Goal-conditioned Imitation Learning
Designing rewards for Reinforcement Learning (RL) is challenging because it needs to convey the desired task, be efficient to optimize, and be easy to compute. The latter is particularly problematic when applying RL to robotics, where detecting wheth…
Authors: Yiming Ding, Carlos Florensa, Mariano Phielipp
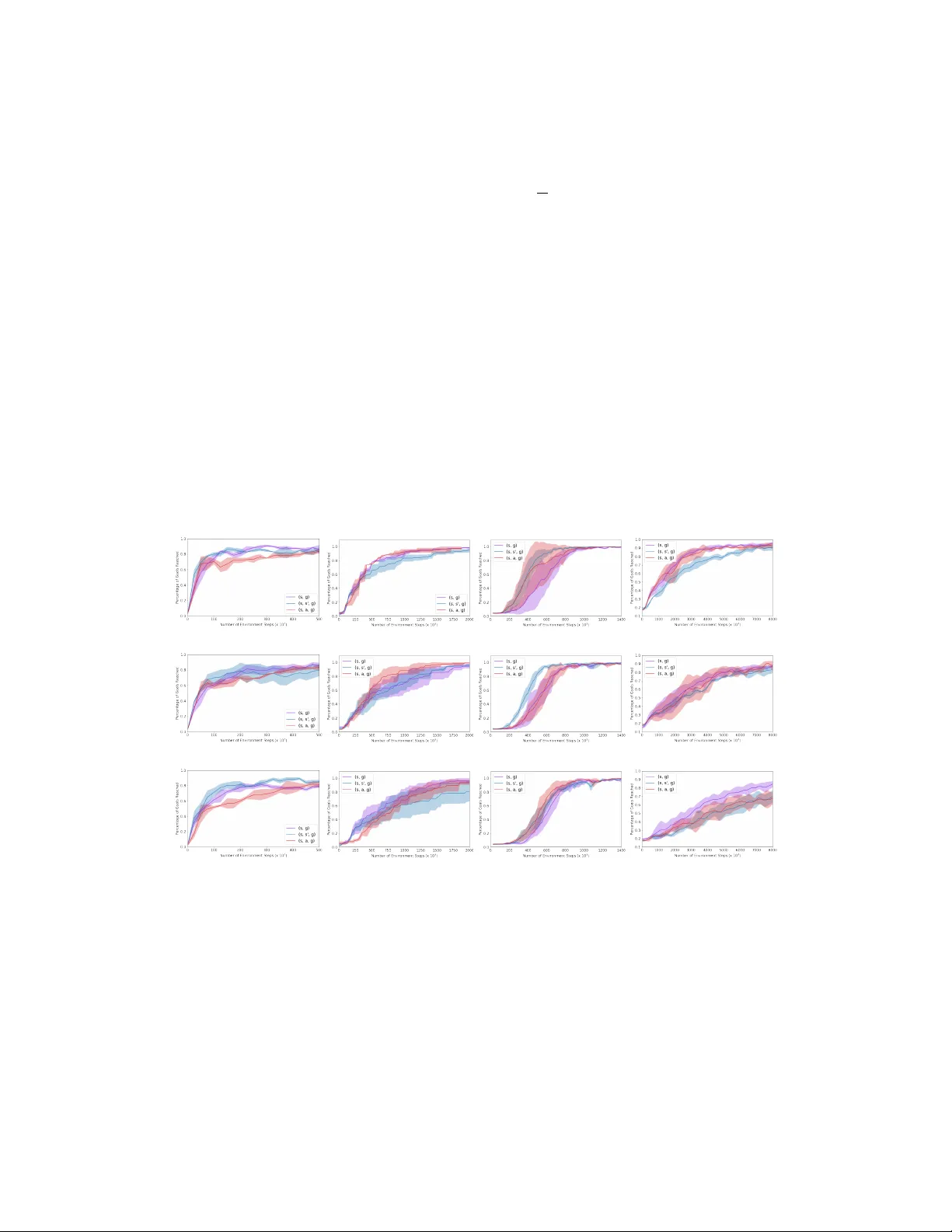
Goal-conditioned Imitation Lear ning Y iming Ding ∗ Department of Computer Science Univ ersity of California, Berkele y dingyiming0427@berkeley.edu Carlos Florensa ∗ Department of Computer Science Univ ersity of California, Berkele y florensa@berkeley.edu Mariano Phielipp Intel AI Labs mariano.j.phielipp@intel.com Pieter Abbeel Department of Computer Science Univ ersity of California, Berkele y pabbeel@berkeley.edu Abstract Designing rew ards for Reinforcement Learning (RL) is challenging because it needs to con v ey the desired task, be ef ficient to optimize, and be easy to compute. The latter is particularly problematic when applying RL to robotics, where detecting whether the desired configuration is reached might require considerable supervision and instrumentation. Furthermore, we are often interested in being able to reach a wide range of configurations, hence setting up a different re ward every time might be unpractical. Methods like Hindsight Experience Replay (HER) hav e recently sho wn promise to learn policies able to reach many goals, without the need of a rew ard. Unfortunately , without tricks lik e resetting to points along the trajectory , HER might require many samples to discover ho w to reach certain areas of the state-space. In this work we propose a novel algorithm goalGAIL , which incorporates demonstrations to drastically speed up the con vergence to a policy able to reach any goal, surpassing the performance of an agent trained with other Imitation Learning algorithms. Furthermore, we show our method can also be used when the av ailable expert trajectories do not contain the actions or when the e xpert is suboptimal, which makes it applicable when only kinesthetic, third-person or noisy demonstrations are av ailable. Our code is open-source 2 . 1 Introduction Reinforcement Learning (RL) has shown impressi ve results in a plethora of simulated tasks, ranging from attaining super-human performance in video-games [ 1 , 2 ] and board-games [ 3 ], to learning complex locomotion beha viors [ 4 , 5 ]. Nev ertheless, these successes are shyly echoed in real world robotics [ 6 , 7 ]. This is due to the difficulty of setting up the same learning environment that is enjoyed in simulation. One of the critical assumptions that are hard to obtain in the real w orld are the access to a rew ard function. Self-supervised methods hav e the po wer to ov ercome this limitation. A very versatile and reusable form of self-supervision for robotics is to learn how to reach an y pre vi- ously observed state upon demand. This problem can be formulated as training a goal-conditioned policy [ 8 , 9 ] that seeks to obtain the indicator rew ard of having the observ ation e xactly match the goal. Such a rew ard does not require any additional instrumentation of the environment be yond the sensors the robot already has. But in practice, this re ward is nev er observed because in continuous spaces like the ones in robotics, it is e xtremely rare to observe twice the exact same sensory input. Luckily , if we ∗ Equal contribution 2 https://sites.google.com/view/goalconditioned-il/ 33rd Conference on Neural Information Processing Systems (NeurIPS 2019), V ancouver , Canada. are using an off-polic y RL algorithm [ 10 , 11 ], we can “relabel" a collected trajectory by replacing its goal by a state actually visited during that trajectory , therefore observing the indicator re w ard as often as we wish. This method was introduced as Hindsight Experience Replay [ 12 ] or HER, although it used special resets, and the re ward was in fact an -ball around the goal, which is only easy to interpret and use in lo wer -dimensional state-spaces. More recently the method was sho wn to work directly from vision with a special reward [ 13 ], and e ven only with the indicator re ward of e xactly matching observation and goal [14]. In theory these approaches could learn how to reach any goal, but the breadth-first nature of the algorithm makes that some areas of the space take a long time to be learned [ 15 ]. This is specially challenging when there are bottlenecks between dif ferent areas of the state-space, and random motion might not traverse them easily [ 16 ]. Some practical e xamples of this are pick-and-place, or na vigating narrow corridors between rooms, as illustrated in Fig. 2 depicting the diverse set of en vironments we work with. In both cases a specific state needs to be reached (grasp the object, or enter the corridor) before a whole new area of the space is discovered (placing the object, or visiting the next room). This problem could be addressed by engineering a re ward that guides the agent towards the bottlenecks, but this defeats the purpose of trying to learn without direct re ward supervision. In this work we study ho w to le verage a fe w demonstrations that traverse those bottlenecks to boost the learning of goal-reaching policies. Learning from Demonstrations, or Imitation Learning (IL), is a well-studied field in robotics [ 17 , 18 , 19 ]. In many cases it is easier to obtain a few demonstrations from an expert than to provide a good re ward that describes the task. Most of the previous work on IL is centered around trajectory following, or doing a single task. Furthermore it is limited by the performance of the demonstrations, or relies on engineered rew ards to improve upon them. In this work we first illustrate ho w IL methods can be extended to the goal-conditioned setting, and study a more powerful relabeling strate gy that extracts additional information from the demonstrations. W e then propose a novel algorithm, goalGAIL , and sho w it can outperform the demonstrator without the need of any additional re ward. W e also inv estigate ho w our method is more robust to sub-optimal e xperts. Finally , the method we dev elop is able to le verage demonstrations that do not include the e xpert actions. This considerably broadens its application in practical robotics, where demonstrations might be gi ven by a motion planner , by kinesthetic demonstrations [ 20 ] (moving the agent e xternally , instead of using its own controls), or ev en by another agent [ 21 ]. T o our knowledge, this is the first framew ork that can boost goal-conditioned policy learning with only state demonstrations. 2 Related W ork Imitation Learning is an alternativ e to reward crafting to train a desired behaviors. There are many w ays to le v erage demonstrations, from Beha vioral Cloning [ 22 ] that directly maximizes the likelihood of the e xpert actions under the training agent policy , to In verse Reinforcement Learning that extracts a rew ard function from those demonstrations and then trains a policy to maximize it [ 23 , 24 , 25 ]. Another formulation close to the latter is Generative Adversarial Imitation Learning (GAIL), introduced by Ho and Ermon [26] . GAIL is one of the building blocks of our own algorithm, and is explained in more details in the Preliminaries section. Unfortunately most work in the field cannot outperform the expert, unless another rew ard is av ailable during training [ 27 , 28 , 29 ], which might defeat the purpose of using demonstrations in the first place. Furthermore, most tasks tackled with these methods consist of tracking expert state trajectories [30, 31], but cannot adapt to unseen situations. In this work we are interested in goal-conditioned tasks, where the objectiv e is to reach any state upon demand [ 8 , 9 ]. This kind of multi-task learning is perv asive in robotics [ 32 , 33 ], but challenging and data-hungry if no reward-shaping is a v ailable. Relabeling methods lik e Hindsight Experience Replay [ 12 ] unlock the learning e ven in the spa rse re ward case [ 14 ]. Nev ertheless, the inherent breath-first nature of the algorithm might still produce inef ficient learning of complex policies. T o ov ercome the exploration issue we in vestigate the ef fect of leveraging a fe w demonstrations. The closest prior work is by Nair et al. [34] , where a Behavioral Cloning loss is used with a Q-filter . W e found that a simple annealing of the Behavioral Cloning loss [ 35 ] works well and allows the agent to outperform demonstrator . Furthermore, we introduce a ne w relabeling technique of the e xpert trajectories that is 2 particularly useful when only fe w demonstrations are av ailable. Finally we propose a no vel algorithm goalGAIL , lev eraging the recently sho wn compatibility of GAIL with of f-polic y algorithms. 3 Preliminaries W e define a discrete-time finite-horizon discounted Markov decision process (MDP) by a tuple M = ( S , A , P , r, ρ 0 , γ , H ) , where S is a state set, A is an action set, P : S × A × S → R + is a transition probability distribution, γ ∈ [0 , 1] is a discount factor, and H is the horizon. Our objectiv e is to find a stochastic polic y π θ that maximizes the expected discounted re ward within the MDP , η ( π θ ) = E τ [ P T t =0 γ t r ( s t , a t , s t +1 )] . W e denote by τ = ( s 0 , a 0 , ..., ) an entire state-action trajectory , where s 0 ∼ ρ 0 ( s 0 ) , a t ∼ π θ ( ·| s t ) , and s t +1 ∼ P ( ·| s t , a t ) . In the goal-conditioned setting that we use here, the polic y and the reward are also conditioned on a “goal" g ∈ S . The reward is r ( s t , a t , s t +1 , g ) = 1 s t +1 == g , and hence the return is the γ h , where h is the number of time- steps to the goal. Given that the transition probability is not af fected by the goal, g can be “relabeled" in hindsight, so a transition ( s t , a t , s t +1 , g , r = 0) can be treated as ( s t , a t , s t +1 , g 0 = s t +1 , r = 1) . Finally , we also assume access to D trajectories ( s j 0 , a j 0 , s j 1 , ... ) D j =0 ∼ τ expert that were collected by an expert attempting to reach the goals { g j } D j =0 sampled uniformly among the feasible goals. Those trajectories must be approximately geodesics, meaning that the actions are taken such that the goal is reached as fast as possible. In GAIL [ 26 ], a discriminator D ψ is trained to distinguish expert transitions ( s, a ) ∼ τ expert , from agent transitions ( s, a ) ∼ τ agent , while the agent is trained to "fool" the discriminator into thinking itself is the expert. F ormally , the discriminator is trained to minimize L GAI L = E ( s,a ) ∼ τ agent [log D ψ ( s, a )] + E ( s,a ) ∼ τ expert [log(1 − D ψ ( s, a ))]; while the agent is trained to maximize E ( s,a ) ∼ τ agent [log D ψ ( s, a )] by using the output of the discriminator log D ψ ( s, a ) as rew ard. Origi- nally , the algorithms used to optimize the policy are on-polic y methods lik e T rust Region Policy Optimization [ 36 ], but recently there has been a wake of w orks le veraging the ef ficienc y of off-polic y algorithms without loss in stability [ 37 , 38 , 39 , 40 ]. This is a ke y capability that we exploit in our goalGAIL algorithm. 4 Demonstrations in Goal-conditioned tasks In this section we describe methods to incorporate demonstrations into Hindsight Experience Replay [ 12 ] for training goal-conditioned policies. First we revisit adding a Behavioral Cloning loss to the polic y update as in [ 34 ], then we propose a nov el e xpert relabeling technique, and finally we formulate for the first time a goal-conditioned GAIL algorithm termed goalGAIL , and propose a method to train it with state-only demonstrations. 4.1 Goal-conditioned Behavioral Cloning The most direct way to le verage demonstrations ( s j 0 , a j 0 , s j 1 , ... ) D j =0 is to construct a data-set D of all state-action-goal tuples ( s j t , a j t , g j ) , and run supervised re gression. In the goal-conditioned case and assuming a deterministic policy π θ ( s, g ) , the loss is: L BC ( θ , D ) = E ( s j t ,a j t ,g j ) ∼D h k π θ ( s j t , g j ) − a j t k 2 2 i (1) This loss and its gradient are computed without any additional en vironments samples from the trained policy π θ . This makes it particularly conv enient to combine a gradient descend step based on this loss together with other policy updates. In particular we can use a standard of f-policy Reinforcement Learning algorithm like DDPG [ 10 ], where we fit the Q φ ( a, s, g ) , and then estimate the gradient of the expected return as: ∇ θ ˆ J = 1 N N X i =1 ∇ a Q φ ( a, s, g ) ∇ θ π θ ( s, g ) (2) In our goal-conditioned case, the Q fitting can also benefit from “relabeling“ like done in HER [ 12 ]. The improv ement guarantees with respect to the task re ward are lost when we combine the BC and 3 the deterministic policy gradient updates, but this can be side-stepped by either applying a Q-filter 1 Q ( s t , a t , g ) > Q ( s t , π ( s t , g ) , g ) to the BC loss as proposed in [ 34 ], or by annealing it as we do in our experiments, which allo ws the agent to e v entually outperform the expert. 4.2 Relabeling the expert (a) Performance on reaching states visited in the 20 giv en demon- strations. The states are green if reached by the policy when attempting so, and red otherwise. (b) Performance on reaching any possible state. Each cell is col- ored green if the policy can reach the center of it when attempting so, and red otherwise. Figure 1: Policy performance on reaching dif- ferent goals in the four rooms, when training with standard Behavioral Cloning (top row) or with our expert relabeling (bottom). The expert trajectories hav e been collected by ask- ing the expert to reach a specific goal g j . But they are also v alid trajectories to reach any other state visited within the demonstration! This is the key motiv ating insight to propose a ne w type of relabel- ing: if we have the transitions ( s j t , a j t , s j t +1 , g j ) in a demonstration, we can also consider the transition ( s j t , a j t , s j t +1 , g 0 = s j t + k ) as also coming from the ex- pert! Indeed that demonstration also went through the state s j t + k , so if that was the goal, the expert would also have generated this transition. This can be understood as a type of data augmentation lev er- aging the assumption that the gi ven demonstrations are geodesics (the y are the faster way to go from any state in it to an y future state in it). It will be particularly effecti ve in the low data regime, where not many demonstrations are av ailable. The effect of expert relabeling can be visualized in the four rooms en vironment as it’ s a 2D task where states and goals can be plotted. In Fig. 1 we compare the final performance of two agents, one trained with pure Behavioral Cloning, and the other one also using e xpert relabeling. 4.3 Goal-conditioned GAIL with Hindsight The compounding error in Behavioral Cloning might make the policy deviate arbitrarily from the demonstrations, and it requires too man y demonstrations when the state dimension increases. The first problem is less se vere in our goal-conditioned case because in fact we do want to visit and be able to purposefully reach all states, ev en the ones that the e xpert did not visit. But the second drawback will become pressing when attempting to scale this method to practical robotics tasks where the observations might be high-dimensional sensory input lik e images. Both problems can be mitigated by using other Imitation Learning algorithms that can lev erage additional rollouts collected by the learning agent in a self-supervised manner, lik e GAIL [ 26 ]. In this section we extend the formulation of GAIL to tackle goal-conditioned tasks, and then we detail how it can be combined with HER [ 12 ], which allows the agent to outperform the demonstrator and generalize to reaching all goals. W e call the final algorithm goalGAIL . W e describe the key points of goalGAIL below . First of all, the discriminator needs to also be conditioned on the goal which results in D ψ ( a, s, g ) , and be trained by minimizing L GAI L ( D ψ , D , R ) = E ( s,a,g ) ∼R [log D ψ ( a, s, g )] + E ( s,a,g ) ∼D [log(1 − D ψ ( a, s, g ))] . (3) Once the discriminator is fitted, we can run our fav orite RL algorithm on the re ward log D ψ ( a h t , s h t , g h ) . In our case we used the off-polic y algorithm DDPG [ 10 ] to allow for the relabeling techniques outlined abov e. In the goal-conditioned case we intepolate between the GAIL rew ard described abov e and an indicator re ward r h t = 1 s h t +1 == g h . This combination is slightly tricky because no w the fitted Q φ does not hav e the same clear interpretation it has when only one of the two re wards is used [ 14 ] . Nevertheless, both rewards are pushing the polic y to wards the goals, so it shouldn’t be too conflicting. Furthermore, to avoid an y drop in final performance, the weight of the rew ard coming from GAIL δ GAI L can be annealed. The final proposed algorithm goalGAL , together with the expert relabeling technique is formalized in Algorithm 1. 4 Algorithm 1 Goal-conditioned GAIL with Hindsight: goalGAIL 1: Input: Demonstrations D = ( s j 0 , a j 0 , s j 1 , ..., g j ) D j =0 , replay buf fer R = {} , policy π θ ( s, g ) , discount γ , hindsight probability p 2: while not done do 3: # Sample r ollout 4: g ∼ Uniform ( S ) 5: R ← R ∪ ( s 0 , a 0 , s 1 , ... ) sampled using π ( · , g ) 6: # Sample fr om expert buf fer and r eplay buffer 7: ( s j t , a j t , s j t +1 , g j ) ∼ D , ( s i t , a i t , s i t +1 , g i ) ∼ R 8: # Relabel agent tr ansitions 9: for each i , with probability p do 10: g i ← s i t + k , k ∼ Unif { t + 1 , . . . , T i } Use futur e HER strategy 11: end for 12: # Relabel expert tr ansitions 13: g j ← s j t + k 0 , k 0 ∼ Unif { t + 1 , . . . , T j } 14: r h t = 1 s h t +1 == g h 15: ψ ← min ψ L GAI L ( D ψ , D , R ) (Eq. 3) 16: r h t = (1 − δ GAI L ) r h t + δ GAI L log D ψ ( a h t , s h t , g h ) Add annealed GAIL reward 17: # F it Q φ 18: y h t = r h t + γ Q φ ( π ( s h t +1 , g h ) , s h t +1 , g h ) Use target networks Q φ 0 for stability 19: φ ← min φ P h k Q φ ( a h t , s h t , g h ) − y h t k 20: # Update P olicy 21: θ + = α ∇ θ ˆ J (Eq. 2) 22: Anneal δ GAI L Ensures outperforming the expert 23: end while 4.4 Use of state-only Demonstrations Both Behavioral Cloning and GAIL use state-action pairs from the expert. This limits the use of the methods, combined or not with HER, to setups where the exact same agent was actuated to reach different goals. Nevertheless, much more data could be cheaply av ailable if the action was not required. For example, non-expert humans might not be able to operate a robot from torque instructions, but might be able to move the robot along the desired trajectory . This is called a kinesthetic demonstration. Another type of state-only demonstration could be the one used in third- person imitation [ 21 ], where the expert performed the task with an embodiment dif ferent from the agent that needs to learn the task. This has mostly been applied to the trajectory-follo wing case. In our case ev ery demonstration might ha ve a dif ferent goal. Furthermore, we would lik e to propose a method that not only le verages state-only demonstrations, but can also outperform the quality and co verage of the demonstrations gi ven, or at least generalize to similar goals. The main insight we ha v e here is that we can replace the action in the GAIL formulation by the next state s 0 , and in most en vironments this should be as informativ e as ha ving access to the action directly . Intuitiv ely , given a desired goal g , it should be possible to determine if a transition s → s 0 is taking the agent in the right direction. The loss function to train a discriminator able to tell apart the current agent and expert demonstrations (alw ays transitioning to wards the goal) is simply: L GAI L s ( D s ψ , D , R ) = E ( s,s 0 ,g ) ∼R [log D s ψ ( s, s 0 , g )] + E ( s,s 0 ,g ) ∼D [log(1 − D s ψ ( s, s 0 , g ))] . 5 Experiments W e are interested in answering the following questions: • W ithout supervision from reward, can goalGAIL use demonstrations to accelerate the learning of goal-conditioned tasks and outperform the demonstrator? • Is the Expert Relabeling an efficient way of doing data-augmentation on the demonstrations? • Compared to Behavioral Cloning methods, is goalGAIL more robust to e xpert action noise? • Can goalGAIL lev erage state-only demonstrations equally well as full trajectories? 5 (a) Continuous Four rooms (b) Pointmass block pusher (c) Fetch Pick & Place (d) Fetch Stack T wo Figure 2: Four continuous goal-conditioned en vironments where we tested the ef fectiv eness of the proposed algorithm goalGAIL and expert relabeling technique. W e e v aluate these questions in four different simulated robotic goal-conditioned tasks that are detailed in the next subsection along with the performance metric used throughout the experiments section. All the results use 20 demonstrations reaching uniformly sampled goals. All curves ha ve 5 random seeds and the shaded area is one standard deviation. 5.1 T asks Experiments are conducted in four continuous environments in MuJoCo [ 41 ]. The performance metric we use in all our experiments is the percentage of goals in the feasible goal space the agent is able to reach. W e call this metric coverage. T o estimate this percentage we sample feasible goals uniformly , and execute a rollout of the current policy . It is consider a success if the agent reaches within of the desired goal. Four r ooms en vir onment : This is a continuous twist on a well studied problem in the Reinforcement Learning literature. A point mass is placed in an en vironment with four rooms connected through small openings as depicted in Fig. 2a. The action space of the agent is continuous and specifies the desired change in state space, and the goals-space exactly corresponds to the state-space. Pointmass Block Pusher : In this task, a Pointmass needs to navigates itself to the block, push the block to a desired position ( x, y ) and then ev entually stops a potentially different spot ( a, b ) . The action space is two dimensional as in four rooms en vironment. The goal space is four dimensional and specifies ( x, y , a, b ) . Fetch Pick and Place : This task is the same as the one described by Nair et al. [34] , where a fetch robot needs to pick a block and place it in a desired point in space. The control is four -dimensional, corresponding to a change in ( x, y , z ) position of the end-ef fector as well as a change in gripper opening. The goal space is three dimensional and is restricted to the position of the block. Fetch Stack T wo : A Fetch robot stacks two blocks on a desired position, as also done in Nair et al. [34] . The control is the same as in Fetch Pick and Place while the goal space is no w the position of two blocks, which is six dimensional. 5.2 Goal-conditioned GAIL with Hindsight: goalGAIL In goal-conditioned tasks, HER [ 12 ] should ev entually con verge to a policy able to reach any desired goal. Nevertheless, this might tak e a long time, specially in en vironments where there are bottlenecks that need to be traversed before accessing a whole ne w area of the goal space. In this section we show ho w the methods introduced in the previous section can lev erage a fe w demonstrations to improv e the con vergence speed of HER. This was already studied for the case of Behavioral Cloning by [ 34 ], and in this work we sho w we also get a benefit when using GAIL as the Imitation Learning algorithm, which brings considerable advantages o v er Behavioral Cloning as sho wn in the next sections. In all four en vironments, we observe that our proposed method goalGAIL considerably outperforms the two baselines it b uilds upon: HER and GAIL. HER alone has a very slo w conv er gence, although as expected it ends up reaching the same final performance if run long enough. On the other hand GAIL by itself learns fast at the beginning, but its final performance is capped. This is because despite collecting more samples on the en vironment, those come with no rew ard of any kind indicating what 6 (a) Continuous Four rooms (b) Pointmass block pusher (c) Fetch Pick & Place (d) Fetch Stack T wo Figure 3: In all four en vironments, the proposed algorithm goalGAIL takes of f and conv er ges faster than HER by le veraging demonstrations. It is also able to outperform the demonstrator unlike standard GAIL, the performance of which is capped. (a) Continuous Four rooms (b) Pointmass block pusher (c) Fetch Pick & Place (d) Fetch Stack T wo Figure 4: Our Expert Relabeling technique boosts final performance of standard BC. It also accelerates con v ergence of BC+HER and goalGAIL on all four en vironments. is the task to perform (reach the giv en goals). Therefore, once it has extracted all the information it can from the demonstrations it cannot keep learning and generalize to goals further from the demonstrations. This is not an issue anymore when combined with HER, as our results sho w . 5.3 Expert relabeling Here we show that the Expert Relabeling technique introduced in Section 4.2 is an ef fecti ve means of data augmentation on demonstrations. W e show the ef fect of Expert Relabeling on three methods: standard beha vioral cloning ( BC ), HER with a beha vioral cloning loss ( BC+HER ) and goalGAIL . For BC+HER , the gradient of the behavior cloning loss L BC (Equation 1) is combined with the gradient of the policy objecti v e ∇ θ ˆ J (Equation 2). The resulting gradient for the policy update is: ∇ θ ˆ J BC+HER = ∇ θ ˆ J − β ∇ θ L BC where β is the weight of the BC loss and is annealed to enable the agent to outperform the expert. As shown in Fig. 4, our e xpert relabeling technique brings considerable performance boosts for both Behavioral Cloning methods and goalGAIL in all four en vironments. W e also perform a further analysis of the benefit of the expert relabeling in the four -rooms en vironment because it is easy to visualize in 2D the goals the agent can reach. W e see in Fig. 1 that without the expert relabeling, the agent fails to learn how to reach many intermediate states visited in demonstrations. The performance of running pure Behavioral Cloning is plotted as a horizontal dotted line given that it does not require any additional en vironment steps. W e observe that combining BC with HER always produces faster learning than running just HER, and it reaches higher final performance than running pure BC with only 20 demonstrations. 5.4 Robustness to sub-optimal expert In the above sections we were assuming access to perfectly optimal experts. Nevertheless, in practical applications the experts might have a more erratic behavior , not always taking the best action to go towards the giv en goal. In this section we study how the different methods perform when a sub-optimal expert is used. T o do so we collect sub-optimal demonstration trajectories by adding noise α to the optimal actions, and making it be -greedy . Thus, the sub-optimal expert is a = 1 [ r < ] u + 1 [ r > ]( π ∗ ( a | s, g ) + α ) , where r ∼ Unif (0 , 1) , α ∼ N (0 , σ 2 α I ) and u is a uniformly sampled random action in the action space. 7 (a) Continuous Four rooms (b) Pointmass block pusher (c) Fetch Pick & Place (d) Fetch Stack T wo Figure 5: Effect of sub-optimal demonstrations on goalGAIL and Beha v orial Cloning method. W e produce sub-optimal demonstrations by making the expert -greedy and adding Gaussian noise to the optimal actions. In Fig. 5 we observe that approaches that directly try to copy the action of the expert, like Behavioral Cloning, greatly suf fer under a sub-optimal expert, to the point that it barely pro vides any improvement ov er performing plain Hindsight Experience Replay . On the other hand, methods based on training a discriminator between expert and current agent behavior are able to leverage much noisier experts. A possible explanation of this phenomenon is that a discriminator approach can gi ve a positi ve signal as long as the transition is "in the right direction", without trying to exactly enforce a single action. Under this lens, having some noise in the expert might actually improv e the performance of these adversarial approaches, as it has been observ ed in many generati ve models literature [42]. 5.5 Using state-only demonstrations Figure 6: Output of the Dis- criminator D ( · , g ) for the four rooms en vironment. The goal is the lo wer left white dot, and the start is at the top right. Behavioral Cloning and standard GAIL rely on the state-action ( s, a ) tuples coming from the expert. Nevertheless there are many cases in robotics where we have access to demonstrations of a task, but without the actions. In this section we want to emphasize that all the results obtained with our goalGAIL method and reported in Fig. 3 and Fig. 4 do not require any access to the action that the e xpert took. Surprisingly , in all environments b ut Fetch Pick & Place, despite the more restricted information goalGAIL has access to, it outperforms BC combined with HER. This might be due to the superior imitation learning performance of GAIL, and also to the fact that these tasks are solvable by only matching the state-distribution of the e xpert. W e run the e xperiment of training GAIL only conditioned on the current state, and not the action (as also done in other non-goal-conditioned works [ 25 ]), and we observe that the discriminator learns a v ery well shaped rew ard that clearly encourages the agent to go towards the goal, as pictured in Fig. 6. See the Appendix for more details. 6 Conclusions and Future W ork Hindsight relabeling can be used to learn useful beha viors without any reward supervision for goal-conditioned tasks, but the y are inef ficient when the state-space is large or includes e xploration bottlenecks. In this work we sho w ho w only a fe w demonstrations can be le veraged to improv e the con v ergence speed of these methods. W e introduce a nov el algorithm, goalGAIL , that conv er ges faster than HER and to a better final performance than a naive goal-conditioned GAIL. W e also study the ef fect of doing expert relabeling as a type of data augmentation on the pro vided demonstrations, and demonstrate it impro ves the performance of our goalGAIL as well as goal-conditioned Behavioral Cloning. W e emphasize that our goalGAIL method only needs state demonstrations, without using expert actions lik e other Beha vioral Cloning methods. Finally , we sho w that goalGAIL is rob ust to sub-optimalities in the expert beha vior . All the abov e factors make our goalGAIL algorithm very suited for real-world robotics. This is a very e xciting future work. In the same line, we also want to test the performance of these methods in vision-based tasks. Our preliminary experiments sho w that Beha vioral Cloning fails completely in the low data re gime in which we operate (less than 20 demonstrations). 8 References [1] V olodymyr Mnih, Koray Kavukcuoglu, David Silver , Andrei a Rusu, Joel V eness, Marc G Bellemare, Alex Grav es, Martin Riedmiller , Andreas K Fidjeland, Georg Ostrovski, Stig Pe- tersen, Charles Beattie, Amir Sadik, Ioannis Antonoglou, Helen King, Dharshan Kumaran, Daan W ierstra, Shane Le gg, and Demis Hassabis. Human-le v el control through deep reinforcement learning. Natur e , 518(7540):529–533, 2015. [2] Oriol V inyals, Igor Babuschkin, Junyoung Chung, Michael Mathieu, Max Jaderberg, W oj- ciech M Czarnecki, Andre w Dudzik, Aja Huang, Petk o Geor giev , Richard Powell, Timo Ewalds, Dan Horgan, Manuel Kroiss, Iv o Danihelka, John Agapiou, Junhyuk Oh, V alentin Dalibard, David Choi, Laurent Sifre, Y ury Sulsky , Sasha V ezhnev ets, James Molloy , Tre vor Cai, Da vid Budden, T om Paine, Caglar Gulcehre, Ziyu W ang, T obias Pfaff, T oby Pohlen, Y uhuai W u, Dani Y ogatama, Julia Cohen, Katrina McKinney , Oli ver Smith, T om Schaul, Timothy Lillicrap, Chris Apps, K oray Kavukcuoglu, Demis Hassabis, and David Silv er . AlphaStar: Mastering the Real-T ime Strategy Game StarCraft II. T echnical report, 2019. [3] David Silv er , Julian Schrittwieser , Karen Simon yan, Ioannis Antonoglou, Aja Huang, Arthur Guez, Thomas Hubert, Lucas Baker , Matthew Lai, Adrian Bolton, Y utian Chen, Timothy Lillicrap, Fan Hui, Laurent Sifre, George V an Den Driessche, Thore Graepel, and Demis Hassabis. Mastering the game of Go without human kno wledge. Nature , 550(7676):354–359, 10 2017. ISSN 14764687. doi: 10.1038/nature24270. URL 00633 . [4] Nicolas Heess, Dhruv a TB, Srini v asan Sriram, Jay Lemmon, Josh Merel, Greg W ayne, Y uval T assa, T om Erez, Ziyu W ang, S. M. Ali Eslami, Martin Riedmiller , and David Silver . Emergence of Locomotion Behaviours in Rich Environments. 7 2017. URL 1707.02286 . [5] Carlos Florensa, Y an Duan, and Pieter Abbeel. Stochastic Neural Networks for Hierarchical Reinforcement Learning. International Confer ence in Learning Repr esentations , pages 1–17, 2017. ISSN 14779129. doi: 10.1002/rcm.765. URL . [6] Martin Riedmiller , Roland Hafner , Thomas Lampe, Michael Neunert, Jonas Degra ve, T om V an De W iele, V olodymyr Mnih, Nicolas Heess, and T obias Springenberg. Learning by Playing – Solving Sparse Reward T asks from Scratch. Internation Conference in Machine Learning , 2018. [7] Henry Zhu, Abhishek Gupta, Aravind Rajeswaran, Serge y Le vine, and V ikash K umar . Dexterous Manipulation with Deep Reinforcement Learning: Efficient, General, and Lo w-Cost. 10 2018. URL . [8] Leslie P . Kaelbling. Learning to Achie ve Goals. International Joint Confer ence on Artificial Intelligence (IJCAI) , pages 1094–1098, 1993. [9] T om Schaul, Dan Horgan, Karol Gregor , and David Silver . Univ ersal V alue Function Ap- proximators. Internation Confer ence in Machine Learning , 2015. URL http://jmlr.org/ proceedings/papers/v37/schaul15.pdf . [10] T imothy P . Lillicrap, Jonathan J. Hunt, Alexander Pritzel, Nicolas Heess, T om Erez, Y uv al T assa, David Silv er , and Daan Wierstra. Continuous control with deep reinforcement learning. arXiv pr eprint arXiv:1509.02971 , pages 1–14, 2015. URL . [11] T uomas Haarnoja, Aurick Zhou, Pieter Abbeel, Serge y Le vine, and Computer Sciences. Soft Actor-Critic: Off-Policy Maximum Entropy Deep Reinforcement Learning with a Stochastic Actor. Internation Confer ence in Machine Learning , pages 1–15, 2018. [12] Marcin Andrycho wicz, Filip W olski, Alex Ray , Jonas Schneider , Rachel F ong, Peter W elinder, Bob McGrew , Josh T obin, Pieter Abbeel, and W ojciech Zaremba. Hindsight Experience Replay. Advances in Neural Information Pr ocessing Systems , 2017. ISSN 10495258. doi: 10.1016/j.surfcoat.2018.06.018. URL . [13] Ashvin Nair , V itchyr Pong, Murtaza Dalal, Shikhar Bahl, Ste v en Lin, and Ser gey Levine. V isual Reinforcement Learning with Imagined Goals. Adavances in Neural Information Pr ocessing Systems , 2018. [14] Carlos Florensa, Jonas Degra ve, Nicolas Heess, Jost T obias Springenberg, and Martin Riedmiller . Self-supervised Learning of Image Embedding for Continuous Control. In W orkshop on Infer ence to Contr ol at NeurIPS , 2018. URL . 9 [15] Carlos Florensa, David Held, Xinyang Geng, and Pieter Abbeel. Automatic Goal Generation for Reinforcement Learning Agents. International Confer ence in Machine Learning , 2018. URL http://arxiv.org/abs/1705.06366 . [16] Carlos Florensa, David Held, Markus W ulfmeier , Michael Zhang, and Pieter Abbeel. Rev erse Curriculum Generation for Reinforcement Learning. Conference on Robot Learning , pages 1–16, 2017. ISSN 1938-7228. doi: 10.1080/00908319208908727. URL abs/1707.05300 . [17] Mrinal Kalakrishnan, Jonas Buchli, Peter Pastor , and Stefan Schaal. Learning locomotion over rough terrain using terrain templates. In International Confer ence on Intelligent Robots and Systems , pages 167–172. IEEE, 2009. ISBN 978-1-4244-3803-7. doi: 10.1109/IR OS.2009. 5354701. URL http://ieeexplore.ieee.org/document/5354701/ . [18] Stéphane Ross, Geoffre y J Gordon, and J Andrew Bagnell. A Reduction of Imitation Learning and Structured Prediction to No-Regret Online Learning. International Conference on Artificial Intelligence and Statistics , 2011. [19] Mariusz Bojarski, Davide Del T esta, Daniel Dworako wski, Bernhard Firner , Beat Flepp, Prasoon Goyal, Lawrence D. Jackel, Mathew Monfort, Urs Muller , Jiakai Zhang, Xin Zhang, Jake Zhao, and Karol Zieba. End to End Learning for Self-Dri ving Cars. 2016. URL http: //arxiv.org/abs/1604.07316 . [20] Simon Manschitz, Jens K ober , Michael Gienger , and Jan Peters. Learning movement primiti ve attractor goals and sequential skills from kinesthetic demonstrations. Robotics and Autonomous Systems , 74:97–107, dec 2015. doi: 10.1016/J.R OBO T .2015.07.005. [21] Bradly C. Stadie, Pieter Abbeel, and Ilya Sutskev er . Third-Person Imitation Learning. Interna- tional Confer ence in Learning Repr esentations , 3 2017. URL 01703 . [22] Dean A Pomerleau. AL VINN: an autonomous land vehicle in a neural network. Advances in Neu- ral Information Pr ocessing Systems , pages 305–313, 1989. URL https://papers.nips.cc/ paper/95- alvinn- an- autonomous- land- vehicle- in- a- neural- network.pdfhttp: //dl.acm.org/citation.cfm?id=89851.89891 . [23] Brian D Ziebart, Andre w Maas, J Andre w Bagnell, and Anind K Dey . Maximum Entropy In v erse Reinforcement Learning. pages 1433–1438, 2008. [24] Chelsea Finn, Sergey Le vine, and Pieter Abbeel. Guided Cost Learning: Deep Inv erse Optimal Control via Policy Optimization. Internation Confer ence in Machine Learning , 3 2016. URL http://arxiv.org/abs/1603.00448 . [25] Justin Fu, Katie Luo, and Ser gey Le vine. Learning Robust Re wards with Adversarial In verse Reinforcement Learning. International Confer ence in Learning Representations , 10 2018. URL http://arxiv.org/abs/1710.11248 . [26] Jonathan Ho and Stefano Ermon. Generati ve Adversarial Imitation Learning. Advances in Neural Information Pr ocessing Systems , 2016. URL . [27] Mel V ecerik, T odd Hester , Jonathan Scholz, Fumin W ang, Olivier Pietquin, Bilal Piot, Nicolas Heess, Thomas Rothörl, Thomas Lampe, and Martin Riedmiller . Le veraging Demonstrations for Deep Reinforcement Learning on Robotics Problems with Sparse Re wards. pages 1–11, 2017. [28] Y ang Gao, Huazhe Harry , Xu Ji, Lin Fisher , Y u Sergey , and Levine Tre vor . Reinforcement Learning from Imperfect Demonstrations. Internation Confer ence in Mac hine Learning , 2018. [29] W en Sun, J. Andrew Bagnell, and Byron Boots. T runcated Horizon Policy Search: Combining Reinforcement Learning & Imitation Learning. pages 1–14, 2018. ISSN 0004-6361. doi: 10.1051/0004- 6361/201527329. URL . [30] Y uke Zhu, Ziyu W ang, Josh Merel, Andrei Rusu, T om Erez, Serkan Cabi, Saran T unyasuvu- nakool, János Kramár , Raia Hadsell, Nando de Freitas, and Nicolas Heess. Reinforcement and Imitation Learning for Div erse V isuomotor Skills. Robotics: Science and Systems , 2018. URL http://arxiv.org/abs/1802.09564 . [31] Xue Bin Peng, Pieter Abbeel, Serge y Le vine, and Michiel v an de Panne. DeepMimic: Example- Guided Deep Reinforcement Learning of Physics-Based Character Skills. T ransactions on 10 Graphics (Pr oc. ACM SIGGRAPH) , 37(4), 2018. doi: 10.1145/3197517.3201311. URL http: //arxiv.org/abs/1804.02717%0Ahttp://dx.doi.org/10.1145/3197517.3201311 . [32] Marcin Andrychowicz, Bo wen Baker , Maciek Chociej, Rafal Jozefo wicz, Bob McGre w , Jakub Pachocki, Arthur Petron, Matthias Plappert, Glenn Po well, and Ale x Ray . Learning Dexterous In-Hand Manipulation. pages 1–27. [33] Xingyu Lin, Pengsheng Guo, Carlos Florensa, and David Held. Adapti ve V ariance for Changing Sparse-Rew ard En vironments. International Conference on Robotics and A utomation , 2019. URL . [34] Ashvin Nair, Bob McGrew , Marcin Andrychowicz, W ojciech Zaremba, and Pieter Abbeel. Overcoming Exploration in Reinforcement Learning with Demonstrations. International Confer ence on Robotics and A utomation , 2018. ISSN 0969-2290. doi: 10.1080/09692290.2013. 809781. URL . [35] Aravind Rajesw aran, V ikash Kumar , Abhishek Gupta, John Schulman, and L G Sep. Learning Complex Dexterous Manipulation with Deep Reinforcement Learning and Demonstrations. Robotics: Science and Systems , 2018. [36] John Schulman, Philipp Moritz, Michael Jordan, and Pieter Abbeel. Trust Region Policy Optimization. International Confer ence in Machine Learning , 2015. [37] Lionel Blondé and Ale xandros Kalousis. Sample-Efficient Imitation Learning via Generati ve Adversarial Nets. AIST A TS , 2019. URL https://youtu.be/- nCsqUJnRKU. [38] Fumihiro Sasaki, T etsuya Y ohira, and Atsuo Kawaguchi. Sample Efficient Imitation Learning for Continuous Control. International Confer ence in Learning Repr esentationsa , pages 1–15, 2019. [39] Y annick Schroecker , Mel V ecerik, and Jonathan Scholz. Generative predecessor models for sample-efficient imitation learning. In International Confer ence on Learning Repr esentations , 2019. URL https://openreview.net/forum?id=SkeVsiAcYm . [40] Ilya Kostriko v , Kumar Krishna Agrawal2, Debidatta Dwibedi, Serge y Levine, and Jonathan T ompson. DISCRIMIN A TOR-A CTOR-CRITIC: ADDRESSING SAMPLE INEFFICIENCY AND REW ARD BIAS IN AD VERSARIAL IMIT A TION LEARNING. International Confer- ence in Learning Repr esentations , 2019. [41] Emanuel T odorov , T om Erez, and Y uval T assa. MuJoCo : A physics engine for model-based control. pages 5026–5033, 2012. [42] Ian J Goodfellow , Jean Pouget-abadie, Mehdi Mirza, Bing Xu, and David W arde-farley . Gener - ativ e Adv ersarial Nets. pages 1–9. 11 A Hyperparameters and Architectures In the four en vironments used in our experiments, i.e. Four Rooms environment, Fetch Pick & Place, Pointmass block pusher and Fetch Stack T wo, the task horizons are set to 300, 100, 100 and 150 respectively . The discount factors are γ = 1 − 1 H . In all experiments, the Q function, policy and discriminator are paramaterized by fully connected neural networks with two hidden layers of size 256. DDPG is used for policy optimization and hindsight probability is set to p = 0 . 8 . The initial value of the beha vior cloning loss weight β is set to 0 . 1 and is annealed by 0.9 per 250 rollouts collected. The initial value of the discriminator reward weight δ GAI L is set to 0 . 1 . W e found empirically that there is no need to anneal δ GAI L . For e xperiments with sub-optimal e xpert in section 5.4, is set to 0 . 4 , 0 . 5 0 . 4 , 0 . 1 , and σ α is set to 1 . 5 , 0 . 3 , 0 . 2 and 0 respectively for the four en vironments. B Effect of Different Input of Discriminator W e trained the discriminator in three settings: • current state and goal: ( s, g ) • current state, next state and goal: ( s, s 0 , g ) • current state, action and goal: ( s, a, g ) W e compare the three different setups in Fig. 7. Four rooms 20 demos Fetch Pick & Place 20 demos Pointmass block pusher 20 demos Fetch Stack T wo 100 demos Four rooms 12 demos Fetch Pick & Place 12 demos Pointmass block pusher 12 demos Fetch Stack T wo 50 demos Four rooms 6 demos Fetch Pick & Place 6 demos Pointmass block pusher 6 demos Fetch Stack T wo 30 demos Figure 7: Study of different discriminator inputs for goalGAIL in four en vironments 12
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment