Improving Sequence-to-Sequence Acoustic Modeling by Adding Text-Supervision
This paper presents methods of making using of text supervision to improve the performance of sequence-to-sequence (seq2seq) voice conversion. Compared with conventional frame-to-frame voice conversion approaches, the seq2seq acoustic modeling method…
Authors: Jing-Xuan Zhang, Zhen-Hua Ling, Yuan Jiang
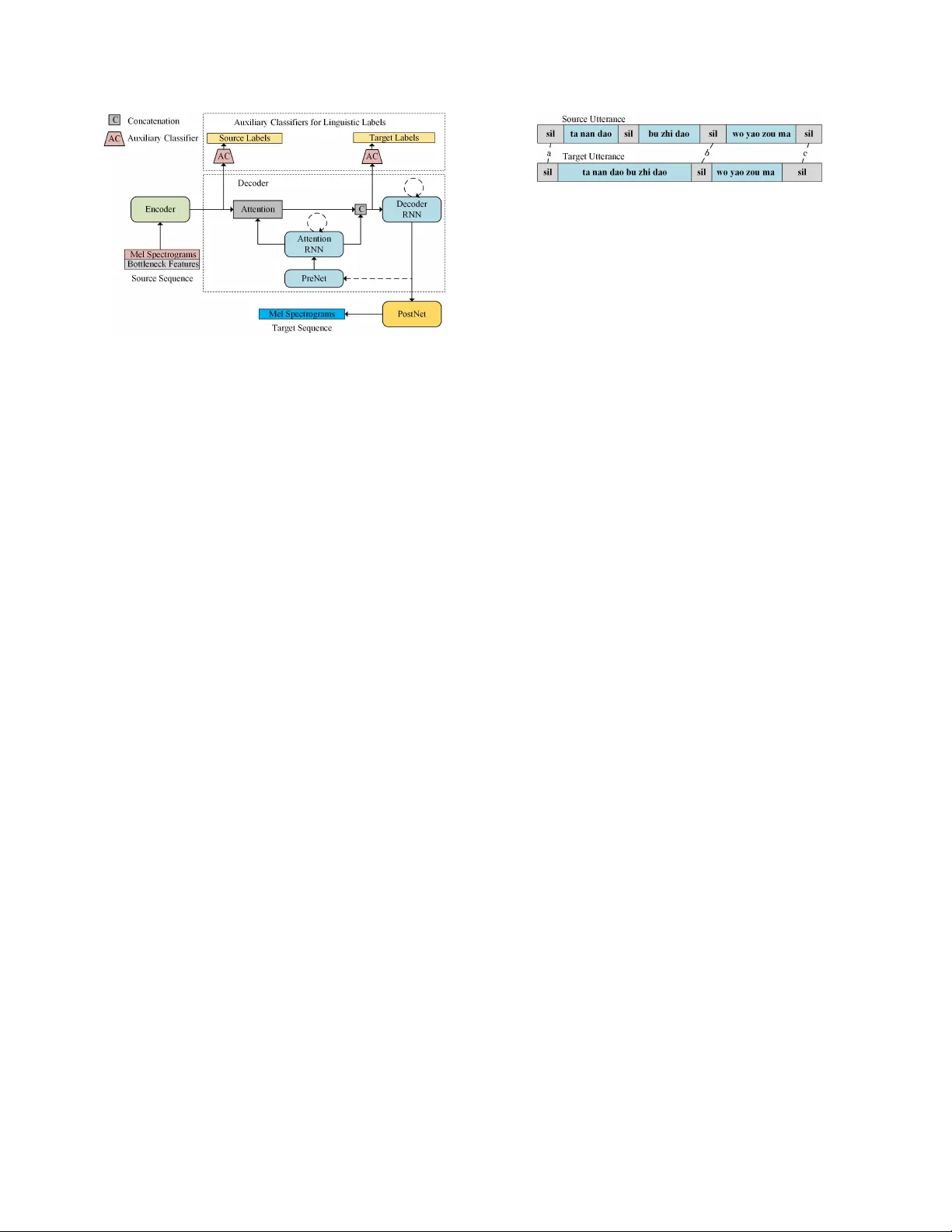
IMPR O VING SEQUENCE-T O-SEQUENCE V OICE CONVERSION BY ADDING TEXT -SUPER VISION Jing-Xuan Zhang 1 , Zhen-Hua Ling 1 , Y uan Jiang 2 , Li-Juan Liu 2 , Chen Liang 3 , Li-Rong Dai 1 1 National Engineering Laboratory for Speech and Language Information Processing, Uni versity of Science and T echnology of China, Hefei, P .R.China 2 iFL YTEK Research, iFL YTEK Co., Ltd., Hefei, P .R.China 3 Anhui Science and T echnology Research Institute, Hefei, P .R.China nosisi@mail.ustc.edu.cn, { zhling,lrdai } @ustc.edu.cn, { yuanjiang,ljliu } @iflytek.com, 279141996@qq.com ABSTRA CT This paper presents methods of making using of text supervision to improv e the performance of sequence-to-sequence (seq2seq) voice con version. Compared with con ventional frame-to-frame voice con version approaches, the seq2seq acoustic modeling method proposed in our previous work achie ved higher naturalness and similarity . In this paper , we further improve its performance by utilizing the text transcriptions of parallel training data. First, a multi-task learning structure is designed which adds auxiliary classifiers to the middle layers of the seq2seq model and predicts linguistic labels as a secondary task. Second, a data-augmentation method is proposed which utilizes text alignment to produce e xtra parallel sequences for model training. Experiments are conducted to e valuate our proposed method with training sets at different sizes. Experimental results sho w that the multi-task learning with linguistic labels is effecti ve at reducing the errors of seq2seq voice con version. The data-augmentation method can further impro ve the performance of seq2seq voice conv ersion when only 50 or 100 training utterances are av ailable. Index T erms — sequence-to-sequence, neural network, voice con version, te xt-supervision 1. INTR ODUCTION V oice con version (VC) aims to con vert the speech of a source speaker into that of tar get while keeping linguistic content un- changed [1]. The VC technique has various applications such as identity switching in a text-to-speech (TTS) system, vocal restora- tion in cases of language impairment and entertainment applications [2]. The most widely-used approach for voice con version is adopting a statistical acoustic model to capture the relationship between acoustic features of source and target speakers. In con ventional method, frame-aligned training data is first prepared using dynamic time wrapping algorithm (DTW) [3]. Then, an acoustic model is trained based on the paired source-target frames. During conv ersion, a mapping function is derived from the acoustic model, and tar get acoustic features are predicted from those of source frame by frame. The acoustic model can be a joint density Gaussian mixture model This work was partially funded by the National Nature Science Foundation of China (Grant No. 61871358) and the Key Science and T echnology Project of Anhui Province under Grant No. 17030901005. (JD-GMM) [4, 5], a deep neural netw ork (DNN) [6, 7] or a recurrent neural network (RNN) [8, 9]. Our previous w ork [10] proposed a sequence-to-sequence (seq2seq) method for VC. A Seq2seq ConvErsion NeT work (SCENT) is designed to model pairs of input and output acoustic feature sequences directly without explicit frame-to- frame alignment. The SCENT follo wed the encoder-decoder with attention architecture [11–15]. This method achie ved effecti ve duration conv ersion, higher naturalness and similarity compared with con ventional GMM and DNN-based methods [10]. Howe ver , utterances con verted by the seq2seq method may have mispronunciations and other instability problems such as repeating phonemes and skipped phonemes. In practical v oice conv ersion tasks with parallel training data, text transcriptions of both speakers are usually av ailable. Thus, this paper presents methods of utilizing text-supervision to improve the seq2seq VC model. First, a multi-task learning structure is designed. Auxiliary classifiers are added to the output layer of the encoder and the input layer of the decoder RNN, and are trained to predict the linguistic labels from the hidden vectors. Thus, the middle layers of the seq2seq model are regularized by the secondary task to be more linguistic-related, which is expected to reduce the issue of mispronunciations at conv ersion time. Second, a data-augmentation method is proposed by utilizing the text alignment information. In previous seq2seq VC method, the whole utterances are used as the sequences for model training. In order to increase the generalization ability of the trained seq2seq model, additional parallel fragments of utterances are derived using the alignment points giv en by text transcriptions, and are used as training samples. The proposed method is evaluated using training sets of different sizes. Experimental results show that our method of adding text supervision to seq2seq VC can generate utterances with higher naturalness and sometimes better similarity . The multi-task learning structure is ef fectiv e at reducing pronunciation errors. The proposed data-augmentation method can further improv e the model perfor- mance when the training set contains only 50 or 100 utterances. 2. PREVIOUS W ORK 2.1. Related w ork Methods of incorporating text information in VC task hav e been in vestigated in previous studies. T e xt information w as usually used as restrictions to improve the alignment between acoustic Fig. 1 . Block diagram of Sequence-to-sequence ConvErsion NeT work (SCENT) with auxiliary classifiers. The dashed lines represent recurrent or auto-regressi ve connections. feature sequences [9, 16]. A CAR T -based voice con version system was proposed in which phonetic information was used to grow the decision tree [17]. A phone-aware LSTM-RNN for VC was proposed [9], which combined the monophones and spectral features as model inputs. Compared with previous studies, te xt transcriptions are utilized for improving the training of the seq2seq acoustic model and are not used at the con version time in our proposed method. Multi-task learning has produced good results in various tasks, such as automatic speech recognition [18, 19], speech synthesis [20] and natural language processing [21]. In DNN-based speech synthesis, a secondary task to predict a perceptual representation of target speech was proposed [20] to improve the perceiv ed quality of generated speech.Y ang et al. [22] proposed a generative adversarial networks (GAN)-based speech synthesis frame work with phoneme classification. In our method, auxiliary classifiers for linguistic labels are added to the middle layers of the model. This secondary task provides additional supervision during training, which is ex- pected to “steer” the hidden layers towards more linguistic-related representations. On image processing tasks, cropping images is common ap- proach of data augmentation [23]. In this paper, we propose to slice fragments from parallel utterances according to text alignment and use them as training samples. This technique could make use of more alignment information within the parallel utterances and is expected to reduce o verfitting of the built seq2seq model. 2.2. Sequence-to-sequence v oice con version In our previous work [10], we proposed SCENT , a seq2seq acoustic model for VC. Ignoring the component of auxiliary classifiers, Figure 1 shows the structure diagram of SCENT , which follows the popular encoder-decoder with attention architecture. Specifically , it is composed of an encoder, a decoder with attention and a post- filtering network (PostNet). The input sequence of the model is the concatenation of mel- spectrograms and bottleneck features of source utterance. The bottleneck features are linguistic-related features which are extracted from speech signal using a speaker -independent automatic speech recognition (ASR) model. The encoder accepts input sequence and transforms it into hidden representations which are more suitable for the decoder to deal with. At each decoder time step, the pre vious generated acoustic frame is fed back into a preprocessing network Fig. 2 . Example of the aligned texts for a pair of parallel utterances. T exts are presented as Chinese pinyin and “sil” represents the silence. “a”,“b” and “c” represent totally three alignment points in this pair of parallel utterances. Therefore, totally C 2 3 (i.e., 3) potential parallel fragments can be sliced from original utterances. (PreNet), the output of which is passed through an attention RNN. The output of the attention RNN is processed by the attention module, which produces a summary of encoder output entries by weighted combination. The weighting f actors are attention probabilities. Then the concatenation of this summary and the output of attention RNN is passed through the decoder RNN to predict output acoustic frame. In order to enhance the quality of the prediction, a PostNet is further employed to produce the final mel- spectrograms of target speaker . At last, a W aveNet neural vocoder [24] conditioned on mel-spectrograms is utilized for the waveform reconstruction. 3. PR OPOSED METHODS Linguistic labels, such as phoneme identity , are firstly extracted from the text transcriptions and then aligned to source and target utterances respectively at the data preparation stage. The alignment can be obtained by manual annotation or automatic methods such as force alignment using a hidden Markov model (HMM). T wo methods of making use of the text supervision to improve the performance of the seq2seq VC model are introduced in this section. 3.1. Multi-task learning with linguistic labels In parallel with learning to predict the acoustic features of target speaker , a secondary task is conducted to predicted linguistic labels from middle layers of the model. As presented in Figure 1, two auxiliary classifiers are added to the outputs of encoder and the inputs of decoder RNN. In each classifier, the input hidden representations are first passed through a dropout layer for increasing generalization. Then, the outputs of the dropout layer are projected to the category number of linguistic labels followed by a softmax operation. The targets of the two classifiers are the linguistic labels that current hidden representations of encoder and decoder RNN correspond to respectively . The cross-entropy losses of these two classifiers are weighted and added with the original loss of mel- spectrograms for training the model. The auxiliary classifiers are designed for improving the seq2seq VC model by using stronger supervision from the text. Intuitiv ely , they help to guide the model to generate more meaningful interme- diate representations which are linguistic-related. Adding classifier to both the encoder and decoder part is also supposed to help the attention module to predict correct alignments. It should be noticed that the classifiers are only used at the training stage and are discarded at the con version time. Therefore, no extra input and computation are required during con version. T able 1 . MCDs and F 0 RMSEs on test set using training sets of different sizes. The minimum MCD and F 0 RMSE for each set size and speaker pair are highlighted in bold fonts. Size of training data Male-Female Female-Male Seq2seq Seq2seq-MT Seq2seq-MT -D A Seq2seq Seq2seq-MT Seq2seq-MT -D A MCD F 0 RMSE MCD F 0 RMSE MCD F 0 RMSE MCD F 0 RMSE MCD F 0 RMSE MCD F 0 RMSE (dB) (Hz) (dB) (Hz) (dB) (Hz) (dB) (Hz) (dB) (Hz) (dB) (Hz) 50 5.116 50.035 4.870 46.962 4.473 44.235 4.888 56.496 4.640 54.023 4.076 46.094 100 4.679 42.830 4.360 38.290 4.161 39.101 4.339 51.159 4.022 47.189 3.970 43.621 200 4.130 40.976 4.000 35.583 3.936 35.558 3.920 45.733 3.811 45.166 3.813 45.515 400 3.959 36.765 3.905 35.787 3.864 35.727 3.726 45.471 3.696 44.952 3.722 45.401 1000 3.802 33.374 3.776 32.155 3.774 34.604 3.556 41.748 3.579 43.652 3.545 44.107 3.2. Data-augmentation by text alignment In our pre vious seq2seq VC method, pairs of whole utterances are used as the input and output sequences for model training. With text alignments, intra-utterance alignments can also be utilized to produce more sequence pairs. In our method, an “alignment point” is defined as a common silence fragment in a pair of parallel utterances. Figure 2 presents an example for illustration. Parallel fragments, which contain the same linguistic contents within two utterances, are extracted by selecting two alignment points as the starting and ending positions. The reason that alignment points are defined at silences is to make sure that the parallel fragments are less influenced by surrounding contents. For a pair of parallel utterances containing N alignment points, totally C 2 N parallel fragments can be extracted. When processing each pair of utterances at training time, a pair of parallel fragments are randomly selected from all C 2 N possibilities instead of using the whole utterances. 4. EXPERIMENTS 4.1. Experimental conditions Our dataset for experiments contained 1060 parallel Mandarin ut- terances of one male speaker (about 53 min) and one female (about 72 min) speaker, which were separated into a training set with 1000 utterances, a v alidation set with 30 utterances and a test set with 30 utterances. Smaller training sets containing 50, 100, 200 and 400 utterances were also constructed by randomly selecting a subset of the 1000 utterances for training. The recordings were sampled at 16kHz. 80-dimensional mel-scale spectrograms were extracted ev ery 10 ms with Hann windo wing of 50 ms frame length and 1024- point Fourier transform. 512-dimensional bottleneck features were extracted using an ASR model ev ery 40 ms and were then upsampled by repeating to match the frame rate of mel-spectrograms. T ext transcriptions were firstly con verted into sequences of phonemes with tone using a rule-based grapheme-to-phoneme model. The phoneme with tone sequences were then aligned to the speech using an HMM aligner . Details of the seq2seq model and the W av eNet vocoder were kept the same as our previous work [10]. The output layer of the decoder in SCENT was a mixture density netw ork (MDN) layer with 2 mixture components. W e used the batch size of 4 and Adam optimizer [25] for model training. The learning rate was 0.001 in the first 20 epochs and exponentially decay 0.95 for 50 more epochs. For W av eNet training, the µ -law companded waveforms were quantized into 10 bits. The learning rate was 10 − 4 . The focus of this paper was acoustic modeling, not W av eNet v ocoder . Therefore, the W av eNet v ocoder of each speaker was trained using the waveforms of his or her full training set for con venience. Three methods were compared in our experiments. The config- uration of each method is described as follows 1 : • Seq2seq: Baseline method using previous proposed sequence-to-sequence acoustic model [10]. • Seq2seq-MT : Improving the baseline method using the multi-task learning structure proposed in Section 3.1. Auxiliary classifiers were adopted for predicting linguistic labels at training time. Each classifier contained two separated linear projection with the softmax activ ation for predicting phoneme identity and tone category simultaneously . The weighting factors for phoneme and tone classification were 0.1 and 0.05 respecti vely , which were tuned on the validation set. • Seq2seq-MT -DA: In addition to multi-task learning, the data-augmentation method introduced in Section 3.2 was also adopted. In our full training set, the av erage number of alignment points in each pair of utterances was 3.15. The learning rate was fixed in first 40 epochs for better model con vergence. W e also tried to use larger batch size because the a verage length of each training sample became shorter . Howev er , the results showed no improvement on the validation set. 4.2. Objective ev aluation F 0 and mel-cepstra were extracted from the con verted utterances using STRAIGHT [26]. Then, mel-cepstrum distortions (MCD) and root mean square error of F 0 ( F 0 RMSE) on test set were reported in T able 1. From the table, we can see that all methods obtained lower MCD and F 0 RMSE giv en more training data. When the training data was limited, i.e. only 50 or 100 training utterances available, the proposed method using multi-task learning outperformed the baseline seq2seq method with a large margin. Adopting the data-augmentation method can further improve the performance of acoustic models. When more training data became av ailable (e.g., 200 and 400 utterances), the performances of the Seq2seq-MT and Seq2seq-MT -DA methods were close and still better than the baseline method. When training with all parallel data, the proposed method obtained close MCD but higher F 0 RMSE than the baseline method. 1 Audio samples are available at https://jxzhanggg.github. io/Text- supervised- Seq2SeqVC . T able 2 . Numbers of mistakes identified subjectiv ely on test set under different sizes of training data and speak er pairs. Size of training data Male-Female Female-Male Seq2seq Seq2seq-MT Seq2seq Seq2seq-MT 50 43 27 38 30 100 22 16 23 15 200 19 12 16 6 400 16 9 10 6 1000 12 3 7 3 In summary , the proposed method achiev ed lower objectiv e error when the training set contains 50, 100, 200 and 400 utterances respectiv ely . Compared with Seq2seq-MT , the Seq2seq-MT -D A method can further improv e the prediction accurac y when the size of training data was 50 and 100. When training with 1000 utter- ances, no significant objecti ve improv ement was observed after data augmentation. The reason may be that the fragments used after data augmentation neglected the influence of their contexts in utterances. This ne gativ e effect may counteract the positive effect of reducing ov erfitting. Besides, the MCD and F 0 RMSE of our proposed method was not better than the baseline method when models were trained with 1000 utterances. Subjecti ve ev aluations were conducted to further in vestigate the ef fecti veness of our proposed method. 4.3. Subjective ev aluation The first subjectiv e ev aluation was conducted to ev aluate the stability of Seq2seq and Seq2seq-MT methods. A native listener was asked to identify the mistakes occurred in the test utterances con verted using these two methods, which included mispronunciation, repeat- ing phoneme, skipped phoneme and unclear voice. The counted numbers of mistakes are presented in T able 2. The ev aluation results indicate that multi-task learning with linguistic labels can alleviate the problem of instability under all size of training data. A closer inspection on the mistakes of the Seq2seq method found that the main problem of instability was mispronunciation when the size of training data was relatively large, i.e. 400 or 1000 utterances. Con verted utterances sometimes suffered from unnatural tone or incorrect phoneme. When the size of training data got smaller, mistakes of skipped phone, repeating phone increased, which were usually caused by improper attention alignments. The multi-task learning could help to alleviate both kind of problems. Furthermore, ABX preference tests were conducted on both similarity and naturalness. T wo conditions with 50 and 1000 training utterances were in vestigated. As we described in Section 4.2, when the size of training data was small, data augmentation method further improv ed the objective performance of the model. When training with 1000 utterances, no significant objectiv e improvement was observed after data augmentation. Therefore, we compared Seq2seq with Seq2seq-MT -D A for using 50 training utterances and Seq2seq with Seq2seq-MT for using 1000 training utterances respectively . 10 native listeners were in volv ed in the ev aluation. 20 sentences in the test set were randomly selected. The con version results were presented for listeners in random order . The experimental results are presented in Figure 3 and Fig- ure 4. The e valuation results from Figure 3 sho w that the pro- posed Seq2seq-MT -D A method obtained significant higher prefer- ence score on both similarity and naturalness, which was consistent with the results of objective ev aluations. These results indicate that the proposed methods improved model training significantly when 0 20 40 60 80 100 Sim ilar ity N at u ral n e s s Sim ila rit y N at u ra l n e s s Fe m ale - M ale Male - F e m ale Se q 2s e q N /P Se q 2s e q - MT - DA Pref e re n ce s core (% ) Fig. 3 . Results of ABX preference test for comparing Seq2seq and Seq2seq-MT -D A method under the condition of 50 training utterances. “N/P” represents no preference. The p -values of student t -test on the ev aluation results are 3 . 84 × 10 − 33 , 1 . 02 × 10 − 24 , 5 . 85 × 10 − 37 and 5 . 83 × 10 − 30 respectiv ely . 0 20 40 60 80 100 Sim ilar ity N at u ra l n e s s Sim ilarit y N at u ral n e s s Fe m a le - M a le Ma le - F e m ale Se q 2s e q N /P Se q 2s e q - MT Pre f e re n ce s cor e (% ) Fig. 4 . Results of ABX preference test for comparing Seq2seq and Seq2seq-MT method under the condition of 1000 training utterances. “N/P” represents no preference. The p -values of student t -test on ev aluation results are 1 . 16 × 10 − 6 , 0.0815, 0.0592 and 0.218 respectiv ely . the training data was limited. Figure 4 sho ws that the multi-task learning method improv ed the naturalness of con verted speech when 1000 training utterances were av ailable. The similarity impro vement on female-to-male conv ersion was insignificant since the p -value was 0.218. 5. CONCLUSION This paper has presented two methods to improving seq2seq voice con version by utilizing te xt supervision. First, a secondary task is introduced based on the framework of multi-task learning. Auxiliary classifiers are added for predicting corresponding linguistic labels from the middle layers of the model. Second, a data-augmentation method is proposed, in which fragments of original utterances are randomly extracted at each training step. Experimental results validated the effecti veness of our proposed method for improving model training. The multi-task learning alleviates the instability problems, such as mispronunciations, in the conv ersion results of seq2seq model. The data-augmentation method can further improve the performance of seq2seq VC model with limited training data. Although the proposed methods can enhance the seq2seq VC model effecti vely , the degradation of model performance is still significant when only small training sets are av ailable. Future work includes further improving the seq2seq model using other techniques in the resource-limited situation, such as model adaptation. 6. REFERENCES [1] D. G. Childers, K e W u, D. M. Hicks, and B. Y egnanarayana, “V oice conv ersion, ” Speech Communication , vol. 8, no. 2, pp. 147–158, 1989. [2] Seyed Hamidreza Mohammadi and Alexander Kain, “ An ov erview of voice con version systems, ” Speech Communica- tion , vol. 88, pp. 65–82, 2017. [3] Meinard M ¨ uller , “Dynamic time warping, ” Information r etrieval for music and motion , pp. 69–84, 2007. [4] A. Kain and M. W . Macon, “Spectral voice conv ersion for text-to-speech synthesis, ” in IEEE International Conference on Acoustics, Speec h and Signal Pr ocessing (ICASSP) , 1998, pp. 285–288 vol.1. [5] T omoki T oda, Alan W . Black, and K eiichi T okuda, “V oice con version based on maximum-likelihood estimation of spectral parameter trajectory , ” IEEE T ransactions on Audio Speech and Languag e Pr ocessing , vol. 15, no. 8, pp. 2222– 2235, 2007. [6] Srini vas Desai, Alan W . Black, B. Y egnanarayana, and Kishore Prahallad, “Spectral mapping using artificial neural networks for voice conv ersion, ” IEEE T ransactions on Audio Speech and Language Pr ocessing , vol. 18, no. 5, pp. 954–964, 2010. [7] Ling Hui Chen, Zhen Hua Ling, Li Juan Liu, and Li Rong Dai, “V oice con version using deep neural networks with layer - wise generative training, ” IEEE/ACM Tr ansactions on A udio Speech and Language Pr ocessing , vol. 22, no. 12, pp. 1859– 1872, 2014. [8] Lifa Sun, Shiyin Kang, Kun Li, and Helen Meng, “V oice con version using deep bidirectional long short-term memory based recurrent neural netw orks, ” in IEEE International Confer ence on Acoustics, Speec h and Signal Processing (ICASSP) , 2015, pp. 4869–4873. [9] Jiahao Lai, Bo Chen, Tian T an, Sibo T ong, and Kai Y u, “Phone-aware LSTM-RNN for voice conv ersion, ” in IEEE International Confer ence on Signal Pr ocessing (ICSP) , 2016, pp. 177–182. [10] Jing-Xuan Zhang, Zhen-Hua Ling, Li-Juan Liu, Y uang Jiang, and Li-Rong Dai, “Sequence-to-sequence acoustic modeling for v oice con version, ” arXiv pr eprint arXiv:1810.06865 , 2018. [11] Ilya Sutske ver , Oriol V inyals, and Quoc V Le, “Sequence to sequence learning with neural networks, ” Neural Information Pr ocessing Systems , pp. 3104–3112, 2014. [12] Dzmitry Bahdanau, Kyunghyun Cho, and Y oshua Bengio, “Neural machine translation by jointly learning to align and translate, ” International Conference on Learning Repr esentations , 2015. [13] Thang Luong, Hieu Pham, and Christopher D Manning, “Effecti ve approaches to attention-based neural machine translation, ” Empirical Methods in Natural Language Pr ocessing , pp. 1412–1421, 2015. [14] Y uxuan W ang, R J Skerryryan, Daisy Stanton, Y onghui W u, Ron J W eiss, Na vdeep Jaitly , Zongheng Y ang, Y ing Xiao, Zhifeng Chen, Samy Bengio, et al., “T acotron: T o wards end-to-end speech synthesis, ” in Pr oceedings of the Annual Confer ence of the International Speech Communication Association, INTERSPEECH , 2017, pp. 4006–4010. [15] Jonathan Shen, Ruoming Pang, Ron J W eiss, Mike Schuster , Navdeep Jaitly , Zongheng Y ang, Zhifeng Chen, Y u Zhang, Y uxuan W ang, R J Skerryryan, et al., “Natural TTS synthesis by conditioning W av eNet on mel spectrogram predictions, ” in IEEE International Conference on Acoustics, Speech and Signal Pr ocessing (ICASSP) , 2018, pp. 4779–4783. [16] Jianhua T ao, Meng Zhang, Jani Nurminen, Jilei Tian, and Xia W ang, “Supervisory data alignment for te xt-independent voice con version, ” IEEE T ransactions on Audio, Speech, and Language Pr ocessing , vol. 18, no. 5, pp. 932–943, 2010. [17] Antonio Bonafonte, Alexander Kain, Jan van Santen, and He- lenca Duxans, “Including dynamic and phonetic information in voice con version systems, ” in Eighth International Confer ence on Spoken Language Pr ocessing , 2004. [18] Michael L Seltzer and Jasha Droppo, “Multi-task learning in deep neural netw orks for improved phoneme recognition, ” in IEEE International Conference on Acoustics, Speech and Signal Pr ocessing (ICASSP) . IEEE, 2013, pp. 6965–6969. [19] Zhuo Chen, Shinji W atanabe, Hakan Erdogan, and John R Hershey , “Speech enhancement and recognition using multi- task learning of long short-term memory recurrent neural networks, ” in Proceedings of the Annual Conference of the International Speech Communication Association, INTERSPEECH , 2015. [20] Zhizheng W u, Cassia V alentini-Botinhao, Oliver W atts, and Simon King, “Deep neural networks employing multi-task learning and stacked bottleneck features for speech synthesis, ” in IEEE International Conference on Acoustics, Speech and Signal Pr ocessing (ICASSP) . IEEE, 2015, pp. 4460–4464. [21] Ronan Collobert and Jason W eston, “ A unified architecture for natural language processing: Deep neural networks with multitask learning, ” in Proceedings of the 25th International Confer ence on Machine Learning . A CM, 2008, pp. 160–167. [22] Shan Y ang, Lei Xie, Xiao Chen, Xiaoyan Lou, Xuan Zhu, Dongyan Huang, and Haizhou Li, “Statistical parametric speech synthesis using generative adversarial networks under a multi-task learning framework, ” in 2017 IEEE A utomatic Speech Recognition and Understanding W orkshop (ASRU) . IEEE, 2017, pp. 685–691. [23] Luis Perez and Jason W ang, “The effecti veness of data augmentation in image classification using deep learning, ” arXiv preprint arXiv:1712.04621 , 2017. [24] Aaron V an Den Oord, Sander Dieleman, Heiga Zen, Karen Simonyan, Oriol V inyals, Ale x Grav es, Nal Kalchbrenner , Andrew W Senior , and K oray Ka vukcuoglu, “W aveNet: A generativ e model for raw audio, ” arXiv: Sound , p. 125, 2016. [25] Diederik Kingma and Jimmy Ba, “ Adam: A method for stochastic optimization, ” Computer Science , 2014. [26] Hideki Kawahara, Ikuyo Masuda-Katsuse, and Alain De Chev eign, “Restructuring speech representations using a pitch-adaptiv e timefrequenc y smoothing and an instantaneous- frequency-based f0 extraction: Possible role of a repetitiv e structure in sounds 1, ” Speec h Communication , vol. 27, no. 34, pp. 187–207, 1999.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment