Choice Set Optimization Under Discrete Choice Models of Group Decisions
The way that people make choices or exhibit preferences can be strongly affected by the set of available alternatives, often called the choice set. Furthermore, there are usually heterogeneous preferences, either at an individual level within small g…
Authors: Kiran Tomlinson, Austin R. Benson
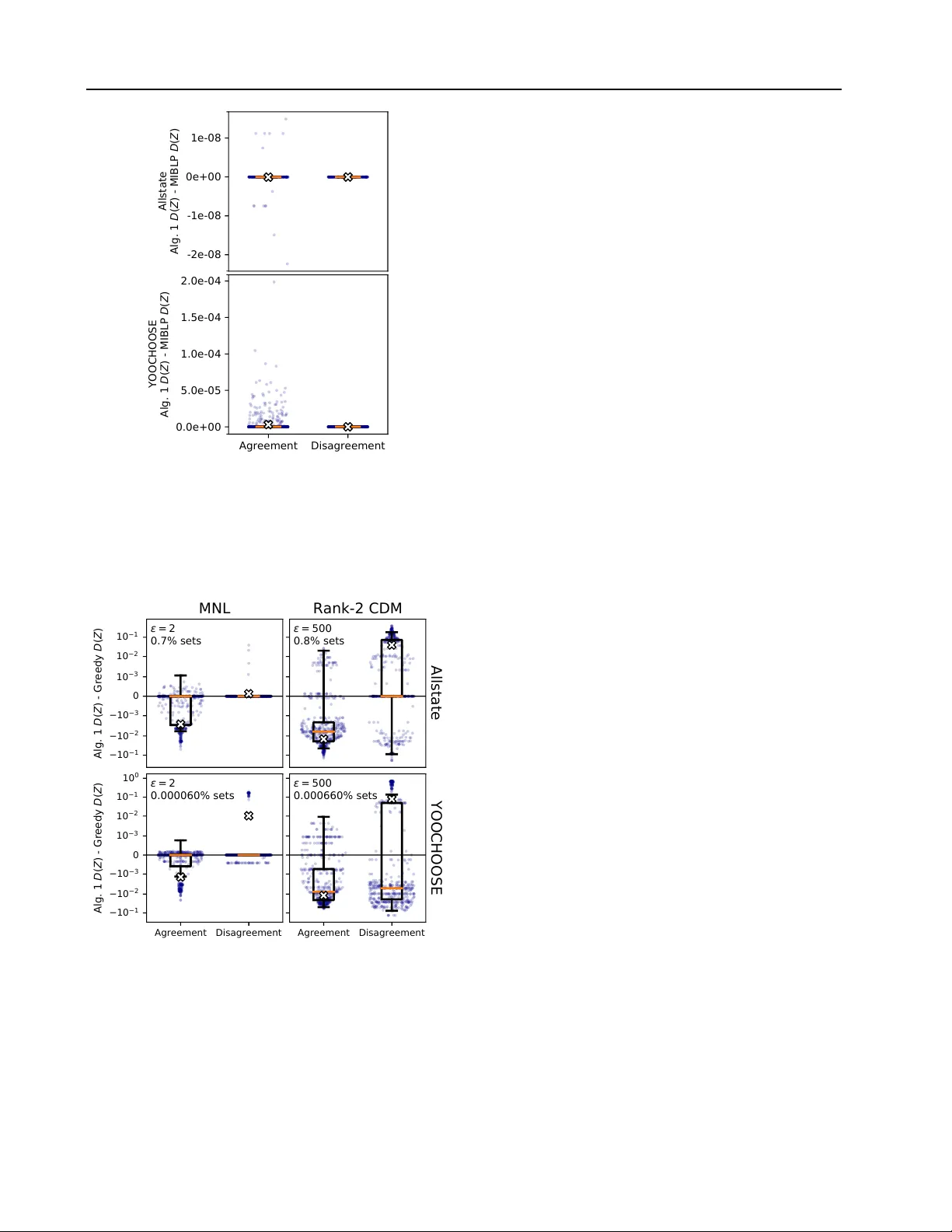
Choice Set Optimization Under Discr ete Choice Models of Gr oup Decisions Kiran T omlinson 1 A ustin R. Benson 1 Abstract The way that people mak e choices or exhibit pref- erences can be strongly affected by the set of a v ail- able alternativ es, often called the choice set. Fur- thermore, there are usually heterogeneous prefer- ences, either at an indi vidual level within small groups or within sub-populations of large groups. Giv en the av ailability of choice data, there are no w many models that capture this behavior in or - der to make effecti v e predictions—ho we v er , there is little work in understanding how directly chang- ing the choice set can be used to influence the preferences of a collection of decision-makers. Here, we use discrete choice modeling to de velop an optimization frame work of such interv entions for se veral problems of group influence, namely maximizing agreement or disagreement and pro- moting a particular choice. W e show that these problems are NP-hard in general, but imposing restrictions rev eals a fundamental boundary: pro- moting a choice can be easier than encouraging consensus or sowing discord. W e design approxi- mation algorithms for the hard problems and show that they work well on real-w orld choice data. 1. Context effects and optimizing choice sets Choosing from a set of alternativ es is one of the most impor- tant actions people take, and choices determine the compo- sition of gov ernments, the success of corporations, and the formation of social connections. For these reasons, choice models ha ve receiv ed significant attention in the fields of economics ( T rain , 2009 ), psychology ( Tv ersky & Kahne- man , 1981 ), and, as human-generated data has become in- creasingly av ailable online, computer science ( Overgoor et al. , 2019 ; Seshadri et al. , 2019 ; Rosenfeld et al. , 2020 ). In 1 Department of Computer Science, Cornell Univ ersity , Ithaca, New Y ork, USA. Correspondence to: Kiran T omlinson , Austin R. Benson . This is the arXiv version of a paper appearing in Proceedings of the 37 th International Confer ence on Machine Learning , Online, PMLR 119, 2020. This v ersion includes material that was rele gated to the appendix in the proceedings version due to space constraints. Copyright 2020 by the authors. many cases, it is important that people ha ve heterogeneous preferences; for example, people li ving in dif ferent parts of a town might prefer dif ferent government policies. Much of the computational work on choice has been dev oted to fitting models for predicting future choices. In addition to prediction, another area of interest is determining ef fecti ve interventions to influence choice—advertising and political campaigning are prime examples. In heterogeneous groups, the goal might be to encourage consensus ( Amir et al. , 2015 ), or , for an ill-intentioned adversary , to so w discord, e.g., amongst political parties ( Rosenberg et al. , 2020 ). One particular method of influence is introducing ne w alter - nativ es or options. While early economic models assume that alternati ves are irrele vant to the relati ve ranking of op- tions ( Luce , 1959 ; McFadden , 1974 ), experimental work has consistently found that new alternati v es hav e strong ef fects on our choices ( Huber et al. , 1982 ; Simonson & Tversk y , 1992 ; Shafir et al. , 1993 ; Trueblood et al. , 2013 ). These effects are often called context ef fects or c hoice set ef fects . A well-kno wn example is the compromise ef fect ( Simonson , 1989 ), which describes ho w people often prefer a middle ground (e.g., the middle-priced wine). Direct measurements on choice data ha ve also revealed choice set effects in sev- eral domains ( Benson et al. , 2016 ; Seshadri et al. , 2019 ). Here, we pose adding ne w alternativ es as a discrete opti- mization problem for influencing a collection of decision makers, such as the inhabitants of a city or the visitors to a website. T o this end, we consider various models for how someone makes a choice from a gi ven set of alternativ es, where the model parameters can be readily estimated from data. In our setup, e veryone has a base set of alternati ves from which they make a choice, and the goal is to find a set of additional alternati ves to optimize some function of the group’ s joint preferences on the base set. W e specifically an- alyze three objectives: (i) agr eement in preferences amongst the group; (ii) disagr eement in preferences amongst the group; and (iii) pr omotion of a particular item (decision). W e use the frame work of discr ete choice ( T rain , 2009 ) to probabilistically model a person’ s choice from a gi ven set of items, called the choice set . These models are parameterized for indi vidual preferences, and when fitting parameters from data, preferences are commonly aggregated at the lev el of a sub-population of individuals. Discrete choice models such Choice Set Optimization Under Discrete Choice Models of Gr oup Decisions as the multinomial logit and elimination-by-aspects have played a central role in behavioral economics for se veral decades with div erse applications, including forest manage- ment ( Hanle y et al. , 1998 ), social netw orks formation ( Over - goor et al. , 2019 ), and marketing campaigns ( F ader & McAl- ister , 1990 ). More recently , new choice data and algo- rithms hav e spurred machine learning research on models for choice set effects ( Ragain & Ugander , 2016 ; Chierichetti et al. , 2018b ; Seshadri et al. , 2019 ; Pfannschmidt et al. , 2019 ; Rosenfeld et al. , 2020 ; Bower & Balzano , 2020 ). W e provide the rele v ant background on discrete choice mod- els in Section 2 . From this, we formally define and ana- lyze three choice set optimization problems—A G R E E M E N T , D I S A G R E E M E N T , and P R O M OT I O N —and analyze them un- der four discrete choice models: multinomial logit ( McFad- den , 1974 ), the context dependent random utility model ( Se- shadri et al. , 2019 ), nested logit ( McFadden , 1978 ), and elimination-by-aspects ( Tversk y , 1972 ). W e first pro ve that the choice set optimization problems are NP-hard in general for these models. After , we identify natural restrictions of the problems under which they become tractable. These restrictions reveal a fundamental boundary: promoting a particular item within a group is easier than minimizing or maximizing consensus. More specifically , we show that re- stricting the choice models can make P R O M O T I O N tractable while leaving A G R E E M E N T and D I S AG R E E M E N T NP-hard, indicating that the interaction between individuals intro- duces significant complexity to choice set optimization. After this, we provide efficient approximation algorithms with guarantees for all three problems under se veral choice models, and we validate our algorithms on choice data. Model parameters are learned for different types of indi vid- uals based on features (e.g., where someone liv es). From these learned models, we apply our algorithms to optimize group-lev el preferences. Our algorithms outperform a natu- ral baseline on real-world data coming from transportation choices, insurance policy purchases, and online shopping. 1.1. Related work Our work fits within recent interest from computer science and machine learning on discrete choice models in general and choice set effects in particular . For example, choice set effects abundant in online data has led to richer data models ( Ieong et al. , 2012 ; Chen & Joachims , 2016 ; Ra- gain & Ugander , 2016 ; Seshadri et al. , 2019 ; Makhijani & Ugander , 2019 ; Rosenfeld et al. , 2020 ; Bower & Balzano , 2020 ), new methods for testing the presence of choice set effects ( Benson et al. , 2016 ; Seshadri et al. , 2019 ; Seshadri & Ugander , 2019 ), and new learning algorithms ( Kleinber g et al. , 2017 ; Chierichetti et al. , 2018b ). More broadly , there are ef forts on learning algorithms for multinomial logit mix- tures ( Oh & Shah , 2014 ; Ammar et al. , 2014 ; Kallus & Udell , 2016 ; Zhao & Xia , 2019 ), Plackett-Luce models ( Maystre & Grossglauser , 2015 ; Zhao et al. , 2016 ), and other random utility models ( Oh et al. , 2015 ; Chierichetti et al. , 2018a ; Benson et al. , 2018 ). One of our optimization problems is maximizing group agreement by introducing new alternatives. This is mo- tiv ated in part by ho w additional context can sway opin- ion on controv ersial topics ( Munson et al. , 2013 ; Liao & Fu , 2014 ; Graells-Garrido et al. , 2014 ). There are also related algorithms for decreasing polarization in social net- works ( Garimella et al. , 2017 ; Matakos et al. , 2017 ; Chen et al. , 2018 ; Musco et al. , 2018 ), although we have no ex- plicit network and adopt a choice-theoretic frame work. Our choice set optimization frame work is similar to assort- ment optimization in operations research, where the goal is find the optimal set of products to of fer in order to maxi- mize rev enue ( T alluri & V an Ryzin , 2004 ). Discrete choice models are extensi vely used in this line of research, includ- ing the multinomial logit ( Rusmevichientong et al. , 2010 ; 2014 ) and nested logit ( Galle go & T opaloglu , 2014 ; Davis et al. , 2014 ) models. W e instead focus our attention primar- ily on optimizing agreement among indi viduals, which has not been explored in traditional rev enue-focused assortment optimization. Finally , our problems relate to group decision-making. In psychology , introducing ne w shared information is critical for group decisions ( Stasser & Titus , 1985 ; Lu et al. , 2012 ). In computer science, the complexity of group Bayesian reasoning is a concern ( H ˛ azła et al. , 2017 ; 2019 ). 2. Background and pr eliminaries W e first introduce the discrete choice models that we analyze. In the setting we explore, one or more indi viduals mak e a (possibly random) choice of a single item (or alternativ e) from a finite set of items called a choice set . W e use U to denote the univ erse of items and C ⊆ U the choice set. Thus, giv en C , an indi vidual chooses some item x ∈ C . Giv en C , a discrete choice model provides a probability for choosing each item x ∈ C . W e analyze four broad discrete choice models that are all random utility models (R UMs), which deriv e from economic rationality . In a RUM, an individual observes a random utility for each item x ∈ C and then chooses the one with the lar gest utility . W e model each individual’ s choices through the same R UM but with possibly dif ferent parameters to capture preference heterogeneity . In this sense, we have a mixture model. Choice data typically contains many observ ations from v ari- ous choice sets. W e occasionally have data specific enough to model the choices of a particular individual, but often only one choice is recorded per person, making accurate pref- Choice Set Optimization Under Discrete Choice Models of Gr oup Decisions erence learning impossible at that scale. Thus, we instead model the heterogeneous preferences of sub-populations or categories of indi viduals. For con venience, we still use “individual” or “person” when referring to components of a mixed population, since we can treat each component as a decision-making agent with its o wn preferences. In contrast, we use the term “group” to refer to the entire population. W e use A to denote the set of individuals (in the broad sense abov e), and a ∈ A indexes model parameters. The parameters of the RUMs we analyze can be inferred from data, and our theoretical results and algorithms assume that we ha ve learned these parameters. Our analysis focuses on how the probability of selecting an item x from a choice set C changes as we add new alternativ e items from C = U \ C to the choice set. W e let n = | A | , k = | C | , and m = | C | for notation. W e mostly use n = 2 , which is suf ficient for hardness proofs. Multinomial logit (MNL). The multinomial logit (MNL) model ( McFadden , 1974 ) is the workhorse of discrete choice theory . In MNL, an individual a ’ s preferences are encoded by a true utility u a ( x ) for ev ery item x ∈ U . The observ a- tions are noisy random utilities ˜ u a ( x ) = u a ( x ) + ε , where ε follows a Gumbel distrib ution. Under this model, the proba- bility that indi vidual a picks item x from choice set C (i.e., x = arg max y ∈ C ˜ u a ( y ) ) is the softmax over item utilities: Pr( a ← x | C ) = e u a ( x ) P y ∈ C e u a ( y ) . (1) W e use the term exp-utility for terms like e u a ( x ) . The utility of an item is often parameterized as a function of features of the item in order to generalize to unseen data. For e xample, a linear function is an additiv e utility model ( Tversky & Simonson , 1993 ) and looks like logistic regression. In our analysis, we work directly with the utilities. The MNL satisfies independence of irr ele vant alternatives (IIA) ( Luce , 1959 ), the property that for any two choice sets C, D and two items x, y ∈ C ∩ D : Pr( a ← x | C ) Pr( a ← y | C ) = Pr( a ← x | D ) Pr( a ← y | D ) . In other words, the choice set has no effect on a ’ s relativ e probability of choosing x or y . 1 Although IIA is intuitiv ely pleasing, beha vioral e xperiments sho w that it is often violated in practice ( Huber et al. , 1982 ; Simonson & Tversk y , 1992 ). Thus, there are many models that account for IIA violations, including the other ones we analyze. Context-dependent random utility model (CDM). The CDM ( Seshadri et al. , 2019 ) is an extension of MNL that can model IIA violations. The core idea is to approximate choice set effects by the effect of each item’ s presence on the 1 Over a ∈ A , we hav e a mixed logit which does not hav e to satisfy IIA ( McFadden & T rain , 2000 ). Here, we are interested in the IIA property at the individual le vel. utilities of the other items. For instance, a diner’ s preference for a ribeye steak may decrease relative to a fish option if filet mignon is also a v ailable. Formally , each item z ex erts a pull on a ’ s utility from x , which we denote p a ( z , x ) . The CDM then resembles the MNL with utilities u a ( x | C ) = u a ( x ) + P z ∈ C p a ( z , x ) . This leads to choice probabilities that are a softmax ov er the context-dependent utilities: Pr( a ← x | C ) = e u a ( x | C ) P y ∈ C e u a ( y | C ) . (2) Nested logit (NL). The nested logit (NL) model ( McFad- den , 1978 ) instead accounts for choice set effects by group- ing similar items into nests that people choose between successi vely . For example, a diner may first choose between a ve getarian, fish, or steak meal and then select a particular dish. NL can be derived by introducing correlation between the random utility noise ε in MNL; here, we instead consider a generalized tree-based version of the model. 2 The (generalized) NL model for an individual a consists of a tree T a with a leaf for each item in U , where the internal nodes represent categories of items. Rather than having a utility only on items, each person a also has utilities u a ( v ) on all nodes v ∈ T a (except the root). Giv en a choice set C , let T a ( C ) be the subtree of T a induced by C and all ancestors of C . T o choose an item from C , a starts at the root and repeatedly picks between the children of the current node according to the MNL model until reaching a leaf. Elimination-by-aspects (EBA). While the previous mod- els are based on MNL, the elimination-by-aspects (EB A) model ( Tversk y , 1972 ) has a different structure. In EBA, each item x has a set of aspects x 0 representing properties of the item, and person a has a utility u a ( χ ) > 0 on each aspect χ . An item is chosen by repeatedly picking an aspect with probability proportional to its utility and eliminating all items that do not have that aspect until only one item remains (or , if all remaining items hav e the same aspects, the choice is made uniformly at random). For example, a diner may first eliminate items that are too expensiv e, then disre gard meat options, and finally look for dishes with pasta before choosing mushroom ravioli. Formally , let C 0 = S x ∈ C x 0 be the set of aspects of items in C and let C 0 = T x ∈ C x 0 be the aspects shared by all items in C . Additionally , let C χ = { x ∈ C | χ ∈ x 0 } . The probability that indi vidual a picks item x from choice set C is recursiv ely defined as Pr( a ← x | C ) = P χ ∈ x 0 \ C 0 u a ( χ ) Pr( a ← x | C χ ) P ψ ∈ C 0 \ C 0 u a ( ψ ) . (3) 2 Certain parameter re gimes in this generalized model do not correspond to RUMs ( T rain , 2009 ), but this model is easier to analyze and captures the salient structure. Choice Set Optimization Under Discrete Choice Models of Gr oup Decisions If all remaining items ha v e the same aspects ( C 0 = C 0 ), the denominator is zero, and Pr( a ← x | C ) = 1 | C | in that case. Encoding MNLs in other models. Although the three models with context ef fects appear quite different, the y all subsume the MNL model. Thus, if we pro ve a problem hard under MNL, then it is hard under all four models. Lemma 1. The MNL model is a special case of the CDM, NL, and EBA models. Pr oof. Let M be an MNL model. For the CDM, use the utilities from M and set all pulls to 0. For NL, make all items children of T a ’ s root and use the utilities from M . Lastly , for EBA, assign a unique aspect χ x to each item x ∈ U with utility u a ( χ x ) = e u a ( x ) . Follo wing ( 3 ), Pr( a ← x | C ) = u a ( χ x ) Pr( a ← x | C χ x ) P ψ ∈ C 0 \ C 0 u a ( ψ ) . Since C χ x = { x } , Pr( a ← x | C χ x ) = 1 and thus Pr( a ← x | C ) ∝ u a ( χ x ) = e u a ( x ) , matching the MNL M . 3. Choice set optimization problems By introducing ne w alternativ es to the choice set C , we can modify the relationships amongst individual prefer- ences, resulting in different dynamics at the collectiv e le vel. Similar ideas are well-studied in v oting models, e.g., intro- ducing alternati ves to change winners selected by Borda count ( Easley & Kleinberg , 2010 ). Here, we study how to optimize choice sets for various group-lev el objectiv es, measured in terms of indi vidual choice probabilities coming from discrete choice models. Agreement and Disagr eement. Since we are modeling the preferences of a collection of decision-mak ers, one im- portant metric is the amount of disagreement (conv ersely , agreement) about which item to select. Giv en a set of al- ternativ es Z ⊆ C we might introduce, we quantify the disagreement this would induce as the sum of all pairwise differences between individual choice probabilities o ver C : D ( Z ) = X { a,b }⊆ A,x ∈ C | Pr( a ← x | C ∪ Z ) − Pr( b ← x | C ∪ Z ) | . (4) Here, we care about the disagreement on the original choice set C that results from preferences ov er the ne w choice set C ∪ Z . In this setup, C could represent core options (e.g., two major health care policies under deliberation) and Z additional alternativ es designed to sway opinions. Concretely , we study the following problem: giv en A, C, C , and a choice model, minimize (or maximize) D ( Z ) ov er Z ⊆ C . W e call the minimization problem A G R E E M E N T and the maximization problem D I S AG R E E M E N T . A G R E E - M E N T has applications in encouraging consensus, while D I S A G R E E M E N T yields insight into how susceptible a group may be to an adversary who wishes to increase conflict. An- other potential application for D I S A G R E E M E N T is to enrich the div ersity of preferences present in a group. Promotion. Promoting an item is another natural objecti v e, which is of considerable interest in online advertising and content recommendation. Giv en A, C, C , a choice model, and a tar get item x ∗ ∈ C , the P RO M O T I O N problem is to find the set of alternatives Z ⊆ C whose introduction maximizes the number of individuals whose “fa v orite” item in C is x ∗ . Formally , this means maximizing the number of individuals a ∈ A for whom Pr( a ← x ∗ | C ∪ Z ) > Pr( a ← x | C ∪ Z ) , x ∈ C , x 6 = x ∗ . This also has applications in voting, where questions about the influence of new candidates constantly arise. One of our contrib utions in this paper is showing that pro- motion can be easier (in a computational complexity sense) than agreement or disagreement optimization. 4. Hardness results W e now characterize the computational complexity of A G R E E M E N T , D I S AG R E E M E N T , and P RO M OT I O N under the four discrete choice models. W e first show that A G R E E - M E N T and D I S AG R E E M E N T are NP-hard under all four models and that P R O M O T I O N is NP-hard under the three models with context ef fects. After , we prov e that imposing additional restrictions on these discrete choice models can make P R O M O T I O N tractable while leaving A G R E E M E N T and D I S AG R E E M E N T NP-hard. The parameters of some choice models have extra degrees of freedom, e.g., MNL has additiv e-shift-in variant utilities. For inference, we use a standard form (e.g., sum of utilities equals zero). For ease of analysis, we do not use such standard forms, but the choice probabilities remain unambiguous. 4.1. A G R E E M E N T Although the MNL model does not hav e any context ef fects, introducing alternativ es to the choice set can still af fect the relativ e preferences of two dif ferent indi viduals. In partic- ular , introducing alternati ves can impact disagreement in a sufficiently complex way to make identifying the optimal set of alternativ es computationally hard. Our proof of Theo- rem 1 uses a v ery simple MNL in the reduction, with only two indi viduals and two items in C , where the two indi vidu- als hav e e xactly the same utilities on alternatives . In other words, e ven when indi viduals agree about new alternati ves, encouraging them to agree ov er the choice set is hard. Theorem 1. In the MNL model, A G R E E M E N T is NP-har d, even with just two items in C and two individuals that have Choice Set Optimization Under Discrete Choice Models of Gr oup Decisions 0 1 2 s Z / t 0.16 0.18 0.20 0.22 D ( Z ) 0 1 2 3 4 5 s Z / t 0.0 0.1 0.2 0.3 0.4 D ( Z ) Figure 1. (Left) Plot of D ( Z ) = t 2 t + s Z − 3 t 5 t + s Z + t 2 t + s Z − 2 t 5 t + s Z from the proof of Theorem 1 . (Right) Plot of D ( Z ) = 2 t 2 t + s Z − t/ 2 t/ 2+ s Z from the proof of Theorem 2 . Both functions are re-parameterized in terms of the ratio s Z /t by di viding through by t and achie ve local optima at s Z /t = 1 (i.e. s Z = t ); this can be verified analytically . identical utilities on items in C . Pr oof. By reduction from P A RT I T I O N , an NP-complete problem ( Karp , 1972 ). Let S be the set of integers we wish to partition into two subsets with equal sum. W e construct an instance of D I S AG R E E M E N T with A = { a, b } , C = { x, y } , C = S (abusing notation to identify alternativ es with the P A RT I T I O N integers). Let t = 1 2 P z ∈ S z . Define the util- ities as: u a ( x ) = log t , u b ( x ) = log 3 t , u a ( y ) = log t , u b ( y ) = log 2 t , and u a ( z ) = u b ( z ) = log z for all z ∈ C . The disagreement induced by a set of alternatives Z ⊆ C is characterized by its sum of exp-utility s Z = P z ∈ Z z : D ( Z ) = t 2 t + s Z − 3 t 5 t + s Z + t 2 t + s Z − 2 t 5 t + s Z . The total exp-utility of all items in C is 2 t . On the interval [0 , 2 t ] , D ( Z ) is minimized at s Z = t (Fig. 1 , left). Thus, if we could ef ficiently find the set Z minimizing D ( Z ) , then we could efficiently solv e P A RT I T I O N . From Lemma 1 , the other models we consider can all encode any MNL instance, which leads to the follo wing corollary . Corollary 1. A G R E E M E N T is NP-har d in the CDM, NL, and EBA models. 4.2. D I S AG R E E M E N T Using a similar strategy , we can construct an MNL instance whose disagreement is maximized rather than minimized at a particular target value (Theorem 2 ). The reduction requires an ev en simpler MNL setup. Theorem 2. In the MNL model, D I S A G R E E M E N T is NP- har d, e ven with just one item in C and two individuals that have identical utilities on items in C . Pr oof. By reduction from S U B S E T S U M ( Karp , 1972 ). Let S be a set of positiv e integers with target t . Let A = { a, b } , C = { x } , C = S , with utilities: u a ( x ) = log 2 t , u b ( x ) = log t/ 2 , and u a ( z ) = u b ( z ) = log z for all z ∈ C . Letting s Z = P z ∈ Z z , including Z ⊆ C makes the disagreement D ( Z ) = 2 t 2 t + s Z − t/ 2 t/ 2 + s Z . For s Z ≥ 0 , D ( Z ) is maximized at s Z = t (Fig. 1 , right). Thus, if we could efficiently maximize D ( Z ) , then we could efficiently solv e S U B S E T S U M . By Lemma 1 , we again hav e the follo wing corollary . Corollary 2. D I S A G R E E M E N T is NP-har d in the CDM, NL, and EBA models. 4.3. P R O M OT I O N In choice models with no context ef fects, P RO M O T I O N has a constant-time solution: under IIA, the presence of alterna- tiv es has no ef fect on an individual’ s relative preference for items in C . Howe ver , P RO M O T I O N is more interesting with context effects, and we show that it is NP-hard for CDM, NL, and EB A. In Section 4.4 , we will show that restric- tions of these models make P RO M O T I O N tractable but k eep A G R E E M E N T and D I S AG R E E M E N T hard. Theorem 3. In the CDM model, P RO M OT I O N is NP-har d, even with just one individual and thr ee items in C . Pr oof. By reduction from S U B S E T S U M . Let set S with target t be an instance of S U B S E T S U M . Let A = { a } , C = { x ∗ , w, y } , C = S . Using tuples interpreted entry- wise for brevity , suppose that we hav e the follo wing utilities: u a ( h x ∗ , w, y i | C ) = h 1 , t, − t i u a ( z ) = −∞ ∀ z ∈ C p a ( z , h x ∗ , w, y i ) = h z , 0 , 2 z i ∀ z ∈ C . W e wish to promote x ∗ . Let s Z = P z ∈ Z z . When we include the alternati ves in Z , x ∗ is the item in C most likely to be chosen if and only if 1+ s Z > t and 1+ s Z > − t + 2 s Z . Since s Z and t are integers, this is only possible if s Z = t . Thus, if we could efficiently promote x ∗ , then we could efficiently solv e S U B S E T S U M . W e use the same Goldilocks strategy in our proofs for the NL and EB A models: by carefully defining utilities, we create choice instances where the optimal promotion solution is to pick just the right quantity of alternativ es to increase preference for one item without overshooting. Ho we ver , the NL model has a novel challenge compared to the CDM. W ith CDM, alternati ves can increase the choice probability of an item in C , but in the NL, new alternati ves only lo wer choice probabilities. Choice Set Optimization Under Discrete Choice Models of Gr oup Decisions Theorem 4. In the NL model, P RO M O T I O N is NP-har d, even with just two individuals and two items in C . Pr oof. By reduction from S U B S E T S U M . Let S = { z 1 , . . . , z n } , t be an instance of S U B S E T S U M . Let A = { a, b } , C = { x ∗ , y } , C = S , and 0 < ε < 1 . The nest structures and utilities are shown in Fig. 2 . W e wish to a ’ s root y r x ∗ z 1 . . . z n 0 log 2 log( t + ε ) log z 1 log z n b ’ s root x ∗ r y z 1 . . . z n 0 log 2 log( t − ε ) log z 1 log z n Figure 2. NL trees used in the proof of Theorem 4 . The left tree is for individual a and the right tree for individual b . promote x ∗ . W ith just the choice set C , a prefers x ∗ to y , but b does not. T o make b prefer x ∗ to y , we need to canni- balize y by adding z i items. Howe v er , this simultaneously cannibalizes x ∗ in a ’ s tree, so we need to be careful not to introduce too much additional utility . T o ensure a prefers x ∗ , we need to pick Z such that Pr( a ← y | C ∪ Z ) < Pr( a ← y | C ∪ Z ) ⇐ ⇒ 1 1 + e log 2 < e log 2 1 + e log 2 · e log( t + ε ) e log( t + ε ) + P z ∈ Z e log z ⇐ ⇒ 1 3 < 2 3 · t + ε t + ε + P z ∈ Z z ⇐ ⇒ X z ∈ Z z < t + ε. T o ensure b prefers x ∗ , we need Pr( b ← x ∗ | C ∪ Z ) > Pr( b ← y | C ∪ Z ) ⇐ ⇒ 1 1 + e log 2 > e log 2 1 + e log 2 · e log( t − ε ) e log( t − ε ) + P z ∈ Z e log z ⇐ ⇒ 1 3 > 2 3 · t − ε t − ε + P z ∈ Z z ⇐ ⇒ X z ∈ Z z > t − ε. Since the z are all integers, we must then ha ve P z ∈ Z z = t . If we could efficiently promote x ∗ , we could efficiently find such a Z . This nested logit construction relies on the two indi viduals having dif ferent nesting structures: notice that x ∗ and y are swapped in the two trees. W e will see in Section 4.4 that this is a necessary condition for the hardness of P R O M OT I O N under the nested logit model. Finally , we hav e the follo wing hardness result for EB A. Theorem 5. In the EBA model, P R O M O T I O N is NP-hard, even with just two individuals and two items in C . Pr oof. By reduction from S U B S E T S U M . Let S, t be an instance of S U B S E T S U M . Let A = { a, b } , C = { x ∗ , y } , C = S , and s = P z ∈ S z . Make aspects χ z , ψ z , γ z for each z ∈ S as well as two more aspects χ, ψ . The items hav e aspects as follows: x ∗0 = { χ } ∪ { χ z | z ∈ S } y 0 = { ψ } ∪ { ψ z | z ∈ S } z 0 = { χ z , ψ z , γ z } ∀ z ∈ S The individuals have the following utilities on aspects, where 0 < ε < 1 : u a ( χ ) = 0 u a ( χ z ) = z u a ( ψ ) = s − t/ 2 − ε u a ( ψ z ) = 0 u a ( γ z ) = s − z u b ( χ ) = s − t/ 2 + ε u b ( χ z ) = 0 u b ( ψ ) = 0 u b ( ψ z ) = z u b ( γ z ) = s − z ∀ z ∈ S ∀ z ∈ S ∀ z ∈ S W e want to promote x ∗ . Notice that x ∗ and y hav e disjoint aspects. Thus the choice probabilities from C are propor- tional to the sum of the item’ s aspects: Pr( a ← x ∗ | C ) ∝ s Pr( a ← y | C ) ∝ s − t 2 − ε Pr( b ← x ∗ | C ) ∝ s − t 2 + ε Pr( b ← y | C ) ∝ s. T o promote x ∗ , we need to make b prefer x ∗ to y . Adding a z item cannibalizes from a ’ s preference for x ∗ and b ’ s preference for y . As in the NL proof, we want to add just enough z items to make b prefer x ∗ to y without making a prefer y to x ∗ . First, notice that the γ z aspects have no eff ect on the indi- viduals’ relative preference for x ∗ and y . If we introduce the alternative z , then if a picks the aspect χ z , y will be eliminated. The remaining aspects of x ∗ , namely x ∗0 \ { χ z } , hav e combined utility s − z , as does γ z . Therefore a will be equallly likely to pick x ∗ and z . Symmetric reasoning shows that if b chooses aspect ψ z , then b will end up picking y with probability 1/2. This means that when we include alternativ es Z ⊆ C , each aspect χ z , ψ z for z ∈ Z effec- tiv ely contrib utes z / 2 to a ’ s utility for x ∗ and b ’ s utility for y rather than the full z . The optimal solution is therefore a set Z of alternatives whose sum is t , since that will cause Choice Set Optimization Under Discrete Choice Models of Gr oup Decisions a to hav e ef fecti v e utility s − t/ 2 on x ∗ , which exceeds its utility s − t/ 2 − ε on y . Meanwhile, b ’ s ef fecti ve utility on y will also be s − t/ 2 , which is smaller than its utility s − t/ 2 + ε on x ∗ . If we include less alternati ve weight, b will prefer y . If we include more, a will prefer y . Therefore if we could efficiently find the optimal set of alternatives to promote x ∗ , we could ef ficiently find a subset of S with sum t . 4.4. Restricted models that make pr omotion easier W e now sho w that, in some sense, P RO M O T I O N is a fundamentally easier problem than A G R E E M E N T or D I S - AG R E E M E N T . Specifically , there are simple restrictions on CDM, NL, and EB A that make P RO M O T I O N tractable but leav e A G R E E M E N T and D I S AG R E E M E N T NP-hard. Impor- tantly , these restrictions still allo w for choice set ef fects. In Section 4.5 , we also prov e a strong restriction on the MNL model where A G R E E M E N T and D I S AG R E E M E N T are tractable, but we could not find meaningful restrictions for similar results on the other models. 2-item CDM with equal context effects. The proof of Theorem 3 shows that P R O M O T I O N is hard with only a sin- gle individual and three items in C . Howe v er , if C only has two items and context effects are the same (i.e., p a ( z , · ) is the same for all z ∈ C ), then P RO M OT I O N is tractable. The optimal solution is to include all alternativ es that in- crease utility for x ∗ more than the other item, as doing so makes strict progress on promoting x ∗ . If individuals ha ve different conte xt ef fects or if there are more than two items, then there can be conflicts between which items should be included (see Appendix A.1 for a proof that 2-item CDM with unequal context ef fects makes P RO M OT I O N NP-hard). Although this restriction makes P RO M O T I O N tractable, it leav es A G R E E M E N T and D I S A G R E E M E N T NP-hard: the proofs of Theorems 1 and 2 can be interpreted as 2-item and 1-item CDMs with equal (zero) context ef fects. Same-tree NL. If we require that all indi viduals share the same NL tree structure, but still allow different utilities, then promotion becomes tractable. For each z ∈ C , we can determine whether it reduces the relative choice probability of x ∗ based on its position in the tree: adding z decreases the relati ve choice probability of x ∗ if and only if z is a sibling of any ancestor of x ∗ (including x ∗ ) or if it causes such a sibling to be added to T a ( C ) . Thus, the solution to P R O M O T I O N is to include all z not in those positions, which is a polynomial-time check. This restriction leav es A G R E E - M E N T and D I S AG R E E M E N T NP-hard via Theorems 1 and 2 as we can still encode any MNL model in a same-tree NL using the tree in which all items are children of the root. Disjoint-aspect EB A. The follo wing condition on aspects makes promoting x ∗ tractable: for all z ∈ C , either z 0 ∩ x ∗0 = ∅ or z 0 ∩ y 0 = ∅ for all y ∈ C , y 6 = x ∗ . That is, alternativ es either share no aspects with x ∗ or share no as- pects with other items in C . This prevents alternati v es from cannibalizing from both x ∗ and its competitors. T o promote x ∗ , we include all alternati ves that share aspects with com- petitors of x ∗ but not x ∗ itself, which strictly promotes x ∗ . This condition is slightly weaker than requiring all items to hav e disjoint aspects, which reduces to MNL. Howe v er , this condition is again not suf ficient to make A G R E E M E N T and D I S A G R E E M E N T tractable, since any MNL model can be encoded in a disjoint-aspect EB A instance. 4.5. Strong r estriction on MNL that makes A G R E E M E N T and D I S AG R E E M E N T tractable As we sa w in the proofs of Theorems 1 and 2 , A G R E E M E N T and D I S AG R E E M E N T are hard in the MNL model even when individuals have identical utilities on alternativ es. This is possible because the individuals hav e different sums of utilities on C ; one unit of utility on an alternativ e has a weaker effect for individuals with higher utility sums on C . T o address the issue of identifiability , we assume each individual’ s utility sum over U is zero in this section. This allows us to meaningfully compare the sum of utilities of two dif ferent indi viduals. Definition 1. If an indi vidual a has P x ∈U u a ( x ) = 0 , then the stubbornness of a is σ a = P x ∈ C e u ( x ) . W e call this quantity “stubbornness” since it quantifies how reluctant an individual is to change its probabilities on C giv en a unit of utility on an alternati v e. Proposition 1. In an MNL model where all individuals ar e equally stubborn and have identical utilities on alternatives, the solution to A G R E E M E N T is C . Pr oof. Assume utilities are in standard form, with P x ∈U u a ( x ) = 0 . Let σ = P x ∈ C e u ( x ) be each indi vid- ual’ s stubborness and let Z be a set of alternatives. Suppose all individuals have the same utility u ( z ) for each alternati ve z . The disagreement between two indi viduals about a single item x in C is then: e u a ( x ) σ + P z ∈ Z e u ( z ) − e u b ( x ) σ + P z ∈ Z e u ( z ) = | e u a ( x ) − e u b ( x ) | σ + P z ∈ Z e u ( z ) . Notice that this strictly decreases if P z ∈ Z e u ( z ) increases, so we minimize D by including all of the alternativ es. The same reasoning also allows us to trivially solve D I S - AG R E E M E N T in this restricted MNL model. Corollary 3. The solution to D I S AG R E E M E N T in an equal alternative utilities, equal stubbornness MNL model is ∅ . While this MNL restriction is too strong to be of practical value, it is interesting from a theoretical perspecti ve as it indicates where the hardness of the problem arises. Choice Set Optimization Under Discrete Choice Models of Gr oup Decisions Algorithm 1 ε -additiv e approximation for A G R E E M E N T in the MNL model. 1 Input: n individuals A , k items C , m alternativ es C , utilities u a ( · ) > 0 for each a ∈ A . For brevity: 2 e ax ← e u a ( x ) , s a ← P z ∈ C e az , δ ← ε/ (2 k m n 2 ) 3 L 0 ← empty n -dimensional array whose a th dimension has size 1+ b log 1+ δ s a c (each cell can store a set Z ⊆ C and its n exp-utility sums for each indi vidual) 4 Initialize L 0 [0 , . . . , 0] ← ( ∅ , 0 , . . . , 0) ( n zeros) 5 for i = 1 to m do 6 z ← C [ i − 1] , L i ← L i − 1 7 for each cell of L i − 1 containing ( Z, t 1 , . . . , t n ) do 8 h ← n -tuple w/ entries b log 1+ δ ( t j + e a j z ) c , ∀ j 9 if L i [ h ] is empty then 10 L i [ h ] ← ( Z ∪ { z } , t 1 + e a 1 z , . . . , t n + e a n z ) 11 Z m ← collection of all sets Z in cells of L m 12 return arg min Z ∈ Z m D ( Z ) (see Eq. ( 4 )) 5. A ppr oximation algorithms Thus far , we hav e seen that sev eral interesting group decision-making problems are NP-hard across standard dis- crete choice models. Here, we provide a positi ve result: we can compute arbitrarily good approximate solutions to many instances of these problems in polynomial time. W e focus our analysis on Algorithm 1 , which is an ε -additiv e approximation algorithm to A G R E E M E N T under MNL, with runtime polynomial in k , m , and 1 ε , but exponential in n (recall that k = | C | , m = | C | , and n = | A | ). In contrast, brute force (testing e very set of alternati ves) is exponential in m and polynomial in k and n . A G R E E M E N T is NP-hard ev en with n = 2 (Theorem 1 ), so our algorithm provides a substantial efficiency improvement. W e discuss how to extend this algorithm to other objectives and other choice models later in the section. Finally , we present a faster b ut less flexible mixed-integer programming approach for MNL A G R E E M E N T and D I S AG R E E M E N T that performs very well in practice. Algorithm 1 is based on an FPT AS for S U B S E T S U M ( Cor- men et al. , 2001 , Sec. 35.5), and the first parts of our anal- ysis follo w some of the same steps. The core idea of our algorithm is that a set of items can be characterized by its exp-utility sums for each indi vidual and that there are only polynomially many combinations of exp-utility sums that differ by more than a multiplicativ e factor 1 + δ . W e can therefore compute all sets of alternativ es with meaningfully different impacts and pick the best one. For the purpose of the algorithm, we ass ume all utilities are positiv e (otherwise we may access a negati ve index); utilities can always be shifted by a constant to satisfy this requirement. W e no w provide an intuitive description of Algorithm 1 . The array L i has one dimension for each individual in ∅ { F } { F , } { } Alice Bob Carla Figure 3. Example of the structure L i used in Algorithm 1 for n = 3 individuals and C = { F , } . Here, Alice has high utility for F and lo w utility for , Bob has medium utility for F and lo w utility for , and Carla has lo w utility for F and high utility for . The exp-utility sums stored in cells are omitted. A (we use a hash table in practice since L i is typically sparse). The cells along a particular dimension discretize the exp-utility sums that the individual corresponding to that dimension could hav e for a particular set of alternativ es (Figure 3 ). In particular , if indi vidual j has total exp-utility t j = P y ∈ Z e u j ( y ) for a set Z , then we store Z at index b log 1+ δ t j c along dimension j . As the algorithm progresses, we place possible sets of al- ternativ es Z in the cells of L i according to their exp-utility sums t 1 , . . . , t n for each individual (we store t 1 , . . . , t n in the cell along with Z ). W e add one element at a time from C to the sets already in L i ( L 0 starts with only the empty set). If two sets have very similar exp-utility sums, they may map to the same cell, in which case only one of them is stored. If the discretization of the array is coarse enough (that is, with large enough δ ), many sets of alternati ves will map to the same cells, reducing the number of sets we con- sider and saving computational work. On the other hand, if the discretization is fine enough ( δ is suf ficiently small), then the best set we are left with at the end of the algorithm cannot induce a disagreement v alue too different from the optimal set. W e now formalize this reasoning, starting with the following technical lemma that sho ws items mapping to same cell hav e similar exp-utility sums. Lemma 2. Let C i be the first i elements pr ocessed by the outer for loop of Algorithm 1 . At the end of the algorithm, for all Z ⊆ C i with exp-utility sums t a , there exists some Z 0 ∈ L i with exp-utility sums t 0 a such that t a (1+ δ ) i < t 0 a < t a (1 + δ ) i , for all a ∈ A (with δ as defined in Algorithm 1 , Line 2 ). Pr oof. If a set Z has total exp-utility t a to indi vidual a , then it is placed in L at position b log 1+ δ t a c in dimension a . So, if two sets Z , Z 0 with exp-utility totals t a , t 0 a for individual a are mapped to the same cell of L , then for all a ∈ A , b log 1+ δ t a c = b log 1+ δ t 0 a c . W e can therefore bound t 0 a : log 1+ δ t a − 1 < log 1+ δ t 0 a < log 1+ δ t a + 1 . Choice Set Optimization Under Discrete Choice Models of Gr oup Decisions Exponentiating both sides with base 1 + δ and simplifying yields t a 1 + δ < t 0 a < t a (1 + δ ) . (5) W ith this fact in hand, we proceed by induction on i . When i = 0 , C i is empty and the lemma holds. No w suppose that i > 0 and that the lemma holds for i − 1 . Every set in C i was made by adding (a) zero elements or (b) one element to a set in C i − 1 . W e consider these two cases separately . (a) For any set Z ⊆ C i that is also contained in C i − 1 , we know by the inducti ve h ypothesis that some element in L i − 1 satisfied the inequality . Since we nev er ov erwrite cells, the lemma also holds for Z after iteration i . (b) Now consider sets Z 0 ⊆ C i that were formed by adding the new element z to a set Z ⊆ C i − 1 . In the inner for loop, we at some point encountered the cell containing the set Y ∈ L i − 1 satisfying the lemma for set Z by the inductiv e hypothesis. Let y a be the exp-utility totals for Y and t a for Z . Notice that the exp-utility totals of Z 0 are exactly t a + e az . Starting with the inducti ve hypothesis, we see that the exp-utility totals of Y ∪ { z } satisfy t a + e az (1 + δ ) i − 1 < y a + e az < ( t a + e az )(1 + δ ) i − 1 . When we go to place Y ∪ { z } in a cell, it might be unoccu- pied, in which case we place it in L i and the lemma holds for Z 0 . If it is occupied by some other set, then by applying Eq. ( 5 ) we find that the lemma also holds for Z 0 . W ith this lemma in hand, we can prove our main construc- tiv e result. Theorem 6. Algorithm 1 is an ε -additive approximation for A G R E E M E N T in the MNL model. Pr oof. Let β = ε/ ( k n 2 ) for brevity . Following our choice of δ and using Lemma 2 , at the end of the algorithm, the optimal set Z ∗ ⊆ C (with exp-utility sums t ∗ a ) has some representativ e Z 0 in L m such that t ∗ a (1 + β / (2 m )) m < t 0 a < t ∗ a (1 + β / (2 m )) m , ∀ a ∈ A. Since e x ≥ (1 + x/m ) m , we have t ∗ a /e β 2 < t 0 a < t ∗ a e β 2 , and since e x ≤ 1 + x + x 2 when x < 1 , t ∗ a 1 + β / 2 + β 2 / 4 < t 0 a < t ∗ a (1 + β / 2 + β 2 / 4) . Finally , t ∗ a 1+ β < t 0 a < t ∗ a (1 + β ) because 0 < β < 1 . Now we show that D ( Z ∗ ) and D ( Z 0 ) differ by at most ε . T o do so, we first bound the difference between Pr( a ← x | C ∪ Z ∗ ) and Pr( a ← x | C ∪ Z 0 ) by β . Let c a = P x ∈ C e ax be the total exp-utility of a on C . By the above reasoning, e ax c a + t ∗ a (1 + β ) < e ax c a + t 0 a < e ax c a + t ∗ a 1+ β , where the middle term is equal to Pr( a ← x | C ∪ Z 0 ) . From the lo wer bound, the dif ference between Pr( a ← x | C ∪ Z ∗ ) and Pr( a ← x | C ∪ Z 0 ) could be as large as e ax c a + t ∗ a − e ax c a + t ∗ a (1 + β ) = e ax t ∗ a β ( c a + t ∗ a )( c a + t ∗ a (1 + β )) < e ax t ∗ a β 2 c a t ∗ a ≤ β 2 . From the upper bound, the dif ference between Pr( a ← x | C ∪ Z ∗ ) and Pr( a ← x | C ∪ Z 0 ) could be as large as e ax c a + t ∗ a 1+ β − e ax c a + t ∗ a = e ax t a (1 − 1 1+ β ) ( c a + t ∗ a 1+ β )( c a + t ∗ a ) = e ax t ∗ a β ( c a (1 + β ) + t ∗ a )( c a + t ∗ a ) < e ax t ∗ a β 2 c a t ∗ a ≤ β 2 . Thus, Pr( a ← x | C ∪ Z ∗ ) and Pr( a ← x | C ∪ Z 0 ) differ by at most β 2 . Using the same argument for an individual b , the disagreement between a and b about x can only increase by β with the set Z compared to the optimal set Z ∗ . Since there are n 2 pairs of individuals and k items in C , the total error of the algorithm is bounded by k n 2 β = ε . W e now show that the runtime of Algorithm 1 is O (( m + k n 2 )(1 + b log 1+ δ s c ) n ) , where s = max a s a is the maxi- mum exp-utility sum for an y indi vidual. Moreover , for any fixed n , this runtime is bounded by a polynomial in k , m , and 1 ε . T o see this, first note that the size of L i is bounded abo ve by (1 + b log 1+ δ s c ) n . For each z ∈ C , we perform constant- time operations 3 on each entry of L i , for a total of O ( m (1 + b log 1+ δ s c ) n ) time. Then we compute D ( Z ) for each cell of L m , which takes O ( k n 2 ) time per cell. The total runtime is therefore O (( m + k n 2 )(1 + b log 1+ δ s c ) n ) , as claimed. Finally , (1 + b log 1+ δ s c ) n is bounded by a polynomial in 3 The algorithm requires computing log 1+ δ , which can be done efficiently using a precomputed change-of-base constant and tak- ing logarithms to a con venient base. Our analysis treats these logarithms as constant-time operations, since we care about how the runtime grows as a function of n, m, k , and 1 ε . Choice Set Optimization Under Discrete Choice Models of Gr oup Decisions m, k , and 1 ε for any fix ed n : (1 + b log 1+ δ s c ) n ≤ 1 + ln s ln 1 + δ n ≤ 1 + (1 + δ ) ln s δ n (since ln(1 + x ) ≥ x 1+ x for x > − 1 ) = 1 + ln s δ + ln s n = 1 + 2 k m n 2 ln s ε + ln s n . A G R E E M E N T is NP-hard ev en when individuals ha v e equal utilities on alternati ves. In this case, we only need to com- pute exp-utility sums for a single individual, which brings the runtime down to O (( m + k n 2 ) log 1+ δ s ) . Extensions to other objectives and models. Algorithm 1 can be easily extended to any objective function that is efficiently computable from utilities. For instance, Algo- rithm 1 can be adapted for D I S AG R E E M E N T by replacing the arg min with an arg max on Line 12 . Algorithm 1 can also be adapted for CDM and NL. The anal- ysis is similar and details are in Appendix B , although the running times and guarantees are different. W ith CDM, the exponent in the runtime increases to nk for A G R E E M E N T and D I S AG R E E M E N T , and the ε -additiv e approximation is guaranteed only if items in C ex ert zero pulls on each other . Howe ver , e v en for the general CDM, our e xperiments will show that the adapted algorithm remains a useful heuris- tic. When we adapt Algorithm 1 for NL, we retain the full approximation guarantee but the exponent in the runtime increases and has a dependence on the tree size. P R O M O T I O N is not interesting under MNL and also has a discrete rather than continuous objecti ve, i.e., the number of people with fav orite item x ∗ in C . For models with context effects, we can define a meaningful notion of approximation. Definition 2. An item y ∈ C ∪ Z is an ε -favorite item of indivi dual a if Pr( a ← y | C ∪ Z ) + ε ≥ Pr( a ← x | C ∪ Z ) for all x ∈ C . A solution ε -appr oximates P RO M O T I O N if the number of people for whom x ∗ is an ε -fa vorite item is at least the value of the optimal P R O M O T I O N solution. Using this, we can adapt Algorithm 1 for P R O M O T I O N un- der CDM and NL. Again, for CDM, the approximation has guarantees in certain parameter regimes and the NL has full approximation guarantees. Since we do not have compute D ( Z ) , the runtimes loses the k n 2 term compared to the A G R E E M E N T and D I S AG R E E M E N T versions (Ap- pendix B.3 ). Finally , EB A has considerably dif ferent structure than the other models. W e leav e algorithms for EB A to future work. 5.1. Fast exact methods f or MNL W e provide another approach for solving A G R E E M E N T and D I S A G R E E M E N T in the MNL model, based on transforming the objecti v e functions into mixed-integer bilinear programs (MIBLPs). MIBLPs can be solved for moderate problem sizes with high-performance branch-and-bound solvers (we use Gurobi’ s implementation). In practice, this approach is faster than Algorithm 1 (for finding optimal solutions— Algorithm 1 will always be faster with sufficiently lar ge ε ) and can optimize over larger sets C . Howe ver , this approach does not easily extend to CDM, NL, or P RO M O T I O N and does not hav e a polynomial-time runtime guarantee. 5 . 1 . 1 . M I B L P F O R M U L A T I O N F O R A G R E E M E N T Let x i be a decision v ariable indicating whether we add in the i th item in C . Let e y a = e u a ( y ) and e C a = P y ∈ C e y a . W e can write A G R E E M E N T as the following 0-1 optimiza- tion problem. min x X a,b ∈ A X y ∈ C e y a e C a + P i ∈ C x i e ia − e y b e C b + P i ∈ C x i e ib s . t . x i ∈ { 0 , 1 } W e can rewrite this with no absolute v alues by introducing new v ariables δ y ab that represent the absolute disagreement about item y between indi viduals a and b . W e then use the standard trick for minimizing an absolute value in linear programs: min x X a,b ∈ A X y ∈ C δ y ab s . t . e y a e C a + P i ∈ C x i e ia − e y b e C b + P i ∈ C x i e ib ≤ δ y ab ∀ y ∈ C, { a, b } ⊂ A , e y b e C b + P i ∈ C x i e ib − e y a e C a + P i ∈ C x i e ia ≤ δ y ab ∀ y ∈ C, { a, b } ⊂ A , x i ∈ { 0 , 1 } ∀ i ∈ C , δ y ab ∈ R ∀ y ∈ C, { a, b } ⊂ A T o get rid of the fractions, we introduce the new v ariables z a = 1 e C a + P i x i e ia for each individual a and add corre- Choice Set Optimization Under Discrete Choice Models of Gr oup Decisions sponding constraints enforcing the definition of z a : min x X a,b ∈ A X y ∈ C δ y ab s . t . z a e y a − z b e y b ≤ δ y ab ∀ y ∈ C, { a, b } ⊂ A, z b e y b − z a e y a ≤ δ y ab ∀ y ∈ C, { a, b } ⊂ A, z a e C a + z a X i ∈ C x i e ia = 1 ∀ a ∈ A, x i ∈ { 0 , 1 } ∀ i ∈ C , δ y ab ∈ R ∀ y ∈ C, { a, b } ⊂ A, z a ∈ R ∀ a ∈ A 5 . 1 . 2 . M I B L P F O R M U L A T I O N F O R D I S AG R E E M E N T A similar technique works for D I S AG R E E M E N T , but maxi- mizing an absolute v alue is slightly trickier than minimizing. In addition to the v ariables δ y ab that we used before, we also add ne w binary v ariables g y ab indicating whether each dif- ference in choice probabilities is positiv e or ne gati ve. W ith these ne w variables (and following the same steps as abov e), D I S A G R E E M E N T can be written as the following MIBLP: max x X a,b ∈ A X y ∈ C δ y ab s . t . z a e y a − z b e y b ≤ δ y ab ∀ y ∈ C, { a, b } ⊂ A, z b e y b − z a e y a ≤ δ y ab ∀ y ∈ C, { a, b } ⊂ A, 2 g y ab + z a e y a − z b e y b ≥ δ y ab ∀ y ∈ C, { a, b } ⊂ A, 2(1 − g y ab ) + z b e y b − z a e y a ≥ δ y ab ∀ y ∈ C, { a, b } ⊂ A, z a e C a + z a X i ∈ C x i e ia = 1 ∀ a ∈ A, x i ∈ { 0 , 1 } ∀ i ∈ C , g y ab ∈ { 0 , 1 } ∀ y ∈ C, { a, b } ⊂ A, δ y ab ∈ R ∀ y ∈ C, { a, b } ⊂ A, z a ∈ R ∀ a ∈ A 6. Numerical experiments W e apply our methods to three datasets (T able 1 ). The S F W O R K dataset ( Koppelman & Bhat , 2006 ) comes from a surve y of San Francisco residents on av ailable (choice set) and selected (choice) transportation options to get to work. W e split the respondents into two segments ( | A | = 2 ) according to whether or not they liv e in the “core residen- tial district of San Fransisco or Berk eley . ” The A L L S TA T E dataset ( Kaggle , 2014 ) consists of insurance policies (items) characterized by anonymous categorical features A–G with 2 to 4 v alues each. Each customer views a set of policies (the choice set) before purchasing one. W e reduce the number T able 1. Dataset statistics: item, observation, and unique choice set counts; and percent of observations in sub-population splits. Dataset # items # obs. # sets split % S F W O R K 6 5029 12 16/84 A L L S T A T E 24 97009 2697 45/55 Y O O C H O O S E 41 90493 1567 47/53 T able 2. Sum of error over all 2-item choice sets C compared to optimal (brute force) on S F W O R K . Algorithm 1 is optimal. Model Problem Greedy Algorithm 1 MNL A G R E E M E N T 0 . 03 0 . 00 D I S A G R E E M E N T 0 . 00 0 . 00 rank-2 CDM A G R E E M E N T 0 . 14 0 . 00 D I S A G R E E M E N T 0 . 13 0 . 00 NL A G R E E M E N T 0 . 00 0 . 00 D I S A G R E E M E N T 0 . 00 0 . 00 of items to 24 by considering only features A, B, and C. T o model dif ferent types of indi viduals, we split the data into homeowners and non-homeowners (again, | A | = 2 ). The Y O O C H O O S E dataset ( Ben-Shimon et al. , 2015 ) contains online shopping data of clicks and purchases of categorized items in user browsing sessions. Choice sets are unique cate- gories bro wsed in a session and the choice is the category of the purchased product (categories appearing fewer than 20 times were omitted). W e split the choice data into two sub- populations by thresholding on the purchase timestamps. For inferring maximum-likelihood models from data, we use PyT orch’ s Adam optimizer ( Kingma & Ba , 2015 ; Paszke et al. , 2019 ) with learning rate 0 . 05 , weight decay 0 . 00025 , batch size 128, and the amsgrad flag ( Reddi et al. , 2018 ). W e use the low-rank (rank-2) CDM ( Seshadri et al. , 2019 ) that e xpresses pulls as the inner product of item embeddings. Our code and data are av ailable at https://github. com/tomlinsonk/choice- set- opt . For S F W O R K under the MNL, CDM, and NL models, we considered all 2-item choice sets C (using all other items for C ) for A G R E E M E N T and D I S AG R E E M E N T (for the NL model, we used the best-performing tree from Koppelman & Bhat ( 2006 )). W e compare Algorithm 1 ( ε = 0 . 01 ) to a greedy approach (henceforth, “Greedy”) that builds Z by repeatedly selecting the item from C that, when added to Z , most improves the objecti ve, if such an item exists. This dataset was small enough to compare against the optimal, brute-force solution (T able 2 ). In all cases, Algorithm 1 finds the optimal solution, while Greedy is often subopti- mal. Howe ver , for this value of ε , we find that Algorithm 1 searches the entire space and actually computes the brute force solution (we get the number of sets analyzed by Al- Choice Set Optimization Under Discrete Choice Models of Gr oup Decisions − 1 0 − 1 − 1 0 − 2 − 1 0 − 3 0 1 0 − 3 1 0 − 2 1 0 − 1 1 0 0 A l g . 1 D ( Z ) - G r e e d y D ( Z ) ε = 0 . 1 2 13% sets MNL ε = 8 0 10% sets Allstate Rank-2 CDM Agreement Disagreement − 1 0 − 1 − 1 0 − 2 − 1 0 − 3 0 1 0 − 3 1 0 − 2 1 0 − 1 1 0 0 A l g . 1 D ( Z ) - G r e e d y D ( Z ) ε = 0 . 4 0.000079% sets Agreement Disagreement ε = 1 3 0 0.000043% sets YOOCHOOSE Figure 4. Algorithm 1 vs. Greedy performance box plots when applied to all 2-item choice sets in A L L S T A T E and Y O O C H O O S E under MNL and CDM (subplots also show ε and the percent of subsets of C computed by Algorithm 1 , written X% sets). Each point is the difference in D ( Z ) when Algorithm 1 and Greedy are run on a particular choice set. Horizontal spread shows approxi- mate density and the Xs mark means. A negati ve (resp. positi ve) y -value for A G R E E M E N T (resp. D I S AG R E E M E N T ) indicates that Algorithm 1 outperformed Greedy . Algorithm 1 performs better in all cases e xcept for D I S AG R E E M E N T under CDM on Y O O C H O O S E . Even in this exception, though, our approach finds a fe w v ery good solutions and Algorithm 1 has better mean performance. gorithm 1 from | L m | for a gi ven ε and compare it to 2 | C | ). Even though we hav e an asymptotic polynomial runtime guarantee, for small enough datasets, we might not see com- putational savings. Running with larger ε yielded similar results, ev en for ε > 2 , when our bounds are vacuous. The results still highlight two important points. First, ev en on small datasets, Greedy can be sub-optimal. For example, for A G R E E M E N T under CDM with C = { driv e alone , transit } , Algorithm 1 found the optimal Z = { bike, walk } , inferring that both sub-populations agree on both dri ving less and taking transit less. Howe ver , Greedy just introduced a carpool option, which has a lower ef fect on discouraging driving alone or taking transit, resulting in lower agreement between city and sub urban residents. Second, our theoretical bounds can be more pessimistic than what happens in practice. Thus, we can consider larger v al- ues of ε to reduce the search space; Algorithm 1 remains a principled heuristic, and we can measure ho w much of the search space Algorithm 1 considers. This is the approach we take for the A L L S TA T E and Y O O C H O O S E data, where we find that Algorithm 1 far outperforms its theoretical worst- 1 0 − 1 1 0 0 1 0 1 1 0 2 1 0 3 A p p r o x i m a t i o n ε 0.0 0.5 1.0 Proportion Solved Algorithm 1 Greedy Brute force 1 0 − 1 1 0 0 1 0 1 1 0 2 1 0 3 A p p r o x i m a t i o n ε 1 0 2 1 0 3 1 0 4 1 0 5 1 0 6 1 0 7 # Sets Computed Figure 5. P R O M OT I O N results on A L L S TA T E 2-item choice sets. (Left) Success rate comparison; Algorithm 1 has near-optimal per- formance (about 9% of instances hav e no P RO M OT I O N solution). (Right) Number of subsets of C computed by Algorithm 1 (dashed gray line at 2 22 = 2 m for brute force computation). case bound. W e again considered all 2-item choice sets C and tested our method under MNL and CDM, 4 setting ε so that the experiment took about 30 minutes to run for A L L - S TA T E and 2 hours for Y O O C H O O S E (of that time, Greedy takes 5 seconds to run; the rest is taken up by Algorithm 1 ). Algorithm 1 consistently outperforms Greedy (Fig. 4 ), even with ε > 2 for CDM. Moreo ver , Algorithm 1 only computes a small fraction of possible sets of alternatives, especially for Y O O C H O O S E . Algorithm 1 does not perform as well with the rank-2 CDM as it does with MNL, which is to be expected as we only ha ve approximation guarantees for CDM under particular parameter regimes (in which these data do not lie). The worse performance on CDM is due to the context effects that items from C ex ert on each other . Greedy does fairly well for D I S A G R E E M E N T under CDM with Y O O C H O O S E , but e ven in this case, Algorithm 1 per- forms significantly better in enough instances for the mean (but not median) performance to be better than Greedy . W e repeated the experiment with 500 choice sets of size up to 5 sampled from data with similar results (Appendix C.3 ). W e also ran the MIBLP approach for MNL, which performed as well as Algorithm 1 and was about 12 x faster on Y O O - C H O O S E and 240 x faster on A L L S TA T E with the ε values we used for Algorithm 1 (Appendix C.2 ). P R O M O T I O N . W e applied the CDM P RO M O T I O N version of Algorithm 1 to A L L S TA T E , since this dataset is small enough to compute brute-force solutions. For each 2-item choice set C , we attempted to promote the less-popular item of the pair using brute-force, Greedy , and Algorithm 1 . Algorithm 1 performed optimally up to ε = 32 , above which it failed in only 2–26 of 252 feasible instances (Fig. 5 , left). (Here, successful promotion means that the item becomes the true fav orite among C .) On the other hand, Greedy failed in 37% of the feasible instances. As in the previous experiment, our algorithm’ s performance in practice far exceeds the w orst-case bounds. The number of sets tested by Algorithm 1 falls dramatically as ε increases (Fig. 5 , right). With more items (or a smaller range of utilities), the 4 In this case, we did not ha ve a v ailable tree structures for NL, which are difficult to deri ve from data ( Benson et al. , 2016 ). Choice Set Optimization Under Discrete Choice Models of Gr oup Decisions value of ε required to achie ve the same speedup over brute force would be smaller (as with Y O O C H O O S E ). In tandem, these results show that we get near-optimal P RO M O T I O N performance with far fe wer computations than brute force. 7. Discussion Our decisions are influenced by the alternati ves that are av ailable, the choice set. In collective decision-making, altering the choice set can encourage agreement or create new conflict. W e formulated this as an algorithmic question: how can we optimize the choice set for some objecti ve? W e showed that choice set optimization is NP-hard for natu- ral objectiv es under standard choice models; ho we ver , we also found that model restrictions makes promoting a choice easier than encouraging a group to agree or disagree. W e de- veloped approximation algorithms for these hard problems that are ef fecti ve in practice, although there remains a gap between theoretical approximation bounds and performance on real-world data. Future work could address choice set optimization in interactiv e group decisions, where group members can communicate their preferences to each other or must collaborate to reach a unified decision. Lastly , Ap- pendix D discusses the ethical considerations of this work. Acknowledgments This research was supported by ARO MURI, AR O A ward W911NF19-1-0057, NSF A ward DMS-1830274, and JP Morgan Chase & Co. W e thank Johan Ugander for helpful con v ersations. References Amir , O., Grosz, B. J., Gajos, K. Z., Swenson, S. M., and Sanders, L. M. From care plans to care coordination: Opportunities for computer support of teamwork in com- plex healthcare. In Proceedings of the 33r d Annual ACM Confer ence on Human F actors in Computing Systems , pp. 1419–1428. A CM, 2015. Ammar , A., Oh, S., Shah, D., and V oloch, L. F . What’ s your choice?: learning the mixed multi-nomial. In ACM SIGMETRICS P erformance Evaluation Review , pp. 565– 566. A CM, 2014. Ben-Shimon, D., Tsikinovsk y , A., Friedmann, M., Shapira, B., Rokach, L., and Hoerle, J. RecSys challenge 2015 and the Y OOCHOOSE dataset. In Pr oceedings of the 9th A CM Conference on Recommender Systems , pp. 357–358, 2015. Benson, A. R., K umar , R., and T omkins, A. On the relev ance of irrelev ant alternati ves. In Pr oceedings of the 25th International Confer ence on W orld W ide W eb , pp. 963– 973. International W orld W ide W eb Conferences Steering Committee, 2016. Benson, A. R., Kumar , R., and T omkins, A. A discrete choice model for subset selection. In Pr oceedings of the Eleventh A CM International Conference on W eb Sear ch and Data Mining , pp. 37–45. A CM, 2018. Bower , A. and Balzano, L. Preference modeling with context-dependent salient features. In Pr oceedings of the 37th International Coference on International Con- fer ence on Mac hine Learning , 2020. Chen, S. and Joachims, T . Predicting matchups and pref- erences in context. In Pr oceedings of the 22nd A CM SIGKDD International Confer ence on Knowledge Dis- covery and Data Mining , pp. 775–784. A CM, 2016. Chen, X., Lijf fijt, J., and De Bie, T . Quantifying and mini- mizing risk of conflict in social networks. In Pr oceedings of the 24th A CM SIGKDD International Confer ence on Knowledge Discovery & Data Mining , pp. 1197–1205. A CM, 2018. Chierichetti, F ., Kumar , R., and T omkins, A. Discrete choice, permutations, and reconstruction. In Pr oceedings of the T wenty-Ninth Annual A CM-SIAM Symposium on Discr ete Algorithms , pp. 576–586. SIAM, 2018a. Chierichetti, F ., Kumar , R., and T omkins, A. Learning a mixture of two multinomial logits. In International Confer ence on Mac hine Learning , pp. 960–968, 2018b. Cormen, T . H., Leiserson, C. E., Riv est, R. L., and Stein, C. Intr oduction to Algorithms . MIT Press, 2001. Davis, J. M., Gallego, G., and T opaloglu, H. Assortment optimization under v ariants of the nested logit model. Operations Resear ch , 62(2):250–273, 2014. Easley , D. and Kleinberg, J. Networks, Cr owds, and Markets . Cambridge Univ ersity Press, 2010. Fader , P . S. and McAlister , L. An elimination by aspects model of consumer response to promotion calibrated on UPC scanner data. J ournal of Marketing Resear c h , 27(3): 322–332, 1990. Gallego, G. and T opaloglu, H. Constrained assortment optimization for the nested logit model. Management Science , 60(10):2583–2601, 2014. Garimella, K., De Francisci Morales, G., Gionis, A., and Mathioudakis, M. Reducing controversy by connecting opposing views. In Pr oceedings of the T enth A CM Inter - national Confer ence on W eb Sear ch and Data Mining , pp. 81–90. A CM, 2017. Choice Set Optimization Under Discrete Choice Models of Gr oup Decisions Graells-Garrido, E., Lalmas, M., and Quercia, D. People of opposing views can share common interests. In Pr oceed- ings of the 23rd International Confer ence on W orld W ide W eb , pp. 281–282. A CM, 2014. Hanley , N., Wright, R. E., and Adamo wicz, V . Using choice experiments to value the en vironment. En vir onmental and Resour ce Economics , 11(3-4):413–428, 1998. H ˛ azła, J., Jadbabaie, A., Mossel, E., and Rahimian, M. A. Bayesian decision making in groups is hard. arXiv:1705.04770 , 2017. H ˛ azła, J., Jadbabaie, A., Mossel, E., and Rahimian, M. A. Reasoning in Bayesian opinion exchange networks is PSP ACE -hard. In Proceedings of the Thirty-Second Con- fer ence on Learning Theory , pp. 1614–1648, 2019. Huber , J., Payne, J. W ., and Puto, C. Adding asymmetrically dominated alternati ves: V iolations of re gularity and the similarity hypothesis. Journal of Consumer Resear ch , 9 (1):90–98, 1982. Ieong, S., Mishra, N., and Sheffet, O. Predicting preference flips in commerce search. In Pr oceedings of the 29th International Cofer ence on International Confer ence on Machine Learning , pp. 1795–1802. Omnipress, 2012. Kaggle. Allstate purchase prediction challenge. https://www.kaggle.com/c/allstate- purchase- prediction- challenge , 2014. Kallus, N. and Udell, M. Re vealed preference at scale: Learning personalized preferences from assortment choices. In Pr oceedings of the 2016 ACM Confer ence on Economics and Computation , pp. 821–837. A CM, 2016. Karp, R. M. Reducibility among combinatorial problems. In Complexity of Computer Computations , pp. 85–103. Springer , 1972. Kingma, D. P . and Ba, J. Adam: A method for stochastic optimization. In International Conference on Learning Repr esentations , 2015. Kleinberg, J., Mullainathan, S., and Ugander , J. Comparison-based choices. In Pr oceedings of the 2017 A CM Confer ence on Economics and Computation , pp. 127–144. A CM, 2017. K oppelman, F . S. and Bhat, C. A self instructing course in mode choice modeling: Multinomial and nested logit models, 2006. Liao, Q. V . and Fu, W .-T . Can you hear me now?: mitigating the echo chamber effect by source position indicators. In Pr oceedings of the 17th A CM Confer ence on Computer Supported Cooperative W ork & Social Computing , pp. 184–196. A CM, 2014. Lu, L., Y uan, Y . C., and McLeod, P . L. T wenty-fiv e years of hidden profiles in group decision making: A meta- analysis. P ersonality and Social Psyc hology Re view , 16 (1):54–75, 2012. Luce, R. D. Individual Choice Behavior . Wile y , 1959. Makhijani, R. and Ugander , J. Parametric models for in- transitivity in pairwise rankings. In The W orld W ide W eb Confer ence , pp. 3056–3062. A CM, 2019. Matakos, A., T erzi, E., and Tsaparas, P . Measuring and mod- erating opinion polarization in social networks. Data Min- ing and Knowledge Discovery , 31(5):1480–1505, 2017. Maystre, L. and Grossglauser , M. Fast and accurate infer- ence of Plackett–Luce models. In Advances in Neural Information Pr ocessing Systems , pp. 172–180, 2015. McFadden, D. Conditional logit analysis of qualitative choice behavior . In Zarembka, P . (ed.), F r ontiers in Econometrics , pp. 105–142. Academic Press, 1974. McFadden, D. Modeling the choice of residential location. T ransportation Resear c h Recor d , 1978. McFadden, D. and Train, K. Mixed MNL models for dis- crete response. Journal of Applied Econometrics , 15(5): 447–470, 2000. Munson, S. A., Lee, S. Y ., and Resnick, P . Encouraging reading of div erse political viewpoints with a bro wser widget. In Seventh International AAAI Confer ence on W eblogs and Social Media , 2013. Musco, C., Musco, C., and Tsourakakis, C. E. Minimizing polarization and disagreement in social networks. In Pr oceedings of the 2018 W orld W ide W eb Conference , pp. 369–378. International W orld W ide W eb Conferences Steering Committee, 2018. Oh, S. and Shah, D. Learning mixed multinomial logit model from ordinal data. In Advances in Neural Informa- tion Pr ocessing Systems , pp. 595–603, 2014. Oh, S., Thekumparampil, K. K., and Xu, J. Collaboratively learning preferences from ordinal data. In Advances in Neural Information Pr ocessing Systems , pp. 1909–1917, 2015. Over goor , J., Benson, A., and Ugander , J. Choosing to grow a graph: modeling network formation as discrete choice. In The W orld W ide W eb Conference , pp. 1409– 1420, 2019. Paszke, A., Gross, S., Massa, F ., Lerer, A., Bradbury , J., Chanan, G., Killeen, T ., Lin, Z., Gimelshein, N., Antiga, L., et al. PyTorch: An imperativ e style, high-performance deep learning library . In Advances in Neural Information Pr ocessing Systems , pp. 8024–8035, 2019. Choice Set Optimization Under Discrete Choice Models of Gr oup Decisions Pfannschmidt, K., Gupta, P ., and Hüllermeier , E. Learn- ing choice functions: Concepts and architectures. arXiv:1901.10860 , 2019. Ragain, S. and Ugander , J. Pairwise choice Marko v chains. In Advances in Neur al Information Pr ocessing Systems , pp. 3198–3206, 2016. Reddi, S. J., Kale, S., and Kumar , S. On the con vergence of Adam and beyond. In International Confer ence on Learning Repr esentations , 2018. Rosenberg, M., Perlroth, N., and Sanger, D. E. ‘Chaos is the point’: Russian hackers and trolls gro w stealthier in 2020, 2020. URL https://www.nytimes. com/2020/01/10/us/politics/russia- hacking- disinformation- election.html . Rosenfeld, N., Oshiba, K., and Singer, Y . Predicting choice with set-dependent aggregation. In Pr oceedings of the 37th International Cofer ence on International Confer ence on Machine Learning , 2020. Rusmevichientong, P ., Shen, Z.-J. M., and Shmoys, D. B. Dynamic assortment optimization with a multinomial logit choice model and capacity constraint. Operations Resear c h , 58(6):1666–1680, 2010. Rusme vichientong, P ., Shmoys, D., T ong, C., and T opaloglu, H. Assortment optimization under the multinomial logit model with random choice parameters. Pr oduction and Operations Manag ement , 23(11):2023–2039, 2014. Seshadri, A. and Ugander , J. Fundamental limits of testing the independence of irrelev ant alternativ es in discrete choice. In Proceedings of the 2019 ACM Confer ence on Economics and Computation , pp. 65–66, 2019. Seshadri, A., Peysakho vich, A., and Ugander, J. Discov ering context ef fects from raw choice data. In International Confer ence on Mac hine Learning , pp. 5660–5669, 2019. Shafir , E., Simonson, I., and Tversky , A. Reason-based choice. Cognition , 49(1-2):11–36, 1993. Simonson, I. Choice based on reasons: The case of at- traction and compromise effects. Journal of Consumer Resear c h , 16(2):158–174, 1989. Simonson, I. and Tv ersky , A. Choice in conte xt: T radeof f contrast and extremeness a version. Journal of Marketing Resear c h , 29(3):281–295, 1992. Stasser , G. and Titus, W . Pooling of unshared information in group decision making: Biased information sampling during discussion. Journal of P ersonality and Social Psychology , 48(6):1467, 1985. T alluri, K. and V an Ryzin, G. Rev enue management under a general discrete choice model of consumer behavior . Management Science , 50(1):15–33, 2004. T rain, K. E. Discr ete Choice Methods with Simulation . Cambridge Univ ersity Press, 2009. T rueblood, J. S., Brown, S. D., Heathcote, A., and Buse- meyer , J. R. Not just for consumers: Context ef fects are fundamental to decision making. Psychological Science , 24(6):901–908, 2013. Tversk y , A. Elimination by aspects: A theory of choice. Psychological Re vie w , 79(4):281, 1972. Tversk y , A. and Kahneman, D. The framing of decisions and the psychology of choice. Science , 211(4481):453– 458, 1981. Tversk y , A. and Simonson, I. Context-dependent prefer- ences. Manag ement Science , 39(10):1179–1189, 1993. Zhao, Z. and Xia, L. Learning mixtures of Plackett-Luce models from structured partial orders. In Advances in Neu- ral Information Pr ocessing Systems , pp. 10143–10153, 2019. Zhao, Z., Piech, P ., and Xia, L. Learning mixtures of Plackett-Luce models. In International Confer ence on Machine Learning , pp. 2906–2914, 2016. Choice Set Optimization Under Discrete Choice Models of Gr oup Decisions A. Hardness proofs A.1. CDM P R O M OT I O N is hard with | A | = 2 , | C | = 2 In the main text, we show CDM P R O M O T I O N is NP-hard when | A | = 1 , | C | = 3 (Theorem 3 ). Here, we provide an additonal proof for the case when | A | = 2 , | C | = 2 . These are the smallest hard instances of the problem ( | A | = 1 , | C | = 2 is easy to solve: introduce alternativ es that in- crease utility for x ∗ for than its competitor). Theorem 7. In the CDM model, P RO M OT I O N is NP-har d, even with just two individuals and two items in C . Pr oof. By reduction from S U B S E T S U M . Let S, t be an instance of S U B S E T S U M . Let A = { a, b } , C = { x, y } , C = S . Using tuples interpreted entrywise, construct a CDM with the following parameters. u a ( h x ∗ , y i ) = h t + ε, 0 i u b ( h x ∗ , y i ) = h ε, t i u a ( z ) = u b ( z ) = −∞ ∀ z ∈ C p a ( z , h x ∗ , y i ) = h 0 , z i ∀ z ∈ C p b ( z , h x ∗ , y i ) = h z , 0 i ∀ z ∈ C T o promote x ∗ , we need to add more than t − ε to b ’ s utility for x ∗ , but add less than t + ε to a ’ s utility for x ∗ . Since all pulls are integral, the only solution is a set Z whose sum of pulls is t . If we could efficiently find such a set, then we could efficiently find the S U B S E T S U M solution. B. A ppr oximation algorithm extensions B.1. Adapting Algorithm 1 for CDM with guarantees for special cases W e can adapt Algorithm 1 for the CDM model, but we only maintain the approximation error bounds under special cases of the structure of the “pulls”. Still, we can use this algorithm as a principled heuristic and it tends to work well in practice, as we saw in Fig. 4 . As a first step, we use the alternative parametrization of the model used by Seshadri et al. ( 2019 , Eq. (1)), which has fewer parameters. In this description of the model, utilities and context ef fects are merged into a single utility-adjusted pull q a ( z , x ) = p a ( z , x ) − u a ( x ) , with the special case q a ( x, x ) = 0 . W e then hav e Pr( a ← x | C ) = exp( P w ∈ C q a ( w , x )) P y ∈ C exp( P z ∈ C q a ( z , y )) . (6) Refer to Seshadri et al. ( 2019 , Appendix C.1) for details of the equiv alence between this formulation and the one we use in the main text. Matching the notation of the proof of Theorem 6 , we use the shorthand e ax = exp( P w ∈ C q a ( w , x )) . T o adapt Algorithm 1 to the CDM, we expand L i to have nk dimensions for each individual-item pair , increasing the runtime to O (( m + k n 2 )(1 + b log 1+ δ s c ) nk ) . This is only practical if nk is small, but as we ha ve seen, A G R E E M E N T , D I S A G R E E M E N T , and P RO M O T I O N are all NP-hard even with n = 2 and k = 2 or 3 . Each indi vidual-item dimension stores e ax , the total exp-utility of that item to that individual giv en that we hav e included some set of alternativ es. When we include an additional item from C , we place the new sets in L i with updated e ax values. This only preserves the ε -additiv e approximation if alterna- tiv es (items in C ) hav e zero context effects on each other; howe ver , the y may still ha ve conte xt ef fects on items in C . Formally , we need q a ( z , z 0 ) = 0 for all z , z 0 ∈ C and a ∈ A . Although this is a serious restriction, it leav es A G R E E M E N T , D I S A G R E E M E N T , and P RO M O T I O N NP-hard, as the CDM we used in our proofs had this form (see also Appendix B.3 for ho w to apply Algorithm 1 to P R O M O T I O N ). If this v er- sion of the algorithm is applied to a general CDM, it may experience higher error . Nonetheless, our real-data experi- ments show it to be a good heuristic. For the following analysis, we assume a CDM with zero context ef fects between items in C . W e need to verify that if e very item’ s exp-utility is approximated to within f actor (1 + β ) ± 1 , then the total disagreement of a set is approx- imated to within ε as we had in the MNL case. The ap- proximation error guarantee increases to 4 ε in the restricted CDM version—to recov er the ε -additiv e approximation, we can make δ smaller by a factor of 4 (that is, we could pick δ = ε/ (8 k m n 2 ) ; we instead keep the old δ for simplicity in the following analysis). Recall that Z 0 is the representativ e in L m of the optimal set of alternativ es Z ∗ . For compactness, we define T a to be the denominator of Eq. ( 6 ), with T 0 a and T ∗ a referring to those denominators under the choice sets C ∪ Z 0 and C ∪ Z ∗ , respectiv ely . This is where we require zero context ef fects between alternativ es: if alternativ es interact, then storing ev ery e ax in the table (from which we can compute T a ) is not enough to determine updated choice probabilities when we add a new alternati ve. The difference in the analysis begins when we bound Pr( a ← x | C ∪ Z 0 ) on both sides using the fact that each exp-utility sum is approximated within a 1 + β factor (so the probability denomiators T a are also approximated Choice Set Optimization Under Discrete Choice Models of Gr oup Decisions within this factor): e ∗ ax 1+ β T ∗ a (1 + β ) = 1 (1 + β ) 2 e ∗ ax T ∗ a < e 0 ax T 0 a = Pr( a ← x | C ∪ Z 0 ) < e ∗ ax (1 + β ) T ∗ a 1+ β = (1 + β ) 2 e ∗ ax T ∗ a . Based on the lower bound, the dif ference between Pr( a ← x | C ∪ Z ∗ ) and Pr( a ← x | C ∪ Z 0 ) could be as large as e ∗ ax T ∗ a − 1 (1 + β ) 2 e ∗ ax T ∗ a ≤ 1 − 1 (1 + β ) 2 . Now considering the upper bound, the dif ference between Pr( a ← x | C ∪ Z ∗ ) and Pr( a ← x | C ∪ Z 0 ) could be as large as (1 + β ) 2 e ∗ ax T ∗ a − e ∗ ax T ∗ a ≤ (1 + β ) 2 − 1 . Therefore, | Pr( a ← x | C ∪ Z 0 ) − Pr( b ← x | C ∪ Z 0 ) | can only exceed | Pr( a ← x | C ∪ Z ∗ ) − Pr( b ← x | C ∪ Z ∗ ) | by at most 1 − 1 (1+ β ) 2 + (1 + β ) 2 − 1 = (1 + β ) 2 − 1 (1+ β ) 2 . This is at most 4 β : 4 β − (1 + β ) 2 + 1 (1 + β ) 2 = β 2 (2 − β 2 ) (1 + β ) 2 > 0 . (for 0 < β < √ 2 ) So D ( Z 0 ) and D ( Z ∗ ) are within 4 β n 2 k = 4 ε . B.2. Adapting Algorithm 1 for NL with full guarantees W e can also adapt Algorithm 1 for the NL model, and unlik e the CDM, the ε -additiv e approximation holds in all parame- ter regimes. Recall that the NL tree has two types of leaves: choice set items and alternativ e items. Let P a be the set of internal nodes of individual a ’ s tree that have at least one alternativ e item as a child and let p = max a ∈ A | P a | . If we know the total e xp-utility that alternati v es contribute as children of each v ∈ P a , then we can compute a ’ s choice probabilites ov er items in C in polynomial time. W ith this in mind, we modify Algorithm 1 by ha ving dimen- sions in L for each individual for each of their nodes in P a . This results in ≤ np dimensions. The algorithm then keeps track of the exp-utility sums from alternatives under each node in P a for each individual. The exponent in the run- time increases to (at most) np , but this remains tractable for some hard instances, such as those in our hardness proofs. In some cases, we can dramatically improv e the runtime of the algorithm: if the subtree under an internal node contains only alternati ves as lea v es in an indi viduals’ s tree, then we only need one dimension L for that indi vidual’ s entire sub- tree, and it has only two cells: one for sets that contain at least one alternativ e in that subtree, and one for sets that do not. The only factor that af fects the choice probabilities of items in C is whether that subtree is “activ e” and its root can be chosen. W e now show how the error from exp-utility sums of al- ternativ es propagates to choice probabilities. In the NL model, Pr( a ← x | C ) is the product of probabilities that a chooses each ancestor of x as a descends down its tree. Let v 1 , . . . , v ` be the nodes in a ’ s tree along the path from the root to x . For compactness, we use Pr( x, Z ) instead of Pr( a ← x | C ∪ Z ) in the following analysis. Pick δ ≤ ([ ε/ (2 k n 2 ) + 1] 1 /` − 1) /m and recall that β = 2 mδ . W e can use the same analysis as in the proof of Theorem 6 to find that for any set Z ∗ ⊆ C , there exists some Z 0 ∈ L such that Pr( x, Z ∗ ) = Pr( v 1 , Z ∗ ) · · · · · Pr( v x , Z ∗ ) < Pr( v 1 , Z 0 ) + β 2 · · · · · Pr( v x , Z 0 ) + β 2 ≤ Pr( x, Z 0 ) + 1 + β 2 ` − 1 ≤ Pr( x, Z 0 ) + ε 2 k n 2 . Now for the lo wer bound, pick δ ≤ (1 − [1 − ε/ (2 k n 2 )] 1 /` ) /m . Again from the proof of Theorem 6 : Pr( x, Z ∗ ) = Pr( v 1 , Z ∗ ) · · · · · Pr( v x , Z ∗ ) > Pr( v 1 , Z 0 ) − β 2 · · · · · Pr( v x , Z 0 ) − β 2 ≥ Pr( x, Z 0 ) + 1 − β 2 ` − 1 ≥ Pr( x, Z 0 ) − ε 2 k n 2 . Let h be the maximum height of any indi vdual’ s NL tree (so ` ≤ h ). Then, by picking δ = min { [ ε/ (2 k n 2 ) + 1] 1 /h − 1 , 1 − [1 − ε/ (2 k n 2 )] 1 /h } /m , we find that Pr( a ← x | C ∪ Z ∗ ) and Pr( a ← x | C ∪ Z 0 ) differ by less than ε/ ( k n 2 ) for all x ∈ C and a ∈ A , meaning that the total disagreement between a and b cannot differ by more than ε as before. Unfortunately , this means we need to make δ exponentially (in h ) smaller in the NL model. Put another way , our error bound gets exponentially worse as h increases if we keep δ constant. Howe ver , we ha ve seen that there are NP-hard families of NL instances in which h is a small constant (e.g., h = 2 in our hardness proof), so once ag ain this algorithm is an exponential impro vement o ver brute force. Moreov er , the error bound here is often far from tight, since we use the very loose bounds Pr( v i , Z 0 ) ≤ 1 in the analysis. This Choice Set Optimization Under Discrete Choice Models of Gr oup Decisions means the algorithm will tend to outperform the worst-case guarantee by a significant margin. B.3. Adapting Algorithm 1 for P R O M O T I O N B . 3 . 1 . C D M P R O M OT I O N W I T H S P E C I A L C A S E G U A R A N T E E S Algorithm 1 can be applied to P R O M O T I O N in the (re- stricted) CDM model with only a small modification to the CDM version described in Appendix B.1 : at the end of the algorithm, we return the set that results in the maxi- mum number of individuals ha ving x ∗ as an ε -fa vorite item. Additionally , we choose δ = ε/ (10 m ) (we don’t need the factors n 2 or k since we aren’t optimizing D ( Z ) ). Follo wing the analysis in Appendix B.1 (with β = 2 mδ = ε/ 5 ), we find that Pr( a ← x | C ∪ Z ∗ ) and Pr( a ← x | C ∪ Z 0 ) dif fer by at most max { 1 − 1 (1+ ε/ 5) 2 , (1 + ε/ 5) 2 − 1 } for all x . On the interv al [0 , 1] , this is bounded by ε/ 2 . Thus, if x ∗ is the fa v orite item for a giv en the optimal choice set C ∪ Z ∗ , then it must be an ε -fa vorite of individual a giv en C ∪ Z 0 (as always, Z 0 is the representativ e of Z ∗ in L m ). This is because when we go from C ∪ Z ∗ to C ∪ Z 0 , the choice probability of x ∗ can shrink by at most ε/ 2 and the choice probability for any other item can gro w by at most ε/ 2 . Thus, including Z 0 makes at least as many indi viduals hav e x ∗ as an ε -favorite item as including Z ∗ makes ha ve x ∗ as a favorite item. This is exactly what it means for Algorithm 1 to ε - approximate P RO M O T I O N in the CDM (when items in C do not ex ert context ef fects on each other). Moreover , not having to compute D ( Z ) makes the runtime of Algorithm 1 O ( m (1 + b log 1+ δ s c ) nk ) when applied to P RO M O T I O N in the CDM. In the general CDM, this algorithm is only a heuristic. B . 3 . 2 . N L P RO M O T I O N W I T H F U L L G UA R A N T E E S A very similar idea allows us to apply the NL version of Algorithm 1 from Appendix B.2 to P RO M O T I O N and retain an approximation guarantee. As before, use the NL version and return the set that results in the maximum number of individuals ha ving x ∗ as an ε -fa vorite item. Howe ver , we instead use δ = min { ( ε/ 4 + 1) 1 /h − 1 , 1 − (1 − ε/ 4) 1 /h } /m , which by the analysis in Appendix B.2 results in Pr( a ← x | C ∪ Z ∗ ) and Pr( a ← x | C ∪ Z 0 ) differing by at most ε/ 2 . As in the CDM case, this guarantees that if x ∗ is the fa vorite item for a gi ven the optimal choice set C ∪ Z ∗ , then it must be an ε -fa vorite of a giv en C ∪ Z 0 . Therefore this version of Algorithm 1 ε -approximates P RO M O T I O N in the NL model with runtime O ( m (1 + b log 1+ δ s c ) np ) . C. Additional experiment details C.1. Simple example of poor performance f or Greedy As we sa w in experimental data, Greedy can perform poorly ev en in small instances of A G R E E M E N T . Below we pro vide an MNL instance with n = m = k = 2 for which the error of the greedy solution is approximately 1. W ith only two individuals, 0 ≤ D ( Z ) ≤ 2 , so an error of 1 is very large. In the bad instance for greedy , A = { a, b } , C = { x, y } , C = { p, q } , and the utilities are as follows. u a ( x ) = 8 u a ( y ) = 2 u a ( p ) = 10 u a ( q ) = 0 u b ( x ) = 8 u b ( y ) = 8 u b ( p ) = 0 u b ( q ) = 15 In this instance of A G R E E M E N T , the greedy solution is D ( ∅ ) ≈ 0 . 9951 (including either p or q alone increases disagreement), while the optimal solution is D ( { p, q } ) ≈ 0 . 0009 . C.2. All-pairs agreement r esults f or MIBLP Figure 6 shows the comparison in performance between Algorithm 1 and the MIBLP approach for the all-pairs A G R E E M E N T and D I S AG R E E M E N T experiment. The meth- ods perform nearly identically on both A L L S TA T E and Y O O - C H O O S E . The MIBLP approach performs marginally better in some cases of Y O O C H O O S E A G R E E M E N T . As noted in the paper, the MIBLP heuristic is considerably faster for the v alues of ε we used ( 12 x and 240 x on Y O O C H O O S E and A L L S TA T E , respecti vely; speed differences v ary sig- nificantly depending on ε ), but pro vides no a priori per- formance guarantee and cannot be applied to CDM or NL. Nonetheless, we can see that it performs very competitiv ely and would be a good approach to use in practice for MNL A G R E E M E N T and D I S AG R E E M E N T . C.3. Choice sets sampled from data W e repeated the all-pairs agreement experiment with 500 choice sets of size up to 5 sampled uniformly from each dataset, allo wing us to e valuate the performance of Algo- rithm 1 on realistic choice sets. W e limited the size of sampled choice sets since the CDM version of Algorithm 1 scales poorly with | C | (see Appendix B.1 ). For this ver - sion of the experiment, we fixed larger values of ε (2 for MNL, 500 for CDM) to handle lar ger choice sets and to keep running time down. Again, Algorithm 1 has better mean performance in ev ery case (Fig. 7 ), showing that it performs well on real choice sets. Choice Set Optimization Under Discrete Choice Models of Gr oup Decisions -2e-08 -1e-08 0e+00 1e-08 Allstate A l g . 1 D ( Z ) - M I B L P D ( Z ) Agreement Disagreement 0.0e+00 5.0e-05 1.0e-04 1.5e-04 2.0e-04 YOOCHOOSE A l g . 1 D ( Z ) - M I B L P D ( Z ) Figure 6. MIBLP vs. Algorithm 1 performance box plots when applied to all 2-item choice sets in A L L S T A T E and Y O O C H O O S E under MNL. Each point is the dif ference in D ( Z ) when MIBLP and Algorithm 1 are run on a choice set, and Xs mark means. − 1 0 − 1 − 1 0 − 2 − 1 0 − 3 0 1 0 − 3 1 0 − 2 1 0 − 1 A l g . 1 D ( Z ) - G r e e d y D ( Z ) ε = 2 0.7% sets MNL ε = 5 0 0 0.8% sets Allstate Rank-2 CDM Agreement Disagreement − 1 0 − 1 − 1 0 − 2 − 1 0 − 3 0 1 0 − 3 1 0 − 2 1 0 − 1 1 0 0 A l g . 1 D ( Z ) - G r e e d y D ( Z ) ε = 2 0.000060% sets Agreement Disagreement ε = 5 0 0 0.000660% sets YOOCHOOSE Figure 7. Results of the agreement e xperiment with 500 choice sets sampled uniformly from each dataset. Compare with Fig. 4 in the main text. Again, Algorithm 1 has better mean performance in all cases. The larger v alues of ε result in slightly worse performance on the margins than in Fig. 4 , b ut also fe wer sets computed. D. A note on ethical considerations Influencing the preferences of decision-makers has the po- tential for malicious applications, so it is important to ad- dress the ethical context of this work. Any problem with positi v e social applications (e.g., A G R E E - M E N T : encouraging consensus, P RO M OT I O N : promot- ing en vironmentally-friendly transportation options, D I S - AG R E E M E N T : increasing div ersity of opinions) has the potential to be used for ill. This should not prevent us from seeking methods to acheiv e these positive ends, but we should certainly be cognizant of the possibility of un- intended applications. In a different vein, understanding when a group is susceptible to undesired interv entions (or detecting such interventions) makes problems like D I S - AG R E E M E N T worth studying from an adv ersarial perspec- ti ve. Along these lines, our hardness results are encouraging since optimal malicious interventions are dif ficult. Finally , we note that all of the theoretical problems we study presuppose access to choice data from which preferences can be learned and the ability to influence choice sets. Any entity which has both of these (such as an online retailer , a gov ernment deciding transportation policy , etc.) already has significant po wer to influence choosers. If such an entity had malicious intent, then near-optimal D I S AG R E E M E N T solutions would be the least of our concerns. T o summarize, these problems are worth studying because of (1) their purely theoretical value in furthering the field of discrete choice, (2) their potential for positiv e applica- tions, (3) insight into the potential for harmful manipulation by an adversary , and (4) the minimal additional risk from undesired use of our methods.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment