Evolutionary Reinforcement Learning for Sample-Efficient Multiagent Coordination
Many cooperative multiagent reinforcement learning environments provide agents with a sparse team-based reward, as well as a dense agent-specific reward that incentivizes learning basic skills. Training policies solely on the team-based reward is oft…
Authors: Shauharda Khadka, Somdeb Majumdar, Santiago Miret
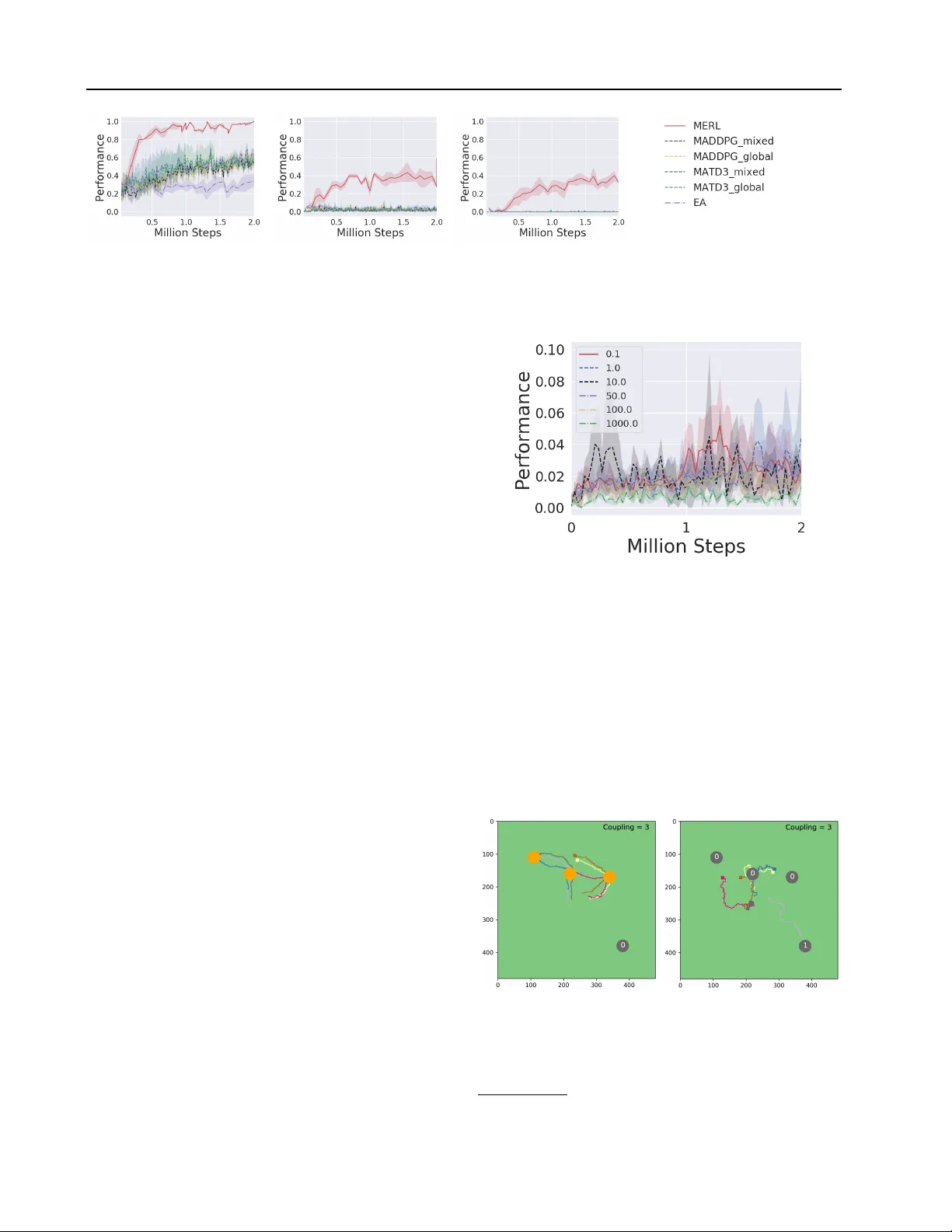
Evolutionary Reinf or cement Learning f or Sample-Efficient Multiagent Coordination Shauharda Khadka * 1 Somdeb Majumdar * 1 Santiago Miret 1 Stephen McAleer 2 Kagan T umer 3 Abstract Many cooperativ e multiagent reinforcement learn- ing en vironments provide agents with a sparse team-based rew ard, as well as a dense agent- specific re ward that incenti vizes learning basic skills. T raining policies solely on the team-based rew ard is often dif ficult due to its sparsity . Fur- thermore, relying solely on the agent-specific re- ward is sub-optimal because it usually does not capture the team coordination objecti ve. A com- mon approach is to use rew ard shaping to con- struct a proxy re ward by combining the individual rew ards. Howe ver , this requires manual tuning for each environment. W e introduce Multiagent Evolutionary Reinforcement Learning (MERL), a split-lev el training platform that handles the two objectiv es separately through two optimization processes. An ev olutionary algorithm maximizes the sparse team-based objecti ve through neuroev o- lution on a population of teams. Concurrently , a gradient-based optimizer trains policies to only maximize the dense agent-specific re wards. The gradient-based policies are periodically added to the e volutionary population as a way of informa- tion transfer between the two optimization pro- cesses. This enables the e volutionary algorithm to use skills learned via the agent-specific rewards tow ard optimizing the global objectiv e. Results demonstrate that MERL significantly outperforms state-of-the-art methods, such as MADDPG, on a number of difficult coordination benchmarks. 1. Introduction Cooperativ e multiagent reinforcement learning (MARL) studies how multiple agents can learn to coordinate as a * Equal contribution 1 Intel Labs 2 Univ ersity of California, Irvine 3 Oregon State Univ ersity . Correspondence to: Shauharda Khadka , Somdeb Majumdar . Pr oceedings of the 37 th International Conference on Machine Learning , V ienna, Austria, PMLR 108, 2020. Copyright 2020 by the author(s). team toward maximizing a global objective. Cooperative MARL has been applied to many real world applications such as air traffic control ( T umer and Agogino , 2007 ), multi- robot coordination ( Sheng et al. , 2006 ; Yliniemi et al. , 2014 ), communication and language ( Lazaridou et al. , 2016 ; Mor- datch and Abbeel , 2018 ), and autonomous dri ving ( Shalev- Shwartz et al. , 2016 ). Many such en vironments endow agents with a team re ward that reflects the team’ s coordination objectiv e, as well as an agent-specific local rew ard that rewards basic skills. For instance, in soccer , dense local rew ards could capture agent- specific skills such as passing, dribbling and running. The agents must then coordinate when and where to use these skills in order to optimize the team objectiv e, which is win- ning the game. Usually , the agent-specific rew ard is dense and easy to learn from, while the team reward is sparse and requires the cooperation of all or most agents. Having each agent directly optimize the team reward and ignore the agent-specific re ward usually fails or leads to sample-inefficienc y for complex tasks due to the sparsity of the team re ward. Con versely , ha ving each agent directly optimize the agent-specific reward also fails because it does not capture the team’ s objecti ve, e ven with state-of-the-art methods such as MADDPG ( Lowe et al. , 2017 ). One approach to this problem is to use rew ard shaping, where e xtensive domain knowledge about the task is used to create a proxy re ward function ( Rahmattalabi et al. , 2016 ). Constructing this proxy reward function is challenging in complex en vironments, and is usually domain-dependent. In addition to requiring domain knowledge and manual tuning, this approach also poses risks of changing the underlying problem itself ( Ng et al. , 1999 ). Common approaches to creating proxy re wards via linear combinations of the two objecti ves also fail to solve or generalize to complex coordi- nation tasks ( Devlin et al. , 2011 ; W illiamson et al. , 2009 ). In this paper , we introduce Multiagent Ev olutionary Rein- forcement Learning (MERL), a state-of-the-art algorithm for cooperative MARL that does not require reward shap- ing. MERL is a split-le vel training platform that combines gradient-based and gradient-free optimization. The gradient- free optimizer is an ev olutionary algorithm that maximizes the team objective through neuroe volution. The gradient- MERL based optimizer is a policy gradient algorithm that maxi- mizes each agent’ s dense, local rew ards. These gradient- based policies are periodically copied into the ev olutionary population, while the two processes operate concurrently and share information through a shared replay buf fer . A k ey strength of MERL is that it is a general method which does not require domain-specific rew ard shaping. This is because MERL optimizes the team objectiv e directly while simultaneously leveraging agent-specific rew ards to learn basic skills. W e test MERL in a number of multiagent coordination benchmarks. Results demonstrate that MERL significantly outperforms state-of-the-art methods such as MADDPG, while using the same observ ations and re ward functions. W e also demonstrate that MERL scales gracefully to increasing complexity of coordination objecti ves where MADDPG and its variants f ail to learn entirely . 2. Background and Related W ork Markov Games: A standard reinforcement learning (RL) setting is formalized as a Markov Decision Process (MDP) and consists of an agent interacting with an environment ov er a finite number of discrete time steps. This formula- tion can be extended to multiagent systems in the form of partially observable Marko v games ( Littman , 1994 ). An N -agent Markov game is defined by a global state of the world, S , and a set of N observations {O i } and N actions {A i } corresponding to the N agents. At each time step t , each agent observes its corresponding observation O t i and maps it to an action A t i using its policy π i . Each agent recei ves a scalar re ward r t i based on the global state S t and joint action of the team. The world then tran- sitions to the next state S t +1 which produces a new set of observations {O i } . The process continues until a terminal state is reached. R i = P T t =0 γ t r t i is the total return for agent i with discount factor γ ∈ (0 , 1] . Each agent aims to maximize its expected return. TD3: Policy gradient (PG) methods frame the goal of max- imizing the e xpected return as the minimization of a loss function. A widely used PG method for continuous, high- dimensional action spaces is DDPG ( Lillicrap et al. , 2015 ). Recently , ( Fujimoto et al. , 2018 ) extended DDPG to T win Delayed DDPG (TD3), addressing its well-known overes- timation problem. TD3 is the state-of-the-art, off-policy algorithm for model-free DRL in continuous action spaces. TD3 uses an actor-critic architecture ( Sutton and Barto , 1998 ) maintaining a deterministic policy (actor) π : S → A , and two distinct critics Q : S × A → R i . Each critic in- dependently approximates the actor’ s action-value function Q π . A separate copy of the actor and critics are kept as target networks for stability and are updated periodically . A noisy v ersion of the actor is used to explore the en vironment during training. The actor is trained using a noisy v ersion of the sampled policy gradient computed by backpropagation through the combined actor-critic networks. This mitigates ov erfitting of the deterministic policy by smoothing the pol- icy gradient updates. Evolutionary Reinf orcement Learning (ERL) is a hybrid algorithm that combines Evolutionary Algorithms (EAs) ( Floreano et al. , 2008 ; Lüders et al. , 2017 ; Fogel , 2006 ; Spears et al. , 1993 ), with policy gradient methods ( Khadka and T umer , 2018 ). Instead of discarding the data generated during a standard EA rollout, ERL stores this data in a cen- tral replay buf fer shared with the policy gradient’ s own roll- outs - thereby increasing the di versity of the data a vailable for the policy gradient learners. Since the EA directly opti- mizes for episode-wide return, it biases exploration towards states with higher long-term returns. The policy gradient algorithm which learns using this state distribution inherits this implicit bias to wards long-term optimization. Concur - rently , the actor trained by the policy gradient algorithm is inserted into the evolutionary population allo wing the EA to benefit from the fast gradient-based learning. Related W ork : ( Lo we et al. , 2017 ) introduced MADDPG which tackled the inherent non-stationarity of a multiagent learning en vironment by lev eraging a critic which had full access to the joint state and action during training. ( Foerster et al. , 2018b ) utilized a similar setup with a centralized critic across agents to tackle StarCraft micromanagement tasks. An algorithm that could explicitly model other agents’ learn- ing was in vestigated in ( Foerster et al. , 2018a ). Howe ver , all these approaches rely on a dense agent reward that properly captures the team objecti ve. Methods to solve for these types of agent-specific re ward functions were in vestigated in ( Li et al. , 2012 ) but were limited to tasks with strong simulators where tree-based planning could be used. A closely related work to MERL is ( Liu et al. , 2019 ) where Population-Based Training (PBT) ( Jaderberg et al. , 2017 ) is used to optimize the relativ e importance between a col- lection of dense, shaped rewards alongside their discount rates automatically during training. This can be interpreted as a singular central re ward function constructed by scalar- izing a collection of rew ard signals where the scalarization coefficients and discount rates are adapti vely learned during training. PBT -MARL a po werful method that can leverage complex mixtures of its re ward signals throughout training. Howe ver , it still relies on finding ideal mixing function be- tween rew ards signals to driv e learning. In contrast, MERL optimizes its reward functions independently , relying in- stead on information transfer across them to dri ve learning. This is facilitated through shared replay buf fers and pol- icy migration directly . This form of information transfer through a shared replay b uffer has been explored e xtensiv ely in recent literature ( Colas et al. , 2018 ; Khadka et al. , 2019 ). MERL 3. Motivating Example (a) Rover domain (b) MERL vs TD3 vs EA Figure 1. (a) Rov er domain with a clear misalignment between agent and team rew ard functions (b) Comparative performance of MERL compared against TD3-mixed, TD3-global and EA. Consider the rov er domain ( Agogino and T umer , 2004 ), a classic multiagent task where a team of rovers coordinate to explore a region. The team objecti ve is to observe all POIs (Points of Interest). Each robot also receives an agent- specific reward defined as negati ve distance to the closest POI. In Figure 1 (a), a team of two rovers R 1 and R 2 seek to explore and observ e POIs P 1 and P 2 . R 1 is closer to P 2 and has enough fuel to reach either of the POIs whereas R 2 can only reach P 2 . There is no communication between the rov ers. If R 1 optimizes only locally by pursuing the closer POI P 2 , then the team objecti ve is not achieved since R 2 can only reach P 2 . The globally optimal solution for R 1 is to spend more fuel and pursue P 1 , which is misaligned with its locally optimal solution. Figure 1 (b) shows the comparativ e performance of four algorithms - namely TD3-global, TD3- mixed, EA and MERL on this coordination task. TD3-global optimizes only the team rew ard and TD3- mixed optimizes a linear mixture of the indi vidual and team rew ards. Since the team rew ard is sparse, TD3-global fails to learn anything meaningful. In contrast, TD3-mixed, due to the dense agent-specific rew ard component, successfully learns to percei ve and na vigate. Howe ver , since the mix ed rew ard does not capture the true team objectiv e, it con verges to the greedy local policy of R 1 pursuing P 2 . EA relies on randomly stumbling onto a solution - e.g., a trajectory that takes the rover to a POI. Since EA directly optimizes the team objecti ve, it has a strong preference for the globally optimal solution. Howe ver , the probability of the rov ers randomly stumbling onto the globally optimal so- lution is extremely lo w . The greedy solution is significantly more likely to be found - and is what EA con ver ges to. MERL combines the core strengths of TD3 and EA. The TD3 component in MERL exploits the dense agent-specific rew ard to learn perception and navigation skills while being agnostic to the global objective. The task is then reduced to its coordination component - picking the right POI to go to. This is ef fectiv ely tackled by the EA module within MERL. This ability to independently lev erage rew ard func- tions across multiple le vels ev en when they are misaligned is the core strength of MERL. 4. Multiagent Evolutionary Reinf orcement Learning MERL leverages both agent-specific and team objectiv es through a hybrid algorithm that combines gradient-free and gradient-based optimization. The gradient-free optimizer is an ev olutionary algorithm that maximizes the team objecti ve through neuroev olution. The gradient-based optimizer trains policies to maximize agent-specific rew ards. These gradient- based policies are periodically added to the ev olutionary population and participate in ev olution. This enables the ev olutionary algorithm to use agent-specific skills learned by training on the agent-specific re wards to ward optimizing the team objectiv e without needing to resort to reward shaping. Figure 2. Multi-headed team policy Policy T opology: W e represent our multiagent ( team ) poli- cies using a multi-headed neural network π as illustrated in Figure 2 . The head π k represents the k -th agent in the team. Giv en an incoming observation for agent k , only the output of π k is considered as agent k ’ s response. In essence, all agents act independently based on their own observations while sharing weights (and by extension, the features) in the lower layers ( trunk ). This is commonly used to improv e learning speed ( Silver et al. , 2017 ). Further , each agent k also has its own replay buf fer ( R k ) which stores its expe- rience defined by the tuple (state, action, next state, local r ewar d) for each interaction with the en vironment ( r ollout ) in volving that agent. T eam Reward Optimization: Figure 3 illustrates the MERL algorithm. A population of M multi-headed teams, each with the same topology , is initialized with random weights. The replay buffer R k is shared by the k -th agent across all teams. The population is then evaluated for each rollout. The team re ward for each team is disbursed at the end of the episode and is considered as its fitness score . MERL A selection operator selects a portion of the population for surviv al with probability proportionate to their fitness scores. The weights of the teams in the population are probabilisti- cally perturbed through mutation and crossover operators to create the next generation of teams. A portion of the teams with the highest relativ e fitness is preserved as elites. At any gi ven time, the team with the highest fitness, or the champion , represents the best solution for the task. Figure 3. High lev el schematic of MERL highlighting the integra- tion of local and global rew ard functions Policy Gradient: The procedure described so f ar resembles a standard EA e xcept that each agent k stores each of its experiences in its associated replay buf fer ( R k ) instead of just discarding it. Ho wever , unlike EA, which only learns based on the lo w-fidelity global reward, MERL also learns from the experiences within episodes of a rollout using policy gradients. T o enable this kind of "local learning", MERL initializes one multi-headed policy network π pg and one critic Q . A noisy version of π pg is then used to conduct its o wn set of rollouts in the environment, storing each agent k ’ s experiences in its corresponding buf fer ( R k ) similar to the ev olutionary rollouts. Agent-Specific Reward Optimization: Crucially , each agent’ s replay buf fer is kept separate from that of every other agent to ensure div ersity amongst the agents. The shared critic samples a random mini-batch uniformly from each replay buf fer and uses it to update its parameters using gradient descent. Each agent π k pg then draws a mini-batch of experiences from its corresponding buf fer ( R k ) and uses it to sample a policy gradient from the shared critic. Unlike the teams in the e volutionary population which directly seek to optimize the team reward, π pg seeks to maximize the agent-specific local reward while exploiting the e xperiences collected via ev olution. Skill Migration: Periodically , the π pg network is copied into the e volving population of teams and propagates its features by participating in e volution. This is the core mech- anism that combines policies learned via agent-specific and team rewards. Reg ardless of whether the two rew ards are aligned, e volution ensures that only the performant deri va- tiv es of the migrated network are retained. This mechanism guarantees protection against destructi ve interference com- monly seen when a direct scalarization between two re ward functions is attempted. Further , the lev el of information exchange is automatically adjusted during the process of learning, in contrast to being manually tuned by an expert. Algorithm 1 MERL 1: Initialize a population of M multi-head teams pop π with k agents each and initialize their weights θ π 2: Initialize a shared critic Q with weights θ Q 3: Initialize an ensemble of N empty cyclic replay buf fers R k , one for each agent 4: Define a white Gaussian noise generator W g random number generator r () ∈ [0 , 1) 5: f or generation = 1, ∞ do 6: for team π ∈ pop π do 7: g , R = Rollout ( π , R , noise=None, ξ ) 8: _ , R = Rollout ( π , R , noise= W g , ξ = 1 ) 9: Assign g as π ’ s fitness 10: end for 11: Rank the population pop π based on fitness scores 12: Select the first e teams π ∈ pop π as elites 13: Select the remaining ( M − e ) teams π from pop π , to form Set S using tournament selection 14: while | S | < ( M − e ) do 15: Single-point crossov er between a randomly sam- pled π ∈ e and π ∈ S and append to S 16: end while 17: for Agent k = 1 , N do 18: Randomly sample a minibatch of T transitions ( o i , a i , l i , o i +1 ) from R k 19: Compute y i = l i + γ min j =1 , 2 Q 0 j ( o i +1 , a ∼ | θ Q 0 j ) 20: where a ∼ = π 0 pg ( k , o i +1 | θ π 0 pg ) [action sampled from the k th head of π 0 pg ] + 21: Update Q by minimizing the loss: L = 1 T P i ( y i − Q ( o i , a i | θ Q ) 2 22: Update π k pg using the sampled policy gradient ∇ θ π pg J ∼ 1 T P ∇ a Q ( o, a | θ Q ) | o = o i ,a = a i ∇ θ π pg π k pg ( s | θ π pg ) | o = o i 24: Soft update target netw orks: 25: θ π 0 ⇐ τ θ π + (1 − τ ) θ π 0 26: θ Q 0 ⇐ τ θ Q + (1 − τ ) θ Q 0 27: end for 28: Migrate the policy gradient team pop j : for weakest π ∈ pop j π : θ π ⇐ θ π pg 29: end f or MERL (a) Predator-Prey (b) Physical Deception (c) Keep-A way (d) Rover Domain Figure 4. Environments tested ( Lo we et al. , 2017 ; Rahmattalabi et al. , 2016 ) Algorithm 1 provides a detailed pseudo-code of the MERL algorithm. The choice of hyperparameters is explained in the Appendix. Additionally , our source code 1 is av ailable online. 5. Experiments W e adopt en vironments from ( Lowe et al. , 2017 ) and ( Rah- mattalabi et al. , 2016 ) to perform our experiments. Each en vironment consists of multiple agents and landmarks in a two-dimensional world. Agents take continuous control actions to mo ve about the world. Figure 4 illustrates the four en vironments which are described in more detail below . Predator -Prey : N slower cooperating agents (predators) must chase the faster adversary (prey) around an environ- ment with L large landmarks in randomly-generated loca- tions. The predators get a reward when they catch (touch) the prey while the prey is penalized. The team rew ard for the predators is the cumulati ve number of pre y-touches in an episode. Each predator can also compute the av erage distance to the prey and use it as its agent-specific re ward. All agents observ e the relative positions and velocities of the other agents, as well as the positions of the landmarks. The prey can accelerate 33% faster than the predator and has a higher top speed. W e tests two versions termed simple and hard predator-pre y where the prey is 30% and 100% faster , respecti vely . Additionally , the pre y itself learns dynamically during training. W e use DDPG ( Lillicrap et al. , 2015 ) as a learning algorithm for training the prey policy . All of our candidate algorithms are tested on their ability to train the team of predators in catching this prey . Physical Deception : N agents cooperate to reach a single target Point of Interest (POI) among N POIs. They are rew arded based on the closest distance of an y agent to the target. A lone adversary also desires to reach the target POI. Howe ver , the adversary does not know which of the POIs is the correct one. Thus the cooperating agents must 1 https://tinyurl.com/y6erclts learn to spread out and cov er all POIs so as to deceiv e the adversary as they are penalized based on the adversary’ s distance to the target. The team reward for the agents is then the cumulative re ward in an episode. W e use DDPG ( Lillicrap et al. , 2015 ) to train the adversary polic y . Keep-A way : In this scenario, a team of N cooperating agents must reach a tar get POI out of L total POIs. Each agent is rewarded based on its distance to the target. W e construct the team rew ard as simply the sum of the agent- specific re wards in an episode. An adversary also has to occupy the tar get while keeping the cooperating agents from reaching the target by pushing them away . T o incentivize this behavior , the adversary is rewarded based on its distance to the target POI and penalized based on the distance of the target from the nearest cooperating agent. Additionally , it does not know which of the POIs is the tar get and must infer this from the movement of the agents. DDPG ( Lillicrap et al. , 2015 ) is used to train the adversary polic y . Rover Domain : This en vironment is adapted from ( Rah- mattalabi et al. , 2016 ). Here, N agents must cooperate to reach a set of K POIs. Multiple agents need to simultane- ously go to the same POI in order to observe it. The number of agents required to observe a POI is termed the coupling requirement. Agents do not know and must infer the cou- pling factor from the re wards obtained. If a team with fewer agents than this number go to a POI, no reward is observ ed. The team’ s re ward is the percentage of POIs observed at the end of an episode. Each agent can also locally compute its distance to its closest POI and use it as its agent-specific re ward. Its observation comprises two channels to detect POIs and rov ers, respec- tiv ely . Each channel receiv es intensity information over 10 ◦ resolution spanning the 360 ◦ around the agent’ s posi- tion loosely based on the characteristic of a Pioneer robot ( Thrun et al. , 2000 ). This is similar to a LID AR. Since it returns the closest reflector , occlusions make the problem partially-observable. A coupling factor of 1 is similar to the cooperativ e navigation task in ( Lowe et al. , 2017 ). W e test coupling factors from 1 to 7 to capture extremely comple x MERL coordination objectiv es. Compared Baselines: W e compare the performance of MERL with a standard neuroevolutionary algorithm (EA) ( Fogel , 2006 ), MADDPG ( Lo we et al. , 2017 ) and MA TD3, a variant of MADDPG that integrates the improvements described within TD3 ( Fujimoto et al. , 2018 ) o ver DDPG. Internally , MERL uses EA and TD3 as its team-reward and agent-specific re ward optimizer , respecti vely . MAD- DPG was chosen as it is the state-of-the-art multiagent RL algorithm. W e implemented MA TD3 to ensure that the dif- ferences between MADDPG and MERL do not originate from having the more stable TD3 o ver DDPG. Further , we implement MADDPG and MA TD3 using ei- ther only global team reward or mixed rewards where the local, team-specific re wards were added to the global re- ward. The local reward function was simply defined as the negati ve of the distance to the closest POI. In this setting, we sweep over different scaling factors to weigh the two rew ards - an approach commonly used to shape rew ards. These experimental v ariations allow us to ev aluate the effi- cacy of the dif ferentiating features of MERL as opposed to improv ements that might come from other ways of combin- ing rew ard functions. Methodology for Reported Metrics: For MA TD3 and MADDPG, the team network was periodically tested on 10 task instances without any e xploratory noise. The av erage score was logged as its performance. For MERL and EA, the team with the highest fitness was chosen as the cham- pion for each generation. The champion was then tested on 10 task instances, and the average score was logged. This protocol shielded the reported metrics from any bias of the population size. W e conduct 5 statistically independent runs with random seeds from { 2019 , 2023 } and report the a ver- age with error bars showing a 95% confidence interval. All scores reported are compared against the number of envi- ronment steps (frames). A step is defined as the multiagent team taking a joint action and receiving a feedback from the en vironment. T o make the comparisons fair across single- team and population-based algorithms, all steps taken by all teams in the population are counted cumulativ ely . 6. Results Predator -Prey: Figure 5 shows the comparativ e perfor- mance in controlling the team of predators in the Predator- Prey en vironment. Note that this is an adversarial en viron- ment where the prey dynamically adapts against the preda- tors. The prey (considered as part of the en vironment in this analysis) uses DDPG to learn constantly against our team of predators. This is why predator performance (measured as number of prey touches) exhibits ebb and flow during learning. MERL outperforms MA TD3, EA, and MADDPG across both simple and hard variations of the task. EA seems to be approaching MERL ’ s performance, but is significantly slow er to learn. This is an e xpected beha vior for neuroev olu- tionary methods, which are known to be sample-inef ficient. In contrast, MERL, by virtue of its f ast policy-gradient com- ponents, learns significantly faster . (a) (b) Figure 5. Results on Predator -Prey where the prey is (a) 30% faster and (b) 100% faster Physical Deception: Figure 6 (left) shows the comparati ve performance in controlling the team of agents in the Physi- cal Deception en vironment. The performance here is lar gely based on ho w close the adversary comes to the target POI. Since the adversary starts out untrained, all compared algo- rithms start out with a fairly high score. As the adversary gradually learns to infer and mo ve to wards the target POI, MA TD3 and MADDPG demonstrate a gradual decline in performance. Ho wev er, MERL and EA are able to hold their performance by concocting effecti ve counter-strate gies in deceiving the adv ersary . EA reaches the same performance as MERL, but is slo wer to learn. Keep-A way: Figure 6 (right) sho w the comparative per- formance in Keep-A w ay . Similar to Physical Deception, MERL and EA are able to hold performance by attaining good counter -measures against the adversary while MA TD3 and MADDPG fail to do so. Howe ver , EA slightly outper - forms MERL on this task. (a) (b) Figure 6. Results on (a) Physical Deception and (b) K eep-A way Rover Domain: Figure 7 shows the comparativ e perfor- mance of MERL, MADDPG, MA TD3, and EA tested in the rov er domain with coupling factors 1 , 3 and 7 . In or- der to benchmark against the proxy rew ard functions that use scalarized linear combinations, we test MADDPG and MA TD3 with two variations of re ward functions. Global represents the scenario where the agents only receiv e the MERL (a) Coupling 1 (b) Coupling 3 (c) Coupling 7 (d) Legend Figure 7. Performance on the Rover Domain. sparse team rew ard as their reinforcement signal. Mixed represents the scenario where the agents receive a linear combination of the team-re ward and agent-specific re ward. Each rew ard is normalized before being combined. A weigh- ing coefficient of 10 is used to amplify the team-rew ard’ s influence in order to counter its sparsity . The weighing coefficient w as tuned using a grid search (see Figure 8 ). MERL significantly outperforms all baselines across all coupling requirements. The tested baselines clearly degrade quickly beyond a coupling of 3 . The increasing coupling requirement is equiv alent to increasing difficulty in joint- space exploration and entanglement in the team objective. Howe ver , it does not increase the size of the state-space, complexity of perception, or na vigation. This indicates that the de gradation in performance is strictly due to the increase in complexity of the team objecti ve. Notably , MERL is able to learn on coupling greater than n = 6 where methods without explicit reward shaping hav e been shown to fail entirely ( Rahmattalabi et al. , 2016 ). MERL successfully completes the task using the same set of information and coarse, unshaped rew ard functions as the other algorithms. This is mainly due to MERL ’ s split-le vel approach, which allows it to leverage the agent-specific rew ard function to solve navigation and perception while concurrently using the team-re ward function to learn team formation and effecti ve coordination. Scalarization Coefficients for Mixed Rewards: Figure 8 shows the performance of MA TD3 in optimizing mixed rew ards computed with different coef fi cients used to amplify the team-reward relative to the agent-rew ard. The results demonstrate that finding a good balance between these two rew ards through linear scalarization is dif ficult, as all values tested fail to make any progress in the task. This is because a static scalarization cannot capture the dynamic properties of which r ewar d is important when and instead leads to an ineffecti ve proxy . In contrast, MERL is able to lev erage both reward functions without the need to explicitly combine them either linearly or via more complex mixing functions. T eam Behaviors: Figure 9 illustrates the trajectories gener- ated for the Rover Domain with a coupling of n = 3 - the Figure 8. MA TD3’ s with varying scalarization coef ficients animations can also be viewed at our code repository online 2 . The trajectories for a team fully trained with MERL is shown in Figure 9 (a). Here, team formation and collabora- ti ve pursuit of the POIs is immediately apparent. T wo teams of 3 agents each form at the start of the episode. Further , the two teams also coordinate to pursue different POIs in order to maximize the team re ward. While not perfect (the bottom POI is left unobserved), they do succeed in observing 3 out of the 4 POIs. (a) MERL (b) MADDPG Figure 9. Agent trajectories for coupling = 3 . Golden/black circles are observed/unobserv ed POIs respectively 2 https://tinyurl.com/ugc ycjk MERL Figure 10. Selection rate for migrating policies In contrast, MADDPG-mixed (sho wn in Figure 9 (b)) fails to observe any POI. From the trajectories, it is apparent that the agents ha ve successfully learned to percei ve and navigate to reach POIs. Howe ver , they are unable to use this skill tow ards fulfilling the team objectiv e. Instead each agent is rather split on the objectiv e that it is optimizing. Some agents seem to be in sole pursuit of POIs without any re gard for team formation or collaboration while others seem to exhibit random movements. The primary reason for this is the mixed rew ard function that directly combines the agent-specific and team reward functions. Since the two rew ard functions have no guarantees of alignment across the state-space of the task, the y inv ariably lead to learning these sub-optimal joint-beha viors that solve a certain form of scalarized mixed objecti ve. In contrast, MERL by virtue of its bi-lev el optimization framework is able to lev erage both reward functions without the need to explicitly com- bine them. This enables MERL to a void these sub-optimal policies and solve the task without any re ward shaping or manual tuning. Conditional Selection Rate: W e ran experiments tracking whether the policies migrated from the policy gradient learn- ers to the ev olutionary population were selected or discarded during the subsequent selection process (Figure 10 ). Math- ematically , this is equi valent to the conditional probability of selection ( sel ), giv en that the individual was a migrant this generation ( mig ), represented as P ( sel | mig ) . The expected selection rate P ( sel ) under uniform random se- lection is 0 . 47 (see Appendix B). Conditional selection rate abov e this baseline indicates that migration is a positiv e pre- dictor for selection, and vice-v ersa. The conditional selec- tion rate are distributed across both sides of this line, v arying by task. The lowest selection rate is seen for Keep-away where e volution virtually discards all migrated indi viduals. This is consistent with the performance in Keep-A way (Fig- ure 6 b) where EA outperforms all other baselines while the policy-gradient methods struggle. Both of the predator-pre y tasks hav e consistently high con- ditional selection rate, indicating positive information trans- fer from the policy-gradient to the ev olutionary population throughout training. This is consistent with Figure 5 where MERL outperforms all other baselines. For a dynamic envi- ronment such as predator -prey where the pre y is consistently adapting against the agents, such information transfer is cru- cial for sustaining success. For physical deception, as well as the rov er domain, the e volutionary population initially benefits heavily from the migrating individuals (consistent with Figure 6 (a)). Howe ver , as these information propagates through the population, the marginal benefit from migration wanes through the course of learning. This form of adaptive information transfer is a key characteristic within MERL, enabling it to integrate two optimization processes to wards maximizing the team objective without being misguided erroneously by either . 7. Conclusion W e introduced MERL, a hybrid multiagent reinforcement learning algorithm that leverages both agent-specific and team objectiv es by combining gradient-based and gradient- free optimization. MERL achieves this by using a fast policy-gradient optimizer to exploit dense agent-specific rew ards while concurrently le veraging neuroev olution to tackle the team-objecti ve. Periodic migration and a shared replay buffer ensure consistent information flow between the two processes. This enables MERL to lev erage both modes of learning tow ards tackling the global team objective. Results demonstrate that MERL significantly outperforms MADDPG, the state-of-the-art MARL method, in a wide array of benchmarks. W e also tested a modification of MAD- DPG to integrate TD3 - the state-of-the-art single-agent RL algorithm. These experiments demonstrate that the core im- prov ements of MERL come from its ability to lev erage team and agent-specific rew ards without the need to explicitly combine them. This differentiates MERL from other ap- proaches like re ward scalarization and re ward shaping that either require extensi ve manual tuning or can detrimentally change the MDP ( Ng et al. , 1999 ) itself. In this paper , MERL expended a constant amount of re- sources across its policy-gradient and EA components throughout training. Exploring automated methods to dy- namically allocate computational resources among the two processes based on the conditional selection rate is an excit- ing thread for further in vestigation. Other future threads will explore MERL for settings such as Pommerman ( Resnick et al. , 2018 ), StarCraft ( Risi and T ogelius , 2017 ; V inyals et al. , 2017 ), RoboCup ( Kitano et al. , 1995 ), football ( Ku- rach et al. , 2019 ) and general multi-reward settings such as multitask learning. MERL References A. K. Agogino and K. T umer . Unifying temporal and structural credit assignment problems. In Proceedings of the Thir d International J oint Confer ence on Autonomous Agents and Multiag ent Systems-V olume 2 , pages 980–987. IEEE Computer Society , 2004. C. Colas, O. Sigaud, and P .-Y . Oude yer . Gep-pg: Decou- pling exploration and e xploitation in deep reinforcement learning algorithms. arXiv pr eprint arXiv:1802.05054 , 2018. S. Devlin, M. Grze ´ s, and D. Kudenko. Multi-agent, reward shaping for robocup keepaway . In The 10th Interna- tional Confer ence on Autonomous Ag ents and Multiagent Systems-V olume 3 , pages 1227–1228. International Foun- dation for Autonomous Agents and Multiagent Systems, 2011. D. Floreano, P . Dürr, and C. Mattiussi. Neuroevolution: from architectures to learning. Evolutionary Intelligence , 1(1):47–62, 2008. J. Foerster , R. Y . Chen, M. Al-Shediv at, S. Whiteson, P . Abbeel, and I. Mordatch. Learning with opponent- learning aw areness. In Pr oceedings of the 17th Interna- tional Confer ence on A utonomous Agents and MultiAg ent Systems , pages 122–130. International Foundation for Autonomous Agents and Multiagent Systems, 2018a. J. N. Foerster , G. Farquhar , T . Afouras, N. Nardelli, and S. Whiteson. Counterfactual multi-agent policy gradi- ents. In Thirty-Second AAAI Conference on Artificial Intelligence , 2018b. D. B. Fogel. Evolutionary computation: towar d a new philosophy of machine intelligence , volume 1. John W iley & Sons, 2006. S. Fujimoto, H. van Hoof, and D. Me ger . Addressing func- tion approximation error in actor-critic methods. arXiv pr eprint arXiv:1802.09477 , 2018. M. Jaderberg, V . Dalibard, S. Osindero, W . M. Czarnecki, J. Donahue, A. Razavi, O. V inyals, T . Green, I. Dunning, K. Simonyan, et al. Population based training of neural networks. arXiv pr eprint arXiv:1711.09846 , 2017. S. Khadka and K. T umer . Evolution-guided polic y gradient in reinforcement learning. In Advances in Neural Infor- mation Pr ocessing Systems , pages 1196–1208, 2018. S. Khadka, S. Majumdar , T . Nassar, Z. Dwiel, E. T umer , S. Miret, Y . Liu, and K. Tumer . Collaborativ e ev olutionary reinforcement learning. arXiv preprint arXiv:1905.00976v2 , 2019. H. Kitano, M. Asada, Y . Kuniyoshi, I. Noda, and E. Osawa. Robocup: The robot world cup initiati ve, 1995. K. Kurach, A. Raichuk, P . Sta ´ nczyk, M. Zaj ˛ ac, O. Bachem, L. Espeholt, C. Riquelme, D. V incent, M. Michalski, O. Bousquet, et al. Google research football: A novel reinforcement learning environment. arXiv preprint arXiv:1907.11180 , 2019. A. Lazaridou, A. Peysakhovich, and M. Baroni. Multi- agent cooperation and the emergence of (natural) lan- guage. arXiv pr eprint arXiv:1612.07182 , 2016. F .-D. Li, M. W u, Y . He, and X. Chen. Optimal control in microgrid using multi-agent reinforcement learning. ISA transactions , 51(6):743–751, 2012. T . P . Lillicrap, J. J. Hunt, A. Pritzel, N. Heess, T . Erez, Y . T assa, D. Silver , and D. Wierstra. Continuous con- trol with deep reinforcement learning. arXiv pr eprint arXiv:1509.02971 , 2015. M. L. Littman. Marko v games as a framew ork for multi- agent reinforcement learning. In Machine learning pr o- ceedings 1994 , pages 157–163. Else vier , 1994. S. Liu, G. Le ver , J. Merel, S. T unyasuvunak ool, N. Heess, and T . Graepel. Emergent coordination through competi- tion. arXiv pr eprint arXiv:1902.07151 , 2019. R. Lowe, Y . W u, A. T amar, J. Harb, O. P . Abbeel, and I. Mor - datch. Multi-agent actor-critic for mixed cooperative- competitiv e en vironments. In Advances in Neural Infor- mation Pr ocessing Systems , pages 6379–6390, 2017. B. Lüders, M. Schläger , A. K orach, and S. Risi. Continual and one-shot learning through neural networks with dy- namic external memory . In European Confer ence on the Applications of Evolutionary Computation , pages 886– 901. Springer , 2017. B. L. Miller and D. E. Goldber g. Genetic algorithms, tour- nament selection, and the effects of noise. In Complex Systems . Citeseer , 1995. I. Mordatch and P . Abbeel. Emergence of grounded compo- sitional language in multi-agent populations. In Thirty- Second AAAI Confer ence on Artificial Intelligence , 2018. A. Y . Ng, D. Harada, and S. Russell. Policy inv ariance under rew ard transformations: Theory and application to rew ard shaping. In ICML , v olume 99, pages 278–287, 1999. A. Rahmattalabi, J. J. Chung, M. Colby , and K. T umer . D++: Structural credit assignment in tightly coupled multiagent domains. In 2016 IEEE/RSJ International Conference on Intelligent Robots and Systems (IR OS) , pages 4424–4429. IEEE, 2016. MERL C. Resnick, W . Eldridge, D. Ha, D. Britz, J. Foerster , J. T o- gelius, K. Cho, and J. Bruna. Pommerman: A multi-agent playground. arXiv pr eprint arXiv:1809.07124 , 2018. S. Risi and J. T ogelius. Neuroev olution in games: State of the art and open challenges. IEEE T ransactions on Computational Intelligence and AI in Games , 9(1):25–41, 2017. T . Salimans, J. Ho, X. Chen, and I. Sutske ver . Evolution strategies as a scalable alternati ve to reinforcement learn- ing. arXiv pr eprint arXiv:1703.03864 , 2017. S. Shalev-Shwartz, S. Shammah, and A. Shashua. Safe, multi-agent, reinforcement learning for autonomous driv- ing. arXiv pr eprint arXiv:1610.03295 , 2016. W . Sheng, Q. Y ang, J. T an, and N. Xi. Distributed multi- robot coordination in area exploration. Robotics and Autonomous Systems , 54(12):945–955, 2006. D. Silver , T . Hubert, J. Schrittwieser, I. Antonoglou, M. Lai, A. Guez, M. Lanctot, L. Sifre, D. Kumaran, T . Graepel, et al. Mastering chess and shogi by self-play with a general reinforcement learning algorithm. arXiv pr eprint arXiv:1712.01815 , 2017. W . M. Spears, K. A. De Jong, T . Bäck, D. B. Fogel, and H. De Garis. An ov erview of e volutionary computation. In European Confer ence on Machine Learning , pages 442–459. Springer , 1993. R. S. Sutton and A. G. Barto. Reinforcement learning: An intr oduction , volume 1. MIT press Cambridge, 1998. S. Thrun, W . Bur gard, and D. F ox. A real-time algorithm for mobile robot mapping with applications to multi-robot and 3d mapping. In ICRA , volume 1, pages 321–328, 2000. K. Tumer and A. Agogino. Distributed agent-based air traffic flow management. In Pr oceedings of the 6th in- ternational joint confer ence on Autonomous agents and multiagent systems , page 255. A CM, 2007. O. V inyals, T . Ewalds, S. Bartunov , P . Georgie v , A. S. V ezh- nev ets, M. Y eo, A. Makhzani, H. Küttler , J. Agapiou, J. Schrittwieser, et al. Starcraft ii: A new challenge for reinforcement learning. arXiv preprint , 2017. S. A. W illiamson, E. H. Gerding, and N. R. Jennings. Re- ward shaping for valuing communications during multi- agent coordination. In Pr oceedings of The 8th Interna- tional Confer ence on Autonomous Ag ents and Multiagent Systems-V olume 1 , pages 641–648. International Foun- dation for Autonomous Agents and Multiagent Systems, 2009. L. Yliniemi, A. K. Agogino, and K. T umer . Multirobot coordination for space exploration. AI Magazine , 35(4): 61–74, 2014. MERL A. Hyperparameters Description T able 1. Hyperparameters used for Predator-Pre y , Keep-a way and Physical Deception Hyperparameter MERL MA TD3/MADDPG Population size 10 N/A Rollout size 10 10 T arget weight 0 . 01 0 . 01 Actor Learning Rate 0 . 01 0 . 01 Critic Learning Rate 0 . 01 0 . 01 Discount Factor 0 . 95 0 . 95 Replay Buffer Size 1 e 6 1 e 6 Batch Size 1024 1024 Mutation Prob 0 . 9 N/A Mutation Fraction 0 . 1 N/A Mutation Strength 0 . 1 N/A Super Mutation Prob 0 . 05 N/A Reset Mutation Prob 0 . 05 N/A Number of elites 4 N/A Exploration Policy N (0 , σ ) N (0 , σ ) Exploration Noise 0 . 4 0 . 4 Rollouts per fitness 10 N/A Actor Architecture [100 , 100] [100 , 100] Critic Architecture [100 , 100] [300 , 300] TD3 Noise V ariance 0 . 2 0 . 2 TD3 Noise Clip 0 . 5 0 . 5 TD3 Update Freq 2 2 T able 1 details the hyperparameters used for MERL, MA TD3, and MADDPG in tackling predator-pre y and co- operativ e navigation. The hyperparmaeters were inherited from ( Lowe et al. , 2017 ) to match the original e xperiments for MADDPG and MA TD3. The only exception to this was the use of hyperbolic tangent instead of Relu activ ation functions. T able 2 details the hyperparameters used for MERL, MA TD3, and MADDPG in the rover domain. The hyperpa- rameters themselves are defined belo w: • Optimizer = Adam Adam optimizer was used to update both the actor and critic networks for all learners. • Population size M This parameter controls the number of different actors (policies) that are present in the e volutionary popula- tion. • Rollout size This parameter controls the number of rollout workers (each running an episode of the task) per generation. Note: The two parameters above (population size k and rollout size) collectiv ely modulates the proportion T able 2. Hyperparameters used for Rov er Domain Hyperparameter MERL MA TD3/MADDPG Population size 10 N/A Rollout size 50 50 T arget weight 1 e − 5 1 e − 5 Actor Learning Rate 5 e − 5 5 e − 5 Critic Learning Rate 1 e − 5 1 e − 5 Discount Factor 0 . 5 0 . 97 Replay Buffer Size 1 e 5 1 e 5 Batch Size 512 512 Mutation Prob 0 . 9 N/A Mutation Fraction 0 . 1 N/A Mutation Strength 0 . 1 N/A Super Mutation Prob 0 . 05 N/A Reset Mutation Prob 0 . 05 N/A Number of elites 4 N/A Exploration Policy N (0 , σ ) N (0 , σ ) Exploration Noise σ 0 . 4 0 . 4 Rollouts per fitness ξ 10 N/A Actor Architecture [100 , 100] [100 , 100] Critic Architecture [100 , 100] [300 , 300] TD3 Noise variance 0 . 2 0 . 2 TD3 Noise Clip 0 . 5 0 . 5 TD3 Update Frequency 2 2 of exploration carried out through noise in the actor’ s parameter space and its action space. • T arget weight τ This parameter controls the magnitude of the soft up- date between the actors and critic networks, and their target counterparts. • Actor Learning Rate This parameter controls the learning rate of the actor network. • Critic Learning Rate This parameter controls the learning rate of the critic network. • Discount Rate This parameter controls the discount rate used to com- pute the return optimized by policy gradient. • Replay Buffer Size This parameter controls the size of the replay buf fer . After the buf fer is filled, the oldest experiences are deleted in order to make room for ne w ones. • Batch Size This parameters controls the batch size used to compute the gradients. MERL • Actor Activation Function Hyperbolic tangent was used as the acti vation function. • Critic Activation Function Hyperbolic tangent was used as the acti vation function. • Number of Elites This parameter controls the fraction of the population that are categorized as elites. Since an elite individual (actor) is shielded from the mutation step and preserv ed as it is, the elite fraction modulates the de gree of explo- ration/exploitation within the e volutionary population. • Mutation Probability This parameter represents the probability that an actor goes through a mutation operation between generation. • Mutation Fraction This parameter controls the fraction of the weights in a chosen actor (neural network) that are mutated, once the actor is chosen for mutation. • Mutation Strength This parameter controls the standard de viation of the Gaussian operation that comprises mutation. • Super Mutation Probability This parameter controls the probability that a super mu- tation (larger mutation) happens in place of a standard mutation. • Reset Mutation Probability This parameter controls the probability a neural weight is instead reset between N (0 , 1) rather than being mu- tated. • Exploration Noise This parameter controls the standard de viation of the Gaussian operation that comprise the noise added to the actor’ s actions during exploration by the learners (learner roll-outs). • TD3 Policy Noise V ariance This parameter controls the standard de viation of the Gaussian operation that comprise the noise added to the policy output before applying the Bellman backup. This is often referred to as the magnitude of policy smoothing in TD3. • TD3 Policy Noise Clip This parameter controls the maximum norm of the policy noise used to smooth the polic y . • TD3 Policy Update Fr equency This parameter controls the number of critic updates per policy update in TD3. B. Expected Selection Rate W e use a multi-step selection process inside MERL. First we select e top-performing individuals as elites sequentially from the population without replacement. Then we con- duct a tournament selection ( Miller and Goldberg , 1995 ) with tournament size t with replacement from the entire population including the elites. t is set to 3 in this paper . The candidates selected from the tournament selection are pruned for duplicates and the resulting set is carried over as the offsprings for this generation. The combined set of offsprings and the elites represent the candidates selected for that generation of ev olution. The expected selection rate P ( s ) is defined as the probabil- ity of selection for an indi vidual if the selection was random. This is equiv alent to conducting selection using a random ranking of the population where the fitness scores were ig- nored and a random number was assigned as an individual’ s fitness. Note that the selection rate is not the probability of selection for a random policy (individual with random neural network weights) inserted into the e volutionary pop- ulation. The probability of selection for such a random policy would be extremely low as the other individuals in the population would be ranked significantly higher . In order to compute the expected selected rate, we need to compute it for the elite set and the of fspring set. The expected selection rate for the elite set is given by e/ M . The expected selection rate for the offspring set in volves multiple rounds of tournament selection with replacement follo wed by pruning of duplicates to compute the combined set along with the elites. W e computed this expectation empirically using an experiment with 1000000 iterations and found the expected selection rate to be 0 . 47 . C. Extended EA Benchmarks W e conducted some additional experiments by v arying the population sizes used for the EA baseline. The purpose of these experiments is to in vestigate if larger population sizes (as is the norm for EA algorithms) can alle viate the need for policy-gradient module within MERL. Additionally , we also inv estigated Evolutionary Strate gies (ES) ( Salimans et al. , 2017 ), which has been widely adopted in the community in recent years. W e perform hyperparam- eter sweeps to tune this baseline. All results are reported in the rov er domain with a coupling of 3. C.1. Evolutionary Strategies (ES) ES P opulation Sweep: Figure 11 (left) compares ES with varyi ng population sizes in the ro ver domain with a coupling of 3 . Sigma for all ES runs are set at 0 . 1 . Among the ES runs, a population size of 100 yields the best results con verging to MERL (a) ES Population Sweep (b) ES Sigma Sweep Figure 11. (a) Evolutionary Strate gies population size sweep on the rover domain with a coupling of 3. (b)Evolutionary Strategies Noise magnitude (sigma) sweep on the rov er domain with a coupling of 3 0 . 1 in 100-millions frames. MERL (red) on the other hand is ran for 2-million frames and con verges to 0 . 48 . ES Noise Sweep: Apart from the population size, a key hyperparameter for ES is the variance of the perturbation factor (sigma). W e run a parameter sweep for sigma and report results in Figure 11 (right). W e do not see a great deal of improv ement with the change of sigma. Figure 12. Evolutionary Algorithm Population size sweep on the rov er domain with a coupling of 3. MERL was run for 2-million steps while the other EA runs were ran for 100-million steps. C.2. EA Population Size Next, we conduct an e xperiment to ev aluate the efficac y of different population sizes from 10 - 1 , 000 for the Evolution- ary algorithm used in the paper . All results are reported for the rov er domain with a coupling factor of 3 and are illus- trated in Figure 12 . The best EA performance was found for a population size of 100 reaching 0 . 3 in 100 -million time steps. Compare this to MERL which reaches a performance of 0 . 48 in only 2 million time steps. This demonstrates a key thesis behid MERL - the efficac y of the guided ev olution approach ov er purely evolutionary approaches. D. Rollout Methodology Algorithm 2 describes an episode of rollout under MERL detailing the connections between the local re ward, global rew ard, and the associated replay buf fer . Algorithm 2 Rollout 1: function Rollout( π , R , noise, ξ ) 2: f itness = 0 3: for j = 1: ξ do 4: Reset en vironment and get initial joint state j s 5: while en v is not done do 6: Initialize an empty list of joint action j a = [] 7: for Each agent (actor head) π k ∈ π and s k in j s do 8: j a ⇐ j a ∪ π k ( s k | θ π k ) + noise t 9: end for 10: Execute j a and observe joint local re ward j l , global rew ard g and joint next state j s 0 11: for Each Replay Buffer R k ∈ R and s k , a k , l k , s 0 k in j s , j a , j l , j s 0 do 12: Append transition ( s k , a k , l k , s 0 k ) to R k 13: end for 14: j s = j s 0 15: if en v is done: then 16: f itness ← g 17: end if 18: end while 19: end for 20: Return f itness ξ , R 21: end function
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment