Spatial Pyramid Encoding with Convex Length Normalization for Text-Independent Speaker Verification
In this paper, we propose a new pooling method called spatial pyramid encoding (SPE) to generate speaker embeddings for text-independent speaker verification. We first partition the output feature maps from a deep residual network (ResNet) into incre…
Authors: Youngmoon Jung, Younggwan Kim, Hyungjun Lim
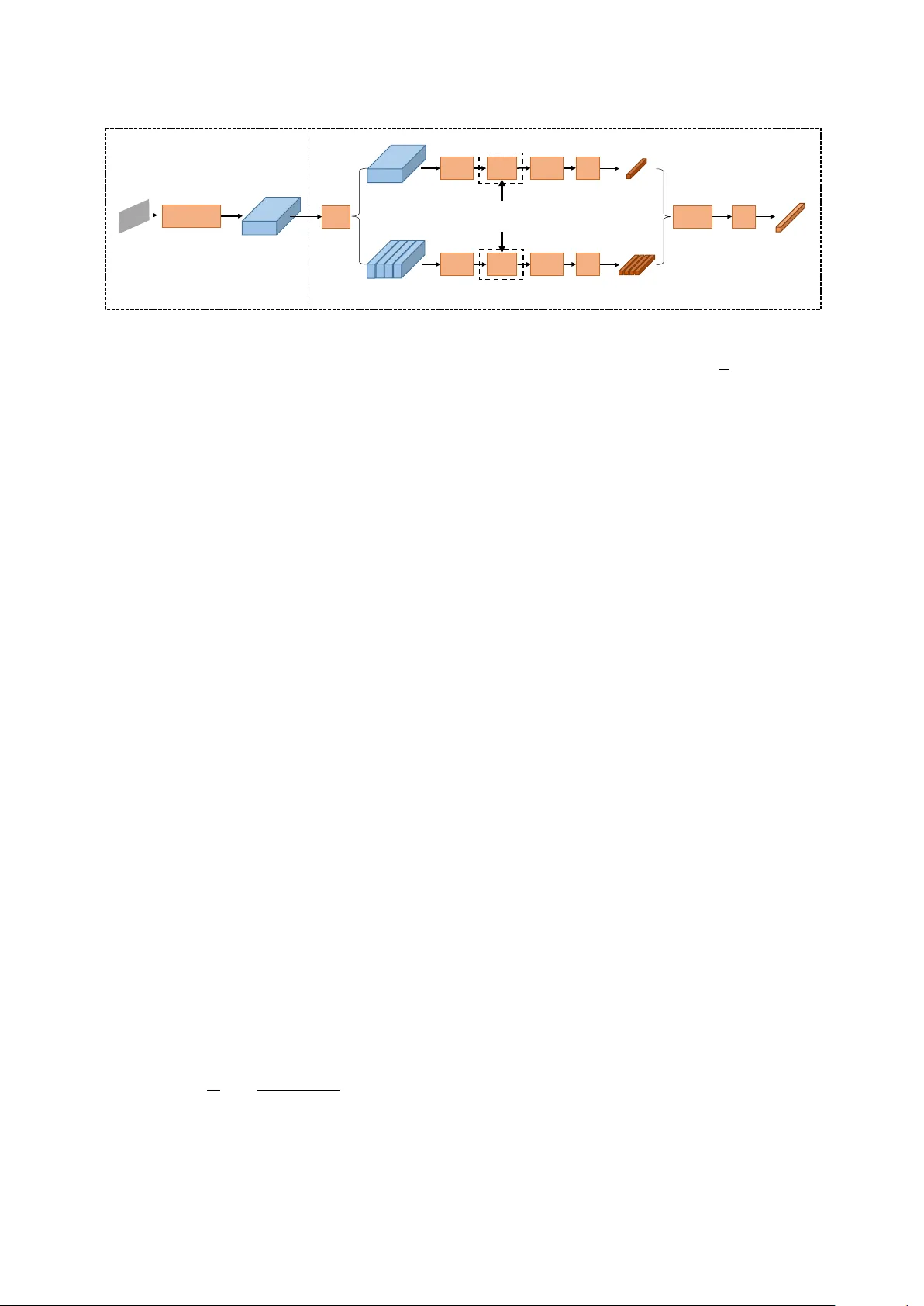
Spatial Pyramid Encoding with Con vex Length Normalization f or T ext-Independent Speaker V erification Y oungmoon Jung 1 , Y ounggwan Kim 2 , Hyungjun Lim 1 , Y eunju Choi 1 , Hoirin Kim 1 1 School of Electrical Engineering, KAIST , Daejeon, South K orea 2 Artificial Intelligence Lab, LG Electronics, Seoul, South K orea dudans@kaist.ac.kr, younggwan.kim@lge.com, { hyungjun.lim,wkadldppdy,hoirkim } @kaist.ac.kr Abstract In this paper , we propose a new pooling method called spatial pyramid encoding (SPE) to generate speaker embeddings for text-independent speaker verification. W e first partition the out- put feature maps from a deep residual network (ResNet) into increasingly fine sub-regions and extract speaker embeddings from each sub-region through a learnable dictionary encoding layer . These embeddings are concatenated to obtain the fi- nal speaker representation. The SPE layer not only generates a fixed-dimensional speaker embedding for a variable-length speech segment, but also aggregates the information of feature distribution from multi-level temporal bins. Furthermore, we apply deep length normalization by augmenting the loss func- tion with ring loss. By applying ring loss, the network grad- ually learns to normalize the speaker embeddings using model weights themselves while preserving con ve xity , leading to more robust speaker embeddings. Experiments on the V oxCeleb1 dataset show that the proposed system using the SPE layer and ring loss-based deep length normalization outperforms both i - vector and d -vector baselines. Index T erms : speaker verification, spatial pyramid encoding, learnable dictionary encoding, ring loss, length normalization 1. Introduction Speaker verification (SV) is the task of verifying a person’ s claimed identity based on his or her voice. Depending on the lexicon constraint on the spoken content, the SV systems can be classified into two categories, text-dependent speaker verifi- cation (TD-SV) and text-independent speaker verification (TI- SV). TD-SV requires the content of input speech to be fixed, while TI-SV operates on unconstrained speech. The combination of i -vector [1] and probabilistic linear discriminant analysis (PLD A) [2] has been the dominant ap- proach for TI-SV tasks [3, 4]. Recently , a deep neural network (DNN) trained for automatic speech recognition (ASR) was in- tegrated into the i -vector system, which improved the conv en- tional Gaussian Mixture Model-Univ ersal Background Model (GMM-UBM) based i -vector system [5, 6]. Howe ver , the use of the additional ASR-DNN drastically increases the computa- tional complexity and also requires transcribed data for training. Another deep learning-based approach is to extract speaker embeddings directly from a speaker discriminativ e network [7–11]. In such systems, the network is trained to classify speakers in the training set, or to separate same-speaker and different-speak er utterance pairs. After training, the utterance- lev el speaker embeddings (called d -vectors) are obtained by ag- gregating the frame-le vel features extracted from the network. Most d -vector based SV systems use a pooling mechanism to map a variable-length segment to a fixed-dimensional em- bedding vector . A verage pooling is the most common method to extract the utterance-level speaker representations [12–14]. Recently , some researchers have proposed more advanced pool- ing methods. Snyder et al. [15] introduced the statistics pool- ing layer in which the standard de viation is used as well as the mean. Okabe et al. [16] combined the attention mechanism and the statistics pooling layer to propose attenti ve statistics pooling layer . Zhang et al. [9] proposed to replace the average pool- ing layer with the spatial pyramid pooling (SPP) layer [17] to maintain spatial information by pooling in local spatial bins. Cai et al. [18] applied the learnable dictionary encoding (LDE) scheme for extracting speaker embeddings. They imitated the process of encoding GMM supervectors within a deep learning framew ork. These approaches improved the performance ov er simple av erage pooling. Once i -vectors or d -v ectors are extracted, we usually ap- ply length normalization for the speaker representations to hav e unit norm [13, 19]. In [20], the authors introduced L 2 - constraint based deep length normalization. They added an L 2 - normalization layer follo wed by a scale layer to constrain the representations to lie on a hypersphere of a fixed radius. They showed that integrating this simple step in the training pipeline boosts the performance of speaker verification. In this work, we propose a new pooling scheme, called spa- tial pyramid encoding (SPE). After the frame-lev el features are extracted from ResNet [21], we divide the feature maps of the last layer into uniform grids at different scales. Unlike using the av erage pooling operation in the SPP layer, we extract em- beddings from each sub-region through the LDE layer . The fi- nal speaker representation is produced by aggreg ating the em- beddings from each sub-region. Furthermore, we apply con- ve x length normalization using ring loss [22] to normalize the speaker embedding. W e show that ring loss-based deep length normalization performs better than the L 2 -constraint based one. In this paper, we first describe the d -vector systems in Sec- tion 2. Section 3 revie ws the related prior works. Section 4 presents our proposed methods. The experimental setup and re- sults are described in Section 5 and Section 6, respectiv ely . W e conclude this work in Section 7. 2. d -vector systems W e can classify d -vector based SV systems according to the loss function used. The first one is based on the softmax loss defined in [23] as the combination of a cross-entropy loss, a softmax function and the last fully connected layer [7, 8, 24]. In this system, a speak er classifier is trained to classify speakers in the training set. The softmax loss encourages the separability of speaker embeddings. Howev er, the softmax loss is not suf ficient to learn the discriminativ e embedding with a large margin, and more researchers began to explore discriminativ e loss functions for enhanced generalization ability . Another type of system is based on the triplet loss [9] which enhances the intra-class compactness and inter-class separabil- ity , leading to better generalization ability . It minimizes the distance between embedding pairs from the same speaker and maximizes the distance between pairs from different speakers. A drawback is that it requires the careful selection of triplets of samples, which is time-consuming and performance-sensitiv e. T o circumvent the triplet-wise computation and learn more discriminativ e representations, the center loss [25] and angular softmax (A-softmax) loss [26] are applied to SV tasks, respec- tiv ely [10, 11]. The center loss minimizes the Euclidean distance between the embeddings and the corresponding class centroids. The angular softmax loss introduces an angular margin into the softmax loss through the designing of a sophisticated differen- tiable angular distance function. The hyperparameter m con- trols the size of the angular margin. Large m giv es more strin- gent constraint on the distribution of the deep embeddings and enforces a larger angular mar gin between classes. For all the systems mentioned above, the frame-level fea- tures are extracted from the speaker discriminativ e network. Then, the d -vector is obtained by a pooling layer that aggregates the frame-level features across time. The speaker-dependent d - vector for each enrollment speaker is stored after the d -vector is divided by its L 2 -norm for length normalization. Finally , scor- ing between enrollment and test d -vector is performed using either the cosine distance or PLD A. 3. Prior works 3.1. Learnable dictionary encoding layer Cai et al. [18] employed the learnable dictionary encoding (LDE) layer [27] for speaker recognition. The LDE layer acts as a pooling layer integrated on top of conv olutional layers, which ports the entire dictionary learning and encoding pipeline into a single model. It accepts variable-length inputs and pro- duces fix ed-length speaker embeddings. W e assume that frame- lev el features are distrib uted in C codew ords and the LDE layer learns a dictionary , a set of codewords. This is essentially the same as the con ventional GMM supervector . The LDE layer considers an input feature map with the shape of H × W × D as a set of D -dimensional input fea- tures X = { x 1 , ..., x L } , where L is the total number of fea- tures given by H × W , which learns an inherent codebook µ = { µ 1 , ..., µ C } containing C number of code words and a set of smoothing factor of the code words S = { s 1 , ..., s C } . The residual encoding e c for code word µ c is generated by aggregat- ing the residuals with soft-assignment weights: e c = L X t =1 e tc = P L t =1 w tc r tc L , (1) where the residuals are given by r tc = x t − µ c . The assigning weight is giv en by a softmax function as follows: w tc = exp ( − s c k r tc k 2 ) P C m =1 exp ( − s m k r tm k 2 ) . (2) The LDE layer concatenates the residual encoding vectors, generating a fixed-length representation E = { e 1 , ..., e C } (in- dependent of the number of input features L ). The resulting vector E has the same role as the supervector in the GMM su- pervector approach. Finally , this supervector is projected to a lower dimension to obtain the final embedding through an addi- tional fully connected (FC) layer . This projection has the same role as the total variability matrix of the i -v ector system. T able 1: The ar chitectur e of the frame-level feature extractor based on 34-layer ResNet [21]. The input size is 64 × T . stage output size ResNet-34 con v1 64 × T × 32 7 × 7 , 32 , stride 1 con v2 64 × T × 32 " 3 × 3 , 32 3 × 3 , 32 # × 3 con v3 32 × T / 2 × 64 " 3 × 3 , 64 3 × 3 , 64 # × 4 con v4 16 × T / 4 × 128 " 3 × 3 , 128 3 × 3 , 128 # × 6 con v5 8 × T / 8 × 256 " 3 × 3 , 256 3 × 3 , 256 # × 3 3.2. L 2 -constraint based deep length normalization Cai et al. [20] applied an L 2 -constraint [28] to the speaker em- bedding during training. As shown in Figure 1, they added an L 2 -normalization layer followed by a scale layer to constrain the speak er embedding to lie on a hypersphere of a fixed radius. - normalization Layer Scale Layer Input Output Figure 1: L 2 -constraint based deep length normalization This module is added just after the penultimate layer of the network which is the pooling layer . The L 2 -normalization layer normalizes the input speaker embedding f ( x ) to a unit vector . The scale layer scales the unit-length embedding vector into a fixed radius gi ven by the parameter α . They showed that this simple step in the training pipeline boosts the performance of speaker verification systems. 4. Proposed appr oaches 4.1. Spatial pyramid encoding layer Figure 2 shows the proposed pooling layer , called the spatial pyramid encoding (SPE) layer . First, the 34-layer ResNet is used to extract frame-lev el features from utterances, which has been widely used in previous studies [13, 18, 20, 29]. The ar - chitecture is described in T able 1. The ResNet takes log Mel- filterbank (Fbank) features of size 64 × T × 1 and outputs frame- lev el features of size 8 × T / 8 × 256 . The resulting feature maps are fed into the SPE layer and then aggregated into a single, utterance-lev el speaker representation. The SPE method includes three steps. In the first step, the input feature maps are divided into increasingly finer sub- regions along the time axis, forming a pyramid of sub-feature maps. This operation is called the spatial pyramid division (SPD). In this work, we apply the pyramids with two levels { 1 × 1 , 1 × 4 } (totally 5 bins). Subsequently , a 1 × 1 con- volutional layer is used for each bin, reducing the number of channels from 256 to 64. After that, we extract speaker em- beddings from each bin through the LDE layer with 64 code- words, follo wed by L 2 -normalization and an FC layer . This FC layer reduces the dimension of the embeddings from 4,096 (= 64 × 64) to 256. Here, the LDE layer is shared across all bins. At last, all the local embeddings are concatenated and passed through an FC layer with 256 neurons to form the final speaker embedding. Local embeddings Speaker embedding Acoustic features Convolutio nal feature maps Frame- level feature ex traction Spatial p yramid encoding Partitioned feature maps LDE × Conv norm FC FC Concat Shared parameters SPD ResNet-34 LDE norm FC × Conv Figure 2: Overview of the pr oposed spatial pyramid encoding (SPE) layer . The SPE layer can be viewed as a combination of the LDE layer and spatial pyramid pooling (SPP) [17] layer . SPP (also known as spatial pyramid matching or SPM [30]), as an exten- sion of the bag-of-words (BoW) model [31], has been widely used in the computer vision community . It partitions an im- age into se veral segments in different scales, then computes the BoW histograms [30] or GMM supervectors [32] of local fea- tures in each se gment. The resulting vectors for all the segments are concatenated to form a high dimensional vector representa- tion of the image. SPP enables us to incorporate the spatial in- formation of feature v ectors. He et al. [17] proposed SPP-net in which the SPP layer is used to replace the last pooling layer of the conv olutional neural network (CNN). Later , the SPP layer was applied to speaker verification tasks [9]. In the SPP layer, the last con volutional feature maps are divided into sub-re gions, and then av erage pooling is applied to each sub-region. The proposed SPE layer replaces the simple average pool- ing operation of the SPP layer with the LDE operation which is found to perform better for speaker verification task in [18]. Therefore, the SPE layer can be seen as the extension of the SPP layer . At the same time, we can also vie w the SPE layer as the extension of the LDE layer . The descriptive po wer of the LDE layer is limited because it discards the temporal infor- mation of local CNN features. This motiv ates us to combine temporal information with the LDE layer . The SPE layer en- hances the LDE layer by taking the temporal information into consideration at both local and global scales. 4.2. Ring loss-based deep length normalization The L 2 -constraint based deep length normalization explained in Section 3.2 uses the norm constraint right before the soft- max loss. Howe ver , according to [22], such a direct approach through the hard normalization operation results in a non- con vex formulation. It results in local minima generated by the loss function itself and leads to difficulties in optimization. It is important to preserve con vexity in loss functions for more effecti ve minimization of the loss gi ven that the network opti- mization itself is non-conv ex. T o deal with this issue, we apply ring loss [22] that normalizes deep speaker embeddings through a con ve x augmentation of the primary loss function (such as softmax loss [23] or A-softmax loss [26]). T o the best of our knowledge, this is the first work to apply ring loss to speaker verification systems. Ring loss L R is defined as L R = 1 m m X i =1 k f ( x i ) k 2 − R E [ k f ( x ) k 2 ] 2 , (3) where f ( x i ) is the speaker embedding for the sample x i . Here, R is the target norm value which is learned during training, m is the batch size, and E [ k f ( x ) k 2 ] = 1 m P m i =1 ( k f ( x i ) k 2 ) , which is the average L 2 -norm of the input embedding vectors for each mini-batch. The loss encourages the norm of the em- beddings being value R (a learned parameter) rather than ex- plicit enforcing through a hard normalization operation as in the L 2 -constraint based method. The total objective function is formulated as L = L P + λL R , (4) where L P is the primary loss function. A scalar λ is used for balancing the two loss functions, which is the only hyperparam- eter in ring loss. In this w ork, the E [ k f ( x ) k 2 ] obtained from the first iteration of training is used as the initial value of R . 5. Experimental setup 5.1. Datasets In this paper, we train our models on the V oxCeleb1 dataset [14]. The V oxCeleb1 dataset is a large scale text-independent speaker recognition dataset, which contains o ver 140,000 utter - ances from 1,251 distinct celebrities, in real-world conditions. For the speaker verification task, there are a total of 1,211 speak- ers in the dev elopment set and the rest 40 speakers are reserved as the test set. For further details, please refer to [14]. W e report the equal error rate (EER) and the minimum de- tection cost function (DCF) [33] at P targ et = 0.01 and P targ et = 0.001. V erification trials are scored using cosine distance. 5.2. Implementation details The input acoustic features are 64-dimensional Fbank features with a frame-length of 25 ms, which are mean-normalized ov er a sliding window of up to 3 s. Both voice activity detection (V AD) and data augmentation are not applied in the systems. For each training step, an integer T is randomly selected within [300, 500] interv al, and the input utterance is cropped or extended to T frames. Thus, the input size of the ResNet-34 model is 64 × T as shown in T able 1. After training, the entire utterance is ev aluated at once in the testing stage. The 256- dimensional speaker embeddings are extracted from a pooling layer . When deep length normalization is applied in training, we do not need an additional length normalization step in testing. The models are implemented with PyT orch [34] and opti- mized by stochastic gradient descent with momentum 0.9. The mini-batch size is 64, and the weight decay parameter is 0.0001. W e use the same learning rate schedule as in [18] with the initial learning rate of 0.1. In LDE layers, the number of codewords C is 64. W e use the angular margin m = 4 for A-softmax loss. The hyperparam- eter for ring loss λ is set to 1. T able 2: The performance comparison of differ ent pooling methods. The softmax loss with ring loss is used. “2D” de- notes that the spatial pyramid division (SPD) of { 1 × 1 , 2 × 2 } is applied as in [9], and “1D” denotes that the SPD of { 1 × 1 , 1 × 4 } is applied as explained in Section 4.1. Pooling EER (%) DCF 10 − 2 DCF 10 − 3 T AP 4.62 0.460 0.581 LDE 4.33 0.435 0.549 2D-SPP 4.59 0.452 0.573 1D-SPP 4.50 0.447 0.564 2D-SPE 4.29 0.428 0.534 1D-SPE 4.20 0.422 0.528 T able 3: The performance comparison of differ ent deep length normalization methods. T emporal average pooling is used. SM denotes the softmax loss, ASM denotes the A-softmax loss, L 2 - Cons denotes L 2 -constraint based deep length normalization, and finally “+ Ring” denotes ring loss augmentation. Loss & Norm R EER (%) DCF 10 − 2 DCF 10 − 3 SM - 6.87 0.538 0.708 L 2 -Cons SM 12 (F) 4.83 0.479 0.572 L 2 -Cons SM 24.1 (L) 5.13 0.498 0.601 SM + Ring 20.5 (L) 4.62 0.460 0.581 ASM - 4.88 0.499 0.597 L 2 -Cons ASM 30 (F) 4.69 0.478 0.584 L 2 -Cons ASM 28.3 (L) 4.73 0.475 0.594 ASM + Ring 24.8 (L) 4.41 0.451 0.559 6. Results 6.1. Comparison of pooling methods T able 2 compares the performance of different pooling methods. W e use the softmax loss with ring loss-based deep length nor- malization for all cases. As in [18], temporal average pooling (T AP) is essentially the same as global average pooling, which takes the av erage over all elements in the 2D feature map. 1D- SPE is our proposed SPE layer, in which the SPD is applied along the time axis as explained in Section 4.1. Both the SPP and LDE layers yield better performance than the simple T AP layer . They provide relativ e improvements of 2.6% and 6.3% in EER over the T AP layer, respectively . In both the SPP and SPE layers, the 1D-SPD performs better than the 2D-SPD. The best result (EER = 4.20%, DCF 10 − 2 = 0.422, DCF 10 − 3 = 0.528) is obtained when the 1D-SPE layer is used. W e can see that our proposed SPE layer (1D-SPE) performs better than both the SPP and LDE layers, achie ving relative im- prov ements of 6.7% and 3.0% in EER, respectiv ely . 6.2. Comparison of deep length normalization methods In T able 3, we compare the performance of different deep length normalization methods. In the second column, we present the target norm value R that we would like the speaker embeddings to be normalized to. In the L 2 -constraint based method ( L 2 - Cons), R is equal to α defined in Section 3.2. “(F)” denotes that a fixed optimal R v alue is used, and “(L)” denotes that the parameter R is learned by the network rather than fixed. The softmax loss is used in the first four entries, and the A-softmax loss is used in the last four entries. W e observe that applying deep length normalization leads to performance im- prov ement. For example, using the softmax loss with the ring loss (SM + Ring) shows a relative improv ement of 32.8% in EER over using the softmax loss without the ring loss (SM). T able 4: Comparison of the proposed and state-of-the-art sys- tems. SAP denotes self-attentive pooling and SP denotes statis- tics pooling. Other abbre viations are the same as in T able 3. Systems Loss & Norm Pooling Scoring EER (%) i -vector [35] - - PLD A 5.4 VGG-M [14] Contrastive T AP Cosine 7.8 VGG (1D) [35] SM SP PLDA 5.3 VGG-13 [36] Center T AP Cosine 4.9 ResNet-34 [18] ASM T AP PLD A 4.46 ResNet-34 [18] ASM SAP PLDA 4.40 ResNet-34 [18] ASM LDE PLDA 4.48 ResNet-34 [20] L 2 -Cons SM T AP PLDA 4.74 Proposed ASM + R SPE Cosine 4.03 Furthermore, we can see that the proposed ring loss-based deep length normalization performs better than the L 2 -constraint based approach. When using the A-softmax loss, the ring loss achiev es a relative improvement of 6.0% in EER ov er the L 2 - Cons with R = 30. The best result (EER = 4.41%, DCF 10 − 2 = 0.451, DCF 10 − 3 = 0.559) is obtained when the A-softmax loss function is used with ring loss-based deep length normalization. 6.3. Comparison with recent methods In T able 4, we compare our proposed system with recently re- ported SV systems in terms of EER. For fair comparisons, we do not include systems that are trained on a larger dataset such as V oxCeleb2 [37], or that use data augmentation such as [16]. The i -vector + PLDA system [35] uses 2,048 Gaussian compo- nents. VGG-M [14] is trained using contrastive loss with the T AP layer . VGG (1D) [35] uses a 1D-CNN instead of a 2D- CNN, and the statistics pooling layer . VGG-13 [36] is trained under the joint supervision of softmax loss and center loss. The ResNet-34 based systems in [18] use the T AP , SAP , and LDE layer , respectiv ely . The ResNet-34 based system in [20] applies L 2 -constraint based deep length normalization. The proposed system uses the SPE layer and A-softmax loss with ring loss. W e obtain an EER of 4.03%, a DCF 10 − 2 of 0.402, and a DCF 10 − 3 of 0.492. Our model outperforms all other state-of-the-art systems, including i -vector and other d -vector systems. It yields relati ve impro vements of 25.4% and 8.4% over the i -vector system and ResNet-34 + SAP (which shows the best performance among the baselines), respecti vely . 7. Conclusions In this paper , we proposed spatial pyramid encoding to ex- tract d -vectors for TI-SV . This method achiev ed better results than the LDE and SPP method. Furthermore, we applied ring loss-based deep length normalization, and it performed bet- ter than the existing L 2 -constraint based one. On the V ox- Celeb1 dataset, our system using the SPE layer and ring loss ob- tained better performance than the state-of-the-art i -vector and d -vector baselines. In the future, we will explore how to auto- matically divide the feature maps of CNNs in the SPE layer . 8. Acknowledgements This material is based upon work supported by the Ministry of T rade, Industry and Energy (MOTIE, K orea) under Industrial T echnology Innov ation Program (No.10063424, Dev elopment of distant speech recognition and multi-task dialog processing technologies for in-door con versational robots). 9. References [1] N. Dehak, P . J. K enny , R. Dehak, P . Dumouchel, and P . Ouellet, “Front-end factor analysis for speaker verification, ” IEEE T rans- actions on Audio, Speech and Language Processing , vol. 19, no. 4, pp. 788–798, 2011. [2] S. Ioffe, “Probabilistic linear discriminant analysis, ” in Proceed- ings of Eur opean Conference on Computer V ision (ECCV) , 2006, pp. 531–542. [3] P . Kenn y , “Bayesian speaker verification with heavy tailed pri- ors, ” in Pr oceedings of Odyssey Speaker and Language Recogni- tion W orkshop , 2010, p. 14. [4] D. Garcia-Romero and C. Espy-W ilson, “ Analysis of ivector length normalization in speak er recognition systems, ” in Proceed- ings of Interspeech , 2011, pp. 249–252. [5] P . Kenny , V . Gupta, T . Stafylakis, P . Ouellet, and J. Alam, “Deep neural networks for extracting baum-welch statistics for speaker recognition, ” in Proceedings of Odyssey Speaker and Language Recognition W orkshop , 2014, pp. 293–298. [6] Y . Lei, N. Scheffer , L. Ferrer, and M. McLaren, “ A novel scheme for speaker recognition using a phonetically-aware deep neural network, ” in Proceedings of the IEEE International Confer ence on Acoustics, Speech and Signal Processing (ICASSP) , 2014, pp. 1695–1699. [7] E. V ariani, X. Lei, E. McDermott, I. Moreno, and J. Gonza- lezDominguez, “Deep neural networks for small footprint text- dependent speaker v erification, ” in Pr oceedings of the IEEE Inter- national Conference on Acoustics, Speech and Signal Processing (ICASSP) , 2014, pp. 4052–4056. [8] Y . Chen, I. Lopez-Moreno, T . N. Sainath, M. V isontai, R. Alvarez, and C. Parada, “Locally-connected and conv olutional neural net- works for small footprint speaker recognition, ” in Proceedings of Interspeech , 2015, pp. 1136–1140. [9] C. Zhang, K. Koishida, and J. Hansen, “T ext-independent speaker verification based on triplet con volutional neural network embed- dings, ” IEEE/ACM T ransactions on Audio Speech and Language Pr ocessing , vol. 26, no. 9, pp. 1633–1644, 2018. [10] N. Li, D. Tuo, D. Su, Z. Li, and D. Y u, “Deep discriminative em- beddings for duration robust speaker v erification, ” in Pr oceedings of Interspeech , 2018, pp. 2262–2266. [11] Z. Huang, S. W ang, and K. Y u, “ Angular softmax for short du- ration text-independent speaker verification, ” in Proceedings of Interspeech , 2018, pp. 3623–3627. [12] D. Sn yder , P . Ghahremani, D. Pov ey , D. Garcia-Romero, Y . Carmiel, and S. Khudanpur , “Deep neural network based speaker embeddings for end-to-end speaker verification, ” in Pr o- ceedings of Spoken Language T echnolo gy W orkshop (SLT) , 2016, pp. 165–170. [13] C. Li, X. Ma, B. Jiang, X. Li, X. Zhang, X. Liu, Y . Cao, A. Kan- nan, and Z. Zhu, “Deep speaker: An end-to-end neural speaker embedding system, ” arXiv pr eprint arXiv:1705.02304 , 2017. [14] A. Nagrani, J. S. Chung, and A. Zisserman, “V oxceleb: A large- scale speaker identification dataset, ” in Pr oceedings of Inter- speech , 2017, pp. 2616–2620. [15] D. Snyder , D. Garcia-Romero, D. Pov ey , and S. Khudanpur , “Deep neural network embeddings for text-independent speaker verification, ” in Proceedings of Interspeec h , 2017, pp. 999–1003. [16] K. Okabe, T . Koshinaka, and K. Shinoda, “ Attentive statistics pooling for deep speaker embedding, ” in Pr oceedings of Inter- speech , 2018, pp. 2252–2256. [17] K. He, X. Zhang, S. Ren, and J. Sun, “Spatial pyramid pooling in deep conv olutional networks for visual recognition, ” in Pr oceed- ings of Eur opean Conference on Computer V ision (ECCV) , 2014, pp. 346–361. [18] W . Cai, J. Chen, and M. Li, “Exploring the encoding layer and loss function in end-to-end speaker and language recognition sys- tem, ” in Pr oceedings of Odysse y Speaker and Languag e Recogni- tion W orkshop , 2018, pp. 74–81. [19] D. Garcia-Romero and C. Y . Espy-W ilson, “ Analysis of i-vector length normalization in speak er recognition systems, ” in Proceed- ings of Interspeech , 2011, pp. 249–252. [20] W . Cai, J. Chen, and M. Li, “ Analysis of length normalization in end-to-end speaker verification system, ” in Pr oceedings of Inter- speech , 2018, pp. 3618–3622. [21] K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition, ” in Proceedings of Computer V ision and P attern Recognition (CVPR) , 2016, pp. 770–778. [22] Y . Zheng, D. K. P al, and M. Savvides, “Ring loss: Con vex feature normalization for face recognition, ” in Pr oceedings of Computer V ision and P attern Recognition (CVPR) , 2018, pp. 5089–5097. [23] W . Liu, Y . W en, Z. Y u, and M. Y ang, “Lar ge-margin softmax loss for convolutional neural networks, ” in Proceedings of Interna- tional Conference on Machine Learning (ICML) , 2016, pp. 507– 516. [24] M. Ravanelli and Y . Bengio, “Speaker recognition from ra w wav e- form with sincnet, ” in Pr oceedings of Spoken Language T echnol- ogy W orkshop (SLT) , 2018. [25] Y . W en, K. Zhang, Z. Li, and Y . Qiao, “ A discriminative fea- ture learning approach for deep face recognition, ” in Pr oceedings of European Conference on Computer V ision (ECCV) , 2016, pp. 499–515. [26] W . Liu, Y . W en, Z. Y u, M. Li, B. Raj, and L. Song, “Sphereface: Deep hypersphere embedding for face recognition, ” in Proceed- ings of Computer V ision and P attern Recognition (CVPR) , 2017, pp. 212–220. [27] H. Zhang, J. Xue, and K. Dana, “Deep ten: T exture encoding network, ” in Proceedings of Computer V ision and P attern Recog- nition (CVPR) , 2017, pp. 708–717. [28] R. Ranjan, C. Castillo, and R. Chellappa, “L2-constrained soft- max loss for discriminative face verification, ” arXiv preprint arXiv:1703.09507 , 2017. [29] N. Le and J. Odobez, “Robust and discriminativ e speaker embed- ding via intra-class distance variance regularization, ” in Proceed- ings of Interspeech , 2018, pp. 2257–2261. [30] S. Lazebnik, C. Schmid, and J. Ponce, “Beyond bags of fea- tures: Spatial p yramid matching for recognizing natural scene cat- egories, ” in Pr oceedings of Computer V ision and P attern Recog- nition (CVPR) , 2006, pp. 2169–2178. [31] J. Sivic and A. Zisserman, “V ideo google: A text retriev al ap- proach to object matching in videos, ” in Pr oceedings of Interna- tional Confer ence on Computer V ision (ICCV) , 2003, pp. 1470– 1477. [32] Y . Kamishima, N. Inoue, and K. Shinoda, “Ev ent detection in con- sumer videos using gmm superv ectors and svms, ” EURASIP Jour- nal on Image and V ideo Processing , v ol. 2013, pp. 1–13, 2013. [33] J. Hansen and T . Hasan, “Speaker recognition by machines and humans: A tutorial review , ” IEEE Signal processing magazine , vol. 32, no. 6, pp. 74–99, 2015. [34] A. Paszke, S. Gross, S. Chintala, G. Chanan, E. Y ang, Z. DeV ito, Z. Lin, A. Desmaison, L. Antiga, and A. Lerer, “ Automatic dif fer- entiation in pytorch, ” in Advances in Neural Information Process- ing Systems (NIPS) Autodif f W orkshop , 2017. [35] S. Shon, H. T ang, and J. Glass, “Frame-level speaker embed- dings for text-independent speaker recognition and analysis of end-to-end model, ” in Proceedings of Spoken Language T echnol- ogy W orkshop (SLT) , 2018. [36] S. Y adav and A. Rai, “Learning discriminative features for speaker identification and verification, ” in Proceedings of Inter- speech , 2018, pp. 2237–2241. [37] J. S. Chung, A. Nagrani, and A. Zisserman, “V oxceleb2: Deep speaker recognition, ” in Pr oceedings of Interspeech , 2018, pp. 1086–1090.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment