PCONV: 모바일 DNN 실시간 가속을 위한 새로운 가중치 희소성
PCONV은 기존 비구조적(미세) 프루닝과 구조적(거친) 프루닝 사이의 중간 단계인 ‘패턴 기반 희소성’을 도입한다. intra‑conv 커널 내부에 고정된 패턴(SCP)을 적용해 정확도를 유지하고, inter‑conv 커널 간 연결을 제거해 압축률을 높인다. 이를 지원하는 컴파일러‑보조 인퍼런스 프레임워크를 구축해 모바일 CPU·GPU에서 VGG‑16, ResNet‑50, MobileNet‑v2 등을 실시간(≤20 ms)으로 실행한다. 기존 …
저자: Xiaolong Ma, Fu-Ming Guo, Wei Niu
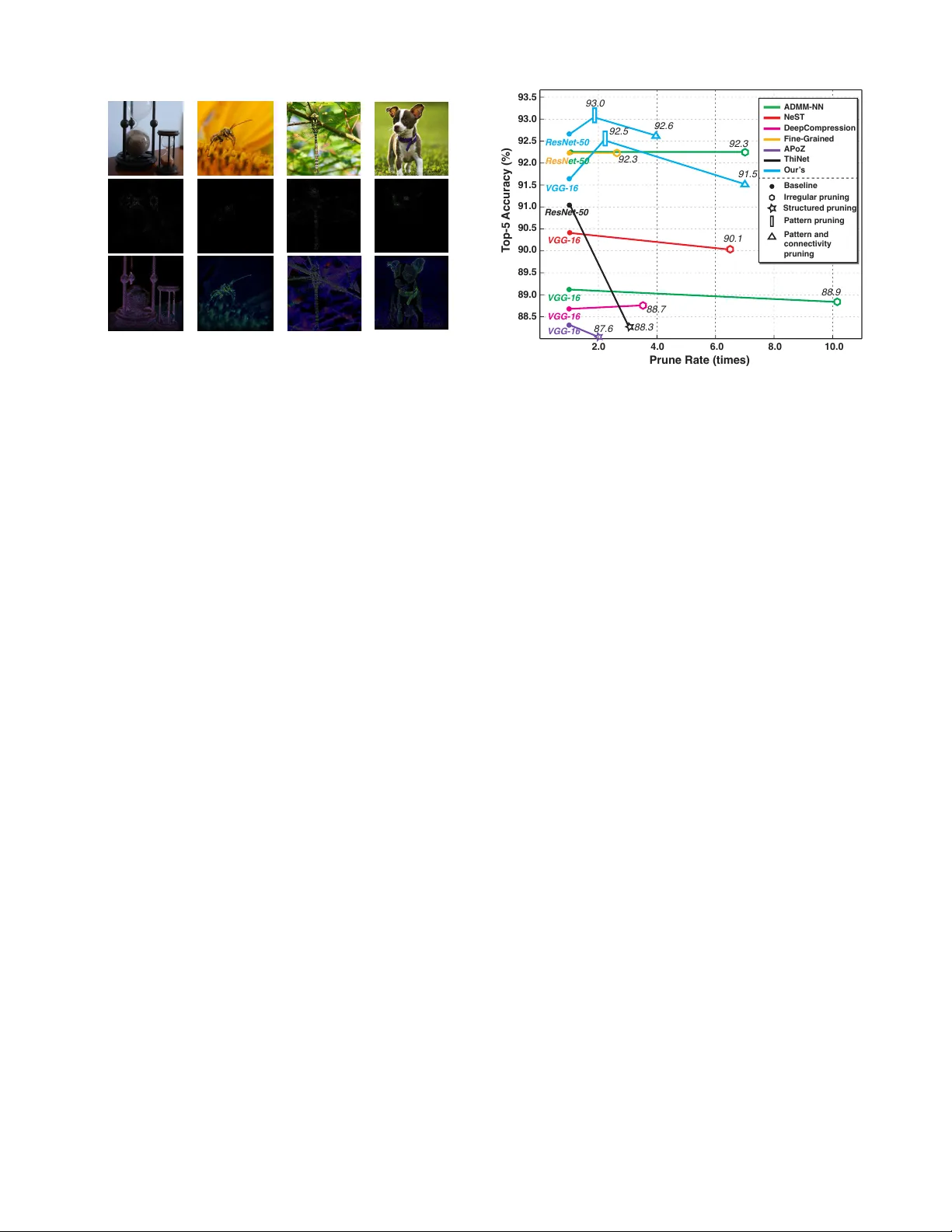
본 논문은 모바일 디바이스에서 대규모 딥 뉴럴 네트워크(DNN)를 실시간으로 실행하기 위한 새로운 가중치 프루닝 기법인 PCONV을 제안한다. 기존 프루닝 방법은 크게 두 가지로 나뉜다. 첫 번째는 비구조적(비정형) 프루닝으로, 가중치를 자유롭게 제거해 높은 희소도와 정확도를 달성하지만, 인덱스 저장과 불규칙 메모리 접근으로 인해 하드웨어 효율이 낮다. 두 번째는 구조적(정형) 프루닝으로, 필터·채널 단위로 일괄 제거해 연산량과 메모리 사용을 크게 줄이지만, 높은 프루닝 비율에서는 정확도가 급격히 떨어진다.
PCONV은 이 두 극단 사이에 위치하는 “패턴 기반 희소성”이라는 새로운 차원을 도입한다. 구체적으로는 두 가지 희소성을 결합한다. ① Sparse Convolution Patterns(SCP): 각 컨볼루션 커널 내부에서 사전에 정의된 몇 가지 패턴(예: Gaussian, Laplacian of Gaussian)만 남기고 나머지를 0으로 마스킹한다. 이는 각 필터가 동일한 프루닝 비율을 유지하도록 하면서, 시각적 핵심 필터의 특성을 보존해 정확도 손실을 최소화한다. ② Connectivity Sparsity: 입력·출력 채널 간 연결을 선택적으로 차단해 커널 자체를 제거한다. 이는 필터 “길이”를 줄여 연산량을 크게 감소시키면서, 필터별 연산량이 균등하게 유지되도록 설계되었다.
알고리즘 차원에서 PCONV은 패턴 프루닝과 연결성 프루닝을 동시에 적용한다. 패턴 프루닝은 각 커널에 고정된 비트마스크를 부여해 연산 시 마스크 연산만 수행하면 되므로, GPU 워프 수준에서 제어 흐름이 거의 없어진다. 연결성 프루닝은 메모리 접근을 연속적으로 만들어 캐시 효율을 높인다.
이러한 희소성을 실제 하드웨어에 적용하기 위해 논문은 컴파일러‑보조 DNN 인퍼런스 프레임워크를 설계한다. 주요 단계는 (1) 고수준 레이어 정보를 추출해 패턴·채널 정보를 메타데이터로 저장, (2) 필터와 커널을 재배열해 메모리 연속성을 확보, (3) 중복 로드를 제거하고 벡터화된 연산 코드를 자동 생성한다. 이 파이프라인은 모바일 CPU와 GPU 모두에 적용 가능하도록 일반화되었다.
실험에서는 ImageNet과 CIFAR‑10 데이터셋에 대해 VGG‑16, ResNet‑50, MobileNet‑v2 모델을 대상으로 평가했다. 동일한 Top‑1 정확도를 유지하면서, Adreno 640 GPU에서 VGG‑16을 19.1 ms(≈52 FPS)로 실행해 실시간 요구를 충족시켰다. 또한, TensorFlow‑Lite, TVM, Alibaba MNN과 비교했을 때, GPU에서는 최대 39.2×, CPU에서는 11.4×, 전체 프레임워크에서는 6.3×의 속도 향상을 기록했다.
결론적으로 PCONV은 비구조적 프루닝이 제공하는 높은 정확도와 구조적 프루닝이 제공하는 하드웨어 친화성을 동시에 만족시키는 새로운 설계 공간을 개척한다. 이는 모바일·엣지 환경에서 대규모 DNN을 실시간으로 구동하려는 다양한 응용(예: AR/VR, 실시간 영상 분석, 스마트 헬스케어)에 직접적인 이점을 제공한다. 다만, 현재는 3×3·5×5 커널에 최적화돼 있어 1×1 컨볼루션이 다수인 모델에 대한 추가 연구와, Apple Silicon·NVIDIA Jetson 등 다른 모바일 아키텍처에 대한 이식성 검증이 향후 과제로 남는다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기