Reweighted Proximal Pruning for Large-Scale Language Representation
Recently, pre-trained language representation flourishes as the mainstay of the natural language understanding community, e.g., BERT. These pre-trained language representations can create state-of-the-art results on a wide range of downstream tasks. …
Authors: Fu-Ming Guo, Sijia Liu, Finlay S. Mungall
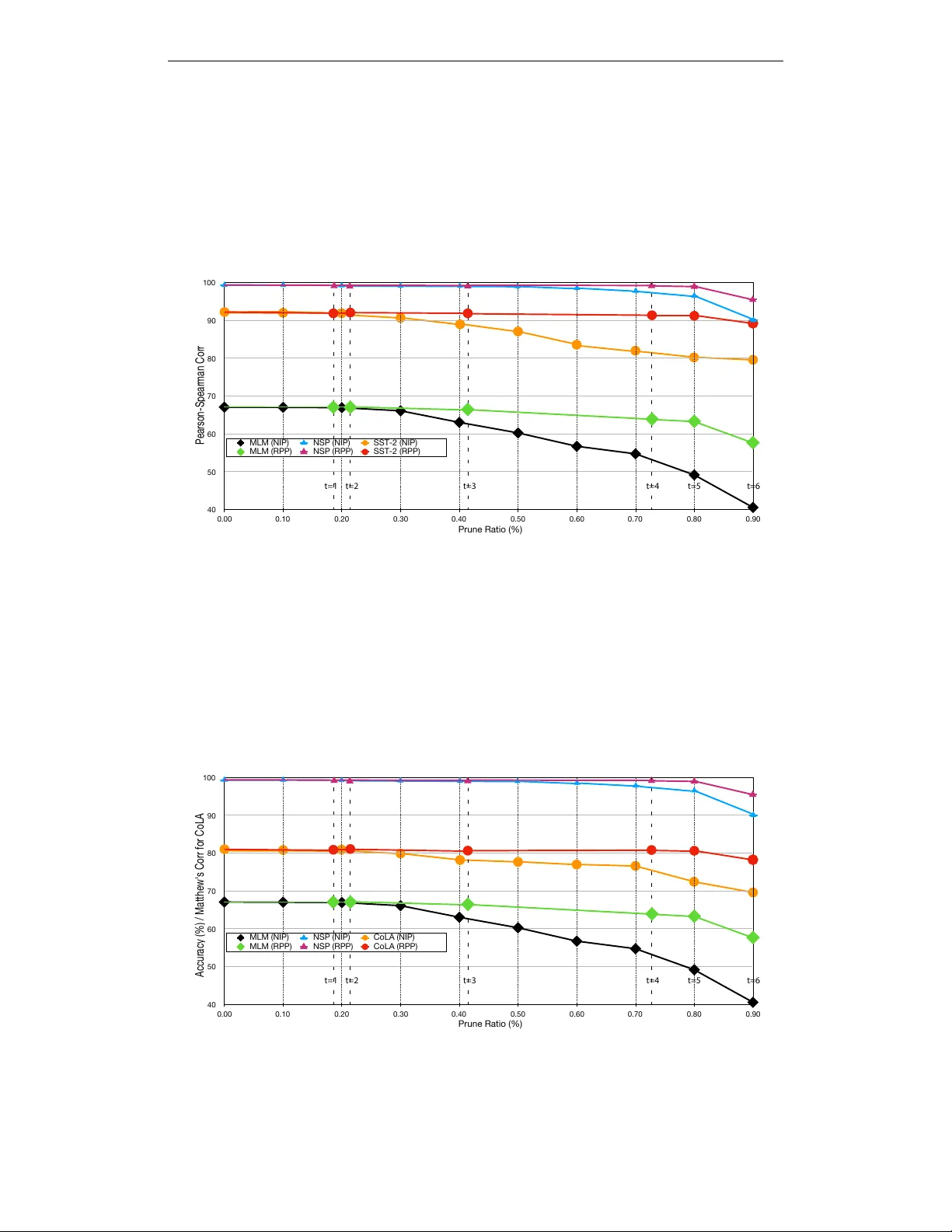
R E W E I G H T E D P R O X I M A L P R U N I N G F O R L A R G E - S C A L E L A N G U A G E R E P R E S E N T A T I O N Fu-Ming Guo 1 , Sijia Liu 2 , Finlay S. Mungall 3 , Xue Lin 1 & Y anzhi W ang 1 1 Northeastern Univ ersity 2 MIT -IBM W atson AI Lab, IBM Research 3 United States Federal A viation Administration guo.fu@husky .neu.edu, sijia.liu@ibm.com, fmungall@gmail.com { xue.lin,yanz.wang } @northeastern.edu A B S T R AC T Recently , pre-trained language representation flourishes as the mainstay of the nat- ural language understanding community , e.g., BER T . These pre-trained language representations can create state-of-the-art results on a wide range of do wnstream tasks. Along with continuous significant performance improvement, the size and complexity of these pre-trained neural models continue to increase rapidly . Is it possible to compress these large-scale language representation models? How will the pruned language representation affect the do wnstream multi-task trans- fer learning objecti ves? In this paper , we propose Reweighted Proximal Pruning (RPP), a new pruning method specifically designed for a large-scale language rep- resentation model. Through e xperiments on SQuAD and the GLUE benchmark suite, we show that proximal pruned BER T keeps high accuracy for both the pre- training task and the downstream multiple fine-tuning tasks at high prune ratio. RPP pro vides a ne w perspecti ve to help us analyze what lar ge-scale language rep- resentation might learn. Additionally , RPP makes it possible to deploy a large state-of-the-art language representation model such as BER T on a series of dis- tinct devices (e.g., online serv ers, mobile phones, and edge devices). 1 I N T RO D U C T I O N Pre-trained language representations such as GPT (Radford et al., 2018), BER T (De vlin et al., 2019) and XLNet (Y ang et al., 2019), have shown substantial performance improvements using self-supervised training on lar ge-scale corpora (Dai & Le, 2015; Peters et al., 2018; Radford et al., 2018; Liu et al., 2019a). More interestingly , the pre-trained BER T model can be fine-tuned with just one additional output layer to create state-of-the-art models for a wide range of tasks, such as question answering (Rajpurkar et al., 2016; 2018), and language inference (Bo wman et al., 2015; W illiams et al., 2017), without substantial task-specific architecture modifications. BER T is concep- tually simple and empirically powerful (De vlin et al., 2019). Howe ver , along with the significant performance enhancement, the parameter volume and com- plexity of these pre-trained language representations significantly increase. As a result, it becomes difficult to deploy these large-scale language representations into real-life computation constrained devices including mobile phones and edge de vices. Throughout this paper , we attempt to answer the following questions. Question 1 : Is it possible to compress lar ge-scale language representations such as BER T via weight pruning? Question 2 : Ho w would the weight-pruned, pre-trained model affect the performance of the down- stream multi-task transfer learning objectiv es? The problem of weight pruning has been studied under many types of deep neural networks (DNNs) (Goodfellow et al., 2016), such as Ale xNet (Krizhe vsky et al., 2012), V GG (Simonyan & Zisserman, 1 2014), ResNet (He et al., 2016), and MobileNet (Ho ward et al., 2017). It is shown that weight prun- ing can result in a notable reduction in the model size. A suite of weight pruning techniques have been dev eloped, such as non-structured weight pruning (Han et al., 2015), structured weight pruning (W en et al., 2016), filter pruning (Li et al., 2016), channel pruning (He et al., 2017), ADMM-NN (Ren et al., 2019) and PCONV (Ma et al., 2019) to name a fe w . Different from pruning CNN- type models, BER T not only considers the metrics on the pre-training task, but also needs to make allow ance for the downstream multi-task transfer learning objecti ves. Thus, the desired weight prun- ing needs to preserve the capacity of transfer learning from a sparse pre-trained model to downstream fine-tuning tasks. In this work, we in vestigate irregular weight pruning techniques on the BER T model, including the iterativ e pruning method (Han et al., 2015) and one-shot pruning method (Liu et al., 2019b). How- ev er , these methods fail to conv erge to a sparse pre-trained model without incurring significant ac- curacy drop, or in many cases do not con verge at all (see supporting results in Appendix). Note that the aforementioned weight pruning techniques are built on dif ferent sparsity-promoting regulariza- tion schemes (Han et al., 2015; W en et al., 2016), e.g., lasso regression ( ` 1 regularization) and ridge regression ( ` 2 regularization). W e find that the failure of previous methods on weight pruning of BER T is possibly due to the inaccurate sparse pattern learnt from the simple ` 1 or ` 2 based sparsity- promoting regularizer . In fact, the difficulty of applying regularization to generate weight sparsity coincides with the observation in (Loshchilov & Hutter, 2018) on the imcompatibility of con ven- tional weight decay ( ` 2 regularization) for training super -deep DNNs as BER T . It is pointed out that the main reason is that the direct optimization of a regularization penalty term causes diver gence from the original loss function and has ne gative ef fect on the ef fectiv eness of gradient-based update. T o mitigate this limitation, (Loshchilov & Hutter, 2018) ha ve modified the regularization in Adam by decoupling weight decay r e gularization fr om the gradient-based update , and have achieved state- of-the-art results on large-scale language pre-training and do wnstream multi-task transfer learning objectiv es (Devlin et al., 2019). M ask LM NSP M ask LM P r e -tr aining Reweighted P r o ximal P runing F ine - T uning Unlabeled S en t enc e A and B P air Unlabeled S en t enc e A and B P air MRPC MNLI C oLA M ask LM NSP M ask LM SQ uAD M asked S en t enc e A M asked S en t enc e B [ CLS] [SEP] ... T ok1 T okN T ok1 ... T okN [ CLS] [SEP] ... T ok1 T okN T ok1 ... T okN [ CLS] [SEP] ... T ok1 T okN T ok1 ... T okN S tar t/End Span M asked S en t enc e A M asked S en t enc e B Iden tical Univ ersal Sparsit y Q uestion A nsw er P air Q uestion P ar a gr aph T 1 T N ... T [SEP] T 1 ` T M ` ... E 1 E N ... E [SEP] E 1 ` E M ` ... E [ CLS] E 1 E N ... E [SEP] E 1 ` E M ` ... E [ CLS] E 1 E N ... E [SEP] E 1 ` E M ` ... E [ CLS] T 1 T N ... T [SEP] T 1 ` T M ` ... T 1 T N ... T [SEP] T 1 ` T M ` ... Figure 1: Overvie w of pruning BER T using Re weighted Proximal Pruning algorithm and then fine-tuning on a wide range of do wnstream transfer learning tasks. Through RPP , we find the identical universal sparsity S ˆ w . The BER T model pruned with RPP could be fine-tuned over the do wnstream transfer learning tasks. In this w ork, we aim at more accurate universal sparse pattern search (see Figure 1 for an overvie w of our approach) moti vated by our experiments and the conclusion from Loshchilov & Hutter (2018). W e propose Reweighted Proximal Pruning (RPP), which integrates reweighted ` 1 minimization (Candes et al., 2008) with proximal algorithm (Parikh et al., 2014). RPP consists of two parts : the reweighted ` 1 minimization and the proximal operator . Reweighted ` 1 minimization serv es as a bet- ter method of generating sparsity in DNN models matching the nature of weight pruning, compared with ` 1 regularization. Thanks to the closed-form solution of proximal operation on a weighted ` 1 norm, in RPP the sparsity pattern search can be decoupled from computing the gradient of the training loss. In this way the aforementioned pitfall in prior weight pruning technique on BER T can be av oided. W e show that RPP achieves ef fective weight pruning on BER T for the first time to the best of our kno wledge. Experimental results demonstrate that the proximal pruned BER T model keeps high accuracy on a wide range of downstream tasks, including SQuAD (Rajpurkar et al., 2016; 2018) and GLUE (W ang et al., 2018). W e summarize our contributions as follows. 2 • W e develop the pruning algorithm Reweighted Proximal Pruning (RPP), which achei ves the first ef fective weight pruning result on lar ge pre-trained language representation model - BER T . RPP achiev es 59 . 3% weight sparsity without inducing the performance loss on both pre-training and fine-tuning tasks. • W e spotlight the relationship between the pruning ratio of the pre-trained DNN model and the performance on the do wnstream multi-task transfer learning objectiv es. W e sho w that many downstream tasks except for SQuAD allows at least 80% pruning ratio compared with 59 . 3% under the more challenging task SQuAD. • W e observe that as the pruning ratio of the pre-trained language model increases, the perfor - mance on the downstream transfer learning tasks decreases. The descending range v aries in different do wnstream transfer learning tasks. Ho wever , the proposed RPP approach is able to achiev e a consistently high pruning ratio compared to iterativ e pruning based methods. • W e sho w that dif ferent from weight pruning in image classification tasks, RPP helps to find the structured sparsity pattern in transformer blocks used in BER T . Moreov er , we peer into the effect of netw ork pruning on the language representation embedded in BER T . 2 R E L A T E D W O R K BER T and prior work on model compr ession BER T (De vlin et al., 2019) is a self-supervised approach for pre-training a deep transformer encoder (V asw ani et al., 2017), before fine-tuning it for particular downstream tasks. Pre-training of BER T optimizes two training objectives − masked language modeling (MLM) and next sentence prediction (NSP) − which require a large collection of unlabeled te xt. W e use BooksCorpus (800M w ords) (Zhu et al., 2015) and the English instance of W ikipedia (2,500M words) as the pre-training corpus, the same as De vlin et al. (2019). For detailed information about the BER T model, readers can refer to the original paper (Devlin et al., 2019). Michel et al. (2019) mask some heads in multi-head attention modules in BER T , and then e valuate the performance on the machine translation task. Similarly , Hao et al. (2019) eliminates certain heads in the multi-head attention module. First, the limited previous work do not consider the pre- training metrics and the other downstream multi-mask transfer learning objecti ves. They only con- sidered the specific machine translation task (out of over 10 transfer tasks), which is only a specific fine-tuning and is limited for the uni versal pre-trained language representation (BER T). Second, the multi-head attention module uses a weight sharing mechanism (V aswani et al., 2017). So masking some heads does not reduce the weight volume. Finally , multi-head attention allows the model to jointly attend to information from dif ferent representation subspaces at different positions, while single attention head inhibits this effect (V asw ani et al., 2017). As a result, masking some heads in multi-head attention harms the weight sharing mechanism, without weight volume reduction. In summary , the limited previous work in this area are not effectiv e weight pruning method on BER T . Shen et al. (2019) reports the quantization result of BER T model, which is orthogonal to our work and can be combined for further compression/acceleration. Reweighted ` 1 and proximal algorithm Candes et al. (2008) present re weighted ` 1 algorithm and demonstrate the remarkable performance and broad applicability in the areas of statistical esti- mation, error correction and image processing. Proximal algorithms can be vie wed as an analogous tool for non-smooth, constrained, large-scale, or distributed v ersions of these problems (Parikh et al., 2014). T o the best of our kno wledge, ours is the first work that applies re weighted ` 1 minimization to network compression, particularly for BER T pruning. , 3 R E W E I G H T E D P R OX I M A L P R U N I N G F O R L A R G E - S C A L E L A N G U A G E R E P R E S E N TA T I O N D U R I N G P R E - T R A I N I N G Pruning for pre-trained language representations should not only consider the performance of pre- training objectiv es, but also make allowance for the downstream fine-tuning transfer learning tasks. Let f i denote the loss function of network for do wnstream task T i ∼ p ( T ) , where p ( T ) denotes the distribution of tasks. Let w denote the parameters of the pre-trained model (pre-training in BER T), and z i denote the i -th task-specified model parameters (fine-tuning in BER T). The downstream 3 tasks hav e separate fine-tuned models, ev en though they are initialized with the same pre-trained parameters (Devlin et al., 2019). Starting from the pre-trained parameters w , the parameters z i ( w ) are obtained through fine-tuning minimize w ∈ R d f i ( w ) (1) 3 . 1 P R U N I N G F O R M U L A T I O N I N T R A N S F E R L E A R N I N G Follo wing the conv entional weight pruning formulation, we first consider the problem of weight pruning during pre-training: minimize w ∈ R d f 0 ( w ) + γ k w k p (2) where f 0 is the loss function of pruning, p ∈ { 0 , 1 } denotes the type of regularization norm, and γ is a regularization term. W e note that the sparsity-promoting regularizer in the objective could also be replaced with a hard ` p constraint, | w k p ≤ τ for some τ . Let ˆ w denote the solution to problem (2), and the corresponding sparse pattern S ˆ w is giv en by S ˆ w = { i | ˆ w i = 0 , ∀ i ∈ [ d ] } (3) For a specific transfer task i , we allow an additional retraining/fine-tuning step to train/fine-tune weights starting from the pre-training results ˆ w and subject to the determined, fixed sparse pattern S ˆ w , denoted as z i ( ˆ w ; S ˆ w ) . That is, we solve the modified problem equation 1 minimize z i f i z i ( ˆ w ; S ˆ w ) (4) Here, different from (1), the task-specific fine tuning weights variable z i ( ˆ w ; S ˆ w ) is now defined ov er S ˆ w . Our goal is to seek a sparse (weight pruned) model during pre-training, with weight collection ˆ w and sparsity S ˆ w , which can perform as well as the original pre-trained model ov er multiple new tasks (index ed by i ). These fine-tuned models z i ( ˆ w ; S ˆ w ) (for different i ) share the identical universal sparsity S ˆ w . 3 . 2 R E W E I G H T E D P RO X I M A L P R U N I N G In order to enhance the performance of pruning pre-trained language representation over multi-task downstream transfer learning objectiv es, we propose Reweighted Proximal Pruning (RPP). RPP consists of two parts: the reweighted ` 1 minimization and the proximal operator . Reweighted ` 1 minimization serves as a better method of generating sparsity in DNN models matching the natural objectiv e of weight pruning, compared with ` 1 regularization. The proximal algorithm then sep- arates the computation of gradient with the proximal operation over a weighted ` 1 norm, without directly optimizing the entire sparsity-penalized loss, which requires gradient backpropagation of the in volved loss. This is necessary in the weight pruning of super-deep language representation models. 3 . 2 . 1 R E W E I G H T E D ` 1 M I N I M I Z AT I O N In the previous pruning methods (Han et al., 2015; W en et al., 2016), ` 1 regularization is used to generate sparsity . Howe ver , consider that two weights w i , w j ( w i < w j ) in the DNN model are penalized through ` 1 regularization. The lar ger weight w j is penalized more heavily than smaller weight w i in ` 1 regularization, which violates the original intention of weight pruning, “removing the unimportant connections” (parameters close to zero) (Han et al., 2015). T o address this imbal- ance, we introduce reweighted ` 1 minimization (Candes et al., 2008) to the DNN pruning domain. Our introduced reweighted ` 1 minimization operates in a systematic and iterative manner (detailed process shown in Algorithm 1), and the first iteration of reweighted ` 1 minimization is ` 1 regular - ization. This designed mechanism helps us to observe the performance difference between ` 1 and reweighted ` 1 minimization. Meanwhile, this mechanism ensures the adv ancement of reweighted ` 1 minimization ov er ` 1 regularization, as the latter is the single, first step of the former . 4 Consider the regularized weight pruning problem (re weighted ` 1 minimization): minimize w f 0 ( w ) + γ X i α i | w i | (5) where α i ( α i > 0) factor is a positi ve value. It is utilized for balancing the penalty , and is different from weight w i in DNN model. α i factors will be updated in the iterati ve reweighted ` 1 minimiza- tion procedure (Step 2 in Algorithm 1) in a systematic way (Candes et al., 2008). If we set T = 1 for reweighted ` 1 , then it reduces to ` 1 sparse training. Algorithm 1 RPP procedure for reweighted ` 1 minimization 1: Input: Initial pre-trained model w 0 , initial re weighted ` 1 minimization ratio γ , initial positi ve value α 0 = 1 2: for t = 1 , 2 , . . . , T do 3: w = w ( t − 1) , α = α ( t − 1) 4: Step 1 : Solve problem (5) to obtain a solution w t via iterativ e proximal algorithm (6) 5: Step 2 : Update re weighted factors α t i = 1 | w t i | ( t ) + (the inside w t i denotes the weight w i in iteration t , and the outside ( t ) denotes the exponent), is a small constant, e.g., = 0 . 001 6: end for 3 . 2 . 2 P RO X I M A L M E T H O D In the previous pruning methods (Han et al., 2015; W en et al., 2016), ` 1 regularization loss is di- rectly optimized through the back-propagation based gradient update of DNN models, and the hard- threshold is adopted to ex ecute the pruning action at the step of pruning (all weights belo w the hard-threshold become zero). In our approach, we derive an ef fective solution to problem (5) for giv en { α i } , namely , in Step 1 of Algorithm 2, in which back-propagation based gradient update is only applied on f 0 ( w ) but not γ P i α i | w i | . W e adopt the proximal algorithm (Parikh et al., 2014) to satisfy this requirement through decou- pling methodology . In this w ay , the sparsity pattern search can be decoupled from back-propagation based gradient update of the training loss. The proximal algorithm is shown in (Parikh et al., 2014) to be highly effecti ve (compared with the original solution) on a wide set of non-con vex optimiza- tion problems. Additionally , our presented reweighted ` 1 minimization (5) has analytical solution through the proximal operator . T o solve problem (5) for a giv en α , the proximal algorithm operates in an iterative manner: w k = pro x λ k ,rw − ` 1 ( w k − 1 − λ k ∇ w f 0 ( w k − 1 )) (6) where the subscript k denotes the time step of the training process inside each iteration of RPP , λ k ( λ k > 0) is the learning rate, and we set the initial w to be w ( t − 1) from the last iteration of reweighted ` 1 . The proximal operator prox λ k ,rw − ` 1 ( a ) is the solution to the problem minimize w γ X i α i | w i | + 1 2 λ k k w − a k 2 2 (7) where a = w k − 1 − λ k ∇ w f ( w k − 1 ) . The above problem has the follo wing analytical solution (Liu et al., 2014) w i,k = ( 1 − γ λ k α i | a i | a i | a i | > λ k γ α i 0 | a i | ≤ λ k γ α i . (8) W e remark that the updating rule (6) can be interpreted as the proximal step (8) ov er the gradient descent step w k − 1 − λ k ∇ w f ( w k − 1 ) . Such a descent can also be obtained through optimizers such as AdamW . W e use the AdamW (Loshchilov & Hutter, 2018) as our optimizer , the same with (Devlin et al., 2019). The concrete process of AdamW with proximal operator is sho wn in Algorithm 3 of Appendix C. Why chooses AdamW rather than Adam? Loshchilov & Hutter (2018) proposes AdamW to improv e the generalization ability of Adam (Kingma & Ba, 2014). Loshchilov & Hutter (2018) shows that the con ventional weight decay is inherently not ef fective in Adam and has negati ve ef fect on the 5 effecti veness of gradient-based update, which is the reason of the difficulty to apply adaptive gradi- ent algorithms to super -deep DNN training for NLU applications (like BER T). Loshchilov & Hutter (2018) mitigates this limitation and improves regularization of Adam, by decoupling weight de- cay regularization from the gradient-based update (Loshchilov & Hutter, 2018). AdamW is widely adopted in pre-training large language representations, e.g., BER T (Devlin et al., 2019), GPT (Rad- ford et al., 2018) and XLNet (Y ang et al., 2019). Our proposed RPP also benefits from the decou- pling design ideology . The dif ference is that RPP is for the generation of s parsity , instead of av oiding ov er-fitting, like decoupled weight decay in AdamW . Our new and working baseline: New Iterativ e Pruning (NIP). T o get the identical universal sparsity S w , we tried a series of pruning techniques, including the iterativ e pruning method (Han et al., 2015) and one-shot pruning method (Liu et al., 2019b). But these methods do not con ver ge to a viable solution. The possible reason for non-con vergence of the iterati ve pruning method is that di- rectly optimizing ` p ( p ∈ { 1 , 2 } ) sparsity-promoting re gularization makes the gradient computation in volv ed and thus harms the loss con vergence (W e provide the loss curve and analysis in Appendix D). T o circumvent the con ver gence issue of conv entional iterative pruning methods, we propose a new iterati ve pruning (NIP) method. Different from iterativ e pruning (Han et al., 2015), NIP reflects the naturally progressi ve pruning performance without any externally introduced penalty. W e hope that other pruning methods should not perform worse than NIP , otherwise, the effect of optimizing the newly introduced sparsity-promoting re gularization is ne gativ e. W e will sho w that NIP is able to successfully prune BER T to certain pruning ratios. W e refer readers to Appendix A for the full detail about NIP , our proposed baseline algorithm. 4 E X P E R I M E N T S In this section, we describe the experiments on pruning pre-trained BER T and demonstrate the per- formance on 10 downstream transfer learning tasks. 4 . 1 E X P E R I M E N T S E T U P W e use the official BER T model from Google as the startpoint. Follo wing the notation from Devlin et al. (2019), we denote the number of layers (i.e., transformer blocks) as L , the hidden size as H , and the number of self-attention heads as A . W e prune two kinds of BER T model: BER T BASE ( L = 12 , H = 768 , A = 12 , total parameters = 110M ) and BER T LARGE ( L = 24 , H = 1024 , A = 16 , total parameters = 340M ). As the parameters of these transformer blocks take up more than 97% weights of the entire BER T , the weights of these transformer blocks are our pruning target. Data: In pre-training, we use the same pre-training corpora as Devlin et al. (2019): BookCorpus ( 800M words) (Zhu et al., 2015) and English W ikipedia ( 2 , 500M words). Based on the same cor- pora, we use the same preprocessing script 1 to create the pre-training data. In fine-tuning, we report our results on the Stanford Question Answering Dataset (SQuAD) and the General Language Under- standing Ev aluation (GLUE) benchmark (W ang et al., 2018). W e use tw o versions of SQuAD: V1.1 and V2.0 (Rajpurkar et al., 2016; 2018). The GLUE is a collection of datasets/tasks for ev aluating natural language understanding systems 2 . Input/Output repr esentations: W e follo w the input/output representation setting from De vlin et al. (2019) for both pre-training and fine-tuning. W e use the W ordPiece (W u et al., 2016) embeddings with a 30 , 000 token vocab ulary . The first token of e very sentence is always a special classification token ([CLS]). The sentences are dif ferentiated with a special token ([SEP]). Evaluation: In pre-training, BER T considers two objectives: mask ed language modeling (MLM) and ne xt sentence prediction (NSP). F or MLM, a random sample of the tokens in the input sequence is selected and replaced with the special token ([ MASK ]) . The MLM objecti ve is a cross-entrop y 1 https://github .com/google-research/bert 2 The datasets/tasks are: CoLA (W arstadt et al., 2018), Stanford Sentiment T reebank (SST) (Socher et al., 2013), Microsoft Research Paragraph Corpus (MRPC) (Dolan & Brockett, 2005), Semantic T exual Similarity Benchmark (STS) (Agirre & Soroa, 2007), Quora Question Pairs (QQP), Multi-Genre NLI (MNLI) (W illiams et al., 2017), Question NLI (QNLI) (Rajpurkar et al., 2016), Recognizing T extual Entailment (R TE) and W ino- grad NLI(WNLI) (Lev esque et al., 2012). 6 loss on predicting the masked tokens. NSP is a binary classification loss for predicting whether two segments follow each other in the original text. In pre-training, we use MLM and NSP as training objectiv es to pre-train, retrain the BER T model, and as metrics to e valuate the BER T model . In fine- tuning, F1 scores are reported for SQuAD, QQP and MRPC. Matthew’ s Corr and Pearson-Spearman Corr are reported for CoLA and SST2 respecti vely . Accurac y scores are reported for the other tasks. All the experiments ex ecute on one Google Cloud TPU V3-512 cluster , three Google Cloud TPU V2-512 clusters and 110 Google Cloud TPU V3-8/V2-8 instances. Baseline: As there is no public effecti ve BER T pruning method, we use the proposed NIP pruning method on BER T as the baseline method. Th detail of NIP is sho wn in Appendix A. The progressiv e pruning ratio is ∇ p = 10% (prune 10% more weights in each iteration). Starting from the official BER T BASE , we use 9 iterations. In each iteration t of NIP , we get the sparse BER T BASE with specific sparsity , as ( w t ; S w t ) . Then we retrain the sparse BER T BASE w t ov er the sparsity S w t . In the retraining process, the initial learning rate is 2 · 10 − 5 , the batch size is 1024 and the retraining lasts for 10 , 000 steps (around 16 epochs). For the other hyperparameters, we follow the original BER T paper De vlin et al. (2019). In each iteration, the well retrained sparse BER T BASE is the starting point for the fine-tuning tasks and the next iteration. 4 . 2 R E W E I G H E D P RO X I M A L P RU N I N G ( R P P ) W e apply the proposed Reweighted Proximal Pruning (RPP) method on both BER T BASE and BER T LARGE , and demonstrate performance improvement. Detailed process of RPP is in Ap- pendix B. For BER T BASE , we use the hyperparameters e xactly the same with our e xperiments using NIP . The initial learning rate is λ = 2 · 10 − 5 and the batch size is 1024. W e iterate the RPP for six times ( T = 6 ), and each iteration lasts for 100 , 000 steps (around 16 epochs). The total number of epochs in RPP is smaller than NIP when achieving 90% sparsity ( 96 < 144 ). There is no retraining process in RPP . W e set γ ∈ { 10 − 2 , 10 − 3 , 10 − 4 , 10 − 5 } and = 10 − 9 in Algorithm 1. Recall that RPP reduces to ` 1 sparse training as t = 1 . In Figure 2, we present the accuracy versus the pruning ratio for pre-training objectiv es MLM and NSP , and fine-tuning task SQuAD 1.1. Here we compare RPP with NIP . Along with the RPP contin- uing to iterate, the performance of RPP becomes notably higher than NIP for both the pre-training task and the fine-tuning task. The gap further increases as the RPP iterates more times. In Figure 2, we find that the NSP accuracy is very rob ust to pruning. Even when 90% of the weights are pruned, the NSP accurac y keeps abo ve 95% in RPP algorithm and around 90% in NIP algorithm. For MLM accuracy and SQuAD F1 score, the performance drops quickly as the prune ratio increases. RPP slows down the decline trend to a great e xtent. On SQuAD 1.1 dataset/task, RPP keeps the F1 score of BER T BASE at 88.5 ( 0 degradation compared with original BER T) at 41 . 2% prune ratio, while the F1 score of BER T BASE applied with NIP drops to 84.6 ( 3 . 9 degradation) at 40% prune ratio. At 80% prune ratio, RPP keeps the F1 score of BER T BASE at 84.7 ( 3 . 8 degradation), while the F1 score of BER T BASE applied with NIP drops to 68.8 ( 19 . 7 degradation compared with the original 40 50 60 70 80 90 100 Prune Ratio (%) 0.00 0.10 0.20 0.30 0.40 0.50 0.60 0.70 0.80 0.90 MLM (NIP) NSP (NIP) SQuAD1.1 (NIP) MLM (RPP) NSP (RPP) SQuAD1.1 (RPP) t=1 t=2 t=3 t=4 t=6 Accuracy (%) / F1 score for SQuAD 1.1 t=5 Figure 2: Ev aluate the performance of pruned BER T BASE using NIP and RPP , respectively (MLM and NSP accuracy on pre-training data and F1 score of fine-tuning on SQuAD 1.1 are reported). 7 BER T). In addition to the fine-tuning task of SQuAD 1.1, the other transfer learning tasks show the same trend (RPP consistently outperforms NIP) and the detailed results are reported in Appendix C. For BER T LARGE , we use the hyperparameters e xactly the same with our experiments using NIP except for the batch size. The initial learning rate is 2 · 10 − 5 and the batch size is 512. W e iterate the RPP for four times ( T = 6 ), and each iteration lasts for 100 , 000 steps (around 8 epochs). There is no retraining process either . W e set γ ∈ { 10 − 2 10 − 3 10 − 4 10 − 5 } and = 10 − 9 in Algorithm 1. The experimental results about pruning BER T LARGE and then fine-tuning are shown in T able 1. T able 1: BER T LARGE pruning results on a set of transfer learning tasks. The degradation is contrasted with the original BER T (without pruning) for transfer learning. Method Prune Ratio( % ) SQuAD 1.1 QQP MNLI MRPC CoLA NIP 50.0 85.3 (-5.6) 85.1 (-6.1) 77.0 (-9.1) 83.5 (-5.5) 76.3 (-5.2) 80.0 75.1 (-15.8) 81.1 (-10.1) 73.81 (-12.29) 68.4 (-20.5) 69.13 (-12.37) RPP 59.3 90.23 (-0.67) 91.2 (-0.0) 86.1 (-0.0) 88.1 (-1.2) 82.8 (+1.3) 88.4 81.69 (-9.21) 89.2 (-2.0) 81.4 (-4.7) 81.9 (-7.1) 79.3 (-2.2) Method Prune Ratio( % ) SQuAD 2.0 QNLI MNLIM SST -2 R TE NIP 50.0 75.3 (-6.6) 90.2 (-1.1) 82.5 (-3.4) 91.3 (-1.9) 68.6 (-1.5) 80.0 70.1 (-11.8) 80.5 (-10.8) 78.4 (-7.5) 88.7 (-4.5) 62.8 (-7.3) RPP 59.3 81.3 (-0.6) 92.3 (+1.0) 85.7 (-0.2) 92.4 (-0.8) 70.1 (-0.0) 88.4 80.7 (-1.2) 88.0 (-3.3) 81.8 (-4.1) 90.5 (-2.7) 67.5 (-2.6) 4 . 3 V I S UA L I Z I N G A T T E N T I O N P AT T E R N I N B E RT W e visualize the sparse pattern of the kernel weights in sparse BER T model applied with RPP , and present se veral e xamples in Figure 3. Since we directly visualize the v alue of identical universal sparsity S w without an y auxiliary function lik e activ ation map, the attention pattern is uni versal and data independent. 0 100 200 300 400 500 600 700 0 100 200 300 400 500 600 700 Layer 2 Query matrix 0 10 20 30 40 50 60 70 80 90 0 100 200 300 400 500 600 700 0 100 200 300 400 500 600 700 Layer 3 Query matrix 0 10 20 30 40 50 60 0 100 200 300 400 500 600 700 0 100 200 300 400 500 600 700 Layer 11 Query matrix 0 10 20 30 40 50 60 0 100 200 300 400 500 600 700 0 100 200 300 400 500 600 700 Layer 2 Key matrix 0 10 20 30 40 50 60 70 0 100 200 300 400 500 600 700 0 100 200 300 400 500 600 700 Layer 3 Key matrix 0 10 20 30 40 50 60 0 100 200 300 400 500 600 700 0 100 200 300 400 500 600 700 Layer 11 Key matrix 0 10 20 30 40 50 Figure 3: V isualization of sparse pattern S in pruned BER T BASE model w . W e sample 6 matrices (3 query matrices at the top row and 3 key matrices at the bottom row) from layer 2, layer 3 and layer 11 in the sparest pruned BER T BASE . 8 BER T’ s model architecture is a multi-layer, bidirectional transformer encoder based on the original implementation (V aswani et al., 2017). Follo wing (V aswani et al., 2017), the transformer archi- tecture is based on “scaled dot-product attention. ” The input consists of queries, ke ys and values, denoted as matrices Q , K and V , respecti vely . The output of attention model is computed as Attention ( Q, K , V ) = softmax QK T √ d k V (9) where d k is the dimension. W e visualize the sparse matrices Q and K of layer 2, layer 3 and layer 11 respectiv ely in Figure 3. From Figure 3, we have the follo wing observations and analyses. Structured pattern: Figure 3 demonstrates the structured pattern of non-zero weights in a pruned transformer block. More specifically , we found that the pruned Q and K matrices within each transformer yield interesting group-wise structures (column-wise non-sparsity for query matrix and row-wise non-sparsity for key matrix). Interestingly , we obtained these structured sparse patterns from our proposed RPP , an irre gular pruning method (namely , no group-wise sparsity is penalized). This is different from the irregular pruning on image classifiers, and thus shows the specialty of pruning on language models. W e also believ e that the use of re weighted ` 1 approach matters to find these fine-grained sparse patterns. Note that the structured sparsity pattern is more friendly to hardware implementation and acceleration than the non-structured pattern. Semantic interpr etation: The structured pattern found by RPP (visualized in Figure 3) has the following semantic interpretation. What might the large-scale language representation learn? The answer becomes clear after the language representation is pruned by RPP . From the perspecti ve of attention mechanism, the query matrix Q (column-wise non-sparsity) mainly models the attention information inside each sequence, while the key matrix K (row-wise non-sparsity) mainly models the attention information between different sequences in the conte xt. 4 . 4 t - S N E V I S U A L I Z AT I O N t -Distributed Stochastic Neighbor Embedding ( t -SNE) is a technique for dimensionality reduction that is particularly well suited for the visualization of high-dimensional datasets (Maaten & Hinton, 2008). Pre-trained word embeddings are an integral part of modern NLP systems (Devlin et al., 2019) and one contribution of BER T is the pre-trained contextual embedding. Hence, we visualize word embedding in the original BER T model and the BER T model applied with RPP in Figure 4 using t -SNE. Since BER T is different from commonly-studied image classifier in network pruning, we would like to examine if pruning on BER T will lead to significant change on the lo w-dimensional manifold of the language representation. From Figure 4, we obtain the following observations and insights. Low-dimensional manifold: Figure 4 illustrates that, for both original BER T and BER T pruned with RPP , the low-dimensional manifolds of the language representations are similar, showing the similar projection. T aking the specific word “intelligent” in Figure 4 as an e xample, the distribution of specific words and corresponding nearest words at the low-dimensional manifold (calculated using cosine/Euclidean distance) remain the high degree of similarity . This implies that the BER T salien t r ibbon salien t r ibbon salien t line salien t line Figure 4: t -SNE visualization of word embeddings in the original BER T model and the pruned BER T model using RPP. From left to right: t -SNE of original BER T embedding, together with an enlarging region around word “intelligent”; t -SNE of embedding in pruned BER T , together with an enlarging region. These visualiza- tions are obtained by running t-SNE for 1000 steps with perplexity=100. 9 applied with RPP keeps most of the language representation information similar to that from the original BER T . Linguistic interpr etation of proper noun: There is one salient ribbon on the upper left of the macroscopical t-SNE visualization of word embeddings in either the original BER T or the pruned BER T through RPP . Each point in the ribbon represents a year number in annals. There is also one salient short line on the lower left of the macroscopical t-SNE visualization of word embeddings in either the original BER T or the BER T applied with RPP . Each point in most of the lines represents an age number . Other proper nouns also re veal similar characteristics. Our proposed RPP remains the embedding information of these proper nouns from the perspectiv e of linguistic interpretation. 5 C O N C L U S I O N S A N D F U T U R E W O R K This paper presents the pruning algorithm RPP , which achieves the first effecti ve weight pruning result on lar ge pre-trained language representation model - BER T . RPP achie ves 59 . 3% weight spar - sity without inducing the performance loss on both pre-training and fine-tuning tasks. W e spotlight the relationship between the pruning ratio of the pre-trained DNN model and the performance on the downstream multi-task transfer learning objectives. W e sho w that many downstream tasks except SQuAD allows at least 80% pruning ratio compared with 59 . 3% under task SQuAD. Our proposed Reweighted Proximal Pruning provides a new perspecti ve to analyze what does a large language representation (BER T) learn. 10 R E F E R E N C E S Eneko Agirre and Aitor Soroa. Semev al-2007 task 02: Evaluating word sense induction and dis- crimination systems. In Pr oceedings of the 4th International W orkshop on Semantic Evaluations , pp. 7–12. Association for Computational Linguistics, 2007. Samuel R Bowman, Gabor Angeli, Christopher Potts, and Christopher D Manning. A large anno- tated corpus for learning natural language inference. arXiv preprint , 2015. Emmanuel J Candes, Michael B W akin, and Stephen P Boyd. Enhancing sparsity by re weighted ` 1 minimization. Journal of F ourier analysis and applications , 14(5-6):877–905, 2008. Andrew M Dai and Quoc V Le. Semi-supervised sequence learning. In Advances in neural infor - mation pr ocessing systems , pp. 3079–3087, 2015. Jacob De vlin, Ming-W ei Chang, K enton Lee, and Kristina T outanov a. Bert: Pre-training of deep bidirectional transformers for language understanding. In Pr oceedings of the 2019 Confer ence of the North American Chapter of the Association for Computational Linguistics: Human Languag e T echnologies, V olume 1 (Long and Short P apers) , pp. 4171–4186, 2019. W illiam B Dolan and Chris Brockett. Automatically constructing a corpus of sentential paraphrases. In Pr oceedings of the Third International W orkshop on P araphrasing (IWP2005) , 2005. Ian Goodfellow , Y oshua Bengio, Aaron Courville, and Y oshua Bengio. Deep learning , volume 1. MIT Press, 2016. Song Han, Jeff Pool, John T ran, and W illiam Dally . Learning both weights and connections for efficient neural network. In Advances in neural information pr ocessing systems , pp. 1135–1143, 2015. Jie Hao, Xing W ang, Shuming Shi, Jinfeng Zhang, and Zhaopeng Tu. Multi-granularity self- attention for neural machine translation. arXiv preprint , 2019. Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recog- nition. In Proceedings of the IEEE conference on computer vision and pattern reco gnition , pp. 770–778, 2016. Y ihui He, Xiangyu Zhang, and Jian Sun. Channel pruning for accelerating very deep neural net- works. In Pr oceedings of the IEEE International Confer ence on Computer V ision , pp. 1389–1397, 2017. Andrew G Ho ward, Menglong Zhu, Bo Chen, Dmitry Kalenichenko, W eijun W ang, T obias W eyand, Marco Andreetto, and Hartwig Adam. Mobilenets: Ef ficient con volutional neural networks for mobile vision applications. arXiv preprint , 2017. Diederik P Kingma and Jimmy Ba. Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980 , 2014. Alex Krizhevsk y , Ilya Sutskev er, and Geoffrey E Hinton. Imagenet classification with deep con vo- lutional neural networks. In Advances in neural information pr ocessing systems , pp. 1097–1105, 2012. Hector Levesque, Ernest Davis, and Leora Mor genstern. The winograd schema challenge. In Thir- teenth International Conference on the Principles of Knowledge Repr esentation and Reasoning , 2012. Hao Li, Asim Kadav , Igor Durdanovic, Hanan Samet, and Hans Peter Graf. Pruning filters for efficient con vnets. arXiv pr eprint arXiv:1608.08710 , 2016. Sijia Liu, Engin Masazade, Makan Fardad, and Pramod K V arshney . Sparsity-aware field estimation via ordinary kriging. In 2014 IEEE International Conference on Acoustics, Speech and Signal Pr ocessing (ICASSP) , pp. 3948–3952. IEEE, 2014. 11 Y inhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy , Mike Lewis, Luke Zettlemoyer , and V eselin Stoyanov . RoBER T a: A rob ustly optimized BER T pre- training approach. arXiv preprint , 2019a. Zhuang Liu, Mingjie Sun, Tinghui Zhou, Gao Huang, and Tre vor Darrell. Rethinking the v alue of network pruning. In ICLR , 2019b. Ilya Loshchilov and Frank Hutter . Decoupled weight decay regularization. 2018. Xiaolong Ma, Fu-Ming Guo, W ei Niu, Xue Lin, Jian T ang, Kaisheng Ma, Bin Ren, and Y anzhi W ang. Pcon v: The missing b ut desirable sparsity in dnn weight pruning for real-time execution on mobile devices. arXiv pr eprint arXiv:1909.05073 , 2019. Laurens van der Maaten and Geoffrey Hinton. V isualizing data using t-sne. J ournal of machine learning r esear ch , 9(Nov):2579–2605, 2008. Paul Michel, Omer Levy , and Graham Neubig. Are sixteen heads really better than one? arXiv pr eprint arXiv:1905.10650 , 2019. Neal Parikh, Stephen Boyd, et al. Proximal algorithms. F oundations and T r ends R in Optimization , 1(3):127–239, 2014. Matthew E Peters, Mark Neumann, Mohit Iyyer , Matt Gardner , Christopher Clark, K enton Lee, and Luke Zettlemoyer . Deep contextualized word representations. arXiv pr eprint arXiv:1802.05365 , 2018. Alec Radford, Karthik Narasimhan, T im Salimans, and Ilya Sutskev er . Improving language un- derstanding by generative pre-training. URL https://s3-us-west-2. amazonaws. com/openai- assets/r esear chcovers/languag eunsupervised/language understanding paper . pdf , 2018. Pranav Rajpurkar , Jian Zhang, K onstantin Lopyrev , and Perc y Liang. Squad: 100,000+ questions for machine comprehension of text. arXiv pr eprint arXiv:1606.05250 , 2016. Pranav Rajpurkar , Robin Jia, and Percy Liang. Know what you don’t know: Unanswerable questions for squad. arXiv preprint , 2018. Ao Ren, Tian yun Zhang, Shaokai Y e, Jiayu Li, W enyao Xu, Xuehai Qian, Xue Lin, and Y anzhi W ang. Admm-nn: An algorithm-hardware co-design frame work of dnns using alternating direc- tion methods of multipliers. In Pr oceedings of the T wenty-F ourth International Conference on Ar chitectural Support for Pro gramming Languages and Operating Systems , pp. 925–938. ACM, 2019. Sheng Shen, Zhen Dong, Jiayu Y e, Linjian Ma, Zhe wei Y ao, Amir Gholami, Michael W Mahoney , and Kurt Keutzer . Q-bert: Hessian based ultra low precision quantization of bert. arXiv pr eprint arXiv:1909.05840 , 2019. Karen Simonyan and Andrew Zisserman. V ery deep con volutional networks for large-scale image recognition. arXiv preprint , 2014. Richard Socher , Alex Perelygin, Jean W u, Jason Chuang, Christopher D Manning, Andre w Ng, and Christopher Potts. Recursiv e deep models for semantic compositionality over a sentiment treebank. In Pr oceedings of the 2013 conference on empirical methods in natural language pr o- cessing , pp. 1631–1642, 2013. Ashish V aswani, Noam Shazeer, Niki Parmar , Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser , and Illia Polosukhin. Attention is all you need. In Advances in neural information pr ocessing systems , pp. 5998–6008, 2017. Alex W ang, Amanpreet Singh, Julian Michael, Felix Hill, Omer Levy , and Samuel R Bowman. Glue: A multi-task benchmark and analysis platform for natural language understanding. arXiv pr eprint arXiv:1804.07461 , 2018. Alex W arstadt, Amanpreet Singh, and Samuel R Bowman. Neural network acceptability judgments. arXiv pr eprint arXiv:1805.12471 , 2018. 12 W ei W en, Chunpeng W u, Y andan W ang, Y iran Chen, and Hai Li. Learning structured sparsity in deep neural networks. In Advances in neural information pr ocessing systems , pp. 2074–2082, 2016. Adina W illiams, Nikita Nangia, and Samuel R Bo wman. A broad-cov erage challenge corpus for sentence understanding through inference. arXiv preprint , 2017. Y onghui W u, Mike Schuster , Zhifeng Chen, Quoc V Le, Mohammad Norouzi, W olfgang Macherey , Maxim Krikun, Y uan Cao, Qin Gao, Klaus Macherey , et al. Google’ s neural machine trans- lation system: Bridging the gap between human and machine translation. arXiv pr eprint arXiv:1609.08144 , 2016. Zhilin Y ang, Zihang Dai, Y iming Y ang, Jaime Carbonell, Ruslan Salakhutdinov , and Quoc V Le. Xlnet: Generalized autoregressiv e pretraining for language understanding. arXiv pr eprint arXiv:1906.08237 , 2019. Y ukun Zhu, Ryan Kiros, Rich Zemel, Ruslan Salakhutdinov , Raquel Urtasun, Antonio T orralba, and Sanja Fidler . Aligning books and movies: T owards story-like visual explanations by watching movies and reading books. In Pr oceedings of the IEEE international confer ence on computer vision , pp. 19–27, 2015. 13 A A L G O R I T H M O F N E W I T E R A T I V E P R U N I N G Algorithm 2 shows the detail process of our proposed NIP algorithm. Algorithm 2 New Iterati ve Pruning (NIP) algorithm 1: Input: Initial model weights w , initial prune ratio p = 0% , progressive prune ratio ∇ p 2: for t = 1 , 2 , . . . , T do 3: w = w ( t − 1) 4: Sample batch of data from the pre-training data 5: Obtain sparsity S w through hard threshold pruning, prune ratio p t = t · ∇ p 6: Retrain w over sparsity constraint S w 7: for all tasks in {T i } do 8: Fine-tune z i ( w ; S w ) over sparsity S w (if the desired prune ratio p t has been reached for downstream task i ) 9: end f or 10: end for B A L G O R I T H M O F R E W E I G H T E D P R O X I M A L P R U N I N G ( R P P ) Algorithm 3 sho ws the detail process of our enhanced AdamW (Loshchilov & Hutter, 2018) with proximal operator . Algorithm 3 Our enhanced AdamW (Loshchilov & Hutter, 2018) with proximal operator 1: Given α = 0 . 001 , β 1 = 0 . 9 , β 2 = 0 . 999 , = 10 − 6 , λ ∈ R 2: Initialize time step k ← 0 , parameters of pre-trained model w , first moment v ector m t =0 ← 0 , second moment vector v t =0 ← 0 , schedule multiplier η k =0 ∈ R 3: repeat 4: k ← k + 1 5: ∇ f k ( w k − 1 ) ← SelectBatch ( w k − 1 ) 6: g k ← ∇ f k ( w k − 1 ) 7: m k ← β 1 m k − 1 + (1 − β 1 ) g k 8: v k ← β 2 v k − 1 + (1 − β 2 ) g 2 k 9: ˆ m k ← m k / 1 − β k 1 10: ˆ v k ← v k / 1 − β k 2 11: η k ← SetScheduleMultiplier( k ) 12: a ← w k − 1 − η k α ˆ m k / ( √ ˆ v k + ) + λ w k − 1 13: w k ← prox λ k ,rw − ` 1 ( a ) 14: until stopping criterion is met 15: return optimized sparse model w in pre-training 14 C D O W N S T R E A M T R A N S F E R L E A R N I N G T A S K S As we mentioned in our main paper, we prune the pre-trained BER T model (using NIP and RPP) and then fine-tune the sparse pre-trained model to different down-stream transfer learning tasks. In this section, we exhibit the performance of pruned BER T using NIP and RPP on a wide range of downstream transfer learning tasks to demonstrate our conclusions in the main paper . Through finetuning the pruning BER T ov er different downstream tasks, we found that SQuAD the most sensitiv e to the pruning ratio, sho wing an evident performance drop after 80% pruning ratio. By contrast, the pruning can be made more aggressiv ely when it is ev aluated under other finetuning tasks. This is not surprising, since SQuAD is a much harder Question Answering (QA) tasks, than other simple classification tasks with limited solution space. On the other hand, as the prune ratio of the pre-trained BER T increases, the performances on dif fer- ent transfer learning tasks descend generally . The descending ranges differ in different do wnstream transfer learning tasks. The descending range on SQuAD is the largest. Our proposed RPP mitigates the descending trend on all do wnstream transfer learning tasks to a great e xtent, compared with NIP . The intrinsic reason of this descending trend is left to future work. C . 1 Q Q P Quora Question Pairs is a binary classification task where the goal is to determine if two questions asked on Quora are semantically equi valent. 40 50 60 70 80 90 100 Prune Ratio (%) 0.00 0.10 0.20 0.30 0.40 0.50 0.60 0.70 0.80 0.90 MLM (NIP) NSP (NIP) QQP (NIP) MLM (RPP) NSP (RPP) QQP (RPP) t=1 t=2 t=3 t=4 t=6 Accuracy (%) / F1 score for QQP t=5 Figure A1: Evaluate the performance of pruned BER T BASE using NIP and RPP , respecti vely (MLM and NSP accuracy on pre-training data and F1 score of fine-tuning on QQP are reported). Finetuning setting: for fine-tuning on QQP , we set learning rate λ = 2 · 10 − 5 , batch size 32 and fine tuned for 3 epochs. 15 C . 2 M R P C Microsoft Research Paraphrase Corpus consists of sentence pairs automatically extracted from on- line ne ws sources, with human annotations for whether the sentences in the pair are semantically equiv alent. Dolan & Brockett (2005) Finetuning setting: for fine-tuning on MRPC, we set learning rate λ = 2 · 10 − 5 , batch size 32 and fine-tune for 3 epochs. 40 50 60 70 80 90 100 Prune Ratio (%) 0.00 0.10 0.20 0.30 0.40 0.50 0.60 0.70 0.80 0.90 MLM (NIP) NSP (NIP) MRPC (NIP) MLM (RPP) NSP (RPP) MRPC (RPP) t=1 t=2 t=3 t=4 t=6 Accuracy (%) / F1 score for MRPC t=5 Figure A2: Evaluate the performance of pruned BER T BASE using NIP and RPP , respecti vely (MLM and NSP accuracy on pre-training data and F1 score of fine-tuning on MRPC are reported). C . 3 M N L I Multi-Genre Natural Language Inference is a large-scale, crowdsourced entailment classification task W illiams et al. (2017). Giv en a pair of sentences, the goal is to predict whether the second sentence is an entailment, contradiction, or neutral with respect to the first one. Finetuning setting: for fine-tuning on MNLI, we set learning rate λ = 2 · 10 − 5 , batch size 32 and fine-tune for 3 epochs. 40 50 60 70 80 90 100 Prune Ratio (%) 0.00 0.10 0.20 0.30 0.40 0.50 0.60 0.70 0.80 0.90 MLM (NIP) NSP (NIP) MNLI(NIP) MLM (RPP) NSP (RPP) MNLI(RPP) t=1 t=2 t=3 t=4 t=6 Accuracy (%) t=5 Figure A3: Evaluate the performance of pruned BER T BASE using NIP and RPP , respecti vely (MLM and NSP accuracy on pre-training data and accurac y of fine-tuning on MNLI are reported). 16 C . 4 M N L I M Multi-Genre Natural Language Inference has a separated ev aluation MNLIM. Following (De vlin et al., 2019), the fine-tuning process on MNLIM is separated from MNLI. So we present our results on MNLIM in this subsection. Finetuning setting: for fine-tuning on MNLIM, we set learning rate λ = 2 · 10 − 5 , batch size 32 and fine-tune for 3 epochs. 40 50 60 70 80 90 100 Prune Ratio (%) 0.00 0.10 0.20 0.30 0.40 0.50 0.60 0.70 0.80 0.90 MLM (NIP) NSP (NIP) MNLIM (NIP) MLM (RPP) NSP (RPP) MNLIM (RPP) t=1 t=2 t=3 t=4 t=6 Accuracy (%) t=5 Figure A4: Evaluate the performance of pruned BER T BASE using NIP and RPP , respecti vely (MLM and NSP accuracy on pre-training data and accurac y of fine-tuning on MNLIM are reported). C . 5 Q N L I Question Natural Language Inference is a version of the Stanford Question Answering Dataset (Ra- jpurkar et al., 2016) which has been con verted to a binary classification task W anget al., 2018a). The positiv e examples are (question, sentence) pairs which do contain the correct answer, and the nega- tiv e examples are (question, sentence) from the same paragraph which do not contain the answer . Finetuning setting: for fine-tuning on QNLI, we set learning rate λ = 2 · 10 − 5 , batch size 32 and fine-tune for 3 epochs. 40 50 60 70 80 90 100 Prune Ratio (%) 0.00 0.10 0.20 0.30 0.40 0.50 0.60 0.70 0.80 0.90 MLM (NIP) NSP (NIP) QNLI(NIP) MLM (RPP) NSP (RPP) QNLI(RPP) t=1 t=2 t=3 t=4 t=6 Accuracy (%) t=5 Figure A5: Evaluate the performance of pruned BER T BASE using NIP and RPP , respecti vely (MLM and NSP accuracy on pre-training data and accurac y of fine-tuning on QNLI are reported). 17 C . 6 S S T - 2 The Stanford Sentiment T reebank is a binary single-sentence classification task consisting of sen- tences extracted from mo vie re views with human annotations of their sentiment(Socher et al., 2013). Finetuning setting: for fine-tuning on SST -2, we set learning rate λ = 2 · 10 − 5 , batch size 32 and fine-tune for 3 epochs. T o consistent with the GLUE benchmark (W ang et al., 2018), the Pearson- Spearman Corr score is reported. 40 50 60 70 80 90 100 Prune Ratio (%) 0.00 0.10 0.20 0.30 0.40 0.50 0.60 0.70 0.80 0.90 MLM (NIP) NSP (NIP) SST-2 (NIP) MLM (RPP) NSP (RPP) SST-2 (RPP) t=1 t=2 t=3 t=4 t=6 Pearson-Spearman Corr t=5 Figure A6: Evaluate the performance of pruned BER T BASE using NIP and RPP , respecti vely (MLM and NSP accuracy on pre-training data and accurac y of fine-tuning on SST -2 are reported). C . 7 C O L A The Corpus of Linguistic Acceptability is a binary single-sentence classification task, where the goal is to predict whether an English sentence is linguistically “acceptable” or not (W arstadt et al., 2018). Finetuning setting: for fine-tuning on CoLA, we set learning rate λ = 2 · 10 − 5 , batch size 32 and fine-tune for 3 epochs. T o consistent with the GLUE benchmark (W ang et al., 2018), the Matthe w’ s Corr score is reported. 40 50 60 70 80 90 100 Prune Ratio (%) 0.00 0.10 0.20 0.30 0.40 0.50 0.60 0.70 0.80 0.90 MLM (NIP) NSP (NIP) CoLA (NIP) MLM (RPP) NSP (RPP) CoLA (RPP) t=1 t=2 t=3 t=4 t=6 Accuracy (%) / Matthew's Corr for CoLA t=5 Figure A7: Evaluate the performance of pruned BER T BASE using NIP and RPP , respecti vely (MLM and NSP accuracy on pre-training data and accurac y of fine-tuning on CoLA are reported). 18 D N O N C O N V E R G E N C E O F P R U N I N G B E RT U S I N G P R E V I O U S M E T H O D S 0 5 10 15 20 25 30 35 Epoch 1 2 3 4 5 6 7 8 9 Loss iterative pruning one shot pruning RPP T=1 RPP T=2 RPP T=3 Figure A8: Training loss curv e of applying iterative pruning and RPP on BER T As we mentioned in our main paper , we in vestigate a series of pruning techniques to prune BER T , include the iterati ve pruning method (Han et al., 2015) and the one-shot pruning (Liu et al., 2019b). Howe ver , most of the pre vious pruning techniques requires to directly optimize the ` 1 /` 2 regular - ization using the back-propagation based gradient update in the original training of DNN models. W e execute a school of experiments and find that, this kind of method to optimize regularization might not be compatible with BER T . W e show the experiment results about this incompatibility in this section. For the sake of fair comparison, we not only adopt the same hyperparameters (in our experiments about NIP and RPP) on iterati ve pruning and one-shot pruning, we execute a wide set of hyperparamters to make the iterati ve pruning and one-shot pruning work. W e set the learn- ing λ ∈ { 2 · 10 − 4 , 10 − 4 , 5 · 10 − 5 , 3 · 10 − 5 , 2 · 10 − 5 , 1 · 10 − 5 , 1 · 10 − 6 , 1 · 10 − 7 , 1 · 10 − 8 } , batch size B ∈ { 256 , 512 , 1024 , 2048 } . W e e xecute the same hyperparameters (with NIP and RPP) and at- tempt more hyperparameters on the iterativ e pruning and one-shot pruning, but iterati ve and one-shot pruning could not conv erge to a valid solution. Figure A8 illustrates training loss curve of applying iterativ e pruning, one-shot pruning and RPP on BER T . It is clear that iterative pruning and one-shot pruning leads to a non-conv ergence result, while different settings of RPP ( T = 0 , T = 1 , T = 2) con verge well. From the perspectiv e of optimization and con vergence, we mak e the following analysis: The pre vious method, such as Iterative Pruning (IP) and one-shot pruning, relies on directly optimiz- ing the ` 1 / ` 2 penalized training loss to conduct DNN pruning (this is discussed by Han et al. (2015) on iterati ve pruning, Section 3.1). As a result, a simultaneous back-propagation (for updating model weights) is conducted ov er both the original training loss as well as the non-smooth sparsity regu- larizer . When the penalty term is back-propagated together with the loss function, this affects the con vergence of the original loss function. The con vergence performance is significantly degraded for extremely large DNN model like BER T . This phenomenon is also observed in the training of BER T (AD AM weight decay) that decouples the re gularization term with the original loss function, instead of using an ov erall back-propagation. For the super-deep DNN model (like BER T), it becomes harder to count on the one-time back- propagation flo w to solve both the original training objectiv e and the sparse regulariztion at the same time. Loshchilov & Hutter (2018) notices this limitation and improves regularization of Adam, by decoupling weight decay regularization from the gradient-based update (Loshchilov & Hutter, 2018). AdamW is widely adopted in pretraining lar ge language representations, e.g., BER T (Devlin et al., 2019), GPT (Radford et al., 2018) and XLNet (Y ang et al., 2019). The difference is that, the decoupled weight decay in AdamW is to av oid overfitting, while our purpose is to generate sparsity . Moreover , previous algorithms with directly optimizing ` 1 through the back-propagation based gradient update penalty on TPU will easily lead to the gradient NaN. 19 Hence we proposed New Iterativ e Pruning (NIP) as our working baseline. W e believe that NIP works since NIP reflects the naturally progressive pruning performance without any externally introduced penalty . As a fix of IP , NIP simplifies the training objective by removing the non-smooth sparsity regularizer . This simple fix improves the con vergence of the training process, and makes new itera- tiv e pruning doable for BER T . W e hope that other pruning methods should not perform worse than NIP , otherwise, the effect of optimizing the ne wly introduced sparsity-promoting re gularization is negati ve. T o further improve the pruning performance, we need to find a better pruning method that exploits our composite objective structure (original training loss + sparsity regularization), so that the back- propagation is not affected for the original training objectiv e of BER T . Motiv ated by that, proximal gradient provides an elegant solution, which splits the updating rule into a) gradient descent ov er the original training loss, and b) proximal operation over non-smooth sparsity regularizers. Moreo ver , reweighted ` 1 minimization serves as a better sparsity generalization method, which self-adjusting the importance of sparsity penalization weights. Furthermore, the incorporation of reweighted ` 1 will not af fect the adv antage of the proximal gradient algorithm. Thanks to the closed-form solution (equation 8) of proximal operation on a weighted ` 1 norm, Reweighted Proximal Pruning (RPP) is a desired pruning method on BER T model. W e hope RPP proves to be effecti ve in more kinds of DNN models in the future. 20
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment