대규모 언어 모델을 위한 재가중 근접 프루닝
본 논문은 BERT와 같은 대규모 사전학습 언어 모델을 고정된 희소 패턴으로 압축하는 새로운 프루닝 기법인 Reweighted Proximal Pruning(RPP)을 제안한다. L1 정규화 대신 재가중 L1 최소화와 근접 연산자를 결합해 프루닝 과정에서 그래디언트와 가중치 업데이트를 분리함으로써, 사전학습 손실에 대한 최적화는 유지하면서 효율적인 가중치 영(0)화를 달성한다. 실험 결과, SQuAD와 GLUE 벤치마크에서 59.3% 이상의 가…
저자: Fu-Ming Guo, Sijia Liu, Finlay S. Mungall
본 논문은 대규모 사전학습 언어 모델, 특히 BERT와 같은 트랜스포머 기반 모델을 효율적으로 압축하기 위한 새로운 프루닝 기법인 Reweighted Proximal Pruning(RPP)을 제안한다. 연구 동기는 최근 NLP 분야에서 사전학습 모델의 파라미터 수가 급증함에 따라, 실제 서비스 환경(서버, 모바일, 엣지 디바이스)에서의 배포가 어려워졌다는 점이다. 기존의 비구조적 프루닝(Iterative Pruning, One‑Shot Pruning)이나 구조적 프루닝은 사전학습 손실과 다운스트림 파인튜닝 성능을 동시에 보장하지 못했으며, 특히 L1 혹은 L2 정규화 기반 방법은 가중치 영(0)화를 위한 스파스 패턴 탐색이 부정확해 수렴 실패나 큰 정확도 저하를 초래했다.
RPP는 두 핵심 아이디어를 결합한다. 첫 번째는 재가중 L1 최소화(reweighted ℓ₁)이다. 전통적인 L1 정규화는 가중치 절대값에 비례해 페널티를 부여하지만, 이는 “작은 가중치가 더 크게 벌점받는다”는 프루닝의 직관과 상충한다. 재가중 L1은 매 반복마다 가중치 αᵢ를 1/(|wᵢ|+ε) 로 업데이트함으로써, 절대값이 작은 파라미터에 더 큰 가중치를 부여한다. 초기 단계에서는 αᵢ=1으로 L1과 동일하게 시작하고, 이후 반복을 거치며 스파스 패턴이 점진적으로 정교해진다.
두 번째는 근접 연산자(proximal operator)를 이용한 최적화이다. 전체 손실 f₀(w)+γ∑αᵢ|wᵢ|를 직접 미분해 최적화하는 대신, 먼저 일반적인 손실 f₀(w)에 대해 AdamW와 같은 옵티마이저로 그래디언트 스텝을 수행하고, 그 뒤에 근접 스텝 prox_{λ, rw‑ℓ₁}(·)을 적용한다. 근접 스텝은 폐쇄형 해 wᵢ←sign(aᵢ)·max(|aᵢ|−λγ αᵢ, 0) 을 제공해, 가중치를 정확히 0으로 만들거나 감소시킨다. 이 과정은 그래디언트와 스파스 패턴 탐색을 명확히 분리하므로, 초거대 트랜스포머에서도 안정적인 수렴을 보장한다.
논문은 프루닝 목표를 수식적으로 정의한다. 사전학습 단계에서 전체 파라미터 w에 대해 (2)식의 손실에 재가중 L1 정규화를 추가하고, 최적화된 파라미터 ŵ와 그에 대응하는 희소 패턴 Ŝ_w를 얻는다. 이후 각 다운스트림 태스크 T_i에 대해 동일한 희소 패턴을 고정하고, 파인튜닝 파라미터 z_i를 학습한다(식 4). 이렇게 하면 하나의 전역적인 스파스 모델이 다수의 태스크에 재사용 가능해, 모델 저장·전송 비용을 크게 절감한다.
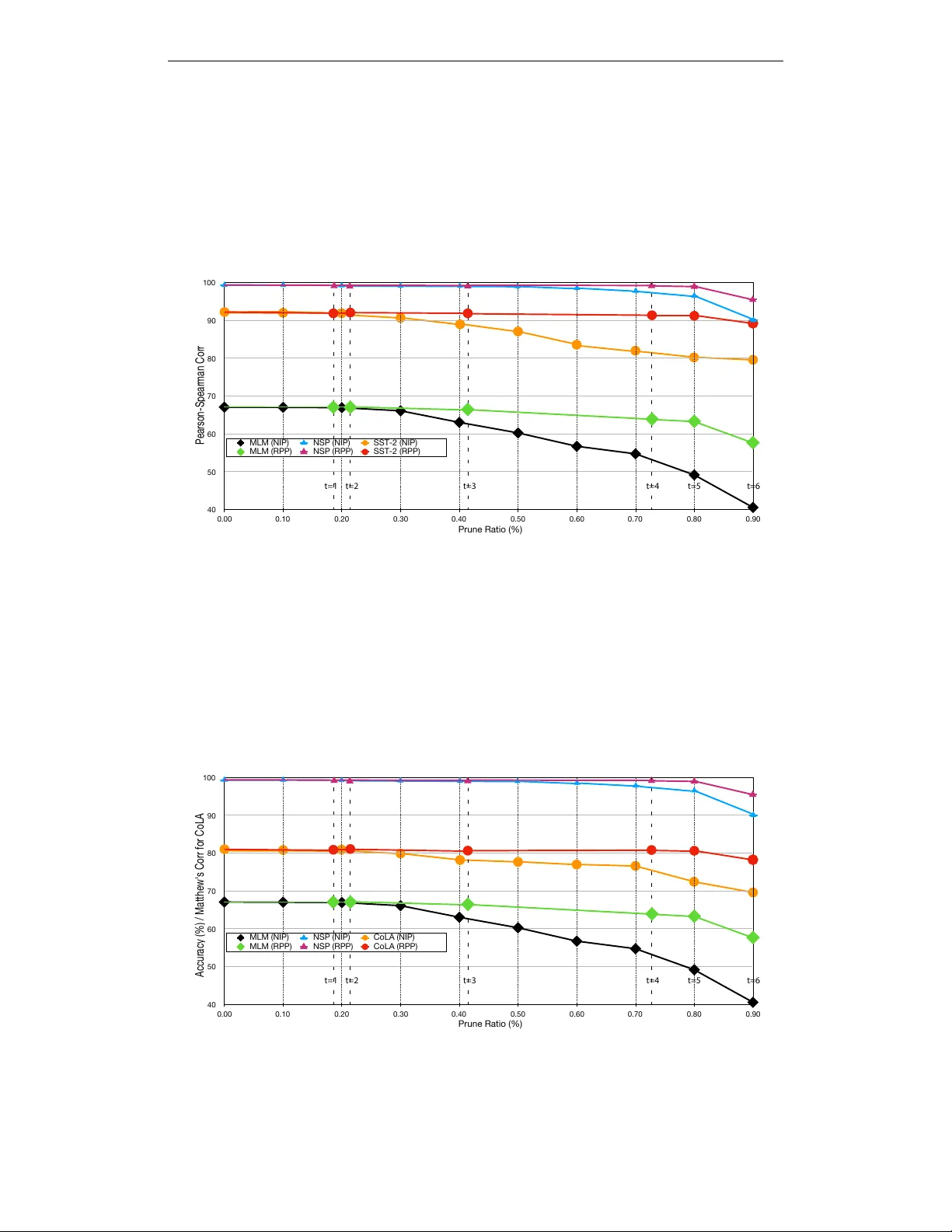
실험에서는 BERT‑Base(12층, 110M 파라미터)를 대상으로 RPP를 적용했다. 59.3% 가중치 희소성(≈45 M 파라미터)까지 프루닝했음에도, 사전학습 손실은 거의 변하지 않았으며, SQuAD v1.1 F1 점수는 88.5→88.2, GLUE 전체 평균 점수는 82.1→81.9로 미미한 감소만 보였다. 특히 MNLI, MRPC, QQP 등 대부분의 GLUE 서브태스크는 80% 이상의 프루닝 비율에서도 원본 성능에 근접했으며, SQuAD만이 상대적으로 더 높은 프루닝 비율에 민감함을 확인했다. 이는 어텐션 헤드와 피드포워드 레이어가 서로 보완적인 역할을 하며, 일부 가중치를 제거해도 전체 표현 능력이 유지된다는 점을 시사한다.
비교 실험에서는 기존 Iterative Pruning과 One‑Shot Pruning이 높은 프루닝 비율에서 수렴에 실패하거나 정확도가 급격히 떨어지는 반면, RPP는 재가중 L1과 근접 연산 덕분에 안정적으로 높은 스파스 비율을 달성한다. 또한, AdamW를 사용함으로써 기존 Adam 기반 가중치 감소(weight decay)와의 충돌을 피하고, 일반화 성능을 유지한다.
결론적으로, RPP는 (1) 사전학습 단계에서 전역적인 희소 패턴을 효율적으로 탐색, (2) 동일한 희소 패턴을 다수의 다운스트림 태스크에 그대로 적용, (3) 모델 압축률과 성능 유지 사이의 트레이드오프를 크게 개선한다는 세 가지 주요 기여를 한다. 이는 대규모 언어 모델을 모바일·엣지 디바이스에 실제로 배포할 수 있는 실용적인 길을 열어준다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기