Variational Recurrent Models for Solving Partially Observable Control Tasks
In partially observable (PO) environments, deep reinforcement learning (RL) agents often suffer from unsatisfactory performance, since two problems need to be tackled together: how to extract information from the raw observations to solve the task, a…
Authors: Dongqi Han, Kenji Doya, Jun Tani
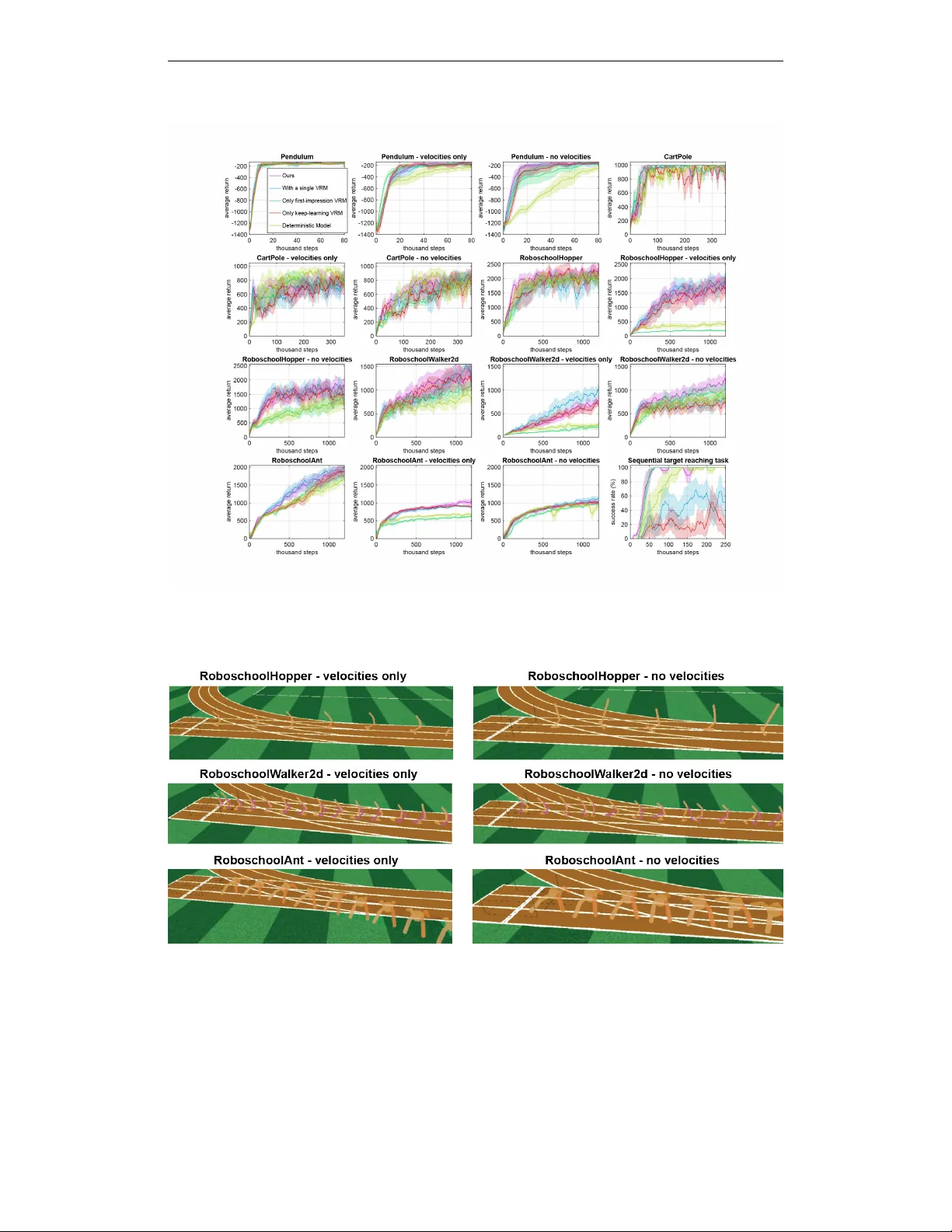
Published as a conference paper at ICLR 2020 V A R I A T I O N A L R E C U R R E N T M O D E L S F O R S O L V I N G P A RT I A L L Y O B S E R V A B L E C O N T RO L T A S K S Dongqi Han Cognitiv e Neurorobotics Research Unit Okinawa Institute of Science and T echnology Okinawa, Japan dongqi.han@oist.jp Kenji Doya Neural Computation Unit Okinawa Institute of Science and T echnology Okinawa, Japan doya@oist.jp Jun T ani ∗ Cognitiv e Neurorobotics Research Unit Okinawa Institute of Science and T echnology Okinawa, Japan jun.tani@oist.jp A B S T R A C T In partially observ able (PO) en vironments, deep reinforcement learning (RL) agents often suf fer from unsatisfactory performance, since two problems need to be tackled together: how to extract information from the raw observ ations to solve the task, and how to improv e the policy . In this study , we propose an RL algorithm for solving PO tasks. Our method comprises two parts: a v ariational recurrent model (VRM) for modeling the environment, and an RL controller that has access to both the en vironment and the VRM. The proposed algorithm was tested in two types of PO robotic control tasks, those in which either coordinates or velocities were not observ able and those that require long-term memorization. Our experiments show that the proposed algorithm achieved better data ef ficiency and/or learned more optimal policy than other alternati ve approaches in tasks in which unobserved states cannot be inferred from raw observ ations in a simple manner 1 . 1 I N T R O D U C T I O N Model-free deep reinforcement learning (RL) algorithms have been dev eloped to solve difficult control and decision-making tasks by self-exploration (Sutton & Barto, 1998; Mnih et al., 2015; Silver et al., 2016). While v arious kinds of fully observ able en vironments hav e been well in vestigated, recently , partially observ able (PO) en vironments (Hafner et al., 2018; Igl et al., 2018; Lee et al., 2019; Jaderberg et al., 2019) hav e commanded greater attention, since real-world applications often need to tackle incomplete information and a non-trivial solution is highly desirable. There are many types of PO tasks; howe ver , those that can be solved by taking the history of observations into account are more common. These tasks are often encountered in real life, such as videos games that require memorization of pre vious events (Kapturo wski et al., 2018; Jaderberg et al., 2019) and robotic control using real-time images as input (Hafner et al., 2018; Lee et al., 2019). While humans are good at solving these tasks by extracting crucial information from the past observations, deep RL agents often have dif ficulty acquiring satisfactory policy and achie ving good data efficienc y , compared to those in fully observable tasks (Hafner et al., 2018; Lee et al., 2019). For solving such PO tasks, se veral cate gories of methods have been proposed. One simple, straight- forward solution is to include a history of raw observ ations in the current “observation” (McCallum, 1993; Lee et al., 2019). Unfortunately , this method can be impractical when decision-making requires a long-term memory because dimension of observ ation become unacceptably large if a long history is included. ∗ Corresponding author . 1 Codes are a vailable at https://github.com/oist- cnru/Variational- Recurrent- Models . 1 Published as a conference paper at ICLR 2020 Another category is based on model-free RL methods with recurrent neural networks (RNN) as func- tion approximators (Schmidhuber, 1990; 1991; Igl et al., 2018; Kapturo wski et al., 2018; Jaderberg et al., 2019), which is usually more tractable to implement. In this case, RNNs need to tackle two problems simultaneously (Lee et al., 2019): learning representation (encoded by hidden states of the RNN) of the underlying states of the environment from the state-transition data, and learning to maximize returns using the learned representation. As most RL algorithms use a bootstrapping strategy to learn the expected return and to improve the policy (Sutton & Barto, 1998), it is challenging to train the RNN stably and efficiently , since RNNs are relatively more dif ficult to train (Pascanu et al., 2013) than feedforward neural networks. The third category considers learning a model of the en vironment and estimating a belief state , extracted from a sequence of state-transitions (Kaelbling et al., 1998; Ha & Schmidhuber, 2018; Lee et al., 2019). The belief state is an agent-estimated variable encoding underlying states of the en vironment that determines state-transitions and re wards. Perfectly-estimated belief states can thus be taken as “observations” of an RL agent that contains complete information for solving the task. Therefore, solving a PO task is se gregated into a representation learning problem and a fully observable RL problem. Since fully observable RL problems have been well explored by the RL community , the critical challenge here is how to estimate the belief state. In this study , we developed a v ariational recurrent model (VRM) that models sequential observations and rew ards using a latent stochastic variable. The VRM is an extension of the variational recurrent neural network (VRNN) model (Chung et al., 2015) that takes actions into account. Our approach falls into the third category by taking the internal states of the VRM together with ra w observations as the belief state. W e then propose an algorithm to solve PO tasks by training the VRM and a feed-forward RL controller network, respectiv ely . The algorithm can be applied in an end-to-end manner , without fine tuning of a hyperparameters. W e then experimentally e valuated the proposed algorithm in v arious PO versions of robotic control tasks. The agents sho wed substantial policy improvement in all tasks, and in some tasks the algorithm performed essentially as in fully observable cases. In particular , our algorithm demonstrates greater performance compared to alternativ e approaches in environments where only v elocity information is observable or in which long-term memorization is needed. 2 R E L A T E D W O R K T ypical model-based RL approaches utilize learned models for dreaming, i.e. generating state- transition data for training the agent (Deisenroth & Rasmussen, 2011; Ha & Schmidhuber, 2018; Kaiser et al., 2019) or for planning of future state-transitions (W atter et al., 2015; Hafner et al., 2018; Ke et al., 2019). This usually requires a well-designed and finely tuned model so that its predictions are accurate and robust. In our case, we do not use VRMs for dreaming and planning, but for auto-encoding state-transitions. Actually , PO tasks can be solved without requiring VRMs to predict accurately (see Appendix E). This distinguishes our algorithm from typical model-based RL methods. The work our method most closely resembles is kno wn as stochastic latent actor-critic (SLA C, Lee et al. (2019)), in which a latent v ariable model is trained and uses the latent state as the belief state for the critic. SLA C showed promising results using pixels-based robotic control tasks, in which velocity information needs to be inferred from third-person images of the robot. Here we consider more general PO environments in which the re ward may depend on a long history of inputs, e.g., in a snooker game one has to remember which ball was potted pre viously . The actor network of SLA C did not take adv antage of the latent v ariable, but instead used some steps of raw observ ations as input, which creates problems in achieving long-term memorization of rew ard-related state-transitions. Furthermore, SLA C did not include raw observations in the input of the critic, which may complicate training the critic before the model con ver ges. 2 Published as a conference paper at ICLR 2020 3 B A C K G R O U N D 3 . 1 P A RT I A L LY O B S E RV A B L E M A R K OV D E C I S I O N P R O C E S S E S The scope of problems we study can be formulated into a frame work known as partially observable Markov decision pr ocesses (POMDP) (Kaelbling et al., 1998). POMDPs are used to describe decision or control problems in which a part of underlying states of the en vironment, which determine state-transitions and rew ards, cannot be directly observed by an agent. A POMDP is usually defined as a 7-tuple ( S , A , T , R, X , O, γ ) , in which S is a set of states, A is a set of actions, and T : S × A → p ( S ) is the state-transition probability function that determines the distribution of the next state gi ven current state and action. The reward function R : S × A → R decides the rew ard during a state-transition, which can also be probabilistic. Moreov er , X is a set of observations, and observ ations are determined by the observation probability function O : S × A → p ( X ) . By defining a POMDP , the goal is to maximize e xpected discounted future rew ards P t γ t r t by learning a good strategy to select actions (polic y function). Our algorithm was designed for general POMDP problems by learning the representation of underly- ing states s t ∈ S via modeling observation-transitions and re ward functions. Howe ver , it is expected to work in PO tasks in which s t or p ( s t ) can be (at least partially) estimated from the history of observations x 1: t . 3 . 2 V A R I A T I O NA L R E C U R R E N T N E U R A L N E T W O R K S T o model general state-transitions that can be stochastic and complicated, we employ a modified version of the VRNN (Chung et a l., 2015). The VRNN was dev eloped as a recurrent version of the variational auto-encoder (V AE, Kingma & W elling (2013)), composed of a variational generation model and a variational inference model. It is a recurrent latent variable model that can learn to encode and predict complicated sequential observations x t with a stochastic latent variable z t . The generation model predicts future observations gi ven the its internal states, z t ∼ N µ p,t , diag ( σ 2 p,t ) , µ p,t , σ 2 p,t = f prior ( d t − 1 ) , x t | z t ∼ N µ y ,t , diag ( σ 2 y ,t ) , µ y ,t , σ 2 y ,t = f decoder ( z t , d t − 1 ) , (1) where f s are parameterized mappings, such as feed-forward neural networks, and d t is the state variable of the RNN, which is recurrently updated by d t = f RNN ( d t − 1 ; z t , x t ) . (2) The inference model approximates the latent variable z t giv en x t and d t . z t | x t ∼ N µ z ,t , diag ( σ 2 z ,t ) , where µ z ,t , σ 2 z ,t = f encoder ( x t , d t − 1 ) . (3) For sequential data that contain T time steps, learning is conducted by maximizing the evidence lower bound E LB O , like that in a VEA (Kingma & W elling, 2013), where E LB O = T X t [ − D K L ( q ( z t | z 1: t − 1 , x 1: t ) || p ( z t | z 1: t − 1 , x 1: t − 1 ))] + E q ( z t | x 1: t , z 1: t − 1 ) [log ( p ( x t | z 1: t , x 1: t − 1 ))] , (4) where p and q are parameterized PDFs of z t by the generative model and the inference model, respecti vely . In a POMDP , a VRNN can be used to model the en vironment and to represent underlying states in its state variable d t . Thus an RL agent can benefit from a well-learned VRNN model since d t provides additional information about the en vironment beyond the current raw observ ation x t . 3 . 3 S O F T A C TO R C R I T I C Soft actor-critic (SAC) is a state-of-the-art model-free RL that uses e xperience replay for dynamic programming, which been tested on v arious robotic control tasks and that sho ws promising perfor- mance (Haarnoja et al., 2018a;b). A SAC agent learns to maximize reinforcement returns as well as entropy of its policy , so as to obtain more rew ards while keeping actions sufficiently stochastic. 3 Published as a conference paper at ICLR 2020 (a) (b) Generative model Inference model (c) Figure 1: Diagrams of the proposed algorithm. (a) Overvie w . (b, c) The generati ve model and the inference model of a VRM. A typical SA C implementation can be described as follows. The state value function V ( s ) , the state-action value function Q ( s , a ) and the policy function π ( a | s ) are parameterized by neural networks, indicated by ψ , λ, η , respecti vely . Also, an entropy coef ficient factor (also kno wn as the temperature parameter), denoted by α , is learned to control the degree of stochasticity of the polic y . The parameters are learned by simultaneously minimizing the following loss functions. J V ( ψ ) = E s t ∼B 1 2 V ψ ( s t ) − E a t ∼ π η [ Q λ ( s t , a t ) − α log π η ( a t | s t )] 2 , (5) J Q ( λ ) = E ( s t , a t ) ∼B 1 2 Q λ ( s t , a t ) − r ( s t , a t ) + γ E s t +1 ∼B [ V ψ ( s t +1 )] 2 , (6) J π ( η ) = E s t ∼B E a η ( s t ) ∼ π η ( s t ) [ α log π η ( a η ( s t ) | s t ) − Q λ ( s t , a η ( s t ))] , (7) J ( α ) = E s t ∼B E a ∼ π η ( s t ) [ − α log π η ( a | s t ) − α H tar ] , (8) where B is the replay b uffer from which s t is sampled, and H tar is the tar get entropy . T o compute the gradient of J π ( η ) (Equation. 7), the reparameterization trick (Kingma & W elling, 2013) is used on action, indicated by a η ( s t ) . Reparameterization of action is not required in minimizing J ( α ) (Equation. 8) since log π η ( a | s t ) does not depends on α . SA C was originally dev eloped for fully observable en vironments; thus, the raw observation at the current step x t was used as network input. In this work, we apply SA C in PO tasks by including the state variable d t of the VRNN in the input of function approximators of both the actor and the critic. 4 M E T H O D S 4 . 1 V A R I A T I O NA L R E C U R R E N T S TA T E - T R A N S I T I O N M O D E L S An overall diagram of the proposed algorithm is summarized in Fig. 1(a), while a more detailed computational graph is plotted in Fig. 2. W e extend the original VRNN model (Chung et al., 2015) to the proposed VRM model by adding action feedback, i.e., actions taken by the agent are used in the inference model and the generati ve model. Also, since we are modeling state-transition and re ward functions, we include the re ward r t − 1 in the current raw observation x t for con venience. Thus, we hav e the inference model (Fig. 1(c)), denoted by φ , as z φ,t | x t ∼ N µ φ,t , diag ( σ 2 φ,t ) , where µ φ,t , σ 2 φ,t = φ ( x t , d t − 1 , a t − 1 ) , (9) The generativ e model (Fig. 1(b)), denoted by θ here, is z t ∼ N µ θ,t , diag ( σ 2 θ,t ) , µ θ,t , σ 2 θ,t = θ prior ( d t − 1 , a t − 1 ) , x t | z t ∼ N µ x,t , diag ( σ 2 x,t ) , µ x,t , σ 2 x,t = θ decoder ( z t , d t − 1 ) . (10) For b uilding recurrent connections, the choice of RNN types is not limited. In our study , the long- short term memory (LSTM) (Hochreiter & Schmidhuber, 1997) is used since it works well in general cases. So we hav e d t = LSTM ( d t − 1 ; z t , x t ) . 4 Published as a conference paper at ICLR 2020 (c) (a) (b) Deterministic node Stochastic node Generative model Inference model RL controller network Interacting with the environment Error back- propagation RL controller Excecution phase Learning phase Figure 2: Computation graph of the proposed algorithm. (a) The RL controller . (b) The ex ecution phase. (c) The learning phase of a VRM. a : action; z : latent variable; d : RNN state variable; x : raw observation (including reward); Q : state-action value function; V : state value function. A bar on a variable means that it is the actual value from the replay buf fer or the en vironment. Each stochastic variable follo ws a parameterized diagonal Gaussian distribution. As in training a VRNN, the VRM is trained by maximizing an evidence lo wer bound (Fig. 1(c)) E LB O = X t E q φ [log p θ ( x t | z 1: t , x 1: t − 1 )] − D K L [ q φ ( z t | z 1: t − 1 , ¯ x 1: t , ¯ a 1: t ) || p θ ( z t | z 1: t − 1 , ¯ x 1: t − 1 , ¯ a 1: t )] } . (11) In practice, the first term E q φ [log p θ ( x t | z 1: t , x 1: t − 1 )] can be obtained by unrolling the RNN using the inference model (Fig. 1(c)) with sampled sequences of x t . Since q φ and p θ are parameterized Gaussian distributions, the KL-di vergence term can be analytically expressed as D K L [ q φ ( z t ) || p θ ( z t )] = log σ φ,t σ θ,t + ( µ φ,t − µ θ,t ) 2 + σ 2 φ,t 2 σ 2 θ,t − 1 2 (12) For computation ef fi cienc y in experience replay , we train a VRM by sampling minibatchs of truncated sequences of fixed length, instead of whole episodes. Details are found in Appendix A.1. Since training of a VRM is segre gated from training of the RL controllers, there are several strate gies for conducting them in parallel. For the RL controller, we adopted a smooth update strategy as in Haarnoja et al. (2018a), i.e., performing one time of experience replay every n steps. T o train the VRM, one can also conduct smooth update. Howe ver , in that case, RL suffers from instability of the representation of underlying states in the VRM before it con verges. Also, stochasticity of RNN state variables d can be meaninglessly high at early stage of training, which may create problems in RL. Another strate gy is to pre-train the VRM for ab undant epochs only before RL starts, which unfortunately , can fail if novel observ ations from the en vironment appear after some degree of policy improv ement. Moreover , if pre-training and smooth update are both applied to the VRM, RL may suffer from a lar ge representation shift of the belief state. T o resolve this conflict, we propose using two VRMs, which we call the first-impr ession model and the keep-learning model , respecti vely . As the names suggest, we pre-train the first-impression model and stop updating it when RL controllers and the keep-learning model start smooth updates. Then we take state v ariables from both VRMs, together with raw observ ations, as input for the RL controller . W e found that this method yields better ov erall performance than using a single VRM (Appendix C). 5 Published as a conference paper at ICLR 2020 Algorithm 1 V ariational Recurrent Models with Soft Actor Critic Initialize the first-impression VRM M f and the k eep-learning VRM M k , the RL controller C , and the replay buf fer D , global step t ← 0 . repeat Initialize an episode, assign M with zero initial states. while episode not terminated do Sample an action a t from π ( a t | d t , x t ) and execute a t , t ← t + 1 . Record ( x t , a t , done t ) into B . Compute 1-step forward of both VRMs using inference models. if t == step start R L then For N epochs, sample a minibatch of samples from B to update M f (Eq. 11). end if if t > step star t R L and mod ( t, tr ain inter v al K LV RM ) == 0 then Sample a minibatch of samples from B to update M k (Eq. 5, 6, 7, 8) . end if if t > step star t R L and mod ( t, tr ain inter v al RL ) == 0 then Sample a minibatch of samples from B to update R (Eq. 11) . end if end while until training stopped 4 . 2 R E I N F O R C E M E N T L E A R N I N G C O N T RO L L E R S As sho wn in Fig. 1(a), we use multi-layer perceptrons (MLP) as function approximators for V , Q , respectiv ely . Inputs for the Q t network are ( x t , d t , a t ) , and V t is mapped from ( x t , d t ) . Follo wing Haarnoja et al. (2018a), we use two Q networks λ 1 and λ 2 and compute Q = min ( Q λ 1 , Q λ 2 ) in Eq. 5 and 7 for better performance and stability . Furthermore, we also used a target value network for computing V in Eq. 6 as in Haarnoja et al. (2018a). The policy function π η follows a parameterized Gaussian distribution N ( µ η ( d t , x t ) , diag ( σ η ( d t , x t ))) where µ η and σ η are also MLPs. In the execution phase (Fig. 1(b)), observation and re ward x t = ( X t , r t − 1 ) are received as VRM inputs to compute internal states d t using inference models. Then, the agent selects an action, sampled from π η ( a t | d t , x t ) , to interact with the en vironment. T o train RL networks, we first sample sequences of steps from the replay buffer as minibatches; thus, d t can be computed by the inference models using recorded observations ¯ x t and actions ¯ a t (See Appendix A.1.2). Then RL networks are updated by minimizing the loss functions with gradient descent. Gradients stop at d t so that training of RL networks does not in volve updating VRMs. 5 R E S U L T S T o empirically ev aluate our algorithm, we performed experiments in a range of (partially observable) continuous control tasks and compared it to the following alternati ve algorithms. The overall procedure is summarized in Algorithm 1. For the RL controllers, we adopted hyperparameters from the original SA C impleme ntation (Haarnoja et al., 2018b). Both the k eep-learning and first-impression VRMs were trained using learning rate 0.0008. W e pre-trained the first-impression VRM for 5,000 epochs, and updated the keep-learning VRM ev ery 5 steps. Batches of size 4, each containing a sequence of 64 steps, were used for training both the VRMs and the RL controllers. All tasks used the same hyperparameters (Appendix A.1). • SA C-MLP : The v anilla soft actor -critic implementation (Haarnoja et al., 2018a;b), in which each function is approximated by a 2-layer MLP taking raw observ ations as input. • SA C-LSTM : Soft actor-critic with recurrent networks as function approximators, where raw observ ations are processed through an LSTM layer followed by 2 layers of MLPs. This allows the agent to make decisions based on the whole history of raw observations. In this case, the network has to conduct representation learning and dynamic programming collectiv ely . Our algorithm is compared with SA C-LSTM to demonstrate the effect of separating representation learning from dynamic programming. 6 Published as a conference paper at ICLR 2020 Pendulum 0 50 100 thousand steps -1500 -1000 -500 average return Pendulum - velocities only 0 50 100 thousand steps -1500 -1000 -500 average return Pendulum - no velocities 0 50 100 thousand steps -1500 -1000 -500 average return CartPole 0 100 200 300 thousand steps 0 500 1000 average return CartPole - velocities only 0 100 200 300 thousand steps 0 500 1000 average return CartPole - no velocities 0 100 200 300 thousand steps 0 500 1000 average return Ours SAC-LSTM SAC-MLP SLAC Pendulum CartPole Figure 3: Learning curves of the classic control tasks. Shaded areas indicate S.E.M.. • SLA C : The stochastic latent actor-critic algorithm introduced in Lee et al. (2019), which is a state-of-the-art RL algorithm for solving POMDP tasks. It was shown that SLAC outperformed other model-based and model-free algorithms, such as (Igl et al., 2018; Hafner et al., 2018), in robotic control tasks with third-person image of the robot as observation 2 . Note that in our algorithm, we apply pre-training of the first-impression model. For a fair comparison, we also perform pre-training for the alternativ e algorithm with the same epochs. For SA C-MLP and SA C-LSTM, pre-training is conducted on RL networks; while for SLA C, its model is pre-trained. 5 . 1 P A RT I A L LY O B S E RV A B L E C L A S S I C C O N T R O L T A S K S The P endlum and CartP ole (Barto et al., 1983) tasks are the classic control tasks for e valuating RL algorithms (Fig. 3, Left). The CartPole task requires learning of a policy that prev ents the pole from falling do wn and keeps the cart from running away by applying a (1-dimensional) force to the cart, in which observable information is the coordinate of the cart, the angle of the pole, and their deriv atives w .r .t time (i.e., velocities). For the Pendulum task, the agent needs to learn a policy to swing an in verse-pendulum up and to maintain it at the highest position in order to obtain more re wards. W e are interested in classic control tasks because they are relatively easy to solve when fully observable, and thus the PO cases can highlight the representation learning problem. Experiments were performed in these two tasks, as well as their PO versions, in which either velocities cannot be observed or only velocities can be observ ed. The latter case is meaningful in real-life applications because an agent may not be able to perceiv e its own position, b ut can estimate its speed. As expected, SA C-MLP failed to solve the PO tasks (Fig. 3). While our algorithm succeeded in learning to solve all these tasks, SAC-LSTM showed poorer performance in some of them. In particular , in the pendulum task with only angular velocity observ able, SA C-LSTM may suffer from the periodicity of the angle. SLAC performed well in the CartPole tasks, but sho wed less satisfactory sample efficienc y in the Pendulum tasks. 5 . 2 P A RT I A L LY O B S E RV A B L E R O B O T I C C O N T R O L T A S K S T o examine performance of the proposed algorithm in more challenging control tasks with higher degrees of freedom (DOF), we also ev aluated performance of the proposed algorithm in the OpenAI Roboschool en vironments (Brockman et al., 2016). The Roboschool environments include a number 2 SLA C was dev eloped for pixel observ ations. T o compare it with our algorithm, we made some modifications of its implementation (see Appendix A.2.3). Nonetheless, we expect the comparison can demonstrate the ef fect of the key dif ferences as aforementioned in Section 2. 7 Published as a conference paper at ICLR 2020 RoboschoolHopper 0 500 1000 thousand steps 0 500 1000 1500 2000 2500 average return Ours SAC-LSTM SAC-MLP SLAC RoboschoolHopper - velocities only 0 500 1000 thousand steps 0 500 1000 1500 2000 2500 average return RoboschoolHopper - no velocities 0 500 1000 thousand steps 0 500 1000 1500 2000 2500 average return RoboschoolWalker2d 0 500 1000 thousand steps 0 500 1000 1500 average return RoboschoolWalker2d - velocities only 0 500 1000 thousand steps 0 500 1000 1500 average return RoboschoolWalker2d - no velocities 0 500 1000 thousand steps 0 500 1000 1500 average return RoboschoolAnt 0 500 1000 thousand steps 0 500 1000 1500 2000 average return RoboschoolAnt - velocities only 0 500 1000 thousand steps 0 500 1000 1500 2000 average return RoboschoolAnt - no velocities 0 500 1000 thousand steps 0 500 1000 1500 2000 average return RoboschoolHopper RoboschoolW alker2d RoboschoolAnt Figure 4: Learning curves of the robotic control tasks, plotted in the same way as in Fig. 3. of continuous robotic control tasks, such as teaching a multiple-joint robot to walk as fast as possible without f alling do wn (Fig. 4, Left). The original Roboschool en vironments are nearly fully observable since observ ations include the robot’ s coordinates and (trigonometric functions of) joint angles, as well as (angular and coordinate) velocities. As in the PO classic control tasks, we also performed experiments in the PO v ersions of the Roboschool en vironments. Using our algorithm, experimental results (Fig. 4) demonstrated substantial policy improv ement in all PO tasks (visualization of the trained agents is in Appendix D). In some PO cases, the agents achiev ed comparable performance to that in fully observ able cases. For tasks with unobserved velocities, our algorithm performed similarly to SA C-LSTM. This is because v elocities can be simply estimated by one-step dif ferences in robot coordinates and joint angles, which eases representation learning. Ho wev er, in en vironments where only v elocities can be observ ed, our algorithm significantly outperformed SA C-LSTM, presumably because SA C-LSTM is less efficient at encoding underlying states from velocity observ ations. Also, we found that learning of a SLA C agent was unstable, i.e., it sometimes could acquire a near -optimal policy , but often its polic y con verged to a poor one. Thus, av erage performance of SLA C was less promising than ours in most of the PO robotic control tasks. 5 . 3 L O N G - T E R M M E M O R I Z A T I O N T A S K S Another common type of PO task requires long-term memorization of past events. T o solve these tasks, an agent needs to learn to extract and to remember critical information from the whole history of raw observ ations. Therefore, we also examined our algorithm and other alternativ es in a long-term memorization task known as the sequential tar get r eaching task (Han et al., 2019), in which a robot agent needs to reach 3 different tar gets in a certain sequence (Fig. 5, Left). The robot can control its two wheels to mov e or turn, and will get one-step small, medium, and large re wards when it reaches the first, second, and third tar gets, respectiv ely , in the correct sequence. The robot senses distances and angles from the 3 targets, but does not receiv e any signal indicating which tar get to reach. In each episode, the robot’ s initial position and those of the three targets are randomly initialized. In order to obtain rew ards, the agent needs to infer the current correct target using historical observ ations. W e found that agents using our algorithm achiev ed almost 100% success rate (reaching 3 tar gets in the correct sequence within maximum steps). SA C-LSTM also achiev ed similar success rate after con ver gence, but spent more training steps learning to encode underlying goal-related information 8 Published as a conference paper at ICLR 2020 Sequential target reaching task 0 50 100 150 200 250 thousand steps 0 20 40 60 80 100 success rate (%) Ours SAC-LSTM SAC-MLP SLAC -1 -0.5 0 0.5 1 0 20 40 60 80 100 Sequential ball touching task Sequential target reaching task Figure 5: Learning curves of the sequential tar get reaching task. from sequential observations. Also, SLA C struggled hard to solve this task since its actor only receiv ed a limited steps of observations, making it dif ficult to infer the correct target. 5 . 4 C O N V E R G E N C E O F T H E K E E P - L E A R N I N G V R M One of the most concerned problems of our algorithm is that input of the RL controllers can experience representation change, because the k eep-learning model is not guaranteed to con verge if nov el observation appears due to improv ed policy (e.g. for a hopper robot, “in-the-air” state can only happen after it learns to hop). T o empirically in vestigate ho w conv ergence of the keep-learning VRM affect policy improv ement, we plot the loss functions (negati ve ELBOs) of the the keep-learning VRM for 3 example tasks (Fig. 6). For a simpler task (CartPole), the policy was already near optimal before the VRM fully conv erged. W e also saw that the policy was gradually improv ed after the VRM mostly con verged (RoboschoolAnt - no velocities), and that the policy and the VRM were being improv ed in parallel (RoboschoolAnt - velocities only). The results suggested that policy could be improved with sufficient sample efficienc y e ven the keep-learning VRM did not con verge. This can be explained by that the RL controller also e xtract information from the first-impression model and the raw observations, which did not experience representation change during RL. Indeed, our ablation study showed performance degradation in many tasks without the first-impression VRM (Appendix C). RoboschoolAnt - no veolocities 0 500 1000 thousand steps 0 500 1000 average return -2 -1 0 1 negative ELBO CartPole 0 100 200 300 400 thousand steps 0 200 400 600 800 1000 average return -4 -3 -2 -1 0 negative ELBO RoboschoolHopper - veolocities only 0 500 1000 thousand steps 500 1000 1500 2000 average return -2 -1 0 negative ELBO Figure 6: Example tasks showing relationship between av erage return of the agent and negati ve ELBO (loss function, dashed) of the keep-learning VRM. 6 D I S C U S S I O N In this paper , we proposed a variational recurrent model for learning to represent underlying states of PO en vironments and the corresponding algorithm for solving POMDPs. Our experimental results demonstrate ef fectiv eness of the proposed algorithm in tasks in which underlying states cannot be simply inferred using a short sequence of observations. Our work can be considered an attempt to understand ho w RL benefits from stochastic Bayesian inference of state-transitions, which actually happens in the brain (Funamizu et al., 2016), but has been considered less often in RL studies. W e used stochastic models in this work which we actually found perform better than deterministic ones, ev en through the en vironments we used are deterministic (Appendix C). The VRNN can 9 Published as a conference paper at ICLR 2020 be replaced with other alternativ es (Bayer & Osendorfer, 2014; Goyal et al., 2017) to potentially improv e performance, although dev eloping model architecture is beyond the scope of the current study . Moreov er , a recent study (Ahmadi & T ani, 2019) showed a novel way of inference using back-propagation of prediction errors, which may also benefit our future studies. Many researchers think that there are two distinct systems for model-based and model-free RL in the brain (Gl ¨ ascher et al., 2010; Lee et al., 2014) and a number of studies in vestigated ho w and when the brain switches between them (Smittenaar et al., 2013; Lee et al., 2014). Howe ver , Stachenfeld et al. (2017) suggested that the hippocampus can learn a successor repr esentation of the en vironment that benefits both model-free and model-based RL, contrary to the aforementioned con ventional vie w . W e further propose another possibility , that a model is learned, but not used for planning or dreaming. This blurs the distinction between model-based and model-free RL. A C K N OW L E D G E M E N T This work was supported by Okinawa Institute of Science and T echnology Graduate University funding, and was also partially supported by a Grant-in-Aid for Scientific Research on Innov ativ e Areas: Elucidation of the Mathematical Basis and Neural Mechanisms of Multi-layer Representation Learning 16H06563. W e would like to thank the lab members in the Cognitive Neurorobotics Research Unit and the Neural Computation Unit of Okinawa Institute of Science and T echnology . In particular , we would lik e to thank Ahmadreza Ahmadi for his help during model de velopment. W e also would like to thank Ste ven Aird for assisting improving the manuscript. R E F E R E N C E S Ahmadreza Ahmadi and Jun T ani. A novel predictiv e-coding-inspired variational rnn model for online prediction and recognition. Neural computation , pp. 1–50, 2019. Andrew G Barto, Richard S Sutton, and Charles W Anderson. Neuronlike adaptive elements that can solve dif ficult learning control problems. IEEE transactions on systems, man, and cybernetics , pp. 834–846, 1983. Justin Bayer and Christian Osendorfer . Learning stochastic recurrent networks. In NIPS 2014 W orkshop on Advances in V ariational Inference , 2014. Greg Brockman, V icki Cheung, Ludwig Pettersson, Jonas Schneider, John Schulman, Jie T ang, and W ojciech Zaremba. OpenAI Gym. arXiv pr eprint arXiv:1606.01540 , 2016. Junyoung Chung, Kyle Kastner , Laurent Dinh, Kratarth Goel, Aaron C Courville, and Y oshua Bengio. A recurrent latent v ariable model for sequential data. In Advances in neural information pr ocessing systems , pp. 2980–2988, 2015. Ian Danforth. Continuous CartPole for openAI Gym. https://gist.github.com/ iandanforth/e3ffb67cf3623153e968f2afdfb01dc8 , 2018. Marc Deisenroth and Carl E Rasmussen. Pilco: A model-based and data-ef ficient approach to policy search. In Pr oceedings of the 28th International Confer ence on machine learning (ICML-11) , pp. 465–472, 2011. Akihiro Funamizu, Bernd Kuhn, and Kenji Do ya. Neural substrate of dynamic Bayesian inference in the cerebral cortex. Nature neur oscience , 19(12):1682, 2016. Jan Gl ¨ ascher , Nathaniel Daw , Peter Dayan, and John P O’Doherty . States versus re wards: dissociable neural prediction error signals underlying model-based and model-free reinforcement learning. Neur on , 66(4):585–595, 2010. Anirudh Goyal Alias P arth Goyal, Alessandro Sordoni, Marc-Ale xandre C ˆ ot ´ e, Nan Rosemary K e, and Y oshua Bengio. Z-forcing: T raining stochastic recurrent networks. In Advances in neural information pr ocessing systems , pp. 6713–6723, 2017. David Ha and J ¨ urgen Schmidhuber . Recurrent world models facilitate policy e volution. In Advances in Neural Information Pr ocessing Systems , pp. 2450–2462, 2018. 10 Published as a conference paper at ICLR 2020 T uomas Haarnoja, Aurick Zhou, Pieter Abbeel, and Serge y Levine. Soft actor-critic: Of f-policy maximum entrop y deep reinforcement learning with a stochastic actor . In International Confer ence on Machine Learning , pp. 1856–1865, 2018a. T uomas Haarnoja, Aurick Zhou, Kristian Hartikainen, George T ucker , Sehoon Ha, Jie T an, V ikash Kumar , Henry Zhu, Abhishek Gupta, Pieter Abbeel, et al. Soft actor-critic algorithms and applications. arXiv pr eprint arXiv:1812.05905 , 2018b. Danijar Hafner , T imothy Lillicrap, Ian Fischer , Ruben V illegas, Da vid Ha, Honglak Lee, and James Davidson. Learning latent dynamics for planning from pixels. arXiv pr eprint arXiv:1811.04551 , 2018. Dongqi Han, K enji Doya, and Jun T ani. Self-organization of action hierarchy and compositionality by reinforcement learning with recurrent networks. arXiv preprint , 2019. Nicolas Heess, Jonathan J Hunt, T imothy P Lillicrap, and David Silver . Memory-based control with recurrent neural networks. arXiv preprint , 2015. Sepp Hochreiter and J ¨ urgen Schmidhuber . Long short-term memory . Neural computation , 9(8): 1735–1780, 1997. Maximilian Igl, Luisa Zintgraf, T uan Anh Le, Frank W ood, and Shimon Whiteson. Deep variational reinforcement learning for pomdps. arXiv pr eprint arXiv:1806.02426 , 2018. Max Jaderberg, W ojciech M Czarnecki, Iain Dunning, Luke Marris, Guy Lev er , Antonio Garcia Castaneda, Charles Beattie, Neil C Rabinowitz, Ari S Morcos, A vraham Ruderman, et al. Human- le vel performance in 3d multiplayer games with population-based reinforcement learning. Science , 364(6443):859–865, 2019. Leslie Pack Kaelbling, Michael L Littman, and Anthon y R Cassandra. Planning and acting in partially observable stochastic domains. Artificial intelligence , 101(1-2):99–134, 1998. Lukasz Kaiser , Mohammad Babaeizadeh, Piotr Milos, Blazej Osinski, Roy H Campbell, K onrad Czechowski, Dumitru Erhan, Chelsea Finn, Piotr K ozakowski, Ser gey Le vine, et al. Model-based reinforcement learning for atari. arXiv pr eprint arXiv:1903.00374 , 2019. Stev en Kapturo wski, Georg Ostrovski, W ill Dabney , John Quan, and Remi Munos. Recurrent experience replay in distrib uted reinforcement learning. OpenRevie w , 2018. Nan Rosemary K e, Amanpreet Singh, Ahmed T ouati, Anirudh Goyal, Y oshua Bengio, Devi Parikh, and Dhruv Batra. Learning dynamics model in reinforcement learning by incorporating the long term future. arXiv pr eprint arXiv:1903.01599 , 2019. Diederik P Kingma and Jimmy Ba. Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980 , 2014. Diederik P Kingma and Max W elling. Auto-encoding v ariational Bayes. arXiv preprint arXiv:1312.6114 , 2013. Alex X Lee, Anusha Nagabandi, Pieter Abbeel, and Serge y Levine. Stochastic latent actor-critic: Deep reinforcement learning with a latent variable model. arXiv pr eprint arXiv:1907.00953 , 2019. Sang W an Lee, Shinsuke Shimojo, and John P O’Doherty . Neural computations underlying arbitration between model-based and model-free learning. Neur on , 81(3):687–699, 2014. Andre w McCallum. Overcoming incomplete perception with utile distinction memory . In Pr oceedings of the T enth International Confer ence on Machine Learning , pp. 190–196, 1993. V olodymyr Mnih, K oray Kavukcuoglu, David Silver , Andrei A Rusu, Joel V eness, Marc G Bellemare, Alex Gra ves, Martin Riedmiller , Andreas K Fidjeland, Geor g Ostrovski, et al. Human-le vel control through deep reinforcement learning. Natur e , 518(7540):529, 2015. Razvan Pascanu, T omas Mikolov , and Y oshua Bengio. On the dif ficulty of training recurrent neural networks. In International conference on mac hine learning , pp. 1310–1318, 2013. 11 Published as a conference paper at ICLR 2020 J ¨ urgen Schmidhuber . Making the world differentiable: On using fully recurrent self-supervised neural networks for dynamic reinforcement learning and planning in non-stationary en vironments. Institut f ¨ ur Informatik, T echnisc he Universit ¨ at M ¨ unchen. T echnical Report FKI-126 , 90, 1990. J ¨ urgen Schmidhuber . Reinforcement learning in Marko vian and non-Marko vian en vironments. In Advances in neural information pr ocessing systems , pp. 500–506, 1991. David Silv er , Aja Huang, Chris J Maddison, Arthur Guez, Laurent Sifre, George V an Den Driessche, Julian Schrittwieser , Ioannis Antonoglou, V eda Panneershelv am, Marc Lanctot, et al. Mastering the game of go with deep neural networks and tree search. nature , 529(7587):484, 2016. Peter Smittenaar , Thomas HB FitzGerald, V incenzo Romei, Nicholas D Wright, and Raymond J Dolan. Disruption of dorsolateral prefrontal cortex decreases model-based in fa vor of model-free control in humans. Neur on , 80(4):914–919, 2013. Kimberly L Stachenfeld, Matthew M Botvinick, and Samuel J Gershman. The hippocampus as a predictiv e map. Natur e neur oscience , 20(11):1643, 2017. Richard S Sutton and Andre w G Barto. Reinforcement learning: An intr oduction , volume 1. MIT press Cambridge, 1998. Manuel W atter , Jost Springenberg, Joschka Boedecker , and Martin Riedmiller . Embed to control: A locally linear latent dynamics model for control from raw images. In Advances in neural information pr ocessing systems , pp. 2746–2754, 2015. 12 Published as a conference paper at ICLR 2020 A I M P L E M E N T A T I O N D E TA I L S In this section we describe the details of implementing our algorithm as well as the alternati ve ones. Summaries of hyperparameters can be found in T able 1 and 2. T able 1: Shared hyperparameters for all the algorithms and tasks in the paper , adopted from the original SA C implementation (Haarnoja et al., 2018b). Hyperparameter Description V alue γ Discount factor 0.99 step start RL From how many steps to start training the RL controllers 1,000 train interv al RL Interval of training the RL controllers 1 lr actor Learning rate for the actor 0.0003 lr critic Learning rate for the critic 0.0003 lr α Learning rate for the entropy coef ficient α 0.0003 H tar T arget entropy − DOF optimizer Optimizers for all the networks Adam (Kingma & Ba, 2014) τ Fraction of updating the target netw ork each gradient step 0.005 policy layers MLP layer sizes for µ η and π η 256, 256 value layers MLP layer sizes for V φ and Q λ 256, 256 T able 2: Hyperparameters for the proposed algorithm. Hyperparameter Description V alue train times FIVRM Epoches of training the first-impression model. 5,000 train interv al KL VRM Interval of training the keep-learning model. 5 lr model Learning rate for the VRMs 0.0008 seq len How man y steps in a sampled sequence for each update 64 batch size How man y sequences to sample for each update 4 A . 1 T H E P RO P O S E D A L G O R I T H M A . 1 . 1 N E T W O R K A R C H I T E C T U R E S The first-impression model and the keep-learning model adopted the same architecture. Size of d and z is 256 and 64, respecti vely . W e used one-hidden-layer fully-connected networks with 128 hidden neurons for the inference models h µ φ,t , σ 2 φ,t i = φ ( x t , d t − 1 , a t − 1 ) , as well as for h µ θ,t , σ 2 θ,t i = θ prior ( d t − 1 , a t − 1 ) in the generati ve models. For the decoder µ x,t , σ 2 x,t = θ decoder ( z t , d t − 1 ) in the generativ e models, we used 2-layers MLPs with 128 neurons in each layer . The input processing layer f x is also an one-layer MLP with size-128. For all the Gaussian variables, output functions for mean are linear and output functions for v ariance are softplus. Other activ ation functions of the VRMs are tanh. The RL controllers are the same as those in SA C-MLP (Section A.2.1) except that network inputs are raw observ ations together with the RNN states from the first-impression model and the keep-learning model. A . 1 . 2 I N I T I A L S T A T E S O F T H E V R M S T o train the VRMs, one can use a number of entire episodes as a mini-batch, using zero initial states, as in Heess et al. (2015). Howe ver , when tackling with long episodes (e.g. there can be 1,000 steps in each episode in the robotic control tasks we used) or e ven infinite-horizon problems, the computation consumption will be huge in back-propagation through time (BPTT). For better computation ef ficiency , we used 4 length-64 sequences for training the RNNs, and applied the b urn-in method for providing the initial states (Kapturo wski et al., 2018), or more specifically , unrolling the RNNs using a portion of the replay sequence (b urn-in period, up to 64 steps in our case) from zero 13 Published as a conference paper at ICLR 2020 initial states. W e assume that proper initial states can be obtained in this way . This is crucial for the tasks that require long-term memorization, and is helpful to reduce bias introduces by incorrect initial states in general cases. A . 2 A LT E R N A T I V E A L G O R I T H M S A . 2 . 1 S AC - M L P W e followed the original implementation of SA C in (Haarnoja et al., 2018a) including hyperparame- ters. Howe ver , we also applied automatic learning of the entropy coef ficient α (in verse of the the rew ard scale in Haarnoja et al. (2018a)) as introduced by the authors in Haarnoja et al. (2018b) to av oid tuning the rew ard scale for each task. A . 2 . 2 S AC - L S T M T o apply recurrency to SA C’ s function approximators, we added an LSTM netw ork with size-256 receiving raw observ ations as input. The function approximators of actor and critic were the same as those in SA C except receiving the LSTM’ s output as input. The gradients can pass through the LSTM so that the training of the LSTM and MLPs were synchronized. The training the network also followed Section A.1.2. A . 2 . 3 S L AC W e mostly followed the implementation of SLA C explained in the authors’ paper (Lee et al., 2019). One modification is that since their work was using pixels as observations, conv olutional neural networks (CNN) and transposed CNNs were chosen for input feature extracting and output decoding layers; in our case, we replaced the CNN and transposed CNNs by 2-layers MLPs with 256 units in each layer . In addition, the authors set the output variance σ 2 y ,t for each image pixel as 0.1. Howe ver , σ 2 y ,t = 0 . 1 can be too large for joint states/velocities as observ ations. W e found that it will lead to better performance by setting σ y ,t as trainable parameters (as that in our algorithm). W e also used a 2-layer MLP with 256 units for approximating σ y ( x t , d t − 1 ) . T o av oid network weights being div ergent, all the acti vation functions of the model were tanh e xcept those for outputs. B E N V I RO N M E N T S For the robotic control tasks and the Pendulum task, we used environments (and modified them for PO versions) from OpenAI Gym (Brockman et al., 2016). The CartPole en vironment with a continuous action space was from Danforth (2018), and the codes for the sequential target reaching tasks were provided by the authors (Han et al., 2019). In the no-velocities cases, velocity information was removed from raw observations; while in the velocities-only cases, only velocity information was retained in raw observ ations. W e summarize key information of each en vironment in T able 3. The performance curves were obtained in e valuation phases in which agents used same polic y but did not update networks or record state-transition data. Each experiment was repeated using 5 different random seeds. C A B L A T I O N S T U DY This section demonstrated a ablation study in which we compared the performance of the proposed algorithm to the same but with some modification: • With a single VRM . In this case, we used only one VRM and applied both pre-training and smooth update to it. • Only first-impression model . In this case, only the first-impression model was used and pre-trained. 14 Published as a conference paper at ICLR 2020 T able 3: Information of environments we used. Name dim( X ) DOF Maximum steps Pendulum 3 1 200 Pendulum (velocities only) 1 1 200 Pendulum (no velocities) 2 1 200 CartPole 4 1 1,000 CartPole (velocities only) 2 1 1,000 CartPole (no velocities) 2 1 1,000 RoboschoolHopper 15 3 1,000 RoboschoolHopper (velocities only) 6 3 1,000 RoboschoolHopper (no velocities) 9 3 1,000 RoboschoolW alker2d 22 6 1,000 RoboschoolW alker2d (velocities only) 9 6 1,000 RoboschoolW alker2d (no velocities) 13 6 1,000 RoboschoolAnt 28 8 1,000 RoboschoolAnt (velocities only) 11 8 1,000 RoboschoolAnt (no velocities) 17 8 1,000 Sequential goal reaching task 12 2 128 • Only keep-lear ning model . In this case, only the keep-learning model was used and smooth-update was applied. • Deterministic model . In this case, the first-imporession model and the keep-learning model were deterministic RNNs which learned to model the state-transitions by minimizing mean-square error between prediction and observations instead of E LB O . The network architecture was mostly the same as the VRM expect that the inference model and the generativ e model were merged into a deterministic one. The learning curves are shown in Fig. 7. It can be seen that the proposed algorithm consistently performed similar as or better than the modified ones. D V I S U A L I Z A T I O N O F T R A I N E D A G E N T S Here we show actual movements of the trained robots in the PO robotic control tasks (Fig. 8). It can be seen that the robots succeeded in learning to hop or walk, although their policy may be sub-optimal. E M O D E L A C C U R AC Y As we discussed in Section 2, our algorithm relies mostly on encoding capacity of models, but does not require models to make accurate prediction of future observations. Fig. 9 sho ws open-loop (using the inference model to compute the latent variable z ) and close-loop (purely using the generativ e model) prediction of raw observation by the keep-learning models of randomly selected trained agents. Here we showcase “RoboschoolHopper - v elocities only” and “Pendulum - no velocities” because in these tasks our algorithm achieved similar performance to those in fully-observable v ersions (Fig. 4), although the prediction accuracy of the models was imperfect. F S E N S I T I V I T Y T O H Y P E R PA R A M E T E R S O F T H E V R M S T o empirically show how choice of hyperparameters of the VRMs af fect RL performance, we conducted experiments using hyperparameters different from those used in the main study . More specifically , the learning rate for both VRMs was randomly selected from { 0.0004, 0.0006, 0.0008, 0.001 } and the sequence length was randomly selected from { 16, 32, 64 } (the batch size was 256 / ( seq uence leng th ) to ensure that the total number of samples in a batch was 256 which matched with the alternativ e approaches). The other hyperparameters were unchanged. 15 Published as a conference paper at ICLR 2020 The results can be checked in Fig 10 for all the en vironments we used. The ov erall performance did not significantly change using different, random hyperparameters of the VRMs, although we could observe significant performance impro vement (e.g. RoboshoolW alker2d) or degradation (e.g. RoboshoolHopper - velocities only) in a fe w tasks using different haperparameters. Therefore, the representation learning part (VRMs) of our algorithm does not suffer from high sensitivity to hyperparameters. This can be explained by the fact that we do not use a bootstrapping (e.g. the estimation of targets of v alue functions depends on the estimation of v alue functions) (Sutton & Barto, 1998) update rule to train the VRMs. G S C A L A B I L I T Y T able 4 showed scalability of our algorithm and the alternati ve ones. Algorithm wall-clock time (100,000 steps) # parameters Ours 8 hr 2.8M SA C-MLP 1 hr 0.4M SA C-LSTM 12 hr 1.1M SLA C 5 hr 2.8M T able 4: W all-clock time and number of parameters of our algorithm and the alternativ e ones. The working en vironment was a desktop computer using Intel i7-6850K CPU and the task is “V elocities- only RoboschoolHopper”. The wall-clock time include training the first-impression VRM or pre- trainings. 16 Published as a conference paper at ICLR 2020 Figure 7: Learning curves of our algorithms and the modified ones. Figure 8: Robots learned to hop or walk in PO environments using our algorithm. Each panel shows trajectory of a trained agent (randomly selected) within one episode. 17 Published as a conference paper at ICLR 2020 RoboschoolHopper - velocities only (open loop) RoboschoolHopper - velocities only (close loop) Pendulum - no velocities (open loop) Pendulum - no velocities (close loop) Figure 9: Examples of observation predictions by k eep-learning VRMs of trained agents. 18 Published as a conference paper at ICLR 2020 Pendulum 0 20 40 60 80 100 thousand steps -1200 -1000 -800 -600 -400 -200 average return hyperparameters we used random hyperparameters Pendulum - velocities only 0 20 40 60 80 100 thousand steps -1400 -1200 -1000 -800 -600 -400 -200 average return Pendulum - no velocities 0 50 100 thousand steps -1200 -1000 -800 -600 -400 -200 average return CartPole 0 100 200 300 thousand steps 0 200 400 600 800 1000 average return CartPole - velocities only 0 100 200 300 thousand steps 0 200 400 600 800 1000 average return CartPole - no velocities 0 100 200 300 thousand steps 0 200 400 600 800 1000 average return RoboschoolHopper 0 500 1000 thousand steps 0 500 1000 1500 2000 2500 average return RoboschoolHopper - velocities only 0 200 400 600 800 1000 thousand steps 0 500 1000 1500 2000 2500 average return RoboschoolHopper - no velocities 0 200 400 600 800 1000 1200 thousand steps 0 500 1000 1500 2000 2500 average return RoboschoolWalker2d 0 200 400 600 800 1000 1200 thousand steps 0 500 1000 1500 average return RoboschoolWalker2d - velocities only 0 500 1000 thousand steps 0 500 1000 1500 average return RoboschoolWalker2d - no velocities 0 200 400 600 800 1000 1200 thousand steps 0 500 1000 1500 average return RoboschoolAnt 0 200 400 600 800 1000 1200 thousand steps 0 500 1000 1500 2000 average return RoboschoolAnt - velocities only 0 500 1000 thousand steps 0 500 1000 1500 2000 average return RoboschoolAnt - no velocities 0 500 1000 thousand steps 0 500 1000 1500 2000 average return Sequential target reaching task 0 50 100 150 200 250 thousand steps 0 20 40 60 80 100 success rate Figure 10: The learning curves of our algorithm using the hyperparameters for the VRMs used in the paper (T able 2), and using a range of random hyperparameters (Appendix F). Data are Mean ± S.E.M., obtained from 20 repeats using different random seeds. 19
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment