 × 10 − 4 5 × 10 − 5 5 × 10 − 4 5 × 10 − 4 5 × 10 − 3 CONV (train.) 5 × 1 0 − 4 5 × 10 − 5 5 × 10 − 5 1.5 × 1 0 − 4 1.5 × 1 0 − 4 – CIF AR-10 FC1 1.5 × 1 0 − 5 1.5 × 1 0 − 5 1.5 × 1 0 − 5 5 × 10 − 5 1.5 × 1 0 − 4 1.5 × 1 0 − 4 FC2 5 × 10 − 6 5 × 10 − 6 5 × 10 − 6 5 × 10 − 5 5 × 10 − 5 5 × 10 − 4 CONV (rand .) 5 × 10 − 6 5 × 10 − 6 5 × 10 − 6 1.5 × 1 0 − 4 1.5 × 1 0 − 4 1.5 × 1 0 − 3 CONV (train.) 1 . 5 × 10 − 4 5 × 10 − 6 5 × 10 − 6 1 . 5 × 10 − 5 5 × 10 − 5 – Data A vailability The datasets used in th is study are pub licly a vailable. Acknowledgmen ts The authors would like to thank Emre Neftci, Giacom o I ndiveri, Marian V erhelst, Simo n Car b onnelle and V incent Schellekens f or fruitful discussions and Christop he De Vleeschouwer for gran ting access to a deep learning worksta- tion. Funding CF was with Université catholiqu e d e Louvain as a Research Fellow from the National Foundatio n for Scien tific Research (FNRS) of Belgium . Conflict of Interest Statement The auth ors declare tha t the r esearch was cond ucted in the ab sence o f any com mercial or fina n cial r e la tio nships that could be construe d as a po tential conflict of interest. A uthor Contributions CF developed th e main idea. CF and ML d eriv ed the mathem atical proofs and worked on th e simulation experimen ts. CF , ML and DB wro te the paper . CF and ML contr ibuted equally to this work. Refer ences [1] F . Rosenblatt, Princip les o f neu r odynamics: P er ceptr on s a nd the theo ry of brain mechanisms , Sparta, NJ, USA: Spartan Books, 196 1 . [2] D. Bassett and E. D. Bullmor e, “Small-world b rain network s, ” Th e Neur oscientist , vol. 12, no. 6, pp . 512 -523, 2006. [3] M. Minsky , “Step s tow ard artificial in telligence, ” Pr oceeding s of the IR E , vol. 4 9, no. 1, pp. 8-30, 196 1. [4] D. Rumelhart, G. Hinton and R. W illiams, “Lear ning repr e sen tations by back - propag ating erro r s, ” Natur e , vol. 3 23, pp. 533 - 536, 19 86. [5] A. Krizh e vsky , I. Sutskev er and G. E. Hinto n, “ImageNet classification with deep conv olution al neural networks, ” Pr oc. of Advan c e s in Neural Info rmation P r oc e ssing Systems (NeurIPS) , pp. 109 7-1105 , 20 12. [6] Y . LeCun, Y . Beng io, and G. E. Hinton , “De e p learning, ” Natu r e , vol. 521, no. 7553, p. 436, 2015 . 14 Learning without feedb ack: Direct random target p rojection C. Frenkel, M. Lefebvre and D. Bol [7] K. He et al., “Deep residual learnin g for imag e recog n ition, ” Pr oc. of IEEE Conference on Computer V ision and P attern Recognition (CVPR) , pp. 770-7 78, 20 1 6. [8] G. E. Hinto n et al., “Deep neu ral networks for acoustic modeling in speech reco gnition, ” IEEE Sig n al Pr oc e ssing Magazine , v o l. 2 9, 2012. [9] D. Amo dei et al., “Deep speech 2: E nd-to-en d speech rec o gnition in english an d mandar in, ” Pr oc. of Internationa l Confer ence on Machine Learning (ICML) , vol. 173-18 2, 2016 . [10] S. Grossbe rg, “Comp etiti ve learning : From interactive ac tivation to ad a ptiv e r esonance, ” Cognitive Scien ce , vol. 1 1, no. 1, pp. 23 -63, 1987. [11] B. Crafton et al., “Loc al lear n ing in RRAM neural networks with sparse direct feedback alignment, ” IEEE/ACM Internation al Symp osium on Low P o wer Electr onics and Design (I SLPED) , 2019. [12] Q. L ia o , J. Z. Le ib o and T . Pog gio, “How importan t is weigh t symmetry in backpr opagation ?, ” Pr oc. of AA AI Confer ence on Artificial In telligence , 20 16. [13] T . P . Lillicrap e t al., “Random synap tic feedbac k weigh ts supp ort erro r b ackprop agation fo r d eep learning, ” Na- tur e Commu nications , v ol. 7 , n o. 13276, 2016 . [14] P . Baldi,P . Sad owski and Z. Lu, “Lear n ing in the ma c h ine: Rand om backpr opagation and the deep learning channel, ” Artifi c ia l intelligence , v ol. 26 0, pp. 1-35, 2018. [15] A. Nøk lan d, “Direct fee d back align ment provid es lea r ning in deep neura l networks, ” Pr oc. of Adva nces in Neural Information Pr ocessing Systems (NeurIPS ) , pp. 1037-10 45, 2016. [16] Y . LeCun an d C. Cortes, “The MNIST d atabase of h andwritten dig its, ” 1998 [Online]. A v ailab le: http: //yann .lecun.com/exdb/mnist/ . [17] A. Krizhevsky , Learnin g multiple layers o f featu r es fr om tiny images , T echnical Repo rt, Univ ersity of T o ronto, 2009. [18] J. Guerguiev , T . P . Lillicrap and A. Richard s, “T owards deep learning with segregated dend rites, ” ELife , v o l. 6, no. e229 01, 2 017. [19] E. Neftci et al., “E ven t-driven rando m back -prop a gation: Enabling neur omorph ic deep learning machines, ” F r on- tiers in Neur oscience , vol. 11, no. 324, 2017 . [20] R. Urbanczik and W . Senn, “Learn ing by the d e ndritic pr ediction of somatic spiking, ” Neur on , vol. 81, no. 3, pp. 521 -528, 2 014. [21] D. H. Lee et al. , “Difference target propaga tio n, ” in Pr oc. o f Springer Joint Eur opean Confer ence on Machine Learning and Knowledge Discovery in Databa ses , pp . 4 98-51 5 , 20 1 5. [22] A. G. Ororbia an d A. Mali, “Biolog ically motiv ated algorithm s fo r propag ating local target represen tations, ” Pr oceedings of the AAAI Conference on A rtificial Intelligence , vol. 3 3, pp. 4651- 4658, 201 9. [23] M. Jaderberg et al., “Decoupled n eural interfaces u sing sy n thetic grad ients, ” Pr oc. o f Interna tional Con fe rence on Machine Learning (ICML) , vol. 70, pp. 1627-1 635, 20 17. [24] W . Czarn e cki et al., “Un derstanding synthetic grad ients an d deco upled n eural interfaces, ” Pr oc. of In ternational Confer ence on Machine Learning (ICML) , vol. 70, pp. 904-9 12, 201 7. [25] H. Mo stafa, V . Ram e sh and G. Cauwe n berghs, “Deep super v ised learnin g u sing lo cal er r ors”, F r on tiers in Neu- r oscience , vol. 12, no. 608, 2018 . [26] J. Kaiser , H. Mostafa and E. Neftci, “Synap tic plasticity dynamics fo r deep continuou s loc al lear ning (DECOLLE), ” F r ontiers in Neur oscience , vol. 14, no. 424, 2018 . [27] A. Nøklan d and L. H. Eidnes, “T rainin g neu ral networks with local error sign als”, Pr oc. of International Con fer - ence on Machine Learning (ICML) , 201 9 . [28] E. Belilovsky , M. Eickenberg and E. Oyallon, “Decoup led greedy learning of CNNs, ” arXiv pr ep rint arXiv:190 1.0816 4 , 2 019. [29] J. Deng et al., “I mageNet: A large-scale hierarch ical imag e database, ” Pr oc. of IEEE Co n fer ence o n Computer V ision and P attern R ecognition (CVPR) , pp. 248-25 5, 2009 . [30] D. Bol, G. de Streel and D. Flandre, “Can we c onnect trillions o f IoT sensors in a sustainab le way? A technol- ogy/circu it perspective, ” Pr oc. of IEEE S OI-3D-S u bthr esho ld Micr oelectr onics T e chn o logy Un ified Conference (S3S) , 201 5. [31] M. B. M ilde et al., “Obstacle av oidanc e an d target acq uisition for robot navigation u sin g a m ixed signa l an a- log/digital neuro morphic p rocessing system, ” F r o ntiers in Neur or obotics , vol. 1 1, no. 28, 201 7. 15 Learning without feedb ack: Direct random target p rojection C. Frenkel, M. Lefebvre and D. Bol [32] S. Bartu nov et a l. , “ Assessing the scalability o f biologica lly-motiv ated deep lear ning algorithm s and arch itec- tures, ” Pr oc. of Advanc es in Neural Informatio n P r o cessing Systems (NeurIPS) , pp. 9368 -9378, 2018. [33] C. Fren kel, J.-D. Legat and D. Bol, “ A 2 8-nm conv olution a l neuromo rphic pro cessor enabling online lear ning with spike-based retinas, ” IEEE In ternational Symposium on Cir cuits an d S ystems (ISCAS) , 202 0. [34] C. Fren kel et al., “ A 0 .086-m m 2 12.7-p J/SOP 64k- sy napse 256- neuron on lin e-learning digital spik ing neu ro- morph ic proc e ssor in 2 8-nm CMOS, ” IEE E T ransactions on Biomed ical Cir cuits and S ystems , vol. 1 3, no. 1, pp. 145 -158, 2 019. [35] C. Fren kel, J.-D. Legat and D. Bol, “MorphI C: A 6 5-nm 738k -synapse/mm 2 quad-c o re bina r y-weight digital neurom orphic proce ssor with stochastic spike-driven online le a rning”, IEEE T ransactions on Biomedical Circuits and Systems , vol. 13, no. 5, pp. 9 99-101 0 2019 . [36] S. Ioffe an d C. Szegedy , “Batch no rmalization: Accelera ting deep network training by reducing internal covariate shift, ” arXiv preprint arXiv1502.03 167, 2 015. [37] F . Pedregosa et al., “Scik it-learn: Mach ine Lear n ing in Python”, Journal of Machine Lea rning Resea r ch (JMLR) , vol. 1 2, pp. 2825 - 2830, 2 011. [38] K. He et al., “Delv ing deep into rectifier s: Surpassing human- le vel perfor m ance on ImageNet classification , ” Pr oc. of IEEE Intern a tional Co n fer ence on Computer V ision ( ICCV) , pp. 1026- 1 034, 2015 . [39] M. Horowitz, “ Computing’ s ene rgy p roblem (an d wh at we can d o ab out it), ” Pr oc. of IEEE Interna tional Solid- State Cir cuits Conference (ISSCC), pp. 10-14, 2014 . [40] J. C. Magee and C. Grien berger, “Sy naptic plasticity form s and function s, ” Annu al re view of n eur oscience , vol. 4 3, pp. 95-11 7, 20 20. [41] C. S. T hakur et al., “L arge-scale neurom orphic spiking array processor s: A qu est to m imic the brain , ” F r on tiers in Neur oscience , vol. 12, no. 891, 2018 . [42] B. Rajendran e t al., “Low-Po wer N e u romor p hic Hard ware f or Sign al Processing Applicatio n s”, I EEE Sig nal Pr ocessing Magazine , 2019. [43] G. G. Bi, and M. M. Poo, “Synaptic mo difications in cultured hippo campal neuro n s: Depende n ce on spike timing, synaptic strength , a n d postsynaptic cell type, ” Journal of Neur oscience , vol. 18, no. 24, pp. 1046 4-104 72, 1 998. [44] J. M. Brader , W . Senn and S. Fusi, “Learning real-world stimu li in a ne u ral network with spike-dr i ven synap tic dynamics, ” Neural Computa tion , vol. 19, no . 1 1, pp. 2881- 2912, 2 007. [45] G. D e torakis et al., “Neural and syn aptic array tran scei ver: A b rain-inspire d compu ting fram ework f or embedd ed learning, ” F r ontiers in Neur oscience , vol. 12, no . 5 83, 2018. [46] J. Park, J. Lee and D. Jeon, “ A 65-nm neuromor phic image classification p rocessor with energy-efficient tr a ining throug h direct spike-o nly feedback, ” IEEE Journal o f Solid-S tate Cir cuits , vol. 55, n o. 1, pp. 108- 119, 2019. [47] J. Launay , I. Po li and F . Kr zakala, “Principled Training of Ne u ral Networks with Direct Feedback Alignment”, arXiv preprint arXiv:1 906.04 554 , 2019. [48] F . Zenke, E. J. Ag nes and W . Ger stner , “Diverse syna ptic plasticity mechanisms o rchestrated to form and r etriev e memories in spikin g n eural networks”, Natur e Commun ic a tions , vol. 6, no. 6922 , 2015. [49] A. Paszke et al., “ Au to matic differentiation in PyT o rch”, 31 st Annua l Con fer ence on Neural Info rmation Pr ocess- ing Systems (NeurIP S) W orkshop , 2017 . 16 Learning without feedb ack: Direct random target p rojection C. Frenkel, M. Lefebvre and D. Bol A B Supplementary Fig ure 1: DR TP outperforms sDF A on t he MNIST dat a set. Both figures are with error bars of one standard d eviation over 10 ru ns. The training and test erro rs are m easured after each epo ch, while the angle is m easured after each m inibatch of 60 exam ples. Both trainin g m ethods use Ad am with a fixed learn ing rate of 1.5 × 10 − 4 . ( A) A 784-1 000-10 network with tanh hidd en un its a nd sigmoid ou tput u n its is train ed to classify MNIST hand written digits with the sDF A and DR TP algo rithms. On average, the error on the trainin g set re a ches 2 . 97% for sDF A and 2.24 % for DR TP , while the err o r o n the test set reaches 4.3 3% f or sDF A and 4. 0 5% f or DR TP after 100 epoch s. (B) While the loss gr adients δ y k estimated by b oth sDF A and DR TP are within 90 ◦ of the on es prescribed by BP , the alignm ent angle is initially better f or DR TP than fo r sDF A. The gap vanishes as the training prog r esses. 17 Learning without feedb ack: Direct random target p rojection C. Frenkel, M. Lefebvre and D. Bol A B Supplementary Figure 2: DRTP outperforms sDF A on the CIF AR - 10 dataset. Both figures are with er ror bars of one standa rd d eviation over 10 run s. The tra ining and test errors are measur ed a f ter each epoch , while the angle is measured after each m inibatch o f 100 examples. Both training meth ods use Adam with a fixed learning rate of 5 × 10 − 5 . (A) A 307 2 -1000 -10 network with tanh hidd en units a nd sigmoid output un its is trained to classify CIF AR- 10 imag es with the sDF A and DR T P algo r ithms. On av erag e, the error o n th e training set r eaches 40. 74% for sDF A and 37. 39% fo r DR TP , while the error o n the test set reaches 5 3 .53% for sDF A and 53.1 2% fo r DR TP after 2 00 epoch s. No early stopping was applied. (B) While the loss g radients δ y k estimated by both sDF A and DR TP are within 90 ◦ of the ones prescrib ed by BP , the alignmen t ang le is approx imately 3.40 ◦ better for DR TP than for sDF A. 18 Learning without feedb ack: Direct random target p rojection C. Frenkel, M. Lefebvre and D. Bol Supplementary Figure 3: Updates t o t he con volutiona l layer w e ights prescribed by feedback-alignment- based algorithms a re random due to a 9 0 ◦ -alignment w it h the BP loss g r a dients δ y k . A convolutional network is trained on the MNIST dataset with F A , DF A and DR TP . Th e network topo logy and train ing parameter s are identical to th ose used fo r the trained CONV network. E rror bars are on e standard deviation over 10 ru ns, th e ang le is measur e d af ter each minibatch of 6 0 exam ples. An gles h a ve been smoothed by an expo n entially-weigh ted moving average filter with a mome ntum co efficient of 0.9 5. 19 Learning without feedb ack: Direct random target p rojection C. Frenkel, M. Lefebvre and D. Bol A B C BP F A , DF A DRTP Supplementary Figure 4 : O n the MNIST da taset, DRTP le a ds t o a distrib ution of the a ctivation values in the hidden la yer that is mo re heavily skewed towards ± 1 than BP , F A and D F A. A 784-10 00-10 network with tanh hidden units an d sigmo id outpu t units is trained to classify MNIST images with the BP ( A ) , F A/DF A ( B ) a n d DR T P ( C ) algorithm s, wh e re the F A and DF A algorithm s are equiv alen t for single-h idden-lay er networks. The network tr aining relies on the Adam optimizer with a b inary cross-entropy loss a nd a fixed lear n ing rate o f 1 .5 × 10 − 4 , the tr aining and test errors are m e asured after e a ch minibatch durin g th e first epoch and then after each ep och during the rest of th e training. T o estimate the pro bability density fun ction of the activ ation s, their values are monitored f or 1 00 different examples in 100 suc cessi ve minib atches over the cou rse of training . The estimated prob ability density f unction hints at a different learn ing mechanism for DR TP: a s the distribution of the activ ation values in the hidden layer is more heavily ske wed towards ± 1, the vanishing value o f the tanh activ ation func tion deriv ative in th is region leads the network to stop learning. 20 Learning without feedb ack: Direct random target p rojection C. Frenkel, M. Lefebvre and D. Bol BP F A, DF A B A DRTP C Supplementary Figure 5 : On the CIF AR-1 0 dat aset, DR TP leads to a distrib utio n of the ac t ivation values in the hidden layer that is more heavily skewed towards ± 1 t ha n BP , F A and DF A. A 3072-1 000-1 0 network with tanh h id den units and sigmoid ou tput un its is trained to classify CIF AR-10 images with th e BP ( A ), F A/DF A ( B ) and DR TP ( C ) alg o rithms. The n etwork training relies on the Adam optimizer with a binary cr o ss-entropy lo ss and a fixed learning rate o f 5 × 10 − 6 for BP and F A/DF A, and 5 × 10 − 5 for DR TP , as per T able 3 in th e main text. Other experimental con ditions ar e similar to the ones used in Fig. 4. Similarly to the exper iments on the MNIST data set, the distribution of the activ ation values in the hidden layer is mo r e h eavily skewed towards ± 1 for DR TP , which hints at a stop learning mechan ism th rough the vanishing value of the tanh activ ation fun c tion deriv ativ e in this region. 21 Learning without feedb ack: Direct random target p rojection C. Frenkel, M. Lefebvre and D. Bol A B MNIST CIF AR-10 Supplementary Figure 6: The estimated probability density function o f the act ivation values at the end of training exhibits a more pronounced skewing towards ± 1 for DR TP than for BP , F A and DF A. Sing le-hidden - layer fully-c onnected ne twork s are trained to classify images from the MNIST ( A ) and CIF AR-10 ( B ) datasets, with the experimental conditions described in Figs. 4 and 5. 22 Learning without feedb ack: Direct random target p rojection C. Frenkel, M. Lefebvre and D. Bol Supplementary T able 1 : Comparison of the sDF A a nd DR TP t r a ining algor it hms on the MNIST dataset, illus- trating that DR TP systematically o utperforms sDF A. The mean an d the standard d eviation of the test err o r over 1 0 trials are p rovided. The n etwork definitions and cond itions ar e identical to tho se of T able 1 . Th e learnin g ra te s are summarized in T able 3 . Network sDF A DR TP FC1-500 DO 0.0 4.74 ± 0.15% 4 . 61 ± 0.1 3% DO 0.1 5.10 ± 0.13% 4 . 92 ± 0.1 3% DO 0.25 6.0 6 ± 0.10 % 5.75 ± 0.09% FC1-1000 DO 0.0 4.22 ± 0.11% 4 . 10 ± 0.0 7% DO 0.1 4.42 ± 0.12% 4 . 31 ± 0.0 6% DO 0.25 5.2 3 ± 0.12 % 4.94 ± 0.06% FC2-500 DO 0.0 4.78 ± 0.11% 4 . 58 ± 0.0 9% DO 0.1 5.16 ± 0.13% 5 . 00 ± 0.0 7% DO 0.25 6.1 3 ± 0.10 % 5.94 ± 0.06% FC2-1000 DO 0.0 4.24 ± 0.09% 4 . 00 ± 0.1 0% DO 0.1 4.51 ± 0.12% 4 . 25 ± 0.0 6% DO 0.25 5.3 9 ± 0.05 % 5.05 ± 0.09% CONV (rando m) DO 0.0 1.88 ± 0.10% 1 . 82 ± 0.1 1% DO 0.1 2.17 ± 0.13% 2 . 06 ± 0.0 8% DO 0.25 2.8 0 ± 0.17 % 2.60 ± 0.14% CONV (trained) DO 0.0 1.69 ± 0.10% 1 . 48 ± 0.1 5% DO 0.1 1.83 ± 0.11% 1 . 50 ± 0.1 7% DO 0.25 2.2 0 ± 0.15 % 1.81 ± 0.20% 23 Learning without feedb ack: Direct random target p rojection C. Frenkel, M. Lefebvre and D. Bol Supplementary T able 2: Comparison o f the sDF A a nd DR TP t raining alg o rithms on the CIF AR-10 dataset, illustrating that DR TP systematically outperforms sDF A. The mean and the stand a r d deviation of the test error over 1 0 trials are p rovided. The network definition s and con ditions are identical to those of T able 2 . The learning rate s are summarized in T able 3 . Network sDF A DR TP FC1-500 DO 0.0 54.80 ± 0 .29% 53. 92 ± 0.2 3% DO 0.1 54.79 ± 0 .24% 53. 77 ± 0.1 7% DO 0.25 55.48 ± 0.27% 54.26 ± 0.1 6% D A 53.83 ± 0.32% 52.73 ± 0.3 1% FC1-1000 DO 0.0 53.73 ± 0 .33% 53. 34 ± 0.1 0% DO 0.1 53.92 ± 0 .31% 53. 15 ± 0.1 5% DO 0.25 54.60 ± 0.38% 53.39 ± 0.1 5% D A 52.95 ± 0.32% 51.87 ± 0.3 2% FC2-500 DO 0.0 54.75 ± 0 .26% 53. 41 ± 0.3 5% DO 0.1 55.35 ± 0 .38% 54. 06 ± 0.4 6% DO 0.25 55.81 ± 0.37% 54.57 ± 0.3 3% D A 53.85 ± 0.34% 52.54 ± 0.3 4% FC2-1000 DO 0.0 53.78 ± 0 .24% 52. 68 ± 0.2 5% DO 0.1 53.87 ± 0 .49% 52. 45 ± 0.1 5% DO 0.25 54.87 ± 0.43% 53.29 ± 0.3 1% D A 52.59 ± 0.20% 51.27 ± 0.2 1% CONV (rando m) DO 0.0 33.08 ± 0 .31% 32. 65 ± 0.3 8% DO 0.1 33.04 ± 0 .42% 32. 57 ± 0.3 4% DO 0.25 34.71 ± 0.37% 33.90 ± 0.5 3% D A 31.52 ± 0.25% 31.04 ± 0.4 5% CONV (trained) DO 0.0 38.69 ± 0 .78% 35. 82 ± 0.5 9% DO 0.1 39.23 ± 0 .82% 35. 17 ± 0.9 1% DO 0.25 40.08 ± 1.03% 35.51 ± 0.6 1% D A 38.43 ± 0.86% 34.39 ± 0.6 4% 24 Learning without feedb ack: Direct random target p rojection C. Frenkel, M. Lefebvre and D. Bol Supplementary Note 1. Detailed proof of alignment between the BP and DRTP modula t ory signals This full version o f th e alignment proof b etween the BP a n d DR TP modulato ry signals is derived f or a neural network composed of linear hidden layers (Figure 4 ) and a single training example ( x , c ∗ ), wher e x is the inpu t data samp le and c ∗ the label. Th e C -dimen sional target vector y ∗ correspo n ds to the one-h ot encodin g of c ∗ , where C is the number o f classes. Our dev elop ments build on the align ment pr oof of [13], which demonstrates th a t the F A and BP modulato ry signals are within 90 ◦ of each other in the case of a single linear h idden lay er , a linear ou tp ut layer an d a mean squar ed err or lo ss. I n the fr a mew ork of classification problems, we extend this pr oof for the case of DR TP and to an arbitrary nu mber of linear hid d en layers, a non linear outp ut layer of sigmo id/softmax units and a binary /categorical cross-entro py loss. Network dynamics. The output of the k -th linear hidden layer is g i ven by y k = z k = W k y k − 1 for k ∈ [1 , K − 1] , where K is the nu mber o f layers and y 0 = x is the inp ut vector . Note that the bias vector b k is omitted without loss of generality . Th e output layer is described by z K = W K y K − 1 , y K = σ ( z K ) , where σ ( · ) is either th e sigmoid o r the softmax activation fun ction. T he loss function J ( · ) is either the b inary cro ss- entropy (BCE) loss fo r sigmo id output units or the categorical cross-en tropy (CCE) loss f or softm ax ou tput units, computed over the C outpu t classes: J BCE ( y K , y ∗ ) = − 1 C C X c =1 y ∗ c log ( y K c ) + (1 − y ∗ c ) log (1 − y K c ) , J CCE ( y K , y ∗ ) = − 1 C C X c =1 y ∗ c log ( y K c ) . The ne twork is traine d with stochastic grad ient descent. In the outpu t laye r, the weight updates of bo th BP and DR TP follow W K,j i ← W K,j i − η C X l =1 ∂ J ∂ z K l ∂ z K l ∂ W K,j i where i, j ∈ N are indices co rrespond ing respectively to the colu mns and rows of the outpu t lay e r weight matrix . For both sigmoid and softmax o utput units, the factors in this upd a te can b e computed as ∂ J ∂ z K l = C X c =1 ∂ J ∂ y K c ∂ y K c ∂ z K l , ∂ z K l ∂ W K,j i = y K − 1 , i if j = l , 0 otherwise. For sigmoid output units, the factors in the par tial de riv ativ e ∂ J ∂ z K l can be co mputed as ∂ J BCE ∂ y K c = − 1 C 1 y K c if c = c ∗ , − 1 C − 1 (1 − y K c ) otherwise, ∂ y K c ∂ z K l = y K c (1 − y K c ) if l = c, 0 otherwise, while for softmax outp ut units, these factors can be computed as ∂ J CCE ∂ y K c = − 1 C 1 y K c if c = c ∗ , 0 other wise, ∂ y K c ∂ z K l = y K c (1 − y K c ) if l = c, − y K c y K l otherwise. 25 Learning without feedb ack: Direct random target p rojection C. Frenkel, M. Lefebvre and D. Bol In both cases, it resu lts that ∂ J ∂ z K l = − 1 C (1 − y K l ) if l = c ∗ , − 1 C ( − y K l ) otherwise, which is equivalent to ∂ J ∂ z K = − 1 C ( y ∗ − y K ) = − e C , where e is the erro r vector . Ther e fore, the weight updates in the outp ut lay er can be rewritten as W K ← W K + η C ey T K − 1 . In the hidde n layer s, the weight updates follow W k ← W k − η δ y k y T k − 1 . On the one h and, if the trainin g relies on the BP algor ith m, th e modulator y sign als δ z k , which are equ ivalent to th e estimated loss grad ients δ y k in the linear case, co rrespond to the loss functio n gradient: δ y k = δ z k = ∂ J ∂ y k = − 1 C K Y i = k +1 W T i ! e. On the other hand , if the DR TP algo rithm is used, the mo dulatory signals are p rojections of th e one- hot-enco ded target vector y ∗ throug h fixed random connectivity m atrices B k : δ y k = δ z k = B T k y ∗ . In order to provide learning , the mod ulatory sig n als prescribe d by BP and DR TP mu st be within 9 0 ◦ of each other , i.e. their dot pro duct m ust be positive: − e T K Y i = k +1 W T i ! T B T k y ∗ > 0 . Lemma. In the case of zero-in itialized weights, i.e. W 0 k = 0 fo r k ∈ [1 , K ] , k ∈ N , and hen ce o f zero - initialized hidden layer outp uts, i.e. y 0 k = 0 for k ∈ [1 , K − 1] and z 0 K = 0 , co nsidering a DR TP-ba sed train in g performed recursively with a single elemen t of th e training set ( x, c ∗ ) and y ∗ denoting the on e-hot enco ding of c ∗ , at every discrete update step t , there are non-negative scalars s t y k and s t W k for k ∈ [1 , K − 1] and a C - dimensional vector s t W K such that y t k = − s t y k B T k y ∗ for k ∈ [1 , K − 1] W t 1 = − s t W 1 B T 1 y ∗ x T W t k = s t W k B T k y ∗ B T k − 1 y ∗ T for k ∈ [2 , K − 1] W t K = − s t W K B T K − 1 y ∗ T . Pr oof. The lemma is proven by in duction. For t = 0 , the co nditions required to satisfy the lem ma are trivially met by choosin g s 0 y k , s 0 W k = 0 for k ∈ [1 , K − 1] , and s 0 W K as a zero vector, given that y 0 k = 0 for k ∈ [1 , K − 1 ] and W 0 k = 0 for k ∈ [1 , K ] . For t > 0 , considering th at th e conditions are satisfied at a gi ven discrete u pdate step t , it must be shown th at they still hold at the n ext discrete update step t + 1 . In the h idden layers, the weig hts are upda ted u sing the modu latory sign als prescribed by DR TP . For the first hidden layer, we have W t +1 1 = W t 1 − η B T 1 y ∗ x T = − s t W 1 B T 1 y ∗ x T − η B T 1 y ∗ x T s t +1 W 1 = s t W 1 + η = s t W 1 + ∆ s t W 1 26 Learning without feedb ack: Direct random target p rojection C. Frenkel, M. Lefebvre and D. Bol and for subseque nt h idden layers, i.e. for k ∈ [2 , K − 1] , we have W t +1 k = W t k − η B T k y ∗ y tT k − 1 = s t W k B T k y ∗ B T k − 1 y ∗ T + η s t y k − 1 B T k y ∗ B T k − 1 y ∗ T s t +1 W k = s t W k + η s t y k − 1 = s t W k + ∆ s t W k . The weights in th e output layer are upd ated acco r ding to the loss functio n grad ient, thus leading to W t +1 K = W t K + η C y ∗ − y t K y tT K − 1 = W t K − η C y ∗ − y t K s t y K − 1 B T K − 1 y ∗ T = − s t W K B T K − 1 y ∗ T − η s t y K − 1 C y ∗ − y t K B T K − 1 y ∗ T s t +1 W K = s t W K + η s t y K − 1 C y ∗ − y t K . The outpu t o f th e first hidden layer is y t +1 1 = W t +1 1 x = W t 1 − η B T 1 y ∗ x T x = W t 1 x | {z } y t 1 − η x T x B T 1 y ∗ = − s t y 1 B T 1 y ∗ − η k x k 2 B T 1 y ∗ s t +1 y 1 = s t y 1 + η k x k 2 = s t y 1 + ∆ s t y 1 and the outp ut o f the k -th hidd e n layer for k ∈ [2 , K − 1] is given b y y t +1 k = W t +1 k y t +1 k − 1 = − s t +1 W k B T k y ∗ B T k − 1 y ∗ T s t +1 y k − 1 B T k − 1 y ∗ = − s t W k + η s t y k − 1 s t y k − 1 + ∆ s t y k − 1 B T k − 1 y ∗ 2 B T k y ∗ = − s t W k s t y k − 1 B T k − 1 y ∗ 2 | {z } s t y k B T k y ∗ − s t W k ∆ s t y k − 1 + η s t y k − 1 s t y k − 1 + ∆ s t y k − 1 B T k − 1 y ∗ 2 B T k y ∗ s t +1 y k = s t y k + s t W k ∆ s t y k − 1 + η s t y k − 1 s t y k − 1 + ∆ s t y k − 1 B T k − 1 y ∗ 2 = s t y k + ∆ s t y k . The coefficients s t W 1 and s t y 1 are updated with strictly p ositiv e quantities ∆ s t W 1 and ∆ s t y 1 at each update step t and are thu s strictly positive for t > 0 . Furth ermore, the coefficients s t W k and s t y k are up dated based on the co efficients of the previous layer and will therefore be strictly positive for k ∈ [1 , K − 1 ] . Theorem. Under th e same conditions as in the lemm a and f or the linear-hidden-lay er network dyna m ics described above, th e k -th layer mo dulatory signals prescr ib ed by DR TP ar e always a negativ e scalar multiple of th e Moor e- Penrose pseud o-inv erse of the pr oduct of forward matrices of laye rs k + 1 to K , locate d in the feedb ack path way between the ou tp ut layer an d the k -th hidd en layer , multiplied by the error . That is, for k ∈ [1 , K − 1] an d t > 0 , − 1 s t k k +1 Y i = K W t i ! + e = B T k y ∗ with s t k > 0 . 27 Learning without feedb ack: Direct random target p rojection C. Frenkel, M. Lefebvre and D. Bol Pr oof. When replacing the forward weights W t i by the expressions gi ven in the lemma, the a bove equality becomes " k +1 Y i = K − 1 s t W i ! s t W K k +1 Y i = K − 1 B T i y ∗ 2 ! B T k y ∗ T # + y ∗ − y t K = s t k B T k y ∗ K − 1 Y i = k +1 s t W i ! − 1 K − 1 Y i = k +1 B T i y ∗ 2 ! − 1 h s t W K B T k y ∗ T i + y ∗ − y t K = s t k B T k y ∗ K − 1 Y i = k +1 s t W i ! − 1 K − 1 Y i = k +1 B T i y ∗ 2 ! − 1 B T k y ∗ T + s t + W K y ∗ − y t K = s t k B T k y ∗ K − 1 Y i = k +1 s t W i ! − 1 K − 1 Y i = k +1 B T i y ∗ 2 ! − 1 B T k y ∗ − 2 B T k y ∗ | {z } ( B T k y ∗ ) T + s t W K − 2 s tT W K | {z } s t + W K y ∗ − y t K = s t k B T k y ∗ K − 1 Y i = k +1 s t W i ! − 1 K − 1 Y i = k B T i y ∗ 2 ! − 1 s t W K − 2 s tT W K y ∗ − y t K B T k y ∗ = s t k B T k y ∗ . By identification , it is f o und that s t k = s tT W K ( y ∗ − y t K ) Q K − 1 i = k +1 s t W i Q K − 1 i = k B T i y ∗ 2 s t W K 2 . From the lemma pr oof, the update formula for the vector s t W K is given by s t +1 W K = s t W K + η s t y K − 1 C y ∗ − y t K , where η , C an d s t y K − 1 are positive scalars. In the framework of classification pro blems w h ere outpu ts are strictly bound ed b etween 0 and 1, for any example ( x , c ∗ ) in the training set, the err or vector e = ( y ∗ − y t K ) has a single strictly positive entry (1 − y K c ) at th e class labe l index c = c ∗ , all the oth er e n tries − y K c with c 6 = c ∗ being strictly negativ e. This sign informatio n is constant as the network is trained with a single train in g example. Gi ven that s 0 W K = 0 from zero-weight initializatio n and th at s t W K is updated in the same direction as e , we h ave at every discrete update step t sign s t W K = sign y ∗ − y t K , and thus s tT W K y ∗ − y t K > 0 . Therefo re, the scalars s t k are strictly positive for t > 0 . Alignment. In the framework o f cla ssification prob lems, as the co e ffi cien ts s t k are strictly positive scalar s for t > 0 , it results from the the orem that the dot prod uct between the BP and DR TP modulato ry signals is strictly p ositi ve, i.e. − e T K Y i = k +1 W T i ! T B T k y ∗ > 0 e T K Y i = k +1 W T i ! T k +1 Y i = K W i ! + | {z } I e s t k > 0 e T e s t k > 0 . The BP an d D R TP mod ulatory signals are thus within 90 ◦ of each other . 28
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment