A Fine-Grained Spectral Perspective on Neural Networks
Are neural networks biased toward simple functions? Does depth always help learn more complex features? Is training the last layer of a network as good as training all layers? How to set the range for learning rate tuning? These questions seem unrela…
Authors: Greg Yang, Hadi Salman
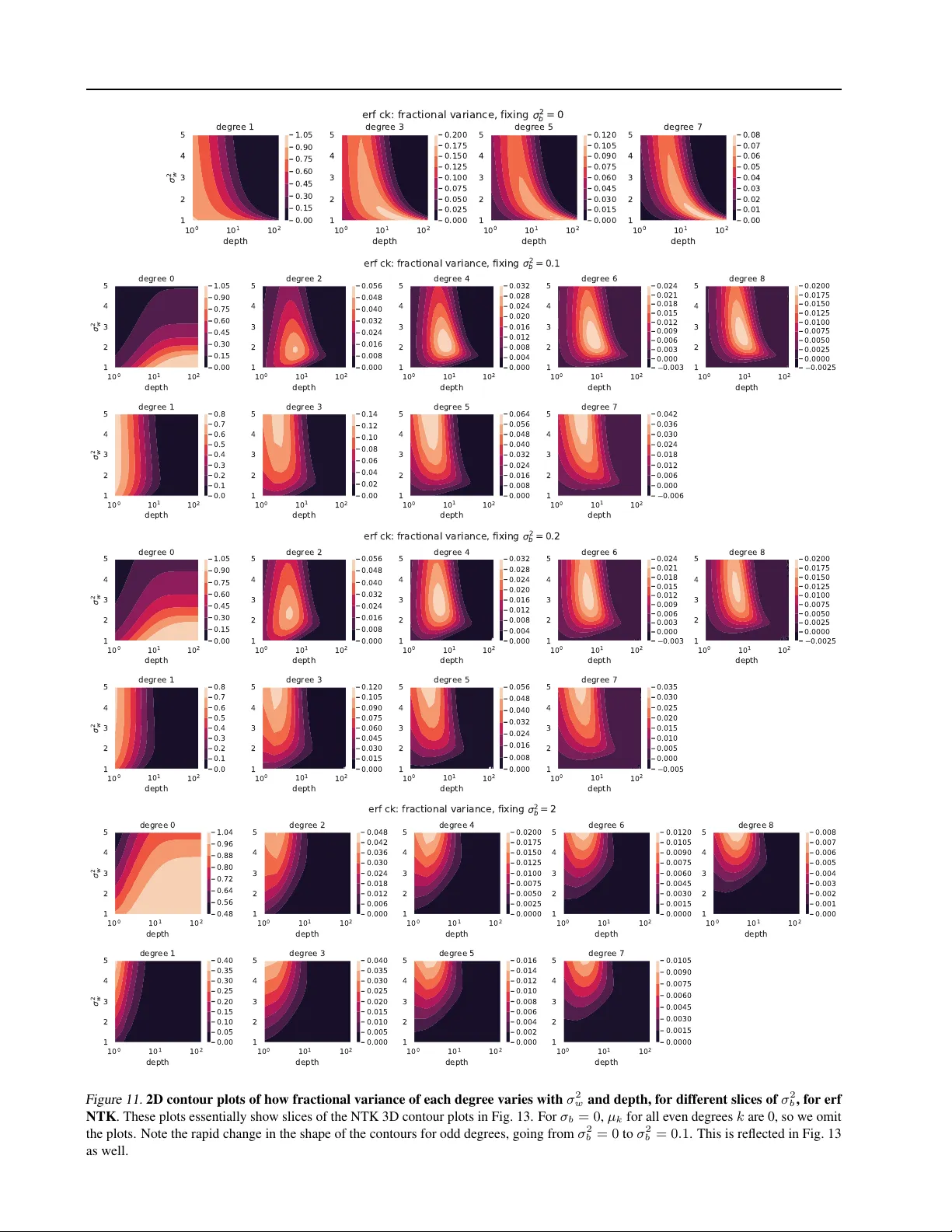
A Fine-Grained Spectral P erspectiv e on Neural Networks Greg Y ang 1 Hadi Salman 1 2 Abstract Are neural networks biased toward simple func- tions? Does depth always help learn more com- plex features? Is training the last layer of a net- work as good as training all layers? How to set the range for learning rate tuning? These questions seem unrelated at face v alue, but in this w ork we giv e all of them a common treatment from the spectral perspectiv e. W e will study the spectra of the Conjugate K ernel, CK, (also called the Neu- ral Network-Gaussian Pr ocess K ernel ), and the Neural T angent K ernel, NTK . Roughly , the CK and the NTK tell us respectively “what a network looks like at initialization” and “what a network looks like during and after training. ” Their spectra then encode v aluable information about the initial distribution and the training and generalization properties of neural networks. By analyzing the eigen v alues, we lend nov el insights into the ques- tions put forth at the beginning, and we verify these insights by extensi ve e xperiments of neural networks. W e deri ve f ast algorithms for comput- ing the spectra of CK and NTK when the data is uniformly distributed o ver the boolean cube, and show this spectra is the same in high dimensions when data is drawn from isotropic Gaussian or uniformly ov er the sphere. Code replicating our results is av ailable at https://github.com/ thegregyang/NNspectra . 1. Introduction Understanding the beha vior of neural networks and why they generalize has been a central pursuit of the theoretical deep learning community . Recently , V alle-Pérez et al. (2018) observed that neural networks hav e a certain “simplicity bias” and proposed this as a solution to the generalization question. One of the ways with which they argued that this bias exists is the following experiment: they drew a large sample of boolean functions by randomly initializing neural netw orks and thresholding the output. They observed 1 Microsoft Research, Redmond, W A, USA 2 W ork done as part of the Microsoft AI Residency Program. Correspondence to: Greg Y ang < gregyang@microsoft.com >. that there is a bias to ward some "simple" functions which get sampled disproportionately more often. Howe ver , their experiments were only done for relu networks. Can one expect this “simplicity bias” to hold universally , for any architecture? A priori , this seems difficult, as the nonlinear nature seems to present an obstacle in reasoning about the distrib ution of random networks. Howe ver , this question turns out to be more easily treated if we allow the width to go to infinity . A long line of works starting with Neal (1995) and extended recently by Lee et al. (2018); Nov ak et al. (2018); Y ang (2019a;b) ha ve shown that randomly initialized, infinite- width networks are distrib uted as Gaussian processes. These Gaussian processes also describe finite width random net- works well (V alle-Pérez et al., 2018). W e will refer to the corresponding kernels as the Conjugate Kernels (CK), fol- lowing the terminology of Daniely et al. (2016). Given the CK K , the simplicity bias of a wide neural network can be read off quickly from the spectrum of K : If the largest eigen- val ue of K accounts for most of tr K , then a typical random network looks like a function from the top eigenspace of K . In this paper , we will use this spectral perspective to probe not only the simplicity bias, but more generally , questions regarding ho w hyperparameters af fect the generalization of neural networks. V ia the usual connection between Gaussian processes and linear models with features, the CK can be thought of as the kernel matrix associated to training only the last layer of a wide randomly initialized network. It is a remarkable recent adv ance (Allen-Zhu et al., 2018a;c; Du et al., 2018; Jacot et al., 2018) that, under a certain regime, a wide neural network of an y depth ev olv es like a linear model e ven when training all parameters. The associated kernel is call the Neu- ral T angent K ernel , which is typically different from CK. While its theory was initially deri ved in the infinite width set- ting, Lee et al. (2019) confirmed with extensiv e experiment that this limit is predicti ve of finite width neural netw orks as well. Thus, just as the CK reveals information about what a network looks like at initialization , NTK rev eals information about what a network looks like after tr aining. As such, if we can understand ho w hyperparameters change the NTK, we can also hope to understand how they af fect the performance of the corresponding finite-width network. Our Contributions In this paper , in addition to showing that the simplicity bias is not uni versal, we will attempt a A Fine-Grained Spectral Perspecti ve on Neural Networks first step at understanding the ef fects of the hyperparameters on generalization from a spectral perspectiv e. At the foundation is a spectral theory of the CK and the NTK on the boolean cube. In Section 3, we show that these kernels, as inte gr al operators on functions o ver the boolean cube, are diagonalized by the natural Fourier basis, echoing similar results for ov er the sphere (Smola et al., 2001). W e also partially diagonalize the kernels over standard Gaussian, and show that, as expected, the kernels ov er the dif ferent dis- tributions (boolean cube, sphere, standard Gaussian) behav e very similarly in high dimensions. Ho we ver , the spectrum is much easier to compute over the boolean cube: while the sphere and Gaussian eigen v alues would require inte gration against a kind of polynomials known as the Gegenbauer polynomials, the boolean ones only require calculating a linear combination of a small number of terms. For this reason, in the rest of the paper we focus on analyzing the eigen v alues ov er the boolean cube. Just as the usual F ourier basis ov er R has a notion of fre- quency that can be interpreted as a measure of complexity , so does the boolean Fourier basis (this is just the de gr ee ; see Section 3.1). While not perfect, we adopt this natural notion of complexity in this work; a “simple” function is then one that is well approximated by “low frequencies. ” This spectral perspectiv e immediately yields that the sim- plicity bias is not uni versal (Section 4). In particular , while it seems to hold more or less for relu networks, for sig- moidal networks, the simplicity bias can be made arbitrarily weak by changing the weight v ariance and the depth. In the extreme case, the random function obtained from sam- pling a deep erf network with large weights is distributed like a “white noise. ” Howe ver , there is a v ery weak sense in which the simplicity bias does hold: the eigen values of more “complex” eigenspaces cannot be bigger than those of less “complex” eigenspaces (Thm 4.1). Next, we e xamine how hyperparameters affect the perfor - mance of neural networks through the lens of NTK and its spectrum. T o do so, we first need to understand the simpler question of how a kernel affects the accuracy of the function learned by kernel regression. A coarse-grained theory , con- cerned with big-O asymptotics, exists from classical kernel literature (Lin and Rosasco; Raskutti et al., 2013; Schölkopf and Smola, 2002; W ei et al.; Y ao et al., 2007). Ho we ver , the fine-grained details, required for discerning the effect of hy- perparameters, have been much less studied. W e mak e a first attempt at a heuristic, fractional variance (i.e. what fraction of the trace of the kernel does an eigenspace contribute), for understanding how a minute change in kernel effects a change in performance. Intuiti vely , if an eigenspace has very lar ge fractional variance, so that it accounts for most of the trace, then a ground truth function from this eigenspace should be very easy to learn. Using this heuristic, we make two predictions about neu- ral networks, motiv ated by observations in the spectra of NTK and CK, and verify them with e xtensi ve e xperiments. • Deeper networks learn more complex features, but ex- cess depth can be detrimental as well. Spectrally , depth can increase fractional variance of an eigenspace, but past an op- timal depth , it will also decrease it. (Section 5) Thus, deeper is not always better . • T raining all layers is better than training just the last layer when it comes to more complex features, but the opposite is true for simpler features. Spec- trally , fractional variances of more “complex” eigenspaces for the NTK are larger than the correponding quantities of the CK. (Section 6) Finally , we use our spectral theory to predict the maximal nondiv er ging learning rate (“max learning rate”) of SGD (Section 7). In general, we will not only verify our theory with experi- ments on the theoretically interesting distributions, i.e. uni- form measures over the boolean cube and the sphere, or the standard Gaussian, b ut also confirm these findings on real data like MNIST and CIF AR10 1 . For space concerns, we re vie w rele v ant literature along the flow of the main te xt, and rele gate a more complete discus- sion of the related research landscape in Appendix A. 2. K ernels Associated to Neural Netw orks As mentioned in the introduction, we now know sev eral kernels associated to infinite width, randomly initialized neural networks. The most prominent of these are the neural tangent kernel (NTK) (Jacot et al., 2018) and the conjugate kernel (CK) (Daniely et al., 2016), which is also called the NNGP kernel (Lee et al., 2018). W e briefly revie w them below . First we introduce the following notation that we will repeatedly use. Definition 2.1. For φ : R → R , write V φ for the function that takes a PSD (positiv e semidefinite) kernel function to a PSD kernel of the same domain by the formula V φ ( K )( x, x 0 ) = E f ∼N (0 ,K ) φ ( f ( x )) φ ( f ( x 0 )) . Conjugate Ker nel Neural networks are commonly thought of as learning a high-quality embedding of inputs to the latent space represented by the network’ s last hidden layer , and then using its final linear layer to read out a clas- sification giv en the embedding. The conjugate kernel is just the kernel associated to the embedding induced by a ran- dom initialization of the neural network. Consider an MLP with widths { n l } l , weight matrices { W l ∈ R n l × n l − 1 } l , and biases { b l ∈ R n l } l , l = 1 , . . . , L . For simplicity of exposition, in this paper , we will only consider scalar output n L = 1 . Suppose it is parametrized by the NTK 1 The code for computing the eigen values and for reproducing the plots of this paper is a v ailable at https://github.com/ thegregyang/NNspectra . A Fine-Grained Spectral Perspecti ve on Neural Networks parametrization , i.e. its computation is given recursi v ely as h 1 ( x ) = σ w √ n 0 W 1 x + σ b b 1 and h l ( x ) = σ w √ n l − 1 W l φ ( h l − 1 ( x )) + σ b b l (MLP) with some hyperparameters σ w , σ b that are fixed through- out training 2 . At initialization time, suppose W l αβ , b l α ∼ N (0 , 1) for each α ∈ [ n l ] , β ∈ [ n l − 1 ] . It can be shown that, for each α ∈ [ n l ] , h l α is a Gaussian process with zero mean and k ernel function Σ l in the limit as all hidden layers become infinitely wide ( n l → ∞ , l = 1 , . . . , L − 1 ), where Σ l is defined inductiv ely on l as Σ 1 ( x, x 0 ) def = σ 2 w ( n 0 ) − 1 h x, x 0 i + σ 2 b , Σ l def = σ 2 w V φ (Σ l − 1 ) + σ 2 b (CK) The kernel Σ L corresponding the the last layer L is the network’ s conjugate kernel , and the associated Gaussian process limit is the reason for its alternati ve name Neural Network-Gaussian pr ocess kernel . In short, if we were to train a linear model with feat ures gi ven by the embedding x 7→ h L − 1 ( x ) when the network parameters are randomly sampled as abov e, then the CK is the kernel of this linear model. See Daniely et al. (2016); Lee et al. (2018) and Appendix F for more details. Neural T angent Ker nel On the other hand, the NTK cor- responds to training the entire model instead of just the last layer . Intuiti vely , if we let θ be the entire set of parame- ters { W l } l ∪ { b l } l of Eq. (MLP), then for θ close to its initialized value θ 0 , we expect h L ( x ; θ ) − h L ( x ; θ 0 ) ≈ h∇ θ h L ( x ; θ 0 ) , θ − θ 0 i via a naive first-order T aylor expansion. In other words, h L ( x ; θ ) − h L ( x ; θ 0 ) behav es like a linear model with fea- ture of x giv en by the gradient taken w .r .t. the initial network, ∇ θ h L ( x ; θ 0 ) , and the weights of this linear model are the deviation θ − θ 0 of θ from its initial value. It turns out that, in the limit as all hidden layer widths tend to infinity , this intuition is correct (Jacot et al., 2018; Lee et al., 2018; Y ang, 2019a;b), and the follo wing inducti ve formula computes the corresponding infinite-width kernel of this linear model: Θ 1 def = Σ 1 , (NTK) Θ l ( x, x 0 ) def = Σ l ( x, x 0 ) + σ 2 w Θ l − 1 ( x, x 0 )V φ 0 (Σ l − 1 )( x, x 0 ) . Computing CK and NTK While in general, computing V φ and V φ 0 requires ev aluating a multiv ariate Gaussian expectation, in specific cases, such as when φ = relu or 2 SGD with learning rate α in this parametrization is roughly equiv alent to SGD with learning rate α/w idth in the standard parametrization with Glorot initialization; see Lee et al. (2018) erf , there exists explicit, ef ficient formulas that only require pointwise ev aluation of some simple functions (see Facts F .1 and F .2). This allo ws us to e v aluate CK and NTK on a set X of inputs in only time O ( |X | 2 L ) . What Do the Spectra of CK and NTK T ell Us? In sum- mary , the CK gov erns the distribution of a randomly ini- tialized neural network and also the properties of training only the last layer of a network, while the NTK governs the dynamics of training (all parameters of) a neural network. A study of their spectra thus informs us of the “implicit prior” of a randomly initialized neural network as well as the “implicit bias” of GD in the context of training neural networks. In regards to the implicit prior at initialization, we know from Lee et al. (2018) that a randomly initialized network as in Eq. (MLP) is distributed as a Gaussian process N (0 , K ) , where K is the corresponding CK, in the infinite-width limit. If we hav e the eigendecomposition K = X i ≥ 1 λ i u i ⊗ u i (1) with eigen v alues λ i in decreasing order and corresponding eigenfunctions u i , then each sample from this GP can be obtained as X i ≥ 1 p λ i ω i u i , ω i ∼ N (0 , 1) . If, for example, λ 1 P i ≥ 2 λ i , then a typical sample function is just a very small perturbation of u 1 . W e will see that for relu, this is indeed the case (Section 4), and this explains the “simplicity bias” in relu networks found by V alle-Pérez et al. (2018). T raining the last layer of a randomly initialized network via full batch gradient descent for an infinite amount of time corresponds to Gaussian process inference with kernel K (Lee et al., 2018; 2019). A similar intuition holds for NTK: training all parameters of the network (Eq. (MLP)) for an infinite amount of time yields the mean prediction of the GP N (0 , NTK ) in expectation; see Lee et al. (2019) and Appendix F .4 for more discussion. Thus, the more the GP prior (gov erned by the CK or the NTK) is consistent with the ground truth function f ∗ , the more we expect the Gaussian process inference and GD training to generalize well. W e can measure this consis- tency in the “alignment” between the eigen values λ i and the squared coefficients a 2 i of f ∗ ’ s expansion in the { u i } i basis. The former can be interpreted as the expected magnitude (squared) of the u i -component of a sample f ∼ N (0 , K ) , and the latter can be interpreted as the actual magnitude squared of such component of f ∗ . In this paper, we will in v estigate an ev en cleaner setting where f ∗ = u i is an eigenfunction. Thus we would hope to use a k ernel whose i th eigen v alue λ i is as large as possible. A Fine-Grained Spectral Perspecti ve on Neural Networks Neural K ernels From the forms of the equation Eqs. (CK) and (NTK) and the fact that V φ ( K )( x, x 0 ) only depends on K ( x, x ) , K ( x, x 0 ) , and K ( x 0 , x 0 ) , we see that CK or NTK of MLPs takes the form K ( x, y ) = Φ h x, y i k x kk y k , k x k 2 d , k y k 2 d (2) for some function Φ : R 3 → R . W e will refer to this kind of kernel as Neural K ernel in this paper . Ker nels as Integral Operators W e will consider input spaces of various forms X ⊆ R d equipped with some proba- bility measure. Then a kernel function K acts as an inte gr al operator on functions f ∈ L 2 ( X ) by K f ( x ) = ( K f )( x ) = E y ∼X K ( x, y ) f ( y ) . W e will use the “juxtaposition syntax” K f to denote this application of the integral operator . 3 Under certain as- sumptions, it then makes sense to speak of the eigenv alues and eigenfunctions of the integral operator K . While we will appeal to an intuitiv e understanding of eigen values and eigenfunctions in the main text below , we include a more formal discussion of Hilbert-Schmidt operators and their spectral theory in Appendix G for completeness. In the next section, we inv estigate the eigendecomposition of neural kernels as integral operators o v er different distrib utions. 3. The Spectra of Neural K ernels In large dimension d , the spectrum of CK (or NTK) is roughly the same when the underlying data distrib ution is the standard Gaussian or the uniform distribution o ver the boolean cube or the sphere: Theorem 3.1. Suppose K is the CK or NTK of an MLP with polynomially bounded activation function, and let Φ be as in Eq. (2) . Let the underlying data distribution be the uniform distribution o ver the boolean cube {± 1 } d , the uni- form distribution o ver the spher e √ d S d − 1 , or the standar d Gaussian distribution N (0 , I ) . F or any d, k > 0 , let κ d,k be the k th larg est unique eigen value of K over this data distribution. Then for any k > 0 , and for suf ficiently lar ge d (depending on k ), κ d,k corr esponds to an eigenspace of dimension d k /k ! + o ( d k ) , and lim d →∞ d k κ d,k = Φ ( k ) (0 , 1 , 1) , wher e Φ ( k ) ( t, q , q 0 ) = d k dt k Φ( t, q , q 0 ) . This is a consequence of Thms H.2, H.13 and H.18. 3 In cases when X is finite, K can be also thought of as a big matrix and f as a vector — but do not confuse K f with their multiplication! If we use · to denote matrix multiplication, then the operator application K f is the same as the matrix multiplication K · D · f where D is the diagonal matrix encoding the probability values of each point in X . W e numerically verify this theorem in Appendix H.4. Note that, in contrast to traditional learning theory literature which typically in vestig ates the decay rate (Lin and Rosasco; W ei et al.; Y ao et al., 2007) of the i th largest (non-unique) eigen v alue λ i with i , we are concerned here only with a constant number k of the top unique eigen values κ d,k . W e argue the latter is a more realistic scenario. This is because these k eigen v alues will altogether account for a subspace of ≈ d k /k ! total dimensions, which, for example when d = 24 2 = 576 (pixel count of an MNIST image) and k = 5 , is ≈ 5 . 2 × 10 11 . Giv en that Imagenet, one of the largest public datasets, only has ≈ 1 . 5 × 10 7 samples, it will be difficult in the near future for one to hav e enough data to ev en detect the smaller eigenv alues κ d,k , k > 5 , based on standard eigen v alue concentration bounds (T ropp, 2015). As the underlying data distribution does not af fect the spec- trum much in high dimension, in the main text we will focus on the case of boolean cube, while we relegate a full theoret- ical treatment of the sphere (Appendix H.2) and Gaussian (Appendix H.3) cases to the appendix. Howe ver , we will verify that our empirical findings over the boolean cube carries ov er the sphere and Gaussian, and ev en real datasets like MNIST and CIF AR10. 3.1. Boolean Cube W e first consider a neural kernel K on the boolean cube X = d def = {± 1 } d , equipped with the uniform measure. In this case, since each x ∈ X has the same norm, K ( x, y ) = Φ h x,y i k x kk y k , k x k 2 d , k y k 2 d effecti vely only depends on h x, y i , so we will treat Φ as a single v ariate function in this section, Φ( c ) = Φ( c, 1 , 1) . Brief review of basic Fourier analysis on the boolean cube d (O’Donnell (2014)). The space of real functions on d forms a 2 d -dimensional space. Any such function has a unique expansion into a multilinear polynomial (poly- nomials whose monomials do not contain x p i , p ≥ 2 , of any variable x i ). For example, the majority function ov er 3 bits has the following unique multilinear e xpansion ma j 3 : 3 → 1 , ma j 3 ( x 1 , x 2 , x 3 ) = 1 2 ( x 1 + x 2 + x 3 − x 1 x 2 x 3 ) . In the language of F ourier analysis, the 2 d multilinear mono- mial functions χ S ( x ) def = x S def = Y i ∈ S x i , for each S ⊆ [ d ] (3) form a Fourier basis of the function space L 2 ( d ) = { f : d → R } , in the sense that their inner products satisfy E x ∼ d χ S ( x ) χ T ( x ) = I ( S = T ) . Thus, any function f : d → R can be always written as f ( x ) = X S ⊆ [ d ] ˆ f ( S ) χ X ( x ) A Fine-Grained Spectral Perspecti ve on Neural Networks for a unique set of coef ficients { ˆ f ( S ) } S ⊆ [ d ] . It turns out that K is always diagonalized by this Fourier basis { χ S } S ⊆ [ d ] . Theorem 3.2. On the d -dimensional boolean cube d , for every S ⊆ [ d ] , χ S is an eigenfunction of K with eigen value µ | S | def = E x ∈ d x S K ( x, 1 ) = E x ∈ d x S Φ X i x i /d ! , (4) wher e 1 = (1 , . . . , 1) ∈ d . This definition of µ | S | does not depend on the choice S , only on the car dinality of S . These ar e all of the eigenfunctions of K by dimensionality considerations. 4 Define T ∆ to be the shift operator on functions over [ − 1 , 1] that sends Φ( · ) to Φ( · − ∆) . Then we can re-express the eigen v alue as follo ws. Lemma 3.3. W ith µ k as in Thm 3.2, µ k = 2 − d ( I − T ∆ ) k ( I + T ∆ ) d − k Φ(1) (5) = 2 − d d X r =0 C d − k,k r Φ d 2 − r ∆ (6) wher e C d − k,k r def = X j =0 ( − 1) r + j d − k j k r − j . (7) Eq. (5) will be important for computational purposes (see Appendix H.1.1). It also turns out µ k affords a pretty ex- pression via the F ourier series coef ficients of Φ . As this is not essential to the main te xt, we rele gate its e xposition to Appendix H.1. 4. Clarifying the “Simplicity Bias” of Random Neural Networks As mentioned in the introduction, V alle-Pérez et al. (2018) claims that neural networks are biased towar d simple func- tions . W e show that this phenomenon depends crucially on the nonlinearity , the sampling variances, and the depth of the network. In Fig. 1(a), we ha ve repeated their experiment for 10 4 random functions obtained by sampling relu neural networks with 2 hidden layers, 40 neurons each, follo wing V alle-Pérez et al. (2018)’ s architectural choices 5 . W e also do the same for erf netw orks of the same depth and width, varying as well the sampling variances of the weights and biases, as shown in the le gend. As discussed in V alle-Pérez et al. (2018), for relu, there is indeed this bias, where a single 4 Readers familiar with boolean Fourier analysis may be re- minded of the noise operator T ρ , ρ ≤ 1 (see Defn 2.45 of O’Donnell (2014)). In the language of this work, T ρ is a neu- ral kernel with eigen v alues µ k = ρ k . 5 V alle-Pérez et al. (2018) actually performed their experiments ov er the { 0 , 1 } 7 cube, not the {± 1 } 7 cube we are using here. This does not affect our conclusion. See Appendix K for more discussion 1 0 0 1 0 1 1 0 2 1 0 3 1 0 4 rank 1 0 4 1 0 3 1 0 2 1 0 1 probability (a) p r o b v s r a n k o f 1 0 4 r a n d o m n e t s | 2 w | 2 b relu | 2 | 2 erf | 1 | 0 erf | 2 | 0 erf | 4 | 0 0 2 4 6 d e g r e e k 1 0 4 1 0 3 1 0 2 1 0 1 1 0 0 n o r m a l i z e d e i g e n v a l u e k (b) e r f n e t s l o s e s i m p l i c i t y b i a s f o r l a r g e 2 w , d e p t h | 2 w | 2 b | d e p t h relu | 2 | 2 | 2 erf | 1 | 0 | 2 erf | 2 | 0 | 2 erf | 4 | 0 | 2 erf | 4 | 0 | 32 Figure 1. The "simplicity bias" is not so simple. (a) Follo w- ing V alle-Pérez et al. (2018), we sample 10 4 boolean functions {± 1 } 7 → {± 1 } as follows: for each combination of nonlinearity , weight variance σ 2 w , and bias variance σ 2 b (as used in Eq. (MLP)), we randomly initialize a network of 2 hidden layers, 40 neurons each. Then we threshold the function output to a boolean output, and obtain a boolean function sample. W e repeat this for 10 4 random seeds to obtain all samples. Then we sort the samples according to their empirical probability (this is the x-axis, rank ), and plot their empirical probability (this is the y-axis, probability ). The high values at the left of the relu curve indicates that a few functions get sampled repeatedly , while this is less true for erf. For erf and σ 2 w = 4 , no function got sampled more than once. (b) For dif ferent combination of nonlinearity , σ 2 w , σ 2 b , and depth, we study the eigenv alues of the corresponding CK. Each CK has 8 different eigen values µ 0 , . . . , µ 7 corresponding to homogeneous polynomials of degree 0 , . . . , 7 . W e plot them in log scale against the degree. Note that for erf and σ b = 0 , the even degree µ k vanish. See main text for explanations. 2 4 6 8 degree 0.0 2.5 5.0 7.5 optimal depth (a) relu opt depths ntk ck 2 4 6 8 degree 0 50 100 (b) erf opt depths ntk ck 3 5 7 degree 0 4 8 12 16 20 depth (c) r e l u n t k , 2 b = 0 0.00 0.02 0.04 0.06 3 5 7 degree 0 50 100 (d) e r f n t k , 2 w = 1 , 2 b = 0 0.0 0.1 0.2 fractional variance Figure 2. The depth maximizing degree k fractional variance increases with k for both relu and erf. For relu (a) and erf (b) , we plot for each degree k the depth such that there exists some combination of other hyperparameters (such as σ 2 b or σ 2 w ) that maximizes the degree k fractional variance. For both relu, σ 2 b = 0 maximizes fractional v ariance in general, and same holds for erf in the odd degrees (see Appendix D), so we take a closer look at this slice by plotting heatmaps of fractional variance of various degrees versus depth for relu (c) and erf (d) NTK, with bright colors representing high variance. Clearly , we see the brightest region of each column, corresponding to a fixed degree, moves up as we increase the degree, barring for the even/odd degree alternating pattern for erf NTK. The pattern for CKs are similar and their plots are omitted. function gets sampled more than 10% of the time. Howe ver , for erf, as we increase σ 2 w , we see this bias disappear, and A Fine-Grained Spectral Perspecti ve on Neural Networks ev ery function in the sample gets sampled only once. This phenomenon can be explained by looking at the eigen- decomposition of the CK, which is the Gaussian process kernel of the distribution of the random networks as their hidden widths tend to infinity . In Fig. 1(b), we plot the normalized eigen v alues { µ k / P 7 i =0 7 i µ i } 7 k =0 for the CKs corresponding to the networks sampled in Fig. 1(a). Imme- diately , we see that for relu and σ 2 w = σ 2 b = 2 , the degree 0 eigenspace, corresponding to constant functions, accounts for more than 80% of the variance. This means that a typ- ical infinite-width relu network of 2 layers is expected to be almost constant, and this should be e ven more true after we threshold the network to be a boolean function. On the other hand, for erf and σ b = 0 , the e ven degree µ k s all vanish, and most of the v ariance comes from degree 1 com- ponents (i.e. linear functions). This concentration in degree 1 also lessens as σ 2 w increases. But because this variance is spread across a dimension 7 eigenspace, we don’t see duplicate function samples nearly as much as in the relu case. As σ w increases, we also see the eigen v alues become more equally distributed, which corresponds to the flatten- ing of the probability-vs-rank curve in Fig. 1(a). Finally , we observe that a 32-layer erf network with σ 2 w = 4 has all its nonzero eigen values (associated to odd degrees) all equal (see points marked by ∗ in Fig. 1(b)). This means that its distribution is a "white noise" on the space of odd functions, and the distribution of boolean functions obtained by thresholding the Gaussian process samples is the uniform distribution on odd functions. This is the complete lack of simplicity bias modulo the oddness constraint. Howe v er , from the spectral perspectiv e, there is a weak sense in which a simplicity bias holds for all neural network- induced CKs and NTKs. Theorem 4.1 (W eak Spectral Simplicity Bias) . Let K be the CK or NTK of an MLP on a boolean cube d . Then the eigen values µ k , k = 0 , . . . , d, satisfy µ 0 ≥ µ 2 ≥ · · · ≥ µ 2 k ≥ · · · , µ 1 ≥ µ 3 ≥ · · · ≥ µ 2 k +1 ≥ · · · . (8) Even though it’ s not true that the fraction of variance con- tributed by the degree k eigenspace is decreasing with k , the eigen v alue themselv es will be in a nonincreasing pattern across even and odd degrees. Of course, as we have seen, this is a very weak sense of simplicity bias, as it doesn’t prev ent “white noise” behavior as in the case of erf CK with large σ 2 w and large depth. 5. Deeper Networks Lear n More Complex F eatures In the rest of this work, we compute the eigen v alues µ k ov er the 128-dimensional boolean cube ( d , with d = 128 ) for a large number of different hyperparameters, and ana- lyze ho w the latter affect the former . W e vary the degree k ∈ [0 , 8] , the nonlinearity between relu and erf, the depth (number of hidden layers) from 1 to 128, and σ 2 b ∈ [0 , 4] . W e fix σ 2 w = 2 for relu kernels, but additionally vary σ 2 w ∈ [1 , 5] for erf kernels. Comprehensive contour plots of how these hyperparameters affect the kernels are included in Appendix D, b ut in the main te xt we summarize se veral trends we see. W e will primarily measure the change in the spectrum by the de gr ee k fractional variance , which is just degree k fractional variance def = d k µ k P d i =0 d i µ i . This terminology comes from the fact that, if we were to sample a function f from a Gaussian process with kernel K , then we expect that r % of the total variance of f comes from degree k components of f , where r % is the degree k fractional v ariance. If we were to try to learn a homogeneous degree- k polynomial using a kernel K , intuitiv ely we should try to choose K such that its µ k is maximized, relative to other eigen v alues. Fig. 3(a) shows that this is indeed the case ev en with neural networks: over a large number of diff erent hyperparameter settings, degree k fractional variance is in versely related to the validation loss incurred when learning a degree k polynomial. Howe ver , this plot also shows that there does not seem like a precise, clean relationship between fractional variance and v alidation loss. Obtaining a better measure for predicting generalization is left for future work. If K were to be the CK or NTK of a relu or erf MLP , then we find that for higher k , the depth of the network helps increase the degree k fractional variance. In Fig. 2(a) and (b), we plot, for each degree k , the depth that (with some combination of other hyperparameters like σ 2 b ) achie ves this maximum, for respectively relu and erf kernels. Clearly , the maximizing depths are increasing with k for relu, and also for erf when considering either odd k or even k only . The slightly dif fering beha vior between e ven and odd k is expected, as seen in the form of Thm 4.1. Note the different scales of y-axes for relu and erf — the depth effect is much stronger for erf than relu. For relu NTK and CK, σ 2 b = 0 maximizes fractional v ari- ance in general, and the same holds for erf NTK and CK in the odd degrees (see Appendix D). In Fig. 2(c) and Fig. 2(d) we give a more fine-grained look at the σ 2 b = 0 slice, via heatmaps of fractional variance against degree and depth. Brighter color indicates higher v ariance, and we see the opti- mal depth for each de gree k clearly increases with k for relu NTK, and likewise for odd degrees of erf NTK. Howe ver , note that as k increases, the dif ference between the maximal fractional v ariance and those slightly suboptimal becomes smaller and smaller , reflected by suppressed range of color moving to the right. The heatmaps for relu and erf CKs look similar and are omitted. W e verify this increase of optimal depth with degree in Fig. 3(b). There we have trained relu networks of vary- A Fine-Grained Spectral Perspecti ve on Neural Networks 0 2 4 6 8 10 layers 0.0 0.2 0.4 0.6 0.8 1.0 best val. loss 1 - frac. var. (b) optimal depth increases with degree deg 0 deg 1 deg 2 deg 3 val loss 1 - fracvar 0.0 0.2 0.4 0.6 0.8 1.0 best val. loss 0.0 0.2 0.4 0.6 0.8 1.0 fractional variance (a) best loss and frac. var. are inversely related ntk ck layers 0 4 8 12 deg 0 1 2 3 layers 0 4 8 12 deg 0 1 2 3 0.0 0.2 0.4 0.6 0.8 1.0 best val loss (last layer) 0.0 0.2 0.4 0.6 0.8 1.0 best val loss (all layers) (c) training last layer vs training all layers deg 0 1 2 3 4 5 Verifying best depths and NTK complexity bias, varying degree of ground truth Figure 3. (a) W e train relu networks of different depths against a ground truth polynomial on 128 of different de grees k . W e either train only the last layer (marked “ck”) or all layers (marked “ntk”), and plot the de gree k fractional v ariance of the corresponding kernel against the best validation loss ov er the course of training. W e see that the best validation loss is in general inv ersely correlated with fraction variance, as e xpected. Howe ver , their precise relationship seems to change depending on the degree, or whether training all layers or just the last. See Appendix E for experimental details. (b) Same experimental setting as (a), with slightly different hyperparameters, and plotting depth against best v alidation loss (solid curv es), as well as the corresponding kernel’ s ( 1 − fractional variance) (dashed curves). W e see that the loss-minimizing depth increases with the degree, as predicted by Fig. 2. Note that we do not expect the dashed and solid curves to match up, just that they are positi v ely correlated as sho wn by (a). In higher degrees, the losses are high across all depths, and the variance is lar ge, so we omit them. See Appendix E for experimental details. (c) Similar experimental setting as (a), but with more hyperparameters, and now comparing training last layer vs training all layers. See Appendix E for experimental details. W e also replicate (b) for MNIST and CIF AR10, and moreover both (b) and (c) o ver the input distrib utions of standard Gaussian and the uniform measure ov er the sphere. See Figs. 6 to 8. 0 2 4 6 8 degree 1 0 4 1 0 2 1 0 0 fractional variance (a) relu examples d e p t h | 2 b 1 | 0.1 128 | 3.0 3 | 0.0 ntk ck 0 2 4 6 8 degree 1 0 4 1 0 2 1 0 0 (b) erf examples d e p t h | 2 w | 2 b 1 | 2 | 0.1 24 | 1 | 0.1 1 | 5 | 4.0 ntk ck 0 1 2 3 4 5 6 7 8 degree 0.0 0.2 0.4 0.6 0.8 1.0 fraction (c) fraction of hyperparams where ntk > ck relu erf ntk favors higher degrees compared to ck Figure 4. Across nonlinearities and hyperparameters, NTK tends to ha ve higher fraction of v ariance attributed to higher degrees than CK. In (a) , we give sev eral examples of the fractional variance curves for relu CK and NTK across sev eral representativ e hyperparameters. In (b) , we do the same for erf CK and NTK. In both cases, we clearly see that, while for de gree 0 or 1, the fractional variance is typically higher for CK, the re verse is true for lar ger degrees. In (c) , for each degree k , we plot the fraction of hyperpar ameters where the degree k fractional variance of NTK is greater than that of CK. Consistent with pre vious observ ations, this fraction increases with the degree. 1 0 2 1 0 1 1 0 0 1 0 1 empirical max lr 1 0 2 1 0 1 1 0 0 1 0 1 theoretical max lr (a) max lr: training the last layer (CK) dist MNIST CIFAR10 Gaussian Sphere BoolCube 1 0 2 1 0 1 1 0 0 1 0 1 empirical max lr 1 0 2 1 0 1 1 0 0 1 0 1 theoretical max lr (b) max lr: training all layers (NTK) dist MNIST CIFAR10 Gaussian Sphere BoolCube 1 0 2 1 0 1 1 0 0 1 0 1 empirical max lr 1 0 2 1 0 1 1 0 0 1 0 1 theoretical max lr (c) max lr: training all layers (NTK) depth 1 2 4 8 16 Boolean cube theory predicts max learning rate for real datasets Figure 5. Spectral theory of CK and NTK over boolean cube predicts max learning rate for SGD over real datasets MNIST and CIF AR10 as well as over boolean cube 128 , the sphere √ 128 S 128 − 1 , and the standard Gaussian N (0 , I 128 ) . In all three plots, for different depth, nonlinearity , σ 2 w , σ 2 b of the MLP , we obtain its maximal nondi ver ging learning rate (“max learning rate”) via binary search. W e center and normalize each image of MNIST and CIF AR10 to the √ d S d − 1 sphere, where d = 28 2 = 784 for MNIST and d = 3 × 32 2 = 3072 for CIF AR10. See Appendix E.2 for more details. (a) W e empirically find max learning rate for training only the last layer of an MLP . Theoretically , we predict 1 / Φ(0) where Φ corresponds to the CK of the MLP . W e see that our theoretical prediction is highly accurate. Note that the Gaussian and Sphere points in the scatter plot coincide with and hide behind the BoolCube points. (b) and (c) W e empirically find max learning rate for training all layers. Theoretically , we predict 1 / Φ(0) where Φ corresponds to the NTK of the MLP . The points are identical between (b) and (c), but the color coding is different. Note that the Gaussian points in the scatter plots coincide with and hide behind the Sphere points. In (b) we see that our theoretical prediction when training all layers is not as accurate as when we train only the last layer , b ut it is still highly correlated with the empirical max learning rate. It in general underpredicts, so that half of the theoretical learning rate should always hav e SGD con ver ge. This is expected, since the NTK limit of training dynamics is only exact in the large width limit, and larger learning rate just means the training dynamics diver ges from the NTK regime, but not necessarily that the training di ver ges. In (c) , we see that deeper networks tend to accept higher learning rate than our theoretical prediction. If we were to preprocess MNIST and CIF AR10 dif ferently , then our theory is less accurate at predicting the max learning rate; see Fig. 9 for more details. A Fine-Grained Spectral Perspecti ve on Neural Networks ing depth against a ground truth multilinear polynomial of varying degree. W e see clearly that the optimal depth is increasing with degree. W e also verify this phenomenon when the input distrib ution changes to the standard Gaussian or the uniform distribution ov er the sphere √ d S d − 1 ; see Fig. 6. Note that implicit in our results here is a highly nontriv- ial observation: Past some point (the optimal depth ), high depth can be detrimental to the performance of the network, beyond just the difficulty to train, and this detriment can already be seen in the corresponding NTK or CK. In par- ticular , it’ s not true that the optimal depth is infinite. W e confirm the existence of such an optimal depth e ven in real distributions like MNIST and CIF AR10; see Fig. 7. This adds significant nuance to the folk wisdom that “depth in- creases expressi vity and allo ws neural networks to learn more complex features. ” 6. NTK F a vors Mor e Complex F eatur es Than CK W e generally find the degree k fractional v ariance of NTK to be higher than that of CK when k is large, and vice versa when k is small, as sho wn in Fig. 4. This means that, if we train only the last layer of a neural network (i.e. CK dynam- ics), we intuiti vely should expect to learn simpler features better , while, if we train all parameters of the network (i.e. NTK dynamics), we should e xpect to learn more complex features better . Similarly , if we were to sample a function from a Gaussian process with the CK as k ernel (recall this is just the distribution of randomly initialized infinite width MLPs (Lee et al., 2018)), this function is more likely to be accurately approximated by low degree polynomials than the same with the NTK. W e verify this intuition by training a large number of neural networks against ground truth functions of various homo- geneous polynomials of different de grees, and sho w a scat- terplot of how training the last layer only measures ag ainst training all layers (Fig. 3(c)). This phenomenon remains true ov er the standard Gaussian or the uniform distrib ution on the sphere (Fig. 8). Consistent with our theory , the only place training the last layer works meaningfully better than training all layers is when the ground truth is a constant function. Ho we ver , we reiterate that fractional variance is an imperfect indicator of performance. Even though for erf neural networks and k ≥ 1 , degree k fractional variance of NTK is not always greater than that of the CK, we do not see any instance where training the last layer of an erf network is better than training all layers. W e leav e an in v estigation of this discrepancy to future work. 7. Predicting the Maximum Lear ning Rate In any setup that tries to push deep learning benchmarks, learning rate tuning is a painful but indispensable part. In this section, we sho w that our spectral theory can accurately predict the maximal nondiv erging learning rate over r eal datasets as well as toy input distributions, which would help set the correct upper limit for a learning rate search. By Jacot et al. (2018), in the limit of large width and infinite data, the function g : X → R represented by our neural network e v olves like g t +1 = g t − 2 αK ( g t − g ∗ ) , t = 0 , 1 , 2 , . . . , (9) when trained under full batch GD (with the entire popula- tion) with L2 loss L ( f , g ) = E x ∼X ( f ( x ) − g ( x )) 2 , ground truth g ∗ , and learning rate α , starting from randomly initial- ization. If we train only the last layer , then K is the CK; if we train all layers, then K is the NTK. Giv en an eigende- composition of K as in Eq. (1), if g 0 − g ∗ = P i a i u i is the decomposition of g 0 in the eigenbasis { u i } i , then one can easily deduce that g t − g ∗ = X i a i (1 − 2 αλ i ) t u i . Consequently , we must have α < (max i λ i ) − 1 in order for Eq. (9) to con v erge 6 When the input distribution is the uniform distrib ution ov er d , the maximum learning rate is max( µ 0 , µ 1 ) by Thm 4.1. By Thm 3.1, as long as the Φ function corresonding to K has Φ(0) 6 = 0 , when d is large, we expect µ 0 ≈ Φ(0) but µ 1 ∼ d − 1 Φ 0 (0) µ 0 . Therefore, we should predict 1 Φ(0) for the maximal learning rate when training on the boolean cube. Howe ver , as Fig. 5 shows, this prediction is accurate not only for the boolean cube, but also o ver the sphere, the standard Gaussian, and ev en MNIST and CIF AR10! 8. Conclusion In this work, we hav e taken a first step at studying how hyperparameters change the initial distribution and the gen- eralization properties of neural networks through the lens of neural kernels and their spectra. W e obtained interesting insights by computing kernel eigen values ov er the boolean cube and relating them to generalization through the frac- tional variance heuristic. While it inspired valid predictions that are backed up by experiments, fractional variance is clearly just a rough indicator . W e hope future work can re- fine on this idea to produce a much more precise prediction of test loss. Nevertheless, we believe the spectral perspec- tiv e is the right line of research that will not only shed light on mysteries in deep learning but also inform design choices in practice. 6 Note that this is the max learning rate of the infinite-width neural network ev olving in the NTK regime, but not necessarily the max learning rate of the finite-wdith neural network, as a lar ger learning rate just means that the network no longer e volv es in the NTK regime. A Fine-Grained Spectral Perspecti ve on Neural Networks References Joshua Achiam, Ethan Knight, and Pieter Abbeel. T o- wards Characterizing Diver gence in Deep Q-Learning. arXiv:1903.08894 [cs] , March 2019. Zeyuan Allen-Zhu, Y uanzhi Li, and Y ingyu Liang. Learn- ing and Generalization in Overparameterized Neural Net- works, Going Beyond T wo Layers. [cs, math, stat] , Nov ember 2018a. Zeyuan Allen-Zhu, Y uanzhi Li, and Zhao Song. On the Con- ver gence Rate of Training Recurrent Neural Networks. arXiv:1810.12065 [cs, math, stat] , October 2018b. Zeyuan Allen-Zhu, Y uanzhi Li, and Zhao Song. A Con v ergence Theory for Deep Learning via Over- Parameterization. arXiv:1811.03962 [cs, math, stat] , Nov ember 2018c. Sanjeev Arora, Simon S. Du, W ei Hu, Zhiyuan Li, Ruslan Salakhutdinov , and Ruosong W ang. On Ex- act Computation with an Infinitely Wide Neural Net. arXiv:1904.11955 [cs, stat] , April 2019a. Sanjeev Arora, Simon S. Du, W ei Hu, Zhiyuan Li, and Ruosong W ang. Fine-Grained Analysis of Optimization and Generalization for Overparameterized T wo-Layer Neural Networks. January 2019b. A. R. Barron. Universal approximation bounds for super- positions of a sigmoidal function. IEEE T r ansactions on Information Theory , 39(3):930–945, May 1993. ISSN 0018-9448. doi: 10.1109/18.256500. Ronen Basri, David Jacobs, Y oni Kasten, and Shira Kritchman. The Conv er gence Rate of Neural Net- works for Learned Functions of Different Frequencies. arXiv:1906.00425 [cs, eess, stat] , June 2019. Agata Bezubik, Agata Da ¸ browska, and Aleksander Stras- bur ger . On spherical expansions of zonal functions on Euclidean spheres. Arc hiv der Mathematik , 90(1):70– 81, January 2008. ISSN 0003-889X, 1420-8938. doi: 10.1007/s00013- 007- 2308- y. Alberto Bietti and Julien Mairal. On the Inductiv e Bias of Neural T angent Kernels. arXiv:1905.12173 [cs, stat] , May 2019. Kenneth Blomqvist, Samuel Kaski, and Markus Heinonen. Deep con v olutional Gaussian processes. arXiv pr eprint arXiv:1810.03052 , 2018. Anastasia Borovykh. A gaussian process perspecti ve on conv olutional neural networks. arXiv preprint arXiv:1810.10798 , 2018. John Bradshaw , Alexander G de G Matthe ws, and Zoubin Ghahramani. Adversarial examples, uncertainty , and transfer testing robustness in gaussian process hybrid deep networks. arXiv preprint , 2017. Emmanuel J. Candès. Harmonic Analysis of Neural Net- works. Applied and Computational Harmonic Analy- sis , 6(2):197–218, March 1999. ISSN 1063-5203. doi: 10.1006/acha.1998.0248. Minmin Chen, Jeffre y Pennington, and Samuel Schoenholz. Dynamical Isometry and a Mean Field Theory of RNNs: Gating Enables Signal Propagation in Recurrent Neural Networks. In Proceedings of the 35th International Con- fer ence on Machine Learning , v olume 80 of Pr oceedings of Machine Learning Researc h , pages 873–882, Stock- holmsmässan, Stockholm Sweden, July 2018. PMLR. Y oungmin Cho and Lawrence K. Saul. Kernel methods for deep learning. In Advances in Neural Information Pr ocessing Systems , pages 342–350, 2009. Andreas Damianou and Neil Lawrence. Deep gaussian processes. In Artificial Intelligence and Statistics , pages 207–215, 2013. Amit Daniely , Roy Frostig, and Y oram Singer . T o- ward Deeper Understanding of Neural Networks: The Power of Initialization and a Dual V iew on Expressi vity . arXiv:1602.05897 [cs, stat] , February 2016. Simon S. Du, Xiyu Zhai, Barnabas Poczos, and Aarti Singh. Gradient Descent Prov ably Optimizes Over- parameterized Neural Networks. arXiv:1810.02054 [cs, math, stat] , October 2018. Ronen Eldan and Ohad Shamir . The Po wer of Depth for Feedforward Neural Networks. In Conference on Learn- ing Theory , pages 907–940, June 2016. Adrià Garriga-Alonso, Laurence Aitchison, and Carl Ed- ward Rasmussen. Deep Conv olutional Networks as shal- low Gaussian Processes. arXiv:1808.05587 [cs, stat] , August 2018. Behrooz Ghorbani, Song Mei, Theodor Misiakie wicz, and Andrea Montanari. Linearized two-layers neural net- works in high dimension. arXiv:1904.12191 [cs, math, stat] , April 2019. Xavier Glorot and Y oshua Bengio. Understanding the dif- ficulty of training deep feedforward neural netw orks. In Y ee Whye T eh and Mike T itterington, editors, Pr oceed- ings of the Thirteenth International Confer ence on Artifi- cial Intelligence and Statistics , volume 9 of Pr oceedings of Machine Learning Resear c h , pages 249–256, Chia La- guna Resort, Sardinia, Italy, May 2010. PMLR. 02641. T ilmann Gneiting. Strictly and non-strictly positiv e defi- nite functions on spheres. Bernoulli , 19(4):1327–1349, September 2013. ISSN 1350-7265. doi: 10.3150/ 12- BEJSP06. Boris Hanin. Which Neural Net Architectures Give Rise T o Exploding and V anishing Gradients? January 2018. A Fine-Grained Spectral Perspecti ve on Neural Networks Boris Hanin and David Rolnick. How to Start Train- ing: The Ef fect of Initialization and Architecture. arXiv:1803.01719 [cs, stat] , March 2018. Soufiane Hayou, Arnaud Doucet, and Judith Rousseau. On the Selection of Initialization and Activ ation Function for Deep Neural Networks. arXiv:1805.08266 [cs, stat] , May 2018. T amir Hazan and T ommi Jaakkola. Steps T o ward Deep Kernel Methods from Infinite Neural Networks. arXiv:1508.05133 [cs] , August 2015. Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Delving deep into rectifiers: Surpassing human-lev el per- formance on imagenet classification. In Pr oceedings of the IEEE International Confer ence on Computer V ision , pages 1026–1034, 2015. Arthur Jacot, Franck Gabriel, and Clément Hongler . Neural T angent Kernel: Con ver gence and Generalization in Neu- ral Networks. arXiv:1806.07572 [cs, math, stat] , June 2018. 00000. Ryo Karakida, Shotaro Akaho, and Shun-ichi Amari. Uni- versal Statistics of Fisher Information in Deep Neural Networks: Mean Field Approach. [cond-mat, stat] , June 2018. Y itzhak Katznelson. An Intr oduction to Harmonic Analysis . Cambridge Mathematical Library . Cambridge University Press, Cambridge, UK ; New Y ork, 3rd ed edition, 2004. ISBN 978-0-521-83829-0 978-0-521-54359-0. V inayak Kumar , V aibhav Singh, PK Srijith, and Andreas Damianou. Deep Gaussian Processes with Conv olutional Kernels. arXiv pr eprint arXiv:1806.01655 , 2018. Neil D Lawrence and Andre w J Moore. Hierarchical Gaus- sian process latent variable models. In Proceedings of the 24th International Confer ence on Machine Learning , pages 481–488. A CM, 2007. Nicolas Le Roux and Y oshua Bengio. Continuous neural networks. In Artificial Intelligence and Statistics , pages 404–411, 2007. Jaehoon Lee, Y asaman Bahri, Roman Nov ak, Sam Schoen- holz, Jeffre y Pennington, and Jascha Sohl-dickstein. Deep Neural Networks as Gaussian Processes. In International Confer ence on Learning Repr esentations , 2018. Jaehoon Lee, Lechao Xiao, Samuel S. Schoenholz, Y asaman Bahri, Jascha Sohl-Dickstein, and Jeffrey Pennington. W ide Neural Networks of Any Depth Evolve as Linear Models Under Gradient Descent. arXiv:1902.06720 [cs, stat] , February 2019. Junhong Lin and Lorenzo Rosasco. Optimal Rates for Multi- pass Stochastic Gradient Methods. page 47. Alexander\ G. \ de\ G. Matthe ws, Jiri Hron, Mark Rowland, Richard E. T urner , and Zoubin Ghahramani. Gaussian Process Behaviour in W ide Deep Neural Networks. In International Confer ence on Learning Repr esentations , April 2018. Radford M Neal. BA YESIAN LEARNING FOR NEURAL NETWORKS . PhD Thesis, Univ ersity of T oronto, 1995. Roman Nov ak, Lechao Xiao, Jaehoon Lee, Y asaman Bahri, Daniel A Abolafia, Jef frey Pennington, and Jascha Sohl- Dickstein. Bayesian Deep Con v olutional Networks with Many Channels are Gaussian Processes. arXiv pr eprint arXiv:1810.05148 , 2018. Ryan O’Donnell. Analysis of Boolean Functions . Cam- bridge Univ ersity Press, New Y ork, NY, 2014. ISBN 978-1-107-03832-5. Jeffre y Pennington and Y asaman Bahri. Geometry of Neural Network Loss Surfaces via Random Matrix Theory . In Doina Precup and Y ee Whye T eh, editors, Pr oceedings of the 34th International Confer ence on Machine Learning , volume 70 of Proceedings of Mac hine Learning Resear ch , pages 2798–2806, International Con vention Centre, Syd- ney , Australia, August 2017. PMLR. 00006. Jeffre y Pennington and Pratik W orah. Nonlinear random matrix theory for deep learning. In Advances in Neural Information Pr ocessing Systems , pages 2634–2643, 2017. 00000. Jeffre y Pennington and Pratik W orah. The Spectrum of the Fisher Information Matrix of a Single-Hidden-Layer Neural Network. In Advances in Neural Information Pr ocessing Systems 31 , page 10, 2018. Jeffre y Pennington, Samuel Schoenholz, and Surya Gan- guli. Resurrecting the sigmoid in deep learning through dynamical isometry: Theory and practice. In I. Guyon, U. V . Luxb ur g, S. Bengio, H. W allach, R. Fergus, S. V ish- wanathan, and R. Garnett, editors, Advances in Neural Information Processing Systems 30 , pages 4788–4798. Curran Associates, Inc., 2017. 00004. Jeffre y Pennington, Samuel S. Schoenholz, and Surya Gan- guli. The Emer gence of Spectral Univ ersality in Deep Networks. arXiv:1802.09979 [cs, stat] , February 2018. George Philipp and Jaime G. Carbonell. The Nonlinearity Coefficient - Predicting Overfitting in Deep Neural Net- works. arXiv:1806.00179 [cs, stat] , May 2018. 00000. Ben Poole, Subhaneil Lahiri, Maithreyi Raghu, Jascha Sohl- Dickstein, and Surya Ganguli. Exponential expressi vity in deep neural networks through transient chaos. In Ad- vances In Neural Information Pr ocessing Systems , pages 3360–3368, 2016. 00047. A Fine-Grained Spectral Perspecti ve on Neural Networks Nasim Rahaman, Aristide Baratin, Dev ansh Arpit, Felix Draxler , Min Lin, Fred A. Hamprecht, Y oshua Bengio, and Aaron Courville. On the Spectral Bias of Neural Networks. arXiv:1806.08734 [cs, stat] , June 2018. Garvesh Raskutti, Martin J. W ainwright, and Bin Y u. Early stopping and non-parametric regression: An optimal data- dependent stopping rule. arXiv:1306.3574 [stat] , June 2013. I. J. Schoenberg. Positiv e definite functions on spheres. Duke Mathematical Journal , 9(1):96–108, March 1942. ISSN 0012-7094, 1547-7398. doi: 10.1215/ S0012- 7094- 42- 00908- 6. Samuel S. Schoenholz, Justin Gilmer , Surya Ganguli, and Jascha Sohl-Dickstein. Deep Information Propagation. 2017. Bernhard Schölkopf and Alexander J. Smola. Learning with K ernels: Support V ector Machines, Re gularization, Optimization, and Beyond . Adaptiv e Computation and Machine Learning. MIT Press, Cambridge, Mass, 2002. ISBN 978-0-262-19475-4. Alex J. Smola, Zoltán L. Óvári, and Robert C W illiamson. Regularization with Dot-Product K ernels. In T . K. Leen, T . G. Dietterich, and V . T resp, editors, Advances in Neural Information Pr ocessing Systems 13 , pages 308–314. MIT Press, 2001. Sho Sonoda and Noboru Murata. Neural Network with Unbounded Acti vation Functions is Universal Approxi- mator . Applied and Computational Harmonic Analysis , 43(2):233–268, September 2017. ISSN 10635203. doi: 10.1016/j.acha.2015.12.005. P .K. Suetin. Ultraspherical polynomials - Encyclopedia of Mathematics. Gabor Szego. Orthogonal polynomials , volume 23. Ameri- can Mathematical Soc., 1939. Joel A. T ropp. An Introduction to Matrix Concentration Inequalities. arXiv:1501.01571 [cs, math, stat] , January 2015. Guillermo V alle-Pérez, Chico Q. Camargo, and Ard A. Louis. Deep learning generalizes because the parameter- function map is biased tow ards simple functions. arXiv:1805.08522 [cs, stat] , May 2018. Mark van der Wilk, Carl Edward Rasmussen, and James Hensman. Conv olutional Gaussian Processes. In Ad- vances in Neural Information Pr ocessing Systems 30 , pages 2849–2858, 2017. Y uting W ei, Fanny Y ang, and Martin J W ainwright. Early stopping for kernel boosting algorithms: A general analy- sis with localized complexities. page 11. Christopher K I W illiams. Computing with Infinite Net- works. In Advances in Neural Information Pr ocessing Systems , page 7, 1997. Andrew G W ilson, Zhiting Hu, Ruslan R Salakhutdinov , and Eric P Xing. Stochastic V ariational Deep Kernel Learning. In Advances in Neural Information Pr ocessing Systems , pages 2586–2594, 2016a. Andrew Gordon W ilson, Zhiting Hu, Ruslan Salakhutdinov , and Eric P Xing. Deep kernel learning. In Artificial Intelligence and Statistics , pages 370–378, 2016b. Lechao Xiao, Y asaman Bahri, Sam Schoenholz, and Jef- frey Pennington. Training ultra-deep CNNs with critical initialization. In NIPS W orkshop , 2017. Bo Xie, Y ingyu Liang, and Le Song. Div erse Neural Net- work Learns True T arget Functions. [cs, stat] , Nov ember 2016. Y uan Xu and E. W . Cheney . Strictly Positiv e Definite Func- tions on Spheres. Pr oceedings of the American Mathe- matical Society , 116(4):977–981, 1992. ISSN 0002-9939. doi: 10.2307/2159477. Zhi-Qin John Xu, Y aoyu Zhang, and Y anyang Xiao. Train- ing beha vior of deep neural network in frequenc y domain. arXiv:1807.01251 [cs, math, stat] , July 2018. Zhi-Qin John Xu, Y aoyu Zhang, T ao Luo, Y anyang Xiao, and Zheng Ma. Frequency Principle: Fourier Analysis Sheds Light on Deep Neural Networks. arXiv:1901.06523 [cs, stat] , January 2019. Zhiqin John Xu. Understanding training and generalization in deep learning by Fourier analysis. [cs, math, stat] , August 2018. Greg Y ang. T ensor programs i: W ide feedforward or re- current neural networks of an y architecture are gaussian processes. arXiv pr eprint arXiv:1910.12478 , 2019a. Greg Y ang. Scaling Limits of Wide Neural Networks with W eight Sharing: Gaussian Process Behavior , Gradi- ent Independence, and Neural T angent Kernel Deriv a- tion. arXiv:1902.04760 [cond-mat, physics:math-ph, stat] , February 2019b. Greg Y ang and Sam S. Schoenholz. Deep Mean Field The- ory: Layerwise V ariance and W idth V ariation as Methods to Control Gradient Explosion. February 2018. Greg Y ang and Samuel S. Schoenholz. Mean Field Residual Network: On the Edge of Chaos. In Advances in Neural Information Pr ocessing Systems , 2017. Greg Y ang, Jeffre y Pennington, V inay Rao, Jascha Sohl- Dickstein, and Samuel S. Schoenholz. A Mean Field Theory of Batch Normalization. arXiv:1902.08129 [cond- mat] , February 2019. A Fine-Grained Spectral Perspecti ve on Neural Networks Y uan Y ao, Lorenzo Rosasco, and Andrea Caponnetto. On Early Stopping in Gradient Descent Learning. Constructive Appr oximation , 26(2):289–315, August 2007. ISSN 0176-4276, 1432-0940. doi: 10.1007/ s00365- 006- 0663- 2. Y aoyu Zhang, Zhi-Qin John Xu, T ao Luo, and Zheng Ma. Explicitizing an Implicit Bias of the Frequency Principle in T wo-layer Neural Networks. arXiv:1905.10264 [cs, stat] , May 2019. Difan Zou, Y uan Cao, Dongruo Zhou, and Quanquan Gu. Stochastic Gradient Descent Optimizes Over- parameterized Deep ReLU Networks. [cs, math, stat] , Nov ember 2018. A Fine-Grained Spectral Perspecti ve on Neural Networks A. Related W orks The Gaussian process behavior of neural networks was found by Neal (1995) for shallo w networks and then extended o ver the years to different settings and architectures (Daniely et al., 2016; Hazan and Jaakkola, 2015; Le Roux and Bengio, 2007; Lee et al., 2018; Matthews et al., 2018; Nov ak et al., 2018; W illiams, 1997). This connection was exploited implicitly or explicitly to build ne w models (Blomqvist et al., 2018; Borovykh, 2018; Bradshaw et al., 2017; Cho and Saul, 2009; Damianou and La wrence, 2013; Garriga-Alonso et al., 2018; Kumar et al., 2018; Lawrence and Moore, 2007; Lee et al., 2018; Nov ak et al., 2018; van der W ilk et al., 2017; W ilson et al., 2016a;b). The Neural T angent Kernel is a much more recent discov ery by Jacot et al. (2018) and later Allen-Zhu et al. (2018a;b;c); Arora et al. (2019b); Du et al. (2018); Zou et al. (2018) came upon the same reasoning independently . Like CK, NTK has also been applied to ward b uilding ne w models or algorithms (Achiam et al., 2019; Arora et al., 2019a). Closely related to the discussion of CK and NTK is the signal propagation literature, which tries to understand how to prev ent pathological beha viors in randomly initialized neural networks when they are deep (Chen et al., 2018; Hanin, 2018; Hanin and Rolnick, 2018; Hayou et al., 2018; Pennington et al., 2017; Philipp and Carbonell, 2018; Poole et al., 2016; Schoenholz et al., 2017; Y ang and Schoenholz, 2018; 2017; Y ang et al., 2019). This line of work can trace its original at least to the advent of the Glor ot and He initialization schemes for deep networks (Glorot and Bengio, 2010; He et al., 2015). The in v estigation of forwar d signal pr opagation , or ho w random neural networks change with depth, corresponds to studying the infinite-depth limit of CK, and the inv estigation of backwar d signal propa gation , or how gradients of random networks change with depth, corresponds to studying the infinite-depth limit of NTK. Some of the quite remarkable results from this literature includes how to train a 10,000 layer CNN (Xiao et al., 2017) and that, counterintuitively , batch normalization causes gradient explosion (Y ang et al., 2019). This signal propagation perspectiv e can be refined via random matrix theory (Pennington et al., 2017; 2018). In these works, free probability is lev eraged to compute the singular value distrib ution of the input-output map giv en by the random neural network, as the input dimension and width tend to infinity together . Other works also in vestig ate various questions of neural network training and generalization from the random matrix perspectiv e (Pennington and Bahri, 2017; Pennington and W orah, 2017; 2018). Y ang (2019a;b) presents a common framework, known as T ensor Pro grams , unifying the GP , NTK, signal propagation, and random matrix perspecti ves, as well as e xtending them to ne w scenarios, like recurrent neural networks. It proves the existence of and allows the computation of a large number of infinite-width limits (including ones relev ant to the above perspectiv es) by e xpressing the quantity of interest as the output of a computation graph and then manipulating the graph mechanically . Sev eral other works also adopt a spectral perspective on neural networks (Barron, 1993; Candès, 1999; Eldan and Shamir, 2016; Sonoda and Murata, 2017; Xu et al., 2018; 2019; Xu, 2018; Zhang et al., 2019); here we highlight a few most relev ant to us. Rahaman et al. (2018) studies the real F ourier frequencies of relu netw orks and perform experiments on real data as well as synthetic ones. They con vincingly sho w that relu netw orks learn lo w frequencies components first. They also in v estigate the subtleties when the data manifold is lo w dimensional and embedded in various ways in the input space. In contrast, our work focuses on the spectra of the CK and NTK (which indirectly informs the Fourier frequencies of a typical network). Nev ertheless, our results are complementary to theirs, as they readily explain the low frequenc y bias in relu that they found. Karakida et al. (2018) studies the spectrum of the Fisher information matrix, which share the nonzero eigen values with the NTK. They compute the mean, v ariance, and maximum of the eigen values Fisher eigen v alues (taking the width to infinity first, and then considering finite amount of data sampled iid from a Gaussian). In comparison, our spectral results yield all eigen v alues of the NTK (and thus also all nonzero eigen v alues of the Fisher) as well as eigenfunctions. Finally , we note that sev eral recent works (Basri et al., 2019; Bietti and Mairal, 2019; Ghorbani et al., 2019; Xie et al., 2016) studied one-hidden layer neural networks over the sphere, building on Smola et al. (2001)’ s observation that spherical harmonics diagonalize dot product kernels, with the latter tw o concurrent to us. This is in contrast to the focus on boolean cube here, which allows us to study the fine-grained effect of hyperparameters on the spectra, leading to a variety of insights into neural networks’ generalization properties. B. Universality of Our Boolean Cube Obser vations in Other Input Distrib utions Using the spectral theory we developed in this paper, we made three observations, that can be roughly summarized as follows: 1) the simplicity bias noted by V alle-Pérez et al. (2018) is not universal; 2) for each function of fix ed “complexity” there is an optimal depth such that networks shallower or deeper will not learn it as well; 3) training last layer only is better than training all layers when learning “simpler” features, and the opposite is true for learning “complex” features. A Fine-Grained Spectral Perspecti ve on Neural Networks 0 2 4 6 8 10 depth 0.0 0.2 0.4 0.6 0.8 1.0 best loss optimal depths exist over standard Gaussian and sphere too deg 0 1 2 3 dist Gaussian Sphere BoolCube Figure 6. Optimal depths exist over the standard Gaussian N (0 , I d ) and the unif orm distribution over the sphere √ d S d − 1 as well. Here we use the exact same experimental setup as Fig. 3(b) (see Appendix E for details) except that the input distribution is changed from uniform over the boolean cube d to standard Gaussian N (0 , I d ) (solid lines) and uniform over the sphere √ d S d − 1 (dashed lines), where d = 128 . W e also compare against the results over the boolean cube from Fig. 3(b), which are dra wn with dotted lines. Colors indicate the degrees of the ground truth polynomial functions. The best validation loss for degree 0 to 2 are all very close no matter which distribution the input is sampled from, such that the curves all sit on top of each other . For degree 3, there is less precise agreement between the v alidation loss o ver the dif ferent distributions, but the ov erall trend is unmistakably the same. W e see that for netw orks deeper or shallower than the optimal depth, the loss monotonically increases as the depth mo ves a way from the optimum. In this section, we discuss the applicability of these observations to distributions that are not uniform over the boolean cube: in particular , the uniform distribution ov er the sphere √ d S d − 1 , the standard Gaussian N (0 , I d ) , as well as realistic data distributions such as MNIST and CIF AR10. Simplicity bias The simplicity bias noted by V alle-Pérez et al. (2018), in particular Fig. 1, depends on the finiteness of the boolean cube as a domain, so we cannot effecti vely test this on the distrib utions abov e, which all hav e uncountable support. Optimal depth W ith reg ard to the second observation, we can test whether an optimal depth exists for learning functions ov er the distrib utions abov e. Since polynomial degrees remain the natural indicator of complexity for the sphere and the Gaussian (see Appendices H.2 and H.3 for the relev ant spectral theory), we replicated the experiment in Fig. 3(b) for these distributions, using the same ground truth functions of polynomials of different degrees. The results are shown in Fig. 6. W e see the same phenomenon as in the boolean cube case, with an optimal depth for each degree, and with the optimal depth increasing with degree. For MNIST and CIF AR10, the notion of “feature complexity” is less clear , so we will not test the hypothesis that “optimal depth increases with degree” for these distrib utions but only test for the e xistence of the optimal depth for the ground truth marked by the labels of the datasets. W e do so by training a large number of MLPs of varying depth on these datasets until con v ergence, and plot the results in Fig. 7. This figure clearly sho ws that such an optimal depth exists, such that shallo wer or deeper networks do monotonically worse as the depth di v erge a way from this optimal depth. Again, the e xistence of the optimal depth is not obvious at all, as con ventional deep learning wisdom would ha ve one believe that adding depth should always help. T raining last layer only vs training all layers Finally , we repeat the experiment in Fig. 3(c) for the sphere and the standard Gaussian, with polynomials of different degrees as ground truth functions. The results are shown in Fig. 8. W e see the same phenomenon as in the boolean cube case: for degree 0 polynomials, training last layer works better in general, but for higher degree polynomials, training all layers fares better . Note that, unlike the sphere and the Gaussian, whose spectral theory tells us that (harmonic) polynomial degree is a natural notion of complexity , for MNIST and CIF AR10 we hav e much less clear idea of what a “complex” or a “simple” feature is. A Fine-Grained Spectral Perspecti ve on Neural Networks 56 58 60 62 CIFAR10 best test err training last layer only last layer 46 48 50 training all layers all layers 0 2 4 6 8 10 depth 10 15 MNIST best test err last layer 0 2 4 6 8 10 depth 2 3 4 all layers optimal depths exist for MNIST and CIFAR10 Figure 7. Optimal depths exist over realistic distributions of MNIST and CIF AR10. Here, we trained relu networks with σ 2 w = 2 , σ 2 b = 0 for all depths from 0 to 10. W e used SGD with learning rate 10 and batch size 256, and trained until con vergence. W e record the best test error throughout the training procedure for each depth. For each configuration, we repeat the randomly initialization and training for 10 random seeds to estimate the v ariance of the best test error. The ro ws demonstrate the best test error o ver the course of training on CIF AR10 and MNIST , and the columns demonstrate the same for training only the last layer or training all layers. As one can see, the best depth when training only the last layer is 1, for both CIF AR10 and MNIST . The best depth when training all layers is around 5 for both CIF AR10 and MNIST . Performance monotically decreases for networks shallower or deeper than the optimal depth. Note that we hav e reached the SO T A accuracy for MLPs reported in Lee et al. (2018) on CIF AR10, and within 1 point of their accuracy on MNIST . Therefore, we did not attempt a similar experiment on these datasets. C. Theoretical vs Empirical Max Lear ning Rates under Differ ent Pr eprocessing f or MNIST and CIF AR10 In the main text Fig. 5, on the MNIST and CIF AR10 datasets, we preprocessed the data by centering and normalizing to the sphere (see Appendix E.2 for a precise description). With this preprocessing, our theory accurately predicts the max learning rate in practice. In general, if we go by another preprocessing, such as PCA or ZCA, or no preprocessing, our theoretical max learning rate 1 / Φ(0) is less accurate but still correlated in general. The only exception seems to be relu networks on PCA- or ZCA- preprocessed CIF AR10. See Fig. 9. D. V isualizing the Spectral Effects of σ 2 w , σ 2 b , and Depth While in the main text, we summarized sev eral trends of interest kn sev eral plots, they do not gi ve the entire picture of ho w eigen v alues and fractional v ariances v ary with σ 2 w , σ 2 b , and depth. Here we try to present this relationship more completely in a series of contour plots. Fig. 10 sho ws ho w v arying depth and σ 2 b changes the fractional v ariances of each de gree, for relu CK and NTK. W e are fixing σ 2 w = 2 in the CK plots, as the fractional variances only depend on the ratio σ 2 b /σ 2 w ; ev en though this is not true for relu NTK, we fix σ 2 w = 2 as well for consistenc y . For erf, howe v er , the fractional variance will crucially depend on both σ 2 w and σ 2 b , so we present 3D contour plots of ho w σ 2 w , σ 2 b , and depth changes fractional v ariance in Fig. 13. Complementarily , we also show in Figs. 11 and 12 a few slices of these 3D contour plots for different fixed values of σ 2 b , for erf CK and NTK. A Fine-Grained Spectral Perspecti ve on Neural Networks 0.0 0.2 0.4 0.6 0.8 1.0 best val loss (last layer) 0.0 0.2 0.4 0.6 0.8 1.0 best val loss (all layers) gaussian deg 0 1 2 3 4 5 0.0 0.2 0.4 0.6 0.8 1.0 best val loss (last layer) 0.0 0.2 0.4 0.6 0.8 1.0 sphere deg 0 1 2 3 4 5 training last layer vs training all layers Figure 8. Just like over the boolean cube: Over the sphere √ d S d − 1 and the standard Gaussian N (0 , I d ) , training only the last layer is better for learning low degree polynomials, but training all layers is better for learning high degree polynomials. Here we use the exact same experimental setup as Fig. 3(c) (see Appendix E for details) except that the input distribution is changed from uniform ov er the boolean cube d to standard Gaussian N (0 , I d ) (left) and uniform ov er the sphere √ d S d − 1 (right) , where d = 128 . 1 0 1 1 0 0 1 0 1 1 0 1 1 0 0 1 0 1 TRAINING LAST LAYER ONLY theoretical max lr No Preprocessing dataset MNIST CIFAR10 nonlin erf relu 1 0 2 1 0 1 1 0 0 1 0 1 1 0 2 1 0 1 1 0 0 1 0 1 PCA128 dataset MNIST CIFAR10 nonlin erf relu 1 0 2 1 0 1 1 0 0 1 0 1 1 0 2 1 0 1 1 0 0 1 0 1 ZCA128 dataset MNIST CIFAR10 nonlin erf relu 1 0 1 1 0 0 1 0 1 empirical max lr 1 0 1 1 0 0 1 0 1 TRAINING ALL LAYERS theoretical max lr dataset MNIST CIFAR10 nonlin erf relu 1 0 3 1 0 2 1 0 1 1 0 0 1 0 1 empirical max lr 1 0 3 1 0 2 1 0 1 1 0 0 1 0 1 dataset MNIST CIFAR10 nonlin erf relu 1 0 2 1 0 1 1 0 0 1 0 1 empirical max lr 1 0 2 1 0 1 1 0 0 1 0 1 dataset MNIST CIFAR10 nonlin erf relu Theoretical vs empirical max learning rate under different preprocessing Figure 9. W e perform binary search for the empirical max learning rate of MLPs of dif ferent depth, acti v ations, σ 2 w , and σ 2 b on MNIST and CIF AR10 preprocessed in dif ferent ways. See Appendix E.2 for experimental details. The first row compares the theoretical and empirical max learning rates when training only the last layer . The second row compares the same when training all layers (under NTK parametrization (Eq. (MLP))). The three columns correspond to the dif ferent preprocessing procedures: no preprocessing, PCA projection to the first 128 components (PCA128), and ZCA projection to the first 128 components (ZCA128). In general, the theoretical prediction is less accurate (compared to preprocessing by centering and projecting to the sphere, as in Fig. 5), though still well correlated with the empirical max learning rate. The most blatant caveat is the relu networks trained on PCA128- and ZCA128-processed CIF AR10. A Fine-Grained Spectral Perspecti ve on Neural Networks 1 0 0 1 0 1 1 0 2 depth 0.0 0.2 0.4 0.6 0.8 1.0 2 b degree 0 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1.0 1 0 0 1 0 1 1 0 2 depth 0.0 0.2 0.4 0.6 0.8 1.0 degree 2 0.00 0.02 0.04 0.06 0.08 0.10 0.12 0.14 0.16 1 0 0 1 0 1 1 0 2 depth 0.0 0.2 0.4 0.6 0.8 1.0 degree 4 0.0000 0.0025 0.0050 0.0075 0.0100 0.0125 0.0150 0.0175 0.0200 1 0 0 1 0 1 1 0 2 depth 0.0 0.2 0.4 0.6 0.8 1.0 degree 6 0.000 0.001 0.002 0.003 0.004 0.005 0.006 0.007 0.008 1 0 0 1 0 1 1 0 2 depth 0.0 0.2 0.4 0.6 0.8 1.0 degree 8 0.0000 0.0005 0.0010 0.0015 0.0020 0.0025 0.0030 0.0035 0.0040 1 0 0 1 0 1 1 0 2 depth 0.0 0.2 0.4 0.6 0.8 1.0 2 b degree 1 0.00 0.08 0.16 0.24 0.32 0.40 0.48 0.56 1 0 0 1 0 1 1 0 2 depth 0.0 0.2 0.4 0.6 0.8 1.0 degree 3 0.000 0.005 0.010 0.015 0.020 0.025 0.030 0.035 0.040 1 0 0 1 0 1 1 0 2 depth 0.0 0.2 0.4 0.6 0.8 1.0 degree 5 0.0000 0.0015 0.0030 0.0045 0.0060 0.0075 0.0090 0.0105 1 0 0 1 0 1 1 0 2 depth 0.0 0.2 0.4 0.6 0.8 1.0 degree 7 0.0000 0.0008 0.0016 0.0024 0.0032 0.0040 0.0048 0.0056 relu ck: fractional variance 1 0 0 1 0 1 1 0 2 depth 0 1 2 3 4 2 b degree 0 0.16 0.24 0.32 0.40 0.48 0.56 0.64 0.72 0.80 1 0 0 1 0 1 1 0 2 depth 0 1 2 3 4 degree 2 0.00 0.03 0.06 0.09 0.12 0.15 0.18 0.21 0.24 1 0 0 1 0 1 1 0 2 depth 0 1 2 3 4 degree 4 0.000 0.006 0.012 0.018 0.024 0.030 0.036 0.042 0.048 0.054 1 0 0 1 0 1 1 0 2 depth 0 1 2 3 4 degree 6 0.000 0.004 0.008 0.012 0.016 0.020 0.024 0.028 0.032 1 0 0 1 0 1 1 0 2 depth 0 1 2 3 4 degree 8 0.0000 0.0025 0.0050 0.0075 0.0100 0.0125 0.0150 0.0175 0.0200 1 0 0 1 0 1 1 0 2 depth 0 1 2 3 4 2 b degree 1 0.00 0.08 0.16 0.24 0.32 0.40 0.48 0.56 1 0 0 1 0 1 1 0 2 depth 0 1 2 3 4 degree 3 0.00 0.01 0.02 0.03 0.04 0.05 0.06 0.07 0.08 1 0 0 1 0 1 1 0 2 depth 0 1 2 3 4 degree 5 0.000 0.005 0.010 0.015 0.020 0.025 0.030 0.035 0.040 1 0 0 1 0 1 1 0 2 depth 0 1 2 3 4 degree 7 0.000 0.003 0.006 0.009 0.012 0.015 0.018 0.021 0.024 relu ntk: fractional variance Figure 10. 2D contour plots of how fractional variance of each degree varies with σ 2 b and depth, fixing σ 2 w = 2 , for relu CK and NTK . For each degree k , and for each selected fractional variance v alue, we plot the level curv e of (depth , σ 2 b ) achieving this v alue. The color indicates the fractional variance, as gi v en in the color bars. A Fine-Grained Spectral Perspecti ve on Neural Networks 1 0 0 1 0 1 1 0 2 depth 1 2 3 4 5 2 w degree 1 0.00 0.15 0.30 0.45 0.60 0.75 0.90 1.05 1 0 0 1 0 1 1 0 2 depth 1 2 3 4 5 degree 3 0.000 0.025 0.050 0.075 0.100 0.125 0.150 0.175 0.200 1 0 0 1 0 1 1 0 2 depth 1 2 3 4 5 degree 5 0.000 0.015 0.030 0.045 0.060 0.075 0.090 0.105 0.120 1 0 0 1 0 1 1 0 2 depth 1 2 3 4 5 degree 7 0.00 0.01 0.02 0.03 0.04 0.05 0.06 0.07 0.08 e r f c k : f r a c t i o n a l v a r i a n c e , f i x i n g 2 b = 0 1 0 0 1 0 1 1 0 2 depth 1 2 3 4 5 2 w degree 0 0.00 0.15 0.30 0.45 0.60 0.75 0.90 1.05 1 0 0 1 0 1 1 0 2 depth 1 2 3 4 5 degree 2 0.000 0.008 0.016 0.024 0.032 0.040 0.048 0.056 1 0 0 1 0 1 1 0 2 depth 1 2 3 4 5 degree 4 0.000 0.004 0.008 0.012 0.016 0.020 0.024 0.028 0.032 1 0 0 1 0 1 1 0 2 depth 1 2 3 4 5 degree 6 0.003 0.000 0.003 0.006 0.009 0.012 0.015 0.018 0.021 0.024 1 0 0 1 0 1 1 0 2 depth 1 2 3 4 5 degree 8 0.0025 0.0000 0.0025 0.0050 0.0075 0.0100 0.0125 0.0150 0.0175 0.0200 1 0 0 1 0 1 1 0 2 depth 1 2 3 4 5 2 w degree 1 0.0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 1 0 0 1 0 1 1 0 2 depth 1 2 3 4 5 degree 3 0.00 0.02 0.04 0.06 0.08 0.10 0.12 0.14 1 0 0 1 0 1 1 0 2 depth 1 2 3 4 5 degree 5 0.000 0.008 0.016 0.024 0.032 0.040 0.048 0.056 0.064 1 0 0 1 0 1 1 0 2 depth 1 2 3 4 5 degree 7 0.006 0.000 0.006 0.012 0.018 0.024 0.030 0.036 0.042 e r f c k : f r a c t i o n a l v a r i a n c e , f i x i n g 2 b = 0 . 1 1 0 0 1 0 1 1 0 2 depth 1 2 3 4 5 2 w degree 0 0.00 0.15 0.30 0.45 0.60 0.75 0.90 1.05 1 0 0 1 0 1 1 0 2 depth 1 2 3 4 5 degree 2 0.000 0.008 0.016 0.024 0.032 0.040 0.048 0.056 1 0 0 1 0 1 1 0 2 depth 1 2 3 4 5 degree 4 0.000 0.004 0.008 0.012 0.016 0.020 0.024 0.028 0.032 1 0 0 1 0 1 1 0 2 depth 1 2 3 4 5 degree 6 0.003 0.000 0.003 0.006 0.009 0.012 0.015 0.018 0.021 0.024 1 0 0 1 0 1 1 0 2 depth 1 2 3 4 5 degree 8 0.0025 0.0000 0.0025 0.0050 0.0075 0.0100 0.0125 0.0150 0.0175 0.0200 1 0 0 1 0 1 1 0 2 depth 1 2 3 4 5 2 w degree 1 0.0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 1 0 0 1 0 1 1 0 2 depth 1 2 3 4 5 degree 3 0.000 0.015 0.030 0.045 0.060 0.075 0.090 0.105 0.120 1 0 0 1 0 1 1 0 2 depth 1 2 3 4 5 degree 5 0.000 0.008 0.016 0.024 0.032 0.040 0.048 0.056 1 0 0 1 0 1 1 0 2 depth 1 2 3 4 5 degree 7 0.005 0.000 0.005 0.010 0.015 0.020 0.025 0.030 0.035 e r f c k : f r a c t i o n a l v a r i a n c e , f i x i n g 2 b = 0 . 2 1 0 0 1 0 1 1 0 2 depth 1 2 3 4 5 2 w degree 0 0.48 0.56 0.64 0.72 0.80 0.88 0.96 1.04 1 0 0 1 0 1 1 0 2 depth 1 2 3 4 5 degree 2 0.000 0.006 0.012 0.018 0.024 0.030 0.036 0.042 0.048 1 0 0 1 0 1 1 0 2 depth 1 2 3 4 5 degree 4 0.0000 0.0025 0.0050 0.0075 0.0100 0.0125 0.0150 0.0175 0.0200 1 0 0 1 0 1 1 0 2 depth 1 2 3 4 5 degree 6 0.0000 0.0015 0.0030 0.0045 0.0060 0.0075 0.0090 0.0105 0.0120 1 0 0 1 0 1 1 0 2 depth 1 2 3 4 5 degree 8 0.000 0.001 0.002 0.003 0.004 0.005 0.006 0.007 0.008 1 0 0 1 0 1 1 0 2 depth 1 2 3 4 5 2 w degree 1 0.00 0.05 0.10 0.15 0.20 0.25 0.30 0.35 0.40 1 0 0 1 0 1 1 0 2 depth 1 2 3 4 5 degree 3 0.000 0.005 0.010 0.015 0.020 0.025 0.030 0.035 0.040 1 0 0 1 0 1 1 0 2 depth 1 2 3 4 5 degree 5 0.000 0.002 0.004 0.006 0.008 0.010 0.012 0.014 0.016 1 0 0 1 0 1 1 0 2 depth 1 2 3 4 5 degree 7 0.0000 0.0015 0.0030 0.0045 0.0060 0.0075 0.0090 0.0105 e r f c k : f r a c t i o n a l v a r i a n c e , f i x i n g 2 b = 2 Figure 11. 2D contour plots of how fractional variance of each degree varies with σ 2 w and depth, for different slices of σ 2 b , for erf NTK . These plots essentially show slices of the NTK 3D contour plots in Fig. 13. For σ b = 0 , µ k for all ev en degrees k are 0, so we omit the plots. Note the rapid change in the shape of the contours for odd degrees, going from σ 2 b = 0 to σ 2 b = 0 . 1 . This is reflected in Fig. 13 as well. A Fine-Grained Spectral Perspecti ve on Neural Networks 1 0 0 1 0 1 1 0 2 depth 1 2 3 4 5 2 w degree 1 0.00 0.15 0.30 0.45 0.60 0.75 0.90 1 0 0 1 0 1 1 0 2 depth 1 2 3 4 5 degree 3 0.00 0.03 0.06 0.09 0.12 0.15 0.18 0.21 1 0 0 1 0 1 1 0 2 depth 1 2 3 4 5 degree 5 0.00 0.02 0.04 0.06 0.08 0.10 0.12 0.14 1 0 0 1 0 1 1 0 2 depth 1 2 3 4 5 degree 7 0.000 0.015 0.030 0.045 0.060 0.075 0.090 0.105 e r f n t k : f r a c t i o n a l v a r i a n c e , f i x i n g 2 b = 0 1 0 0 1 0 1 1 0 2 depth 1 2 3 4 5 2 w degree 0 0.00 0.15 0.30 0.45 0.60 0.75 0.90 1.05 1 0 0 1 0 1 1 0 2 depth 1 2 3 4 5 degree 2 0.000 0.015 0.030 0.045 0.060 0.075 0.090 1 0 0 1 0 1 1 0 2 depth 1 2 3 4 5 degree 4 0.000 0.008 0.016 0.024 0.032 0.040 0.048 0.056 0.064 1 0 0 1 0 1 1 0 2 depth 1 2 3 4 5 degree 6 0.006 0.000 0.006 0.012 0.018 0.024 0.030 0.036 0.042 0.048 1 0 0 1 0 1 1 0 2 depth 1 2 3 4 5 degree 8 0.005 0.000 0.005 0.010 0.015 0.020 0.025 0.030 0.035 0.040 1 0 0 1 0 1 1 0 2 depth 1 2 3 4 5 2 w degree 1 0.0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 1 0 0 1 0 1 1 0 2 depth 1 2 3 4 5 degree 3 0.00 0.02 0.04 0.06 0.08 0.10 0.12 0.14 0.16 1 0 0 1 0 1 1 0 2 depth 1 2 3 4 5 degree 5 0.000 0.015 0.030 0.045 0.060 0.075 0.090 1 0 0 1 0 1 1 0 2 depth 1 2 3 4 5 degree 7 0.008 0.000 0.008 0.016 0.024 0.032 0.040 0.048 0.056 0.064 e r f n t k : f r a c t i o n a l v a r i a n c e , f i x i n g 2 b = 0 . 1 1 0 0 1 0 1 1 0 2 depth 1 2 3 4 5 2 w degree 0 0.00 0.15 0.30 0.45 0.60 0.75 0.90 1.05 1 0 0 1 0 1 1 0 2 depth 1 2 3 4 5 degree 2 0.000 0.015 0.030 0.045 0.060 0.075 0.090 1 0 0 1 0 1 1 0 2 depth 1 2 3 4 5 degree 4 0.000 0.008 0.016 0.024 0.032 0.040 0.048 0.056 0.064 1 0 0 1 0 1 1 0 2 depth 1 2 3 4 5 degree 6 0.006 0.000 0.006 0.012 0.018 0.024 0.030 0.036 0.042 0.048 1 0 0 1 0 1 1 0 2 depth 1 2 3 4 5 degree 8 0.005 0.000 0.005 0.010 0.015 0.020 0.025 0.030 0.035 0.040 1 0 0 1 0 1 1 0 2 depth 1 2 3 4 5 2 w degree 1 0.00 0.08 0.16 0.24 0.32 0.40 0.48 0.56 0.64 1 0 0 1 0 1 1 0 2 depth 1 2 3 4 5 degree 3 0.00 0.02 0.04 0.06 0.08 0.10 0.12 0.14 1 0 0 1 0 1 1 0 2 depth 1 2 3 4 5 degree 5 0.00 0.01 0.02 0.03 0.04 0.05 0.06 0.07 0.08 1 0 0 1 0 1 1 0 2 depth 1 2 3 4 5 degree 7 0.008 0.000 0.008 0.016 0.024 0.032 0.040 0.048 0.056 e r f n t k : f r a c t i o n a l v a r i a n c e , f i x i n g 2 b = 0 . 2 1 0 0 1 0 1 1 0 2 depth 1 2 3 4 5 2 w degree 0 0.00 0.15 0.30 0.45 0.60 0.75 0.90 1.05 1 0 0 1 0 1 1 0 2 depth 1 2 3 4 5 degree 2 0.00 0.01 0.02 0.03 0.04 0.05 0.06 0.07 0.08 1 0 0 1 0 1 1 0 2 depth 1 2 3 4 5 degree 4 0.000 0.008 0.016 0.024 0.032 0.040 0.048 0.056 1 0 0 1 0 1 1 0 2 depth 1 2 3 4 5 degree 6 0.000 0.005 0.010 0.015 0.020 0.025 0.030 0.035 0.040 1 0 0 1 0 1 1 0 2 depth 1 2 3 4 5 degree 8 0.000 0.004 0.008 0.012 0.016 0.020 0.024 0.028 0.032 1 0 0 1 0 1 1 0 2 depth 1 2 3 4 5 2 w degree 1 0.00 0.05 0.10 0.15 0.20 0.25 0.30 0.35 1 0 0 1 0 1 1 0 2 depth 1 2 3 4 5 degree 3 0.00 0.01 0.02 0.03 0.04 0.05 0.06 0.07 0.08 1 0 0 1 0 1 1 0 2 depth 1 2 3 4 5 degree 5 0.000 0.006 0.012 0.018 0.024 0.030 0.036 0.042 0.048 1 0 0 1 0 1 1 0 2 depth 1 2 3 4 5 degree 7 0.000 0.005 0.010 0.015 0.020 0.025 0.030 0.035 e r f n t k : f r a c t i o n a l v a r i a n c e , f i x i n g 2 b = 2 Figure 12. 2D contour plots of how fractional variance of each degree varies with σ 2 w and depth, for different slices of σ 2 b , for erf CK . These plots essentially sho w slices of the CK 3D contour plots in Fig. 13. For σ b = 0 , µ k for all e ven de grees k are 0, so we omit the plots. Note the rapid change in the shape of the contours for odd degrees, going from σ 2 b = 0 to σ 2 b = 0 . 1 . This is reflected in Fig. 13 as well. A Fine-Grained Spectral Perspecti ve on Neural Networks Figure 13. 3D contour plots of how fractional variance of each degree varies with σ 2 w , σ 2 b and log 2 (depth) , for erf CK and NTK . For each v alue of fractional v ariance, as gi v en in the legend on the right, we plot the lev el surface in the ( σ 2 w , σ 2 b , log 2 (depth)) -space achieving this v alue in the corresponding color . The closer to blue the color , the higher the v alue. Note that the contour for the highest values in higher de gree plots “floats in mid-air”, implying that there is an optimal depth for learning features of that de gree that is not particularly small nor particularly big. A Fine-Grained Spectral Perspecti ve on Neural Networks E. Experimental Details E.1. Fig. 3 Fig. 3(a), (b) and (c) differ in the set of hyperparameters they in volv e (to be specified below), but in all of them, we train relu networks against a randomly generated ground truth multilinear polynomial, with input space 128 and L2 loss L ( f ) = E x ∈ d ( f ( x ) − f ∗ ( x )) 2 . T raining W e perform SGD with batch size 1000. In each iteration, we freshly sample a new batch, and we train for a total of 100,000 iterations, so the network potentially sees 10 8 different e xamples. At ev ery 1000 iterations, we validate the current network on a freshly dra wn batch of 10,000 examples. W e thus record a total of 100 validation losses, and we take the lowest to be the “best v alidation loss. ” Generating the Ground T ruth Function The ground truth function f ∗ ( x ) is generated by first sampling 10 monomials m 1 , . . . , m 10 of degree k , then randomly sampling 10 coef ficients a 1 , . . . , a 10 for them. The final function is obtained by normalizing { a i } such that the sum of their squares is 1: f ∗ ( x ) def = 10 X i =1 a i m i / 10 X j =1 a 2 j . (10) Hyperparameters f or Fig. 3(a) • The learning rate is half the theoretical maximum learning rate 7 1 2 max( µ 0 , µ 1 ) − 1 • Ground truth degree k ∈ { 0 , 1 , 2 , 3 } • Depth ∈ { 0 , . . . , 10 } • activ ation = relu • σ 2 w = 2 • σ 2 b = 0 • width = 1000 • 10 random seeds per hyperparameter combination • training last layer (marked “ck”), or all layers (marked “ntk”). In the latter case, we use the NTK parametrization of the MLP (Eq. (MLP)). Hyperparameters f or Fig. 3(b) • The learning rate is half the theoretical maximum learning rate 1 2 max( µ 0 , µ 1 ) − 1 • Ground truth degree k ∈ { 0 , 1 , 2 , 3 } • Depth ∈ { 0 , . . . , 10 } • activ ation = relu • σ 2 w = 2 • σ 2 b = 0 • width = 1000 • 100 random seeds per hyperparameter combination • training last layer weight and bias only 7 Note that, because the L2 loss here is L ( f ) = E x ∈ d ( f ( x ) − f ∗ ( x )) 2 , the maximum learning rate is λ − 1 max = max( µ 0 , µ 1 ) − 1 (see Thm 4.1). If we instead adopt the con vention L ( f ) = E x ∈ d 1 2 ( f ( x ) − f ∗ ( x )) 2 , then the maximum learning rate would be 2 λ − 1 max = 2 max( µ 0 , µ 1 ) − 1 A Fine-Grained Spectral Perspecti ve on Neural Networks Algorithm 1 Binary Search for Empirical Max Learning Rate upper ← 16 × theoretical max lr low er ← 0 tol ← 0 . 01 × theoretical max lr while | upper − low er | > tol do α ← ( upper + low er ) / 2 Run SGD with learning rate α for 1000 iterations if loss div er ges then upper ← α else low er ← α end if end while Ensure: upper Hyperparameters f or Fig. 3(c) • The learning rate ∈ { 0 . 05 , 0 . 1 , 0 . 5 } • Ground truth degree k ∈ { 0 , 1 , . . . , 6 } • Depth ∈ { 1 , . . . , 5 } • activ ation ∈ { relu , erf } • σ 2 w = 2 for relu, but σ 2 w ∈ { 1 , 2 , . . . , 5 } for erf • σ 2 b ∈ { 0 , 1 , . . . , 4 } • width = 1000 • 1 random seed per hyperparameter combination • T raining all layers, using the NTK parametrization of the MLP (Eq. (MLP)) E.2. Max Learning Rate Experiments Here we describe the experimental details for the e xperiments underlying Figs. 5 and 9. Theoretical max lear ning rate For a fix ed setup, we compute Φ according to Eq. (CK) (if only last layer is trained) or Eq. (NTK) (if all layers are trained). For ground truth problems where the output is n -dimensional, the theoretical max learning rate is n Φ(0) − 1 ; in particular , the max learning rates for MNIST and CIF AR10 are 10 times those for boolean cube, sphere, and Gaussian. This is because the kernel for an multi-output problem effecti v ely becomes 1 n K ⊕ n = 1 n K 0 0 0 . . . 0 0 0 K where the 1 n factor is due to the 1 n factor in the scaled square loss L ( f , f ∗ ) = E x ∼X 1 n P n i =1 ( f ( x ) i − f ∗ ( x ) i ) 2 . The top eigen v alue for 1 n K ⊕ n is just 1 n times the top eigen v alue for K . Empirical max learning rate For a fixed setup, we perform binary search for the empirical max learning rate as in Algorithm 1. A Fine-Grained Spectral Perspecti ve on Neural Networks Prepr ocessing In Fig. 5, for MNIST and CIF AR10, we center and project each image onto the sphere √ d S d − 1 , where d = 28 × 28 = 784 for MNIST and d = 3 × 32 × 32 = 3072 for CIF AR10. More precisely , we compute the av erage image ¯ x ov er the entire dataset, and we preprocess each image x as √ d x − ¯ x k x − ¯ x k . In Fig. 9, there are three dif ferent preprocessing schemes. For “no preprocessing, ” we load the MNIST and CIF AR10 data as is. In “PCA128, ” we take the top 128 eigencomponents of the data, so that the data has only 128 dimensions. In “ZCA128, ” we take the top 128 eigencomponents but rotate it back to the original space, so that the data still has dimension d , where d = 28 × 28 = 784 for MNIST and d = 3 × 32 × 32 = 3072 for CIF AR10. Hyperparameters • T arget function: For boolean cube, sphere, and standard Gaussian, we randomly sample a de gree 1 polynomial as in Eq. (10). For MNIST and CIF AR10, we just use the label in the dataset, encoded as a one-hot vector for square-loss regression. • Depth ∈ { 1 , 2 , 4 , 8 , 16 } • activ ation ∈ { relu , erf } • σ 2 w = 2 for relu, but σ 2 w ∈ { 1 , 2 , . . . , 5 } for erf • σ 2 b ∈ { 1 , . . . , 4 } • width = 1000 • 1 random seed per hyperparameter combination • T raining last layer (CK) or all layers (NTK). In the latter case, we use the NTK parametrization of the MLP (Eq. (MLP)). F . Review of the Theory of Neural T angent Ker nels F .1. Conv ergence of Infinite-W idth Ker nels at Initialization Conjugate Kernel V ia a central-limit-like intuition, each unit h l ( x ) α of Eq. (MLP) should behav e like a Gaussian as width n l − 1 → ∞ , as it is a sum of a large number of roughly independent random variables (Poole et al., 2016; Schoenholz et al., 2017; Y ang and Schoenholz, 2017). The devil, of course, is in what “roughly independent” means and ho w to apply the central limit theorem (CL T) to this setting. It can be done, howe v er , (Lee et al., 2018; Matthews et al., 2018; Nov ak et al., 2018), and in the most general case, using a “Gaussian conditioning” technique, this result can be rigorously generalized to almost any architecture Y ang (2019a;b). In any case, the consequence is that, for an y finite set S ⊆ X , { h l α ( x ) } x ∈ S con v erges in distrib ution to N (0 , Σ l ( S, S )) , as min { n 1 , . . . , n l − 1 } → ∞ , where Σ l is the CK as giv en in Eq. (CK). Neural T angent Kernel By a slightly more inv olv ed version of the “Gaussian conditioning” technique, Y ang (2019b) also showed that, for an y x, y ∈ X , h∇ θ h L ( x ) , ∇ θ h L ( y ) i conv er ges almost surely to Θ L ( x, y ) as the widths tend to infinity , where Θ l is the NTK as giv en in Eq. (NTK). F .2. Fast Evaluations of CK and NTK For certain φ like relu or erf, V φ and V 0 φ can be e valuated v ery quickly , so that both the CK and NTK can be computed in O ( |X | 2 L ) time, where X is the set of points we want to compute the kernel function ov er , and L is the number of layers. Fact F .1 (Cho and Saul (2009)) . F or any kernel K V relu ( K )( x, x 0 ) = 1 2 π ( p 1 − c 2 + ( π − arccos c ) c ) p K ( x, x ) K ( x 0 , x 0 ) V 0 relu ( K )( x, x 0 ) = 1 2 π ( π − arccos c ) A Fine-Grained Spectral Perspecti ve on Neural Networks wher e c = K ( x, x 0 ) / p K ( x, x ) K ( x 0 , x 0 ) . Fact F .2 (Neal (1995)) . F or any kernel K , V erf ( K )( x, x 0 ) = 2 π arcsin K ( x, x 0 ) p ( K ( x, x ) + 0 . 5)( K ( x 0 , x 0 ) + 0 . 5) V 0 erf ( K )( x, x 0 ) = 4 π p (1 + 2 K ( x, x ))(1 + 2 K ( x 0 , x 0 )) − 4 K ( x, x 0 ) 2 . Fact F .3. Let φ ( x ) = exp( x/σ ) for some σ > 0 . F or any kernel K , V φ ( K )( x, x 0 ) = exp K ( x, x ) + 2 K ( x, x 0 ) + K ( x 0 , x 0 ) 2 σ 2 . F .3. Linear Evolution of Neural Network under GD Remarkably , the NTK gov erns the ev olution of the neural netw ork function under gradient descent in the infinite-width limit. First, let’ s consider how the parameters θ and the neural network function f ev olv e under continuous time gradient flo w . Suppose f is only defined on a finite input space X = { x 1 , . . . , x k } . W e will visualize f ( X ) = f ( x 1 ) . . . f ( x k ) , ∇ f L = ∂ L ∂ f ( x 1 ) . . . ∂ L ∂ f ( x k ) , θ = θ 1 . . . θ n , ∇ θ f = ∂ f ( x 1 ) ∂ θ 1 · · · ∂ f ( x k ) ∂ θ 1 . . . . . . . . . ∂ f ( x 1 ) ∂ θ n · · · ∂ f ( x k ) ∂ θ n (best viewed in color). Then under continuous time gradient descent with learning rate η , ∂ t θ t = − η ∇ θ L ( f t ) = − η ∇ θ f t · ∇ f L ( f t ) , ∂ t f t = ∇ θ f t > · ∂ t θ t = − η ∇ θ f t > · ∇ θ f t · ∇ f L ( f t ) = − η Θ t · ∇ f L ( f t ) (11) where Θ t = ∇ θ f > t · ∇ θ f t ∈ R k × k is of course the (finite width) NTK. These equations can be visualized as ∂ t = − η · , ∂ t = · ∂ t = − η · · = − η · Thus f undergoes kernel gradient descent with (functional) loss L ( f ) and kernel Θ t . This kernel Θ t of course changes as f ev olv es, but remarkably , it in fact stays constant for f being an infinitely wide MLP (Jacot et al., 2018): ∂ t f t = − η Θ · ∇ f L ( f t ) , (T raining All Layers) where Θ is the infinite-width NTK corresponding to f . A similar equation holds for the CK Σ if we train only the last layer, ∂ t f t = − η Σ · ∇ f L ( f t ) . (T raining Last Layer) If L is the square loss against a ground truth function f ∗ , then ∇ f L ( f t ) = 1 2 k ∇ f k f t − f ∗ k 2 = 1 k ( f t − f ∗ ) , and the equations abov e become linear differential equations. Howe ver , typically we only have a training set X train ⊆ X of size far less than |X | . In this case, the loss function is effecti vely L ( f ) = 1 2 |X train | X x ∈X train ( f ( x ) − f ∗ ( x )) 2 , with functional gradient ∇ f L ( f ) = 1 |X train | D train · ( f − f ∗ ) , where D train is a diagonal matrix of size k × k whose diagonal is 1 on x ∈ X train and 0 else. Then our function still ev olves linearly ∂ t f t = − η ( K · D train ) · ( f t − f ∗ ) (12) where K is the CK or the NTK depending on which parameters are trained. A Fine-Grained Spectral Perspecti ve on Neural Networks F .4. Relationship to Gaussian Process Inference. Recall that the initial f 0 in Eq. (12) is distributed as a Gaussian process N (0 , Σ) in the infinite width limit. As Eq. (12) is a linear differential equation, the distrib ution of f t will remain a Gaussian process for all t , whether K is CK or NTK. Under suitable conditions, it can be sho wn that (Lee et al., 2019), in the limit as t → ∞ , if we train only the last layer , then the resulting function f ∞ is distributed as a Gaussian process with mean ¯ f ∞ giv en by ¯ f ∞ ( x ) = Σ( x, X train )Σ( X train , X train ) − 1 f ∗ ( X train ) and kernel V ar f ∞ giv en by V ar f ∞ ( x, x 0 ) = Σ( x, x 0 ) − Σ( x, X train )Σ( X train , X train ) − 1 Σ( X train , x 0 ) . These formulas precisely described the posterior distribution of f giv en prior N (0 , Σ) and data { ( x, f ∗ ( x )) } x ∈X train . If we train all layers, then similarly as t → ∞ , the function f ∞ is distributed as a Gaussian process with mean ¯ f ∞ giv en by (Lee et al., 2019) ¯ f ∞ ( x ) = Θ( x, X train )Θ( X train , X train ) − 1 f ∗ ( X train ) . This is, again, the mean of the Gaussian process posterior given prior N (0 , Θ) and the training data { ( x, f ∗ ( x )) } x ∈X train . Howe v er , the k ernel of f ∞ is no longer the kernel of this posterior, but rather is an e xpression in v olving both the NTK Θ and the CK Σ ; see Lee et al. (2019). In any case, we can make the follo wing informal statement in the limit of large width T raining the last layer (r esp. all layers) of an MLP infinitely long , in expectation, yields the mean pr ediction of the GP infer ence given prior N (0 , Σ) (r esp. N (0 , Θ) ). G. A Brief Review of Hilbert-Schmidt Operators and Their Spectral Theory In this section, we briefly revie w the theory of Hilbert-Schmidt kernels, and more importantly , to properly define the notion of eigen v alues and eigenfunctions. A function K : X 2 → R is called a Hilbert-Schmidt operator if K ∈ L 2 ( X × X ) , i.e. k K k 2 H S def = E x,y ∼X K ( x, y ) 2 < ∞ . k K k 2 H S is known as the Hilbert-Schmidt norm of K . K is called symmetric if K ( x, y ) = K ( y , x ) and positive definite (r esp. semidefinite) if E x,y ∼X f ( x ) K ( x, y ) f ( y ) > 0 (resp. ≥ 0 ) for all f ∈ L 2 ( X ) not a.e. zero. A spectral theorem (Mercer’ s theorem) holds for Hilbert-Schmidt operators. Fact G.1. If K is a symmetric positive semidefinite Hilbert-Schmidt kernel, then there is a sequence of scalars λ i ≥ 0 (eigen values) and functions f i ∈ L 2 ( X ) (eigenfunctions), for i ∈ N , such that ∀ i, j, h f i , f j i = I ( i = j ) , and K ( x, y ) = X i ∈ N λ i f i ( x ) f i ( y ) wher e the con ver gence is in L 2 ( X × X ) norm. This theorem allows us to speak of the eigenfunctions and eigen v alues, which are important for training and generalization considerations when K is a kernel used in machine learning, as discussed in the main te xt. A sufficient condition for K to be a Hilbert-Schmidt kernel in our case (concerning only probability measure on X ) is just that K is bounded. All K s in this paper satisfy this property . H. Eigendecomposition of Neural K ernel on Differ ent Domains Below , we will build a spectral theory of CK and NTK ov er the boolean cube, the sphere, and the standard Gaussian distribution. The unifying statement we can make over all three dif ferent distrib utions is A Fine-Grained Spectral Perspecti ve on Neural Networks - 2 - 1 1 2 0.5 1.0 1.5 2.0 2.5 f f ˜ Figure 14. Example of ˜ f gi ven f Theorem 3.1. Suppose K is the CK or NTK of an MLP with polynomially bounded activation function, and let Φ be as in Eq. (2) . Let the underlying data distribution be the uniform distribution over the boolean cube {± 1 } d , the uniform distribution o ver the spher e √ d S d − 1 , or the standar d Gaussian distrib ution N (0 , I ) . F or any d, k > 0 , let κ d,k be the k th lar gest unique eig en value of K over this data distribution. Then for any k > 0 , and for sufficiently lar g e d (depending on k ), κ d,k corr esponds to an eigenspace of dimension d k /k ! + o ( d k ) , and lim d →∞ d k κ d,k = Φ ( k ) (0 , 1 , 1) , wher e Φ ( k ) ( t, q , q 0 ) = d k dt k Φ( t, q , q 0 ) . Consequently , the fractional variances con verge as follo ws: Corollary H.1. Let K , Φ , and κ d,k be as in Thm 3.1. Then for every k , the fractional variance of the eigenspace corr esponding to κ d,k con ver g es to ( k !) − 1 Φ ( k ) (0 , 1 , 1) / Φ(1 , 1 , 1) = ( k !) − 1 Φ ( k ) (0 , 1 , 1) P j ≥ 0 ( j !) − 1 Φ ( j ) (0 , 1 , 1) as the input dimension d → ∞ . W e start with the spectral theory over the boolean cube, continuing the e xposition from the main text. Then we discuss the spectral theory ov er the sphere and the standard Gaussian. Long proofs are omitted but can be found in Appendix J. H.1. Boolean Cube W e first recall the main eigendecomposition theorems from the main text. Theorem 3.2. On the d -dimensional boolean cube d , for every S ⊆ [ d ] , χ S is an eigenfunction of K with eigen value µ | S | def = E x ∈ d x S K ( x, 1 ) = E x ∈ d x S Φ X i x i /d ! , (4) wher e 1 = (1 , . . . , 1) ∈ d . This definition of µ | S | does not depend on the choice S , only on the car dinality of S . These are all of the eigenfunctions of K by dimensionality considerations. 8 Lemma 3.3. W ith µ k as in Thm 3.2, µ k = 2 − d ( I − T ∆ ) k ( I + T ∆ ) d − k Φ(1) (5) = 2 − d d X r =0 C d − k,k r Φ d 2 − r ∆ (6) 8 Readers familiar with boolean Fourier analysis may be reminded of the noise operator T ρ , ρ ≤ 1 (see Defn 2.45 of O’Donnell (2014)). In the language of this work, T ρ is a neural kernel with eigen v alues µ k = ρ k . A Fine-Grained Spectral Perspecti ve on Neural Networks wher e C d − k,k r def = X j =0 ( − 1) r + j d − k j k r − j . (7) W ith a more detailed understanding of Φ , one can sho w the boolean eigen v alues con verge in the d → ∞ limit. Theorem H.2. Let K be the CK or NTK of an MLP on a boolean cube d . Then K can be expr essed as K ( x, y ) = Φ( h x, y i /d ) for some Φ : [ − 1 , 1] → R . If we fix k and let d → ∞ , then lim d →∞ d k µ k = Φ ( k ) (0) , wher e Φ ( k ) denotes the k th derivative of Φ . From the Fourier Series Perspecti ve. Recall that T ∆ is the shift operator on functions that sends Φ( · ) to Φ( · − ∆) . Notice that, if we let Φ( t ) = e κt for some κ ∈ C , then T ∆ Φ( s ) = e − κ ∆ · e κt . Thus Φ is an “eigenfunction” of the operator T ∆ with eigen v alue e − κ ∆ . In particular, this implies that Proposition H.3. Suppose Φ( t ) = e t/σ 2 , as in the case when K is the CK or NTK of a 1-layer neural network with nonlinearity exp( · /σ ) , up to multiplicative constant (F act F .3). Then the eigen value µ k over the boolean cube d equals µ k = 2 − d (1 − exp( − ∆ /σ 2 )) k (1 + exp( − ∆ /σ 2 )) d − k · exp(1 /σ 2 ) wher e ∆ = 2 /d . It would be nice if we can express any Φ as a linear combination of exponentials, so that Eq. (5) simplifies in the fashion of Prop H.3 — this is precisely the idea of Fourier series. W e will use the theory of Fourier analysis on the circle, and for this we need to discuss periodic functions. Let ˜ Φ : [ − 2 , 2] → R be defined as ˜ Φ( x ) = Φ( x ) if x ∈ [ − 1 , 1] Φ(2 − x ) if x ∈ [1 , 2] Φ( − 2 − x ) if x ∈ [ − 2 , − 1] . See Fig. 14 for an example illustration. Note that if Φ is continuous on [ − 1 , 1] , then ˜ Φ is continuous as a periodic function on [ − 2 , 2] . The Fourier basis on functions over [ − 2 , 2] is the collection { t 7→ e 1 2 π ist } s ∈ Z . Under generic conditions (for example if Ψ ∈ L 2 [ − 2 , 2] ), a function Ψ has an associated Fourier series P s ∈ Z ˆ Ψ( s ) e 1 2 π ist . W e briefly revie w basic f acts of Fourier analysis on the circle. Recall the following notion of functions of bounded variation . Definition H.4. A function f : [ a, b ] → R is said to have bounded variation if sup P n P − 1 X i =0 | f ( x i +1 ) − f ( x i ) | < ∞ , where the supremum is taken ov er all partitions P of the interval [ a, b ] , P = { x 0 , . . . , x n P } , x 0 ≤ x 1 ≤ · · · ≤ x n P . Intuitiv ely , a function of bounded v ariation has a graph (in [ a, b ] × R ) of finite length. Fact H.5 (Katznelson (2004)) . A bounded variation function f : [ − 2 , 2] → R that is periodic (i.e . f ( − 2) = f (2) ) has a pointwise-con ver g ent F ourier series: lim T →∞ X s ∈ [ − T ,T ] ˆ Ψ( s ) e 1 2 π ist → Ψ( t ) , ∀ t ∈ [ − 2 , 2] . From this fact easily follo ws the follo wing lemma. A Fine-Grained Spectral Perspecti ve on Neural Networks Lemma H.6. Suppose Φ is continuous and has bounded variation on [ − 1 , 1] . Then ˜ Φ is also continuous and has bounded variation, and its F ourier Series (on [ − 2 , 2] ) conver ges pointwise to ˜ Φ . Pr oof. ˜ Φ is obviously continuous and has bounded v ariation as well, and from Fact H.5, we kno w a periodic continuous function with bounded variation has a pointwise-con vergent F ourier Series. Certainly , T ∆ sends continuous bounded v ariation functions to continuous bounded variation functions. Because T ∆ e 1 2 π ist = e − 1 2 π is ∆ e 1 2 π ist , T ∆ X s ∈ Z ˆ Ψ( s ) e 1 2 π ist = X s ∈ Z ˆ Ψ( s ) e − 1 2 π is ∆ e 1 2 π ist whenev er both sides are well defined. If Ψ is continuous and has bounded v ariation then T ∆ Ψ is also continuous and has bounded variation, and thus its F ourier series, the RHS abo ve, con verges pointwise to T ∆ Ψ . Now , observe ( I − T ∆ ) k ( I + T ∆ ) d − k ˜ Φ( x ) = d X r =0 C d − k,k r ˜ Φ ( x − r ∆) ( I − T ∆ ) k ( I + T ∆ ) d − k ˜ Φ(1) = d X r =0 C d − k,k r Φ d 2 − r ∆ = µ k Expressing the LHS in Fourier basis, we obtain Theorem H.7. µ k = X s ∈ Z i s (1 − e − 1 2 π is ∆ ) k (1 + e − 1 2 π is ∆ ) d − k ˆ ˜ Φ( s ) wher e ˆ ˜ Φ( s ) = 1 4 Z 2 − 2 ˜ Φ( t ) e − 1 2 π ist d t = 1 4 Z 1 − 1 Φ( t )( e − 1 2 π ist + ( − 1) s e 1 2 π ist ) d t = ( 1 2 R 1 − 1 Φ( t ) cos( 1 2 π st ) d t if s is even − i 2 R 1 − 1 Φ( t ) sin( 1 2 π st ) d t if s is odd denote the F ourier coefficients of ˜ Φ on [ − 2 , 2] . (Here i is the imaginary unit her e, not an index). Recovering the v alues of Φ given the eigen v alues µ 0 , . . . , µ d . Con v ersely , giv en eigen v alues µ 0 , . . . , µ d corresponding to each monomial degree, we can reco ver the entries of the matrix K . Theorem H.8. F or any x, y ∈ d with Hamming distance r , K ( x, y ) = Φ d 2 − r ∆ = d X k =0 C d − r,r k µ k , wher e C d − r,r k = P j =0 ( − 1) k + j d − r j r k − j as in Eq. (7) . Pr oof. Recall that for any S ⊆ [ d ] , χ S ( x ) = x S is the Fourier basis corresponding to S (see Eq. (3)). Then by con verting from the Fourier basis to the re gular basis, we get Φ d 2 − r ∆ = K ( x, y ) for any x, y ∈ d with Hamming distance r = d X k =0 µ k X | S | = k χ S ( x ) χ S ( y ) . A Fine-Grained Spectral Perspecti ve on Neural Networks If x and y differ on a set T ⊆ [ d ] , then we can simplify the inner sum Φ d 2 − r ∆ = d X k =0 µ k X | S | = k ( − 1) | S ∩ T | = d X k =0 µ k C d − r,r k . Remark H.9 . If we let T be the operator that sends µ • 7→ µ • +1 , then we hav e the follo wing operator expression Φ d 2 − r ∆ = [(1 + T ) d − r (1 − T ) r µ ] 0 Remark H.10 . The above sho ws that the matrix C = { C d − r,r k } d k,r =0 satisfies C 2 = 2 d I . H . 1 . 1 . C O M P U T I N G T H E B O O L E A N E I G E N V A L U E S Focusing on the boolean cube eigen values has the benefit of being much easier to compute. Each eigen v alue o ver the sphere and the standard Gaussian requires an integration of Φ against a Gegenbauer polynomial. In high dimension d , these Gegenbauer polynomials v aries wildly in a sinusoidal fashion, and blo ws up to ward the boundary (see Fig. 15). As such, it is difficult to obtain a numerically stable estimate of this integral in an ef ficient manner when d is large. In contrast, we hav e multiple ways of computing boolean cube eigen v alues, via Eqs. (5) and (6). In either case, we just take some linear combination of the v alues of Φ at a grid of points on [ − 1 , 1] , spaced apart by ∆ = 2 /d . While the coefficients C d − k,k r (defined in Eq. (7)) are relatively efficient to compute, the change in the sign of C d − k,k r makes this procedure numerically unstable for lar ge d . Instead, we use Eq. (5) to isolate the alternating part to e v aluate in a numerically stable way: Since µ k = I + T ∆ 2 d − k I −T ∆ 2 k Φ(1) , we can ev aluate ˜ Φ def = I −T ∆ 2 k Φ via k finite dif ferences, and then compute I + T ∆ 2 d − k ˜ Φ(1) = 1 2 d − k d − k X r =0 d − k r ˜ Φ(1 − r ∆) . (13) When Φ arises from the CK or the NTK o f an MLP , all deriv ati ves of Φ at 0 are nonnegati ve ( Thm I.1). Thus intuitiv ely , the finite dif ference ˜ Φ should be also all nonneg ativ e, and this sum can be e v aluated without w orry about floating point errors from cancellation of large terms. A slightly more clev er way to impro ve the numerical stability when 2 k ≤ d is to note that ( I + T ∆ ) d − k ( I − T ∆ ) k Φ(1) = ( I + T ∆ ) d − 2 k I − T 2 ∆ k Φ(1) = ( I + T ∆ ) d − 2 k ( I − T 2∆ ) k Φ(1) . So an improv ed algorithm is to first compute the k th finite difference ( I − T 2∆ ) k with the larger step size 2∆ , then compute the sum ( I + T ∆ ) d − 2 k as in Eq. (13). H.2. Sphere Now let’ s consider the case when X = √ d S d − 1 is the radius- √ d sphere in R d equipped with the uniform measure. Again, because x ∈ X all hav e the same norm, we will consider Φ as a uni v ariate function with K ( x, y ) = Φ( h x, y i / k x kk y k ) = Φ( h x, y i /d ) . As is long known (Gneiting, 2013; Schoenberg, 1942; Smola et al., 2001; Xu and Cheney, 1992), K is diagonalized by spherical harmonics. W e revie w these results briefly belo w , as we will build on them to deduce spectral information of K on isotropic Gaussian distributions. A Fine-Grained Spectral Perspecti ve on Neural Networks - 1.0 - 0.5 0.5 1.0 - 2 × 10 6 2 × 10 6 4 × 10 6 C 0 ( 63 ) ( x ) C 1 ( 63 ) ( x ) C 2 ( 63 ) ( x ) C 3 ( 63 ) ( x ) C 4 ( 63 ) ( x ) C 8 ( 63 ) ( x ) Figure 15. Examples of Gegenbauer Polynomials for d = 128 (or α = 63 ). Review: spherical harmonics and Gegenbauer polynomials. Spherical harmonics are L 2 functions on S d − 1 that are eigenfunctions of the Laplace-Beltrami operator ∆ S d − 1 of S d − 1 . They can be described as the restriction of certain homogeneous polynomials in R d to S d − 1 . Denote by H d − 1 , ( l ) the space of spherical harmonics of degree l on sphere S d − 1 . Then we have the orthogonal decomposition L 2 ( S d − 1 ) ∼ = L ∞ l =0 H d − 1 , ( l ) . It is a standard fact that dim H d − 1 , ( l ) = d − 1+ l d − 1 − d − 3+ l d − 1 . There is a special class of spherical harmonics called zonal harmonics that can be represented as x 7→ p ( h x, y i ) for specific polynomials p : R → R , and that possess a special r epr oducing pr operty which we will describe shortly . Intuiti vely , the value of an y zonal harmonics only depends on the “height” of x along some fixed axis y , so a typical zonal harmonics looks like Fig. 16. The polynomials p must be one of the Ge genbauer polynomials. Ge genbauer polynomials { C ( α ) l ( t ) } ∞ l =0 are orthogonal polynomials with respect to the measure (1 − t 2 ) α − 1 2 on [ − 1 , 1] (see Fig. 15 for examples), and here we adopt the con v ention that Z 1 − 1 C ( α ) n ( t ) C ( α ) l ( t )(1 − t 2 ) α − 1 2 d t = π 2 1 − 2 α Γ( n + 2 α ) n !( n + α )[Γ( α )] 2 I ( n = l ) . (14) Then for each (oriented) axis y ∈ S d − 1 and degree l , there is a unique zonal harmonic Z d − 1 , ( l ) y ∈ H d − 1 , ( l ) , Z d − 1 , ( l ) y ( x ) def = c − 1 d,l C ( d − 2 2 ) l ( h x, y i ) for any x, y ∈ S d − 1 , where c d,l = d − 2 d +2 l − 2 . V ery importantly , they satisfy the following Fact H.11 (Reproducing property (Suetin)) . F or any f ∈ H d − 1 , ( m ) , E z ∼S d − 1 Z d − 1 , ( l ) y ( z ) f ( z ) = f ( y ) I ( l = m ) E z ∼S d − 1 Z d − 1 , ( l ) y ( z ) Z d − 1 , ( m ) x ( z ) = Z d − 1 , ( l ) y ( x ) I ( l = m ) = c − 1 d,l C ( d − 2 2 ) l ( h x, y i ) I ( l = m ) Gegenbauer polynomials also satisfy other properties Facts J.7 and J.8 described later that we will use to build a spectral theory ov er the sphere. By a result of Schoenberg (1942), we ha ve the follo wing eigendecomposition of K on the sphere. Theorem H.12 (Schoenberg) . Suppose Φ : [ − 1 , 1] → R is in L 2 ((1 − t 2 ) d − 1 2 − 1 ) , so that it has the Ge genbauer e xpansion Φ( t ) a.e. = ∞ X l =0 a l c − 1 d,l C ( d − 2 2 ) l ( t ) . Then K has eigenspaces H d − 1 , ( l ) √ d def = { f ( x/ √ d ) : f ∈ H d − 1 , ( l ) } with corr esponding eigen values a l . Since L ∞ l =0 H d − 1 , ( l ) √ d is an orthogonal decomposition of L 2 ( √ d S d − 1 ) , this describes all eigenfunctions of K consider ed as an operator on L 2 ( √ d S d − 1 ) . A Fine-Grained Spectral Perspecti ve on Neural Networks Figure 16. V isualization of a zonal harmonic, which depends only on the “height” of the input along a fixed axis. Color indicates function value. For completeness, we include the proof of this theorem in Appendix J. As the dimension d of the sphere tends to ∞ , the eigen v alues in fact simplify to the deri v ativ es of Φ at 0: Theorem H.13. Let K be the CK or NTK of an MLP on the sphere √ d S d − 1 . Then K can be expr essed as K ( x, y ) = Φ( h x, y i /d ) for some smooth Φ : [ − 1 , 1] → R . Let a ` denote K ’ s eig en values on the spher e (as in Thm H.12). If we fix ` and let d → ∞ , then lim d →∞ d ` a ` = Φ ( ` ) (0) , wher e Φ ( ` ) denotes the ` th derivative of Φ . This theorem is the same as Thm H.2 except that it concerns the sphere rather than the boolean cube. H.3. Isotropic Gaussian Now let’ s consider X = R d equipped with standard isotropic Gaussian N (0 , I ) , so that K behaves lik e K f ( x ) = E y ∼N (0 ,I ) K ( x, y ) f ( y ) = E y ∼N (0 ,I ) Φ h x, y i k x kk y k , k x k 2 d , k y k 2 d f ( y ) for any f ∈ L 2 ( N (0 , I )) . In contrast to the previous two sections, K will essentially depend on the effect of the norms k x k and k y k on Φ . Note that an isotropic Gaussian v ector z ∼ N (0 , I ) can be sampled by independently sampling its direction v uniformly from the sphere S d − 1 and sampling its magnitude r from a chi distribution χ d with d degrees of freedom. Proceeding along this line of logic yields the following spectral theorem: Theorem H.14. A function K : ( R d ) 2 → R of the form K ( x, y ) = Φ h x, y i k x kk y k , k x k 2 d , k y k 2 d forms a positive semidefinite Hilbert-Schmidt oper ator on L 2 ( N (0 , I )) iff Φ can be decomposed as Φ( t, q , q 0 ) = ∞ X l =0 A l ( q , q 0 ) c − 1 d,l C ( d − 2 2 ) l ( t ) (15) A Fine-Grained Spectral Perspecti ve on Neural Networks satisfying the norm condition ∞ X l =0 k A l k 2 c − 2 d,l k C ( d − 2 2 ) l k 2 = ∞ X l =0 k A l k 2 c − 2 d,l π 2 3 − d Γ( l + d − 2) l !( l + d − 2 2 )Γ d − 2 2 2 < ∞ , (16) wher e • c d,l = d − 2 d +2 l − 2 • C ( d − 2 2 ) l ( t ) ar e Geg enbauer polynomials as in Appendix H.2, with k C ( d − 2 2 ) l k = q R 1 − 1 C ( d − 2 2 ) l ( t ) 2 (1 − t 2 ) d − 1 2 − 1 d t denoting the norm of C ( d − 2 2 ) l in L 2 ((1 − t 2 ) d − 1 2 − 1 ) . • and A l ar e positive semidefinite Hilbert-Schmidt k ernels on L 2 ( 1 d χ 2 d ) , the L 2 space over the pr obability measure of a χ 2 d -variable divided by d , and with k A l k denoting the Hilbert-Schmidt norm of A l . In addition, K is positive definite iff all A l ar e. See Appendix J for a proof. As a consequence, K has an eigendecomposition as follows under the standard Gaussian measure in d dimensions. Corollary H.15 (Eigendecomposition ov er Gaussian) . Suppose K and Φ ar e as in Thm H.14 and K is a positive semidefinite Hilbert-Schmidt oper ator , so that Eq. (15) holds, with Hilbert-Schmidt kernels A l . Let A l have eigendecomposition A l ( q , q 0 ) = ∞ X i =0 a li u li ( q ) u li ( q 0 ) (17) for eigen values a li ≥ 0 and eigenfunctions u li ∈ L 2 ( 1 d χ 2 d ) with E q ∼ 1 d χ 2 d u li ( q ) 2 = 1 . Then K has eigen values { a li : l, i ∈ [0 , ∞ ) } , and each eigen value a li corr esponds to the eigenspace u li ⊗ H d − 1 , ( l ) def = u li k x k 2 d f x k x k : f ∈ H d − 1 , ( l ) , wher e H d − 1 , ( l ) is the space of de gr ee l spherical harmonics on the unit spher e S d − 1 of ambient dimension d . For certain simple F , we can obtain { A l } l ≥ 0 explicitly . For example, suppose K is de gr ee- s positive-homogeneous , in the sense that, for a, b > 0 , K ( ax, by ) = ( ab ) s K ( x, y ) . This happens when K is the CK or NTK of an MLP with degree- s positiv e-homogeneous. Then it’ s easy to see that Φ( t, q , q 0 ) = ( q q 0 ) s ¯ Φ( t ) for some ¯ Φ : [ − 1 , 1] → R , and Φ( t, q , q 0 ) = ∞ X l =0 ( q q 0 ) s a l c − 1 d,l C ( d − 2 2 ) l ( t ) where { a l } l are the Gegenbauer coef ficients of ¯ Φ , ¯ Φ( t ) = ∞ X l =0 a l c − 1 d,l C ( d − 2 2 ) l ( t ) . W e can then conclude with the following theorem. Theorem H.16. Suppose K : ( R d ) 2 → R is a kernel given by K ( x, y ) = R ( k x k /d ) R ( k x k /d ) ¯ Φ( h x, y i / k x kk y k ) for some functions R : [0 , ∞ ) → R , ¯ Φ : [ − 1 , 1] → R . Let ¯ Φ( t ) = ∞ X l =0 a l c − 1 d,l C ( d − 2 2 ) l ( t ) A Fine-Grained Spectral Perspecti ve on Neural Networks be the Ge genbauer e xpansion of ¯ Φ . Also define λ def = r E q ∼ 1 d χ 2 d R ( q ) 2 . Then over the standar d Gaussian in R d , K has the following eigendecomposition • F or each l ≥ 0 , λ − 1 R ⊗ H d − 1 , ( l ) = { λ − 1 R ( k x k 2 /d ) f ( x/ k x k ) : f ∈ H d − 1 , ( l ) } is an eigenspace with eigen value λ 2 a l . • F or any S ∈ L 2 ( 1 d χ 2 d ) that is orthogonal to R , i.e. E q ∼ 1 d χ 2 d S ( q ) R ( q ) = 0 , the function S ( k x k 2 /d ) f ( x/ k x k ) for any f ∈ L 2 ( S d − 1 ) is in the null space of K . Pr oof. The A l in Eq. (15) for K are all equal to A l ( q , q 0 ) = λ 2 R ( q ) λ R ( q 0 ) λ . This is a rank 1 kernel (on L 2 ( 1 d χ 2 d ) ), with eigenfunction R/λ and eigen v alue λ 2 . The rest then follows straightforwardly from Thm H.12. A common e xample where Thm H.16 applies is when K is the CK of an MLP with relu, or more generally de gree- s positi ve homogeneous activ ation functions, so that the R in Thm H.16 is a polynomial. In general, we cannot expect K can be exactly diagonalized in a natural basis, as { A l } l ≥ 0 cannot e ven be simultaneously diagonalizable. W e can, howe v er , in v estigate the “v ariance due to each degree of spherical harmonics” by computing a l def = E q ∼ d − 1 χ 2 d A l ( q , q ) (18) which is the coefficient of Ge genbauer polynomials in ˆ Φ d ( t ) def = E q ∼ d − 1 χ 2 d Φ( t, q , q ) = ∞ X l =0 a l c − 1 d,l C ( d − 2 2 ) l ( t ) . (19) Proposition H.17. Assume that Φ( t, q , q 0 ) is continuous in q and q 0 . Suppose for any d and any t ∈ [ − 1 , 1] , the random variable Φ( t, q , q 0 ) with q , q 0 ∼ d − 1 χ 2 d has a bound | Φ( t, q , q 0 ) | ≤ Y for some random variable Y with E | Y | < ∞ . Then for every t ∈ [ − 1 , 1] , lim d →∞ | ˆ Φ d ( t ) − Φ( t, 1 , 1) | = 0 . Pr oof. By the strong la w of lar ge number , d − 1 χ 2 d con v erges to 1 almost surely . Because Φ( t, q , q 0 ) is continuous in q and q 0 , almost surely we ha ve Φ( t, q , q 0 ) → Φ( t, 1 , 1) almost surely . Since Φ is bounded by Y , by dominated con vergence, we ha ve ˆ Φ d ( t ) − Φ( t, 1 , 1) = E q ,q 0 ∼ d − 1 χ 2 d Φ( t, q , q 0 ) − Φ( t, 1 , 1) → 0 as desired. Finally , in the limit of large input dimension d , the top eigenv alues of K ov er the standard Gaussian con ver ge to the deriv atives of Φ . A Fine-Grained Spectral Perspecti ve on Neural Networks erf NTK σ w 2 = 2, σ b 2 = 0.05,L = 3 - 1.0 - 0.5 0.5 1.0 - 4 - 2 2 4 6 erf CK σ w 2 = 2, σ b 2 = 0.05,L = 3 - 1.0 - 0.5 0.5 1.0 - 0.5 0.5 1.0 erf NTK σ w 2 = 2, σ b 2 = 2,L = 3 - 1.0 - 0.5 0.5 1.0 3.05 3.10 3.15 3.20 3.25 3.30 3.35 Φ d d = 2 d = 4 d = 8 d = 32 d = 128 Φ S Figure 17. In high dimension d , ˆ Φ d as defined in Eq. (19) approximates Φ very well. W e show for 3 different erf kernels that the function Φ defining K as an integral operator on the sphere is well-approximated by ˆ Φ d when d is moderately large ( d ≥ 32 seems to work well). This suggests that the eigenv alues of K as an integral operator on the standard Gaussian should approximate those of K as an integral operator on the sphere. Theorem H.18. Suppose K is the CK or NTK of an MLP with polynomially bounded activation function. F or every de gr ee l , K over N (0 , I d ) has an eigen value a l 0 at spherical harmonics de gr ee l (in the sense of Cor H.15) with a l 0 ∈ " E q ,q 0 ∼ 1 d χ 2 d A l ( q , q 0 ) , E q ∼ 1 d χ 2 d A l ( q , q ) # , wher e A l is as in Eq. (17) . Furthermore , lim d →∞ d l a l 0 = lim d →∞ d l E q ,q 0 ∼ 1 d χ 2 d A l ( q , q 0 ) = lim d →∞ d l E q ∼ 1 d χ 2 d A l ( q , q ) = Φ ( l ) (0 , 1 , 1) . Her e Φ ( l ) is the l th derivative of Φ( t, q , q 0 ) against t . H.4. In High Dimension, Boolean Cube ≈ Sphere ≈ Standard Gaussian W e have already sho wn theoretically that the eigen values o ver the three distrib utions are close in high dimension ( Thm 3.1). In this section, we numerically verify this, and also detail our justification of the limit where the degree k is fixed while the input dimension d → ∞ . For the same neural kernel K with K ( x, y ) = Φ( h x, y i / k x kk y k , k x k 2 /d, k y k 2 /d ) , let ˆ Φ d be as defined in Eq. (19), and let Φ S def = Φ( t, 1 , 1) . Thus Φ S is the univ ariate Φ that we studied in Appendix H.2 in the context of the sphere. Empirical verification of the spectral closeness As d → ∞ , 1 d χ 2 d con v erges almost surely to 1, and each A l in Eq. (15) con v erges weakly to the simple operator that multiplies the input function by A l (1 , 1) . W e verify in Fig. 17 that, for different erf kernels, ˆ Φ d approximates Φ S when d is large, which would then imply that their spectra become identical for large d . Note that this is tautologically true for relu kernels with no bias σ b = 0 because they are positi ve-homogeneous. Next, we compute the eigenv alues of K on the boolean cube and the sphere, as well as the eigen v alues of the kernel ˆ K ( x, y ) def = ˆ Φ d ( h x, y i / k x kk y k ) on the sphere, which “summarizes” the eigenv alues of K on the standard Gaussian distribution. In Fig. 18, we compare them for different dimensions d up to degree 5 (there, “Gaussian” means ˆ K on the sphere). W e see that by dimension 128, all eigen v alues shown are v ery close to each other for each data distrib ution. Practically speaking, only the top eigen values matter . Observe that, in the empirical and theoretical results abo ve, we only verify that the top eigenv alues ( µ k , a k , or a k 0 for k small compared to d ) are close when d is large. While this result may seem very weak at face v alue, in practice, the closeness of these top eigen v alues is the only thing that matters. Indeed, in machine learning, we will only ev er hav e a finite number , say N , of training samples to work with. Thus, we can only use a finite N × N submatrix of the kernel K . This submatrix, of course, has only N eigen v alues. Furthermore, if these samples are collected in an iid fashion (as is typically assumed), then these eigen values approximate the largest N eigen v alues (top A Fine-Grained Spectral Perspecti ve on Neural Networks erf CK σ w 2 = 2, σ b 2 = 0.001,L = 2 ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ⨯ ⨯ ⨯ ⨯ ⨯ ⨯ ⨯ ⨯ ⨯ ⨯ ⨯ ⨯ ⨯ ⨯ ⨯ ⨯ ⨯ ⨯ ⨯ ⨯ ⨯ ⨯ ⨯ ⨯ + + + + + + + + + + + + + + + + + + + + + + + + 1 2 3 4 5 degree k 10 - 9 10 - 6 10 - 3 eigenvalue μ k ● d = 16 ● d = 32 ● d = 64 ● d = 128 ● boolean ⨯ sphere + Gaussian Figure 18. In high dimension d , the eigenv alues are very close for the kernel over the boolean cube, the sphere, and standard Gaussian. W e plot the eigen v alues µ k of the erf CK, with σ 2 w = 2 , σ 2 b = 0 . 001 , depth 2, ov er the boolean cube, the sphere, as well as kernel on the sphere induced by ˆ Φ d (Eq. (19)). W e do so for each degree k ≤ 5 and for dimensions d = 16 , 32 , 64 , 128 . W e see that by dimension d = 128 , the eigenv alues sho wn are already very close to each other . N counting multiplicity) of the kernel K itself (T ropp, 2015). As such, the smaller eigenv alues of K can hardly be detected in the training sample, and cannot affect the machine learning process v ery much. Let’ s discuss a more concrete example: Fig. 18 shows that the boolean cube eigenv alues µ k are very close to the sphere eigen v alues a k for all k ≤ 5 . Over the boolean cube, µ 0 , . . . , µ 5 cov er eigenspaces of total dimension d 0 + · · · + d 5 , which is 275,584,033 when d = 128 . W e need at least that many samples to be able to e ven detect the eigen value µ 6 and the possible dif ference between it and the sphere eigen value a 6 . But note in comparison, Imagenet, one of the most common large datasets in use today , has only about 15 million samples, 10 times less than the number above. Additionally , in this same comparison, d = 128 dramatically pales compared to Imagenet’ s input dimension 3 × 256 2 = 196608 , and even to the those of the smaller common datasets like CIF AR10 ( d = 3 × 32 2 = 3072 ) and MNIST ( d = 24 2 = 576 ) — if we were to ev en use the input dimension of MNIST above, then µ 0 , . . . , µ 5 would cov er eigenspaces of 523 billion total dimensions! Hence, it is quite practically rele vant to consider the effect of large d on the eigen v alues, while keeping k small. Again, we remark that even when one fix es k and increases d , the dimension of eigenspaces affected by our limit theorems Thms H.2, H.13 and H.18 increases like Θ( d k ) , which implies one needs an increasing number Θ( d k ) of training samples to see the difference of eigen values in higher de grees k . Finally , from the perspectiv e of fractional variance, we also can see that only the top k spectral closeness matters: By Cor H.1, for any > 0 , there is a k such that the total fractional variance of degree 0 to degree k (corresponding to eigenspaces of total dimension Θ( d k ) ) sums up to more than 1 − , for the cube, the sphere, and the standard Gaussian simultaneously , when d is sufficiently lar ge. This is because the asymptotic fractional variance is completely determined by the deriv atives of Φ at t = 0 . I. Basic Properties of Neural K ernel Functions W e derive a fe w facts about the Φ function associated to a neural kernel K (as defined in Eq. (2)). These will be crucial for proving the spectral theorems we stated earlier . Below , by nontrivial activation function we mean any φ : R → R that is not zero almost everywhere. Theorem I.1. Let K be the CK or NTK of an MLP with nontrivial activation function with domain √ d S d − 1 ⊆ R d . Then K ( x, y ) = Φ h x,y i k x kk y k wher e Φ : [ − 1 , 1] → R has a T aylor series expansion ar ound 0 Φ( c ) = a 0 + a 1 c + a 2 c 2 + · · · (20) with the pr operties that a i ≥ 0 for all i and P i a i = Φ(1) ≤ ∞ , so that Eq. (20) is absolutely con ver gent on c ∈ [ − 1 , 1] . Pr oof. W e first prove this statement for the CK of an L layer MLP with nonlinearity φ . Let Φ l be the corresponding A Fine-Grained Spectral Perspecti ve on Neural Networks Φ -function for the CK Σ L of the L -layer MLP . It suffices to pro ve this by induction on depth L . For L = 1 , Σ 1 ( x, x 0 ) = σ 2 w ( n 0 ) − 1 h x, x 0 i + σ 2 b by Eq. (CK), so clearly Φ 1 ( c ) = a 0 + a 1 c where a 0 and a 1 are nonnegati v e. Now for the inductiv e step, suppose Σ l − 1 satisfies the property that Φ l − 1 has T aylor expansion of the desired form. W e seek to show the same for Σ l and Φ l . First notice that it suffices to sho w this for V φ (Σ l − 1 ) , since multiplication by σ 2 w and addition of σ 2 b preserves the property . But V φ (Σ l − 1 )( x, x 0 ) = E φ ( z ) φ ( z 0 ) where ( z , z 0 ) ∼ N 0 , Σ l − 1 ( x, x ) Σ l − 1 ( x, x 0 ) Σ l − 1 ( x, x 0 ) Σ l − 1 ( x 0 , x 0 ) = N 0 , Φ l − 1 (1) Φ l − 1 ( c ) Φ l − 1 ( c ) Φ l − 1 (1) . Using the notation of Lem I.3, we can express this as V φ (Σ l − 1 )( x, x 0 ) = Φ l (1) ˆ φ Φ l − 1 ( c ) Φ l − 1 (1) . (21) Substituting the T aylor expansion of Φ l − 1 ( c ) Φ l − 1 (1) into the T aylor expansion of ˆ φ giv en by Lem I.3 giv es us a T aylor series whose coefficients are all nonne gati ve, since those of Φ l − 1 ( c ) Φ l − 1 (1) and ˆ φ are nonnegati v e as well. In addition, plugging in 1 for c in this T aylor series shows that the sum of the coefficients equal ˆ φ (1) = 1 , so the series is absolutely con vergent for c ∈ [ − 1 , 1] . This prov es the inducti ve step. For the NTK, the proof is similar , except we now also ha ve a product step where we multiply V φ 0 (Σ l − 1 ) with Θ l − 1 , and we simply just need to use the fact that product of tw o T aylor series with nonnegati ve coef ficients is another T aylor series with nonnegati v e coefficients, and that the resulting radius of con v ergence is the minimum of the original two radii of con v ergence. Theorem I.2. Let K be the CK or NTK of an MLP with nontrivial activation function with domain R d \ { 0 } . Then K ( x, y ) = Φ h x,y i k x kk y k , k x k 2 d , k y k 2 d wher e Φ : [ − 1 , 1] × ( R + ) 2 → [ − 1 , 1] × ( R + ) 2 is 1) continuous jointly in all 3 ar guments, 2) Φ( t, q , q 0 ) is analytic in t for any fixed q , q 0 ∈ R + , and 3) d r dt r Φ( t, q , q 0 ) is continuous in ( t, q , q 0 ) ∈ ( − 1 , 1) ∈ ( R + ) 2 for any r ≥ 0 . If, furthermor e, the MLP’ s activation function is polynomially bounded, then the Φ corr esponding to its CK is polynomially bounded as well. Likewise, if the MLP’ s activation function has a polynomially bounded derivative , then the Φ corr esponding to its NTK is polynomially bounded as well. Pr oof. W e first show the result for the CK. Let Λ( t, q , q 0 ) = σ 2 w t √ q q 0 + σ 2 b p ( σ 2 w q + σ 2 b )( σ 2 w q 0 + σ 2 b ) , σ 2 w q + σ 2 b , σ 2 w q 0 + σ 2 b ! . Note that, since σ w > 0 , Λ is continuous on [ − 1 , 1] × ( R + ) 2 , and is trivially analytic in t for fixed q , q 0 ∈ R + . Let φ be the nonlinearity of the MLP . W e can write Φ as a composition of ˆ φ as defined in Lem I.4 and Λ as follo ws: Φ( t, q , q 0 ) = ( ˆ φ ◦ Λ) L ( t, q , q 0 ) where the superscript L denotes L -fold repeated composition. Then claim 1, 2, and 3 follow from the same properties of Λ and ˆ φ (by Lem I.4) and the fact that they are preserved under composition. Like wise, when φ is polynomially bounded, ˆ φ is as well (by Lem I.4). Because the composition of polynomially bounded functions is polynomially bounded, this implies that Φ is polynomially bounded, as desired. The proof for the NTK case is similar, and just requires noting that the properties 1 and 2, along with the polynomially- bounded property , are preserved under multiplication and summation as well. A Fine-Grained Spectral Perspecti ve on Neural Networks Lemma I.3. Consider any σ > 0 and any nontrival φ : R → R that is squar e-inte gr able against N (0 , σ 2 ) . Then the function ˆ φ : [ − 1 , 1] → [ − 1 , 1] , ˆ φ ( c ) def = E φ ( x ) φ ( y ) E φ ( x ) 2 , wher e ( x, y ) ∼ N 0 , σ 2 σ 2 c σ 2 c σ 2 , has a T aylor series expansion ar ound 0 ˆ φ ( c ) = a 0 + a 1 c + a 2 c 2 + · · · (22) with the pr operties that a i ≥ 0 for all i and P i a i = ˆ φ (1) = 1 , so that Eq. (22) is absolutely con ver g ent on c ∈ [ − 1 , 1] . Pr oof. Since the denominator of ˆ φ doesn’t depend on c , it suf fices to prov e this T aylor expansion e xists for its numerator . Let ˜ φ ( c ) def = φ ( σ c ) . Then E φ ( x ) φ ( y ) : ( x, y ) ∼ N 0 , σ 2 σ 2 c σ 2 c σ 2 = E ˜ φ ( x ) ˜ φ ( y ) : ( x, y ) ∼ N 0 , 1 c c 1 By Fact I.5, this is just b 2 0 + b 2 1 c + b 2 2 c 2 + · · · where b i are the Hermite coefficients of ˜ φ . Since φ ∈ L 2 ( N (0 , σ 2 )) , X i b 2 i < ∞ as desired. Lemma I.4. Consider any nontrival φ : R → R that is squar e-integr able against N (0 , σ 2 ) for all σ > 0 . Then the function ˆ φ : [ − 1 , 1] × ( R + ) 2 → [ − 1 , 1] × ( R + ) 2 , ˆ φ ( t, q , q 0 ) def = E φ ( x ) φ ( y ) p E φ ( x ) 2 E φ ( y ) 2 , E φ ( x ) 2 , E φ ( y ) 2 ! , wher e ( x, y ) ∼ N 0 , q t p q q 0 t p q q 0 q 0 , is 1) is continuous in ( t, q , q 0 ) ∈ [ − 1 , 1] × ( R + ) 2 , 2) is analytic in t ∈ [ − 1 , 1] for every q , q 0 ∈ R + , and 3) its derivatives d r dt r ˆ φ ( t, q , q 0 ) is continuous in ( t, q , q 0 ) ∈ ( − 1 , 1) × ( R + ) 2 for any r ≥ 0 . If furthermor e φ is polynomially bounded (i.e. ther e is some polynomial P such that | φ ( z ) | ≤ P ( z ) for all z ∈ R ), then ˆ φ is also polynomially bounded. Pr oof. The continuity claim 1) follows from the continuity of E φ ( x ) φ ( y ) , E φ ( x ) 2 , E φ ( y ) 2 in the entries of the covariance matrix q , q 0 , and t √ q q 0 . The claim 3) follows from simple computation of d r dt r E φ ( x ) φ ( y ) . The polynomially-bounded claim also trivially follo ws from simple calculations. For analyticity claim 2), let φ q ( c ) def = φ ( c √ q ) and φ q 0 ( c ) def = φ ( c √ q 0 ) . Note that ˆ φ ( t, q , q 0 ) 1 = E φ q ( ζ 1 ) φ q 0 ( ζ 2 ) , ( ζ 1 , ζ 2 ) ∼ N 0 , 1 t t 1 . By Fact I.5, ˆ φ ( t, q , q 0 ) 1 = a 0 b 0 + a 1 b 1 t + a 2 b 2 t 2 + · · · where a i and b i are the Hermite coefficients of φ q and φ q 0 . This series is absolutely conv er gent because | t | ≤ 1 , so that | ˆ φ ( t, q , q 0 ) 1 | ≤ | a 0 b 0 | + | a 1 b 1 | + | a 2 b 2 | + · · · ≤ q ( a 2 0 + a 2 1 + · · · ) q ( b 2 0 + b 2 1 + · · · ) = q ( E φ q ( z ) 2 ) ( E φ q 0 ( z ) 2 ) by Cauchy-Schwartz, where z ∼ N (0 , 1) . A Fine-Grained Spectral Perspecti ve on Neural Networks Fact I.5 (O’Donnell (2014)) . F or any φ, ψ ∈ L 2 ( N (0 , 1)) , E φ ( x ) ψ ( y ) : ( x, y ) ∼ N 0 , 1 c c 1 = a 0 b 0 + a 1 b 1 c + a 2 b 2 c 2 + · · · wher e a i and b i ar e r espectively the Hermite coefficients of φ and ψ . Therefor e, ˆ φ ( t, q , q 0 ) 1 is analytic in t ∈ [ − 1 , 1] , as desir ed. J. Omitted Pr oofs J.1. Boolean Cube Spectral Theory Theorem 3.2. On the d -dimensional boolean cube d , for every S ⊆ [ d ] , χ S is an eigenfunction of K with eigen value µ | S | def = E x ∈ d x S K ( x, 1 ) = E x ∈ d x S Φ X i x i /d ! , (4) wher e 1 = (1 , . . . , 1) ∈ d . This definition of µ | S | does not depend on the choice S , only on the car dinality of S . These are all of the eigenfunctions of K by dimensionality considerations. 9 Pr oof. W e directly verify K χ S = µ | S | χ S . Notice first that K ( x, y ) = Φ( h x, y i ) = Φ( h x y , 1 i ) = K ( x y , 1 ) where is Hadamard product. W e then calculate K χ S ( y ) = E x K ( y , x ) x S = E x K ( 1 , x y )( x y ) S y S . Here we are using the fact that x and y are boolean to get x S = ( x y ) S y S . Changing variable z def = x y , we get K χ S ( y ) = y S E z K ( 1 , z ) z S = µ | S | χ S ( y ) as desired. Finally , note that µ | S | is in v ariant under permutation of [ d ] , so indeed it depends only on the size of S . Lemma 3.3. W ith µ k as in Thm 3.2, µ k = 2 − d ( I − T ∆ ) k ( I + T ∆ ) d − k Φ(1) (5) = 2 − d d X r =0 C d − k,k r Φ d 2 − r ∆ (6) wher e C d − k,k r def = X j =0 ( − 1) r + j d − k j k r − j . (7) Pr oof. Because P i x i /d only takes on v alues {− d 2 ∆ , ( − d 2 + 1)∆ , . . . , ( d 2 − 1)∆ , d 2 ∆ } , where ∆ = 2 d , we can collect like terms in Eq. (4) and obtain µ k = 2 − d d X r =0 X x has r ‘ − 1 ’ s k Y i =1 x i ! Φ d 2 − r ∆ 9 Readers familiar with boolean Fourier analysis may be reminded of the noise operator T ρ , ρ ≤ 1 (see Defn 2.45 of O’Donnell (2014)). In the language of this work, T ρ is a neural kernel with eigen v alues µ k = ρ k . A Fine-Grained Spectral Perspecti ve on Neural Networks which can easily be shown to be equal to µ k = 2 − d d X r =0 C d − k,k r Φ d 2 − r ∆ , proving Eq. (6) in the claim. Finally , observe that C d − k,k r is also the coef ficient of x r in the polynomial (1 − x ) k (1 + x ) d − k . Some operator arithmetic then yields Eq. (5). J . 1 . 1 . W E A K S P E C T R A L S I M P L I C I T Y B I A S Theorem 4.1 (W eak Spectral Simplicity Bias) . Let K be the CK or NTK of an MLP on a boolean cube d . Then the eigen values µ k , k = 0 , . . . , d, satisfy µ 0 ≥ µ 2 ≥ · · · ≥ µ 2 k ≥ · · · , µ 1 ≥ µ 3 ≥ · · · ≥ µ 2 k +1 ≥ · · · . (8) Pr oof. Again, there is a function Φ such that K ( x, y ) = Φ( h x, y i / k x kk y k ) . By Thm I.1, Φ has a T aylor expansion with only nonnegati v e coef ficients. Φ( c ) = a 0 + a 1 c + a 2 c 2 + · · · . By Lem J.1, Eq. (8) is true for polynomials Φ( c ) = c r , µ 0 ( c r ) ≥ µ 2 ( c r ) ≥ · · · , µ 1 ( c r ) ≥ µ 3 ( c r ) ≥ · · · . (23) Then since each µ k = µ k (Φ) is a linear function of Φ , µ k (Φ) = P ∞ r =0 a r µ k ( c r ) also follows the same ordering. Lemma J .1. Let T ∆ be the shift oper ator with step ∆ that sends a function Φ( · ) to Φ( · − ∆) . Let Φ( c ) = c t for some t . Let µ d k be the eigen value of K ( x, y ) = Φ( h x, y i / k x kk y k ) on the boolean cube d . Then for any 0 ≤ k ≤ d , µ d k = 0 if t + k is odd (24) 1 ≥ µ d k − 2 ≥ µ d k ≥ 0 if t + k is even. (25) W e furthermor e have the identity µ d k − 2 − µ d k = d − 2 d t µ d − 2 k − 2 for any 2 ≤ k ≤ d . Pr oof. As in Eq. (5), 2 − d ( I − T ∆ ) k ( I + T ∆ ) d − k Φ(1) = 2 − d d X r =0 C d − k,k r Φ d 2 − r ∆ where C d − k,k r def = P j =0 ( − 1) r + j d − k j k r − j . It’ s easy to observ e that C d − k,k r = C d − k,k d − r if k is even C d − k,k r = − C d − k,k d − r if k is odd. In the first case, when Φ( c ) = c t with t odd, then by symmetry µ k = 0 . Similarly for the second case when t is ev en. This finishes the proof for Eq. (24). Note that it’ s clear from the form of Eq. (5) that µ d k ≤ Φ(1) = 1 always. So we show via induction on d that the rest of Eq. (25) is true for an y t ∈ N . The induction will reduce the case of d to the case of d − 2 . So for the base case, we need both d = 0 and d = 1 . Both can be shown by some simple calculations. A Fine-Grained Spectral Perspecti ve on Neural Networks Now for the inducti ve step, assume Eq. (25) for d − 2 , and we observe that µ d k − 2 − µ d k = 2 − d ( I − T 2 /d ) k − 2 ( I + T 2 /d ) d − k (( I + T 2 /d ) 2 − ( I − T 2 /d ) 2 )Φ(1) = 2 − d ( I − T 2 /d ) k − 2 ( I + T 2 /d ) d − k (4 T 2 /d )Φ(1) = 2 − d +2 ( I − T 2 /d ) k − 2 ( I + T 2 /d ) d − k Φ(1 − 2 /d ) . By Eq. (5), we can expand this into 2 − d +2 d − 2 X r =0 C d − k,k − 2 r Φ 1 − 2 d − r 2 d = 2 − d +2 d − 2 X r =0 C d − k,k − 2 r 1 − 2 d − r 2 d t = d − 2 d t 2 − d +2 d − 2 X r =0 C d − k,k − 2 r 1 − r 2 d − 2 t = d − 2 d t µ d − 2 k − 2 . By induction, µ d − 2 k − 2 ≥ 0 , so we have µ d k − 2 − µ d k = d − 2 d t µ d − 2 k − 2 ≥ 0 as desired. J . 1 . 2 . d → ∞ L I M I T Theorem H.2. Let K be the CK or NTK of an MLP on a boolean cube d . Then K can be expr essed as K ( x, y ) = Φ( h x, y i /d ) for some Φ : [ − 1 , 1] → R . If we fix k and let d → ∞ , then lim d →∞ d k µ k = Φ ( k ) (0) , wher e Φ ( k ) denotes the k th derivative of Φ . Let’ s first give some intuition for wh y Thm H.2 should be true. By Eqs. (5) and (13), µ k = 1 + T ∆ 2 d − k 1 − T ∆ 2 k Φ(1) = 1 2 d d − k X r =0 d − k r Φ [ k ] (1 − r ∆) where Φ [ k ] = (1 − T ∆ ) k Φ is the k th backward finite dif ference with step ∆ = 2 /d . Approximating the finite difference with deriv ative, we thus w ould expect that, as suggested by Lem J.3, Φ [ k ] ( x ) ≈ ∆ k Φ ( k ) ( x ) = (2 /d ) k Φ ( k ) ( x ) , when d is large, where Φ ( k ) is the k th deriv ati ve of Φ . Since 1 2 d − k d − k r is the probability mass at 1 − r ∆ of the binomial variable B def = 1 d − k P d − k i =1 X i , where X i is the Bernoulli variable taking ± 1 value with half chance each. This random v ariable con v erges almost surely to the delta distrib ution at 0, by law of lar ge numbers. Therefore, we would expect µ k ∼ (1 /d ) k Φ ( k ) (0) A Fine-Grained Spectral Perspecti ve on Neural Networks as d → ∞ . There is a single difficulty when trying to formalize this intuition. One is the possibility that the k th deriv ati v e Φ ( k ) does not exist at the endpoints 1 and − 1 (note that it must exist in the interior , because by Thm I.1, Φ is analytic on ( − 1 , 1) ). In this case, we must sho w that the portion of the interv al [ − 1 , 1] near the endpoints contributes exponentially little mass to the probability distribution of the binomial v ariable B , that it suppresses any blo wup that can happen at the edge. W e formalize this reasoning in the proof below . Pr oof. W e first pr event any blowup that may happen at the edge. Let Φ [ k ] be the k th backward dif ference of Φ with step size ∆ = 2 /d , as in Lem J.3. First note the trivial bound Φ [ k ] ( x ) = k X s =0 ( − 1) s k s Φ( x − s ∆) ≤ k X s =0 k s Φ( x − s ∆) ≤ 2 k Φ( x ) ≤ 2 k Φ(1) since Φ is nondecreasing by Lem J.2. Then for any R ∈ [0 , ( d − k ) / 2 − 1] , d k µ k = d k 2 d d − k X r =0 d − k r Φ [ k ] (1 − r ∆) = d k 2 d d − k − R − 1 X r = R +1 d − k r Φ [ k ] (1 − r ∆) + d k 2 d R X r =0 + d − k X r = d − k − R ! d − k r Φ [ k ] (1 − r ∆) . Now , in the second term, Φ [ k ] (1 − r ∆) ≤ 2 k Φ(1) as above, so that, by the binomial coef ficient entrop y bound (Fact J.4), 0 ≤ d k µ k − d k 2 d d − k − R − 1 X r = R +1 d − k r Φ [ k ] (1 − r ∆) ≤ d k 2 d R X r =0 + d − k X r = d − k − R ! d − k r 2 k Φ(1) ≤ d k 2 d − k 2 · 2 H ( p )( d − k ) Φ(1) = d k Φ(1) 2 (1 − H ( p )) d − (1 − H ( p )) k − 1 , (26) where p = R/ ( d − k ) . If we choose R = b ˜ p ( d − k ) c for a fixed ˜ p < 1 / 10 , then H ( p ) < 1 , and (26) is decreasing exponentially fast to 0 with d . Now we formalize the law of lar ge number intuition. It then suf fices to show that d k 2 d d − k − R − 1 X r = R +1 d − k r Φ [ k ] (1 − r ∆) → Φ ( k ) (0) . W e will do so by presenting an upper and a lower bound which both con v erge to this limit. W e first discuss the upper bound. By Lem J.3, d k 2 d d − k − R − 1 X r = R +1 d − k r Φ [ k ] (1 − r ∆) ≤ 1 2 d − k d − k − R − 1 X r = R +1 d − k r Φ ( k ) (1 − r ∆) . The RHS can be upper bounded by an expectation ov er a binomial random variable: Let X i be ± 1 Bernoulli variables, and let Φ ( k ) 1 2 ˜ p be the function Φ ( k ) 1 2 ˜ p ( x ) = ( Φ ( k ) ( x ) if x ∈ [ − 1 + 1 2 ˜ p, 1 − 1 2 ˜ p ] 0 otherwise A Fine-Grained Spectral Perspecti ve on Neural Networks Note that Φ ( k ) 1 2 ˜ p ( x ) is a bounded function. Then with the binomial v ariable B = 1 d P d − k i =1 ( X i + k / ( d − k )) , we ha ve 1 2 d − k d − k − R − 1 X r = R +1 d − k r Φ ( k ) (1 − r ∆) ≤ E Φ ( k ) 1 2 ˜ p ( B ) . By strong law of lar ge numbers, B con ver ges almost surely to 0 as d → ∞ with k fixed. Thus the RHS con ver ges to Φ ( k ) 1 2 ˜ p (0) = Φ ( k ) (0) as desired. A similar argument proceeds for the lo wer bound, after noting that, by Lem J.3, 1 2 d − k d − k − R − 1 X r = R +1 d − k r Φ ( k ) (1 − ( r + k )∆) ≤ d k 2 d d − k − R − 1 X r = R +1 d − k r Φ [ k ] (1 − r ∆) . Lemma J.2. Let K be the CK or NTK of an MLP with domain √ d S d − 1 ⊆ R d . Then K ( x, y ) = Φ h x,y i k x kk y k wher e Φ : [ − 1 , 1] → R is analytic on ( − 1 , 1) , and all derivatives of Φ ar e nonnegative on ( − 1 , 1) . Pr oof. Note that, by Thm I.1, Φ has a conv ergent T aylor expansion on ( − 1 , 1) , i.e Φ is analytic on ( − 1 , 1) . Thus, all deriv atives of Φ exist (and are finite) on the interv al ( − 1 , 1) and hav e the obvious T aylor series deri ved from Eq. (20). For example, Φ 0 ( c ) = a 1 c + 2 a 2 c + 3 a 3 c 2 + · · · . Such T aylor series also con ver ge on the open interv al ( − 1 , 1) (but could diver ge on the endpoints − 1 and 1 ). W e get the desired result by noting that all a i are nonnegati v e. By expressing finite dif ference as an inte gral, it’ s easy to see that Lemma J.3. W ith the same setting as in Lem J .2, let Φ [ k ] be the k th backwar d finite differ ence with step size ∆ = 2 /d , Φ [ k ] ( x ) def = (1 − T ∆ ) k Φ( x ) . Then Φ [ k ] is analytic on ( − 1 , 1) , has all derivatives nonnegative , and 0 ≤ ∆ k Φ ( k ) ( x − k ∆) ≤ Φ [ k ] ( x ) ≤ ∆ k Φ ( k ) ( x ) , (27) wher e Φ ( k ) is the k th derivative of Φ . Pr oof. Everything follows immediately from Φ [ k ] ( x ) = Z ∆ 0 · · · Z ∆ 0 Φ ( k ) ( x − h 1 − · · · − h k ) d h 1 · · · d h k and Lem J.2. Fact J .4 (Entrop y bound on sum of binomial coefficients) . F or any k ≤ d and R ≤ d/ 2 , R X r =0 d − k r ≤ 2 H ( p )( d − k ) wher e p = R/ ( d − k ) , and H is the binary entropy H ( p ) = − p log 2 p − (1 − p ) log 2 (1 − p ) . A Fine-Grained Spectral Perspecti ve on Neural Networks J.2. Spherical Spectral Theory Theorem H.12 (Schoenberg) . Suppose Φ : [ − 1 , 1] → R is in L 2 ((1 − t 2 ) d − 1 2 − 1 ) , so that it has the Ge genbauer e xpansion Φ( t ) a.e. = ∞ X l =0 a l c − 1 d,l C ( d − 2 2 ) l ( t ) . Then K has eigenspaces H d − 1 , ( l ) √ d def = { f ( x/ √ d ) : f ∈ H d − 1 , ( l ) } with corr esponding eigen values a l . Since L ∞ l =0 H d − 1 , ( l ) √ d is an orthogonal decomposition of L 2 ( √ d S d − 1 ) , this describes all eigenfunctions of K consider ed as an operator on L 2 ( √ d S d − 1 ) . Pr oof. Let f ∈ H d − 1 , ( n ) . Then for any x ∈ √ d S d − 1 , E y ∈ √ d S d − 1 K ( x, y ) f ( y / √ d ) = E y ∈ √ d S d − 1 Φ( h x, y i /d ) f ( y / √ d ) = E ˜ y ∈S d − 1 Φ( h x/ √ d, ˜ y i ) f ( ˜ y ) = E ˜ y ∈S d − 1 ∞ X l =0 a l 1 c d,l C ( d − 2 2 ) l ( h x/ √ d, ˜ y i ) ! f ( ˜ y ) = E ˜ y ∈S d − 1 ∞ X l =0 a l Z d − 1 , ( l ) x/ √ d ( ˜ y ) ! f ( ˜ y ) = a n E ˜ y ∈S d − 1 Z d − 1 , ( n ) x/ √ d ( ˜ y ) f ( ˜ y ) by orthogonality = a n f ( x/ √ d ) by reproducing property . Theorem H.13. Let K be the CK or NTK of an MLP on the sphere √ d S d − 1 . Then K can be expr essed as K ( x, y ) = Φ( h x, y i /d ) for some smooth Φ : [ − 1 , 1] → R . Let a ` denote K ’ s eig en values on the spher e (as in Thm H.12). If we fix ` and let d → ∞ , then lim d →∞ d ` a ` = Φ ( ` ) (0) , wher e Φ ( ` ) denotes the ` th derivative of Φ . Pr oof. By Thm I.1, Φ ’ s T aylor expansion around 0 is absolutely con vergent on [ − 1 , 1] , so that the condition of Fact J.5 is satisfied. Therefore, Eq. (28) holds and is absolutely conv er gent. By dominated con v ergence theorem, we can exchange the limit and the summation, and get lim d →∞ d l a l = lim d →∞ d l Γ d 2 ∞ X k =0 Φ ( l +2 k ) (0) 2 l +2 k k !Γ d 2 + l + k = ∞ X k =0 Φ ( l +2 k ) (0) lim d →∞ d l Γ d 2 2 l +2 k k !Γ d 2 + l + k = ∞ X k =0 Φ ( l +2 k ) (0) lim d →∞ d 2 − k ( k !) − 1 2 − 2 k = Φ ( l ) (0) as desired. By Bezubik et al. (2008), we can express the Gegenbauer coefficients, and thus equi v alently the eigen v alues, via deri vati ves of Φ : A Fine-Grained Spectral Perspecti ve on Neural Networks Fact J .5 (Bezubik et al. (2008)) . If the T aylor expansion of Φ at 0, Φ( t ) = ∞ X n =0 Φ ( n ) (0) n ! t n , is absolutely con ver gent on the closed interval [ − 1 , 1] , then the Ge g enbauer coefficients a l in Thm H.12 in dimension d is equal to the absolute con ver g ent series a l = Γ d 2 ∞ X k =0 Φ ( l +2 k ) (0) 2 l +2 k k !Γ d 2 + l + k . (28) Even though e very L 2 ((1 − t 2 ) α − 1 2 ) function has a Gegenbauer expansion, typically there is no guarantee that the expansion holds for ev ery t in [ − 1 , 1] . Howe v er , the follo wing theorem guarantees this under the analyticity assumption. Fact J .6 (Thm 9.1.1 of Sze go (1939)) . Let α > − 1 / 2 , and let f ∈ L 2 ((1 − t ) α − 1 2 ) have Ge genbauer e xpansion f ( t ) a.e. = ∞ X l =0 b l C ( α ) l ( t ) . If f is analytic on the closed interv al [ − 1 , 1] , then the Geg enbauer expansion of f con ver ges to f pointwise on [ − 1 , 1] , i.e. f ( t ) = ∞ X l =0 b l C ( α ) l ( t ) , for every t ∈ [ − 1 , 1] . W e record the following useful facts about Ge genbauer polynomials. Fact J .7 (Suetin) . C ( α ) l ( ± 1) = ( ± 1) l l + 2 α − 1 l Fact J .8 (Rodrigues’ F ormula) . C ( α ) n ( x ) = ( − 1) n N α,n (1 − x 2 ) − α + 1 2 d n dx n h (1 − x 2 ) n + α − 1 2 i wher e N α,n = Γ( α + 1 2 )Γ( n + 2 α ) 2 n n !Γ(2 α )Γ( α + n + 1 2 ) . J.3. Gaussian Spectral Theory Theorem H.14. A function K : ( R d ) 2 → R of the form K ( x, y ) = Φ h x, y i k x kk y k , k x k 2 d , k y k 2 d forms a positive semidefinite Hilbert-Schmidt oper ator on L 2 ( N (0 , I )) iff Φ can be decomposed as Φ( t, q , q 0 ) = ∞ X l =0 A l ( q , q 0 ) c − 1 d,l C ( d − 2 2 ) l ( t ) (15) satisfying the norm condition ∞ X l =0 k A l k 2 c − 2 d,l k C ( d − 2 2 ) l k 2 = ∞ X l =0 k A l k 2 c − 2 d,l π 2 3 − d Γ( l + d − 2) l !( l + d − 2 2 )Γ d − 2 2 2 < ∞ , (16) wher e A Fine-Grained Spectral Perspecti ve on Neural Networks • c d,l = d − 2 d +2 l − 2 • C ( d − 2 2 ) l ( t ) ar e Geg enbauer polynomials as in Appendix H.2, with k C ( d − 2 2 ) l k = q R 1 − 1 C ( d − 2 2 ) l ( t ) 2 (1 − t 2 ) d − 1 2 − 1 d t denoting the norm of C ( d − 2 2 ) l in L 2 ((1 − t 2 ) d − 1 2 − 1 ) . • and A l ar e positive semidefinite Hilbert-Schmidt k ernels on L 2 ( 1 d χ 2 d ) , the L 2 space over the pr obability measure of a χ 2 d -variable divided by d , and with k A l k denoting the Hilbert-Schmidt norm of A l . In addition, K is positive definite iff all A l ar e. Pr oof. Note that an isotropic Gaussian vector z ∼ N (0 , I ) can be sampled by independently sampling its direction v uniformly from the sphere S d − 1 and sampling its magnitude r from a chi distribution χ d with d degrees of freedom. In the following, we adopt the follo wing notations x, y ∈ R d , q = k x k 2 /d, q 0 = k y k 2 /d, v = x/ k x k , v 0 = y / k y k Then, by the reasoning abov e, K f ( x/ √ d ) = E v 0 ∼S d − 1 q 0 ∼ d − 1 χ 2 d Φ ( h v , v 0 i , q , q 0 ) f ( p q 0 v ) . Here f ∈ L 2 ( N (0 , I /d )) (so that f ( · / √ d ) ∈ L 2 ( N (0 , I )) ) and d − 1 χ 2 d is the distribution of a χ 2 d random variable di vided by d . Because of this decomposition of N (0 , I ) into a product distribution of direction and magnitude, its space of L 2 functions naturally decomposes into a tensor product of corresponding L 2 spaces L 2 ( N (0 , I )) = L 2 ( S d − 1 ) ⊗ L 2 ( d − 1 χ 2 d ) . where ev ery f ∈ L 2 ( N (0 , I )) can be written as a sum f ( x ) = ∞ X l =0 R l ( q ) P l ( v ) where q = k x k 2 /d, v = x/ k x k as above, P l ∈ H d − 1 , ( l ) is a spherical harmonic of degree l , and R l ∈ L 2 ( d − 1 χ 2 d ) (i.e. R l ( · /d ) ∈ L 2 ( χ 2 d ) ). Here, the equality is understood as a conv ergence of the RHS partial sums in the Hilbert space L 2 ( S d − 1 ) ⊗ L 2 ( d − 1 χ 2 d ) . Like wise, assuming K is Hilbert-Schmidt, then its Hilbert-Schmidt norm (measured against the uniform distribution ov er the sphere) is bounded: k K k 2 H S = E v ,v 0 ∼S d − 1 q ,q 0 ∼ d − 1 χ 2 d Φ( h v , v 0 i , q , q 0 ) 2 = E q ,q 0 ∼ d − 1 χ 2 d Z 1 − 1 Φ( t, q , q 0 ) 2 (1 − t 2 ) d − 1 2 − 1 d t. Thus Φ resides in the tensor product space Φ ∈ F def = L 2 ((1 − t 2 ) d − 1 2 − 1 ) ⊗ L 2 ( d − 1 χ 2 d ) ⊗ L 2 ( d − 1 χ 2 d ) and therefore can be expanded as Φ( t, q , q 0 ) = ∞ X l =0 A l ( q , q 0 ) c − 1 d,l C ( d − 2 2 ) l ( t ) where C ( d − 2 2 ) l ( t ) are Gegenbauer polynomials as in Appendix H.2 and A l ∈ L 2 ( d − 1 χ 2 d ) ⊗ 2 . By Lem J.9 below , K being Hilbert-Schmidt implies that each A l is, as well. Furthermore, since k K k 2 H S = k Φ k 2 F is finite, we hav e k Φ k 2 F = ∞ X l =0 k A l k 2 c − 2 d,l k C ( d − 2 2 ) l k 2 < ∞ . A Fine-Grained Spectral Perspecti ve on Neural Networks Here, k A l k = q E q ,q 0 ∼ 1 d χ 2 d A l ( q , q 0 ) 2 is the Hilbert-Schmidt norm of A l (i.e. its norm in L 2 ( d − 1 χ 2 d ) ⊗ 2 ), and k C ( d − 2 2 ) l k = q R 1 − 1 C ( d − 2 2 ) l ( t ) 2 (1 − t 2 ) d − 1 2 − 1 d t is the norm of C ( d − 2 2 ) l in L 2 ((1 − t 2 ) d − 1 2 − 1 ) . Simplifying according to Eq. (14) yields the equality in the claim. Con v ersely , if each A l is Hilbert-Schmidt satisfying Eq. (16), then K is obviously a Hilbert-Schmidt k ernel as it has finite Hilbert-Schmidt norm. Lemma J.9. F or each l , A l is a positive semidefinite Hilbert-Schmidt kernel. It is positive definite if K is. Pr oof. W ith q = k x k 2 /d, v = x/ k x k as above, let f ( x/ √ d ) = f ( √ q v ) = R m ( q ) P m ( v ) for some degree m nonzero spherical harmonics P m ∈ H d − 1 , ( m ) and some scalar function R m ∈ L 2 ( d − 1 χ 2 d ) that is not a.e. zero. W e hav e K φ ( x/ √ d ) = E v 0 ∼S d − 1 q 0 ∼ d − 1 χ 2 d Φ( h v , v 0 i , q , q 0 ) f ( p q 0 v ) = E v 0 ∼S d − 1 q 0 ∼ d − 1 χ 2 d R m ( q 0 ) P m ( v 0 ) ∞ X l =0 A l ( q , q 0 ) c − 1 d,l C ( d − 2 2 ) l ( h v , v 0 i ) = E v 0 ∼S d − 1 q 0 ∼ d − 1 χ 2 d R m ( q 0 ) P m ( v 0 ) ∞ X l =0 A l ( q , q 0 ) Z d − 1 , ( l ) v ( v 0 ) = P m ( v ) E q 0 ∼ d − 1 χ 2 d A m ( q , q 0 ) R m ( q 0 ) . Therefore, E x ∼N (0 ,I ) f ( x ) K f ( x/ √ d ) = E v ∼S d − 1 P m ( v ) 2 E q ,q 0 ∼ d − 1 χ 2 d R m ( q ) A m ( q , q 0 ) R m ( q 0 ) is nonnegati v e, and is positiv e if K is positiv e definite, by the assumption above that f is not a.e. zero. Since E P m ( v ) 2 > 0 as P m 6 = 0 , we must hav e E q ,q 0 ∼ d − 1 χ 2 d R m ( q ) A m ( q , q 0 ) R m ( q 0 ) ≥ 0 (or > 0 if K is positive definite) . This argument holds for any R m ∈ L 2 ( d − 1 χ 2 d ) that is not a.e. zero, so this implies that A l is positiv e semidefinite, and positiv e definite if K is so. Theorem H.18. Suppose K is the CK or NTK of an MLP with polynomially bounded activation function. F or every de gr ee l , K over N (0 , I d ) has an eigen value a l 0 at spherical harmonics de gr ee l (in the sense of Cor H.15) with a l 0 ∈ " E q ,q 0 ∼ 1 d χ 2 d A l ( q , q 0 ) , E q ∼ 1 d χ 2 d A l ( q , q ) # , wher e A l is as in Eq. (17) . Furthermore , lim d →∞ d l a l 0 = lim d →∞ d l E q ,q 0 ∼ 1 d χ 2 d A l ( q , q 0 ) = lim d →∞ d l E q ∼ 1 d χ 2 d A l ( q , q ) = Φ ( l ) (0 , 1 , 1) . Her e Φ ( l ) is the l th derivative of Φ( t, q , q 0 ) against t . Pr oof. Let a l = E q ∼ 1 d χ 2 d A l ( q , q ) as in Eq. (18), and let b l def = E q 0 ∼ 1 d χ 2 d A l ( q , q 0 ) . Let a li be the i th largest eigenv alue of A l as in Eq. (17), with a l 0 being the largest. Note that all of these quantities a l , b l , a li depend on d , but we suppress this notationally . W e seek to prove the follo wing claims: 1. a l 0 ≤ a l A Fine-Grained Spectral Perspecti ve on Neural Networks 2. a l 0 ≥ b l 3. d l b l → Φ ( l ) (0 , 1 , 1) 4. d l a l → Φ ( l ) (0 , 1 , 1) Claim 1: a l 0 ≤ a l . First note that a l is the trace of the operator A l , so that a l = P ∞ i =0 a li . Thus, any eigen value a li is at most a l . Claim 2: a l 0 ≥ b l . Now , by Min-Max theorem, the largest eigen value a l 0 of A l is equal to a l 0 = sup f E q ,q 0 f ( q ) f ( q 0 ) A l ( q , q 0 ) E q f ( q ) 2 where 0 6 = f ∈ L 2 ( 1 d χ 2 d ) and q , q 0 ∼ 1 d χ 2 d . If we set f ( q ) = 1 identically , then we get a l 0 ≥ E q ,q 0 A l ( q , q 0 ) = b l , as desired. Claim 3 By definition, A l ( q , q 0 ) = R − 1 c d,l Z 1 − 1 Φ( t, q , q 0 ) C ( d − 2 2 ) l ( t )(1 − t 2 ) d − 2 2 − 1 2 d t where c d,l = d − 2 d +2 l − 2 and R = π 2 3 − d Γ( l + d − 2) l !( l + d − 2 2 )Γ( d − 2 2 ) 2 is the squared norm of C ( d − 2 2 ) l ( t ) in L 2 ((1 − t 2 ) d − 2 2 − 1 2 ) . Let I d b 1 a 1 | b 2 a 2 | b 3 a 3 def = R − 1 c d,l Z b 1 a 1 Z b 2 a 2 Z b 3 a 3 Φ( t, q , q 0 ) C ( d − 2 2 ) l ( t )(1 − t 2 ) d − 2 2 − 1 2 f d ( q ) f d ( q 0 ) d q d q 0 d t | I d | b 1 a 1 | b 2 a 2 | b 3 a 3 def = R − 1 c d,l Z b 1 a 1 Z b 2 a 2 Z b 3 a 3 Φ( t, q , q 0 ) C ( d − 2 2 ) l ( t ) (1 − t 2 ) d − 2 2 − 1 2 f d ( q ) f d ( q 0 ) d q d q 0 d t where f d is the pdf of 1 d χ 2 d . Note that E q ,q 0 ∼ 1 d χ 2 d A l ( q , q 0 ) = I d 1 − 1 | ∞ 0 | ∞ 0 . Subclaim 3.1 W e claim that for any fixed > 0 , as d → ∞ , I d 1 − 1 | ∞ 0 | ∞ 0 − I d − | 1+ 1 − | 1+ 1 − = E q ,q 0 ∼ 1 d χ 2 d A l ( q , q 0 ) − I d − | 1+ 1 − | 1+ 1 − → 0 . Since | I d 1 − 1 | ∞ 0 | ∞ 0 − I d − | 1+ 1 − | 1+ 1 − | ≤ | I d | 1 − 1 | ∞ 1+ | ∞ 0 + | I d | 1 − 1 | ∞ 0 | ∞ 1+ + | I d | 1 − 1 | 1 − 0 | ∞ 0 + | I d | 1 − 1 | ∞ 0 | 1 − 0 + | I d | 1 | ∞ 0 | ∞ 0 + | I d | − − 1 | ∞ 0 | ∞ 0 , we will show each of the terms on the RHS abo v e con ver ges to 0. Indeed, observe that f d ( q ) decays like e − d 2 ( q − 1) when q > 1 . Since Φ( t, q , q 0 ) ≤ max { Φ(1 , q , q ) , Φ(1 , q 0 , q 0 ) } ( Lem J.10) and Φ(1 , q , q ) is polynomially bounded in q by a fixed polynomial in q independent of d (Thm I.2), | I d | 1 − 1 | ∞ 1+ | ∞ 0 = | I d | 1 − 1 | ∞ 0 | ∞ 1+ → 0 A Fine-Grained Spectral Perspecti ve on Neural Networks Next, note that f d ( q ) → 0 for any q < 1 , so by dominated con ver gence, we also hav e | I d | 1 − 1 | 1 − 0 | ∞ 0 = | I d | 1 − 1 | ∞ 0 | 1 − 0 → 0 . Like wise, since R − 1 c d,l C ( d − 2 2 ) l ( t )(1 − t 2 ) d − 2 2 − 1 2 → 0 for any t > 0 and any t < 0 , by dominated con v ergence we also hav e | I d | 1 | ∞ 0 | ∞ 0 , | I d | − − 1 | ∞ 0 | ∞ 0 → 0 . This prov es the claim. Subclaim 3.2 W e claim that for any fixed > 0 , as d → ∞ , I d 1+ 1 − | 1+ 1 − | − → Φ ( l ) (0 , 1 , 1) . By Rodrigues’ Formula F act J.8, Z − Φ( t, q , q 0 ) C ( d − 2 2 ) l ( t )(1 − t 2 ) d − 2 2 − 1 2 d t = Z − Φ( t, q , q 0 )( − 1) l N d l dt l h (1 − t 2 ) l + d − 2 2 − 1 2 i d t where N = N d − 2 2 ,l = Γ( d − 2 2 + 1 2 )Γ( l +2 d − 2 2 ) 2 l l !Γ( d − 2)Γ( d − 2 2 + l + 1 2 ) is as in Fact J.8. Since by Thm I.2, Φ( t, q , q 0 ) is smooth on t ∈ ( − 1 , 1) , for any q, q 0 , we can apply l -times integration by parts to obtain I d − | 1+ 1 − | 1+ 1 − = ( − 1) l N R − 1 c d,l Z 1+ 1 − Z 1+ 1 − Φ( t, q , q 0 ) d l − 1 dt l − 1 h (1 − t 2 ) l + d − 2 2 − 1 2 i − − d dt Φ( t, q , q 0 ) d l − 2 dt l − 2 h (1 − t 2 ) l + d − 2 2 − 1 2 i − · · · + ( − 1) l − 1 d l − 1 dt l − 1 Φ( t, q , q 0 ) (1 − t 2 ) l + d − 2 2 − 1 2 − + ( − 1) l Z − (1 − t 2 ) l + d − 2 2 − 1 2 d l dt l Φ( t, q , q 0 ) d t f d ( q ) f d ( q 0 ) d q d q 0 . Since d r dt r Φ( t, q , q 0 ) is continuous in ( t, q , q 0 ) for any r ≥ 0 by Thm I.2, and because [1 − , 1 + ] × [1 − , 1 + ] × [ − , ] is compact, we see that d r dt r Φ( t, q , q 0 ) is bounded in this domain. On the other hand, N R − 1 c d,l d r dt r h (1 − t 2 ) l + d − 2 2 − 1 2 i → 0 at t = ± when d → ∞ . Therefore, all the non- t -integral terms abo ve v anish, and I d − | 1+ 1 − | 1+ 1 − − N R − 1 c d,l Z − Z 1+ 1 − Z 1+ 1 − (1 − t 2 ) l + d − 2 2 − 1 2 d l dt l Φ( t, q , q 0 ) f d ( q ) f d ( q 0 ) d q d q 0 d t → 0 . Howe ver , the distribution with density function proportional to ( t, q , q 0 ) 7→ (1 − t 2 ) l + d − 2 2 − 1 2 f d ( q ) f d ( q 0 ) on ( t, q , q 0 ) ∈ [1 − , 1 + ] × [1 − , 1 + ] × [ − , ] con v erges in probability (and thus in distrib ution) to the delta distrib ution centered at (0 , 1 , 1) . Additionally , N R − 1 c d,l R − R 1+ 1 − R 1+ 1 − (1 − t 2 ) l + d − 2 2 − 1 2 f d ( q ) f d ( q 0 ) d q d q 0 d t → 1 as d → 1 . Since d l dt l Φ( t, q , q 0 ) is continuous on [1 − , 1 + ] × [1 − , 1 + ] × [ − , ] by Thm I.2 and thus bounded, we ha v e N R − 1 c d,l Z − Z 1+ 1 − Z 1+ 1 − (1 − t 2 ) l + d − 2 2 − 1 2 d l dt l Φ( t, q , q 0 ) f d ( q ) f d ( q 0 ) d q d q 0 d t → Φ ( l ) (0 , 1 , 1) . A Fine-Grained Spectral Perspecti ve on Neural Networks Thus, I d 1+ 1 − | 1+ 1 − | − → Φ ( l ) (0 , 1 , 1) . T ying it all together, we ha ve E q ,q 0 ∼ 1 d χ 2 d A l ( q , q 0 ) → Φ ( l ) (0 , 1 , 1) as desired. Claim 4. A similar argument to Claim 3 sho ws that E q ∼ 1 d χ 2 d A l ( q , q 0 ) → Φ ( l ) (0 , 1 , 1) as well. Lemma J.10. Suppose K : ( R + ) 2 → R is a continuous function and forms a Hilbert-Schmidt kernel on L 2 ( µ ) for some absolutely continuous pr obability measur e µ on R + def = { x ∈ R : x > 0 } whose pr obability density function f : R + → R is continuous and has full support. Then for any x ∈ R + , we have K ( x, x ) ≥ 0 , and, for any x, y ∈ R + , we have max { K ( x, x ) , K ( y , y ) } ≥ p K ( x, x ) K ( y , y ) ≥ | K ( x, y ) | . Note our proof would work when we replace R + with any open set of R . Pr oof. W e first show max { K ( x, x ) , K ( y , y ) } ≥ | K ( x, y ) | ; then K ( x, x ) ≥ 0 follows from setting x = y . Let U x , U y be indicator functions of the intervals of radius around resp. x and y . Then U x , U y ∈ L 2 ( µ ) . Let α, β ∈ R be two constants that we will set later . Thus, by the positiv e-definiteness of K , E a,b ∼ µ α 2 U x ( a ) K ( a, b ) U x ( b ) + β 2 U y ( a ) K ( a, b ) U y ( b ) − 2 αβ U x ( a ) K ( a, b ) U y ( b ) = E a,b ∼ µ ( αU x ( a ) − β U y ( a )) K ( a, b )( α U x ( b ) − β U y ( b )) ≥ 0 . Then by intermediate-value theorem and the continuity of f and K , 1 2 E a,b ∼ µ α 2 U x ( a ) K ( a, b ) U x ( b ) → α 2 f ( x ) 2 K ( x, x ) 1 2 E a,b ∼ µ β 2 U y ( a ) K ( a, b ) U y ( b ) → β 2 f ( y ) 2 K ( y , y ) 1 2 E a,b ∼ µ αβ U x ( a ) K ( a, b ) U y ( b ) → αβ f ( x ) f ( y ) K ( x, y ) . Therefore, taking the → 0 limit, we hav e the inequality α 2 f ( x ) 2 K ( x, x ) + β 2 f ( y ) 2 K ( y , y ) ≥ 2 αβ f ( x ) f ( y ) K ( x, y ) = ⇒ max { α 2 f ( x ) 2 K ( x, x ) , β 2 f ( y ) 2 K ( y , y ) } ≥ αβ f ( x ) f ( y ) K ( x, y ) . By the “full support” assumption, both f ( x ) and f ( y ) are positive. Therefore, we can set α = 1 f ( x ) and β = ± 1 f ( y ) to recov er max { K ( x, x ) , K ( y , y ) } ≥ | K ( x, y ) | . If both K ( x, x ) and K ( y , y ) are positive, then we can set α = 1 f ( x ) 4 q K ( y ,y ) K ( x,x ) and β = ± 1 f ( y ) 4 q K ( x,x ) K ( y ,y ) to show p K ( x, x ) K ( y , y ) ≥ | K ( x, y ) | . If, WLOG, K ( y , y ) = 0 , then we can take β → ∞ to see that | K ( x, y ) | must be less than any positi v e number , and therefore it is 0. A Fine-Grained Spectral Perspecti ve on Neural Networks Lemma J.11. Suppose K is the CK or NTK of an MLP , and let Φ be the corr esponding function as in Eq. (2) . F ix a dimension d . F or every de gr ee l , let A l ( − , − ) be the positive semidefinite Hilbert-Schmidt kernel on L 2 ( 1 d χ 2 d ) such that Eq. (15) holds (note that A l depends on d but we suppr ess this notationally). Then A l is continuous. Pr oof. By Thm I.2, Φ is continuous. Then the continuity of A l follows from the follo wing integral expression: A l ( q , q 0 ) = R − 1 d − 2 d + 2 l − 2 Z 1 − 1 Φ( t, q , q 0 ) C ( d − 2 2 ) l ( t )(1 − t 2 ) d − 2 2 − 1 d t where R is the squared norm of C ( d − 2 2 ) l ( t ) in L 2 ((1 − t 2 ) d − 2 2 − 1 ) . Lemma J.12. Suppose K is the CK or NTK of an MLP , and let Φ be the corr esponding function as in Eq. (2) . F ix a dimension d . F or every de gr ee l , let A l ( − , − ) be the positive semidefinite Hilbert-Schmidt kernel on L 2 ( 1 d χ 2 d ) such that Eq. (15) holds (note that A l depends on d but we suppr ess this notationally). Then for any q , q 0 > 0 , | A l ( q , q 0 ) | × d + 2 l − 2 d − 2 l + d − 3 l ≤ p Φ(1 , q , q )Φ(1 , q 0 , q 0 ) ≤ max { Φ(1 , q , q ) , Φ(1 , q 0 , q 0 ) } . Pr oof. Note that A l is continuous by Lem J.11. Since the measure of 1 d χ 2 d has a continuous density function supported on R + , we can apply Lem J.10, which shows that, for an y q, q 0 ∈ R + , | A l ( q , q 0 ) | ≤ p A l ( q , q ) A l ( q 0 , q 0 ) . (29) Let c d,l and C ( d − 2 2 ) l be as in Thm H.14. By the analyticity of Φ( t, q , q 0 ) in t for e very q , q 0 ∈ R + (as a result of Thm I.2), Fact J.6 sho ws Φ(1 , q , q 0 ) = ∞ X l =0 A l ( q , q 0 ) c − 1 d,l C ( d − 2 2 ) l (1) = ∞ X l =0 A l ( q , q 0 ) d + 2 l − 2 d − 2 l + d − 3 l where the second equality follo ws from Fact J.7. By Lem J.10 again, A l ( q , q ) ≥ 0 for all q ∈ R + , so that in the RHS, all summands are nonnegati v e. When q = q 0 , we then hav e the tri vial bound Φ(1 , q , q ) ≥ A l ( q , q ) d + 2 l − 2 d − 2 l + d − 3 l for each l ≥ 0 . Combined with Eq. (29), this yields | A l ( q , q 0 ) | ≤ p A l ( q , q ) A l ( q 0 , q 0 ) ≤ d + 2 l − 2 d − 2 l + d − 3 l − 1 p Φ(1 , q , q )Φ(1 , q 0 , q 0 ) as desired. K. The { 0 , 1 } d vs the {± 1 } d Boolean Cube V alle-Pérez et al. (2018) actually did their experiments on the { 0 , 1 } d boolean cube, whereas here, we have focused on the {± 1 } d boolean cube. As datasets are typically centered before feeding into a neural network (for example, using Pytorch’ s torchvision.transform.Normalize ), {± 1 } d is much more natural. In comparison, using the { 0 , 1 } d cube is equiv alent to adding a bias in the input of a network and reducing the weight variance in the input layer , since any x ∈ {± 1 } d corresponds to 1 2 ( x + 1) ∈ { 0 , 1 } d . As such, one would expect there is mor e bias towar d low fr equency components with inputs fr om { 0 , 1 } d . A Fine-Grained Spectral Perspecti ve on Neural Networks 1 0 0 1 0 1 1 0 2 1 0 3 1 0 4 rank 1 0 4 1 0 3 1 0 2 1 0 1 probability p r o b a b i l i t y v s r a n k o f 1 0 4 r a n d o m n e t w o r k s o n { ± 1 } 7 | 2 w | 2 b | d e p t h relu | 2 | 2 | 2 erf | 1 | 0 | 2 erf | 2 | 0 | 2 erf | 4 | 0 | 2 erf | 4 | 0 | 32 Figure 19. The same experiments as Fig. 1 but ov er { 0 , 1 } 7 . Nev ertheless, here we verify that our observations of Section 4 abov e still holds over the { 0 , 1 } d cube by repeating the same experiments as Fig. 1 in this setting (Fig. 19). Just like ov er the {± 1 } d cube, the relu network biases significantly toward certain functions, but with erf, and with increasing σ 2 w , this lessens. With depth 32 and σ 2 w , the boolean functions obtained from erf network see no bias at all.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment