멀티에이전트 진화·강화학습을 통한 샘플 효율적 협동 조정
본 논문은 팀 기반 희소 보상과 개별 에이전트의 밀집 보상이 동시에 존재하는 협동 MARL 환경에서, 진화 알고리즘과 정책 그라디언트 학습을 병행하는 MERL(Multiagent Evolutionary Reinforcement Learning) 프레임워크를 제안한다. 진화 단계는 팀 목표를 직접 최적화하고, 그라디언트 단계는 개별 스킬을 학습한다. 두 단계는 공유 리플레이 버퍼와 정책 이주 메커니즘을 통해 정보를 교환하며, 실험 결과 MADDP…
저자: Shauharda Khadka, Somdeb Majumdar, Santiago Miret
**1. 연구 배경 및 문제 정의**
협동 다중 에이전트 강화학습(MARL)에서는 종종 두 종류의 보상이 동시에 제공된다. 팀 전체의 목표를 나타내는 희소 보상은 협동 행동을 유도하지만, 그 자체만으로는 학습이 매우 비효율적이다. 반면 개별 에이전트에게 주어지는 밀집 보상은 기본적인 스킬(예: 이동, 목표 탐색)을 빠르게 학습하게 하지만, 팀 목표와는 정렬되지 않아 최종 협동 성과를 보장하지 못한다. 기존 연구들은 두 보상을 선형 결합하거나, 도메인 전문가가 설계한 보상 shaping을 통해 하나의 복합 보상으로 변환하려 했지만, 이는 보상 스케일링 문제와 도메인 의존성을 야기한다.
**2. MERL 프레임워크 개요**
본 논문은 이러한 문제를 해결하기 위해 *분할‑수준* 학습 접근법을 제안한다. MERL은 두 개의 최적화 프로세스를 병렬로 운영한다.
- **진화 단계**: 팀 보상만을 목표로 하는 신경진화 알고리즘을 적용한다. 인구(population) 내 각 팀은 동일한 다중 헤드 신경망 구조를 사용한다. 헤드마다 하나의 에이전트를 담당하며, 하위 레이어는 모든 에이전트가 공유한다(특징 추출 효율성 향상). 각 팀의 적합도는 에피소드 종료 시 팀 보상의 총합으로 측정되고, 선택·돌연변이·교차 연산을 통해 새로운 세대가 생성된다.
- **그라디언트 단계**: TD3 기반 정책 그라디언트 학습기를 사용해 개별 에이전트가 자신의 로컬 보상만을 최대화하도록 학습한다. 각 에이전트는 독립적인 리플레이 버퍼(R_k)를 가지고, 공유된 크리틱(Q) 네트워크가 모든 버퍼에서 샘플을 뽑아 업데이트한다. 이 과정에서 진화 단계에서 생성된 트래젝터리도 버퍼에 저장되므로, 정책 그라디언트는 진화가 탐색한 고보상 상태를 활용한다.
**3. 정책 이주와 정보 교환 메커니즘**
두 단계는 단순히 병렬로 실행되는 것이 아니라, **정책 이주(Policy Migration)** 라는 메커니즘을 통해 상호 보완한다. 일정 주기마다 그라디언트 단계에서 학습된 다중 헤드 정책(π_pg)을 진화 인구에 복제한다. 복제된 정책은 진화 연산(선택·돌연변이·교차)에 그대로 참여하므로, 개별 스킬이 팀 수준의 진화 과정에 자연스럽게 스며든다. 반대로, 진화 단계에서 우수한 팀이 선택되면 그 파라미터는 다음 그라디언트 업데이트에 사용될 수 있다(공유 버퍼를 통한 간접 피드백). 이 양방향 흐름은 보상 스칼라화 없이도 두 보상의 장점을 동시에 활용한다는 점에서 핵심적인 혁신이다.
**4. 알고리즘 상세**
Algorithm 1에 제시된 바와 같이 MERL은 다음 순서로 진행된다.
1) 초기 인구 M개의 다중 헤드 팀을 무작위 가중치로 생성한다.
2) 공유 크리틱 Q와 N개의 빈 리플레이 버퍼(R_k)를 초기화한다.
3) 각 세대마다 인구 내 모든 팀에 대해 두 번의 롤아웃을 수행한다(노이즈 유무에 따라 탐색·활용을 구분).
4) 팀의 팀 보상 합계로 적합도를 부여하고, 엘리트와 토너먼트 선택을 통해 다음 세대 후보를 만든다.
5) 교차·돌연변이 연산을 통해 인구를 보충한다.
6) 각 에이전트는 자신의 버퍼에서 미니배치를 샘플링해 TD3 업데이트를 수행한다(크리틱 손실 최소화, 정책 그라디언트 계산).
7) 일정 주기마다 가장 약한 팀을 현재 그라디언트 정책(π_pg)의 파라미터로 교체한다(정책 이주).
**5. 실험 설정 및 결과**
MERL은 네 가지 표준 협동 MARL 벤치마크에서 평가되었다.
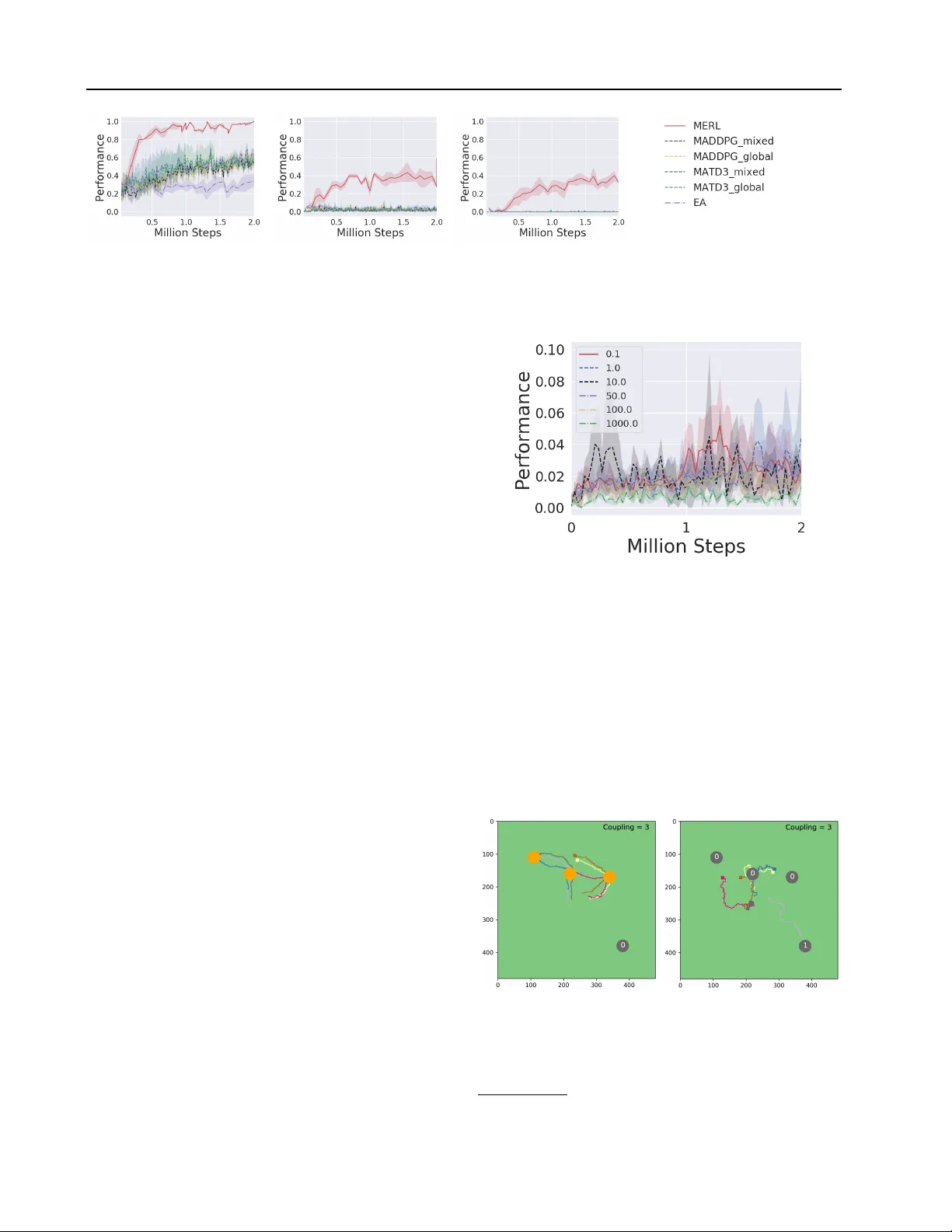
- **Rover 도메인**: 두 로버가 POI를 탐색해야 하는 환경으로, 팀 보상은 모든 POI를 관측했을 때만 주어지고, 개별 보상은 가장 가까운 POI와의 거리 부정값이다. 팀 보상은 희소하고, 개별 보상과 목표가 상충한다. MERL은 TD3‑global이 전혀 학습하지 못하고, TD3‑mixed가 로컬 최적해에 머무는 반면, EA는 탐색 확률이 낮아 전역 최적해에 도달하지 못한다. MERL은 두 단계의 장점을 결합해 빠르게 전역 최적해를 찾았다.
- **Predator‑Prey, Physical Deception, Keep‑Away** 등 다른 환경에서도 MERL은 MADDPG, TD3‑mixed, 순수 EA보다 높은 성공률과 더 빠른 수렴 속도를 보였다. 특히 팀 보상이 매우 희소하거나 에이전트 간 역할이 비대칭적인 경우 MERL의 샘플 효율성이 두드러졌다.
**6. 논의 및 한계**
MERL은 보상 설계에 대한 도메인 지식 의존도를 크게 낮추고, 샘플 효율성을 향상시킨다. 그러나 몇 가지 제한점이 존재한다.
- **네트워크 구조 제한**: 모든 에이전트가 동일한 하위 레이어를 공유함으로써, 역할이 크게 다른 에이전트(예: 리더와 팔로워)에서는 표현력이 제한될 수 있다.
- **하이퍼파라미터 민감도**: 인구 크기, 교차·돌연변이 비율, 정책 이주 주기 등은 성능에 큰 영향을 미치며, 자동 튜닝 메커니즘이 필요하다.
- **액션 공간 제약**: 현재 구현은 연속 액션 공간에 최적화돼 있어, 이산형 행동이 주된 환경에서는 추가적인 변형이 요구된다.
**7. 결론**
MERL은 팀 보상과 개별 보상이 서로 정렬되지 않는 협동 MARL 문제를 해결하기 위한 새로운 프레임워크이다. 진화 기반 팀 최적화와 정책 그라디언트 기반 스킬 학습을 동시에 수행하고, 공유 리플레이 버퍼와 정책 이주를 통해 두 단계가 효율적으로 정보를 교환한다. 실험 결과는 MERL이 기존 최첨단 방법(MADDPG, TD3‑mixed, 순수 EA)보다 샘플 효율성과 최종 성능 모두에서 우수함을 입증한다. 향후 연구에서는 역할 기반 네트워크 구조, 자동 하이퍼파라미터 조정, 이산 액션 지원 등을 통해 MERL의 적용 범위를 확대할 수 있을 것이다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기