Gradient Descent Maximizes the Margin of Homogeneous Neural Networks
In this paper, we study the implicit regularization of the gradient descent algorithm in homogeneous neural networks, including fully-connected and convolutional neural networks with ReLU or LeakyReLU activations. In particular, we study the gradient…
Authors: Kaifeng Lyu, Jian Li
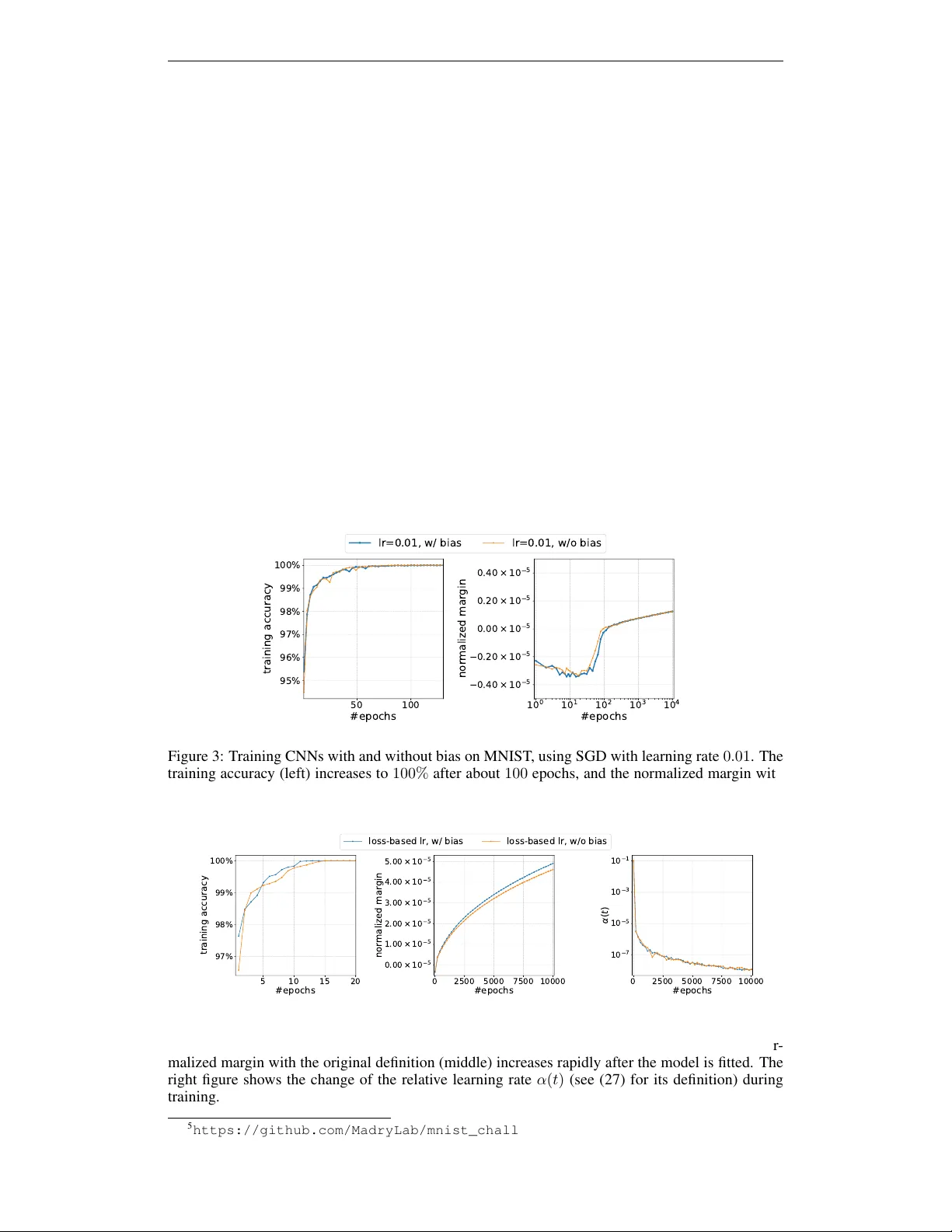
Published as a conference paper at ICLR 2020 G R A D I E N T D E S C E N T M A X I M I Z E S T H E M A R G I N O F H O M O G E N E O U S N E U R A L N E T W O R K S Kaifeng L yu & Jian Li Institute for Interdisciplinary Information Sciences Tsinghua Univ ersity Beijing, China vfleaking@gmail.com,lijian83@mail.tsinghua.edu.cn A B S T R AC T In this paper , we study the implicit re gularization of the gradient descent algorithm in homogeneous neural networks, including fully-connected and con volutional neural networks with ReLU or Leak yReLU acti vations. In particular , we study the gradient descent or gradient flo w (i.e., gradient descent with infinitesimal step size) optimizing the logistic loss or cross-entropy loss of any homogeneous model (possibly non-smooth), and sho w that if the training loss decreases below a certain threshold, then we can define a smoothed version of the normalized mar gin which increases ov er time. W e also formulate a natural constrained optimization problem related to mar gin maximization, and prove that both the normalized margin and its smoothed version con ver ge to the objectiv e value at a KKT point of the optimiza- tion problem. Our results generalize the previous results for logistic regression with one-layer or multi-layer linear networks, and provide more quantitativ e con- ver gence results with weaker assumptions than previous results for homogeneous smooth neural networks. W e conduct several experiments to justify our theoretical finding on MNIST and CIF AR-10 datasets. Finally , as margin is closely related to robustness, we discuss potential benefits of training longer for improving the robustness of the model. 1 I N T RO D U C T I O N A major open question in deep learning is why gradient descent or its v ariants, are biased towards solutions with good generalization performance on the test set. T o achie ve a better understanding, previous works ha ve studied the implicit bias of gradient descent in different settings. One simple but insightful setting is linear logistic regression on linearly separable data. In this setting, the model is parameterized by a weight vector w , and the class prediction for any data point x is determined by the sign of w > x . Therefore, only the direction w / k w k 2 is important for making prediction. Soudry et al. (2018a;b); Ji & T elgarsky (2018; 2019c); Nacson et al. (2019c) in vestigated this prob- lem and proved that the direction of w con verges to the direction that maximizes the L 2 -margin while the norm of w diver ges to + ∞ , if we train w with (stochastic) gradient descent on logistic loss. Interestingly , this conv ergent direction is the same as that of any re gularization path : any se- quence of weight vectors { w t } such that every w t is a global minimum of the L 2 -regularized loss L ( w ) + λ t 2 k w k 2 2 with λ t → 0 (Rosset et al., 2004). Indeed, the trajectory of gradient descent is also pointwise close to a regularization path (Suggala et al., 2018). The aforementioned linear logistic regression can be viewed as a single-layer neural network. A nat- ural and important question is to what extent gradient descent has similiar implicit bias for modern deep neural networks. For theoretical analysis, a natural candidate is to consider homogeneous neu- ral networks . Here a neural network Φ is said to be (positiv ely) homogeneous if there is a number L > 0 (called the order ) such that the netw ork output Φ( θ ; x ) , where θ stands for the parameter and x stands for the input, satisfies the following: ∀ c > 0 : Φ( c θ ; x ) = c L Φ( θ ; x ) for all θ and x . (1) It is important to note that many neural networks are homogeneous (Neyshabur et al., 2015a; Du et al., 2018). For example, deep fully-connected neural networks or deep CNNs with ReLU or 1 Published as a conference paper at ICLR 2020 LeakyReLU acti vations can be made homogeneous if we remo ve all the bias terms, and the order L is exactly equal to the number of layers. In (W ei et al., 2019), it is shown that the regularization path does con ver ge to the max-margin di- rection for homogeneous neural networks with cross-entropy or logistic loss. This result suggests that gradient descent or gradient flow may also con verges to the max-margin direction by assuming homogeneity , and this is indeed true for some sub-classes of homogeneous neural netw orks. For gra- dient flow , this conv ergent direction is prov en for linear fully-connected networks (Ji & T elgarsky, 2019a). For gradient descent on linear fully-connected and conv olutional networks, (Gunasekar et al., 2018b) formulate a constrained optimization problem related to margin maximization and prov e that gradient descent con verges to the direction of a KKT point or even the max-margin di- rection, under various assumptions including the conv ergence of loss and gradient directions. In an independent work, (Nacson et al., 2019a) generalize the result in (Gunasekar et al., 2018b) to smooth homogeneous models (we will discuss this work in more details in Section 2). 1 . 1 M A I N R E S U LT S In this paper , we identify a minimal set of assumptions for proving our theoretical results for ho- mogeneous neural networks on classification tasks. Besides homogeneity , we make two additional assumptions: 1. Exponential-type Loss Function. W e require the loss function to ha ve certain exponential tail (see Appendix A for the details). This assumption is not restrictiv e as it includes the most popular classfication losses: exponential loss, logistic loss and cross-entrop y loss. 2. Separability . The neural network can separate the training data during training (i.e., the neural network can achie ve 100% training accurac y) 1 . While the first assumption is natural, the second requires some explanation. In fact, we assume that at some time t 0 , the training loss is smaller than a threshold, and the threshold here is chosen to be so small that the training accuracy is guaranteed to be 100% (e.g., for the logistic loss and cross-entropy loss, the threshold can be set to ln 2 ). Empirically , state-of-the-art CNNs for image classification can ev en fit randomly labeled data easily (Zhang et al., 2017). Recent theoretical work on ov er-parameterized neural netw orks (Allen-Zhu et al., 2019; Zou et al., 2018) sho w that gradient descent can fit the training data if the width is large enough. Furthermore, in order to study the margin, ensuring the training data can be separated is inevitable; otherwise, there is no positive margin between the data and decision boundary . Our Contribution. Similar to linear models, for homogeneous models, only the direction of parameter θ is important for making predictions, and one can see that the margin γ ( θ ) scales linearly with k θ k L 2 , when fixing the direction of θ . T o compare mar gins among θ in different directions, it makes sense to study the normalized mar gin , ¯ γ ( θ ) := γ ( θ ) / k θ k L 2 . In this paper , we focus on the training dynamics of the network after t 0 (recall that t 0 is a time that the training loss is less than the threshold). Our theoretical results can answer the following questions regarding the normalized mar gin. First, how does the normalized mar gin change during tr aining? The answer may seem complicated since one can easily come up with examples in which ¯ γ increases or decreases in a short time interval. Howe ver , we can show that the overall trend of the normalized margin is to increase in the following sense: there exists a smoothed version of the normalized margin, denoted as ˜ γ , such that (1) | ˜ γ − ¯ γ | → 0 as t → ∞ ; and (2) ˜ γ is non-decreasing for t > t 0 . Second, how larg e is the normalized mar gin at con ver gence? T o answer this question, we formulate a natural constrained optimization problem which aims to directly maximize the margin. W e show that every limit point of { θ ( t ) / k θ ( t ) k 2 : t > 0 } is along the direction of a KKT point of the max- margin problem. This indicates that gradient descent/gradient flow performs margin maximization implicitly in deep homogeneous networks. This result can be seen as a significant generalization of previous works (Soudry et al., 2018a;b; Ji & T elgarsky, 2019a; Gunasekar et al., 2018b) from linear classifiers to homogeneous classifiers. 1 Note that this does NO T mean the training loss is 0. 2 Published as a conference paper at ICLR 2020 1 0 0 1 0 1 1 0 2 1 0 3 1 0 4 #epochs 1 0 5 1 0 4 1 0 3 1 0 2 1 0 1 1 0 0 training loss 1 0 0 1 0 1 1 0 2 1 0 3 1 0 4 #epochs 0 . 5 0 × 1 0 3 0 . 0 0 × 1 0 3 0 . 5 0 × 1 0 3 1 . 0 0 × 1 0 3 1 . 5 0 × 1 0 3 normalized margin lr=0.01, w/ bias lr=0.01, w/o bias (a) 0 2500 5000 7500 10000 #epochs 1 0 8 0 0 1 0 6 0 0 1 0 4 0 0 1 0 2 0 0 1 0 0 training loss 0 2500 5000 7500 10000 #epochs 0 . 5 0 × 1 0 3 0 . 0 0 × 1 0 3 0 . 5 0 × 1 0 3 1 . 0 0 × 1 0 3 1 . 5 0 × 1 0 3 normalized margin loss-based lr, w/ bias loss-based lr, w/o bias (b) Figure 1: (a) Training CNNs with and without bias on MNIST , using SGD with learning rate 0 . 01 . The training loss (left) decreases o ver time, and the normalized margin (right) k eeps increasing after the model is fitted, but the growth rate is slow ( ≈ 1 . 8 × 10 − 4 after 10000 epochs). (b) T raining CNNs with and without bias on MNIST , using SGD with the loss-based learning rate scheduler . The training loss (left) decreases e xponentially ov er time ( < 10 − 800 after 9000 epochs), and the normal- ized margin (right) increases rapidly after the model is fitted ( ≈ 1 . 2 × 10 − 3 after 10000 epochs, 10 × larger than that of SGD with learning rate 0 . 01 ). Experimental details are in Appendix K. As by-products of the above results, we deriv e tight asymptotic con vergence/gro wth rates of the loss and weights. It is shown in (Soudry et al., 2018a;b; Ji & T elgarsk y, 2018; 2019c) that the loss de- creases at the rate of O (1 /t ) , the weight norm grows as O (log t ) for linear logistic re gression. In this work, we generalize the result by showing that the loss decreases at the rate of O (1 / ( t (log t ) 2 − 2 /L )) and the weight norm grows as O ((log t ) 1 /L ) for homogeneous neural networks with exponential loss, logistic loss, or cross-entropy loss. Experiments. 2 The main practical implication of our theoretical result is that training longer can enlarge the normalized margin. T o justify this claim empiricaly , we train CNNs on MNIST and CIF AR-10 with SGD (see Section K.1). Results on MNIST are presented in Figure 1. For constant step size, we can see that the normalized margin keeps increasing, b ut the growth rate is rather slow (because the gradient gets smaller and smaller). Inspired by our con vergence results for gradient descent, we use a learning rate scheduling method which enlarges the learning rate according to the current training loss, then the training loss decreases exponentially faster and the normalized margin increases significantly faster as well. For feedforward neural netw orks with ReLU acti vation, the normalized mar gin on a training sample is closely related to the L 2 -r obustness (the L 2 -distance from the training sample to the decision boundary). Indeed, the former di vided by a Lipschitz constant is a lower bound for the latter . For example, the normalized margin is a lower bound for the L 2 -robustness on fully-connected networks with ReLU activ ation (see, e.g., Theorem 4 in (Sokolic et al., 2017)). This f act suggests that training longer may have potential benefits on improving the robustness of the model. In our e xperiments, we observe noticeable impro vements of L 2 -robustness on both training and test sets (see Section K.2). 2 R E L A T E D W O R K Implicit Bias in T raining Linear Classifiers. For linear logistic regression on linearly separable data, Soudry et al. (2018a;b) showed that full-batch gradient descent con verges in the direction of the max L 2 -margin solution of the corresponding hard-mar gin Support V ector Machine (SVM). Subse- quent works extended this result in sev eral ways: Nacson et al. (2019c) extended the results to the case of stochastic gradient descent; Gunasekar et al. (2018a) considered other optimization methods; Nacson et al. (2019b) considered other loss functions including those with poly-exponential tails; Ji & T elgarsky (2018; 2019c) characterized the con vergence of weight direction without assuming separability; Ji & T elgarsky (2019b) prov ed a tighter con vergence rate for the weight direction. Those results on linear logistic regression have been generalized to deep linear networks. Ji & T el- garsky (2019a) sho wed that the product of weights in a deep linear network with strictly decreasing loss conv erges in the direction of the max L 2 -margin solution. Gunasekar et al. (2018b) showed 2 Code av ailable: https://github.com/vfleaking/max- margin 3 Published as a conference paper at ICLR 2020 more general results for gradient descent on linear fully-connected and con volutional networks with exponential loss, under v arious assumptions on the conv ergence of the loss and gradient direction. Margin maximization phenomenon is also studied for boosting methods (Schapire et al., 1998; Rudin et al., 2004; 2007; Schapire & Freund, 2012; Shale v-Shwartz & Singer, 2010; T elgarsky, 2013) and Normalized Perceptron (Ramdas & Pena, 2016). Implicit Bias in T raining Nonlinear Classifiers. Soudry et al. (2018a) analyzed the case where there is only one trainable layer of a ReLU netw ork. Xu et al. (2018) characterized the implicit bias for the model consisting of one single ReLU unit. Our work is closely related to a recent independent work by (Nacson et al., 2019a) which we discuss in details belo w . Comparison with (Nacson et al., 2019a). V ery recently , (Nacson et al., 2019a) analyzed gradient descent for smooth homogeneous models and proved the con vergence of parameter direction to a KKT point of the aforementioned max-margin problem. Compared with their w ork, our work adopt much weaker assumptions: (1) They assume the training loss conv erges to 0 , but in our work we only require that the training loss is lower than a small threshold value at some time t 0 (and we prov e the e xact con vergence rate of the loss after t 0 ); (2) They assume the con ver gence of parameter direction 3 , while we prove that KKT conditions hold for all limit points of { θ ( t ) / k θ ( t ) k 2 : t > 0 } , without requiring any conv ergence assumption; (3) They assume the con vergence of the direction of losses (the direction of the vector whose entries are loss values on ev ery data point) and Linear Independence Constraint Qualification (LICQ) for the max-mar gin problem, while we do not need such assumptions. Besides the above differences in assumptions, we also prove the monotonicity of the normalized margin and provide tight conv ergence rate for training loss. W e believ e both results are interesting in their own right. Another technical difference is that their work analyzes discrete gradient descent on smooth homo- geneous models (which fails to capture ReLU networks). In our work, we analyze both gradient descent on smooth homogeneous models and also gradient flow on homogeneous models which could be non-smooth. Other W orks on Implicit Bias. Banburski et al. (2019) also studied the dynamics of gradient flo w and among other things, provided mathematical insights to the implicit bias tow ards max margin solution for homogeneous networks. W e note that their analysis of gradient flow decomposes the dynamics to the tangent component and radial component, which is similar to our proof of Theo- rem 4.1 in spirit. Wilson et al. (2017); Ali et al. (2019); Gunasekar et al. (2018a) sho wed that for the linear least-square problem gradient-based methods con verge to the unique global minimum that is closest to the initialization in L 2 distance. Du et al. (2019); Jacot et al. (2018); Lee et al. (2019); Arora et al. (2019b) showed that o ver -parameterized neural networks of sufficient width (or infinite width) behave as linear models with Neural T angent Kernel (NTK) with proper initialization and gradient descent con verges linearly to a global minimum near the initial point. Other related works include (Ma et al., 2019; Gidel et al., 2019; Arora et al., 2019a; Suggala et al., 2018; Blanc et al., 2019; Neyshab ur et al., 2015b;a). 3 P R E L I M I NA R I E S Basic Notations. For any N ∈ N , let [ N ] = { 1 , . . . , N } . k v k 2 denotes the L 2 -norm of a vector v . The default base of log is e . For a function f : R d → R , ∇ f ( x ) stands for the gradient at x if it exists. A function f : X → R d is C k -smooth if f is k times continuously dif ferentiable. A function f : X → R is locally Lipschitz if for every x ∈ X there exists a neighborhood U of x such that the restriction of f on U is Lipschitz continuous. Non-smooth Analysis. For a locally Lipschitz function f : X → R , the Clarke’ s subdifferential (Clarke, 1975; Clarke et al., 2008; Da vis et al., 2020) at x ∈ X is the con vex set ∂ ◦ f ( x ) := conv lim k →∞ ∇ f ( x k ) : x k → x , f is differentiable at x k . 3 Assuming the con vergence of the parameter direction may seem quite reasonable, howe ver , the problem here can be quite subtle in theory . In Appendix J, we present a smooth homogeneuous function f , based on the Mexican hat function (Absil et al. (2005)), such that ev en the direction of the parameter does not con verge along gradient flow (it mo ves around a cirle when t increases). 4 Published as a conference paper at ICLR 2020 For brevity , we say that a function z : I → R d on the interval I is an arc if z is absolutely continuous for any compact sub-interval of I . For an arc z , z 0 ( t ) (or d z dt ( t ) ) stands for the deriv ati ve at t if it exists. Follo wing the terminology in (Da vis et al., 2020), we say that a locally Lipschitz function f : R d → R admits a chain rule if for any arc z : [0 , + ∞ ) → R d , ∀ h ∈ ∂ ◦ f ( z ( t )) : ( f ◦ z ) 0 ( t ) = h h , z 0 ( t ) i holds for a.e. t > 0 (see also Appendix I). Binary Classification. Let Φ be a neural network, assumed to be parameterized by θ . The output of Φ on an input x ∈ R d x is a real number Φ( θ ; x ) , and the sign of Φ( θ ; x ) stands for the classification result. A dataset is denoted by D = { ( x n , y n ) : n ∈ [ N ] } , where x n ∈ R d x stands for a data input and y n ∈ {± 1 } stands for the corresponding label. For a loss function ` : R → R , we define the training loss of Φ on the dataset D to be L ( θ ) := P N n =1 ` ( y n Φ( θ ; x n )) . Gradient Descent. W e consider the process of training this neural network Φ with either gradient descent or gradient flow . For gradient descent, we assume the training loss L ( θ ) is C 2 -smooth and describe the gradient descnet process as θ ( t + 1) = θ ( t ) − η ( t ) ∇L ( θ ( t )) , where η ( t ) is the learning rate at time t and ∇L ( θ ( t )) is the gradient of L at θ ( t ) . Gradient Flow . F or gradient flow , we do not assume the differentibility but only some regu- larity assumptions including locally Lipschitz. Gradient flow can be seen as gradient descent with infinitesimal step size. In this model, θ changes continuously with time, and the trajectory of param- eter θ during training is an arc θ : [0 , + ∞ ) → R d , t 7→ θ ( t ) that satisfies the differential inclusion d θ ( t ) dt ∈ − ∂ ◦ L ( θ ( t )) for a.e. t ≥ 0 . The Clarke’ s subdifferential ∂ ◦ L is a natural generalization of the usual dif ferential to non-differentiable functions. If L ( θ ) is actually a C 1 -smooth function, the abov e differential inclusion reduces to d θ ( t ) dt = −∇L ( θ ( t )) for all t ≥ 0 , which corresponds to the gradient flow with dif ferential in the usual sense. 4 G R A D I E N T D E S C E N T / G R A D I E N T F L O W O N H O M O G E N E O U S M O D E L In this section, we first state our results for gradient flo w and gradient descent on homogeneous models with exponential loss ` ( q ) := e − q for simplicity of presentation. Due to space limit, we defer the more general results which hold for a large family of loss functions (including logistic loss and cross-entropy loss) to Appendix A, F and G. 4 . 1 A S S U M P T I O N S Gradient Flow . For gradient flo w , we assume the following: (A1). (Regularity). For any fix ed x , Φ( · ; x ) is locally Lipschitz and admits a chain rule; (A2). (Homogeneity). There e xists L > 0 such that ∀ α > 0 : Φ( α θ ; x ) = α L Φ( θ ; x ) ; (A3). (Exponential Loss). ` ( q ) = e − q ; (A4). (Separability). There e xists a time t 0 such that L ( θ ( t 0 )) < 1 . (A1) is a technical assumption about the regularity of the network output. As sho wn in (Da vis et al., 2020), the output of almost ev ery neural network admits a chain rule (as long as the neural network is composed by definable pieces in an o-minimal structure, e.g., ReLU, sigmoid, LeakyReLU). (A2) assumes the homogeneity , the main property we assume in this work. (A3), (A4) correspond to the two conditions introduced in Section 1. The exponential loss in (A3) is main focus of this section. (A4) is a separability assumption: the condition L ( θ ( t 0 )) < 1 ensures that ` ( y n Φ( θ ( t 0 ); x n )) < 1 for all n ∈ [ N ] , and thus y n Φ( θ ( t 0 ); x n ) > 0 , meaning that Φ classifies every x n correctly . Gradient Descent. F or gradient descent, we assume (A2), (A3), (A4) similarly as for gradient flow , and the following tw o assumptions (S1) and (S5). (S1). (Smoothness). F or any fix ed x , Φ( · ; x ) is C 2 -smooth on R d \ { 0 } . (S5). (Learning rate condition, Informal). η ( t ) = η 0 for a sufficiently small constant η 0 . In fact, η ( t ) is even allowed to be as large as O ( L ( t ) − 1 p olylog 1 L ( t ) ) . See Appendix E.1 for the details. 5 Published as a conference paper at ICLR 2020 (S5) is natural since deep neural networks are usually trained with constant learning rates. (S1) ensures the smoothness of Φ , which is often assumed in the optimization literature in order to analyze gradient descent. While (S1) does not hold for neural networks with ReLU, it does hold for neural networks with smooth homogeneous activ ation such as the quadratic acti vation φ ( x ) := x 2 (Li et al., 2018b; Du & Lee, 2018) or powers of ReLU φ ( x ) := ReLU( x ) α for α > 2 (Zhong et al., 2017; Klusowski & Barron, 2018; Li et al., 2019). 4 . 2 M A I N T H E O R E M : M O N OT O N I C I T Y O F N O R M A L I Z E D M A R G I N S The margin for a single data point ( x n , y n ) is defined to be q n ( θ ) := y n Φ( θ ; x n ) , and the margin for the entire dataset is defined to be q min ( θ ) := min n ∈ [ N ] q n ( θ ) . By homogenity , the margin q min ( θ ) scales linearly with k θ k L 2 for any fixed direction since q min ( c θ ) = c L q min ( θ ) . So we consider the normalized mar gin defined as below: ¯ γ ( θ ) := q min θ k θ k 2 = q min ( θ ) k θ k L 2 . (2) W e say f is an -additive approximation for the normalized margin if ¯ γ − ≤ f ≤ ¯ γ , and c - multiplicative appr oximation if c ¯ γ ≤ f ≤ ¯ γ . Gradient Flow . Our first result is on the overall trend of the normalized margin ¯ γ ( θ ( t )) . For both gradient flow and gradient descent, we identify a smoothed version of the normalized margin, and show that it is non-decreasing during training. More specifically , we ha ve the follo wing theorem for gradient flow . Theorem 4.1 (Corollary of Theorem A.7) . Under assumptions (A1) - (A4), ther e exists an O ( k θ k − L 2 ) -additive appr oximation function ˜ γ ( θ ) for the normalized margin such that the following statements ar e true for gradient flow: 1. F or a.e . t > t 0 , d dt ˜ γ ( θ ( t )) ≥ 0 ; 2. F or a.e . t > t 0 , either d dt ˜ γ ( θ ( t )) > 0 or d dt θ ( t ) k θ ( t ) k 2 = 0 ; 3. L ( θ ( t )) → 0 and k θ ( t ) k 2 → ∞ as t → + ∞ ; therefor e, | ¯ γ ( θ ( t )) − ˜ γ ( θ ( t )) | → 0 . More concretely , the function ˜ γ ( θ ) in Theorem 4.1 is defined as ˜ γ ( θ ) := log 1 L ( θ ) k θ k L 2 = − log P N n =1 e − q n ( θ ) k θ k L 2 . (3) Note that the only difference between ¯ γ ( θ ) and ˜ γ ( θ ) is that the margin q min ( θ ) in ¯ γ ( θ ) is replaced by log 1 L ( θ ) = − LSE( − q 1 ( θ ) , . . . , − q N ( θ )) , where LSE( a 1 , . . . , a N ) = log(exp( a 1 ) + · · · + exp( a N )) is the LogSumExp function. Approximating q min with LogSumExp is a natural idea, and it also appears in previous studies on the margins of Boosting (Rudin et al., 2007; T elgarsky, 2013) and linear networks (Nacson et al., 2019b). It is easy to see why ˜ γ ( θ ) is an O ( k θ k − L 2 ) -additiv e approximation for ¯ γ ( θ ) : e a max ≤ P N n =1 e a n ≤ N e a max holds for a max = max { a 1 , . . . , a N } , so a max ≤ LSE( a 1 , . . . , a N ) ≤ a max + log N ; combining this with the definition of ˜ γ ( θ ) giv es ¯ γ ( θ ) − k θ k − L 2 log N ≤ ˜ γ ( θ ) ≤ ¯ γ ( θ ) . Gradient Descent. For gradient descent, Theorem 4.1 holds similarly with a slightly different function ˆ γ ( θ ) that approximates ¯ γ ( θ ) multiplicati vely rather than additi vely . Theorem 4.2 (Corollary of Theorem E.2) . Under assumptions (S1), (A2) - (A4), (S5), there exists an (1 − O (1 / (log 1 L ))) -multiplicative appr oximation function ˆ γ ( θ ) for the normalized mar gin such that the following statements ar e true for gradient descent: 1. F or all t > t 0 , ˆ γ ( θ ( t + 1)) ≥ ˆ γ ( θ ( t )) ; 2. F or all t > t 0 , either ˆ γ ( θ ( t + 1)) > ˆ γ ( θ ( t )) or θ ( t +1) k θ ( t +1) k 2 = θ ( t ) k θ ( t ) k 2 ; 3. L ( θ ( t )) → 0 and k θ ( t ) k 2 → ∞ as t → + ∞ ; therefor e, | ¯ γ ( θ ( t )) − ˆ γ ( θ ( t )) | → 0 . Due to the discreteness of gradient descent, the explicit formula for ˆ γ ( θ ) is somewhat technical, and we refer the readers to Appendix E for full details. 6 Published as a conference paper at ICLR 2020 Con vergence Rates. It is sho wn in Theorem 4.1, 4.2 that L ( θ ( t )) → 0 and k θ ( t ) k 2 → ∞ . In f act, with a more refined analysis, we can prove tight loss con vergence and weight gro wth rates using the monotonicity of normalized margins. Theorem 4.3 (Corollary of Theorem A.10 and E.5) . F or gradient flow under assumptions (A1) - (A4) or gradient descent under assumptions (S1), (A2) - (A4), (S5), we have the following tight bounds for training loss and weight norm: L ( θ ( t )) = Θ 1 T (log T ) 2 − 2 /L and k θ ( t ) k 2 = Θ (log T ) 1 /L , wher e T = t for gradient flow and T = P t − 1 τ = t 0 η ( τ ) for gradient descent. 4 . 3 M A I N T H E O R E M : C O N V E R G E N C E T O K K T P O I N T S For gradient flo w , ˜ γ is upper -bounded by ˜ γ ≤ ¯ γ ≤ sup { q n ( θ ) : k θ k 2 = 1 } . Combining this with Theorem 4.1 and the monotone con ver gence theorem, it is not hard to see that lim t → + ∞ ¯ γ ( θ ( t )) and lim t → + ∞ ˜ γ ( θ ( t )) exist and equal to the same value. Using a similar argument, we can dra w the same conclusion for gradient descent. T o understand the implicit regularization effect, a natural question arises: what optimality property does the limit of normalized margin hav e? T o this end, we identify a natural constrained optimization problem related to margin maximization, and prov e that θ ( t ) directionally con verges to its KKT points, as shown below . W e note that we can extend this result to the finite time case, and show that gradient flow or gradient descent passes through an approximate KKT point after a certain amount of time. See Theorem A.9 in Appendix A and Theorem E.4 in Appendix E for the details. W e will briefly revie w the definition of KKT points and approximate KKT points for a constraint optimization problem in Appendix C.1. Theorem 4.4 (Corollary of Theorem A.8 and E.3) . F or gradient flow under assumptions (A1) - (A4) or gradient descent under assumptions (S1), (A2) - (A4), (S5), any limit point ¯ θ of n θ ( t ) k θ ( t ) k 2 : t ≥ 0 o is along the dir ection of a KKT point of the following constrained optimization pr oblem (P): min 1 2 k θ k 2 2 s.t. q n ( θ ) ≥ 1 ∀ n ∈ [ N ] That is, for any limit point ¯ θ , ther e exists a scaling factor α > 0 such that α ¯ θ satisfies Karush-K uhn- T uck er (KKT) conditions of (P). Minimizing (P) over its feasible region is equiv alent to maximizing the normalized margin over all possible directions. The proof is as follows. Note that we only need to consider all feasible points θ with q min ( θ ) > 0 . For a fixed θ , α θ is a feasible point of (P) iff α ≥ q min ( θ ) − 1 /L . Thus, the minimum objective value over all feasible points of (P) in the direction of θ is 1 2 k θ /q min ( θ ) 1 /L k 2 2 = 1 2 ¯ γ ( θ ) − 2 /L . T aking minimum over all possible directions, we can conclude that if the maximum normalized margin is ¯ γ ∗ , then the minimum objectiv e of (P) is 1 2 ¯ γ − 2 /L ∗ . It can be proved that (P) satisfies the Mangasarian-Fromovitz Constraint Qualification (MFCQ) (See Lemma C.7). Thus, KKT conditions are first-order necessary conditions for global optimality . For linear models, KKT conditions are also sufficient for ensuring global optimality; ho wev er, for deep homogeneous networks, q n ( θ ) can be highly non-con ve x. Indeed, as gradient descent is a first-order optimization method, if we do not make further assumptions on q n ( θ ) , then it is easy to construct examples that gradient descent does not lead to a normalized margin that is globally optimal. Thus, proving the con vergence to KKT points is perhaps the best we can hope for in our setting, and it is an interesting future work to prov e stronger conv ergence results with further natural assumptions. Moreov er, we can prove the follo wing corollary , which characterizes the optimality of the normal- ized margin using SVM with Neural T angent Kernel (NTK, introduced in (Jacot et al., 2018)) defined at limit points. The proof is deferred to Appendix C.6. Corollary 4.5 (Corollary of Theorem 4.4) . Assume (S1). Then for gradient flow under assump- tions (A2) - (A4) or gradient descent under assumptions (A2) - (A4), (S5), any limit point ¯ θ of { θ ( t ) / k θ ( t ) k 2 : t ≥ 0 } is along the max-margin dir ection for the hard-mar gin SVM with kernel 7 Published as a conference paper at ICLR 2020 K ¯ θ ( x , x 0 ) = ∇ Φ x ( ¯ θ ) , ∇ Φ x 0 ( ¯ θ ) , where Φ x ( θ ) := Φ( θ ; x ) . That is, for some α > 0 , α ¯ θ is the optimal solution for the following constrained optimization pr oblem: min 1 2 k θ k 2 2 s.t. y n θ , ∇ Φ x n ( ¯ θ ) ≥ 1 ∀ n ∈ [ N ] If we assume (A1) instead of (S1) for gradient flow , then ther e e xists a mapping h ( x ) ∈ ∂ ◦ Φ x ( ¯ θ ) such that the same conclusion holds for K ¯ θ ( x , x 0 ) = h h ( x ) , h ( x 0 ) i . 4 . 4 O T H E R M A I N R E S U LT S The abov e results can be extended to other settings as shown belo w . Other Binary Classification Loss. The results on exponential loss can be generalized to a much broader class of binary classification loss. The class includes the logistic loss which is one of the most popular loss functions, ` ( q ) = log (1 + e − q ) . The function class also includes other losses with exponential tail, e.g., ` ( q ) = e − q 3 , ` ( q ) = log(1 + e − q 3 ) . For all those loss functions, we can use its in verse function ` − 1 to define the smoothed normalized margin as follo ws ˜ γ ( θ ) := ` − 1 ( L ( θ )) k θ k L 2 . Then all our results for gradient flow continue to hold (Appendix A). Using a similar modification, we can also extend it to gradient descent (Appendix F). Cross-entr opy Loss. In multi-class classification, we can define q n to be the difference between the classification score for the true label and the maximum score for the other labels, then the mar gin q min := min n ∈ [ N ] q n and the normalized margin ¯ γ ( θ ) := q min ( θ ) k θ k L 2 can be similarly defined as before. In Appendix G, we define the smoothed normalized mar gin for cross-entropy loss to be the same as that for logistic loss (See Remark A.4). Then we show that Theorem 4.1 and Theorem 4.4 still hold (but with a slightly different definition of (P)) for gradient flow , and we also extend the results to gradient descent. Multi-homogeneous Models. Some neural networks indeed possess a stronger property than homogeneity , which we call multi-homogeneity . For example, the output of a CNN (without bias terms) is 1 -homogeneous with respect to the weights of each layer . In general, we say that a neu- ral network Φ( θ ; x ) with θ = ( w 1 , . . . , w m ) is ( k 1 , . . . , k m ) -homogeneous if for any x and any c 1 , . . . , c m > 0 , we ha ve Φ( c 1 w 1 , . . . , c m w m ; x ) = Q m i =1 c k i i · Φ( w 1 , . . . , w m ; x ) . In the pre vious example, an L -layer CNN with layer weights θ = ( w 1 , . . . , w L ) is (1 , . . . , 1) -homogeneous. One can easily see that that ( k 1 , . . . , k m ) -homogeneity implies L -homogeneity , where L = P m i =1 k i , so our previous analysis for homogeneous models still applies to multi-homogeneous mod- els. But it would be better to define the normalized mar gin for multi-homogeneous model as ¯ γ ( w 1 , . . . , w m ) := q min ( w 1 k w 1 k 2 , . . . , w m k w m k 2 ) = q min Q m i =1 k w i k k i 2 . (4) In this case, the smoothed approximation of ¯ γ for general binary classification loss (under some conditions) can be similarly defined for gradient flow: ˜ γ ( w 1 , . . . , w m ) := ` − 1 ( L ) Q m i =1 k w i k k i 2 , (5) It can be shown that ˜ γ is also non-decreasing during training when the loss is small enough (Ap- pendix H). In the case of cross-entropy loss, we can still define ˜ γ by (5) while ` ( · ) is set to the logistic loss in the formula. 5 P RO O F S K E T C H : G R A D I E N T F L OW O N H O M O G E N E O U S M O D E L W I T H E X P O N E N T I A L L O S S In this section, we present a proof sketch in the case of gradient flow on homogeneous model with exponential loss to illustrate our proof ideas. Due to space limit, the proof for the main theorems on gradient flow and gradient descent in Section 4 are deferred to Appendix A and E respecti vely . 8 Published as a conference paper at ICLR 2020 For con venience, we introduce a few more notations for a L -homogeneous neural network Φ( θ ; x ) . Let S d − 1 = { θ ∈ R d : k θ k 2 = 1 } be the set of L 2 -normalized parameters. Define ρ := k θ k 2 and ˆ θ := θ k θ k 2 ∈ S d − 1 to be the length and direction of θ . For both gradient descent and gradient flow , θ is a function of time t . For con venience, we also view the functions of θ , in- cluding L ( θ ) , q n ( θ ) , q min ( θ ) , as functions of t . So we can write L ( t ) := L ( θ ( t )) , q n ( t ) := q n ( θ ( t )) , q min ( t ) := q min ( θ ( t )) . Lemma 5.1 belo w is the k ey lemma in our proof. It decomposes the gro wth of the smoothed normal- ized margin into the ratio of two quantities related to the radial and tangential velocity components of θ respectively . W e will gi ve a proof sketch for this later in this section. W e belie ve that this lemma is of independent interest. Lemma 5.1 (Corollary of Lemma B.1) . F or a.e . t > t 0 , d dt log ρ > 0 and d dt log ˜ γ ≥ L d dt log ρ − 1 d ˆ θ dt 2 2 . Using Lemma 5.1, the first two claims in Theorem 4.1 can be directly proved. For the third claim, we make use of the monotonicity of the margin to lower bound the gradient, and then show L → 0 and ρ → + ∞ . Recall that ˜ γ is an O ( ρ − L ) -additiv e approximation for ¯ γ . So this proves the third claim. W e defer the detailed proof to Appendix B. T o show Theorem 4.4, we first change the time measure to log ρ , i.e., now we see t as a function of log ρ . So the second inequality in Lemma 5.1 can be rewritten as d log ˜ γ d log ρ ≥ L k d ˆ θ d log ρ k 2 2 . Integrating on both sides and noting that ˜ γ is upper-bounded, we know that there must be many instant log ρ such that k d ˆ θ d log ρ k 2 is small. By analyzing the landscape of training loss, we show that these points are “approximate” KKT points. Then we show that every con vergent sub-sequence of { ˆ θ ( t ) : t ≥ 0 } can be modified to be a sequence of “approximate” KKT points which con verges to the same limit. Then we conclude the proof by applying a theorem from (Dutta et al., 2013) to sho w that the limit of this con ver gent sequence of “approximate” KKT points is a KKT point. W e defer the detailed proof to Appendix C. Now we giv e a proof sketch for Lemma 5.1, in which we derive the formula of ˜ γ step by step. In the proof, we obtain sev eral clean close form formulas for se veral relev ant quantities, by using the chain rule and Euler’ s theorem for homogeneous functions extensi vely . Pr oof Sketch of Lemma 5.1. For ease of presentation, we ignore the regularity issues of taking deriv ativ es in this proof sketch. W e start from the equation d L dt = − ∂ ◦ L ( θ ( t )) , d θ dt = − d θ dt 2 2 which follows from the chain rule (see also Lemma I.3). Then we note that d θ dt can be decomposed into two parts: the radial component v := ˆ θ ˆ θ > d θ dt and the tangent component u := ( I − ˆ θ ˆ θ > ) d θ dt . The radial component is easier to analyze. By the chain rule, k v k 2 = ˆ θ > d θ dt = 1 ρ θ , d θ dt = 1 ρ · 1 2 dρ 2 dt . For 1 2 dρ 2 dt , we hav e an exact formula: 1 2 dρ 2 dt = θ , d θ dt = * N X n =1 e − q n ∂ ◦ q n , θ + = L N X n =1 e − q n q n . (6) The last equality is due to h ∂ ◦ q n , θ i = Lq n by homogeneity of q n . This is sometimes called Euler’ s theorem for homogeneous functions (see Theorem B.2). For differentiable q n , it can be easily proved by taking the deriv ativ e over c on both sides of q n ( c θ ) = c L q n ( θ ) and letting c = 1 . W ith (6), we can lower bound 1 2 dρ 2 dt by 1 2 dρ 2 dt = L N X n =1 e − q n q n ≥ L N X n =1 e − q n q min ≥ L · L log 1 L , (7) where the last inequality uses the fact that e − q min ≤ L . (7) also implies that 1 2 dρ 2 dt > 0 for t > t 0 since L ( t 0 ) < 1 and L is non-increasing. As d dt log ρ = 1 2 ρ 2 dρ 2 dt , this also proves the first inequality of Lemma 5.1. 9 Published as a conference paper at ICLR 2020 Now , we ha ve k v k 2 2 = 1 ρ 2 1 2 dρ 2 dt 2 = 1 2 dρ 2 dt · d dt log ρ on the one hand; on the other hand, by the chain rule we hav e d ˆ θ dt = 1 ρ 2 ( ρ d θ dt − dρ dt θ ) = 1 ρ 2 ( ρ d θ dt − ( ˆ θ > d θ dt ) θ ) = u ρ . So we hav e − d L dt = d θ dt 2 2 = k v k 2 2 + k u k 2 2 = 1 2 dρ 2 dt · d dt log ρ + ρ 2 d ˆ θ dt 2 2 Dividing 1 2 dρ 2 dt on the leftmost and rightmost sides, we hav e − d L dt · 1 2 dρ 2 dt − 1 = d dt log ρ + d dt log ρ − 1 d ˆ θ dt 2 2 . By − d L dt ≥ 0 and (7), the LHS is no greater than − d L dt · L · L log 1 L − 1 = 1 L d dt log log 1 L . Thus we hav e d dt log log 1 L − L d dt log ρ ≥ L d dt log ρ − 1 d ˆ θ dt 2 2 , where the LHS is exactly d dt log ˜ γ . 6 D I S C U S S I O N A N D F U T U R E D I R E C T I O N S In this paper , we analyze the dynamics of gradient flow/descent of homogeneous neural networks under a minimal set of assumptions. The main technical contribution of our work is to prove rigor - ously that for gradient flow/descent, the normalized margin is increasing and conv erges to a KKT point of a natural max-margin problem. Our results leads to some natural further questions: • Can we generalize our results for gradient descent on smooth neural networks to non- smooth ones? In the smooth case, we can lo wer bound the decrement of training loss by the gradient norm squared, multiplied by a factor related to learning rate. Howe ver , in the non-smooth case, no such inequality is known in the optimization literature. • Can we make more structural assumptions on the neural netw ork to prov e stronger results? In this work, we use a minimal set of assumptions to show that the con vergent direction of parameters is a KKT point. A potential research direction is to identify more k ey properties of modern neural networks and show that the normalized margin at con vergence is locally or globally optimal (in terms of optimizing (P)). • Can we extend our results to neural networks with bias terms? In our experiments, the normalized margin of the CNN with bias also increases during training despite that its output is non-homogeneous. It is very interesting (and technically challenging) to provide a rigorous proof for this fact. A C K N O W L E D G M E N T S The research is supported in part by the National Natural Science Foundation of China Grant 61822203, 61772297, 61632016, 61761146003, and the Zhongguancun Haihua Institute for Fron- tier Information T echnology and Turing AI Institute of Nanjing. W e thank Liwei W ang for helpful suggestions on the connection between mar gin and robustness. W e thank Sanjee v Arora, T ianle Cai, Simon Du, Jason D. Lee, Zhiyuan Li, T engyu Ma, Ruosong W ang for helpful discussions. R E F E R E N C E S Pierre-Antoine Absil, Robert Mahony , and Benjamin Andrews. Conv ergence of the iterates of de- scent methods for analytic cost functions. SIAM Journal on Optimization , 16(2):531–547, 2005. Alnur Ali, J. Zico Kolter , and Ryan J. T ibshirani. A continuous-time view of early stopping for least squares regression. In Kamalika Chaudhuri and Masashi Sugiyama (eds.), Pr oceedings of Machine Learning Researc h , v olume 89 of Pr oceedings of Machine Learning Researc h , pp. 1370–1378. PMLR, 16–18 Apr 2019. 10 Published as a conference paper at ICLR 2020 Zeyuan Allen-Zhu, Y uanzhi Li, and Zhao Song. A con vergence theory for deep learning via ov er- parameterization. In Kamalika Chaudhuri and Ruslan Salakhutdinov (eds.), Pr oceedings of the 36th International Confer ence on Machine Learning , volume 97 of Pr oceedings of Machine Learning Resear ch , pp. 242–252, Long Beach, California, USA, 09–15 Jun 2019. PMLR. Cem Anil, James Lucas, and Roger Grosse. Sorting out Lipschitz function approximation. In Ka- malika Chaudhuri and Ruslan Salakhutdinov (eds.), Proceedings of the 36th International Con- fer ence on Machine Learning , volume 97 of Pr oceedings of Machine Learning Resear ch , pp. 291–301, Long Beach, California, USA, 09–15 Jun 2019. PMLR. Sanjeev Arora, Nadav Cohen, W ei Hu, and Y uping Luo. Implicit regularization in deep matrix fac- torization. In H. W allach, H. Larochelle, A. Beygelzimer , F . d'Alch ´ e-Buc, E. Fox, and R. Garnett (eds.), Advances in Neural Information Pr ocessing Systems 32 , pp. 7411–7422. Curran Asso- ciates, Inc., 2019a. Sanjeev Arora, Simon S Du, W ei Hu, Zhiyuan Li, Russ R Salakhutdinov , and Ruosong W ang. On exact computation with an infinitely wide neural net. In H. W allach, H. Larochelle, A. Beygelz- imer , F . d'Alch ´ e-Buc, E. Fox, and R. Garnett (eds.), Advances in Neur al Information Pr ocessing Systems 32 , pp. 8139–8148. Curran Associates, Inc., 2019b. Anish Athalye, Nicholas Carlini, and David W agner . Obfuscated gradients give a false sense of security: Circumventing defenses to adv ersarial examples. In Jennifer Dy and Andreas Krause (eds.), Pr oceedings of the 35th International Conference on Machine Learning , volume 80 of Pr o- ceedings of Machine Learning Resear ch , pp. 274–283, Stockholmsm ¨ assan, Stockholm Sweden, 10–15 Jul 2018. PMLR. Andrzej Banburski, Qianli Liao, Brando Miranda, T omaso Poggio, Lorenzo Rosasco, and Jack Hidary . Theory III: Dynamics and generalization in deep networks. CBMM Memo No: 090, version 20 , 2019. Peter L Bartlett, Dylan J Foster , and Matus J T elgarsky . Spectrally-normalized margin bounds for neural netw orks. In I. Guyon, U. V . Luxbur g, S. Bengio, H. W allach, R. Fergus, S. V ishwanathan, and R. Garnett (eds.), Advances in Neural Information Processing Systems 30 , pp. 6240–6249. Curran Associates, Inc., 2017. Battista Biggio, Igino Corona, Davide Maiorca, Blaine Nelson, Nedim ˇ Srndi ´ c, Pavel Lasko v , Gior- gio Giacinto, and Fabio Roli. Evasion attacks against machine learning at test time. In Hendrik Blockeel, Kristian K ersting, Siegfried Nijssen, and Filip ˇ Zelezn ´ y (eds.), Machine Learning and Knowledge Discovery in Databases , pp. 387–402, Berlin, Heidelberg, 2013. Springer Berlin Hei- delberg. Guy Blanc, Neha Gupta, Gregory V aliant, and Paul V aliant. Implicit regularization for deep neural networks dri ven by an ornstein-uhlenbeck like process. arXiv preprint , 2019. Nicholas Carlini and David W agner . T owards ev aluating the robustness of neural networks. In 2017 IEEE Symposium on Security and Privacy (SP) , pp. 39–57, May 2017. doi: 10.1109/SP .2017.49. Moustapha Cisse, Piotr Bojanowski, Edouard Grave, Y ann Dauphin, and Nicolas Usunier . Parse- val networks: Improving robustness to adversarial examples. In Doina Precup and Y ee Whye T eh (eds.), Pr oceedings of the 34th International Conference on Machine Learning , volume 70 of Pr oceedings of Machine Learning Resear ch , pp. 854–863, International Con vention Centre, Sydney , Australia, 06–11 Aug 2017. PMLR. Francis H. Clarke, Y uri S. Ledyaev , Ronald J. Stern, and Peter R. W olenski. Nonsmooth analysis and contr ol theory , volume 178. Springer Science & Business Media, 2008. Frank H. Clarke. Generalized gradients and applications. T ransactions of the American Mathemat- ical Society , 205:247–262, 1975. Frank H Clarke. Optimization and Nonsmooth Analysis . Society for Industrial and Applied Mathe- matics, 1990. doi: 10.1137/1.9781611971309. Michel Coste. An Intr oduction to O-minimal Geometry . 2002. 11 Published as a conference paper at ICLR 2020 Haskell B Curry . The method of steepest descent for non-linear minimization problems. Quarterly of Applied Mathematics , 2(3):258–261, 1944. Damek Davis, Dmitriy Drusvyatskiy , Sham Kakade, and Jason D. Lee. Stochastic subgradient method con ver ges on tame functions. F oundations of Computational Mathematics , 20(1):119– 154, Feb 2020. Dmitriy Drusvyatskiy , Alexander D Iof fe, and Adrian S Lewis. Curves of descent. SIAM J ournal on Contr ol and Optimization , 53(1):114–138, 2015. Simon Du and Jason Lee. On the power of over -parametrization in neural networks with quadratic activ ation. In Jennifer Dy and Andreas Krause (eds.), Pr oceedings of the 35th International Confer ence on Machine Learning , volume 80 of Pr oceedings of Machine Learning Resear ch , pp. 1329–1338, Stockholmsm ¨ assan, Stockholm Sweden, 10–15 Jul 2018. PMLR. Simon Du, Jason Lee, Haochuan Li, Liwei W ang, and Xiyu Zhai. Gradient descent finds global minima of deep neural networks. In Kamalika Chaudhuri and Ruslan Salakhutdinov (eds.), Pr o- ceedings of the 36th International Conference on Machine Learning , volume 97 of Pr oceedings of Machine Learning Resear ch , pp. 1675–1685, Long Beach, California, USA, 09–15 Jun 2019. PMLR. Simon S. Du, W ei Hu, and Jason D. Lee. Algorithmic regularization in learning deep homogeneous models: Layers are automatically balanced. In S. Bengio, H. W allach, H. Larochelle, K. Grauman, N. Cesa-Bianchi, and R. Garnett (eds.), Advances in Neural Information Processing Systems 31 , pp. 382–393. Curran Associates, Inc., 2018. Joydeep Dutta, Kalyanmoy Deb, Rupesh T ulshyan, and Ramnik Arora. Approximate KKT points and a proximity measure for termination. Journal of Global Optimization , 56(4):1463–1499, 2013. Gauthier Gidel, Francis Bach, and Simon Lacoste-Julien. Implicit regularization of discrete gradient dynamics in linear neural networks. In H. W allach, H. Larochelle, A. Beygelzimer , F . d'Alch ´ e- Buc, E. Fox, and R. Garnett (eds.), Advances in Neural Information Pr ocessing Systems 32 , pp. 3196–3206. Curran Associates, Inc., 2019. Giorgio Giorgi, Angelo Guerraggio, and J ¨ org Thierfelder . Chapter IV - Nonsmooth Optimization Problems. In Mathematics of Optimization , pp. 359 – 457. Elsevier Science, Amsterdam, 2004. ISBN 978-0-444-50550-7. Noah Golowich, Alexander Rakhlin, and Ohad Shamir . Size-independent sample complexity of neural networks. In S ´ ebastien Bubeck, V ianney Perchet, and Philippe Rigollet (eds.), Pr oceedings of the 31st Conference On Learning Theory , volume 75 of Pr oceedings of Machine Learning Resear ch , pp. 297–299. PMLR, 06–09 Jul 2018. Suriya Gunasekar , Jason Lee, Daniel Soudry , and Nathan Srebro. Characterizing implicit bias in terms of optimization geometry . In Jennifer Dy and Andreas Krause (eds.), Pr oceedings of the 35th International Confer ence on Machine Learning , volume 80 of Pr oceedings of Machine Learning Researc h , pp. 1832–1841, Stockholmsm ¨ assan, Stockholm Sweden, 10–15 Jul 2018a. PMLR. Suriya Gunasekar , Jason D Lee, Daniel Soudry , and Nati Srebro. Implicit bias of gradient descent on linear con volutional networks. In S. Bengio, H. W allach, H. Larochelle, K. Grauman, N. Cesa- Bianchi, and R. Garnett (eds.), Advances in Neural Information Pr ocessing Systems 31 , pp. 9482– 9491. Curran Associates, Inc., 2018b. Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Delving deep into rectifiers: Surpassing human-lev el performance on ImageNet classification. In The IEEE International Conference on Computer V ision (ICCV) , December 2015. Arthur Jacot, Franck Gabriel, and Clement Hongler . Neural tangent kernel: Con vergence and gen- eralization in neural networks. In S. Bengio, H. W allach, H. Larochelle, K. Grauman, N. Cesa- Bianchi, and R. Garnett (eds.), Advances in Neural Information Pr ocessing Systems 31 , pp. 8571– 8580. Curran Associates, Inc., 2018. 12 Published as a conference paper at ICLR 2020 Ziwei Ji and Matus T elgarsky . Risk and parameter conv ergence of logistic re gression. arXiv pr eprint arXiv:1803.07300 , 2018. Ziwei Ji and Matus T elgarsk y . Gradient descent aligns the layers of deep linear networks. In International Confer ence on Learning Representations , 2019a. Ziwei Ji and Matus T elgarsky . A refined primal-dual analysis of the implicit bias. arXiv pr eprint arXiv:1906.04540 , 2019b. Ziwei Ji and Matus T elgarsky . The implicit bias of gradient descent on nonseparable data. In Alina Beygelzimer and Daniel Hsu (eds.), Pr oceedings of the Thirty-Second Conference on Learn- ing Theory , volume 99 of Pr oceedings of Machine Learning Researc h , pp. 1772–1798, Phoenix, USA, 25–28 Jun 2019c. PMLR. Jason M Klusowski and Andrew R Barron. Approximation by combinations of relu and squared relu ridge functions with ` 1 and ` 0 controls. IEEE T ransactions on Information Theory , 64(12): 7649–7656, 2018. Jaehoon Lee, Lechao Xiao, Samuel Schoenholz, Y asaman Bahri, Roman Novak, Jascha Sohl- Dickstein, and Jeffre y Pennington. Wide neural networks of any depth ev olve as linear models under gradient descent. In H. W allach, H. Larochelle, A. Beygelzimer , F . d'Alch ´ e-Buc, E. Fox, and R. Garnett (eds.), Advances in Neural Information Processing Systems 32 , pp. 8570–8581. Curran Associates, Inc., 2019. Bo Li, Shanshan T ang, and Haijun Y u. Better approximations of high dimensional smooth functions by deep neural networks with rectified po wer units. arXiv pr eprint arXiv:1903.05858 , 2019. Xingguo Li, Junwei Lu, Zhaoran W ang, Jarvis Haupt, and T uo Zhao. On tighter generalization bound for deep neural networks: CNNs, ResNets, and beyond. arXiv pr eprint arXiv:1806.05159 , 2018a. Y uanzhi Li, T engyu Ma, and Hongyang Zhang. Algorithmic regularization in ov er-parameterized matrix sensing and neural networks with quadratic activations. In S ´ ebastien Bubeck, V ianney Perchet, and Philippe Rigollet (eds.), Pr oceedings of the 31st Confer ence On Learning Theory , volume 75 of Pr oceedings of Machine Learning Resear ch , pp. 2–47. PMLR, 06–09 Jul 2018b. Cong Ma, Kaizheng W ang, Y uejie Chi, and Y uxin Chen. Implicit regularization in nonconv ex statis- tical estimation: Gradient descent con verges linearly for phase retriev al, matrix completion, and blind decon volution. F oundations of Computational Mathematics , Aug 2019. Mor Shpigel Nacson, Suriya Gunasekar , Jason Lee, Nathan Srebro, and Daniel Soudry . Le xico- graphic and depth-sensitive margins in homogeneous and non-homogeneous deep models. In Kamalika Chaudhuri and Ruslan Salakhutdinov (eds.), Pr oceedings of the 36th International Confer ence on Machine Learning , volume 97 of Pr oceedings of Machine Learning Researc h , pp. 4683–4692, Long Beach, California, USA, 09–15 Jun 2019a. PMLR. Mor Shpigel Nacson, Jason Lee, Suriya Gunasekar , Pedro Henrique Pamplona Savarese, Nathan Srebro, and Daniel Soudry . Con vergence of gradient descent on separable data. In Kamalika Chaudhuri and Masashi Sugiyama (eds.), Proceedings of Machine Learning Resear ch , v olume 89 of Pr oceedings of Machine Learning Resear ch , pp. 3420–3428. PMLR, 16–18 Apr 2019b. Mor Shpigel Nacson, Nathan Srebro, and Daniel Soudry . Stochastic gradient descent on separa- ble data: Exact con vergence with a fixed learning rate. In Kamalika Chaudhuri and Masashi Sugiyama (eds.), Pr oceedings of Machine Learning Resear ch , volume 89 of Pr oceedings of Ma- chine Learning Resear ch , pp. 3051–3059. PMLR, 16–18 Apr 2019c. Behnam Neyshabur , Ruslan R Salakhutdinov , and Nati Srebro. Path-SGD: Path-normalized opti- mization in deep neural networks. In C. Cortes, N. D. Lawrence, D. D. Lee, M. Sugiyama, and R. Garnett (eds.), Advances in Neur al Information Pr ocessing Systems 28 , pp. 2422–2430. Curran Associates, Inc., 2015a. 13 Published as a conference paper at ICLR 2020 Behnam Neyshab ur, Ryota T omioka, and Nathan Srebro. In search of the real inductive bias: On the role of implicit regularization in deep learning. In 3r d International Conference on Learning Repr esentations, ICLR 2015, San Die go, CA, USA, May 7-9, 2015, W orkshop T rack Pr oceedings , 2015b. Behnam Neyshab ur, Srinadh Bhojanapalli, and Nathan Srebro. A P A C-bayesian approach to spectrally-normalized mar gin bounds for neural networks. In International Confer ence on Learn- ing Repr esentations , 2018. J Jr Palis and W elington De Melo. Geometric theory of dynamical systems: an intr oduction . Springer Science & Business Media, 2012. Aaditya Ramdas and Javier Pena. T ow ards a deeper geometric, analytic and algorithmic understand- ing of margins. Optimization Methods and Softwar e , 31(2):377–391, 2016. Saharon Rosset, Ji Zhu, and T revor J. Hastie. Mar gin maximizing loss functions. In S. Thrun, L. K. Saul, and B. Sch ¨ olkopf (eds.), Advances in Neural Information Pr ocessing Systems 16 , pp. 1237–1244. MIT Press, 2004. Cynthia Rudin, Ingrid Daubechies, and Robert E Schapire. The dynamics of adaboost: Cyclic behavior and con vergence of margins. Journal of Machine Learning Resear ch , 5(Dec):1557– 1595, 2004. Cynthia Rudin, Robert E. Schapire, and Ingrid Daubechies. Analysis of boosting algorithms using the smooth margin function. The Annals of Statistics , 35(6):2723–2768, 2007. ISSN 00905364. Robert E. Schapire and Y oav Freund. Boosting: F oundations and Algorithms . The MIT Press, 2012. ISBN 0262017180, 9780262017183. Robert E. Schapire, Y oav Freund, Peter Bartlett, and W ee Sun Lee. Boosting the margin: A new explanation for the effecti veness of v oting methods. Ann. Statist. , 26(5):1651–1686, 10 1998. doi: 10.1214/aos/1024691352. Shai Shale v-Shwartz and Y oram Singer . On the equi valence of weak learnability and linear sepa- rability: New relaxations and efficient boosting algorithms. Machine learning , 80(2-3):141–163, 2010. Jure Sokolic, Raja Giryes, Guillermo Sapiro, and Miguel R. D. Rodrigues. Robust large margin deep neural networks. IEEE T rans. Signal Pr ocessing , 65(16):4265–4280, 2017. doi: 10.1109/ TSP .2017.2708039. Daniel Soudry , Elad Hoffer , Mor Shpigel Nacson, Suriya Gunasekar , and Nathan Srebro. The im- plicit bias of gradient descent on separable data. Journal of Machine Learning Resear ch , 19(70): 1–57, 2018a. Daniel Soudry , Elad Hoffer , and Nathan Srebro. The implicit bias of gradient descent on separable data. In International Conference on Learning Repr esentations , 2018b. Arun Suggala, Adarsh Prasad, and Pradeep K Ravikumar . Connecting optimization and regulariza- tion paths. In S. Bengio, H. W allach, H. Larochelle, K. Grauman, N. Cesa-Bianchi, and R. Garnett (eds.), Advances in Neural Information Pr ocessing Systems 31 , pp. 10608–10619. Curran Asso- ciates, Inc., 2018. Christian Szegedy , W ojciech Zaremba, Ilya Sutskev er , Joan Bruna, Dumitru Erhan, Ian Goodfel- low , and Rob Fergus. Intriguing properties of neural networks. In International Conference on Learning Repr esentations , 2013. Matus T elgarsk y . Margins, shrinkage, and boosting. In Sanjoy Dasgupta and Da vid McAllester (eds.), Pr oceedings of the 30th International Conference on Machine Learning , volume 28 of Pr oceedings of Mac hine Learning Researc h , pp. 307–315, Atlanta, Georgia, USA, 17–19 Jun 2013. PMLR. Lou van den Dries and Chris Miller. Geometric categories and o-minimal structures. Duke Mathe- matical Journal , 84(2):497–540, 1996. 14 Published as a conference paper at ICLR 2020 Colin W ei and T engyu Ma. Improved sample complexities for deep neural networks and robust classification via an all-layer margin. In International Confer ence on Learning Repr esentations , 2020. Colin W ei, Jason D Lee, Qiang Liu, and T engyu Ma. Regularization matters: Generalization and optimization of neural nets v .s. their induced kernel. In H. W allach, H. Larochelle, A. Beygelz- imer , F . d'Alch ´ e-Buc, E. Fox, and R. Garnett (eds.), Advances in Neur al Information Pr ocessing Systems 32 , pp. 9709–9721. Curran Associates, Inc., 2019. Ashia C Wilson, Rebecca Roelofs, Mitchell Stern, Nati Srebro, and Benjamin Recht. The marginal value of adaptive gradient methods in machine learning. In I. Guyon, U. V . Luxbur g, S. Bengio, H. W allach, R. Fergus, S. V ishwanathan, and R. Garnett (eds.), Advances in Neural Information Pr ocessing Systems 30 , pp. 4148–4158. Curran Associates, Inc., 2017. T engyu Xu, Y i Zhou, Kaiyi Ji, and Y ingbin Liang. When will gradient methods conv erge to max- margin classifier under relu models? arXiv preprint , 2018. Chiyuan Zhang, Samy Bengio, Moritz Hardt, Benjamin Recht, and Oriol V inyals. Understanding deep learning requires rethinking generalization. In International Conference on Learning Rep- r esentations , 2017. Hongyi Zhang, Y ann N. Dauphin, and T engyu Ma. Fixup initialization: Residual learning without normalization. In International Conference on Learning Repr esentations , 2019. Kai Zhong, Zhao Song, Prateek Jain, Peter L. Bartlett, and Inderjit S. Dhillon. Recovery guarantees for one-hidden-layer neural networks. In Doina Precup and Y ee Whye T eh (eds.), Pr oceedings of the 34th International Confer ence on Machine Learning , volume 70 of Pr oceedings of Machine Learning Resear ch , pp. 4140–4149, International Conv ention Centre, Sydney , Australia, 06–11 Aug 2017. PMLR. Difan Zou, Y uan Cao, Dongruo Zhou, and Quanquan Gu. Stochastic gradient descent optimizes ov er-parameterized deep relu networks. arXiv preprint , 2018. Guus Zoutendijk. Mathematical programming methods. 1976. 15 Published as a conference paper at ICLR 2020 A R E S U L T S F O R G E N E R A L L O S S In this section, we state our results for a broad class of binary classification loss. A major con- sequence of this generalization is that the logistic loss, one of the most popular loss functions, ` ( q ) = log(1 + e − q ) is included. The function class also includes other losses with exponential tail, e.g., ` ( q ) = e − q 3 , ` ( q ) = log(1 + e − q 3 ) . A . 1 A S S U M P T I O N S W e first focus on gradient flo w . W e assume (A1), (A2) as we do for e xponential loss. For (A3), (A4), we replace them with two weaker assumptions (B3), (B4). All the assumptions are listed below: (A1). (Regularity). For any fix ed x , Φ( · ; x ) is locally Lipschitz and admits a chain rule; (A2). (Homogeneity). There e xists L > 0 such that ∀ α > 0 : Φ( α θ ; x ) = α L Φ( θ ; x ) ; (B3). The loss function ` ( q ) can be expressed as ` ( q ) = e − f ( q ) such that (B3.1). f : R → R is C 1 -smooth. (B3.2). f 0 ( q ) > 0 for all q ∈ R . (B3.3). There exists b f ≥ 0 such that f 0 ( q ) q is non-decreasing for q ∈ ( b f , + ∞ ) , and f 0 ( q ) q → + ∞ as q → + ∞ . (B3.4). Let g : [ f ( b f ) , + ∞ ) → [ b f , + ∞ ) be the in verse function of f on the domain [ b f , + ∞ ) . There exists b g ≥ max { 2 f ( b f ) , f (2 b f ) } , K ≥ 1 such that g 0 ( x ) ≤ K g 0 ( θ x ) and f 0 ( y ) ≤ K f 0 ( θ y ) for all x ∈ ( b g , + ∞ ) , y ∈ ( g ( b g ) , + ∞ ) and θ ∈ [1 / 2 , 1) . (B4). (Separability). There e xists a time t 0 such that L ( t 0 ) < e − f ( b f ) = ` ( b f ) . (A1) and (A2) remain unchanged. (B3) is satisfied by exponential loss ` ( q ) = e − q (with f ( q ) = q ) and logistic loss ` ( q ) = log (1 + e − q ) (with f ( q ) = − log log (1 + e − q ) ). (B4) are essentially the same as (A4) b ut (B4) uses a threshold value that depends on the loss function. Assuming (B3), it is easy to see that (B4) ensures the separability of data since ` ( q n ) < e − f ( b f ) implies q n > b f ≥ 0 . For logistic loss, we can set b f = 0 (see Remark A.2). So the corresponding threshold value in (B4) is ` (0) = log 2 . Now we discuss each of the assumptions in (B3). (B3.1) is a natural assumption on smoothness. (B3.2) requires ` ( · ) to be monotone decreasing, which is also natural since ` ( · ) is used for binary classification. The rest of two assumptions in (B3) characterize the properties of ` 0 ( q ) when q is large enough. (B3.3) is an assumption that appears naturally from the proof. For exponential loss, f 0 ( q ) q = q is always non-decreasing, so we can set b f = 0 . In (B3.4), the inv erse function g is defined. It is guaranteed by (B3.1) and (B3.2) that g alw ays exists and g is also C 1 -smooth. Though (B3.4) looks very complicated, it essentially says that f 0 (Θ( q )) = Θ( f 0 ( q )) , g 0 (Θ( q )) = Θ( g 0 ( q )) as q → ∞ . (B3.4) is indeed a technical assumption that enables us to asymptotically compare the loss or the length of gradient at different data points. It is possible to base our results on weaker assumptions than (B3.4), but we use (B3.4) for simplicity since it has already been satisfied by man y loss functions such as the aforementioned examples. W e summarize the corresponding f , g and b f for exponential loss and logistic loss belo w: Remark A.1. Exponential loss ` ( q ) = e − q satisfies (B3) with f ( q ) = q f 0 ( q ) = 1 g ( q ) = q g 0 ( q ) = 1 b f = 0 ` ( b f ) = 1 . Remark A.2. Logistic loss ` ( q ) = log (1 + e − q ) satisfies (B3) with f ( q ) = − log log (1 + e − q ) = Θ( q ) f 0 ( q ) = e − q (1 + e − q ) log (1 + e − q ) = Θ(1) g ( q ) = − log( e e − q − 1) = Θ( q ) g 0 ( q ) = e − q e e − q − 1 = Θ(1) b f = 0 ` ( b f ) = log 2 . The proof for Remark A.1 is trivial. For Remark A.2, we gi ve a proof below . 16 Published as a conference paper at ICLR 2020 Pr oof for Remark A.2. By simple calculations, the formulas for f ( q ) , f 0 ( q ) , g ( q ) , g 0 ( q ) are correct. (B3.1) is trivial. f 0 ( q ) = e − q (1+ e − q ) log (1+ e − q ) > 0 , so (B3.2) is satisfied. For (B3.3), note that f 0 ( q ) q = q (1+ e q ) log (1+ e − q ) . The denominator is a decreasing function since d dq (1 + e q ) log (1 + e − q ) = e q log(1 + e − q ) − 1 < e q · e − q − 1 = 0 . Thus, f 0 ( q ) q is a strictly increasing function on R . As b f is required to be non-negati ve, we set b f = 0 . For proving that f 0 ( q ) q → + ∞ and (B4), we only need to notice that f 0 ( q ) ∼ e − q 1 · e − q = 1 and g 0 ( x ) = 1 /f 0 ( g ( x )) ∼ 1 . A . 2 S M O OT H E D N O R M A L I Z E D M A R G I N For a loss function ` ( · ) satisfying (B3), it is easy to see from (B3.2) that its in verse function ` − 1 ( · ) must exist. For this kind of loss functions, we define the smoothed normalized margin as follo ws: Definition A.3. For a loss function ` ( · ) satisfying (B3), the smoothed normalized margin ˜ γ ( θ ) of θ is defined as ˜ γ ( θ ) := ` − 1 ( L ) ρ L = g (log 1 L ) ρ L = g − log P N n =1 e − f ( q n ( θ )) ρ L , where ` − 1 ( · ) is the inv erse function of ` ( · ) and ρ := k θ k 2 . Remark A.4. F or logistic loss ` ( q ) = log (1 + e − q ) , ˜ γ ( θ ) = ρ − L log 1 exp( L ) − 1 ; for exponential loss ` ( q ) = e − q , ˜ γ ( θ ) = ρ − L log 1 L , which is the same as (3) . Now we giv e some insights on how well ˜ γ ( θ ) approximates ¯ γ ( θ ) using a similar argument as in Section 4.2. Using the LogSumExp function, the smoothed normalized margin ˜ γ ( θ ) can also be written as ˜ γ ( θ ) = g ( − LSE( − f ( q 1 ) , . . . , − f ( q N ))) ρ L . LSE is a (log N ) -additive approximation for max . So we can roughly approximate ˜ γ ( θ ) by ˜ γ ( θ ) ≈ g ( − max {− f ( q 1 ) , . . . , − f ( q N ) } ) ρ L = g ( f ( q min )) ρ L = ¯ γ ( θ ) . Note that (B3.3) is crucial to make the above approximation reasonable. Similar to exponential loss, we can show the follo wing lemma asserting that ˜ γ is a good approximation of ¯ γ . Lemma A.5. Assuming (B3) 4 , we have the following pr operties about the mar gin: (a) f ( q min ) − log N ≤ log 1 L ≤ f ( q min ) . (b) If log 1 L > f ( b f ) , then ther e exists ξ ∈ ( f ( q min ) − log N , f ( q min )) ∩ ( b f , + ∞ ) such that ¯ γ − g 0 ( ξ ) log N ρ L ≤ ˜ γ ≤ ¯ γ . (c) F or a seuqnce of parameters { θ m ∈ R d : m ∈ N } , if L ( θ m ) → 0 , then | ˜ γ ( θ m ) − ¯ γ ( θ m ) | → 0 . Pr oof. (a) can be easily deduced from e − f ( q min ) ≤ L ≤ N e − f ( q min ) . Combining (a) and the monotonicity of g ( · ) , we further hav e g ( s ) ≤ g (log 1 L ) ≤ q min for s := max { f ( b f ) , f ( q min ) − log N } . By the mean value Theorem, there exists ξ ∈ ( s, f ( q min )) such that g ( s ) = g ( f ( q min )) − g 0 ( ξ )( f ( q min ) − s ) ≥ q min − g 0 ( ξ ) log N . Dividing ρ L on each side of q min − g 0 ( ξ ) log N ≤ g (log 1 L ) ≤ q min prov es (b) . Now we prov e (c) . Without loss of generality , we assume log 1 L ( θ m ) > f ( b f ) for all θ m . It follows from (b) that for e very θ m there exists ξ m ∈ ( f ( q min ( θ m )) − log N , f ( q min ( θ m ))) ∩ ( b f , + ∞ ) such that ¯ γ ( θ m ) − ( g 0 ( ξ m ) log N ) /ρ ( θ m ) L ≤ ˜ γ ( θ m ) ≤ ¯ γ ( θ m ) . (8) 4 Indeed, (B3.4) is not needed for showing Lemma A.5 and Theorem A.7. 17 Published as a conference paper at ICLR 2020 Note that ξ m ≥ f ( q min ( θ m )) − log N ≥ log 1 L ( θ m ) − log N → + ∞ . So g ( ξ m ) g 0 ( ξ m ) = f 0 ( g ( ξ m )) g ( ξ m ) → + ∞ by (B3.3). Also note that there exists a constant B 0 such that ¯ γ ( θ m ) ≤ B 0 for all m since ¯ γ is continuous on the unit sphere S d − 1 . So we hav e g 0 ( ξ m ) ρ ( θ m ) L = g 0 ( ξ m ) g ( ξ m ) g ( ξ m ) ρ ( θ m ) L ≤ g 0 ( ξ m ) g ( ξ m ) q min ( θ m ) ρ ( θ m ) L = g 0 ( ξ m ) g ( ξ m ) · ¯ γ ( θ m ) ≤ g 0 ( ξ m ) g ( ξ m ) · B → 0 , where the first inequality follows since ξ m ≤ f ( q min ( θ m )) . T ogether with (8), we ha ve | ˜ γ ( θ m ) − ¯ γ ( θ m ) | → 0 . Remark A.6. F or e xponential loss, we have already shown in Section 4.2 that ˜ γ ( θ ) is an O ( ρ − L ) - additive appr oximation for ¯ γ ( θ ) . F or logistic loss, it follows easily from g 0 ( q ) = Θ(1) and (b) of Lemma A.5 that ˜ γ ( θ ) is an O ( ρ − L ) -additive appr oximation for ¯ γ ( θ ) if L is sufficiently small. A . 3 T H E O R E M S Now we state our main theorems. For the monotonicity of the normalized margin, we have the following theorem. The proof is provided in Appendix B. Theorem A.7. Under assumptions (A1), (A2), (B3) 4 , (B4), the following statements ar e true for gradient flow: 1. F or a.e. t > t 0 , d dt ˜ γ ( θ ( t )) ≥ 0 ; 2. F or a.e. t > t 0 , either d dt ˜ γ ( θ ( t )) > 0 or d dt θ ( t ) k θ ( t ) k 2 = 0 ; 3. L ( θ ( t )) → 0 and k θ ( t ) k 2 → ∞ as t → + ∞ ; therefor e, | ¯ γ ( θ ( t )) − ˜ γ ( θ ( t )) | → 0 . For the normalized margin at con ver gence, we ha ve two theorems, one for infinite-time limiting case, and the other being a finite-time quantitati ve result. Their proofs can be found in Appendix C. As in the exponential loss case, we define the constrained optimization problem (P) as follo ws: min 1 2 k θ k 2 2 s.t. q n ( θ ) ≥ 1 ∀ n ∈ [ N ] First, we show the directional con ver gence of θ ( t ) to a KKT point of (P). Theorem A.8. Consider gradient flow under assumptions (A1), (A2), (B3), (B4). F or every limit point ¯ θ of n ˆ θ ( t ) : t ≥ 0 o , ¯ θ /q min ( ¯ θ ) 1 /L is a KKT point of (P). Second, we show that after finite time, gradient flo w can pass through an approximate KKT point. Theorem A.9. Consider gradient flow under assumptions (A1), (A2), (B3), (B4). F or any , δ > 0 , ther e exists r := Θ(log δ − 1 ) and ∆ := Θ( − 2 ) such that θ /q min ( θ ) 1 /L is an ( , δ ) -KKT point at some time t ∗ satisfying log k θ ( t ∗ ) k 2 ∈ ( r , r + ∆) . For the definitions for KKT points and approximate KKT points, we refer the readers to Ap- pendix C.1 for more details. W ith a refined analysis, we can also provide tight rates for loss con vergence and weight growth. The proof is giv en in Appendix D. Theorem A.10. Under assumptions (A1), (A2), (B3), (B4), we have the following tight r ates for loss con verg ence and weight growth: L ( θ ( t )) = Θ g (log t ) 2 /L t (log t ) 2 and k θ ( t ) k 2 = Θ( g (log t ) 1 /L ) . Applying Theorem A.10 to exponential loss and logistic loss, in which g ( x ) = Θ( x ) , we have the following corollary: Corollary A.11. If ` ( · ) is the e xponential or logistic loss, then, L ( θ ( t )) = Θ 1 t (log t ) 2 − 2 /L and k θ ( t ) k 2 = Θ((log t ) 1 /L ) . 18 Published as a conference paper at ICLR 2020 B M A R G I N M O N O T O N I C I T Y F O R G E N E R A L L O S S In this section, we consider gradient flow and prove Theorem A.7. W e assume (A1), (A2), (B3), (B4) as mentioned in Appendix A. W e follo w the notations in Section 5 to define ρ := k θ k 2 and ˆ θ := θ k θ k 2 ∈ S d − 1 , and sometimes we view the functions of θ as functions of t . B . 1 P R O O F F O R P R O P O S I T I O N 1 A N D 2 T o prove the first tw o propositions, we generalize our ke y lemma (Lemma 5.1) to general loss. Lemma B.1. F or ˜ γ defined in Definition A.3, the following holds for all t > t 0 , d dt log ρ > 0 and d dt log ˜ γ ≥ L d dt log ρ − 1 d ˆ θ dt 2 2 . (9) Before proving Lemma B.1, we revie w two important properties of homogeneous functions. Note that these two properties are usually sho wn for smooth functions. By considering Clarke’ s subdif- ferential, we can generalize it to locally Lipschitz functions that admit chain rules: Theorem B.2. Let F : R d → R be a locally Lipschitz function that admits a chain rule. If F is k -homogeneous, then (a) F or all x ∈ R d and α > 0 , ∂ ◦ F ( αx ) = α k − 1 ∂ ◦ F ( x ) That is, ∂ ◦ F ( αx ) = { α k − 1 h : h ∈ ∂ ◦ F ( x ) } . (b) (Euler’ s Theor em for Homogeneous Functions). F or all x ∈ R d , h x , ∂ ◦ F ( x ) i = k · F ( x ) That is, h x , h i = k · F ( x ) for all h ∈ ∂ ◦ F ( x ) . Pr oof. Let D be the set of points x such that F is differentiable at x . According to the definition of Clarke’ s subdif ferential, for proving (a) , it is sufficient to sho w that { lim k →∞ ∇ F ( α x k ) : x k → x , α x k ∈ D } = { α k − 1 lim k →∞ ∇ F ( x k ) : x k → x , x k ∈ D } (10) Fix x k ∈ D . Let U be a neighborhood of x k . By definition of homogeneity , for any h ∈ R d and any y ∈ U \ { x k } , F ( α y ) − F ( α x k ) − α y − α x k , α k − 1 h k α y − α x k k 2 = α k − 1 · F ( y ) − F ( x k ) − h y − x k , h i k y − x k k 2 . T aking limits y → x k on both sides, we know that the LHS con ver ges to 0 if f the RHS con ver ges to 0 . Then by definition of dif feretiability and gradient, F is dif ferentiable at α x k iff it is differentiable at x k , and ∇ F ( α x k ) = α k − 1 h iff ∇ F ( x k ) = h . This prov es (10). T o prove (b) , we fix x ∈ R d . Let z : [0 , + ∞ ) → R d , α 7→ α x be an arc. By definition of homogeneity , ( F ◦ z )( α ) = α k F ( x ) for α > 0 . T aking deri vati ve with respect to α on both sides (for differentiable points), we ha ve ∀ h ∈ ∂ ◦ F ( α x ) : h x , h i = k α k − 1 F ( x ) (11) holds for a.e. α > 0 . Pick an arbitrary α > 0 making (11) hold. Then by (a) , (11) is equi valent to ∀ h ∈ ∂ ◦ F ( x ) : x , α k − 1 h = k α k − 1 F ( x ) , which proves (b) . Applying Theorem B.2 to homogeneous neural networks, we ha ve the following corollary: Corollary B.3. Under the assumptions (A1) and (A2), for any θ ∈ R d and x ∈ R d x , h θ , ∂ ◦ Φ x ( θ ) i = L · Φ x ( θ ) , wher e Φ x ( θ ) = Φ( θ ; x ) is the network output for a fixed input x . 19 Published as a conference paper at ICLR 2020 Corollary B.3 can be used to deriv e an exact formula for the weight growth during training. Theorem B.4. F or a.e. t ≥ 0 , 1 2 dρ 2 dt = L N X n =1 e − f ( q n ) f 0 ( q n ) q n . Pr oof. The proof idea is to use Corollary B.3 and chain rules (See Appendix I for chain rules in Clarke’ s sense). Applying the chain rule on t 7→ ρ 2 = k θ k 2 2 yields 1 2 dρ 2 dt = − h θ , h i for all h ∈ ∂ ◦ L and a.e. t > 0 . Then applying the chain rule on θ 7→ L , we have − ∂ ◦ L ⊆ N X n =1 e − f ( q n ) f 0 ( q n ) ∂ ◦ q n = ( N X n =1 e − f ( q n ) f 0 ( q n ) h n : h n ∈ ∂ ◦ q n ) . By Corollary B.3, h θ , h n i = Lq n , and thus 1 2 dρ 2 dt = L P N n =1 e − f ( q n ) f 0 ( q n ) q n . For con venience, we define ν ( t ) := P N n =1 e − f ( q n ) f 0 ( q n ) q n for all t ≥ 0 . Then Theorem B.4 can be rephrased as 1 2 dρ 2 dt = Lν ( t ) for a.e. t ≥ 0 . Lemma B.5. F or all t > t 0 , ν ( t ) ≥ g (log 1 L ) g 0 (log 1 L ) L . Pr oof. By Lemma A.5, q n ≥ g (log 1 L ) for all n ∈ [ N ] . Then by Assumption (B3), f 0 ( q n ) q n ≥ f 0 ( g (log 1 L )) · g (log 1 L ) = g (log 1 L ) g 0 (log 1 L ) . Combining this with the definitions of ν ( t ) and L gi ves ν ( t ) = N X n =1 e − f ( q n ) f 0 ( q n ) q n ≥ N X n =1 e − f ( q n ) g (log 1 L ) g 0 (log 1 L ) = g (log 1 L ) g 0 (log 1 L ) L . Pr oof for Lemma B.1. Note that d dt log ρ = 1 2 ρ 2 dρ 2 dt = L ν ( t ) ρ 2 by Theorem B.4. Then it simply follows from Lemma B.5 that d dt log ρ > 0 for a.e. t > t 0 . For the second inequality , we first prove that log ˜ γ = log ` − 1 ( L ) /ρ L = log g (log 1 L ) /ρ L exists for all t ≥ t 0 . L ( t ) is non-increasing with t . So L ( t ) < e − f ( b f ) for all t ≥ t 0 . This implies that (1) log 1 L is always in the domain of g ; (2) ρ > 0 (otherwise L ≥ N e − f (0) > e − f ( b f ) , contradicting (B4)). Therefore, ˜ γ := g (log 1 L ) /ρ L exists and is alw ays positive for all t ≥ t 0 , which prov es the existence of log ˜ γ . By the chain rule and Lemma B.5, we hav e d dt log ˜ γ = d dt log g (log 1 L ) − L log ρ = g 0 (log 1 L ) g (log 1 L ) · 1 L · − d L dt − L 2 · ν ( t ) ρ 2 ≥ 1 ν ( t ) · − d L dt − L 2 · ν ( t ) ρ 2 ≥ 1 ν ( t ) · − d L dt − L 2 ν ( t ) 2 ρ 2 . On the one hand, − d L dt = d θ dt 2 2 for a.e. t > 0 by Lemma I.3; on the other hand, Lν ( t ) = θ , d θ dt by Theorem B.4. Combining these together yields d dt log ˜ γ ≥ 1 ν ( t ) d θ dt 2 2 − ˆ θ , d θ dt 2 ! = 1 ν ( t ) ( I − ˆ θ ˆ θ > ) d θ dt 2 2 . 20 Published as a conference paper at ICLR 2020 By the chain rule, d ˆ θ dt = 1 ρ ( I − ˆ θ ˆ θ > ) d θ dt for a.e. t > 0 . So we hav e d dt log ˜ γ ≥ ρ 2 ν ( t ) d ˆ θ dt 2 2 = L d dt log ρ − 1 d ˆ θ dt 2 2 . B . 2 P R O O F F O R P R O P O S I T I O N 3 T o prove the third proposition, we prove the following lemma to show that L → 0 by giving an upper bound for L . Since L can never be 0 for bounded ρ , L → 0 directly implies ρ → + ∞ . For showing | ¯ γ − ˜ γ | → 0 , we only need to apply (c) in Lemma A.5, which shows this when L → 0 . Lemma B.6. F or all t > t 0 , G (1 / L ( t )) ≥ L 2 ˜ γ ( t 0 ) 2 /L ( t − t 0 ) for G ( x ) := Z x 1 / L ( t 0 ) g 0 (log u ) 2 g (log u ) 2 − 2 /L du. Ther efore , L ( t ) → 0 and ρ ( t ) → + ∞ as t → ∞ . Pr oof for Lemma B.6. By Lemma I.3 and Theorem B.4, − d L dt = d θ dt 2 2 ≥ ˆ θ , d θ dt 2 = L 2 · ν ( t ) 2 ρ 2 Using Lemma B.5 to lo wer bound ν and replacing ρ with g (log 1 L ) / ˜ γ 1 /L by the definition of ˜ γ , we hav e − d L dt ≥ L 2 · g (log 1 L ) g 0 (log 1 L ) L 2 · ˜ γ ( t ) g (log 1 L ) 2 /L ≥ L 2 ˜ γ ( t 0 ) 2 /L · g (log 1 L ) 2 − 2 /L g 0 (log 1 L ) 2 L , where the last inequality uses the monotonicity of ˜ γ . So the following holds for a.e. t ≥ t 0 , g 0 (log 1 L ) 2 g (log 1 L ) 2 − 2 /L · d dt 1 L ≥ L 2 ˜ γ ( t 0 ) 2 /L . Integrating on both sides from t 0 to t , we can conclude that G (1 / L ) ≥ L 2 ˜ γ ( t 0 ) 2 /L ( t − t 0 ) . Note that 1 / L is non-decreasing. If 1 / L does not grow to + ∞ , then neither does G (1 / L ) . But the RHS grows to + ∞ , which leads to a contradiction. So L → 0 . T o make L → 0 , q min must con verge to + ∞ . So ρ → + ∞ . C C O N V E R G E N C E T O T H E M A X - M A R G I N S O L U T I O N In this section, we analyze the con vergent direction of θ and prov e Theorem A.8 and A.9, assuming (A1), (A2), (B3), (B4) as mentioned in Section A. W e follo w the notations in Section 5 to define ρ := k θ k 2 and ˆ θ := θ k θ k 2 ∈ S d − 1 , and sometimes we view the functions of θ as functions of t . C . 1 P R E L I M I N A R I E S F O R K K T C O N D I T I O N S W e first re view the definition of Karush-Kuhn-T ucker (KKT) conditions for non-smooth optimiza- tion problems following from (Dutta et al., 2013). Consider the following optimization problem (P) for x ∈ R d : min f ( x ) s.t. g n ( x ) ≤ 0 ∀ n ∈ [ N ] where f , g 1 , . . . , g n : R d → R are locally Lipschitz functions. W e say that x ∈ R d is a feasible point of (P) if x satisfies g n ( x ) ≤ 0 for all n ∈ [ N ] . 21 Published as a conference paper at ICLR 2020 Definition C.1 (KKT Point) . A feasible point x of (P) is a KKT point if x satisfies KKT conditions: there exists λ 1 , . . . , λ N ≥ 0 such that 1. 0 ∈ ∂ ◦ f ( x ) + P n ∈ [ N ] λ n ∂ ◦ g n ( x ) ; 2. ∀ n ∈ [ N ] : λ n g n ( x ) = 0 . It is important to note that a global minimum of (P) may not be a KKT point, but under some regularity assumptions, the KKT conditions become a necessary condition for global optimality . The regularity condition we shall use in this paper is the non-smooth v ersion of Mangasarian-Fromo vitz Constraint Qualification (MFCQ) (see, e.g., the constraint qualification (C.Q.5) in (Giorgi et al., 2004)): Definition C.2 (MFCQ) . For a feasible point x of (P), (P) is said to satisfy MFCQ at x if there exists v ∈ R d such that for all n ∈ [ N ] with g n ( x ) = 0 , ∀ h ∈ ∂ ◦ g n ( x ) : h h , v i > 0 . Follo wing from (Dutta et al., 2013), we define an approximate version of KKT point, as sho wn below . Note that this definition is essentially the modified -KKT point defined in their paper, but these two definitions differ in the follo wing two ways: (1) First, in their paper, the subdif ferential is allowed to be evaluated in a neighborhood of x , so our definition is slightly stronger; (2) Second, their paper fixes δ = 2 , but in our definition we mak e them independent. Definition C.3 (Approximate KKT Point) . For , δ > 0 , a feasible point x of (P) is an ( , δ ) -KKT point if there exists λ n ≥ 0 , k ∈ ∂ ◦ f ( x ) , h n ∈ ∂ ◦ g n ( x ) for all n ∈ [ N ] such that 1. k + P n ∈ [ N ] λ n h n ( x ) 2 ≤ ; 2. ∀ n ∈ [ N ] : λ n g n ( x ) ≥ − δ . As shown in (Dutta et al., 2013), ( , δ ) -KKT point is an approximate version of KKT point in the sense that a series of ( , δ ) -KKT points can con verge to a KKT point. W e restate their theorem in our setting: Theorem C.4 (Corollary of Theorem 3.6 in (Dutta et al., 2013)) . Let { x k ∈ R d : k ∈ N } be a sequence of feasible points of (P), { k > 0 : k ∈ N } and { δ k > 0 : k ∈ N } be two sequences. x k is an ( k , δ k ) -KKT point for every k , and k → 0 , δ k → 0 . If x k → x as k → + ∞ and MFCQ holds at x , then x is a KKT point of (P). C . 2 K K T C O N D I T I O N S F O R ( P ) Recall that for a homogeneous neural network, the optimization problem (P) is defined as follo ws: min 1 2 k θ k 2 2 s.t. q n ( θ ) ≥ 1 ∀ n ∈ [ N ] Using the terminologies and notations in Appendix C.1, the objectiv e and constraints are f ( x ) = 1 2 k x k 2 2 and g n ( x ) = 1 − q n ( x ) . The KKT points and approximate KKT points for (P) are defined as follows: Definition C.5 (KKT Point of (P)) . A feasible point θ of (P) is a KKT point if there exist λ 1 , . . . , λ N ≥ 0 such that 1. θ − P N n =1 λ n h n = 0 for some h 1 , . . . , h N satisfying h n ∈ ∂ ◦ q n ( θ ) ; 2. ∀ n ∈ [ N ] : λ n ( q n ( θ ) − 1) = 0 . Definition C.6 (Approximate KKT Point of (P)) . A feasible point θ of (P) is an ( , δ ) -KKT point of (P) if there exists λ 1 , . . . , λ N ≥ 0 such that 1. θ − P N n =1 λ n h n 2 ≤ for some h 1 , . . . , h N satisfying h n ∈ ∂ ◦ q n ( θ ) ; 22 Published as a conference paper at ICLR 2020 2. ∀ n ∈ [ N ] : λ n ( q n ( θ ) − 1) ≤ δ . By the homogeneity of q n , it is easy to see that (P) satisfies MFCQ, and thus KKT conditions are first-order necessary condition for global optimality . Lemma C.7. (P) satisfies MFCQ at every feasible point θ . Pr oof. T ake v := θ . For all n ∈ [ N ] satisfying q n = 1 , by homogeneity of q n , h v , h i = Lq n ( θ ) = L > 0 holds for any h ∈ − ∂ ◦ q n ( θ ) = ∂ ◦ (1 − q n ( θ )) . C . 3 K E Y L E M M A S Define β ( t ) := 1 k d θ dt k 2 D ˆ θ , d θ dt E to be the cosine of the angle between θ and d θ dt . Here β ( t ) is only defined for a.e. t > 0 . Since q n is locally Lipschitz, it can be shown that q n is (globally) Lipschitz on the compact set S d − 1 , which is the unit sphere in R d . Define B 0 := sup q n ρ L : θ ∈ R d \ { 0 } = sup q n : θ ∈ S d − 1 < ∞ . B 1 := sup k h k 2 ρ L − 1 : θ ∈ R d \ { 0 } , h ∈ ∂ ◦ q n , n ∈ [ N ] = sup k h k 2 : θ ∈ S d − 1 , h ∈ ∂ ◦ q n , n ∈ [ N ] < ∞ . For showing Theorem A.8 and Theorem A.9, we first prove Lemma C.8. In light of this lemma, if we aim to show that θ is along the direction of an approximate KKT point, we only need to sho w β → 1 (which makes → 0 ) and L → 0 (which makes δ → 0 ). Lemma C.8. Let C 1 , C 2 be two constants defined as C 1 := √ 2 ˜ γ ( t 0 ) 1 /L , C 2 := 2 eN K 2 L ˜ γ ( t 0 ) 2 /L B 1 ˜ γ ( t 0 ) log 2 K , wher e K, b g ar e constants specified in (B3.4). If log 1 L ≥ b g at time t > t 0 , then ˜ θ := θ /q min ( θ ) 1 /L is an ( , δ ) -KKT point of (P), wher e := C 1 √ 1 − β and δ := C 2 / (log 1 L ) . Pr oof. Let h ( t ) := d θ dt ( t ) for a.e. t > 0 . By the chain rule, there exist h 1 , . . . , h N such that h n ∈ ∂ ◦ q n and h = P n ∈ [ N ] e − f ( q n ) f 0 ( q n ) h n . Let ˜ h n := h n /q 1 − 1 /L min ∈ ∂ ◦ q n ( ˜ θ ) (Recall that ˜ θ := θ /q min ( θ ) 1 /L ). Construct λ n := q 1 − 2 /L min ρ · e − f ( q n ) f 0 ( q n ) / k h k 2 . No w we only need to show ˜ θ − N X n =1 λ n ˜ h n 2 2 ≤ 2 ˜ γ 2 /L (1 − β ) (12) N X n =1 λ n ( q n ( ˜ θ ) − 1) ≤ 2 eN K 2 L ˜ γ 2 /L B 1 ˜ γ log 2 K ! 1 f ( ˜ γ ρ L ) . (13) Then ˜ θ can be shown to be an ( , δ ) -KKT point by the monotonicity ˜ γ ( t ) ≥ ˜ γ ( t 0 ) for t > t 0 . Proof of (12) . From our construction, P N n =1 λ n ˜ h n = q − 1 /L min ρ h / k h k 2 . So ˜ θ − N X n =1 λ n ˜ h n 2 2 = q − 2 /L min ρ 2 ˆ θ − h k h k 2 2 2 = q − 2 /L min ρ 2 (2 − 2 β ) ≤ 2 ˜ γ 2 /L (1 − β ) , where the last equality is by Lemma A.5. 23 Published as a conference paper at ICLR 2020 Proof f or (13) . According to our construction, N X n =1 λ n ( q n ( ˜ θ ) − 1) = q − 2 /L min ρ k h k 2 N X n =1 e − f ( q n ) f 0 ( q n )( q n − q min ) . Note that k h k 2 ≥ D h , ˆ θ E = Lν /ρ . By Lemma B.5 and Lemma D.1, we hav e ν ≥ g (log 1 L ) g 0 (log 1 L ) L ≥ 1 2 K log 1 L · L ≥ 1 2 K f ( ˜ γ ρ L ) e − f ( q min ) , where the last inequality uses f ( ˜ γ ρ L ) = log 1 L and L ≥ e − f ( q min ) . Combining these gi ves N X n =1 λ n ( q n ( ˜ θ ) − 1) ≤ 2 K q − 2 /L min ρ 2 Lf ( ˜ γ ρ L ) N X n =1 e f ( q min ) − f ( q n ) f 0 ( q n )( q n − q min ) . If q n > q min , then by the mean v alue theorem there exists ξ n ∈ ( q min , q n ) such that f ( q n ) − f ( q min ) = f 0 ( ξ n )( q n − q min ) . By Assumption (B3.4), we know that f 0 ( q n ) ≤ K d log 2 ( q n /ξ n ) e f 0 ( ξ n ) . Note that d log 2 ( q n /ξ n ) e ≤ log 2 (2 B 1 ρ L /q min ) ≤ log 2 (2 B 1 / ˜ γ ) . Then we have N X n =1 λ n ( q n ( ˜ θ ) − 1) ≤ 2 K q − 2 /L min ρ 2 Lf ( ˜ γ ρ L ) K log 2 (2 B 1 / ˜ γ ) X n : q n 6 = q min e − f 0 ( ξ n )( q n − q min ) f 0 ( ξ n )( q n − q min ) ≤ 2 K ˜ γ − 2 /L ρ 2 Lf ( ˜ γ ρ L ) K log 2 (2 B 1 / ˜ γ ) · N e where the second inequality uses q − 2 /L min ρ 2 ≤ ˜ γ − 2 /L by Lemma A.5 and the fact that the function x 7→ e − x x on (0 , + ∞ ) attains the maximum v alue e at x = 1 . By Theorem A.7, we ha ve already known that L → 0 . So it remains to bound β ( t ) . For this, we first prov e the following lemma to bound the integral of β ( t ) . Lemma C.9. F or all t 2 > t 1 ≥ t 0 , Z t 2 t 1 β ( τ ) − 2 − 1 · d dτ log ρ ( τ ) · dτ ≤ 1 L log ˜ γ ( t 2 ) ˜ γ ( t 1 ) . Pr oof. By Lemma B.4, d dt log ρ = 1 2 ρ 2 dρ 2 dt = Lν ρ 2 for a.e. t > 0 . By Lemma B.1, for a.e. t ∈ ( t 1 , t 2 ) , d dt log ˜ γ ≥ L · ρ 2 Lν d ˆ θ dt 2 2 · d dt log ρ. (14) By the chain rule, d ˆ θ dt = 1 ρ ( I − ˆ θ ˆ θ > ) d θ dt . So we hav e ρ 2 Lν d ˆ θ dt 2 2 = ρ Lν ( t ) ( I − ˆ θ ˆ θ > ) d θ dt 2 2 = d θ dt 2 2 − D d θ dt , ˆ θ E 2 D d θ dt , ˆ θ E 2 = β − 2 − 1 . (15) where the last equality follows from the definition of β . Combining 14 and 15, we have d dt log ˜ γ ≥ L β − 2 − 1 · d dt log ρ. Integrating on both sides from t 1 to t 2 prov es the lemma. A direct corollary of Lemma C.9 is the upper bound for the minimum β 2 − 1 within a time interv al: Corollary C.10. F or all t 2 > t 1 ≥ t 0 , then ther e exists t ∗ ∈ ( t 1 , t 2 ) such that β ( t ∗ ) − 2 − 1 ≤ 1 L · log ˜ γ ( t 2 ) − log ˜ γ ( t 1 ) log ρ ( t 2 ) − log ρ ( t 1 ) . 24 Published as a conference paper at ICLR 2020 Pr oof. Denote the RHS as C . Assume to the contrary that β ( τ ) − 2 − 1 > C for a.e. τ ∈ ( t 1 , t 2 ) . By Lemma B.1, log ρ ( τ ) > 0 for a.e. τ ∈ ( t 1 , t 2 ) . Then by Lemma C.9, we hav e 1 L log ˜ γ ( t 2 ) ˜ γ ( t 1 ) > Z t 2 t 1 C · d dτ log ρ ( τ ) · dτ = C · (log ρ ( t 2 ) − log ρ ( t 1 )) = 1 L log ˜ γ ( t 2 ) ˜ γ ( t 1 ) , which leads to a contradiction. In the rest of this section, we present both asymptotic and non-asymptotic analyses for the directional con vergence by using Corollary C.10 to bound β ( t ) . C . 4 A S Y M P T O T I C A NA L Y S I S W e first prove an auxiliary lemma which gi ves an upper bound for the change of ˆ θ . Lemma C.11. F or a.e. t > t 0 , d ˆ θ dt 2 ≤ B 1 L ˜ γ · d dt log ρ. Pr oof. Observe that d ˆ θ dt 2 = 1 ρ ( I − ˆ θ ˆ θ > ) d θ dt 2 ≤ 1 ρ d θ dt 2 . It is sufficient to bound d θ dt 2 . By the chain rule, there e xists h 1 , . . . , h N : [0 , + ∞ ) → R d satisfying that for a.e. t > 0 , h n ( t ) ∈ ∂ ◦ q n and d θ dt = P n ∈ [ N ] e − f ( q n ) f 0 ( q n ) h n ( t ) . By definition of B 1 , k h n k 2 ≤ B 1 ρ L − 1 for a.e. t > 0 . So we hav e d θ dt 2 ≤ X n ∈ [ N ] e − f ( q n ) f 0 ( q n ) k h n k 2 ≤ X n ∈ [ N ] e − f ( q n ) f 0 ( q n ) q n · 1 q n · B 1 ρ L − 1 . Note that ev ery summand is positiv e. By Lemma A.5, q n is lower-bounded by q n ≥ q min ≥ g (log 1 L ) , so we can replace q n with g (log 1 L ) in the above inequality . Combining with the fact that P n ∈ [ N ] e − f ( q n ) f 0 ( q n ) q n is just ν , we hav e d θ dt 2 ≤ ν g (log 1 L ) · B 1 ρ L − 1 = B 1 ν ˜ γ ρ . (16) So we hav e d ˆ θ dt 2 ≤ 1 ρ d θ dt 2 ≤ B 1 L ˜ γ · Lν ρ 2 = B 1 L ˜ γ · d dt log ρ . T o prove Theorem A.8, we consider each limit point ¯ θ /q min ( ¯ θ ) 1 /L , and construct a series of ap- proximate KKT points con verging to it. Then ¯ θ /q min ( ¯ θ ) 1 /L can be shown to be a KKT point by Theorem C.4. The follo wing lemma ensures that such construction exists. Lemma C.12. F or every limit point ¯ θ of n ˆ θ ( t ) : t ≥ 0 o , there exists a sequence of { t m : m ∈ N } such that t m ↑ + ∞ , ˆ θ ( t m ) → ¯ θ , and β ( t m ) → 1 . Pr oof. Let { m > 0 : m ∈ N } be an arbitrary sequence with m → 0 . No w we construct { t m } by induction. Suppose t 1 < t 2 < · · · < t m − 1 hav e already been constructed. Since ¯ θ is a limit point and ˜ γ ( t ) ↑ ˜ γ ∞ (recall that ˜ γ ∞ := lim t → + ∞ ˜ γ ( t ) ), there exists s m > t m − 1 such that ˆ θ ( s m ) − ¯ θ 2 ≤ m and 1 L log ˜ γ ∞ ˜ γ ( s m ) ≤ 3 m . Let s 0 m > s m be a time such that log ρ ( s 0 m ) = log ρ ( s m ) + m . According to Theorem A.7, log ρ → + ∞ , so s 0 m must exist. W e construct t m ∈ ( s m , s 0 m ) to be a time that β ( t m ) − 2 − 1 ≤ 2 m , where the existence can be sho wn by Corollary C.10. 25 Published as a conference paper at ICLR 2020 Now we show that this construction meets our requirement. It follo ws from β ( t m ) − 2 − 1 ≤ 2 m that β ( t m ) ≥ 1 / p 1 + 2 m → 1 . By Lemma C.11, we also kno w that ˆ θ ( t m ) − ¯ θ 2 ≤ ˆ θ ( t m ) − ˆ θ ( s m ) 2 + ˆ θ ( s m ) − ¯ θ 2 ≤ B 1 L ˜ γ ( t 0 ) · m + m → 0 . This completes the proof. Pr oof of Theor em A.8. Let ˜ θ := ¯ θ /q min ( ¯ θ ) 1 /L for short. Let { t m : m ∈ N } be the sequence con- structed as in Lemma C.12. For each t m , define ( t m ) and δ ( t m ) as in Lemma C.8. Then we know that θ ( t m ) /q min ( t m ) 1 /L is an ( ( t m ) , δ ( t m )) -KKT point and θ ( t m ) /q min ( t m ) 1 /L → ˜ θ , ( t m ) → 0 , δ ( t m ) → 0 . By Lemma C.7, (P) satisfies MFCQ. Applying Theorem C.4 proves the theorem. C . 5 N O N - A S Y M P T O T I C A N A L Y S I S Pr oof of Theor em A.9. Let C 0 := 1 L log ˜ γ ∞ ˜ γ ( t 0 ) . W ithout loss of generality , we assume < √ 6 2 C 1 and δ < C 2 /f ( b f ) . Let t 1 be the time such that log ρ ( t 1 ) = 1 L log g ( C 2 δ − 1 ) ˜ γ ( t 0 ) = Θ(log δ − 1 ) and t 2 be the time such that log ρ ( t 2 ) − log ρ ( t 1 ) = 1 2 C 0 C 2 1 − 2 = Θ( − 2 ) . By Corollary C.10, there exists t ∗ ∈ ( t 1 , t 2 ) such that β ( t ∗ ) − 2 − 1 ≤ 2 2 C − 2 1 . Now we argue that ˜ θ ( t ∗ ) is an ( , δ ) -KKT point. By Lemma C.8, we only need to show C 1 p 1 − β ( t ∗ ) ≤ and C 2 /f ( ˜ γ ( t ∗ ) ρ ( t ∗ ) L ) ≤ δ . For the first inequality , by assumption < √ 6 2 C 1 , we know that β ( t ∗ ) − 2 − 1 < 3 , which implies | β ( t ∗ ) | < 1 2 . Then we have 1 − β ( t ∗ ) ≤ 2 2 C − 2 1 · β ( t ∗ ) 2 1+ β ( t ∗ ) ≤ 2 C − 2 1 . Therefore, C 1 p 1 − β ( t ∗ ) ≤ holds. For the second inequality , ˜ γ ( t ∗ ) ρ ( t ∗ ) L ≥ ˜ γ ( t ∗ ) · g ( C 2 δ − 1 ) ˜ γ ( t 0 ) ≥ g ( C 2 δ − 1 ) . Therefore, C 2 /f ( ˜ γ ( t ∗ ) ρ ( t ∗ ) L ) ≤ δ holds. C . 6 P R O O F F O R C O R O L L A RY 4 . 5 By the homogeneity of q n , we can characterize KKT points using kernel SVM. Lemma C.13. If θ ∗ is KKT point of (P), then there exists h n ∈ ∂ ◦ Φ x n ( θ ∗ ) for n ∈ [ N ] such that 1 L θ ∗ is an optimal solution for the following constrained optimization pr oblem (Q): min 1 2 k θ k 2 2 s.t. y n h θ , h n i ≥ 1 ∀ n ∈ [ N ] Pr oof. It is easy to see that (Q) is a conv ex optimization problem. For θ = 2 L θ ∗ , from Theorem B.2, we can see that y n h θ , h n i = 2 q n ( θ ∗ ) ≥ 2 > 1 , which implies Slater’ s condition. Thus, we only need to show that 1 L θ ∗ satisfies KKT conditions for (Q). By the KKT conditions for (P), we can construct h n ∈ ∂ ◦ q n ( θ ∗ ) for n ∈ [ N ] such that θ ∗ − P N n =1 λ n y n h n = 0 for some λ 1 , . . . , λ N ≥ 0 and λ n ( q n ( θ ∗ ) − 1) = 0 . Thus, 1 L θ ∗ satisfies 1. 1 L θ ∗ − P N n =1 1 L λ n y n h n = 0 ; 2. 1 L λ n y n 1 L θ ∗ , h n − 1 = 1 L λ n ( q n ( θ ) − 1) ≥ 0 . So 1 L θ ∗ satisfies KKT conditions for (Q). Now we pro ve Corollary 4.5 in Section 4.3. Pr oof. By Theorem A.8, ev ery limit point ¯ θ is along the direction of a KKT point of (P). Combining this with Lemma C.13, we know that e very limit point ¯ θ is also along the max-margin direction of (Q). 26 Published as a conference paper at ICLR 2020 For smooth models, h n in (Q) is exactly the gradient ∇ Φ x n ( ¯ θ ) . So, (Q) is the optimization problem for SVM with kernel K ¯ θ ( x , x 0 ) = ∇ Φ x ( ¯ θ ) , ∇ Φ x 0 ( ¯ θ ) . For non-smooth models, we can construct an arbitrary function h ( x ) ∈ ∂ ◦ Φ x ( ¯ θ ) that ensures h ( x n ) = h n . Then, (Q) is the optimization problem for SVM with kernel K ¯ θ ( x , x 0 ) = h h ( x ) , h ( x 0 ) i . D T I G H T B O U N D S F O R L O S S C O N V E R G E N C E A N D W E I G H T G R O W T H In this section, we gi ve proof for Theorem A.10, which gi ves tight bounds for loss con vergence and weight growth under Assumption (A1), (A2), (B3), (B4). D . 1 C O N S E Q U E N C E S O F ( B 3 . 4 ) Before proving Theorem A.10, we sho w some consequences of (B3.4). Lemma D.1. F or f ( · ) and g ( · ) , we have 1. F or all x ∈ [ b g , + ∞ ) , g ( x ) g 0 ( x ) ∈ [ 1 2 K x, 2 K x ] ; 2. F or all y ∈ [ g ( b g ) , + ∞ ) , f ( y ) f 0 ( y ) ∈ [ 1 2 K y , 2 K y ] . Thus, g ( x ) = Θ( xg 0 ( x )) , f ( y ) = Θ( y f 0 ( y )) . Pr oof. T o prove Item 1, it is suf ficient to show that g ( x ) = b f + Z x f ( b f ) g 0 ( u ) du ≥ Z x x/ 2 g 0 ( u ) du ≥ ( x/ 2) · g 0 ( x ) K = 1 2 K · xg 0 ( x ) . x = f ( b f ) + Z x f ( b f ) g 0 ( u ) f 0 ( g ( u )) du ≥ f 0 ( g ( x )) K Z x f ( g ( x ) / 2) g 0 ( u ) du = ( g ( x ) / 2) · f 0 ( g ( x )) K = 1 2 K · g ( x ) g 0 ( x ) . T o prov e Item 2, we only need to notice that Item 1 implies y f 0 ( y ) = g ( f ( y )) g 0 ( f ( y )) ∈ [ 1 2 K f ( y ) , 2 K f ( y )] for all y ∈ [ g ( b g ) , + ∞ ) . Recall that (B3.4) directly implies that f 0 (Θ( x )) = Θ( f 0 ( x )) and g 0 (Θ( x )) = Θ( g 0 ( x )) . Combin- ing this with Lemma D.1, we hav e the following corollary: Corollary D .2. f (Θ( x )) = Θ( f ( x )) and g (Θ( x )) = Θ( g ( x )) . Also, note that Lemma D.1 essentially shows that (log f ( x )) 0 = Θ(1 /x ) and (log g ( x )) 0 = Θ(1 /x ) . So log f ( x ) = Θ(log x ) and log g ( x ) = Θ(log x ) , which means that f and g gro w at most polyno- mially . Corollary D .3. f ( x ) = x Θ(1) and g ( x ) = x Θ(1) . D . 2 P R O O F F O R T H E O R E M A . 1 0 W e follo w the notations in Section 5 to define ρ := k θ k 2 and ˆ θ := θ k θ k 2 ∈ S d − 1 , and sometimes we view the functions of θ as functions of t . And we use the notations B 0 , B 1 from Appendix C.3. The ke y idea to prov e Theorem A.10 is to utilize Lemma B.6, in which L ( t ) is bounded from abov e by 1 G − 1 (Ω( t )) . So upper bounding L ( t ) reduces to lower bounding G − 1 . In the following lemma, we obtain tight asymptotic bounds for G ( · ) and G − 1 ( · ) : 27 Published as a conference paper at ICLR 2020 Lemma D.4. F or function G ( · ) defined in Lemma B.6 and its in verse function G − 1 ( · ) , we have the following bounds: G ( x ) = Θ g (log x ) 2 /L (log x ) 2 x and G − 1 ( y ) = Θ (log y ) 2 g (log y ) 2 /L y . Pr oof. W e first prove the bounds for G ( x ) , and then pro ve the bounds for G − 1 ( y ) . Bounding for G ( x ) . Let C G = R exp( b g ) 1 / L ( t 0 ) g 0 (log u ) 2 g (log u ) 2 − 2 /L du . For x ≥ exp( b g ) , G ( x ) = C G + Z x exp( b g ) g 0 (log u ) 2 g (log u ) 2 − 2 /L du = C G + Z x exp( b g ) g 0 (log u ) log u g (log u ) 2 g (log u ) 2 /L (log u ) 2 du, By Lemma D.1, G ( x ) ≤ C G + 4 K 2 g (log x ) 2 /L Z x exp( b g ) 1 (log u ) 2 du = O g (log x ) 2 /L (log x ) 2 x . On the other hand, for x ≥ exp(2 b g ) , we hav e G ( x ) ≥ 1 4 K 2 Z x √ x g (log u ) 2 /L (log u ) 2 du ≥ g ((log x ) / 2) 2 /L 4 K 2 Z x √ x 1 (log u ) 2 du = Ω g (log x ) 2 /L (log x ) 2 x . Bounding for G − 1 ( y ) . Let x = G − 1 ( y ) for y ≥ 0 . G ( x ) always has a finite value whenev er x is finite. So x → + ∞ when y → + ∞ . According to the first part of the proof, we know that y = Θ g (log x ) 2 /L (log x ) 2 x . T aking logarithm on both sides and using Corollary D.3, we hav e log y = Θ(log x ) . By Corollary D.2, g (log y ) = g (Θ(log x )) = Θ( g (log x )) . Therefore, (log y ) 2 g (log y ) 2 /L y = Θ (log x ) 2 g (log x ) 2 /L y = Θ( x ) . This implies that x = Θ (log y ) 2 g (log y ) 2 /L y . For other bounds, we deriv e them as follows. W e first show that g (log 1 L ) = Θ( ρ L ) . With this equiv alence, we derive an upper bound for the gradient at each time t in terms of L , and take an integration to bound L ( t ) from below . Now we hav e both lower and upper bounds for L ( t ) . Plugging these two bounds to g (log 1 L ) = Θ( ρ L ) gives the lo wer and upper bounds for ρ ( t ) . Pr oof for Theor em A.10. W e first prove the upper bound for L . Then we deriv e lower and upper bounds for ρ in terms of L , and use these bounds to give a lower bound for L . Finally , we plug in the tight bounds for L to obtain the lower and upper bounds for ρ in terms of t . Upper Bounding L . By Lemma B.6, we hav e 1 L ≥ G − 1 (Ω( t )) . Using Lemma D.4, we hav e 1 L = Ω (log t ) 2 g (log t ) 2 /L t , which completes the proof. Bounding ρ in T erms of L . ˜ γ ( t ) ≥ ˜ γ ( t 0 ) , so ρ L ≤ 1 ˜ γ ( t 0 ) g (log 1 L ) = O ( g (log 1 L )) . On the other hand, g (log 1 L ) ≤ q min ≤ B 0 ρ L . So ρ L = Ω( g (log 1 L )) . Therefore, we have the following relationship between ρ L and g (log 1 L ) : ρ L = Θ( g (log 1 L )) . (17) 28 Published as a conference paper at ICLR 2020 Lower Bounding L . Let h 1 , . . . , h N be a set of vectors such that h n ∈ ∂ q n ∂ θ and d θ dt = N X n =1 e − f ( q n ) f 0 ( q n ) h n . By (17) and Corollary D.2, f 0 ( q n ) = f 0 ( O ( ρ L )) = f 0 ( O ( g (log 1 L ))) = O ( f 0 ( g (log 1 L ))) = O (1 /g 0 (log 1 L )) . Again by (17), we have k h n k 2 ≤ B 1 ρ L − 1 = O ( g (log 1 L ) 1 − 1 /L ) . Combining these two bounds together , it follows from Corollary D.2 that f 0 ( q n ) k h n k 2 = O g (log 1 L ) 1 − 1 /L g 0 (log 1 L ) ! = O log 1 L g (log 1 L ) 1 /L . Thus, − d L dt = d θ dt 2 2 = N X n =1 e − f ( q n ) f 0 ( q n ) h n 2 2 ≤ N X n =1 e − f ( q n ) · max n ∈ [ N ] { f 0 ( q n ) k h n k 2 } ! 2 ≤ L 2 · O (log 1 L ) 2 g (log 1 L ) 2 /L . By definition of G ( · ) , this implies that there exists a constant c such that d dt G ( 1 L ) ≤ c for any L that is small enough. W e can complete our proof by applying Lemma D.4. Bounding ρ in T erms of t . By (17) and the tight bound for L ( t ) , ρ L = Θ( g (log 1 L )) = Θ( g (Θ(log t ))) . Using Corollary D.2, we can conclude that ρ L = Θ( g (log t )) . E G R A D I E N T D E S C E N T : S M O O T H H O M O G E N E O U S M O D E L S W I T H E X P O N E N T I A L L O S S In this section, we discretize our proof to prove similar results for gradient descent on smooth ho- mogeneous models. As usual, the update rule of gradient descent is defined as θ ( t + 1) = θ ( t ) − η ( t ) ∇L ( t ) (18) Here η ( t ) is the learning rate, and ∇L ( t ) := ∇L ( θ ( t )) is the gradient of L at θ ( t ) . W e first focus on the exponential loss. At the end of this section (Appendix F), we discuss ho w to extend the proof to general loss functions with a similar assumption as (B3). The main difficulty for discretizing our previous analysis comes from the fact that the original ver- sion of the smoothed normalized margin ˜ γ ( θ ) := ρ − L log 1 L becomes less smooth when ρ → + ∞ . Thus, if we take a T aylor expansion for ˜ γ ( θ ( t + 1)) from the point θ ( t ) , although one can show that the first-order term is positiv e as in the gradient flow analysis, the second-order term is unlikely to be bounded during gradient descent with a constant step size. T o get a smoothed version of the normalized mar gin that is monotone increasing, we need to define another one that is ev en smoother than ˜ γ . T echnically , recall that d L dt = −k∇Lk 2 2 does not hold exactly for gradient descent. Howe ver , if the smoothness can be bounded by s ( t ) , then it is well-kno wn that L ( t + 1) − L ( t ) ≤ − η ( t )(1 − s ( t ) η ( t )) k∇Lk 2 2 . By analyzing the landscape of L , one can easily find that the smoothness is bounded locally by O ( L · polylog ( 1 L )) . Thus, if we set η ( t ) to a constant or set it appropriately according to the loss, then this discretization error becomes negligible. Using this insight, we define the new smoothed normalized margin ˆ γ in a way that it increases slightly slo wer than ˜ γ during training to cancel the effect of discretization error . 29 Published as a conference paper at ICLR 2020 E . 1 A S S U M P T I O N S As stated in Section 4.1, we assume (A2), (A3), (A4) similarly as for gradient flow , and two addi- tional assumptions (S1) and (S5). (S1). (Smoothness). F or any fix ed x , Φ( · ; x ) is C 2 -smooth on R d \ { 0 } . (A2). (Homogeneity). There e xists L > 0 such that ∀ α > 0 : Φ( α θ ; x ) = α L Φ( θ ; x ) ; (A3). (Exponential Loss). ` ( q ) = e − q ; (A4). (Separability). There e xists a time t 0 such that L ( θ ( t 0 )) < 1 . (S5). (Learing rate condition). P t ≥ 0 η ( t ) = + ∞ and η ( t ) ≤ H ( L ( θ ( t ))) . Here H ( L ) is a function of the current training loss. The e xplicit formula of H ( L ) is gi ven below: H ( x ) := µ ( x ) C η κ ( x ) = Θ 1 x (log 1 x ) 3 − 2 /L , where C η is a constant, and κ ( x ) , µ ( x ) are two non-decreasing functions. For constant learning rate η ( t ) = η 0 , (S5) is satisfied when η 0 if sufficiently small. Roughly speaking, C η κ ( x ) is an upper bound for the smoothness of L in a neighborhood of θ when x = L ( θ ) . And we set the learning rate η ( t ) to be the inv erse of the smoothness multiplied by a factor µ ( x ) = o (1) . In our analysis, µ ( x ) can be any non-decreasing function that maps (0 , L ( t 0 )] to (0 , 1 / 2] and makes the inte gral R 1 / 2 0 µ ( x ) dx exist. But for simplicity , we define µ ( x ) as µ ( x ) := log 1 L ( t 0 ) 2 log 1 x = Θ 1 log 1 x . The value of C η will be specified later . The definition of κ ( x ) depends on L . For 0 < L ≤ 1 , we define κ ( x ) as κ ( x ) := x log 1 x 2 − 2 /L For L > 1 , we define κ ( x ) as κ ( x ) := ( x log 1 x 2 − 2 /L x ∈ (0 , e 2 /L − 2 ] κ max x ∈ ( e 2 /L − 2 , 1) where κ max := e (2 − 2 /L )(ln(2 − 2 /L ) − 1) . The specific meaning of C η , κ ( x ) and µ ( x ) will become clear in our analysis. E . 2 S M O OT H E D N O R M A L I Z E D M A R G I N Now we define the smoothed normalized margins. As usual, we define ˜ γ ( θ ) := log 1 L ρ L . At the same time, we also define ˆ γ ( θ ) := e φ ( L ) ρ L . Here φ : (0 , L ( t 0 )] → (0 , + ∞ ) is constructed as follows. Construct the first-order deriv ative of φ ( x ) as φ 0 ( x ) = − sup 1 + 2(1 + λ ( w ) /L ) µ ( w ) w log 1 w : w ∈ [ x, L ( t 0 )] , where λ ( x ) := (log 1 x ) − 1 . And then we set φ ( x ) to be φ ( x ) = log log 1 x + Z x 0 φ 0 ( w ) + 1 w log 1 w dw . It can be verified that φ ( x ) is well-defined and φ 0 ( x ) is indeed the first-order deriv ative of φ ( x ) . Moreov er, we ha ve the following relationship among ˆ γ , ˜ γ and ¯ γ . 30 Published as a conference paper at ICLR 2020 Lemma E.1. ˆ γ ( θ ) is well-defined for L ( θ ) ≤ L ( t 0 ) and has the following pr operties: (a) If L ( θ ) ≤ L ( t 0 ) , then ˆ γ ( θ ) < ˜ γ ( θ ) ≤ ¯ γ ( θ ) . (b) Let { θ m ∈ R d : m ∈ N } be a sequence of parameters. If L ( θ m ) → 0 , then ˆ γ ( θ m ) ¯ γ ( θ m ) = 1 − O log 1 L ( θ m ) − 1 ! → 1 . Pr oof. First we verify that ˆ γ is well-defined. T o see this, we only need to verify that I ( x ) := Z x 0 φ 0 ( w ) + 1 w log 1 w dw exists for all x ∈ (0 , L ( t 0 )] , then it is trivial to see that φ 0 ( w ) is indeed the deri vati ve of φ ( w ) by I 0 ( x ) = φ 0 ( x ) + 1 x log 1 x . Note that I ( x ) exists for all x ∈ (0 , L ( t 0 )] as long as I ( x ) exists for a small enough x > 0 . By definition, it is easy to verify that r ( w ) := 1+2(1+ λ ( w ) /L ) µ ( w ) w log 1 w is decreasing when w is small enough. Thus, for a small enough w > 0 , we ha ve − φ 0 ( w ) = r ( w ) = 1 + 2(1 + 1 L (log 1 w ) − 1 ) log 1 L ( t 0 ) 2 log 1 w w log 1 w = 1 w log 1 w + log 1 L ( t 0 ) (1 + 1 L (log 1 w ) − 1 ) w (log 1 w ) 2 . So we hav e the following for small enough x : I ( x ) = Z x 0 − log 1 L ( t 0 ) (1 + 1 L (log 1 w ) − 1 ) w (log 1 w ) 2 dw = − log 1 L ( t 0 ) 1 log 1 w + 1 2 L (log 1 w ) 2 x 0 = − log 1 L ( t 0 ) 1 log 1 x + 1 2 L (log 1 x ) 2 . (19) This prov es the existence of I ( x ) . Now we prove (a). By Lemma A.5, ˜ γ ( θ ) ≤ ¯ γ ( θ ) , so we only need to prove that ˆ γ ( θ ) < ˜ γ ( θ ) . T o see this, note that for all w ≤ L ( t 0 ) , r ( w ) > 1 w log 1 w . So we hav e − φ 0 ( w ) > 1 w log 1 w , and this implies I ( x ) < 0 for all x ≤ L ( t 0 ) . Then it holds for all θ with L ( θ ) ≤ L ( t 0 ) that ˆ γ ( θ ) ˜ γ ( θ ) = e φ ( L ( θ )) log 1 L ( θ ) = e log log 1 L ( θ ) + I ( L ( θ )) e log log 1 L ( θ ) = e I ( L ( θ )) < 0 . (20) T o prove (b), we combine (19) and (20), then for small enough L ( θ m ) , we hav e ˆ γ ( θ ) ¯ γ ( θ ) = ˆ γ ( θ ) ˜ γ ( θ ) · ˜ γ ( θ ) ¯ γ ( θ ) = exp − log 1 L ( t 0 ) 1 log 1 L ( θ m ) + 1 2 L (log 1 L ( θ m ) ) 2 !! · log 1 L ( θ m ) q min ( θ m ) = exp − O 1 log 1 L ( θ m ) !! · log 1 L ( θ m ) log 1 L ( θ m ) + O (1) = 1 − O log 1 L ( θ m ) − 1 ! . So ˆ γ ( θ ) ¯ γ ( θ ) = 1 − O (log 1 L ( θ m ) ) − 1 → 1 . 31 Published as a conference paper at ICLR 2020 Now we specify the v alue of C η . By (S1) and (S2), we can define B 0 , B 1 , B 2 as follows: B 0 := sup q n : θ ∈ S d − 1 , n ∈ [ N ] , B 1 := sup k∇ q n k 2 : θ ∈ S d − 1 , n ∈ [ N ] , B 2 := sup ∇ 2 q n 2 : θ ∈ S d − 1 , n ∈ [ N ] . Then we set C η := 1 2 B 2 1 + ρ ( t 0 ) − L B 2 min n ˆ γ ( t 0 ) − 2+2 /L , B − 2+2 /L 0 o . E . 3 T H E O R E M S Now we state our main theorems for the monotonicity of the normalized mar gin and the con ver gence to KKT points. W e will prove Theorem E.2 in Appendix E.4, and prove Theorem E.3 and E.4 in Appendix E.5. Theorem E.2. Under assumptions (S1), (A2) - (A4), (S5), the following are true for gradient de- scent: 1. F or all t ≥ t 0 , ˆ γ ( t + 1) ≥ ˆ γ ( t ) ; 2. F or all t ≥ t 0 , either ˆ γ ( t + 1) > ˆ γ ( t ) or ˆ θ ( t + 1) = ˆ θ ( t ) ; 3. L ( t ) → 0 and ρ ( t ) → ∞ as t → + ∞ ; ther efor e, | ¯ γ ( t ) − ˜ γ ( t ) | → 0 . Theorem E.3. Consider gradient flow under assumptions (S1), (A2) - (A4), (S5). F or every limit point ¯ θ of n ˆ θ ( t ) : t ≥ 0 o , ¯ θ /q min ( ¯ θ ) 1 /L is a KKT point of (P). Theorem E.4. Consider gradient descent under assumptions (S1), (A2) - (A4), (S5). F or any , δ > 0 , ther e exists r := Θ(log δ − 1 ) and ∆ := Θ( − 2 ) such that θ /q min ( θ ) 1 /L is an ( , δ ) -KKT point at some time t ∗ satisfying log ρ ( t ∗ ) ∈ ( r , r + ∆) . W ith a refined analysis, we can also deriv e tight rates for loss con ver gence and weight growth. W e defer the proof to Appendix E.6. Theorem E.5. Under assumptions (S1), (A2) - (A4), (S5), we have the following tight rates for training loss and weight norm: L ( t ) = Θ 1 T (log T ) 2 − 2 /L and ρ ( t ) = Θ((log T ) 1 /L ) , wher e T = P t − 1 τ = t 0 η ( τ ) . E . 4 P R O O F F O R T H E O R E M E . 2 W e define ν ( t ) := P N n =1 e − q n ( t ) q n ( t ) as we do for gradient flow . Then we can get a closed form for h θ ( t ) , −∇L ( t ) i easily from Corollary B.3. Also, we can get a lower bound for ν ( t ) using Lemma B.5 for exponential loss directly . Corollary E.6. h θ ( t ) , −∇L ( t ) i = Lν ( t ) . If L ( t ) < 1 , then ν ( t ) ≥ L ( t ) λ ( L ( t )) . As we are analyzing gradient descent, the norm of ∇L and ∇ 2 L appear naturally in discretization error terms. T o bound them, we ha ve the following lemma when ˜ γ ( θ ) and ρ ( θ ) have lower bounds: Lemma E.7. F or any θ , if ˜ γ ( θ ) ≥ ˆ γ ( t 0 ) , ρ ( θ ) ≥ ρ ( t 0 ) , then k∇L ( θ ) k 2 2 ≤ 2 C η κ ( L ( θ )) L ( θ ) and ∇ 2 L ( θ ) 2 ≤ 2 C η κ ( L ( θ )) . 32 Published as a conference paper at ICLR 2020 Pr oof. By the chain rule and the definitions of B 1 , B 2 , we hav e k∇Lk 2 = − N X n =1 e − q n ∇ q n 2 ≤ L ρ L − 1 B 1 ∇ 2 L 2 = N X n =1 e − q n ( ∇ q n ∇ q > n − ∇ 2 q n ) 2 ≤ N X n =1 e − q n B 2 1 ρ 2 L − 2 + B 2 ρ L − 2 ≤ L ρ 2 L − 2 B 2 1 + ρ − L B 2 . Note that ˆ γ ( t 0 ) ρ L ≤ ˜ γ ρ L ≤ log 1 L ≤ B 0 ρ L . So ˆ γ ( t 0 ) − 1 log 1 L ≤ ρ L ≤ B − 1 0 log 1 L . Combining all these formulas together giv es k∇Lk 2 2 ≤ B 2 1 min n ˆ γ ( t 0 ) − 2+2 /L , B − 2+2 /L 0 o L 2 · log 1 L 2 − 2 /L ≤ 2 C η κ ( L ) L ∇ 2 L 2 ≤ B 2 1 + ρ − L B 2 min n ˆ γ ( t 0 ) − 2+2 /L , B − 2+2 /L 0 o L · log 1 L 2 − 2 /L ≤ 2 C η κ ( L ) , which completes the proof. For proving the first tw o propositions in Theorem E.2, we only need to prove Lemma E.8. (P1) gives a lo wer bound for ˜ γ . (P2) gi ves both lo wer and upper bounds for the weight growth using ν ( t ) . (P3) giv es a lo wer bound for the decrement of training loss. Finally , (P4) shows the monotonicity of ˆ γ , and it is trivial to deduce the first tw o propositions in Theorem E.2 from (P4). Lemma E.8. F or all t = t 0 , t 0 + 1 , . . . , we interpolate between θ ( t ) and θ ( t + 1) by defining θ ( t + α ) = θ ( t ) − αη ( t ) ∇L ( t ) for α ∈ (0 , 1) . Then for all inte ger t ≥ t 0 , ν ( t ) > 0 , and the following holds for all α ∈ [0 , 1] : (P1). ˜ γ ( t + α ) > ˆ γ ( t 0 ) . (P2). 2 Lαη ( t ) ν ( t ) ≤ ρ ( t + α ) 2 − ρ ( t ) 2 ≤ 2 Lαη ( t ) ν ( t ) 1 + λ ( L ( t )) µ ( L ( t )) L . (P3). L ( t + α ) − L ( t ) ≤ − αη ( t )(1 − µ ( L ( t ))) k∇L ( t ) k 2 2 . (P4). log ˆ γ ( t + α ) − log ˆ γ ( t ) ≥ ρ ( t ) 2 Lν ( t ) 2 I − ˆ θ ( t ) ˆ θ ( t ) > ∇L ( t ) 2 2 · log ρ ( t + α ) ρ ( t ) . T o prove Lemma E.8, we only need to pro ve the following lemma and then use an induction: Lemma E.9. Fix an integ er T ≥ t 0 . Suppose that (P1), (P2), (P3), (P4) hold for any t + α ≤ T . Then if (P1) holds for ( t, α ) ∈ { T } × [0 , A ) for some A ∈ (0 , 1] , then all of (P1), (P2), (P3), (P4) hold for ( t, α ) ∈ { T } × [0 , A ] . Pr oof for Lemma E.8. W e prov e this lemma by induction. For t = t 0 , α = 0 , ν ( t ) > 0 by (S4) and Corollary E.6. (P2), (P3), (P4) hold trivially since log ˆ γ ( t + α ) = log ˆ γ ( t ) , L ( t + α ) = L ( t ) and log ˆ γ ( t + α ) = log ˆ γ ( t ) . By Lemma E.1, (P1) also holds trivially . Now we fix an integer T ≥ t 0 and assume that (P1), (P2), (P3), (P4) hold for an y t + α ≤ T (where t ≥ t 0 is an integer and α ∈ [0 , 1] ). By (P3), L ( t ) ≤ L ( t 0 ) < 1 , so ν ( t ) > 0 . W e only need to sho w that (P1), (P2), (P3), (P4) hold for t = T and α ∈ [0 , 1] . Let A := inf { α ∈ [0 , 1] : α = 1 or (P1) does not hold for ( T , α ) } . If A = 0 , then (P1) holds for ( T , A ) since (P1) holds for ( T − 1 , 1) ; if A > 0 , we can also kno w that (P1) holds for ( T , A ) by Lemma E.9. Suppose that A < 1 . Then by the continuity of ˜ γ ( T + α ) (with respect to α ), we kno w that there exists A 0 > A such that ˜ γ ( T + α ) > ˆ γ ( t 0 ) for all α ∈ [ A, A 0 ] , which contradicts to the definition of A . Therefore, A = 1 . Using Lemma E.9 again, we can conclude that (P1), (P2), (P3), (P4) hold for t = T and α ∈ [0 , 1] . 33 Published as a conference paper at ICLR 2020 Now we turn to pro ve Lemma E.9. Pr oof for Lemma E.9. Applying (P3) on ( t, α ) ∈ { t 0 , . . . , T − 1 } × 1 , we hav e L ( t ) ≤ L ( t 0 ) < 1 . Then by Corollary E.6, we have ν ( t ) > 0 . Applying (P2) on ( t, α ) ∈ { t 0 , . . . , T − 1 } × 1 , we can get ρ ( t ) ≥ ρ ( t 0 ) . Fix t = T . By (P2) with α ∈ [0 , A ) and the continuity of ˜ γ , we hav e ˜ γ ( t + A ) ≥ ˆ γ ( t 0 ) . Thus, ˜ γ ( t + α ) ≥ ˆ γ ( t 0 ) for all α ∈ [0 , A ] . Proof for (P2). By definition, ρ ( t + α ) 2 = k θ ( t ) − αη ( t ) ∇L ( t ) k 2 2 = ρ ( t ) 2 + α 2 η ( t ) 2 k∇L ( t ) k 2 2 − 2 αη ( t ) h θ ( t ) , ∇L ( t ) i . By Corollary E.6, we hav e ρ ( t + α ) 2 − ρ ( t ) 2 = α 2 η ( t ) 2 k∇L ( t ) k 2 2 + 2 Lα η ( t ) ν ( t ) . So ρ ( t + α ) 2 − ρ ( t ) 2 ≥ 2 Lαη ( t ) ν ( t ) . For the other direction, we hav e the following using Corol- lary E.6 and Lemma E.7, ρ ( t + α ) 2 − ρ ( t ) 2 = 2 Lαη ( t ) ν ( t ) 1 + αη ( t ) k∇L ( t ) k 2 2 2 Lν ( t ) ! ≤ 2 Lαη ( t ) ν ( t ) 1 + C − 1 η κ ( L ( t )) − 1 µ ( L ( t )) · 2 C η κ ( L ( t )) L ( t ) 2 L L ( t ) λ ( L ( t )) − 1 ! = 2 Lαη ( t ) ν ( t ) (1 + λ ( L ( t )) µ ( L ( t )) /L ) . Proof for (P3). (P3) holds trivially for α = 0 or ∇L ( t ) = 0 . So now we assume that α 6 = 0 and ∇L ( t ) 6 = 0 . By the update rule (18) and T aylor expansion, there exists ξ ∈ (0 , α ) such that L ( t + α ) = L ( t ) + ( θ ( t + α ) − θ ( t )) > ∇L ( t ) + 1 2 ( θ ( t + α ) − θ ( t )) > ∇ 2 L ( t + ξ )( θ ( t + α ) − θ ( t )) ≤ L ( t ) − αη ( t ) k∇L ( t ) k 2 2 + 1 2 α 2 η ( t ) 2 ∇ 2 L ( t + ξ ) 2 k∇L ( t ) k 2 2 = L ( t ) − αη ( t ) 1 − 1 2 αη ( t ) ∇ 2 L ( t + ξ ) 2 k∇L ( t ) k 2 2 . By Lemma E.7, ∇ 2 L ( t + ξ ) 2 ≤ 2 C η · κ ( L ( t + ξ )) , so we have L ( t + α ) ≤ L ( t ) − αη ( t ) (1 − α C η η ( t ) κ ( L ( t + ξ ))) k∇L ( t ) k 2 2 . (21) Now we only need to show that L ( t + α ) < L ( t ) for all α ∈ (0 , A ] . Assuming this, we can have κ ( L ( t + ξ )) ≤ κ ( L ( t )) by the monotonicity of κ , and thus L ( t + α ) ≤ L ( t ) − αη ( t ) (1 − α C η η ( t ) κ ( L ( t ))) k∇L ( t ) k 2 2 ≤ L ( t ) − αη ( t ) (1 − µ ( L ( t ))) k∇L ( t ) k 2 2 . Now we show that L ( t + α ) < L ( t ) for all α ∈ (0 , A ] . Assume to the contrary that α 0 := inf { α 0 ∈ (0 , A ] : L ( t + α 0 ) ≥ L ( t ) } exists. If α 0 = 0 , let p : [0 , 1] → R , α 7→ L ( t + α ) , then p 0 (0) = lim α ↓ 0 L ( t + α ) −L ( t ) α ≥ 0 , but it contradicts to p 0 (0) = − η ( t ) k∇L ( t ) k 2 2 < 0 . If α 0 > 0 , then by the monotonicity of κ we have κ ( L ( t + ξ )) < κ ( L ( t )) for all ξ ∈ (0 , α 0 ) , and thus L ( t + α ) ≤ L ( t ) − αη ( t ) (1 − µ ( L ( t ))) k∇L ( t ) k 2 2 < L ( t ) , which leads to a contradiction. Proof for (P4). W e define v ( t ) := ˆ θ ( t ) ˆ θ ( t ) > ( −∇L ( t )) and u ( t ) := I − ˆ θ ( t ) ˆ θ ( t ) > ( −∇L ( t )) similarly as in the analysis for gradient flow . For v ( t ) , we have k v ( t ) k 2 = 1 ρ ( t ) h θ ( t ) , −L ( t ) i = 1 ρ ( t ) · Lν ( t ) . 34 Published as a conference paper at ICLR 2020 Decompose k∇L ( t ) k 2 2 = k v ( t ) k 2 2 + k u ( t ) k 2 2 . Then by (P3), we hav e L ( t + α ) − L ( t ) ≤ − αη ( t )(1 − µ ( L ( t ))) 1 ρ ( t ) 2 · L 2 ν ( t ) 2 + k u k 2 2 . Multiplying 1+ λ ( L ( t )) µ ( L ( t )) /L (1 − µ ( L ( t ))) ν ( t ) on both sides, we hav e 1 + λ ( L ( t )) µ ( L ( t )) /L (1 − µ ( L ( t ))) ν ( t ) ( L ( t + α ) − L ( t )) ≤ − αη ( t ) 1 + λ ( L ( t )) µ ( L ( t )) L L 2 ν ( t ) ρ ( t ) 2 + k u k 2 2 ν ( t ) ! By Corollary E.6, we can bound ν ( t ) by ν ( t ) ≥ L ( t ) /λ ( L ( t )) . By (P2), we have the inequality αη ( t ) ν ( t ) 1 + λ ( L ( t )) µ ( L ( t )) L ≥ ρ ( t + α ) 2 − ρ ( t ) 2 2 L . So we further hav e 1 + λ ( L ( t )) µ ( L ( t )) /L (1 − µ ( L ( t ))) L ( t ) /λ ( L ( t )) ( L ( t + α ) − L ( t )) ≤ − 1 ρ ( t ) 2 ( ρ ( t + α ) 2 − ρ ( t ) 2 ) L 2 + ρ ( t ) 2 2 Lν ( t ) 2 k u k 2 2 From the definition φ , it is easy to see that − φ 0 ( L ( t )) ≥ 1+ λ ( L ( t )) µ ( L ( t )) /L (1 − µ ( L ( t ))) L ( t ) /λ ( L ( t )) . Let ψ ( x ) = − log x , then ψ 0 ( x ) = − 1 x . Combining these together gi ves φ 0 ( L ( t ))( L ( t + α ) − L ( t )) + ψ 0 ( ρ ( t ) 2 )( ρ ( t + α ) 2 − ρ ( t ) 2 ) L 2 + ρ ( t ) 2 2 Lν ( t ) 2 k u k 2 2 ≥ 0 Then by con vexity of φ and ψ , we have ( φ ( L ( t + α )) − φ ( L ( t ))) + log 1 ρ ( t + α ) 2 − log 1 ρ ( t ) 2 L 2 + ρ ( t ) 2 2 Lν ( t ) 2 k u k 2 2 ≥ 0 And by definition of ˆ γ , this can be re-written as log ˆ γ ( t + α ) − log ˆ γ ( t ) = ( φ ( L ( t + α )) − φ ( L ( t ))) + L log 1 ρ ( t + α ) − log 1 ρ ( t ) ≥ − log 1 ρ ( t + α ) 2 − log 1 ρ ( t ) 2 ρ ( t ) 2 2 Lν ( t ) 2 k u k 2 2 = ρ ( t ) 2 Lν ( t ) 2 k u k 2 2 · log ρ ( t + α ) ρ ( t ) . Proof f or (P1). By (P4), log ˆ γ ( t + α ) ≥ log ˆ γ ( t ) ≥ log ˆ γ ( t 0 ) . Note that φ ( x ) ≥ log log 1 x . So we hav e ˜ γ ( t + α ) > ˆ γ ( t + α ) ≥ ˆ γ ( t 0 ) , which completes the proof. For showing the third proposition in Theorem E.2, we use (P1) to gi ve a lower bound for k∇L ( t ) k 2 , and use (P3) to show the speed of loss decreasing. Then it can be seen that L ( t ) → 0 and ρ ( t ) → + ∞ . By Lemma E.1, we then hav e | ¯ γ − ˆ γ | → 0 . Lemma E.10. Let E 0 := L ( t 0 ) 2 (log 1 L ( t 0 ) ) 2 − 2 /L . Then for all t > t 0 , E ( L ( t )) ≥ 1 2 L 2 ˆ γ ( t 0 ) 2 /L t − 1 X τ = t 0 η ( τ ) for E ( x ) := Z L ( t 0 ) x 1 min { u 2 (log 1 u ) 2 − 2 /L , E 0 } du. Ther efore , L ( t ) → 0 and ρ ( t ) → + ∞ as t → ∞ . Pr oof. For any inte ger t ≥ t 0 , µ ( L ( t )) ≤ 1 2 and k∇L ( t ) k 2 ≥ k v ( t ) k 2 . Combining these with (P3), we hav e L ( t + 1) − L ( t ) ≤ − 1 2 η ( t ) k v ( t ) k 2 2 = − 1 2 η ( t ) L 2 ν ( t ) 2 ρ ( t ) 2 . 35 Published as a conference paper at ICLR 2020 By (P1), ρ ( t ) − 2 ≤ ˆ γ ( t 0 ) 2 /L log 1 L ( t ) − 2 /L . By Corollary E.6, ν ( t ) 2 ≥ L ( t ) 2 log 1 L ( t ) 2 . Thus we hav e L ( t + 1) − L ( t ) ≤ − 1 2 η ( t ) · L 2 ˆ γ ( t 0 ) 2 /L L ( t ) 2 log 1 L ( t ) 2 − 2 /L . It is easy to see that 1 u 2 (log 1 u ) 2 − 2 /L is unimodal in (0 , 1) , so E 0 ( x ) is non-decreasing and E ( x ) is con vex. So we have E ( L ( t + 1)) − E ( L ( t )) ≥ E 0 ( L ( t )) ( L ( t + 1) − L ( t )) ≥ 1 2 η ( t ) · L 2 ˆ γ ( t 0 ) 2 /L · L ( t ) 2 log 1 L ( t ) 2 − 2 /L min {L ( t ) 2 (log 1 L ( t ) ) 2 − 2 /L , E 0 } ≥ 1 2 η ( t ) · L 2 ˆ γ ( t 0 ) 2 /L , which proves E ( L ( t )) ≥ 1 2 L 2 ˆ γ ( t 0 ) 2 /L P t − 1 τ = t 0 η ( τ ) . Note that L is non-decreasing. If L does not decreases to 0 , then neither does E ( L ) . But the RHS grows to + ∞ , which leads to a contradiction. So L → 0 . T o make L → 0 , q min must con verge to + ∞ . So ρ → + ∞ . E . 5 P R O O F F O R T H E O R E M E . 3 A N D E . 4 The proofs for Theorem E.3 and E.4 are similar as those for Theorem A.8 and A.9 in Appendix C. Define β ( t ) := 1 k∇L ( t ) k 2 D ˆ θ , −∇L ( t ) E as we do in Appendix C. It is easy to see that Lemma C.8 still holds if we replace ˜ γ ( t 0 ) with ˆ γ ( t 0 ) . So we only need to show L → 0 and β → 1 for proving con vergence to KKT points. L → 0 can be followed from Theorem E.2. Similar as the proof for Lemma C.9, it follows from Lemma E.8 and (15) that for all t 2 > t 1 ≥ t 0 , t 2 − 1 X t = t 1 β ( t ) − 2 − 1 · log ρ ( t + 1) ρ ( t ) ≤ 1 L log ˆ γ ( t 2 ) ˆ γ ( t 1 ) . (22) Now we pro ve Theorem E.4. Pr oof for Theor em E.4. W e make the following changes in the proof for Theorem A.9. First, we replace ˜ γ ( t 0 ) with ˆ γ ( t 0 ) , since ˜ γ ( t ) ( t ≥ t 0 ) is lower bounded by ˆ γ ( t 0 ) rather than ˜ γ ( t 0 ) . Second, when choosing t 1 and t 2 , we make log ρ ( t 1 ) and log ρ ( t 2 ) equal to the chosen v alues approximately with an additiv e error o (1) , rather than make them equal exactly . This is possible because it can be shown from (P2) in Lemma E.8 that the follo wing holds: ρ ( t + 1) 2 − ρ ( t ) 2 = O ( η ( t ) ν ( t )) = o ( κ ( L ( t )) − 1 · L ( t ) ρ ( t ) L ) = o ρ ( t ) L (log 1 L ( t ) ) 2 − 2 /L ! = o ( ρ ( t ) − L +2 ) . Dividing ρ ( t ) 2 on the leftmost and rightmost sides, we hav e ρ ( t + 1) /ρ ( t ) = 1 + o ( ρ ( t ) − L ) = 1 + o (1) , which implies that log ρ ( t + 1) − log ρ ( t ) = o (1) . Therefore, for any R , we can always find the minimum time t such that log ρ ( t ) ≥ R , and it holds for sure that log ρ ( t ) − R → 0 as R → + ∞ . For pro ving Theorem E.3, we also need the following lemma as a variant of Lemma C.11. Lemma E.11. F or all t ≥ t 0 , ˆ θ ( t + 1) − ˆ θ ( t ) 2 ≤ B 1 L ˜ γ ( t ) · ρ ( t + 1) ρ ( t ) + 1 log ρ ( t + 1) ρ ( t ) 36 Published as a conference paper at ICLR 2020 Pr oof. According to the update rule, we hav e ˆ θ ( t + 1) − ˆ θ ( t ) 2 = 1 ρ ( t + 1) θ ( t + 1) − ρ ( t + 1) ρ ( t ) θ ( t ) 2 ≤ 1 ρ ( t + 1) k θ ( t + 1) − θ ( t ) k 2 + ρ ( t + 1) ρ ( t ) − 1 θ ( t ) 2 = η ( t ) ρ ( t + 1) k∇L ( t ) k 2 + 1 − ρ ( t ) ρ ( t + 1) . By (16), k∇L ( t ) k 2 ≤ B 1 ν ( t ) ˜ γ ( t ) ρ ( t ) . So we can bound the first term as η ( t ) ρ ( t + 1) k∇L ( t ) k 2 ≤ B 1 ˜ γ ( t ) · η ( t ) ν ( t ) ρ ( t + 1) ρ ( t ) ≤ B 1 ˜ γ ( t ) · ρ ( t + 1) 2 − ρ ( t ) 2 2 Lρ ( t + 1) ρ ( t ) = B 1 2 L ˜ γ ( t ) · ρ ( t + 1) 2 − ρ ( t ) 2 ρ ( t + 1) 2 · ρ ( t + 1) ρ ( t ) ≤ B 1 L ˜ γ ( t ) · ρ ( t + 1) ρ ( t ) log ρ ( t + 1) ρ ( t ) where the last inequality uses the inequality a − b a ≤ log ( a/b ) . Using this inequality again, we can bound the second term by 1 − ρ ( t ) ρ ( t + 1) ≤ log ρ ( t + 1) ρ ( t ) . Combining these together giv es ˆ θ ( t + 1) − ˆ θ ( t ) 2 ≤ B 1 L ˜ γ ( t ) · ρ ( t +1) ρ ( t ) + 1 log ρ ( t +1) ρ ( t ) . Now we are ready to pro ve Theorem E.3. Pr oof for Theor em E.3. As discussed above, we only need to sho w a variant of Lemma C.12 for gradient descent: for every limit point ¯ θ of n ˆ θ ( t ) : t ≥ 0 o , there exists a sequence of { t m : m ∈ N } such that t m ↑ + ∞ , ˆ θ ( t m ) → ¯ θ , and β ( t m ) → 1 . W e only need to change the choices of s m , s 0 m , t m in the proof for Lemma C.12. W e choose s m > t m − 1 to be a time such that ˆ θ ( s m ) − ¯ θ 2 ≤ m and 1 L log lim t → + ∞ ˆ γ ( t ) ˆ γ ( s m ) ≤ 3 m . Then we let s 0 m > s m be the minimum time such that log ρ ( s 0 m ) ≥ log ρ ( s m ) + m . According to Theorem E.2, s m and s 0 m must e xist. Finally , we construct t m ∈ { s m , . . . , s 0 m − 1 } to be a time that β ( t m ) − 2 − 1 ≤ 2 m , where the existence can be sho wn by (22). T o see that this construction meets our requirement, note that β ( t m ) − 2 − 1 ≤ 2 m → 0 and ˆ θ ( t m ) − ¯ θ 2 ≤ ˆ θ ( t m ) − ˆ θ ( s m ) 2 + ˆ θ ( s m ) − ¯ θ 2 ≤ B 1 L ˆ γ ( t 0 ) e m + 1 · m + m → 0 , where the last inequality is by Lemma E.11. E . 6 P R O O F F O R T H E O R E M E . 5 Pr oof. By a similar analysis as Lemma D.4, we hav e E ( x ) = Z L ( t 0 ) x Θ 1 u 2 (log 1 u ) 2 − 2 /L du = Z 1 /x 1 / L ( t 0 ) Θ 1 (log u ) 2 − 2 /L du = Θ 1 x (log 1 x ) 2 − 2 /L . 37 Published as a conference paper at ICLR 2020 W e can also bound the in verse function E − 1 ( y ) by Θ 1 y (log y ) 2 − 2 /L . With these, we can use a similar analysis as Theorem A.10 to prov e Theorem E.5. First, using a similar proof as for (17), we have ρ L = Θ(log 1 L ) . So we only need to show L ( t ) = Θ( 1 T (log T ) 2 − 2 /L ) . With a similar analysis as for (P3) in Lemma E.9, we have the follo wing bound for L ( τ + 1) − L ( τ ) : L ( τ + 1) − L ( τ ) ≥ − η ( τ )(1 + µ ( L ( τ ))) k∇L ( τ ) k 2 2 . Using the fact that µ ≤ 1 / 2 , we hav e L ( τ + 1) − L ( τ ) ≥ − 3 2 η ( τ ) k∇L ( τ ) k 2 2 . By Lemma E.7, k∇L ( τ ) k 2 ≤ 2 C η κ ( L ( τ )) L ( τ ) . Using a similar proof as for Lemma E.10, we can show that E ( L ( t )) ≤ O ( T ) . Combining this with Lemma E.10, we have E ( L ( t )) = Θ( T ) . Therefore, L ( t ) = Θ( 1 T (log T ) 2 − 2 /L ) . F G R A D I E N T D E S C E N T : G E N E R A L L O S S F U N C T I O N S It is worth to note that the abov e analysis can be extended to other loss functions. For this, we need to replace (B3) with a strong assumption (S3), which takes into account the second-order deriv ati ves of f . (S3). The loss function ` ( q ) can be expressed as ` ( q ) = e − f ( q ) such that (S3.1). f : R → R is C 2 -smooth. (S3.2). f 0 ( q ) > 0 for all q ∈ R . (S3.3). There exists b f ≥ 0 such that f 0 ( q ) q is non-decreasing for q ∈ ( b f , + ∞ ) , and f 0 ( q ) q → + ∞ as q → + ∞ . (S3.4). Let g : [ f ( b f ) , + ∞ ) → [ b f , + ∞ ) be the in verse function of f on the domain [ b f , + ∞ ) . There exists p ≥ 0 such that for all x > f ( b f ) , y > b f , g 00 ( x ) g 0 ( x ) ≤ p x and f 00 ( y ) f 0 ( y ) ≤ p y . It can be verified that (S3) is satisfied by exponential loss and logistic loss. Now we explain each of the assumptions in (S3). (S3.2) and (S3.3) are essentially the same as (B3.2) and (B3.3). (S3.1) and (B3.1) are the same except that (S3.1) assumes f is C 2 -smooth rather than C 1 -smooth. (S3.4) can also be written in the following form: d dx log g 0 ( x ) ≤ p · d dx log x and d dy log f 0 ( y ) ≤ p · d dy log y . (23) That is, log g 0 ( x ) and log f 0 ( y ) grow no faster than O (log x ) and O (log y ) , respectiv ely . In fact, (B3.4) can be deduced from (S3.4). Recall that (B3.4) ensures that Θ( g 0 ( x )) = g 0 (Θ( x )) and Θ( f 0 ( y )) = f 0 (Θ( y )) . Thus, (S3.4) also giv es us the interchangeability between f 0 , g 0 and Θ . Lemma F .1. (S3.4) implies (B3.4) with b g = max { 2 f ( b f ) , f (2 b f ) } and K = 2 p . Pr oof. Fix x ∈ ( b g , + ∞ ) , y ∈ ( g ( b g ) , + ∞ ) and θ ∈ [1 / 2 , 1) . Integrating (23) on both sides of the inequalities from θ x to x and θy to y , we hav e | log g 0 ( x ) − log g 0 ( θ x ) | ≤ p · log 1 θ and | log f 0 ( y ) − log f 0 ( θ y ) | ≤ p · log 1 θ . Therefore, we hav e g 0 ( x ) ≤ θ − p g 0 ( θ x ) ≤ K g 0 ( θ x ) and f 0 ( y ) ≤ θ − p f 0 ( θ y ) ≤ K f 0 ( θ x ) . T o extend our results to general loss functions, we need to redefine κ ( x ) , λ ( x ) , φ ( x ) , C η , H ( x ) in order . For κ ( x ) and λ ( x ) , we redefine them as follo ws: κ ( x ) := sup ( w (log 1 w ) 2 − 2 /L g 0 (log 1 w ) 2 : w ∈ (0 , x ] ) λ ( x ) := g 0 (log 1 x ) g (log 1 x ) . 38 Published as a conference paper at ICLR 2020 By Lemma D.1, w (log 1 w ) 2 − 2 /L g 0 (log 1 w ) 2 = O w (log 1 w ) 4 − 2 /L /g (log 1 w ) 2 → 0 . So κ ( x ) is well-defined. Using λ ( x ) , we can define φ ( x ) and ˆ γ ( θ ) as follo ws. φ 0 ( x ) := − sup λ ( w ) w (1 + 2(1 + λ ( w ) /L ) µ ( w )) : w ∈ [ x, L ( t 0 )] φ ( x ) := log g (log 1 x ) + Z x 0 φ 0 ( w ) + λ ( w ) w dw ˆ γ ( θ ) := e φ ( L ( θ )) ρ L . Using a similar argument as in Lemma E.1, we can show that ˆ γ ( θ ) is well-defined and ˆ γ ( θ ) < ˜ γ ( θ ) := g (log 1 L ) /ρ L ≤ ¯ γ ( θ ) . When L ( θ ) → 0 , we also have ˆ γ ( θ ) / ¯ γ ( θ ) → 1 . For C η , we define it to be the following. C η := 1 2 B 1 B 0 ˆ γ ( t 0 ) p B 1 + 2 p +1 log 1 L ( t 0 ) ( pB 1 + B 2 ) ! B 0 ˆ γ ( t 0 ) p min n ˆ γ ( t 0 ) − 2+2 /L , B − 2+2 /L 0 o . Finally , the definitions for µ ( x ) := (log 1 L ( t 0 ) ) / (2 log 1 x ) and H ( x ) := µ ( x ) / ( C η κ ( x )) in (S5) remain unchanged except that κ ( x ) and C η now use the ne w definitions. Similar as gradient flow , we define ν ( t ) := P N n =1 e − f ( q n ( t )) f 0 ( q n ( t )) q n ( t ) . The key idea behind the above definitions is that we can prov e similar bounds for ν ( t ) , k∇Lk 2 , k∇ 2 Lk 2 as Corollary E.6 and Lemma E.7. Lemma F .2. h θ ( t ) , −∇L ( t ) i = Lν ( t ) . If L ( t ) < e − f ( b f ) , then ν ( t ) ≥ L ( t ) λ ( L ( t )) and λ ( L ( t )) has the lower bound λ ( L ( t )) ≤ 2 p +1 log 1 L ( t ) − 1 . Pr oof. It can be easily prov ed by combining Theorem B.4, Lemma B.5 and Lemma D.1 together . Lemma F .3. F or any θ , if L ( θ ) ≤ L ( t 0 ) , ˜ γ ( θ ) ≥ ˆ γ ( t 0 ) , then k∇L ( θ ) k 2 2 ≤ 2 C η κ ( L ( θ )) L ( θ ) and ∇ 2 L ( θ ) 2 ≤ 2 C η κ ( L ( θ )) . Pr oof. Note that a direct corollary of (23) is that f 0 ( x 1 ) ≤ f 0 ( x 2 )( x 1 /x 2 ) p for x 1 ≥ x 2 > b f . So we hav e f 0 ( q n ) ≤ f 0 g (log 1 L ) q n g (log 1 L ) p = 1 g 0 (log 1 L ) q n /ρ L ˜ γ p ≤ R g 0 (log 1 L ) , where R := ( B 0 / ˆ γ ( t 0 )) p . Applying (S3.4), we can also deduce that | f 00 ( q n ) | ≤ p q n · f 0 ( q n ) ≤ pR g (log 1 L ) g 0 (log 1 L ) . Now we bound k∇Lk 2 and ∇ 2 L 2 . By the chain rule, we hav e k∇Lk 2 = − N X n =1 e − f ( q n ) f 0 ( q n ) ∇ q n 2 ≤ B 1 R · L ρ L − 1 g 0 (log 1 L ) ∇ 2 L 2 = N X n =1 e − f ( q n ) ( f 0 ( q n ) 2 − f 00 ( q n )) ∇ q n ∇ q > n − f 0 ( q n ) ∇ 2 q n 2 ≤ N X n =1 e − f ( q n ) R 2 g 0 (log 1 L ) 2 + pR g (log 1 L ) g 0 (log 1 L ) B 2 1 ρ 2 L − 2 + R g 0 (log 1 L ) B 2 ρ L − 2 ≤ L ρ 2 L − 2 g 0 (log 1 L ) 2 ( R + pλ ( L )) B 2 1 + g 0 (log 1 L ) ρ L B 2 R. 39 Published as a conference paper at ICLR 2020 For ρ we hav e ˆ γ ( t 0 ) ρ L ≤ log 1 L ≤ B 0 ρ L , so we can bound ρ 2 L − 2 by ρ 2 L − 2 ≤ M (log 1 L ) 2 L − 2 , where M := min n ˆ γ ( t 0 ) − 2+2 /L , B − 2+2 /L 0 o . By Lemma F .2, we have λ ( L ) ≤ 2 p +1 1 log 1 L ≤ 2 p +1 log 1 L ( t 0 ) , and also g 0 (log 1 L ) ρ L = λ ( L ) · ˜ γ ≤ 2 p +1 B 1 log 1 L ( t 0 ) . Combining all these formulas together gi ves k∇Lk 2 2 ≤ B 2 1 R 2 M L 2 g 0 (log 1 L ) 2 log 1 L 2 − 2 /L ≤ 2 C η κ ( L ) L ∇ 2 L 2 ≤ R + p 2 p +1 log 1 L ( t 0 ) ! B 2 1 + 2 p +1 B 1 B 2 log 1 L ( t 0 ) ! RM L g 0 (log 1 L ) 2 log 1 L 2 − 2 /L ≤ 2 C η κ ( L ) , which completes the proof. W ith Corollary E.6 and Lemma E.7, we can prov e Lemma E.8 with exactly the same argument. Then Theorem E.2, E.3, E.4 can also be proved similarly . For Theorem E.5, we can follow the argument for gradient flo w to show that it holds with slightly dif ferent tight bounds: Theorem F .4. Under assumptions (S1), (A2), (S3), (A4), (S5), we have the following tight rates for training loss and weight norm: L ( t ) = Θ g (log T ) 2 /L T (log T ) 2 and ρ ( t ) = Θ( g (log T ) 1 /L ) , wher e T = P t − 1 τ = t 0 η ( τ ) . G E X T E N S I O N : M U LT I - C L A S S C L A S S I FI C AT I O N In this section, we generalize our results to multi-class classification with cross-entropy loss. This part of analysis is inspired by Theorem 1 in (Zhang et al., 2019), which gives a lo wer bound for the gradient in terms of the loss L . Since now a neural network has multiple outputs, we need to redefine our notations. Let C be the number of classes. The output of a neural network Φ is a vector Φ ( θ ; x ) ∈ R C . W e use Φ j ( θ ; x ) ∈ R to denote the j -th output of Φ on the input x ∈ R d x . A dataset is denoted by D = { x n , y n } N n =1 = { ( x n , y n ) : n ∈ [ N ] } , where x n ∈ R d x is a data input and y n ∈ [ C ] is the corresponding label. The loss function of Φ on the dataset D is defined as L ( θ ) := N X n =1 − log e Φ y n ( θ ; x n ) P C j =1 e Φ j ( θ ; x n ) . The mar gin for a single data point ( x n , y n ) is defined to be q n ( θ ) := Φ y n ( θ ; x n ) − max j 6 = y n { Φ j ( θ ; x n ) } , and the margin for the entire dataset is defined to be q min ( θ ) = min n ∈ [ N ] q n ( θ ) . W e define the normalized margin to be ¯ γ ( θ ) := q min ( ˆ θ ) = q min ( θ ) /ρ L , where ρ := k θ k 2 and ˆ θ := θ /ρ ∈ S d − 1 as usual. Let ` ( q ) := log(1 + e − q ) be the logistic loss. Recall that ` ( q ) satisfies (B3). Let f ( q ) = − log ` ( q ) = − log log(1 + e − q ) . Let g be the in verse function of f . So g ( q ) = − log ( e e − q − 1) . The cross-entropy loss can be re written in other ways. Let s nj := Φ y n ( θ ; x n ) − Φ j ( θ ; x n ) . Let ˜ q n := − LSE( {− s nj : j 6 = y n } ) = − log P j 6 = y n e − s nj . Then L ( θ ) := N X n =1 log 1 + X j 6 = y n e − s nj = N X n =1 log(1 + e − ˜ q n ) = N X n =1 ` ( ˜ q n ) = N X n =1 e − f ( ˜ q n ) . Gradient Flow . For gradient flo w , we assume the following: (M1). (Regularity). For an y fixed x and j ∈ [ C ] , Φ j ( · ; x ) is locally Lipschitz and admits a chain rule; 40 Published as a conference paper at ICLR 2020 (M2). (Homogeneity). There exists L > 0 such that ∀ j ∈ [ C ] , ∀ α > 0 : Φ j ( α θ ; x ) = α L Φ j ( θ ; x ) ; (M3). (Cross-entropy Loss). L ( θ ) is defined as the cross-entropy loss on the training set; (M4). (Separability). There e xists a time t 0 such that L ( t 0 ) < log 2 . If L < log 2 , then P j 6 = y n e − s nj < 1 for all n ∈ [ N ] , and thus s nj > 0 for all n ∈ [ N ] , j ∈ [ C ] . So (M4) ensures the separability of training data. Definition G.1. For cross-entropy loss, the smoothed normalized mar gin ˜ γ ( θ ) of θ is defined as ˜ γ ( θ ) := ` − 1 ( L ) ρ L = − log ( e L − 1) ρ L , where ` − 1 ( · ) is the inv erse function of the logistic loss ` ( · ) . Theorem 4.1 and 4.4 still hold. Here we redefine the optimization problem (P) to be min 1 2 k θ k 2 2 s.t. s nj ( θ ) ≥ 1 ∀ n ∈ [ N ] , ∀ j ∈ [ C ] \ { y n } Most of our proofs are very similar as before. Here we only show the proof for the generalized version of Lemma 5.1. Lemma G.2. Lemma 5.1 is also true for the smoothed normalized mar gin ˜ γ defined in Defini- tion G.1. Pr oof. Define ν ( t ) by the follo wing formula: ν ( t ) := N X n =1 P j 6 = y n e − s nj s nj 1 + P j 6 = y n e − s nj . Using a similar argument as in Theorem B.4, it can be pro ved that 1 2 dρ 2 dt = Lν ( t ) for a.e. t > 0 . It can be shown that Lemma B.5, which asserts that ν ( t ) ≥ g (log 1 L ) g 0 (log 1 L ) L , still holds for this ne w definition of ν ( t ) . By definition, s nj ≥ q n for j 6 = y n . Also note that e − ˜ q n ≥ e − q n . So s nj ≥ q n ≥ ˜ q n . Then we hav e ν ( t ) ≥ N X n =1 P j 6 = y n e − s nj 1 + P j 6 = y n e − s nj · ˜ q n = N X n =1 e − ˜ q n 1 + e − ˜ q n · ˜ q n = N X n =1 e − f ( ˜ q n ) f 0 ( ˜ q n ) ˜ q n . Note that L = P N n =1 e − f ( ˜ q n ) . Then using Lemma B.5 for logistic loss can conclude that ν ( t ) ≥ g (log 1 L ) g 0 (log 1 L ) L . The rest of the proof for this lemma is exactly the same as that for Lemma 5.1. Gradient Descent. For gradient descent, we only need to replace (M1) with (S1) and make the assumption (S5) on the learning rate. (S1). (Smoothness). F or any fix ed x and j ∈ [ C ] , Φ j ( · ; x ) is C 2 -smooth; (S5). (Learing rate condition). P t ≥ 0 η ( t ) = + ∞ and η ( t ) ≤ H ( L ( θ ( t ))) . Here H ( x ) := µ ( x ) / ( C η κ ( x )) is defined to be the same as in Appendix F (when ` ( · ) is set to logistic loss) except that we use another C η which will be specified later . W e only need to show that Lemma F .2 and Lemma F .3 continue to hold. Using the same argument as we do for gradient flow , we can show that γ ( t ) and λ ( x ) do satisfy the propositions in Lemma F .2. 41 Published as a conference paper at ICLR 2020 For Lemma F .3, we first note the original definition of C η in volves B 0 , B 1 , B 2 , which are undefined in the multi-class setting. So no w we redefine them as B 0 := sup s nj : θ ∈ S d − 1 , n ∈ [ N ] , j ∈ [ C ] , B 1 := sup k∇ s nj k 2 : θ ∈ S d − 1 , n ∈ [ N ] , j ∈ [ C ] , B 2 := sup ∇ 2 s nj 2 : θ ∈ S d − 1 , n ∈ [ N ] , j ∈ [ C ] . By the property of LSE , we can use B 0 , B 1 , B 2 to bound ˜ q n , ∇ ˜ q n , ∇ 2 ˜ q n . ˜ q n ≤ q n ≤ B 0 ρ L , k∇ ˜ q n k 2 = C X j =1 e − s nj P C k =1 e − s nk ∇ s nj 2 ≤ C X j =1 e − s nj P C k =1 e − s nk k∇ s nj k 2 ≤ B 1 ρ L − 1 , ∇ 2 ˜ q n 2 = C X j =1 e − s nj P C k =1 e − s nk ( ∇ 2 s nj − ∇ s nj ∇ s > nj ) + e − 2 s nj P C k =1 e − s nk 2 ∇ s nj ∇ s > nj 2 ≤ B 2 ρ L − 2 + 2 B 2 1 ρ 2 L − 2 . Using these bounds, we can prov e with the constant C η defined as follows: C η := 1 2 B 0 ˆ γ ( t 0 ) p + p 2 p +1 log 1 L ( t 0 ) ! B 2 1 + (2 log 2) B 2 ρ ( t 0 ) L + 2 B 2 1 ! B 0 ˆ γ ( t 0 ) p M , where M := min n ˆ γ ( t 0 ) − 2+2 /L , B − 2+2 /L 0 o . H E X T E N S I O N : M U LT I - H O M O G E N E O U S M O D E L S In this section, we extend our results to multi-homogeneous models. For this, the main dif ference from the proof for homogeneous models is that no w we have to separate the norm of each homo- geneous parts of the parameter, rather than consider them as a whole. So only a small part to proof needs to be changed. W e focus on gradient flo w , but it is worth to note that following the same argument, it is not hard to e xtend the results to gradient descent. Let Φ( w 1 , . . . , w m ; x ) be ( k 1 , . . . , k m ) -homogeneous. Let ρ i = k w i k 2 and ˆ w i = w i k w i k 2 . The smoothed normalized margin defined in (5) can be re written as follows: Definition H.1. F or a multi-homogeneous model with loss function ` ( · ) satisfying (B3), the smoothed normalized margin ˜ γ ( θ ) of θ is defined as ˜ γ ( θ ) := g (log 1 L ) Q m i =1 ρ k i i = ` − 1 ( L ) Q m i =1 ρ k i i . W e only prove the generalized v ersion of Lemma 5.1 here. The other proofs are almost the same. Lemma H.2. F or all t > t 0 , d dt log ρ i > 0 for all i ∈ [ m ] and d dt log ˜ γ ≥ m X i =1 k i d dt log ρ i − 1 d ˆ w i dt 2 2 . (24) Pr oof. Note that d dt log ρ i = 1 2 ρ 2 i dρ 2 i dt = k i ν ( t ) ρ 2 i by Theorem B.4. It simply follows from Lemma B.5 that d dt log ρ > 0 for a.e. t > t 0 . And it is easy to see that log ˜ γ = log g (log 1 L ) /ρ L exists for all 42 Published as a conference paper at ICLR 2020 t ≥ t 0 . By the chain rule and Lemma B.5, we hav e d dt log ˜ γ = d dt log g (log 1 L ) − m X i =1 k i log ρ i ! = g 0 (log 1 L ) g (log 1 L ) · 1 L · − d L dt − m X i =1 k 2 i ν ( t ) ρ 2 i ≥ 1 ν ( t ) · − d L dt − m X i =1 k 2 i ν ( t ) ρ 2 i ≥ 1 ν ( t ) · − d L dt − m X i =1 k 2 i ν ( t ) 2 ρ 2 i ! . On the one hand, − d L dt = P m i =1 d w i dt 2 2 for a.e. t > 0 by Lemma I.3; on the other hand, k i ν ( t ) = w i , d w i dt by Theorem B.4. Combining these together yields d dt log ˜ γ ≥ 1 ν ( t ) m X i =1 d w i dt 2 2 − ˆ w i , d w i dt 2 ! = 1 ν ( t ) ( I − ˆ w i ˆ w > i ) d w i dt 2 2 . By the chain rule, d ˆ w i dt = 1 ρ i ( I − ˆ w i ˆ w i > ) d w i dt for a.e. t > 0 . So we hav e d dt log ˜ γ ≥ m X i =1 ρ 2 i ν ( t ) d ˆ w i dt 2 2 = m X i =1 k i d dt log ρ i − 1 d ˆ w i dt 2 2 . For cross-entropy loss, we can combine the proofs in Appendix G to show that Lemma H.2 holds if we use the following definition of the smoothed normalized mar gin: Definition H.3. For a multi-homogeneous model with cross-entrop y , the smoothed normalized mar - gin ˜ γ ( θ ) of θ is defined as ˜ γ = ` − 1 ( L ) Q m i =1 ρ k i i = − log ( e L − 1) Q m i =1 ρ k i i . where ` − 1 ( · ) is the inv erse function of the logistic loss ` ( · ) . The only place we need to change in the proof for Lemma H.2 is that instead of using Lemma B.5, we need to prove ν ( t ) ≥ g (log 1 L ) g 0 (log 1 L ) L in a similar way as in Lemma G.2. The other parts of the proof are exactly the same as before. I C H A I N R U L E S F O R N O N - D I FF E R E N T I A B L E F U N C T I O N S In this section, we pro vide some background on the chain rule for non-dif ferentiable functions. The ordinary chain rule for differentiable functions is a very useful formula for computing deriv ativ es in calculus. Howe ver , for non-differentiable functions, it is difficult to find a natural definition of subdifferential so that the chain rule equation holds exactly . T o solve this issue, Clarke proposed Clarke’ s subdif ferential (Clarke, 1975; 1990; Clarke et al., 2008) for locally Lipschitz functions, for which the chain rule holds as an inclusion rather than an equation: Theorem I.1 (Theorem 2.3.9 and 2.3.10 of (Clarke, 1990)) . Let z 1 , . . . , z n : R d → R and f : R n → R be locally Lipschitz functions. Let ( f ◦ z )( x ) = f ( z 1 ( x ) , . . . , z n ( x )) be the composition of f and z . Then, ∂ ◦ ( f ◦ z )( x ) ⊆ conv ( n X i =1 α i h i : α ∈ ∂ ◦ f ( z 1 ( x ) , . . . , z n ( x )) , h i ∈ ∂ ◦ z i ( x ) ) . For analyzing gradient flow , the chain rule is crucial. For a differentiable loss function L ( θ ) , we can see from the chain rule that the function v alue keeps decreasing along the gradient flow d θ ( t ) dt = −∇L ( θ ( t )) : d L ( θ ( t )) dt = ∇L ( θ ( t )) , d θ ( t ) dt = − d θ ( t ) dt 2 2 . (25) 43 Published as a conference paper at ICLR 2020 But for locally Lipschitz functions which could be non-differentiable, (25) may not hold in general since Theorem I.1 only holds for an inclusion. Follo wing (Davis et al., 2020; Drusvyatskiy et al., 2015), we consider the functions that admit a chain rule for any arc. Definition I.2 (Chain Rule) . A locally Lipschitz function f : R d → R admits a chain rule if for any arc z : [0 , + ∞ ) → R d , ∀ h ∈ ∂ ◦ f ( z ( t )) : ( f ◦ z ) 0 ( t ) = h h , z 0 ( t ) i (26) holds for a.e. t > 0 . It is sho wn in (Davis et al., 2020; Drusvyatskiy et al., 2015) that a generalized version of (25) holds for such functions: Lemma I.3 (Lemma 5.2 (Davis et al., 2020)) . Let L : R d → R be a locally Lipschitz function that admits a chain rule . Let θ : [0 , + ∞ ) → R d be the gradient flow on L : d θ ( t ) dt ∈ − ∂ ◦ L ( θ ( t )) for a.e. t ≥ 0 , Then d L ( θ ( t )) dt = − d θ ( t ) dt 2 2 = − min {k h k 2 2 : h ∈ ∂ ◦ L ( θ ( t )) } holds for a.e. t > 0 . W e can see that C 1 -smooth functions admit chain rules. As shown in (Davis et al., 2020), if a locally Lipschitz function is subdifferentiablly regular or Whitney C 1 -stratifiable, then it admits a chain rule. The latter one includes a large family of functions, e.g., semi-algebraic functions, semi- analytic functions, and definable functions in an o-minimal structure (Coste, 2002; van den Dries & Miller, 1996). It is worth noting that the class of functions that admits chain rules is closed under composition. This is indeed a simple corollary of Theorem I.1. Theorem I.4. Let z 1 , . . . , z n : R d → R and f : R n → R be locally Lipschitz functions and assume all of them admit chain rules. Let ( f ◦ z )( x ) = f ( z 1 ( x ) , . . . , z n ( x )) be the composition of f and z . Then f ◦ z also admits a chain rule . Pr oof. W e can see that f ◦ z is locally Lipschitz. Let x : [0 , + ∞ ) → R d , t 7→ x ( t ) be an arc. First, we show that z ◦ x : [0 , + ∞ ) → R d , t 7→ z ( x ( t )) is also an arc. For any closed sub-interval I , z ( x ( I )) must be contained in a compact set U . Then it can be sho wn that the locally Lipschitz continuous function z is (globally) Lipschitz continuous on U . By the fact that the composition of a Lipschitz continuous and an absolutely continuous function is absolutely continuous, z ◦ x is absolutely continuous on I , and thus it is an arc. Since f and z admit chain rules on arcs z ◦ x and x respectively , the follo wing holds for a.e. t > 0 , ∀ α ∈ ∂ ◦ f ( z ( x ( t ))) : ( f ◦ ( z ◦ x )) 0 ( t ) = h α , ( z ◦ x ) 0 ( t ) i , ∀ h i ∈ ∂ ◦ z i ( x ( t )) : ( z i ◦ x ) 0 ( t ) = h h i , x 0 ( t ) i . Combining these we obtain that for a.e. t > 0 , ( f ◦ z ◦ x ) 0 ( t ) = n X i =1 α i h h i , x 0 ( t ) i , for all α ∈ ∂ ◦ f ( z ( x ( t ))) and for all h i ∈ ∂ ◦ z i ( x ( t )) . The RHS can be rewritten as h P n i =1 α i h i , x 0 ( t ) i . By Theorem I.1, every k ∈ ∂ ◦ ( f ◦ z )( x ( t )) can be written as a con ve x combi- nation of a finite set of points in the form of P n i =1 α i h i . So ( f ◦ z ◦ x ) 0 ( t ) = h k , x 0 ( t ) i holds for a.e. t > 0 . 44 Published as a conference paper at ICLR 2020 J M E X I C A N H A T In this section, we give an example to illustrate that gradient flow does not necessarily conv erge in direction, ev en for C ∞ -smooth homogeneous models. It is known that gradient flow (or gradient descent) may not con verge to any point e ven when opti- mizing an C ∞ function (Curry, 1944; Zoutendijk, 1976; Palis & De Melo, 2012; Absil et al., 2005). One famous counterexample is the “Me xican Hat” function described in (Absil et al., 2005): f ( u, v ) := f ( r cos ϕ, r sin ϕ ) := ( e − 1 1 − r 2 1 − C ( r ) sin ϕ − 1 1 − r 2 r < 1 0 r ≥ 1 where C ( r ) = 4 r 4 4 r 4 +(1 − r 2 ) 4 ∈ [0 , 1] . It can be shown that f is C ∞ -smooth on R 2 but not analytic. See Figure 2 for a plot for f ( u, v ) . Figure 2: A plot for the Mexican Hat function f ( u, v ) . Howe ver , the Maxican Hat function is not homogeneous, and Absil et al. (2005) did not consider the directional conv ergence, either . T o make it homogeneous, we introduce an extra v ariable z , and normalize the parameter before ev aluate f . In particular, we fix L > 0 and define h ( θ ) = h ( x, y , z ) = ρ L (1 − f ( u, v )) where u = x/ρ, v = y /ρ, ρ = p x 2 + y 2 + z 2 . W e can show the follo wing theorem. Theorem J.1. Consider gradient flow on L ( θ ) = P N n =1 e − q n ( θ ) , wher e q n ( θ ) = h ( θ ) for all n ∈ [ N ] . Suppose the polar repr esentation of ( u, v ) is ( r cos ϕ, r sin ϕ ) . If 0 < r < 1 and ϕ = 1 1 − r 2 holds at time t = 0 , then θ ( t ) k θ ( t ) k 2 does not con verge to any point, and the limit points of { θ ( t ) k θ ( t ) k 2 : t > 0 } form a circle { ( x, y , z ) ∈ S 2 : x 2 + y 2 = 1 , z = 0 } . Pr oof. Define ψ = ϕ − 1 1 − r 2 . Our proof consists of two parts, following from the idea in (Absil et al., 2005). First, we show that dψ dt = 0 as long as ψ = 0 . Then we can infer that ψ = 0 for all t ≥ 0 . Next, we show that r → 1 as t → + ∞ . Using ψ = 0 , we know that the polar angle ϕ → + ∞ as t → + ∞ . Therefore, ( u, v ) circles around { ( u, v ) : u 2 + v 2 = 1 } , and thus it does not con ver ge. Proof for dψ dt = 0 . For con venience, we use w to denote z /ρ . By simple calculation, we have the following formulas for partial deri vati ves: ∂ h ∂ x = ρ L − 1 Lu (1 − f ) − (1 − u 2 ) ∂ f ∂ u + uv ∂ f ∂ v ∂ h ∂ y = ρ L − 1 Lv (1 − f ) + uv ∂ f ∂ u − (1 − v 2 ) ∂ f ∂ v ∂ h ∂ z = ρ L − 1 Lw (1 − f ) + uw ∂ f ∂ u + v w ∂ f ∂ v ( ∂ f ∂ u = u r · ∂ f ∂ r − v r 2 · ∂ f ∂ ϕ ∂ f ∂ v = v r · ∂ f ∂ r + u r 2 · ∂ f ∂ ϕ 45 Published as a conference paper at ICLR 2020 For gradient flo w , we hav e d θ dt = N e − h ∇ h du dt = 1 ρ (1 − u 2 ) dx dt − uv dy dt − uw dz dt = N e − h ρ L − 2 − (1 − u 2 ) ∂ f ∂ u + uv ∂ f ∂ v dv dt = 1 ρ (1 − v 2 ) dy dt − uv dx dt − v w dz dt = N e − h ρ L − 2 − (1 − v 2 ) ∂ f ∂ v + uv ∂ f ∂ u By writing down the mo vement of ( u, v ) in the polar coordinate system, we have dr dt = u r · du dt + v r · dv dt = − N e − h ρ L − 2 r u (1 − r 2 ) ∂ f ∂ u + v (1 − r 2 ) ∂ f ∂ v = − N e − h ρ L − 2 (1 − r 2 ) ∂ f ∂ r dϕ dt = − v r 2 · du dt + u r 2 · dv dt = N e − h ρ L − 2 r 2 v ∂ f ∂ u − u ∂ f ∂ v = − N e − h ρ L − 2 1 r 2 · ∂ f ∂ ϕ For ψ = 0 , the partial deriv ati ves of f with respect to r and ϕ can be ev aluated as follo ws: ∂ f ∂ r = d dr e − 1 1 − r 2 − e − 1 1 − r 2 C 0 ( r ) sin ψ − e − 1 1 − r 2 C ( r ) cos ψ · ∂ ψ ∂ r = d dr e − 1 1 − r 2 + e − 1 1 − r 2 C ( r ) d dr 1 1 − r 2 = − 2 r (1 − r 2 ) 2 (1 − C ( r )) e − 1 1 − r 2 . ∂ f ∂ ϕ = − e − 1 1 − r 2 C ( r ) cos ψ · ∂ ψ ∂ ϕ = − e − 1 1 − r 2 C ( r ) . So if ψ = 0 , then dψ dt = 0 by the direct calculation below: dψ dt = dϕ dt − d dr 1 1 − r 2 · dr dt = N e − h ρ L − 2 − 1 r 2 ∂ f ∂ ϕ + 2 r (1 − r 2 ) 2 ∂ f ∂ r = N e − h ρ L − 2 e − 1 1 − r 2 1 r 2 + 4 r 2 (1 − r 2 ) 4 C ( r ) − 4 r 2 (1 − r 2 ) 4 = 0 . Proof for r → 1 . Let ( ¯ u, ¯ v ) be a con ver gent point of { ( u, v ) : t ≥ 0 } . Define ¯ r = √ u 2 + v 2 . It is easy to see that r ≤ 1 from the normalization of θ in the definition. According to Theorem 4.4, we know that ( ¯ u, ¯ v ) is a stationary point of ¯ γ ( u ( t ) , v ( t )) = 1 − f ( u ( t ) , v ( t )) . If ¯ r = 0 , then f ( ¯ u, ¯ v ) > f ( u (0) , v (0)) , which contradicts to the monotonicity of ˜ γ ( t ) = ¯ γ ( t ) = 1 − f ( u ( t ) , v ( t )) . If ¯ r < 1 , then ¯ ψ = 0 (defined as ψ for ( ¯ u, ¯ v ) ). So ∂ f ∂ r = − 2 r (1 − r 2 ) 2 (1 − C ( r )) e − 1 1 − r 2 6 = 0 , which again leads to a contradiction. Therefore, ¯ r = 1 , and thus r → 1 . K E X P E R I M E N T S T o validate our theoretical results, we conduct several experiments. W e mainly focus on MNIST dataset. W e trained two models with T ensorflo w . The first one (called the CNN with bias ) is a stan- dard 4-layer CNN with exactly the same architecture as that used in MNIST Adversarial Examples 46 Published as a conference paper at ICLR 2020 Challenge 5 . The layers of this model can be described as conv -32 with filter size 5 × 5 , max-pool , conv -64 with filter size 3 × 3 , max-pool , fc -1024, fc -10 in order . Notice that this model has bias terms in each layer, and thus does not satisfy homogeneity . T o make its outputs homogeneous to its parameters, we also trained this model after removing all the bias terms except those in the first layer (the modified model is called the CNN without bias ). Note that keeping the bias terms in the first layer prevents the model to be homogeneous in the input data while retains the homogeneity in parameters. W e initialize all layer weights by He normal initializer (He et al., 2015) and all bias terms by zero. In training the models, we use SGD with batch size 100 without momentum. W e normalize all the images to [0 , 1] 32 × 32 by dividing 255 for each pixel. K . 1 E V A L UA T I O N F O R N O R M A L I Z E D M A R G I N In the first part of our experiments, we e valuate the normalized margin e very fe w epochs to see ho w it changes over time. From now on, we view the bias term in the first layer as a part of the weight in the first layer for conv enience. Observe that the CNN without bias is multi-homogeneous in layer weights (see (4) in Section 4.4). So for the CNN without bias, we define the normalized margin ¯ γ as the mar gin divided by the product of the L 2 -norm of all layer weights. Here we compute the L 2 -norm of a layer weight parameter after flattening it into a one-dimensional vector . For the CNN with bias, we still compute the smoothed normalized margin in this way . When computing the L 2 - norm of ev ery layer weight, we simply ignore the bias terms if they are not in the first layer . For completeness, we include the plots for the normalized margin using the original definition (2) in Figure 3 and 4. 50 100 #epochs 95% 96% 97% 98% 99% 100% training accuracy 1 0 0 1 0 1 1 0 2 1 0 3 1 0 4 #epochs 0 . 4 0 × 1 0 5 0 . 2 0 × 1 0 5 0 . 0 0 × 1 0 5 0 . 2 0 × 1 0 5 0 . 4 0 × 1 0 5 normalized margin lr=0.01, w/ bias lr=0.01, w/o bias Figure 3: Training CNNs with and without bias on MNIST , using SGD with learning rate 0 . 01 . The training accuracy (left) increases to 100% after about 100 epochs, and the normalized margin with the original definition (right) keeps increasing after the model is fitted. 5 10 15 20 #epochs 97% 98% 99% 100% training accuracy 0 2500 5000 7500 10000 #epochs 0 . 0 0 × 1 0 5 1 . 0 0 × 1 0 5 2 . 0 0 × 1 0 5 3 . 0 0 × 1 0 5 4 . 0 0 × 1 0 5 5 . 0 0 × 1 0 5 normalized margin 0 2500 5000 7500 10000 #epochs 1 0 7 1 0 5 1 0 3 1 0 1 ( t ) loss-based lr, w/ bias loss-based lr, w/o bias Figure 4: Training CNNs with and without bias on MNIST , using SGD with the loss-based learning rate scheduler . The training accuracy (left) increases to 100% after about 20 epochs, and the nor- malized margin with the original definition (middle) increases rapidly after the model is fitted. The right figure shows the change of the relative learning rate α ( t ) (see (27) for its definition) during training. 5 https://github.com/MadryLab/mnist_challenge 47 Published as a conference paper at ICLR 2020 SGD with Constant Learning Rate. W e first train the CNNs using SGD with constant learning rate 0 . 01 . After about 100 epochs, both CNNs hav e fitted the training set. After that, we can see that the normalized mar gins of both CNNs increase. Ho wever , the gro wth rate of the normalized mar gin is rather slow . The results are shown in Figure 1 in Section 1. W e also tried other learning rates other than 0 . 01 , and similar phenomena can be observed. SGD with Loss-based Learning Rate. Indeed, we can speed up the training by using a proper scheduling of learning rates for SGD. W e propose a heuristic learning rate scheduling method, called the loss-based learning rate scheduling . The basic idea is to find the maximum possible learning rate at each epoch based on the current training loss (in a similar way as the line search method). See Appendix L.1 for the details. As sho wn in Figure 1, SGD with loss-based learning rate schedul- ing decreases the training loss exponentially faster than SGD with constant learning rate. Also, a rapid growth of normalized margin is observed for both CNNs. Note that with this scheduling the training loss can be as small as 10 − 800 , which may lead to numerical issues. T o address such is- sues, we applied some re-parameterization tricks and numerical tricks in our implementation. See Appendix L.2 for the details. Experiments on CIF AR-10. T o verify whether the normalized margin is increasing in practice, we also conduct experiments on CIF AR-10. W e use a modified version of VGGNet-16. The layers of this model can be described as conv -64 × 2 , max-pool , conv -128 × 2 , max-pool , conv -256 × 3 , max-pool , conv -512 × 3 , max-pool , conv -512 × 3 , max-pool , fc -10 in order , where each conv has filter size 3 × 3 . W e train two networks: one is exactly the same as the VGGNet we described, and the other one is the VGGNet without any bias terms except those in the first layer (similar as in the experiments on MNIST). The experiment results are shown in Figure 5 and 6. W e can see that the normalize margin is increasing o ver time. 1 0 0 1 0 1 1 0 2 1 0 3 1 0 4 #epochs 1 0 7 1 0 5 1 0 3 1 0 1 training loss 1 0 0 1 0 1 1 0 2 1 0 3 1 0 4 #epochs 0 . 3 0 × 1 0 1 7 0 . 2 0 × 1 0 1 7 0 . 1 0 × 1 0 1 7 0 . 0 0 × 1 0 1 7 normalized margin lr=0.1, w/ bias lr=0.1, w/o bias Figure 5: T raining VGGNet with and without bias on CIF AR-10, using SGD with learning rate 0 . 1 . 0 1250 2500 3750 5000 #epochs 1 0 6 0 0 0 1 0 4 0 0 0 1 0 2 0 0 0 1 0 0 training loss 0 1250 2500 3750 5000 #epochs 0 . 0 0 × 1 0 1 7 1 . 0 0 × 1 0 1 7 2 . 0 0 × 1 0 1 7 3 . 0 0 × 1 0 1 7 4 . 0 0 × 1 0 1 7 5 . 0 0 × 1 0 1 7 normalized margin loss-based lr, w/ bias loss-based lr, w/o bias Figure 6: T raining VGGNet with and without bias on CIF AR-10, using SGD with the loss-based learning rate scheduler . T est Accuracy . Pre vious works on margin-based generalization bounds (Neyshabur et al., 2018; Bartlett et al., 2017; Golowich et al., 2018; Li et al., 2018a; W ei et al., 2019; Banburski et al., 48 Published as a conference paper at ICLR 2020 2019) usually suggest that a lar ger margin implies a better generalization bound. T o see whether the generalization error also gets smaller in practice, we plot train and test accuracy for both MNIST and CIF AR-10. As shown in Figure 7, the test accuracy changes only slightly after training with loss- based learning rate scheduling for 10000 epochs, although the normalized margin does increase a lot. W e leav e it as a future work to study this interesting gap between margin-based generalization bound and generalization error . Concurrent to this work, W ei & Ma (2020) proposed a generalization bound based on a new notion of margin called all-layer margin, and showe d via experiments that enlarging all-layer margin can indeed improv e generalization. It would be an interesting research direction to study how dif ferent definitions of margin may lead to dif ferent generalization abilities. 0 2000 4000 6000 8000 10000 #epochs 0.970 0.975 0.980 0.985 0.990 0.995 1.000 accuracy (MNIST) 0 2000 4000 6000 8000 10000 #epochs 0.80 0.85 0.90 0.95 1.00 accuracy (CIFAR-10) train test Figure 7: (Left). T raining and test accuracy during training CNNs without bias on MNIST , using SGD with the loss-based learning rate scheduler . Every number is averaged ov er 10 runs. (Right). T raining and test accuracy during training VGGNet without bias on CIF AR-10, using SGD with the loss-based learning rate scheduler . Every number is a veraged ov er 3 runs. K . 2 E V A L UA T I O N F O R R O B U S T N E S S Recently , robustness of deep learning has received considerable attention (Szegedy et al., 2013; Big- gio et al., 2013; Athalye et al., 2018), since most state-of-the-arts deep neural networks are found to be very vulnerable against small but adversarial perturbations of the input points. In our experi- ments, we found that enlarging the normalized mar gin can improv e the robustness. In particular, by simply training the neural network for a longer time with our loss-based learning rate, we observ e noticeable improv ements of L 2 -robustness on both the training set and test set. W e first elaborate the relationship between the normalized margin and the robustness from a theo- retical perspectiv e. For a data point z = ( x , y ) , we can define the robustness (with respect to some norm k · k ) of a neural network Φ for z to be R θ ( z ) := inf x 0 ∈ X {k x − x 0 k : ( x 0 , y ) is misclassified } . where X is the data domain (which is [0 , 1] 32 × 32 for MNIST). It is well-known that the normalized margin is a lower bound of L 2 -robustness for fully-connected networks (See, e.g., Theorem 4 in (Sokolic et al., 2017)). Indeed, a general relationship between those two quantities can be easily shown. Note that a data point z is correctly classified iff the margin for z , denoted as q θ ( z ) , is larger than 0 . For homogeneous models, the margin q θ ( z ) and the normalized margin q ˆ θ ( z ) for x ha ve the same sign. If q ˆ θ ( · ) : R d x → R is β -Lipschitz (with respect to some norm k · k ), then it is easy to see that R θ ( z ) ≥ q ˆ θ ( z ) /β . This suggests that improving the normalize margin on the training set can improve the robustness on the training set. Therefore, our theoretical analysis suggests that training longer can improv e the robustness of the model on the training set. This observation does match with our experiment results. In the experiments, we measure the L 2 - robustness of the CNN without bias for the first time its loss decreases below 10 − 10 , 10 − 15 , 10 − 20 , 10 − 120 (labelled as model-1 to model-4 respectiv ely). W e also measure the L 2 -robustness for the final model after training for 10000 epochs (labelled as model-5 ), whose training loss is about 10 − 882 . The normalized margin of each model is monotone increasing with respect to the number of epochs, as shown in T able 1. 49 Published as a conference paper at ICLR 2020 0.0 0.2 0.4 0.6 90% 92% 94% 96% 98% 100% accuracy (train) 0 2 4 6 8 0% 20% 40% 60% 80% 100% 0.0 0.2 0.4 0.6 90% 92% 94% 96% 98% 100% accuracy (test) 0 2 4 6 8 0% 20% 40% 60% 80% 100% model-1 model-2 model-3 model-4 model-5 Figure 8: L 2 -robustness of the models of CNNs without bias trained for different number of epochs (see T able 1 for the statistics of each model). Figures on the first row show the robust accuracy on the training set, and figures on the second ro w sho w that on the test set. On e very row , the left figure and the right figure plot the same curves but they are in different scales. From model-1 to model-4 , noticeable robust accuracy improvements can be observed. The improvement of model-5 upon model-4 is marginal or nonexistent for some , but the improvement upon model-1 is always significant. T able 1: Statistics of the CNN without bias after training for different number of epochs. model name number of epochs train loss normalized margin train acc test acc model-1 38 10 − 10 . 04 5 . 65 × 10 − 5 100% 99 . 3% model-2 75 10 − 15 . 12 9 . 50 × 10 − 5 100% 99 . 3% model-3 107 10 − 20 . 07 1 . 30 × 10 − 4 100% 99 . 3% model-4 935 10 − 120 . 01 4 . 61 × 10 − 4 100% 99 . 2% model-5 10000 10 − 881 . 51 1 . 18 × 10 − 3 100% 99 . 1% W e use the standard method for ev aluating L 2 -robustness in (Carlini & W agner, 2017) and the source code from the authors with default hyperparameters 6 . W e plot the robust accuracy (the percentage of data with robustness > ) for the training set in the figures on the first row of Figure 8. It can be seen from the figures that for small (e.g., < 0 . 3 ), the relati ve order of robust accuracy is just the order of model-1 to model-5 . For relativ ely large (e.g., > 0 . 3 ), the improvement of model-5 upon model-2 to model-4 becomes marginal or nonexistent in certain intervals of , but model-1 to model-4 still hav e an increasing order of robust accuracy and the improvement of model-5 upon model-1 is always significant. This shows that training longer can help to improv e the L 2 -robust accurac y on the training set. W e also ev aluate the robustness on the test set, in which a misclassified test sample is considered to have robustness 0 , and plot the robust accuracy in the figures on the second ro w of Figure 8. It can be seen from the figures that for small (e.g., < 0 . 2 ), the curves of the robust accuracy of model-1 to model-5 are almost indistinguishable. Howe ver , for relati vely lar ge (e.g., > 0 . 2 ), again, model-1 to model-4 ha ve an increasing order of robust accurac y and the improvement of 6 https://github.com/carlini/nn_robust_attacks 50 Published as a conference paper at ICLR 2020 model-5 upon model-1 is always significant. This shows that training longer can also help to improv e the L 2 -robust accurac y on the test set. W e tried various different settings of hyperparameters for the ev aluation method (including different learning rates, different binary search steps, etc.) and we observed that the shapes and relativ e positions of the curves in Figure 8 are stable across dif ferent hyperparameter settings. It is worth to note that the normalized margin and robustness do not grow in the same speed in our experiments, although the theory suggests R θ ( z ) ≥ q ˆ θ ( z ) /β . This may be because the Lipschitz constant β (if defined locally) is also changing during training. Combining training longer with existing techniques for constraining Lipschitz number (Anil et al., 2019; Cisse et al., 2017) could potentially alleviate this issue, and we lea ve it as a future work. L A D D I T I O NA L E X P E R I M E N T A L D E T A I L S In this section, we provide additional details of our e xperiments. L . 1 L O S S - B A S E D L E A R N I N G R AT E S C H E D U L I N G The intuition of the loss-based learning rate scheduling is as follows. If the training loss is α - smooth, then optimization theory suggests that we should set the learning rate to roughly 1 /α . For a homogeneous model with cross-entropy loss, if the training accuracy is 100% at θ , then a simple calculation can show that the smoothness (the L 2 -norm of the Hessian matrix) at θ is O ( ¯ L · p oly( ρ )) , where ¯ L is the average training loss and p oly( ρ ) is some polynomial. Motiv ated by this fact, we parameterize the learning rate η ( t ) at epoch t as η ( t ) := α ( t ) ¯ L ( t − 1) , (27) where ¯ L ( t − 1) is the average training loss at epoch t − 1 , and α ( t ) is a relativ e learning rate to be tuned (Similar parameterization has been considiered in (Nacson et al., 2019b) for linear model). The loss-based learning rate scheduling is indeed a v ariant of line search. In particular , we initialize α (0) by some v alue, and do the following at each epoch t : Step 1. Initially α ( t ) ← α ( t − 1) ; Let ¯ L ( t − 1) be the training loss at the end of the last epoch; Step 2. Run SGD through the whole training set with learning rate η ( t ) := α ( t ) / L ( t − 1) ; Step 3. Ev aluate the training loss ¯ L ( t ) on the whole training set; Step 4. If ¯ L ( t ) < ¯ L ( t − 1) , α ( t ) ← α ( t ) · r u and end this epoch; otherwise, α ( t ) ← α ( t ) /r d and go to Step 2. In all our experiments, we set α (0) := 0 . 1 , r u := 2 1 / 5 ≈ 1 . 149 , r d := 2 1 / 10 ≈ 1 . 072 . This specific choice of those hyperparameters is not important; other choices can only affact the computational efficienc y , but not the o verall tendency of normalized margin. L . 2 A D D R E S S I N G N U M E R I C A L I S S U E S Since we are dealing with extremely small loss (as small as 10 − 800 ), the current T ensorflow imple- mentation would run into numerical issues. T o address the issues, we work as follows. Let ¯ L B ( θ ) be the (average) training loss within a batch B ⊆ [ N ] . W e use the notations C , s nj , ˜ q n , q n from Appendix G. W e only need to show ho w to perform forward and backward passes for ¯ L B ( θ ) . Forward P ass. Suppose we have a good estimate e F for log ¯ L B ( θ ) in the sense that R B ( θ ) := ¯ L B ( θ ) e − e F = 1 B X n ∈ B log 1 + X j 6 = y n e − s nj ( θ ) e − e F (28) is in the range of float64 . R B ( θ ) can be thought of a relative training loss with respect to e F . Instead of ev aluating the training loss ¯ L B ( θ ) directly , we turn to ev aluate this relative training loss in a numerically stable way: 51 Published as a conference paper at ICLR 2020 Step 1. Perform forward pass to compute the v alues of s nj with float32 , and conv ert them into float64 ; Step 2. Let Q := 30 . If q n ( θ ) > Q for all n ∈ B , then we compute R B ( θ ) = 1 B X n ∈ B e − ( ˜ q n ( θ )+ e F ) , where ˜ q n ( θ ) := − LSE( {− s nj : j 6 = y n } ) = − log P j 6 = y n e − s nj is e v aluated in a numerically stable way; otherwise, we compute R B ( θ ) = 1 B X n ∈ B log1p X j 6 = y n e − s nj ( θ ) e − e F , where log1p( x ) is a numerical stable implementation of log (1 + x ) . This algorithm can be explained as follows. Step 1 is numerically stable because we observe from the experiments that the layer weights and layer outputs grow slowly . Now we consider Step 2. If q n ( θ ) ≤ Q for some n ∈ [ B ] , then ¯ L B ( θ ) = Ω( e − Q ) is in the range of float64 , so we can compute R B ( θ ) by (28) directly except that we need to use a numerical stable implementation of log(1 + x ) . For q n ( θ ) > Q , arithmetic underflo w can occur . By T aylor e xpansion of log(1 + x ) , we know that when x is small enough log (1 + x ) ≈ x in the sense that the relati ve error | log(1+ x ) − x | log(1+ x ) = O ( x ) . Thus, we can do the follo wing approximation log 1 + X j 6 = y n e − s nj ( θ ) e − e F ≈ X j 6 = y n e − s nj ( θ ) · e − e F (29) for q n ( θ ) > Q , and only introduce a relative error of O ( C e − Q ) (recall that C is the number of classes). Using a numerical stable implementation of LSE , we can compute ˜ q n easily . Then the RHS of (29) can be rewritten as e − ( ˜ q n ( θ )+ e F ) . Note that computing e − ( ˜ q n ( θ )+ e F ) does not hav e underflow or o verflow problems if e F is a good approximation for log ¯ L B ( θ ) . Backward Pass. T o perform backward pass, we build a computation graph in T ensorflow for the abov e forward pass for the relative training loss and use the automatic differentiation. W e parame- terize the learning rate as η = ˆ η · e e F . Then it is easy to see that taking a step of gradient descent for L B ( θ ) with learning rate η is equivalent to taking a step for R B ( θ ) with ˆ η . Thus, as long as ˆ η can fit into float64 , we can perform gradient descent on R B ( θ ) to ensure numerical stability . The Choice of e F . The only question remains is how to choose e F . In our experiments, we set e F ( t ) := log ¯ L ( t − 1) to be the training loss at the end of the last epoch, since the training loss cannot change a lot within one single epoch. For this, we need to maintain log ¯ L ( t ) during training. This can be done as follows: after e valuating the relative training loss R ( t ) on the whole training set, we can obtain log ¯ L ( t ) by adding e F ( t ) and log R ( t ) together . It is worth noting that with this choice of e F , ˆ η ( t ) = α ( t ) in the loss-based learning rate scheduling. As shown in the right figure of Figure 4, α ( t ) is alw ays between 10 − 9 and 10 0 , which ensures the numerical stability of backward pass. 52
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment