목표조건 모방학습
본 논문은 목표조건 강화학습에서 보상 설계의 어려움을 극복하기 위해 소수의 전문가 시연을 활용한 goalGAIL이라는 새로운 알고리즘을 제안한다. HER와 행동 복제(BC)를 결합한 전문가 재라벨링 기법과 목표조건 GAIL을 도입해, 행동 정보가 없는 시연까지도 학습에 이용한다. 실험 결과, 제안 방법은 기존 IL 기법을 능가하고, 전문가보다 높은 성공률을 달성한다.
저자: Yiming Ding, Carlos Florensa, Mariano Phielipp
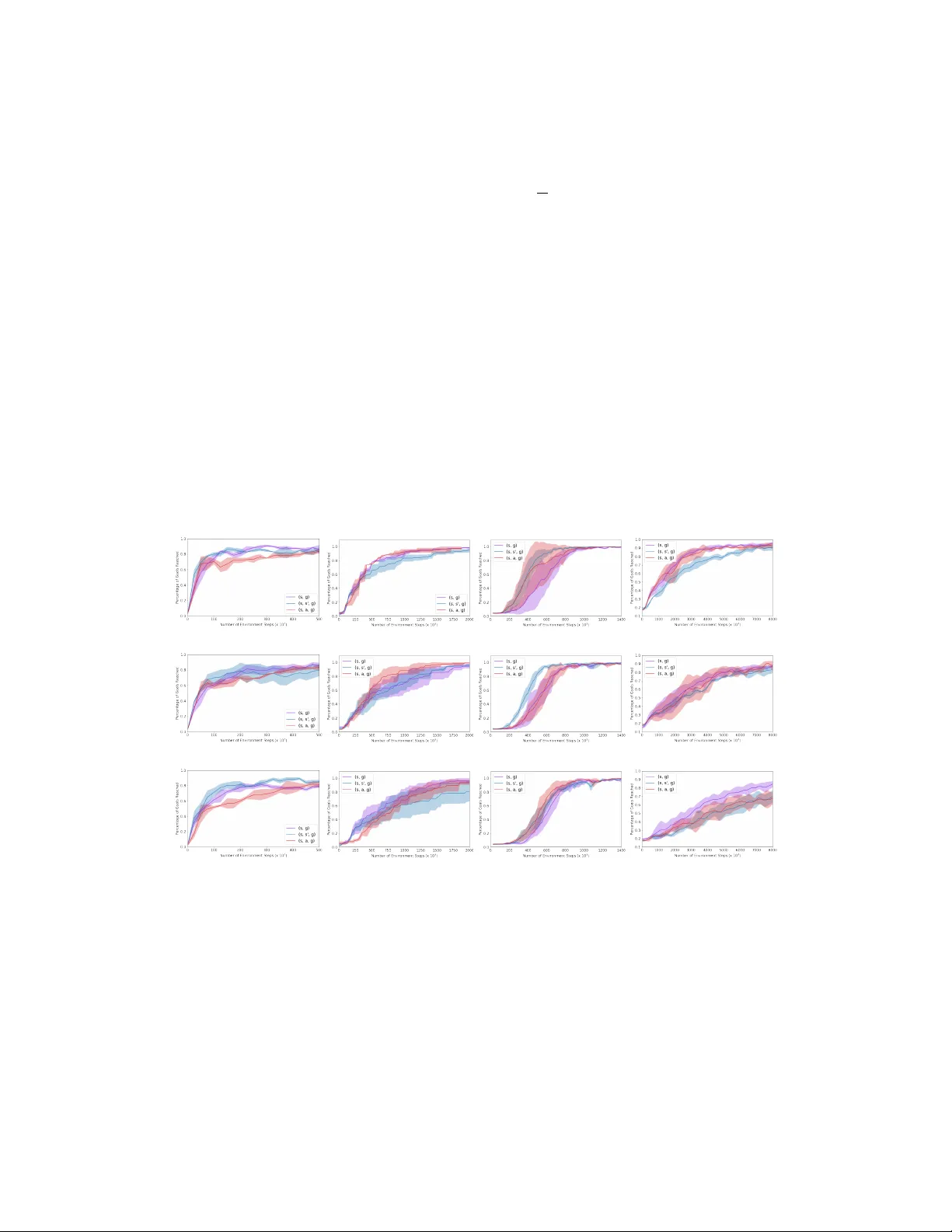
본 연구는 로봇 제어와 같은 연속적인 상태공간에서 목표조건 정책을 학습할 때, 보상 함수를 직접 설계하는 것이 어렵고 비용이 많이 든다는 문제를 출발점으로 삼는다. 기존의 Hindsight Experience Replay(HER)는 목표를 뒤에서 재라벨링함으로써 인디케이터 보상을 인위적으로 늘릴 수 있지만, 탐색이 병목을 통과하기 어려워 학습 속도가 느리다. 이러한 한계를 극복하기 위해 저자는 소수의 전문가 시연을 활용한 새로운 알고리즘 goalGAIL을 제안한다.
먼저, 목표조건 행동 복제(Goal‑conditioned Behavioral Cloning, BC) 손실을 정의한다. 시연 데이터 D에서 (s_t, a_t, g) 삼중항을 추출해, deterministic 정책 π_θ(s,g)와 전문가 행동 a_t 사이의 L2 손실을 최소화한다. 이 손실은 오프‑폴리시 RL 업데이트와 동시에 적용될 수 있어, DDPG와 같은 알고리즘과 자연스럽게 결합한다. 그러나 BC만으로는 정책이 전문가 수준을 넘어서는 것이 어렵다. 이를 보완하기 위해 전문가 재라벨링 기법을 도입한다. 시연에서 연속된 상태 s_t, s_{t+k}를 관찰하면, s_{t+k}를 새로운 목표 g'로 설정하고 해당 전이를 (s_t, a_t, s_{t+k}, g') 형태로 재사용한다. 이는 시연이 실제로 여러 목표를 달성한 것과 동일한 효과를 제공해, 데이터 증강을 통해 학습 효율을 크게 높인다.
다음으로, 목표조건 GAIL(goalGAIL)을 설계한다. 기존 GAIL는 (s,a) 쌍을 구분하는 판별자를 사용했지만, 목표조건 환경에서는 (s,a,g) 혹은 (s,s',g) 형태로 목표를 명시적으로 포함시켜야 한다. 판별자 D_ψ는 로그 확률을 보상으로 반환하고, 이 보상은 DDPG의 보상 신호에 가중합된다. 보상은 r_t = (1−δ)·𝟙
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기