비구조적 가중치 프루닝, 모든 플랫폼에서 해로울까
본 논문은 최신 ADMM 기반 프레임워크 ADMM‑NN‑S를 제안하고, 양자화와 결합된 비구조적 프루닝과 구조적 프루닝을 동일한 정확도 조건에서 저장 용량과 연산 효율을 기준으로 공정하게 비교한다. 실험 결과, 인덱스 오버헤드와 낮은 Pruning‑to‑Performance Ratio(PPR) 때문에 비구조적 프루닝은 저장·연산 측면에서 구조적 프루닝보다 열등함을 입증하고, 비구조적 프루닝을 ‘해롭다’고 결론짓는다.
저자: Xiaolong Ma, Sheng Lin, Shaokai Ye
본 논문은 대규모 딥 뉴럴 네트워크(DNN)의 에너지 효율성을 저해하는 주요 원인인 DRAM 접근 비용을 감소시키기 위해, 가중치 프루닝과 가중치 양자화를 결합한 모델 압축 기법을 심도 있게 분석한다. 기존 연구에서는 비구조적 프루닝이 높은 자유도와 높은 프루닝 비율을 제공하지만, 불규칙한 가중치 패턴으로 인해 인덱스 저장 및 접근 비용이 발생한다는 단점을 지적해 왔다. 반면 구조적 프루닝은 필터, 채널, 필터‑쉐이프 등 일정한 구조를 유지함으로써 인덱스가 필요 없고, 실제 하드웨어 가속에서 높은 속도 향상을 보인다. 그러나 구조적 프루닝은 프루닝 비율이 제한적이라는 문제가 있다.
이러한 상황에서 저자들은 두 가지 질문에 답하고자 한다. 첫째, 양자화가 이미 적용된 상황에서 비구조적 프루닝과 구조적 프루닝 중 어느 쪽이 더 효율적인가? 둘째, 이를 평가하기 위한 공정하고 근본적인 비교 방법은 무엇인가?
이를 위해 저자들은 기존 ADMM‑NN 프레임워크를 확장하여 ADMM‑NN‑S를 개발하였다. ADMM(Alternating Direction Method of Multipliers) 기반 최적화는 가중치 프루닝과 양자화를 동시에 다루는 데 강력한 도구이며, 구조적 프루닝 제약을 추가함으로써 필터 수, 채널 수, 레이어 깊이 등 다양한 구조적 제한을 명시적으로 모델링한다. 또한 동적 ADMM 규제, 마스크 매핑, 재학습 과정을 도입해 제약을 만족하면서도 높은 정확도를 유지한다.
비교 방법론은 두 가지 핵심 메트릭으로 구성된다. 첫 번째는 전체 저장 용량(가중치 + 인덱스)이다. 인덱스는 절대 위치와 상대 위치 두 가지 CSR(Compressed Sparse Row) 포맷을 고려하며, 비구조적 프루닝에서는 인덱스 비트 수가 가중치 비트 수보다 크게 증가할 수 있음을 정량화한다. 두 번째는 연산 효율성을 나타내는 Pruning‑to‑Performance Ratio(PPR)이다. 여기서 α는 프루닝 비율(예: 10배 감소 → α=10), β는 실제 가속 비율(예: 3배 가속 → β=3)이며, PPR=α/β로 정의한다. PPR이 1에 가까울수록 프루닝이 연산 효율에 직접 기여한다는 의미이며, 비구조적 프루닝은 인덱스 처리 비용으로 인해 PPR이 2.7 이상으로 크게 증가한다는 점을 강조한다.
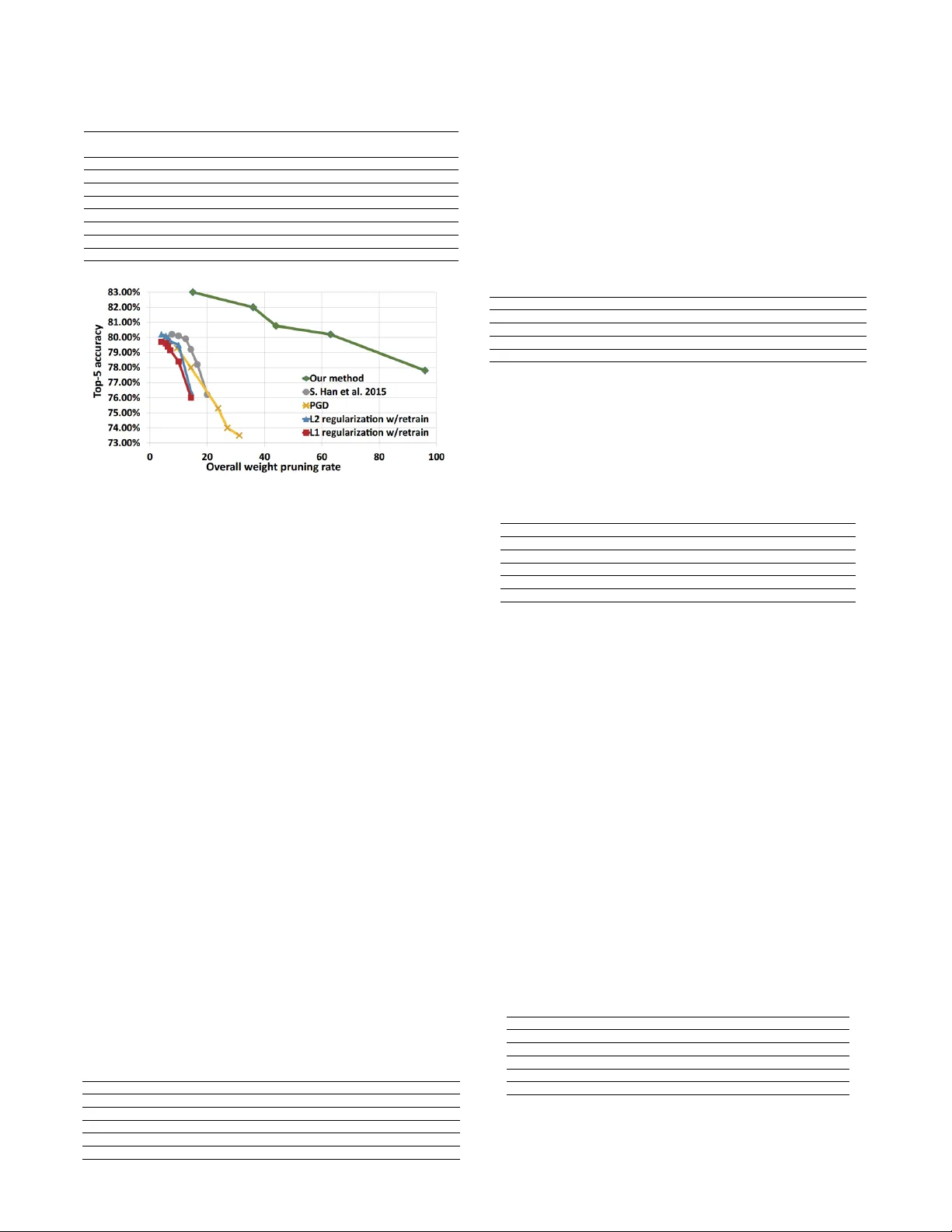
실험은 LeNet‑5, AlexNet, VGG‑16, ResNet‑18/50, MobileNet 등 다양한 CNN 모델과 MNIST, CIFAR‑10, ImageNet 데이터셋을 대상으로 수행되었다. 주요 결과는 다음과 같다. (1) ADMM‑NN‑S는 비구조적 프루닝에서 LeNet‑5에 348배, AlexNet에 36배, ResNet‑50에 8배의 가중치 감소를 달성했으며, 정확도 손실은 거의 없었다. (2) 3‑bit 양자화와 결합된 비구조적 프루닝에서도 인덱스 비트(예: 9비트) 때문에 전체 저장량이 구조적 프루닝보다 크게 늘어났다. (3) 비구조적 프루닝은 GPU(1080Ti)에서 실제 연산 속도가 20% 감소하는 역효과를 보였으며, PPR이 2.7~3.5 수준으로 구조적 프루닝에 비해 비효율적이었다. (4) 구조적 프루닝은 인덱스가 필요 없고, PPR이 1~1.2 수준으로 일관된 가속을 제공했다. (5) 완전 이진화(fully binarized) 모델을 손실 없이 구현하는 데 성공했으며, 이는 양자화와 프루닝이 상호 보완적으로 작용함을 보여준다.
이러한 결과를 바탕으로 저자들은 “비구조적 가중치 프루닝은 저장 및 연산 효율 측면에서 구조적 프루닝보다 열등하며, 따라서 해롭다”고 결론짓는다. 또한 비구조적 스파시티 기반 가속기 연구를 중단하고, 양자화와 구조적 프루닝에 집중할 것을 권고한다.
비판적 관점에서 보면, 논문의 비교는 현재 상용화된 CSR 기반 인덱스 구현에 크게 의존한다. 차세대 메모리 기술(예: 스파시티‑인식 DRAM, 비정형 메모리)이나 특수 ASIC 설계가 인덱스 오버헤드를 크게 감소시킬 경우 비구조적 프루닝의 효율성이 재평가될 여지가 있다. 또한 PPR 기준값 2.7은 기존 비구조적 가속기 구현에 기반한 것이므로, 향후 최적화된 하드웨어가 이 값을 낮출 가능성도 존재한다. 마지막으로, 구조적 프루닝이 모든 레이어와 모델에 동일한 정확도 보장을 제공한다는 가정은 제한된 실험(주로 CONV 레이어)으로 검증되었으며, RNN이나 트랜스포머와 같은 비전 모델에 대한 일반화 가능성은 아직 확인되지 않았다. 따라서 비구조적 프루닝을 완전히 배제하기보다는 하드웨어‑소프트웨어 공동 설계 관점에서 지속적인 탐색이 필요하다는 점을 강조한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기