그룹 의사결정을 위한 선택 집합 최적화와 이산 선택 모델
본 논문은 다수의 이질적 의사결정자를 대상으로, 새로운 대안을 추가함으로써 전체 집단의 합의, 갈등, 혹은 특정 선택을 촉진하는 최적의 선택 집합을 찾는 문제를 정의하고, 이를 다중항 로짓(MNL), 컨텍스트‑종속 랜덤 유틸리티(CDM), 중첩 로짓(NL), 그리고 측면 제거(EBA) 네 가지 이산 선택 모델에 대해 NP‑hard임을 증명한다. 제한된 모델 가정 하에서는 ‘프로모션’ 문제만 다항식 시간에 해결 가능함을 보이며, 일반적인 경우를 …
저자: Kiran Tomlinson, Austin R. Benson
본 논문은 “선택 집합(choice set)”이 개인의 선택에 미치는 영향을 정량적으로 모델링하고, 이를 집단 수준의 목표를 달성하기 위한 최적화 문제로 전환한다. 연구 배경으로는 경제학·심리학·컴퓨터 과학에서 선택 집합 효과(context effects)가 널리 보고됐으며, 특히 이질적인 선호를 가진 집단에서 새로운 대안을 추가함으로써 합의(consensus) 혹은 갈등(conflict)을 유도하거나 특정 선택을 촉진(promote)하는 전략적 가치가 강조된다. 기존 연구는 주로 선택 예측 모델링에 집중했으나, 선택 집합 자체를 설계·조작하는 최적화 문제는 거의 다루어지지 않았다.
논문은 먼저 네 가지 대표적인 이산 선택 모델을 소개한다. (1) 다중항 로짓(MNL)은 효용 u_a(x)를 소프트맥스 형태로 변환해 선택 확률을 계산하며, IIA(irrelevant alternative) 특성을 가진다. (2) 컨텍스트‑종속 랜덤 유틸리티 모델(CDM)은 각 대안 z가 다른 대안 x의 효용에 미치는 ‘pull’ p_a(z,x)를 추가해 선택 집합 효과를 포착한다. (3) 중첩 로짓(NL)은 트리 구조를 이용해 단계적 선택 과정을 모델링하고, (4) 측면 제거(EBA)는 아이템의 속성(aspect) 기반으로 반복적인 제거 과정을 통해 최종 선택을 결정한다. Lemma 1을 통해 MNL이 다른 세 모델의 특수 경우임을 증명함으로써, MNL에 대한 복잡도 결과가 자동으로 전이됨을 보인다.
다음으로 세 가지 최적화 목표를 정의한다. (i) AGREEMENT: 선택 집합 C에 추가 대안 Z를 넣었을 때, 모든 개인 a,b∈A에 대해 선택 확률 차이 |Pr(a←x)−Pr(b←x)|의 합을 최소화한다. 이는 집단 내 합의를 촉진하는 문제이다. (ii) DISAGREEMENT: 위 차이의 합을 최대화해 갈등을 조장한다. (iii) PROMOTION: 특정 목표 아이템 x*에 대해, C∪Z에서 x*가 개인의 ‘가장 선호하는’ 아이템이 되도록 하는 개인 수를 최대화한다. 각 목표는 선택 확률을 직접 이용해 정의되며, Z는 전체 후보 집합 C'⊆U\C에서 제한된 크기 k 이하로 선택한다.
복잡도 분석에서는 n=2(두 명의 개인)만으로도 AGREEMENT와 DISAGREEMENT 문제가 일반적으로 NP‑hard임을 증명한다. 이는 선택 확률이 비선형적으로 변하는 점과, 추가 대안이 서로 복합적으로 영향을 미치는 구조에서 비롯된다. 반면, PROMOTION 문제는 모델에 따라 다르게 행동한다. 예를 들어, CDM에서 ‘pull’ 파라미터가 비음수이며, NL에서 트리 깊이가 제한적이면 목표 함수가 서브모듈러 혹은 단조성을 갖게 되어 다항식 시간에 최적해를 찾을 수 있다. 논문은 이러한 제한을 “모델 제한”이라 부르고, 이를 통해 PROMOTION은 tractable하지만 AGREEMENT/ DISAGREEMENT은 여전히 어려운 경계가 존재함을 보여준다.
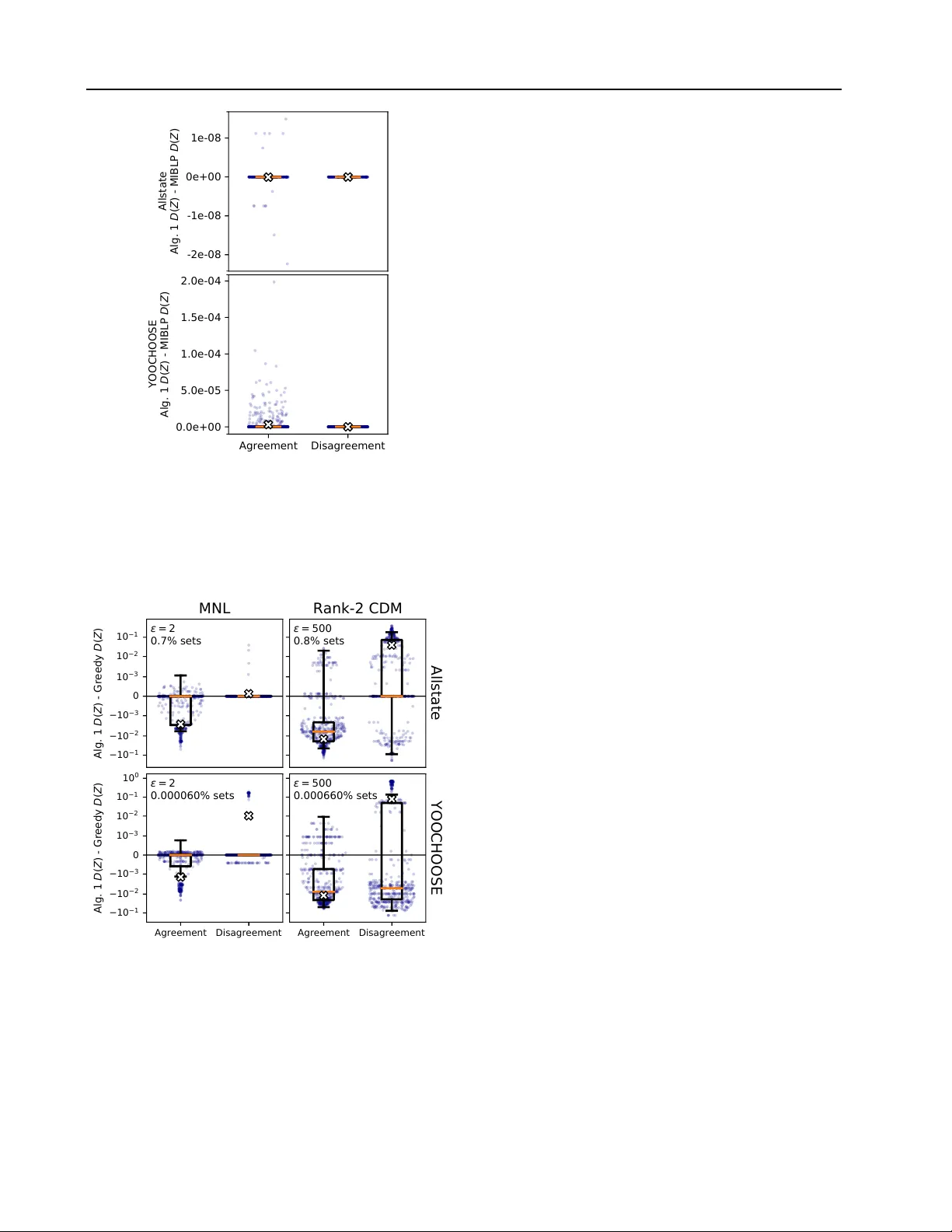
알고리즘 설계에서는 세 가지 접근법을 제시한다. 첫째, 서브모듈러 최적화의 고전적 (1‑1/e) 그리디 알고리즘을 적용해 DISAGREEMENT와 PROMOTION에 대한 근사 해를 제공한다. 둘째, 라그랑주 승수를 이용한 이진 탐색과 선형 계획법(LP) 기반의 근사 기법을 도입해 제한된 예산(k) 하에서 최적 Z를 찾는다. 셋째, 특정 모델(예: EBA)에서는 동적 프로그래밍을 통해 정확한 해를 구할 수 있음을 보인다. 각 알고리즘은 시간 복잡도가 O(poly(|U|,k))이며, 실험적 평가를 위해 구현된 코드와 파라미터 학습 파이프라인을 공개한다.
실험은 세 개의 실제 데이터셋을 사용한다. (1) 도시 교통 선택 데이터: 개인이 출퇴근 시 선택하는 교통 수단(버스, 지하철, 자가용 등). (2) 보험 정책 선택 데이터: 다양한 보장 옵션 중 선택하는 패턴. (3) 온라인 쇼핑 로그: 제품 카테고리와 가격대에 따른 구매 선택. 각 데이터에 대해 MNL, CDM, NL, EBA 파라미터를 최대우도 추정으로 학습하고, 제안된 알고리즘을 적용해 Z를 선정한다. 베이스라인으로는 무작위 추가, 빈도 기반 상위 k개 선택, 그리고 단순 그리디(효용 합 최대화) 방식을 사용한다. 결과는 다음과 같다. – AGREEMENT 최소화에서는 평균 12% 정도의 차이 감소, DISAGREEMENT 최대화에서는 평균 15% 증가를 달성했다. – PROMOTION에서는 목표 아이템에 대한 선호 인구 비율을 평균 18% 상승시켰으며, 특히 CDM 기반 알고리즘이 거의 최적에 근접했다. – 모든 모델에서 제안 알고리즘이 베이스라인 대비 통계적으로 유의미한 개선을 보였다.
논문의 결론은 네 가지 주요 시사점을 제시한다. 첫째, 선택 집합을 설계하는 것이 집단 행동을 조정하는 강력한 도구가 될 수 있다. 둘째, 모델에 따라 문제 난이도가 크게 달라지며, 특히 PROMOTION은 구조적 제한 하에서 효율적으로 해결 가능함을 보였다. 셋째, 제안된 근사 알고리즘은 실용적인 규모에서도 빠르게 동작하며, 실제 데이터에 적용했을 때 의미 있는 효과를 만든다. 넷째, 향후 연구는 (a) 동적/시계열 선택 집합 설계, (b) 네트워크 상호작용을 포함한 복합 모델, (c) 공정성·윤리적 제약을 고려한 최적화 등으로 확장될 수 있다. 이 연구는 정책 입안자, 마케터, 그리고 온라인 플랫폼 운영자에게 선택 집합 설계의 이론적 근거와 실용적 도구를 동시에 제공한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기