그라디언트 하강이 동질 신경망의 마진을 최대로 만든다
본 논문은 ReLU·LeakyReLU 활성화를 갖는 동질(동차) 신경망에서, 로지스틱·교차 엔트로피 손실을 최소화하는 그라디언트 하강(또는 그라디언트 흐름) 과정이 훈련 손실이 일정 이하로 떨어지면 정규화 마진을 점진적으로 증가시킨다는 이론을 제시한다. 정규화 마진의 스무딩 버전이 단조 증가함을 보이고, 최종 파라미터 방향이 마진 최대화 문제의 KKT 조건을 만족하는 점으로 수렴함을 증명한다. 실험을 통해 MNIST·CIFAR‑10에서 장시간 …
저자: Kaifeng Lyu, Jian Li
본 논문은 현대 딥러닝 모델이 왜 좋은 일반화 성능을 보이는지에 대한 근본적인 질문, 즉 최적화 알고리즘이 어떤 암묵적 편향(implicit bias)을 갖는지를 탐구한다. 특히, ReLU·LeakyReLU 활성화를 사용하고 편향(bias) 파라미터를 제거한 경우 동질(positively homogeneous) 특성을 갖는 완전 연결 신경망과 컨볼루션 신경망을 대상으로 한다. 동질성은 파라미터를 스칼라 c로 확대하면 출력이 c^L 배가 되는 성질이며, 여기서 L은 네트워크 깊이(층 수)와 동일하다. 이 특성 덕분에 파라미터의 크기와 방향이 분리되어, 방향만이 예측에 영향을 미친다.
논문은 두 가지 기본 가정을 둔다. 첫째, 로지스틱 손실, 교차 엔트로피 손실, 지수 손실 등 지수형 꼬리를 갖는 손실 함수이다. 이는 대부분의 분류 문제에서 사용되는 손실이며, 수학적으로는 손실값이 큰 마진에 대해 빠르게 감소한다는 특성을 의미한다. 둘째, 훈련 과정 중 어느 시점 t₀에서 손실이 충분히 작아(예: ln 2 이하) 데이터가 완전히 분리될 수 있다는 가정이다. 이는 과대 파라미터화된 현대 네트워크가 훈련 데이터에 100 % 정확도로 맞출 수 있음을 전제로 한다.
이러한 전제 하에, 저자들은 다음과 같은 주요 결과를 제시한다.
1. **정규화 마진의 단조 증가**
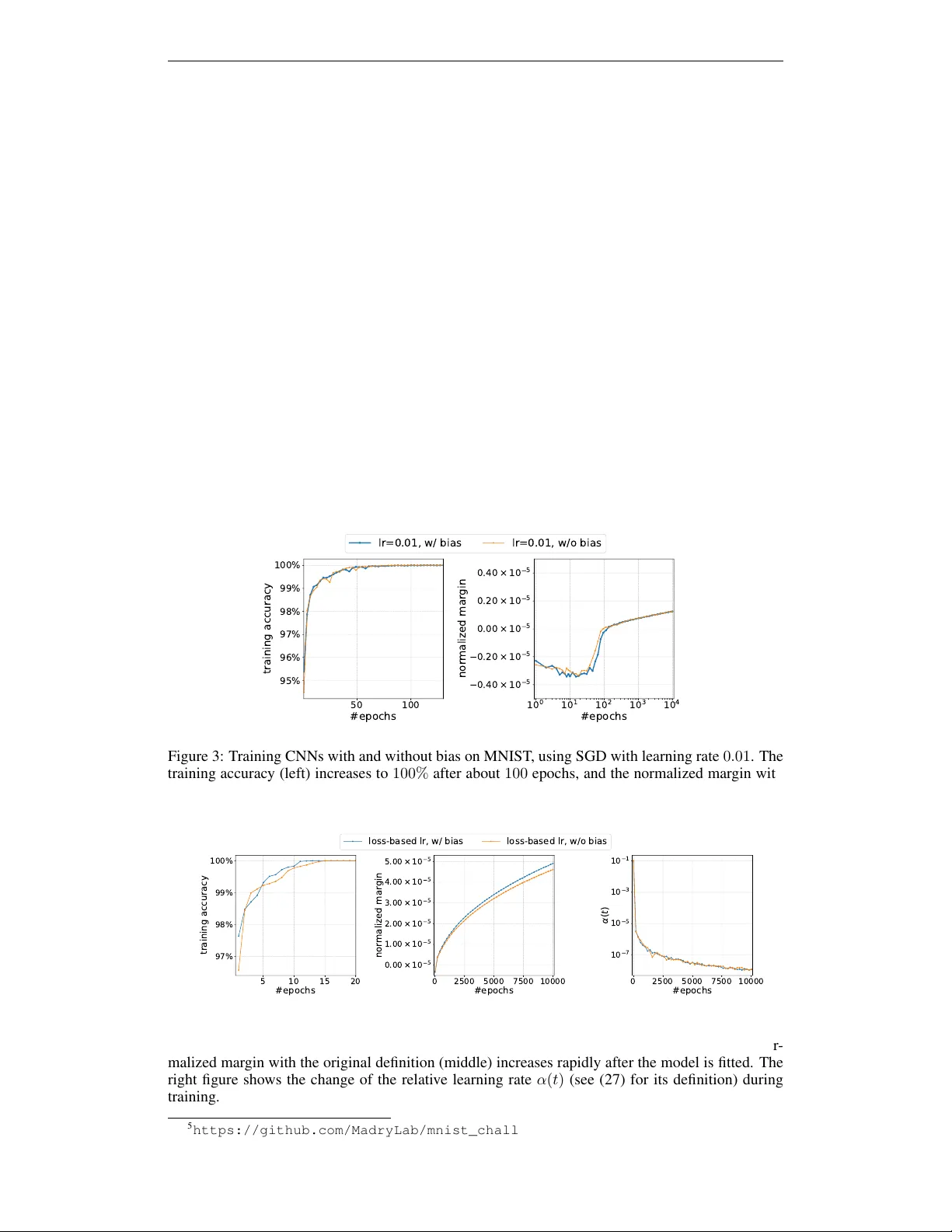
마진 γ(θ)=min_n y_n·Φ(θ;x_n) 은 파라미터 노름 ‖θ‖_L와 선형적으로 스케일한다. 따라서 정규화 마진 \barγ(θ)=γ(θ)/‖θ‖_L² 를 정의한다. 논문은 \barγ가 순간적으로 변동할 수 있더라도, 시간 t가 충분히 크면 \barγ와 거의 일치하는 스무딩 마진 \tildeγ가 존재하고, \tildeγ는 t>t₀ 구간에서 비감소한다는 정리를 증명한다. 이는 그라디언트 흐름을 방사(radial)와 접선(tangential) 성분으로 분해하고, 방사 성분이 노름을 증가시키는 반면 접선 성분이 마진을 개선한다는 직관을 수학적으로 정형화한 결과이다. 비스무스(ReLU) 활성화에서도 Clarke 서브다이버전스를 이용해 동일한 결론을 얻는다.
2. **마진 최대화와 KKT 점 수렴**
마진을 직접 최대화하는 제약 최적화 문제
\
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기