텍스트 감독을 활용한 시퀀스투시퀀스 음성 변환 성능 향상
본 논문은 병렬 음성 데이터의 텍스트 전사 정보를 이용해 시퀀스투시퀀스(Seq2Seq) 기반 음성 변환 모델의 품질을 개선하는 두 가지 방법을 제안한다. 첫 번째는 인코더와 디코더 중간층에 보조 분류기를 추가해 언어 라벨을 예측하도록 하는 다중작업 학습(Multi‑Task Learning)이다. 두 번째는 텍스트 정렬 정보를 활용해 원문과 목표 음성 사이의 정렬 지점을 기준으로 짧은 병렬 구간을 추출, 이를 데이터 증강으로 사용한다. 실험 결과…
저자: Jing-Xuan Zhang, Zhen-Hua Ling, Yuan Jiang
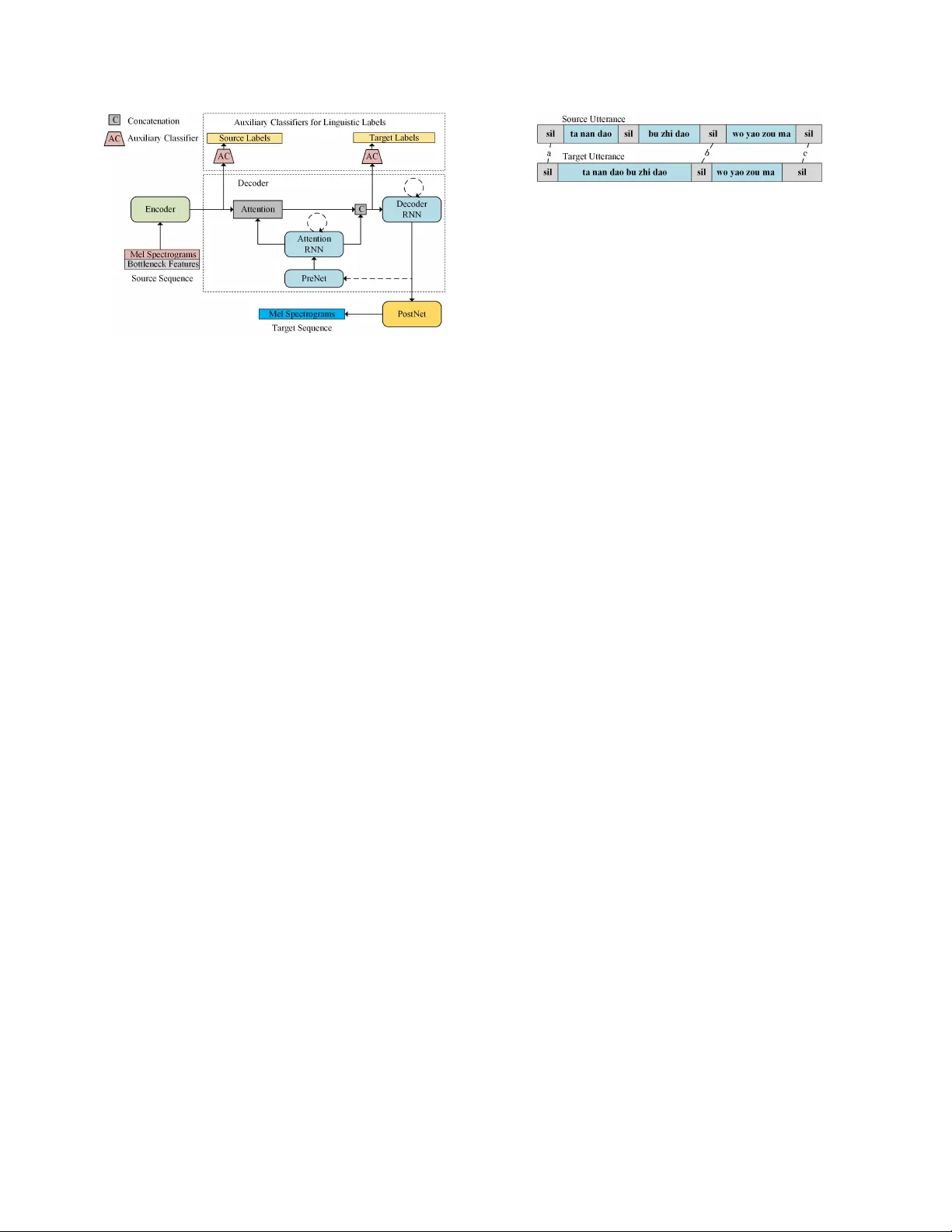
본 논문은 병렬 음성 데이터에 대한 텍스트 전사 정보를 활용해 시퀀스투시퀀스(Seq2Seq) 기반 음성 변환(Voice Conversion, VC) 모델의 품질을 향상시키는 두 가지 방법을 제안한다. 기존의 프레임‑대‑프레임 방식은 DTW 기반 정렬 후 GMM, DNN, RNN 등으로 소스와 타깃 음성의 프레임을 매핑했지만, 발음 오류와 지속 시간 변환의 한계가 있었다. 저자들은 이전 연구에서 제안한 SCENT(Seq2Seq ConvErsion Net) 모델을 기반으로, 텍스트 정보가 훈련 단계에서만 사용되는 새로운 감독 메커니즘을 도입한다.
첫 번째 방법은 다중작업 학습(Multi‑Task Learning, MT)이다. 인코더와 디코더 사이의 중간 레이어에 각각 보조 분류기를 삽입하고, 이 분류기가 음소와 톤 라벨을 예측하도록 학습한다. 보조 분류기의 입력은 해당 레이어의 은닉 표현이며, 드롭아웃을 거친 뒤 소프트맥스 레이어를 통해 라벨을 출력한다. 손실 함수는 원래의 멜‑스펙트럼 손실과 두 보조 분류기의 교차 엔트로피 손실을 가중합한 형태이며, 라벨 예측이 정확할수록 은닉 표현이 언어적 의미와 더 잘 정렬된다. 이는 어텐션 메커니즘이 보다 정확한 정렬을 학습하도록 돕고, 결과적으로 변환 시 발음 오류, 반복·누락 현상을 감소시킨다. 보조 분류기는 훈련 시에만 존재하고 변환 단계에서는 제거되므로 추론 비용에 영향을 주지 않는다.
두 번째 방법은 텍스트 정렬 기반 데이터 증강(Data Augmentation, DA)이다. 병렬 음성 쌍에서 텍스트 정렬 정보를 이용해 ‘sil’(무음) 구간을 정렬점으로 정의하고, 두 정렬점 사이의 구간을 추출한다. N개의 정렬점이 존재하면 C(N,2)개의 병렬 구간을 만들 수 있어, 원본 전체 발화보다 훨씬 많은 학습 샘플을 생성한다. 훈련 시에는 전체 발화 대신 무작위로 선택된 구간을 사용해 모델을 학습함으로써, 특히 데이터가 적은 상황에서 과적합을 방지하고 일반화 능력을 향상시킨다.
실험은 중국어 남·여 화자 각각 1060개의 병렬 발화를 사용했으며, 훈련 데이터 규모를 50, 100, 200, 400, 1000 발화로 제한해 비교했다. 평가 지표는 멜‑cepstrum distortion(MCD)과 기본 주파수(F0) RMSE이며, 주관적 평가로는 발음 오류 카운트와 ABX 선호 테스트(자연스러움·유사성)를 수행했다. 결과는 다음과 같다.
1. **객관적 성능**: 데이터가 50~100 발화일 때, Seq2Seq‑MT 모델은 Baseline Seq2Seq 대비 MCD가 약 0.2~0.3 dB, F0 RMSE가 4~5 Hz 정도 개선되었다. 데이터 증강을 추가한 Seq2Seq‑MT‑DA는 특히 50·100 발화 조건에서 추가적인 MCD 감소(0.1~0.2 dB)와 F0 RMSE 감소를 보였다. 데이터가 200·400 발화로 늘어나면 두 방법의 차이는 축소되지만 여전히 Baseline보다 우수했다. 1000 발화에서는 MCD는 비슷하지만 F0 RMSE가 약간 높아지는 현상이 관찰되었다.
2. **주관적 평가**: 발음 오류, 반복·누락 등 불안정성 측면에서 Seq2Seq‑MT는 모든 데이터 규모에서 오류 수를 크게 줄였다. 특히 작은 데이터(50~100)에서는 오류가 절반 이하로 감소했다. 데이터 증강은 50 발화 조건에서 자연스러움 선호도에서 유의미한 향상을 보였으며, 1000 발화에서는 큰 차이가 없었다.
3. **분석**: 다중작업 학습은 은닉 표현을 언어적 라벨에 정렬시켜 어텐션이 보다 정확한 정렬을 학습하도록 돕는다. 데이터 증강은 훈련 샘플 수를 늘려 과적합을 방지하지만, 전체 문맥을 무시한 짧은 구간만 사용하면 큰 데이터에서는 오히려 성능 저하 요인이 될 수 있다.
결론적으로, 텍스트 감독을 이용한 다중작업 학습은 Seq2Seq 기반 VC 모델의 발음 안정성을 크게 향상시키며, 데이터가 제한된 저자원 상황에서 텍스트 정렬 기반 데이터 증강이 추가적인 이점을 제공한다. 향후 연구에서는 텍스트 정보를 변환 단계에도 활용하거나, 보다 정교한 정렬점 선택 및 문맥 정보를 보존하는 증강 전략을 탐색할 여지가 있다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기