딥러닝 훈련 중 헤시안 스펙트럼의 비밀: NTK 기반 완전 해석
본 논문은 무한 폭 신경망에서 고정된 신경망 탄젠트 커널(NTK)을 이용해 손실 함수 헤시안의 스펙트럼을 정확히 분석한다. NTK가 고정된 경우 헤시안을 두 행렬 I와 S로 분해하고, I는 데이터의 커널 PCA와 동일한 양의 반정치 행렬, S는 수렴 과정에서 사라지는 잔여 항으로 보인다. 두 행렬은 대규모 폭 한계에서 서로 직교하므로 전체 헤시안의 고계 모멘트는 I와 S의 모멘트 합으로 표현된다. 또한 평균‑필드(limit)에서 초기 순간의 1…
저자: Arthur Jacot, Franck Gabriel, Clement Hongler
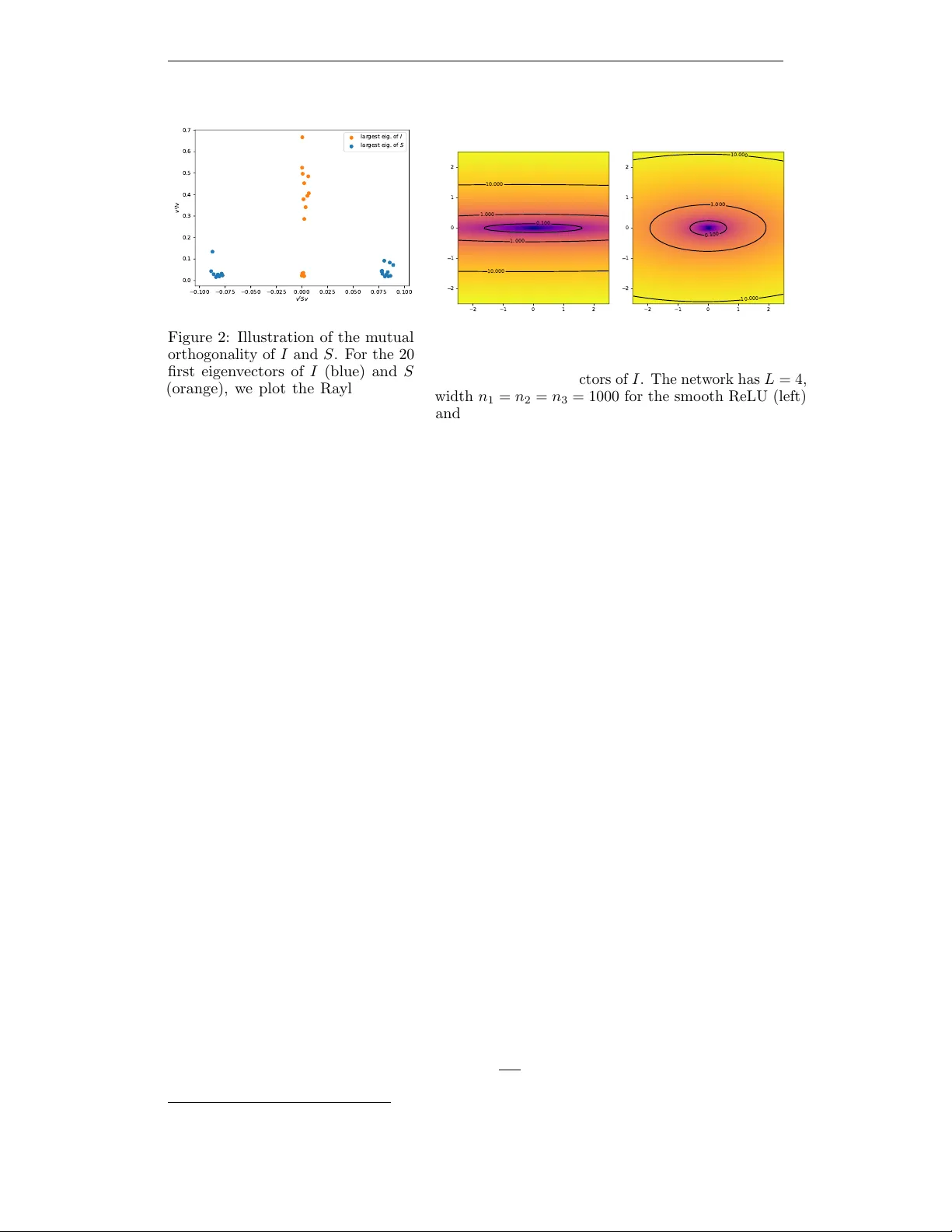
**1. 연구 배경 및 목표**
딥러닝 모델은 비선형, 비볼록 손실표면을 가지며, 그 2차 미분인 헤시안은 최적화와 일반화 특성을 설명하는 핵심 도구이다. 기존 연구는 수치 실험을 통해 “많은 평평한 방향”, “음의 고유값이 적은 고차원 사다리형 구조” 등을 보고했지만, 이들을 이론적으로 정량화한 결과는 부족했다. 최근 신경망 탄젠트 커널(NTK) 이론은 무한 폭 한계에서 신경망의 학습을 선형 커널 회귀와 동등하게 만든다. 저자들은 이 NTK를 이용해 헤시안을 두 부분 I와 S 로 분해하고, 각각을 정확히 분석함으로써 헤시안 스펙트럼의 전체 구조를 밝히고자 한다.
**2. 모델 설정**
- L + 1 층 완전 연결 신경망, 각 은닉층에 \(n_\ell\) 뉴런, 파라미터 수 \(P = \sum_{\ell=0}^{L-1} (n_{\ell}+1)n_{\ell}\).
- 파라미터는 i.i.d. \( \mathcal N(0,1) \) 로 초기화, 편향 스케일을 조정하는 \(\beta\) 를 도입.
- 활성화 함수 \(\sigma\) 는 4차 연속 미분 가능하고 유계인 \(C^4_b(\mathbb R)\) 로 가정.
- 손실은 일반적인 엄격 볼록 함수 \(c_i\) 를 평균한 형태이며, “Gradient norm bounded over sublevel sets (BGOSS)” 조건을 만족한다.
**3. NTK와 무한 폭 한계**
재귀적으로 정의된 전/후 활성화와 가중치에 대해, 폭을 순차적으로 무한히 보낼 때( \(n_1\to\infty, n_2\to\infty,\dots\) ), NTK \(\Theta^{(L)}\) 은 확정적인 커널 \(\Theta^{(L)}_\infty\) 로 수렴하고 훈련 전 과정에서 거의 변하지 않는다. 이 커널은 입력 간 공분산 \(\Sigma^{(\ell)}_\infty\) 와 그 미분 \(\dot\Sigma^{(\ell)}_\infty\) 를 이용해
\(\Theta^{(L)}_\infty = \sum_{\ell=1}^{L} \Sigma^{(\ell)}_\infty \dot\Sigma^{(\ell+1)}_\infty \dots \dot\Sigma^{(L)}_\infty\)
로 구성된다.
**4. 헤시안 분해 I + S**
손실 \(C\) 와 네트워크 함수 \(f_\theta\) 를 합성한 전체 손실 \(C\circ F^{(L)}\) 의 파라미터에 대한 헤시안은
\(H = I + S\) 로 정확히 분해된다.
- \(I = D Y^{(L)}{}^{\top} H_C D Y^{(L)}\) : 여기서 \(D Y^{(L)}\) 은 훈련 데이터에 대한 Jacobian, \(H_C\) 는 출력‑출력 Hessian. MSE와 같은 2차 손실에서는 \(H_C = \frac{1}{N} I\) 로 상수이므로, I는 전적으로 NTK와 데이터 Gram 행렬 \(\tilde\Theta\) 에 의해 결정된다. 고유값은 \(\tilde\Theta\) 의 커널 PCA와 동일하고, 큰 고유값은 데이터의 주요 변동을, 다수의 거의 0 고유값은 “flat directions”를 의미한다.
- \(S = \nabla C \cdot H_Y^{(L)}\) : 파라미터‑파라미터 3차 텐서 \(H_Y^{(L)}\) 와 손실 기울기 \(\nabla C\) 의 스칼라 곱. 이 항은 네트워크가 전역 최소점에 수렴할수록 사라지는 잔여 항이며, 첫 번째 모멘트는 \( \operatorname{tr}(S(t)) = G(t)^{\top}\nabla C(Y(t))\) 로 표현된다. 여기서 \(G(t)\) 는 초기값 \(G(0)\) 와 NTK‑연관 커널 \(\tilde\Lambda\) 의 동역학을 통해 정의된다.
**5. 모멘트와 직교성**
주요 정리(Theorem 1)는 모든 고차 모멘트 \(k\ge1\) 에 대해
\(\operatorname{tr}(H^k) \approx \operatorname{tr}(I^k) + \operatorname{tr}(S^k)\)
가 성립함을 보인다. 이를 위해 두 행렬이 **상호 직교**함을 증명한다:
\(\lim_{n\to\infty} I S = 0\) (Proposition 5). 직교성은 I와 S가 각각 큰 영공간을 가지며, 파라미터 수 \(P\) 가 폭의 제곱에 비례해 급증하는 상황에서도 유지된다.
- **I의 모멘트**: \( \operatorname{tr}(I^k) \) 은 \(\tilde\Theta\) 의 k‑중 곱에 대한 트레이스로, 정확히
\(\operatorname{tr}(I^k) \to \operatorname{tr}\big( H_C(Y(t)) \tilde\Theta \big)^k\)
로 수렴한다.
- **S의 모멘트**: 첫 번째 모멘트는 위에서 언급한 \(G(t)\) 와 \(\nabla C\) 로 표현되고, 두 번째 모멘트는
\(\operatorname{tr}(S^2) \to \nabla C^{\top} \tilde\Upsilon \nabla C\)
이며, 세 번째 이상은 모두 0으로 사라진다.
**6. 평균‑필드(limit) 확장**
출력 스케일을 \(\frac{1}{\sqrt{w}}\) 로, 학습률을 \(w\) 배 늘리면 NTK가 훈련 중 변한다(Mean‑field limit). 이 경우 Hessian은
\(H = \frac{1}{w} I + \frac{1}{\sqrt{w}} S\)
로 스케일링된다. I는 변하지 않지만 S는 상대적으로 더 큰 영향을 미친다. 저자들은 초기 순간에만 적용 가능한 1·2 차 모멘트를 새로운 커널 \(\Upsilon, \Xi, \Phi\) 로 정확히 기술하고, 이는 기존 고정‑NTK 결과와 일관된다.
**7. 실험 검증**
- 네트워크: 두 은닉층, 각각 5000 뉴런, ReLU 및 정규화 ReLU 사용.
- 데이터: 14×14 MNIST (256 샘플).
- 손실: MSE.
- 측정: 첫 4차 트레이스 \(\operatorname{tr}(H^k)\) 를 250번 독립 실행 후 평균.
결과: 이론적 곡선(색선)과 실험값(검은 교차점)이 거의 일치, 특히 k=1,2에서 S의 기여가 뚜렷이 관찰됨. k≥3에서는 I만이 지배함을 확인했다.
**8. 의의 및 향후 연구**
이 논문은 (i) 헤시안 스펙트럼을 NTK와 직접 연결, (ii) 고차 모멘트까지 정확히 계산, (iii) I와 S의 직교성을 증명함으로써 기존 “F + S” 분해가 단순한 경험적 가설이 아니라 수학적으로 정당화된 구조임을 보여준다. 결과는 과대 파라미터화된 DNN이 왜 많은 평평한 고유값을 갖는지, 그리고 이러한 평탄성이 일반화와 어떤 관계가 있는지를 이론적으로 설명한다. 향후 연구는 (a) 비‑Gaussian 초기화, (b) 배치 정규화·드롭아웃 등 실용적 트릭이 I·S 구조에 미치는 영향, (c) 최적화 스키마(예: Adam)와의 상호작용을 확장하는 방향으로 진행될 수 있다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기