고온 재가중치를 이용한 역이징 추정법
본 논문은 관측된 이진 스핀 구성만을 이용해 이징 모델의 파라미터를 효율적으로 추정하는 새로운 알고리즘을 제안한다. 관측 데이터의 빈도를 고온(β→0) 재가중치로 평탄화함으로써 파티션 함수 계산을 2^M 항에서 단순히 2^M 로 축소하고, 기대값을 관측 데이터와 재가중치된 모델 두 곳에서 쉽게 구한다. 실험 결과, 제안된 ‘ε‑머신’은 강한 결합·소규모 샘플 상황에서도 기존 최대우도(MLE)·의사우도(PLE)보다 높은 정확도와 훨씬 짧은 실행 …
저자: Junghyo Jo, Danh-Tai Hoang, Vipul Periwal
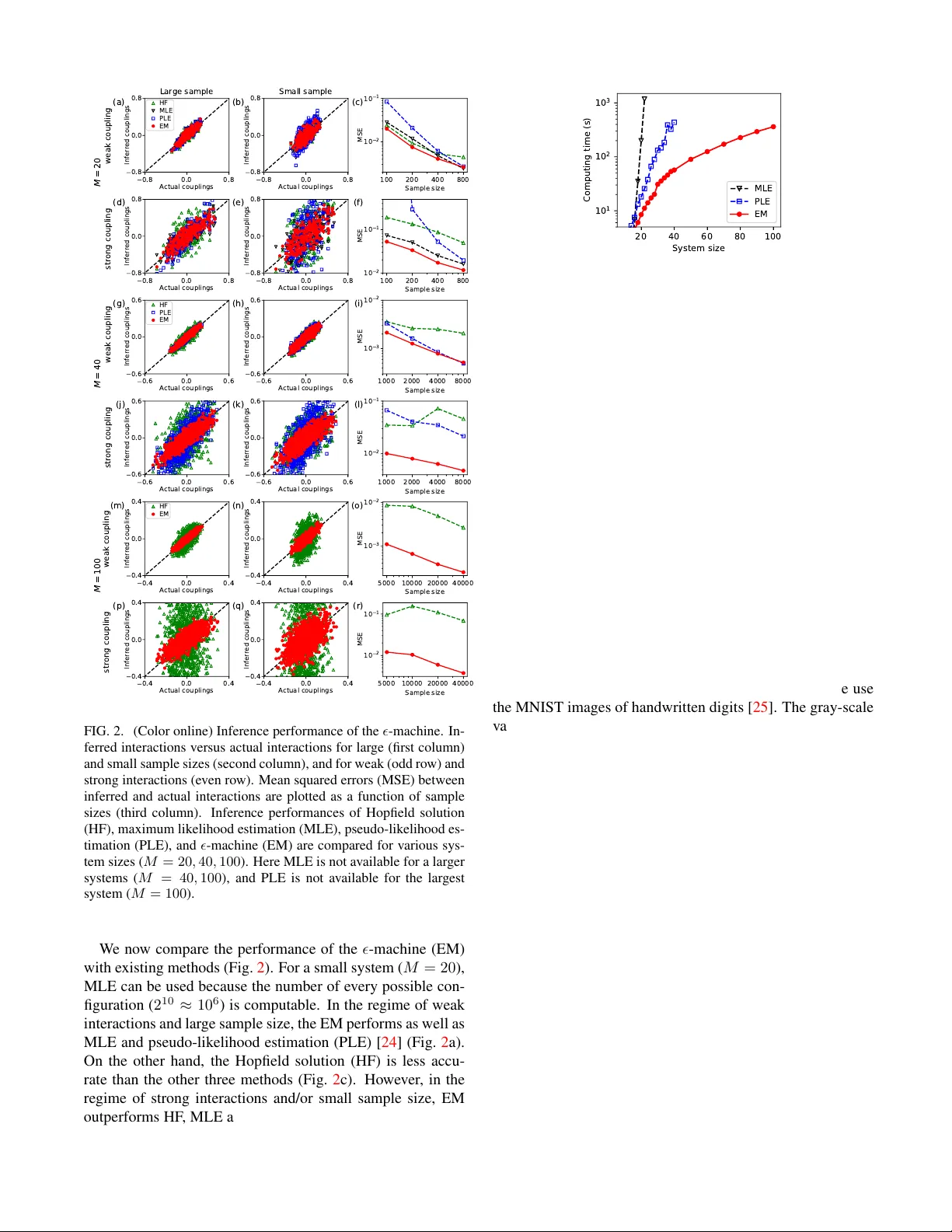
본 연구는 이징 및 포츠와 같은 마코프 무작위장(undirected graphical model)에서 파라미터를 추정하는 전통적인 최대우도 추정법(Maximum Likelihood Estimation, MLE)의 근본적인 계산 병목인 파티션 함수 Z(w)의 지수적 복잡성을 극복하고자 한다. MLE는 관측된 구성 σ̂의 빈도 fσ를 그대로 확률 추정치 p*σ=fσ/N으로 두고, 모델 확률 pσ(w)=exp(w_I O_I(σ))/Z(w)와의 차이를 최소화한다. 그러나 Z(w)=∑_σ exp(w_I O_I(σ))는 2^M개의 모든 가능한 스핀 구성에 대해 합을 수행해야 하므로 M이 20~100 정도가 되면 실용적인 계산이 불가능해진다. 기존에는 변분 근사, 클러스터 전개, 의사우도(pseudo‑likelihood) 등 다양한 근사법이 제안되었지만, 이들 역시 강한 결합이나 고차원 데이터에서 성능이 제한적이었다.
저자들은 “관측된 구성들을 평탄하게 만들면 파티션 함수가 단순히 2^M이 된다”는 직관을 바탕으로 새로운 재가중치 기법을 도입한다. 구체적으로, 관측 빈도 fσ에 임의의 분포 qσ를 ε‑지수로 재가중치하여 ˜fσ∝fσ qσ^{‑ε}를 정의한다. 여기서 qσ를 실제 모델 분포 pσ(w)와 동일하게 잡으면, ˜fσ∝fσ pσ^{‑ε}가 되고, ε=0이면 ˜fσ는 모든 구성에 대해 동일한 값이 된다. 즉, 관측 데이터가 완전히 평탄화된 상황을 가정함으로써 파티션 함수 ˜Z=∑_σ exp(‑ε Eσ)≈2^M이 된다.
이 재가중된 데이터에 대해 다시 최대우도 추정을 수행하면, 로그우도 ˜L=∑_σ ˜pσ ln˜fσ에 대한 w에 대한 그라디언트는
∂ln˜L/∂w_I = ε ⟨O_I⟩_{˜f} − ε ⟨O_I⟩_{˜p}
가 된다. 여기서 ⟨·⟩_{˜f}는 관측된 구성에만 정의된 기대값이며, ⟨·⟩_{˜p}는 재가중된 모델 분포 ˜pσ∝exp(‑ε Eσ)에서 계산된다. ε가 충분히 작을 경우, ˜pσ에 대한 기대값을 ε‑전개하면 ⟨O_I⟩_{˜p}=ε w_I (2차 항까지)라는 간단한 관계가 성립한다. 따라서 두 기대값의 차이는 ε (⟨O_I⟩_{˜f} − w_I) 로 표현되며, 복잡한 샘플링 없이도 파라미터 업데이트가 가능해진다.
업데이트 식은
δw_I = α (⟨O_I⟩_{˜f} − w_I)
이며, 여기서 α는 학습률이다. 두 번째 항 –w_I는 파라미터 크기를 억제하는 암묵적 정규화 역할을 수행한다. ε=1이면 이 식은 고전적인 Hopfield 학습법 w_I=⟨O_I⟩_{f}와 동일해지며, ε를 조절함으로써 강한 결합·소규모 데이터에서도 안정적인 수렴을 얻는다.
실험에서는 M=20, 40, 100인 이징 시스템에 대해 다양한 결합 강도(표준편차)와 샘플 크기(N=5 000~40 000)를 사용했다. 결과는 다음과 같다. (1) 약한 결합·대규모 샘플에서는 ε‑머신(ε‑Machine, EM)이 MLE와 의사우도(PLE)와 거의 동일한 평균제곱오차(MSE)를 기록했다. (2) 강한 결합·소규모 샘플에서는 MLE와 PLE가 수렴하지 못하거나 큰 오차를 보이는 반면, EM은 낮은 MSE와 빠른 수렴을 달성했다. (3) ε 값을 너무 작게 잡으면 정규화가 부족해 w가 발산하고, 너무 크게 잡으면 ε‑전개의 근사오차가 커져 성능이 저하된다. 적절한 ε 범위에서는 MSE가 평탄하게 최소값을 유지한다. (4) 계산 시간 측면에서 EM은 관측된 구성만을 사용하므로 O(N·M) 복잡도로 실행되며, M=40일 때 PLE 대비 약 8배, M=20일 때 MLE 대비 약 25배 빠른 성능을 보였다.
추가 실험으로 MNIST 손글씨 이미지 복원을 수행했다. 28×28 픽셀을 이진화한 뒤, 10 % 이상의 픽셀을 결손시켰다. 결손 픽셀 중 80 % 이상이 동일값을 갖는 경우는 단순히 그 값을 채워 넣고, 나머지 픽셀에 대해서는 EM을 적용해 픽셀 간 바이어스와 상호작용을 학습하였다. 학습된 모델 p(σ_m|σ_c)∝p(σ_m,σ_c)를 최대화함으로써 결손 픽셀을 복원했으며, 원본 이미지와 거의 동일한 복원 결과를 얻었다. 이는 관측된 데이터만으로도 고차원 이진 변수 사이의 복잡한 상관관계를 효과적으로 모델링할 수 있음을 입증한다.
결론적으로, 이 논문은 고온(ε→0) 재가중치를 이용해 관측 데이터의 빈도를 평탄화함으로써 파티션 함수 계산을 회피하고, 기대값을 관측 데이터와 재가중된 모델 두 곳에서 간단히 구해 파라미터를 업데이트하는 새로운 프레임워크를 제시한다. 이 방법은 강한 결합·소규모 샘플 상황에서도 높은 정확도와 낮은 계산 비용을 제공하며, 이미지 복원 등 실제 응용에도 성공적으로 적용될 수 있다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기