The asymptotic spectrum of the Hessian of DNN throughout training
The dynamics of DNNs during gradient descent is described by the so-called Neural Tangent Kernel (NTK). In this article, we show that the NTK allows one to gain precise insight into the Hessian of the cost of DNNs. When the NTK is fixed during traini…
Authors: Arthur Jacot, Franck Gabriel, Clement Hongler
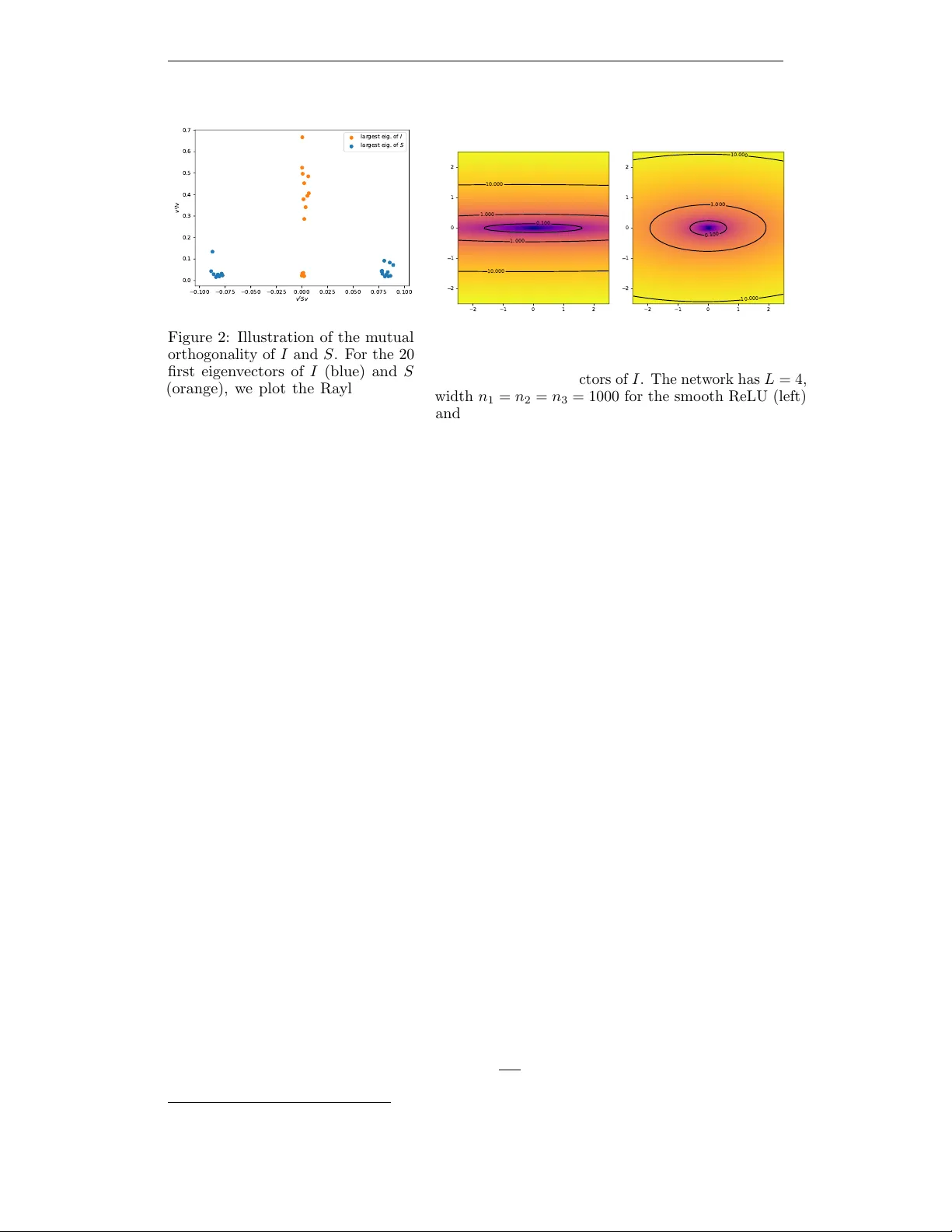
Published as a conference pap er at ICLR 2020 The asymptotic spectr um of the Hessian of DNN thr oughout training Arth ur Jacot, F ranc k Gabriel & Cl ´ emen t Hongler Chair of Statistical Field Theory Ecole P olytechnique F ´ ed ´ erale de Lausanne { arthur.jacot,franck.grabriel,clement.hongler } @epfl.ch Abstra ct The dynamics of DNNs during gradien t descent is describ ed by the so-called Neural T angen t Kernel (NTK). In this article, we sho w that the NTK allows one to gain precise insight in to the Hessian of the cost of DNNs. When the NTK is fixed during training, we obtain a full characterization of the asymptotics of the sp ectrum of the Hessian, at initialization and during training. In the so-called mean-field limit, where the NTK is not fixed during training, w e describ e the first tw o moments of the Hessian at initialization. 1 Intr oduction The adven t of deep learning has sparked a lot of interest in the loss surface of deep neural net works (DNN), and in particular its Hessian. Ho wev er to our knowledge, there is still no theoretical description of the sp ectrum of the Hessian. Nev ertheless a num b er of phenomena ha ve b een observed numerically . The loss surface of neural netw orks has b een compared to the energy landscap e of differen t ph ysical mo dels (Choromansk a et al., 2015; Geiger et al., 2018; Mei et al., 2018). It app ears that the loss surface of DNNs may c hange significan tly dep ending on the width of the netw ork (the n umber of neurons in the hidden lay er), motiv ating the distinction b et ween the under- and o ver-parametrized regimes (Baity-Jesi et al., 2018; Geiger et al., 2018; 2019). The non-conv exity of the loss function implies the existence of a very large num ber of saddle p oin ts, which could slow down training. In particular, in (Pascan u et al., 2014; Dauphin et al., 2014), a relation b etw een the rank of saddle p oin ts (the num b er of negative eigen v alues of the Hessian) and their loss has b een observ ed. F or ov erparametrized DNNs, a p ossibly more imp ortan t phenomenon is the large num ber of flat directions (Baity-Jesi et al., 2018). The existence of these flat minima is conjectured to b e related to the generalization of DNNs and may dep end on the training pro cedure (Ho c hreiter & Schmidh uber, 1997; Chaudhari et al., 2016; W u et al., 2017). In (Jacot et al., 2018) it has b een shown, using a functional approach, that in the infinite- width limit, DNNs b ehav e lik e kernel metho ds with resp ect to the so-called Neural T angen t Kernel, which is determined by the architecture of the net work. This leads to con vergence guaran tees for DNNs (Jacot et al., 2018; Du et al., 2019; Allen-Zhu et al., 2018; Huang & Y au, 2019) and strengthens the connections b etw een neural netw orks and kernel metho ds (Neal, 1996; Cho & Saul, 2009; Lee et al., 2018). Our approach also allows one to prob e the so-called mean-field/activ e limit (studied in (Rotsk off & V anden-Eijnden, 2018; Chizat & Bac h, 2018a; Mei et al., 2018) for shallow net works), where the NTK v aries during training. This raises the question: can we use these new results to gain insigh t into the b ehavior of the Hessian of the loss of DNNs, at least in the small region explored by the parameters during training? 1 Published as a conference pap er at ICLR 2020 1.1 Contributions F ollowing ideas introduced in (Jacot et al., 2018), we consider the training of L + 1-la yered DNNs in a functional setting. F or a functional cost C , the Hessian of the loss R P 3 θ 7→ C F ( L ) ( θ ) is the sum of tw o P × P matrices I and S . W e sho w the following results for large P and for a fixed num b er of datap oints N : • The first matrix I is p ositiv e semi-definite and its eigenv alues are given by the (w eighted) kernel PCA of the dataset with resp ect to the NTK. The dominating eigen v alues are the principal comp onents of the data follow ed by a high num b er of small eigenv alues. The “flat directions” are spanned by the small eigenv alues and the null-space (of dimension at least P − N when there is a single output). Because the NTK is asymptotically constant (Jacot et al., 2018), these results apply at initialization, during training and at con vergence. • The second matrix S can b e viewed as residual contribution to H , since it v anishes as the netw ork conv erges to a global minimum. W e compute the limit of the first momen t T r ( S ) and characterize its evolution during training, of the second momen t T r S 2 whic h stays constant during training, and show that the higher moments v anish. • Regarding the sum H = I + S , we show that the matrices I and S are asymptotically orthogonal to each other at initialization and during training. In particular, the momen ts of the matrices I and S add up: tr ( H k ) ≈ tr ( I k ) + tr ( S k ). These results give, for any depth and a fairly general non-linearity , a complete description of the sp ectrum of the Hessian in terms of the NTK at initialization and throughout training. Our theoretical results are consistent with a num b er of observ ations ab out the Hessian (Ho c hreiter & Schmidh ub er, 1997; Pascan u et al., 2014; Dauphin et al., 2014; Chaudhari et al., 2016; W u et al., 2017; Pennington & Bahri, 2017; Geiger et al., 2018), and sheds a new ligh t on them. 1.2 Rela ted works The Hessian of the loss has b een studied through the decomp osition I + S in a num b er of previous w orks (Sagun et al., 2017; Pennington & Bahri, 2017; Geiger et al., 2018). F or least-squares and cross-entrop y costs, the first matrix I is equal to the Fisher matrix (W agenaar, 1998; P ascanu & Bengio, 2013), whose moments hav e b een describ ed for shallow net works in (Pennington & W orah, 2018). F or deep netw orks, the first tw o moments and the op erator norm of the Fisher matrix for a least squares loss were computed at initialization in (Karakida et al., 2018) conditionally on a certain indep endence assumption; our metho d do es not require suc h assumptions. Note that their approach implicitly uses the NTK. The second matrix S has b een studied in (Pennington & Bahri, 2017; Geiger et al., 2018) for shallow netw orks, conditionally on a num b er of assumptions. Note that in the setting of (P ennington & Bahri, 2017), the matrices I and S are assumed to b e freely indep enden t, whic h allows them to study the sp ectrum of the Hessian; in our setting, we sho w that the t wo matrices I and S are asymptotically orthogonal to each other. 2 Setup W e consider deep fully connected artificial neural netw orks (DNNs) using the setup and NTK parametrization of (Jacot et al., 2018), taking an arbitrary nonlinearity σ ∈ C 4 b ( R ) (i.e. σ : R → R that is 4 times contin uously differentiable function with all four deriv atives b ounded). The la yers are num bered from 0 (input) to L (output), each containing n ` neurons for ` = 0 , . . . , L . The P = P L − 1 ` =0 ( n ` + 1) n ` +1 parameters consist of the weigh t matrices W ( ` ) ∈ R n ` +1 × n ` and bias vectors b ( ` ) ∈ R n ` +1 for ` = 0 , . . . , L − 1. W e aggregate the parameters in to the vector θ ∈ R P . 2 Published as a conference pap er at ICLR 2020 The activ ations and pre-activ ations of the lay ers are defined recursively for an input x ∈ R n 0 , setting α (0) ( x ; θ ) = x : ˜ α ( ` +1) ( x ; θ ) = 1 √ n ` W ( ` ) α ( ` ) ( x ; θ ) + β b ( ` ) , α ( ` +1) ( x ; θ ) = σ ˜ α ( ` +1) ( x ; θ ) . The parameter β is added to tune the influence of the bias on training 1 . All parameters are initialized as iid N (0 , 1) Gaussians. W e will in particular study the netw ork function, which maps inputs x to the activ ation of the output la yer (b efore the last non-linearity): f θ ( x ) = ˜ α ( L ) ( x ; θ ) . In this pap er, w e will study the limit of v arious ob jects as n 1 , . . . , n L → ∞ se quential ly , i.e. w e first take n 1 → ∞ , then n 2 → ∞ , etc. This greatly simplifies the pro ofs, but they could in principle b e extended to the simultaneous limit, i.e. when n 1 = ... = n L − 1 → ∞ . All our numerical exp eriments are done with ‘rectangular’ netw orks (with n 1 = ... = n L − 1 ) and matc h closely the predictions for the sequential limit. In the limit we study in this pap er, the NTK is asymptotically fixed, as in (Jacot et al., 2018; Allen-Zh u et al., 2018; Du et al., 2019; Arora et al., 2019; Huang & Y au, 2019). By rescaling the outputs of DNNs as the width increases, one can reach another limit where the NTK is not fixed (Chizat & Bac h, 2018a;b; Rotsk off & V anden-Eijnden, 2018; Mei et al., 2019). Some of our results can b e extended to this setting, but only at initialization (see Section 3.3). The b eha vior during training b ecomes how ev er muc h more complex. 2.1 Functional viewpoint The netw ork function lives in a function space f θ ∈ F := [ R n 0 → R n L ] and we call the function F ( L ) : R P → F that maps the parameters θ to the netw ork function f θ the r e alization function . W e study the differential b ehavior of F ( L ) : • The deriv ativ e D F ( L ) ∈ R P ⊗ F is a function-v alued vector of dimension P . The p -th entry D p F ( L ) = ∂ θ p f θ ∈ F represen ts how mo difying the parameter θ p mo difies the function f θ in the space F . • The Hes sian H F ( L ) ∈ R P ⊗ R P ⊗ F is a function-v alued P × P matrix. The net work is trained with resp ect to the cost functional: C ( f ) = 1 N N X i =1 c i ( f ( x i )) , for strictly conv ex c i , summing ov er a finite dataset x 1 , . . . , x N ∈ R n 0 of size N . The parameters are then trained with gradient descent on the comp osition C ◦ F ( L ) , which defines the usual loss surface of neural net works. In this setting, w e define the finite realization function Y ( L ) : R P → R N n L mapping parameters θ to b e the restriction of the netw ork function f θ to the training set y ik = f θ,k ( x i ). The Jacobian D Y ( L ) is hence an N n L × P matrix and its Hessian H Y ( L ) is a P × P × N n L tensor. Defining the restricted cost C ( y ) = 1 N P i c i ( y i ), w e hav e C ◦ F ( L ) = C ◦ Y ( L ) . F or our analysis, w e require that the gradient norm kD C k do es not explo de during training. The follo wing condition is sufficient: Definition 1. A loss C : R N n L → R has b ounded gradients ov er sublevel sets (BGOSS) if the norm of the gradien t is b ounded ov er all sets U a = Y ∈ R N n L : C ( Y ) ≤ a . F or example, the Mean Square Error (MSE) C ( Y ) = 1 2 N k Y ∗ − Y k 2 for the lab els Y ∗ ∈ R N n L has BGOSS b ecause k∇ C ( Y ) k 2 = 1 N k Y ∗ − Y k 2 = 2 C ( Y ). F or the binary and softmax cross-en tropy the gradient is uniformly b ounded, see Prop osition 2 in App endix A. 1 In our exp erimen ts, we take β = 0 . 1. 3 Published as a conference pap er at ICLR 2020 2.2 Neural T angent Kernel The b ehavior during training of the netw ork function f θ in the function space F is describ ed b y a (multi-dimensional) kernel, the Neur al T angent Kernel (NTK) Θ ( L ) k,k 0 ( x, x 0 ) = P X p =1 ∂ θ p f θ,k ( x ) ∂ θ p f θ,k 0 ( x 0 ) . During training, the function f θ follo ws the so-called kernel gr adient desc ent with resp ect to the NTK, whic h is defined as ∂ t f θ ( t ) ( x ) = −∇ Θ ( L ) C | f θ ( t ) ( x ) := − 1 N N X i =1 Θ ( L ) ( x, x i ) ∇ c i ( f θ ( t ) ( x i )) . In the infinite-width limit (letting n 1 → ∞ , . . . , n L − 1 → ∞ sequen tially) and for losses with BGOSS, the NTK conv erges to a deterministic limit Θ ( L ) → Θ ( L ) ∞ ⊗ I d n L , which is constant during training, uniformly on finite time in terv als [0 , T ] (Jacot et al., 2018). F or the MSE loss, the uniform con vergence of the NTK was prov en for T = ∞ in (Arora et al., 2019). The limiting NTK Θ ( L ) ∞ : R n 0 × R n 0 → R is constructed as follo ws: 1. F or f , g : R → R and a kernel K : R n 0 × R n 0 → R , define the k ernel L f ,g K : R n 0 × R n 0 → R b y L f ,g K ( x 0 , x 1 ) = E ( a 0 ,a 1 ) [ f ( a 0 ) g ( a 1 )] , for ( a 0 , a 1 ) a cen tered Gaussian v ector with cov ariance matrix ( K ( x i , x j )) i,j =0 , 1 . F or f = g , w e denote by L f K the k ernel L f ,f K . 2. W e define the kernels Σ ( ` ) ∞ for each lay er of the net work, starting with Σ (1) ∞ ( x 0 , x 1 ) = 1 / n 0 ( x T 0 x 1 ) + β 2 and then recursively by Σ ( ` +1) ∞ = L σ Σ ( ` ) ∞ + β 2 , for ` = 1 , . . . , L − 1, where σ is the netw ork non-linearity . 3. The limiting NTK Θ ( L ) ∞ is defined in terms of the kernels Σ ( ` ) ∞ and the kernels ˙ Σ ( ` ) ∞ = L ˙ σ Σ ( ` − 1) ∞ : Θ ( L ) ∞ = L X ` =1 Σ ( ` ) ∞ ˙ Σ ( ` +1) ∞ . . . ˙ Σ ( L ) ∞ . The NTK leads to con vergence guarantees for DNNs in the infinite-width limit, and connect their generalization to that of k ernel metho ds (Jacot et al., 2018; Arora et al., 2019). 2.3 Gram Ma trices F or a finite dataset x 1 , . . . , x N ∈ R n 0 and a fixed depth L ≥ 1, we denote by ˜ Θ ∈ R N n L × N n L the Gram matrix of x 1 , . . . , x N with resp ect to the limiting NTK, defined by ˜ Θ ik,j m = Θ ( L ) ∞ ( x i , x j ) δ km . It is blo c k diagonal b ecause different outputs k 6 = m are asymptotically uncorrelated. Similarly , for any (scalar) k ernel K ( L ) (suc h as the limiting k ernels Σ ( L ) ∞ , Λ ( L ) ∞ , Υ ( L ) ∞ , Φ ( L ) ∞ , Ξ ( L ) ∞ in tro duced later), we denote the Gram matrix of the datap oints by ˜ K . 3 Main Theorems 3.1 Hessian as I + S Using the ab ov e setup, the Hessian H of the loss C ◦ F ( L ) is the sum of tw o terms, with the en try H p,p 0 giv en by H p,p 0 = HC | f θ ( ∂ θ p F , ∂ θ p 0 F ) + DC | f θ ( ∂ θ p ,θ p 0 F ) . 4 Published as a conference pap er at ICLR 2020 F or a finite dataset, the Hessian matrix H C ◦ Y ( L ) is equal to the sum of t wo matrices I = D Y ( L ) T H C D Y ( L ) and S = ∇ C · H Y ( L ) where D Y ( L ) is a N n L × P matrix, H C is a N n L × N n L matrix and H Y ( L ) is a P × P × N n L tensor to which we apply a scalar pro duct (denoted by · ) in its last dimension with the N n L v ector ∇ C to obtain a P × P matrix. Our main con tribution is the follo wing theorem, which describ es the limiting moments T r H k in terms of the momen ts of I and S : Theorem 1. F or any loss C with BGOSS and σ ∈ C 4 b ( R ) , in the se quential limit n 1 → ∞ , . . . , n L − 1 → ∞ , we have for al l k ≥ 1 T r H ( t ) k ≈ T r I ( t ) k + T r S ( t ) k . The limits of T r I ( t ) k and T r S ( t ) k c an b e expr esse d in terms of the NTK Θ ( L ) ∞ , the kernels Υ ( L ) ∞ , Ξ ( L ) ∞ and the non-symmetric kernels Φ ( L ) ∞ , Λ ( L ) ∞ define d in App endix C: • The moments T r I ( t ) k c onver ge to the fol lowing limits (with the c onvention that i k +1 = i 1 ): T r I ( t ) k → T r H C ( Y ( t )) ˜ Θ k = 1 N k N X i 1 ,...,i k =1 k Y m =1 c 00 i m ( f θ ( t ) ( x i m ))Θ ( L ) ∞ ( x i m , x i m +1 ) . • The first moment T r ( S ( t )) c onver ges to the limit: T r ( S ( t )) = ( G ( t )) T ∇ C ( Y ( t )) . At initialization ( G (0) , Y (0)) form a Gaussian p air of N n L -ve ctors, indep endent for differing output indic es k = 1 , ..., n L and with c ovarianc e E [ G ik (0) G i 0 k 0 (0)] = δ kk 0 Ξ ( L ) ∞ ( x i , x i 0 ) and E [ G ik (0) Y i 0 k 0 (0)] = δ kk 0 Φ ( L ) ∞ ( x i , x i 0 ) for the limiting kernel Ξ ( L ) ∞ ( x, y ) and non-symmetric kernel Φ ( L ) ∞ ( x, y ) . During tr aining, b oth ve ctors fol low the differ ential e quations ∂ t G ( t ) = − ˜ Λ ∇ C ( Y ( t )) ∂ t Y ( t ) = − ˜ Θ ∇ C ( Y ( t )) . • The se c ond moment T r S ( t ) 2 c onver ges to the fol lowing limit define d in terms of the Gr am matrix ˜ Υ : T r S 2 → ( ∇ C ( Y ( t ))) T ˜ Υ ∇ C ( Y ( t )) • The higher moments T r S ( t ) k for k ≥ 3 vanish. Pr o of. The momen ts of I and S can b e studied separately b ecause the moments of their sum is asymptotically equal to the sum of their moments by Prop osition 5 b elow. The limiting momen ts of I and S are resp ectively describ ed by Prop ositions 1 and 4 b elo w. In the case of a MSE loss C ( Y ) = 1 2 N k Y − Y ∗ k 2 , the first and second deriv ativ es take simple forms ∇ C ( Y ) = 1 N ( Y − Y ∗ ) and H C ( Y ) = 1 N I d N n L and the differential equations can b e solv ed to obtain more explicit formulae: 5 Published as a conference pap er at ICLR 2020 1 0 1 1 0 0 1 0 1 t 1 0 2 1 0 3 T r [ H ( t ) k ] k = 1 k = 2 k = 3 k = 4 1 0 1 1 0 0 1 0 1 t 1 0 2 3 × 1 0 1 4 × 1 0 1 6 × 1 0 1 T r [ H ( t ) k ] k = 1 k = 2 k = 3 k = 4 Figure 1: Comparison of the theoretical prediction of Corollary 1 for the exp ectation of the first 4 momen ts (colored lines) to the empirical av erage ov er 250 trials (black crosses) for a rectangular netw ork with tw o hidden lay ers of finite widths n 1 = n 2 = 5000 ( L = 3) with the smo oth ReLU (left) and the normalized smo oth ReLU (right), for the MSE loss on scaled do wn 14x14 MNIST with N = 256. Only the first tw o moments are affected by S at the b eginning of training. Corollary 1. F or the MSE loss C and σ ∈ C 4 b ( R ) , in the limit n 1 , ..., n L − 1 → ∞ , we have uniformly over [0 , T ] T r H ( t ) k → 1 N k T r ˜ Θ k + T r S ( t ) k wher e T r ( S ( t )) → − 1 N ( Y ∗ − Y (0)) T I d N n L + e − t ˜ Θ ˜ Θ − 1 ˜ Λ T e − t ˜ Θ ( Y ∗ − Y (0)) + 1 N G (0) T e − t ˜ Θ ( Y ∗ − Y (0)) T r S ( t ) 2 → 1 N 2 ( Y ∗ − Y (0)) T e − t ˜ Θ ˜ Υ e − t ˜ Θ ( Y ∗ − Y (0)) T r S ( t ) k → 0 when k > 2 . In exp e ctation we have: E [T r ( S ( t ))] → − 1 N T r I d N n L + e − t ˜ Θ ˜ Θ − 1 ˜ Λ T e − t ˜ Θ ˜ Σ + Y ∗ Y ∗ T + 1 N T r e − t ˜ Θ ˜ Φ T E T r S ( t ) 2 → 1 N 2 T r e − t ˜ Θ ˜ Υ e − t ˜ Θ ˜ Σ + Y ∗ Y ∗ T . Pr o of. The moments of I are constant b ecause H C = 1 N I d N n L is constant. F or the moments of S , w e first solve the differential equation for Y ( t ): Y ( t ) = Y ∗ − e − t ˜ Θ ( Y ∗ − Y (0)) . Noting Y ( t ) − Y (0) = − ˜ Θ R t 0 ∇ C ( s ) ds , we hav e G ( t ) = G (0) − ˜ Λ Z t 0 ∇ C ( s ) ds = G (0) + ˜ Λ ˜ Θ − 1 ( Y ( t ) − Y (0)) = G (0) + ˜ Λ ˜ Θ − 1 I d N n L + e − t ˜ Θ ( Y ∗ − Y (0)) The exp ectation of the first momen t of S then follows. 6 Published as a conference pap er at ICLR 2020 3.2 Mutual Or thogonality of I and S A first k ey ingredient to prov e Theorem 1 is the asymptotic mutual orthogonality of the matrices I and S Prop osition (Prop osition 5 in App endix D) . F or any loss C with BGOSS and σ ∈ C 4 b ( R ) , we have uniformly over [0 , T ] lim n L − 1 →∞ · · · lim n 1 →∞ k I S k F = 0 . As a c onse quenc e lim n L − 1 →∞ · · · lim n 1 →∞ T r [ I + S ] k − T r I k + T r S k = 0 . R emark 1 . If tw o matrices A and B are mutualy orthogonal (i.e. AB = 0) the range of A is con tained in the nullspace of B and vice versa. The non-zero eigenv alues of the sum A + B are therefore given by the union of the non-zero eigenv alues of A and B . F urthermore the momen ts of A and B add up: T r [ A + B ] k = T r A k + T r B k . Prop osition 5 shows that this is what happ ens asymptotically for I and S . Note that b oth matrices I and S ha ve large nullspaces: indeed assuming a constant width w = n 1 = ... = n L − 1 , we hav e Rank ( I ) ≤ N n L and Rank ( S ) ≤ 2( L − 1) w N n L (see App endix C), while the num b er of parameters P scales as w 2 (when L > 2). Figure 2 illustrates the m utual orthogonality of I and S . All numerical exp eriments are done for rectangular net works (when the width of the hidden la yers are equal) and agree w ell with our predictions obtained in the sequen tial limit. 3.3 Mean-field Limit F or a rectangular net work with width w , if the output of the net work is divided by √ w and the learning rate is m ultiplied by w (to keep similar dynamics at initialization), the training dynamics changes and the NTK v aries during training when w go es to infinit y . The new parametrization of the output c hanges the scaling of the tw o matrices: H C 1 √ w Y ( L ) = 1 w D Y ( L ) T H C D Y ( L ) + 1 √ w ∇ C · H Y ( L ) = 1 w I + 1 √ w S. The scaling of the learning rate essentially multiplies the whole Hessian b y w . In this setting, the matrix I is left unchanged while the matrix S is multiplied by √ w (the k -th moment of S is hence multiplied b y w k / 2 ). In particular, the tw o moments of the Hessian are dominated b y the moments of S , and the higher moments of S (and the op erator norm of S ) should not v anish. This suggests that the active regime may b e characterised b y the fact that k S k F k I k F . Under the conjecture that Theorem 1 holds for the infinite-width limit of rectangular net works, the asymptotic of the tw o first moments of H is given by: 1 / √ w T r ( H ) → N (0 , ∇ C T ˜ Ξ ∇ C ) 1 / w T r H 2 → ∇ C T ˜ Υ ∇ C, where for the MSE loss w e hav e ∇ C = − Y ∗ . 3.4 The ma trix S The matrix S = ∇ C · H Y ( L ) is b est understo o d as a p erturbation to I , which v anishes as the net work conv erges b ecause ∇ C → 0. T o calculate its moments, we note that T r ∇ C · H Y ( L ) = P X p =1 ∂ 2 θ 2 p Y ! T ∇ C = G T ∇ C, where the vector G = P P k =1 ∂ 2 θ 2 p Y ∈ R N n L is the ev aluation of the function g θ ( x ) = P P k =1 ∂ 2 θ 2 p f θ ( x ) on the training set. 7 Published as a conference pap er at ICLR 2020 F or the second moment we hav e T r ∇ C · H Y ( L ) 2 = ∇ C T P X p,p 0 =1 ∂ 2 θ p θ p 0 Y ∂ 2 θ p θ p 0 Y T ∇ C = ∇ C T ˜ Υ ∇ C for ˜ Υ the Gram matrix of the k ernel Υ ( L ) ( x, y ) = P P p,p 0 =1 ∂ 2 θ p θ p 0 f θ ( x ) ∂ 2 θ p θ p 0 f θ ( y ) T . The follo wing prop osition desrib es the limit of the function g θ and the k ernel Υ ( L ) and the v anishing of the higher moments: Prop osition (Prop osition 4 in App endix C) . F or any loss C with BGOSS and σ ∈ C 4 b ( R ) , the first two moments of S take the form T r ( S ( t )) = G ( t ) T ∇ C ( t ) T r S ( t ) 2 = ∇ C ( t ) T ˜ Υ( t ) ∇ C ( t ) - At initialization, g θ and f θ c onver ge to a (c enter e d) Gaussian p air with c ovarianc es E [ g θ,k ( x ) g θ,k 0 ( x 0 )] = δ kk 0 Ξ ( L ) ∞ ( x, x 0 ) E [ g θ,k ( x ) f θ,k 0 ( x 0 )] = δ kk 0 Φ ( L ) ∞ ( x, x 0 ) E [ f θ,k ( x ) f θ,k 0 ( x 0 )] = δ kk 0 Σ ( L ) ∞ ( x, x 0 ) and during tr aining g θ evolves ac c or ding to ∂ t g θ,k ( x ) = N X i =1 Λ ( L ) ∞ ( x, x i ) ∂ ik C ( Y ( t )) · - Uniformly over any interval [0 , T ] , the kernel Υ ( L ) has a deterministic and fixe d limit lim n L − 1 →∞ · · · lim n 1 →∞ Υ ( L ) kk 0 ( x, x 0 ) = δ kk 0 Υ ( L ) ∞ ( x, x 0 ) with limiting kernel: Υ ( L ) ∞ ( x, x 0 ) = L − 1 X ` =1 Θ ( ` ) ∞ ( x, x 0 ) 2 ¨ Σ ( ` ) ∞ ( x, x 0 ) + 2Θ ( ` ) ∞ ( x, x 0 ) ˙ Σ ( ` ) ∞ ( x, x 0 ) ˙ Σ ( ` +1) ∞ ( x, x 0 ) · · · ˙ Σ ( L − 1) ∞ ( x, x 0 ) . - The higher moment k > 2 vanish: lim n L − 1 →∞ · · · lim n 1 →∞ T r S k = 0 . This result has a n umber of consequences for infinitely wide netw orks: 1. A t initialization, the matrix S has a finite F rob enius norm k S k 2 F = T r S 2 = ∇ C T ˜ Υ ∇ C , b ecause Υ conv erges to a fixed limit. As the netw ork conv erges, the deriv ative of the cost go es to zero ∇ C ( t ) → 0 and so do es the F rob enius norm of S . 2. In contrast the op erator norm of S v anishes already at initialization (b ecause for all ev en k , w e hav e k S k op ≤ k p T r ( S k ) → 0). A t initialization, the v anishing of S in op erator norm but not in F rob enius norm can b e explained by the matrix S ha ving a gro wing num ber of eigenv alues of shrinking intensit y as the width grows. 3. When it comes to the first moment of S , Prop osition 4 shows that the sp ectrum of S is in general not symmetric. F or the MSE loss the exp ectation of the first moment at initialization is E [T r( S )] = E ( Y − Y ∗ ) T G = E Y T G − ( Y ∗ ) T E [ G ] = T r ˜ Φ − 0 whic h may b e p ositive or negative dep ending on the c hoice of nonlinearity: with a smo oth ReLU, it is p ositive, while for the arc-tangent or the normalized smo oth ReLU, it can b e negativ e (see Figure 1). This is in contrast to the result obtained in (Pennington & Bahri, 2017; Geiger et al., 2018) for the shallo w ReLU netw orks, taking the second deriv ative of the ReLU to b e zero. Under this assumption the sp ectrum of S is symmetric: if the eigenv alues are ordered from lo west to highest, λ i = − λ P − i and T r( S ) = 0. 8 Published as a conference pap er at ICLR 2020 0.100 0.075 0.050 0.025 0.000 0.025 0.050 0.075 0.100 v t S v 0.0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 v t I v l a r g e s t e i g . o f I l a r g e s t e i g . o f S Figure 2: Illustration of the mutual orthogonalit y of I and S . F or the 20 first eigenv ectors of I (blue) and S (orange), we plot the Rayleigh quo- tien ts v T I v and v T S v (with L = 3, n 1 = n 2 = 1000 and the normal- ized ReLU on 14x14 MNIST with N = 256). W e see that the direc- tions where I is large are directions where S is small and vice versa. 2 1 0 1 2 2 1 0 1 2 0.100 1.000 1.000 10.000 10.000 2 1 0 1 2 2 1 0 1 2 0.100 1.000 10.000 10.000 Figure 3: Plot of the loss surface around a global mini- m um along the first (along the y co ordinate) and fourth (x co ordinate) eigen vectors of I . The netw ork has L = 4, width n 1 = n 2 = n 3 = 1000 for the smo oth ReLU (left) and the normalized smo oth ReLU (right). The data is uniform on the unit disk. Normalizing the non-linearity greatly reduces the narrow v alley structure of the loss th us sp eeding up training. These observ ations suggest that S has little influence on the shap e of the surface, esp ecially to wards the end of training, the matrix I how ever has an interesting structure. 3.5 The ma trix I A t a global minimizer θ ∗ , the sp ectrum of I describ es ho w the loss b ehav es around θ ∗ . Along the eigenv ectors of the biggest eigenv alues of I , the loss increases rapidely , while small eigen v alues corresp ond to flat directions. Numerically , it has b een observed that the matrix I features a few dominating eigenv alues and a bulk of small eigen v alues (Sagun et al., 2016; 2017; Gur-Ari et al., 2018; Pap yan, 2019). This leads to a narrow v alley structure of the loss around a minimum: the biggest eigenv alues are the ‘cliffs’ of the v alley , i.e. the directions along which the loss grows fastest, while the small eigenv alues form the ‘flat directions’or the b ottom of the v alley . Note that the rank of I is b ounded by N n L and in the ov erparametrized regime, when N n L < P , the matrix I will hav e a large nullspace, these are directions along which the v alue of the function on the training set do es not change. Note that in the ov erparametrized regime, global minima are not isolated: they lie in a manifold of dimension at least P − N n L and the n ullspace of I is tangent to this solution manifold. The matrix I is closely related to the NTK Gram matrix: ˜ Θ = D Y ( L ) D Y ( L ) T and I = D Y ( L ) T H C D Y ( L ) . As a result, the limiting sp ectrum of the matrix I can b e directly obtained from the NTK 2 Prop osition 1. F or any loss C with BGOSS and σ ∈ C 4 b ( R ) , uniformly over any interval [0 , T ] , the moments T r I k c onver ge to the fol lowing limit (with the c onvention that i k +1 = i 1 ): lim n L − 1 →∞ · · · lim n 1 →∞ T r I k = T r H C ( Y t ) ˜ Θ k = 1 N k N X i 1 ,...,i k =1 k Y m =1 c 00 i m ( f θ ( t ) ( x i m ))Θ ( L ) ∞ ( x i m , x i m +1 ) 2 This result w as already obtained in (Karakida et al., 2018), but without identifying the NTK explicitely and only at initialization. 9 Published as a conference pap er at ICLR 2020 Pr o of. It follo ws from T r I k = T r D Y ( L ) T H C D Y ( L ) k = T r H C ˜ Θ k and the asymptotic of the NTK (Jacot et al., 2018). 3.5.1 Mean-Square Error When the loss is the MSE, H C is equal to 1 N I d N n L . As a result, ˜ Θ and I ha ve the same non-zero eigenv alues up to a scaling of 1 / N . Because the NTK is assymptotically fixed, the sp ectrum of I is also fixed in the limit. The eigenv ectors of the NTK Gram matrix are the kernel principal comp onents of the data. The biggest principal comp onents are the directions in function space which are most fa vorised by the NTK. This giv es a functional interpretation of the narro w v alley structure in DNNs: the cliffs of the v alley are the biggest principal comp onents, while the flat directions are the smallest comp onen ts. R emark 2 . As the depth L of the net work increases, one can observe tw o regimes (Poole et al., 2016; Jacot et al., 2019): Order/F reeze where the NTK conv erges to a constan t and Chaos where the NTK conv erges to a Kroneck er delta. In the Order/F reeze the N n L × N n L Gram matrix approaches a blo ck diagonal matrix with n L constan t blo cks, and as a result n L eigen v alues of I dominate the other ones, corresp onding to constan t directions along each outputs (this is in line with the observ ations of (P apy an, 2019)). This leads to a narrow v alley for the loss and slo ws down training. In contrast, in the Chaos regime, the NTK Gram matrix approaches a scaled iden tity matrix, and the sp ectrum of I should hence concentrate around a p ositive v alue, hence sp eeding up training. Figure 3 illustrates this phenomenon: with the smo oth ReLU w e observe a narro w v alley , while with the normalized smo oth ReLU (whic h lies in the Chaos according to (Jacot et al., 2019)) the narrowness of the loss is reduced. A similar phenomenon ma y explain why normalization helps smo othing the loss surface and sp eed up training (San turk ar et al., 2018; Ghorbani et al., 2019). 3.5.2 Cross-Entr opy Loss F or a binary cross-entrop y loss with lab els Y ∗ ∈ {− 1 , +1 } N C ( Y ) = 1 N N X i =1 log 1 + e − Y ∗ i Y i , H C is a diagonal matrix whose en tries dep end on Y (but not on Y ∗ ): H ii C ( Y ) = 1 N 1 1 + e − Y i + e Y i . The eigenv ectors of I then corresp ond to the weigh ted kernel principal comp onen t of the data. The p ositive weigh ts 1 1+ e − Y i + e Y i approac h 1 / 3 as Y i go es to 0, i.e. when it is close to the decision b oundary from one class to the other, and as Y i → ±∞ the weigh t go to zero. The weigh ts evolv e in time through Y i , the sp ectrum of I is therefore not asymptotically fixed as in the MSE case, but the functional interpretation of the sp ectrum in terms of the k ernel principal comp onents remains. 4 Conclusion W e ha v e given an explicit formula for the limiting moments of the Hessian of DNNs throughout training. W e hav e used the common decomp osition of the Hessian in tw o terms I and S and ha ve shown that the tw o terms are asymptotically m utually orthogonal, such that they can b e studied separately . The matrix S v anishes in F rob enius norm as the net work conv erges and has v anishing op erator norm throughout training. The matrix I is arguably the most imp ortant as it describ es the narro w v alley structure of the loss around a global minimum. The eigendecomp osition of I is related to the (w eighted) kernel principal comp onents of the data w.r.t. the NTK. 10 Published as a conference pap er at ICLR 2020 A cknowledgements Cl ´ ement Hongler ackno wledges supp ort from the ERC SG CONST AMIS grant, the NCCR SwissMAP gran t, the NSF DMS-1106588 grant, the Minerv a F oundation, the Bla v atnik F amily F oundation, and the Latsis foundation. References Zeyuan Allen-Zhu, Y uanzhi Li, and Zhao Song. A Conv ergence Theory for Deep Learning via Ov er-Parameterization. CoRR , abs/1811.03962, 2018. URL 1811.03962 . Sanjeev Arora, Simon S Du, W ei Hu, Zhiyuan Li, Ruslan Salakhutdino v, and Ruosong W ang. On exact computation with an infinitely wide neural net. arXiv pr eprint arXiv:1904.11955 , 2019. Marco Bait y-Jesi, Leven t Sagun, Mario Geiger, Stefano Spigler, Gerard Ben Arous, Chiara Cammarota, Y ann LeCun, Matthieu Wyart, and Giulio Biroli. Comparing Dynamics: Deep Neural Netw orks v ersus Glassy Systems. In Jennifer Dy and Andreas Krause (eds.), Pr o c e e dings of the 35th International Confer enc e on Machine L e arning , volume 80, pp. 314–323. PMLR, 10–15 Jul 2018. URL http://proceedings.mlr.press/v80/baity- jesi18a.html . Pratik Chaudhari, Anna Choromansk a, Stefano Soatto, Y ann LeCun, Carlo Baldassi, Chris- tian Borgs, Jennifer Chay es, Leven t Sagun, and Riccardo Zecchina. Entrop y-sgd: Biasing gradien t descent into wide v alleys. arXiv pr eprint arXiv:1611.01838 , 2016. L ´ ena ¨ ıc Chizat and F rancis Bac h. On the Global Con vergence of Gradien t Descent for Over-parameterized Mo dels using Optimal T ransp ort. In A dvanc es in Neur al Information Pr o c essing Systems 31 , pp. 3040–3050. Curran Asso ciates, Inc., 2018a. URL http://papers.nips.cc/paper/7567- on- the- global- convergence- of- gradient- descent- for- over- parameterized- models- using- optimal- transport.pdf . Lenaic Chizat and F rancis Bach. A note on lazy training in sup ervised differen tiable programming. arXiv pr eprint arXiv:1812.07956 , 2018b. Y oungmin Cho and Lawrence K. Saul. Kernel Metho ds for Deep Learning. In A dvanc es in Neur al Information Pr o c essing Systems 22 , pp. 342–350. Curran Asso ciates, Inc., 2009. URL http://papers.nips.cc/paper/3628- kernel- methods- for- deep- learning.pdf . Anna Choromansk a, Mik ael Henaff, Michael Mathieu, G´ erard Ben Arous, and Y ann LeCun. The Loss Surfaces of Multila yer Netw orks. Journal of Machine L e arning R ese ar ch , 38: 192–204, no v 2015. URL . Y ann N. Dauphin, Razv an Pascan u, Caglar Gulcehre, Kyungh yun Cho, Surya Ganguli, and Y oshua Bengio. Identifying and Attac king the Saddle Poin t Problem in High-dimensional Non-con vex Optimization. In Pr o c e e dings of the 27th International Confer enc e on Neur al Information Pr o c essing Systems - V olume 2 , NIPS’14, pp. 2933–2941, Cambridge, MA, USA, 2014. MIT Press. Simon S. Du, Xiyu Zhai, Barnab´ as P´ oczos, and Aarti Singh. Gradien t Descent Prov ably Optimizes Ov er-parameterized Neural Netw orks. 2019. Mario Geiger, Stefano Spigler, St´ ephane d’Ascoli, Leven t Sagun, Marco Baity-Jesi, Giulio Biroli, and Matthieu Wy art. The jamming transition as a paradigm to understand the loss landscap e of deep neural netw orks. arXiv pr eprint arXiv:1809.09349 , 2018. Mario Geiger, Arth ur Jacot, Stefano Spigler, F ranck Gabriel, Leven t Sagun, St ´ ephane d’Ascoli, Giulio Biroli, Cl´ emen t Hongler, and Matthieu Wyart. Scaling description of generalization with n umber of parameters in deep learning . abs/1901.01608, 2019. URL http://arxiv.org/abs/1901.01608 . 11 Published as a conference pap er at ICLR 2020 Behro oz Ghorbani, Shank ar Krishnan, and Ying Xiao. An inv estigation into neural net opti- mization via hessian eigen v alue density . In Kamalik a Chaudhuri and Ruslan Salakhutdino v (eds.), Pr o c e e dings of the 36th International Confer enc e on Machine L e arning , volume 97 of Pr o c e e dings of Machine L e arning R ese ar ch , pp. 2232–2241, Long Beach, California, USA, 09–15 Jun 2019. PMLR. URL http://proceedings.mlr.press/v97/ghorbani19b.html . Guy Gur-Ari, Daniel A. Rob erts, and Ethan Dyer. Gradient descen t happ ens in a tiny subspace. CoRR , abs/1812.04754, 2018. URL . Sepp Ho chreiter and J ¨ urgen Schmidh ub er. Flat minima. Neur al Computation , 9(1):1–42, 1997. Jiao yang Huang and Horng-Tzer Y au. Dynamics of deep neural netw orks and neural tangent hierarc hy . arXiv pr eprint arXiv:1909.08156 , 2019. Arth ur Jacot, F ranck Gabriel, and Cl ´ ement Hongler. Neural T angent Ker- nel: Con vergence and Generalization in Neural Netw orks. In A dvanc es in Neur al Information Pr o c essing Systems 31 , pp. 8580–8589. Curran Asso ciates, Inc., 2018. URL http://papers.nips.cc/paper/8076- neural- tangent- kernel- convergence- and- generalization- in- neural- networks.pdf . Arth ur Jacot, F ranck Gabriel, and Cl´ ement Hongler. F reeze and chaos for dnns: an NTK view of batch normalization, chec kerboard and b oundary effects. CoRR , abs/1907.05715, 2019. URL . Ry o Karakida, Shotaro Ak aho, and Shun-Ic hi Amari. Univ ersal Statistics of Fisher In- formation in Deep Neural Netw orks: Mean Field Approach. jun 2018. URL http: //arxiv.org/abs/1806.01316 . Jae Ho on Lee, Y asaman Bahri, Roman Nov ak, Samuel S. Schoenholz, Jeff rey Pennington, and Jasc ha Sohl-Dickstein. Deep Neural Netw orks as Gaussian Pro cesses. ICLR , 2018. Song Mei, Andrea Montanari, and Phan-Minh Nguyen. A mean field view of the landscap e of tw o-lay er neural netw orks. Pr o c e e dings of the National A c ademy of Scienc es , 115(33): E7665–E7671, 2018. Song Mei, Theo dor Misiakiewicz, and Andrea Mon tanari. Mean-field theory of tw o-lay ers neural netw orks: dimension-free b ounds and kernel limit. arXiv pr eprint arXiv:1902.06015 , 2019. Radford M. Neal. Bayesian L e arning for Neur al Networks . Springer-V erlag New Y ork, Inc., Secaucus, NJ, USA, 1996. ISBN 0387947248. V ardan Pap y an. Measuremen ts of three-lev el hierarchical structure in the outliers in the sp ectrum of deepnet hessians. CoRR , abs/1901.08244, 2019. URL abs/1901.08244 . Razv an Pascan u and Y oshua Bengio. Revisiting Natural Gradient for Deep Netw orks. jan 2013. URL . Razv an Pascan u, Y ann N Dauphin, Sury a Ganguli, and Y oshua Bengio. On the saddle p oint problem for non-conv ex optimization. arXiv pr eprint , 2014. URL pdf/1405.4604.pdf . Jeffrey Pennington and Y asaman Bahri. Geometry of Neural Netw ork Loss Surfaces via Random Matrix Theory. In Pr o c e e dings of the 34th International Confer enc e on Machine L e arning , volume 70, pp. 2798–2806. PMLR, 06–11 Aug 2017. URL http://proceedings. mlr.press/v70/pennington17a.html . Jeffrey Pennington and Pratik W orah. The Sp ectrum of the Fisher Informa- tion Matrix of a Single-Hidden-La yer Neural Netw ork. In A dvanc es in Neu- r al Information Pr o c essing Systems 31 , pp. 5415–5424. Curran Asso ciates, Inc., 2018. URL http://papers.nips.cc/paper/7786- the- spectrum- of- the- fisher- information- matrix- of- a- single- hidden- layer- neural- network.pdf . 12 Published as a conference pap er at ICLR 2020 Ben P o ole, Subhaneil Lahiri, Maithra Ragh u, Jascha Sohl-Dic kstein, and Sury a Gan- guli. Exp onential expressivit y in deep neural net works through transient chaos. In D. D. Lee, M. Sugiyama, U. V. Luxburg, I. Guyon, and R. Garnett (eds.), A d- vanc es in Neur al Information Pr o c essing Systems 29 , pp. 3360–3368. Curran Asso ciates, Inc., 2016. URL http://papers.nips.cc/paper/6322- exponential- expressivity- in- deep- neural- networks- through- transient- chaos.pdf . Gran t Rotsk off and Eric V anden-Eijnden. P arameters as interacting particles: long time conv ergence and asymptotic error scaling of neural net works. In A dvanc es in Neur al Information Pr o c essing Systems 31 , pp. 7146–7155. Curran Asso ciates, Inc., 2018. URL http://papers.nips.cc/paper/7945- parameters- as- interacting- particles- long- time- convergence- and- asymptotic- error- scaling- of- neural- networks.pdf . Lev ent Sagun, L´ eon Bottou, and Y ann LeCun. Singularity of the hessian in deep learning. CoRR , abs/1611.07476, 2016. URL . Lev ent Sagun, Utku Evci, V. Ugur G ¨ uney , Y ann Dauphin, and L´ eon Bottou. Empirical Analysis of the Hessian of Over-P arametrized Neural Netw orks. CoRR , abs/1706.04454, 2017. Shibani Santurk ar, Dimitris Tsipras, Andrew Ilyas, and Aleksander Madry . Ho w do es batch normalization help optimization? In S. Bengio, H. W allac h, H. Laro chelle, K. Grauman, N. Cesa-Bianchi, and R. Garnett (eds.), A dvanc es in Neur al Information Pr o c essing Systems 31 , pp. 2483–2493. Curran Asso ciates, Inc., 2018. URL http://papers.nips. cc/paper/7515- how- does- batch- normalization- help- optimization.pdf . Daniel W agenaar. Information geometry of neural netw orks. 1998. ISSN 0302-9743. Lei W u, Zhanxing Zhu, and W einan E. T ow ards Understanding Generalization of Deep Learning: Perspective of Loss Landscap es. CoRR , abs/1706.10239, 2017. URL http: //arxiv.org/abs/1706.10239 . A Pr oofs F or the pro ofs of the theorems and prop ositions presented in the main text, we reformulate the setup of (Jacot et al., 2018). F or a fixed training set x 1 , ..., x N , w e consider a (p ossibly random) time-v arying training direction D ( t ) ∈ R N n L whic h describ es how each of the outputs must b e mo dified. In the case of gradient descent on a cost C ( Y ), the training direction is D ( t ) = ∇ C ( Y ( t )). The parameters are up dated according to the differential equation ∂ t θ ( t ) = ( ∂ θ Y ( t )) T D ( t ) . Under the condition that R T 0 k D ( t ) k 2 dt is sto chastically b ounded as the width of the netw ork go es to infinit y , the NTK Θ ( L ) con verges to its fixed limit uniformly ov er [0 , T ]. The reason w e consider a general training direction (and not only a gradient of a loss) is that w e can split a netw ork in tw o at a lay er ` and the training of the smaller netw ork will b e according to the training direction D ( ` ) i ( t ) giv en by D ( ` ) i ( t ) = diag ˙ σ α ( ` ) ( x i ) 1 √ n ` W ( ` ) T ...diag ˙ σ α ( L − 1) ( x i ) 1 √ n L − 1 W ( L − 1) T D i ( t ) b ecause the deriv ativ es ˙ σ are b ounded and by Lemma 1 of the App endix of (Jacot et al., 2018), this training direction satisfies the constraints even though it is not the gradient of a loss. As a consequence, as n 1 → ∞ , ..., n ` − 1 → ∞ the NTK of the smaller netw ork Θ ( ` ) also con verges to its limit uniformly ov er [0 , T ]. As we let n ` → ∞ the pre-activ ations ˜ α ( ` ) i and w eights W ( ` ) ij mo ve at a rate of 1 / √ n ` . W e will use this rate of change to pro ve that other t yp es of kernels are constant during training. 13 Published as a conference pap er at ICLR 2020 When a netw ork is trained with gradient descen t on a loss C with BGOSS, the integral R T 0 k D ( t ) k 2 dt is sto c hastically b ounded. Because the loss is decreasing during training, the outputs Y ( t ) lie in the sublevel set U C ( Y (0)) for all times t . The norm of the gradient is hence b ounded for all times t . Because the distribution of Y (0) conv erges to a m ultiv ariate Gaussian, b ( C ( Y (0))) is sto chastically b ounded as the width grows, where b ( a ) is a b ound on the norm of the gradient on U a . W e then hav e the b ound R T 0 k D ( t ) k 2 dt ≤ T b ( C ( Y (0))) whic h is itself sto chastically b ounded. F or the binary and softmax cross-entrop y losses the gradient is uniformly b ounded: Prop osition 2. F or the binary cr oss-entr opy loss C and any Y ∈ R N , k∇ C ( Y ) k 2 ≤ 1 √ N . F or the softmax cr oss-entr opy loss C on c ∈ N classes and any Y ∈ R N c , k∇ C ( Y ) k 2 ≤ √ 2 c √ N . Pr o of. The binary cross-entrop y loss with lab els Y ∗ ∈ { 0 , 1 } N is C ( Y ) = − 1 N N X i =1 log e Y i Y ∗ i 1 + e Y i = 1 N N X i =1 log 1 + e Y i − Y i Y ∗ i and the gradien t at an input i is ∂ i C ( Y ) = 1 N e Y i − Y ∗ i (1 + e Y i ) 1 + e Y i whic h is b ounded in absolute v alue by 1 N for b oth Y ∗ i = 0 , 1 such that k∇ C ( Y ) k 2 ≤ 1 √ N . The softmax cross-en tropy loss ov er c classes with lab els Y ∗ ∈ { 1 , . . . , c } N is defined b y C ( Y ) = − 1 N N X i =1 log e Y iY ∗ i P c k =1 e Y ik = 1 N N X i =1 log c X k =1 e Y ik ! − Y iY ∗ i . The gradien t is at an input i and output class m is ∂ im C ( Y ) = 1 N e Y im P c k =1 e Y ik − δ Y ∗ i m whic h is b ounded in absolute v alue by 2 N suc h that k∇ C ( Y ) k 2 ≤ √ 2 c √ N . B Preliminaries T o study the moments of the matrix S , we first ha ve to show that t wo tensors v anish as n 1 , ..., n L − 1 → ∞ : Ω ( L ) k 0 ,k 1 ,k 2 ( x 0 , x 1 , x 2 ) = ( ∇ f θ,k 0 ( x 0 )) T H f θ,k 1 ( x 1 ) ∇ f θ,k 2 ( x 2 ) Γ ( L ) k 0 ,k 1 ,k 2 ,k 3 ( x 0 , x 1 , x 2 , x 4 ) = ( ∇ f θ,k 0 ( x 0 )) T H f θ,k 1 ( x 1 ) H f θ,k 2 ( x 2 ) ∇ f θ,k 3 ( x 3 ) . W e study these tensors recursively , for this, we need a recursive definition for the first deriv atives ∂ θ p f θ,k ( x ) and second deriv ativ es ∂ 2 θ p θ p 0 f θ,k ( x ). The v alue of these deriv ativ es dep end on the la y er ` the parameters θ p and θ p 0 b elong to, and on whether they are connection w eights W ( ` ) mk or biases b ( ` ) k . The deriv atives with respect to the parameters of the last lay er are ∂ W ( L − 1) mk f θ,k 0 ( x ) = 1 √ n L − 1 α ( L − 1) m ( x ) δ kk 0 ∂ b ( L − 1) k f θ,k 0 ( x ) = β 2 δ kk 0 for parameters θ p whic h b elong to the lo wer lay ers the deriv atives can b e defined recursively b y ∂ θ p f θ,k ( x ) = 1 √ n L − 1 n L − 1 X m =1 ∂ θ p ˜ α ( L − 1) m ( x ) ˙ σ ˜ α ( L − 1) m ( x ) W ( L − 1) mk . 14 Published as a conference pap er at ICLR 2020 F or the second deriv ativ es, we first note that if either of the parameters θ p or θ p 0 are bias of the last lay er, or if they are b oth connection weigh ts of the last lay er, then ∂ 2 θ p θ p 0 f θ,k ( x ) = 0. Tw o cases are left: when one parameter is a connection weigh t of the last lay er and the others b elong to the low er lay ers, and when b oth b elong to the lo wer lay ers. Both cases can b e defined recursively in terms of the first and second deriv atives of ˜ α ( L − 1) m : ∂ 2 θ p W ( L ) mk f θ,k 0 ( x ) = 1 √ n L − 1 ∂ θ p ˜ α ( L − 1) m ( x ) ˙ σ ˜ α ( L − 1) m ( x ) δ kk 0 ∂ 2 θ p θ p 0 f θ,k 0 ( x ) = 1 √ n L − 1 n L − 1 X m =1 ∂ 2 θ p θ p 0 ˜ α ( L − 1) m ( x ) ˙ σ ˜ α ( L − 1) m ( x ) W ( L − 1) mk + 1 √ n L − 1 n L − 1 X m =1 ∂ θ p ˜ α ( L − 1) m ( x ) ∂ θ p 0 ˜ α ( L − 1) m ( x ) ¨ σ ˜ α ( L − 1) m ( x ) W ( L − 1) mk . Using these recursive definitions, the tensors Ω ( L +1) and Γ ( L +1) are given in terms of Θ ( L ) ,Ω ( L ) and Γ ( L ) , in the same manner that the NTK Θ ( L +1) is defined recursively in terms of Θ ( L ) in (Jacot et al., 2018). Lemma 1. F or any loss C with BGOSS and σ ∈ C 4 b ( R ) , we have uniformly over [0 , T ] lim n L − 1 →∞ · · · lim n 1 →∞ Ω ( L ) k 0 ,k 1 ,k 2 ( x 0 , x 1 , x 2 ) = 0 Pr o of. The pro of is done by induction. When L = 1 the second deriv ativ es ∂ 2 θ p θ p 0 f θ,k ( x ) = 0 and Ω ( L ) k 0 ,k 1 ,k 2 ( x 0 , x 1 , x 2 ) = 0. F or the induction step, we write Ω ( ` +1) k 0 ,k 1 ,k 2 ( x 0 , x 1 , x 2 ) recursiv ely as n − 3 / 2 ` X m 0 ,m 1 ,m 2 Θ ( ` ) m 0 ,m 1 ( x 0 , x 1 )Θ ( ` ) m 1 ,m 2 ( x 1 , x 2 ) ˙ σ ( ˜ α ( ` ) m 0 ( x 0 )) ¨ σ ( ˜ α ( ` ) m 1 ( x 1 )) ˙ σ ( ˜ α ( ` ) m 2 ( x 2 )) W ( ` ) m 0 k 0 W ( ` ) m 1 k 1 W ( ` ) m 2 k 2 + n − 3 / 2 ` X m 0 ,m 1 ,m 2 Ω ( ` ) m 0 ,m 1 ,m 2 ( x 0 , x 1 , x 2 ) ˙ σ ( ˜ α ( ` ) m 0 ( x 0 )) ˙ σ ( ˜ α ( ` ) m 1 ( x 1 )) ˙ σ ( ˜ α ( ` ) m 2 ( x 2 )) W ( ` ) m 0 k 0 W ( ` ) m 1 k 1 W ( ` ) m 2 k 2 + n − 3 / 2 ` X m 0 ,m 1 Θ ( ` ) m 0 ,m 1 ( x 0 , x 1 ) ˙ σ ( ˜ α ( ` ) m 0 ( x 0 )) ˙ σ ( ˜ α ( ` ) m 1 ( x 1 )) σ ( ˜ α ( ` ) m 1 ( x 2 )) W ( ` ) m 0 k 0 δ k 1 k 2 + n − 3 / 2 ` X m 1 ,m 2 Θ ( ` ) m 1 ,m 2 ( x 1 , x 2 ) σ ( ˜ α ( ` ) m 1 ( x 0 )) ˙ σ ( ˜ α ( ` ) m 1 ( x 1 )) ˙ σ ( ˜ α ( ` ) m 2 ( x 2 )) δ k 0 k 1 W ( ` ) m 2 k 2 . As n 1 , ..., n ` − 1 → ∞ and for any times t < T , the NTK Θ ( ` ) con verges to its limit while Ω ( ` ) v anishes. The second summand hence v anishes and the others conv erge to n − 3 / 2 ` X m Θ ( ` ) ∞ ( x 0 , x 1 )Θ ( ` ) ∞ ( x 1 , x 2 ) ˙ σ ( ˜ α ( ` ) m ( x 0 )) ¨ σ ( ˜ α ( ` ) m ( x 1 )) ˙ σ ( ˜ α ( ` ) m ( x 2 )) W ( ` ) mk 0 W ( ` ) mk 1 W ( ` ) mk 2 + n − 3 / 2 ` X m Θ ( ` ) ∞ ( x 0 , x 1 ) ˙ σ ( ˜ α ( ` ) m ( x 0 )) ˙ σ ( ˜ α ( ` ) m ( x 1 )) σ ( ˜ α ( ` ) m ( x 2 )) W ( ` ) mk 0 δ k 1 k 2 + n − 3 / 2 ` X m Θ ( ` ) ∞ ( x 1 , x 2 ) σ ( ˜ α ( ` ) m ( x 0 )) ˙ σ ( ˜ α ( ` ) m ( x 1 )) ˙ σ ( ˜ α ( ` ) m ( x 2 )) δ k 0 k 1 W ( ` ) mk 2 . A t initialization, all terms v anish as n ` → ∞ b ecause all summands are independent with zero mean and finite v ariance: in the n 1 → ∞ , . . . , n ` − 1 → ∞ limit, the ˜ α ( ` ) m ( x ) are indep enden t for different m , see (Jacot et al., 2018). During training, the weigh ts W ( ` ) and preactiv ations ˜ α ( ` ) mo ve at a rate of 1 / √ n ` (see the pro of of conv ergence of the NTK in (Jacot et al., 2018)). Since ˙ σ is Lipsc hitz, we obtain that the motion during training of each of the sums is of order n − 3 / 2 + 1 / 2 ` = n − 1 ` . As a result, uniformly o ver times t ∈ [0 , T ], all the sums v anish. Similarily , we hav e 15 Published as a conference pap er at ICLR 2020 Lemma 2. F or any loss C with BGOSS and σ ∈ C 4 b ( R ) , we have uniformly over [0 , T ] lim n L − 1 →∞ · · · lim n 1 →∞ Γ ( L ) k 0 ,k 1 ,k 2 ,k 3 ( x 0 , x 1 , x 2 , x 3 ) = 0 Pr o of. The pro of is done by induction. When L = 1 the hessian H F (1) = 0, such that Γ ( L ) k 0 ,k 1 ,k 2 ,k 3 ( x 0 , x 1 , x 2 , x 3 ) = 0. F or the induction step, Γ ( ` +1) can b e defined recursiv ely: Γ ( L +1) k 0 ,k 1 ,k 2 ,k 3 ( x 0 , x 1 , x 2 , x 3 ) = n − 2 L X m 0 ,m 1 ,m 2 ,m 3 Γ ( L ) m 0 ,m 1 ,m 2 ,m 3 ( x 0 , x 1 , x 2 , x 3 ) ˙ σ ( α ( L ) m 0 ( x 0 )) ˙ σ ( α ( L ) m 1 ( x 1 )) ˙ σ ( α ( L ) m 2 ( x 2 )) ˙ σ ( α ( L ) m 3 ( x 3 )) W ( L ) m 0 k 0 W ( L ) m 1 k 1 W ( L ) m 2 k 2 W ( L ) m 3 k 3 + n − 2 L X m 0 ,m 1 ,m 2 ,m 3 Θ ( L ) m 0 ,m 1 ( x 0 , x 1 )Ω ( L ) m 1 ,m 2 ,m 3 ( x 1 , x 2 , x 3 ) ˙ σ ( α ( L ) m 0 ( x 0 )) ¨ σ ( α ( L ) m 1 ( x 1 )) ˙ σ ( α ( L ) m 2 ( x 2 )) ˙ σ ( α ( L ) m 3 ( x 3 )) W ( L ) m 0 k 0 W ( L ) m 1 k 1 W ( L ) m 2 k 2 W ( L ) m 3 k 3 + n − 2 L X m 0 ,m 1 ,m 2 ,m 3 Ω ( L ) m 0 ,m 1 ,m 2 ( x 0 , x 1 , x 2 )Θ ( L ) m 2 ,m 3 ( x 2 , x 3 ) ˙ σ ( α ( L ) m 0 ( x 0 )) ˙ σ ( α ( L ) m 1 ( x 1 )) ¨ σ ( α ( L ) m 2 ( x 2 )) ˙ σ ( α ( L ) m 3 ( x 3 )) W ( L ) m 0 k 0 W ( L ) m 1 k 1 W ( L ) m 2 k 2 W ( L ) m 3 k 3 + n − 2 L X m 0 ,m 1 ,m 2 ,m 3 Θ ( L ) m 0 ,m 1 ( x 0 , x 1 )Θ ( L ) m 1 ,m 2 ( x 1 , x 2 )Θ ( L ) m 2 ,m 3 ( x 2 , x 3 ) ˙ σ ( α ( L ) m 0 ( x 0 )) ¨ σ ( α ( L ) m 1 ( x 1 )) ¨ σ ( α ( L ) m 2 ( x 2 )) ˙ σ ( α ( L ) m 3 ( x 3 )) W ( L ) m 0 k 0 W ( L ) m 1 k 1 W ( L ) m 2 k 2 W ( L ) m 3 k 3 + n − 2 L X m 1 ,m 2 ,m 3 Ω ( L ) m 1 ,m 2 ,m 3 ( x 1 , x 2 , x 3 ) σ ( α ( L ) m 1 ( x 0 )) ˙ σ ( α ( L ) m 1 ( x 1 )) ˙ σ ( α ( L ) m 2 ( x 2 )) ˙ σ ( α ( L ) m 3 ( x 3 )) δ k 0 k 1 W ( L ) m 2 k 2 W ( L ) m 3 k 3 + n − 2 L X m 1 ,m 2 ,m 3 Θ ( L ) m 1 ,m 2 ( x 1 , x 2 )Θ ( L ) m 2 ,m 3 ( x 2 , x 3 ) σ ( α ( L ) m 1 ( x 0 )) ˙ σ ( α ( L ) m 1 ( x 1 )) ¨ σ ( α ( L ) m 2 ( x 2 )) ˙ σ ( α ( L ) m 3 ( x 3 )) δ k 0 k 1 W ( L ) m 2 k 2 W ( L ) m 3 k 3 + n − 2 L X m 0 ,m 1 ,m 2 Ω ( L ) m 0 ,m 1 ,m 2 ( x 0 , x 1 , x 2 ) ˙ σ ( α ( L ) m 0 ( x 0 )) ˙ σ ( α ( L ) m 1 ( x 1 )) ˙ σ ( α ( L ) m 2 ( x 2 )) σ ( α ( L ) m 2 ( x 3 )) W ( L ) m 0 k 0 W ( L ) m 1 k 1 δ k 2 k 3 + n − 2 L X m 0 ,m 1 ,m 2 Θ ( L ) m 0 ,m 1 ( x 0 , x 1 )Θ ( L ) m 1 ,m 2 ( x 1 , x 2 ) ˙ σ ( α ( L ) m 0 ( x 0 )) ¨ σ ( α ( L ) m 1 ( x 1 )) ˙ σ ( α ( L ) m 2 ( x 2 )) σ ( α ( L ) m 2 ( x 3 )) W ( L ) m 0 k 0 W ( L ) m 1 k 1 δ k 2 k 3 + n − 2 L X m 1 ,m 2 Θ ( L ) m 1 ,m 2 ( x 1 , x 2 ) σ ( α ( L ) m 1 ( x 0 )) ˙ σ ( α ( L ) m 1 ( x 1 )) ˙ σ ( α ( L ) m 2 ( x 2 )) σ ( α ( L ) m 2 ( x 3 )) δ k 0 k 1 δ k 2 k 3 + n − 2 L X m 0 ,m 1 ,m 3 Θ ( L ) m 0 ,m 1 ( x 0 , x 1 )Θ ( L ) m 1 ,m 3 ( x 2 , x 3 ) ˙ σ ( α ( L ) m 0 ( x 0 )) ˙ σ ( α ( L ) m 1 ( x 1 )) ˙ σ ( α ( L ) m 1 ( x 2 )) ˙ σ ( α ( L ) m 3 ( x 3 )) W ( L ) m 0 k 0 δ k 1 k 2 W ( L ) m 3 k 3 As n 1 , ..., n ` − 1 → ∞ and for any times t < T , the NTK Θ ( ` ) con verges to its limit while Ω ( ` ) and Γ ( ` ) v anishes. Γ ( L +1) k 0 ,k 1 ,k 2 ,k 3 ( x 0 , x 1 , x 2 , x 3 ) therefore con verges to: + n − 2 L X m Θ ( L ) ∞ ( x 0 , x 1 )Θ ( L ) ∞ ( x 1 , x 2 )Θ ( L ) ∞ ( x 2 , x 3 ) ˙ σ ( α ( L ) m ( x 0 )) ¨ σ ( α ( L ) m ( x 1 )) ¨ σ ( α ( L ) m ( x 2 )) ˙ σ ( α ( L ) m ( x 3 )) W ( L ) mk 0 W ( L ) mk 1 W ( L ) mk 2 W ( L ) mk 3 16 Published as a conference pap er at ICLR 2020 + n − 2 L X m Θ ( L ) ∞ ( x 1 , x 2 )Θ ( L ) ∞ ( x 2 , x 3 ) σ ( α ( L ) m ( x 0 )) ˙ σ ( α ( L ) m ( x 1 )) ¨ σ ( α ( L ) m ( x 2 )) ˙ σ ( α ( L ) m ( x 3 )) δ k 0 k 1 W ( L ) mk 2 W ( L ) mk 3 + n − 2 L X m Θ ( L ) ∞ ( x 0 , x 1 )Θ ( L ) ∞ ( x 1 , x 2 ) ˙ σ ( α ( L ) m ( x 0 )) ¨ σ ( α ( L ) m ( x 1 )) ˙ σ ( α ( L ) m ( x 2 )) σ ( α ( L ) m ( x 3 )) W ( L ) mk 0 W ( L ) mk 1 δ k 2 k 3 + n − 2 L X m Θ ( L ) ∞ ( x 1 , x 2 ) σ ( α ( L ) m ( x 0 )) ˙ σ ( α ( L ) m ( x 1 )) ˙ σ ( α ( L ) m ( x 2 )) σ ( α ( L ) m ( x 3 )) δ k 0 k 1 δ k 2 k 3 + n − 2 L X m Θ ( L ) ∞ ( x 0 , x 1 )Θ ( L ) ∞ ( x 2 , x 3 ) ˙ σ ( α ( L ) m ( x 0 )) ˙ σ ( α ( L ) m ( x 1 )) ˙ σ ( α ( L ) m ( x 2 )) ˙ σ ( α ( L ) m ( x 3 )) W ( L ) mk 0 δ k 1 k 2 W ( L ) mk 3 F or the conv ergence during training, w e pro ceed similarily to the pro of of Lemma 1. A t initialization, all terms v anish as n ` → ∞ b ecause all summands are indep endent (after taking the n 1 , . . . , n L − 1 → ∞ limit) with zero mean and finite v ariance. During training, the weigh ts W ( ` ) and preactiv ations ˜ α ( ` ) mo ve at a rate of 1 / √ n ` whic h leads to a change of order n − 2+ 1 / 2 ` = n − 1 . 5 ` , whic h v anishes for all times t to o. C The Ma trix S W e now hav e the theoretical to ols to describ e the moments of the matrix S . W e first give a b ound for the rank of S : Prop osition 3. Rank ( S ) ≤ 2( n 1 + ... + n L − 1 ) N n L Pr o of. W e first observ e that S is given by a sum of N n L matrices: S pp 0 = N X i =1 n L X k =1 ∂ ik C ∂ 2 θ p θ p f θ,k ( x i ) . It is therefore suffician t to show that the rank of eac h matrices H f θ,k ( x ) = ∂ 2 θ p θ p 0 f θ,k ( x i ) p,p 0 is b ounded by 2( n 1 + ... + n L ). The deriv atives ∂ θ p f θ,k ( x ) ha ve different definition dep ending on whether the parameter θ p is a connection w eight W ( ` ) ij or a bias b ( ` ) j : ∂ W ( ` ) ij f θ,k ( x ) = 1 √ n ` α ( ` ) i ( x ; θ ) ∂ ˜ α ( ` +1) j ( x ; θ ) f θ,k ( x ) ∂ b ( ` ) j f θ,k ( x ) = β ∂ ˜ α ( ` +1) j ( x ; θ ) f θ,k ( x ) These formulas only dep end on θ through the v alues α ( ` ) i ( x ; θ ) `,i and ∂ ˜ α ( ` ) i ( x ; θ ) f θ,k ( x ) `,i for ` = 1 , ..., L − 1 (note that b oth α (0) i ( x ) = x i and ∂ ˜ α ( L ) i ( x ; θ ) f θ,k ( x ) = δ ik do not depend on θ ). T ogether there are 2( n 1 + ... + n L − 1 ) of them. As a consequence, the map θ 7→ ∂ θ p f θ,k ( x i ) p can b e written as a comp osition θ ∈ R P 7→ α ( ` ) i ( x ; θ ) , ∂ ˜ α ( ` ) i ( x ; θ ) f θ,k ( x ) `,i ∈ R 2( n 1 + ... + n L − 1 ) 7→ ∂ θ p f θ,k ( x i ) p ∈ R P and the matrix H f θ,k ( x ) is equal to the Jacobian of this map. By the chain rule, H f θ,k ( x ) is the matrix multiplication of the Jacobians of the tw o submaps, whose rank are b ounded b y 2( n 1 + ... + n L − 1 ), hence b ounding the rank of H f θ,k ( x ). And b ecause S is a sum of N n L matrices of rank smaller than 2( n 1 + ... + n L − 1 ), the rank of S is b ounded by 2( n 1 + ... + n L − 1 ) N n L . 17 Published as a conference pap er at ICLR 2020 C.1 Moments Let us no w prov e Prop osition 4: Prop osition 4. F or any loss C with BGOSS and σ ∈ C 4 b ( R ) , the first two moments of S take the form T r ( S ( t )) = G ( t ) T ∇ C ( t ) T r S ( t ) 2 = ∇ C ( t ) T ˜ Υ( t ) ∇ C ( t ) - At initialization, g θ and f θ c onver ge to a (c enter e d) Gaussian p air with c ovarianc es E [ g θ,k ( x ) g θ,k 0 ( x 0 )] = δ kk 0 Ξ ( L ) ∞ ( x, x 0 ) E [ g θ,k ( x ) f θ,k 0 ( x 0 )] = δ kk 0 Φ ( L ) ∞ ( x, x 0 ) E [ f θ,k ( x ) f θ,k 0 ( x 0 )] = δ kk 0 Σ ( L ) ∞ ( x, x 0 ) and during tr aining g θ evolves ac c or ding to ∂ t g θ,k ( x ) = N X i =1 Λ ( L ) ∞ ( x, x i ) ∂ ik C ( Y ( t )) · - Uniformly over any interval [0 , T ] wher e R T 0 k∇ C ( t ) k 2 dt is sto chastic al ly b ounde d, the kernel Υ ( L ) has a deterministic and fixe d limit lim n L − 1 →∞ · · · lim n 1 →∞ Υ ( L ) kk 0 ( x, x 0 ) = δ kk 0 Υ ( L ) ∞ ( x, x 0 ) with limiting kernel: Υ ( L ) ∞ ( x, x 0 ) = L − 1 X ` =1 Θ ( ` ) ∞ ( x, x 0 ) 2 ¨ Σ ( ` ) ( x, x 0 ) + 2Θ ( ` ) ∞ ( x, x 0 ) ˙ Σ ( ` ) ( x, x 0 ) ˙ Σ ( ` +1) ( x, x 0 ) · · · ˙ Σ ( L − 1) ( x, x 0 ) . - The higher moment k > 2 vanish: lim n L − 1 →∞ · · · lim n 1 →∞ T r S k = 0 . Pr o of. The first moment of S takes the form T r ( S ) = X p ( ∇ C ) T H p,p Y = ( ∇ C ) T G where G is the restriction to the training set of the function g θ ( x ) = P p ∂ 2 θ p θ p f θ ( x ). This pro cess is random at initialization and v aries during training. Lemma 3 b elo w shows that, in the infinite width limit, it is a Gaussian pro cess at initialization which then ev olves according to a simple differential equation, hence describing the evolution of the first moment during training. The second momen t of S takes the form: T r( S 2 ) = P X p 1 ,p 2 =1 N X i 1 ,i 2 =1 ∂ 2 θ p 1 ,θ p 2 f θ,k 1 ( x 1 ) ∂ 2 θ p 2 ,θ p 1 f θ,k 2 ( x 2 ) c 0 i 1 ( x i 1 ) c 0 i 2 ( x i 2 ) = ( ∇ C ) T ˜ Υ ∇ C where Υ ( L ) k 1 ,k 2 ( x 1 , x 2 ) = P P p 1 ,p 2 =1 ∂ 2 θ p 1 ,θ p 2 f θ,k 1 ( x 1 ) ∂ 2 θ p 2 ,θ p 1 f θ,k 2 ( x 2 ) is a m ultidimensional ker- nel and ˜ Υ is its Gram matrix. Lemma 4 b elow shows that in the infinite-width limit, Υ ( L ) k 1 ,k 2 ( x 1 , x 2 ) con verges to a deterministic and time-indep endent limit Υ ( L ) ∞ ( x 1 , x 2 ) δ k 1 k 2 . T o show that T r ( S k ) → 0 for all k > 2, it suffices to show that S 2 F → 0 as T r( S k ) < S 2 F k S k k − 2 F and w e know that k S k F → ( ∂ Y C ) T ˜ Υ ∂ Y C is finite. W e hav e that S 2 F = N X i 0 ,i 1 ,i 2 ,i 3 =1 n L X k 0 ,k 1 ,k 2 ,k 3 =1 Ψ ( L ) k 0 ,k 1 ,k 2 ,k 3 ( x i 0 , x i 1 , x i 2 , x i 3 ) ∂ f θ,k 0 ( x i 0 ) C ∂ f θ,k 1 ( x i 1 ) C 18 Published as a conference pap er at ICLR 2020 ∂ f θ,k 2 ( x i 2 ) C ∂ f θ,k 3 ( x i 3 ) C = ˜ Ψ · ( ∂ Y C ) ⊗ 4 for ˜ Ψ the N n L × N n L × N n L × N n L finite v ersion of Ψ ( L ) k 0 ,k 1 ,k 2 ,k 3 ( x i 0 , x i 1 , x i 2 , x i 3 ) = P X p 0 ,p 1 ,p 2 ,p 3 =1 ∂ 2 θ p 0 ,θ p 1 f θ,k 0 ( x 0 ) ∂ 2 θ p 1 ,θ p 2 f θ,k 1 ( x 1 ) ∂ 2 θ p 2 ,θ p 3 f θ,k 2 ( x 2 ) ∂ 2 θ p 3 ,θ p 0 f θ,k 3 ( x 3 ) . whic h v anishes in the infinite width limit by Lemma 5 b elow. Lemma 3. F or any loss C with BGOSS and σ ∈ C 4 b ( R ) , at initialization g θ and f θ c onver ge to a (c enter e d) Gaussian p air with c ovarianc es E [ g θ,k ( x ) g θ,k 0 ( x 0 )] = δ kk 0 Ξ ( L ) ∞ ( x, x 0 ) E [ g θ,k ( x ) f θ,k 0 ( x 0 )] = δ kk 0 Φ ( L ) ∞ ( x, x 0 ) E [ f θ,k ( x ) f θ,k 0 ( x 0 )] = δ kk 0 Σ ( L ) ∞ ( x, x 0 ) and during tr aining g θ evolves ac c or ding to ∂ t g θ ( x ) = N X i =1 Λ ( L ) ∞ ( x, x i ) D i ( t ) Pr o of. When L = 1, g θ ( x ) is 0 for an y x and θ . F or the inductive step, the trace g ( L +1) θ,k ( x ) is defined recursiv ely as 1 √ n L n L X m =1 g ( L ) θ,m ( x ) ˙ σ ˜ α ( L ) m ( x ) W ( L ) mk + T r ∇ f θ,m ( x ) ( ∇ f θ,m ( x )) T ¨ σ ˜ α ( L ) m ( x ) W ( L ) mk First note that T r ∇ f θ,m ( x ) ( ∇ f θ,m ( x )) T = Θ ( L ) mm ( x, x ). Now let n 1 , ...n L − 1 → ∞ , b y the induction hypothesis, the pairs ( g ( L ) θ,m , ˜ α ( L ) m ) conv erge to iid Gaussian pairs of pro cesses with co v ariance Φ ( L ) ∞ at initialization. A t initialization, conditioned on the v alues of g ( L ) m , ˜ α ( L ) m the pairs ( g ( L +1) k , f θ ) follo w a centered Gaussian distribution with (conditioned) co v ariance E [ g ( L +1) θ,k ( x ) g ( L +1) θ,k 0 ( x 0 ) | g ( L ) θ,m , ˜ α ( L ) m ] = δ kk 0 n L n L X m =1 g ( L ) θ,m ( x ) ˙ σ ˜ α ( L ) m ( x ) + Θ ( L ) ∞ ( x, x ) ¨ σ ˜ α ( L ) m ( x ) g ( L ) θ,m ( x 0 ) ˙ σ ˜ α ( L ) m ( x 0 ) + Θ ( L ) ∞ ( x 0 , x 0 ) ¨ σ ˜ α ( L ) m ( x 0 ) E [ g ( L +1) θ,k ( x ) f θ,k 0 ( x 0 ) | g ( L ) θ,m , ˜ α ( L ) m ] = δ kk 0 n L n L X m =1 g ( L ) θ,m ( x ) ˙ σ ˜ α ( L ) m ( x ) + Θ ( L ) ∞ ( x, x ) ¨ σ ˜ α ( L ) m ( x ) σ ˜ α ( L ) m ( x 0 ) E [ f θ,k ( x ) f θ,k 0 ( x 0 ) | g ( L ) θ,m , ˜ α ( L ) m ] = δ kk 0 n L n L X m =1 σ ˜ α ( L ) m ( x ) σ ˜ α ( L ) m ( x 0 ) + β 2 . As n L → ∞ , by the law of large n umber, these (random) cov ariances con verge to their exp ectations which are deterministic, hence the pairs ( g ( L +1) k , f θk ) hav e asymptotically the same Gaussian distribution indep enden t of g ( L ) m , ˜ α ( L ) m : E h g ( L ) θ,k ( x ) g ( L ) θ,k 0 ( x 0 ) i → δ kk 0 Ξ ( L ) ∞ ( x, x 0 ) 19 Published as a conference pap er at ICLR 2020 E h g ( L ) θ,k ( x ) f ( L ) θ,k 0 ( x 0 ) i → δ kk 0 Φ ( L ) ∞ ( x, x ) E h f ( L ) θ,k ( x ) f ( L ) θ,k 0 ( x 0 ) i → δ kk 0 Σ ( L ) ∞ ( x, x ) with Ξ (1) ∞ ( x, x 0 ) = Φ (1) ∞ ( x, x 0 ) = 0 and Ξ ( L +1) ∞ ( x, x 0 ) = E [ g g 0 ˙ σ ( α ) ˙ σ ( α 0 )] + Θ ( L ) ∞ ( x 0 , x 0 ) E [ g ˙ σ ( α ) ¨ σ ( α 0 )] + Θ ( L ) ∞ ( x, x ) E [ g 0 ˙ σ ( α 0 ) ¨ σ ( α )] + Θ ( L ) ∞ ( x, x )Θ ( L ) ∞ ( x 0 , x 0 ) E [ ¨ σ ( α 0 ) ¨ σ ( α )] = Ξ ( L ) ∞ ( x, x 0 ) ˙ Σ ( L ) ∞ ( x, x 0 ) + Φ ( L ) ∞ ( x, x 0 )Φ ( L ) ∞ ( x 0 , x ) + Φ ( L ) ∞ ( x, x )Φ ( L ) ∞ ( x 0 , x 0 ) ¨ Σ ( L ) ∞ ( x, x 0 ) + Φ ( L ) ∞ ( x, x 0 )Φ ( L ) ∞ ( x 0 , x 0 ) E [ ˙ σ ( α ) ... σ ( α 0 )] + Φ ( L ) ∞ ( x, x )Φ ( L ) ∞ ( x 0 , x ) E [ ... σ ( α ) ˙ σ ( α 0 )] + Θ ( L ) ∞ ( x 0 , x 0 ) Φ ( L ) ∞ ( x, x ) ¨ Σ ( L ) ∞ ( x, x 0 ) + Φ ( L ) ∞ ( x, x 0 ) E [ ˙ σ ( α ) ... σ ( α 0 )] + Θ ( L ) ∞ ( x, x ) Φ ( L ) ∞ ( x 0 , x 0 ) ¨ Σ ( L ) ∞ ( x, x 0 ) + Φ ( L ) ∞ ( x 0 , x ) E [ ... σ ( α ) ˙ σ ( α 0 )] + Θ ( L ) ∞ ( x, x )Θ ( L ) ∞ ( x 0 , x 0 ) ¨ Σ ( L ) ∞ ( x, x 0 ) and Φ ( L +1) ∞ ( x, x 0 ) = E [ g ˙ σ ( α ) σ ( α 0 )] + Θ ( L ) ∞ ( x, x ) E [ ¨ σ ( α ) σ ( α 0 )] = Φ ( L ) ∞ ( x, x 0 ) ˙ Σ ( L +1) ( x, x 0 ) + Φ ( L ) ∞ ( x, x ) + Θ ( L ) ∞ ( x, x ) E [ ¨ σ ( α ) σ ( α 0 )] where ( g , g 0 , α, α 0 ) is a Gaussian quadruple of co v ariance Ξ ( L ) ∞ ( x, x ) Ξ ( L ) ∞ ( x, x 0 ) Φ ( L ) ∞ ( x, x ) Φ ( L ) ∞ ( x, x 0 ) Ξ ( L ) ∞ ( x, x 0 ) Ξ ( L ) ∞ ( x 0 , x 0 ) Φ ( L ) ∞ ( x 0 , x ) Φ ( L ) ∞ ( x 0 , x 0 ) Φ ( L ) ∞ ( x, x ) Φ ( L ) ∞ ( x 0 , x ) Σ ( L ) ∞ ( x, x ) Σ ( L ) ∞ ( x, x 0 ) Φ ( L ) ∞ ( x, x 0 ) Φ ( L ) ∞ ( x 0 , x 0 ) Σ ( L ) ∞ ( x, x 0 ) Σ ( L ) ∞ ( x 0 , x 0 ) . During training, the parameters follow the gradient ∂ t θ ( t ) = ( ∂ θ Y ( t )) T D ( t ). By the induction h yp othesis, the traces g ( L ) θ,m then ev olve according to the differential equation ∂ t g ( L ) θ,m ( x ) = 1 √ n L N X i =1 n L X m =1 Λ ( L ) mm 0 ( x, x i ) ˙ σ ( ˜ α ( L ) m 0 ( x )) W ( L ) m 0 T D i ( t ) and in the limit as n 1 , ..., n L − 1 → ∞ , the kernel Λ ( L ) mm 0 ( x, x i ) conv erges to a deterministic and fixed limit δ mm 0 Λ ( L ) ∞ ( x, x i ). Note that as n L gro ws, the g ( L ) θ,m ( x ) mov e at a rate of 1 / √ n L just like the pre-activ ations ˜ α ( L ) m . Even though they mov e less and less, together they affect the trace g ( L +1) θ,k whic h follows the differential equation ∂ t g ( L +1) θ,k ( x ) = N X i =1 n L X k 0 =1 Λ ( L +1) kk 0 ( x, x i ) D ik 0 ( t ) where Λ ( L +1) kk 0 ( x, x 0 ) = 1 n L X m,m 0 Λ ( L ) mm 0 ( x, x 0 ) ˙ σ ˜ α ( L ) m ( x ) ˙ σ ˜ α ( L ) m 0 ( x 0 ) W ( L ) mk W ( L ) m 0 k 0 + 1 n L X m,m 0 g ( L ) θ,m ( x )Θ ( L ) mm 0 ( x, x 0 ) ¨ σ ˜ α ( L ) m ( x ) ˙ σ ˜ α ( L ) m 0 ( x 0 ) W ( L ) mk W ( L ) m 0 k 0 + 1 n L X m g ( L ) θ,m ( x ) ˙ σ ˜ α ( L ) m ( x ) σ ˜ α ( L ) m ( x 0 ) δ kk 0 20 Published as a conference pap er at ICLR 2020 + 2 n L X m,m 0 Ω ( L ) m 0 mm ( x 0 , x, x ) ¨ σ ˜ α ( L ) m ( x ) ˙ σ ˜ α ( L ) m 0 ( x 0 ) W ( L ) mk W ( L ) m 0 k 0 + 1 n L X m,m 0 Θ ( L ) mm ( x, x )Θ ( L ) mm 0 ( x, x 0 ) ... σ ˜ α ( L ) m ( x ) ˙ σ ˜ α ( L ) m 0 ( x 0 ) W ( L ) mk W ( L ) m 0 k 0 + 1 n L X m Θ ( L ) mm ( x, x ) ¨ σ ˜ α ( L ) m ( x ) σ ˜ α ( L ) m ( x 0 ) δ kk 0 . As n 1 , ..., n L − 1 → ∞ , the kernels Θ ( L ) mm 0 ( x, x 0 ) and Λ ( L ) mm 0 ( x, x 0 ) con verge to their limit and Ω ( L ) m 0 mm ( x 0 , x, x ) v anishes: Λ ( L ) kk 0 ( x, x 0 ) → 1 n L X m Λ ( L ) ∞ ( x, x 0 ) ˙ σ ˜ α ( L ) m ( x ) ˙ σ ˜ α ( L ) m ( x 0 ) W ( L ) mk W ( L ) mk 0 + 1 n L X m g ( L ) θ,m ( x )Θ ( L ) ∞ ( x, x 0 ) ¨ σ ˜ α ( L ) m ( x ) ˙ σ ˜ α ( L ) m ( x 0 ) W ( L ) mk W ( L ) mk 0 + 1 n L X m g ( L ) θ,m ( x ) ˙ σ ˜ α ( L ) m ( x ) σ ˜ α ( L ) m ( x 0 ) δ kk 0 + 1 n L X m Θ ( L ) ∞ ( x, x )Θ ( L ) ∞ ( x, x 0 ) ... σ ˜ α ( L ) m ( x ) ˙ σ ˜ α ( L ) m ( x 0 ) W ( L ) mk W ( L ) mk 0 + 1 n L X m Θ ( L ) ∞ ( x, x ) ¨ σ ˜ α ( L ) m ( x ) σ ˜ α ( L ) m ( x 0 ) δ kk 0 By the law of large num b ers, as n L → ∞ , at initialization Λ ( L +1) kk 0 ( x, x 0 ) → δ kk 0 Λ ( L +1) ∞ ( x, x 0 ) where Λ ( L +1) ∞ ( x, x 0 ) = Λ ( L ) ∞ ( x, x 0 ) ˙ Σ ( L +1) ∞ ( x, x 0 ) + Θ ( L ) ∞ ( x, x 0 ) E [ g ¨ σ ( α ) ˙ σ ( α 0 )] + E [ g ˙ σ ( α ) σ ( α 0 )] + Θ ( L ) ∞ ( x, x )Θ ( L ) ∞ ( x, x 0 ) E [ ... σ ( α ) ˙ σ ( α 0 )] + Θ ( L ) ∞ ( x, x ) E [ ¨ σ ( α ) σ ( α 0 )] = Λ ( L ) ∞ ( x, x 0 ) ˙ Σ ( L +1) ∞ ( x, x 0 ) + Θ ( L ) ∞ ( x, x 0 ) Φ ( L ) ∞ ( x, x 0 ) ¨ Σ ( L +1) ∞ ( x, x 0 ) + Φ ( L ) ∞ ( x, x ) E [ ... σ ( α ) ˙ σ ( α 0 )] + Φ ( L ) ∞ ( x, x 0 ) ˙ Σ ( L +1) ∞ ( x, x 0 ) + Φ ( L ) ∞ ( x, x ) E [ ¨ σ ( α ) σ ( α 0 )] + Θ ( L ) ∞ ( x, x )Θ ( L ) ∞ ( x, x 0 ) E [ ... σ ( α ) ˙ σ ( α 0 )] + Θ ( L ) ∞ ( x, x ) E [ ¨ σ ( α ) ˙ σ ( α 0 )] During training Θ ( L ) ∞ and Λ ( L ) ∞ are fixed in the limit n 1 , .., n L − 1 → ∞ , and the v alues g ( L ) θ,m ( x ), ˜ α ( L ) m ( x ) and W ( L ) mk v ary at a rate of 1 / √ n L whic h induce a c hange of the same rate to Λ ( L ) kk 0 ( x, x 0 ), whic h is therefore asymptotically fixed during training as n L → ∞ . The next lemma describ es the asymptotic limit of the k ernel Υ ( L ) : Lemma 4. F or any loss C with BGOSS and σ ∈ C 4 b ( R ) , the se c ond moment of the Hessian of the r e alization function H F ( L ) c onver ges uniformly over [0 , T ] to a fixe d limit as n 1 , ...n L − 1 → ∞ Υ ( L ) kk 0 ( x, x 0 ) → δ kk 0 L − 1 X ` =1 Θ ( ` ) ∞ ( x, x 0 ) 2 ¨ Σ ( ` ) ∞ ( x, x 0 ) + 2Θ ( ` ) ∞ ( x, x 0 ) ˙ Σ ( ` ) ∞ ( x, x 0 ) ˙ Σ ( ` +1) ∞ ( x, x 0 ) · · · ˙ Σ ( L − 1) ∞ ( x, x 0 ) . 21 Published as a conference pap er at ICLR 2020 Pr o of. The pro of is by induction on the depth L . The case L = 1 is trivially true b ecause ∂ 2 θ p θ p 0 f θ,k ( x ) = 0 for all p, p 0 , k , x . F or the induction step we observe that Υ ( L ) k,k 0 ( x, x 0 ) = P X p 1 ,p 2 =1 ∂ 2 θ p 1 ,θ p 2 f θ,k ( x ) ∂ 2 θ p 2 ,θ p 1 f θ,k 0 ( x 0 ) = 1 n L n L X m,m 0 =1 Υ ( L ) m,m 0 ( x, x 0 ) ˙ σ ˜ α ( L ) m ( x ) ˙ σ ˜ α ( L ) m 0 ( x 0 ) W ( L ) mk W ( L ) m 0 k 0 + 1 n L n L X m,m 0 =1 Ω ( L ) m 0 ,m,m 0 ( x 0 , x, x 0 ) ˙ σ ˜ α ( L ) m ( x ) ¨ σ ˜ α ( L ) m 0 ( x 0 ) W ( L ) mk W ( L ) m 0 k 0 + 1 n L n L X m,m 0 =1 Ω ( L ) m,m 0 ,m ( x, x 0 , x ) ¨ σ ˜ α ( L ) m ( x ) ˙ σ ˜ α ( L ) m 0 ( x 0 ) W ( L ) mk W ( L ) m 0 k 0 + 1 n L n L X m,m 0 =1 Θ ( L ) m,m 0 ( x, x 0 )Θ ( L ) m 0 ,m ( x 0 , x ) ¨ σ ˜ α ( L ) m ( x ) ¨ σ ˜ α ( L ) m 0 ( x 0 ) W ( L ) mk W ( L ) m 0 k 0 + 2 n L n L X m =1 Θ ( L ) m,m 0 ( x, x 0 ) ˙ σ ˜ α ( L ) m ( x ) ˙ σ ˜ α ( L ) m 0 ( x 0 ) δ kk 0 if we now let the width of the low er la yers grow to infinity n 1 , ...n L − 1 → ∞ , the tensor Ω ( L ) v anishes and Υ ( L ) m,m 0 and the NTK Θ ( L ) m,m 0 con verge to limits which are non-zero only when m = m 0 . As a result, the term ab o ve conv erges to 1 n L n L X m =1 Υ ( L ) ∞ ( x, x 0 ) ˙ σ ˜ α ( L ) m ( x ) ˙ σ ˜ α ( L ) m ( x 0 ) W ( L ) mk W ( L ) mk 0 + 1 n L n L X m =1 Θ ( L ) ∞ ( x, x 0 ) 2 ¨ σ ˜ α ( L ) m ( x ) ¨ σ ˜ α ( L ) m ( x 0 ) W ( L ) mk W ( L ) mk 0 + 2 n L n L X m =1 Θ ( L ) ∞ ( x, x 0 ) ˙ σ ˜ α ( L ) m ( x ) ˙ σ ˜ α ( L ) m ( x 0 ) δ kk 0 A t initialization, we can apply the law of large num bers as n L → ∞ suc h that it conv erges to Υ ( L +1) ∞ ( x, x 0 ) δ kk 0 , for the k ernel Υ ( L +1) ∞ ( x, x 0 ) defined recursiv ely by Υ ( L +1) ∞ ( x, x 0 ) =Υ ( L ) ∞ ( x, x 0 ) ˙ Σ ( L ) ∞ ( x, x 0 ) + Θ ( L ) ∞ ( x, x 0 ) 2 ¨ Σ ( L ) ∞ ( x, x 0 ) + 2Θ ( L ) ∞ ( x, x 0 ) ˙ Σ ( L ) ∞ ( x, x 0 ) and Υ (1) ∞ ( x, x 0 ) = 0. F or the con vergence during training, we pro ceed similarily to the pro of of Lemma 1: the activ ations ˜ α ( L ) m ( x ) and weigh ts W ( L ) mk mo ve at a rate of 1 / √ n L and the change to Υ ( L +1) kk 0 is therefore of order 1 / √ n L and v anishes as n L → 0. Finally , the next lemma shows the v anishing of the tensor Ψ ( L ) k 0 ,k 1 ,k 2 ,k 3 to prov e that the higher momen ts of S v anish. Lemma 5. F or any loss C with BGOSS and σ ∈ C 4 b ( R ) , uniformly over [0 , T ] lim n L − 1 →∞ · · · lim n 1 →∞ Ψ ( L ) k 0 ,k 1 ,k 2 ,k 3 ( x i 0 , x i 1 , x i 2 , x i 3 ) = 0 Pr o of. When L = 1 the Hessian is zero and Ψ (1) k 0 ,k 1 ,k 2 ,k 3 ( x i 0 , x i 1 , x i 2 , x i 3 ) = 0. F or the induction step, we write Ψ ( L +1) k 0 ,k 1 ,k 2 ,k 3 ( x i 0 , x i 1 , x i 2 , x i 3 ) recursively , b ecause it contains man y terms, we c hange the notation, writing x 0 x 1 m 0 m 1 for 22 Published as a conference pap er at ICLR 2020 Θ ( L ) m 0 ,m 1 ( x 0 , x 1 ), x 0 x 1 x 2 m 0 m 1 m 2 for Ω ( L ) m 0 ,m 1 ,m 2 ( x 0 , x 1 , x 2 ) and x 0 x 1 x 2 x 3 m 0 m 1 m 2 m 3 for Γ ( L ) m 0 ,m 1 ,m 2 ,m 3 ( x 0 , x 1 , x 2 , x 3 ). The v alue Ψ ( L +1) k 0 ,k 1 ,k 2 ,k 3 ( x i 0 , x i 1 , x i 2 , x i 3 ) is then equal to n − 2 L X m 0 ,m 1 ,m 2 ,m 3 Ψ ( L ) m 0 ,m 1 ,m 2 ,m 3 ( x 0 , x 1 , x 2 , x 3 ) ˙ σ ˜ α ( L ) m 0 ( x 0 ) ˙ σ ˜ α ( L ) m 1 ( x 1 ) ˙ σ ˜ α ( L ) m 2 ( x 2 ) ˙ σ ˜ α ( L ) m 3 ( x 3 ) W ( L ) m 0 k 0 W ( L ) m 1 k 1 W ( L ) m 2 k 2 W ( L ) m 3 k 3 + n − 2 L X m 0 ,m 1 ,m 2 ,m 3 x 0 x 1 m 0 m 1 x 1 x 2 m 1 m 2 x 2 x 3 m 2 m 3 x 3 x 0 m 3 m 0 ¨ σ ˜ α ( L ) m 0 ( x 0 ) ¨ σ ˜ α ( L ) m 1 ( x 1 ) ¨ σ ˜ α ( L ) m 2 ( x 2 ) ¨ σ ˜ α ( L ) m 3 ( x 3 ) W ( L ) m 0 k 0 W ( L ) m 1 k 1 W ( L ) m 2 k 2 W ( L ) m 3 k 3 + n − 2 L X m 0 ,m 1 ,m 2 ,m 3 x 0 x 1 x 2 m 0 m 1 m 2 x 2 x 3 m 2 m 3 x 3 x 0 m 3 m 0 ¨ σ ˜ α ( L ) m 0 ( x 0 ) ˙ σ ˜ α ( L ) m 1 ( x 1 ) ¨ σ ˜ α ( L ) m 2 ( x 2 ) ¨ σ ˜ α ( L ) m 3 ( x 3 ) W ( L ) m 0 k 0 W ( L ) m 1 k 1 W ( L ) m 2 k 2 W ( L ) m 3 k 3 + n − 2 L X m 0 ,m 1 ,m 2 ,m 3 x 0 x 1 m 0 m 1 x 1 x 2 x 3 m 1 m 2 m 3 x 3 x 0 m 3 m 0 ¨ σ ˜ α ( L ) m 0 ( x 0 ) ¨ σ ˜ α ( L ) m 1 ( x 1 ) ˙ σ ˜ α ( L ) m 2 ( x 2 ) ¨ σ ˜ α ( L ) m 3 ( x 3 ) W ( L ) m 0 k 0 W ( L ) m 1 k 1 W ( L ) m 2 k 2 W ( L ) m 3 k 3 + n − 2 L X m 0 ,m 1 ,m 2 ,m 3 x 0 x 1 m 0 m 1 x 1 x 2 m 1 m 2 x 2 x 3 x 0 m 2 m 3 m 0 ¨ σ ˜ α ( L ) m 0 ( x 0 ) ¨ σ ˜ α ( L ) m 1 ( x 1 ) ¨ σ ˜ α ( L ) m 2 ( x 2 ) ˙ σ ˜ α ( L ) m 3 ( x 3 ) W ( L ) m 0 k 0 W ( L ) m 1 k 1 W ( L ) m 2 k 2 W ( L ) m 3 k 3 + n − 2 L X m 0 ,m 1 ,m 2 ,m 3 x 1 x 2 m 1 m 2 x 2 x 3 m 2 m 3 x 3 x 0 x 1 m 3 m 0 m 1 ˙ σ ˜ α ( L ) m 0 ( x 0 ) ¨ σ ˜ α ( L ) m 1 ( x 1 ) ¨ σ ˜ α ( L ) m 2 ( x 2 ) ¨ σ ˜ α ( L ) m 3 ( x 3 ) W ( L ) m 0 k 0 W ( L ) m 1 k 1 W ( L ) m 2 k 2 W ( L ) m 3 k 3 + n − 2 L X m 0 ,m 1 ,m 2 ,m 3 x 0 x 1 x 2 m 0 m 1 m 2 x 2 x 3 x 0 m 2 m 3 m 0 ¨ σ ˜ α ( L ) m 0 ( x 0 ) ˙ σ ˜ α ( L ) m 1 ( x 1 ) ¨ σ ˜ α ( L ) m 2 ( x 2 ) ˙ σ ˜ α ( L ) m 3 ( x 3 ) W ( L ) m 0 k 0 W ( L ) m 1 k 1 W ( L ) m 2 k 2 W ( L ) m 3 k 3 + n − 2 L X m 0 ,m 1 ,m 2 ,m 3 x 1 x 2 x 3 m 1 m 2 m 3 x 3 x 0 x 1 m 3 m 0 m 1 ˙ σ ˜ α ( L ) m 0 ( x 0 ) ¨ σ ˜ α ( L ) m 1 ( x 1 ) ˙ σ ˜ α ( L ) m 2 ( x 2 ) ¨ σ ˜ α ( L ) m 3 ( x 3 ) W ( L ) m 0 k 0 W ( L ) m 1 k 1 W ( L ) m 2 k 2 W ( L ) m 3 k 3 + n − 2 L X m 0 ,m 1 ,m 2 ,m 3 x 0 x 1 x 2 x 3 m 0 m 1 m 2 m 3 x 3 x 0 m 3 m 0 ¨ σ ˜ α ( L ) m 0 ( x 0 ) ˙ σ ˜ α ( L ) m 1 ( x 1 ) ˙ σ ˜ α ( L ) m 2 ( x 2 ) ¨ σ ˜ α ( L ) m 3 ( x 3 ) W ( L ) m 0 k 0 W ( L ) m 1 k 1 W ( L ) m 2 k 2 W ( L ) m 3 k 3 + n − 2 L X m 0 ,m 1 ,m 2 ,m 3 x 0 x 1 m 0 m 1 x 1 x 2 x 3 x 0 m 1 m 2 m 3 m 0 ¨ σ ˜ α ( L ) m 0 ( x 0 ) ¨ σ ˜ α ( L ) m 1 ( x 1 ) ˙ σ ˜ α ( L ) m 2 ( x 2 ) ˙ σ ˜ α ( L ) m 3 ( x 3 ) W ( L ) m 0 k 0 W ( L ) m 1 k 1 W ( L ) m 2 k 2 W ( L ) m 3 k 3 + n − 2 L X m 0 ,m 1 ,m 2 ,m 3 x 1 x 2 m 1 m 2 x 2 x 3 x 0 x 1 m 2 m 3 m 0 m 1 ˙ σ ˜ α ( L ) m 0 ( x 0 ) ¨ σ ˜ α ( L ) m 1 ( x 1 ) ¨ σ ˜ α ( L ) m 2 ( x 2 ) ˙ σ ˜ α ( L ) m 3 ( x 3 ) W ( L ) m 0 k 0 W ( L ) m 1 k 1 W ( L ) m 2 k 2 W ( L ) m 3 k 3 23 Published as a conference pap er at ICLR 2020 + n − 2 L X m 0 ,m 1 ,m 2 ,m 3 x 2 x 3 m 2 m 3 x 3 x 0 x 1 x 2 m 3 m 0 m 1 m 2 ˙ σ ˜ α ( L ) m 0 ( x 0 ) ˙ σ ˜ α ( L ) m 1 ( x 1 ) ¨ σ ˜ α ( L ) m 2 ( x 2 ) ¨ σ ˜ α ( L ) m 3 ( x 3 ) W ( L ) m 0 k 0 W ( L ) m 1 k 1 W ( L ) m 2 k 2 W ( L ) m 3 k 3 + n − 2 L X m,m 1 ,m 2 x 0 x 1 m m 1 x 1 x 2 m 1 m 2 x 2 x 3 m 2 m ˙ σ ˜ α ( L ) m ( x 0 ) ¨ σ ˜ α ( L ) m 1 ( x 1 ) ¨ σ ˜ α ( L ) m 2 ( x 2 ) ˙ σ ˜ α ( L ) m ( x 3 ) W ( L ) m 1 k 1 W ( L ) m 2 k 2 δ k 0 k 3 + n − 2 L X m,m 2 ,m 3 x 1 x 2 m m 2 x 2 x 3 m 2 m 3 x 3 x 0 m 3 m ˙ σ ˜ α ( L ) m ( x 0 ) ˙ σ ˜ α ( L ) m ( x 1 ) ¨ σ ˜ α ( L ) m 2 ( x 2 ) ¨ σ ˜ α ( L ) m 3 ( x 3 ) W ( L ) m 2 k 2 W ( L ) m 3 k 3 δ k 0 k 1 + n − 2 L X m,m 3 ,m 0 x 0 x 1 m 0 m x 2 x 3 m m 3 x 3 x 0 m 3 m 0 ¨ σ ˜ α ( L ) m 0 ( x 0 ) ˙ σ ˜ α ( L ) m ( x 1 ) ˙ σ ˜ α ( L ) m ( x 2 ) ¨ σ ˜ α ( L ) m 3 ( x 3 ) W ( L ) m 0 k 0 W ( L ) m 3 k 3 δ k 1 k 2 + n − 2 L X m,m 0 ,m 1 x 0 x 1 m 0 m 1 x 1 x 2 m 1 m x 3 x 0 m m 0 ¨ σ ˜ α ( L ) m 0 ( x 0 ) ¨ σ ˜ α ( L ) m 1 ( x 1 ) ˙ σ ˜ α ( L ) m ( x 2 ) ˙ σ ˜ α ( L ) m ( x 3 ) W ( L ) m 0 k 0 W ( L ) m 1 k 1 δ k 2 k 3 + n − 2 L X m,m 1 ,m 2 x 0 x 1 x 2 m m 1 m 2 x 2 x 3 m 2 m ˙ σ ˜ α ( L ) m ( x 0 ) ˙ σ ˜ α ( L ) m 1 ( x 1 ) ¨ σ ˜ α ( L ) m 2 ( x 2 ) ˙ σ ˜ α ( L ) m ( x 3 ) W ( L ) m 1 k 1 W ( L ) m 2 k 2 δ k 0 k 3 + n − 2 L X m,m 2 ,m 3 x 1 x 2 x 3 m m 2 m 3 x 3 x 0 m 3 m ˙ σ ˜ α ( L ) m ( x 0 ) ˙ σ ˜ α ( L ) m ( x 1 ) ˙ σ ˜ α ( L ) m 2 ( x 2 ) ¨ σ ˜ α ( L ) m 3 ( x 3 ) W ( L ) m 2 k 2 W ( L ) m 3 k 3 δ k 0 k 1 + n − 2 L X m,m 3 ,m 0 x 0 x 1 m 0 m x 2 x 3 x 0 m m 3 m 0 ¨ σ ˜ α ( L ) m 0 ( x 0 ) ˙ σ ˜ α ( L ) m ( x 1 ) ˙ σ ˜ α ( L ) m ( x 2 ) ˙ σ ˜ α ( L ) m 3 ( x 3 ) W ( L ) m 0 k 0 W ( L ) m 3 k 3 δ k 1 k 2 + n − 2 L X m,m 0 ,m 1 x 1 x 2 m 1 m x 3 x 0 x 1 m m 0 m 1 ˙ σ ˜ α ( L ) m 0 ( x 0 ) ¨ σ ˜ α ( L ) m 1 ( x 1 ) ˙ σ ˜ α ( L ) m ( x 2 ) ˙ σ ˜ α ( L ) m ( x 3 ) W ( L ) m 0 k 0 W ( L ) m 1 k 1 δ k 2 k 3 + n − 2 L X m,m 1 ,m 2 x 0 x 1 m m 1 x 1 x 2 x 3 m 1 m 2 m ˙ σ ˜ α ( L ) m ( x 0 ) ¨ σ ˜ α ( L ) m 1 ( x 1 ) ˙ σ ˜ α ( L ) m 2 ( x 2 ) ˙ σ ˜ α ( L ) m ( x 3 ) W ( L ) m 1 k 1 W ( L ) m 2 k 2 δ k 0 k 3 + n − 2 L X m,m 2 ,m 3 x 1 x 2 m m 2 x 2 x 3 x 0 m 2 m 3 m ˙ σ ˜ α ( L ) m ( x 0 ) ˙ σ ˜ α ( L ) m ( x 1 ) ¨ σ ˜ α ( L ) m 2 ( x 2 ) ˙ σ ˜ α ( L ) m 3 ( x 3 ) W ( L ) m 2 k 2 W ( L ) m 3 k 3 δ k 0 k 1 + n − 2 L X m,m 3 ,m 0 x 2 x 3 m m 3 x 3 x 0 x 1 m 3 m 0 m ˙ σ ˜ α ( L ) m 0 ( x 0 ) ˙ σ ˜ α ( L ) m ( x 1 ) ˙ σ ˜ α ( L ) m ( x 2 ) ¨ σ ˜ α ( L ) m 3 ( x 3 ) W ( L ) m 0 k 0 W ( L ) m 3 k 3 δ k 1 k 2 24 Published as a conference pap er at ICLR 2020 + n − 2 L X m,m 0 ,m 1 x 0 x 1 x 2 m 0 m 1 m x 3 x 0 m m 0 ¨ σ ˜ α ( L ) m 0 ( x 0 ) ˙ σ ˜ α ( L ) m 1 ( x 1 ) ˙ σ ˜ α ( L ) m ( x 2 ) ˙ σ ˜ α ( L ) m ( x 3 ) W ( L ) m 0 k 0 W ( L ) m 1 k 1 δ k 2 k 3 + n − 2 L X m,m 1 ,m 2 x 0 x 1 x 2 x 3 m m 1 m 2 m ˙ σ ˜ α ( L ) m ( x 0 ) ˙ σ ˜ α ( L ) m 1 ( x 1 ) ˙ σ ˜ α ( L ) m 2 ( x 2 ) ˙ σ ˜ α ( L ) m ( x 3 ) W ( L ) m 1 k 1 W ( L ) m 2 k 2 δ k 0 k 3 + n − 2 L X m,m 2 ,m 3 x 1 x 2 x 3 x 0 m m 2 m 3 m ˙ σ ˜ α ( L ) m ( x 0 ) ˙ σ ˜ α ( L ) m ( x 1 ) ˙ σ ˜ α ( L ) m 2 ( x 2 ) ˙ σ ˜ α ( L ) m 3 ( x 3 ) W ( L ) m 2 k 2 W ( L ) m 3 k 3 δ k 0 k 1 + n − 2 L X m,m 3 ,m 0 x 2 x 3 x 0 x 1 m m 3 m 0 m ˙ σ ˜ α ( L ) m 0 ( x 0 ) ˙ σ ˜ α ( L ) m ( x 1 ) ˙ σ ˜ α ( L ) m ( x 2 ) ˙ σ ˜ α ( L ) m 3 ( x 3 ) W ( L ) m 0 k 0 W ( L ) m 3 k 3 δ k 1 k 2 + n − 2 L X m,m 0 ,m 1 x 3 x 0 x 1 x 2 m m 0 m 1 m ˙ σ ˜ α ( L ) m 0 ( x 0 ) ˙ σ ˜ α ( L ) m 1 ( x 1 ) ˙ σ ˜ α ( L ) m ( x 2 ) ˙ σ ˜ α ( L ) m ( x 3 ) W ( L ) m 0 k 0 W ( L ) m 1 k 1 δ k 2 k 3 + n − 2 L X m,m 0 x 0 x 1 m m 0 x 2 x 3 m 0 m ˙ σ ˜ α ( L ) m ( x 0 ) ˙ σ ˜ α ( L ) m 0 ( x 1 ) ˙ σ ˜ α ( L ) m 0 ( x 2 ) ˙ σ ˜ α ( L ) m ( x 3 ) δ k 0 k 1 δ k 2 k 3 + n − 2 L X m,m 0 x 1 x 2 m m 0 x 3 x 0 m 0 m ˙ σ ˜ α ( L ) m ( x 0 ) ˙ σ ˜ α ( L ) m ( x 1 ) ˙ σ ˜ α ( L ) m 0 ( x 2 ) ˙ σ ˜ α ( L ) m 0 ( x 3 ) δ k 0 k 3 δ k 1 k 2 Ev en though this is a v ery large form ula one can notice that most terms are “rotation of eac h other”. Moreo ver, as n 1 , ..., n L − 1 → ∞ , all terms containing either an Ψ ( L ) , an Ω ( L ) or a Γ ( L ) v anish. F or the remaining terms, w e may replace the NTKs Θ ( L ) b y their limit and as a result Ψ ( L +1) k 0 ,k 1 ,k 2 ,k 3 ( x i 0 , x i 1 , x i 2 , x i 3 ) con verges to n − 2 L X m Θ ( L ) ∞ ( x 0 , x 1 )Θ ( L ) ∞ ( x 1 , x 2 )Θ ( L ) ∞ ( x 2 , x 3 )Θ ( L ) ∞ ( x 3 , x 0 ) ¨ σ ˜ α ( L ) m ( x 0 ) ¨ σ ˜ α ( L ) m ( x 1 ) ¨ σ ˜ α ( L ) m ( x 2 ) ¨ σ ˜ α ( L ) m ( x 3 ) W ( L ) mk 0 W ( L ) mk 1 W ( L ) mk 2 W ( L ) mk 3 + n − 2 L X m Θ ( L ) ∞ ( x 0 , x 1 )Θ ( L ) ∞ ( x 1 , x 2 )Θ ( L ) ∞ ( x 2 , x 3 ) ˙ σ ˜ α ( L ) m ( x 0 ) ¨ σ ˜ α ( L ) m ( x 1 ) ¨ σ ˜ α ( L ) m ( x 2 ) ˙ σ ˜ α ( L ) m ( x 3 ) W ( L ) mk 1 W ( L ) mk 2 δ k 0 k 3 + n − 2 L X m Θ ( L ) ∞ ( x 1 , x 2 )Θ ( L ) ∞ ( x 2 , x 3 )Θ ( L ) ∞ ( x 3 , x 0 ) ˙ σ ˜ α ( L ) m ( x 0 ) ˙ σ ˜ α ( L ) m ( x 1 ) ¨ σ ˜ α ( L ) m ( x 2 ) ¨ σ ˜ α ( L ) m ( x 3 ) W ( L ) mk 2 W ( L ) mk 3 δ k 0 k 1 + n − 2 L X m Θ ( L ) ∞ ( x 0 , x 1 )Θ ( L ) ∞ ( x 2 , x 3 )Θ ( L ) ∞ ( x 3 , x 0 ) ¨ σ ˜ α ( L ) m ( x 0 ) ˙ σ ˜ α ( L ) m ( x 1 ) ˙ σ ˜ α ( L ) m ( x 2 ) ¨ σ ˜ α ( L ) m ( x 3 ) W ( L ) mk 0 W ( L ) mk 3 δ k 1 k 2 + n − 2 L X m Θ ( L ) ∞ ( x 0 , x 1 )Θ ( L ) ∞ ( x 1 , x 2 )Θ ( L ) ∞ ( x 3 , x 0 ) ¨ σ ˜ α ( L ) m ( x 0 ) ¨ σ ˜ α ( L ) m ( x 1 ) ˙ σ ˜ α ( L ) m ( x 2 ) ˙ σ ˜ α ( L ) m ( x 3 ) W ( L ) mk 0 W ( L ) mk 1 δ k 2 k 3 25 Published as a conference pap er at ICLR 2020 + n − 2 L X m Θ ( L ) ∞ ( x 0 , x 1 )Θ ( L ) ∞ ( x 2 , x 3 ) ˙ σ ˜ α ( L ) m ( x 0 ) ˙ σ ˜ α ( L ) m ( x 1 ) ˙ σ ˜ α ( L ) m ( x 2 ) ˙ σ ˜ α ( L ) m ( x 3 ) δ k 0 k 1 δ k 2 k 3 + n − 2 L X m Θ ( L ) ∞ ( x 1 , x 2 )Θ ( L ) ∞ ( x 3 , x 0 ) ˙ σ ˜ α ( L ) m ( x 0 ) ˙ σ ˜ α ( L ) m ( x 1 ) ˙ σ ˜ α ( L ) m ( x 2 ) ˙ σ ˜ α ( L ) m ( x 3 ) δ k 0 k 3 δ k 1 k 2 And all these sums v anish as n L → ∞ thanks to the prefactor n − 2 L , proving the v anishing of Ψ ( L +1) k 0 ,k 1 ,k 2 ,k 3 ( x i 0 , x i 1 , x i 2 , x i 3 ) in the infinite width limit. During training, the activ ations ˜ α ( L ) m ( x ) and weigh ts W ( L ) mk mo ve at a rate of 1 / √ n L whic h induces a c hange to Ψ ( L +1) of order n − 3 / 2 L whic h v anishes in the infinite width limit. D Or thogonality of I and S F rom Lemma 2 and the v anishing of the tensor Γ ( L ) as prov en in Lemma 2, we can easily pro ve the orthogonality of I and S of Prop osition 5: Prop osition 5. F or any loss C with BGOSS and σ ∈ C 4 b ( R ) , we have uniformly over [0 , T ] lim n L − 1 →∞ · · · lim n 1 →∞ k I S k F = 0 . As a c onse quenc e lim n L − 1 →∞ · · · lim n 1 →∞ T r [ I + S ] k − T r I k + T r S k = 0 . Pr o of. The F rob enius norm of I S is equal to k I S k 2 F = D Y H C ( D Y ) T ( ∇ C · H Y ) 2 F = P X p 1 ,p 2 =1 P X p =1 N X i 1 ,i 2 =1 n L X k 1 ,k 2 =1 ∂ θ p 1 f θ,k 1 ( x i 1 ) c 00 k 1 ( x i 1 ) ∂ θ p f θ,k 1 ( x i 1 ) ∂ 2 θ p ,θ p 3 f θ,k 2 ( x 2 )( x i 2 ) c 0 k 2 ( x i 2 ) 2 = N X i 1 ,i 2 ,i 0 1 ,i 0 2 =1 n L X k 1 ,k 2 ,k 0 1 ,k 0 2 =1 c 00 k 1 ( x i 1 ) c 00 k 0 1 ( x i 0 1 ) c 0 k 2 ( x i 2 ) c 0 k 0 2 ( x i 0 2 )Θ k 1 ,k 0 1 ( x i 1 , x i 0 1 )Γ k 1 ,k 2 ,k 0 2 ,k 0 1 ( x i 1 , x i 2 , x i 0 2 , x i 0 1 ) and Γ v anishes as n 1 , ..., n L − 1 → ∞ b y Lemma 2. The k -th momen t of the sum T r ( I + S ) k is equal to the sum ov er all T r ( A 1 · · · A k ) for an y w ord A 1 . . . A k of A i ∈ { I , S } . The difference T r [ I + S ] k − T r I k + T r S k is hence equal to the sum o ver all mixed words, i.e. words A 1 . . . A k whic h contain at least one I and one S . Suc h words must contain tw o consecutiv e terms A m A m +1 one equal to I and the other equal to S . W e can then b ound the trace by | T r ( A 1 · · · A k ) | ≤ k A 1 k F · · · k A m − 1 k F k A m A m +1 k F k A m +2 k F · · · k A k k F whic h v anishes in the infinite width limit b ecause k I k F and k S k F are b ounded and k A m A m +1 k F = k I S k F v anishes. 26
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment