Non-Structured DNN Weight Pruning -- Is It Beneficial in Any Platform?
Large deep neural network (DNN) models pose the key challenge to energy efficiency due to the significantly higher energy consumption of off-chip DRAM accesses than arithmetic or SRAM operations. It motivates the intensive research on model compressi…
Authors: Xiaolong Ma, Sheng Lin, Shaokai Ye
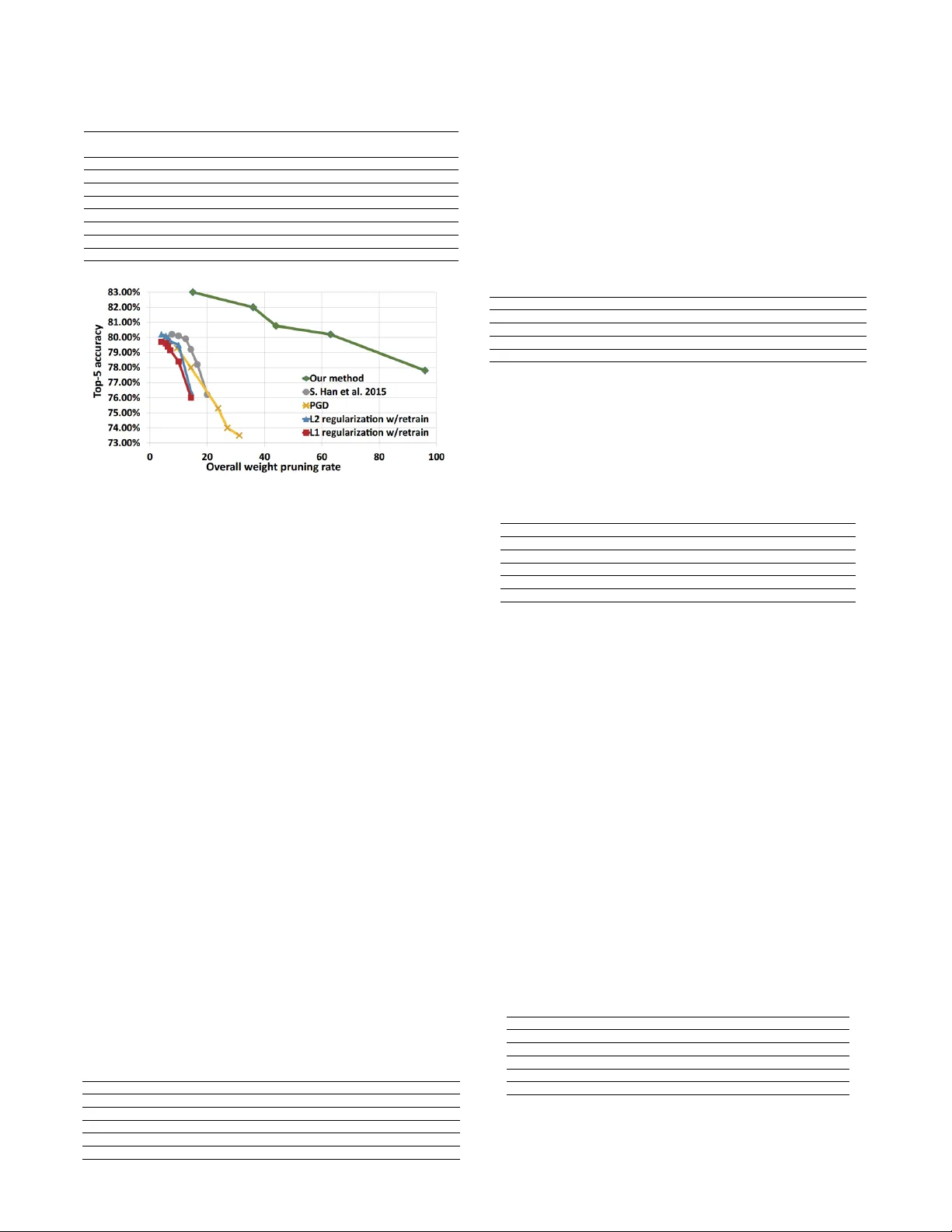
JOURNAL OF L A T E X CLASS FILES, VOL. 14, NO. 8, A UGUST 2015 1 Non-Structured DNN W eight Pruning – Is It Beneficial in An y Platform? Xiaolong Ma † , Sheng Lin † , Shaokai Y e, Zhezhi He, Linfeng Zhang, Geng Y uan, Sia Huat T an, Zhengang Li, Deliang Fan, Xuehai Qian, Xue Lin, Kaisheng Ma, and Y anzhi W ang Abstract —Large deep neural network (DNN) models pose the key challenge to ener gy efficiency due to the significantly higher energy consumption of off-chip DRAM accesses than arithmetic or SRAM operations. It motivates the intensi ve resear ch on model compression with two main approaches. W eight pruning leverages the redundancy in the number of weights and can be performed in a non-structured, which has higher flexibility and pruning rate b ut incurs index accesses due to irregular weights, or structur ed manner , which pr eserves the full matrix structure with lower pruning rate. W eight quantization le verages the redundancy in the number of bits in weights. Compared to pruning, quantization is much more hardware-friendly , and has become a “must-do” step for FPGA and ASIC implementations. Thus, any ev aluation of the effectiveness of pruning should be on top of quantization. The k ey open question is, with quantization, what kind of pruning (non-structured vs. structured) is most beneficial? This question is fundamental because the answer will determine the design aspects that we should really f ocus on to av oid diminishing return of certain optimizations. This paper pr ovides a definitiv e answer to the question for the first time. First, we build ADMM-NN-S by extending and enhancing ADMM-NN, a recently proposed joint weight pruning and quantization framework, with the algorithmic supports for structured pruning, dynamic ADMM regulation, and masked mapping and retraining . Second, we dev elop a methodology for fair and fundamental comparison of non-structured and structured pruning in terms of both storage and computation efficiency . Our r esults show that ADMM-NN-S consistently outperforms the prior art: (i) it achieves 348 × , 36 × , and 8 × overall weight pruning on LeNet-5, AlexNet, and ResNet-50, respecti vely , with (almost) zero accuracy loss; (ii) we demonstrate the first fully binarized (for all layers) DNNs can be lossless in accuracy in many cases. These results provide a strong baseline and credibility of our study . Based on the proposed comparison framework, with the same accuracy and quantization, the results show that non-structured pruning is not competitive in terms of both storage and computation efficiency . Thus, we conclude that non-structured pruning is considered harmful. W e urge the community not to continue the DNN inference acceleration f or non-structured sparsity . Index T erms —Deep neural network, W eight pruning, Quanti- zation, Hardware acceleration. I . I N T R O D U C T IO N D EEP neural networks (DNNs) with very large model sizes are the key enabler for the recent success of deep learning. Howe ver , large models incur excessiv e DRAM ac- cesses which consume significant more energy than arithmetic or SRAM operations. Thus, model compression of DNNs became an acti ve and intensively studied research topic. These techniques, which are applied during the training phase of † These authors contributed equally . Filter Pruning Channel Pruning Filter Shape Pruning Filter 1 Filter 2 Filter A Filter 1 Filter 2 Filter 1 Filter 2 ... ... ... (a) (b) pruning synapses Before pruning After pruning pruning neurons i Filter A i Filter A i Fig. 1. (a) Non-structured weight pruning (arbitrary weight can be pruned) and (b) three types of structured pruning. the DNNs, exploit the redundancy in weights. The aim is to simultaneously reduce the model size (thus, the storage requirement) and accelerate the computation for inference, — all to be achiev ed with minor classification accuracy loss. These techniques are of particular interests to the hardware acceleration of DNN inference engine [1]–[70]. T wo important model compression techniques are weight pruning and weight quantization. W eight pruning leverages the redundancy in the number of weights. One early work [71] used heuristic and iterative weight pruning to achiev e weight parameter reduction with negligible accuracy loss. It has been extended in [72]–[75] with more sophisticated heuristics. On the do wnside, such non- structur ed methods lead to irr e gular , sparse weight matrices (as shown in Figure 1 (a), arbitrary weight can be pruned), which rely on indices to be stored in a compressed format. As a result, they are less compatible with the data parallel ex ecution model in GPUs and multicore CPUs. This drawback is confirmed by the throughput degradation reported in recent works [76], [77]. T o overcome the limitation of non-structured pruning, recent works [76], [78] proposed the idea of incor- porating re gularity or “structures” in weight pruning , such as filter pruning, channel pruning, and filter shape pruning, shown in Figure 1 (b). The structured approaches maintain a full matrix with reduced dimensions, and indices are no longer needed . As a result, it leads to much higher speedups in GPUs. W eight quantization is an orthogonal compression technique that lev erages the redundancy in the number of bits of weight JOURNAL OF L A T E X CLASS FILES, VOL. 14, NO. 8, A UGUST 2015 2 GPU Multi-core CPU FPGA ASIC Non-Structured Pruning Structured Pruning Not Suitable Not Suitable Suitable Suitable Storage/Computation Dependent Fig. 2. Is non-structured pruning beneficial at all? representation [79]–[86]. Compared to weight pruning, weight quantization is inherently more hardware-friendly , since both storage and computation of DNNs will be reduced proportion- ally to the weight precision without additional ov erhead due to indices. Moreover , multiplication operations may be elimi- nated with binary , ternary , or power -of-2 weight quantizations [84]–[86]. Thanks to these adv antages, weight quantization has been a “must-do” step for DNN inference engines. Besides FPGA and ASIC, it is also well supported in GPU, CPU, and mobile devices, e.g., [87], [88]. Giv en the pros and cons of non-structured/structured weight pruning and weight quantization, they need to be in vestigated jointly to fully understand the interactions between them. In particular , since weight quantization is a must-do step, especially for FPGA and ASIC, i.e., weight pruning will not be performed alone. The key open question is, with quan- tization, what kind of pruning (non-structured vs. structur ed) is most beneficial ? The answer to the question is far from obvious. Using LeNet-5 (for MNIST data set) as an example, we achiev e an unprecedented 348 × (non-structured) weight reduction with 3-bit quantization, maintaining 99 %+ accuracy . Howe ver , each index needs to be at least 9-bit on account of 348 × weight pruning. This makes index storage lar ger than that of weights (in addition, indices cannot be further quantized). In this example, non-structured weight pruning results in lar ger actual storage than structured pruning. Thus, we can see the importance of answering such question: it will determine the design aspects that we should really focus on to av oid diminishing return of certain optimizations. As shown in Figure 2, we need answers for all platforms. T wo recent works ADMM-NN [89] and [79], that perform systematic joint weight pruning and quantization, are in the best position to perform this study . Using advanced variable- splitting optimization method ADMM (Alternating Direction Methods of Multipliers) [90]–[92], state-of-the-art results are achiev ed (e.g., 21 × weight reduction [93] in AlexNet), — out- performing heuristic counterparts. Unfortunately , the current framew ork is insufficient to perform such study . First, ADMM- NN lacks the algorithmic mechanisms to enforce structured weight pruning, and guarantee the solution feasibility . Second, we lack the methodology to fairly and fundamentally compare non-structured and structured pruning in an “apple-to-apple” manner . This paper is the first study to provide the answer to the open question with two key contributions. The first contribution of the paper is the de velopment of ADMM-NN-S by extending and enhancing of ADMM- NN [89]. It is extended with the algorithmic supports for structured pruning. W e achiev e this by adjusting the constraints in each layer to express the structured requirements. For example, for filter pruning, the constraint for a layer can be specified as number of non-zer o filters is less than or equal to a threshold. Moreov er , we dev elop a systematic frame work of dynamic ADMM regulation, masked mapping and retraining to guarantee solution feasibility (satisfying all constraints) and provide high solution quality (ensuring pruning and quantiza- tion rate under the same accuracy). The second contribution is the methodology for the fair and fundamental comparison of non-structured and struc- tured weight pruning with quantization in place. W e focus on two metrics with the same accuracy : 1) total storage (weight+indices), which is computed based on both absolute and relative indices; 2) computation ef ficiency , which is cap- tured by a new metrics called pruning-to-performance ratio (PPR). After pruning, suppose α × weight reduction results in β × speedup, the PPR v alue is defined as α/β . Intuiti vely , the less the value of PPR, the higher the computation efficiency , — same speedup can be achiev ed by smaller pruning rate. For structured pruning, PPR v alue is approximately 1 due to the absence of indices. For non-structured pruning, recent accelerators based on non-structured sparsity [94]–[97] show that PPR values are larger than 2.7. W e can fairly compare non-structured and structured pruning by conservati vely com- paring PPR: non-structured pruning is more beneficial if it can achiev e 2.7 × or higher pruning rate than structured pruning. No prior work has conducted such study and the answer to the abov e comparison is unknown . The fairness of the proposed methodology is ensured due to three reasons: 1) it is performed by our ne w ADMM-NN- S framework that significantly outperforms prior arts (in both non-structured and structured pruning); 2) the comparison of storage and computation is har dwar e implementation-agnostic ; 3) the comparison is performed at the same rate of accuracy . W e also strengthen weight quantization after non-structured pruning by selectiv ely lev eraging state-of-art ternary quanti- zation solution [98]. Based on the proposed ideas, we perform extensi ve and representativ e testing of our comparison framework with AlexNet, VGGNet, ResNet-18/50, MobileNet, and LeNet-5 models based on ImageNet, CIF AR-10, and MNIST data sets. Due to space limitation, we focus on con volutional (CONV) layers, which are the most computationally intensiv e layers in DNNs and are becoming the major storage as well as in state- of-art ResNet and MobileNet models. W e do observe similar (and more significant) effect on fully-connected (FC) layers and on RNNs. W e highlight our results and findings. First, ADMM-NN-S framework guarantees solution fea- sibility while providing high solution quality . Our results consistently and significantly outperform prior art. This is the key to ensure the credibility of our conclusion. Specifically , we 1) achiev e unpr ecedented 348 × , 36 × , and 8 × overall weight pruning on LeNet-5, AlexNet, and ResNet-50 models, respectiv ely , with (almost) zero accuracy loss; 2) deriv e the first lossless, fully binarized (for all layers) LeNet-5 for MNIST and VGG-16 for CIF AR-10; and 3) deriv e the first fully binarized (for all layers) ResNet for ImageNet with reasonable accuracy loss. Second, comparing non-structured and structured pruning, we find that the storage overhead of indices for non-structured JOURNAL OF L A T E X CLASS FILES, VOL. 14, NO. 8, A UGUST 2015 3 pruning is always more than its additional weight storage reduction, thus the amount of total storage for non-structured pruning is actually larger . In term of computation efficiency , we find that the PPR for structured pruning in all models are less than 2.7 × . For the first time, our results show that, despite more flexibility and weight pruning rate, non- structur ed pruning is not competitive in terms of both storag e and computation efficiency with quantization and the same accuracy . In a few cases, the storage size of non-structured pruning is comparable (or slightly better than) to that of structured pruning, howe ver it is still not a desirable choice considering the additional complexity of hardware design to support non-structured sparsity . As a result, we reach the conclusion that non-structured weight pruning is considered harmful , and we recommend not to continue inv estigating DNN inference engines using non-structured sparsity . W e release codes and all the models of this work at anonymous link: http://bit.ly/2WMQSRi. I I . M O D E L C O M P R E S S I O N B AC K G RO U N D A. W eight Pruning Non-structured weight pruning. The early work by Han et al. [71] achieved 9 × reduction in the number of parameters in AlexNet and 13 × in VGG-16. Howe ver , most reduction is achieved in FC layers, and the 2.7 × reduction achie ved in CONV layers will not lead to an overall acceleration in GPUs [76]. Extensions of iterativ e weight pruning, such as [74] (dynamic network surgery), [72] (NeST) and [99], use more delicate algorithms such as selecti ve weight gro wing and pruning. But the weight pruning rates on CONV layers are still limited, e.g., 3.1 × in [74], 3.23 × in [72], and 4.16 × in [99] for AlexNet with no accuracy degradation. This le vel of non-structured weight pruning cannot guarantee suf ficient speedups in GPUs. In fact, based on the enhanced ADMM- NN framework, we can achiev e 11.2 × non-structured weight pruning in CONV layers with almost no accuracy degradation. Ironically , it e ven results in 20% speed de gradation on an NVIDIA 1080T i GPU. Structured weight pruning. T o overcome the limitation in non-structured, irregular weight pruning, SSL [76] proposes to learn structured sparsity at the lev els of filters, channels, filter shapes, layer depth, etc. This work is among the firsts that reported the actually measured GPU accelerations. This is because CONV layers after structured pruning will transform to a full matrix multiplication with reduced matrix size. Ho w- ev er , the weight pruning rate is limited in the prior work on structured pruning. The average weight pruning rate on CONV layers of AlexNet is only 1.4 × without accuracy loss. More recently , [78] achie ved 2 × channel pruning with 1% accurac y degradation on VGGNet. More importantly , the structured pruning has nev er been ev aluated with weight quantization. B. W eight Quantization W eight quantization. This method takes advantages of the inherent redundancy in the number of bits for weight representation. Many of the prior works [79]–[86] focused on quantization of weights to binary values, ternary v alues, or powers of 2 to facilitate hardware implementation, with acceptable accuracy loss. The state-of-the-art techniques [79], [86] adopt an iterativ e quantization and retraining framew ork, with some degree of randomness incorporated into the quanti- zation step. This method results in less than 3% accuracy loss on AlexNet for binary weight quantization [79]. Compared to weight pruning, weight quantization is the major DNN model compression technique utilized in industry , due to its “hardware-friendliness” and the proportional reduc- tion of computation and storage. Thus, weight quantization has been a must-do step in FPGA and ASIC designs of DNN inference engines. Also, it is well supported in GPUs and mobile de vices, e.g., PyT orch [88] in NVIDIA GPU and T ensorFlow Lite [87] for mobile de vices. C. ADMM for W eight Pruning/Quantization Recent work [79], [89] ha ve incorporated ADMM for DNN weight pruning and weight quantization, respectively . ADMM is a po werful tool for optimization, by decomposing an original problem into two subproblems that can be solved separately and ef ficiently . For example, considering optimization problem min x f ( x ) + g ( x ) . In ADMM, this problem is decomposed into two subproblems on x and z (auxiliary variable), which will be solved iteratively until con ver gence. The first sub- problem deriv es x giv en z : min x f ( x ) + q 1 ( x | z ) . The second subproblem derives z given x : min z g ( z ) + q 2 ( z | x ) . Both q 1 and q 2 are quadratic functions. ADMM is con ventionally utilized to accelerate the con ver- gence of conv ex optimization problems and enable distributed optimization, in which the optimality and fast con ver gence rate has been proven [90], [92]. As a special property , ADMM can ef fectiv ely deal with a subset of combinatorial constraints and yields optimal (or at least high quality) solutions [100], [101]. Luckily , the associated constraints in the DNN weight pruning and quantization belong to this subset of combina- torial constraints, making ADMM applicable to DNN mode compression. Howe ver , due to the non-con ve x nature of the objectiv e function for DNN training, there is still a lack of guarantee in the prior work [79], [89] on solution feasibility and solution quality . Moreo ver , [89] only supports non- structured pruning. I I I . N O N - S T R U C T U RE D V S . S T RU C T U R E D W E I G H T P RU N I N G A. Non-Structur ed Pruning: Indexing Overhead Indices are used to represent weight matrices in the sparse format, thereby achieving storage reduction in non-structured weight pruning. A representative sparse representation format is the compr essed sparse row (CSR) format, which was also utilized in prior work [6], [71]. As shown in Figure 3 (a), it represents a matrix by three arrays, which respecti vely contains nonzero (weight) values, column indices and the extents of ro ws. This representation requires 2 n + r + 1 numbers, where n is the number of nonzero values and r is the number of rows. W e call the abov e representation as CSR with absolute in- dices . Instead of storing the absolute position, we can compute JOURNAL OF L A T E X CLASS FILES, VOL. 14, NO. 8, A UGUST 2015 4 2 0 0 3 0 0 0 0 0 0 0 0 0 0 9 0 8 0 0 4 0 0 0 0 0 1 6 0 0 7 5 0 0 0 0 0 2 3 9 8 4 1 6 7 5 1 4 3 5 2 2 3 6 1 1 3 3 5 6 9 10 2 3 9 8 4 1 6 7 5 1 3 11 2 3 6 1 3 1 2 3 9 8 4 1 6 7 5 1 3 3 2 3 6 1 3 1 Non-zero value Column index Row pointer Non-zero value Relative Position V alue Relative Position(3-bit) 0 8 (a) (b) W eight Matrix Absolute Position Indices Relative Position Indices Dummy zero Fig. 3. Compressed sparse row (CSR) format with (a) absolute indices and (b) relati ve indices. Layer i Layer i+1 Pruned filters: Pruned filters result in pruned feature maps: Pruned channels: Fig. 4. Relation between filter pruning and channel pruning. Pruned filters in layer i results in pruned feature maps and therefore pruned (inactiv ated) channels in layer i + 1 . the inde x dif ference and store the indices with relati ve position. This representation requires 2 n numbers, where n is the number of nonzero (weight) values. For further compression, one can restrict the number of bits (3 bits in this example) to represent the relativ e position and add a dummy zero weight when the relative position exceeds the largest value (8 for this example) that can be represented, both shown in Figure 3 (b). These cases are called CSR with r elative indices . Comparing the two options, CSR with relative indices is good for compression [71], while CSR with absolute indices leads to better hardware acceleration [94], [96], [97]. In this work, we aim to allow the highest freedom for non-structured pruning in storage and computation ev aluations, — we allow CSR with relati ve indices in storage calculation and CSR with absolute indices for computation estimation for non-structured pruning. B. Structur ed Pruning: Three T ypes W en et al. [76] introduced three types of structured pruning: filter pruning , channel pruning , and filter shape pruning , as shown in Figure 1 (b). Filter pruning removes whole filter(s); channel pruning removes whole channels; and filter shape pruning removes the weights in the same locations of all filters in one specific layer . Moreov er , as shown in Figure 4, filter pruning and channel pruning are correlated. Pruning a filter in layer i is equi valent to pruning the corresponding channel in layer i + 1 , which is generated by this specific filter . As a result, filter pruning (and channel pruning) has a roughly quadratic effect on the weight parameter reduction (and the amount of computations) of the DNNs. The CONV operations in (one layer of) DNNs are com- monly transformed to matrix multiplications by con verting weight tensors and feature map tensors to matrices [52], named general matrix multiplication or GEMM, as sho wn in Figure 5. From Figure 5 (b), filter pruning corresponds to reducing one row , and thus is also termed r ow pruning . Filter shape pruning corresponds to reducing one column, and thus is also termed column pruning . Channel pruning corresponds to reducing multiple consecutiv e columns. The three structured pruning techniques, along with their combinations, will reduce the dimensions in GEMM while maintaining a full matrix format. Thus, indices are not needed. It is why structured pruning is in general more suitable for hardware accelerations. On one hand, the major adv antage of filter/channel pruning has the superlinear effect on storage/computation reduction, i.e., α × filter pruning on all layers results in o ver α × reduction in number of weight parameters. On the other hand, column pruning has a higher de gree of flexibility . These techniques can be largely combined in order to achiev e the highest rates in reductions of computation and storage, and effecti ve heuristic for the desirable combination is needed. I V . A D M M - N N - S F R A M E W O R K In this section, we build ADMM-NN-S, a unified so- lution framew ork of both non-structured and structured weight pruning, as well as weight quantization problems by extending ADMM-NN, the state-of-the-art ADMM-based framew ork [89]. The differences between ADMM-NN-S and ADMM-NN are: 1) it supports structured pruning; 2) it can guarantee solution feasibility and provide high solution quality; and 3) we propose effecti ve techniques for enhancing con ver gence. A. Enfor cing Structur ed Pruning This section discusses the extension of ADMM-NN with structured pruning constraints. Consider an N -layer DNN with both CONV and FC layers. The weights and biases of the i -th layer are respectiv ely denoted by W i and b i , and the loss function associated with the DNN is denoted by f { W i } N i =1 , { b i } N i =1 ; see [93]. In our discussion, { W i } N i =1 and { b i } N i =1 respectiv ely characterize the collection of weights and biases from layer 1 to layer N . Then DNN weight pruning or weight quantization is formulated as optimization problem: minimize { W i } , { b i } f { W i } N i =1 , { b i } N i =1 , subject to W i ∈ S i , i = 1 , . . . , N , (1) Next we introduce constraint sets S i ’ s corresponding to the non-structured weight pruning, different types of structured pruning, as well as weight quantization. W e use CONV layers as illustrativ e example since CONV layers are the most computationally intensive. The problem formulation can be well applied to FC layers [93]. The collection of weights in the i -th CONV layer is a four-dimensional tensor , i.e., W i ∈ R A i × B i × C i × D i , where A i , B i , C i , and D i are respecti vely the number of filters, the JOURNAL OF L A T E X CLASS FILES, VOL. 14, NO. 8, A UGUST 2015 5 ... w 0,0,0 w 0,0,1 w 0,0,k ... w 1,0,0 w 1,0,1 w 1,0,k ... w n,0,0 w n,0,1 w n,0,k ... ... ... ... ... w 0,1,0 w 0,1,1 w 0,1,k ... w 1,1,0 w 1,1,1 w 1,1,k ... w n,1,0 w n,1,1 w n,1,k ... ... ... ... ... w 0,m,0 w 0,m,1 w 0,m,k ... w 1,m,0 w 1,m,1 w 1,m,k ... w n,m,0 w n,m,1 w n,m,k ... Channel 0 Channel 1 Channel m Num of filters (a) (b) ... ... ... ... ... ... ... ... ... Filter Pruning Channel Pruning Filter Shape Pruning (filter width) x (filter height) x (number of channels) Fig. 5. (a) T o support GEMM, weight tensor representation of a CONV layer is transformed into weight matrix representation. (b) How different structured weight pruning schemes are implemented on weight matrix representation. number of channels in a filter , the height of the filter , and the width of the filter , in layer i . In the following, if X denotes the weight tensor in a specific layer, let ( X ) a, : , : , : denote the a -th filter in X , ( X ) : ,b, : , : denote the b -th channel, and ( X ) : ,b,c,d denote the collection of weights located at position (: , b, c, d ) in ev ery filter of X , as illustrated in Figure 1 (b). W eight pruning : F or non-structur ed weight pruning , the constraint on the weights in i -th layer is W i ∈ S i := { X | number of nonzero elements in X is less than or equal to α i } . For filter pruning (row pruning), the constraint in the i - th CONV layer becomes W i ∈ S i := { X | the number of nonzero filters in X is less than or equal to β i } . For channel pruning , the constraint becomes W i ∈ S i := { X | the number of nonzero channels in X is less than or equal to γ i } . Finally , for filter-shape pruning (column pruning), the constraint in the i -th CONV layer is W i ∈ S i := { X | the number of nonzero vectors in { X : ,b,c,d } B i ,C i ,D i b,c,d =1 is less than or equal to θ i } . These α i , β i , γ i , and θ i values are hyperparameters determined in prior , and the determination procedure will be discussed in Section IV -D. W eight quantization : For weight quantization, elements in W i assume one of q i, 1 , q i, 2 , ..., q i,M i values, where M i denotes the number of these fixed v alues. The q i,j values are quantization levels of weights of layer i in increasing order , and we focus on equal-distance quantization (the same distance between adjacent quantization lev els) to facilitate hardware implementation. B. Enhancing Solution F easibility and High Solution Quality In problem (1), the constraint is combinatorial. As a result, this problem cannot be solved directly by stochastic gradient descent methods like original DNN training. Howe ver , the form of the combinatorial constraints on W i is compatible with ADMM which is recently sho wn to be an effecti ve method to deal with such clustering-like constraints [100], [101]. Despite such compatibility , it is still challenging to directly apply ADMM due to the non-conv exity in objectiv e function. T o o vercome this challenge, we propose dynamic ADMM Su bpr oblem 1: find W , b Su bpr oblem 2: find Z Updat e: U Pr etrained Model or Hyper P aras. ADMM R egularization Mask ed R etraining Pruned or Quantized model Euclidean pr ojection Mask ed r etraining Euclidean pr ojection } } Fig. 6. Procedure of ADMM-NN-S. regularization, masked mapping and retraining steps for both non-structured and structured pruning. By integrating these techniques, ADMM-NN-S can guarantee solution feasibility (satisfying all constraints) and provide high solution quality (pruning/quantization rate under the same accuracy). The procedure of ADMM-NN-S is shown in Figure 6. ADMM Regularization Step : The ADMM regularization decomposes the original problem (1) into two subproblems through 1 (i) defining indicator function g i ( W i ) = ( 0 if W i ∈ S i , + ∞ otherwise corresponding to e very set S i ; (ii) incorporating auxiliary variables Z i , i = 1 , . . . , N ; and (iii) adopting augmented Lagrangian [92]. These decomposed subproblems will be iterativ ely solved until con vergence. The first subproblem is minimize { W i } , { b i } f { W i } N i =1 , { b i } N i =1 + N X i =1 ρ i 2 k W i − Z k i + U k i k 2 F , (2) where U k i := U k − 1 i + W k i − Z k i . The first term in the objectiv e function of (2) is the differentiable loss function of the DNN, and the second term is a quadratic re gularization term of the W i ’ s, which is differentiable and con ve x. As a result (2) can be solved by stochastic gradient descent as original DNN training. Please note that this first subproblem maintains the same form and solution for (non-structured and structured) weight pruning and quantization problems. The second subproblem is given by minimize { Z i } N X i =1 g i ( Z i ) + N X i =1 ρ i 2 k W k +1 i − Z i + U k i k 2 F . (3) Note that g i ( · ) is the indicator function of S i , thus this subproblem can be solved analytically and optimally [92]. For i = 1 , . . . , N , the optimal solution is the Euclidean projection of W k +1 i + U k i onto S i . For non-structured weight pruning , we can prove that the Euclidean projection results in keeping α i elements in W k +1 i + U k i with the lar gest magnitudes and setting the remaining weights to zeros. For filter pruning , we first calculate O a = k ( W k +1 i + U k i ) a, : , : , : k 2 F for a = 1 , . . . , A i , where k · k F denotes the Frobenius norm. W e then keep β i elements in ( W k +1 i + U k i ) a, : , : , : corresponding to the β i 1 The details of ADMM are presented in [92], [93]. W e omit the details due to space limitation. JOURNAL OF L A T E X CLASS FILES, VOL. 14, NO. 8, A UGUST 2015 6 largest values in { O a } A i a =1 and set the rest to zero. For channel pruning , we first calculate O b = k ( W k +1 i + U k i ) : ,b, : , : k 2 F for b = 1 , . . . , B i . W e then keep γ i elements in ( W k +1 i + U k i ) : ,b, : , : corresponding to the γ i largest v alues in { O b } B i b =1 and set the rest to zero. The optimal solution of the second subproblem for filter shape pruning is similar , and is omitted due to space limitation. For weight quantization , we can prove that the Euclidean projection results in mapping e very element of W k +1 i + U k i to the quantization level closest to that element. After both subproblems solved, we update the dual v ariables U i ’ s according to the ADMM rule [92] and thereby complete one iteration in ADMM regularization. Overall the ADMM regularization step can be understood as a smart, dynamic L 2 regularization, in which the regularization target Z k i − U k i will change judiciously and analytically in each iteration. On the other hand, con ventional regularization methods (based on L 1 , L 2 norms or their combinations) use a fixed regularization target, and the penalty is applied on all the weights. This will inevitably cause accuracy degradation. Sample comparison results are in Section V. Mask ed mapping and retraining : After ADMM regular- ization, we obtain intermediate W i solutions. The subsequent step of masked mapping and retraining will guarantee the solution feasibility and improv e solution quality . For non- structured and structured weight pruning, the procedure is more straightforward. W e first perform the said Euclidean projection (mapping) to guarantee that pruning constraints are satisfied. Next, we mask the zero weights and retrain the DNN with non-zero weights using training sets, while keeping the masked weights 0. In this way test accuracy (solution quality) can be (partially) restored, and solution feasibility (constraints) will be maintained. For weight quantization, the procedure is more complicated. The reason is that the retraining process will affect the quantization results, thereby solution feasibility . T o deal with this issue, we first perform Euclidean projection (mapping) of weights that are close enough (defined by a threshold v alue ) to nearby quantization lev els. Then we perform retrain- ing on the remaining, unquantized weights (with quantized weights fixed) for accuracy improvement. Finally we perform Euclidean mapping on the remaining weights as well. In this way the solution feasibility will be guaranteed. C. T echniques for Enhancing Conver gence In this section we discuss two techniques for enhancing con ver gence (rate and results): multi- ρ method in ADMM regularization, and progressi ve weight pruning. W e abandon the extragradient descent method in [79] as we did not find the advantage in con vergence speed, not to mention the additional hyperparameters introduced by this method. Increasing ρ in ADMM regularization : The ρ i values are the most critical hyperparameter in ADMM regularization. W e start from smaller ρ i values, say ρ 1 = · · · = ρ N = 1 . 5 × 10 − 3 , and gradually increase with ADMM iterations. This coincides with the theory of ADMM con ver gence [100], [101]. It in general takes 8 - 12 ADMM iterations for conv ergence, cor- responding to 100 - 150 epochs in PyT orch. This con vergence rate is comparable with the original DNN training. Progressive weight pruning : The ADMM regularization is L 2 regularization. As a result, there is a large portion of very small weights values after one round of ADMM-based (non- structured or structured) weight pruning. This giv es rise to the opportunity to perform a second round of weight pruning. In practice, we perform two r ounds of ADMM-based weight pruning consecutiv ely , where the weight pruning results in the first round will be the starting point of the second round (weights that are already pruned to zero will not be recovered). This method has an additional benefit of reducing the search space in each step, thereby accelerating con vergence. D. Determining Hyperparameters Hyperparameter determination mainly refers to the determi- nation process of pruning rate (e.g., the α i value) and/or the number of quantization le vels per layer of DNN. This is a more challenging task for pruning than quantization in general. For quantization, it is typically preferred for the same number of quantization levels for all (or most of) layers, like binarized or ternarized weights, which is preferred by hardware. For weight pruning, on the other hand, these pruning rate v alues are flexible and shall be judiciously determined. As hyperparameter determination is not our primary focus, we use a heuristic method as follo ws. W e observe that we can achiev e at least 3 × more weight pruning than prior, heuristic weight pruning methods without accurac y loss. Hence, we adopt the per-layer pruning rates reported in prior work, and increase proportionally . In the progressiv e pruning procedure, we set the target of the first round to be 1.5 × pruning than prior work, and the second round to be doubled based on that. W e will further increase the pruning rates if there is still margin for weight pruning without accuracy loss. V . N O N - S T RU C T U R E D D N N W E I G H T P R U NI N G A N D Q UA N T I Z A T I O N R E S U L T S In this section, we demonstrate the effecti veness of ADMM- NN-S for non-structure pruning and quantization, based on Im- ageNet ILSVRC-2012, CIF AR-10, and MNIST data sets, using AlexNet [102], VGGNet [103], ResNet-18/ResNet-50 [104], MobileNet V2 [105], and LeNet-5 DNN models. Due to space limitation, we only show the results of the ov erall DNN model (which has the most prior work for comparison), and binarized quantization of DNNs. Our implementations are based on PyT orch, and the baseline accuracy results are in many cases higher than those utilized in prior work, which reflects the recent training adv ances. For example, in the AlexNet model we utilize a baseline with T op-1 accuracy 60.0% and T op-5 accuracy 82.2%, both higher than prior work (57.2% T op-1 and 80.2% T op-5). W e conduct a fair comparison because we focus on relative accuracy with our baseline instead of the absolute accuracy (which has outperformed prior work). Thanks to the compatibility of ADMM-NN-S with DNN training, directly training a DNN model using the framew ork achiev es the same result as using a pre-trained DNN model. When a pre-trained DNN model is utilized, we limit the number of epochs in both steps in the progressiv e framew ork to be 120, similar to the original DNN training in PyT orch and is much lower than the iterati ve pruning heuristic [71]. JOURNAL OF L A T E X CLASS FILES, VOL. 14, NO. 8, A UGUST 2015 7 T ABLE I O V E RA L L W E I G HT P RU NI N G R ATE CO M PAR I S O NS O N A L EX N E T M O D EL F O R I M AG E N E T D A TA S E T . Method T op-5 accuracy Relativ e accuracy loss Overall prun. rate Iter . prun. [71] 80 . 3 % − 0 . 1 % 9.1 × NeST [72] 80 . 3% − 0 . 1 % 15.7 × Dyn. surg. [74] 80 . 0% +0 . 2 % 17.7 × ADMM [93] 80 . 2% − 0 . 0 % 17.7 × Our method 82 . 0% +0 . 2 % 36 × Our method 80 . 8% +1 . 4 % 44 × Our method 80 . 3% +1 . 9 % 63 × Our method 77 . 8% +4 . 4 % 96 × Fig. 7. T op-5 accuracies for different pruning methods on AlexNet for ImageNet dataset. A. Non-Structur ed W eight Pruning Results AlexNet Results for ImageNet Dataset : T able I compares the o verall pruning rates of the whole Ale xNet model (CONV and FC layers) vs. accuracy , between the proposed framework and various prior methods. W e can clearly observe that the proposed framework outperforms prior methods, including the prior ADMM method [93]. W ith almost no accuracy loss e ven based on the high baseline accuracy , we achie ve 36 × overall pruning rate. W e achiev e a notable 63 × weight reduction with 80.3% T op-5 accuracy , just slightly below the baseline accuracy in prior work. Figure 7 illustrates the absolute top-5 accuracy for different pruning methods, on AlexNet model for ImageNet dataset. These methods include our proposed solution, iterati ve pruning [71], fixed regularization techniques like L 1 and L 2 regular - izations, and projected gradient descent (PGD). The results clearly sho w that the proposed method outperforms the others both in absolute accuracy and in relativ e accuracy loss. ResNet-50 Results f or ImageNet Dataset : Due to the lack of existing effecti ve pruning results, we conduct uniform weight pruning, — use the same pruning rate for all CONV and FC layers. The results are shown in T able II. W e achiev e 8 × ov erall pruning rate (also 8 × pruning rate on CONV layers) on ResNet-50 without accuracy loss. These results clearly outperform the prior work. T ABLE II C O MPA R IS O N S O F OV E R A LL W EI G H T P RU N I NG R ES U LTS ON R ES N E T - 5 0 F O R I M AG E N E T D A TA S E T . Method T op-5 Acc. Loss Pruning rate Uncompressed 0.0% 1 × Fine-grained [99] 0.1% 2.6 × ADMM-NN [106] 0.0% 7 × Our method 0.0% 8 × Our method 0.7% 17.4 × MobileNet V2 Results for CIF AR-10 Dataset : The baseline accuracy is as high as 95.07% due to the adoption of mixup technique. W e present our results in T able III due to the lack of prior work for fair comparison. W e achiev e 5.7 × weight pruning with almost no accuracy loss, starting from the high- accuracy baseline. W e achiev e 10 × weight pruning (which is highly challenging for MobileNet) with only 1.3% accuracy loss. T ABLE III O U R W E IG H T P RU N I N G R ES U LTS O N M O BI L E N ET V 2 F O R C I FAR - 1 0 DAT A S E T . Method Accuracy Pruning rate Uncompressed 95.07% 1 × Our method 94.95% 5.7 × Our method 94.70% 6.7 × Our method 93.75% 10 × LeNet-5 Results for MNIST Dataset : T able IV demon- strates the comparison results on LeNet-5 model using MNIST data set. W e achie ve an unprecedented 348 × overall weight reduction with almost no accurac y loss. It clearly outperforms prior methods including one-shot ADMM-based method [93]. T ABLE IV C O MPA R IS O N S O F OV E R A LL W EI G H T P RU N I NG R ES U LTS ON L E N E T -5 F OR M N IS T DA TA S E T . Method Accuracy Pruning rate Uncompressed 99.2% 1 × Network Pruning [71] 99.2% 12.5 × ADMM [93] 99.2% 71.2 × Our method 99.2% 246 × Our method 99.0% 348 × B. Binary W eight Quantization Results Due to space limitation, we mainly show the results on fully binarized DNN models (i.e., weights in all layers, including the first and the last, are binarized), which is a highly challenging task. Please note that the amount of prior work on fully binarized weight quantization is v ery limited due to the highly challenging nature. W eight Quantization Results on LeNet-5 and CIF AR-10 : T o the best of our knowledge, we achieve the first lossless, fully binarized LeNet-5 model . The accuracy is still 99.21%, lossless compared with baseline. In prior works, achieving lossless is challenging e ven for MNIST . For example, recent work [107] results in 2.3% accuracy degradation on MNIST for full binarization, with baseline accuracy 98.66%. W e also achiev e the first lossless, fully binarized VGG-16 for CIF AR- 10 . The accurac y is 93.53%. W e would like to point out that fully ternarized quantization results in 93.66% accuracy . T able V shows our results and comparisons. T ABLE V C O MPA R IS O N S O F F U L L Y B I NA RY ( T E R NA RY ) W EI G H T Q UA N T IZ ATI O N R E SU LT S O N V GG - 1 6 F O R C I F A R - 10 DAT A S E T . Method Accurac y Num. of bits Baseline of [107] 84.80% 32 Binary [107] 81.56% 1 Our baseline 93.70% 32 Our ternary 93.66% 2 (ternary) Our binary 93.53% 1 Binary W eight Quantization Results on ResNet for Im- ageNet : The binarization of ResNet models on ImageNet data set is widely acknowledged as an extremely challenging JOURNAL OF L A T E X CLASS FILES, VOL. 14, NO. 8, A UGUST 2015 8 task. As a result, there are very limited prior work (e.g., the prior ADMM-based method [79]) with binarization results on ResNet models. As [79] targets ResNet-18, we make a fair comparison on the same model. T able VI demonstrates the comparison results (T op-5 accuracy loss). In prior work, by default the first and last layers are not quantized (to 8 bits) as these layers ha ve a significant ef fect on ov erall accuracy . When leaving the first and last layers unquantized, we observe the higher accuracy compared with the prior method. The T op-1 accuracy has similar result: 3.8% degradation in our method and 4.3% in [79]. Furthermore, we can deriv e a fully binarized ResNet-18 , in which weights in all layers are binarized. The accuracy degradation is 5.8%, which is noticeable and sho ws that the full binarization of ResNet is a challenging task even for the proposed framework. W e did not find prior work to compare with this result. T ABLE VI C O MPA R IS O N S O F W E I GH T QU AN T I Z A T I O N R E SU LT S O N R E S N E T -1 8 FO R I M AG E N E T D A TA S ET . Method Relativ e T op-5 acc. loss Num. of bits Uncompressed 0.0% 32 ADMM [79] 2.9% 1 (8 for the first and last) Our method 2.5% 1 (8 for the first and last) Our method 5.8% 1 Summary The results presented in this section sho w that ADMM-NN-S can achiev e better results compared to state- of-the-art. In certain cases, ADMM-NN-S achieves unprece- dented weight reduction. These results provide a strong base- line and credibility of our study . V I . N O N - S T R U C T UR E D V S . S T RU C T U R E D : T H E C O M PAR I S O N S M E T H O D O L O G Y A Motivation Example: The previous section has shown the superior results on joint weight pruning and quantization. Using LeNet-5 (MNIST data set) as an example, we achie ve an unprecedented 348 × non-structured weight reduction together with 3-bit quantization, maintaining 99 %+ accuracy . When indices are not accounted for, the overall compression rate is an unprecedented 3,712 × compared with the original LeNet-5 model without compression. Ho we ver , each inde x needs to be at least 9-bit considering 348 × weight pruning. This makes index storage ev en larger than weights, and indices cannot be further quantized. As a result, non-structur ed weight pruning in fact results in lar ger actual storag e than structured pruning . The fundamental phenomena shown here is that, with quantization the weight reduction by non-structured pruning is offset by the extra index storage. It motiv ates us to study whether it is a common trend with weight quantization in place? If the answer is yes, then the value of non-structured weight pruning will be further in doubt. This is because non- structured pruning is already less preferred for GPU and CPUs [76], [77], the only benefit is the potentially higher pruning rates due to greater pruning flexibility . If this benefit is also lost, there will be nearly no merit of non-structured sparsity for hardw are acceleration of DNNs, considering the impacts on computation efficienc y and degraded parallelism. Importantly , such conclusion will also be true for FPGA and ASIC and guide us to the design aspects that we should really focus on. In this section, we conduct the first(to the best of our knowledge) comprehensive study to understand the value of non-structur ed and structur ed pruning, with quantization in place and the same accuracy . It is worth noting that without ADMM-NN-S framework, this study is not possible , — we need a framework that achieves competitiv e results and can jointly perform both weight pruning and quantization. A Hardware Implementation-Agnostic Comparison Methodology: W e conduct a fair comparison between non- structured and structured weight pruning with quantization in place, based on the unified solution framew ork. Note that the comparison frame work is more FPGA and ASIC oriented as flexible weight quantization is assumed. Howe ver , we would like to point out that a moderate, fixed weight quantization, e.g., 8 bit, supported in GPU [88], TPU [108], and mobile devices [87], will result in a similar conclusion. The key characteristic of our comparison framework is that it is har dwar e implementation-agnostic . Our intention is that the comparison results will be independent of specific hardware implementations, and as a result, the conclusion will unlikely to change for architectural advances in either type of pruning. Therefore, we directly compare the amounts of storage and estimated computation efficiency for non- structured and structured weight pruning with quantization in place, which capture the fundamental trade-offs. Intuitiv ely , storage is measured as the total weight and index storage with quantization in place. Storage of intermediate results is not considered, and this fav ors non-structured pruning, — structured, filter/channel pruning will likely benefit more in intermediate results storage reduction. On the other hand, computation ef ficiency is estimated using the pruning-to-performance ratio (PPR) values derived from prior work on non-structured sparsity accelerators [94]–[97]. For structured pruning, α × weight reduction results in around α × speedup (slightly higher or lower depending on platform and problem), and the PPR value is approximately 1. F or non- structured pruning, α × weight reduction only results in β × speedup with β < α . In the state-of-art tapeouts [94], the PPR value α/β > 3 , which is close to 3 with a low pruning rate and higher than 4 for a high pruning rate. In synthesis results [95]–[97], this PPR value ranges from 2.7 to 3.5. W e use the smallest value 2.7 that fav ors non-structured pruning the most. In other words, if non-structured pruning achie ves more than 2.7 × pruning rate than structured one (or equiv alently , structured pruning rate is less than 37% of non-structured one) under the same accuracy and quantization level, the former is more preferred in terms of computation. Otherwise, the latter is more preferred. Maintaining the Same Accuracy for Comparison: The proposed comparison is performed under the same accuracy for non-structured and structured pruning with quantization in place. The precise accuracy control , which is challenging for prior work, is enabled by the unified solution framework. For most cases, we would like to have (almost) no accuracy degradation compared with the baseline DNN model without pruning or quantization. For non-structured pruning, it is JOURNAL OF L A T E X CLASS FILES, VOL. 14, NO. 8, A UGUST 2015 9 Non-Structured Pruning Structured Pruning: W eight Pruning W eight Quantization Column Pruning Filter Pruning Remove Channels No (or minor) Acc. Loss No (or minor) Acc. Loss W eight Quantization Fig. 8. Procedure for maintaining accurac y . achiev ed in two steps: 1) perform weight pruning to the maximum extent such that there will be no accuracy loss; and 2) perform weight quantization (hopefully) not to cause accuracy loss. For structured pruning, we gi ve priority to column pruning, and perform three steps: 1) perform column pruning to the maximum extent without accuracy loss; 2) perform filter pruning and reduce corresponding redundant channels; and 3) perform weight quantization (hopefully) without accuracy loss. Figure 8 illustrates the procedure for maintaining accuracy . Of course the proposed framew ork is also applicable if certain accuracy degradation is allowed. A larger margin of accuracy loss in general fav ors structured pruning, because higher pruning rates can be achieved for both pruning schemes, but non-structured pruning requires more bits for indices. There is more subtlety in the combination of non-structured pruning and quantization. If a weight is non-zero after prun- ing but quantized to zero, this weight can be added to the pruned list to achieve a higher pruning rate. Please note that this phenomenon does not apply to structured pruning. T o better exploit this phenomenon and achiev e e ven higher stor- age/computation reduction for non-structured pruning (plus quantization), we leverage the state-of-art ternary quantization technique [98] with dedicated optimizations. W e apply this technique for weight quantization after non-structured pruning in cases when it outperforms our proposed method, thereby providing enough opportunity to non-structured weight prun- ing. V I I . C O M PA R I S O N O F N O N - S T RU C T U R E D A N D S T RU C T U R E D W E I G H T P R U N I N G Due to space limitation, we focus on CONV layers, which are the most computationally intensiv e layers in DNNs and are becoming the major storage in state-of-art ResNet and Mo- bileNet models. W e do observe similar (and more significant) effect on FC layers and on RNNs, without providing detailed results due to space. As discussed in Section V, our implementations are based on PyT orch with high baseline accuracies. W e limit the number of epochs in both structured pruning and non-structured prun- ing to be 240 (much lo wer than the iterativ e pruning heuristic [71]), and the number of epochs in weight quantization to be 120. W e adopt hyperparameter determination heuristic dis- cussed in Section IV -D for both structured and non-structured pruning. For non-structured weight pruning, we sho w results on both CSR with relativ e indices and with absolute indices. The former is more appropriate for storage reduction, but the latter achie ves higher computation efficienc y . For absolute indices we assume 4K = 64 × 64 blocks that are reasonable for hardware [94]. Besides the comparison between two pruning schemes, our results also consistently outperform prior work, in terms of both non-structured and structured pruning, as well as combination with weight quantization. A. Comparison Results on ImageNet Dataset T able VII and T able VIII demonstrate the comparison results using AlexNet and ResNet-18 models on ImageNet dataset. In these tables, “CONV Prune Rate” refers to the reduction ratio in the number of weights in overall CONV layers, and the number of remaining weights is “CONV No. of W eights”. “CONV Quant Bits” refers to the number of bits used for equal-distance weight quantization, while “CONV W eight Store” is the storage required only for weights (not account for indices). “Index Bits” refers to the number of bits in CSR with relative indices. In our results, we already optimized this index bit value to minimize the ov erall storage (accounting for the additional dummy zeros as well). The next two columns refer to the total storage size accounting for relati ve indices and absolute indices, respecti vely . For structured pruning, they are the same as weight storage. The final column “CONV Compress Rate” refers to the storage compression rate compared with the original baseline DNN model without compression, assuming relati ve indices that are more fav orable to non-structured pruning. W e use “N/A” if the specific prior work only focuses on weight pruning without performing quantization. It can be observed that we achie ve significant pruning rate gains for both non-structured and structured pruning. Especially for structured pruning, we achiev e 5.1 × and 2.5 × structured weight pruning in CONV layers of AlexNet and ResNet-18 models, respecti vely , without accuracy loss. W e further achie ve 4.3 × structured pruning with minor accuracy loss around 1%. For ResNet on ImageNet dataset, it is difficult for prior work to achie ve lossless structured pruning. For example, [78] results in 1% accuracy loss with 2 × structured pruning, on ResNet-50 model with more redundanc y . When comparing non-structured vs. structured pruning, the ov erall CONV compression rate is comparable for the Ale xNet case and the 1% accuracy loss case for ResNet-18. For the lossless case in ResNet-18, non-structured pruning is slightly better in storage, especially when relative indices are utilized. This is because the number of bits for indexing is relati vely small in this case, and the slight benefit will diminish if certain accuracy loss is tolerable. The occasional gain cannot outweigh the difficulty in hardware support of non-structured sparsity . It would be dif ficult to choose non-structured pruning ov er the other one even if the storage results are comparable. B. Comparison Results on CIF AR-10 Dataset T able IX and T able X demonstrate the comparison results using VGG-16 and ResNet-18 models on CIF AR-10 dataset. W e observe that v ery significant pruning rates can be achieved compared with prior work (over 35 × improvement in certain case). W e inv estigated deeper and found that the underlying reason is the CIF AR-10 dataset itself, in that it is both “simple” and “difficult”. “Simple” means that the input image JOURNAL OF L A T E X CLASS FILES, VOL. 14, NO. 8, A UGUST 2015 10 T ABLE VII C O MPA R IS O N O N N O N - S TR UC T U R ED VS . S T R UC T U R ED P R U NI N G U S I NG A LE X N E T O N I M AG E N E T D A TAS E T Method T op-5 Accuracy CONV Prune Rate CONV No. of W eights CONV Quant Bits CONV W eight Store Index Bits W eight+Index Storage (Relative) W eight+Index Storage (Absolute) CONV Compress Rate Baseline AlexNet 82.2% 1.0 × 2.3M 32 9.3MB - 9.3MB 9.3MB 1.0 × Non- structured Han [109] 80.3% 2.7 × 0.86M 8 0.86MB 4 1.3MB N/A 7.1 × Dyn. surg. [74] 80.0% 3.1 × 0.74M N/A N/A N/A N/A N/A N/A Nest [72] 80.3% 3.23 × 0.71M N/A N/A N/A N/A N/A N/A Fine-grained [99] 80.3% 4.16 × 0.55M N/A N/A N/A N/A N/A N/A our’s 81.9% 11.2 × 0.3M 7 0.26MB 6 0.51MB 0.61MB 25.5 × Structured SSL [76] 80.4% 1.4 × 1.6M N/A N/A - N/A N/A N/A T aylor [110] 79.8% 2.5 × 0.92M N/A N/A - N/A N/A N/A NISP [111] 80.2% 1.9 × 1.2M N/A N/A - N/A N/A N/A our’s 81.8% 5.1 × 0.65M 7 0.56MB - 0.56MB 0.56MB 23.3 × T ABLE VIII C O MPA R IS O N O N N O N - S TR UC T U R ED VS . S T R UC T U R ED P R U NI N G U S I NG R ES N E T - 1 8 ( R E S N E T - 5 0 I N P R I O R W OR K NI S P A N D T H I N ET , W I T H S TART I N G T OP - 5 A CC U R AC Y 9 1 . 1% ) , I M AG E N ET D A TA SE T Method Accuracy CONV Prune Rate CONV No. of W eights CONV Quant Bits CONV W eight Store Index Bits W eight+Index Storage (Relative) W eight+Index Storage (Absolute) CONV Compress Rate Baseline ResNet-18 89.1% 1.0 × 11.2M 32 44.7MB - 44.7MB 44.7MB 1.0 × Non- structured our’s 89.1% 6.4 × 1.75M 6 1.32MB 5 2.47MB 3.11MB 18.1 × our’s 87.9% 8.9 × 1.26M 6 0.94MB 5 1.89MB 2.29MB 23.6 × Structured DCP [112] 87.6% 2 × 5.7M N/A N/A - N/A N/A N/A DCP [112] 85.7% 3.3 × 3.5M N/A N/A - N/A N/A N/A ThiNet-50 [113] 90.7% 2 × 12.8M N/A N/A - N/A N/A N/A ThiNet-30 [113] 88.3% 3.3 × 7.7M N/A N/A - N/A N/A N/A NISP [111] 90.2% 1.8 × 14.2M N/A N/A - N/A N/A N/A our’s 89.1% 2.5 × 4.46M 6 3.34MB - 3.34MB 3.34MB 13.4 × our’s 87.8% 4.3 × 2.60M 6 1.95MB - 1.95MB 1.95MB 22.9 × scale is small and the number of classes is only 10; while “difficult” means that input images are blurred and feature extraction is not straightforward. As a result, researchers tend to migrate large-scale DNN models originally designed for ImageNet, such as VGG-16 and ResNet-18 (prior work even used ResNet-50). Consequently , there is significant margin of model compression, which can be exploited in the proposed systematic framew ork but difficult for heuristic methods. Another observation is that non-structured pruning has only marginal gain in pruning rates (reduction in the number of weights) compared with structured one. Our hypothesis is that it is due to the high search space in non-structured pruning. T ogether with the large number of index bits due to high pruning rates, non-structured pruning is not preferable compared with structured one considering total storage size. The storage size gap is becoming surprisingly large when absolute indices are utilized. T able XI demonstrates the comparison results using Mo- bileNet V2 model on CIF AR-10 dataset. MobileNet is already compact and relativ ely difficult for further weight pruning, but we still achiev e 5 × structured pruning along with 4-bit quantization. Again non-structured pruning only shows minor gain in weight reduction, and it is not preferable considering indexing overheads. C. Comparison Results on MNIST Dataset T able XII demonstrates the comparison results using LeNet- 5 model on MNIST data set. It is a simple dataset, and we achiev e 87.9 × structured pruning on CONV layers, together with 3-bit quantization. Non-structured pruning is again not preferred due to the high index bit and marginal increase in weight reduction rate. Ironically , it results in multiple times the amount of storage compared with structured pruning, when weight quantization is in place. D. Comparison on Computation Efficiency W e hav e shown that non-structured pruning is not prefer - able in terms of storage ev en assuming the storage-friendly CSR format with relative indices, not to mention absolute indices. Based on our methodology , we find that computation efficienc y shows the similar trend. As discussed before, structured pruning will have higher computation efficienc y if it achieves more than 37% in the pruning rate as non-structured pruning. In all our testing, the ratio between weight pruning rates of structured vs. non- structured pruning ranges from 40% to 87%, with a lar ge variation but consistently higher than 37%. Even for the 40% case, the choice is clear considering the difficulty in hardware design for non-structured sparsity . As a result, we draw the final conclusion that non-structured weight pruning is in general not preferred compared with structured pruning across dif ferent platforms, application scenarios, DNN types, etc. V I I I . D I S C U S S I O N S In this section, we discuss additional factors and variations in different platforms, and explain why our conclusion is unlikely to change. As a result, we draw the final conclusion that non-structured weight pruning is in general not preferred compared with structured pruning across different platforms, application scenarios, DNN types, etc. A. Algorithm Impr ovement and Gener alization Enhancement W e consider the following question: will our conclusion change if there is further algorithm improv ement (that outper- forms the ADMM-based unified solution in this paper)? Also, how about using a number of other recently proposed gen- eralization enhancement techniques, such as warmup, mixup, JOURNAL OF L A T E X CLASS FILES, VOL. 14, NO. 8, A UGUST 2015 11 T ABLE IX C O MPA R IS O N O N N O N - S TR UC T U R ED VS . S T R UC T U R ED P R U NI N G U S I NG VG G - 1 6 O N CI FA R- 1 0 D A TA S ET Method Accuracy CONV Prune Rate CONV No. of W eights CONV Quant Bits CONV W eight Store Index Bits W eight+Index Storage (Relative) W eight+Index Storage (Absolute) CONV Compress Rate Baseline VGG-16 93.7% 1.0 × 14.7M 32 58.8MB - 58.8MB 58.8MB 1.0 × Non-Structured Iter . prun. [71], [114] 92.2% 2 × ≈ 7.4M N/A N/A - N/A N/A N/A One-shot prun. [114] 92.4% 2.5 × ≈ 5.9M N/A N/A - N/A N/A N/A our’s 93.1% 57.4 × 0.26M 5 0.16MB 7 0.54MB 0.72MB 109 × Structured 2PFPCE [115] 92.8% 4 × 3.7M N/A N/A - N/A N/A N/A 2PFPCE [115] 91.0% 8.3 × 1.8M N/A N/A - N/A N/A N/A Con vNet [116] 93.4% 2.7 × 5.3M N/A N/A - N/A N/A N/A our’s 93.1% 50.0 × 0.29M 5 0.18MB - 0.18MB 0.18MB 327 × T ABLE X C O MPA R IS O N R E S U L T S O N N O N -S T RU C T UR E D V S . S T RU C T UR E D P RU N I N G U S IN G R E S N E T - 1 8 ( R E S N E T - 50 I N P RI O R W O R K A M C A N D R E S N ET - 56 I N P R IO R WO R K N I S P) O N C I F A R -1 0 D A TAS E T Method Accuracy CONV Prune Rate CONV No. of W eights CONV Quant Bits CONV W eight Store Index Bits W eight+Index Storage (Relative) W eight+Index Storage (Absolute) CONV Compress Rate Baseline ResNet-18 93.9% 1.0 × 11.2M 32 44.6MB - 44.6MB 44.6MB 1.0 × Non-Structured our’s 93.3% 69.0 × 0.16M 5 0.10MB 8 0.33MB 0.53MB 135 × Structured AMC [117] 93.5% 1.7 × N/A N/A N/A - N/A N/A N/A NISP [111] 93.2% 1.7 × N/A N/A N/A - N/A N/A N/A our’s 93.3% 59.8 × 0.19M 5 0.12MB - 0.12MB 0.12MB 372 × T ABLE XI C O MPA R IS O N R E S U L T S O N N O N -S T RU C T UR E D V S . S T RU C T UR E D P RU N I N G U S IN G M O B I L E N E T - V 2 O N C I FAR - 1 0 D AT A S E T Method Accuracy CONV Prune Rate CONV No. of W eights CONV Quant Bits CONV W eight Store Index Bits W eight+Index Storage (Relative) W eight+Index Storage (Absolute) CONV Compress Rate Baseline MobileNet-V2 95.1% 1.0 × 2.2M 32 9.0MB - 9.0MB 9.0MB 1.0 × Non-Structured our’s 94.9% 6.1 × 0.37M 4 0.19MB 4 0.48MB 0.55MB 18.8 × Structured DCP [112] 94.7% 1.3 × 1.68M N/A N/A - N/A N/A N/A our’s 95.1% 4.9 × 0.45M 4 0.23MB - 0.23MB 0.23MB 39.2 × T ABLE XII C O MPA R IS O N O N N O N - S TR UC T U R ED VS . S T R UC T U R ED P R U NI N G U S I NG L E N E T -5 O N M N IS T D A TAS E T Method Accuracy CONV Prune Rate CONV No. of W eights CONV Quant Bits CONV W eight Store Index Bits W eight+Index Storage (Relative) W eight+Index Storage (Absolute) CONV Compress Rate Baseline LeNet-5 99.2% 1.0 × 25.5K 32 102KB - 102KB 102KB 1.0 × Non- structured Han [109] 99.2% 7.7 × 3.33K 8 3.33KB 5 7.0KB N/A 14.5 × our’ s 99.0% 114.3 × 223 3 0.08KB 8 0.39KB 0.93KB 262 × Structured SSL [76] 99.0% 26.1 × 975 N/A N/A - N/A N/A N/A our’ s 99.0% 87.9 × 290 3 0.11KB - 0.11KB 0.11KB 944 × cosine decay in bag of tric ks [118]? Mixup is already utilized in MobileNet V2 training in this work and can notably enhance con ver gence and stability in training (the original MobileNet training is very dif ficult). W e hypothesize that the conclusion is likely to maintain unchanged, as these techniques are lik ely to enhance the results for both non-structured and structured weight pruning schemes. As the pruning rates increase, the number of bits for index representation will also increase. The results will likely e ven fa vor structured pruning to a greater extent. B. T ransfer Learning and Adversarial Robustness In many critical applications of deep learning, such as autonomous driving and medical imaging, there is lack of sufficient labelled training data as standard image classification tasks. As a result, the tr ansfer learning technique [119]–[121] is widely applied via (i) pre-training a DNN model using standard data set (say ImageNet); (ii) transferring to the target application domain; and (iii) performing fine tuning using target domain data. It is recently sho wn [122] that sufficient number of weight parameters is needed in order to maintain the generality , i.e., the ability in domain transfer . This coincides with practice that VGGNet and deep ResNets are the major types for transfer learning instead of MobileNet. From the DNN security aspects, recent w ork [123] sho ws that sufficient number of parameters is required to maintain the robustness of DNN against adversarial attacks. W e hypothesize that structured pruning may be preferred in this way because of the larger number of remaining weight parameters (compared with non-structured), which will lead to higher probability to satisfy the generality and adversarial robustness requirements. W e belie ve that it will be a challenge to quantify such requirements, and deriv e the best combina- tion of structured pruning and quantization for performance optimization while satisfying such requirements. C. FC Layers and RNNs The comparison results conducted in this paper focus on CONV layers, which is the major computation part in DNNs. On the other hand, the FC layers are not negligible in DNNs. Besides, FC layers constitute major computations in r ecurrent neural networks (RNNs), which is as important as con volu- tional neural networks [108]. Our preliminary inv estigation shows that the gain of structured pruning in FC layers and in RNNs is ev en higher . This is an intuitive result because FC layers ha ve higher degree of redundancy , and more number of JOURNAL OF L A T E X CLASS FILES, VOL. 14, NO. 8, A UGUST 2015 12 bits for indices if non-structured pruning is utilized. It is also worth mentioning that a number of structured matrix-based techniques, such as block-circulant matrices [124] and cyclic matrices [125], serv e as good candidates of structured pruning in FC layers. Superior results are already demonstrated in FC layers using these methods. D. Effects of W eight Quantization In the current industry’ s practice, weight quantization is the major method in DNN model compression and is typically prioritized ov er weight pruning. As a result, it is unlikely that weight pruning is conducted alone (especially for FPGA/ASIC systems) without quantization. Howe ver , for such systems, it is possible that a fixed quantization le vel (or a set of lev els) is utilized to accommodate different DNN models and applications, e.g., TPU supports 8 bit and 16 bit computation. Such moderate, fixed weight quantization (e.g., 8 bits) will unlikely change the general conclusion in this paper, espe- cially accounting for the dif ficulty in developing dedicated hardware supporting non-structured sparsity . For GPUs, multi- core CPUs, and even mobile devices, 8-bit/16-bit weight quantization is already well supported. Structured pruning is known to be more suitable for such systems. T o the other extreme case, researchers are inv estigat- ing weight quantization-only solution, including binary and ternary quantizations. As pointed out in Section V, bi- nary/ternary quantization can be almost lossless in many cases. Howe ver , we observe that there is still a large mar gin of structured pruning as shown in the compression results on CIF AR-10, and such compression rate cannot be achie ved by weight quantization alone. As a result, we recommend to perform structured pruning in combination with weight quantization, I X . C O N C L U S I O N Non-structured and structured weight pruning and weight quantization are major methods for model compression, but the interaction among different techniques are nev er clearly understood. This paper is the first to in vestigate the value of non-structured and structured DNN weight pruning, when the weight quantization is in place. W e build ADMM-NN- S, a joint weight pruning and quantization framework with algorithmic supports for structured pruning, dynamic ADMM regulation, and masked mappling and retraining. T o perform fair and fundamental comparison between non-structured and structured pruning in an implementation-agnostic manner , we propose a methodology that captures storage overhead and computation efficienc y . W e perform extensiv e and representa- tiv e testing of ADMM-NN-S with AlexNet, VGGNet, ResNet- 18/50, MobileNet, and LeNet-5 models based on ImageNet, CIF AR-10, and MNIST data sets. W e sho w that ADMM-NN-S can significant outperform the state-of-the-art results for non- structured pruning with quantization. More importantly , for the first time we show that with quantization in place and the same accuracy , non-structured pruning is not preferable in terms of both storage overhead and computation efficienc y . Thus, we recommend the community not to continue in vestigating DNN inference engines based on non-structured sparsity . A C K N O W L E D G M E N T This work was supported in part by the NSF aw ards CNS- 1739748, CCF-1937500, CCF-1919117, CCF-1901378, CCF- 1919289. R E F E R E N C E S [1] Y . Li, J. Park, M. Alian, Y . Y uan, Z. Qu, P . Pan, R. W ang, A. Schwing, H. Esmaeilzadeh, and N. S. Kim, “ A network-centric hardware/algorithm co-design to accelerate distrib uted training of deep neural networks, ” in 2018 51st Annual IEEE/ACM International Sym- posium on Microar chitectur e (MICRO) . IEEE, 2018, pp. 175–188. [2] H. Sharma, J. Park, D. Mahajan, E. Amaro, J. K. Kim, C. Shao, A. Mishra, and H. Esmaeilzadeh, “From high-level deep neural models to fpgas, ” in The 49th Annual IEEE/ACM International Symposium on Micr oarc hitecture . IEEE Press, 2016, p. 17. [3] H. Mao, M. Song, T . Li, Y . Dai, and J. Shu, “Ler gan: A zero-free, lo w data movement and pim-based gan architecture, ” in 2018 51st Annual IEEE/ACM International Symposium on Micr oarc hitecture (MICR O) . IEEE, 2018, pp. 669–681. [4] K. He gde, R. Agra wal, Y . Y ao, and C. W . Fletcher , “Morph: Fle xible ac- celeration for 3d cnn-based video understanding, ” in 2018 51st Annual IEEE/ACM International Symposium on Micr oarc hitecture (MICR O) . IEEE, 2018, pp. 933–946. [5] P . Chi, S. Li, C. Xu, T . Zhang, J. Zhao, Y . Liu, Y . W ang, and Y . Xie, “Prime: A novel processing-in-memory architecture for neural network computation in reram-based main memory , ” in ACM SIGARCH Com- puter Arc hitecture News , vol. 44, no. 3. IEEE Press, 2016, pp. 27–39. [6] S. Han, X. Liu, H. Mao, J. Pu, A. Pedram, M. A. Horowitz, and W . J. Dally , “Eie: efficient inference engine on compressed deep neural network, ” in 2016 ACM/IEEE 43r d Annual International Symposium on Computer Architectur e (ISCA) . IEEE, 2016, pp. 243–254. [7] J. Albericio, P . Judd, T . Hetherington, T . Aamodt, N. E. Jerger , and A. Mosho vos, “Cnvlutin: Ineffectual-neuron-free deep neural network computing, ” ACM SIGARCH Computer Architectur e News , vol. 44, no. 3, pp. 1–13, 2016. [8] F . Tu, W . W u, S. Yin, L. Liu, and S. W ei, “Rana: towards efficient neural acceleration with refresh-optimized embedded dram, ” in Pr o- ceedings of the 45th Annual International Symposium on Computer Ar chitectur e . IEEE Press, 2018, pp. 340–352. [9] C. Eckert, X. W ang, J. W ang, A. Subramaniyan, R. Iyer , D. Sylv ester, D. Blaauw , and R. Das, “Neural cache: bit-serial in-cache acceleration of deep neural networks, ” in Pr oceedings of the 45th Annual Interna- tional Symposium on Computer Ar chitectur e . IEEE Press, 2018, pp. 383–396. [10] M. Buckler, P . Bedoukian, S. Jayasuriya, and A. Sampson, “Eva 2 : Exploiting temporal redundancy in liv e computer vision, ” in 2018 ACM/IEEE 45th Annual International Symposium on Computer Ar- chitectur e (ISCA) . IEEE, 2018, pp. 533–546. [11] A. Y azdanbakhsh, K. Samadi, N. S. Kim, and H. Esmaeilzadeh, “Ganax: A unified mimd-simd acceleration for generati ve adversarial networks, ” in Pr oceedings of the 45th Annual International Symposium on Computer Architectur e . IEEE Press, 2018, pp. 650–661. [12] K. Hegde, J. Y u, R. Agra wal, M. Y an, M. Pellauer , and C. W . Fletcher , “Ucnn: Exploiting computational reuse in deep neural networks via weight repetition, ” in Proceedings of the 45th Annual International Symposium on Computer Arc hitecture . IEEE Press, 2018, pp. 674– 687. [13] H. Sharma, J. Park, N. Suda, L. Lai, B. Chau, V . Chandra, and H. Es- maeilzadeh, “Bit fusion: Bit-level dynamically composable architecture for accelerating deep neural networks, ” in Pr oceedings of the 45th Annual International Symposium on Computer Ar chitectur e . IEEE Press, 2018, pp. 764–775. [14] C. Zhang, T . Meng, and G. Sun, “Pm3: Power modeling and power management for processing-in-memory , ” in 2018 IEEE International Symposium on High P erformance Computer Arc hitecture (HPCA) . IEEE, 2018, pp. 558–570. [15] L. Song, J. Mao, Y . Zhuo, X. Qian, H. Li, and Y . Chen, “Hypar: T owards hybrid parallelism for deep learning accelerator array , ” arXiv pr eprint arXiv:1901.02067 , 2019. [16] X. W ang, J. Y u, C. Augustine, R. Iyer , and R. Das, “Bit prudent in- cache acceleration of deep conv olutional neural networks, ” in 2019 IEEE International Symposium on High P erformance Computer Ar chi- tectur e (HPCA) . IEEE, 2019, pp. 81–93. JOURNAL OF L A T E X CLASS FILES, VOL. 14, NO. 8, A UGUST 2015 13 [17] D. Liu, T . Chen, S. Liu, J. Zhou, S. Zhou, O. T eman, X. Feng, X. Zhou, and Y . Chen, “Pudiannao: A polyv alent machine learning accelerator, ” in ACM SIGARCH Computer Arc hitecture News , vol. 43, no. 1. ACM, 2015, pp. 369–381. [18] M. Gao, J. Pu, X. Y ang, M. Horowitz, and C. K ozyrakis, “T etris: Scalable and efficient neural network acceleration with 3d memory , ” ACM SIGOPS Operating Systems Review , vol. 51, no. 2, pp. 751–764, 2017. [19] A. Ren, Z. Li, C. Ding, Q. Qiu, Y . W ang, J. Li, X. Qian, and B. Y uan, “Sc-dcnn: Highly-scalable deep con volutional neural network using stochastic computing, ” ACM SIGOPS Operating Systems Review , vol. 51, no. 2, pp. 405–418, 2017. [20] H. Kwon, A. Samajdar, and T . Krishna, “Maeri: Enabling flexible dataflow mapping over dnn accelerators via reconfigurable intercon- nects, ” in Pr oceedings of the T wenty-Third International Confer ence on Ar chitectural Support for Pr ogramming Languag es and Operating Systems . A CM, 2018, pp. 461–475. [21] R. Cai, A. Ren, N. Liu, C. Ding, L. W ang, X. Qian, M. Pedram, and Y . W ang, “V ibnn: Hardware acceleration of bayesian neural networks, ” in Pr oceedings of the T wenty-Thir d International Conference on Ar chi- tectural Support for Pr ogramming Languages and Operating Systems . A CM, 2018, pp. 476–488. [22] Y . Ji, Y . Zhang, W . Chen, and Y . Xie, “Bridge the gap between neural networks and neuromorphic hardware with a neural network compiler , ” in Proceedings of the T wenty-Third International Conference on Ar chitectural Support for Pr ogramming Languag es and Operating Systems . A CM, 2018, pp. 448–460. [23] C. Zhang, P . Li, G. Sun, Y . Guan, B. Xiao, and J. Cong, “Optimizing fpga-based accelerator design for deep conv olutional neural networks, ” in Proceedings of the 2015 A CM/SIGDA International Symposium on F ield-Pr ogrammable Gate Arrays . A CM, 2015, pp. 161–170. [24] N. Suda, V . Chandra, G. Dasika, A. Mohanty , Y . Ma, S. Vrudhula, J.-s. Seo, and Y . Cao, “Throughput-optimized opencl-based fpga accelerator for large-scale con volutional neural networks, ” in Proceedings of the 2016 ACM/SIGD A International Symposium on F ield-Pro grammable Gate Arrays . A CM, 2016, pp. 16–25. [25] J. Qiu, J. W ang, S. Y ao, K. Guo, B. Li, E. Zhou, J. Y u, T . T ang, N. Xu, S. Song et al. , “Going deeper with embedded fpga platform for con volutional neural netw ork, ” in Pr oceedings of the 2016 A CM/SIGD A International Symposium on Field-Pr ogrammable Gate Arrays . ACM, 2016, pp. 26–35. [26] R. Zhao, W . Song, W . Zhang, T . Xing, J.-H. Lin, M. Srivasta va, R. Gupta, and Z. Zhang, “ Accelerating binarized convolutional neural networks with software-programmable fpgas, ” in Pr oceedings of the 2017 ACM/SIGD A International Symposium on F ield-Pro grammable Gate Arrays . A CM, 2017, pp. 15–24. [27] J. Zhang and J. Li, “Improving the performance of opencl-based fpga accelerator for con volutional neural network, ” in Pr oceedings of the 2017 ACM/SIGD A International Symposium on F ield-Pro grammable Gate Arrays . A CM, 2017, pp. 25–34. [28] C. Zhang and V . Prasanna, “Frequency domain acceleration of con- volutional neural networks on cpu-fpga shared memory system, ” in Pr oceedings of the 2017 ACM/SIGD A International Symposium on F ield-Pr ogrammable Gate Arrays . A CM, 2017, pp. 35–44. [29] Y . Ma, Y . Cao, S. Vrudhula, and J.-s. Seo, “Optimizing loop opera- tion and dataflow in fpga acceleration of deep con volutional neural networks, ” in Pr oceedings of the 2017 ACM/SIGD A International Symposium on F ield-Pr ogrammable Gate Arr ays . A CM, 2017, pp. 45–54. [30] U. A ydonat, S. O’Connell, D. Capalija, A. C. Ling, and G. R. Chiu, “ An opencl deep learning accelerator on arria 10, ” in Pr oceedings of the 2017 ACM/SIGD A International Symposium on F ield-Pro grammable Gate Arrays . A CM, 2017, pp. 55–64. [31] Y . Umuroglu, N. J. Fraser, G. Gambardella, M. Blott, P . Leong, M. Jahre, and K. Vissers, “Finn: A framework for fast, scalable binarized neural network inference, ” in Pr oceedings of the 2017 ACM/SIGD A International Symposium on Field-Pr ogrammable Gate Arrays . ACM, 2017, pp. 65–74. [32] C. Gao, D. Neil, E. Ceolini, S.-C. Liu, and T . Delbruck, “Deltarnn: A power-ef ficient recurrent neural network accelerator , ” in Pr oceed- ings of the 2018 ACM/SIGD A International Symposium on F ield- Pr ogrammable Gate Arrays . ACM, 2018, pp. 21–30. [33] J. Shen, Y . Huang, Z. W ang, Y . Qiao, M. W en, and C. Zhang, “T owards a uniform template-based architecture for accelerating 2d and 3d cnns on fpga, ” in Pr oceedings of the 2018 A CM/SIGDA International Symposium on F ield-Pr ogrammable Gate Arr ays . A CM, 2018, pp. 97–106. [34] H. Zeng, R. Chen, C. Zhang, and V . Prasanna, “ A framew ork for generating high throughput cnn implementations on fpgas, ” in Pro- ceedings of the 2018 A CM/SIGD A International Symposium on F ield- Pr ogrammable Gate Arrays . ACM, 2018, pp. 117–126. [35] E. Nurvitadhi, J. Cook, A. Mishra, D. Marr , K. Nealis, P . Colangelo, A. Ling, D. Capalija, U. A ydonat, A. Dasu et al. , “In-package domain- specific asics for intel R stratix R 10 fpgas: A case study of accelerat- ing deep learning using tensortile asic, ” in 2018 28th International Confer ence on F ield Pr ogrammable Logic and Applications (FPL) . IEEE, 2018, pp. 106–1064. [36] Z. Chen, A. Howe, H. T . Blair, and J. Cong, “Fpga-based lstm acceleration for real-time eeg signal processing, ” in Proceedings of the 2018 ACM/SIGD A International Symposium on F ield-Pro grammable Gate Arrays . A CM, 2018, pp. 288–288. [37] Y . Du, Q. Liu, S. W ei, and C. Gao, “Software-defined fpga-based accel- erator for deep con volutional neural networks, ” in Proceedings of the 2018 ACM/SIGD A International Symposium on F ield-Pro grammable Gate Arrays . A CM, 2018, pp. 291–291. [38] S. Liu, X. Niu, and W . Luk, “ A lo w-power deconv olutional accelerator for conv olutional neural network based segmentation on fpga, ” in Pr oceedings of the 2018 ACM/SIGD A International Symposium on F ield-Pr ogrammable Gate Arrays . A CM, 2018, pp. 293–293. [39] Y . Y ang, Q. Huang, B. W u, T . Zhang, L. Ma, G. Gambardella, M. Blott, L. Lavagno, K. V issers, J. W awrzynek et al. , “Synetgy: Algorithm- hardware co-design for convnet accelerators on embedded fpgas, ” in Pr oceedings of the 2019 ACM/SIGD A International Symposium on F ield-Pr ogrammable Gate Arrays . A CM, 2019, pp. 23–32. [40] J. Shen, Y . Huang, M. W en, and C. Zhang, “ Accelerating 3d cnn-based lung nodule segmentation on a multi-fpga system. ” [41] L. Jing, J. Liu, and F . Y u, “ A deep learning inference accelerator based on model compression on fpga, ” in Pr oceedings of the 2019 ACM/SIGD A International Symposium on Field-Pr ogrammable Gate Arrays . ACM, 2019, pp. 118–118. [42] W . Y ou and C. W u, “ A reconfigurable accelerator for sparse conv o- lutional neural networks, ” in Pr oceedings of the 2019 ACM/SIGD A International Symposium on Field-Pr ogrammable Gate Arrays . ACM, 2019, pp. 119–119. [43] X. W ei, Y . Liang, P . Zhang, C. H. Y u, and J. Cong, “Ov ercoming data transfer bottlenecks in dnn accelerators via layer -conscious memory managment, ” in Proceedings of the 2019 ACM/SIGD A International Symposium on F ield-Pr ogrammable Gate Arr ays . A CM, 2019, pp. 120–120. [44] J. Zhang and J. Li, “Unleashing the power of soft logic for con- volutional neural network acceleration via product quantization, ” in Pr oceedings of the 2019 ACM/SIGD A International Symposium on F ield-Pr ogrammable Gate Arrays . A CM, 2019, pp. 120–120. [45] S. Zeng, Y . Lin, S. Liang, J. Kang, D. Xie, Y . Shan, S. Han, Y . W ang, and H. Y ang, “ A fine-grained sparse accelerator for multi- precision dnn, ” in Proceedings of the 2019 A CM/SIGD A International Symposium on F ield-Pr ogrammable Gate Arr ays . A CM, 2019, pp. 185–185. [46] H. Nakahara, A. Jinguji, M. Shimoda, and S. Sato, “ An fpga-based fine tuning accelerator for a sparse cnn, ” in Proceedings of the 2019 ACM/SIGD A International Symposium on Field-Pr ogrammable Gate Arrays . ACM, 2019, pp. 186–186. [47] L. Lu, Y . Liang, R. Huang, W . Lin, X. Cui, and J. Zhang, “Speedy: An accelerator for sparse convolutional neural networks on fpgas, ” in Proceedings of the 2019 A CM/SIGDA International Symposium on F ield-Pr ogrammable Gate Arrays . A CM, 2019, pp. 187–187. [48] Z. T ang, G. Luo, and M. Jiang, “Ftconv: Fpga acceleration for transposed con volution layers in deep neural networks, ” in Proceed- ings of the 2019 ACM/SIGD A International Symposium on F ield- Pr ogrammable Gate Arrays . ACM, 2019, pp. 189–189. [49] K. Guo, S. Liang, J. Y u, X. Ning, W . Li, Y . W ang, and H. Y ang, “Com- pressed cnn training with fpga-based accelerator, ” in Pr oceedings of the 2019 ACM/SIGD A International Symposium on F ield-Pro grammable Gate Arrays . A CM, 2019, pp. 189–189. [50] E. W u, X. Zhang, D. Berman, I. Cho, and J. Thendean, “Compute- efficient neural-network acceleration, ” in Pr oceedings of the 2019 ACM/SIGD A International Symposium on Field-Pr ogrammable Gate Arrays . ACM, 2019, pp. 191–200. [51] S. V ogel, J. Springer , A. Guntoro, and G. Ascheid, “Efficient accelera- tion of cnns for semantic segmentation on fpgas, ” in Pr oceedings of the 2019 ACM/SIGD A International Symposium on F ield-Pro grammable Gate Arrays . A CM, 2019, pp. 309–309. JOURNAL OF L A T E X CLASS FILES, VOL. 14, NO. 8, A UGUST 2015 14 [52] S. Chetlur , C. W oolley , P . V andermersch, J. Cohen, J. T ran, B. Catan- zaro, and E. Shelhamer, “cudnn: Efficient primitiv es for deep learning, ” arXiv preprint arXiv:1410.0759 , 2014. [53] T . Chen, Z. Du, N. Sun, J. W ang, C. W u, Y . Chen, and O. T emam, “Diannao: A small-footprint high-throughput accelerator for ubiquitous machine-learning, ” ACM Sigplan Notices , vol. 49, pp. 269–284, 2014. [54] P . Judd, J. Albericio, T . Hetherington, T . M. Aamodt, and A. Mosho vos, “Stripes: Bit-serial deep neural network computing, ” in Proceedings of the 49th Annual IEEE/ACM International Symposium on Micr oarchi- tectur e . IEEE Computer Society , 2016, pp. 1–12. [55] Y . Chen, T . Luo, S. Liu, S. Zhang, L. He, J. W ang, L. Li, T . Chen, Z. Xu, N. Sun et al. , “Dadiannao: A machine-learning supercomputer, ” in Pr oceedings of the 47th Annual IEEE/A CM International Symposium on Micr oarc hitecture . IEEE Computer Society , 2014, pp. 609–622. [56] S. V enkataramani, A. Ranjan, S. Banerjee, D. Das, S. A v ancha, A. Ja- gannathan, A. Durg, D. Nagaraj, B. Kaul, P . Dube y et al. , “Scaledeep: A scalable compute architecture for learning and ev aluating deep networks, ” in Computer Architectur e (ISCA), 2017 ACM/IEEE 44th Annual International Symposium on . IEEE, 2017, pp. 13–26. [57] B. Reagen, P . Whatmough, R. Adolf, S. Rama, H. Lee, S. K. Lee, J. M. Hern ´ andez-Lobato, G.-Y . W ei, and D. Brooks, “Minerva: Enabling lo w- power , highly-accurate deep neural network accelerators, ” in Computer Ar chitectur e (ISCA), 2016 ACM/IEEE 43r d Annual International Sym- posium on . IEEE, 2016, pp. 267–278. [58] Z. Du, R. Fasthuber , T . Chen, P . Ienne, L. Li, T . Luo, X. Feng, Y . Chen, and O. T emam, “Shidiannao: Shifting vision processing closer to the sensor, ” in Computer Architectur e (ISCA), 2015 ACM/IEEE 42nd Annual International Symposium on . IEEE, 2015, pp. 92–104. [59] M. Song, K. Zhong, J. Zhang, Y . Hu, D. Liu, W . Zhang, J. W ang, and T . Li, “In-situ ai: T owards autonomous and incremental deep learning for iot systems, ” in High P erformance Computer Architectur e (HPCA), 2018 IEEE International Symposium on . IEEE, 2018, pp. 92–103. [60] D. Mahajan, J. Park, E. Amaro, H. Sharma, A. Y azdanbakhsh, J. K. Kim, and H. Esmaeilzadeh, “T abla: A unified template-based frame- work for accelerating statistical machine learning, ” in High P erfor- mance Computer Architectur e (HPCA), 2016 IEEE International Sym- posium on . IEEE, 2016, pp. 14–26. [61] Y .-H. Chen, T . Krishna, J. S. Emer, and V . Sze, “Eyeriss: An ener gy- efficient reconfigurable accelerator for deep conv olutional neural net- works, ” IEEE Journal of Solid-State Circuits , vol. 52, no. 1, pp. 127– 138, 2017. [62] B. Moons, R. Uytterhoeven, W . Dehaene, and M. V erhelst, “14.5 en vi- sion: A 0.26-to-10tops/w subword-parallel dynamic-v oltage-accuracy- frequency-scalable conv olutional neural network processor in 28nm fdsoi, ” in Solid-State Circuits Confer ence (ISSCC), 2017 IEEE Inter- national . IEEE, 2017, pp. 246–247. [63] G. Desoli, N. Chawla, T . Boesch, S.-p. Singh, E. Guidetti, F . De Am- broggi, T . Majo, P . Zambotti, M. A yodhya wasi, H. Singh et al. , “14.1 a 2.9 tops/w deep con volutional neural network soc in fd-soi 28nm for intelligent embedded systems, ” in Solid-State Cir cuits Confer ence (ISSCC), 2017 IEEE International . IEEE, 2017, pp. 238–239. [64] P . N. Whatmough, S. K. Lee, H. Lee, S. Rama, D. Brooks, and G.-Y . W ei, “14.3 a 28nm soc with a 1.2 ghz 568nj/prediction sparse deep- neural-network engine with¿ 0.1 timing error rate tolerance for iot applications, ” in Solid-State Cir cuits Confer ence (ISSCC), 2017 IEEE International . IEEE, 2017, pp. 242–243. [65] J. Sim, J.-S. Park, M. Kim, D. Bae, Y . Choi, and L.-S. Kim, “14.6 a 1.42 tops/w deep conv olutional neural network recognition processor for intelligent ioe systems, ” in Solid-State Cir cuits Conference (ISSCC), 2016 IEEE International . IEEE, 2016, pp. 264–265. [66] S. Bang, J. W ang, Z. Li, C. Gao, Y . Kim, Q. Dong, Y .-P . Chen, L. Fick, X. Sun, R. Dreslinski et al. , “14.7 a 288 µ w programmable deep-learning processor with 270kb on-chip weight storage using non- uniform memory hierarchy for mobile intelligence, ” in Solid-State Cir cuits Conference (ISSCC), 2017 IEEE International . IEEE, 2017, pp. 250–251. [67] C. Zhang, Z. Fang, P . Zhou, P . P an, and J. Cong, “Caffeine: tow ards uniformed representation and acceleration for deep con volutional neural networks, ” in Proceedings of the 35th International Conference on Computer-Aided Design . ACM, 2016, p. 12. [68] C. Zhang, D. Wu, J. Sun, G. Sun, G. Luo, and J. Cong, “Energy- efficient cnn implementation on a deeply pipelined fpga cluster, ” in Pr oceedings of the 2016 International Symposium on Low P ower Electr onics and Design . ACM, 2016, pp. 326–331. [69] http://www .techradar.com/ne ws/computing- components/processors/ google- s- tensor- processing- unit- e xplained- \ this- is- what- the- future- of- computing- looks- \ like- 1326915. [70] https://www .sdxcentral.com/articles/news/intels- deep- learning- chips- will- arriv e- 2017/2016/11/. [71] S. Han, J. Pool, J. T ran, and W . Dally , “Learning both weights and connections for efficient neural network, ” in Advances in neural information pr ocessing systems , 2015, pp. 1135–1143. [72] X. Dai, H. Y in, and N. K. Jha, “Nest: a neural network syn- thesis tool based on a grow-and-prune paradigm, ” arXiv preprint arXiv:1711.02017 , 2017. [73] T .-J. Y ang, Y .-H. Chen, and V . Sze, “Designing energy-efficient con vo- lutional neural networks using energy-aware pruning, ” arXiv pr eprint arXiv:1611.05128 , 2016. [74] Y . Guo, A. Y ao, and Y . Chen, “Dynamic network sur gery for efficient dnns, ” in Advances In Neural Information Pr ocessing Systems , 2016, pp. 1379–1387. [75] X. Dong, S. Chen, and S. Pan, “Learning to prune deep neural networks via layer-wise optimal brain surgeon, ” in Advances in Neur al Information Pr ocessing Systems , 2017, pp. 4857–4867. [76] W . W en, C. W u, Y . W ang, Y . Chen, and H. Li, “Learning structured sparsity in deep neural networks, ” in Advances in Neural Information Pr ocessing Systems , 2016, pp. 2074–2082. [77] J. Y u, A. Lukef ahr, D. Palframan, G. Dasika, R. Das, and S. Mahlk e, “Scalpel: Customizing dnn pruning to the underlying hardware par- allelism, ” in Computer Architectur e (ISCA), 2017 ACM/IEEE 44th Annual International Symposium on . IEEE, 2017, pp. 548–560. [78] Y . He, X. Zhang, and J. Sun, “Channel pruning for accelerating very deep neural networks, ” in Pr oceedings of the IEEE International Confer ence on Computer V ision , 2017, pp. 1389–1397. [79] C. Leng, H. Li, S. Zhu, and R. Jin, “Extremely low bit neural netw ork: Squeeze the last bit out with admm, ” arXiv preprint , 2017. [80] E. Park, J. Ahn, and S. Y oo, “W eighted-entropy-based quantization for deep neural networks, ” in Proceedings of the IEEE Confer ence on Computer V ision and P attern Recognition , 2017, pp. 7197–7205. [81] A. Zhou, A. Y ao, Y . Guo, L. Xu, and Y . Chen, “Incremental network quantization: T owards lossless cnns with low-precision weights, ” in International Conference on Learning Representations (ICLR) , 2017. [82] D. Lin, S. T alathi, and S. Annapureddy , “Fixed point quantization of deep con volutional networks, ” in International Conference on Machine Learning , 2016, pp. 2849–2858. [83] J. W u, C. Leng, Y . W ang, Q. Hu, and J. Cheng, “Quantized con vo- lutional neural networks for mobile devices, ” in Pr oceedings of the IEEE Conference on Computer V ision and P attern Reco gnition , 2016, pp. 4820–4828. [84] M. Rastegari, V . Ordonez, J. Redmon, and A. Farhadi, “Xnor-net: Imagenet classification using binary con volutional neural networks, ” in European Conference on Computer V ision . Springer , 2016, pp. 525–542. [85] I. Hubara, M. Courbariaux, D. Soudry , R. El-Y aniv , and Y . Bengio, “Binarized neural networks, ” in Advances in neural information pr o- cessing systems , 2016, pp. 4107–4115. [86] M. Courbariaux, Y . Bengio, and J.-P . Da vid, “Binaryconnect: T raining deep neural networks with binary weights during propagations, ” in Advances in neural information pr ocessing systems , 2015, pp. 3123– 3131. [87] https://www .tensorflow .org/mobile/tflite/. [88] A. Paszke, S. Gross, S. Chintala, and G. Chanan, “Pytorch, ” 2017. [89] A. Ren, J. Li, T . Zhang, S. Y e, W . Xu, X. Qian, X. Lin, and Y . W ang, “ADMM-NN: An Algorithm-Hardware Co-Design Frame- work of DNNs Using Alternating Direction Methods of Multipliers, ” in International conference on Ar chitectural Support for Pro gramming Languages and Operating Systems , 2019. [90] H. Ouyang, N. He, L. T ran, and A. Gray , “Stochastic alternating direc- tion method of multipliers, ” in International Confer ence on Machine Learning , 2013, pp. 80–88. [91] T . Suzuki, “Dual averaging and proximal gradient descent for online alternating direction multiplier method, ” in International Conference on Machine Learning , 2013, pp. 392–400. [92] S. Boyd, N. Parikh, E. Chu, B. Peleato, J. Eckstein et al. , “Distributed optimization and statistical learning via the alternating direction method of multipliers, ” F oundations and Tr ends R in Machine learning , vol. 3, no. 1, pp. 1–122, 2011. [93] T . Zhang, S. Y e, K. Zhang, J. T ang, W . W en, M. F ardad, and Y . W ang, “ A systematic dnn weight pruning frame work using alternating direc- tion method of multipliers, ” arXiv preprint , 2018. [94] Z. Y uan, J. Y ue, H. Y ang, Z. W ang, J. Li, Y . Y ang, Q. Guo, X. Li, M.-F . Chang, H. Y ang et al. , “Stick er: A 0.41-62.1 tops/w 8bit neural network processor with multi-sparsity compatible con volution arrays JOURNAL OF L A T E X CLASS FILES, VOL. 14, NO. 8, A UGUST 2015 15 and online tuning acceleration for fully connected layers, ” in 2018 IEEE Symposium on VLSI Cir cuits . IEEE, 2018, pp. 33–34. [95] A. Ren, T . Zhang, S. Y e, J. Li, W . Xu, X. Qian, X. Lin, and Y . W ang, “ Admm-nn: An algorithm-hardware co-design framew ork of dnns using alternating direction method of multipliers, ” arXiv pr eprint arXiv:1812.11677 , 2018. [96] S. Zhang, Z. Du, L. Zhang, H. Lan, S. Liu, L. Li, Q. Guo, T . Chen, and Y . Chen, “Cambricon-x: An accelerator for sparse neural networks, ” in The 49th Annual IEEE/ACM International Symposium on Micr oarc hi- tectur e . IEEE Press, 2016, p. 20. [97] A. Parashar, M. Rhu, A. Mukkara, A. Puglielli, R. V enkatesan, B. Khailany , J. Emer, S. W . Keckler , and W . J. Dally , “Scnn: An accelerator for compressed-sparse con volutional neural networks, ” in 2017 A CM/IEEE 44th Annual International Symposium on Computer Ar chitectur e (ISCA) . IEEE, 2017, pp. 27–40. [98] Z. He and D. Fan, “Simultaneously optimizing weight and quantizer of ternary neural network using truncated gaussian approximation, ” arXiv pr eprint arXiv:1810.01018 , 2018. [99] H. Mao, S. Han, J. Pool, W . Li, X. Liu, Y . W ang, and W . J. Dally , “Exploring the regularity of sparse structure in convolutional neural networks, ” arXiv pr eprint arXiv:1705.08922 , 2017. [100] M. Hong, Z.-Q. Luo, and M. Razaviyayn, “Conv ergence analysis of alternating direction method of multipliers for a family of noncon vex problems, ” SIAM Journal on Optimization , vol. 26, no. 1, pp. 337–364, 2016. [101] S. Liu, J. Chen, P .-Y . Chen, and A. Hero, “Zeroth-order online alternating direction method of multipliers: Conver gence analysis and applications, ” in International Conference on Artificial Intelligence and Statistics , 2018, pp. 288–297. [102] A. Krizhevsky , I. Sutskever , and G. E. Hinton, “Imagenet classification with deep con volutional neural networks, ” in Advances in neural information pr ocessing systems , 2012, pp. 1097–1105. [103] K. Simonyan and A. Zisserman, “V ery deep conv olutional networks for large-scale image recognition, ” arXiv pr eprint arXiv:1409.1556 , 2014. [104] K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition, ” in Pr oceedings of the IEEE confer ence on computer vision and pattern recognition , 2016, pp. 770–778. [105] M. Sandler, A. Howard, M. Zhu, A. Zhmoginov , and L.-C. Chen, “Mo- bilenetv2: In verted residuals and linear bottlenecks, ” in Proceedings of the IEEE Conference on Computer V ision and P attern Recognition , 2018, pp. 4510–4520. [106] A. Ren, T . Zhang, S. Y e, J. Li, W . Xu, X. Qian, X. Lin, and Y . W ang, “ Admm-nn: An algorithm-hardware co-design framework of dnns using alternating direction methods of multipliers, ” in Pr oceedings of the T wenty-F ourth International Conference on Ar chitectural Support for Pr ogramming Languages and Operating Systems . ACM, 2019, pp. 925–938. [107] H.-P . Cheng, Y . Huang, X. Guo, F . Y an, Y . Huang, W . W en, H. Li, and Y . Chen, “Differentiable fine-grained quantization for deep neural network compression, ” in NIPS 2018 CDNNRIA W orkshop , 2018. [108] Google supercharges machine learning tasks with TPU custom chip, https://cloudplatform.googleblog.com/2016/05/Google-supercharges- machine-learning-tasks-with-custom-chip.html. [109] S. Han, H. Mao, and W . J. Dally , “Deep compression: Compressing deep neural networks with pruning, trained quantization and huf fman coding, ” in International Conference on Learning Repr esentations (ICLR) , 2016. [110] P . Molchanov , S. T yree, T . Karras, T . Aila, and J. Kautz, “Pruning con volutional neural networks for resource efficient inference, ” arXiv pr eprint arXiv:1611.06440 , 2016. [111] R. Y u, A. Li, C.-F . Chen, J.-H. Lai, V . I. Morariu, X. Han, M. Gao, C.-Y . Lin, and L. S. Davis, “Nisp: Pruning networks using neuron importance score propag ation, ” in Pr oceedings of the IEEE Confer ence on Computer V ision and P attern Recognition , 2018, pp. 9194–9203. [112] Z. Zhuang, M. T an, B. Zhuang, J. Liu, Y . Guo, Q. W u, J. Huang, and J. Zhu, “Discrimination-aware channel pruning for deep neural networks, ” in Advances in Neural Information Pr ocessing Systems , 2018, pp. 875–886. [113] J.-H. Luo, J. W u, and W . Lin, “Thinet: A filter level pruning method for deep neural network compression, ” in Pr oceedings of the IEEE international conference on computer vision , 2017, pp. 5058–5066. [114] Z. Liu, M. Sun, T . Zhou, G. Huang, and T . Darrell, “Rethinking the value of network pruning, ” arXiv pr eprint arXiv:1810.05270 , 2018. [115] C. Min, A. W ang, Y . Chen, W . Xu, and X. Chen, “2pfpce: T wo- phase filter pruning based on conditional entropy , ” arXiv preprint arXiv:1809.02220 , 2018. [116] H. Li, A. Kadav , I. Durdanovic, H. Samet, and H. P . Graf, “Pruning filters for efficient convnets, ” arXiv preprint , 2016. [117] Y . He, J. Lin, Z. Liu, H. W ang, L.-J. Li, and S. Han, “ Amc: Automl for model compression and acceleration on mobile de vices, ” in The Eur opean Conference on Computer V ision (ECCV) , September 2018. [118] J. Xie, T . He, Z. Zhang, H. Zhang, Z. Zhang, and M. Li, “Bag of tricks for image classification with conv olutional neural networks, ” arXiv preprint arXiv:1812.01187 , 2018. [119] S. J. Pan and Q. Y ang, “ A surve y on transfer learning, ” IEEE T ransac- tions on knowledge and data engineering , vol. 22, no. 10, pp. 1345– 1359, 2010. [120] J. Y osinski, J. Clune, Y . Bengio, and H. Lipson, “How transferable are features in deep neural networks?” in Advances in neural information pr ocessing systems , 2014, pp. 3320–3328. [121] K. W eiss, T . M. Khoshgoftaar, and D. W ang, “ A surve y of transfer learning, ” J ournal of Big Data , vol. 3, no. 1, p. 9, 2016. [122] Z. Allen-Zhu, Y . Li, and Y . Liang, “Learning and generalization in overparameterized neural networks, going beyond two layers, ” arXiv pr eprint arXiv:1811.04918 , 2018. [123] S. Y e, K. Xu, S. Liu, H. Cheng, J.-H. Lambrechts, H. Zhang, A. Zhou, K. Ma, Y . W ang, and X. Lin, “Second rethinking of network pruning in the adversarial setting, ” arXiv pr eprint arXiv:1903.12561 , 2019. [124] C. Ding, S. Liao, Y . W ang, Z. Li, N. Liu, Y . Zhuo, C. W ang, X. Qian, Y . Bai, G. Y uan et al. , “C ir cnn: accelerating and compressing deep neural networks using block-circulant weight matrices, ” in Pr oceedings of the 50th Annual IEEE/ACM International Symposium on Micr oar- chitectur e . A CM, 2017, pp. 395–408. [125] C. Deng, S. Liao, Y . Xie, K. Parhi, X. Qian, and B. Y uan, “Permdnn: Efficient compressed deep neural network architecture with permuted diagonal matrices, ” in 2018 51st Annual IEEE/ACM International Symposium on Microar chitectur e (MICRO) . IEEE, 2018.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment