MLPerf 훈련 벤치마크: 딥러닝 성능 평가의 새로운 표준
MLPerf 훈련 벤치마크는 딥러닝 학습의 품질·성능·재현성을 동시에 측정하도록 설계된 산업 표준이다. 최적화가 정확도에 미치는 영향, 대규모 분산 학습 시 배치 크기와 학습률의 상호작용, 실행마다 달라지는 stochastic 변동성, 그리고 다양한 프레임워크·하드웨어 환경을 모두 고려한다. 7개의 대표 워크로드와 품질 임계값, 엄격한 타이밍 규칙, 공개 레퍼런스 구현을 통해 공정한 비교를 가능하게 하며, 두 차례의 베팅 라운드에서 다수 벤더의…
저자: Peter Mattson, Christine Cheng, Cody Coleman
MLPerf 훈련 벤치마크 논문은 딥러닝 학습 성능을 공정하고 재현 가능하게 측정하기 위한 산업 표준을 제시한다. 서론에서는 딥러닝이 컴퓨터 비전, 자연어 처리, 음성 인식, 강화학습 등 다양한 분야를 혁신했으며, 그에 따라 대규모 DNN 모델을 학습하기 위한 하드웨어·소프트웨어 투자가 급증했음을 강조한다. 기존 벤치마크(SPEC, TPC 등)는 정형화된 작업을 측정하는 데 초점을 맞추었지만, 딥러닝 학습은 최적화가 정확도와 직접 연결되는 복합적인 특성을 가진다. 따라서 MLPerf은 이러한 특성을 반영한 설계 목표 다섯 가지(공정 비교, 혁신 촉진, 재현성 보장, 상업·연구 커뮤니티 지원, 비용 효율성)를 정의한다.
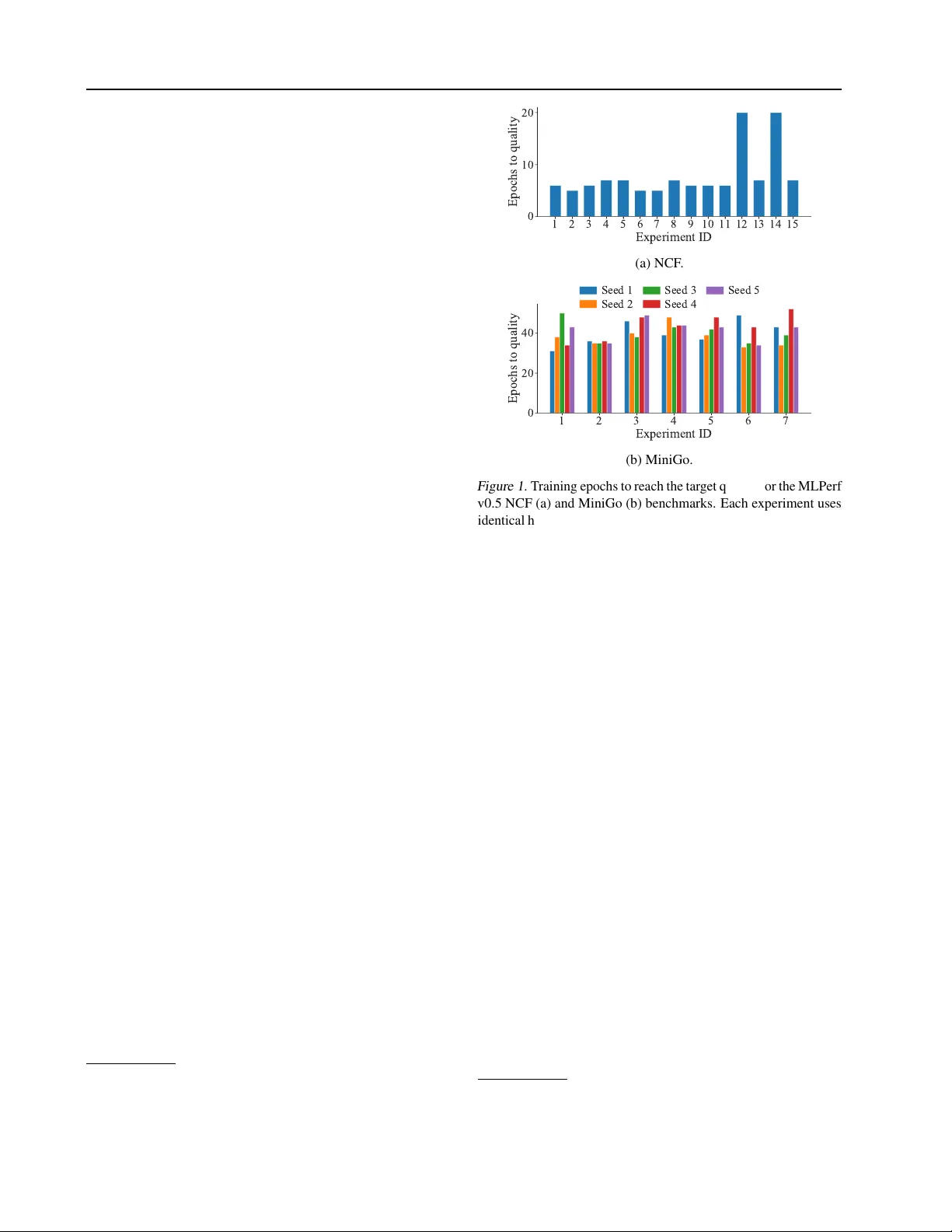
2장에서는 딥러닝 학습 벤치마크가 직면한 네 가지 고유 도전을 상세히 논의한다. 첫째, 최적화가 처리량을 높이면서도 정확도에 부정적 영향을 줄 수 있다. 저정밀 연산, 레이어 융합 등은 초기 학습 단계에서는 차이를 보이지 않지만, 최종 정확도에서 격차가 나타난다. 둘째, 대규모 분산 학습에서는 배치 크기와 학습률을 조정해야 하며, 이는 수렴 속도와 전체 연산량을 변화시킨다. 예시로 ResNet‑50 v0.5는 4K 배치에서 64에포크, 16K 배치에서는 80에포크가 필요해 연산량이 30 % 증가한다. 셋째, 딥러닝은 무작위 초기화·데이터 셔플·비동기 업데이트 등으로 실행마다 결과가 달라지는 run‑to‑run 변동성이 크다. 논문은 이를 완화하기 위해 동일 시드·다중 실행·통계적 신뢰구간을 제시한다. 넷째, 다양한 프레임워크와 라이브러리(예: cuDNN, TensorFlow, PyTorch) 사이의 연산 구현 차이와 수치 오차가 존재한다. 같은 수학적 연산이라도 알고리즘 선택·블록 크기·패딩 방식 등에 따라 결과가 미세하게 달라진다.
3장에서는 MLPerf 훈련 벤치마크 스위트를 소개한다. 총 7개의 워크로드가 선정되었으며, 각각 이미지 분류(ImageNet‑ResNet‑50), 경량 객체 검출(COCO‑SSD‑ResNet‑34), 무거운 객체 검출·인스턴스 세그멘테이션(COCO‑Mask‑RCNN), 추천(NCF), 강화학습(MiniGo) 등 다양한 도메인을 포괄한다. 각 워크로드는 실용적인 데이터셋과 산업 수준의 품질 임계값(예: Top‑1 74.9 %, mAP 21.2 %)을 정의한다. 타이밍 규칙은 “시간‑to‑accuracy” 방식으로, 목표 정확도에 최초 도달한 시점을 측정한다. 이를 위해 학습 시작 시점·정확도 검증 시점·종료 시점을 명확히 규정하고, 변동성을 최소화하기 위해 동일 하이퍼파라미터·시드·평가 주기를 강제한다.
4장에서는 제출·검증·보고 절차를 설명한다. Closed Division은 레퍼런스 구현과 동일한 연산 흐름·하이퍼파라미터를 사용하도록 강제해 하드웨어·소프트웨어 최적화만을 비교한다. Open Division은 자유로운 최적화를 허용하지만, 동일 품질 목표와 타이밍 규칙을 준수해야 한다. 모든 제출 코드는 오픈소스로 공개돼 재현성을 확보한다. 검증 단계에서는 정확도·시간·리소스 사용량을 자동화된 파이프라인으로 검증하고, 결과는 MLPerf 웹사이트에 투명하게 공개한다.
5·6장은 두 차례의 베팅 라운드(버전 0.5와 1.0) 결과를 분석한다. 첫 라운드에서는 주로 GPU 기반 시스템이 참여했으며, 평균 1.8배의 성능 향상이 관찰되었다. 두 번째 라운드에서는 ASIC(A100, TPU v4)과 대규모 클러스터가 추가돼 평균 2.3배의 향상이 기록되었다. 특히 대규모 분산 학습에서 배치 크기를 4배 확대하고, 학습률 스케줄링을 최적화한 사례가 시간‑to‑accuracy를 50 % 이상 단축했다. 벤치마크는 이러한 개선이 단순 하드웨어 성능 상승이 아니라, 소프트웨어 스택·알고리즘·하이퍼파라미터 튜닝의 복합 효과임을 강조한다.
마지막으로 미래 작업을 제시한다. 새로운 모델(Transformer 기반 NLP, 3D 비전, 멀티‑모달)과 데이터셋을 추가해 스위트를 확장하고, 에너지 효율·탄소 배출량 측정 항목을 도입해 지속 가능한 AI 평가 체계를 구축한다. 또한, 자동화된 하이퍼파라미터 탐색·베이즈 최적화 등을 벤치마크에 통합해 최적화 연구를 촉진한다.
결론적으로, MLPerf 훈련 벤치마크는 딥러닝 학습의 복합적인 품질·성능·재현성 요구를 충족시키는 최초의 포괄적 표준이며, 산업·학계 전반에 걸친 공정한 비교와 혁신 가속화를 실현한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기