Inverse Ising inference from high-temperature re-weighting of observations
Maximum Likelihood Estimation (MLE) is the bread and butter of system inference for stochastic systems. In some generality, MLE will converge to the correct model in the infinite data limit. In the context of physical approaches to system inference, …
Authors: Junghyo Jo, Danh-Tai Hoang, Vipul Periwal
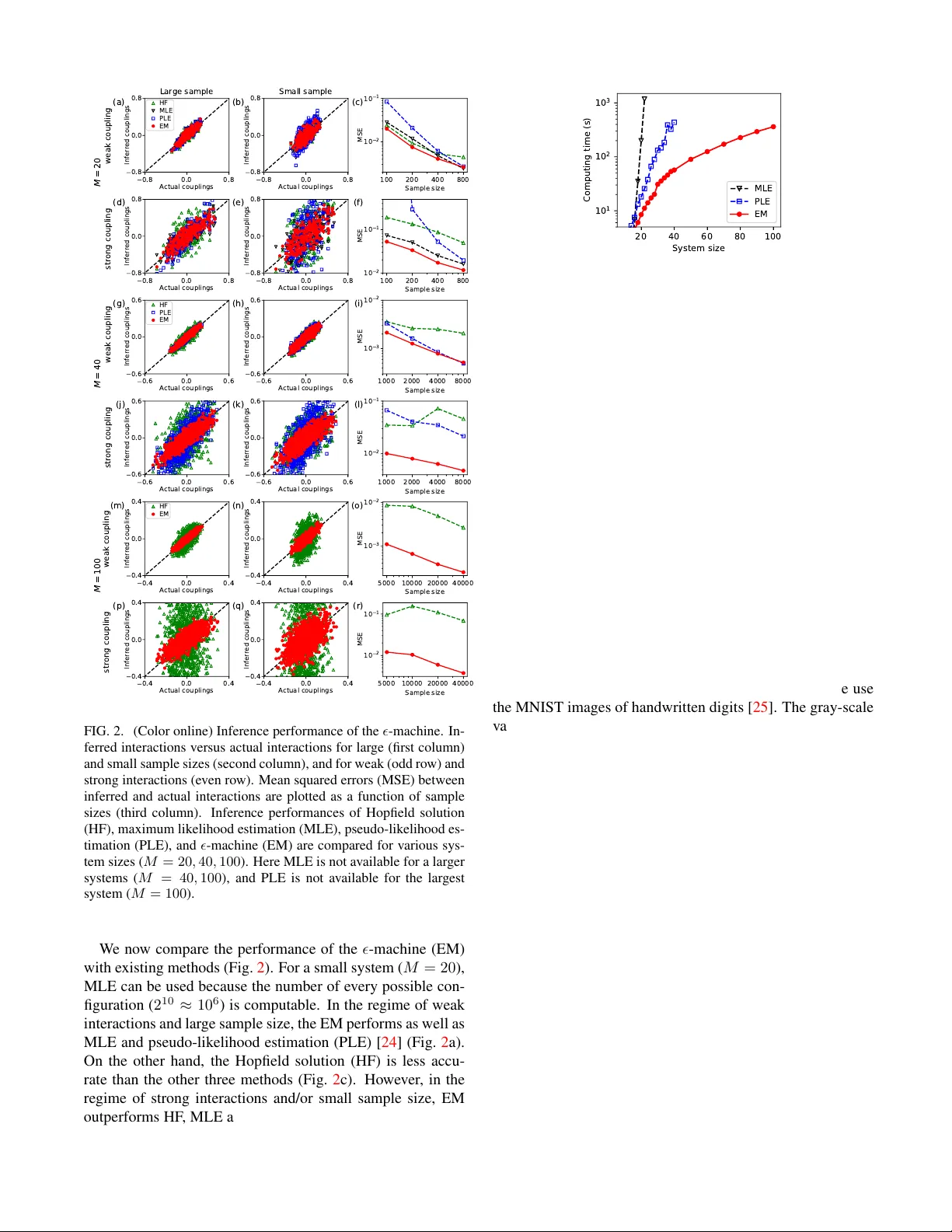
In verse Ising inference from high-temperatur e re-weighting of observations Junghyo Jo, 1, 2, 3 , ∗ Danh-T ai Hoang, 4, 5 and V ipul Periwal 4 , † 1 Department of Statistics, Keimyung University , Dae gu 42601, K orea 2 School of Computational Sciences, Kor ea Institute for Advanced Study , Seoul 02455, Kor ea 3 Department of Physics Education, Seoul National University , Seoul 08826, K orea 4 Laboratory of Biolo gical Modeling, National Institute of Diabetes and Dig estive and Kidney Diseases, National Institutes of Health, Bethesda, Maryland 20892, USA 5 Department of Natural Sciences, Quang Binh University , Dong Hoi, Quang Binh 510000, V ietnam (Dated: September 11, 2019) Maximum Likelihood Estimation (MLE) is the bread and b utter of system inference for stochastic systems. In some generality , MLE will con verge to the correct model in the infinite data limit. In the context of physical approaches to system inference, such as Boltzmann machines, MLE requires the arduous computation of parti- tion functions summing over all configurations, both observ ed and unobserved. W e present here a conceptually and computationally transparent data-driven approach to system inference that is based on the simple question: How should the Boltzmann weights of observ ed configurations be modified to make the probability distribution of observed configurations close to a flat distribution? This algorithm gives accurate inference by using only observed configurations for systems with a large number of degrees of freedom where other approaches are intractable. Intr oduction. Inferring underlying models from observed configurations is a general task for machine learning. Maxi- mum Likelihood Estimation (MLE) is a mathematically rigor- ous approach to parameter estimation for stochastic systems. If a system is observed in configuration σ with frequency n σ in a set of N observations, then MLE posits that an estimate of the true probabilities { p σ } is { p ∗ σ } = arg max { p σ } Y σ p n σ σ . (1) T aking the constraint P σ p σ = 1 into account, one obtains the intuitiv e result p ∗ σ = n σ N ≡ f σ . (2) Ising and Potts models, kno wn as Markov random fields or undirected graphical models in the machine learning and statistical inference fields, are important classes of physical models to represent p σ of observed configurations σ . In par- ticular , the models ha ve been adopted to explain neural activi- ties [ 1 – 3 ], gene expression lev els [ 4 ], protein structures [ 5 , 6 ], gene recombinations [ 7 ], bird interactions [ 8 ], financial mar- kets [ 9 , 10 ], and human interactions [ 11 ]. Searching in the space of graph structures encoding interactions between vari- ables is an NP-hard problem [ 12 ]. As a concrete example, for a dataset comprised of N observed configurations of M binary variables σ i = ± 1 , the binary v ariables are associated with Ising spins and the probability of observing a specific configuration σ = ( σ 1 , σ 2 , · · · , σ M ) is assumed to be the normalized Boltzmann weight: p σ ( w ) = exp( w I O I ( σ )) Z ( w ) with Z ( w ) ≡ X σ exp( w I O I ( σ )) , (3) using the Einstein summation con vention between repeated raised and lo wered indices, where { O I } is a set of operators appropriate for the problem of interest, for example the set of products { σ i σ j , i < j } . The inference problem is to de- termine the parameters w I from the data. Applying MLE es- timation, we wish to find p ∗ σ that maximizes the likelihood L ≡ Q σ p f σ σ = Q ˆ σ p f ˆ σ ˆ σ as the frequency f σ of unobserved configurations is 0. Note that ˆ σ represents observed configu- rations in { σ } . T aking the logarithm of L , we find ∂ ln L ∂ w I = h O I i f − h O I i p . (4) Here, for any observable O I defined on the set of all config- urations, h O I i f ≡ P ˆ σ f ˆ σ O I ( ˆ σ ) is summed ov er the set of observed configurations, and the model prediction h O I i p ≡ P σ p σ ( w ) O I ( σ ) is summed o ver all configurations. The cou- pling dependence is entirely in h O I i p . Gradient ascent using Eq. ( 4 ) to find w has the usual issues with local maxima but the most computationally intensive part is the ev aluation of h O I i p for ev ery step. No matter the size of the available data, N , this computation is a sum with 2 M terms. The computational intractability of the partition function is well-known to physicists [ 13 ]. Due to the centrality of this in verse problem, many approximate solutions have been de- veloped [ 14 ], including machine learning with variational au- toregressi ve networks [ 15 ]. First and second moments of the data are suf ficient statistics to solve the problem, but attempts to use this information alone giv e inaccurate results for large numbers of spins, suggesting the use of higher moments to im- prov e inference. The adaptiv e cluster expansion uses heuris- tics to truncate likelihood computations [ 16 , 17 ], and the prob- abilistic flo w method uses relaxation dynamics to aim for pre- specified analytically tractable target distributions, extracting information about the true distribution from rev ersed dynam- ics [ 18 ]. Howe ver , both approaches are computationally ex- pensiv e and thus not applicable for large systems. It has become clear ov er a decade of work that methods based on logistic regression perform much better for strongly coupled interactions than mean-field approaches. Many of 2 these approaches use regularized pseudo-likelihood estima- tors assuming local interaction graphs with restricted connec- tivity [ 19 , 20 ]. The pseudo-likelihood attempts to circumvent the difficulty of computing the exact partition function. The initial work of Ravikumar et al. [ 19 ] provides incorrect infer- ence for large couplings but recent improvements [ 21 ] have found extensions to this regime as well and achie ved very good performance on graphs with limited a verage degrees, necessary for the locality assumption underlying this regular - ized approach. In particular, their estimation procedure sets a threshold for small couplings, infers an interaction graph and then learns the values of couplings set to zero by the regular- ization but only for the graph structure already inferred. De- celle and Ricci-T ersenghi [ 22 ] sho wed that the local character of the pseudo-likelihood leads to inaccuracies for the interac- tion inferred between two spins if their local neighborhoods lead to very dif ferent estimates. They av oid this problem by using decimation and obtain excellent results for graphs with bounded degree distrib utions. Of course, when we are faced with an inference problem, we ha ve no way of knowing if the couplings are large or small, or if the interaction graphs of the spins ha ve dense or sparse connectivity or have heavy-tailed degree distributions. Our aim in this Letter is to rethink model inference for such problems to simplify the calculation of Z ( w ) using elemen- tary considerations. W e show that this entirely data-driven algorithm is computationally very fast, and accurate ev en in the hard inference regime of strong coupling with small num- ber of samples. Complete source code with documentation is av ailable on GitHub [ 23 ]. Theory . The key idea is to trivialize observed configurations by re-weighting their frequencies to mak e e very configuration equally likely . Then, the partition function becomes trivially computable as ˜ Z ≈ 2 M . Suppose we re-weight f σ by multi- plying q − 1 σ of an arbitrary distribution q σ : ˜ f σ ∝ f σ q − 1 σ (5) for any with the normalization P σ ˜ f σ = 1 . The MLE solu- tion for the re-weighted distribution is then ˜ p ∗ σ = ˜ f σ following Eq. ( 2 ). Here, if we set q σ = p ∗ σ , then we have ˜ p ∗ σ ∝ f σ , which becomes exactly flat for = 0 . In other words, complete erasure of the information in observed configurations implies knowing the true distribution p ∗ σ . Now the re-weighted model probability is ˜ p σ ∝ p σ q − 1 σ = p σ (6) with a specific choice of q σ = p σ . Therefore, we obtain ˜ p σ = exp( − E σ ) ˜ Z with ˜ Z ≡ X σ exp( − E σ ) , (7) where energy E σ = − w I O I ( σ ) or more specifically E σ = P i h i σ i + P j 1 or σ i = − 1 otherwise (Fig. 4 a). Given a test image, we randomly select 90 pixels ( > 10 % of total 784 pixels), and define them ( σ i = 0 ) as missing pixels (Fig. 4 b). Our goal is to reconstruct the missing pixels, and recover the original image. Specifically , we use N = 5851 samples of digit 8 in the MNIST training data. First, if the i -th pixel has a com- mon value of σ i for more than 80% of the training samples, the i -th missing pixel in the test image is simply reconstructed by the common σ i value. Howev er , the remaining M = 222 pixels hav e a large sample variation. Therefore, we apply the -machine to obtain p σ by inferring pixel bias and interac- tions. Here we divide the pixel vector σ = ( σ m , σ c m ) into missing pixels σ m and observed pixels σ c m . Then, by max- imizing p ( σ m | σ c m ) ∝ p ( σ m , σ c m ) ≡ p σ , we can reconstruct σ m (Fig. 4 c). Discussion. Inferring underlying models from observed configurations has become a cynosure with the present flood of big data. Howe ver , big data is not yet big enough to use most av ailable inference methods for large systems. In this study , we proposed a data-dri ven algorithm for solving the in verse Ising problem without any assumption on the connec- 5 (a) original image (b) noisy image (c) recovered image FIG. 4. (Color online) Image reconstruction by the -machine. (a) An MNIST image. (b) 90 pixel values are missed (green pix- els). (c) Recovered image with missing pixels reconstructed by the -machine. tivity (e.g., weak coupling, sparse networks, no cycles, etc.) of underlying systems. Unlike standard maximum likelihood estimation, our algorithm relies entirely on observed configu- rations with no need to sum over the vast number of unseen configurations. W e systematically re-weighted the frequency of observed configurations to increase the entropy of the re- weighted observed configuration distribution, and in the pro- cess tri vialized the computation of the exact partition function for every parameter value. Since the -machine requires only the computation of expectation values of observables in the re-weighted observed ensemble, it is very fast. Furthermore, it gi ves more accurate inference results than state-of-the-art pseudo-likelihood methods in the dif ficult inference regime of limited sample size or strong coupling. The concept of flattening the observed distribution and tri v- ializing the partition function can be further extended to con- sider hidden variables [ 26 , 27 ], continuous variables [ 18 , 28 ], non-equilibrium asymmetric couplings [ 29 ], and other infer- ence problems where the computation of the partition function is unfeasible. W e thank Juyong Song for discussions during the initial stages of this study . This work was supported by Intramu- ral Research Program of the National Institutes of Health, NIDDK (D.-T .H., V .P .), and by the Ne w Faculty Startup Fund from Seoul National University and the National Research Foundation of K orea (NRF) grant funded by the K orea gov- ernment (MSIT) (No. 2019R1F1A1052916) (J.J.). J.J. and D.-T .H. contributed equally to this work. ∗ Corresponding author: jojunghyo@snu.ac.kr † Corresponding author: vipulp@mail.nih.gov [1] E. Schneidman, M. J. Berry II, R. Se gev , and W . Bialek, Nature 440 , 1007 (2006). [2] S. Cocco, S. Leibler , and R. Monasson, Proceedings of the Na- tional Academy of Sciences 106 , 14058 (2009). [3] T . W atanabe, S. Hirose, H. W ada, Y . Imai, T . Machida, I. Shi- rouzu, S. Konishi, Y . Miyashita, and N. Masuda, Nature com- munications 4 , 1370 (2013). [4] T . R. Lezon, J. R. Banav ar, M. Cieplak, A. Maritan, and N. V . Fedoroff, Proceedings of the National Academy of Sciences 103 , 19033 (2006). [5] M. W eigt, R. A. White, H. Szurmant, J. A. Hoch, and T . Hwa, Proceedings of the National Academy of Sciences 106 , 67 (2009). [6] S. Cocco, C. Feinauer , M. Figliuzzi, R. Monasson, and M. W eigt, Reports on Progress in Physics 81 , 032601 (2018). [7] T . Mora, A. M. W alczak, W . Bialek, and C. G. Callan, Proceed- ings of the National Academy of Sciences 107 , 5405 (2010). [8] W . Bialek, A. Ca vagna, I. Giardina, T . Mora, E. Silvestri, M. V iale, and A. M. W alczak, Proceedings of the National Academy of Sciences 109 , 4786 (2012). [9] T . Bury , Journal of Statistical Mechanics: Theory and Experi- ment 2013 , P11004 (2013). [10] S. S. Borysov , Y . Roudi, and A. V . Balatsky , The European Physical Journal B 88 , 321 (2015). [11] N. Eagle, A. S. Pentland, and D. Lazer , Proceedings of the na- tional academy of sciences 106 , 15274 (2009). [12] D. M. Chickering, in Learning from data (Springer , 1996), pp. 121–130. [13] D. W elsh and D. J. W elsh, Complexity: knots, colourings and countings , vol. 186 (Cambridge uni versity press, 1993). [14] H. C. Nguyen, R. Zecchina, and J. Berg, Advances in Physics 66 , 197 (2017). [15] D. W u, L. W ang, and P . Zhang, Physical revie w letters 122 , 080602 (2019). [16] S. Cocco and R. Monasson, Physical revie w letters 106 , 090601 (2011). [17] H. C. Nguyen and J. Berg, Physical revie w letters 109 , 050602 (2012). [18] J. Sohl-Dickstein, P . B. Battaglino, and M. R. DeW eese, Physi- cal revie w letters 107 , 220601 (2011). [19] P . Ravikumar , M. J. W ainwright, J. D. Lafferty , et al., The An- nals of Statistics 38 , 1287 (2010). [20] E. Aurell and M. Ekeber g, Physical revie w letters 108 , 090201 (2012). [21] A. Y . Lokhov , M. V uffray , S. Misra, and M. Chertkov , Science advances 4 , e1700791 (2018). [22] A. Decelle and F . Ricci-T ersenghi, Physical revie w letters 112 , 070603 (2014). [23] J. Jo, D.-T . Hoang, and V . Periwal, Epsilon Machine (Accessed: September 4, 2019), https://nihcompmed.github. io/e- machine/ . [24] E. D. Lee and B. C. Daniels, Journal of Open Research Soft- ware 7 (2019). [25] Y . Lecun, L. Bottou, Y . Bengio, and P . Haffner , Proceedings of the IEEE 86 , 2278 (1998), ISSN 0018-9219. [26] D.-T . Hoang, J. Jo, and V . Periwal, Physical Revie w E 99 , 042114 (2019). [27] Y . Roudi and J. Hertz, Physical revie w letters 106 , 048702 (2011). [28] C. Donner and M. Opper , Physical Revie w E 96 , 062104 (2017). [29] D.-T . Hoang, J. Song, V . Periwal, and J. Jo, Physical Revie w E 99 , 023311 (2019).
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment