VoxCeleb2: Deep Speaker Recognition
The objective of this paper is speaker recognition under noisy and unconstrained conditions. We make two key contributions. First, we introduce a very large-scale audio-visual speaker recognition dataset collected from open-source media. Using a fu…
Authors: Joon Son Chung, Arsha Nagrani, Andrew Zisserman
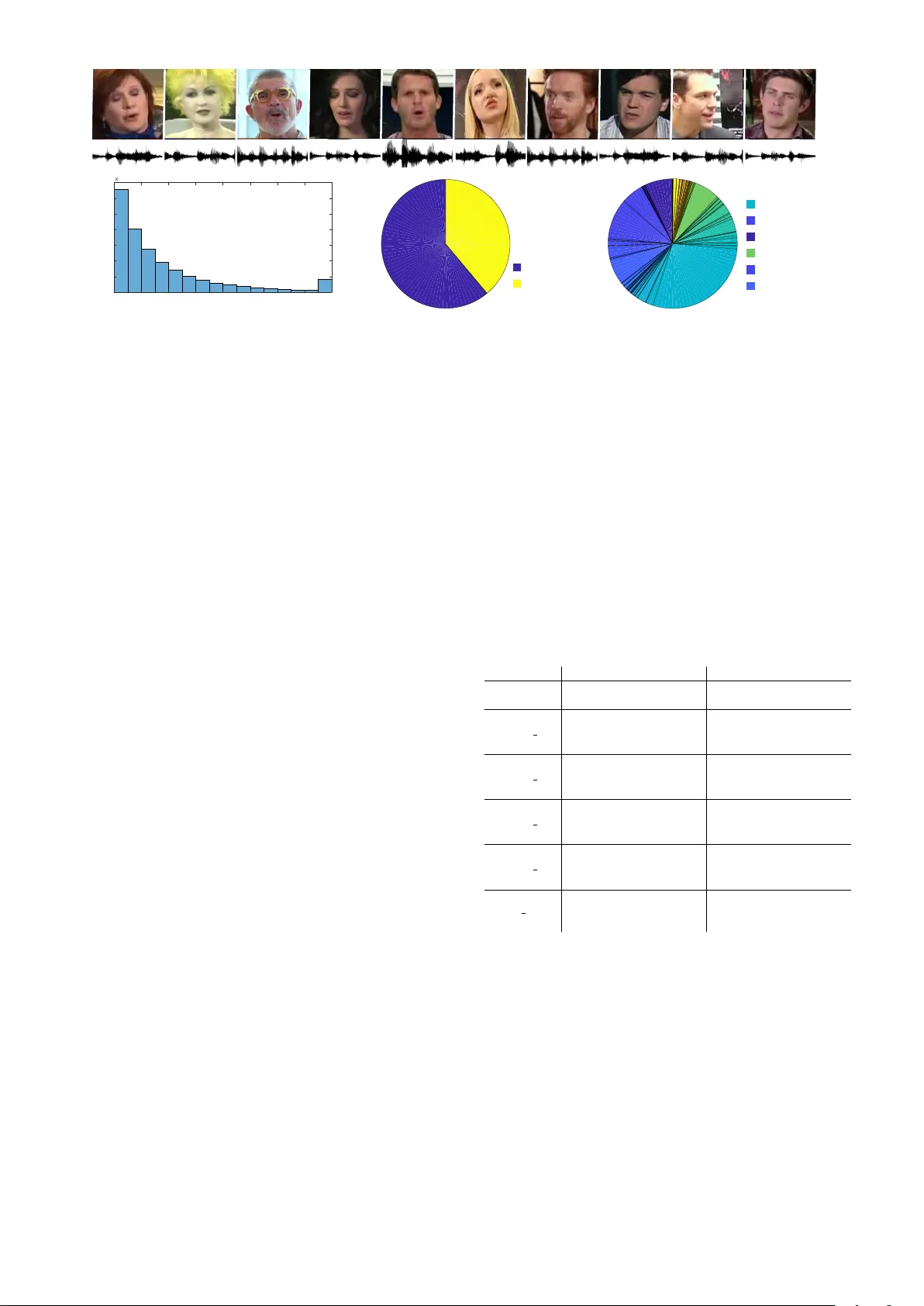
V oxCeleb2: Deep Speaker Recognition J oon Son Chung † , Arsha Nagr ani † , Andr e w Zisserman V isual Geometry Group, Department of Engineering Science, Uni versity of Oxford, UK { joon,arsha,az } @robots.ox.ac.uk Abstract The objectiv e of this paper is speaker recognition under noisy and unconstrained conditions. W e make two key contrib utions. First, we introduce a very large-scale audio-visual speaker recognition dataset collected from open-source media. Using a fully automated pipeline, we curate VoxCeleb2 which contains o ver a million utterances from over 6,000 speakers. This is several times larger than any publicly av ailable speaker recognition dataset. Second, we dev elop and compare Con v olutional Neural Network (CNN) models and training strategies that can effec- tiv ely recognise identities from voice under various conditions. The models trained on the VoxCeleb2 dataset surpass the performance of previous works on a benchmark dataset by a significant margin. Index T erms : speaker identification, speaker verification, large-scale, dataset, con volutional neural network 1. Introduction Despite recent advances in the field of speaker recognition, pro- ducing single, compact representations for speak er segments that can be used efficiently under noisy and unconstrained con- ditions is still a significant challenge. In this paper , we present a deep CNN based neural speaker embedding system, named VGGV ox, trained to map voice spectrograms to a compact Eu- clidean space where distances directly correspond to a measure of speaker similarity . Once such a space has been produced, other tasks such as speak er verification, clustering and diarisa- tion can be straightforw ardly implemented using standard tech- niques, with our embeddings as features. Such a mapping has been learnt ef fecti vely for face images, through the use of deep CNN architectures [1, 2, 3] trained on large-scale face datasets [4, 5, 6]. Unfortunately , speaker recog- nition still faces a dearth of large-scale freely a v ailable datasets in the wild. VoxCeleb1 [7] and SITW [8] are valuable con- tributions, ho wev er they are still an order of magnitude smaller than popular face datasets, which contain millions of images. T o address this issue we curate VoxCeleb2 , a large scale speaker recognition dataset obtained automatically from open-source media. VoxCeleb2 consists of over a million utterances from ov er 6k speakers. Since the dataset is collected ‘in the wild’, the speech segments are corrupted with real world noise including laughter , cross-talk, channel ef fects, music and other sounds. The dataset is also multilingual, with speech from speak ers of 145 different nationalities, covering a wide range of accents, ages, ethnicities and languages. The dataset is audio-visual, so is also useful for a number of other applications, for example – visual speech synthesis [9, 10], speech separation [11, 12], † These authors contributed equally to this work. cross-modal transfer from f ace to voice or vice versa [13, 14] and training face recognition from video to complement exist- ing face recognition datasets [4, 5, 6]. Both audio and video for the dataset will be released. W e train VGGV ox on this dataset in order to learn speaker discriminativ e embeddings. Our system consists of three main variable parts: an underlying deep CNN trunk architecture, which is used to extract the features, a pooling method which is used to aggregate features to provide a single embedding for a given utterance, and a pairwise loss trained on the features to directly optimise the mapping itself. W e experiment with both VGG-M [15] and ResNet [16] based trunk CNN architectures. W e make the follo wing four contributions: (i) we curate and release a large-scale dataset which is significantly larger than any other speaker verification dataset. It also addresses a lack of ethnic div ersity in the VoxCeleb1 dataset (section 3); (ii) we propose deep ResNet-based architectures for speaker em- bedding suitable for spectrogram inputs (section 4); (iii) we beat the current state of the art for speaker verification on the VoxCeleb1 test set using our embeddings (section 5); and (iv) we propose and ev aluate on a new verification benchmark test set which in volv es the entire VoxCeleb1 dataset. The VoxCeleb2 dataset can be downloaded from http: //www.robots.ox.ac.uk/ ˜ vgg/data/voxceleb2 . 2. Related works T raditional methods. T raditionally , the field of speaker recog- nition has been dominated by i-vectors [17], classified us- ing techniques such as heavy-tailed PLD A [18] and Gauss- PLD A [19]. While defining the state-of-the-art for a long time, such methods are disadvantaged by their reliance on hand- crafted feature engineering. An in-depth revie w of these tra- ditional methods is giv en in [20]. Deep learning methods. The success of deep learning in com- puter vision and speech recognition has motivated the use of deep neural networks (DNN) as feature extractors combined with classifiers, though not trained end-to-end [21, 22, 23, 24, 25]. While such fusion methods are highly ef fecti ve, they still require hand-crafted engineering. In contrast, CNN architec- tures can be applied directly to raw spectrograms and trained in an end-to-end manner . For example, [26] uses a Siamese feed- forward DNN to discriminati vely compare two v oices, ho we ver this relies on pre-computed MFCC features, whilst [27] also learns the features instead of using MFCCs. The most relev ant to our w ork is [28], who train a neural embedding system us- ing the triplet loss. Ho wev er , they use priv ate internal datasets for both training and ev aluation, and hence a direct comparison with their work is not possible. Datasets. Existing speaker recognition datasets usually suffer from one or more of the follo wing limitations: (i) the y are ei- Dataset V oxCeleb1 V oxCeleb2 # of POIs 1,251 6,112 # of male POIs 690 3,761 # of videos 22,496 150,480 # of hours 352 2,442 # of utterances 153,516 1,128,246 A vg # of videos per POI 18 25 A vg # of utterances per POI 116 185 A vg length of utterances (s) 8.2 7.8 T able 1: Dataset statistics for both VoxCeleb1 and VoxCeleb2 . Note VoxCeleb2 is mor e than 5 times lar ger than VoxCeleb1 . POI: P erson of Interest. Dataset Dev T est T otal # of POIs 5,994 118 6,112 # of videos 145,569 4,911 150,480 # of utterances 1,092,009 36,237 1,128,246 T able 2: Development and test set split. ther obtained under controlled conditions (e.g., from telephone calls [29, 30] or acoustic laboratories [31, 32, 33]), (ii) they are manually annotated and hence limited in size [8], or (iii) not freely av ailable to the speaker community [34, 33] (see [7] for a full revie w of existing datasets). In contrast, the VoxCeleb2 dataset does not suffer from an y of these limitations. 3. The VoxCeleb2 Dataset 3.1. Description VoxCeleb2 contains over 1 million utterances for over 6,000 celebrities, extracted from videos uploaded to Y ouT ube. The dataset is fairly gender balanced, with 61% of the speakers male. The speakers span a wide range of dif ferent ethnicities, accents, professions and ages. V ideos included in the dataset are shot in a large number of challenging visual and auditory en vironments. These include intervie ws from red carpets, out- door stadiums and quiet indoor studios, speeches given to lar ge audiences, excerpts from professionally shot multimedia, and ev en crude videos shot on hand-held devices. Audio segments present in the dataset are degraded with background chatter, laughter , overlapping speech and v arying room acoustics. W e also provide face detections and face-tracks for the speakers in the dataset, and the face images are similarly ‘in the wild’, with variations in pose (including profiles), lighting, image quality and motion blur . T able 1 gi ves the general statistics, and Fig- ure 1 sho ws examples of cropped f aces as well as utterance length, gender and nationality distributions. The dataset contains both de velopment (train/val) and test sets. Ho wev er , since we use the VoxCeleb1 dataset for test- ing, only the dev elopment set will be used for the speaker recog- nition task (Sections 4 and 5). The V oxCeleb2 test set should prov e useful for other applications of audio-visual learning for which the dataset might be used. The split is given in T able 2. The de velopment set of VoxCeleb2 has no ov erlap with the identities in the VoxCeleb1 or SITW datasets. 3.2. Collection Pipeline W e use an automatic computer vision pipeline to cu- rate VoxCeleb2 . While the pipeline is similar to that used to compile VoxCeleb1 [7], the details hav e been modified to in- crease efficiency and allow talking faces to be recognised from multiple poses, not only near -frontal. In fact, we change the im- plementation of every key component of the pipeline: the face detector , the face track er , the SyncNet model used to perform activ e speaker v erification, and the final face recognition model at the end. W e also add an additional step for automatic dupli- cate removal. This pipeline allows us to obtain a dataset that is fiv e times the size of [7]. W e also note that the list of celebrity names spans a wider range of nationalities, and hence unlike [7], the dataset obtained is multi-lingual. For the sake of clarity , the key stages are discussed in the follo wing paragraphs: Stage 1. Candidate list of Persons of Interest (POIs). The first stage is to obtain a list of POIs. W e start from the list of peo- ple that appear in the V GGFace2 dataset [4], which has consid- erable ethnic di versity and di versity in profession. This list con- tains ov er 9,000 identities, ranging from actors and sportspeople to politicians. Identities that ov erlap with those of VoxCeleb1 and SITW are remov ed from the dev elopment set. Stage 2. Downloading videos. The top 100 videos for each of the POIs are automatically downloaded using Y ouTube search. The word ‘interview’ is appended to the name of the POI in search queries to increase the likelihood that the videos contain an instance of the POI speaking, as opposed to sports or music videos. Stage 3. Face tracking. The CNN face detector based on the Single Shot MultiBox Detector (SSD) [35] is used to detect face appearances on e very frame of the video. This detector is a dis- tinct improvement from that used in [7], allowing the detection of faces in profile and extreme poses. W e used the same tracker as [7] based on R OI ov erlap. Stage 4. F ace verification. A face recognition CNN is used to classify the face tracks into whether they are of the POI or not. The classification network used here is based on the ResNet- 50 [16] trained on the V GGFace2 dataset. V erification is done by directly using this classification score. Stage 5. Active speaker verification. The goal of this stage is to determine if the visible face is the speaker . This is done by using a multi-view adaptation [36] of ‘SyncNet’ [37, 38], a tw o- stream CNN which determines the acti ve speaker by estimating the correlation between the audio track and the mouth motion of the video. The method can reject clips that contain dubbing or voice-o ver . Stage 6. Duplicate removal. A ca veat of using Y ouTube as a source for videos is that often the same video (or a section of a video) can be uploaded twice, albeit with different URLs. Duplicates are identified and removed as follows: each speech segment is represented by a 1024D vector using the model in [7] as a feature e xtractor . The Euclidean distance is computed be- tween all pairs of features from the same speak er . If any two speech segments have a distance smaller than a very conserva- tiv e threshold (of 0 . 1 ), then the the speech se gments are deemed to be identical, and one is removed. This method will certainly identify all exact duplicates, and in practice we find that it also succeeds in identifying near-duplicates, e.g. speech segments of the same source that are differently trimmed. Stage 7. Obtaining nationality labels. Nationality labels are crawled from W ikipedia for all the celebrities in the dataset. W e crawl for country of citizenship , and not ethnicity , as this is often more indicative of accent. In total, nationality labels are obtained for all but 428 speakers, who were labelled as un- known. Speakers in the dataset were found to hail from 145 nationalities (compared to 36 for VoxCeleb1 ), yielding a far more ethnically di verse dataset (See Figure 1 (bottom, right) for the distrib ution of nationalities). Note also the percentage of U.S. speakers is smaller in VoxCeleb2 ( 29% ) compared to VoxCeleb1 ( 64% ) where it dominates. Discussion. In order to ensure that our system is extremely confident that a person has been correctly identified (Stage 4), 4 6 8 10 12 14 16 18 20 Length (sec) 0 0.5 1 1.5 2 2.5 3 3.5 Frequency 10 5 29% 6 % 10 % 7 % 6 % 6 % 61% 39 % U. S . A. U. K . U n k n ow n G e r m an y In d i a F r an c e M al e F e m al e 4 6 8 10 12 14 16 18 20 Length (sec) 0 0.5 1 1.5 2 2.5 3 3.5 Frequency 10 5 29% 6% 10% 7% 6% 6% 61% 39% U.S .A. U.K . Un known Ger man y Indi a Fr ance Male Female Figure 1: T op row : Examples fr om the V oxCeleb2 dataset. W e show cropped faces of some of the speakers in the dataset. Both audio and face detections ar e pr ovided. Bottom r ow : (left) distrib ution of utterance lengths in the dataset – lengths shorter than 20 s ar e binned in 1 s intervals and all utterances of 20 s + ar e binned to gether; (middle) gender distribution and (right) nationality distrib ution of speaker s. F or r eadability , the percentag e fr equencies of only the top-5 nationalities ar e shown. Best viewed zoomed in and in colour . and that are speaking (Stage 5) without any manual interfer- ence, we set conservati ve thresholds in order to minimise the number of false positiv es. Since VoxCeleb2 is designed pri- marily as a training-only dataset, the thresholds are less strict compared to those used to compile VoxCeleb1 , so that fewer videos are discarded. Despite this, we have only found v ery few label errors after manual inspection of a significant subset of the dataset. 4. V GGV ox In this section we describe our neural embedding system, called VGGV ox. The system is trained on short-term magnitude spec- trograms extracted directly from raw audio segments, with no other pre-processing. A deep neural network trunk architecture is used to extract frame le vel features, which are pooled to ob- tain utterance-level speaker embeddings. The entire model is then trained using contrastiv e loss. Pre-training using a soft- max layer and cross-entropy ov er a fixed list of speakers im- prov es model performance; hence we pre-train the trunk archi- tecture model for the task of identification first. 4.1. Evaluation The model is trained on the VoxCeleb2 dataset. At train time, pairs are sampled on-line using the method described in Section 4.3. The testing is done on the VoxCeleb1 dataset, with the test pairs provided in that dataset. W e report tw o performance metrics: (i) the Equal Error Rate (EER) which is the rate at which both acceptance and re- jection errors are equal; and (ii) the cost function C det = C miss × P miss × P tar + C f a × P f a × (1 − P tar ) (1) where we assume a prior target probability P tar of 0.01 and equal weights of 1.0 between misses C miss and false alarms C f a . Both metrics are commonly used for e v aluating identity verification systems. 4.2. T runk architectures V GG-M: The baseline trunk architecture is the CNN intro- duced in [7]. This architecture is a modification of the VGG- M [15] CNN, known for high efficiency and good classification performance on image data. In particular , the fully connected fc6 layer from the original VGG-M is replaced by two layers – a fully connected layer of 9 × 1 (support in the frequency do- main), and an a verage pool layer with support 1 × n , where n depends on the length of the input speech segment (for example for a 3 second segment, n = 8 ). The benefit of this modification is that the network becomes in variant to temporal position but not frequenc y , which is desirable for speech, b ut not for images. It also helps to keep the output dimensions the same as those of the original fully connected layer, and reduces the number of network parameters by fi vefold. ResNets: The residual-network (ResNet) architecture [16] is similar to a standard multi-layer CNN, b ut with added skip con- nections such that the layers add residuals to an identity map- ping on the channel outputs. W e experiment with both ResNet- 34 and ResNet-50 architectures, and modify the layers to adapt to the spectrogram input. W e apply batch normalisation before computing rectified linear unit (ReLU) acti v ations. The archi- tectures are specified in T able 3. layer name res-34 res-50 con v1 7 × 7 , 64 , stride 2 7 × 7 , 64 , stride 2 pool1 3 × 3 , max pool, stride 2 3 × 3 , max pool, stride 2 con v2 x 3 × 3 , 64 3 × 3 , 64 × 3 1 × 1 , 64 3 × 3 , 64 1 × 1 , 256 × 3 con v3 x 3 × 3 , 128 3 × 3 , 128 × 4 1 × 1 , 128 3 × 3 , 128 1 × 1 , 512 × 4 con v4 x 3 × 3 , 256 3 × 3 , 256 × 6 1 × 1 , 256 3 × 3 , 256 1 × 1 , 1024 × 6 con v5 x 3 × 3 , 512 3 × 3 , 512 × 3 1 × 1 , 512 3 × 3 , 512 1 × 1 , 2048 × 3 fc1 9 × 1 , 512, stride 1 9 × 1 , 2048, stride 1 pool time 1 × N , avg pool, stride 1 1 × N , avg pool, stride 1 fc2 1 × 1 , 5994 1 × 1 , 5994 T able 3: Modified Res-34 and Res-50 ar c hitectur es with aver- age pool layer at the end. ReLU and batchnorm layers are not shown. Each r ow specifies the number of con volutional filters and their sizes as size × size, # filters . 4.3. T raining Loss strategies W e employ a contrastive loss [39, 40] on paired embeddings, which seeks to minimise the distance between the embeddings of positiv e pairs and penalises the negati ve pair distances for being smaller than a mar gin parameter α . Pair-wise losses such as the contrasti ve loss are notoriously difficult to train [41], and hence to av oid suboptimal local minima early on in training, we proceed in two stages: first, pre-training for identifcation using a softmax loss, then, second, fine-tuning with the contrastive loss. Pre-training for identification: Our first strategy is to use soft- max pre-training to initialise the weights of the netw ork. The cross entropy loss produces more stable con ver gence than the contrastiv e loss, possibly because softmax training is not im- pacted by the difficulty of pairs when using the contrasti v e loss. T o e v aluate the identification performance, we create a held-out validation test which consists of all the speech se gments from a single video for each identity . Learning an embedding with contrastive loss – hard nega- tive mining: W e take the model pre-trained on the identifica- tion task, and replace the 5994-w ay classification layer with a fully connected layer of output dimension 512. This network is trained with contrastiv e loss. A key challenge associated with learning embeddings via the contrastiv e loss is that as the dataset gets larger , the number of possible pairs grows quadratically . In such a scenario, the network rapidly learns to correctly map the easy examples, and hard negativ e mining is often required to improve performance to provide the network with a more useful learning signal. W e use an of fline hard neg ativ e mining strategy , which allo ws us to select harder negati ves ( e.g. top 1-percent of randomly gener - ated pairs) than is possible with online (in-batch) hard negati ve mining methods [42, 41, 43] limited by the batch size. W e do not mine hard positives, since false positiv e pairs are much more likely to occur than false negati ve pairs in a random sample (due to possible label noise on the face verification), and these label errors will lead to poor learning dynamics. 4.4. T est time augmentation [7] use av erage pooling at test time by ev aluating the entire test utterance at once by changing the size of the apool6 layer . Here, we experiment with different augmentation protocols for e v alu- ating the performance at test time. W e propose three methods: (1) Baseline: variable av erage pooling as described in [7]; (2) Sample ten 3-second temporal crops from each test segment, and use the mean of the features; (3) Sample ten 3-second temporal crops from each test segment, compute the distances between the ev ery possible pair of crops ( 10 × 10 = 100 ) from the two speech se gments, and use the mean of the 100 distances. The method results in a marginal improv ement in performance, as shown in T able 4. 4.5. Implementation Details Input features. Spectrograms are computed from raw audio in a sliding window fashion using a hamming window of width 25ms and step 10ms, in exactly the same manner as [7]. This giv es spectrograms of size 512 x 300 for 3 seconds of speech. Mean and variance normalisation is performed on every fre- quency bin of the spectrum. T raining. During training, we randomly sample 3-second seg- ments from each utterance. Our implementation is based on the deep learning toolbox MatCon vNet [44]. Each network is trained on three Titan X GPUs for 30 epochs or until the validation error stops decreasing, whiche ver is sooner , using a batch-size of 64 . W e use SGD with momentum ( 0 . 9 ), weight decay ( 5 E − 4 ) and a logarithmically decaying learning rate (initialised to 10 − 2 and decaying to 10 − 8 ). 5. Results Original VoxCeleb1 test set. T able 4 provides the perfor- mance of our models on the original VoxCeleb1 test set. As might be expected, performance improves with greater net- work depth, and also with more training data ( VoxCeleb2 vs VoxCeleb1 ). This also demonstrates that VoxCeleb2 pro- vides a suitable training regime for use on other datasets. Models T rained on C min det EER (%) I-vectors + PLD A (1) [7] VoxCeleb1 0.73 8.8 VGG-M (Softmax) [7] VoxCeleb1 0.75 10.2 VGG-M (1) [7] VoxCeleb1 0.71 7.8 VGG-M (1) VoxCeleb2 0.609 5.94 ResNet-34 (1) VoxCeleb2 0.543 5.04 ResNet-34 (2) VoxCeleb2 0.553 5.11 ResNet-34 (3) VoxCeleb2 0.549 4.83 ResNet-50 (1) VoxCeleb2 0.449 4.19 ResNet-50 (2) VoxCeleb2 0.454 4.43 ResNet-50 (3) VoxCeleb2 0.429 3.95 T able 4: Results for verification on the original VoxCeleb1 test set (lower is better). The number in brackets r efer to the test time augmentation methods described in Section 4.4. New VoxCeleb1-E test set – using the entire dataset. Pop- ular speake r v erification test sets in the wild [7, 8] are limited in the number of speakers. This yields the possible danger of optimising performance to overfit the small number of speak- ers in the test set, and results are not always indicative of good generalised performance. Hence we propose a new ev aluation protocol consisting of 581,480 random pairs sampled from the entire VoxCeleb1 dataset, cov ering 1,251 speakers, and set benchmark performance for this test set. The result is given in T able 5. New VoxCeleb1-H test set – within the same nationality and gender . By using the whole of VoxCeleb1 as a test set, we are able to test only on the pairs with same nationality and gender . W e propose a new e valuation list consisting of 552,536 pairs sampled from the VoxCeleb1 dataset, all of which are from the same nationality and gender . 18 nationality-gender combinations each with at least 5 individuals are used to gen- erate this list, of which ‘USA-Male’ is the most common. The result is giv en in T able 5. Models T ested on C min det EER (%) ResNet-50 (3) VoxCeleb1-E 0.524 4.42 ResNet-50 (3) VoxCeleb1-H 0.673 7.33 T able 5: Results for verification on the extended VoxCeleb1 test sets. 6. Conclusion In this paper , we ha ve introduced new architectures and training strategies for the task of speaker verification, and demonstrated state-of-the-art performance on the VoxCeleb1 dataset. Our learnt identity embeddings are compact ( 512 D ) and hence easy to store and useful for other tasks such as diarisation and re- triev al. W e have also introduced the VoxCeleb2 dataset, which is several times larger than any speaker recognition dataset, and hav e re-purposed the VoxCeleb1 dataset, so that the entire dataset of 1,251 speakers can be used as a test set for speaker verification. Choosing pairs from all speakers allows a better assessment of performance than from the 40 speakers of the original test set. W e hope that this ne w test set will be adopted, alongside SITW , as a standard for the speech commu- nity to ev aluate on. Acknowledgements. Funding for this research is pro vided by the EPSRC Programme Grant Seebibyte EP/M013774/1. 7. References [1] F . Schroff, D. Kalenichenko, and J. Philbin, “Facenet: A unified embedding for face recognition and clustering, ” in Pr oc. CVPR , 2015. [2] Y . T aigman, M. Y ang, M. Ranzato, and L. W olf, “Deepf ace: Clos- ing the gap to human-le vel performance in face verification, ” in Pr oceedings of the IEEE conference on computer vision and pat- tern r ecognition , 2014, pp. 1701–1708. [3] O. M. Parkhi, A. V edaldi, and A. Zisserman, “Deep face recogni- tion, ” in Proc. BMVC. , 2015. [4] Q. Cao, L. Shen, W . Xie, O. M. Parkhi, and A. Zisserman, “VG- GFace2: a dataset for recognising faces across pose and age, ” arXiv pr eprint arXiv:1710.08092 , 2017. [5] I. K emelmacher-Shlizerman, S. M. Seitz, D. Miller, and E. Brossard, “The megaface benchmark: 1 million faces for recog- nition at scale, ” in Pr oceedings of the IEEE Conference on Com- puter V ision and P attern Recognition , 2016, pp. 4873–4882. [6] Y . Guo, L. Zhang, Y . Hu, X. He, and J. Gao, “MS-Celeb-1M: A dataset and benchmark for large-scale f ace recognition, ” in Eu- r opean Conference on Computer V ision . Springer, 2016, pp. 87–102. [7] A. Nagrani, J. S. Chung, and A. Zisserman, “V oxCeleb: a large- scale speaker identification dataset, ” in INTERSPEECH , 2017. [8] M. McLaren, L. Ferrer , D. Castan, and A. Lawson, “The speak- ers in the wild (SITW) speaker recognition database, ” in INTER- SPEECH , 2016. [9] J. S. Chung, A. Jamaludin, and A. Zisserman, “Y ou said that?” in Pr oc. BMVC. , 2017. [10] T . Karras, T . Aila, S. Laine, A. Herv a, and J. Lehtinen, “ Audio- driv en facial animation by joint end-to-end learning of pose and emotion, ” ACM T ransactions on Graphics (TOG) , vol. 36, no. 4, p. 94, 2017. [11] T . Afouras, J. S. Chung, and A. Zisserman, “The con versation: Deep audio-visual speech enhancement, ” in , 2018. [12] A. Ephrat, I. Mosseri, O. Lang, T . Dekel, K. W ilson, A. Hassidim, W . T . Freeman, and M. Rubinstein, “Looking to listen at the cock- tail party: A speaker-independent audio-visual model for speech separation, ” arXiv preprint , 2018. [13] A. Nagrani, S. Albanie, and A. Zisserman, “Seeing voices and hearing faces: Cross-modal biometric matching, ” in IEEE Con- fer ence on Computer V ision and P attern Recognition , 2018. [14] A. Nagrani, S. Albanie, and A. Zisserman, “Learnable pins: Cross-modal embeddings for person identity , ” arXiv preprint arXiv:1805.00833 , 2018. [15] K. Chatfield, K. Simonyan, A. V edaldi, and A. Zisserman, “Re- turn of the devil in the details: Delving deep into conv olutional nets, ” in Proc. BMVC. , 2014. [16] K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition, ” arXiv preprint , 2015. [17] N. Dehak, P . J. Kenn y , R. Dehak, P . Dumouchel, and P . Ouellet, “Front-end factor analysis for speaker verification, ” IEEE T rans- actions on Audio, Speech, and Language Processing , vol. 19, no. 4, pp. 788–798, 2011. [18] P . Mat ˇ ejka, O. Glembek, F . Castaldo, M. J. Alam, O. Plchot, P . Kenny , L. Burget, and J. ˇ Cernocky , “Full-covariance ubm and heavy-tailed plda in i-vector speaker verification, ” in Acoustics, Speech and Signal Processing (ICASSP), 2011 IEEE Interna- tional Confer ence on . IEEE, 2011, pp. 4828–4831. [19] S. Cumani, O. Plchot, and P . Laface, “Probabilistic linear dis- criminant analysis of i-vector posterior distributions, ” in Acous- tics, Speec h and Signal Pr ocessing (ICASSP), 2013 IEEE Inter- national Confer ence on . IEEE, 2013, pp. 7644–7648. [20] J. H. Hansen and T . Hasan, “Speaker recognition by machines and humans: A tutorial revie w , ” IEEE Signal pr ocessing magazine , vol. 32, no. 6, pp. 74–99, 2015. [21] E. V ariani, X. Lei, E. McDermott, I. L. Moreno, and J. Gonzalez- Dominguez, “Deep neural networks for small footprint text- dependent speaker verification, ” in Acoustics, Speech and Signal Pr ocessing (ICASSP), 2014 IEEE International Conference on . IEEE, 2014, pp. 4052–4056. [22] Y . Lei, N. Scheffer , L. Ferrer, and M. McLaren, “ A novel scheme for speaker recognition using a phonetically-aware deep neural network, ” in Acoustics, Speech and Signal Pr ocessing (ICASSP), 2014 IEEE International Confer ence on . IEEE, 2014, pp. 1695– 1699. [23] S. H. Ghalehjegh and R. C. Rose, “Deep bottleneck features for i-v ector based text-independent speaker verification, ” in A u- tomatic Speec h Reco gnition and Understanding (ASR U), 2015 IEEE W orkshop on . IEEE, 2015, pp. 555–560. [24] D. Snyder , D. Garcia-Romero, D. Pov ey , and S. Khudanpur , “Deep neural network embeddings for text-independent speaker verification, ” Pr oc. Interspeech 2017 , pp. 999–1003, 2017. [25] D. Snyder , D. Garcia-Romero, G. Sell, D. Pove y , and S. Khudan- pur , “X-vectors: Robust dnn embeddings for speaker recognition, ” ICASSP , Calgary , 2018. [26] D. Chen, S. Tsai, V . Chandrasekhar, G. T akacs, H. Chen, R. V edantham, R. Grzeszczuk, and B. Girod, “Residual enhanced visual vectors for on-de vice image matching, ” in Asilomar , 2011. [27] S. H. Y ella, A. Stolcke, and M. Slaney , “ Artificial neural network features for speaker diarization, ” in Spoken Languag e T echnolo gy W orkshop (SLT), 2014 IEEE . IEEE, 2014, pp. 402–406. [28] C. Li, X. Ma, B. Jiang, X. Li, X. Zhang, X. Liu, Y . Cao, A. Kan- nan, and Z. Zhu, “Deep speaker: an end-to-end neural speaker embedding system, ” arXiv preprint , 2017. [29] D. van der Vloed, J. Bouten, and D. A. v an Leeuwen, “NFI- FRITS: a forensic speaker recognition database and some first ex- periments, ” in The Speaker and Language Recognition W orkshop , 2014. [30] J. Hennebert, H. Melin, D. Petrovska, and D. Genoud, “POL Y - COST : a telephone-speech database for speaker recognition, ” Speech communication , v ol. 31, no. 2, pp. 265–270, 2000. [31] J. B. Millar, J. P . V onwiller, J. M. Harrington, and P . J. Dermody , “The Australian national database of spoken language, ” in Pr oc. ICASSP , vol. 1. IEEE, 1994, pp. I–97. [32] J. S. Garofolo, L. F . Lamel, W . M. Fisher , J. G. Fiscus, and D. S. Pallett, “DARP A TIMIT acoustic-phonetic continous speech cor- pus CD-R OM. NIST speech disc 1-1.1, ” NASA STI/Recon techni- cal r eport , vol. 93, 1993. [33] W . M. Fisher , G. R. Doddington, and K. M. Goudie-Marshall, “The D ARP A speech recognition research database: specifica- tions and status, ” in Proc. DARP A W orkshop on speech reco gni- tion , 1986, pp. 93–99. [34] C. S. Greenberg, “The NIST year 2012 speaker recognition ev al- uation plan, ” NIST , T echnical Report , 2012. [35] W . Liu, D. Anguelov , D. Erhan, C. Szegedy , S. Reed, C.-Y . Fu, and A. C. Berg, “Ssd: Single shot multibox detector , ” in Pr oc. ECCV . Springer, 2016, pp. 21–37. [36] J. S. Chung and A. Zisserman, “Lip reading in profile, ” in Proc. BMVC. , 2017. [37] J. S. Chung and A. Zisserman, “Out of time: automated lip sync in the wild, ” in W orkshop on Multi-view Lip-r eading, A CCV , 2016. [38] J. S. Chung and A. Zisserman, “Learning to lip read words by watching videos, ” CVIU , 2018. [39] S. Chopra, R. Hadsell, and Y . LeCun, “Learning a similarity met- ric discriminatively , with application to face verification, ” in Proc. CVPR , vol. 1. IEEE, 2005, pp. 539–546. [40] R. Hadsell, S. Chopra, and Y . LeCun, “Dimensionality reduction by learning an in v ariant mapping, ” in CVPR , vol. 2. IEEE, 2006, pp. 1735–1742. [41] A. Hermans, L. Be yer , and B. Leibe, “In defense of the triplet loss for person re-identification, ” arXiv pr eprint arXiv:1703.07737 , 2017. [42] K.-K. Sung, “Learning and example selection for object and pat- tern detection, ” Ph.D. dissertation, 1996. [43] H. O. Song, Y . Xiang, S. Jegelka, and S. Savarese, “Deep metric learning via lifted structured feature embedding, ” in Computer V i- sion and P attern Recognition (CVPR), 2016 IEEE Conference on . IEEE, 2016, pp. 4004–4012. [44] A. V edaldi and K. Lenc, “Matconvnet – con volutional neural net- works for matlab, ” CoRR , vol. abs/1412.4564, 2014.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment