MLPerf Training Benchmark
Machine learning (ML) needs industry-standard performance benchmarks to support design and competitive evaluation of the many emerging software and hardware solutions for ML. But ML training presents three unique benchmarking challenges absent from o…
Authors: Peter Mattson, Christine Cheng, Cody Coleman
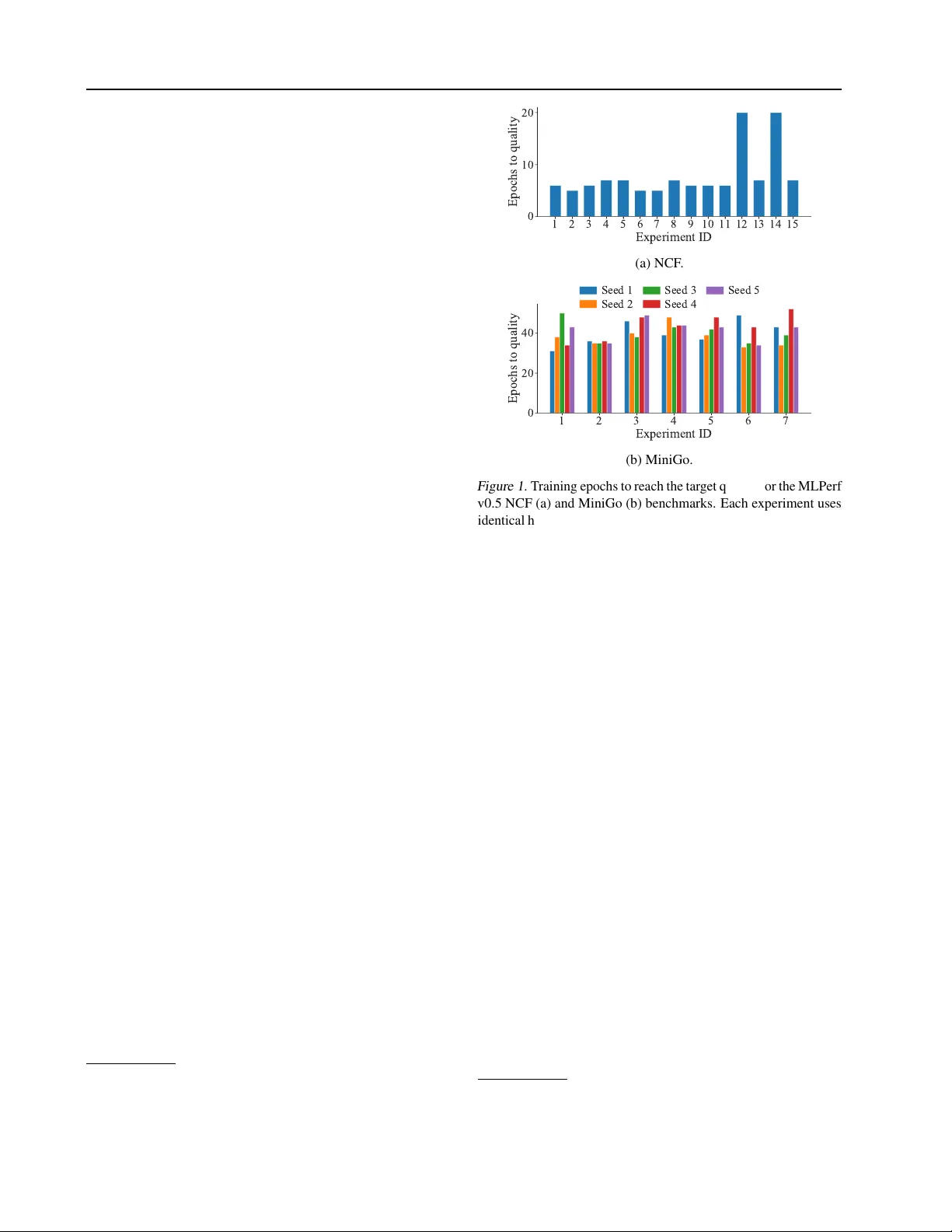
M L P E R F T R A I N I N G B E N C H M A R K Peter Mattson 1 Christine Cheng 2 Cody Coleman 3 Greg Diamos 4 Paulius Micike vicius 5 David P atterson 1 6 Hanlin T ang 2 Gu-Y eon W ei 7 Peter Bailis 3 V ictor Bittorf 1 David Br ooks 7 Dehao Chen 1 Debojyoti Dutta 8 Udit Gupta 7 Kim Hazelwood 9 Andrew Hock 10 Xinyuan Huang 8 Atsushi Ike 11 Bill Jia 9 Daniel Kang 3 David Kanter 12 Nav een Kumar 1 Jeffery Liao 13 Guokai Ma 2 Deepak Narayanan 3 T ayo Oguntebi 1 Gennady Pekhimenk o 14 15 Lillian Pentecost 7 V ijay Janapa Reddi 7 T aylor Robie 1 T om St. John 16 Tsuguchika T abaru 11 Carole-J ean W u 9 Lingjie Xu 17 Masafumi Y amazaki 11 Cliff Y oung 1 Matei Zaharia 3 A B S T R AC T Machine learning (ML) needs industry-standard performance benchmarks to support design and competitiv e ev aluation of the many emer ging software and hardware solutions for ML. But ML training presents three unique benchmarking challenges absent from other domains: optimizations that improve training throughput can increase the time to solution, training is stochastic and time to solution exhibits high variance, and software and hardw are systems are so di verse that fair benchmarking with the same binary , code, and even h yperparameters is difficult. W e therefore present MLPerf, an ML benchmark that overcomes these challenges. Our analysis quantitatively ev aluates MLPerf ’ s ef ficac y at dri ving performance and scalability impro vements across tw o rounds of results from multiple vendors. 1 I N T R O D U C T I O N Machine learning (ML) has re volutionized numerous do- mains, including computer vision ( Krizhevsk y et al. , 2012 ), language processing ( Devlin et al. , 2018 ; Radford et al. , 2019 ), speech recognition ( Hinton et al. , 2012 ), and gam- ing ( Silver et al. , 2018 ; Mnih et al. , 2013 ; Chan , 2018 ). Much of this progress o wes to deep learning (DL), which in- volv es training of lar ge deep-neural-netw ork (DNN) models on massive data sets. T o keep up with this growing com- putational demand, hardware and software systems hav e garnered sizable in vestments ( Amodei & Hernandez , 2018 ). As the number of hardware and software systems for DL training increases ( Paszke et al. , 2017 ; Abadi et al. , 2016 ; Chen et al. , 2015 ; Jia et al. , 2014 ; Jouppi et al. , 2017 ; Chen et al. , 2018 ; Markidis et al. , 2018 ; Intel , 2019 ), so does the need for a comprehensi ve benchmark. History shows that benchmarks accelerate progress ( Hennessy & Patterson , 2011 ); for example, breakthroughs in microprocessor and relational-database systems in the 1980s inspired industry consortiums to create Standar d P erformance Evaluation 1 Google 2 Intel 3 Stanford University 4 Landing AI 5 NVIDIA 6 Univ ersity of California, Berkeley 7 Harvard University 8 Cisco 9 Facebook 10 Cerebras 11 Fujitsu 12 Real W orld T echnologies 13 Synopsys 14 Univ ersity of T oronto 15 V ector Institute 16 T esla 17 Alibaba. Correspondence to: Peter Mattson < petermatt- son@google.com > . Pr oceedings of the 3 rd MLSys Conference , Austin, TX, USA, 2020. Copyright 2020 by the author(s). Corporation (SPEC) for Unix servers ( Dixit , 1991 ) and the T ransaction Pr ocessing P erformance Council (TPC) for transaction processing and databases ( Council , 2005 ). These organizations helped de velop and maintain benchmarks that their respectiv e communities then embraced. Their success inspired the formation of MLPerf, a consortium of commer- cial and academic organizations, to design a comprehensive benchmark suite for DL. Unlike other computational w orkloads, DL allows a range of statistical, hardware, and software optimizations that can change the mathematical semantics of the underlying opera- tors. Although these optimizations can boost performance (i.e., training speed), some change the learning dynamics and affect the final model’ s quality (i.e., accuracy). Even accommodating different system scales (e.g., varying the number of chips) requires changing hyperparameters, po- tentially af fecting the amount of computation necessary to reach a particular quality target. By contrast, other com- pute benchmarks can ev aluate systems through targeted microbenchmarks. DL is also intrinsically approximate and stochastic, allo w- ing multiple equally correct solutions—unlike conv entional computing, which tends to allow just one correct solution. As a result, implementations and training times can v ary while the final quality remains the same. Since it is ap- proximate, DL requires careful definition of equally valid solution classes and the appropriate degrees of freedom. Prior work has varied in granularity but has either left the MLPerf T raining Benchmark abov e challenges unaddressed or lacked critical w orkloads representativ e of modern ML. Microbenchmarks such as DeepBench ( Baidu , 2017 ) are af fordable to run and enable a fair comparison of competing systems by isolating hardware and software from statistical optimizations, b ut they fail to reflect the complexity of real workloads and have limited utility . Although throughput benchmarks like F athom and TBD ( Adolf et al. , 2016 ; Zhu et al. , 2018 ; Google , 2017 ) ev aluate full model architectures across a broad range of tasks to better reflect the diversity and complexity of real workloads, they limit model architecture and training innov a- tions that advance the state-of-the-art. DA WNBench ( Cole- man et al. , 2017 ) measures end-to-end training time, subject to a quality threshold (i.e., time to train), and it accommo- dates innov ativ e solutions (i.e., new model architectures and training techniques, such as progressive resizing and cyclic learning rates). It additionally collects source code to promote reproducibility . D A WNBench’ s flexibility , how- ev er, also made it dif ficult to dra w f air comparisons between hardware and software platforms. MLPerf builds on the strengths of prior work; it combines a broad set of bench- marks like Fathom or TBD, an end-to-end training metric like D A WNBench, and the backing of a broad consortium like SPEC. MLPerf aims to create a representativ e benchmark suite for ML that fairly ev aluates system performance to meet fiv e high-lev el goals: • Enable fair comparison of competing systems while still encouraging ML innov ation. • Accelerate ML progress through f air and useful mea- surement. • Enforce reproducibility to ensure reliable results. • Serve both the commercial and research communities. • Keep benchmarking ef fort affordable so all can partici- pate. This paper focuses on the design and rationale for the MLPerf Training benchmark (a related MLPerf Inference benchmark is beyond the present scope). Although prior ML benchmarking efforts ( Coleman et al. , 2017 ; Adolf et al. , 2016 ; Google , 2017 ; Baidu , 2017 ; Zhu et al. , 2018 ) each contributed to meeting one or more of the abo ve goals, we created MLPerf to address all of them holistically , build- ing on the lessons learned from these efforts. T o this end, MLPerf T raining does the following: • Establish a comprehensi ve benchmark suite that co vers div erse applications, DNN models, and optimizers. • Create reference implementations of each benchmark to precisely define models and training procedures. • Establish rules that ensure submissions are equi valent to these reference implementations and use equiv alent hyperparameters. • Establish timing rules to minimize the effects of stochasticity when comparing results. • Make submission code open source so that the ML and systems communities can study and replicate the results. • Form w orking groups to keep the benchmark suite up to date. The rest of the paper is organized as follows. In § 2 , we dis- cuss the main challenges to benchmarks for DL training, as well as related prior work. In § 3 , we re view the benchmarks in our suite, the time-to-train metric, and quality thresholds. In § 4 , we describe the submission, revie w , and reporting of results for the various cate gories. Finally , in § 5 and § 6 , we revie w progress between the first two MLPerf benchmarking rounds, along with future work directions. 2 B AC K G R O U N D W e begin by describing in § 2.1 the unique challenges of benchmarking ML relative to other compute tasks ( Don- garra , 1988 ; Council , 2005 ) and then revie w prior ML- benchmarking efforts in § 2.2 . 2.1 Unique Challenges of Benchmark T raining ML benchmarking faces unique challenges relativ e to other compute benchmarks, such as LINP A CK ( Dongarra , 1988 ) and SPEC ( Dixit , 1991 ), that necessitate an end-to-end ap- proach. After an ML practitioner selects a data set, opti- mizer , and DNN model, the system trains the model to its state-of-the-art quality (e.g., T op-1 accuracy for image clas- sification). Provided the system meets this requirement, the practitioner can make dif ferent operation, implementation, and numerical-representation choices to maximize system performance —that is, how f ast the training executes. Thus, an ML performance benchmark must ensure that systems under test achiev e state-of-the-art quality while providing sufficient flexibility to accommodate different implemen- tations. This tradeoff between quality and performance is challenging because multiple factors af fect both the final quality and the time to achiev e it. 2.1.1 Effect of Optimizations on Quality Although many optimizations immediately improve tradi- tional performance metrics such as throughput, some can decrease the final model quality , an effect that is only observ- able by running an entire training session. For example, the accuracy dif ference between single-precision training and MLPerf T raining Benchmark lower -precision training only emerges in later epochs ( Zhu et al. , 2016 ). Across se veral representation and training choices, the validation-error curv es may only separate after tens of epochs, and some numerical representations nev er match the final validation error of full-precision training (lower validation error directly corresponds to higher ac- curacy: accuracy = 1 − error validation ). Thus, ev en though microbenchmarks ( Baidu , 2017 ; Chetlur et al. , 2014 ) can assess an optimization’ s performance impact, a complete training session is necessary to determine the quality impact and whether the model achie ves the desired accurac y . Ow- ing to the introduction of systems with varying numerics ( Abadi et al. , 2016 ; Banner et al. , 2018 ; Kster et al. , 2017 ; Micike vicius et al. , 2018 ) and performance optimizations, ML benchmarks must include accuracy metrics. 2.1.2 Effect of Scale on T ime to T rain ML training on large distributed systems with many pro- cessors typically in volv es data parallelism and large mini- batches to maximize system utilization and minimize train- ing time. In turn, these large minibatches require ad- justments to optimizer parameters, such as the learning rate ( Krizhevsk y , 2014 ; Goyal et al. , 2017 ). T ogether, these changes affect the learning dynamics and can alter the num- ber of iterations required to achieve the target accurac y . For example, MLPerf v0.5 ResNet-50 takes about 64 epochs to reach the target T op-1 accurac y of 74.9% at a minibatch size of 4K, 1 whereas a minibatch size of 16K can require more than 80 epochs to reach the same accuracy , increasing computation by 30%. Larger minibatches, ho wev er , per- mit efficient scaling to lar ger distributed systems, reducing the time to train the model. The tradeoffs between system size, minibatch size, and learning dynamics present another challenge for a DL-focused performance benchmark. 2.1.3 Run-to-Run V ariation DNN training in volv es many stochastic influences that man- ifest in substantial run-to-run variation ( Choromanska et al. , 2015 ; Gori & T esi , 1992 ; Auer et al. , 1996 ; Coleman et al. , 2019 ). Different training sessions for the same model us- ing the same hyperparameters can yield slightly different accuracies after a fixed number of epochs. Alternativ ely , different training sessions can take a dif ferent number of epochs to reach a gi ven target accuracy . For e xample, Fig- ure 1 shows the number of epochs needed to reach target accuracy for two MLPerf v0.5 benchmarks using reference implementations and default batch sizes. Sev eral factors contribute to this variation, such as application behavior (e.g., random weight initialization and random data trav er- sal) and system characteristics (e.g., profile-driven algorithm 1 Source: MLPerf v0.5 results ( https://mlperf.org/ training- results- 0- 5 ). 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 Experiment ID 0 10 20 Epochs to quality (a) NCF . 1 2 3 4 5 6 7 Experiment ID 0 20 40 Epochs to quality Seed 1 Seed 2 Seed 3 Seed 4 Seed 5 (b) MiniGo. Figure 1. T raining epochs to reach the target quality for the MLPerf v0.5 NCF (a) and MiniGo (b) benchmarks. Each experiment uses identical hyperparameters e xcept for the random seed. F or MiniGo, we observed considerable variability across runs e ven when fixing the random seed (same color). selection and the non-commutati ve nature of floating-point addition). Large distrib uted-training tasks can inv olve asyn- chronous updates, altering the gradient-accumulation order . These variations make it hard to reliably compare system performance. 2.1.4 Diverse Softwar e Multiple ML software framew orks hav e emerged, each of which ex ecutes similar b ut distinct computations o wing to vari ous implementations and constraints ( Abadi et al. , 2016 ; Paszke et al. , 2017 ; Chen et al. , 2015 ; Jia et al. , 2014 ). Software frame works and the underlying math libraries em- ploy dif ferent algorithms to implement the same operation. For example, con volutional and fully connected layers— two compute-intensi ve operators pre valent in modern DNN models—typically use cache blocking to exploit processor memory hierarchies. Different block sizes and processing orders (which optimize for dif ferent hardware), although algebraically equiv alent, yield slightly diver gent results. In addition, operators can execute using v arious algorithms. For e xample, con volution layers can be executed using a v a- riety of algorithms, including GEMM-based and transform- based (e.g., FFT or Winograd) v ariants. In fact, the cuDNN v7.6 library provides roughly 10 algorithms for the forward pass of a con volutional layer , 2 some of which vary in tiling 2 Source: cuDNN ( https://docs.nvidia.com/ deeplearning/sdk/cudnn- developer- guide ). MLPerf T raining Benchmark or blocking choices depending on the hardware. Although mathematically equi valent, dif ferent implementations will produce dif ferent numerical results, as floating-point repre- sentations hav e finite precision. Additionally , framew orks occasionally implement the same function in mathematically different ways. For example, modern training framew orks implement stochastic gradient descent with momentum in two ways: momentum = α · momentum + η · ∂ L ∂ w w = w − momentum (1) momentum = α · momentum + ∂ L ∂ w w = w − η · momentum (2) The Caffe frame work ( Jia et al. , 2014 ) implements the first approach, whereas PyT orch ( Paszk e et al. , 2017 ) and T ensor- Flow ( Abadi et al. , 2016 ) implement the second. These ap- proaches dif fer mathematically if the learning rate η changes during training—a common technique. Although this differ - ence is tiny in many cases, it can hinder training con ver gence for larger minibatches. V ariations also arise owing to the frame works’ programming interface. For example, PyT orch and T ensorFlow interpret asymmetric padding dif ferently , complicating the task of porting model weights between them. Data-augmentation pipelines across framew orks can also apply image augmen- tations (e.g., crop, zoom, and rotation) in different orders. Although ONNX ( Bai et al. , 2019 ), TVM ( Chen et al. , 2018 ), and similar emerging tools enable interoperability of model architectures across framew orks, their support re- mains limited. Moreov er , ML systems in volv e a range of optimizations that extend beyond the model architecture, such as preprocessing, precision, and communication meth- ods. Benchmarks must accommodate the wide div ersity of deployed systems despite this lack of a standard w ay to specify ev ery training aspect. 2.2 Prior W ork Prior ML benchmarks vary in granularity and scope. Mi- crobenchmarks such as DeepBench ( Baidu , 2017 ) measure kernel-le vel operations that appear in commonly deployed models. Benchmarking such low-le vel operations fails to address the challenges associated with numerical precision, hyperparameter choices, and system scale, which we de- scribed in the previous section. Furthermore, it neither cap- tures the end-to-end application, nor accounts for memory- and cache-hierarchy effects across layers and operations, nor measures the data preprocessing that deep learning com- monly employs. Sev eral benchmarks are defined at the granularity of entire DNN models. Fathom and Google TF Benchmarks ( Adolf et al. , 2016 ; Google , 2017 ) provide a reference suite of DNN models that span a wide application space, but they specifically measure model throughput and fail to account for accuracy . Similarly , TBD (Training Benchmarks for DNNs) ( Zhu et al. , 2018 ) profiles training on GPUs (b ut not other architectures) across diverse workloads, measuring characteristics such as memory and hardware utilization. Our benchmark builds on the div ersity of applications in these projects while also capturing the quality and perfor- mance tradeoffs. D A WNBench ( Coleman et al. , 2017 ) was the first multi- entrant benchmark competition to use “time to train” (orig- inally called time to accuracy) to measure the end-to-end performance of deep-learning systems; it allowed optimiza- tions across model architectures, optimization procedures, software frame works, and hardware platforms. Our bench- mark follo ws a similar approach b ut handles more-di verse tasks ( § 3.1 ), and it uses important rules and mechanisms in the Closed di vision ( § 4.2.1 ) to enable fair comparisons of hardware and software systems. Sev eral other benchmarks are under de velopment. AI Matrix measures workloads at dif ferent granularities (microbench- marks, layer-wise benchmarks, end-to-end model bench- marks, and synthetic benchmarks) ( aim ). Deep500, al- though not a benchmark, provides a software framew ork for measuring DL-training performance ( Ben-Nun et al. , 2019 ). 3 M L P E R F T R A I N I N G B E N C H M A R K W e now present the MLPerf T raining benchmark, detailing the workloads ( § 3.1 ), timing rules ( § 3.2 ), quality-threshold choices ( § 3.3 ), and reference implementations and hyper - parameters ( § 3.4 ). 3.1 Benchmark Suite T o create a fair and useful benchmark suite for modern ML workloads, we curated a representativ e set of tasks from several major ML areas, including vision, language, recommendation, and reinforcement learning. Our selec- tion of benchmarks was primarily based on commercial and research relev ance, representing div erse compute mo- tifs. T o establish relev ance, we relied on feedback from the tens of commercial and academic or ganizations that support MLPerf. T o keep the suite affordable, we selected a com- pact but representati ve set of se ven benchmarks, which we describe belo w and summarize in T able 1 . Although these benchmarks already cov er a wide range of research and industrial tasks, we are continuously exploring additional ones to keep the suite rele vant to the ML community ( § 6 ). MLPerf T raining Benchmark T able 1. MLPerf Training v0.5 benchmarks. Benchmark Data set Model Quality Threshold Image classification ImageNet ( Deng et al. , 2009 ) ResNet-50 v1.5 ( MLPerf , 2019b ) 74.9% T op-1 accuracy Object detection (lightweight) COCO 2017 ( Lin et al. , 2014 ) SSD-ResNet-34 ( Liu et al. , 2016 ) 21.2 mAP Instance segmentation and object detection (heavyweight) COCO 2017 ( Lin et al. , 2014 ) Mask R-CNN ( He et al. , 2017a ) 37.7 Box min AP , 33.9 Mask min AP T ranslation (recurrent) WMT16 EN-DE ( WMT , 2016 ) GNMT ( W u et al. , 2016 ) 21.8 Sacre BLEU T ranslation (nonrecurrent) WMT17 EN-DE ( WMT , 2017 ) T ransformer ( V aswani et al. , 2017 ) 25.0 BLEU Recommendation MovieLens-20M ( GroupLens , 2016 ) NCF ( He et al. , 2017b ) 0.635 HR@10 Reinforcement learning Go (9x9 Board) MiniGo ( MLPerf , 2019a ) 40.0% Professional mov e prediction 3.1.1 Image Classification Image classification is the most common task for ev aluat- ing ML-system performance ( Coleman et al. , 2017 ; Adolf et al. , 2016 ; Zhu et al. , 2018 ; Goyal et al. , 2017 ; Jia et al. , 2018 ; Mikami et al. , 2018 ; Y ing et al. , 2018 ; Google , 2017 ; Narayanan et al. , 2019 ). A classifier selects a class that best describes the contents of a giv en image. Classification model architectures also serve as feature extractors for many other computer -vision workloads, including object detec- tion, captioning, and style transfer . W e use the ILSVRC 2012 ImageNet classification data set, consisting of 1.28 million training images and 50,000 v alidation images ( Deng et al. , 2009 ). Our model-quality metric is the T op-1 accurac y on the validation set. ResNet-50 is a residual network ( He et al. , 2016a ; b ); such networks and their deriv atives remain the state of the art in image classification, and system studies commonly use them ( Goyal et al. , 2017 ; Jia et al. , 2018 ; Mikami et al. , 2018 ; Y ing et al. , 2018 ; Sun et al. , 2019 ). Several slightly different ResNet-50 implementations appear in training- framew ork repositories, preventing comparison of earlier system-performance claims because of model differences. T o ensure meaningful system comparison, MLPerf uses the ResNet-50 v1.5 model, which performs addition after batch normalization, omits 1 × 1 con volution from the skip connec- tion of the first residual block, and applies downsampling by the 3 × 3 con volutions. MLPerf also specifies the appro- priate parameter initialization, optimizer schedule, and data augmentation. 3.1.2 Object Detection and Se gmentation Object detection and segmentation are crucial components of man y industrial systems for robotics, autonomous driving, video analytics, and social networks. Object detection is a regression task as opposed to a classification task: it returns bounding-box coordinates for objects in a gi ven image. Seg- mentation assigns an object class to each input-image pixel. Although pretrained image-classification models commonly serve as the backbone (feature extractor) for DNN object de- tectors and segmenters, these DNN tasks dif fer from image classification in their compute characteristics. Examples include additional layer types (upscaling, R OIalign, NMS, and sorting); moreover , the inputs have greater resolution. MLPerf uses the 2017 COCO data set ( Lin et al. , 2014 ) consisting of 118,000 training images and 5,000 validation images. Model-quality measurement uses mAP for both detection and segmentation. Mask R-CNN ( He et al. , 2017a ) is a popular object- detection and instance-segmentation model for images. It has two stages: the first proposes regions of interest, and the second processes them to compute bounding boxes and segmentation masks. Mask R-CNN provides high-accuracy results for these tasks, but at the cost of higher latency as well as greater compute and memory requirements. The benchmark training uses images resized to 800 pix els on the shorter side and employs ResNet-50 as the backbone. Single Shot Detection (SSD) ( Liu et al. , 2016 ) serves in real-time applications that require low-latency solutions. These applications include autonomous driving, robotics, and video analytics. Compared with Mask R-CNN ( Huang et al. , 2016 ) and other two-stage solutions, SSD trades speed for accurac y . Instead of full images, training uses 300 × 300 MLPerf T raining Benchmark crops. W e chose a ResNet-34 backbone to represent current real-time applications. ResNet-34 has a different residual- block structure than ResNet-50, increasing the di versity of computational motifs that MLPerf cov ers. 3.1.3 T ranslation Neural machine translation conv erts a sequence of words from the source language to a target language; many indus- trial applications employ this technology . As is common in translation research, we use the WMT English-to-German (EN-DE) data set ( WMT , 2017 ), which contains about 4.5 million sentence pairs. Our model-quality metric is the Bilingual Evaluation Understudy Score (Bleu) score on the Newstest2014 test set. W e include two translation bench- marks to account for the two model architectures that trans- lation and other sequence-data tasks often employ . T ransformer ( V asw ani et al. , 2017 ) is an attention-based model that achieves state-of-the-art language-translation quality . It consists of an encoder and decoder, each being a stack of six blocks. Every block comprises a multihead attention layer and point-wise fully connected layers. GNMT ( W u et al. , 2016 ) is a recurrent neural network (RNN) for language translation. Even though it achie ves lower accuracy than T ransformer on the WMT English-to- German data set, it appears in the suite to represent RNN applications. These applications span numerous tasks, but language-translation data sets and publications are more common, enabling clearer system comparison. GNMT is the suite’ s only RNN. It consists of an eight-layer encoder and an eight-layer decoder, each using 1,024 LSTM cells with skip connections. 3.1.4 Reinfor cement Learning Reinforcement learning (RL) is responsible for the recent dramatic increase in compute demand ( Amodei & Hernan- dez , 2018 ), and it serves in control systems. RL algorithms can train agents (which includes neural networks) that riv al humans at video games, go, and chess—major milestones in machine learning ( Silv er et al. , 2018 ; Mnih et al. , 2013 ; Chan , 2018 ). RL has a different computational profile than the other ML benchmarks: it generates training data through exploration instead of relying on a predetermined data set. MiniGo ( MLPerf , 2019a ), inspired by AlphaGo ( Silver et al. , 2016 ; 2017 ; 2018 ), trains a single model that rep- resents both value and policy functions for a 9 × 9 game board. T raining uses self-play (simulated games) between agents to generate data; rather than using a simulator, it performs many forward passes through the model to gener - ate actions. W e chose MiniGo to keep MLPerf more ML oriented, since many other RL problems employ simulators (physics, video-game en vironments, etc.) to generate data, spending most of their time in computations unrelated to ML. T o measure quality , we calculate the percentage of predicted mov es that match human reference games. 3.1.5 Recommendation Recommendation systems are a major commercial workload for Internet companies ( Naumov et al. , 2019 ; Zhou et al. , 2018 ; Cheng et al. , 2016 ). These workloads are character- ized by large embedding tables follo wed by linear layers. Neural collaborative filtering (NCF) ( He et al. , 2017b ) was our choice for the benchmark. It is trained to predict user-item interactions. More so than for other tasks, this recommender’ s compute characteristics depend on the data set. For e xample, the data set defines the embedding-table size as well as the memory-access patterns. Thus, a repre- sentativ e data set is crucial to a representativ e benchmark. Unfortunately , howe ver , public data sets tend to be orders of magnitude smaller than industrial data sets. Although MLPerf v0.5 adopted the Mo vieLens-20M data set ( Grou- pLens , 2016 ) for its NCF benchmark, v0.7 will employ a synthetically generated data set and benchmark while re- taining the characteristics of the original data ( Belletti et al. , 2019 ) 3.2 Time-to-T rain Perf ormance Metric T o address the ML-benchmarking challenges of system op- timization and scale that we outlined in § 2.1.1 and § 2.1.2 , MLPerf’ s performance metric is the time to train to a defined quality target. It incorporates both system speed and accu- racy and is most rele vant to ML practitioners. As an end-to- end metric, it also captures the auxiliary operations neces- sary for training such models, including data-pipeline and accuracy calculations. The metric’ s generality enables ap- plication to reinforcement learning, unsupervised learning, generati ve adversarial netw orks, and other training schemes. T ime to train ov ercomes the challenges in § 2.1.1 and § 2.1.2 by pre venting submissions from using quality-reducing op- timizations while still allo wing for extensi ve system-scale and software-en vironment flexibility . 3.2.1 T iming Rules W e chose the timing requirements to ensure fair system comparisons and to represent various training use cases. T iming begins when the system touches any training or validation data, and it stops when the system achiev es the defined quality target on the v alidation data set. W e exclude from timing se veral components that can carry substantial overhead and that are unrepresentativ e of real- world dif ferences. System initialization. Initialization, especially at large MLPerf T raining Benchmark scales, v aries on the basis of cluster -administrator choices and system-queue load. For example, it may in volve run- ning diagnostics on each node before starting the training job . Such overheads are unindicati ve of a system’ s training capability , so we exclude them from timing. Model creation and initialization. Some frame works can compile the model graph to optimize subsequent execution. This compilation time is insignificant for the longer train- ing sessions when using industry-scale data sets. MLPerf, howe ver , uses public data sets that are usually much smaller than industry ones. Therefore, large distributed systems can train some MLPerf benchmarks in minutes, making com- pilation times a substantial portion of the total time. T o make benchmarks representati ve of training on the lar gest industrial data sets, we allow e xclusion of up to 20 minutes of model-creation time. This limit ensures that MLPerf cap- tures smaller training jobs, and it discourages submissions with compilation approaches that are too computationally and operationally expensi ve to use in practice. Data reformatting . The raw input data commonly under- goes reformatting once and then serves in many subsequent training sessions. Reformatting examples include changing image-file formats and creating a database (e.g., LMDB, TFRecords, or RecordIO) for more-efficient access. Be- cause these operations ex ecute once for many training ses- sions, MLPerf timing excludes reformatting. But it prohibits any data processing or augmentation that occurs in training from moving to the reformatting stage (e.g., it pre vents dif- ferent crops of each image from being created and sa ved before the timed training stage). 3.2.2 Number of T iming Runs T o address the stochastic nature and resulting run-to-run variance of modern deep-learning methods described in § 2.1.3 , MLPerf requires that submissions pro vide sev eral runs of each benchmark to stabilize timing. W e determined the number of runs, which v aries among benchmarks, by studying the behavior of reference implementations. V ision tasks require 5 runs to ensure 90% of entries from the same system are within 5%; all other tasks require 10 runs to ensure 90% of entries from the same system are within 10%. MLPerf drops the fastest and slowest times, reporting the arithmetic mean of the remaining runs as the result. 3.3 Choice of Quality Thresholds For each benchmark, we chose quality metrics near the state of the art for the corresponding model and data set (T able 1 ), basing our choice on experiments with the reference imple- mentations. Some of these thresholds are slightly lower than results in the literature, enabling us to benchmark across software frameworks and to ensure that training sessions 0 20 40 60 80 Epochs 0 25 50 75 100 Accuracy (%) Seed 1 Seed 2 Seed 3 Seed 4 Seed 5 Figure 2. T op-1 accuracy of MLPerf v0.5 ResNet-50 benchmark ov er 100 epochs for five runs (denoted by color) with identical hyperparameters but different random seeds. The dashed line indicates the quality target of 74.9% T op-1 accuracy . The early training phase exhibits much more v ariability than later phases. consistently achie ve the quality metric. Although selecting a lower threshold that is achie vable earlier in a training session reduces submission resources, we chose higher thresholds that require longer training sessions for two reasons: First, we must prev ent optimizations from adversely af fecting the final results (challenges described in § 2.1.1 and § 2.1.2 ). Second, we must minimize run-to-run v ariation, which tends to be much higher early in training. For example, Figure 2 shows accurac y for five training sessions of MLPerf v0.5’ s ResNet-50 v1.5 reference implementation, where the first 30 epochs exhibit considerably more noise. 3.4 References and Hyper parameters MLPerf provides a reference implementation for each bench- mark, using either the PyT orch or T ensorFlow frame work. References also include scripts or directions to download and preprocess public data sets. References are not opti- mized for performance (meaning they should not be used for performance assessment or comparison), as their main purpose is to define a concrete implementation of a bench- mark model and training procedure. All submitters must follow these references—they may reimplement a bench- mark in their framew ork of choice as long as the DNN model and training operations are mathematically equiv a- lent to the reference. Furthermore, MLPerf uses reference implementations to establish the required quality thresholds. MLPerf rules specify the modifiable hyperparameters (T a- ble 2 ) as well as restrictions on their modification. These restrictions are intended to balance the need to tune for dif- ferent systems with limiting the size of the hyperparamter search space to be fair to submitters with smaller compute resources. For example, to accommodate a wide range of training-system scales, submissions must be able to adjust the minibatch size used by SGD in order to showcase maxi- mum system efficienc y (this approach is similar in concept to the T op500 LINP ACK benchmark, which allo ws systems to choose the problem size). T o ensure that training still MLPerf T raining Benchmark T able 2. MLPerf modifiable hyperparameters. Model Modifiable Hyperparmeters All that use SGD Batch size, Learning-rate schedule parameters ResNet-50 v1.5 SSD-ResNet-34 Maximum samples per training patch Mask R-CNN Number of image candidates GNMT Learning-rate decay function, Learning rate, Decay start, Decay interval, W armup function, W armup steps T ransformer Optimizer: Adam ( Kingma & Ba , 2015 ) or Lazy Adam, Learning rate, W armup steps NCF Optimizer: Adam or Lazy Adam, Learning rate, β 1 , β 2 Go (9x9 board) con verges to the required threshold, other hyperparameters— such as the learning rate schedule—may need adjustment to match. For e xample, a common ResNet training practice is to to increase the learning rate linearly with the minibatch size ( Goyal et al. , 2017 ). Although these hyperparameter searches are a common ML task, MLPerf’ s focus is on sys- tem optimization rather than hyperparameter exploration and we do not want to penalize submitters who are unable to do extensi ve searches. Therefore we restrict hyperparamter tuning to subset of all possible parameters and values. Further , we allow “hyperparameter borro wing” during the post-submission revie w process in which one submitter may adopt another submitter’ s hyperparamters for a spe- cific benchmark and resubmit their result (with no other hardware or software changes allowed). In the first two rounds, hyperparameter borrowing was used successfully to improv e sev eral submissions indicating hyperparamters are some what portable. T ypically borro wing occured across sys- tems of similiar scale, b ut did result in con ver gence across different numerics (FP16, bfloat16, and FP32), architec- tures (CPU, GPU, and TPU), and software implementations (TF , cuDNN, and MKL-DNN). MLPerf working groups re- view the hyperparameter choices and requirements for each benchmark round to account for advances in training ML models at scale. 4 B E N C H M A R K I N G P RO C E S S Next, we outline the process for submission and revie w ( § 4.1 ) and for reporting results ( § 4.2 ) to account for inno- vati ve solutions, av ailability , and scale. W e hav e run two rounds of the MLPerf benchmark: v0.5 and v0.6. The time between rounds is about a few months, allowing us to up- date the suite after each one. Every round has a submission and revie w period followed by publication of results. 4.1 Submission and Review An MLPerf submission consists of a system description, training-session log files, and all code and libraries required to reproduce the training sessions. All of this information is publicly a v ailable on the MLPerf GitHub site, along with the MLPerf results, allowing for reproducibility and enabling the community to improve the results in subsequent rounds. A system description includes both the hardw are (number of nodes, processor and accelerator counts and types, stor- age per node, and network interconnect) and the software (operating system as well as libraries and their versions). A training-session log file contains a variety of structured information including time stamps for important workload stages, quality-metric ev aluations at prescribed intervals, and hyperparameter choices. These logs are the foundation for analyzing results. Before publishing results, submissions are peer-re viewed for compliance with MLPerf rules. Submitters receiv e noti- fication of noncompliance, where applicable, and they may resubmit after addressing any such problems. Additionally , we permit some hyperparameter borro wing as described earlier during this period. 4.2 Reporting Results Each MLPerf submission has sev eral labels: division (open or closed), category (av ailable, pre view , or research), and system type (on-Premises or cloud). 4.2.1 Submission Divisions MLPerf has two submission divisions: closed and open. Both require that submissions employ the same data set and quality metric as the corresponding reference implementa- tion. The closed division is intended for direct system compari- son, so it striv es to ensure workload equiv alence by requiring that submissions be equi v alent to reference implementations. Equiv alence includes mathematically identical model imple- mentations, parameter initialization, optimizer and training schedules, and data processing and traversal. T o ensure fairness, this di vision also restricts hyperparameter modifi- cation. The open division is intended to encourage innov ativ e so- lutions of important practical problems and to encourage hardware/software co-design. It allows submissions to em- ploy model architectures, optimization procedures, and data augmentations that differ from the reference implementa- MLPerf T raining Benchmark tions. 4.2.2 System Cate gories T o allow for a broad range of research and industry systems, we defined three submission categories: av ailable, previe w , and research. These categories encourage nov el techniques and systems (e.g., from academic researchers), b ut they also distinguish between shipping products and proof-of-concept or early engineering samples. The available category imposes requirements on both hard- ware and software av ailability . Hardware must be either av ailable for third-party rental on a cloud service or , in the case of on-premises equipment, a vailable for purchase. Sup- ply and lead times for renting or purchasing should befit the system scale and company size. T o ensure that bench- mark submissions are widely consumable and to discourage benchmark-specific engineering, we also require that soft- ware in this category be versioned and supported for general use. Pr eview systems contain components that meet the av ailable- category criteria within 60 days of the submission date or by the next submission c ycle, whichev er is later . Any pre view system must also be submitted to the a vailable cate gory by that time. Resear ch submissions contain components unintended for production. An example is an academic-research prototype designed as a proof of concept rather than a robust product. This category also includes systems that are b uilt from pro- duction hardware and softw are but are larger in scale than av ailable-category configurations. 4.2.3 Reporting Scale Modern ML training spans multiple orders of magnitude in system power draw and cost. Therefore, comparisons are more useful if the reported performance includes the scale. A common scale metric, such as cost or power , is not definable across a wide range of systems (cloud, on- premises, and preproduction), so it requires dif ferentiation by system type. In the first two MLPerf rounds, we included the system con- figuration (number of processors and/or accelerators) along- side the performance scores. For on-premises examples, future versions will include a power -measurement specifica- tion. For cloud systems, we deri ved a “cloud-scale” metric from the number of host processors, amount of host memory , and number and type of accelerators. W e empirically veri- fied that cloud scale correlates closely with cost across three major cloud pro viders. Reporting of these scale metrics w as optional in MLPerf v0.5 and v0.6. ResNet-50 SSD Mask R-CNN GNMT Transformer Model 0 1 2 Speedup from v0.5 to v0.6 (a) Speedup. Model Metric v0.5 v0.6 ResNet-50 T op-1 accuracy 74.9 75.9 SSD mAP 21.2 23 Mask R-CNN Box / Mask min AP 37.7 / 39.9 Same GNMT Sacre BLEU 21.8 24 T ransformer BLEU 25 Same (b) Quality targets. Figure 3. Speedup in the fastest 16-chip entry from MLPerf version v0.5 to v0.6 for various benchmarks common to both (Figure 3a), along with quality-target increases (Figure 3b). 4.2.4 Reporting Scor es An MLPerf results report provides the time to train for each benchmark. Although a single summary score that spans the entire suite may be desirable for system comparisons, it is unsuited to MLPerf for two main reasons. First, a summary score implies some weighting of indi vidual bench- mark scores. Giv en the div ersity of system users and the wide range of applications that MLPerf cov ers, no weighting scheme is univ ersally representativ e. Second, a summary score becomes less meaningful if a submitter declines to report results on all benchmarks. Submitters can hav e mul- tiple reasons for omitting some benchmarks—not all are practical at e very system scale (for e xample, some models are untrainable at the minibatch sizes that the largest sys- tems require for data-parallel training). Additionally , some processors may target only certain applications. 5 R E S U L T S MLPerf, like all benchmarks, aims to to encourage innov a- tion through constructiv e competition; we measure progress by comparing results across submission rounds. W e have conducted two MLPerf T raining rounds thus far: v0.5 and v0.6. They were six months apart, and the underlying hard- ware systems were unchanged. The results that were ei- ther unmodified or underwent minor modifications between rounds show that MLPerf is dri ving rapid performance and scaling improv ement in both the implementations and soft- ware stacks. Figure 3 shows that between the two sub- mission rounds, the best performance results for a 16-chip system increased by an a verage of 1 . 3 × despite the higher MLPerf T raining Benchmark ResNet-50 SSD Mask R-CNN GNMT Transformer Model 0 500 1000 Number of chips v0.5 v0.6 Figure 4. Number of chips necessary to produce the fastest time to solution for MLPerf versions v0.5 to v0.6. This number increased by as much as 5 . 5 × . quality targets. Figure 4 reveals that the number of chips necessary to produce the best overall performance result increased by an a verage of 5 . 5 × . Some of this improv ement owes to better benchmark implementations and some to rule changes, such as allowing the LARS ( Y ou et al. , 2017 ) optimizer for large ResNet batches. But we believ e sub- mitters incorporated much of the performance and scaling improv ements into the underlying software infrastructure and passed them on to users. W e expect MLPerf to drive similar improv ements through focused hardware innov ation. 6 C O N C L U S I O N S MLPerf T raining is a suite of ML benchmarks that represent both industrial and academic use cases. In addition to being the only widely used ML-training benchmark suite boasting such cov erage, it has made the following contrib utions: • Precise definition of model architectures and training procedures for each benchmark. This feature enables system comparisons for equi valent w orkloads, whereas previous results often in volved substantially dif ferent variants of a gi ven model (for example, ResNet-50 has at least fiv e variants). • Reference implementations and rule definitions to ad- dress the challenges unique to benchmarking ML train- ing. These challenges include the stochastic nature of training processes, the necessity of training to comple- tion to determine the quality impact of performance optimizations, and the need for w orkload v ariation at different system scales ( § 2.1 ). Although MLPerf focuses on relati ve system performance, as the online results demonstrate, it also of fers general lessons about ML and benchmarking: • Realistic data-set size is critical to ensuring realis- tic memory-system behavior —for example, the initial NCF data set was too small and could reside entirely in memory . Furthermore, when benchmarking data sets that are smaller than industrial scale, training time should exclude the startup time, which would be pro- portionally less in actual use. • Small hyperparameter changes can produce consider - able performance changes. But, based on our experi- ence with hyperparameter borro wing, hyperparameters are relativ ely portable at similiar system scales, ev en across architectures, numerics, or software stacks. • Framew orks exhibit subtle optimizer-algorithm v aria- tions that affect con ver gence. ML is an e volving field, ho we ver , and we have much more to learn. T o keep pace, MLPerf establishes a process to maintain and update the suite. For example, MLPerf v0.6 includes sev eral updates: the ResNet-50 benchmark added LARS ( Y ou et al. , 2017 ), GNMT’ s model architecture im- prov ed to increase translation quality , and the MiniGo ref- erence switched from Python to C++ to increase perfor- mance. The MLPerf org anization welcomes input and con- tributions: https://mlperf.org/get- involved A C K N OW L E D G E M E N T S In this section, we acknowledge all those who helped pro- duce the first set of results or supported the ov erall bench- mark dev elopment. Intel: Cong Xu, Deng Xu, Feng T ian, Haihao Shen, Mingx- iao Huang, Rachita Prem Seelin, T eng Lu, Xin Qiu, and Zhongyuan W u. Facebook: Maxim Naumov , Dheev atsa Mudigere, Mustafa Ozdal, Misha Smelyanskiy , Joe Spisak, Sy Choudhury , and Brian Gamidos. Stanford: W ork at Stanford received support in part from af filiate members and other Stanford D A WN project participants—Ant Financial, Facebook, Google, Infosys, NEC, and VMware—as well as T oyota Research Institute, Northrop Grumman, Cisco, SAP , NSF CAREER grant CNS- 1651570, and NSF Graduate Research Fellowship grant DGE-1656518. Any opinions, findings, conclusions, or rec- ommendations expressed in this material are those of the authors and do not necessarily reflect the views of the NSF . Harvard: W ork at Harvard receiv ed partial support from the Applications Driving Architectures (ADA) Research Center , a JUMP Center cosponsored by the SRC and D ARP A, NSF CCF#1704834, and Intel Corporation. W e would also like to thank Brandon Reagen. University of T oronto: W ork at the Univ ersity of T oronto receiv ed partial support from an NSERC Discovery grant, the Canada Foundation for Innov ation JELF grant, the Con- naught Fund, and Huawei grants. MLPerf T raining Benchmark R E F E R E N C E S AI Matrix. URL https://aimatrix.ai . Abadi, M., Barham, P ., Chen, J., Chen, Z., Davis, A., Dean, J., De vin, M., Ghemaw at, S., Irving, G., Isard, M., et al. T ensorFlow: A System for Lar ge-Scale Machine Learn- ing. In OSDI , volume 16, pp. 265–283, 2016. Adolf, R., Rama, S., Reagen, B., W ei, G.-Y ., and Brooks, D. Fathom: Reference W orkloads for Modern Deep Learn- ing Methods. In W orkload Characterization (IISWC), 2016 IEEE International Symposium on , pp. 1–10. IEEE, 2016. Amodei, D. and Hernandez, D. AI and Com- pute, 2018. URL https://blog.openai.com/ ai- and- compute/ . Auer , P ., Herbster , M., and W armuth, M. K. Exponentially Many Local Minima for Single Neurons. In Advances in neural information pr ocessing systems , pp. 316–322, 1996. Bai, J., Lu, F ., Zhang, K., et al. ONNX: Open Neural Network Exchange. https://github.com/onnx/ onnx , 2019. Baidu. DeepBench: Benchmarking Deep Learning Op- erations on Different Hardware. https://github. com/baidu- research/DeepBench , 2017. Banner , R., Hubara, I., Hoffer , E., and Soudry , D. Scal- able Methods for 8-bit T raining of Neural Networks. In Advances in Neural Information Pr ocessing Systems , pp. 5145–5153, 2018. Belletti, F ., Lakshmanan, K., Krichene, W ., Chen, Y .-F ., and Anderson, J. Scalable Realistic Recommendation Datasets through Fractal Expansions. arXiv pr eprint arXiv:1901.08910 , 2019. Ben-Nun, T ., Besta, M., Huber, S., Ziogas, A. N., Peter , D., and Hoefler , T . A Modular Benchmarking Infrastructure for High-Performance and Reproducible Deep Learning. arXiv pr eprint arXiv:1901.10183 , 2019. Chan, B. OpenAI Five, Jun 2018. URL https:// openai.com/blog/openai- five/ . Chen, T ., Li, M., Li, Y ., Lin, M., W ang, N., W ang, M., Xiao, T ., Xu, B., Zhang, C., and Zhang, Z. MXNet: A Flexible and Ef ficient Machine Learning Library for Heterogeneous Distributed Systems. arXiv preprint arXiv:1512.01274 , 2015. Chen, T ., Moreau, T ., Jiang, Z., Zheng, L., Y an, E., Shen, H., Co wan, M., W ang, L., Hu, Y ., Ceze, L., et al. { TVM } : An Automated End-to-End Optimizing Compiler for Deep Learning. In 13th { USENIX } Symposium on Operating Systems Design and Implementation ( { OSDI } 18) , pp. 578–594, 2018. Cheng, H.-T ., Koc, L., Harmsen, J., Shaked, T ., Chandra, T ., Aradhye, H., Anderson, G., Corrado, G., Chai, W ., Ispir , M., et al. W ide & Deep Learning for Recommender Systems. In Pr oceedings of the 1st workshop on deep learning for r ecommender systems , pp. 7–10. A CM, 2016. Chetlur , S., W oolley , C., V andermersch, P ., Cohen, J., T ran, J., Catanzaro, B., and Shelhamer , E. CuDNN: Efficient Primitives for Deep Learning. arXiv preprint arXiv:1410.0759 , 2014. Choromanska, A., Henaf f, M., Mathieu, M., Arous, G. B., and LeCun, Y . The Loss Surfaces of Multilayer Net- works. In Artificial Intelligence and Statistics , pp. 192– 204, 2015. Coleman, C., Narayanan, D., Kang, D., Zhao, T ., Zhang, J., Nardi, L., Bailis, P ., Olukotun, K., R ´ e, C., and Zaharia, M. D A WNBench: An End-to-End Deep Learning Bench- mark and Competition. NIPS ML Systems W orkshop , 2017. Coleman, C., Kang, D., Narayanan, D., Nardi, L., Zhao, T ., Zhang, J., Bailis, P ., Olukotun, K., R ´ e, C., and Zaharia, M. Analysis of D A WNBench, a T ime-to-Accuracy Ma- chine Learning Performance Benchmark. ACM SIGOPS Operating Systems Re view , 53(1):14–25, 2019. Council, T . P . P . T ransaction Processing Performance Coun- cil. W eb Site, http://www . tpc. or g , 2005. Deng, J., Dong, W ., Socher, R., Li, L.-J., Li, K., and Fei- Fei, L. ImageNet: A Large-scale Hierarchical Image Database. In 2009 IEEE confer ence on computer vision and pattern r ecognition , pp. 248–255. Ieee, 2009. Devli n, J., Chang, M.-W ., Lee, K., and T outanov a, K. BER T : Pre-training of Deep Bidirectional T ransformers for Lan- guage Understanding. arXiv preprint , 2018. Dixit, K. M. The SPEC Benchmarks. P arallel computing , 17(10-11):1195–1209, 1991. Dongarra, J. The LINP ACK Benchmark: An Expla- nation. In Proceedings of the 1st International Con- fer ence on Supercomputing , pp. 456–474, London, UK, UK, 1988. Springer-V erlag. ISBN 3-540-18991- 2. URL http://dl.acm.org/citation.cfm? id=647970.742568 . Google. T ensorFlow Benchmarks. https://www. tensorflow.org/performance/benchmarks , 2017. MLPerf T raining Benchmark Gori, M. and T esi, A. On the Problem of Local Minima in Backpropagation. IEEE T ransactions on P attern Analysis & Machine Intelligence , (1):76–86, 1992. Goyal, P ., Doll ´ ar , P ., Girshick, R., Noordhuis, P ., W esolowski, L., K yrola, A., T ulloch, A., Jia, Y ., and He, K. Accurate, Large Minibatch SGD: T raining ImageNet in 1 Hour. arXiv preprint , 2017. GroupLens. MovieLens 20M Dataset, Oct 2016. URL https://grouplens.org/datasets/ movielens/20m/ . He, K., Zhang, X., Ren, S., and Sun, J. Deep Residual Learn- ing for Image Recognition. In Pr oceedings of the IEEE confer ence on computer vision and pattern r ecognition , pp. 770–778, 2016a. He, K., Zhang, X., Ren, S., and Sun, J. Identity Mappings in Deep Residual Networks. In Eur opean confer ence on computer vision , pp. 630–645. Springer , 2016b. He, K., Gkioxari, G., Doll ´ ar , P ., and Girshick, R. Mask R-CNN. In Pr oceedings of the IEEE international con- fer ence on computer vision , pp. 2961–2969, 2017a. He, X., Liao, L., Zhang, H., Nie, L., Hu, X., and Chua, T .-S. Neural Collaborativ e Filtering. In Pr oceedings of the 26th international conference on world wide web , pp. 173–182. International W orld W ide W eb Conferences Steering Committee, 2017b. Hennessy , J. L. and Patterson, D. A. Computer Ar chitectur e: A Quantitative Appr oach . Elsevier , 2011. Hinton, G., Deng, L., Y u, D., Dahl, G., Mohamed, A.-r ., Jaitly , N., Senior , A., V anhoucke, V ., Nguyen, P ., Kings- bury , B., et al. Deep Neural Networks for Acoustic Mod- eling in Speech Recognition. IEEE Signal pr ocessing magazine , 29, 2012. Huang, J., Rathod, V ., Sun, C., Zhu, M., K orattikara, A., Fathi, A., Fischer, I., W ojna, Z., Song, Y ., Guadarrama, S., and Murphy , K. Speed/Accuracy T rade-offs for Modern Con volutional Object Detectors, 2016. Intel. BigDL: Distributed Deep Learning Library for Apache Spark, 2019. URL https://github.com/ intel- analytics/BigDL . Jia, X., Song, S., He, W ., W ang, Y ., Rong, H., Zhou, F ., Xie, L., Guo, Z., Y ang, Y ., Y u, L., et al. Highly Scalable Deep Learning T raining System with Mixed-Precision: T raining ImageNet in Four Minutes. arXiv pr eprint arXiv:1807.11205 , 2018. Jia, Y ., Shelhamer , E., Donahue, J., Karayev , S., Long, J., Girshick, R., Guadarrama, S., and Darrell, T . Caffe: Con volutional Architecture for Fast Feature Embedding. In ACM International Confer ence on Multimedia , pp. 675–678. A CM, 2014. Jouppi, N. P ., Y oung, C., P atil, N., Patterson, D., Agrawal, G., Bajwa, R., Bates, S., Bhatia, S., Boden, N., Borchers, A., et al. In-Datacenter Performance Analysis of a T ensor Processing Unit. In 2017 ACM/IEEE 44th Annual Inter - national Symposium on Computer Arc hitectur e (ISCA) , pp. 1–12. IEEE, 2017. Kingma, D. P . and Ba, J. Adam: A Method for Stochastic Optimization. ICLR , 2015. Krizhevsk y , A. One W eird Trick for P arallelizing Con volu- tional Neural Networks, 2014. Krizhevsk y , A., Sutskev er , I., and Hinton, G. E. ImageNet Classification with Deep Conv olutional Neural Networks. In Advances in neural information pr ocessing systems , pp. 1097–1105, 2012. Kster , U., W ebb, T . J., W ang, X., Nassar , M., Bansal, A. K., Constable, W . H., Elibol, O. H., Gray , S., Hall, S., Hornof, L., Khosrowshahi, A., Kloss, C., Pai, R. J., and Rao, N. Flexpoint: An Adaptiv e Numerical Format for Ef ficient T raining of Deep Neural Networks. NIPS , 2017. Lin, T .-Y ., Maire, M., Belongie, S., Hays, J., Perona, P ., Ra- manan, D., Doll ´ ar , P ., and Zitnick, C. L. Microsoft COCO: Common Objects in Context. In Eur opean Confer ence on Computer V ision , pp. 740–755. Springer, 2014. Liu, W ., Anguelov , D., Erhan, D., Szegedy , C., Reed, S., Fu, C.-Y ., and Berg, A. C. SSD: Single Shot Multibox Detector. In Eur opean confer ence on computer vision , pp. 21–37. Springer , 2016. Markidis, S., Der Chien, S. W ., Laure, E., Peng, I. B., and V etter, J. S. NVIDIA T ensor Core Programmability , Per- formance & Precision. arXiv preprint , 2018. Micike vicius, P ., Narang, S., Alben, J., Diamos, G., Elsen, E., Garcia, D., Ginsbur g, B., Houston, M., Kuchaiev , O., V enkatesh, G., and W u, H. Mixed Precision T raining. In Pr oceedings of the International Conference on Learning Repr esentations , 2018. Mikami, H., Suganuma, H., U-chupala, P ., T anaka, Y ., and Kageyama, Y . Massively Distributed SGD: ImageNet/ResNet-50 T raining in a Flash. arXiv preprint arXiv:1811.05233 , 2018. MLPerf. MLPerf Reference: MiniGo. https: //github.com/mlperf/training/tree/ master/reinforcement , 2019a. MLPerf T raining Benchmark MLPerf. MLPerf Reference: ResNet in T ensorFlow . https://github.com/mlperf/training/ tree/master/image_classification/ tensorflow/official , 2019b. Mnih, V ., Kavukcuoglu, K., Silv er , D., Gra ves, A., Antonoglou, I., W ierstra, D., and Riedmiller , M. Playing Atari with Deep Reinforcement Learning. arXiv preprint arXiv:1312.5602 , 2013. Narayanan, D., Harlap, A., Phanishayee, A., Seshadri, V ., Dev anur , N. R., Ganger , G. R., Gibbons, P . B., and Za- haria, M. PipeDream: Generalized Pipeline Parallelism for DNN Training. In Pr oceedings of the 27th ACM Symposium on Operating Systems Principles , pp. 1–15, 2019. Naumov , M., Mudigere, D., Shi, H.-J. M., Huang, J., Sun- daraman, N., Park, J., W ang, X., Gupta, U., W u, C.-J., Azzolini, A. G., et al. Deep Learning Recommendation Model for Personalization and Recommendation Systems. arXiv pr eprint arXiv:1906.00091 , 2019. Paszke, A., Gross, S., Chintala, S., Chanan, G., Y ang, E., DeV ito, Z., Lin, Z., Desmaison, A., Antiga, L., and Lerer , A. Automatic Differentiation in PyT orch. 2017. Radford, A., W u, J., Child, R., Luan, D., Amodei, D., and Sutske ver , I. Language Models are Unsupervised Multi- task Learners. OpenAI Blog , 1(8), 2019. Silver , D., Huang, A., Maddison, C. J., Guez, A., Sifre, L., V an Den Driessche, G., Schrittwieser, J., Antonoglou, I., Panneershelv am, V ., Lanctot, M., et al. Mastering the Game of Go with Deep Neural Networks and T ree Search. natur e , 529(7587):484, 2016. Silver , D., Schrittwieser, J., Simonyan, K., Antonoglou, I., Huang, A., Guez, A., Hubert, T ., Baker , L., Lai, M., Bolton, A., et al. Mastering the Game of Go without Human Knowledge. Nature , 550(7676):354, 2017. Silver , D., Hubert, T ., Schrittwieser , J., Antonoglou, I., Lai, M., Guez, A., Lanctot, M., Sifre, L., Kumaran, D., Grae- pel, T ., et al. A General Reinforcement Learning Algo- rithm that masters Chess, Shogi, and Go through Self- Play . Science , 362(6419):1140–1144, 2018. Sun, P ., Feng, W ., Han, R., Y an, S., and W en, Y . Optimizing Network Performance for Distrib uted DNN T raining on GPU Clusters: ImageNet/AlexNet T raining in 1.5 Min- utes. arXiv preprint , 2019. V aswani, A., Shazeer , N., Parmar , N., Uszkoreit, J., Jones, L., Gomez, A. N., Kaiser , Ł ., and Polosukhin, I. Attention is All Y ou Need. In Advances in neural information pr ocessing systems , pp. 5998–6008, 2017. WMT . First Conference on Machine T ranslation, 2016. URL http://www.statmt.org/wmt16/ . WMT . Second Conference on Machine T ranslation, 2017. URL http://www.statmt.org/wmt17/ . W u, Y ., Schuster , M., Chen, Z., Le, Q. V ., Norouzi, M., Macherey , W ., Krikun, M., Cao, Y ., Gao, Q., Macherey , K., et al. Google’ s Neural Machine T ranslation System: Bridging the Gap between Human and Machine Transla- tion. arXiv preprint , 2016. Y ing, C., Kumar , S., Chen, D., W ang, T ., and Cheng, Y . Im- age Classification at Supercomputer Scale. arXiv pr eprint arXiv:1811.06992 , 2018. Y ou, Y ., Gitman, I., and Ginsburg, B. Large Batch T raining of Con volutional Networks. arXiv preprint arXiv:1708.03888 , 2017. Zhou, G., Zhu, X., Song, C., Fan, Y ., Zhu, H., Ma, X., Y an, Y ., Jin, J., Li, H., and Gai, K. Deep Interest Network for Click-through Rate Prediction. In Pr oceedings of the 24th A CM SIGKDD International Confer ence on Knowledge Discovery & Data Mining , pp. 1059–1068. A CM, 2018. Zhu, C., Han, S., Mao, H., and Dally , W . J. T rained T ernary Quantization. arXiv preprint , 2016. Zhu, H., Akrout, M., Zheng, B., Pelegris, A., Jayarajan, A., Phanishayee, A., Schroeder, B., and Pekhimenko, G. Benchmarking and Analyzing Deep Neural Network T raining. In 2018 IEEE International Symposium on W orkload Characterization (IISWC) , pp. 88–100. IEEE, 2018. MLPerf T raining Benchmark A A RT I FAC T A P P E N D I X A.1 Abstract This artifact description contains information about the com- plete workflo w to reproduce Nvidia’ s v0.5 image classifi- cation submissions to MLPerf. W e describe how to run this submission on a single-node DGX-1 system. More de- tails for DGX-2 and multi-node systems are provided in the official MLPerf results repositories: • Nvidia’ s v0.5 ResNet-50 submissions Results from other tasks and submitters are also av ailable: • MLPerf v0.5 training results • MLPerf v0.6 training results Howe ver , these results hav e not been independently verified for reproducibility . Please see the MLPerf website ( https: //mlperf.org/ ) for the most up-to-date information and feel free to report issues on Github . A.2 Artifact check-list (meta-information) • Algorithm: Image classification ResNet-50 CNN • Program: MLPerf ( https://mlperf.org/ ) • Compilation: n vidia-docker • Model: ResNet-50 v1.5 3 • Data set: ImageNet ( http://image- net.org/ ) • Hardware: NVIDIA DGX-1 or DGX-2 • Metrics: T ime-to-T rain: minutes to reach accuracy thresh- old (74.9% T op-1 for v0.5) • Output: MLPerf compliant log file with timestamps and ev aluation accuracy . Execution ends once the accuracy threshold is reached. • Experiments: shell script included with the code (./run.sub) • How much disk space required (approximately)?: 300 GB • How much time is needed to pr epare w orkflow (approxi- mately)?: 2 hours • How much time is needed to complete experiments (ap- proximately)?: 8 hours • Publicly available: Y es • Code licenses: Apache License 2.0 • W orkflow framework used?: MXNet • Archived (pr ovide DOI)?: http://doi.org/10.5281/zenodo.3610717 3 https://github.com/mlperf/training/tree/ master/image_classification/tensorflow/ official A.3 Description A.3.1 How to access MLPerf v0.5 training results on Github: https://github.com/mlperf/training_results_ v0.5 . A.4 Installation See the README.md for Nvidia’s v0.5 ResNet-50 submission: https://github.com/mlperf/training_results_ v0.5/tree/master/v0.5.0/nvidia/submission/ code/image_classification/mxnet/README.md . A.5 Evaluation and expected r esult T ime-to-T rain: 134.6 minutes.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment