부분관측 제어를 위한 변분 순환 모델과 강화학습 통합
본 논문은 관측이 제한된(POMDP) 환경에서 효율적인 정책 학습을 위해, 환경을 변분 순환 모델(VRM)로 추정하고, 이를 소프트 액터-크리틱(SAC) 기반 강화학습 컨트롤러와 결합한 알고리즘을 제안한다. 실험 결과, 좌표·속도 누락 혹은 장기 기억이 요구되는 로봇 제어 과제에서 기존 방법보다 데이터 효율성과 정책 최적화 측면에서 우수함을 보였다.
저자: Dongqi Han, Kenji Doya, Jun Tani
본 논문은 부분관측(Partially Observable) 환경에서 강화학습(RL) 에이전트가 직면하는 두 가지 핵심 과제—관측으로부터 숨겨진 환경 상태를 추정하는 표현 학습과, 추정된 상태를 이용해 최적 정책을 학습하는 제어 문제—를 동시에 해결하기 위한 새로운 프레임워크를 제시한다. 저자들은 이를 위해 변분 순환 모델(VRM)을 설계하고, 이를 Soft Actor‑Critic(SAC) 기반의 RL 컨트롤러와 결합한다.
1. **문제 정의 및 배경**
- 부분관측 마코프 결정 과정(POMDP)에서는 상태 S가 직접 관측되지 않아, 에이전트는 관측 X와 행동 A의 시퀀스를 통해 숨겨진 상태를 추정해야 한다. 기존 접근법은 (i) 관측 히스토리를 직접 입력으로 사용하거나, (ii) RNN을 이용해 표현을 학습하거나, (iii) 모델 기반 방법으로 믿음 상태(belief state)를 추정하는 방식으로 나뉜다. 각각은 장기 기억 요구, 학습 안정성, 모델 정확도 등의 문제를 안고 있다.
2. **변분 순환 모델(VRM)**
- VRM은 변분 순환 신경망(VRNN)을 기반으로 하며, 행동 aₜ₋₁과 보상 rₜ₋₁을 인코더·디코더에 추가한다. 매 타임스텝마다 잠재 변수 zₜ∼𝒩(μₜ,σₜ²)를 샘플링하고, LSTM 은닉 상태 dₜ를 업데이트한다(dₜ = LSTM(dₜ₋₁; zₜ, xₜ)).
- 학습 목표는 ELBO를 최대화하는 변분 추정이며, KL 발산과 재구성 로그우도 두 항을 명시적으로 계산한다. 경험 재플레이 버퍼에서 고정 길이 시퀀스를 샘플링해 미니배치 학습을 수행함으로써 효율성을 높인다.
3. **강화학습 컨트롤러**
- 최신 모델프리 알고리즘인 Soft Actor‑Critic을 채택한다. 기존 SAC는 현재 관측 xₜ만을 입력으로 사용했지만, 본 방법은 VRM의 은닉 상태 dₜ를 정책 π(aₜ|dₜ,xₜ)와 가치 함수 Q(s,a), V(s)의 입력에 포함한다. 이를 통해 “신념 상태”와 원시 관측을 동시에 활용해 부분관측 문제를 완전관측 문제로 변환한다.
- 정책은 가우시안 분포 N(μ_η(dₜ,xₜ), diag(σ_η(dₜ,xₜ)))로 파라미터화되며, 두 개의 Q‑네트워크를 사용해 최소값을 취함으로써 과대평가를 방지한다.
4. **학습 스케줄링 및 두 개의 VRM**
- VRM을 두 개(첫인상 모델 M_f와 지속학습 모델 M_k)로 운용한다. M_f는 초기 단계에서 충분히 사전학습된 후 고정하고, M_k는 RL과 병행하여 지속적으로 업데이트한다. 두 모델의 은닉 상태를 모두 RL 컨트롤러에 제공함으로써 초기 신념의 급격한 변동을 억제하고, 정책 학습의 안정성을 확보한다.
- 알고리즘 흐름은 (1) 행동 샘플링 → 환경 상호작용 → (2) 두 VRM의 전방 패스 → (3) 일정 스텝마다 M_f 사전학습, (4) 일정 간격마다 M_k와 SAC 업데이트, (5) 반복한다.
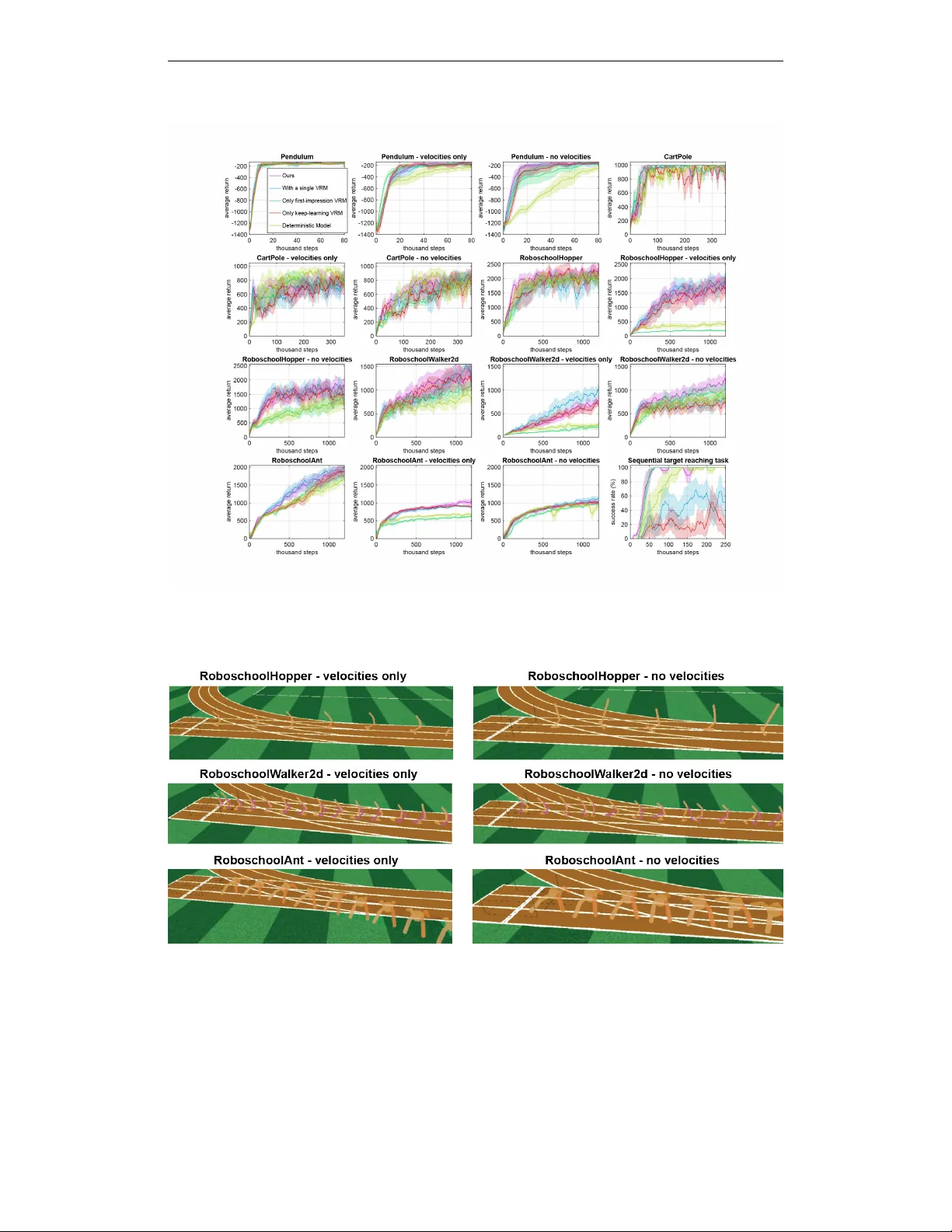
5. **실험 설정 및 결과**
- 두 종류의 로봇 제어 태스크를 사용했다. 첫 번째는 좌표 혹은 속도 중 하나가 관측되지 않는 부분관측 버전이며, 두 번째는 보상이 과거 이벤트(예: 공이 포팅된 여부)를 기억해야 하는 장기 기억 요구 태스크이다.
- 비교 대상은 (i) 단순히 히스토리 포함 RNN, (ii) 모델프리 RNN‑기반 방법, (iii) Stochastic Latent Actor‑Critic(SLAC) 등이다.
- 결과: 제안 방법은 데이터 효율성(학습 샘플당 평균 보상)과 최종 정책 성능 모두에서 우수했으며, 특히 속도 정보가 완전히 누락된 환경에서는 거의 완전관측 상황과 동등한 성능을 달성했다. 장기 기억이 필요한 태스크에서는 기억 지속 시간이 길어질수록 기존 방법보다 성능 격차가 크게 나타났다.
6. **논의 및 한계**
- VRM은 정확한 미래 예측을 목표로 하지 않으며, 신념 상태의 품질은 관측‑행동‑보상 구조에 크게 의존한다. 두 개의 VRM을 동시에 유지하는 것이 메모리와 연산 비용을 증가시킨다.
- 향후 연구는 (a) 모델 압축 및 경량화, (b) 온라인 적응 메커니즘, (c) 이미지와 같은 고차원 센서 입력에 대한 확장, (d) 실제 로봇 시스템에의 적용을 통한 실시간 성능 검증 등을 제안한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기