깊은 신경망으로 단일 분자 위치 추정 혁신
본 논문은 시퀀스 영상의 시간적 컨텍스트를 활용하고 베이지안 손실함수를 도입한 새로운 딥러닝 구조 DECODE를 제안한다. 시뮬레이터 학습과 결합 학습을 통해 고밀도 및 저신호‑대‑노이즈 환경에서도 기존 SMLM 알고리즘을 크게 능가하는 검출·위치 정확도와 불확실성 추정 능력을 제공한다.
저자: Artur Speiser, Lucas-Raphael M"uller, Ulf Matti
본 연구는 단일 분자 위치 추정(Single‑Molecule Localization Microscopy, SMLM) 분야의 근본적인 한계를 극복하기 위해, 딥러닝 기반 새로운 알고리즘 DECODE(Deep Context Dependent)를 개발하였다. 기존 SMLM 파이프라인은 (1) 플루오레신 검출, (2) 고해상도 PSF 모델에 대한 비선형 피팅이라는 두 단계로 구성되며, 특히 고밀도 데이터에서 겹치는 점광원을 구분하는 것이 어려웠다. 또한 대부분의 기존 방법은 각 프레임을 독립적으로 처리해 시간적 정보를 활용하지 못했다.
DECODE는 이러한 문제점을 해결하기 위해 세 가지 주요 설계 원칙을 도입한다. 첫째, **시간적 컨텍스트 통합**이다. 네트워크는 연속된 세 프레임을 입력으로 받아, 프레임 분석 모듈이 각 프레임별 특징 맵을 추출하고, 이를 시간적 컨텍스트 모듈이 결합한다. 플루오레신이 여러 프레임에 걸쳐 지속적으로 발광하는 특성을 이용해, 겹치는 PSF를 시간적으로 분리할 수 있다.
둘째, **베이지안 손실 함수**를 사용한다. 출력은 8개의 채널로 구성되며, 검출 확률(p), 밝기(α), 서브픽셀 위치 오프셋(Δx, Δy, Δz) 및 각각의 불확실성(σx, σy, σz, σα)이다. 이들 변수는 가우시안 혼합 모델(GMM)의 파라미터로 해석되며, 손실은 시뮬레이션된 실제 좌표에 대한 로그우도 최대화 형태로 정의된다. 따라서 네트워크는 단순히 점을 예측하는 것이 아니라, 각 점에 대한 확률분포와 신뢰구간을 동시에 학습한다.
셋째, **학습 전략의 다변화**이다. 시뮬레이터 학습(Simulator Learning, SL)은 광학 PSF, 배경, 감마 노이즈 등을 정밀히 모델링한 물리 기반 시뮬레이션 데이터를 이용해 지도 학습을 수행한다. 그러나 시뮬레이션과 실제 현미경 데이터 사이에는 도메인 갭이 존재한다는 점을 인식하고, 자동인코더 학습(Auto Encoder Learning, AEL)과 결합한 결합 학습(Combined Learning, CL)을 제안한다. CL은 실제 데이터의 통계적 특성을 네트워크가 스스로 학습하도록 하여, 시뮬레이션‑실험 불일치에 대한 강인성을 확보한다.
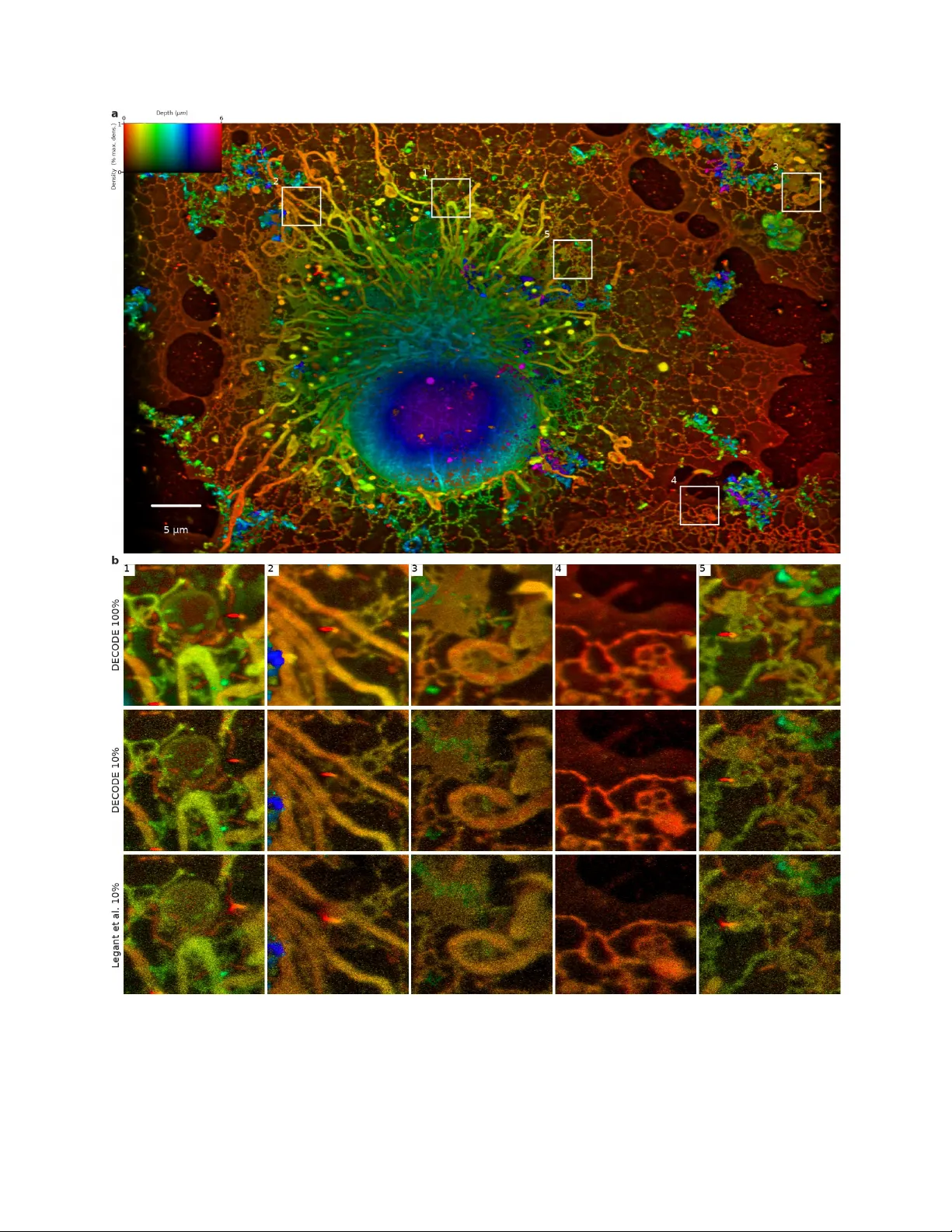
실험은 SMLM2016 챌린지에서 제공된 12개의 합성 데이터셋을 대상으로 수행되었다. 데이터셋은 2D, Astigmatism, Double‑Helix 등 다양한 PSF 형태와, 저·고 SNR, 저·고 밀도 조건을 포함한다. 성능 평가지표는 (1) RMSE(위치 오차), (2) Jaccard Index(검출 정확도), (3) 종합 효율성 점수(Detection + Localization)이다. DECODE는 모든 데이터셋에서 최고 점수를 획득했으며, 특히 고밀도·저SNR 상황에서 기존 최우수 알고리즘 대비 7배 이상의 효율성 향상을 보였다. 불확실성 추정값은 Cramér‑Rao bound와 일치함을 검증했으며, 밀도가 높을수록 불확실성이 증가하지만 시간적 컨텍스트를 활용하면 이를 크게 억제한다는 결과도 제시하였다.
추가 실험으로는 동일 시료(Tubulin‑A647)를 서로 다른 활성 밀도로 촬영한 4개의 실제 데이터셋에 DECODE를 적용하였다. 결과는 기존 방법 대비 10배 적은 촬영 시간으로도 고품질 재구성이 가능함을 보여준다. 또한, 대규모 3D COS‑7 세포 라티스 라이트 시트 영상에 적용해, 전체 촬영 기간을 며칠에서 몇 시간으로 단축하면서도 세포 내부 구조를 정밀히 복원하였다.
논문의 의의는 다음과 같다. (1) **시간적 정보 활용**을 통해 고밀도 상황에서도 정확한 검출·위치를 구현, (2) **베이지안 프레임워크**를 도입해 불확실성 추정을 제공함으로써 후처리 및 정량 분석에 활용 가능, (3) **시뮬레이터와 자동인코더 결합 학습**으로 실험 데이터와의 도메인 차이를 최소화, (4) **출력 형식의 효율성**—픽셀당 8채널만으로 연산량을 제한하면서도 연속적인 좌표와 불확실성을 제공. 이러한 설계는 SMLM뿐 아니라, 시간에 따라 변화하는 점 소스(예: 단일 입자 트래킹, 초고속 현미경)와 같은 다른 바이오·물리 영상 문제에도 확장 가능성을 시사한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기