얼굴 행동을 한 번에: 표현·감정·액션 유닛을 통합한 단일 네트워크
본 논문은 5백만 장 이상의 in‑the‑wild 이미지와 7가지 기본 표정, 17개 액션 유닛, 연속적인 가치‑각성(V‑A) 차원을 동시에 학습하는 다중 과제·다중 도메인·다중 라벨 네트워크인 FaceBehaviorNet을 제안한다. 기존에 각각 별도 데이터셋과 모델로 다루어졌던 표정 인식, 액션 유닛 검출, 감정 차원 추정을 하나의 통합 프레임워크로 학습함으로써 개별 과제별 모델보다 일관되게 성능을 향상시켰으며, ‘공동 주석(co‑annot…
저자: Dimitrios Kollias, Viktoriia Sharmanska, Stefanos Zafeiriou
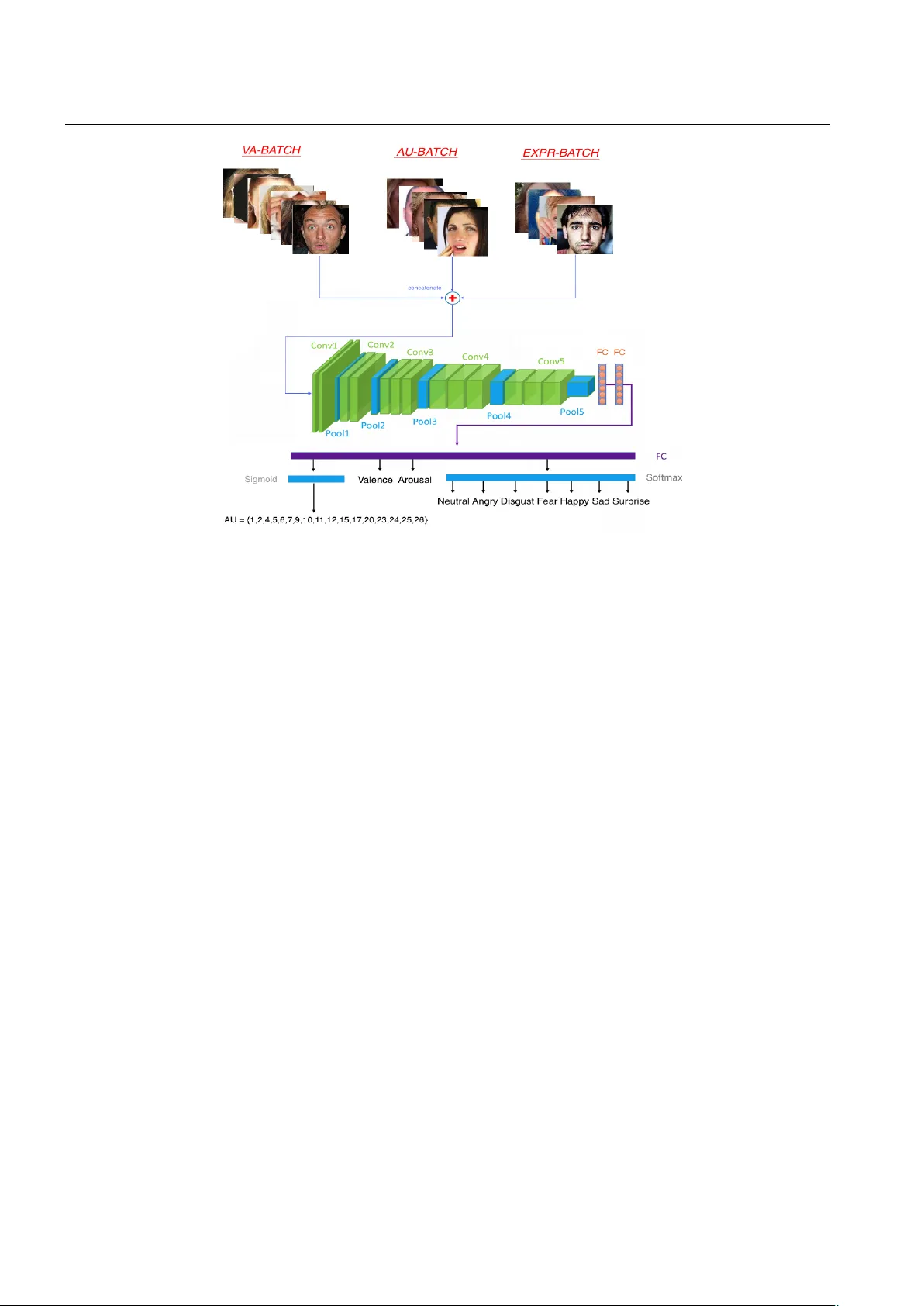
본 논문은 얼굴 행동 분석의 세 가지 핵심 과제—기본 표정 인식, 얼굴 액션 유닛(AU) 검출, 연속 감정 차원(가치‑각성, VA) 추정—를 하나의 통합 네트워크인 FaceBehaviorNet에 결합한다. 기존 연구는 각각의 과제를 별도 데이터셋과 모델로 다루어 왔으며, 데이터셋 간 라벨 겹침이 거의 없었다. 저자들은 이러한 한계를 극복하고자, 5백만 장 이상의 in‑the‑wild 이미지가 포함된 10여 개 공개 데이터셋을 모두 활용하였다. 각 데이터셋은 표정, AU, VA 중 일부 라벨만을 제공하지만, FaceBehaviorNet은 이러한 비중첩 라벨을 동시에 학습할 수 있도록 설계되었다.
네트워크 구조는 VGG‑Face의 13개 convolution‑pooling 레이어를 백본으로 사용하고, 뒤에 2개의 4096‑노드 fully‑connected 레이어를 두어 고차원 특징을 추출한다. 이후 세 개의 독립적인 헤드가 각각 7‑class softmax(표정), 17‑dim sigmoid(AU), 2‑dim linear(VA) 출력을 만든다. 손실 함수는 L_EMO, L_AU, L_VA 세 부분으로 구성되며, λ1, λ2를 통해 AU와 VA 손실의 비중을 조절한다. L_VA는 연속 감정 추정에 널리 쓰이는 Concordance Correlation Coefficient(CCC)를 1‑minus 형태로 최소화한다.
핵심 기여는 두 가지 과제 결합 전략이다. 첫 번째는 ‘공동 주석(co‑annotation)’이다. 인지·심리학 연구
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기