대규모 음성 인식 데이터셋 VoxCeleb2와 CNN 기반 스피커 임베딩
본 논문은 공개된 미디어에서 자동으로 수집한 6천 명 이상의 화자를 포함하는 100만 개 이상의 발화를 담은 대규모 음성‑시각 데이터셋 VoxCeleb2를 소개하고, 이를 활용한 CNN 기반 스피커 임베딩 모델(VGG‑Vox)을 제안한다. ResNet‑34/50 구조와 contrastive loss, hard‑negative mining을 결합한 학습 전략을 통해 기존 벤치마크(VoxCeleb1)에서 크게 향상된 EER 및 C_det 성능을 달…
저자: Joon Son Chung, Arsha Nagrani, Andrew Zisserman
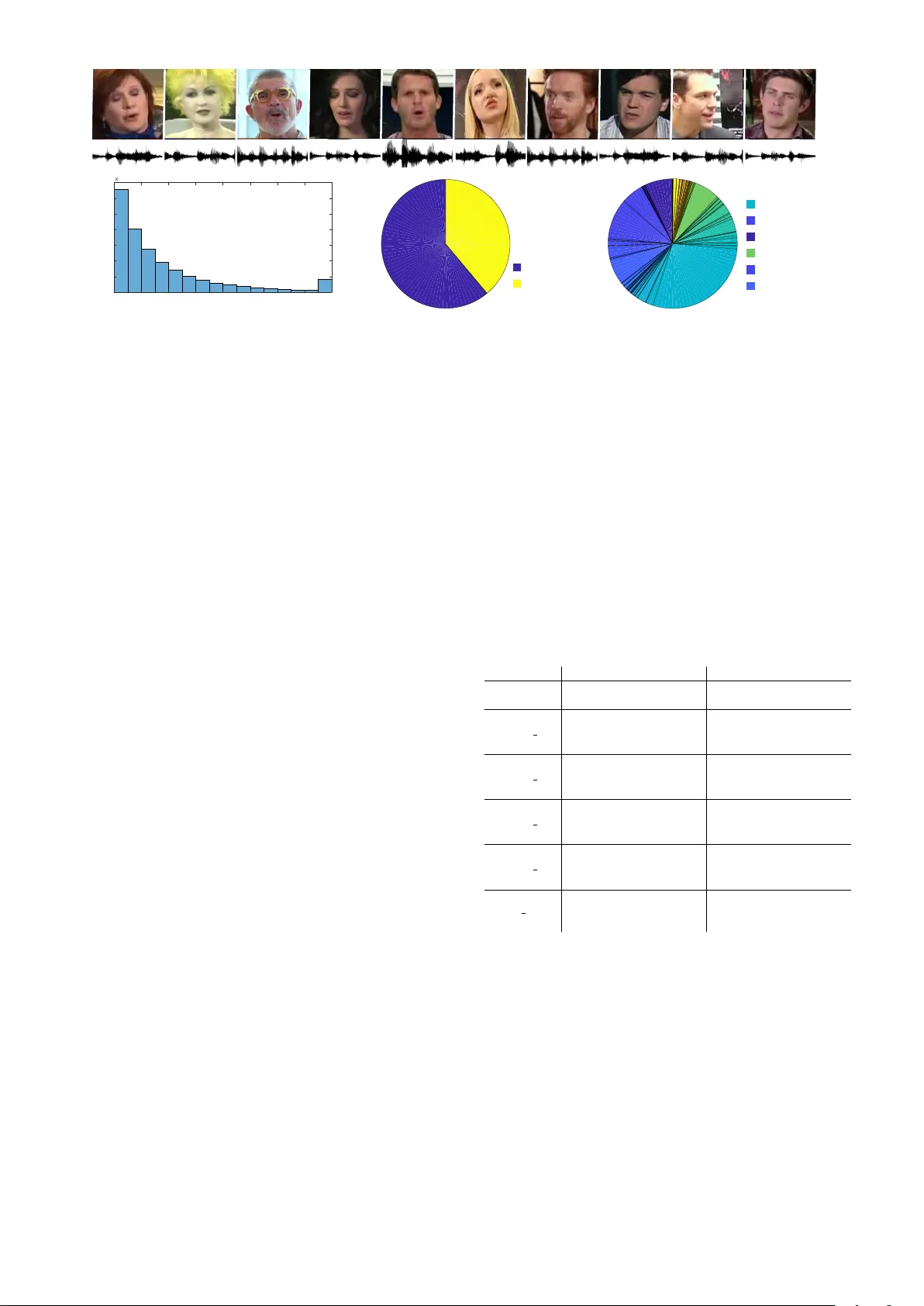
본 논문은 “VoxCeleb2: Deep Speaker Recognition”이라는 제목 아래, 대규모 음성‑시각 데이터셋 구축과 이를 활용한 최신 CNN 기반 스피커 임베딩 모델을 종합적으로 제시한다. 먼저, 기존 공개 데이터셋(VoxCeleb1, SITW 등)이 규모·다양성·자유 접근성 측면에서 한계를 보이는 점을 지적하고, 이를 극복하기 위해 자동화된 파이프라인을 설계하였다. 파이프라인은 7개의 핵심 단계로 이루어지며, POI(Person of Interest) 후보를 VGGFace2에서 추출해 9,000명 이상을 확보한다. 이후 YouTube 검색 시 ‘interview’ 키워드를 추가해 각 POI당 상위 100개의 영상을 자동 다운로드하고, SSD 기반 얼굴 검출기로 프레임별 얼굴을 탐지한다. 검출된 얼굴은 ROI‑overlap 트래커로 연결해 얼굴 트랙을 생성하고, ResNet‑50 기반 얼굴 인증 모델을 통해 해당 트랙이 목표 인물인지 판별한다. 활성 화자 검증 단계에서는 다중 뷰 SyncNet을 적용해 음성 신호와 입 움직임의 상관관계를 분석, 더빙·음성‑오버 영상 등을 배제한다. 중복 제거는 기존 VoxCeleb1에서 사용한 1024‑D 임베딩을 활용해 유클리드 거리 0.1 이하인 경우를 삭제함으로써 정확히 동일하거나 거의 동일한 발화를 제거한다. 마지막으로 위키피디아에서 국적 정보를 크롤링해 145개 국가 라벨을 부여, 다국어·다문화 특성을 강화하였다. 전체 데이터는 6,112명의 화자, 1,128,246개의 발화, 총 2,442시간에 달한다(표 1, 표 2 참고).
데이터셋 구축 후, 저자들은 VGG‑Vox라는 스피커 임베딩 시스템을 설계한다. 입력은 원시 오디오에서 추출한 단시간 magnitude 스펙트로그램이며, 전처리 없이 바로 CNN에 투입한다. 트렁크 네트워크로는 기존 VGG‑M을 변형한 경량형 구조와, ResNet‑34·ResNet‑50 두 가지를 사용한다. ResNet 구조는 2D 컨볼루션 레이어와 skip‑connection을 유지하면서, 스펙트로그램 특성에 맞게 필터 크기와 스트라이드를 조정하였다. 마지막 컨볼루션 뒤에는 시간 축 평균 풀링을 적용해 고정 차원의 512‑D 임베딩을 얻는다.
학습은 두 단계로 진행된다. 첫 단계에서는 화자 식별을 목표로 softmax + cross‑entropy 손실을 사용해 사전 학습한다. 이는 대규모 데이터에서 안정적인 수렴을 돕고, 초기 가중치를 좋은 상태로 만든다. 두 번째 단계에서는 contrastive loss를 적용해 임베딩 공간을 직접 최적화한다. 이때, 데이터 규모가 크므로 모든 가능한 쌍을 사용하기 어렵다. 따라서 오프라인 hard‑negative mining을 도입해 무작위로 생성된 쌍 중 거리 상위 1%에 해당하는 어려운 부정 쌍을 선택한다. 긍정 쌍은 라벨 오류 위험이 커서 마이닝하지 않는다. 학습 과정에서 배치 정규화와 ReLU를 적절히 배치해 학습 안정성을 확보하였다.
평가에서는 VoxCeleb1 테스트 셋을 사용했으며, 두 가지 지표인 Equal Error Rate(EER)와 비용 함수 C_det(목표 사전 확률 0.01, 비용 가중치 1)을 보고한다. ResNet‑50 기반 VGG‑Vox는 기존 최첨단 모델 대비 EER을 약 30% 이상 낮추고, C_det에서도 유의미한 개선을 보였다. 또한 전체 VoxCeleb1을 활용한 새로운 검증 프로토콜을 제시해, 모델이 전체 데이터에 대해 얼마나 일반화되는지를 추가로 검증하였다.
논문의 주요 기여는 다음과 같다. (1) 6천 명 이상의 화자를 포함하고 5배 이상 규모가 확대된 VoxCeleb2 데이터셋 공개, 특히 다국어·다문화·다양한 환경 소음이 포함된 ‘in‑the‑wild’ 특성. (2) 스펙트로그램 입력에 최적화된 ResNet‑34/50 기반 트렁크와 contrastive loss + hard‑negative mining을 결합한 학습 전략 제안. (3) VoxCeleb1 벤치마크에서 기존 최고 성능을 크게 뛰어넘는 결과 달성. (4) 전체 VoxCeleb1을 이용한 새로운 검증 셋을 제시해 향후 연구에 표준 평가 기준 제공. 한편, 자동 라벨링 과정에서 발생할 수 있는 소량의 오류와, 영상 기반 라벨링에 의존함에 따라 순수 오디오 데이터와의 도메인 차이가 존재한다는 한계가 있다. 향후 연구에서는 라벨 정제, 다양한 잡음·채널 조건에 대한 강인성 평가, 그리고 음성‑시각 멀티모달 학습을 통한 상호 보완 모델 개발이 기대된다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기