Addressing the confounds of accompaniments in singer identification
Identifying singers is an important task with many applications. However, the task remains challenging due to many issues. One major issue is related to the confounding factors from the background instrumental music that is mixed with the vocals in m…
Authors: Tsung-Han Hsieh, Kai-Hsiang Cheng, Zhe-Cheng Fan
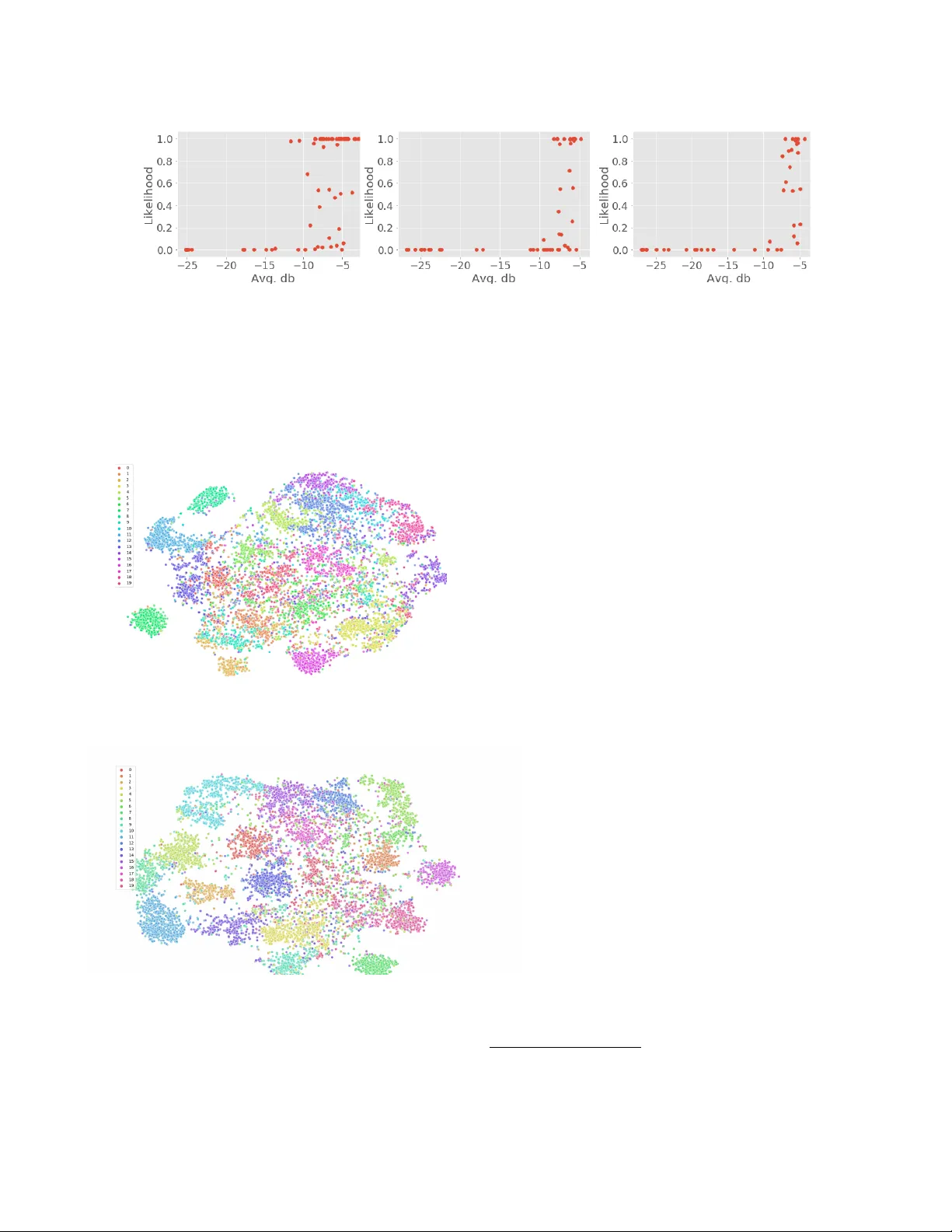
ADDRESSING THE CONFOUNDS OF A CCOMP ANIMENTS IN SINGER IDENTIFICA TION Tsung-Han Hsieh 1 , 2 , Kai-Hsiang Cheng 1 , Zhe-Cheng F an 1 , Y u-Ching Y ang 2 , Y i-Hsuan Y ang 1 1 Research Center for IT Innov ation, Academia Sinica, T aiwan 2 Data Science T eam, KKBO X Inc., T aiwan { bill317996,kevinco27,zcfan } @citi.sinica.edu.tw, janetyang@kkbox.com, yang@citi.sinica.edu.tw ABSTRA CT Identifying singers is an important task with many applica- tions. Howe ver , the task remains challenging due to many issues. One major issue is related to the confounding factors from the background instrumental music that is mixed with the v ocals in music production. A singer identification model may learn to extract non-vocal related features from the in- strumental part of the songs, if a singer only sings in certain musical contexts (e.g., genres). The model cannot therefore generalize well when the singer sings in unseen contexts. In this paper, we attempt to address this issue. Specifically , we employ open-unmix , an open source tool with state-of-the-art performance in source separation, to separate the vocal and instrumental tracks of music. W e then inv estigate two means to train a singer identification model: by learning from the separated v ocal only , or from an augmented set of data where we “shuf fle-and-remix” the separated v ocal tracks and instru- mental tracks of different songs to artificially mak e the singers sing in dif ferent contexts. W e also incorporate melodic fea- tures learned from the vocal melody contour for better per- formance. Ev aluation results on a benchmark dataset called the artist20 sho ws that this data augmentation method greatly improv es the accuracy of singer identification. Index T erms — Signer identification, singing voice sepa- ration, melody extraction, data augmentation 1. INTR ODUCTION Singer identification (SID), a.k.a., artist identification, is a classic task in the field of music information retriev al (MIR). It aims at identifying the performing singers in giv en audio samples to facilitate management of music libraries. When properly trained, an SID model also learns the embedding of singing voices that can be used in do wnstream singing-related applications such as similarity search, playlist generation, or singing synthesis [1 – 5]. W e refer readers to [5] for a recent ov erview of research on singing voice analysis and process- ing, and the role of SID in related tasks. Despite of its importance, SID is to date not yet a settled task [5]. There are at least two main challenges. First, as hu- man beings share similar mechanism in producing sounds [7], Mel - sp ectr ogr am Mel ody (CR EP E) Con v . blo c k Con v . bloc k Con v . bloc k Con v . bloc k Con v . bloc k Con v . blo c k Con v . bloc k Con v . bloc k Dense GRU GRU Pr edict ion Cha nn el: [64, 128, 128, 128] K erne l siz e: ( 3, 3) Ac ti v a ti on: EL U Ba t c h Normali z a ti on: c han ne l Ma x - P ool i ng siz e: [(2, 2) , (4 , 2) , ( 4, 2 ),(4 , 2 )] Dr opout: 0.1 Con v bloc k Fig. 1 . The architecture of the proposed convolutional r ecur- r ent neural network with melody (CRNNM) model for singer identification. The inputs are mel-spectrograms, and melody contours extracted by CREPE [6]. The model cascades con- volutional blocks, gate recurrent units (GRUs), and a dense layer . The “+” symbol stands for channel-wise concatenation. the dif ference in the singing voices of two singers may not be always obvious. This becomes more severe as the num- ber of singers to be considered increases. Second, due to the difficulty in acquiring solo recordings of singers, the training data for SID usually consists of audio recordings of singers singing o ver instrumental accompaniment tracks. The vocal track and instrumental track of a song are usually mixed in such an audio recording [8]. The presence of instrumental ac- companiment not only makes it difficult for an SID model to extract only v ocal-related features from the audio, b ut also in- troduces confounding factors [9] that hurt the model’ s gener- alizability . This is especially the case as singers usually have their preferred musical genres or styles. In trying to repro- duce the most ground truth artist labels of a training dataset (e.g., while minimizing a classification error related loss func- tion), an SID model may learn to capitalize non-vocal related features, which is not what the task is actually about. W e intend to address the second challenge in this paper . Intuitiv ely , the challenge can be tackled by enhancing, or iso- lating out, the vocal part of a song, to minimize the effect of the instrumental part on the SID model. While singing voice enhancement or separation were dif ficult just a few years ago [10, 11], state-of-the-art models now can perform the task with low distortion, interference and artifact [8, 12, 13], thanks to the advance in deep learning. Using source separation (SS) to improv e SID therefore becomes feasible. While the idea of using SS to impro ve SID has been at- tempted before [11, 14 – 16], our work dif fers from the prior arts in tw o ways. First, e xcept for the concurrent work [16], the prior arts that we are aware of did not use deep learning- based SS models. In contrast, in our work both the SS model and the SID model employ deep learning. Specifically , we use open-unmix [12], an open-source three-layer bidirectional deep recurrent neural network for SS. Moreover , we build upon our SID model based on the implementation of a con vo- lutional recurrent neural network made av ailable by Nasrullah and Zhao [17], which attains the highest song-lev el F1-score of 0.67 on the per-alb um split of the artist20 dataset [18], a standard dataset for SID. As neural networks may find their own way extracting relev ant features or patterns from the in- put, it remains to be studied whether the use of SS can im- prov e the performance of a deep learning based SID model. Second, unlike prior arts (including [16]), we in vestigate one additional way to employ SS to impro ve SID. Gi ven the separated vocal tracks and instrumental tracks of the audio recordings in the training set, we perform the so-called “data augmentation” [19 – 22] by randomly shuffling the separated tracks of different songs and then remixing them. For exam- ple, we remix the vocal part of a song from a singer with the instrumental part of another song from a different singer . In this way , we artificially make the singers sing ov er a v ariety of accompaniment tracks, and may therefore break the “bonds” between the vocal and accompaniment tracks, mitigating the confounds from the accompaniments. W e intend to empiri- cally validate the effecti veness of such a data augmentation method, which can be said to be task-specific to SID. As a secondary contrib ution, we explore adding to our SID model features e xtracted from the vocal melody contour , which is related to singing timbre [23]. While the extraction of the vocal melody contour is done by using CREPE [6], an open-source tool with state-of-the-art performance in melody extraction, we use a stack of con volutional layers and gated recurrent unit (GR U) layers [24] to learn features not only from the mel-spectrogram but also the melody contour . 1 Figure 1 shows the architecture of our SID model, dubbed con volutional r ecurr ent neural network with melody (CRNNM). Code av ailable at https://github.com/bill317996/ Singer- identification- in- artist20 . 1 Features extracted from the melody contour hav e been shown useful in many other MIR tasks [23, 25–27]. Howev er, we note that most existing work used hand-crafted features, rather than features learned by a neural network. O ri gi nal V oca l Accompaniment V ocal Data aug (shuffle) Remix Fig. 2 . A diagram of the “shuffle-and-remix” data augmenta- tion method, which has been used before for SS [22]. 2. METHODOLOGY 2.1. Singer Identification (SID) Models W e consider as the baseline model the con volutional recurrent neural network proposed in [17], which represents the state- of-the-art for SID on the artist20 dataset. This model uses a stack of four con volutional layers, two GRU layers, and one dense (i.e., fully-connected) layer , as depicted in Fig. 1, b ut without the lower melody-related branch. W e follow exactly the same design (i.e., encompassing number of filters, kernel sizes, acti vation functions, loss function, optimizer , learning rate, etc) of [17]. W e refer to this model as ‘CRNN’ below . The proposed CRNNM model e xtends the CRNN model in two w ays. First, in addition to the mel-spectrogram, we use CREPE [6] to extract the melody contour from the mixture audio recordings and establish an additional con volutional branch to learn melodic features for SID. For simplicity , we use the same design for the mel-spectrogram branch and the melody contour branch. Second, instead of using the mel-spectrogram of the mixture audio recordings, we em- ploy open-unmix [12] to remo ve the instrumental part of the music, and use the proposed data augmentation technique to increase the size of the training data, as described below . As CRNNM has more parameters than CRNN, in our ex- periment we also implement a v ariant of CRNN, denoted as CRNN † , that has similar number of parameters as CRNNM. 2.2. Data A ugmentation: Separate, Shuffle, and Remix Data augmentation is to synthetically create training e xam- ples to improv e generalizability and to help capture in vari- ances of data [19]. This technique has been popular for some time among the machine learning community . It has also been shown beneficial for MIR tasks such as singing voice detec- tion and source separation [20 – 22] (but not yet for SID). As discussed in [20], data augmentation techniques for MIR can be classified into data-independent, audio-specific, and task-specific methods. Data-independent methods, like dropout, achiev e augmentation from model perspecti ve, and then can be data-agnostic. Audio-specific methods, lik e pitch shifting and time stretching, perform data transformation di- rectly on audio data. T ask-specific methods consider the task- specific prior knowledge into the training data. F or example, it has been kno wn that remixing sources from different songs improv es the performance of SS models [22]. Our approach is motiv ated by [22]. Our conjecture is that the same shuf fle-and-remix technique can also be used for SID: when the v ocal part of a song is mixed with the instru- mental part of another song, its singer label should remain the same. This process is illustrated in Figure 2. Follo wing this light, we create another three datasets, V ocals , Remix , and Data aug to ev aluate our model. Origin : The original audio recordings of artist20 [18]. It contains six alb ums per artist for 20 artists, with in total 1,413 sound tracks. V ocal and acconamniments are mixed. V ocal-only : The vocal tracks separated by open-unmix [12]. In other words, all the accompaniments are removed. Remix : The dataset is generated by randomly mixing the separated vocal and instrumental tracks of artist20. The size of this dataset is the same as Origin and V ocal-only . Data aug : Combination of the three sets above. 2.3. Implementation Details In the literature of SID, data splitting can be done in two ways: song-split or album-split. The former splits a dataset by ran- domly assigning songs to the three subsets, whereas the latter makes sure that songs from the same album are either in the training, v alidation, or the test split. It has been kno wn [17] that song-split may leak production details associated with an album over the training and testing subsets, giving an SID model additional clues for classification. Accordingly , the ac- curacy for song-split may be overly optimistic and tends to be higher than that of album-split. W e therefore focus on and only consider album-split in our w ork. Under the album-split, we consider and compare the result of models trained using the four types of data listed by the end of Section 2.2. The same test set (i.e., the Origin type) is used. Follo wing [17], we cut the songs into 5-sec segments for training a 20-class classification model. The final prediction result for a song is made by majority voting from the per- segment results. For ev aluation, we consider both “per 5-sec segment” and “per song” F1 score; both the higher the better . For CRNNM, we quantize the frequency axis of the melody contour to 128 bins before feeding to the next layers. 3. EXPERIMENTS The models are e valuated using artist20 [18] under the album split, av eraging the F1 scores of three independent runs. T able 1 . A verage testing F1 score on the artist20 dataset; note that ‘CRNN+Origin’ resembles the model in [17]. Model Data F1 / 5-sec F1 / Song CRNN Origin 0.50 0.67 V ocal-only 0.39 0.61 Remix 0.39 0.65 Data aug. 0.47 0.74 CRNN † Origin 0.54 0.67 V ocal-only 0.48 0.71 Remix 0.46 0.71 Data aug. 0.50 0.74 CRNNM Origin 0.53 0.69 V ocal-only 0.42 0.66 Remix 0.39 0.65 Data aug. 0.45 0.75 3.1. Experimental results From T able 1, we see that CRNNM performs the best among the three models. This result shows that using melody contour as additional features helps SID. Our ‘CRNNM+Data aug’ model achieves 0.75 song-lev el F1 score, which is greatly higher than that (0.67) obtained by the best existing model (‘CRNN+Origin’) [17] for artist20. T able 1 also shows that, for all the three models, train- ing on Data aug outperforms those trained on Origin for the song-lev el result, validating the ef fecti veness of the data aug- mentation method. W e also note that, using V ocal-only per- forms ev en worse than using Origin for the case of CRNN and CRNNM, suggesting that the models trained with Origin may benefit from the additional (unwanted confounding) informa- tion in the accompaniment. Using Remix alone addresses this issue, but its result is no better than using Origin alone. The combination of the three data (i.e., Origin, V ocal-only , and Remix) significantly boosts the song-lev el F1 score. The F1 score at the 5-sec level is much worse than that at the song level, highlighting the importance of majority v oting in aggregating the result. One important reason for this is the presence of non-vocal parts in a song. T o demonstrate this, we regard “vocalness” as the mean volume of the v ocal-separated clip for each 5-sec segment, and then compute the correlation between the vocalness and the prediction of the ground truth singer for test songs by our CRNN model trained with Data aug training set. The resulting correlation coefficient (0.39) indicates a weak relationship between these two factors. Fig- ure 3 sho ws the result for three random test songs. W e see that the model assigns high likelihood scores to the correct singer for the v ocal frames (i.e., frames with lar ger avg db) b ut not for the non-vocal frames. W e therefore suggest that 1) song- lev el accurac y is more important than 5-sec le vel accuracy , 2) future work may consider employing a vocal/non-v ocal de- tector (e.g., [20]) in both the training and testing stages. (a) 05-W inter .mp3 (b) 07-Calypso.mp3 (c) 01-Black Friday .mp3 A r t i st : to r i am os Al b u m : L i t t l e E a r t h q u a ke s So n g : 05 - Wi n t e r . m p 3 A r t i st : su za n n e ve g a Al b u m : So l i t u d e St a n d i n g So n g : 07 - C a l yp so . m p 3 A r t i st : st e e l y dan Al b u m : K a t y L i e d So n g : 01 - B l a ck_ F r i d a y . m p 3 (a ) (b ) ( c) Fig. 3 . The scatter plots sho wing the lik elihood score for the correct singer of a testing song for different 5-sec segments of that song, predicted by the CRNN model trained on ‘Data aug. ’ The se gments are sorted from left to right in each plot according to vocalness, the average decibel value of the vocal-separated part of that song. The three plots show the same trend: the model do predict the correct singer for the frames with av erage vocal db greater than − 10 , b ut not for the non-vocal frames. The t-SNE of CRNN The t-SNE of CRNNM Fig. 4 . V isualization of the embeddings (projected into 2D by t-SNE) generated by the models trained on the Origin training set for the testing samples (5s segment; under the album split). Upper: the result of CRNN (i.e., the model shown in Figure 1 but without the melody branch); lo wer: the result of CRNNM (i.e., the model shown in Figure 1). 3.2. V isualization After training, we can re gard the output of the final fully- connected layer as an embedding of the input data. V isu- alizing the representations can giv e us some ideas of the behaviour and performance of our SID models. Therefore, we employ t-Distributed Stochastic Neighbor Embedding (t- SNE) [28] to project the computed embedding vectors to a 2-D space for visualization, and to explore the structure of the predictions. For space limit, only the result of CRNN and CRNNM models trained on Origin are presented. The audio samples of testing set are drew and colored according to the ground truth artist labels in Figure 4. It can be seen from the result of CRNNM that samples from different singers are fairly well-separated in the embedding space. 2 The result of CRNN looks less separated, suggesting again that a model taking additional melody feature may do SID better . 4. CONCLUSIONS The paper proposes a new SID model extending from CRNN and in volving the use of melody information by leveraging CREPE [6]. Also, a data augmentation method called shuffle- and-remix is adopted to a void the confounds from the accom- paniments by using source separation [12]. Our ev aluation shows that both melody information and data augmentation improv e the result, especially the latter . Future work includes three directions. First, to use a vocal detector [20] as a pre- filter for SID. Second, to in vestigate replacing con volutions by GR Us for the melody branch since the melody contour is a time series. Lastly , to try other data augmentation methods such as pitch shifting, time stretching, or a shuffle-and-remix variant that considers the k ey and tempo while remixing. 2 W e note that similar visualization of the learned embedding space is also provided in [17]. Y et, they consider the song-split setting in their visualiza- tion, while we consider the more challenging yet realistic case of album-split. Therefore, although the embeddings shown in their work seem to be even more separated, we still consider the result here promising. 5. REFERENCES [1] A. Demetriou, A. Jansson, A. Kumar , and R. M. Bittner , “V o- cals in music matter: the relev ance of v ocals in the minds of listeners, ” in Pr oc. Int. Soci ety for Music Information Retrieval Confer ence , 2018, pp. 514–520. [2] K. Lee and J. Nam, “Learning a joint embedding space of monophonic and mixed music signals for singing voice, ” in Pr oc. Int. Society for Music Information Retrieval Confer ence , 2019. [3] M. Umbert, J. Bonada, M. Goto, T . Nakano, and J. Sundberg, “Expression control in singing voice synthesis: Features, ap- proaches, e valuation, and challenges, ” IEEE Signal Pr ocessing Magazine , v ol. 32, no. 6, pp. 55–73, 2015. [4] J.-Y . Liu, Y .-H. Chen, Y .-C. Y eh, and Y .-H. Y ang, “Score and lyrics-free singing voice generation, ” arXiv pr eprint arXiv:1912.11747 , 2019. [5] E. J. Humphrey, S. Reddy, P . Seetharaman, A. Kumar , R. M. Bittner , A. Demetriou, S. Gulati, A. Jansson, T . Jehan, B. Lehner, A. Krupse, and L. Y ang, “ An introduction to signal processing for singing-voice analysis: High notes in the effort to automate the understanding of vocals in music, ” IEEE Sig- nal Pr ocessing Magazine , v ol. 36, no. 1, pp. 82–94, 2019. [6] J.-W . Kim, J. Salamon, P . Li, and J. P . Bello, “CREPE: A con- volutional representation for pitch estimation, ” in Proc. IEEE Int. Conf . Acoustics, Speech and Signal Pr ocessing , 2018, [On- line] https://github.com/marl/crepe . [7] J. Sundberg, The Science of the Singing V oice , Northern Illi- nois Univ ersity Press, 1989. [8] Z. Rafii, A. Liutkus, F .-R. St ¨ oter , S. I. Mimilakis, D. FitzGer- ald, and B. Pardo, “ An ov erview of lead and accompani- ment separation in music, ” IEEE/ACM T ransactions on Audio, Speech, and Language Pr ocessing , vol. 26, no. 8, pp. 1307– 1335, 2018. [9] B. L. Sturm, “ A simple method to determine if a music in- formation retrieval system is a horse, ” IEEE T ransactions on Multimedia , vol. 16, no. 6, pp. 1636–1644, 2014. [10] J. Durrieu, G. Richard, and B. David, “ An iterativ e approach to monaural musical mixture de-soloing, ” in Pr oc. IEEE Int. Conf. Acoustics, Speech and Signal Pr ocessing , 2009, pp. 105– 108. [11] C.-Y . Sha, Y .-H. Y ang, Y .-C. Lin, and H. H. Chen, “Singing voice timbre classification of Chinese popular music, ” in Pr oc. IEEE Int. Conf. Acoustics, Speech and Signal Pr ocess- ing , 2013. [12] F .-R. St ¨ oter , S. Uhlich, A. Liutkus, and Y . Mitsufuji, “Open- unmix - A reference implementation for music source sepa- ration, ” Journal of Open Source Softwar e , 2019, [Online] https://sigsep.github.io/open- unmix/ . [13] J.-Y . Liu and Y .-H. Y ang, “Dilated con volution with dilated GR U for music source separation, ” in Pr oc. Int. Joint Conf . Artificial Intelligence , 2019, pp. 4718–4724. [14] A. Mesaros, T . V irtanen, and A. Klapuri, “Singer identification in polyphonic music using vocal separation and pattern recog- nition methods., ” in Proc. Int. Society for Music Information Retrieval Confer ence , 2007. [15] L. Su and Y .-H. Y ang, “Sparse modeling for artist identifica- tion: Exploiting phase information and vocal separation, ” in Pr oc. Int. Society for Music Information Retrieval Confer ence , 2013, pp. 349–354. [16] B. Sharma, R. K. Das, and H. Li, “On the importance of audio- source separation for singer identification in polyphonic mu- sic, ” in Pr oc. INTERSPEECH , 2019, pp. 2020–2024. [17] Z. Nasrullah and Y . Zhao, “Musical artist classifica- tion with con volutional recurrent neural networks, ” in Pr oc. Int. Joint Conf. Neural Network , 2019, [On- line] https://github.com/ZainNasrullah/ music- artist- classification- crnn . [18] D. Ellis, “Classifying music audio with timbral and chroma features, ” in Proc. Int. Society for Music Information Re- trieval Conference , 2007, [Online] https://labrosa. ee.columbia.edu/projects/artistid/ . [19] S. C. W ong, A. Gatt, V . Stamatescu, and M. D. McDonnell, “Understanding data augmentation for classification: When to warp?, ” in Pr oc. Int. Conf. Digital Imag e Computing: T ech- niques and Applications , 2016. [20] J. Schl ¨ uter and T . Grill, “Exploring data augmentation for im- prov ed singing v oice detection with neural networks, ” in Pr oc. Int. Society for Music Information Retrieval Confer ence , 2015. [21] S. Uhlich, M. Porcu, F . Giron, M. Enenkl, T . Kemp, N. T aka- hashi, and Y . Mitsufuji, “Improving music source separation based on deep neural networks through data augmentation and network blending, ” in Pr oc. IEEE Int. Conf . Acoustics, Speech and Signal Pr ocessing , 2017. [22] J.-Y . Liu and Y .-H. Y ang, “Denoising auto-encoder with recur- rent skip connections and residual regression for music source separation, ” in Pr oc. IEEE Int. Conf . Machine Learning and Applications , 2018. [23] M. Panteli, R. Bittner, J. P . Bello, and S. Dixon, “T o wards the characterization of singing styles in world music, ” in Pr oc. IEEE Int. Conf. Acoustics, Speech and Signal Pr ocess- ing , 2017. [24] K. Cho, B. Merrienboer, C. Gulcehre, D. Bahdanau, F . Bougares, H. Schwenk, and Y . Bengio, “Learning phrase representations using rnn encoder-decoder for statistical ma- chine translation, ” arXiv pr eprint arXiv:1406.1078 , 2014. [25] J. Salamon, B. Rocha, and E. Gomez, “Musical genre classifi- cation using melody features e xtracted from polyphonic music signals, ” in Pr oc. IEEE Int. Conf . Acoustics, Speech and Signal Pr ocessing , 2012. [26] B. Rocha, R. Panda, and R. P . Pai va, “Music emotion recogni- tion: The importance of melodic features, ” in Proc. Int. W ork- shop on Machine Learning and Music , 2013. [27] R. M. Bittner, J. Salamon, J. J. Bosch, and J. P . Bello, “Pitch contours as a mid-level representation for music informatics, ” in Pr oc. AES Conf. Semantic A udio , 2017. [28] L. van der Maaten and G. Hinton, “V isualizing data using t-SNE, ” Journal of Machine Learning Resear ch , vol. 9, pp. 2579–2605, 2008.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment