Face Behavior a la carte: Expressions, Affect and Action Units in a Single Network
Automatic facial behavior analysis has a long history of studies in the intersection of computer vision, physiology and psychology. However it is only recently, with the collection of large-scale datasets and powerful machine learning methods such as…
Authors: Dimitrios Kollias, Viktoriia Sharmanska, Stefanos Zafeiriou
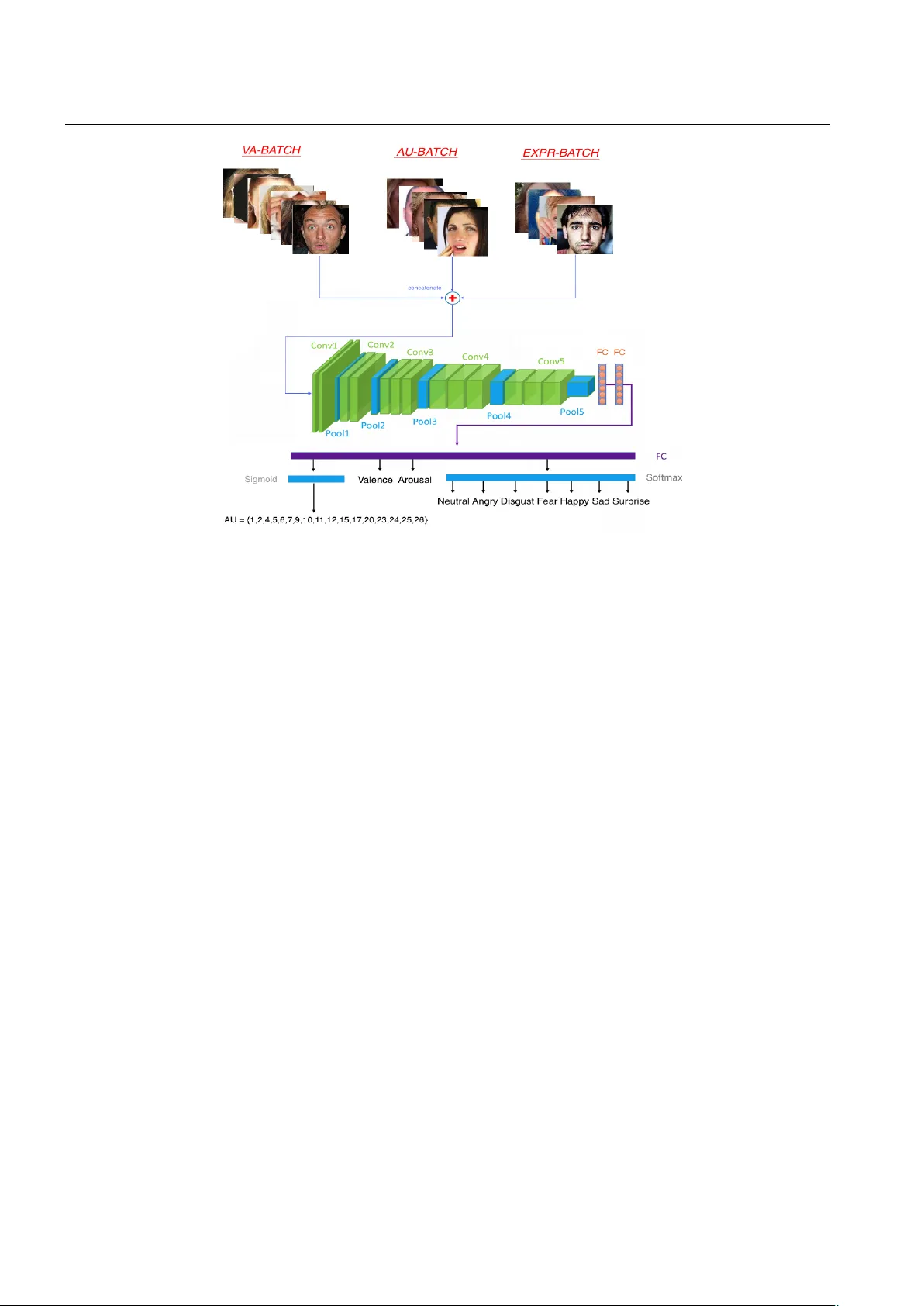
Noname manuscript No. (will be inserted by the editor) F ace Beha vior ` a la carte: Expr essions, Affect and Action Units in a Single Network Dimitrios Kollias ? · V iktoriia Sharmanska † · Stefanos Zafeiriou 2 Receiv ed: / Accepted: Abstract Automatic facial beha vior analysis has a long his- tory of studies in the intersection of computer vision, phys- iology and psychology . Ho we ver it is only recently , with the collection of large-scale datasets and powerful machine learning methods such as deep neural networks, that auto- matic facial behavior analysis started to thriv e. Three of its iconic tasks are automatic recognition of basic expressions (e.g. happiness, sadness, surprise), estimation of continu- ous affect (e.g., valence and arousal), and detection of fa- cial action units (activ ations of e.g. upper/inner eyebrows, nose wrinkles). Up until now these tasks hav e been studied independently by collecting a dedicated dataset and train- ing a single-task model. W e present the first and the largest study of all facial behaviour tasks learned jointly in a sin- gle holistic framew ork, which we call FaceBeha viorNet. F or this we utilize all publicly av ailable datasets in the com- munity (over 5M images) that study facial behaviour tasks in-the-wild. W e demonstrate that training jointly an end-to- end network for all tasks has consistently better performance than training each of the single-task networks. Furthermore, we propose two simple strategies for coupling the tasks dur - ing training, co-annotation and distribution matching, and show the advantages of this approach. Finally we show that FaceBeha viorNet has learned features that encapsulate all aspects of facial behaviour , and can be successfully applied to perform tasks (compound emotion recognition) beyond the ones that it has been trained in a zero- and few-shot ? dimitrios.kollias15@imperial.ac.uk † sharmanska.v@imperial.ac.uk 2 s.zafeiriou@imperial.ac.uk ?, † , 2 Department of Computing, Imperial College London, Queens Gate, London SW7 2AZ, UK ?, † , 2 FaceSoft Ltd 2 Center for Machine V ision and Signal Analysis, University of Oulu, Oulu, Finland learning setting. The model and source code will be made publicly av ailable. 1 Introduction Holistic frameworks, where several parts, e.g. learning tasks, are interconnected and explicable by the reference to the whole, are common in computer vision. The di verse exam- ples range from the scene understanding framework that rea- sons about 3D object detection, pose estimation, semantic segmentation and depth reconstruction [ 39 ], the face analy- sis framew ork that addresses face detection, landmark local- ization, gender recognition, age estimation [ 34 ], to the uni- versal networks for low-, mid-, high-lev el vision [ 20 ] and for v arious visual tasks [ 47 ]. Most if not all of these prior works rely on b uilding a multi-task frame work where learn- ing is done based on the ground truth annotations with full or partial overlap across tasks. During training, all the tasks are optimised simultaneously aiming for representation learning that supports the holistic view . In this work we propose the first holistic frame work for emotional behaviour analysis in-the-wild, where different emotional states such as binary action units activ ations, ba- sic categorical emotions and continuous dimensions of va- lence and arousal constitute the interconnected tasks that are explicable by the human’ s af fectiv e state. What makes it dif- ferent from the aforementioned holistic approaches is ex- ploring the idea of task-relatedness, gi ven explicitly either as external expert kno wledge or from empirical e vidence. In this form, it is similarly motiv ated to the classical multi- task literature exploring feature sharing [ 1 ] and task relat- edness [ 18 ] during training; more examples can be found in the surveys [ 49 , 32 ]. Howe ver in the multi-task setting, one typically assumes homogeneity of the tasks, i.e. tasks of the same type such as object classifiers or attribute detectors. 2 D. K ollias The main dif ference and novelty of our work is that the pro- posed holistic framework (i) explores the relatedness of non- homogeneous tasks, e.g. tasks for classification, detection, regression; (ii) operates ov er datasets with partial or non- ov erlapping annotations of the tasks; (iii) encodes explicit relationship between tasks to improv e transparency and to enable expert input. Recently , a lot of effort has been made tow ards collect- ing large scale datasets of naturalistic beha viour captured in uncontrolled conditions, in-the-wild [ 23 , 46 , 30 , 3 ], which is the focus of our study . There is a rich literature on recogni- tion of basic emotion categories or expressions [ 13 ] such as anger , disgust, fear , happiness, sadness, surprise and neutral in-the-wild [ 8 , 7 ]. Continuous affect dimensions such as va- lence (how positiv e/negati ve a person is) and arousal (how activ e/passiv e a person is) have attracted attention (V A) re- cently , as they are naturally suited to represent emotional state and its changes ov er time. Datasets for continuous af- fect are simpler to collect while benefiting from human com- puter interactions techniques. Automatic facial analysis has been also studied in terms of the facial action units (A Us) coding system [ 14 ]. This system is a systematic way to code the facial motion with respect to activ ation of facial mus- cles. It has been widely adopted as a common standard to- wards systematically categorising physical manifestation of complex facial expressions. The dataset collection of action units is very costly , as it requires skilled annotators to per- form the task. Nevertheless there has been a lot of effort to collect action unit annotations and de velop automatic A Us annotation toolboxes [ 3 , 2 ]. Up until now facial behaviour in-the-wild has been pri- marily addressed by collecting in-the-wild datasets to solve individual tasks. Howe ver the three aforementioned tasks of facial behaviour analysis are interconnected. In [ 14 ], the facial action coding system (F ACS) has been b uilt to indi- cate for each of the basic expressions its prototypical action units. In [ 12 ], a dedicated user study has been conducted to study the relationship between A Us activ ations and emo- tion expressions beyond basic types – compound emotions (e.g. happily surprised). In [ 19 ], the authors show that neural networks trained for expression recognition implicitly learn facial action units. Also, in [ 29 ] the authors hav e discovered that valence and arousal dimensions could be interpreted by A Us. For example, A U12 (lip corner puller) is related to positiv e va- lence. Our main contributions are as follo ws: – W e propose a fle xible holistic framew ork that can accom- modate non-homogeneous tasks with encoding prior knowl- edge of tasks relatedness. In our experiments we e v aluate two effecti ve strategies of task relatedness: a) obtained from a cogniti ve and psychological study , e.g. how ac- tion units are related to basic emotion categories [ 12 ], and b) inferred empirically from external dataset annotations; the annotations will be made publicly av ailable. – W e propose an effecti ve algorithmic approach of coupling the tasks via co-annotation and distribution matching and show its ef fectiveness for f acial behaviour analysis; – W e present the first, to the best of our kno wledge, holistic network for facial behaviour analysis (FaceBehaviorNet) and train it end-to-end for predicting simultaneously 7 ba- sic expressions, 17 action units and continuous valence- arousal in-the-wild. For network training we utilize all publicly a vailable in-the-wild databases that, in total, con- sist of ov er 5M images with partial and/or non-ov erlapping annotations for different tasks. – W e sho w that FaceBeha viorNet greatly outperforms each of the single-task networks, validating that our network’ s emotion recognition capabilities are enhanced when it is jointly trained for all related tasks. W e further explored the feature representation learned in the joint training and show its generalization abilities on the task of compound expressions recognition when no or little training data is av ailable (zero-shot and fe w-shot learning). 2 Related work W orks exist in literature that use emotion labels to com- plement missing A U annotations or increase generalization of A U classifiers [ 35 , 43 , 40 ]. Our work deviates from such methods, as we target a joint learning of three facial be- haviour tasks via a single holistic framew ork, whilst these works perform only A U detection and not emotion recogni- tion (nor valence-arousal estimation). Multi-task learning (MTL) was first studied in [ 5 ], where the authors propose to jointly learn parallel tasks sharing a common representation and transferring part of the kno wl- edge learned to solve one task to improv e the learning of the other related tasks. Since then, several approaches hav e adopted MTL for solving different problems in computer vi- sion and machine learning. In the face analysis domain, the use of MTL is somewhat limited. In [ 42 ], MTL was tackled through a neural network that jointly handled face recogni- tion and facial attribute prediction tasks. MTL helped cap- ture global feature and local attribute information simulta- neously . One of the closest goals to ours is [ 6 ], where an in- tegrated deep learning framework (F A T A UV A-Net) for se- quential facial attribute recognition, A U detection, and v alence- arousal estimation w as proposed. This frame work employed face attributes as lo w-lev el (first component) and A Us as mid-lev el (second component) representations for predict- ing quantized v alence-arousal v alues (third component). How- ev er training of this model is made of transfer learning and fine-tuning steps, is hierarchical and not end-to-end. In a similar work of [ 41 ], a two-le vel attention with two stage Face Beha vior ` a la carte: Expressions, Affect and Action Units in a Single Netw ork 3 multi-task learning framework was constructed for emotion recognition and valence-arousal estimation; this work was based on a database (Af fectNet [ 30 ]) annotated for both tasks. In the first attention level, a CNN extracted position-lev el features and then in the second an RNN with self-attention was proposed to model the relationship between layer-le vel features. 3 The Proposed A pproach W e start with the multi-task formulation of the facial be- haviour model. In this model we have three objecti ves: (1) learning sev en basic emotions, (2) detecting acti vations of 17 binary facial action units, (3) learning the intensity of the valence and arousal continuous affect dimensions. W e train a multi-task neural network model to jointly perform (1)-(3). For a given image x ∈ X , we can hav e label annotations of either one of sev en basic emotions y emo ∈ { 1 , 2 , . . . , 7 } , or 17 1 binary action units activ ations y au ∈ { 0 , 1 } 17 , or two continuous affect dimensions, valence and arousal, y v a ∈ [ − 1 , 1] 2 . For simplicity of presentation, we use the same no- tation x for all images leaving the context to be explained by the label notations. W e train the multi-task model by mini- mizing the following objecti ve: L M T = L E mo + λ 1 L AU + λ 2 L V A (1) L E mo = E x,y emo [ − log p ( y emo | x )] L AU = E x,y au [ − log p ( y au | x )] L V A = 1 − C C C ( y v a , ¯ y v a ) , where the first term is the cross entropy loss computed over images with a basic emotion label, the second term is the bi- nary cross entropy loss computed over images with 17 A Us activ ations, log p ( y au | x ) := [ P 17 k =1 δ k ] − 1 · P 17 i =1 δ i · [ y i au log p ( y i au | x ) + (1 − y i au ) log (1 − p ( y i au | x ))] , where δ i ∈ { 0 , 1 } indicates whether the image contains annotation for AU i . The third term measures the concordance correlation coefficient between the ground truth v alence and arousal y v a and the predicted ¯ y v a , C C C ( y v a , ¯ y v a ) = ρ a + ρ v 2 , where for i ∈ { v , a } , y i is the ground truth, ¯ y i is the predicted value and ρ i = 2 · E [( y i − E y i ) · ( ¯ y i − E ¯ y i )] E 2 [( y i − E y i ) 2 ] + E 2 [( ¯ y i − E ¯ y i ) 2 ] + ( E y i − E ¯ y i ) 2 . Coupling of basic emotions and A Us via co-annotation In the seminal work [ 12 ], the authors conduct a study on the relationship between emotions (basic and compound) and facial action units acti vations. The summary of the study is 1 In fact, 17 is an aggregate of action units in all datasets; typically each dataset has from 10 to 12 A Us labelled by purposely trained an- notators. T able 1: Basic emotions and their prototypical and observa- tional A Us from [ 12 ]. The weights w in brackets correspond to the fraction of annotators that observ ed the A U acti vation. Emotion Protot. A Us Observ . A Us (with weights w ) happiness 12, 25 6 (0.51) sadness 4, 15 1 (0.6), 6 (0.5), 11 (0.26), 17 (0.67) fear 1, 4, 20, 25 2 (0.57), 5 (0.63), 26 (0.33) anger 4, 7, 24 10 (0.26), 17 (0.52), 23 (0.29) surprise 1, 2, 25, 26 5 (0.66) disguste 9, 10, 17 4 (0.31), 24 (0.26) a table of the emotions and their prototypical and observ a- tional actions units (T able 1 in [ 12 ]) which we include in T able 1 for completeness. Prototypical are action units that are labelled as activ ated across all annotators’ responses, ob- servational are action units that are labelled as activ ated by a fraction of annotators. For example, in emotion happiness the prototypical are A U12 and A U25, the observational is A U6 with weight 0 . 51 (observed by 51% of the annotators). Here let us mention that T able 1 constitutes the relat- edness between the emotion categories and action units ob- tained from a cogniti ve study . In our experiments, in Section 4.2 , we also show that such relatedness can be inferred em- pirically from external dataset annotations. Other means of describing task relatedness in a holistic framework will be further explored in the future. W e propose a simple strategy of co-annotation to couple the training of emotions and action unit predictions. Giv en an image x with the ground truth basic emotion y emo , we en- force the prototypical and observ ational A Us of this emotion to be acti vated. W e co-annotate the image ( x, y emo ) with y au ; this image contributes to both L E mo and L AU 2 in eq. 1 . W e re-weight the contributions of the observational A Us with the annotators’ agreement score (from T able 1 ). Similarly , for an image x with the ground truth action units y au , we check whether we can co-annotate it with an emotion label. For an emotion to be present, all its proto- typical and observational A Us hav e to be present. In cases when more than one emotion is possible, we assign the label y emo of the emotion with the largest requirement of pro- totypical and observational A Us. The image ( x, y au ) that is co-annotated with the emotion label y emo contributes to both L AU and L E mo in eq. 1 . W e call this approach the FaceBeha viorNet with co-annotation. Coupling of basic emotions and A Us via distrib ution matc h- ing The aim here is to align the pr edictions of the emotions and action units tasks during training. For each sample x we hav e the predictions of emotions p ( y emo | x ) as the softmax scores over seven basic emotions and we hav e the prediction 2 Here we overload slightly our notations; for co-annotated images, y au has variable length and only contains prototypical and observa- tional A Us. 4 D. K ollias of A Us activ ations p ( y i au | x ) , i = 1 , . . . , 17 as the sigmoid scores ov er 17 A Us. The distribution matching idea is simple: we match the distribution o ver A U predictions p ( y i au | x ) with the distrib u- tion q ( y i au | x ) , where the A Us are modeled as a mixture o ver the basic emotion categories: q ( y i au | x ) = X y emo ∈{ 1 ,..., 7 } p ( y emo | x ) p ( y i au | y emo ) , (2) where p ( y i au | y emo ) is defined deterministically from T able 1 and is 1 for prototypical/observ ational action units, or 0 oth- erwise. For example, A U2 is prototypical for emotion sur- prise and observ ational for emotion fear and thus q ( y A U2 | x ) = 1 2 ( p ( y surprise | x ) + p ( y fear | x )) 3 . This matching aims to make the network’ s predicted A Us consistent with the prototypical and observational A Us of the network’ s predicted emotions. So if, e.g., the network predicts the emotion happiness with probability 1, i.e., p ( y happiness | x ) = 1 , then the prototypical and observ ational A Us of happiness -A Us 12, 25 and 6- need to be acti vated in the distribution q: q ( y A U12 | x ) = q ( y A U25 | x ) = q ( y A U6 | x ) = 1 ; q ( y i au | x ) = 0 , i ∈ { 1 , .., 14 } . In spirit of the distillation approach [ 17 ], we match the distributions p ( y i au | x ) and q ( y i au | x ) by minimizing the cross entropy with the soft tar gets loss term 4 : L DM = E x 17 X i =1 [ − p ( y i au | x ) log q ( y i au | x )] , (3) where all av ailable training samples are used to match the predictions. W e call this approach FaceBeha viorNet with distr-matching. A mix of the two strategies, co-annotation and distribu- tion matching, is also possible. Giv en an image x with the ground truth annotation of the action units y au , we can first co-annotate it with a soft label in form of the distribution ov er emotions and then match it with the predictions of emo- tions p ( y emo | x ) . More specifically , for each basic emotion, we compute the score ov er its prototypical and observ ational A Us being present. F or example, for emotion happiness , we compute ( y A U12 + y A U25 + 0 . 51 · y A U6 ) / (1 + 1 + 0 . 51) , or all weights equal 1 if without reweighting. W e take a soft- max over the scores to produce the probabilities ov er emo- tion categories. In this v ariant, e very single image that has ground truth annotation of A Us will have a soft emotion la- bel assigned. Finally we match the predictions p ( y emo | x ) and the soft label by minimizing the cross entropy with the soft tar gets similarly to eq. 3 . W e call this approach FaceBe- haviorNet with soft co-annotation. 3 W e also tried a variant with reweighting for observ ational A Us, i.e. p ( y i au | y emo ) = w 4 This can be seen as minimizing the KL-div ergence K L ( p || q ) across the 17 action units. Coupling of categorical emotions, A Us with continuous af- fect In our work, continuous af fect (v alence and arousal) is implicitly coupled with the basic expressions and action units via a joint training procedure. Also one of the datasets we used has annotations for categorical and continuous emo- tions (AffectNet [ 30 ]). Studying an explicit relationship be- tween them is a nov el research direction beyond the scope of this work. F aceBehaviorNet structur e Fig. 1 shows the structure of the holistic (multi-task, multi-domain and multi-label) FaceBe- haviorNet, based on the 13 conv olutional and pooling lay- ers of VGG-F A CE [ 33 ] (its fully connected layers are dis- carded), followed by 2 fully connected layers, each with 4096 hidden units. A (linear) output layer follows that gi ves final estimates for valence and arousal; it also giv es 7 basic expression logits that are passed through a softmax function to get the final 7 basic expression predictions; lastly , it gi ves 17 A U logits that are passed through a sigmoid function to get the final 17 A U predictions. One can see that the predic- tions for all tasks are pooled from the same feature space. 4 Experimental Study Databases Let us first describe the databases that we uti- lized in all our experiments. W e selected to work with these databases because they provide a large number of samples with accurate annotations of valence-arousal, basic expres- sions and A Us. Training with these datasets allows our net- works to learn to recognize af fectiv e states under a large number of image conditions (e.g., each database includes images at dif ferent resolutions, poses, orientations and light- ing conditions). These datasets also include a variety of sam- ples in both genders, ethnicities and races. The Aff-Wild database [ 23 ] [ 46 ] has been the first large scale captured in-the-wild database, containing 298 videos (200 subjects) of around 1.25M frames, annotated in terms of valence-arousal. It serv ed as benchmark for the Aff-W ild Challenge organized in CVPR 2017. The AffectNet database [ 30 ] contains around 1M facial images, 400K of which were manually annotated in terms of 7 discrete expressions (plus contempt) and valence-arousal. The AFEW database[ 9 ] is used in the EmotiW Challenges that focus on audiovisual classification of each of the 1,809 video clips into the 7 ba- sic emotion cate gories. The RAF-DB database [ 27 ] contains 15.2K facial images annotated in terms of the 7 basic and 11 compound emotion categories. The EmotioNet database [ 15 ] is a large-scale database with around 1M facial expression images; 950K images were automatically annotated and the remaining 50K images were manually annotated with 11 A Us. Additionally , a subset of about 2.5K images was annotated with the 6 basic and 10 Face Beha vior ` a la carte: Expressions, Affect and Action Units in a Single Netw ork 5 Fig. 1: The holistic (multi-task, multi-domain, multi-label) F aceBehaviorNet; ’V A/A U/EXPR-B A TCH’ refers to batches annotated in terms of V A/A U/7 basic expressions compound emotions. It was released for the EmotioNet Chal- lenge in 2017 [ 4 ]. The DISF A database [ 28 ] is a lab con- trolled database with spontaneous emotion expressions, an- notated for the presence, absence and intensity of 12 A Us. It consists of 260K video frames of 27 subjects recorded by two cameras. The BP4D-Spontaneous database[ 48 ] (in the rest of the paper we refer to it as BP4D) contains 61 sub- jects with 223K frames and is annotated for the occurrence and intensity of 27 A Us. It has been used as a part of the FERA 2015 Challenge [ 37 ]. The BP4D+ database [ 50 ] is an extension of BP4D incorporating different modalities as well as more subjects (140). It is annotated for occurrence of 34 A Us and intensity for 5 of them. It has been used as a part of the FERA 2017 Challenge [ 38 ]. Here let us note that for AffectNet, AFEW , BP4D and BP4D+, no test set is released; thus we use the released vali- dation set to test on and randomly divide the training set into a training and a validation subset (with a 85/15 split). P erformance Measures W e use: i) the CCC for Af f-W ild (CCC was the ev aluation criterion of Aff-W ild Challenge) and Affectnet, ii) the total accuracy for AFEW (this metric was the ev aluation criterion of the EmotiW Challenges), the mean diagonal v alue of the confusion matrix for RAF-DB (this criterion was selected for ev aluating the performance on this database by [ 27 ]), the F1 score for AffectNet, iii) the F1 score for DISF A, BP4D and BP4D+ (this metric was the ev aluation criterion of the FERA 2015 and 2017 Chal- lenges); for A U detection in EmotioNet the Challenge’ s met- ric was the average between: a) the mean (across all A Us) F1 score and b) the mean (across all A Us) accuracy; for the expression classification, it was the average between: a) the mean (across all emotions) F1 score and b) the unweighted av erage recall (U AR) over all emotion cate gories. Pr e-Pr ocessing W e used the SSH detector [ 31 ] based on ResNet and trained on the W iderFace dataset [ 44 ] to extract, from all images, face bounding boxes and 5 facial land- marks; the latter were used for face alignment. All cropped and aligned images were resized to 96 × 96 × 3 pixel reso- lution and their intensity values were normalized to [ − 1 , 1] . 4.1 T raining Implementation Details At this point let us describe the strategy that was used for feeding images from different databases to FaceBehavior - Net. At first, the training set was split into three different sets, each of which contained images that were annotated in terms of either v alence-arousal, or action units, or sev en ba- sic expressions; let us denote these sets as V A-Set, A U-Set and EXPR-Set, respectively . During training, at each itera- tion, three batches, one from each of these sets (as can be seen in Fig. 1 ), were concatenated and fed to FaceBehavior - Net. This step is important for network training, because: i) the network minimizes the objective function of eq. 1 ; at 6 D. K ollias each iteration, the network has seen images from all cat- egories and thus all loss terms contribute to the objective function, ii) since the network sees an adequate number of images from all categories, the weight updates (during gra- dient descent) are not based on noisy gradients; this in turn prev ents poor conv ergence behaviors; otherwise, we would need to tackle these problems, e.g. do asynchronous SGD as proposed in [ 20 ] to make the task parameter updates decou- pled, iii) the CCC cost function (defined in Section 3 ) needs an adequate sequence of predictions. Since V A-Set, A U-Set and EXPR-Set had dif ferent sizes, they needed to be ’aligned’. T o do so, we selected the batches of these sets in such a manner , so that after one epoch we will have sampled all images in the sets. In particular , we chose batches of size 401, 247 and 103 for the V A-Set, A U- Set and EXPR-Set, respectively . The training of F aceBehav- iorNet was performed in an end-to-end manner , with a learn- ing rate of 10 − 4 . A 0.5 Dropout value was used in the fully connected layers. T raining was performed on a T esla V100 32GB GPU; training time was about 2 days. 4.2 T ask-Relatedness from Empirical Evidences T able 1 was created using a cognitive and psychological study with human participants. Here, we create another T a- ble inferred empirically from external dataset annotations. In particular , we use the recently proposed Af f-W ild2 database [ 26 , 24 , 25 , 22 ], which is the first in-the-wild database that contains annotations for all three behavior tasks that we are dealing with in this paper . It consists of 558 videos: all con- tain V A annotations, 63 contain A U annotations and 84 con- tain basic expression annotations. It served as benchmark for the AB A W Competition or ganized in IEEE FG 2020. At first, we trained a network for A U detection on the union of Aff-W ild2 and GFT databases [ 16 ]. Next, this net- work was used for automatically annotating all Aff-W ild2 videos with A Us. These annotations will be made publicly av ailable. T able 3 sho ws the distribution of A Us for each ba- sic expression. In parenthesis next to each A U (e.g. A U12) is the percentage of images (0.82) annotated with the spe- cific expression (happiness) in which this A U (A U12) was activ ated. 4.3 Results: Ablation Study At first, we compare the performance of FaceBeha viorNet when trained: i) with only the losses of eq. 1 and without using the coupling losses described in Section 3 , ii) with co- annotation coupling loss, iii) with soft co-annotation cou- pling loss and iv) with distr-matching coupling loss, vi) with soft co-annotation and distr -matching coupling losses. T able 2 shows the results for all these approaches, when T ables 1 and 3 are used for the task relatedness. Many deductions can be made. F irstly , when FaceBe- haviorNet is trained with any coupling loss, or any com- bination of these, it displays a better (or in the worst case equal) performance on all databases, in both dif ferent task relatedness scenarios. This validates the fact that the pro- posed losses help to couple the three studied tasks regard- less of which relatedness scenario was followed; this shows the generality of the proposed losses that boosted the per- formance of the network. Secondly , the performance in es- timation of valence and arousal improved, although we did not explicitly designed a coupling loss for this; we only cou- pled emotion cate gories and action units. W e conjecture that when action unit detection and expression classification ac- curacy is improving (due to coupling), valence and arousal performance also impro ves, because valence and arousal are implicitly coupled with emotions via joint dataset annota- tions for both emotion types. Thir dly , in all scenarios, the co-annotation loss results in FaceBeha viorNet having the worst performance when com- pared to all other coupling losses. Furthermore , in both set- tings, when the network was trained with the soft co-annotation loss, the performance increase in A Us was bigger than the corresponding increase in expressions, whereas when the network was trained with the distr-matching loss the per- formance increase in expressions w as bigger than the corre- sponding increase in A Us. Finally , overall best results have been achieved, in both scenarios, when FaceBehaviorNet was trained with both soft co-annotation and distr-matching losses. In particular , in both settings, an av erage performance increase of more than 2% has been observed when using both coupling losses, compared to the (two) cases when only one of them was used. 4.4 Results: Comparison with State-of-the-Art and Single-T ask Methods Next, we trained a VGG-F ACE network on all the dimen- sionally annotated databases to predict valence and arousal; we also trained another VGG-F ACE network on all categori- cally annotated databases, to perform sev en basic expression classification; finally we trained a third VGG-F A CE network on all databases annotated with action units, so as to perform A U detection. For bre vity these three single-task networks are denoted as ’(3 × ) V GG-F A CE single-task’ in one row of T able 4 . W e compared these networks’ performances with the per- formance of FaceBeha viorNet when trained with and with- out the coupling losses. W e also compare them with the per - formances of the state-of-the-art methodologies of each uti- lized database: i) F A T A UV A-Net [ 6 ] (described in Section 2 ), which was the winner of Aff-W ild Challenge; ii) the best Face Beha vior ` a la carte: Expressions, Affect and Action Units in a Single Netw ork 7 T able 2: Performance ev aluation of valence-arousal, se ven basic expression and action units predictions on all used databases provided by the F aceBehaviorNet when trained with/without the coupled losses, under the two task relatedness scenarios. Databases Relatedness Aff-W ild AffectNet AFEW RAF-DB EmotioNet DISF A BP4D BP4D+ FaceBehaviorNet CCC-V CCC-A CCC-V CCC-A F1 Score T otal Accuracy Mean diag. of conf. matrix F1 Score Accuracy F1 Score F1 Score F1 Score no coupling loss - 0.55 0.36 0.56 0.46 0.54 0.38 0.67 0.49 0.94 0.52 0.61 0.57 co-annotation [ 12 ] 0.56 0.38 0.56 0.46 0.55 0.40 0.67 0.49 0.94 0.54 0.64 0.58 soft co-annotation [ 12 ] 0.56 0.39 0.57 0.47 0.57 0.41 0.67 0.50 0.94 0.54 0.64 0.60 distr-matching [ 12 ] 0.56 0.37 0.57 0.49 0.57 0.42 0.68 0.50 0.94 0.56 0.66 0.58 soft co-annotation and distr -matching [ 12 ] 0.59 0.41 0.59 0.50 0.60 0.43 0.70 0.51 0.95 0.57 0.67 0.60 co-annotation Aff-W ild2 0.55 0.37 0.56 0.47 0.54 0.40 0.67 0.50 0.93 0.54 0.61 0.57 soft co-annotation Aff-W ild2 0.56 0.37 0.57 0.47 0.55 0.42 0.68 0.52 0.94 0.58 0.63 0.59 distr-matching Aff-W ild2 0.57 0.39 0.60 0.51 0.57 0.42 0.69 0.50 0.94 0.57 0.62 0.58 soft co-annotation and distr -matching Aff-W ild2 0.60 0.40 0.61 0.51 0.60 0.42 0.71 0.54 0.94 0.60 0.66 0.60 T able 3: Relatedness between basic emotions and A Us, in- ferred from Aff-W ild2. Emotion A Us (with weights w ) happy 12 (0.82), 25 (0.7), 6 (0.57), 7 (0.83), 10 (0.63) sad 4 (0.53), 15 (0.42), 1 (0.31), 7 (0.13), 17 (0.1) fearful 1 (0.52), 4 (0.4), 25 (0.85), 5 (0.38), 7 (0.57), 10 (0.57) angry 4 (0.65), 7 (0.45), 25 (0.4), 10 (0.33), 9 (0.15) surprised 1 (0.38), 2 (0.37), 25 (0.85), 26 (0.3), 5 (0.5), 7 (0.2) disgusted 9 (0.21), 10 (0.85), 17 (0.23), 4 (0.6), 7 (0.75), 25 (0.8) performing CNN (VGG-F A CE) on Aff-W ild [ 21 ][ 23 ]; iii) the baseline netw orks (Ale xNet) on Af fectNet [ 30 ] (in T able 4 they are denoted as ’(2 × ) AlexNet’ as they are two dif- ferent networks: one for V A estimation and another for ex- pression classification); i v) the baseline network (non-linear Chi-square kernel based SVM) [ 10 ] on EmotiW Challenges; v) VGG-F ACE-mSVM [ 27 ] on RAF-DB; vi) the baseline network (AlexNet) on EmotioNet [ 4 ]; vii) ResNet-34, which was the best performing network on EmotioNet [ 11 ]; viii) Discriminant Laplacian Embedding extension (DLE extension)[ 45 ], which was the winner of FERA 2015 on BP4D; ix) [ 36 ], which was the winner of FERA 2017 on BP4D+. T able 4 displays the performances of all these networks. Here, let us mention that in Aff-W ild the best perform- ing netw ork is Af fW ildNet [ 23 ] [ 21 ], that has a CCC of 0.57 and 0.43 in v alence and arousal respectiv ely; this network is a CNN-RNN that exploits the fact that the Af f-W ild database is an audio-visual one. Additionally , facial landmarks were provided as additional inputs to this network, thus improv- ing its performance. The latter is not included in T able 4 . Howe ver , although being a CNN-RNN network, its average CCC is the same as the average CCC of our CNN network, FaceBeha viorNet trained with the two coupling losses (in both task relatedness settings). Let us also mention that on RAF-DB the best perform- ing network is the Deep Locality-preserving CNN (DLP- CNN) of [ 27 ] with a performance metric value of 0.74; this network was trained using a joint classical softmax loss - which forces different classes to stay apart - and a newly created loss - that pulls the locally neighboring faces of the same class together . For the task of expression recognition, our approach used the standard cross entropy loss; therefore a fair comparison cannot be made with our model because DLP-CNN uses a different cost function that we do not use and thus DLP-CNN is not listed in T able 4 . It might be argued that the more data used for network training (ev en if they contain partial or non-overlapping an- notations), the better network performance will be in all tasks. Howe ver this may not be true, as the three studied tasks are non-homogeneous and each one of them contains am- biguous cases: i) there is generally discrepancy in the per- ception of the disgust, fear , sadness and (negati ve) surprise emotions across different people and across databases; ii) the exact valence and arousal v alue for a particular affect is also not consistent among databases; iii) the A U anno- tation process is a hard to do and error prone one. Nev- ertheless, from T able 4 , it can be verified that FaceBeha v- iorNet achiev ed a better performance on all databases than the independently trained VGG-F A CE single-task models. This shows that, all described facial behavior understand- ing tasks are coherently correlated to each other; training an end-to-end architecture with heterogeneous databases si- multaneously , therefore, leads to improved performance. In T able 4 , it can be observed that FaceBeha viorNet trained with no coupling loss: i) ouperforms the state-of-the-art by 3.5% (average CCC) on Aff-W ild, 4% (av erage CCC) on AffectNet, 9% on RAF-DB and 2% on BP4D; ii) has the same performance on AFEW; iii) sho ws inferior performance by 4% on AffectNet and 1.5% (on average) on EmotioNet, 1% on BP4D+. Howe ver , when FaceBehaviorNet is trained with soft co-annotation and distr -matching losses (either when task relatedness is inferred from Aff-W ild2 or from [ 12 ]), it shows superior performance to all state-of-the-art methods. The fact that it outperforms these methods and the single- task networks, in both task relatedness settings, verifies the generality of the proposed losses; network performance is 8 D. K ollias T able 4: Performance ev aluation of v alence-arousal, sev en basic expression and action units predictions on all utilized databases provided by the F aceBehaviorNet and state-of-the-art methods. Databases Aff-W ild AffectNet AFEW RAF-DB EmotioNet DISF A BP4D BP4D+ CCC-V CCC-A CCC-V CCC-A F1 Score T otal Accuracy Mean diagonal of conf. matrix F1 Score Mean Accuracy F1 Score F1 Score F1 Score best performing CNN[ 21 ] [ 23 ] 0.51 0.33 - - - - - - - - - - F A T A UV A-Net [ 6 ] 0.40 0.28 - - - - - - - - - - (2 × ) AlexNet [ 30 ] - - 0.60 0.34 0.58 - - - - - - - non-linear SVM[ 9 ] - - - - - 0.38 - - - - - - VGG-F ACE-mSVM[ 27 ] - - - - - - 0.58 - - - - - AlexNet [ 4 ] - - - - - - - 0.39 0.83 - - - ResNet-34 [ 11 ] - - - - - - - 0.64 0.82 - - - DLE extension [ 45 ] - - - - - - - - - - 0.59 - [ 36 ] - - - - - - - - - - - 0.58 (3 × ) VGG-F ACE single-task 0.52 0.31 0.53 0.43 0.51 0.37 0.59 0.41 0.92 0.47 0.56 0.54 FaceBehaviorNet, no coupling loss 0.55 0.36 0.56 0.46 0.54 0.38 0.67 0.49 0.94 0.52 0.61 0.57 FaceBeha viorNet, soft co-annotation and distr -matching, [ 12 ] 0.59 0.41 0.59 0.50 0.60 0.43 0.70 0.51 0.95 0.57 0.67 0.60 FaceBeha viorNet, soft co-annotation and distr -matching, Aff-Wild2 0.60 0.40 0.61 0.51 0.60 0.42 0.71 0.54 0.94 0.60 0.66 0.60 boosted independently of the T able of task relatedness which was used. 4.5 Results: Zero-Shot and Fe w-Shot Learning In order to further pro ve and v alidate that FaceBeha vior- Net learned good features encapsulating all aspects of fa- cial behavior , we conducted zero-shot learning experiments for classifying compound expressions. Gi ven that there ex- ist only 2 datasets (EmotioNet and RAF-DB) annotated with compound expressions and that they do not contain a lot of samples (less than 3,000 each), at first, we used the predic- tions of FaceBeha viorNet together with the rules from [ 12 ] to generate compound emotion predictions. Additionally , to demonstrate the superiority of FaceBeha viorNet, we used it as a pre-trained network in a fe w-shot learning experiment. W e took advantage of the fact that our network has learned good features and used them as priors for fine-tuning the network to perform compound emotion classification. RAF-DB database At first, we performed zero-shot experi- ments on the 11 compound categories of RAF-DB. W e com- puted a candidate score, C s ( y emo ) , for each class y emo : C s ( y emo ) = [ 17 X k =1 p ( y k au | y emo )] − 1 · 17 X k =1 p ( y k au | x ) p ( y k au | y emo ) + p ( y emo 1 ) + p ( y emo 2 ) + 0 . 5 · ( p ( y v | x ) | p ( y v | x ) | + 1) , p ( y v | x ) 6 = 0 , where: i) the first term of the sum is FaceBeha viorNet’ s pre- dictions of only the prototypical (and observational) A Us that are associated with this compound class according to [ 12 ]; in this manner, every A U acts as an indicator for this particular emotion class; this terms describes the confidence (probability) of A Us that this compound emotion is present; ii) p ( y emo 1 ) and p ( y emo 2 ) are FaceBeha viorNet’ s predic- tions of only the basic expression classes emo 1 and emo 2 that are mixed and form the compound class (e.g., if the compound class is happily surprised then emo 1 is happy and emo 2 is surprised); iii) the last term of the sum is added only to the happily surprised and happily disgusted classes and is either 0 or 1 depending on whether FaceBeha viorNet’ s va- lence prediction is negativ e or positiv e, respectively; the ra- tionale is that only happily surprised and (maybe) happily disgusted classes hav e positiv e valence; all other classes are expected to have negati ve valence as they correspond to neg- ativ e emotions. Our final prediction was the class that had the maximum candidate score. T able 5 sho ws the results of this approach when we used the predictions of FaceBeha viorNet trained with and without the soft co-annotation and distr-matching losses. Best results hav e been obtained when the network was trained with the coupling losses. One can observ e, that this approach outper - formed by 4.8% the VGG-F ACE-mSVM [ 27 ] which has the same architecture as our network and it has been trained for compound emotion classification. Next, we target few-shot learning. In particular , we fine- tune the FaceBeha viorNet (trained with and without the soft co-annotation and distr-matching losses) on the small train- ing set of RAF-DB. In T able 5 we compare its performance to a state-of-the-art network. It can be seen that our fine- tuned FaceBeha viorNet, trained with and without the cou- pling losses, outperformed by 1.2% and 3.7%, respectively , the best performing network, DLP-CNN, that was trained with a loss designed for this specific task. EmotioNet database Next, we performed zero-shot experi- ments on the EmotioNet basic and compound set that was released for the related Challenge. This set includes 6 basic plus 10 compound categories, as described at the beginning Face Beha vior ` a la carte: Expressions, Affect and Action Units in a Single Netw ork 9 T able 5: Performance e valuation of generated compound emotion predictions on EmotioNet and RAF-DB databases. Databases EmotioNet RAF-DB Methods F1 Score Unweighted A verage Recall Mean diagonal of conf. matrix zero-shot, FaceBeha viorNet, no coupling loss 0.243 0.260 0.342 zero-shot, F aceBehaviorNet, both coupling losses 0.312 0.329 0.364 NT echLab [ 4 ] 0.255 0.243 - VGG-F A CE-mSVM [ 27 ] - - 0.316 DLP-CNN [ 27 ] - - 0.446 fine-tuned FaceBeha viorNet, no coupling loss - - 0.458 fine-tuned FaceBeha viorNet, both coupling losses - - 0.483 of this Section. Our zero-shot methodology was similar to the one described abov e for the RAF-DB database. The results of this experiment can be found in T able 5 . Best results hav e also been obtained when the network was trained with the two coupling losses. It can be observ ed that this approach outperformed by 5.7% and 8.6% in F1 score and Unweighted A verage Recall (U AR), respectively , the state-of-the-art NT echLab’ s [ 4 ] approach, which used the Emotionet’ s images with compound annotation. 5 Conclusions In this paper , we presented F aceBehaviorNet, the first holis- tic frame work for emotional beha viour analysis in-the-wild. FaceBeha viorNet is an end-to-end network trained for joint: basic expression recognition, action unit detection and v alence- arousal estimation. All publicly av ailable databases, con- taining ov er 5M images, that study facial beha viour tasks in-the-wild, have been utilized. Additionally we proposed two simple strategies for coupling the tasks during training, namely co-annotation and distribution matching. W e per- formed e xperiments comparing the performance of FaceBe- haviorNet to single-task netw orks, as well as state-of-the-art methodologies. FaceBehaviorNet consistently outperformed all of them. Finally , we explored the feature representation learned in the joint training and showed its generalization abilities on the task of compound expressions, under zero- shot or few-shot learning settings. References 1. Andreas Argyriou, Theodoros Evgeniou, and Massimiliano Pontil. Multi-task feature learning. In Advances in neural information pr ocessing systems , pages 41–48, 2007. 1 2. T adas Baltru ˇ saitis, Marwa Mahmoud, and Peter Robinson. Cross- dataset learning and person-specific normalisation for automatic action unit detection. In 2015 11th IEEE International Conference and W orkshops on A utomatic F ace and Gesture Recognition (FG) , volume 6, pages 1–6, 2015. 2 3. C.F . Benitez-Quiroz, R. Sriniv asan, and A.M. Martinez. Emo- tionet: An accurate, real-time algorithm for the automatic anno- tation of a million facial expressions in the wild. In Pr oceedings of IEEE International Conference on Computer V ision & P attern Recognition (CVPR’16) , Las V egas, NV , USA, June 2016. 2 4. C Fabian Benitez-Quiroz, Ramprakash Sriniv asan, Qianli Feng, Y an W ang, and Aleix M Martinez. Emotionet challenge: Recog- nition of facial expressions of emotion in the wild. arXiv preprint arXiv:1703.01210 , 2017. 5 , 7 , 8 , 9 5. Rich Caruana. Multitask learning. Machine learning , 28(1):41– 75, 1997. 2 6. W ei-Y i Chang, Shih-Huan Hsu, and Jen-Hsien Chien. Fatauva-net : An integrated deep learning framew ork for facial attrib ute recog- nition, action unit (au) detection, and valence-arousal estimation. In Proceedings of the IEEE Conference on Computer V ision and P attern Recognition W orkshop , 2017. 2 , 6 , 8 7. Roddy Cowie and Randolph R Cornelius. Describing the emo- tional states that are expressed in speech. Speech communication , 40(1):5–32, 2003. 2 8. T im Dalgleish and Mick Power . Handbook of cognition and emo- tion . John W iley & Sons, 2000. 2 9. Abhinav Dhall, Roland Goecke, Shreya Ghosh, Jyoti Joshi, Jesse Hoey , and T om Gedeon. From indi vidual to group-lev el emotion recognition: Emotiw 5.0. In Pr oceedings of the 19th ACM Inter - national Conference on Multimodal Interaction , pages 524–528. A CM, 2017. 4 , 8 10. Abhinav Dhall, Amanjot Kaur , Roland Goecke, and T om Gedeon. Emotiw 2018: Audio-video, student engagement and group-lev el affect prediction. In Proceedings of the 2018 on International Confer ence on Multimodal Interaction , pages 653–656. A CM, 2018. 7 11. W an Ding, Dong-Y an Huang, Zhuo Chen, Xinguo Y u, and W eisi Lin. Facial action recognition using very deep netw orks for highly imbalanced class distrib ution. In 2017 Asia-P acific Signal and In- formation Pr ocessing Association Annual Summit and Conference (APSIP A ASC) , pages 1368–1372. IEEE, 2017. 7 , 8 12. Shichuan Du, Y ong T ao, and Aleix M Martinez. Compound facial expressions of emotion. Pr oceedings of the National Academy of Sciences , 111(15):E1454–E1462, 2014. 2 , 3 , 7 , 8 13. Paul Ekman and W allace V Friesen. Constants across cultures in the face and emotion. Journal of personality and social psychol- ogy , 17(2):124, 1971. 2 14. Rosenberg Ekman. What the face r eveals: Basic and applied stud- ies of spontaneous expr ession using the F acial Action Coding Sys- tem (F ACS) . Oxford University Press, USA, 1997. 2 15. C Fabian Benitez-Quiroz, Ramprakash Sriniv asan, and Aleix M Martinez. Emotionet: An accurate, real-time algorithm for the au- tomatic annotation of a million facial expressions in the wild. In Pr oceedings of the IEEE Conference on Computer V ision and P at- tern Recognition , pages 5562–5570, 2016. 4 16. Jeffre y M Girard, W en-Sheng Chu, L ´ aszl ´ o A Jeni, and Jeffre y F Cohn. Sayette group formation task (gft) spontaneous facial ex- pression database. In 2017 12th IEEE International Confer ence on A utomatic F ace & Gestur e Recognition (FG 2017) , pages 581– 588. IEEE, 2017. 6 10 D. K ollias 17. Geoffre y Hinton, Oriol V inyals, and Jef f Dean. Distilling the knowledge in a neural netw ork. , 2015. 4 18. Dinesh Jayaraman, Fei Sha, and Kristen Grauman. Decorrelating semantic visual attributes by resisting the urge to share. In Pro- ceedings of the IEEE Confer ence on Computer V ision and P attern Recognition , pages 1629–1636, 2014. 1 19. Pooya Khorrami, Thomas Paine, and Thomas Huang. Do deep neural networks learn facial action units when doing expression recognition? In Pr oceedings of the IEEE International Confer ence on Computer V ision W orkshops , pages 19–27, 2015. 2 20. Iasonas K okkinos. Ubernet: T raining a universal conv olutional neural network for lo w-, mid-, and high-lev el vision using div erse datasets and limited memory . In Pr oceedings of the IEEE Confer- ence on Computer V ision and P attern Recognition , pages 6129– 6138, 2017. 1 , 6 21. Dimitrios Kollias, Mihalis A Nicolaou, Irene Kotsia, Guoying Zhao, and Stefanos Zafeiriou. Recognition of affect in the wild us- ing deep neural networks. In Computer V ision and P attern Recog- nition W orkshops (CVPRW), 2017 IEEE Conference on , pages 1972–1979. IEEE, 2017. 7 , 8 22. Dimitrios Kollias, Attila Schulc, Elnar Hajiyev , and Stefanos Zafeiriou. Analysing affectiv e behavior in the first abaw 2020 competition. arXiv pr eprint arXiv:2001.11409 , 2020. 6 23. Dimitrios K ollias, Panagiotis Tzirakis, Mihalis A. Nicolaou, Athanasios Papaioannou, Guoying Zhao, Bjrn Schuller, Irene K ot- sia, and Stefanos Zafeiriou. Deep af fect prediction in-the-wild: Aff-wild database and challenge, deep architectures, and beyond. International Journal of Computer V ision , feb 2019. 2 , 4 , 7 , 8 24. Dimitrios Kollias and Stefanos Zafeiriou. Aff-wild2: Extend- ing the aff-wild database for affect recognition. arXiv pr eprint arXiv:1811.07770 , 2018. 6 25. Dimitrios Kollias and Stefanos Zafeiriou. A multi-task learning & generation frame work: V alence-arousal, action units & primary expressions. arXiv preprint , 2018. 6 26. Dimitrios Kollias and Stefanos Zafeiriou. Expression, affect, ac- tion unit recognition: Aff-wild2, multi-task learning and arcface. arXiv pr eprint arXiv:1910.04855 , 2019. 6 27. Shan Li, W eihong Deng, and JunPing Du. Reliable crowdsourcing and deep locality-preserving learning for expression recognition in the wild. In Proceedings of the IEEE Conference on Computer V ision and P attern Recognition , pages 2852–2861, 2017. 4 , 5 , 7 , 8 , 9 28. S Mohammad Mavadati, Mohammad H Mahoor, Kevin Bartlett, Philip T rinh, and Jeffre y F Cohn. Disfa: A spontaneous facial action intensity database. Affective Computing, IEEE T ransactions on , 4(2):151–160, 2013. 5 29. Marc Mehu and Klaus R Scherer. Emotion categories and di- mensions in the facial communication of affect: An inte grated ap- proach. Emotion , 15(6):798, 2015. 2 30. Ali Mollahosseini, Behzad Hasani, and Mohammad H Mahoor . Affectnet: A database for facial expression, valence, and arousal computing in the wild. arXiv pr eprint arXiv:1708.03985 , 2017. 2 , 3 , 4 , 7 , 8 31. Mahyar Najibi, Pouya Samangouei, Rama Chellappa, and Larry Davis. SSH: Single stage headless face detector . In The IEEE International Confer ence on Computer V ision (ICCV) , 2017. 5 32. Sinno Jialin Pan and Qiang Y ang. A survey on transfer learn- ing. IEEE T ransactions on knowledge and data engineering , 22(10):1345–1359, 2010. 1 33. Omkar M Parkhi, Andrea V edaldi, and Andrew Zisserman. Deep face recognition. In British Machine V ision Conference (BMVC) , 2015. 4 34. Rajeev Ranjan, Swami Sankaranarayanan, Carlos D Castillo, and Rama Chellappa. An all-in-one con volutional neural network for face analysis. In 2017 12th IEEE International Confer ence on Automatic F ace & Gestur e Recognition (FG 2017) , pages 17–24. IEEE, 2017. 1 35. Adria Ruiz, Joost V an de W eijer , and Xavier Binefa. From emo- tions to action units with hidden and semi-hidden-task learning. In Pr oceedings of the IEEE International Conference on Computer V ision , pages 3703–3711, 2015. 2 36. Chuangao T ang, W enming Zheng, Jingwei Y an, Qiang Li, Y ang Li, T ong Zhang, and Zhen Cui. V iew-independent facial action unit detection. In 2017 12th IEEE International Conference on Automatic F ace & Gestur e Recognition (FG 2017) , pages 878– 882. IEEE, 2017. 7 , 8 37. Michel F V alstar, Timur Almaev , Jeffre y M Girard, Gary McK- eown, Marc Mehu, Lijun Yin, Maja Pantic, and Jeffrey F Cohn. Fera 2015-second facial expression recognition and analysis chal- lenge. In Automatic F ace and Gestur e Recognition (FG), 2015 11th IEEE International Confer ence and W orkshops on , volume 6, pages 1–8. IEEE, 2015. 5 38. Michel F V alstar, Enrique S ´ anchez-Lozano, Jeffre y F Cohn, L ´ aszl ´ o A Jeni, Jeffre y M Girard, Zheng Zhang, Lijun Y in, and Maja Pantic. Fera 2017-addressing head pose in the third facial expression recognition and analysis challenge. In 2017 12th IEEE International Conference on Automatic F ace & Gestur e Recogni- tion (FG 2017) , pages 839–847. IEEE, 2017. 5 39. Shenlong W ang, Sanja Fidler, and Raquel Urtasun. Holistic 3d scene understanding from a single geo-tagged image. In Pro- ceedings of the IEEE Confer ence on Computer V ision and P attern Recognition , pages 3964–3972, 2015. 1 40. Shangfei W ang, Quan Gan, and Qiang Ji. Expression-assisted fa- cial action unit recognition under incomplete au annotation. P at- tern Recognition , 61:78–91, 2017. 2 41. Xiaohua W ang, Muzi Peng, Lijuan P an, Min Hu, Chunhua Jin, and Fuji Ren. T wo-lev el attention with two-stage multi-task learning for facial emotion recognition. arXiv pr eprint arXiv:1811.12139 , 2018. 2 42. Zhanxiong W ang, K eke He, Y anwei Fu, Rui Feng, Y u-Gang Jiang, and Xiangyang Xue. Multi-task deep neural network for joint face recognition and facial attribute prediction. In Pr oceedings of the 2017 ACM on International Conference on Multimedia Retrieval , pages 365–374. A CM, 2017. 2 43. Jiajia Y ang, Shan W u, Shangfei W ang, and Qiang Ji. Multi- ple facial action unit recognition enhanced by facial expressions. In 2016 23rd International Confer ence on P attern Recognition (ICPR) , pages 4089–4094. IEEE, 2016. 2 44. Shuo Y ang, Ping Luo, Chen Change Lo y , and Xiaoou T ang. Wider face: A face detection benchmark. In IEEE Conference on Com- puter V ision and P attern Recognition (CVPR) , 2016. 5 45. Anıl Y ¨ uce, Hua Gao, and Jean-Philippe Thiran. Discriminant multi-label manifold embedding for facial action unit detection. In 2015 11th IEEE International Conference and W orkshops on Automatic F ace and Gestur e Recognition (FG) , volume 6, pages 1–6. IEEE, 2015. 7 , 8 46. Stefanos Zafeiriou, Dimitrios K ollias, Mihalis A Nicolaou, Athanasios Papaioannou, Guoying Zhao, and Irene Kotsia. Aff- wild: V alence and arousal in-the-wildchallenge. In Computer V i- sion and P attern Recognition W orkshops (CVPRW), 2017 IEEE Confer ence on , pages 1980–1987. IEEE, 2017. 2 , 4 47. Amir R Zamir, Ale xander Sax, W illiam Shen, Leonidas J Guibas, Jitendra Malik, and Silvio Sav arese. T askonomy: Disentangling task transfer learning. In Proceedings of the IEEE Conference on Computer V ision and P attern Recognition , pages 3712–3722, 2018. 1 48. Xing Zhang, Lijun Y in, Jeffrey F Cohn, Shaun Canavan, Michael Reale, Andy Horowitz, Peng Liu, and Jeffre y M Girard. Bp4d- spontaneous: a high-resolution spontaneous 3d dynamic facial ex- pression database. Image and V ision Computing , 32(10):692–706, 2014. 5 49. Y u Zhang and Qiang Y ang. A survey on multi-task learning. arXiv pr eprint arXiv:1707.08114 , 2017. 1 50. Zheng Zhang, Jeff M Girard, Y ue Wu, Xing Zhang, Peng Liu, Umur Ciftci, Shaun Canav an, Michael Reale, Andy Horowitz, Face Beha vior ` a la carte: Expressions, Affect and Action Units in a Single Netw ork 11 Huiyuan Y ang, et al. Multimodal spontaneous emotion corpus for human behavior analysis. In Pr oceedings of the IEEE Confer ence on Computer V ision and P attern Recognition , pages 3438–3446, 2016. 5
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment