가십 기반 액터 러너 아키텍처로 강화학습 효율 향상
본 논문은 다수의 시뮬레이터를 활용하는 강화학습에서, 에이전트들을 피어‑투‑피어 토폴로지로 연결하고 비동기 가십을 통해 파라미터를 교환하는 GALA 방식을 제안한다. 이론적으로 각 에이전트의 파라미터가 ε‑볼 안에 머무름을 보장하고, 실험적으로 A2C 대비 샘플 효율성·계산 효율성을 크게 개선함을 확인하였다.
저자: Mahmoud Assran, Joshua Romoff, Nicolas Ballas
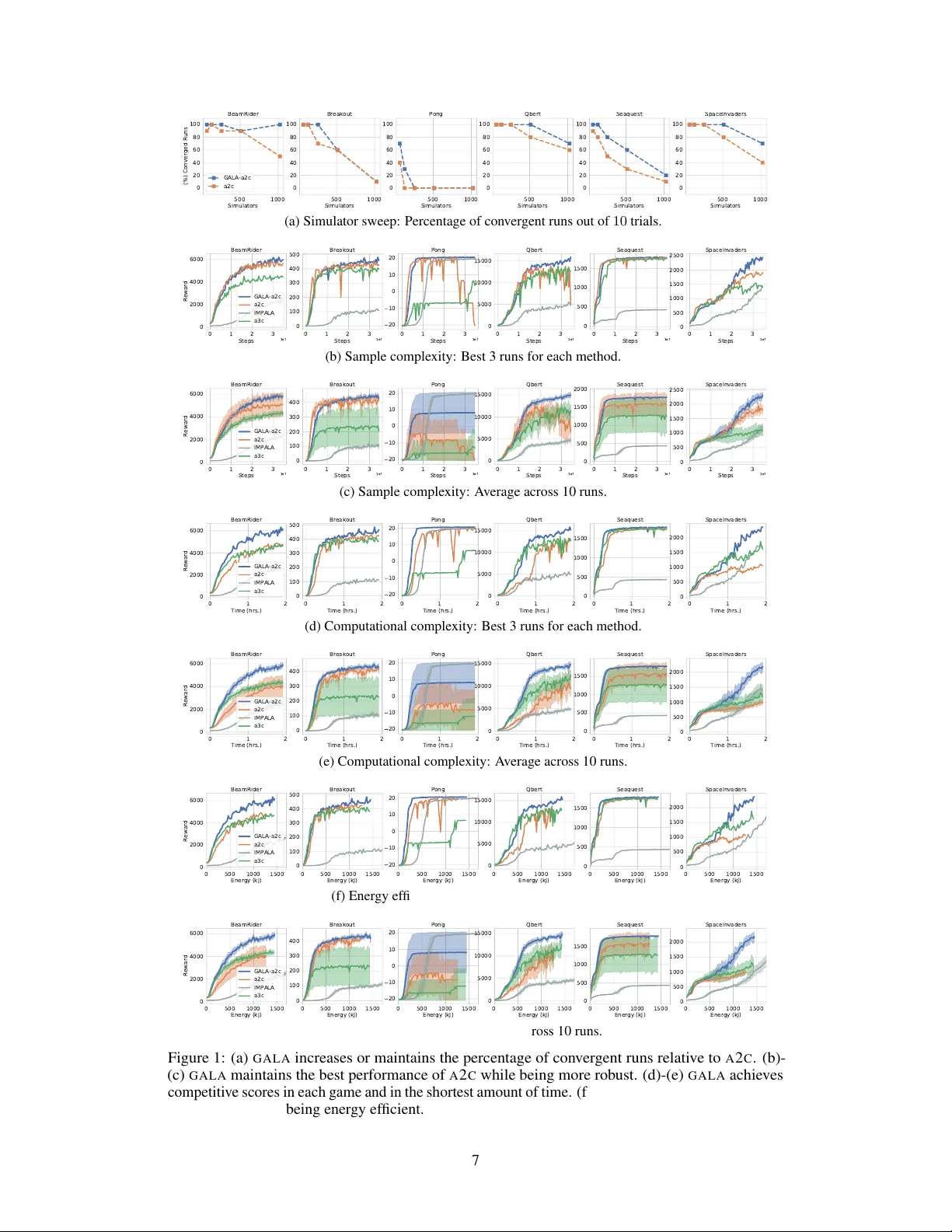
본 논문은 딥 강화학습(Deep Reinforcement Learning, DRL)에서 다수의 시뮬레이터를 활용한 학습 효율성을 높이기 위해 새로운 분산 학습 프레임워크인 Gossip‑based Actor‑Learner Architectures(GALA)를 제안한다. 기존의 A2C(Advantage Actor‑Critic)와 A3C(Asynchronous Advantage Actor‑Critic)는 각각 동기식과 비동기식으로 파라미터를 공유하거나 업데이트하지만, 시뮬레이터 수가 증가함에 따라 스트래글러(straggler) 문제와 그라디언트 스터일스(staleness) 문제가 심화된다. GALA는 이러한 문제를 해결하기 위해 각 학습자‑액터 쌍을 독립적인 에이전트로 두고, 피어‑투‑피어(peer‑to‑peer) 토폴로지를 구성한 뒤 비동기 가십(gossip) 알고리즘을 통해 파라미터를 교환한다.
### 이론적 배경 및 수학적 모델
가십은 분산 평균화 문제를 해결하기 위한 알고리즘으로, 각 에이전트 i가 파라미터 벡터 x_i를 보유하고 혼합 행렬 P(k) 를 통해 업데이트한다. P(k) 가 행 확률(row‑stochastic)이면, 시간이 충분히 흐르면 모든 에이전트의 파라미터는 평균값으로 수렴한다. GALA는 이 원리를 강화학습에 적용한다. 각 에이전트 v_i는 정책 파라미터 ω_i와 가치 파라미터 θ_i를 포함하는 x_i=(ω_i,θ_i)를 갖는다. 로컬 학습 단계에서는 기존 A2C와 동일하게 N‑step TD와 정책 그라디언트를 수행한다. 이후 비동기 가십 단계에서 에이전트는 자신의 파라미터를 out‑peer에게 비블로킹 방식으로 전송하고, in‑peer 로부터 모든 메시지를 수신하면 단순 평균을 취한다.
논문은 두 가지 핵심 정리를 제시한다.
1. **Proposition 1**은 전체 파라미터 행렬 X(k)의 변화량이 학습률 α와 그래프의 공동 스펙트럴 반경 β에 의해 상한이 잡힌다는 것을 보인다. 즉, 파라미터가 급격히 발산하지 않으며, β가 1에 가까울수록 수렴 속도가 느려진다.
2. **Proposition 2**는 그래프가 B‑strongly connected하고 메시지 지연 τ가 유한할 때, 모든 에이전트의 파라미터가 평균 파라미터와 ε‑볼 안에 머무른다는 강력한 보장을 제공한다. 여기서 ε = α·β̃·L/(1‑β)이며, L은 로컬 업데이트 크기의 상한이다. 이 식은 학습률, 토폴로지 연결성, 그리고 그라디언트 클리핑 등 실제 구현에서 조절 가능한 요인들을 명시한다.
### 알고리즘 구현
Algorithm 1에 요약된 GALA‑A2C는 다음 순서로 동작한다.
1. 각 에이전트는 현재 정책 π_{ω_i} 로 N개의 행동을 수행하고 전이 데이터를 수집한다.
2. N‑step 반환 G_t와 어드밴티지 A_t를 계산한다.
3. 기존 A2C와 동일하게 정책 그라디언트와 TD 손실을 이용해 파라미터를 업데이트한다.
4. 비동기적으로 파라미터 x_i를 out‑peer에게 전송한다.
5. in‑peer 로부터 모든 메시지를 받으면, (1+|N_in|) 로 나눈 평균을 취해 새로운 파라미터로 교체한다.
비동기성은 τ 파라미터를 통해 제한 가능하며, 실제 실험에서는 τ=0(즉시 업데이트) 설정이 가장 좋은 성능을 보였다.
### 실험 설정 및 결과
실험은 Atari‑2600의 6가지 게임(예: Pong, Breakout, Seaquest 등)을 대상으로 수행되었다. 비교 대상은 A2C, A3C(대규모 배치 변형), IMPALA이며, 모두 동일한 하이퍼파라미터(학습률, 배치 크기, 엔트로피 보너스 등)를 사용하였다. 주요 결과는 다음과 같다.
- **샘플 효율성**: GALA‑A2C는 A2C와 거의 동일하거나 약간 우수한 학습 곡선을 보였으며, 특히 시뮬레이터 수가 64개 이상일 때 학습 안정성이 크게 향상되었다. 이는 가십이 도입하는 작은 잡음이 정책 파라미터를 과도하게 동기화하지 않게 하여, 지역 최소점에 빠지는 위험을 감소시킨 것으로 해석된다.
- **계산 효율성 및 확장성**: 동일 GPU 하나에 여러 GALA 에이전트를 동시에 배치했을 때 프레임당 처리량이 기존 A2C 대비 2~3배 증가했으며, 전력 소비는 비슷한 수준을 유지했다. 이는 동기화 비용이 크게 감소하고, GPU 연산 파이프라인을 보다 효율적으로 활용한 결과이다.
- **성능 비교**: 최종 점수 기준으로 IMPALA와 A3C와 경쟁 가능한 수준을 기록했으며, 일부 게임에서는 GALA‑A2C가 두 방법을 앞섰다.
### 관련 연구와 차별점
기존 분산 강화학습은 주로 중앙 파라미터 서버를 이용하거나 완전 동기화 방식을 채택했다. 이러한 접근은 스트래글러와 네트워크 대역폭에 민감하다. 반면 GALA는 피어‑투‑피어 가십을 사용해 네트워크 부하를 분산시키고, 이론적으로 수렴을 보장한다. 또한 가십 기반 분산 최적화가 이미지 분류와 같은 감독 학습에 적용된 사례는 많지만, 비선형 함수 근사와 비동기 강화학습이라는 복합 환경에 적용한 최초 사례 중 하나이다.
### 결론 및 향후 연구
GALA는 “분산·비동기·가십”이라는 세 축을 결합해 강화학습 시스템의 확장성을 크게 개선한다. 특히 대규모 시뮬레이터 클러스터를 보유한 연구기관이나 기업에서 기존 A2C/A3C 파이프라인에 가십 모듈만 추가하면 하드웨어 활용도와 학습 속도를 눈에 띄게 높일 수 있다. 향후 연구에서는 토폴로지 최적화(예: 작은 지름·높은 연결성 그래프 설계), 가십 주기 동적 조절, 그리고 오프‑폴리시 알고리즘과의 결합을 통해 ε‑볼 크기를 더욱 축소하고, 더욱 다양한 환경에 적용 가능성을 탐색할 예정이다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기