분산 비동기 환경에서 모멘텀을 제어하는 DANA 기법
본 논문은 비동기 분산 SGD에서 모멘텀 사용 시 발생하는 그래디언트 스테일리시 문제를 ‘갭(gap)’이라는 새로운 지표로 분석하고, Nesterov식 미래 파라미터 예측을 활용한 DANA‑Zero 알고리즘을 제안한다. 각 워커별 모멘텀 벡터를 유지·합산해 마스터가 예측 파라미터를 전송함으로써 갭을 크게 감소시키고, 대규모 클러스터(64 워커, 배치 16K)에서도 높은 최종 정확도와 빠른 수렴을 달성한다.
저자: Ido Hakimi, Saar Barkai, Moshe Gabel
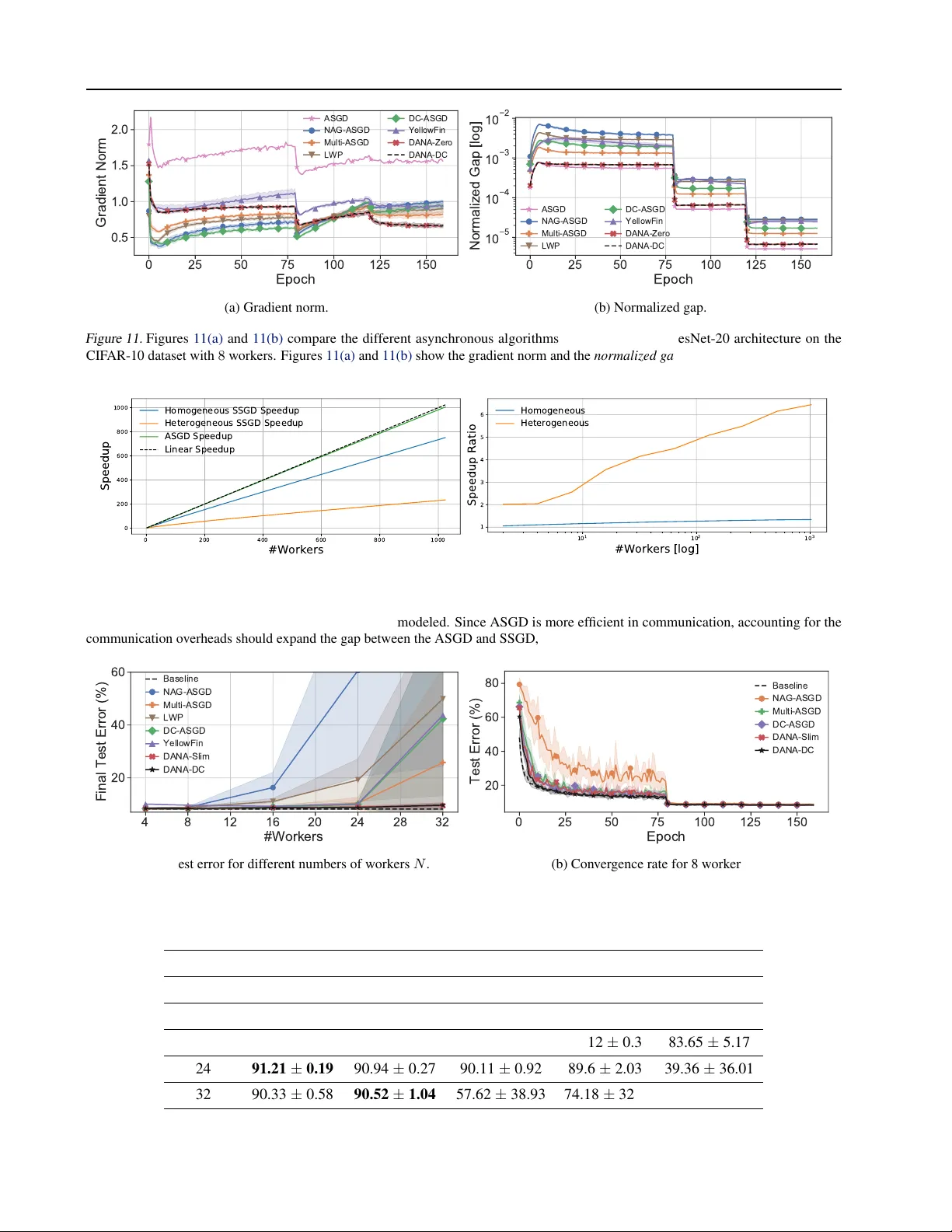
본 논문은 대규모 딥러닝 모델 학습에 있어 비동기 분산 SGD(ASGD)의 핵심 병목인 그래디언트 스테일리시 문제를 재조명하고, 모멘텀과 결합했을 때 발생하는 추가적인 스테일리시를 효과적으로 완화하는 새로운 알고리즘 DANA(Distributed Adaptive NAG ASGD)를 제안한다.
1. **배경 및 문제 정의**
- SGD는 순차적 업데이트 특성 때문에 단일 디바이스에서 학습 속도가 제한된다.
- ASGD는 워커 간 동기화를 없애며 거의 선형적인 스케일업을 가능하게 하지만, 워커가 현재 파라미터 θₜ 에 대해 계산한 그래디언트 gₜ 를 마스터가 최신 파라미터 θₜ₊τ 에 적용하면서 ‘스테일리시’가 발생한다.
- 기존 연구는 스테일리시를 지연 τ 로만 측정했으나, τ는 파라미터 변화량을 반영하지 못한다.
2. **갭(gap) 지표 도입**
- 저자들은 파라미터 차이 Δₜ₊τ = θₜ₊τ − θₜ 의 RMS G(Δ) = ‖Δ‖₂/√k 을 ‘갭’이라 정의하고, L‑Lipschitz 연속성을 가정해 그래디언트 오차 상한을 L·√k·G(Δ) 으로 표현한다.
- 실험적으로 워커 수가 증가할수록 갭이 로그 스케일로 급증함을 확인했으며, 이는 수렴 속도 저하와 최종 정확도 감소의 직접 원인임을 보였다.
3. **모멘텀과 NAG의 영향**
- 모멘텀 γ 가 큰 경우, 기존 ASGD에 Nesterov 가속(NAG)을 적용하면 갭이 더욱 확대된다. 이는 모멘텀 벡터 vₜ 가 크면 θ̂ₜ = θₜ − ηγvₜ₋₁ 이라는 미래 파라미터 예측이 실제 마스터 파라미터와 큰 차이를 보이기 때문이다.
- Linear Weight Prediction(LWP)은 θ̂ₜ ≈ θₜ₋τ − ηvₜ₋₁ 으로 근사하지만, τ가 커질수록 vₜ₋₁의 기여도가 감소해 갭 감소 효과가 제한적이다.
4. **DANA‑Zero 설계**
- 마스터는 각 워커 i 에 대해 독립적인 모멘텀 vᵢ 를 유지하고, 워커가 전송한 gᵢ 로만 업데이트한다(멀티‑ASGD).
- 마스터는 모든 vᵢ 의 합을 이용해 θ̂_DANA = θ₀ − ηγ∑ₙvⱼ 을 계산하고, 이를 워커에 반환한다. 워커는 이 예측 파라미터에 대해 그래디언트를 계산함으로써 실제 마스터가 N 번 업데이트 후 도달할 위치를 미리 사용한다.
- 수식적으로 E
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기