보컬과 반주 구분으로 가수 식별 정확도 향상
본 논문은 가수 식별(SID)에서 반주가 가져오는 혼동을 줄이기 위해 최신 음원 분리 모델인 open‑unmix를 활용한다. 분리된 보컬만을 사용하거나, 보컬과 반주를 서로 섞어 새로운 학습 데이터를 만든 “shuffle‑and‑remix” 데이터 증강 기법을 적용한다. 또한 멜로디 컨투어를 CREPE로 추출해 멜로디 전용 브랜치를 추가한 CRNNM 모델을 제안하고, artist20 데이터셋의 앨범‑split 평가에서 기존 최고 성능을 크게 뛰…
저자: Tsung-Han Hsieh, Kai-Hsiang Cheng, Zhe-Cheng Fan
본 논문은 음악 정보 검색(MIR) 분야에서 중요한 과제인 가수 식별(Singer Identification, SID)의 성능을 제한하는 핵심 요인, 즉 반주와 보컬이 혼합된 오디오에서 발생하는 ‘컨퓨전(confound)’ 문제를 해결하고자 한다. 기존 SID 모델은 전체 믹스 신호를 입력으로 사용하면서, 가수가 특정 장르나 프로덕션 스타일에만 등장하는 경우 반주에 내재된 장르·템포·악기 특성을 부정확하게 학습하게 된다. 이러한 현상은 모델이 보컬이 아닌 반주에 의존해 분류를 수행하게 만들며, 새로운 음악적 컨텍스트에서 일반화가 어려워진다.
이를 극복하기 위해 저자들은 두 가지 주요 전략을 제시한다. 첫 번째는 최신 딥러닝 기반 음원 분리 모델인 open‑unmix를 활용해 원본 믹스에서 보컬 트랙과 반주 트랙을 고품질로 분리하는 것이다. open‑unmix는 3‑layer bidirectional RNN 구조를 갖추고 있어, 기존 비딥러닝 기반 분리기보다 왜곡과 잔향을 현저히 감소시킨다. 이를 통해 보컬 전용 멜‑스펙트로그램을 얻음으로써, 모델이 비보컬 특성에 의존하는 위험을 크게 낮춘다.
두 번째 전략은 ‘shuffle‑and‑remix’라는 데이터 증강 기법이다. 분리된 보컬 트랙과 반주 트랙을 서로 다른 곡에서 무작위로 조합해 새로운 학습 샘플을 생성한다. 이때 가수 라벨은 보컬 트랙에 그대로 유지되므로, 동일 가수가 다양한 반주 환경에서도 일관된 보컬 특성을 학습하도록 강제한다. 이는 특히 가수가 특정 장르에만 등장하는 경우, 모델이 반주에 내재된 장르 정보를 부정확하게 학습하는 현상을 방지한다.
모델 아키텍처는 기존 최고 성능을 보였던 CRNN(Convolutional Recurrent Neural Network) 구조를 기반으로 하며, 멜로디 정보를 추가로 활용하기 위해 CREPE를 이용해 추출한 멜로디 컨투어를 별도의 브랜치에 입력한다. 이 멜로디 브랜치는 동일한 컨볼루션‑GRU 블록을 거쳐 보컬 스펙트로그램과 채널‑와이즈(concatenation) 방식으로 결합된다. 최종적으로는 두 브랜치의 특징을 통합해 20개의 가수 클래스를 분류한다. 이 모델을 CRNNM이라 명명한다.
실험은 표준 벤치마크인 artist20 데이터셋(20명, 각 6앨범, 총 1,413곡)을 앨범‑split 방식으로 진행하였다. 앨범‑split은 동일 앨범 내 곡이 학습·검증·테스트에 동시에 포함되지 않도록 하여, 제작 스타일에 의한 정보 누수를 방지한다. 각 곡은 5초 세그먼트로 나누어 학습하고, 곡 전체 예측은 세그먼트별 결과의 다수결(majority voting)로 결정한다. 평가 지표는 5초 세그먼트와 곡 단위 모두에 대해 F1 점수를 사용한다.
다양한 학습 데이터 조합에 대한 실험 결과는 다음과 같다. ‘Origin’(원본 믹스)만 사용한 CRNN은 곡 단위 F1 0.67을 기록했으며, ‘Vocal‑only’(분리된 보컬)만 사용했을 때는 0.61로 감소한다. ‘Remix’(보컬과 반주를 무작위로 재조합)만 사용했을 때는 0.65로 원본과 비슷한 수준이다. 그러나 ‘Data aug’(Origin, Vocal‑only, Remix를 모두 포함)로 학습한 경우, CRNN은 0.74, CRNN†(파라미터 수 동일)도 0.74, CRNNM은 0.75의 곡 단위 F1 점수를 달성하며, 기존 최고 성능을 크게 뛰어넘는다. 특히 멜로디 브랜치를 추가한 CRNNM이 가장 높은 점수를 기록함으로써, 멜로디 정보가 가수 식별에 유의미한 보조 특성임을 입증한다.
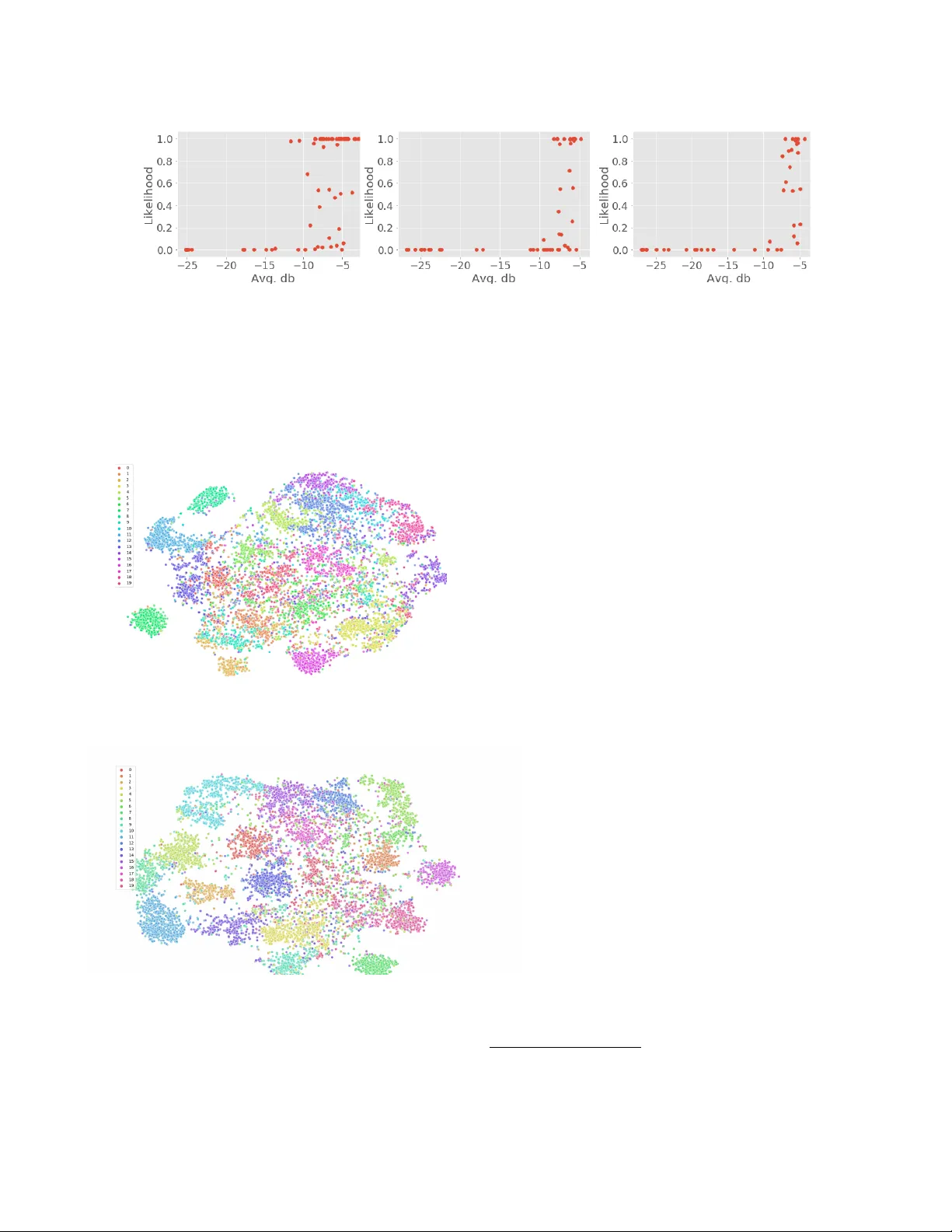
시각화(t‑SNE) 결과에서도 CRNNM이 학습한 임베딩이 서로 다른 가수를 보다 명확히 구분하는 것을 확인할 수 있다. 이는 멜로디 브랜치가 고차원 특징 공간을 보다 구조화한다는 증거다. 또한 5초 세그먼트 수준의 F1 점수가 낮은 이유는 비보컬 구간이 포함되기 때문이며, ‘vocalness’(보컬 분리 클립의 평균 dB)와 예측 정확도 사이의 상관계수가 0.39에 불과함을 통해 비보컬 구간을 사전에 필터링하는 것이 향후 성능 개선에 도움이 될 것임을 제안한다.
결론적으로, 이 연구는 (1) 고성능 음원 분리 모델을 활용한 보컬 순수화, (2) 작업 특화 데이터 증강인 shuffle‑and‑remix, (3) 멜로디 기반 다중 모달 특징 학습이라는 세 축을 결합해 가수 식별의 핵심 한계인 반주 혼동을 효과적으로 해소하였다. 실험 결과는 기존 최고 수준을 크게 넘어서는 성능 향상을 입증한다. 향후 연구 방향으로는 (a) 보컬/비보컬 검출기와의 연계, (b) 멜로디 브랜치에 GRU 적용, (c) 피치‑시프트·타임‑스트레칭 등 추가적인 증강 기법 탐색을 제시한다. 이러한 확장은 SID 시스템을 더욱 견고하고 실용적으로 만들 전망이다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기