Taming Momentum in a Distributed Asynchronous Environment
Although distributed computing can significantly reduce the training time of deep neural networks, scaling the training process while maintaining high efficiency and final accuracy is challenging. Distributed asynchronous training enjoys near-linear …
Authors: Ido Hakimi, Saar Barkai, Moshe Gabel
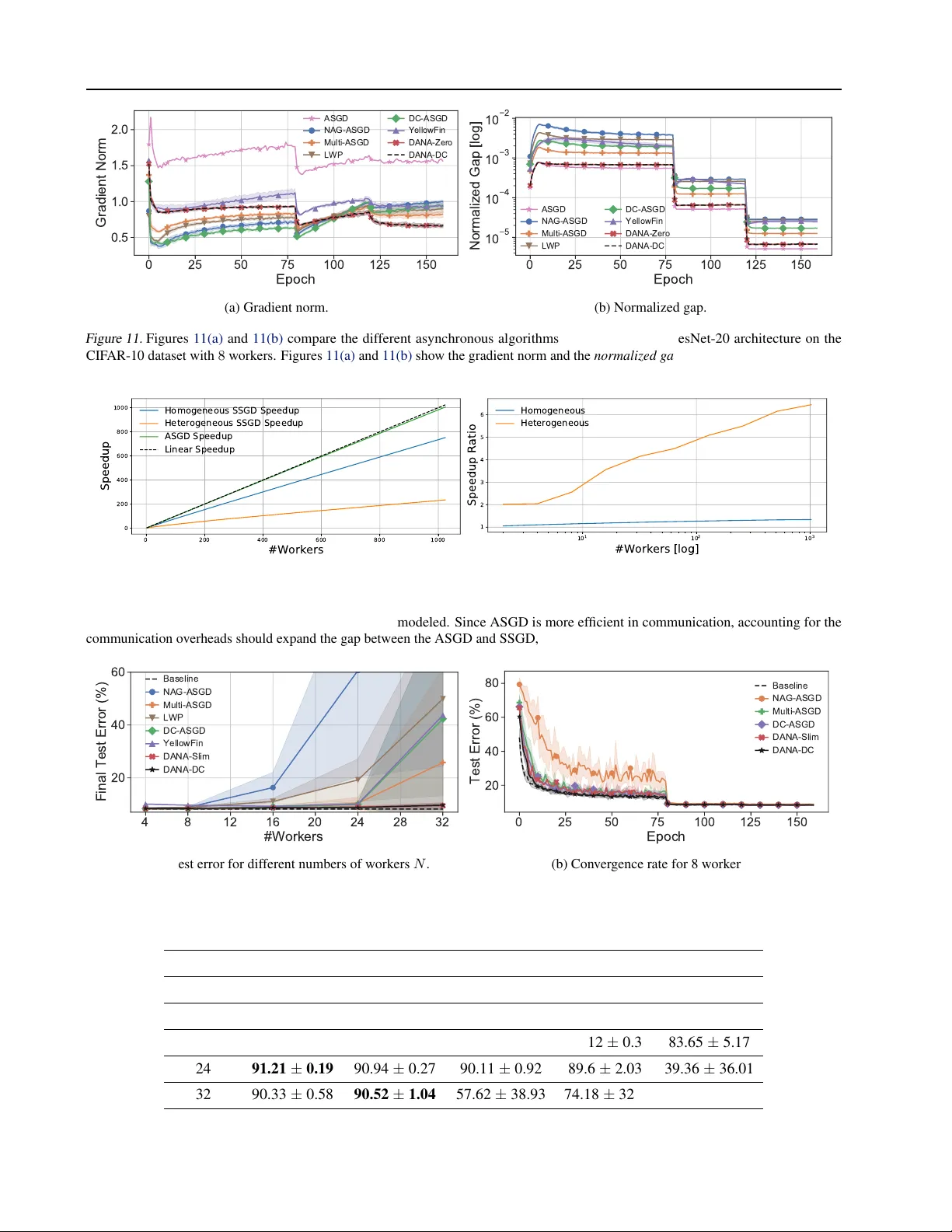
T A M I N G M O M E N T U M I N A D I S T R I B U T E D A S Y N C H RO N O U S E N V I R O N M E N T Ido Hakimi * 1 Saar Barkai * 1 Moshe Gabel 2 Assaf Schuster 1 A B S T R AC T Although distributed computing can significantly reduce the training time of deep neural netw orks, scaling the training process while maintaining high ef ficiency and final accuracy is challenging. Distributed asynchronous training enjoys near-linear speedup, but asynchrony causes gradient staleness - the main difficulty in scaling stochastic gradient descent to lar ge clusters. Momentum, which is often used to accelerate con ver gence and escape local minima, exacerbates the gradient staleness, thereby hindering conv ergence. W e propose D AN A: a nov el technique for asynchronous distributed SGD with momentum that mitigates gradient staleness by computing the gradient on an estimated future position of the model’ s parameters. Thereby , we sho w for the first time that momentum can be fully incorporated in asynchronous training with almost no ramifications to final accuracy . Our ev aluation on the CIF AR and ImageNet datasets shows that D AN A outperforms existing methods, in both final accuracy and con vergence speed while scaling up to a total batch size of 16 K on 64 asynchronous workers. 1 I N T R O D U C T I O N Modern deep neural networks are comprised of millions of parameters, which require massi ve amounts of data and long training time ( Silver et al. , 2016 ; Raffel et al. , 2019 ). The steady growth of neural networks over the years has made it impractical to train them from scratch on a single worker (computational device). Distributing the computa- tions ov er se veral w orkers can drastically reduce the training time ( Dean et al. , 2012 ; Cho et al. , 2019 ; Lerer et al. , 2019 ). Unfortunately , stochastic gradient descent (SGD), which is typically used to train these networks, is an inherently sequential algorithm. Thus, it is difficult to train deep neu- ral networks on multiple workers, especially when trying to maintain fast con ver gence and high final test accuracy ( Keskar et al. , 2016 ; Go yal et al. , 2017 ; Y ou et al. , 2020 ). Synchr onous SGD (SSGD) is a straightforward method to distribute the training process across multiple workers: each worker computes the gradient over its own separate mini- batches, which are then aggregated to update a single model. Because SSGD relies on synchronizations to coordinate the workers, its progress is limited by the slo west worker . Asynchr onous SGD (ASGD) addresses the drawbacks of SSGD by eliminating synchronization between the workers, * Equal contribution 1 Department of Computer Science, T ech- nion – Israel Institute of T echnology , Haifa, Israel 2 Department of Computer and Mathematical Sciences, University of T oronto Scar- borough, T oronto, Canada. Correspondence to: Ido Hakimi < ido- hakimi@gmail.com > , Saar Barkai < saarbarkai@gmail.com > , Moshe Gabel < mgabel@cs.toronto.edu > , Assaf Schuster < as- saf@cs.technion.ac.il > . Preprint. Under re view . allowing it to scale almost linearly . Howe ver , eliminating the synchronizations induces gradient staleness : gradients were computed on parameters that are older than the param- eter server’ s current parameters. Gradient staleness is one of the main difficulties in scaling ASGD, since it w orsens as the number of w orkers grows ( Zhang et al. , 2016 ). Due to gradient staleness, ASGD suffers from slow con vergence and reduced final accuracy ( Chen et al. , 2016 ; Cui et al. , 2016 ; Ben-Nun & Hoefler , 2019 ). In fact, ASGD might not con ver ge at all if the number of workers is too large. Momentum ( Polyak , 1964 ) has been demonstrated to accel- erate SGD con vergence and reduce oscillation ( Sutske ver et al. , 2013 ). Momentum is crucial for high accuracy and is typically used for training deep neural netw orks ( He et al. , 2016 ; Zagoruyko & K omodakis , 2016 ). Howe ver , when paired with ASGD, momentum exacerbates the gradient staleness ( Mitliagkas et al. , 2016 ; Dai et al. , 2019 ), to the point that it div erges when trained on lar ge clusters. Our contribution: W e propose D AN A: a novel technique for asynchronous distributed SGD with momentum. By adapting Nesterov’ s Accelerated Gradient to a distributed setting, D AN A computes the gradient on an estimated fu- ture position of the model’ s parameters, thereby mitigating the gradient staleness. As a result, D AN A efficiently scales to large clusters, despite using momentum, while main- taining high accuracy and fast conv ergence. W e show for the first time that momentum can be fully incorporated in asynchronous training with almost no ramifications to final accuracy . W e ev aluate D ANA in simulations as well as in two real-world settings: priv ate dedicated compute clusters and cloud data-centers. DAN A consistently outperformed T aming Momentum in a Distributed Asynchr onous En vironment other ASGD methods, in both final accuracy and conv er- gence speed while scaling up to a total batch size of 16 K on 64 asynchronous workers. 2 B AC K G R O U N D The goal of SGD is to find the global minimum of J ( θ ) where J is the objecti ve function (i.e., loss) and the vector θ ∈ R k is the model’ s parameters from dimensional k . x t denotes the value of some variable x at iteration t . ξ ∈ Ξ denotes a random v ariable from Ξ , the indices of the entire set of training samples Ξ = { 1 , · · · , M } . J ( θ ; ξ ) is the stochastic loss function with respect to the training sample index ed by ξ . The SGD iterative update rule is the follo wing: g t = ∇ J ( θ t ; ξ ) ; θ t +1 = θ t − η g t (1) Where η is the learning rate. W e also denote ∇ J ( θ ) as the full-batch gradient at point θ : ∇ J ( θ ) = 1 M P M i =1 ∇ J ( θ ; i ) . Momentum Polyak ( 1964 ) proposed momentum, which has been demonstrated to accelerate SGD con ver gence and reduce oscillation ( Sutske ver et al. , 2013 ). Momentum can be described as a heavy ball that rolls downhill while accu- mulating speed on its way tow ards the minima. The gathered inertia accelerates and smoothes the descent, which helps dampen oscillations and overcome narrow valle ys, small humps and local minima ( Goh , 2017 ). Mathematically , the momentum update rule (without dampening) is simply an exponentially-weighted moving av erage of gradients that adds a fraction of the pre vious momentum vector v t − 1 to the current momentum vector v t . g t = ∇ J ( θ t ; ξ ) ; v t = γ v t − 1 + g t θ t +1 = θ t − η v t (2) The momentum coefficient γ in Equation ( 2 ) controls the portion of the past gradients that is added to the current momentum vector v t . When successi ve gradients hav e a similar direction, momentum results in larger steps (higher speed), yielding up to quadratic speedup in the conv ergence rate for SGD ( Loizou & Richt ´ arik , 2017b ; a ). Nestero v In the analogy of the heavy ball rolling do wnhill, a higher speed may cause the heavy ball to ov ershoot the bottom of the valle y (the minima), if it does not slow do wn in time. Nesterov ( 1983 ) proposed Nester ov’ s Accelerated Gradient (N A G), which allo ws the ball to slow down in advance. N A G approximates ˆ θ t , the future value of θ t , based on the previous momentum v ector v t : ˆ θ t = θ t − η γ v t − 1 ; g t = ∇ J ( ˆ θ t ; ξ ) v t = γ v t − 1 + g t ; θ t +1 = θ t − η v t (3) N A G computes the gradient using the parameters’ estimated future v alue ˆ θ instead of their current v alue θ . Thus, NA G slows the heavy ball down near the minima so it doesn’t ov ershoot the goal and climb back up the hill. W e refer to this attribute as look-ahead , since it allows peeking at the future position of θ . The gradient g t is computed based on the approximated future parameters ˆ θ t and applied to the original parameters θ t via v t . θ t +1 − ˆ θ t = θ t − η v t +1 − θ t + η γ v t = η γ v t − η ( γ v t + g t ) = − η g t (4) Equation ( 4 ) shows that the dif ference between the updated parameters θ t +1 and the approximated future position ˆ θ t is only affected by the newly computed gradient g t , and not by v t . Therefore, N A G can accurately compute the gradient ev en when the momentum vector v t is large. 3 G R A D I E N T S T A L E N E S S In this work we consider the common implementation of distributed ASGD that uses a parameter serv er (also referred to as master ), which is commonly used in large-scale dis- tributed settings ( Li et al. , 2014 ; Peng et al. , 2019 ; Jayarajan et al. , 2019 ; Hashemi et al. , 2019 ; Zhao et al. , 2020 ). Fig- ure 1 illustrates the ASGD training process and the origin of gradient staleness ( Recht et al. , 2011 ). In ASGD training, each work er pulls the up-to-date parameters θ t from the master and computes a gradient of a single sample (Algo- rithm 1 ). Once the computations finish, the worker sends the gradient g t to the master . The master (Algorithm 2 ) then applies the gradient g t to its current set of parameters θ t + τ , where τ is the lag . The variable x for worker i is denoted as x i (for the master , i = 0 ). The lag τ of gradient g i t is defined as the number of updates the master recei ved from other workers while w orker i was computing g i t . Algorithm 1 ASGD: worker Receiv e parameters θ t from master Compute gradient g t ← ∇ J ( θ t ; ξ ) Send g t to master at iteration t + τ Algorithm 2 ASGD: master Receiv e gradient g t from worker i (at iteration t + τ ) Update master’ s weights θ t + τ +1 ← θ t + τ − η g t Send parameters θ t + τ +1 to worker i In other words, gradient g i t is stale if it was computed on parameters θ t but applied to θ t + τ . This gradient staleness is a major obstacle when scaling ASGD: the lag τ increases as the number of workers N grows ( Zhang et al. , 2016 ), decreasing gradient accuracy and ultimately reducing the accuracy of the trained model. As a result, ASGD suffers T aming Momentum in a Distributed Asynchr onous En vironment θ t − 1 θ t θ t + τ Pull θ t + 1 θ t + 1 θ t + τ + τ ′ Worker i Push g t g t Pull θ t Worker j Push g t + 1 g t + 1 ASGD Master θ t + τ + 1 Worker i Pull θ t + τ + 1 Figure 1. Gradient staleness in the ASGD training process, adapted from Zheng et al. ( 2017 ). Gradient g t is stale, since it is computed from parameters θ t but applied to θ t + τ . from slo w conv ergence and reduced final accurac y . In fact, ASGD may not con ver ge at all if the number of workers is too large ( Chen et al. , 2016 ; Cui et al. , 2016 ). From Lag to Gap Previous w orks analyze ASGD stale- ness using the lag τ ( Zhang et al. , 2016 ; Dai et al. , 2019 ). W e argue that τ fails to accurately reflect the ef fects of the staleness. Instead, we measure the gradient staleness with the recently introduced gap ( Barkai et al. , 2020 ). W e denote ∆ t + τ = θ t + τ − θ t as the dif ference between the master and worker parameters, and define the gap as: G(∆ t + τ ) = RMSE(∆ t + τ ) = k ∆ t + τ k 2 √ k Where k is the number of parameters. When ∆ t + τ = 0 , the gradient is computed on the same parameters to which it will be applied. This is the case for sequential and synchronous methods such as SGD and SSGD. Howe ver , in asynchronous algorithms more workers result in an increased lag τ and thus a larger gap . Figure 2(a) illustrates that in ASGD adding more worker increases the gap . Next, we sho w that the gap is directly correlated with gradi- ent accuracy . A common assumption is that the gradient of J is an L-Lipschitz continuous function: k∇ J ( x ) − ∇ J ( y ) k 2 ≤ L k x − y k 2 , x, y ∈ R k (5) Setting x = θ t + τ , y = θ t into Equation ( 5 ), we get that the inaccuracy of the stale gradient (with respect to the gradient on θ t + τ ) is bounded by the gap : k∇ J ( θ t + τ ) − ∇ J ( θ t ) k 2 ≤ L k θ t + τ − θ t k 2 = L · √ k · G(∆ t + τ ) (6) Equation ( 6 ) shows that a smaller gap implies that the stale gradient is more accurate. Con versely , a larger gap means a larger upper bound on the inaccurac y of the stale gradient. The advantage of measuring the staleness using the gap instead of the lag can be illustrated by a simple extreme example of a work er with a lag of τ = 2 at time step t + τ . If the tw o pre vious updates are in e xactly opposite directions and are of the same magnitude, the worker will compute the gradient on the same parameters as the master θ t + τ = θ t . Therefore, the gradient will be accurately computed ∇ J ( θ t + τ ) = ∇ J ( θ t ) , as if the lag were zero. Howe ver , the lag remains the same ( τ = 2 ), while the gap adjusts according to the two updates and is indeed equal to zero. The Effect of Momentum While momentum and NA G improv e the conv ergence rate and accuracy of SGD, they make it more difficult to scale to additional asynchronous workers. T o simplify the analysis, we henceforth assume that all workers have equal computation po wer . This as- sumption can be reliev ed by monitoring the rate of each worker’ s updates and weighting them accordingly . W e de- note by pr ev ( i, t ) the last iteration in which worker i sent a gradient to the master before time t . For ASGD and N A G- ASGD 1 , E [∆ t + τ ] is the sum of the gradients and the sum of the momentum vectors, respecti vely: E [∆ ASGD t + τ ] = − η N X i =1 g i prev ( i,t + τ ) (7) E [∆ NA G-ASGD t + τ ] = − η N X i =1 v prev ( i,t + τ ) (8) Figure 2(b) demonstrates empirically that the gap of N A G- ASGD is considerably larger than that of ASGD due to momentum 2 , e ven though the lag τ in both algorithms is exactly the same. 3.1 Parameter Pr ediction The gap arises from the fact that we can not access the future parameters θ t + τ . K osson et al. ( 2020 ) proposed Linear W eight Pr ediction (L WP) to estimate future parameters: θ t + τ ≈ ˆ θ L WP t , θ 0 t − τ ηv t − 1 (9) T o reduce the gap , L WP approximate the master’ s future pa- rameters θ t + τ in τ update steps. In other words, L WP scales the N A G estimation according to the number of times v t − 1 is used throughout the ne xt τ updates. The worker then com- putes its gradient on ˆ θ L WP t instead of θ 0 t . L WP is frequently 1 N AG-ASGD is Algorithm 2 , where the optimizer uses the aforementioned N AG method (Section 2 ) 2 This is quite intuitive since generally the momentum vector is larger than the gradient. T aming Momentum in a Distributed Asynchr onous En vironment 0 25 50 75 100 125 150 Epoch 1 0 5 1 0 4 1 0 3 Gap [log] ASGD 32 Workers ASGD 16 Workers ASGD 8 Workers ASGD 4 Workers (a) Comparison of the number of workers. 0 25 50 75 100 125 150 Epoch 1 0 5 1 0 4 1 0 3 Gap [log] ASGD NAG-ASGD Multi-ASGD LWP DC-ASGD YellowFin DANA-Zero DANA-DC (b) Algorithm comparison (all with 8 workers). Figure 2. The gap between θ t + τ and θ t while training ResNet-20 on the CIF AR-10 dataset with (a) different numbers of workers, and (b) different asynchronous algorithms. all algorithms share the same w orker update schedules and therefore hav e an identical lag. Adding workers or using momentum increases the ef fect of the lag τ on the gap. The large drops in the gap are caused by learning rate decay . The gap drops at the exact same rate at which the learning rate decays, which empirically sho ws that the gap correlates linearly with the learning rate η . The details for the dif ferent algorithms are explained in Section 5 . used in asynchronous model parallel pipelines ( Guan et al. , 2019 ; Chen et al. , 2018 ; Narayanan et al. , 2019 ) to reduce the staleness in the backpropagation; during the forward pass L WP estimates the parameters of the backw ards pass. Algorithm 3 describes the L WP master algorithm. Algorithm 3 L WP: master Receiv e gradient g i from worker i Update momentum v ← γ v + g i Update master’ s weights θ 0 ← θ 0 − η v Send estimate ˆ θ = θ 0 − τ ηv to worker i Howe ver , in large-scale asynchronous settings L WP is not beneficial because as τ increases, the effect of v t − 1 on reaching θ t + τ diminishes. Figure 2(b) shows that despite L WP parameter estimation ˆ θ L WP t , its gap is still large and only slightly lower than N AG-ASGD. D AN A-Zero, detailed in the next section, maintains a small gap throughout training, despite using momentum. The small gap enables D ANA-Zero to compute more accurate gradients, as giv en by Equation ( 6 ), and therefore achiev e fast con ver gence and high final accuracy . 4 DA N A D AN A (Distributed Adapti ve N A G ASGD) is a distributed asynchronous technique that achie ves state-of-the-art ac- curacy and fast con vergence, even when trained with mo- mentum on large clusters. D ANA is designed to reduce the gap by computing the gradient g t on parameters that ap- proximate the master’ s future position θ t + τ using a similar look-ahead to that of N A G. Thus, for the same lag , D AN A benefits from a reduced gap , as sho wn by Figure 2(b) , and therefore suffers less from gradient staleness. 4.1 The D ANA-Zer o Update Rule T o rectify the problem of L WP we propose to maintain at the master a separate momentum vector v i for each worker i ; these v ectors are updated e xclusiv ely with the correspond- ing worker’ s gradients g i using the same update rule as in vanilla SGD with momentum (Equation ( 2 )). W e refer to this method as Multi-ASGD (Appendix A.1 ). T o complete our adaptation of N A G to the distributed case, we propose to perform the look-ahead using the most recent momentum vectors of all of the workers. W e name this method DAN A-Zer o . Instead of sending the master’ s cur- rent parameters θ 0 t , D AN A-Zero sends ˆ θ D ANA t , the estimated future position of the master’ s parameters after the next N updates, one for each worker: v i t , γ v i prev ( i,t − 1) + g i t (10) ˆ θ D ANA t , θ 0 t − η γ N X i =1 v i prev ( i,t − 1) (11) Algorithm 4 D AN A-Zero: master Receiv e gradient g i from worker i Update worker’ s momentum v i ← γ v i + g i Update master’ s weights θ 0 ← θ 0 − η v i Send estimate ˆ θ = θ 0 − η γ P N j =1 v j to worker i Algorithm 4 sho ws the D ANA-Zero master algorithm. Un- like ASGD (Algorithm 2 ), the master now sends back to the worker a future prediction of the parameters ˆ θ = θ 0 − η γ P N j =1 v j instead of the current parameters θ 0 . This future prediction is what allo ws D ANA-Zero to decrease the gap and therefore compute accurate gradients. The worker remains the same as in ASGD (Algorithm 1 ). Figure 2(b) T aming Momentum in a Distributed Asynchr onous En vironment shows that D AN A-Zero accurately estimates the future pa- rameters θ t + τ and therefore decreases its gap . Equation ( 12 ) proves that E ∆ D ANA t + τ = E ∆ ASGD t + τ in an asynchronous en vironment of N equal computational pow- ered workers: E ∆ D ANA t + τ = E [ θ t + τ ] − E h ˆ θ t i = |{z} Equation ( 11 ) θ t − η N X i =1 v i prev ( i,t + τ ) − θ t − η γ N X i =1 v i prev ( i,t − 1) ! = |{z} Equation ( 10 ) θ t − η N X i =1 γ v i prev ( i,t − 1) + g i prev ( i,t + τ ) − θ t − η γ N X i =1 v i prev ( i,t − 1) ! = − η N X i =1 g i prev ( i,t + τ ) = |{z} Equation ( 7 ) E ∆ ASGD t + τ (12) Equation ( 12 ) shows that despite using momentum, D ANA- Zero has a similar gap to that of ASGD. Figure 2(b) demon- strates this empirically: D ANA-Zero maintains a small gap throughout the training process. W e note that, due to mo- mentum, D AN A-Zero con verges f aster than ASGD, result- ing in smaller gradients, and therefore a smaller gap . For more details and an empirical v alidation see Appendix B.3 . W e note that computing the full summation P N i =1 v i prev ( i,t − 1) in D ANA-Zero can be done in O ( k ) , instead of O ( k · N ) by maintaining v 0 = P N i =1 v i prev ( i,t − 1) and updating it using v 0 t = v 0 t − v i prev ( i,t − 1) + v i t . For further details please see Appendix A.2 . D ANA-Zer o Equi valence to Nester ov When running with one work er ( N = 1) D AN A-Zero reduces to a sin- gle N A G optimizer . This can be shown by merging the worker and master (Algorithms 1 and 4 ) into a single algo- rithm: since at all times θ 1 t = θ 0 t − η γ v t − 1 , the resulting algorithm trains one set of parameters θ , which is exactly the NA G update rule. Algorithm 5 shows the combined algorithm, equiv alent to the standard N A G optimizer . Algorithm 5 Fused D AN A-Zero (when N = 1 ) Compute gradient g t ← ∇ J ( θ t − η γ v t − 1 ) Update momentum v t ← γ v t − 1 + g t Update weights θ t +1 ← θ t − η v t 4.2 Optimizing D ANA In D AN A-Zero, the master maintains a momentum v ector for ev ery worker , and must also compute ˆ θ D ANA at each iter- ation. This adds a small computation and memory overhead to the master . DAN A-Slim, a variation of D AN A-Zero, ob- tains the same look-ahead as D ANA-Zero b ut without any computation or memory ov erhead. Thus, D AN A-Slim main- tains the same gradient staleness mitigation as DAN A-Zero. Bengio-NA G Bengio et al. ( 2013 ) proposed a variation of NA G that simplifies the implementation and reduces computation cost. Known as Bengio-N A G, it defines a new variable Θ to stand for θ after the momentum update: Θ t , θ t − η γ v t − 1 (13) Substituting θ t with Θ t in the N AG update rule, using Equa- tion ( 13 ), yields the Bengio-N A G update rule: θ t +1 = θ t − η v t Θ t +1 + η γ v t = Θ t + η γ v t − 1 − η v t Θ t +1 = Θ t − η ( γ v t + ∇ J (Θ t ; ξ )) (14) Equation ( 14 ) shows the Bengio-NA G update rule, where the gradient is both computed on and applied to Θ , rather than computed on ˆ θ but applied to θ . Hence, an imple- mentation of Bengio-N AG needs to store only one set of parameters Θ in memory and doesn’t require computing ˆ θ . The D ANA-Slim Update Rule In creating D AN A-Slim, we optimized D AN A-Zero by lev eraging the Bengio-NA G approach. W e re-define Θ t as θ t after applying the momen- tum update from all future workers. Therefore, Θ t +1 is Θ t after the current worker’ s update: Θ t , θ t − η γ N X j =1 v j prev ( j,t − 1) Θ t +1 = θ t +1 − η γ v i t + X j 6 = i v j prev ( j,t − 1) (15) D AN A-Slim eliminates both the computational and memory ov erhead at the master by substituting θ t with Θ t . θ t +1 = θ t − η v i t ⇓ Equation ( 15 ) Θ t +1 + η γ v i t + N X j 6 = i v j prev ( j,t − 1) = Θ t + η γ N X j =1 v j prev ( j,t − 1) − η v i t Θ t +1 = Θ t + η γ v i prev ( i,t − 1) − 1 + 1 γ · v i t ⇓ Equation ( 10 ) Θ t +1 = Θ t − η ( γ v i t + ∇ J (Θ prev ( i,t ) ; ξ )) (16) T aming Momentum in a Distributed Asynchr onous En vironment Equation ( 16 ) shows that DAN A-Slim benefits from the same gradient staleness mitigation as DAN A-Zero up to a parameter switch. In DAN A-Slim the master sends its current parameters Θ t instead of computing the future pa- rameters ˆ θ . Therefore, the master doesn’t need to maintain the momentum vectors of all the work ers. Algorithm 6 describes the worker algorithm of D ANA-Slim. D AN A-Slim only changes the worker algorithm, while us- ing the same master algorithm as ASGD 3 (Algorithm 2 ). Hence, it completely eliminates the o verhead at the master and enjoys the same linear speedup scaling capabilities of ASGD. D AN A-Slim is equi valent to D AN A-Zero in all other aspects and provides the same gradient staleness mitigation. Algorithm 6 D AN A-Slim: worker i Receiv e parameters Θ i from master Compute gradient g i ← ∇ J (Θ i ; ξ ) Update momentum v i ← γ v i + g i Send update vector γ v i + g i to master 4.3 Delay Compensation Zheng et al. ( 2017 ) proposed Delay Compensated ASGD (DC-ASGD), which tackles the problem of stale gradients by adjusting the gradient with a second-order T aylor expansion. Due to the high computation and space complexity of the Hessian matrix, they propose a cheap yet ef fecti ve Hessian approximator , which is solely based on pre vious gradients. W e denote by a matrix element-wise multiplication. g t = ∇ J ( θ t ; ξ ) ; ˆ g t = g t + λg t g t ( θ t + τ − θ t ) θ t + τ +1 = θ t + τ − η ˆ g t (17) Equation ( 17 ) describes DC-ASGD. The delay compensa- tion term, λg t g t ( θ t + τ − θ t ) , adjusts the gradient g t as if it were computed on θ t + τ instead of θ t ; thus, mitigating the gradient staleness. Howe ver , DC-ASGD adds a memory ov erhead to the master since it no w stores the previously sent parameters for each worker . A T aylor expansion is more accurate when the source θ t is in close vicinity to the approximation point θ t + τ (a small gap ). Momentum increases the gap , thus reducing the ef fectiv e- ness of DC-ASGD. D AN A-Zero ensures that the gap is kept small throughout training, e ven when using momentum; this amplifies the ef fectiv eness of the delay compensation. The combined method, referred to as DAN A with Delay Compensation (D AN A-DC), is described in Algorithm 7 . 3 Although Algorithm 2 receives g t while Algorithm 6 sends v t , there is no inconsistency since v t , g t ∈ R k . Algorithm 7 D AN A-DC: master Receiv e gradient g i from worker i Update the gradient according to the delay compensation term ˆ g i = g i + λg i g i ( θ 0 − θ i ) Update momentum v i ← γ v i + ˆ g i Update master’ s weights θ 0 ← θ 0 − η v i Send estimate ˆ θ = θ 0 − η γ P N j =1 v j to worker i 5 E X P E R I M E N T S In this section, we present our ev aluations and insights re- garding D AN A. In Sections 5.1 and 5.2 we focus on accu- racy rather than communication ov erheads, and therefore we simulate multiple distributed w orkers 4 and measure the final test error and con ver gence speed of different cluster sizes. In Section 5.3 we show the importance of decreas- ing the gap in asynchronous en vironments and point to the high correlation between small gap and high final test accu- racy . Finally , in Sections 5.4 and 5.5 we present real-world distributed asynchronous results that are trained in two set- tings: dedicated priv ate compute cluster and public cloud data-center (Google cloud). W e show that D ANA trains ov er 25% faster than an optimized SSGD algorithm while maintaining high final test accuracy and fast con vergence. Simulation W e simulate the work ers’ execution time us- ing a gamma-distributed model ( Ali et al. , 2000 ), where the ex ecution time for each individual batch is dra wn from a gamma distribution. The gamma distribution is a well- accepted model for task ex ecution time that naturally giv es rise to stragglers. W e use the formulation proposed by ( Ali et al. , 2000 ) and set V = 0 . 1 and µ = B ∗ V 2 , where B is the batch size, yielding a mean execution time of B simulated time units (additional details in Appendix A.4 ). Figure 3 visualizes the distribution of work ers’ batch ex- ecution time. As expected, stragglers appear much more frequently in the heterogeneous en vironment than in the homogeneous en vironment. Since one of our main goals in these experiments is to verify that decreasing the gap leads to a better final test error and con ver gence rate, we use the same hyperparameters across all algorithms. These are the original hyperparameters sug- gested by the authors of each neural network architecture’ s respectiv e paper , tuned for a single worker (for additional details please see Appendix A.5 ). This eases the scaling to more workers since it doesn’t require re-tuning the hyperpa- rameters when increasing the cluster size. 4 A single worker may be more than a single GPU. DAN A, like all ASGD algorithms, treats each machine with multiple GPUs as a single worker . For example, D AN A can run on 32 workers with 8 GPUs each (256 GPUs in total), where each worker performs SSGD internally , which is transparent to the ASGD algorithm. T aming Momentum in a Distributed Asynchr onous En vironment 80 100 120 140 160 180 Batch Execution Time 0.00 0.01 0.02 0.03 Density (a) Homogeneous gamma distribution model. 0 200 400 600 800 Batch Execution Time 0.000 0.002 0.004 0.006 Density (b) Heterogeneous gamma distribution model. Figure 3. Gamma-distribution in homogeneous and heterogeneous en vironments. The x-axis is the simulated time units the iteration takes while the y-axis is the probability . Both environments ha ve the same mean (128 time units). The red area represents the probability to hav e an iteration which takes more than 1.25x longer than the mean iteration time. 4 8 12 16 20 24 28 32 #Workers 20 40 60 80 100 Final Test Error (%) Baseline NAG-ASGD Multi-ASGD LWP DC-ASGD YellowFin DANA-Slim DANA-DC (a) CIF AR10 ResNet-20 4 8 12 16 20 24 28 32 #Workers 20 40 60 80 100 Final Test Error (%) (b) CIF AR10 Wide ResNet 16-4 4 8 12 16 20 24 28 32 #Workers 40 60 80 100 Final Test Error (%) (c) CIF AR100 Wide ResNet 16-4 Figure 4. Final test error for different numbers of w orkers N . Algorithms Our goal is to produce a scalable method that works well with momentum and therefore all e valu- ated algorithms use momentum (as does the baseline). Our ev aluations consist of the follo wing algorithms: • Baseline: Single worker with the same tuned hyperpa- rameters as in the respectiv e neural network’ s paper . This baseline does not suffer from gradient staleness, thus it is ideal in terms of final accuracy and con vergence speed. • N AG-ASGD: Asynchronous SGD, which uses a single N A G optimizer for all workers. • Multi-ASGD: Asynchronous SGD, which maintains a sep- arate N A G optimizer for each worker . • DC-ASGD: Delay compensation asynchronous SGD, as described in Section 4.3 , for which we set γ = 0 . 95 as suggested by Zheng et al. ( 2017 ). • Y ellowF in: An algorithm proposed by Zhang & Mitliagkas ( 2019 ), that automatically tunes the momen- tum γ and learning rate η throughout the training process. W e used the asynchronous variation of Y ello wFin, named Closed-Loop, and set the hyperparameters η = 1 e − 4 and γ = 0 . 0 as suggested by Zhang & Mitliagkas ( 2019 ). • L WP: Linear W eight Prediction, described in Section 3.1 . • D ANA-Slim: A variation of D AN A-Zero, which elimi- nates the ov erhead, as described in Section 4.2 . • D ANA-DC: A combination of D ANA-Zero with DC- ASGD, as described in Section 4.3 , for which we set λ = 2 , as suggested by Zheng et al. ( 2017 ). 5.1 Evaluation on the CIF AR Datasets W e ev aluate D AN A with the ResNet-20 ( He et al. , 2016 ) and Wide ResNet 16-4 ( Zagoruyko & K omodakis , 2016 ) architectures on the CIF AR-10 and CIF AR-100 datasets ( Hinton , 2007 ). In the CIF AR experiments, bold lines sho w the mean ov er fiv e different runs with random seeds, while transparent bands show the standard deviation. The baseline is the mean of fiv e different runs with a single w orker . Figure 4 shows that the final test error of both D AN A-Slim and D AN A-DC is lower than all the other algorithms for an y number of w orkers, especially for lar ge numbers of w orkers. Both variations of D AN A exhibit a very small standard de- viations, which points to the high stability D AN A provides, ev en for large numbers of w orkers. The final accuracies of all the CIF AR experiments are listed in Appendix B.1 . N A G-ASGD demonstrates how gradient staleness is e xac- erbated by momentum. N A G-ASGD yields good accuracy T aming Momentum in a Distributed Asynchr onous En vironment 0 50 100 150 Epoch 20 40 60 80 Test Error (%) Baseline NAG-ASGD Multi-ASGD LWP DC-ASGD YellowFin DANA-Slim DANA-DC (a) CIF AR10 ResNet-20 0 50 100 150 200 Epoch 20 40 60 80 Test Error (%) (b) CIF AR10 Wide ResNet 16-4 0 50 100 150 200 Epoch 20 40 60 80 Test Error (%) (c) CIF AR100 Wide ResNet 16-4 Figure 5. Con vergence rate for 8 w orkers. with few work ers, but fails to con verge when trained with more than 16 workers. L WP scales better than NA G-ASGD but falls short of Multi-ASGD. Multi-ASGD serves as an ablation study: its poor scalability demonstrates that it is not sufficient to simply maintain a momentum vector for ev ery worker . Hence, D ANA (Section 4 ) is also required to achiev e fast con ver gence and low test error . Figure 5 sho ws the mean and standard deviation of the test error throughout the training of the different algorithms when trained on eight workers. This figure demonstrates the significantly better con vergence rate of D AN A-DC. It is usually similar to the baseline or ev en faster and outperforms all the other algorithms. It is noteworthy that D ANA-DC’ s con ver gence rate surpasses that of D ANA-Slim; howe ver , D AN A-DC incurs an overhead and both algorithms usually reach a similar final test error , as seen in Figure 4 . 4 8 12 16 20 24 28 32 #Workers 20 40 60 Final Test Error (%) Baseline NAG-ASGD Multi-ASGD LWP DC-ASGD YellowFin DANA-Slim DANA-DC Figure 6. Final test error for different numbers of work ers N when training ResNet-20 on CIF AR10 in a heterogeneous environment. When attempting to utilize different computational re- sources ( Y ang et al. , 2018 ; 2020 ; W oodworth et al. , 2020 ), workers may have considerably different computational power from one another . This heterogeneous en vironment creates high variance in batch execution times, as shown in Figure 3(b) . Therefore, in heterogeneous en vironments, asynchronous algorithms hav e a distinct speedup adv antage ov er synchronous algorithms which are slowed do wn by the slowest worker if not addressed ( Dutta et al. , 2018 ; Hanna et al. , 2020 ). Figure 6 sho ws that even in heterogeneous en vironments, D AN A achieves high final accurac y on large clusters of workers. For additional details about the hetero- geneous experiments please see Appendix D . 5.2 Evaluation on the ImageNet Dataset Figure 7 shows e xperiments where we e valuate D AN A with ResNet-50 ( He et al. , 2016 ) on the ImageNet dataset ( Rus- sakovsk y et al. , 2015 ). In this experiment, every asyn- chronous worker is a machine with 8 GPUs, so the 64- worker experiment simulates a total of 512 GPUs with a total batch size of 16K. Figure 7(a) compares final test er- rors on different cluster sizes and sho ws that the scalability in terms of final accuracy of D ANA-Slim and D ANA-DC is much greater than all the other algorithms. Figure 7(b) shows that both variations of D ANA significantly outper- form all the other algorithms in both con ver gence speed and final accuracy when trained on 32 asynchronous workers. Appendix B.2 lists the final test accuracies on ImageNet. 5.3 The Importance of the Gap Although all algorithms share the same av erage lag (for a given number of workers), the algorithms that achiev e a lower a verage gap (Figure 2(b) ) also demonstrate low final error (Figure 4 ) and fast con vergence rate (Figure 5 ). Ergo, we conclude that the gap is more informati ve than the lag when battling gradient staleness and that gap reduction is paramount to asynchronous training. W e note that the av erage gap of both D ANA-Zero and D AN A-DC is an order of magnitude smaller than that of N A G-ASGD and L WP , as shown in Figure 2(b) . Further details of our analysis on the gap are discussed in Appendix B.3 . T aming Momentum in a Distributed Asynchr onous En vironment 16 32 48 64 #Workers 20 40 60 80 Final Test Error (%) NAG-ASGD Multi-ASGD LWP DC-ASGD YellowFin DANA-Slim DANA-DC (a) Final test error on 16, 32, 48, and 64 workers 0 20 40 60 80 Epoch 40 60 80 100 Test Error (%) Baseline NAG-ASGD Multi-ASGD LWP DC-ASGD YellowFin DANA-Slim DANA-DC (b) Con vergence rate on 32 w orkers Figure 7. (a) and (b) show the final test errors and con vergence speed, respectiv ely , when training a ResNet-50 architecture on the ImageNet dataset. The black dashed line represents the baseline of a single worker . 5.4 Evaluation on a Pri vate Compute Cluster While this work focuses on improving the accuracy of ASGD, we also measured acceleration in training time. W e conduct our experiments on a system with 8 Nvidia 2080ti GPUs that each hav e 11GB and base our code on PyT orch ( Paszke et al. , 2019 ). W e use an efficient implemen- tation for synchronous training 5 ( DistibutedDataP arallel known as SSGD) based on the Ring-AllReduce communi- cation algorithm that is implemented by Nvidia’ s NCCL collectiv e communication package. Furthermore, in SSGD, we ov erlap its computations with communications to accel- erate the training by ov er 15% ( Li et al. , 2020 ). Shared Memory GPU Pinned Memory CPU GPU Pinned Memory CPU GPU Pinned Memory CPU GPU Pinned Memory CPU GPU Pinned Memory CPU GPU Pinned Memory CPU GPU Pinned Memory CPU GPU Pinned Memory CPU Figure 8. Our asynchronous lock-free training setup. Figure 8 shows our asynchronous training setup. Each worker is ex ecuted on a different process with a dedicated GPU. The shared parameters are stored and updated on the shared memory similar to Hogwild ( Recht et al. , 2011 ). The communications between the GPU and shared memory are transferred via pinned memory for fast parallel data transfer . Figure 9 presents results when training the ResNet-50 archi- tecture on ImageNet with dif ferent total batch sizes where ev ery asynchronous worker is a single GPU. For total batch sizes that are larger than 256 (batch size of 32 per GPU) we use gradient accumulation ( Aji & Heafield , 2019 ) to reduce memory footprint as well as reduce the synchronization frequency and communication o verhead. Therefore, larger 5 https://github.com/pytorch/examples/ tree/master/imagenet total batch sizes result in higher communication efficienc y and shorter training times. Figure 9(a) compares the final test error on different total batch sizes. Multi-ASGD quickly drops in final accuracy when scaling the total batch size. D AN A-Slim, on the other hand, not only scales well but in some cases ev en surpasses the final accuracy of SSGD. Fig- ure 9(b) shows that D ANA-Slim con verges faster than both Multi-ASGD and SSGD. DAN A-Slim trains 25% faster than SSGD while achie ving similar final accuracy . T able 1 lists the final accuracies, training time, and the speedup over a single GPU. D AN A-Slim achiev es perfect linear scaling while maintaining final accuracy similar to the baseline. 5.5 Evaluation on a Public Cloud Data-center W e e v aluate the scalability of DAN A-Slim on a public cloud data-center (Google cloud) with a single parameter serv er and one Nvidia T esla V100 GPU per machine. Our cross- machine communications are based on CUD A-A ware MPI (OpenMPI) with a 10Gb Ethernet NIC per machine. Fig- ure 10 shows that D ANA-Slim successfully scales up to 20 workers in agreement with the simulations of Figure 4(a) with high speedup and lo w final test error (less than 1% higher than the baseline). W e consider parameter server op- timizations to be beyond the scope of this paper and detail popular parameter server optimization techniques that are orthogonal and compatible with D AN A in Appendix C . 6 R E L A T E D W O R K Asynchronous training causes gradient staleness, which hin- ders the con ver gence. Several approaches ( Dai et al. , 2019 ; Zhang et al. , 2016 ; Zhou et al. , 2018 ) proposed to mitigate gradient staleness by tuning the learning rate with regard to the lag τ . These approaches are designed for SGD without momentum and therefore do not address the massive gap that momentum generates. Mitliagkas et al. ( 2016 ) show that asynchronous training induces implicit momentum . Thus, the momentum coefficient γ must be decayed when scaling T aming Momentum in a Distributed Asynchr onous En vironment 256 512 1024 2048 Total Batch Size 23 24 25 26 Final Test Error (%) SSGD Multi-ASGD DANA-Slim (a) Final test error on 256, 512, 1024, and 2048 total batch sizes 0 5 10 15 20 Time (hours) 40 60 80 100 Test Error (%) SSGD Multi-ASGD DANA-Slim (b) Con vergence rate on a total batch size of 2048 Figure 9. ImageNet ResNet-50 distributed training with 8 GPUs. The black dashed line in (a) represents the baseline with a single worker . T able 1. Distributed results of ResNet-50 on ImageNet with an 8 GPU machine (time in hours) D ANA-Slim Multi-ASGD SSGD T otal Batch Size Accuracy Time Speedup Accuracy T ime Speedup Accuracy Time Speedup 256 75.71% 20.3 6.78x 75.44% 20.5 6.72x 75.7% 25.5 5.40x 512 75.31% 18 7.65x 75.03% 18 7.65x 75.42% 22.9 6.01x 1024 75.18% 16.9 8.15x 75.08% 16.9 8.15x 75.06% 20.9 6.59x 2048 74.85% 16.4 8.39x 74.39% 16.3 8.45x 74.84% 20.17 6.83x 0 5 10 15 20 25 30 Workers 5 10 15 Speedup 10 15 Final Test Error (%) Figure 10. Speedup (solid line) and final test error (dashed) of D ANA-Slim on CIF AR-10 using ResNet-20 on Google cloud. Each worker is one Nvidia V100 GPU with a 10 Gb Ethernet NIC. up the cluster size. By decreasing the gap caused by mo- mentum, we sho w that fast con vergence and high final test accuracy is possible in an asynchronous en vironment with D AN A, ev en when γ is relativ ely high. Other approaches for mitigating gradient staleness include DC-ASGD ( Zheng et al. , 2017 ), which uses a T aylor expan- sion to reduce the gradient staleness. Y ellowFin ( Zhang & Mitliagkas , 2019 ) is an SGD based algorithm that automati- cally tunes the momentum coefficient γ and learning rate η throughout the training process. Both Y ello wFin and DC- ASGD achiev e high accuracy on small clusters, but fall short when trained on large clusters (Figure 4 ) due to the massi ve negati ve ef fects of the gradient staleness. Communication- efficient asynchronous algorithms, such as Elastic A ver- aging SGD (EASGD) by Zhang et al. ( 2015 ), can reduce communication ov erhead. EASGD is an asynchronous algo- rithm that uses a center for ce to pull the work ers’ parameters tow ards the master’ s parameters. This allows each worker to train asynchronously and synchronize with the master once ev ery few iterations. Not only are these approaches compatible with (and indeed orthogonal to) DAN A, we show that D ANA can amplify the ef fectiv eness of the other approaches, as demonstrated with D ANA-DC (Section 4.3 ). 7 C O N C L U S I O N In this paper we tackle gradient staleness, one of the main difficulties in scaling SGD to large clusters in an asyn- chronous en vironment. W e introduce D AN A: a novel asyn- chronous distributed technique that mitig ates gradient stal- eness by computing the gradient on an estimated future position of the model’ s parameters. Despite using momen- tum, D AN A efficiently scales to large clusters while main- taining high final accuracy and fast con vergence. Thereby , we showed for the first time that momentum can be fully incorporated in asynchronous training with almost no ram- ifications to final accuracy . W e performed an extensi ve set of e valuations on simulations, pri vate compute clusters, and public cloud data-centers. Throughout our e valuations, D AN A consistently outperformed all the other algorithms in both final test error and con vergence rate. For future work, we plan on adapting DAN A to ne wer optimizers, such as Nadam ( Dozat , 2016 ), and to more recent asynchronous algorithms, in particular EASGD and Y ellowFin. T aming Momentum in a Distributed Asynchr onous En vironment A C K N OW L E D G E M E N T The work on this paper was supported by the Israeli Min- istry of Science, T echnology , and Space and by The Hasso Plattner Institute. R E F E R E N C E S Aji, A. F . and Heafield, K. Making asynchronous stochastic gradient descent work for transformers. In Pr oceedings of the 3r d W orkshop on Neural Generation and T ranslation , 2019. Ali, S., Sie gel, H. J., Mahesw aran, M., Ali, S., and Hensgen, D. T ask execution time modeling for heterogeneous com- puting systems. In Pr oceedings of the 9th Heter ogeneous Computing W orkshop , 2000. Barkai, S., Hakimi, I., and Schuster , A. Gap-aware mitig a- tion of gradient staleness. In International Confer ence on Learning Repr esentations , 2020. Ben-Nun, T . and Hoefler , T . Demystifying parallel and dis- tributed deep learning: An in-depth concurrency analysis. A CM Computing Surveys (CSUR) , 2019. Bengio, Y ., Boulanger-Lew andowski, N., and Pascanu, R. Advances in optimizing recurrent networks. In IEEE In- ternational Confer ence on Acoustics, Speech and Signal Pr ocessing , 2013. Bernstein, J., W ang, Y .-X., Azizzadenesheli, K., and Anand- kumar , A. signSGD: Compressed optimisation for non- con vex problems. In Proceedings of the 35th Interna- tional Confer ence on Machine Learning . PMLR, 2018. Chen, C.-C., Y ang, C.-L., and Cheng, H.-Y . Efficient and robust parallel dnn training through model parallelism on multi-gpu platform. arXiv pr eprint arXiv:1809.02839 , 2018. Chen, J., P an, X., Monga, R., Bengio, S., and Jozefowicz, R. Revisiting distributed synchronous sgd. arXiv pr eprint arXiv:1604.00981 , 2016. Cho, M., Finkler , U., K ung, D., and Hunter , H. Blueconnect: Decomposing all-reduce for deep learning on heteroge- neous network hierarchy . In T alwalkar , A., Smith, V ., and Zaharia, M. (eds.), Pr oceedings of Machine Learning and Systems . 2019. Cui, H., Zhang, H., Ganger , G. R., Gibbons, P . B., and Xing, E. P . Geeps: Scalable deep learning on distributed gpus with a gpu-specialized parameter serv er . In Pr oceed- ings of the Eleventh Eur opean Confer ence on Computer Systems , 2016. Dai, W ., Zhou, Y ., Dong, N., Zhang, H., and Xing, E. T o- ward understanding the impact of staleness in distributed machine learning. In International Conference on Learn- ing Repr esentations , 2019. Dean, J., Corrado, G., Monga, R., Chen, K., Devin, M., Le, Q. V ., Mao, M. Z., Ranzato, M., Senior , A. W ., T ucker , P . A., Y ang, K., and Ng, A. Y . Large scale distributed deep networks. In Advances in Neur al Information Pr o- cessing Systems 25: 26th Annual Conference on Neur al Information Pr ocessing Systems , 2012. Dozat, T . Incorporating Nesterov momentum into Adam. ICLR W orkshop , 2016. Dutta, S., Joshi, G., Ghosh, S., Dube, P ., and Nagpurkar , P . Slow and stale gradients can win the race: Error-runtime trade-offs in distributed sgd. Proceedings of Machine Learning Research. PMLR, 2018. Goh, G. Why momentum really works. Distill , 2017. doi: 10.23915/distill.00006. URL http://distill. pub/2017/momentum . Goyal, P ., Doll ´ ar , P ., Girshick, R., Noordhuis, P ., W esolowski, L., K yrola, A., T ulloch, A., Jia, Y ., and He, K. Accurate, large minibatch sgd: Training imagenet in 1 hour . arXiv pr eprint arXiv:1706.02677 , 2017. Guan, L., Y in, W ., Li, D., and Lu, X. Xpipe: Efficient pipeline model parallelism for multi-gpu dnn training. arXiv pr eprint arXiv:1911.04610 , 2019. Hanna, S. K., Bitar , R., Parag, P ., Dasari, V ., and El Rouay- heb, S. Adaptiv e distributed stochastic gradient descent for minimizing delay in the presence of stragglers. In ICASSP 2020-2020 IEEE International Confer ence on Acoustics, Speech and Signal Pr ocessing (ICASSP) . IEEE, 2020. Hashemi, S. H., Abdu Jyothi, S., and Campbell, R. T ictac: Accelerating distributed deep learning with communica- tion scheduling. In T alwalkar , A., Smith, V ., and Zaharia, M. (eds.), Pr oceedings of Machine Learning and Systems . 2019. He, K., Zhang, X., Ren, S., and Sun, J. Deep residual learning for image recognition. In 2016 IEEE Conference on Computer V ision and P attern Recognition , 2016. Hinton, G. E. Learning multiple layers of representation. T rends in Cognitive Sciences , 2007. Jayarajan, A., W ei, J., Gibson, G., Fedorov a, A., and Pekhi- menko, G. Priority-based parameter propagation for dis- tributed dnn training. In T alwalkar , A., Smith, V ., and Zaharia, M. (eds.), Pr oceedings of Machine Learning and Systems . 2019. T aming Momentum in a Distributed Asynchr onous En vironment Jia, Z., Zaharia, M., and Aiken, A. Beyond data and model parallelism for deep neural networks. arXiv pr eprint arXiv:1807.05358 , 2018. Keskar , N. S., Mudigere, D., Nocedal, J., Smelyanskiy , M., and T ang, P . T . P . On large-batch training for deep learning: Generalization gap and sharp minima. arXiv pr eprint arXiv:1609.04836 , 2016. K osson, A., Chiley , V ., V enigalla, A., Hestness, J., and K ¨ oster , U. Pipelined backpropagation at scale: Train- ing large models without batches. arXiv preprint arXiv:2003.11666 , 2020. Lerer , A., W u, L., Shen, J., Lacroix, T ., W ehrstedt, L., Bose, A., and Peysakho vich, A. Pytorch-biggraph: A large scale graph embedding system. In T alwalkar , A., Smith, V ., and Zaharia, M. (eds.), Pr oceedings of Machine Learning and Systems , pp. 120–131. 2019. Li, M., Andersen, D. G., P ark, J. W ., Smola, A. J., Ahmed, A., Josifovski, V ., Long, J., Shekita, E. J., and Su, B.-Y . Scaling distributed machine learning with the parameter server . In 11th { USENIX } Symposium on Operating Systems Design and Implementation ( { OSDI } 14) , 2014. Li, S., Zhao, Y ., V arma, R., Salpekar , O., Noordhuis, P ., Li, T ., Paszke, A., Smith, J., V aughan, B., Damania, P ., et al. Pytorch distributed: experiences on accelerating data parallel training. arXiv pr eprint arXiv:2006.15704 , 2020. Lim, H., Andersen, D. G., and Kaminsky , M. 3lc: Lightweight and effecti ve traffic compression for distributed machine learning. arXiv pr eprint arXiv:1802.07389 , 2018. Lim, H., Andersen, D. G., and Kaminsky , M. 3lc: Lightweight and effecti ve traffic compression for dis- tributed machine learning. In T alwalkar , A., Smith, V ., and Zaharia, M. (eds.), Pr oceedings of Machine Learning and Systems . 2019. Lin, Y ., Han, S., Mao, H., W ang, Y ., and Dally , B. Deep gra- dient compression: Reducing the communication band- width for distributed training. In International Conference on Learning Repr esentations , 2018. Loizou, N. and Richt ´ arik, P . Linearly conv ergent stochastic heavy ball method for minimizing generalization error . CoRR , abs/1710.10737, 2017a. Loizou, N. and Richt ´ arik, P . Momentum and stochastic mo- mentum for stochastic gradient, ne wton, proximal point and subspace descent methods. CoRR , abs/1712.09677, 2017b. Luo, L., W est, P ., Nelson, J., Krishnamurthy , A., and Ceze, L. Plink: Discovering and e xploiting locality for acceler- ated distributed training on the public cloud. In Dhillon, I., Papailiopoulos, D., and Sze, V . (eds.), Pr oceedings of Machine Learning and Systems . 2020. Mikami, H., Suganuma, H., U.-Chupala, P ., T anaka, Y ., and Kageyama, Y . Imagenet/resnet-50 training in 224 seconds. CoRR , abs/1811.05233, 2018. URL http: //arxiv.org/abs/1811.05233 . Mitliagkas, I., Zhang, C., Hadjis, S., and R ´ e, C. Asynchrony begets momentum, with an application to deep learning. In 54th Annual Allerton Confer ence on Communication, Contr ol, and Computing , 2016. Narayanan, D., Harlap, A., Phanishayee, A., Seshadri, V ., Dev anur , N. R., Ganger , G. R., Gibbons, P . B., and Za- haria, M. Pipedream: generalized pipeline parallelism for dnn training. In Pr oceedings of the 27th ACM Symposium on Operating Systems Principles , 2019. Nesterov , Y . A method of solving a con vex programming problem with con ver gence rate o(1/k2). In Soviet Mathe- matics Doklady , 1983. Or , A., Zhang, H., and Freedman, M. Resource elasticity in distributed deep learning. In Dhillon, I., Papailiopoulos, D., and Sze, V . (eds.), Pr oceedings of Machine Learning and Systems . 2020. Paszke, A., Gross, S., Massa, F ., Lerer , A., Bradbury , J., Chanan, G., Killeen, T ., Lin, Z., Gimelshein, N., Antiga, L., et al. Pytorch: An imperative style, high-performance deep learning library . In Advances in neural information pr ocessing systems , 2019. Peng, Y ., Zhu, Y ., Chen, Y ., Bao, Y ., Y i, B., Lan, C., W u, C., and Guo, C. A generic communication scheduler for dis- tributed dnn training acceleration. In Pr oceedings of the 27th A CM Symposium on Operating Systems Principles , 2019. Polyak, B. Some methods of speeding up the con ver gence of iteration methods. USSR Computational Mathematics and Mathematical Physics , 1964. Raffel, C., Shazeer, N., Roberts, A., Lee, K., Narang, S., Matena, M., Zhou, Y ., Li, W ., and Liu, P . J. Exploring the limits of transfer learning with a unified text-to-te xt transformer . arXiv pr eprint arXiv:1910.10683 , 2019. Recht, B., Re, C., Wright, S., and Niu, F . Hogwild: A lock- free approach to parallelizing stochastic gradient descent. In Advances in neural information processing systems , 2011. T aming Momentum in a Distributed Asynchr onous En vironment Russakovsk y , O., Deng, J., Su, H., Krause, J., Satheesh, S., Ma, S., Huang, Z., Karpathy , A., Khosla, A., Bernstein, M. S., Berg, A. C., and Li, F . ImageNet large scale visual recognition challenge. International J ournal of Computer V ision , 2015. Silver , D., Huang, A., Maddison, C. J., Guez, A., Sifre, L., van den Driessche, G., Schrittwieser , J., Antonoglou, I., Panneershelv am, V ., Lanctot, M., Dieleman, S., Grewe, D., Nham, J., Kalchbrenner, N., Sutske ver , I., Lillicrap, T . P ., Leach, M., Kavukcuoglu, K., Graepel, T ., and Has- sabis, D. Mastering the game of go with deep neural networks and tree search. Natur e , 2016. Sutske ver , I., Martens, J., Dahl, G. E., and Hinton, G. E. On the importance of initialization and momentum in deep learning. In Pr oceedings of the 30th International Confer ence on Machine Learning , 2013. T ang, H., Y u, C., Lian, X., Zhang, T ., and Liu, J. Dou- blesqueeze: P arallel stochastic gradient descent with double-pass error-compensated compression. In Inter- national Confer ence on Machine Learning , 2019. W ang, G., V enkataraman, S., Phanishayee, A., Dev anur , N., Thelin, J., and Stoica, I. Blink: Fast and generic collec- ti ves for distributed ml. In Dhillon, I., Papailiopoulos, D., and Sze, V . (eds.), Pr oceedings of Machine Learning and Systems . 2020. W ang, J. and Joshi, G. Adapti ve communication strategies to achiev e the best error-runtime trade-of f in local-update sgd. arXiv pr eprint arXiv:1810.08313 , 2018. W oodworth, B., P atel, K. K., and Srebro, N. Minibatch vs local sgd for heterogeneous distributed learning. arXiv pr eprint arXiv:2006.04735 , 2020. Xing, E. P ., Ho, Q., Dai, W ., Kim, J. K., W ei, J., Lee, S., Zheng, X., Xie, P ., Kumar , A., and Y u, Y . Petuum: A ne w platform for distrib uted machine learning on big data. IEEE T ransactions on Big Data , 2015. Y amazaki, M., Kasagi, A., T abuchi, A., Honda, T ., Miwa, M., Fukumoto, N., T abaru, T ., Ike, A., and Nakashima, K. Y et another accelerated SGD: resnet-50 training on imagenet in 74.7 seconds. CoRR , abs/1903.12650, 2019. URL . Y ang, E., Kim, S.-H., Kim, T .-W ., Jeon, M., Park, S., and Y oun, C.-H. An adapti ve batch-orchestration algorithm for the heterogeneous gpu cluster environment in dis- tributed deep learning system. In 2018 IEEE Interna- tional Confer ence on Big Data and Smart Computing (BigComp) . IEEE, 2018. Y ang, E., Kang, D.-K., and Y oun, C.-H. Boa: batch orches- tration algorithm for straggler mitigation of distributed dl training in heterogeneous gpu cluster . The Journal of Super computing , 2020. Y ing, C., Kumar , S., Chen, D., W ang, T ., and Cheng, Y . Image classification at supercomputer scale. CoRR , abs/1811.06992, 2018. URL abs/1811.06992 . Y ou, Y ., Li, J., Reddi, S., Hseu, J., Kumar , S., Bhojanapalli, S., Song, X., Demmel, J., Keutzer , K., and Hsieh, C.-J. Large batch optimization for deep learning: T raining bert in 76 minutes. In International Confer ence on Learning Repr esentations , 2020. Zagoruyko, S. and K omodakis, N. W ide residual networks. In Pr oceedings of the British Machine V ision Conference , 2016. Zhang, J. and Mitliagkas, I. Y ellowfin and the art of mo- mentum tuning. In T alw alkar, A., Smith, V ., and Zaharia, M. (eds.), Pr oceedings of Machine Learning and Systems . 2019. Zhang, S., Choromanska, A., and LeCun, Y . Deep learning with elastic averaging SGD. In Advances in Neural In- formation Pr ocessing Systems 28: Annual Confer ence on Neural Information Pr ocessing Systems , 2015. Zhang, W ., Gupta, S., Lian, X., and Liu, J. Staleness-aware async-SGD for distributed deep learning. In Proceedings of the T wenty-F ifth International Joint Confer ence on Artificial Intelligence , 2016. Zhao, W ., Xie, D., Jia, R., Qian, Y ., Ding, R., Sun, M., and Li, P . Distributed hierarchical gpu parameter server for massiv e scale deep learning ads systems. In Dhillon, I., Papailiopoulos, D., and Sze, V . (eds.), Pr oceedings of Machine Learning and Systems . 2020. Zheng, S., Meng, Q., W ang, T ., Chen, W ., Y u, N., Ma, Z., and Liu, T . Asynchronous stochastic gradient descent with delay compensation. In Pr oceedings of the 34th International Confer ence on Machine Learning , 2017. Zhou, Z., Mertikopoulos, P ., Bambos, N., Glynn, P ., Y e, Y ., Li, L.-J., and Fei-Fei, L. Distributed asynchronous optimization with unbounded delays: How slo w can you go? In Proceedings of the 35th International Confer ence on Machine Learning , 2018. T aming Momentum in a Distributed Asynchr onous En vironment A E X P E R I M E N T A L S E T U P A.1 Algorithms Algorithms 8 to 10 only change the master’ s algorithm; the complementary worker algorithm is the same as ASGD (Algorithm 1 ). The master’ s scheme is a simple FIFO. W e consider parameter server optimizations to be beyond the scope of this paper . Algorithm 8 N A G-ASGD: master Receiv e gradient g i from worker i Update momentum v ← γ v + g i Update master’ s weights θ 0 ← θ 0 − η v Send θ 0 to worker i Algorithm 9 Multi-ASGD: master Receiv e gradient g i from worker i Update momentum v i ← γ v i + g i Update master’ s weights θ 0 ← θ 0 − η v i Send θ 0 to worker i Algorithm 10 DC-ASGD: master Receiv e gradient g i from worker i Update the gradient according to the delay compensation term ˆ g i = g i + λg i g i ( θ 0 − θ i ) Update momentum v i ← γ v i + ˆ g i Update master’ s weights θ 0 ← θ 0 − η v i Send θ 0 to worker i A.2 Efficient computation in D ANA-Zer o Computing the full summation P N i =1 v i prev ( i,t − 1) of the fu- ture position of the master’ s parameters can be computa- tionally expensiv e since its computational cost scales up with the number of workers. In practice, DAN A-Zero doesn’t compute the full summation for e very work er that requires the future position of the masters parameters. In- stead, DAN A-Zero maintains v 0 , which is equiv alent to the summation of all current momentum vectors at step t . After an update from worker i , DAN A-Zero subtracts the worker’ s pre vious momentum vector v i prev ( i,t − 1) from v 0 t and adds the worker’ s updated momentum vector v i t to v 0 t . Thus, after each worker update, v 0 t is updated by v 0 t = v 0 t − v i prev ( i,t − 1) + v i t . Hence, the computation cost of the summation reduces from O ( k · N ) to O ( k ) ; this is the same cost as computing the traditional N AG look-ahead, which isn’t af fected by the number of workers N . A.3 Datasets CIF AR The CIF AR-10 ( Hinton , 2007 ) dataset comprises of 60K RGB images partitioned into 50K training images and 10K test images. Each image contains 32x32 RGB pixels and belongs to 1 of 10 equal-sized classes. CIF AR- 100 is similar but contains 100 classes. Link . ImageNet The ImageNet dataset ( Russakovsk y et al. , 2015 ), kno wn as ILSVRC2012, consists of RGB images, each labeled as 1 of 1000 classes. Images are partitioned into 1.28 million training images and 50K validation images. Each image is randomly cropped and re-sized to 224x224 (1-crop validation). Link . A.4 Gamma Distrib ution Ali et al. ( 2000 ) suggest a method called CVB to simulate the run-time of a distributiv e network of computers. The method is based on sev eral definitions: T ask execution time variables: • µ task - mean time of tasks • V task - variance of tasks • µ mach - mean computation power of machines • V mach - variance of computation po wer of machines • α task = 1 V 2 task • α mach = 1 V 2 mach G ( α, β ) is a random number generated using a gamma dis- tribution, where α is the shape and β is the scale. For our case, all tasks are similar and run on a batch size of B. Therefore, the algorithm for deciding the ex ecution-time of e very task on a certain machine is reduced to one of the following: Algorithm 11 T ask execution time - homogeneous ma- chines β task = µ task α task q = G ( α task , β task ) β mach = q α mach for i from 0 to K − 1 : time = G ( α mach , β mach ) Algorithm 12 T ask execution time - heterogeneous ma- chines β mach = µ mach α mach for j from 0 to M : p [ j ] = G ( α mach , β mach ) β task [ j ] = p [ j ] α task for i from 0 to K − 1 : time = G ( α task , β task [ cur r ]) T aming Momentum in a Distributed Asynchr onous En vironment where K is the total amount of tasks of all the machines combined (the total number of batch iterations), M is the to- tal number of machines (workers), and cur r is the machine currently about to run. W e note that Algorithms 11 and 12 naturally give rise to stragglers. In the homogeneous algorithm, all workers hav e the same mean execution time but some tasks can still be very slow; this generally means that in every epoch a dif- ferent machine will be the slowest. In the heterogeneous algorithm, e very machine has a different mean execution time throughout the training. W e further note that p [ j ] is the mean ex ecution time of machine j on the av erage task. In our experiments, we simulated execution times using the follo wing parameters as suggested by Ali et al. ( 2000 ): µ task = µ mach = B · V 2 mach , where B is the batch size, yielding a mean execution time of µ simulated time units, which is proportionate to B . In the homogeneous set- ting V mach = 0 . 1 , whereas in the heterogeneous setting V mach = 0 . 6 . For both settings, V task = 0 . 1 . Figure 3 illustrates the dif ferences between the homoge- neous and heterogeneous gamma-distribution. Both en vi- ronments hav e the same mean (128) b ut the probability of having an iteration that is at least 1.25x longer than the mean (which means 160 or more) is significantly higher in the heterogeneous environment (27.9% in heterogeneous en vironment as opposed to 1% in the homogeneous en viron- ment). A.5 Hyperparameters T o verify that decreasing the gap leads to a better final test error and con ver gence rate, especially when scaling to more workers, we used the same hyperparameters across all the tested algorithms. These hyperparameters are the original hyperparameters of the respectiv e neural network architecture, which are tuned for a single worker . CIF AR-10 ResNet-20 • Initial learning rate η : 0 . 1 • Momentum coef ficient γ : 0 . 9 with NA G • Dampening: 0 (no dampening) • Batch size B : 128 • W eight decay: 1 e − 4 • Learning rate decay: 0 . 1 • Learning rate decay schedule: epochs 80 and 120 • T otal epochs: 160 CIF AR-10/100 Wide ResNet 16-4 • Initial learning rate η : 0 . 1 • Momentum coef ficient γ : 0 . 9 with NA G • Dampening: 0 (no dampening) • Batch size B : 128 • W eight decay: 5 e − 4 • Learning rate decay: 0 . 2 • Learning rate decay schedule: epochs 60 , 120 and 160 • T otal epochs: 200 ImageNet ResNet-50 • Initial learning rate η : 0 . 1 • Momentum coef ficient γ : 0 . 9 with NA G • Dampening: 0 (no dampening) • Batch size B : 256 • W eight decay: 1 e − 4 • Learning rate decay: 0 . 1 • Learning rate decay schedule: epochs 30 and 60 • T otal epochs: 90 Learning Rate W arm-Up In the early stages of training, the network generally changes rapidly , causing error spikes. For all algorithms, we followed the gradual warm-up ap- proach proposed by Goyal et al. ( 2017 ) to overcome this problem. W e divided the initial learning rate by the number of workers N and ramped it up linearly until it reached its original value after fi ve epochs. W e also used momentum correction ( Goyal et al. , 2017 ) in all algorithms to stabilize training when the learning rate changes. B A D D I T I O N A L R E S U L T S B.1 CIF AR Final Accuracies D AN A-DC starts to show signs of div ergence when it reaches 32 . Howe ver , when we tuned the learning rate η , D AN A-DC reached a significantly lo wer test error than that sho wn in T ables 2 to 4 . More precisely , when trained on 32 workers with η = 0 . 025 , D AN A-DC reached a test error of only 2.5% higher than the baseline on both CIF AR10 scenarios and 4.5% higher than the baseline on CIF AR100. B.2 ImageNet Final Accuracies T able 5 lists the final test accuracy of the different algorithms when training the ResNet-50 architecture ( He et al. , 2016 ) on ImageNet. D ANA consistently outperforms all the other algorithms. B.3 Normalized Gap As shown in Figure 2(b) , the gap of D AN A-Zero is smaller than that of ASGD, despite Equation ( 12 ). This is because D AN A-Zero uses momentum, which accelerates the con ver - gence and leads to smaller gradients. T o make a more accu- rate comparison between the gaps of dif ferent algorithms, we define the normalized gap as G ∗ (∆ t + τ ) = G(∆ t + τ ) k g t k . Figure 11(b) shows that the normalized gap of ASGD is roughly similar to that of DAN A-Zero, empirically confirm- T aming Momentum in a Distributed Asynchr onous En vironment T able 2. ResNet-20 CIF AR10 Final T est Accuracy (Baseline 91.63%) #W orkers D AN A-DC D AN A-Slim DC-ASGD Multi-ASGD NA G-ASGD Y ellowFin 4 91.79 ± 0.21 91.65 ± 0.15 91.68 ± 0.18 91.55 ± 0.15 91.41 ± 0.23 90.05 ± 0.37 8 91.51 ± 0.16 91.52 ± 0.16 90.67 ± 0.26 91.28 ± 0.21 90.83 ± 0.18 90.29 ± 0.14 12 91.49 ± 0.18 91.32 ± 0.16 72.16 ± 5.32 90.42 ± 0.08 82.41 ± 4.41 90.54 ± 0.18 16 91.01 ± 0.25 91.02 ± 0.16 18.35 ± 16.7 84.88 ± 1.28 17.45 ± 12.39 41.19 ± 38.21 20 90.78 ± 0.32 90.56 ± 0.32 10.0 ± 0.0 57.32 ± 23.9 10.17 ± 0.33 10.0 ± 0.0 24 89.76 ± 0.37 89.81 ± 0.4 17.65 ± 15.3 23.83 ± 18.43 19.81 ± 12.2 10.0 ± 0.0 28 87.82 ± 0.83 84.91 ± 3.6 10.0 ± 0.0 15.58 ± 9.38 18.5 ± 17.0 10.0 ± 0.0 32 82.99 ± 3.38 79.33 ± 4.68 10.0 ± 0.0 12.04 ± 4.08 12.06 ± 4.11 10.0 ± 0.0 T able 3. W ide ResNet 16-4 CIF AR10 Final T est Accuracy (Baseline 95 . 17% ) #W orkers D AN A-DC D AN A-Slim DC-ASGD Multi-ASGD N AG-ASGD Y ellowFin 4 95.08 ± 0.13 95.04 ± 0.11 93.66 ± 0.16 94.97 ± 0.11 94.81 ± 0.11 92.81 ± 0.04 8 94.84 ± 0.19 94.91 ± 0.2 89.76 ± 1.0 94.25 ± 0.12 92.83 ± 0.61 93.52 ± 0.08 12 94.35 ± 0.16 94.45 ± 0.21 18.24 ± 16.49 92.64 ± 0.17 44.35 ± 28.22 93.78 ± 0.08 16 93.67 ± 0.15 93.66 ± 0.2 22.29 ± 24.59 70.86 ± 14.08 23.36 ± 26.72 93.19 ± 0.18 20 92.73 ± 0.37 92.72 ± 0.13 24.59 ± 29.18 16.13 ± 12.25 33.41 ± 30.31 26.03 ± 32.06 24 90.4 ± 0.4 88.76 ± 1.85 24.27 ± 28.54 26.98 ± 23.0 11.62 ± 3.23 10.0 ± 0.0 28 76.88 ± 4.65 71.62 ± 5.0 34.92 ± 30.88 31.77 ± 26.66 31.91 ± 17.68 10.0 ± 0.0 32 69.35 ± 6.86 69.13 ± 6.85 10.0 ± 0.0 14.51 ± 7.4 19.52 ± 19.03 10.0 ± 0.0 ing Equation ( 12 ). This suggests that D AN A-Zero’ s future position approximation is close to optimal, ev en when train- ing with stragglers. C A S Y N C H R O N O U S S P E E D U P C.1 CIF AR-10 Distributed Experiments D AN A-Slim successfully scales up to 20 workers (similarly to the simulations) with high speedup and low final test error (less than 1% higher than the baseline). Abov e 20 work ers, the master becomes a bottleneck. This is consistent with the literature on ASGD ( Xing et al. , 2015 ). T o overcome this bottleneck, existing parameter server optimization tech- niques can be used, such as sharding ( Dean et al. , 2012 ; Li et al. , 2014 ), synchronization frequency reduction ( W ang & Joshi , 2018 ), network utilization improv ements ( Jia et al. , 2018 ; Zhao et al. , 2020 ; W ang et al. , 2020 ), communication compression ( T ang et al. , 2019 ; Lim et al. , 2018 ; Lin et al. , 2018 ; Bernstein et al. , 2018 ; Lim et al. , 2019 ), and overlap- ping communications with computations ( Hashemi et al. , 2019 ; Jayarajan et al. , 2019 ). W e note that D ANA is com- patible with these optimizations. The speedup superiority of ASGD methods compared to SSGD methods is discussed in Appendix C . Figure 10 sho ws the speedup and final test error when run- ning D ANA-Slim on the Google Cloud Platform with a single parameter server (master) and one Nvidia T esla V100 GPU per machine, when training ResNet-20 on the CIF AR- 10 dataset. It shows speedup of up to 16 × when training with N = 24 workers. As before, its final test error remains close to the baseline for up to N = 24 w orkers. Cloud computing is becoming increasingly popular as a plat- form to perform distributed training of deep neural networks ( Or et al. , 2020 ). Although synchronous SGD is currently the primary method ( Mikami et al. , 2018 ; Y ing et al. , 2018 ; Y amazaki et al. , 2019 ; Goyal et al. , 2017 ; Luo et al. , 2020 ) used to distrib ute the learning process, it suf fers from sub- stantial slowdo wns when run in non-dedicated en vironments such as the cloud. This shortcoming is magnified in hetero- geneous en vironments and non-dedicated networks. ASGD addresses the SSGD drawback and enjoys linear speedup in terms of the number of workers in both heterogeneous and homogeneous en vironments ev en in non-dedicated net- T aming Momentum in a Distributed Asynchr onous En vironment T able 4. W ide ResNet 16-4 CIF AR100 Final T est Accuracy (Baseline 76 . 72% ) #W orkers D AN A-DC D AN A-Slim DC-ASGD Multi-ASGD NA G-ASGD Y ellowFin 4 76.22 ± 0.15 76.27 ± 0.33 74.03 ± 0.26 76.07 ± 0.23 76.27 ± 0.2 66.91 ± 0.25 8 76.05 ± 0.23 76.07 ± 0.17 70.48 ± 0.48 75.33 ± 0.29 74.24 ± 0.27 68.05 ± 0.21 12 75.57 ± 0.24 75.64 ± 0.28 65.7 ± 0.68 73.63 ± 0.29 69.29 ± 0.56 69.36 ± 0.22 16 74.69 ± 0.28 74.97 ± 0.1 56.5 ± 1.75 70.68 ± 0.23 67.37 ± 0.74 69.85 ± 0.29 20 73.14 ± 0.58 73.48 ± 0.35 45.61 ± 4.16 68.12 ± 0.48 37.98 ± 7.21 69.62 ± 0.18 24 71.19 ± 0.32 71.91 ± 0.27 50.24 ± 2.63 66.12 ± 0.58 9.67 ± 4.89 67.9 ± 0.49 28 69.14 ± 0.62 69.77 ± 0.83 48.49 ± 1.31 54.3 ± 2.29 6.35 ± 7.41 13.76 ± 25.52 32 67.19 ± 0.79 67.91 ± 0.7 45.98 ± 2.26 29.43 ± 8.11 12.71 ± 7.69 1.0 ± 0.0 T able 5. ResNet-50 ImageNet Final T est Accuracy (Baseline 75 . 64% ) #W orkers DAN A-DC DAN A-Slim DC-ASGD Multi-ASGD NA G-ASGD Y ellowFin L WP 16 75.54% 74.95% 72.64% 74.96% 73.22% 53.74% 74.12% 32 74.86% 74.89% 59.99% 71.72% 70.64% 57.88% 71.84% 48 73.80% 73.75% 31.71% 65.13% 66.78% 63.07% 67.34% 64 73.58% 69.88% 8.1% 54.04% 59.81% 0.15% 61.8% 128 69.50% NaN NaN NaN NaN NaN NaN works. This makes ASGD a potentially better alternativ e for cloud computing. Figure 12(a) sho ws the theoretically achie vable speedup, based on the detailed gamma-distrib uted model, for asyn- chronous (GA and other ASGD v ariants) and synchronous algorithms using homogeneous and heterogeneous workers. The asynchronous algorithms can achieve linear speedup while the synchronous algorithm (SSGD) f alls short as we increase the number of w orkers. This occurs because SSGD must wait in each iteration until all w orkers complete their batch. Figure 12(b) shows that ASGD-based algorithms (including GA, SA and DAN A versions) are up to 21% faster than SSGD in homogeneous environments. In het- erogeneous en vironments, ASGD methods can be 6x faster than SSGD. W e note that this speedup is an underestimate, since our simulation includes only batch execution times. It does not model the e xecution time of barriers, all-gather operations, and other overheads which usually increase com- munication time, especially in SSGD. D H E T E R O G E N E O U S E N V I R O N M E N T In our experiments, the algorithms scale better in the hetero- geneous en vironment Figure 13(a) than in the homogeneous en vironment (Figure 4(a) ). The reason is that stragglers naturally hav e less impact on the training process. W e will demonstrate this with a simplistic example. Consider an asynchronous en vironment with only N = 2 workers, where one worker is significantly faster than the other . The fast worker will run as in sequential SGD, since its gap and lag will mostly be zero. Conv ersely , the slo w workers will have minimal impact and therefore its stale gradients wouldn’t harm the con ver gence process. This suggests that high accuracy can be attained more easily in asynchronous heterogeneous en vironments than in homo- geneous en vironments. Figures 13(a) and 13(b) sho w that ev en in a heterogeneous en vironment, D AN A-DC con verges the fastest and achiev es the highest final accuracy . The final accuracies are listed in T able 6 belo w . T aming Momentum in a Distributed Asynchr onous En vironment 0 25 50 75 100 125 150 Epoch 0.5 1.0 1.5 2.0 Gradient Norm ASGD NAG-ASGD Multi-ASGD LWP DC-ASGD YellowFin DANA-Zero DANA-DC (a) Gradient norm. 0 25 50 75 100 125 150 Epoch 1 0 5 1 0 4 1 0 3 1 0 2 Normalized Gap [log] ASGD NAG-ASGD Multi-ASGD LWP DC-ASGD YellowFin DANA-Zero DANA-DC (b) Normalized gap. Figure 11. Figures 11(a) and 11(b) compare the different asynchronous algorithms when training the ResNet-20 architecture on the CIF AR-10 dataset with 8 workers. Figures 11(a) and 11(b) show the gradient norm and the normalized gap , respectiv ely , throughout the training process. The large drops in Figure 11(b) are caused by learning rate decay . 0 200 400 600 800 1000 #Workers 0 200 400 600 800 1000 Speedup Homogeneous SSGD Speedup Heterogeneous SSGD Speedup ASGD Speedup Linear Speedup (a) ASGD and SSGD speedups. 1 0 1 1 0 2 1 0 3 #Workers [log] 1 2 3 4 5 6 Speedup Ratio Homogeneous Heterogeneous (b) ASGD speedup ov er SSGD. X axis is in log scale. Figure 12. Theoretical speedups for any ASGD (such as D AN A) and SSGD algorithms when batch execution times are drawn from a gamma distribution. Communication ov erheads aren’t modeled. Since ASGD is more efficient in communication, accounting for the communication ov erheads should expand the gap between the ASGD and SSGD, in fa vor of ASGD. 4 8 12 16 20 24 28 32 #Workers 20 40 60 Final Test Error (%) Baseline NAG-ASGD Multi-ASGD LWP DC-ASGD YellowFin DANA-Slim DANA-DC (a) Final test error for different numbers of w orkers N . 0 25 50 75 100 125 150 Epoch 20 40 60 80 Test Error (%) Baseline NAG-ASGD Multi-ASGD DC-ASGD DANA-Slim DANA-DC (b) Con vergence rate for 8 w orkers. Figure 13. T raining of ResNet-20 on CIF AR10 in a heterogeneous en vironment. T able 6. Heterogeneous En vironment ResNet 20 CIF AR10 Final T est Accuracy (Baseline 91.63%) #W orkers D AN A-DC D AN A-Slim DC-ASGD Multi-ASGD N A G-ASGD 4 91.57 ± 0.14 91.7 ± 0.18 91.6 ± 0.14 91.77 ± 0.22 91.38 ± 0.12 8 91.57 ± 0.18 91.55 ± 0.28 91.72 ± 0.21 91.59 ± 0.11 91.15 ± 0.23 16 91.28 ± 0.21 91.31 ± 0.17 90.98 ± 0.5 91.12 ± 0.3 83.65 ± 5.17 24 91.21 ± 0.19 90.94 ± 0.27 90.11 ± 0.92 89.6 ± 2.03 39.36 ± 36.01 32 90.33 ± 0.58 90.52 ± 1.04 57.62 ± 38.93 74.18 ± 32.1 37.52 ± 34.12
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment