PCONV: The Missing but Desirable Sparsity in DNN Weight Pruning for Real-time Execution on Mobile Devices
Model compression techniques on Deep Neural Network (DNN) have been widely acknowledged as an effective way to achieve acceleration on a variety of platforms, and DNN weight pruning is a straightforward and effective method. There are currently two m…
Authors: Xiaolong Ma, Fu-Ming Guo, Wei Niu
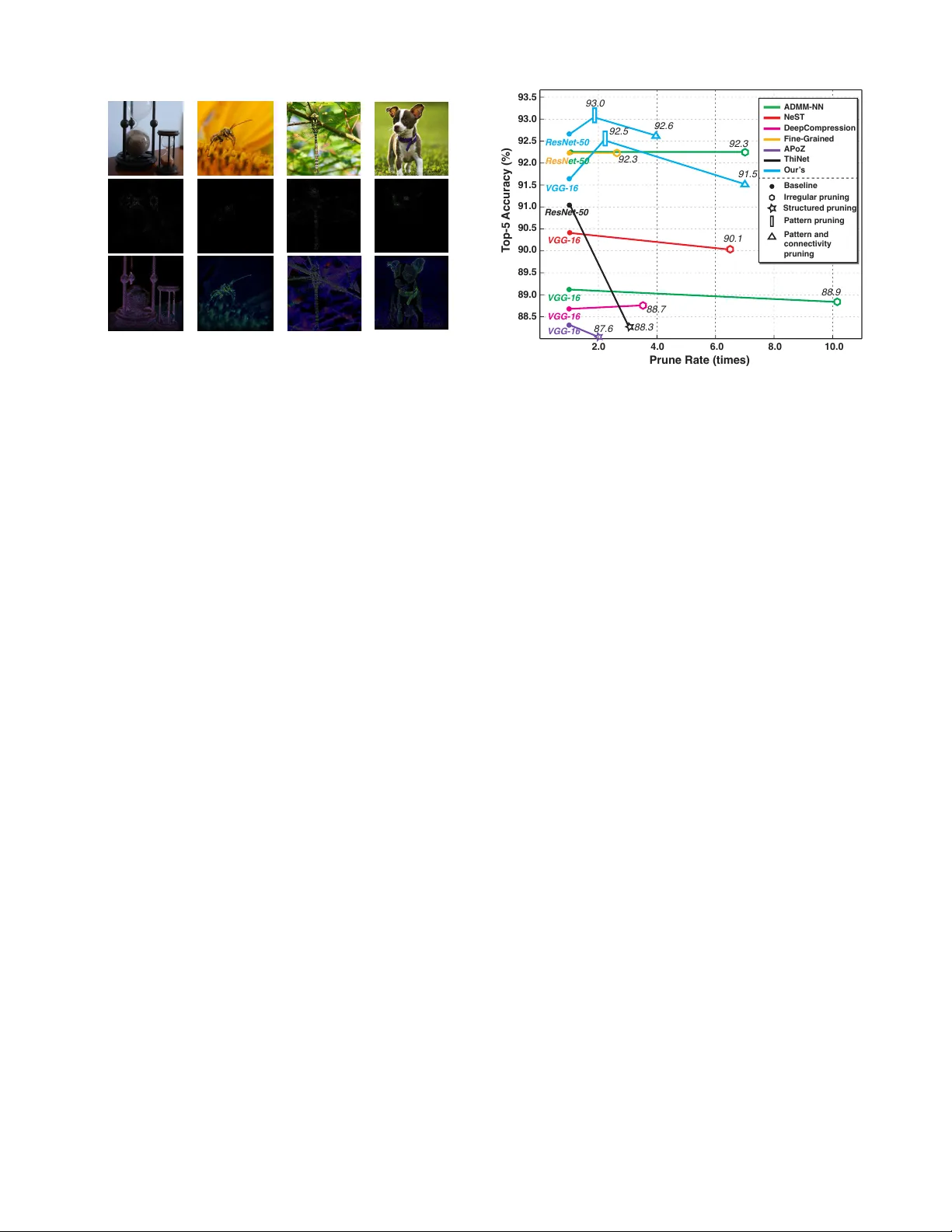
PCONV : The Missing b ut Desirable Sparsity in DNN W eight Pruning f or Real-time Execution on Mobile Devices Xiaolong Ma † 1 , Fu-Ming Guo † 1 , W ei Niu 2 , Xue Lin 1 , Jian T ang 3,4 , Kaisheng Ma 5 , Bin Ren 2 , Y anzhi W ang 1 1 Northeastern Univ ersity , 2 College of W illiam and Mary , 3 DiDi AI Labs, 4 Syracuse Univ ersity , 5 Tsinghua Univ ersity E-mail: 1 { ma.xiaol, guo.fu } @husky .neu.edu, 1 { xue.lin, yanz.wang } @northeastern.edu, 2 wniu@email.wm.edu, 2 bren@cs.wm.edu, 3 tangjian@didiglobal.com, 5 kaisheng@mail.tsinghua.edu.cn Abstract Model compression techniques on Deep Neural Network (DNN) hav e been widely acknowledged as an effecti ve way to achiev e acceleration on a variety of platforms, and DNN weight pruning is a straightforward and ef fective method. There are currently two mainstreams of pruning methods rep- resenting tw o e xtremes of pruning regularity: non-structur ed , fine-grained pruning can achie ve high sparsity and accuracy , but is not hardware friendly; structur ed , coarse-grained prun- ing exploits hardware-ef ficient structures in pruning, b ut suf- fers from accuracy drop when the pruning rate is high. In this paper , we introduce PCONV , comprising a new sparsity di- mension, – fine-grained pruning patterns inside the coarse- grained structures. PCONV comprises two types of sparsi- ties, Sparse Con volution Patterns (SCP) which is generated from intra-conv olution k ernel pruning and connecti vity spar- sity generated from inter-con volution kernel pruning. Essen- tially , SCP enhances accuracy due to its special vision prop- erties, and connectivity sparsity increases pruning rate while maintaining balanced workload on filter computation. T o de- ploy PCONV , we de velop a nov el compiler-assisted DNN in- ference framew ork and execute PCONV models in real-time without accurac y compromise, which cannot be achiev ed in prior work. Our experimental results sho w that, PCONV outperforms three state-of-art end-to-end DNN frameworks, T ensorFlo w-Lite, TVM, and Alibaba Mobile Neural Network with speedup up to 39 . 2 × , 11 . 4 × , and 6 . 3 × , respectiv ely , with no accuracy loss. Mobile devices can achieve real-time inference on large-scale DNNs. Introduction Deep neural network (DNN) has emerged as the fundamen- tal element and core enabler in machine learning applica- tions due to its high accurac y , excellent scalability , and self- adaptiv eness (Goodfellow et al. 2016). A well trained DNN model can be deployed as inference system for multiple ob- jectiv es, such as image classification (Krizhevsk y , Sutske ver , and Hinton 2012), object detection (Ren et al. 2015), and natural language processing (Hinton, Deng, and Y u 2012). Howe ver , the state-of-art DNN models such as VGG-16 (Si- monyan and Zisserman 2014), ResNet-50 (He et al. 2016) † These authors contributed equally . Copyright c 2020, Association for the Advancement of Artificial Intelligence (www .aaai.org). All rights reserv ed. and MobileNet (Howard et al. 2017) in volv e intensiv e com- putation and high memory storage, making it very challeng- ing to e xecute inference system on current mobile platforms in a real-time manner . Recently , high-end mobile platforms are rapidly over - taking desktop and laptop as primary computing devices for broad DNN applications such as wearable devices, video streaming, unmanned vehicles, smart health de- vices, etc. (Philipp, Durr , and Rothermel 2011)(Lane et al. 2015)(Boticki and So 2010). Developing a real-time DNN inference system is desirable but still yield to the limited computation resources of embedded processors on a mo- bile platform. Multiple end-to-end mobile DNN acceleration framew orks, such as TVM (Chen et al. 2018), T ensorFlow- Lite (TFLite) (T en ) and Alibaba Mobile Neural Network (MNN) (Ali ), ha ve been de veloped. Ho wever , the inference time of large-scale DNNs (e.g., 242ms inference time using TVM on Adreno 640 GPU with VGG-16) is still far from real-time requirement. In order to mitigate the challenge brings by the DNN’ s bulk y computation and achieve the goal of real-time in- ference, it is necessary to consider algorithm-lev el innov a- tions. V arious DNN model compression techniques are stud- ied, among which weight pruning (Han, Mao, and Dally 2015)(Mao et al. 2017)(Dai, Y in, and Jha 2017)(W en et al. 2016)(He, Zhang, and Sun 2017) can result in a no- table reduction in the model size. Early work (Han, Mao, and Dally 2015) on non-structur ed weight pruning (fine- grained) prunes weights at arbitrary location, resulting in a sparse model to be stored in the compressed sparse col- umn (CSC) format. It leads to an undermined processing throughput because the indices in the compressed weight representation cause stall or complex workload on highly parallel architectures (Han, Mao, and Dally 2015)(W en et al. 2016). On the other hand, structur ed weight pruning (W en et al. 2016) (coarse-grained) is more hardware friendly . By exploiting filter pruning and channel pruning, the pruned model is more regular in its shape, which eliminates the storage requirement in weight indices. Howe ver , it is ob- served that structured pruning hurts accuracy more signifi- cantly than non-structured sparsity . It is imperative to find a new granularity lev el that can satisfy high accuracy demand as well as re gularity in DNN model structure. W e make the observation that non- structured and structured pruning are two extremes of the full design space. The two missing ke ys are: (i) Find a new , intermediate sparsity dimension that can fully le ver - age both the high accuracy from fine-grained model and high regularity le vel from coarse-grained model; (ii) Find the corresponding (algorithm-compiler-hardware) optimiza- tion framework which can seamlessly bridge the gap be- tween hardware efficiency and the new sparsity dimen- sion. T o address the abov e problems, this paper proposes PCONV , comprising (a) a new sparsity dimension that ex- ploits both intra-conv olution and inter-con volution kernel sparsities, exhibiting both high accuracy and regularity , and rev ealing a pre viously unknown point in design space; and (b) a compiler-assisted DNN infer ence framework that fully lev erages the new sparsity dimension and achie ves real-time DNN acceleration on mobile devices. In PCONV , we call our intra-conv olution kernel pruning pattern pruning and inter-con volution kernel pruning con- nectivity pruning . For pattern pruning, a fixed number of weights are pruned in each conv olution kernel. Different from non-structured weight pruning, pattern pruning pro- duces the same sparsity ratio in each filter and a limited number of pattern shapes. Essentially , our designed patterns correspond to the computer vision concept of key conv olu- tion filters, such as Gaussian filter for smoothing, Laplacian of Gaussian filter for smoothing and sharpening. For connec- tivity pruning, the key insight is to cut the connections be- tween certain input and output channels, which is equiv alent to remov al of corresponding kernels, making filter “length” shorter than original model. W ith connectivity pruning, we further enlar ge compression rate and provide greater DNN acceleration potential, while maintaining balanced w orkload in filter-wise computation of DNNs. Pattern and connectiv- ity pruning can be combined at algorithm lev el and acceler- ated under the unified compiler-assisted acceleration frame- work. F or our adv anced compiler-assisted DNN infer ence frame work , we use execution code generation which con- verts DNN models into computational graphs and applies multiple optimizations including a high-level, fine-grained DNN layerwise information extraction, filter kernel reorder and load redundancy elimination. All design optimizations are general, and applicable to both mobile CPUs and GPUs. W e demonstrate that pattern pruning consistently impro ve model accuracy . When combined with connectivity pruning, the results still outperform current DNN pruning methods, both non-structured and structured weight pruning. In Sec- tion “ Accuracy Analysis”, we show PCONV is the most de- sirable sparsity among current prune-for-acceleration works. W e also deploy PCONV model on our compiler-assisted mo- bile acceleration framework and compare with three state- of-art frame works on mobile CPU and GPU, T ensorFlow Lite, TVM, and MNN, using three widely used DNNs, VGG-16, ResNet-50, and MobileNet-v2 and two benchmark datasets, ImageNet and CIF AR-10. Evaluation results sho w that PCONV achiev es up to 39 . 2 × speedup without any ac- curacy drop. Using Adreno 640 embedded GPU, PCONV achiev es an unprecedented 19.1 ms inference time of VGG- Filter Prune Channel Prune Filters Filters Convolution Kernel Channels Channels Irregular Prune Filters Channels The Missing Sparsity T ypes Regular Sparsity Irregular Sparsity Pruned Filter Pruned Channel Pruned weight Figure 1: Overvie w of different weight pruning dimensions. 16 on ImageNet dataset. T o the best of our knowledge, it is the first time to achiev e real-time execution of such repre- sentativ e large-scale DNNs on mobile de vices. Background DNN Model Compression DNN model compression is a promising method to remove redundancy in the original model. It targets on the pur- pose that inference time can be reduced if fe wer weights are inv olved in the computation graph. The weight pruning method acts as a surgeon to remove the inherently redun- dant neurons or synapses. As Figure 1 shows, two main ap- proaches of weight pruning are the general, non-structured pruning and structured pruning, which produce irregular and regular compressed DNN models, respecti vely . Non-structured pruning: Early work is (Han, Mao, and Dally 2015), in which an iterative, heuristic method is used with limited, non-uniform model compression rates. Flour- ished by (Zhang et al. 2018) and (Ren et al. 2019) with the powerful ADMM (Boyd et al. 2011) optimization frame- work, non-structured pruning achiev es very high weight re- duction rate and promising accuracy . Ho we ver , for compiler and code optimization, irregular weight distribution within kernels requires heavy control-flow instructions, which de- grades instruction-le vel parallelism. Also, kernels in differ - ent filters hav e div ergent workloads, which burdens thread- lev el parallelism when filters are processed through multi- threading. Moreov er, irregular memory access causes low memory performance and thereby ex ecution overheads. Structured pruning: This method has been proposed to address the index overhead and imbalanced workload caused by non-structured pruning. Pioneered by (W en et al. 2016)(He, Zhang, and Sun 2017), structured weight pruning generates regular and smaller weight matrices, eliminating ov erhead of weight indices and achieving higher accelera- tion performance in CPU/GPU executions. Howe ver , it suf- fers from notable accuracy drop when the pruning rate in- creases. Patter ns in Computer V ision Con volution operations exist in dif ferent research areas for an extended period of time, such as image processing, signal processing, probability theory , and computer vision. In this work, we focus on the relationship between con ventional image processing and state-of-art con volutional neural net- works in the usage of conv olutions. In image processing, the con volution operator is manually crafted with prior kno wl- edge from the particular characteristics of di verse patterns, such as Gaussian filter . On the other hand, in con volutional neural networks, the conv olution kernels are randomly ini- tialized, then trained on large datasets using gradient-based learning algorithms for value updating. (Mairal et al. 2014) deri ved a network architecture named Con volutional Kernel Networks (CKN), with lower accu- racy than current DNNs, thus limited usage. (Zhang 2019) proposed to apply the blur filter to DNNs before pooling to maintain the shift-equiv alence property . The limited prior work on the application of conv entional vision filters to DNNs require network structure change and do not focus on weight pruning/acceleration, thus distinct from PCONV . DNN Acceleration Frameworks on Mobile Platf orm Recently , researchers from academia and industry hav e in- vestigated DNN inference acceleration frameworks on mo- bile platforms, including TFLite (T en ), TVM (Chen et al. 2018), Alibaba Mobile Neural Network (MNN) (Ali ), DeepCache (Xu et al. 2018) and DeepSense (Y ao et al. 2017). These works do not account for model compression techniques, and the performance is far from real-time re- quirement. There are other researches that exploit model sparsity to accelerate DNN inference, e.g., (Liu et al. 2015), SCNN (Parashar et al. 2017), but they either do not target mobile platforms (require new hardware) or trade off com- pression rate and accuracy , thus having different challenges than our work. Motivations Based on the current research progress on DNN model compression vs. acceleration, we analyze and rethink the whole design space, and are motiv ated by the following three points: Achieving both high model accuracy and pruning regularity . In non-structured pruning, any weight can be pruned. This kind of pruning has the largest flexibility , thus achiev es high accuracy and high prune rate. But it is not hardware-friendly . On the other hand, structured pruning produces hardw are-friendly models, but the pruning method lacks flexibility and suf fers from accuracy drop. Our motiv a- tion is to use the best of the abo ve two sparsities. T o achie ve that, we introduce a new dimension, pattern-based sparsity , rev ealing a pre viously unkno wn design point with high ac- curacy and structural re gularity simultaneously . Image enhancement inspired sparse con volution pat- terns. The contemporary DNN weight pruning methods originate from the motiv ation that eliminating redundant in- formation (weights) will not hurt accuracy . On the other hand, these pruning methods scarcely treat pruning as a spe- cific kind of binary con volution operator, not to mention exploiting corresponding opportunities. Along this line, we find that sparse con volution patterns have the potential in Filter 1 Filter 2 Filter n Kernel pattern Pruned weights Connectivity pruning Convolution kernel Figure 2: Illustration of pattern pruning and connecti vity pruning. enhancing image quality thanks to its special vision proper- ties. Moti vated by the fact that sparse con volution patterns can potentially enhance image quality , we propose our care- fully designed patterns which are deriv ed from mathematical vision theory . Compiler -assisted DNN inference framework. W ith the higher accuracy enabled by fine-grained pruning patterns, the key question is how to re-gain similar (or ev en surpass) hardware efficienc y as coarse-gained structured pruning. W e take a unique approach and design an optimized, compiler- assisted DNN inference frame work to close the performance gap between full structured pruning and pattern-based prun- ing. Theory of Sparse Con volution Patter ns (SCP) Let an image with resolution H × W be represented by X ∈ R H × W × 3 . An L − layer DNN can be expressed as a feature extractor F L ( F L − 1 ( . . . F 1 ( X ) . . . )) , with layer in- dex l ∈ { 1 , . . . , L } . Inside the DNN, each conv olutional layer is defined as F l ( X l ) ∈ R H l × W l × F l × C l , with filter kernel shape H l × W l , number of filters F l and number of channels C l . Besides treating pruning as a redundant information re- mov al technique, we consider it as incorporating an addi- tional con volution kernel P to perform element-wise mul- tiplication with the original kernel. P is termed the Sparse Con volution P attern (SCP), with dimension H l × W l and binary-valued elements (0 and 1). Specific SCPs fit the mathematical vision theory well according to our follow- ing deriv ation. Based on the mathematical rigority , we pro- pose the novel pattern pruning scheme, i.e., applying SCPs to con volution kernels. As illustrated in Figure 2, the white blocks denote a fix ed number of pruned weights in each k er- nel. The remaining red blocks in each kernel hav e arbitrary weight values, while their locations form a specific SCP P i . Different kernels can ha ve different SCPs, but the total num- ber of SCP types shall be limited. In order to further increase the pruning ratio and DNN inference speed, we can selectiv ely cut the connections be- tween particular input and output channels, which is equiv a- lent to the removal of corresponding kernels. This is termed connectivity pruning . Connectivity pruning is illustrated in Figure 2, with gray kernels as pruned ones. The rationale of connectivity pruning stems from the desirability of local- ity in layerwise computations inspired by human visual sys- tems (Y amins and DiCarlo 2016). It is a good supplement to pattern pruning. Both pruning schemes can be integrated in the same algorithm-level solution and compiler-assisted mobile acceleration framew ork. The Con volution Operator In conv entional image processing, a conv olution operator is formally defined by the follo wing formula, where the output pixel v alue g ( x, y ) is the weighted sum of input pixel values f ( x, y ) , and h ( k, l ) is the weight kernel value g ( x, y ) = X k,l f ( x + k , y + l ) h ( k , l ) (1) This formula could transform to g ( x, y ) = X k,l f ( k , l ) h ( x − k , y − l ) (2) Then we deriv e the notation of conv olution operator as: g = f ∗ h (3) Con volution is a linear shift-inv ariant (LSI) operator, sat- isfying the commutativ e property , the superposition property and the shift-in variance property . Additionally , con volution satisfies the associativ e property following the Fubini’ s the- orem. Sparse Con volution Patter n (SCP) Design Our designed SCPs could be transformed to a series of steer- able filters (Freeman and Adelson 1991), i.e., the Gaussian filter and Laplacian of Gaussian filter , which function as im- age smoothing, edge detection or image sharpening in math- ematical vision theory . Gaussian filter: Consider a two-dimensional Gaussian filter G : G ( x, y, σ ) = 1 2 π σ 2 e − x 2 + y 2 2 σ 2 (4) x and y are input coordinates, and σ is standard deviation of the Gaussian distribution. T ypically , the Gaussian filter performs image smoothing, and further sophisticated filters can be created by first smoothing the image input with a unit area Gaussian filter , then applying other steerable filters. Laplacian of Gaussian filter: The Laplacian operator is the second deriv ativ e operator . According to the associativ e property , smoothing an image with Gaussian filter and then applying Laplacian operator is equiv alent to con volve the image with the Laplacian of Gaussian (LoG) filter: ∇ 2 G ( x, y, σ ) = x 2 + y 2 σ 4 − 2 σ 2 G ( x, y, σ ) (5) The LoG filter is a bandpass filter that eliminates both the high-frequency and low-frequenc y noises. LoG has elegant mathematical properties, and is valid for a variety of appli- cations including image enhancement, edge detection, and stereo matching. T aylor series expansion is utilized to determine the ap- proximate values of the LoG filter with 3 × 3 filter size. First, we consider the 1-D situation. The T aylor series expansions of 1-D Gaussian filter G ( x ) are gi ven by: G ( x + h ) = G ( x ) + hG 0 ( x ) + 1 2 h 2 G 00 ( x ) + 1 3! h 3 G 000 ( x ) + O h 4 (6) G ( x − h ) = G ( x ) − hG 0 ( x ) + 1 2 h 2 G 00 ( x ) − 1 3! h 3 G 000 ( x ) + O h 4 (7) By summing (6) and (7), we hav e G ( x + h ) + G ( x − h ) = 2 G ( x ) + h 2 G 00 ( x ) + O h 4 (8) The second deriv ative of Gaussian G 00 ( x ) is equiv alent to LoG ∇ 2 G ( x ) . Equation (8) is further transformed to G ( x − h ) − 2 G ( x ) + G ( x + h ) h 2 = ∇ 2 G ( x ) + O h 2 (9) Applying central dif ference approximation of LoG ∇ 2 G ( x ) , we deriv e the 1-D approximation of LoG filter as [ 1 − 2 1 ] . Then we procure the 2-D approximation of LoG fil- ter by con volving [ 1 − 2 1 ] and h 1 − 2 1 i , and get result as h − 1 2 − 1 2 − 4 2 − 1 2 − 1 i . According to the property of second deriv ative: ∇ 2 G ( x, y ) = G xx ( x, y ) + G yy ( x, y ) (10) and Equation (9), we hav e G xx ( x, y ) + G yy ( x, y ) = [ 1 − 2 1 ] + h 1 − 2 1 i ∗ G ( x, y ) (11) Based on (11), we deriv e another approximation of LoG as h 0 1 0 1 − 4 1 0 1 0 i . According to the central limit theorem, the con volution of two Gaussian functions is still a Gaussian function, and the new variance is the sum of the variances of the two origi- nal Gaussian functions. Hence, we con volv e the abov e two approximations of LoG and then apply normalization, and get the Enhanced Laplacian of Gaussian (ELoG) filter as h 0 1 0 1 8 1 0 1 0 i . (Siyuan, Raef, and Mikhail 2018) have prov ed the con- ver gence of the interpolation in the context of (multi-layer) DNNs, so we utilize the interpolated probability density es- timation to make the further approximation. In ELoG filter where 1 appears, we mask it to 0 with the probability of (1 − p ) . Because we uniformly con volve SCPs into n con vo- lutional layers, this random masking operation can be treated as distrib uted interpolation of SCPs. In continuous probabil- ity space, interpolating SCPs into conv olution function is a specific Probability Density Function (PDF), so the ef fect of interpolating SCPs is accumulating probability expecta- tions of interpolation into n con volutional layers. Besides, the con volution function is normalized to unity , so we sepa- rate the coefficient p in the following equation. 0 1 0 1 1 1 0 0 0 0 1 0 1 1 0 0 1 0 0 0 0 1 1 1 0 1 0 0 1 0 0 1 1 0 1 0 0 p 0 p 1 p 0 p 0 0 1 0 1 1/ p 1 0 1 0 p n n = = n interpolations (12) The four SCPs are shown in colored positions in (12). In order to get the best approximation to ELoG filter, we set Hourglass Bee Dragonfly Chihuahua Ori. Img Baseline Guided BP Pattern-pruned Guided BP Figure 3: V isualization of intermediate results ( saliency map of gradient images ) in original VGG-16 model and pattern pruned VGG-16 model through guided-bac kpropa gation . p = 0 . 75 and n = 8 , then the desired filter is equal to in- terpolating these four SCPs for eight times. The coefficient p has no ef fect after normalization. Upper bound: According to (C.Blakemore and Camp- bell 1969), the optimal times for applying the LoG filter is six and the maximum is ten. Thus the desired number of times to interpolate the SCP in (12) is around 24 and the maximum number is around 55. This upper bound covers most of the existing effecti ve DNNs, e ven for ResNet-152, which comprises 50 con volutional layers with filter kernel size of 3 × 3 . The four SCPs in (12) form the ELoG filter through in- terpolation. Hence, the designed SCPs inherit the de-noising and sharpening characteristics of LoG filters. W e visualize the intermediate results of DNNs to interpret and verify the advancement of our designed SCPs in the following section. V isualization and Interpretation Explanations of individual DNN decision hav e been ex- plored by generating informati ve heatmaps such as CAM and grad-CAM (Selvaraju et al. 2017), or through guided- backpropagation (BP) (Springenber g and Alex ey Doso vit- skiy 2015) conditioned on the final prediction. Utilizing guided-backpropagation, we can visualize what a DNN has learned. The visualization results of applying SCPs to an original DNN model ( pattern pruning ) are demonstrated in Figure 3. W e sample four input images from the ImageNet dataset, as “hourglass”, “bee”, “dragonfly” and “chihuahua”, then apply the guided-backpropagation to propagate back from each tar get class label and get the gradient images. Eventually , we generate the saliency maps of gradient im- ages. Compared with the original VGG-16 model, the pat- tern pruned VGG-16 model captures more detailed informa- tion of the input image with less noise. W e conclude that by applying our designed SCPs, pattern pruning enhances DNNs’ image processing ability , which will potentially enhance the inference accuracy of a DNN. 88.5 89.0 89.5 90.0 90.5 91.0 91.5 92.0 92.5 93.0 93.5 2.0 4.0 6.0 8.0 10.0 92.3 88.7 87.6 88.3 90.1 88.9 93.0 92.6 91.5 92.3 92.5 ResN et-50 ResNet-50 VGG-16 VGG-16 VGG-16 VGG-16 VGG-16 ResNet-50 Our ’ s ADMM-NN NeST DeepCompression Fine-Grained APoZ Baseline Irregular pruning Structured pruning Pattern pruning Pattern and connectivity pruning ThiNet T op-5 Accuracy (%) Prune Rate (times) Figure 4: Comparison results of our pattern and connectiv- ity pruning of VGG-16 and ResNet-50 on ImageNet dataset with: ADMM-NN (Ren et al. 2019), NeST (Dai, Y in, and Jha 2017), Deep Compression (Han, Mao, and Dally 2015), Fine-grained pruning (Mao et al. 2017), APoZ (Hu et al. 2016) and ThiNet (Luo, W u, and Lin 2017). Accuracy Analysis In our pre vious deri vation, we have determined the (four) SCPs as our pattern set. Our algorithm-level solution starts from a pre-trained DNN model, or can train from scratch. T o generate PCONV model, we need to assign SCPs to each kernel (pattern pruning) or prune specific kernels (connec- tivity pruning), and train the active (unpruned) weights. T o achiev e this goal, we extend the ADMM-NN framew ork in (Ren et al. 2019) to produce pattern and connectivity- pruned models. Accuracy results are illustrated in Figure 4. Starting from the baseline accuracy results that are in many cases higher than prior work, we have the first conclusion that the accu- racy will impr ove when applying our designed SCPs on each con volution kernel . For ImageNet dataset, pattern pruning improv es the top-5 accuracy of VGG-16 from 91 . 7% to 92 . 5% , and ResNet-50 from 92 . 7% to 93 . 0% with SCPs ap- plied to each conv olution k ernel. The accurac y impro vement is attributed to the enhanced image processing ability of our designed SCPs. Pruning vs. accuracy for non-structured pruning, structured pruning and PCONV . Combined with connec- tivity pruning , PCONV achie ves higher compression rate without accuracy compromise. Comparing with other prun- ing methods, i.e., non-structured pruning and structured pruning, we conclude that: (i) PCONV achiev es higher accu- racy and higher compression rate compared with prior non- structured pruning, and close to the results in ADMM-NN; (ii) compared with structured pruning, under the same com- pression rate, PCONV achieves higher accuracy , and can structurally prune more weights without hurting accuracy . The detailed comparisons on dif ferent sparsity and compres- sion rates are shown in Figure 4 PCONV Model C omputa tion g r aph la y er shape w eigh ts ker nel pa tt er n distr ibution c onnec tivit y inf or ma tion Filter kernel reorder Layerwise information extraction Load redundant elimination 4 Ex ecution c ode f or CPU/GPU Deploy on mobile device C ompac t model Guide AI Algorithm Optimization Platform x x x 1 2 3 4 x x 1 3 2 4 6 5 1 3 2 4 6 5 1 3 2 4 6 5 1 3 2 4 6 5 Load Kernel f o r ... : f o r ... : f o r ... : f o r ... : Figure 5: Overview of PCONV acceleration framework. From algorithm-lev el design to platform-level implementa- tion. Compiler -assisted DNN Inference Framework In this section, we propose our novel compiler-assisted DNN inference acceleration framew ork for mobile devices. Moti- vated by the two merits – fle xibility and regularity of the PCONV model, our compiler-assisted platform uniquely en- ables optimized code generation to guarantee end-to-end e x- ecution ef ficiency . As DNN’ s computation paradigm is in a manner of layerwise e xecution, we can conv ert a DNN model into computational graph, which is embodied by static C++ (for CPU execution) or OpenCL (for GPU execu- tion) code. The code generation process includes three steps as Figure 5 shows: (i) layerwise information extraction; (ii) filter kernel reorder; (iii) load redundancy elimination. Layerwise information extraction is a model analysis procedure. In particular , it analyzes detailed kernel pattern and connectivity-related information. Key information such as pattern distribution, pattern order and connection be- tween input/output channel through kernels are utilized by the compiler to perform optimizations in steps (ii) and (iii). Filter kernel reorder is designed to achieve the best of instruction-lev el and thread-lev el parallelism. When a PCONV model is trained, patterns and connections of all kernels are already known, i.e., the computation pattern is already fixed before deploying the model for inference. All these information of patterns are collected from layerwise information extraction, and is lev eraged by filter kernel re- order to (i) organize the filters with similar kernels together to improve inter-thr ead parallelism, and (ii) order the same kernels in a filter together to improve intra-thr ead paral- lelism. Figure 6 illustrates the two key steps of filter kernel reorder: (i) organizes similar filters next to each other; (ii) groups kernels with identical patterns in each filter together . As a result, the generated ex ecution code eliminates much of ex ecution branches, implying higher instruction-lev el paral- lelism; meanwhile, similar filter groups escalate execution similarity and result in a good load balance, achie ving better thread-lev el parallelism. Load redundancy elimination addresses the issue of ir- regular memory access that causes memory overhead. In DNN ex ecution, the data access pattern of input/output is de- cided by the (none-zero elements) patterns of kernels. There- 3 1 2 4 4 1 1 1 3 1 4 4 1 1 2 1 2 2 3 1 2 4 4 1 1 1 3 1 4 4 1 1 2 1 2 2 4 1 1 2 4 1 1 1 3 1 4 1 3 2 1 2 2 4 4 Organize filters Pattern pruned weights Group kernels kernels filters kernels filters kernels filters group 1 group 2 Figure 6: Steps of filter kernel reorder: each square repre- sents a conv olution kernel; the number represents the spe- cific pattern type of this kernel. fore, we can generate data access code with this informa- tion for each kernel pattern and call them dynamically dur- ing DNN ex ecution. Because the data access code consists of all information at kernel-le vel computation, it is possi- ble to directly access valid input data that is associated with the non-zero elements in a pattern-based kernel. After steps (i) and (ii), patterns are distributed in a structured manner , which reduces the calling frequency of data access code and as a result, reduces the memory ov erhead. Experimental Results In this section, we ev aluate the e xecution performance of our compiler-assisted framework with our PCONV model deployed. All of our ev aluation models are generated by ADMM pruning algorithm, and are trained on an eight NVIDIA R TX-2080T i GPUs server using PyT orch. Methodology In order to show acceleration of PCONV on mobile devices, we compare it with three state-of-art DNN inference accel- eration frame works, TFLite (T en ), TVM (Chen et al. 2018), and MNN (Ali ) using same sparse DNN models. Our e xper- iments are conducted on a Samsung Galaxy S10 cell phone with the latest Qualcomm Snapdragon 855 mobile platform that consists of a Qualcomm Kryo 485 Octa-core CPU and a Qualcomm Adreno 640 GPU. In our experiment, our generated PCONV models are based on three widely used network structures, VGG-16 (Si- monyan and Zisserman 2014), ResNet-50 (He et al. 2016) and MobileNet-v2 (Howard et al. 2017). Since con volution operation is most time-consuming (more than 95% of the total inference time) in DNN computation, our ev aluation on the above network structures focus on con volutional lay- ers performance. In order to pro vide a very clear illustration on how PCONV enhances mobile performance, the whole device-le vel ev aluation is sho wn in three aspects: (i) execu- tion time, (ii) on-de vice GFLOPS performance and (iii) ho w pattern counts affect performance. Perf ormance Evaluation In this part, we demonstrate our e valuation results on mobile device from the three aspects we discussed above. In order to illustrate PCONV has the best acceleration performance on mobile devices, our comparison baselines, i.e., TFLite, TVM and MNN use the fully optimized configurations (e.g., W inograd optimization is turned on). ImageNet CPU ImageNet GPU Cifar-10 GPU Cifar-10 CPU Cifar-10 GPU Cifar-10 CPU Cifar-10 GPU Cifar-10 CPU ImageNet GPU ImageNet GPU ImageNet CPU ImageNet CPU VGG-16 ResNet-50 MobileNet-v2 N/A GPU CPU 0 10 20 30 0 6 12 18 0 20 40 60 MNN TVM TFLITE PCONV 164 0 50 100 150 0 20 40 60 0 100 200 300 MNN TVM TFLITE PCONV 699 0 50 100 150 MNN TVM TFLITE PCONV 0 10 20 30 106.3 0 10 20 30 51 0 300 600 900 TFLITE MNN TVM PCONV 0 80 160 240 MNN TVM TFLITE PCONV 0 8 16 24 MNN TVM TFLITE PCONV Inference Time (ms) Inference Time (ms) 2.95 10.34 14.15 57.31 32.88 2.71 2.87 52.65 19.10 1 1.48 5.37 3.98 Figure 7: Mobile CPU/GPU inference time ( ms ) on dif ferent network structures inferring Cifar -10 and ImageNet images. Execution time. Figure 7 shows mobile CPU/GPU per- formance of PCONV model ex ecuting on our compiler- assisted DNN inference framew ork. On CPU, PCONV achiev es 9 . 4 × to 39 . 2 × speedup over TFLite, 2 . 2 × to 5 . 1 × speedup ov er TVM and 1 . 7 × to 6 . 3 × speedup over MNN. On GPU, PCONV achiev es 2 . 2 × to 18 . 0 × speedup over TFLite, 2 . 5 × to 11 . 4 × speedup ov er TVM and 1 . 5 × to 5 . 8 × speedup over MNN. For the largest DNN (VGG-16) and largest data set (ImageNet), our framew ork completes com- putations on a single input image within 19 . 1 ms (i.e., 52.4 frames/sec) on GPU, which meets the real-time requirement (usually 30 frames/sec, i.e., 33 ms /frame). On-device GFLOPS performance. From the previous comparison results we see that MNN has the higher per- formance than TVM and TFLite. T o show that PCONV has better throughput on mobile devices, we compare PCONV with MNN by measuring their run-time GFLOPS on both CPU and GPU. Figure 8 demonstrates layerwise GFLOPS performance comparison between PCONV and MNN. The 9 layers we pick from VGG-16’ s 13 con volutional layers are representing 9 unique layers with 9 unique layer sizes. The other 4 layers are omitted in Figure 8 because they have re- peated layer sizes which product repeated GFLOPS results. From the results we can see that for both CPU and GPU throughputs, PCONV outperforms MNN. Pattern counts vs. performance. In order to determine how pattern counts af fects e xecution performance, we de- sign some random patterns with 4 non-zero elements in one kernel alongside with our designed SCPs. T able 1 and T able 2 show accuracy and execution time under different pattern counts using VGG-16 on Cifar-10 and ImageNet datasets. The results show that the accuracy losses are not L1 L2 L3 L4 L5 L6 L7 L8 L9 0 50 100 150 CPU -M NN GPU-MN N GPU-Patter n CPU -P a tt e rn GFLOPS Figure 8: On-device GFLOPS performance ev aluation of MNN and PCONV . necessarily related to the increase of pattern counts, but the ex ecution performance drops quickly , especially on Ima- geNet dataset. The pattern counts vs. performance results prov e that our designed SCPs result in ideal performance with a negligible accurac y loss. T able 1: Pattern counts vs. performance. Evaluation uses model with pattern (2.25 × ) and connectivity (8.8 × ) sparsity on VGG-16 Cifar -10 dataset. T op-1 accuracy displayed. Dataset Pattern# Acc. (%) Acc. loss (%) Device Speed (ms) Cifar-10 4 93.8 -0.3 CPU 2.7 GPU 2.9 8 93.7 -0.2 CPU 2.9 GPU 3.0 12 93.8 -0.3 CPU 3.1 GPU 3.3 T able 2: Pattern counts vs. performance. Evaluation uses model with pattern (2.25 × ) and connectivity (3.1 × ) sparsity on VGG-16 ImageNet dataset. T op-5 accuracy displayed. Dataset Pattern# Acc. (%) Acc. loss (%) De vice Speed (ms) ImageNet 4 91.5 0.2 CPU 52.7 GPU 19.1 8 91.6 0.1 CPU 58.9 GPU 22.0 12 91.6 0.1 CPU 105.2 GPU 32.1 Conclusion This paper presents PCONV , a desirable sparsity type in DNN weight pruning that elicits mobile de vices accelera- tion, leading to real-time mobile inference. PCONV inherits the high fle xibility in non-structured pruning which helps achieving high accurac y and compression rate, and main- tains highly structured weight composition like structured pruning which leads to hardw are friendlinesses such as opti- mized memory access, balanced workload and computation parallelism etc. T o show PCONV ’ s real-time performance on mobile de vices, we design a compiler-assisted DNN inference framework, which can fully lev erage PCONV ’ s structural characteristics and achiev e very high inference speed on representativ e large-scale DNNs. References https://github .com/alibaba/MNN. Boticki, I., and So, H.-J. 2010. Quiet captures: A tool for cap- turing the evidence of seamless learning with mobile devices. In International Confer ence of the Learning Sciences-V olume 1 . Boyd, S.; Parikh, N.; Chu, E.; Peleato, B.; and Eckstein, J. 2011. Distributed optimization and statistical learning via the alternating direction method of multipliers. F oundations and T rends R in Ma- chine Learning 3(1):1–122. C.Blakemore, and Campbell, F . W . 1969. On the e xistence of neu- rones in the human visual system selectively sensitiv e to the ori- entation and size of retinal images. In The Journal of Physiology . The Physiological Society . Chen, T .; Moreau, T .; Jiang, Z.; Zheng, L.; Y an, E.; Shen, H.; Cow an, M.; W ang, L.; Hu, Y .; Ceze, L.; et al. 2018. TVM: An automated end-to-end optimizing compiler for deep learning. In OSDI . Dai, X.; Y in, H.; and Jha, N. K. 2017. Nest: a neural network synthesis tool based on a gro w-and-prune paradigm. arXiv preprint arXiv:1711.02017 . Freeman, W ., and Adelson, E. 1991. The design and use of steer- able filters. In IEEE T ransactions on P attern Analysis and Machine Intelligence , v olume 13, 891–906. IEEE. Goodfellow , I.; Bengio, Y .; Courville, A.; and Bengio, Y . 2016. Deep learning , volume 1. MIT press Cambridge. Han, S.; Mao, H.; and Dally , W . J. 2015. Deep compression: Com- pressing deep neural networks with pruning, trained quantization and huffman coding. arXiv pr eprint arXiv:1510.00149 . He, K.; Zhang, X.; Ren, S.; and Sun, J. 2016. Deep residual learn- ing for image recognition. In Pr oceedings of the IEEE Confer ence on Computer V ision and P attern Recognition , 770–778. He, Y .; Zhang, X.; and Sun, J. 2017. Channel pruning for acceler- ating very deep neural networks. In Computer V ision (ICCV), 2017 IEEE International Confer ence on , 1398–1406. IEEE. Hinton, G.; Deng, L.; and Y u, D. e. a. 2012. Deep neural netw orks for acoustic modeling in speech recognition: The shared views of four research groups. IEEE Signal Processing Magazine . How ard, A. G.; Zhu, M.; Chen, B.; Kalenichenko, D.; W ang, W .; W eyand, T .; Andreetto, M.; and Adam, H. 2017. Mobilenets: Ef fi- cient con volutional neural networks for mobile vision applications. arXiv pr eprint arXiv:1704.04861 . Hu, H.; Peng, R.; T ai, Y .-W .; and T ang, C.-K. 2016. Netw ork trimming: A data-dri ven neuron pruning approach to wards ef ficient deep architectures. arXiv preprint . Krizhevsk y , A.; Sutskever , I.; and Hinton, G. E. 2012. Ima- genet classification with deep con volutional neural networks. In NeurIPS . Lane, N. D.; Bhattacharya, S.; Georgie v , P .; Forli vesi, C.; and Kawsar , F . 2015. An early resource characterization of deep learn- ing on wearables, smartphones and internet-of-things devices. In International workshop on IO T towar ds applications . Liu, B.; W ang, M.; F oroosh, H.; T appen, M.; and Pensky , M. 2015. Sparse con volutional neural networks. In CVPR , 806–814. Luo, J.-H.; W u, J.; and Lin, W . 2017. Thinet: A filter lev el pruning method for deep neural network compression. In Pr oceedings of the IEEE international conference on computer vision , 5058–5066. Mairal, J.; Konius z, P .; Harchaoui, Z.; and Schmid, C. 2014. Con- volutional k ernel networks. In NeurIPS . Mao, H.; Han, S.; Pool, J.; Li, W .; Liu, X.; W ang, Y .; and Dally , W . J. 2017. Exploring the regularity of sparse structure in con vo- lutional neural networks. arXiv preprint . Parashar , A.; Rhu, M.; Mukkara, A.; Puglielli, A.; V enkatesan, R.; Khailany , B.; Emer, J.; Keckler , S. W .; and Dally , W . J. 2017. Scnn: An accelerator for compressed-sparse con volutional neural networks. In ISCA . Philipp, D.; Durr, F .; and Rothermel, K. 2011. A sensor net- work abstraction for flexible public sensing systems. In 2011 IEEE Eighth International Conference on Mobile Ad-Hoc and Sensor Systems , 460–469. IEEE. Ren, S.; He, K.; Girshick, R.; and Sun, J. 2015. F aster r-cnn: T owards real-time object detection with region proposal networks. In Advances in neural information processing systems , 91–99. Ren, A.; Zhang, T .; Y e, S.; Xu, W .; Qian, X.; Lin, X.; and W ang, Y . 2019. Admm-nn: an algorithm-hardware co-design framework of dnns using alternating direction methods of multipliers. In ASP- LOS . Selvaraju, R. R.; Cogswell, M.; Das, A.; V edantam, R.; P arikh, D.; and Batra, D. 2017. Grad-cam: V isual e xplanations from deep net- works via gradient-based localization. In Computer V ision (ICCV), 2019 IEEE International Confer ence on . IEEE. Simonyan, K., and Zisserman, A. 2014. V ery deep conv olu- tional networks for large-scale image recognition. arXiv preprint arXiv:1409.1556 . Siyuan, M.; Raef, B.; and Mikhail, B. 2018. The power of inter- polation: Understanding the effecti veness of sgd in modern over - parametrized learning. In 2018 International Conference on Ma- chine Learning (ICML) . A CM/IEEE. Springenberg, J. T ., and Alexe y Dosovitskiy , T . B. a. R. 2015. Striving for simplicity: The all con volutional net. In ICLR-2015 workshop trac k . https://www .tensorflo w .org/mobile/tflite/. W en, W .; Wu, C.; W ang, Y .; Chen, Y .; and Li, H. 2016. Learning structured sparsity in deep neural networks. In Advances in neural information pr ocessing systems , 2074–2082. Xu, M.; Zhu, M.; Liu, Y .; Lin, F . X.; and Liu, X. 2018. Deepcache: Principled cache for mobile deep vision. In Pr oceedings of the 24th Annual International Confer ence on Mobile Computing and Networking , 129–144. ACM. Y amins, D. L., and DiCarlo, J. J. 2016. Using goal-driv en deep learning models to understand sensory cortex. Nature neur oscience 19(3):356. Y ao, S.; Hu, S.; Zhao, Y .; Zhang, A.; and Abdelzaher, T . 2017. Deepsense: A unified deep learning frame work for time-series mo- bile sensing data processing. In Pr oceedings of the 26th Interna- tional Confer ence on W orld W ide W eb . Zhang, T .; Y e, S.; Zhang, K.; T ang, J.; W en, W .; Fardad, M.; and W ang, Y . 2018. A systematic dnn weight pruning frame work using alternating direction method of multipliers. In Pr oceedings of the Eur opean Conference on Computer V ision (ECCV) , 184–199. Zhang, R. 2019. Making conv olutional networks shift-in variant again. In ICML .
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment