Gossip-based Actor-Learner Architectures for Deep Reinforcement Learning
Multi-simulator training has contributed to the recent success of Deep Reinforcement Learning by stabilizing learning and allowing for higher training throughputs. We propose Gossip-based Actor-Learner Architectures (GALA) where several actor-learner…
Authors: Mahmoud Assran, Joshua Romoff, Nicolas Ballas
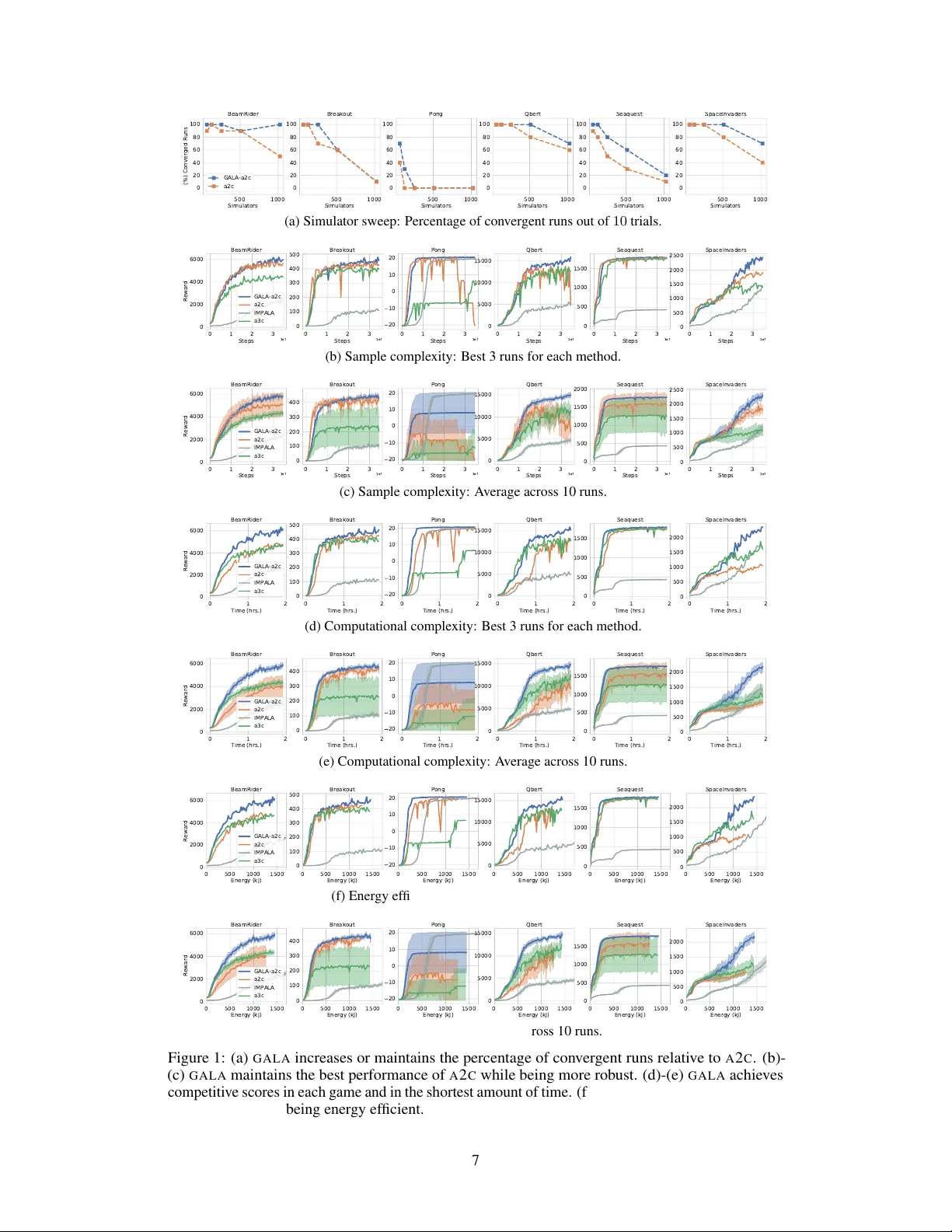
Gossip-based Actor -Lear ner Ar chitectur es f or Deep Reinf orcement Lear ning Mahmoud Assran Facebook AI Research & Department of Electrical and Computer Engineering McGill Univ ersity mahmoud.assran@mail.mcgill.ca Joshua Romoff Facebook AI Research & Department of Computer Science McGill Univ ersity joshua.romoff@mail.mcgill.ca Nicolas Ballas Facebook AI Research ballasn@fb.com Joelle Pineau Facebook AI Research jpineau@fb.com Michael Rabbat Facebook AI Research mikerabbat@fb.com Abstract Multi-simulator training has contrib uted to the recent success of Deep Reinforce- ment Learning by stabilizing learning and allowing for higher training throughputs. W e propose Gossip-based Actor-Learner Architectures ( G A L A ) where se veral actor - learners (such as A 2 C agents) are organized in a peer -to-peer communication topology , and exchange information through asynchronous gossip in order to take advantage of a lar ge number of distributed simulators. W e prove that G A L A agents remain within an -ball of one-another during training when using loosely cou- pled asynchronous communication. By reducing the amount of synchronization between agents, G A L A is more computationally ef ficient and scalable compared to A 2 C , its fully-synchronous counterpart. G A L A also outperforms A 3 C , being more robust and sample efficient. W e sho w that we can run se veral loosely coupled G A L A agents in parallel on a single GPU and achie v e significantly higher hardware utilization and frame-rates than vanilla A 2 C at comparable po wer dra ws. 1 Introduction Deep Reinforcement Learning (Deep RL) agents hav e reached superhuman performance in a few domains [Silver et al., 2016, 2018, Mnih et al., 2015, V inyals et al., 2019], but this is typically at significant computational expense [Tian et al., 2019]. T o both reduce running time and stabilize training, current approaches rely on distributed computation wherein data is sampled from many parallel simulators distributed ov er parallel devices [Espeholt et al., 2018, Mnih et al., 2016]. Despite the gro wing ubiquity of multi-simulator training, scaling Deep RL algorithms to a lar ge number of simulators remains a challenging task. On-policy approaches train a policy by using samples generated from that same policy , in which case data sampling (acting) is entangled with the training procedure (learning). T o perform distributed training, these approaches usually introduce multiple learners with a shar ed policy , and multiple actors (each with its o wn simulator) associated to each learner . The shared policy can either be updated in a synchronous fashion (e.g., learners synchronize gradients before each optimization step [Stooke and Abbeel, 2018]), or in an asynchronous fashion [Mnih et al., 2016]. Both approaches hav e drawbacks: synchronous approaches suffer from straggler ef fects (bottlenecked by the slo west individual simulator), and therefore may not exhibit strong scaling ef ficienc y; asynchronous methods are rob ust to stragglers, but prone to gradient staleness, and may become unstable with a large number of actors [Clemente et al., 2017]. 33rd Conference on Neural Information Processing Systems (NeurIPS 2019), V ancouver , Canada. Alternativ ely , off-policy approaches typically train a policy by sampling from a replay buf fer of past transitions [Mnih et al., 2015]. T raining off-polic y allows for disentangling data-generation from learning, which can greatly increase computational efficiency when training with man y parallel actors [Espeholt et al., 2018, Horgan et al., 2018, Kapturowski et al., 2019, Gruslys et al., 2018]. Generally , off-polic y updates need to be handled with care as the sampled transitions may not conform to the current policy and consequently result in unstable training [Fujimoto et al., 2018]. W e propose Gossip-based Actor-Learner Architectures ( G A L A ), which aim to retain the robustness of synchronous on-policy approaches, while improving both their computational efficiency and scalability . G A L A leverages multiple agents, where each agent is composed of one learner and possibly multiple actors/simulators. Unlike classical on-policy approaches, G A L A does not require that each agent share the same policy , but rather it inherently enforces (through gossip) that each agent’ s policy r emain -close to all others thr oughout training . Relaxing this constraint allows us to reduce the synchronization needed between learners, thereby improving the algorithm’ s computational efficienc y . Instead of computing an exact average between all the learners after a local optimization step, gossip- based approaches compute an approximate av erage using loosely coupled and possibly asynchronous communication (see Nedi ´ c et al. [2018] and references therein). While this approximation implicitly injects some noise in the aggre gate parameters, we prove that this is in fact a principled approach as the learners’ policies stay within an -ball of one-another (ev en with non-linear function approximation), the size of which is directly proportional to the spectral-radius of the agent communication topology and their learning rates. As a practical algorithm, we propose G A L A - A 2 C , an algorithm that combines gossip with A 2 C agents. W e compare our approach on six Atari games [Machado et al., 2018] following Stook e and Abbeel [2018] with vanilla A 2 C , A 3 C and the I M PA L A off-polic y method [Dhariwal et al., 2017, Mnih et al., 2016, Espeholt et al., 2018]. Our main empirical findings are: 1. Follo wing the theory , G A L A - A 2 C is empirically stable. Moreover , we observe that G A L A can be more stable than A 2 C when using a large number of simulators, suggesting that the noise introduced by gossiping can hav e a beneficial ef fect. 2. G A L A - A 2 C has similar sample efficienc y to A 2 C and greatly improves its computational efficienc y and scalability . 3. G A L A - A 2 C achieves significantly higher hardware utilization and frame-rates than v anilla A 2 C at comparable power dra ws, when using a GPU. 4. G A L A - A 2 C is competiti ve in term of performance relati ve to A 3 C and I M PA L A . Perhaps most remarkably , our empirical findings for G A L A - A 2 C are obtained by simply using the default hyper-parameters from A 2 C . Our implementation of G A L A - A 2 C is publicly av ailable at https://github .com/facebookresearch/gala. 2 T echnical Backgr ound Reinfor cement Learning. W e consider the standard Reinforcement Learning setting [Sutton and Barto, 1998], where the agent’ s objective is to maximize the expected v alue from each state V ( s ) = E P ∞ i =0 γ i r t + i | s t = s , γ is the discount factor which controls the bias towards nearby re wards. T o maximize this quantity , the agent chooses at each discrete time step t an action a t in the current state s t based on its policy π ( a t | s t ) and transitions to the next state s t +1 receiving re ward r t based on the en vironment dynamics. T emporal dif ference (TD) learning [Sutton, 1984] aims at learning an approximation of the expected return parameterized by θ , i.e., the value function V ( s ; θ ) , by iterativ ely updating its parameters via gradient descent: ∇ θ G N t − V ( s t ; θ ) 2 (1) where G N t = P N − 1 i =0 γ i r t + i + γ N V ( s t + n ; θ t ) is the N -step return. Actor -critic methods [Sutton et al., 2000, Mnih et al., 2016] simultaneously learn both a parameterized policy π ( a t | s t ; ω ) with parameters ω and a critic V ( s t ; θ ) . They do so by training a v alue function via the TD error defined 2 in (1) and then proceed to optimize the policy using the policy gradient (PG) with the value function as a baseline: ∇ ω ( − log π ( a t | s t ; ω ) A t ) , (2) where A t = G N t − V ( s t ; θ t ) is the adv antage function, which represents the relati ve value the current action has ov er the a v erage. In order to both speed up training time and decorrelate observations, Mnih et al. [2016] collect samples and perform updates with sev eral asynchronous actor-learners. Specifi- cally , each worker i ∈ { 1 , 2 , .., W } , where W is the number of parallel workers, collects samples according to its current version of the policy weights ω i , and computes updates via the standard actor-critic gradient defined in (2) , with an additional entropy penalty term that prev ents premature con vergence to deterministic policies: ∇ ω i − log π ( a t | s t ; ω i ) A t − η X a π ( a | s t ; ω i ) log π ( a | s t ; ω i ) ! . (3) The workers then perform H O G W I L D ! [Recht et al., 2011] style updates (asynchronous writes) to a shared set of master weights before synchronizing their weights with the master’ s. More recently , Dhariwal et al. [2017] remov ed the asynchron y from A 3 C , referred to as A 2 C , by instead synchronously collecting transitions in parallel environments i ∈ { 1 , 2 , .., W } and then performing a large batched update: ∇ ω " 1 W W X i =1 − log π ( a i t | s i t ; ω ) A i t − η X a π ( a | s i t ; ω ) log π ( a | s i t ; ω ) !# . (4) Gossip algorithms. Gossip algorithms are used to solve the distributed averaging problem. Suppose there are n agents connected in a peer-to-peer graph topology , each with parameter vector x (0) i ∈ R d . Let X (0) ∈ R n × d denote the row-wise concatenation of these v ectors. The objectiv e is to iterati vely compute the a verage v ector 1 n P n i =1 x (0) i across all agents. T ypical gossip iterations hav e the form X ( k +1) = P ( k ) X ( k ) , where P ( k ) ∈ R n × n is referred to as the mixing matrix and defines the communication topology . This corresponds to the update x ( k +1) i = P n j =1 p ( k ) i,j x ( k ) j for an agent v i . At an iteration k , an agent v i only needs to recei ve messages from other agents v j for which p ( k ) i,j 6 = 0 , so sparser matrices P ( k ) correspond to less communication and less synchronization between agents. The mixing matrices P ( k ) are designed to be ro w stochastic (each entry is greater than or equal to zero, and each row sums to 1) so that lim K →∞ Q K k =0 P ( k ) = 1 π > , where π is the ergodic limit of the Markov chain defined by P ( k ) and 1 is a vector with all entries equal to 1 [Seneta, 1981]. 1 Consequently , the gossip iterations conv erge to a limit X ( ∞ ) = 1 ( π > X (0) ) ; meaning the value at an agent i con verges to x ( ∞ ) i = P n j =1 π j x (0) j . In particular, if the matrices P ( k ) are symmetric and doubly-stochastic (each row and each column must sum to 1), we obtain an algorithm such that π j = 1 /n for all j , and therefore x ( ∞ ) i = 1 /n P n j =1 x (0) j con verges to the av erage of the agents’ initial vectors. For the particular case of G A L A , we only require the matrices P ( k ) to be ro w stochastic in order to show the -ball guarantees. 3 Gossip-based Actor -Learner Architectur es W e consider the distributed RL setting where n agents (each composed of a single learner and se veral actors) collaborate to maximize the expected return V ( s ) . Each agent v i has a parameterized policy network π ( a t | s t ; ω i ) and v alue function V ( s t ; θ i ) . Let x i = ( ω i , θ i ) denote agent v i ’ s complete set of trainable parameters. W e consider the specific case where each v i corresponds to a single A 2 C agent, and the agents are configured in a directed and peer-to-peer communication topology defined by the mixing matrix P ∈ R n × n . In order to maximize the e xpected reward, each G A L A - A 2 C agent alternates between one local policy- gradient and TD update, and one iteration of asynchronous gossip with its peers. Pseudocode is 1 Assuming that information from ev ery agent e ventually reaches all other agents 3 Algorithm 1 Gossip-based Actor-Learner Architectures for agent v i using A 2 C Require: Initialize trainable policy and critic parameters x i = ( ω i , θ i ) . 1: for t = 0, 1, 2, . . . do 2: T ake N actions { a t } according to π ω i and store transitions { ( s t , a t .r t , s t +1 ) } 3: Compute returns G N t = P N − 1 i =0 γ i r t + i + γ N V ( s t + n ; θ i ) and advantages A t = G N t − V ( s t ; θ i ) 4: Perform A 2 C optimization step on x i using TD in (1) and batched policy-gradient in (4) 5: Broadcast (non-blocking) new parameters x i to all out-peers in N out i 6: if Receiv e b uffer contains a message m j from each in-peer v j in N in i then 7: x i ← 1 1+ |N in i | ( x i + P j m j ) 1 A verage parameters with messages 8: end if 9: end for 1 W e set the non-zero mixing weights for agent v i to p i,j = 1 1+ |N in i | . provided in Algorithm 1, where N in i : = { v j | p i,j > 0 } denotes the set of agents that send messages to agent v i (in-peers), and N out i : = { v j | p j,i > 0 } the set of agents that v i sends messages to (out- peers). During the gossip phase, agents broadcast their parameters to their out-peers, asynchronously (i.e., don’ t wait for messages to reach their destination), and update their own parameters via a con vex combination of all recei ved messages. Agents broadcast new messages when old transmissions are completed and aggregate all recei ved messages once the y hav e recei ved a message from each in-peer . Note that the G A L A agents use non-blocking communication, and therefore operate asynchronously . Local iteration counters may be out-of-sync, and physical message delays may result in agents incorporating outdated messages from their peers. One can algorithmically enforce an upper bound on the message staleness by having the agent block and wait for communication to complete if more than τ ≥ 0 local iterations hav e passed since the agent last recei ved a message from its in-peers. Theoretical -ball guarantees: Next we provide the -ball theoretical guarantees for the asyn- chronous G A L A agents, proofs of which can be found in Appendix B. Let k ∈ N denote the global iteration counter , which increments whene ver an y agent (or subset of agents) completes an iteration of the loop defined in Algorithm 1. W e define x ( k ) i ∈ R d as the value of agent v i ’ s trainable parameters at iteration k , and X ( k ) ∈ R n × d as the row-concatenation of these parameters. For our theoretical guarantees we let the communication topologies be directed and time-varying graphs, and we do not make any assumptions about the base G A L A learners. In particular, let the mapping T i : x ( k ) i ∈ R d 7→ x ( k ) i − αg ( k ) i ∈ R d characterize agent v i ’ s local training dynamics (i.e., agent v i optimizes its parameters by computing x ( k ) i ← T i ( x ( k ) i ) ), where α > 0 is a reference learning rate, and g ( k ) i ∈ R d can be any update vector . Lastly , let G ( k ) ∈ R n × d denote the row-concatenation of these update vectors. Proposition 1. F or all k ≥ 0 , it holds that X ( k +1) − X ( k +1) ≤ α k X s =0 β k +1 − s G ( s ) , wher e X ( k +1) : = 1 n 1 T n n X ( k +1) denotes the avera ge of the learners’ parameter s at iter ation k + 1 , and β ∈ [0 , 1] is r elated to the joint spectral radius of the graph sequence defining the communication topology at each iter ation. Proposition 1 sho ws that the distance of a learners’ parameters from consensus is bounded at each iteration. Howe ver , without additional assumptions on the communication topology , the constant β may equal 1 , and the bound in Proposition 1 can be tri vial. In the following proposition, we make sufficient assumptions with respect to the graph sequence that ensure β < 1 . Proposition 2. Suppose ther e exists a finite inte ger B ≥ 0 such that the (potentially time-varying) graph sequence is B -str ongly connected, and suppose that the upper bound τ on the message delays in Algorithm 1 is finite. If learners run Algorithm 1 from iter ation 0 to k + 1 , wher e k ≥ τ + B , then it holds that X ( k +1) − X ( k +1) ≤ α ˜ β L 1 − β , 4 wher e β < 1 is r elated to the joint spectral r adius of the graph sequence , α is the r efer ence learning rate, ˜ β : = β − τ + B τ + B +1 , and L : = sup s =1 , 2 ,... G ( s ) denotes an upper bound on the magnitude of the local optimization updates during training . Proposition 2 states that the agents’ parameters are guaranteed to reside within an -ball of their av erage at all iterations k ≥ τ + B . The size of this ball is proportional to the reference learning-rate, the spectral radius of the graph topology , and the upper bound on the magnitude of the local gradient updates. One may also be able to control the constant L in practice since Deep RL agents are typically trained with some form of gradient clipping. 4 Related work Sev eral recent works have approached scaling up RL by using parallel environments. Mnih et al. [2016] used parallel asynchronous agents to perform H O G W I L D ! [Recht et al., 2011] style updates to a shared set of parameters. Dhariwal et al. [2017] proposed A 2 C , which maintains the parallel data collection, but performs updates synchronously , and found this to be more stable empirically . While A3C was originally designed as a purely CPU-based method, Babaeizadeh et al. [2017] proposed GA3C, a GPU implementation of the algorithm. Stooke and Abbeel [2018] also scaled up various RL algorithms by using significantly larger batch sizes and distributing computation onto sev eral GPUs. Dif ferently from those works, we propose the use of Gossip Algorithms to aggregate information between diff erent agents and thus simulators. Nair et al. [2015], Horgan et al. [2018], Espeholt et al. [2018], Kapturo wski et al. [2019], Gruslys et al. [2018] use parallel en vironments as well, but disentangle the data collection (actors) from the network updates (learners). This provides se veral computational benefits, including better hardw are utilization and reduced straggler ef fects. By disentangling acting from learning these algorithms must use off-polic y methods to handle learning from data that is not directly generated from the current policy (e.g., slightly older policies). Gossip-based approaches have been extensi v ely studied in the control-systems literature as a way to aggregate information for distributed optimization algorithms [Nedi ´ c et al., 2018]. In particular, recent works ha v e proposed to combine gossip algorithms with stochastic gradient descent in order to train Deep Neural Networks [Lian et al., 2018, 2017, Assran et al., 2019], but unlike our work, focus only on the supervised classification paradigm. 5 Experiments W e ev aluate G A L A for training Deep RL agents on Atari-2600 games [Machado et al., 2018]. W e focus on the same six games studied in Stooke and Abbeel [2018]. Unless otherwise-stated, all learning curves sho w averages over 10 random seeds with 95% confidence interv als shaded in. W e follow the reproducibility checklist [Pineau, 2018], see Appendix A for details. W e compare A 2 C [Dhariwal et al., 2017], A 3 C [Mnih et al., 2016], I M PA L A [Espeholt et al., 2018], and G A L A - A 2 C . All methods are implemented in PyT orch [Paszke et al., 2017]. While A 3 C was originally proposed with CPU-based agents with 1-simulator per agent, Stooke and Abbeel [2018] propose a large-batch variant in which each agent manages 16-simulators and performs batched inference on a GPU. W e found this large-batch variant to be more stable and computationally efficient (cf. Appendix C.1). W e use the Stooke and Abbeel [2018] variant of A 3 C to provide a more competitiv e baseline. W e parallelize A 2 C training via the canonical approach outlined in Stooke and Abbeel [2018], whereby individual A 2 C agents (running on potentially different de vices), all av erage their gradients together before each update using the A L L R E D U C E primitiv e. 2 For A 2 C and A 3 C we use the hyper-parameters suggested in Stooke and Abbeel [2018]. For I M PA L A we use the hyper- parameters suggested in Espeholt et al. [2018]. For G A L A - A 2 C we use the same hyper-parameters as the original (non-gossip-based) method. All G A L A agents are configured in a directed ring graph. All implementation details are described in Appendix C. For the I M PA L A baseline, we use a prerelease of T orchBeast [Küttler et al., 2019] av ailable at https://github .com/facebookresearch/torchbeast. 2 This is mathematically equiv alent to a single A 2 C agent with multiple simulators (e.g., n agents, with b simulators each, are equiv alent to a single agent with nb simulators). 5 T able 1: Across all training seeds we select the best final policy produced by each method at the end of training and e v aluate it o ver 10 ev aluation episodes (up to 30 no-ops at the start of the episode). Evaluation actions generated from arg max a π ( a | s ) . The table depicts the mean and standard error across these 10 ev aluation episodes. Steps BeamRider Break out Pong Qbert Seaquest SpaceIn vaders I M PA L A 1 50M 8220 641 21 18902 1717 1727 I M PA L A 40M 7118 ± 2536 127 ± 65 21 ± 0 7878 ± 2573 462 ± 2 4071 ± 393 A 3 C 40M 5674 ± 752 414 ± 56 21 ± 0 14923 ± 460 1840 ± 0 2232 ± 302 A 2 C 25M 8755 ± 811 419 ± 3 21 ± 0 16805 ± 172 1850 ± 5 2846 ± 22 A 2 C 40M 9829 ± 1355 495 ± 57 21 ± 0 19928 ± 99 1894 ± 6 3021 ± 36 G A L A - A 2 C 25M 9500 ± 1020 690 ± 72 21 ± 0 18810 ± 37 1874 ± 4 2726 ± 189 G A L A - A 2 C 40M 10188 ± 1316 690 ± 72 21 ± 0 20150 ± 28 1892 ± 6 3074 ± 69 1 Espeholt et al. [2018] results using shallow netw ork (identical to the network used in our e xperiments). Con vergence and stability: W e begin by empirically studying the conv ergence and stability prop- erties of A 2 C and G A L A - A 2 C . Figure 1a depicts the percentage of successful runs (out of 10 trials) of standard policy-gradient A 2 C when we sweep the number of simulators across six dif ferent games. W e define a run as successful if it achieves better than 50% of nominal 16 -simulator A 2 C scores. When using A 2 C , we observe an identical trend across all games in which the number of successful runs decreases significantly as we increase the number of simulators. Note that the A 2 C batch size is proportional to the number of simulators, and when increasing the number of simulators we adjust the learning rate following the recommendation in Stook e and Abbeel [2018]. Figure 1a also depicts the percentage of successful runs when A 2 C agents communicate their parameters using gossip algorithms ( G A L A - A 2 C ). In every simulator sweep across the six games (600 runs), the gossip-based architecture increases or maintains the percentage of successful runs relativ e to vanilla A 2 C , when using identical hyper-parameters. W e hypothesize that ex ercising slightly different policies at each learner using gossip-algorithms can provide enough decorrelation in gradients to improv e learning stability . W e revisit this point later on (cf. Figure 3b). W e note that Stooke and Abbeel [2018] find that stepping through a random number of uniform random actions at the start of training can partially mitig ate this stability issue. W e did not use this random start action mitigation in the reported experiments. While Figure 1a shows that G A L A can be used to stabilize multi-simulator A 2 C and increase the number of successfull runs, it does not directly say anything about the final performance of the learned models. Figures 1b and 1c show the rew ards plotted against the number of environment steps when training with 64 simulators. Using gossip-based architectures stabilizes and maintains the peak performance and sample ef ficienc y of A 2 C across all six games (Figure 1b), and also increases the number of con vergent runs (Figure 1c). Figures 1d and 1e compare the wall-clock time con vergence of G A L A - A 2 C to vanilla A 2 C . Not only is G A L A - A 2 C more stable than A 2 C , but it also runs at a higher frame-rate by mitigating straggler effects. In particular , since G A L A - A 2 C learners do not need to synchronize their gradients, each learner is free to run at its own rate without being hampered by v ariance in peer stepping times. Comparison with distributed Deep RL appr oaches: Figure 1 also compares G A L A - A 2 C to state- of-the-art methods like I M PA L A and A 3 C . 3 In each game, the G A L A - A 2 C learners exhibited good sample ef ficiency and computational ef ficiency , and achie ved highly competiti ve final game scores. Next we e v aluate the final policies produced by each method at the end of training. After training across 10 different seeds, we are left with 10 distinct policies per method. W e select the best final policy and ev aluate it over 10 ev aluation episodes, with actions generated from arg max a π ( a | s ) . In almost e very single g ame, the G A L A - A 2 C learners achiev ed the highest e v aluation scores of an y method. Notably , the G A L A - A 2 C learners that were trained for 25M steps achie ved (and in most cases surpassed) the scores for I M PA L A learners trained for 50M steps [Espeholt et al., 2018]. 3 W e report results for both the T orchBeast implementation of I M PA L A , and from T able C. 1 from Espeholt et al. [2018] 6 500 1000 Simulators 0 20 40 60 80 100 (%) Converged Runs BeamRider GALA-a2c a2c 500 1000 Simulators 0 20 40 60 80 100 Breakout 500 1000 Simulators 0 20 40 60 80 100 Pong 500 1000 Simulators 0 20 40 60 80 100 Qbert 500 1000 Simulators 0 20 40 60 80 100 Seaquest 500 1000 Simulators 0 20 40 60 80 100 SpaceInvaders (a) Simulator sweep: Percentage of con ver gent runs out of 10 trials. 0 1 2 3 Steps 1e7 0 2000 4000 6000 Reward BeamRider GALA-a2c a2c IMPALA a3c 0 1 2 3 Steps 1e7 0 100 200 300 400 500 Breakout 0 1 2 3 Steps 1e7 20 10 0 10 20 Pong 0 1 2 3 Steps 1e7 0 5000 10000 15000 Qbert 0 1 2 3 Steps 1e7 0 500 1000 1500 Seaquest 0 1 2 3 Steps 1e7 0 500 1000 1500 2000 2500 SpaceInvaders (b) Sample complexity: Best 3 runs for each method. 0 1 2 3 Steps 1e7 0 2000 4000 6000 Reward BeamRider GALA-a2c a2c IMPALA a3c 0 1 2 3 Steps 1e7 0 100 200 300 400 Breakout 0 1 2 3 Steps 1e7 20 10 0 10 20 Pong 0 1 2 3 Steps 1e7 0 5000 10000 15000 Qbert 0 1 2 3 Steps 1e7 0 500 1000 1500 2000 Seaquest 0 1 2 3 Steps 1e7 0 500 1000 1500 2000 2500 SpaceInvaders (c) Sample complexity: A verage across 10 runs. 0 1 2 Time (hrs.) 0 2000 4000 6000 Reward BeamRider GALA-a2c a2c IMPALA a3c 0 1 2 Time (hrs.) 0 100 200 300 400 500 Breakout 0 1 2 Time (hrs.) 20 10 0 10 20 Pong 0 1 2 Time (hrs.) 0 5000 10000 15000 Qbert 0 1 2 Time (hrs.) 0 500 1000 1500 Seaquest 0 1 2 Time (hrs.) 0 500 1000 1500 2000 SpaceInvaders (d) Computational complexity: Best 3 runs for each method. 0 1 2 Time (hrs.) 0 2000 4000 6000 Reward BeamRider GALA-a2c a2c IMPALA a3c 0 1 2 Time (hrs.) 0 100 200 300 400 Breakout 0 1 2 Time (hrs.) 20 10 0 10 20 Pong 0 1 2 Time (hrs.) 0 5000 10000 15000 Qbert 0 1 2 Time (hrs.) 0 500 1000 1500 Seaquest 0 1 2 Time (hrs.) 0 500 1000 1500 2000 SpaceInvaders (e) Computational complexity: A verage across 10 runs. 0 500 1000 1500 Energy (kJ) 0 2000 4000 6000 Reward BeamRider GALA-a2c a2c IMPALA a3c 0 500 1000 1500 Energy (kJ) 0 100 200 300 400 500 Breakout 0 500 1000 1500 Energy (kJ) 20 10 0 10 20 Pong 0 500 1000 1500 Energy (kJ) 0 5000 10000 15000 Qbert 0 500 1000 1500 Energy (kJ) 0 500 1000 1500 Seaquest 0 500 1000 1500 Energy (kJ) 0 500 1000 1500 2000 SpaceInvaders (f) Energy ef ficienc y: Best 3 runs for each method. 0 500 1000 1500 Energy (kJ) 0 2000 4000 6000 Reward BeamRider GALA-a2c a2c IMPALA a3c 0 500 1000 1500 Energy (kJ) 0 100 200 300 400 Breakout 0 500 1000 1500 Energy (kJ) 20 10 0 10 20 Pong 0 500 1000 1500 Energy (kJ) 0 5000 10000 15000 Qbert 0 500 1000 1500 Energy (kJ) 0 500 1000 1500 Seaquest 0 500 1000 1500 Energy (kJ) 0 500 1000 1500 2000 SpaceInvaders (g) Energy ef ficienc y: A verage across 10 runs. Figure 1: (a) G A L A increases or maintains the percentage of conv ergent runs relativ e to A 2 C . (b)- (c) G A L A maintains the best performance of A 2 C while being more rob ust. (d)-(e) G A L A achiev es competiti ve scores in each g ame and in the shortest amount of time. (f)-(g) G A L A achie ves competitiv e game scores while being energy ef ficient. 7 0 20000 40000 Steps 0 1 2 3 X ( k + 1 ) X ( k + 1 ) F b a l l o f p a r a m e t e r s d u r i n g t r a i n i n g Prop. 1 Theoretical Bound Empirical Parameter Deviations (a) Agent 1 Agent 2 Agent 3 Agent 4 Agent 1 Agent 2 Agent 3 Agent 4 peer peer peer peer peer peer peer peer GALA-A2C avg. gradient correlation during training Agent 1 Agent 2 Agent 3 Agent 4 Agent 1 Agent 2 Agent 3 Agent 4 A2C avg. gradient correlation during training (b) Figure 2: (a) The radius of the -ball within which the agents’ parameters reside during training. The theoretical upper bound in Proposition 1 is explicitly calculated and compared to the true empirical quantity . The bound in Proposition 1 is remarkably tight. (b) A verage correlation between agents’ gradients during training (darker colors depict lo w correlation and lighter colors depict higher correlations). Neighbours in the G A L A - A 2 C topology are annotated with the label “peer . ” The G A L A - A 2 C heatmap is generally much darker than the A 2 C heatmap, indicating that G A L A - A 2 C agents produce more div erse gradients with significantly less correlation. 0 50 100 150 200 GPU Power Draw (Watts) 0 10 20 30 40 50 60 70 80 90 100 GPU Utilization (%) 64 Simulators GALA-a2c a2c 0 50 100 150 200 GPU Power Draw (Watts) 0 10 20 30 40 50 60 70 80 90 100 128 Simulators GALA-a2c a2c 0 50 100 150 200 GPU Power Draw (Watts) 0 10 20 30 40 50 60 70 80 90 100 192 Simulators GALA-a2c a2c (a) 0 10 20 30 40 50 60 70 80 90 Avg. GPU Utilization (%) 64 128 192 Simulators GPU Utilization GALA-a2c a2c 0 10 20 30 40 50 60 70 80 90 Avg. CPU Utilization (%) 64 128 192 CPU Utilization 0 12 24 36 48 60 72 84 96 108 Thousand Frames per Kilojoule 64 128 192 Energy Efficiency (b) Figure 3: Comparing G A L A - A 2 C hardware utilization to that of A 2 C when using one NVIDIA V100 GPU and 48 Intel CPUs. (a) Samples of instantaneous GPU utilization and power draw plotted against each other . Bubble sizes indicate frame-rates obtained by the corresponding algorithms; larger bubbles depict higher frame-rates. G A L A - A 2 C achie ves higher hardware utilization than A 2 C at comparable po wer draws. This translates to much higher frame-rates and increased energy efficienc y . (b) Hardware utilization/ener gy ef ficiency vs. number of simulators. G A L A - A 2 C benefits from increased parallelism and achiev es a 10-fold improvement in GPU utilization ov er A 2 C . Effects of gossip: T o better understand the stabilizing effects of G A L A , we ev aluate the div ersity in learner policies during training. Figure 2a shows the distance of the agents’ parameters from consensus throughout training. The theoretical upper bound in Proposition 1 is also explicitly calculated and plotted in Figure 2a. As expected, the learner policies remain within an -ball of one-another in weight-space, and this size of this ball is remarkably well predicted by Proposition 1. Next, we measure the di versity in the agents’ gradients. W e hypothesize that the -div ersity in the policies predicted by Proposition 1, and empirically observed in Figure 2a, may lead to less correlation in the agents’ gradients. The categorical heatmap in Figure 2b sho ws the pair -wise cosine-similarity between agents’ gradients throughout training, computed after every 500 local en vironment steps, and av eraged o ver the first 10M training steps. Dark colors depict lo w correlations and light colors depict high correlations. W e observe that G A L A - A 2 C agents exhibited less gradient correlations than A 2 C agents. Interestingly , we also observe that G A L A - A 2 C agents’ gradients are more correlated with those of peers that they explicitly communicate with (graph neighbours), and less correlated with those of agents that they do not e xplicitly communicate with. Computational performance: Figure 3 showcases the hardw are utilization and energy ef ficienc y of G A L A - A 2 C compared to A 2 C as we increase the number of simulators. Specifically , Figure 3a shows that G A L A - A 2 C achieves significantly higher hardware utilization than v anilla A 2 C at com- parable power draws. This translates to much higher frame-rates and increased energy efficienc y . Figure 3b sho ws that G A L A - A 2 C is also better able to le verage increased parallelism and achiev es a 10-fold improvement in GPU utilization over vanilla A 2 C . Once again, the improved hardware utilization and frame-rates translate to increased ener gy ef ficiency . In particular, G A L A - A 2 C steps 8 through roughly 20 thousand more frames per Kilojoule than v anilla A 2 C . Figures 1f and 1g compare game scores as a function of ener gy utilization in Kilojoules. G A L A - A 2 C is distinctly more energy efficient than the other methods, achie ving higher game scores with less energy utilization. 6 Conclusion W e propose Gossip-based Actor-Learner Architectures ( G A L A ) for accelerating Deep Reinforcement Learning by leveraging parallel actor-learners that exchange information through asynchronous gossip. W e prov e that the G A L A agents’ policies are guaranteed to remain within an -ball during training, and verify this empirically as well. W e ev aluated our approach on six Atari games, and find that G A L A - A 2 C improves the computational efficienc y of A 2 C , while also providing e xtra stability and robustness by decorrelating gradients. G A L A - A 2 C also achiev es significantly higher hardware utilization than vanilla A 2 C at comparable power draws, and is competitiv e with state-of-the-art methods like A 3 C and I M PA L A . Acknowledgments W e would like to thank the authors of T orchBeast for providing their pytorch implementation of I M PA L A . References Mahmoud Assran. Asynchronous subgradient push: Fast, robust, and scalable multi-agent optimiza- tion. Master’ s thesis, McGill Uni versity , 2018. Mahmoud Assran and Michael Rabbat. Asynchronous subgradient-push. arXiv preprint arXiv:1803.08950 , 2018. Mahmoud Assran, Nicolas Loizou, Nicolas Ballas, and Michael Rabbat. Stochastic gradient push for distributed deep learning. Proceedings of the 36th International Confer ence on Machine Learning , 97:344–353, 2019. Mohammad Babaeizadeh, Iuri Frosio, Stephen T yree, Jason Clemons, and Jan Kautz. Reinforce- ment learning through asynchronous advantage actor-critic on a gpu. In Proceedings of the 5th International Confer ence on Learning Repr esentations , 2017. V incent D Blondel, Julien M Hendrickx, Alex Olshevsk y , and John N Tsitsiklis. Con ver gence in multiagent coordination, consensus, and flocking. Pr oceedings of the 44th IEEE Confer ence on Decision and Contr ol , pages 2996–3000, 2005. Alfredo V Clemente, Humberto N Castejón, and Arjun Chandra. Efficient parallel methods for deep reinforcement learning. arXiv preprint , 2017. Prafulla Dhariwal, Christopher Hesse, Oleg Klimo v , Alex Nichol, Matthias Plappert, Alec Radford, John Schulman, Szymon Sidor , Y uhuai W u, and Peter Zhokho v . Openai baselines, 2017. Lasse Espeholt, Hubert Soyer , Remi Munos, Karen Simonyan, V olodymir Mnih, T om W ard, Y otam Doron, Vlad Firoiu, T im Harley , Iain Dunning, et al. Impala: Scalable distributed deep-rl with importance weighted actor-learner architectures. Proceedings of the 35th International Confer ence on Machine Learning , 80:1407–1416, 2018. Scott Fujimoto, Herke van Hoof, and David Meger . Addressing function approximation error in actor-critic methods. Pr oceedings of the 35th International Confer ence on Machine Learning , 80: 1582–1591, 2018. Audrunas Gruslys, Mohammad Gheshlaghi Azar, Marc G. Bellemare, and Rémi Munos. The reactor: A sample-ef ficient actor -critic architecture. Pr oceedings of the 6th International Confer ence on Learning Repr esentations , 2018. Christoforos N Hadjicostis and Themistoklis Charalambous. A verage consensus in the presence of delays in directed graph topologies. IEEE T ransactions on Automatic Contr ol , 59(3):763–768, 2013. Dan Horgan, John Quan, David Budden, Gabriel Barth-Maron, Matteo Hessel, Hado van Hasselt, and David Silv er . Distributed prioritized experience replay . Pr oceedings of the 6th International Confer ence on Learning Repr esentations , 2018. 9 Stev en Kapturowski, Georg Ostrovski, Will Dabney , John Quan, and Remi Munos. Recurrent experience replay in distributed reinforcement learning. Proceedings of the 7th International Confer ence on Learning Repr esentations , 2019. Heinrich Küttler, Nantas Nardelli, Thibaut Lavril, Marco Selvatici, V iswanath Siv akumar , T im Rocktäschel, and Edward Grefenstette. T orchbeast: A pytorch platform for distributed rl. arXiv pr eprint arXiv:1910.03552 , 2019. Xiangru Lian, Ce Zhang, Huan Zhang, Cho-Jui Hsieh, W ei Zhang, and Ji Liu. Can decentralized algorithms outperform centralized algorithms? a case study for decentralized parallel stochastic gradient descent. Advances in Neural Information Pr ocessing Systems , pages 5330–5340, 2017. Xiangru Lian, W ei Zhang, Ce Zhang, and Ji Liu. Asynchronous decentralized parallel stochastic gradient descent. Proceedings of the 35th International Confer ence on Machine Learning , 80: 3043–3052, 2018. Marlos C. Machado, Marc G. Bellemare, Erik T alvitie, Joel V eness, Matthew J. Hausknecht, and Michael Bowling. Re visiting the arcade learning environment: Evaluation protocols and open problems for general agents. Proceedings of the 27th International J oint Conference on Artificial Intelligence , pages 5573–5577, 2018. V olodymyr Mnih, K oray Ka vukcuoglu, Da vid Silver , Andrei A Rusu, Joel V eness, Marc G Bellemare, Alex Gra ves, Martin Riedmiller , Andreas K Fidjeland, Geor g Ostro vski, et al. Human-lev el control through deep reinforcement learning. Nature , 518(7540):529, 2015. V olodymyr Mnih, Adria Puigdomenech Badia, Mehdi Mirza, Alex Gra ves, T imothy Lillicrap, T im Harley , David Silver , and Koray Kavukcuoglu. Asynchronous methods for deep reinforcement learning. Proceedings of the 33r d International confer ence on machine learning , 48:1928–1937, 2016. Arun Nair , Pra veen Sriniv asan, Sam Blackwell, Cagdas Alcicek, Rory Fearon, Alessandro De Maria, V eda vyas Panneershelv am, Mustafa Sule yman, Charles Beattie, Stig Petersen, Shane Legg, V olodymyr Mnih, Koray Kavukcuoglu, and David Silver . Massively parallel methods for deep reinforcement learning. CoRR , abs/1507.04296, 2015. Angelia Nedi ´ c, Alex Olshevsky , and Michael G Rabbat. Network topology and communication- computation tradeof fs in decentralized optimization. Pr oceedings of the IEEE , 106(5):953–976, 2018. Adam Paszk e, Sam Gross, Soumith Chintala, Gregory Chanan, Edward Y ang, Zachary DeV ito, Zeming Lin, Alban Desmaison, Luca Antiga, and Adam Lerer . Automatic differentiation in pytorch. 2017. Joelle Pineau. The machine learning reproducibility checklist (version 1.0), 2018. Benjamin Recht, Christopher Re, Stephen Wright, and Feng Niu. Hogwild: A lock-free approach to parallelizing stochastic gradient descent. Advances in Neural Information Pr ocessing Systems , 24: 693–701, 2011. Eugene Seneta. Non-negative Matrices and Mark ov Chains . Springer , 1981. David Silv er , Aja Huang, Chris J Maddison, Arthur Guez, Laurent Sifre, George V an Den Driessche, Julian Schrittwieser , Ioannis Antonoglou, V eda Panneershelv am, Marc Lanctot, et al. Mastering the game of go with deep neural networks and tree search. Natur e , 529(7587):484, 2016. David Silv er , Thomas Hubert, Julian Schrittwieser , Ioannis Antonoglou, Matthew Lai, Arthur Guez, Marc Lanctot, Laurent Sifre, Dharshan Kumaran, Thore Graepel, et al. A general reinforcement learning algorithm that masters chess, shogi, and go through self-play . Science , 362(6419): 1140–1144, 2018. Adam Stooke and Pieter Abbeel. Accelerated methods for deep reinforcement learning. arXiv pr eprint arXiv:1803.02811 , 2018. Richard S Sutton and Andre w G Barto. Introduction to r einfor cement learning , volume 135. MIT press Cambridge, 1998. Richard S Sutton, David A McAllester , Satinder P Singh, and Y ishay Mansour . Policy gradient methods for reinforcement learning with function approximation. Advances in neural information pr ocessing systems , pages 1057–1063, 2000. 10 Richard Stuart Sutton. T emporal credit assignment in r einforcement learning . PhD thesis, Uni versity of Massachusetts Amherst, 1984. Y uandong Tian, Jerry Ma, Qucheng Gong, Shubho Sengupta, Zhuoyuan Chen, James Pinkerton, and C Lawrence Zitnick. Elf opengo: An analysis and open reimplementation of alphazero. Pr oceedings of the 36th International Conference on Mac hine Learning , 97:6244–6253, 2019. John Tsitsiklis, Dimitri Bertsekas, and Michael Athans. Distributed asynchronous deterministic and stochastic gradient optimization algorithms. IEEE transactions on automatic contr ol , 31(9): 803–812, 1986. O V inyals, I Babuschkin, J Chung, M Mathieu, M Jaderberg, W Czarnecki, A Dudzik, A Huang, P Georgie v , R Powell, et al. Alphastar: Mastering the real-time strategy game starcraft ii, 2019. Jacob W olfowitz. Products of indecomposable, aperiodic, stochastic matrices. Pr oceedings of the American Mathematical Society , 14(5):733–737, 1963. 11 A ppendices A Reproducibility Checklist W e follow the reproducibility checklist Pineau [2018]: For all algorithms presented, check if you include: • A clear description of the algorithm. See Algorithm 1 • An analysis of the complexity (time, space, sample size) of the algorithm. See Figures 1 and 3 for an analysis of sample efficienc y , wall-clock time, and ener gy ef ficiency . • A link to a downloadable source code, including all dependencies. See the attached zip file. For an y theoretical claim, check if you include: • A statement of the result. See Propositions 1 and 2 in the main text. • A clear explanation of any assumptions. See Appendix B for full details. • A complete proof of the claim. See Appendix B for full details. For all figures and tables that present empirical results, check if you include: • A complete description of the data collection process, including sample size. W e used the Arcade Learning En vironment [Machado et al., 2018], specifically we used the gym package - see: github .com/openai/gym • A link to downloadable version of the dataset or simulation en vironment. See: github .com/openai/gym • An explanation of how samples were allocated for training / validation / testing. W e didn’t use explicit training / validation/ testing splits - but ran each algorithm with 10 different random seeds. • An explanation of any data that were excluded. W e only used 6 atari games due to time constraints - the same 6 games that were used in Stooke and Abbeel [2018]. • The range of hyper -parameters considered, method to select the best hyper -parameter configuration, and specification of all hyper -parameters used to generate results. W e used standard hyper-parameters from Dhariwal et al. [2017], Stooke and Abbeel [2018], Espeholt et al. [2018]. • The exact number of evaluation runs. W e used 10 seeds for the Atari experiments. • A description of how experiments were run. See Appendix C for full details. • A clear definition of the specific measure or statistics used to report results. 95% confidence intervals are used in all plots / tables unless otherwise stated. • Clearly defined error bars. 95% confidence interv als are used in all plots / tables unless otherwise stated. • A description of results with central tendency (e.g. mean) and variation (e.g. stddev). 95% confidence interv als are used in all plots / tables unless otherwise stated. • A description of the computing infrastructure used. See Appendix C for full details. B Proofs Setting and Notation Before presenting the theoretical guarantees, we define some notation. Suppose we ha ve n learners (e.g., actor -critic agents) configured in a peer-to-peer communication topology represented by a directed and potentially time-v arying graph (the non-zero entries in the mixing matrix P ( k ) define the communication topology at each iteration k ). Learners constitute vertices in the graph, denoted by v i for all i ∈ [ n ] , and edges constitute directed communication links. Let N out i denote agent v i ’ s out-peers , the set of agents that v i can send messages 12 to, and let N in i denote agent v i ’ s in-peers , the set of agents that can send messages to v i . If the graph is time-v arying, these sets are annotated with time indices. Let x i ∈ R d denote the agent v i ’ s complete set of trainable parameters, and let the training function T i : R d 7→ R d define agent v i ’ s training dynamics (i.e., agent v i optimizes its parameters by iterativ ely computing x i ← T i ( x i ) ). For each agent v i we define send- and receiv e-buf fers, B i and R i respectiv ely , which are used by the underlying communication system (standard in the gossip literature [Tsitsiklis et al., 1986]). When an agent wishes to broadcast a message to its out-peers, it simply copies the message into its broadcast buf fer . Similarly , when agent recei ves a message, it is automatically copied into the recei ve b uffer . For con venience, we assume that each learner v i can hold at most one message from in-peer v j in its receiv e buffer , R i at any time k ; i.e., a ne wly received message from agent v j ov erwrites the older one in the receiv e buffer . Let k ∈ N denote the global iteration counter . That is, k increments whenev er any agent (or subset of agents) completes one loop in Algorithm 1. Consequently , at each global iteration k , there is a set of agents I that are activ ated, and within this set there is a (possibly non-empty) subset of agents C ⊆ I that gossip in the same iteration. If a message from agent v j is recei ved by agent v i at time k , let τ ( k ) j,i denote the time at which this message was sent. Let τ ≥ τ ( k ) j,i for all i, j ∈ [ n ] and k > 0 denote an upper bound on the message delays. For analysis purposes, messages are sent with an effecti ve delay such that they arri ve right when the agent is ready to process the messages. That is, a message that is sent by agent v j at iteration k 0 and processed by agent v i at iteration k , where k ≥ k 0 , is treated as having e xperienced a delay τ ( k ) j,i = k − k 0 , ev en if the message actually arrives before iteration k and waits in the recei ve-b uffer . Let αg ( k ) i : = T i ( x ( k ) i ) − x ( k ) i denote agent v i ’ s local computation update at iteration k after scaling by some reference learning rate α > 0 , and define g ( k ) i : = 0 if agent v i is not activ e at iteration k . Algorithm 1 can thus be written as follows. If agent v i does not gossip at iteration k , then its update is simply x ( k +1) i = x ( k ) i + αg ( k ) i . (5) If agent v i does gossip at iteration k , then its update is x ( k +1) i = 1 1 + |N in i | x ( k ) i + X j ∈N in i x τ ( k ) j,i j + αg ( k ) i , (6) where x τ ( k ) j,i j is the parameter value of the agent v j , at the time where the message was sent, i.e., τ ( k ) j,i . W e can analyze Algorithm 1 in matrix form by stacking all n agents’ parameters, x ( k ) i ∈ R d , into a matrix X ( k ) , and equiv alently stacking all of the update vectors, g ( k ) i ∈ R d , into a matrix G ( k ) . In order to represent the state of messages that are in transit (sent but not yet received), for analysis purposes, we augment the graph topology with virtual nodes using a standard graph augmentation [Hadjicostis and Charalambous, 2013] (we add τ virtual nodes for each non-virtual agent, where each virtual node stores a learner’ s parameters at a specific point within the last τ iterations). Let ˜ n : = n ( τ + 1) denote the cardinality of the augmented graph’ s vertex set. Equation (6) can be re-written as X ( k +1) = ˜ P ( k ) X ( k ) + α G ( k ) , (7) where X ( k ) , G ( k ) ∈ R ˜ n × d , and the mixing matrix ˜ P ( k ) ∈ R ˜ n × ˜ n corresponding to the augmented graph is ro w-stochastic for all iterations k , i.e., all entries are non-ne gati v e, and all ro ws sum to 1 . Mapping (6) to (7) may not be obvious, but is quite standard in the recent literature. W e refer the interested reader to Assran and Rabbat [2018], Hadjicostis and Charalambous [2013]. Pr oof of Pr oposition 1. The proof is very similar to the proofs in Assran et al. [2019] and Assran and Rabbat [2018], and makes use of the graph augmentations in Hadjicostis and Charalambous [2013], the lo wer dimensional stochastic matrix dynamics in Blondel et al. [2005], and the er godic matrix results in W olfo witz [1963]. Since the matrices ˜ P ( k ) are row-stochastic, their lar gest singular value is 1 , which corresponds to singular vectors in span { 1 ˜ n } . Let the matrix Q ∈ R ( ˜ n − 1) × ˜ n define an orthogonal projection onto the space orthogonal to span { 1 ˜ n } . Associated to each matrix 13 ˜ P ( k ) ∈ R ˜ n × ˜ n there is a unique matrix ˜ P 0 ( k ) ∈ R ( ˜ n − 1) × ( ˜ n − 1) such that Q ˜ P ( k ) = ˜ P 0 ( k ) Q . Let ˜ P 0 denote the collection of matrices ˜ P 0 ( k ) for all k . The spectrum of the matrices ˜ P 0 ( k ) is the spectrum of ˜ P ( k ) after removing one multiplicity of the singular v alue 1 . From (7), we have QX ( k +1) = Q ˜ P ( k ) · · · ˜ P (1) ˜ P (0) X (0) + α k X s =0 Q ˜ P ( k ) · · · ˜ P ( s +1) ˜ P ( s ) G ( s ) = ˜ P 0 ( k ) · · · ˜ P 0 (1) ˜ P 0 (0) QX (0) + α k X s =0 ˜ P 0 ( k ) · · · ˜ P 0 ( s +1) ˜ P 0 ( s ) QG ( s ) . (8) Note that Q ( X ( k +1) − X ( k +1) ) = 0 and ( X ( k +1) − X ( k +1) ) T 1 ˜ n = 0 . Thus X ( k +1) − X ( k +1) = Q ( X ( k +1) − X ( k +1) ) ≤ ˜ P 0 ( k ) · · · ˜ P 0 ( s +1) ˜ P 0 (0) QX (0) + α k X s =0 ˜ P 0 ( k ) · · · ˜ P 0 ( s +1) ˜ P 0 ( s ) QG ( s ) , where we hav e implicitly also made use of (8). Defining β : = sup s =0 , 1 ,...,k σ 2 ( ˜ P 0 ( k ) · · · ˜ P 0 ( s +1) ˜ P 0 ( s ) ) , it follows that X ( k +1) − X ( k +1) ≤ β k +1 QX (0) + α k X s =0 β k +1 − s QG ( s ) . (9) Assuming all learners are initialized with the same parameters, the first exponentially decay term on the right hand side of (9) vanishes and we ha ve X k +1 − X ( k +1) ≤ α k X s =0 β k +1 − s G ( s ) . Pr oof of Pr oposition 2. The proof extends readily from Proposition 1. Giv en the assumptions on the graph sequence, the product of the matrices ˜ P ( k ) · · · ˜ P ( s +1) ˜ P ( s ) is ergodic for an y k − s ≥ τ + B (cf. [Assran, 2018]). Letting β : = sup s =0 , 1 ,...,k σ 2 ( ˜ P 0 ( k ) · · · ˜ P 0 ( s ) ) , it follows from W olfo witz [1963] and Blondel et al. [2005] that β < 1 . C Implementation Details C.1 A 3 C Implementation Comparison While A 3 C was originally proposed with CPU-based agents with 1-simulator per agent, Stooke and Abbeel [2018] propose a variant in which each agent manages 16-simulators and performs batched inference on a GPU. Figure 4 compares 64-simulator learning curves using A 3 C as originally proposed in Mnih et al. [2016] to the large-batch variant in Stooke and Abbeel [2018]. The large-batch variant appears to be more robust and computationally ef ficient, therefore we use this GPU-based version of A 3 C in our main experiments to provide a more competiti ve baseline. C.2 Experimental Setup All experiments use the network suggested by Dhariwal et al. [2017]. Specifically , the network contains 3 con volutional layers and one hidden layer, followed by a linear output layer for the policy/linear output layer for the critic. The hyper-parameters for A 2 C , A 3 C and G A L A - A 2 C are summarized in T able 2. I M PA L A hyperparameters are the same as reported in Espeholt et al. [2018] (cf. table G. 1 in their appendix). In all GA L A experiments we used 16 en vironments per learner , e.g., in the 64 simulator e xperiments in Section 5 we use 4 learners. G A L A agents communicate using a 1-peer ring network . Figure 5 shows an example of such a ring network. The non-zero weight p i,j of the mixing matrix P corresponding to the 1-peer ring are set to 1 1+ |N in i | , which is equal to 1 / 2 as |N in i | = 1 for all i in the 1-peer ring graph. 14 0 1 2 3 Steps 1e7 1000 2000 3000 4000 Reward BeamRider a3c a3c (Mnih et al. [2016]) 0 1 2 3 Steps 1e7 0 100 200 300 Breakout 0 1 2 3 Steps 1e7 20 15 10 5 Pong 0 1 2 3 Steps 1e7 0 5000 10000 Qbert 0 1 2 3 Steps 1e7 0 500 1000 1500 Seaquest 0 1 2 3 Steps 1e7 250 500 750 1000 1250 SpaceInvaders (a) Sample complexity: A verage across 10 runs. 0 1 2 Time (hrs.) 1000 2000 3000 4000 Reward BeamRider a3c a3c (Mnih et al. [2016]) 0 1 2 Time (hrs.) 0 100 200 300 Breakout 0 1 2 Time (hrs.) 20 15 10 5 Pong 0 1 2 Time (hrs.) 0 2500 5000 7500 10000 12500 Qbert 0 1 2 Time (hrs.) 0 500 1000 1500 Seaquest 0 1 2 Time (hrs.) 500 1000 1500 SpaceInvaders (b) Computational complexity: A verage across 10 runs. Figure 4: Comparing large-batch A 3 C [Stooke and Abbeel, 2018] to original A 3 C [Mnih et al., 2016]. Running A 3 C with larger -batches provides more stable and sample efficient con ver gence (top ro w), while also maintaining computational efficienc y by leveraging GPU acceleration (bottom ro w). Hyper -parameter V alue Image W idth 84 Image Height 84 Grayscaling Y es Action Repetitions 4 Max-pool ov er last k action repeat frames 2 Frame Stacking 4 End of episode when life lost Y es Rew ard Clipping [ − 1 , 1] RMSProp momentum 0 . 0 RMSProp 0 . 01 Clip global gradient norm 0 . 5 Number of simulators per learner( B ) 16 Base Learning Rate( α ) 7 × 10 − 4 Learning Rate Scaling √ number of learners (not used in A 3 C ) VF coeff 0 . 5 Horizon(N) 5 Entropy Coef f. 0 . 01 Discount ( γ ) .99 Max number of no-ops at the start of the episode 30 T able 2: Hyperparameters for both A 2 C , G A L A - A 2 C , and A 3 C v 1 v 2 · · · v n − 1 v n Figure 5: Example of an n-agents/1-peer ring communication topology used in our experiment 15
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment