텍스트 무관 화자 검증을 위한 공간 피라미드 인코딩과 볼록 길이 정규화
본 논문은 ResNet 기반 프레임‑레벨 특징을 다중 스케일 시간 구역으로 분할하고, 각 구역에 학습 가능한 사전 인코딩(LDE) 레이어를 적용한 공간 피라미드 인코딩(SPE) 풀링 방식을 제안한다. 또한, 손실 함수에 Ring loss를 추가해 볼록성을 유지하면서 임베딩 길이를 자동 정규화한다. VoxCeleb1 실험에서 SPE와 Ring loss를 결합한 시스템이 기존 i‑vector·d‑vector 대비 낮은 EER과 DCF를 달성하였다.
저자: Youngmoon Jung, Younggwan Kim, Hyungjun Lim
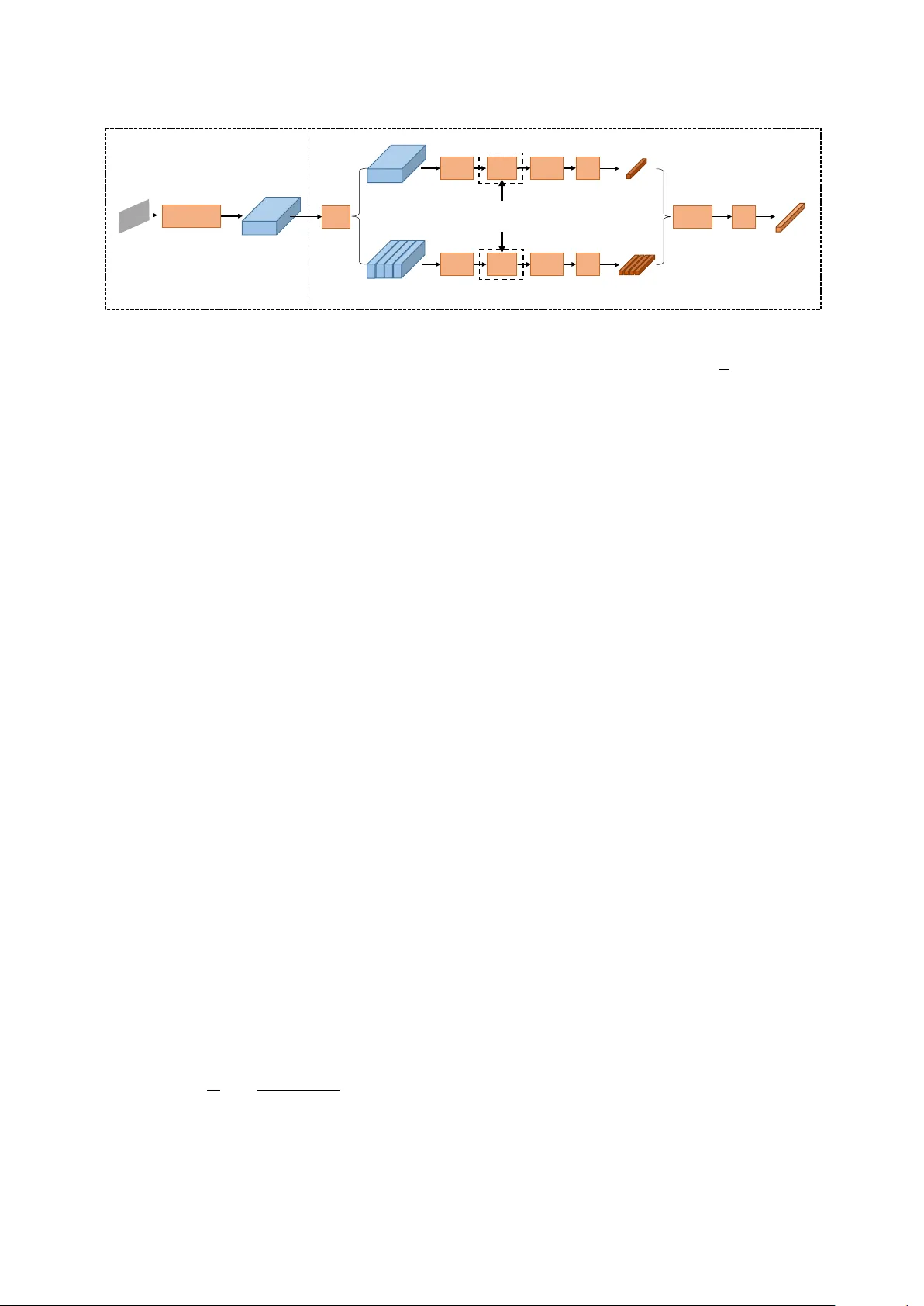
본 논문은 텍스트 무관 화자 검증(TI‑SV)에서 변동적인 발화 길이를 고정 차원의 화자 임베딩으로 변환하는 새로운 풀링 기법인 공간 피라미드 인코딩(SPE)을 제안한다. 기존의 i‑vector와 d‑vector 기반 시스템은 프레임‑레벨 특징을 평균 풀링하거나 통계 풀링으로 요약했지만, 이는 시간적·지역적 정보를 충분히 보존하지 못한다. 최근에는 SPP(Spatial Pyramid Pooling)와 LDE(Learnable Dictionary Encoding)와 같은 방법이 제안되었지만, 각각 평균 풀링에 의존하거나 전역적인 통계만을 활용한다는 한계가 있다.
저자들은 ResNet‑34를 이용해 입력 64 × T × 1 형태의 로그 멜‑필터뱅크(Fbank) 특징을 프레임‑레벨 특징 맵(8 × T/8 × 256)으로 변환한다. 이 특징 맵을 시간 축을 기준으로 두 레벨의 피라미드 구역, 즉 {1 × 1, 1 × 4} 로 분할한다(총 5개의 구역). 각 구역은 1 × 1 컨볼루션을 통해 채널 수를 256에서 64로 축소하고, 동일한 LDE 레이어에 입력한다. LDE는 64개의 코드북을 학습하고, 입력 특징과 코드북 간의 잔차를 소프트 어사인먼트 가중치로 가중합해 64 × 64 = 4096 차원의 초벡터를 만든다. 이 초벡터는 L2 정규화와 FC 레이어(4096→256)로 압축된다. 모든 구역의 256‑차원 임베딩을 연결(concatenation)한 뒤, 최종 FC 레이어(256)를 통과시켜 최종 화자 임베딩을 얻는다. 이 과정은 SPP가 평균 풀링을 수행하던 것을 LDE 기반 인코딩으로 대체함으로써, 지역적 시간 정보를 보존하면서도 GMM‑supervector와 유사한 통계적 표현을 제공한다.
또한, 임베딩 정규화 단계에서 Ring loss를 도입한다. 기존 L2‑constraint 방식은 학습 중에 강제적인 정규화 연산을 삽입해 손실 함수가 비볼록해지는 문제를 야기한다. Ring loss는 배치 평균 L2 노름과 목표 반경 R(학습 가능한 파라미터) 사이의 차이를 제곱해 손실에 가중치 λ를 두어 추가한다. 전체 손실은 L = L_primary + λ·L_R 형태이며, 여기서 L_primary은 Softmax 혹은 A‑Softmax 손실이다. 이 방식은 임베딩이 점진적으로 동일한 반경으로 수렴하도록 유도하면서도 손실 함수 자체는 볼록성을 유지한다.
실험은 VoxCeleb1 데이터셋을 사용해 진행되었다. 학습 시에는 무작위 길이 T∈
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기