신경망 스펙트럼으로 보는 미세한 구조와 일반화
본 논문은 무한 폭 신경망의 Conjugate Kernel(CK)과 Neural Tangent Kernel(NTK)의 스펙트럼을 분석하여 초기 편향과 학습 후 편향을 정량화한다. Boolean cube, 구면, 가우시안 분포에서의 고차원 동등성을 보이고, 깊이, 활성화 함수, 가중치 분산 등 하이퍼파라미터가 스펙트럼에 미치는 영향을 통해 ‘단순성 편향’, 깊이의 이중성, 전층 학습 vs. 마지막 층 학습의 trade‑off 등을 설명한다. 또한…
저자: Greg Yang, Hadi Salman
본 논문은 “신경망이 단순한 함수를 선호하는가?”, “깊이가 복잡한 특징을 학습하는데 언제 도움이 되는가?”, “마지막 층만 학습하는 것이 전체 층을 학습하는 것과 동등한가?”와 같은 직관적인 질문들을 하나의 통일된 프레임워크, 즉 스펙트럼 관점에서 풀어낸다. 핵심 도구는 무한 폭 신경망이 가우시안 프로세스로 수렴한다는 사실을 이용해 정의되는 Conjugate Kernel(CK, NNGP kernel)와 Neural Tangent Kernel(NTK)이다. CK는 초기 가중치 분포가 정의하는 ‘사전’ 역할을, NTK는 전체 파라미터를 학습했을 때의 ‘사후’ 동역학을 각각 나타낸다.
**1. 스펙트럼 이론 구축**
저자들은 먼저 CK와 NTK를 Boolean cube {±1}^d 위의 적분 연산자로 정의하고, Fourier(윌시‑해다마드) 기저가 이 연산자를 완전 대각화한다는 사실을 증명한다. 이때 커널은 K(x,y)=Φ(⟨x,y⟩,‖x‖²,‖y‖²) 형태이며, Φ는 활성화 함수와 가중치·바이어스 분산에 의해 결정된다. 고차원(d→∞)에서는 동일한 Φ에 대해 구면·가우시안 분포에서도 동일한 고유값 구조가 나타난다(정리 3.1). 고유값 λ_k는 Φ를 (t,q,q′)에 대해 k번째 미분한 값으로 표현되며, 이는 기존의 Gegenbauer 다항식 적분보다 훨씬 계산적으로 효율적이다.
**2. 단순성 편향의 스펙트럼 해석**
ReLU 네트워크의 경우 λ₁이 전체 트레이스(trace) 대비 압도적으로 큰 비율을 차지한다. 따라서 무작위 초기화된 네트워크는 주로 1차(저주파) 고유함수에 투영되어 ‘단순한’ Boolean 함수들을 더 자주 생성한다. 반면, erf·시그모이드와 같이 비선형성이 부드러운 활성화에 큰 가중치 분산을 적용하면 고차수 고유값이 크게 늘어나, 스펙트럼이 평탄해져 ‘백색 잡음’에 가까운 함수가 샘플링된다. 이는 단순성 편향이 활성화와 가중치 스케일에 의존한다는 강력한 증거이다. 또한, 정리 4.1은 복잡한 차수의 고유값이 낮은 차수보다 클 수 없다는 약한 형태의 편향을 제시한다.
**3. 하이퍼파라미터와 NTK 스펙트럼**
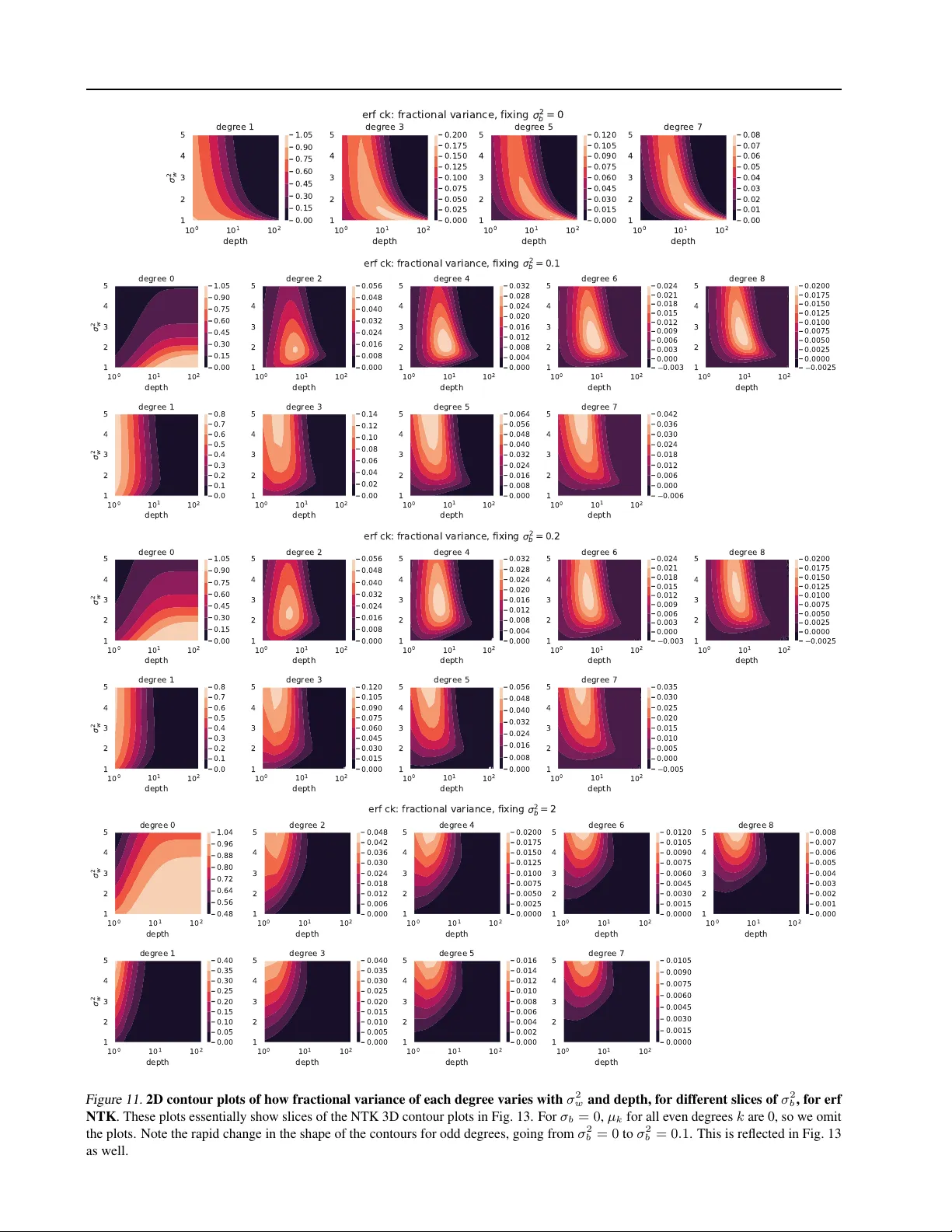
학습 단계에서는 NTK의 고유값이 학습 난이도를 결정한다. 저자들은 fractional variance(고유값이 차지하는 트레이스 비율)를 도입해, 특정 차수 k의 eigenspace가 전체 학습에 기여하는 비중을 정량화한다. 실험 결과, 깊이가 증가하면 초기에는 고차수 차원의 fractional variance가 상승해 복잡한 특징을 더 잘 학습하지만, 일정 깊이를 넘어서면 다시 감소한다. 따라서 “깊이가 항상 좋다”는 일반화된 믿음은 틀리며, 최적 깊이는 데이터와 목표 함수의 복잡도에 따라 달라진다.
또한, 전층 학습(NTK)과 마지막 층 학습(CK)을 비교했을 때, 복잡한(고주파) 차수에서는 NTK의 fractional variance가 CK보다 크게 나타난다. 이는 전체 파라미터를 업데이트할 때 고차수 특징이 더 효과적으로 학습된다는 것을 의미한다. 반대로 저주파(단순) 차수에서는 CK가 더 큰 비중을 차지해, 마지막 층만 학습해도 충분히 좋은 성능을 얻을 수 있음을 설명한다.
**4. 최대 학습률 예측**
SGD의 안정적인 학습률은 NTK의 최대 고유값 λ_max와 역비례한다는 가설을 제시한다. λ_max를 스펙트럼 분석을 통해 추정하면, 실험적으로 관측되는 “max learning rate”와 매우 높은 일치도를 보인다. 이는 스펙트럼이 학습 동역학을 직접적으로 예측할 수 있음을 보여준다.
**5. 실험 검증**
저자들은 Boolean cube, 구면, 가우시안 합성 데이터에 대해 정확한 스펙트럼을 계산하고, MNIST·CIFAR‑10 같은 실제 이미지 데이터에 대해 동일한 현상을 관찰했다. 특히, ReLU와 erf 네트워크의 단순성 편향 차이, 깊이에 따른 성능 변곡점, 전층 vs. 마지막 층 학습의 차이, 그리고 학습률 예측 모두 실험적으로 재현되었다. 코드와 데이터는 공개 저장소에 제공되어 재현성을 보장한다.
**결론**
스펙트럼 관점은 신경망 초기 사전, 학습 후 사후, 그리고 하이퍼파라미터가 일반화에 미치는 영향을 하나의 수학적 프레임워크로 통합한다. 이를 통해 단순성 편향이 보편적이지 않음, 깊이와 학습 전략이 복잡도에 따라 최적화돼야 함, 그리고 학습률 선택이 커널 고유값에 의해 결정될 수 있음을 명확히 밝혔다. 향후 연구는 비선형성, 비대칭 데이터 분포, 그리고 제한된 데이터 regime에서의 스펙트럼 변동을 탐구함으로써 이론을 확장할 여지를 남긴다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기