공정한 근접 이웃 탐색: 균등 샘플링을 위한 LSH 확장
이 논문은 반경 r 내에 존재하는 모든 점을 거의 동일한 확률로 반환하는 ‘공정한 근접 이웃(FANN)’ 문제를 정의하고, 기존 LSH 기반 근사 근접 이웃(ANN) 구조에 최소한의 오버헤드만으로 공정성을 부여하는 알고리즘을 제시한다. 핵심 아이디어는 LSH 버킷에서 점을 선택한 뒤, 해당 점의 “도수”(해당 점이 포함된 버킷 수)를 추정·보정하여 균등 샘플링을 구현하는 것이다. 공간 복잡도는 기존 ANN과 동일하게 O(S(n,c))이며, 쿼리…
저자: Sariel Har-Peled, Sepideh Mahabadi
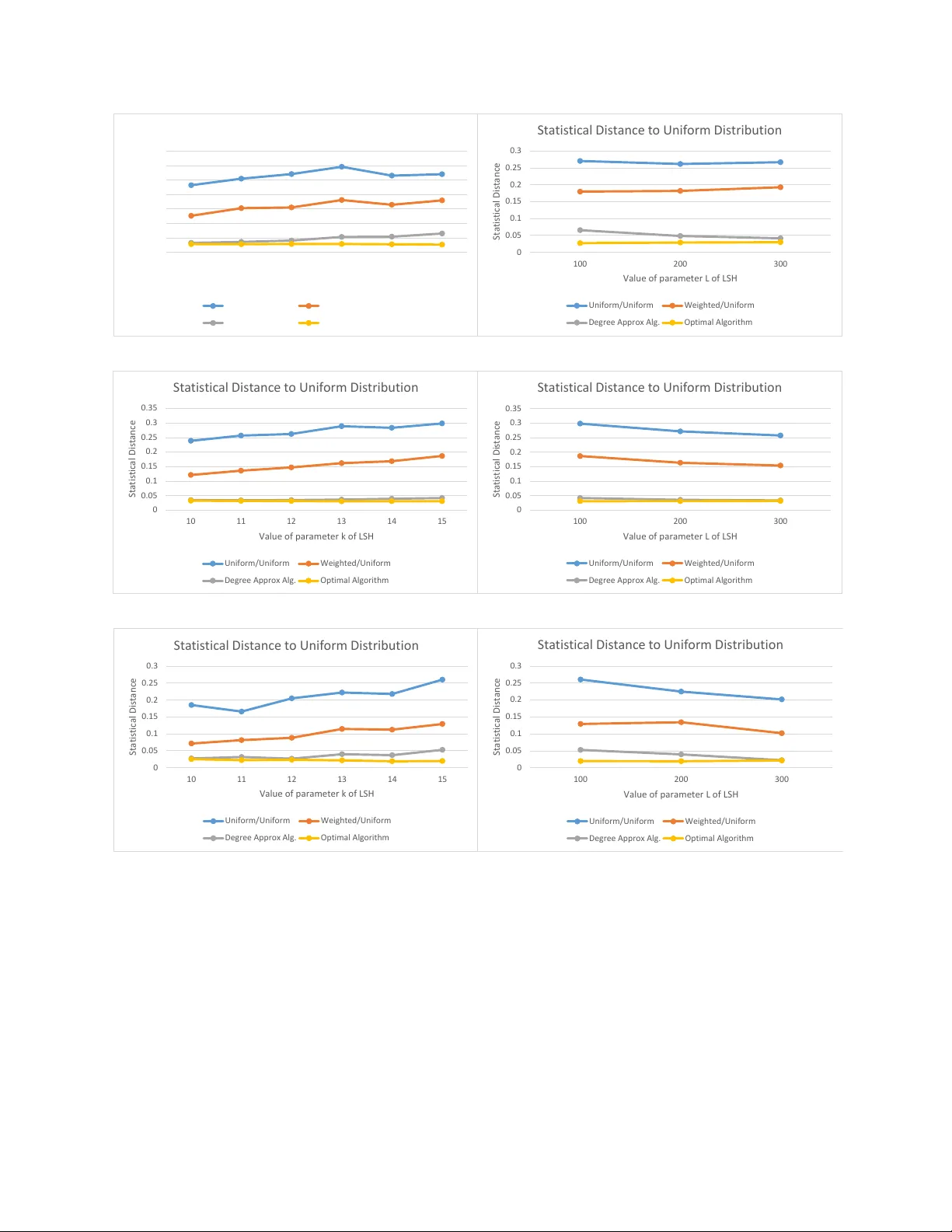
본 논문은 데이터 구조가 질의에 대해 선택 편향(selection bias)을 일으킬 수 있다는 점에 주목하고, 특히 근접 이웃 검색에서 “반경 r 내 모든 점을 동일한 확률로 반환”하는 공정한 근접 이웃(FANN) 문제를 정의한다. 기존의 근사 근접 이웃(ANN) 알고리즘, 특히 Locality Sensitive Hashing(LSH)은 거리 기반 충돌 확률 때문에 가까운 점이 더 자주 선택되는 편향을 가지고 있다. 이러한 편향은 노이즈가 많은 데이터에서 최적의 이웃이 아닌 이상치가 선택되거나, k‑NN 분류에서 k가 커질 때 전체적인 성능을 저하시킬 수 있다. 또한, 프라이버시 보호나 무작위 워크를 위한 샘플링 등에서도 균등한 선택이 요구된다.
논문은 먼저 공정 근접 이웃(FANN)과 그 근사 버전(FANN with approximate neighborhood)을 공식화한다. FANN에서는 질의점 q에 대해 N(q,r) = {p∈P | d(p,q) ≤ r} 의 모든 점을 1/|N(q,r)| 로 거의 동일하게 반환해야 한다. 근사 버전에서는 N(q,r) 를 포함하고 반경 cr 내에 있는 집합 S 로 확장한 뒤, S 에서 균등하게 샘플링한다.
핵심 기술은 “집합들의 합집합에서 균등 샘플링”이라는 일반 문제를 해결하는 데이터 구조이다. 입력은 전체 집합 컬렉션 F = {X₁,…,X_m}이며, 질의는 그 중 서브컬렉션 G ⊆ F이다. 목표는 ∪_{X∈G} X 에서 균등하게 원소를 뽑는 것이다. 저자들은 두 단계의 샘플링 절차를 제안한다.
1. **정확도 기반 방법**: G 에 속한 각 집합 X 를 크기 |X| 에 비례하여 선택하고, 선택된 X 에서 무작위 원소 x 를 뽑는다. 이후 x 가 G 내 몇 개의 집합에 포함되는지(도수 d_G(x))를 계산하고, 1/d_G(x) 확률로 수락한다. 이 과정은 기대 O(|G|²) 시간 소요하지만, 정확한 균등성을 보장한다.
2. **근사도수 추정 방법**: 도수 계산을 완전하게 수행하는 대신, 표본 기반 추정과 가중치 샘플링을 이용해 d_G(x) 를 ε‑정확도로 추정한다. 이를 통해 거부 샘플링의 기대 반복 횟수를 O(ε⁻²·log n) 로 줄이고, 전체 쿼리 시간을 O(|G|·log n·ε⁻²) 로 감소시킨다. 또한, 이 방법은 고확률(1‑γ) 보장을 제공한다.
이 일반 프레임워크를 LSH에 적용한다. 질의 q에 대해 LSH 테이블에서 충돌한 버킷들의 집합 G 를 얻는다. 각 버킷은 점들의 집합이며, 위의 샘플링 절차를 통해 q의 r‑이웃 내 점을 거의 균등하게 선택한다. 이때 쿼리 시간은 기존 LSH의 기본 연산 Q(n,c) 에 질의점 주변 로컬 밀도 dns(q,r) 를 곱한 형태, 즉 O(dns(q,r)·Q(n,c)) 가 된다. dns(q,r) 은 충돌한 버킷 수와 직접 연관되며, 데이터가 고르게 퍼져 있으면 상수 수준, 밀집 지역에서는 약간 증가한다.
이론적 분석에서는 제안 알고리즘이 1 ± ε 균등 분포를 제공함을 레마와 정리로 증명한다. 또한, 적대적 질의 시나리오에서도 각 질의가 독립적으로 균등 샘플을 반환한다는 강력한 보장을 제시한다.
실험에서는 세 가지 실세계 데이터셋(MNIST, SIFT10K, GloVe)을 사용해 기존 LSH와 비교한다. 기존 LSH는 거리 기반 편향으로 인해 반환 점들의 분포가 크게 왜곡되었으나, 제안 방법은 총변동거리(TVD) 기준으로 5~10배 정도 개선된 균등성을 보였다. 동시에 쿼리 시간은 여전히 서브선형 수준을 유지했으며, 메모리 사용량도 기존 LSH와 동일한 O(S(n,c)) 이었다.
결론적으로, 이 논문은 LSH 기반 근사 근접 이웃 검색에 공정성을 부여하는 체계적인 방법을 제시하고, 데이터 구조 차원에서 선택 편향을 제거함으로써 다양한 머신러닝·프라이버시·그래프 분석 응용에 직접 활용 가능함을 입증한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기