Near Neighbor: Who is the Fairest of Them All?
$\newcommand{\ball}{\mathbb{B}}\newcommand{\dsQ}{{\mathcal{Q}}}\newcommand{\dsS}{{\mathcal{S}}}$In this work we study a fair variant of the near neighbor problem. Namely, given a set of $n$ points $P$ and a parameter $r$, the goal is to preprocess th…
Authors: Sariel Har-Peled, Sepideh Mahabadi
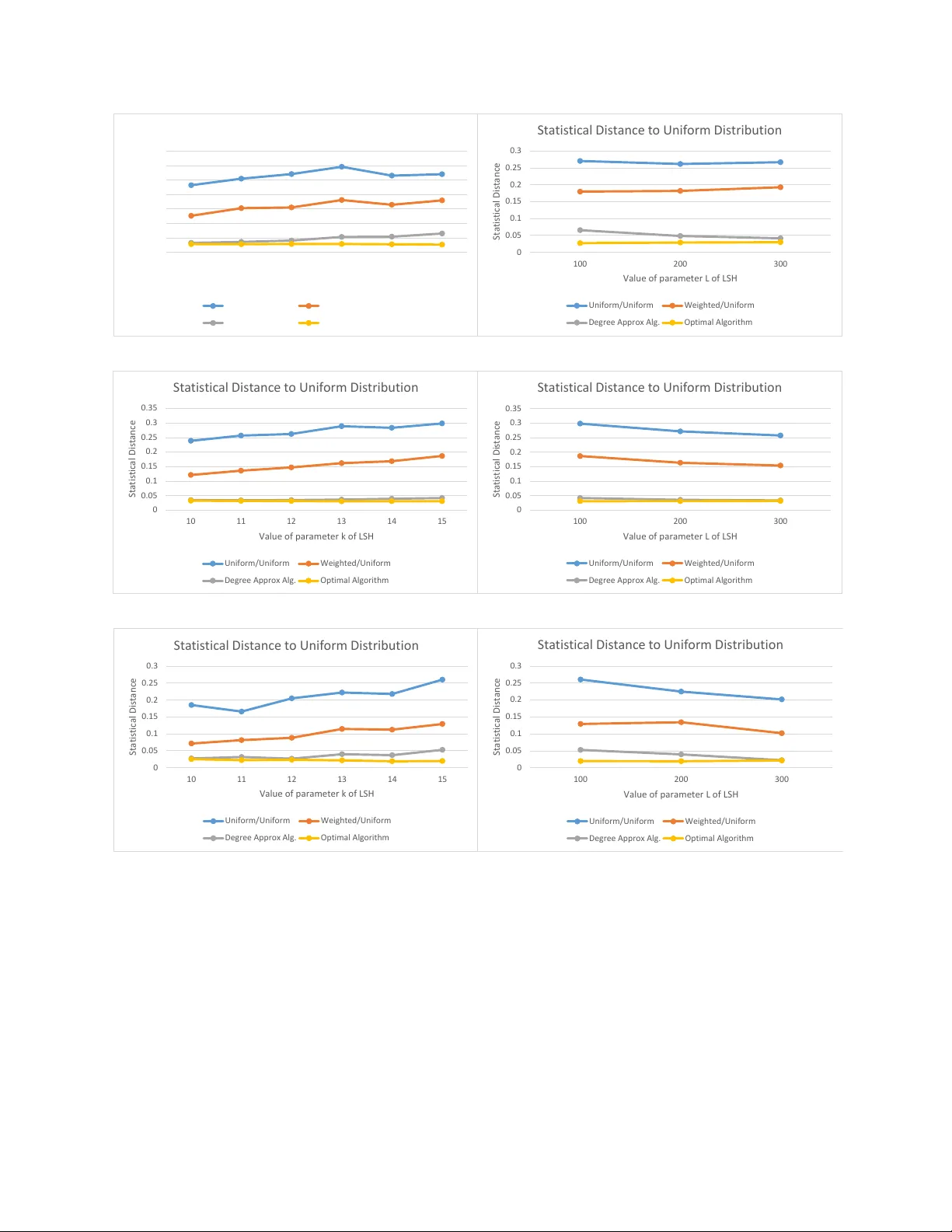
Near Neigh b or: Who is the F airest of Them All? Sariel Har-P eled ∗ Sepideh Mahabadi † No vem b er 25, 2019 Abstract In this w ork w e study a fair v arian t of the near neighbor problem. Namely , given a set of n p oin ts P and a parameter r , the goal is to prepro cess the p oints, suc h that giv en a query p oint q , an y p oin t in the r -neigh b orho o d of the query , i.e., B p q , r q , ha ve the same probabilit y of b eing rep orted as the near neighbor. W e sho w that LSH based algorithms can b e made fair, without a significant loss in efficiency . Sp ecifically , w e sho w an algorithm that reports a p oint in the r -neighborho o d of a query q with almost uniform probabilit y . The query time is proportional to O ` dns p q .r q Q p n, c q ˘ , and its space is O p S p n, c qq , where Q p n, c q and S p n, c q are the query time and space of an LSH algorithm for c -appro ximate near neighbor, and dns p q , r q is a function of the lo cal density around q . Our approach works more generally for sampling uniformly from a sub-collection of sets of a giv e n collection and can b e used in a few other applications. Finally , we run exp erimen ts to show p erformance of our approac h on real data. 1. In tro duction No wada ys, man y important decisions, such as college admissions, offering home loans, or es- timating the likelihoo d of recidivism, rely on machine learning algorithms. There is a gro wing concern ab out the fairness of the algorithms and creating bias tow ard a sp ecific p opulation or feature [ HPS16 , Cho17 , MSP16 , KLL ` 17 ]. While algorithms are not inheren tly biased, nev ertheless, they may amplify the already existing biases in the data. Hence, this concern has led to the design of fair algorithms for man y differen t applications, e.g., [ DOBD ` 18 , ABD ` 18 , PR W ` 17 , CKL V19 , EJJ ` 19 , O A18 , CKL V17 , BIO ` 19 , BCN19 , KSAM19 ]. Bias in the data used for training mac hine learning algorithms is a monumen tal c hallenge in creating fair algorithms [ HGB ` 07 , TE11 , ZVGR G17 , Cho17 ]. Here, w e are interested in a somewhat differen t problem, of handling the bias in tro duced b y the data-structures used b y ∗ Departmen t of Computer Science; Universit y of Illinois; 201 N. Go o dwin Aven ue; Urbana, IL, 61801, USA; sariel@illinois.edu ; http://sarielhp.org/ . W ork on this pap er was partially supp orted by a NSF AF aw ard CCF-1907400. † mahabadi@ttic.edu . 1 suc h algorithms. Specifically , data-structures may in tro duce bias in the data stored in them, and the w ay they answer queries, b ecause of the wa y the data is stored and ho w it is b eing accessed. Suc h a defect leads to selection bias b y the algorithms using such data-structures. It is natural to w ant data-structures that do not in tro duce a selection bias in to the data when handling queries. The target as such is to deriv e data-structures that are bias-neutral. T o this end, imagine a data-structure that can return, as an answ er to a query , an item out of a set of acceptable answ ers. The purpose is then to return uniformly a random item out of the set of acceptable outcomes, without explicitly computing the whole set of acceptable answ ers (which might b e prohibitiv ely exp ensive). Sev eral notions of fairness hav e b een studied, including gr oup fairness 1 (where demo- graphics of the population is preserv ed in the outcome) and individual fairness (where the goal is to treat individuals with similar conditions similarly) [ DHP ` 12 ]. In this work, we study the near neighbor problem from the p ersp ectiv e of individual fairness. Near Neigh b or is a fundamental problem that has applications in man y areas suc h as mac hine learning, databases, computer vision, information retriev al, and man y others, see [ SDI06 , AI08 ] for an ov erview. The problem is formally defined as follo ws. Let p M , d q b e a metric space. Given a set P Ď M of n p oints and a parameter r , the goal of the ne ar neighb or problem is to prepro cess P , such that for a query point q P M , one can report a p oin t p P P , suc h that d p p, q q ď r if such a p oin t exists. As all the existing algorithms for the exact v ariant of the problem ha ve either space or query time that dep ends exp onentially on the am bient dimension of M , p eople hav e considered the appro ximate v arian t of the problem. In the c -appr oximate ne ar neighb or ( ANN ) problem, the algorithm is allow ed to rep ort a p oin t p whose distance to the query is at most cr if a p oint within distance r of the query exists, for some presp ecified constan t c ą 1. P erhaps the most prominen t approach to get an ANN data structure is via Lo cality Sensitiv e Hashing ( LSH ) [ IM98 , HIM12 ], which leads to sub-linear query time and sub- quadratic space. In particular, for M “ R d , b y using LSH one can get a query time of n ρ ` o p 1 q and space n 1 ` ρ ` o p 1 q where for the L 1 distance metric ρ “ 1 { c [ IM98 , HIM12 ], and for the L 2 distance metric ρ “ 1 { c 2 ` o c p 1 q [ AI08 ]. The idea of the LSH metho d is to hash all the p oin ts using sev eral hash functions that are chosen randomly , with the prop ert y that closer p oin ts ha v e a higher probabilit y of collision than the far p oints. Therefore, the closer p oints to a query hav e a higher probabilit y of falling in to a buck et b eing prob ed than far points. Th us, rep orting a random p oint from a random buck et computed for the query , pro duces a distribution that is biased by the distance to the query: closer points to the query ha ve a higher probabilit y of b eing c hosen. When random nearby is b etter than nearest. The bias mentioned ab o ve to wards nearer p oints is usually a goo d prop ert y , but is not alwa ys desirable. Indeed, consider the follo wing scenarios: 1 The concept is denoted as statistical fairness to o, e.g., [ Cho17 ]. 2 (I) The nearest neighbor migh t not b e the b est if the input is noisy , and the closest p oin t migh t b e view ed as an unrepresentativ e outlier. An y p oin t in the neigh b orho o d might b e then considered to b e equiv alently b eneficial. This is to some extent why k - NN classification [ ELL09 ] is so effective in reducing the effect of noise. (I I) How ever, k - NN w orks b etter in man y cases if k is large, but computing the k nearest- neigh b ors is quite exp ensive if k is large [ HAAA14 ]. Computing quic kly a random nearb y neigh b or can significantly sp eed-up such classification. (I I I) W e are in terested in annon ymizing the query [ Ada07 ], th us returning a random near- neigh b or might serve as first line of defense in trying to make it harder to recov er the query . Similarly , one migh t wan t to anonymize the nearest-neighbor [ QA08 ], for applications were we are interested in a “typical” data item close to the query , without iden tifying the nearest item. (IV) If one w an ts to estimate the n umber of items with a desired property within the neigh- b orho o d, then the easiest w ay to do it is via uniform random sampling from the neigh- b orho o d. In particular, this is useful for density estimation [ KLK12 ]. (V) Another natural application is simulating a random walk in the graph where tw o items are connected if they are in distance at most r from eac h other. Such random walks are used b y some graph clustering algorithms [ HK01 ]. 1.1. Results Our goal is to solve the near-neigh b or problem, and yet b e fair among “all the p oin ts” in the neigh b orho o d. W e introduce and study the fair ne ar neighb or problem – where the goal is to rep ort any p oin t of N p q , r q with uniform distribution. That is, rep ort a p oint within distance r of the query p oint with probabilit y of P p q , r q “ 1 { n p q , r q , where n p q , r q “ | N p q , r q| . Naturally , we study the appro ximate fair near neighbor problem, where one can hop e to get efficien t data-structures. W e ha ve the follo wing results: (I) Exact neigh b orho o d. W e presen t a data structure for rep orting a neigh b or accord- ing to an “almost uniform” distribution with space S p n, c q , and query time r O ` Q p n, c q ¨ n p q ,cr q n p q ,r q ˘ , where S p n, c q and Q p n, c q are, resp ectiv ely , the space and query time of the standard c - ANN data structure. Note that, the query time of the algorithm migh t be high if the appro ximate neighborho o d of the query is m uch larger than the exact neigh- b orho o d. 2 Guaran tees of this data structure hold with high pr ob ability . See Lemma 4.9 for the exact statement. (I I) Appro ximate neigh b orho o d. This form ulation rep orts an almost uniform distribu- tion from an appro ximate neigh b orho o d S of the query . W e can pro vide suc h a data structure that uses space S p n, c q and whose query time is r O p Q p n, c qq , alb eit in exp e cta- tion . See Lemma 4.3 for the exact statemen t. 2 As we sho w, the term Q p n, r q ¨ n p q ,cr q n p q ,r q can also b e replaced by Q p n, r q ` | N p q , cr qz N p q , r q| which can p oten tially b e smaller. 3 Moreo ver, the algorithm pro duces the samples indep endently of past queries. In particular, one can assume that an adv ersary is producing the set of queries and has full knowledge of the data structure. Ev en then the generated samples hav e the same (almost) uniform guaran tees. F urthermore, we remark that the new sampling strategy can b e embedded in the existing LSH metho d to achiev e unbiased query results. Finally , w e remark that to get a distribution that is p 1 ` ε q -uniform (See preliminaries for the definition), the dep endence of our algorithms on ε is only O p log p 1 { ε qq . V ery recen tly , indep enden t of our work, [ APS19 ] also provides a similar definition for the fair near neighbor problem. Exp erimen ts. Finally , w e compare the p erformance of our algorithm with the algorithm that uniformly pic ks a buc ket and rep orts a random point, on the MNIST , SIFT10K, and GloV e data sets. Our empirical results show that while the standard LSH algorithm fails to fairly sample a p oin t in the neigh b orho o d of the query , our algorithm pro duces an empirical distribution which is m uc h closer to the uniform distribution: it improv es the statistical distance to the uniform distribution b y a significan t factor. 1.2. Data-structure: Sampling from a sub-collection of sets W e first study the more generic problem – given a collection F of sets from a universe of n elemen ts, a query is a sub-collection G Ď F of these sets and the goal is to sample (almost) uniformly from the union of the sets in this sub-collection. W e do this by first sampling a set X in the sub-collection G prop ortional to the size of the set X , and then sampling an element x P X uniformly at random. This pro duces a distribution on elements in the sub-collection such that an y elemen t x is c hosen prop ortional to its degree d p x q (i.e., the n umber of sets X P G that x P X ). Therefore, we can use rejection sampling and only rep ort x with probability 1 { d p x q . W e can compute the degree b y chec king if x P X for all sets X P G in the collection, whic h tak es time prop ortional to g “ | G | . Also b ecause of the rejection sampling, w e migh t need to repeat this process O p deg av g q times which can b e as large as g . This leads to exp ected run time O p g 2 q to generate a single sample, see Lemma 3.1 . As a first impro vemen t, w e appr oximate the degree using standard sampling tec hniques, whic h can b e done in time r O p g { d p x qq . Although this can still b e large for small degrees, ho wev er, those small v alues will also b e rejected with a smaller probabilit y . Using this, w e can b ound the run time of a query b y O p ε ´ 2 g log n q , see Lemma 3.3 (the sampling is p 1 ˘ ε q -uniform), where n is (roughly) the input size. Our second impro vemen t, whic h the authors b eliev e to b e quite in teresting, follo ws by sim ulating this rejection sampling directly . This follo ws b y first in tro ducing a heuristic to appro ximate the degree, and then shortcutting it to get the desired sim ulation. Section 3.4 describ es this mo dified algorithm. In particular, one can get uniform sampling with high probabilit y . Sp ecifically , one can sample uniformly in exp ected O p g log γ ´ 1 q time, where the sampling succeeds with probabilit y ě 1 ´ γ . Alternativ ely , one can sample p 1 ˘ ε q -uniformly , 4 with the exp ected running time b eing O ` g log p n { ε q ˘ . This is a significant impro v ement, in b oth simplicit y and dep endency on ε , ov er the previous sc heme. W e also show ho w to mo dify that data-structure to handle outliers, as it is the case for LSH , as the sampling algorithm needs to ignore such p oin ts once they are rep orted as a sample. Applications. Here are a few examples of applications of such a data-structure (for sampling from a union of sets): (A) Giv en a subset X of v ertices in the graph, randomly pick (with uniform distribution) a neighbor to one of the v ertices of X . This can b e used in sim ulating disease spread [ KE05 ]. (B) Here, w e use a v ariant of this data-structure to implement the fair ANN . (C) Uniform sampling for range searc hing [ HQT14 , A W17 , AP19 ]. Indeed, consider a set of points, stored in a data-structure for range queries. Using the abov e, we can supp ort sampling from the p oints reported b y sev eral queries, even if the reported answ ers are not disjoin t. Being unaw are of an y previous work on this problem, w e b eliev e this data-structure is of indep enden t in terest. 1.3. P ap er organization W e describe some basic sampling and appro ximation to ols in Section 2 . W e describ e the sampling from union of set data-structure in Section 3 . The application of the data-structure to LSH is describ ed in Section 4 . The exp erimen ts are describ ed in Section 5 . 2. Preliminaries Neigh b orho o d, fair nearest-neigh b or, and appro ximate neigh b orho o d. Let p M , d q b e a metric space and let P Ď M b e a set of n p oints. Let B p c, r q “ t x P M | d p c, x q ď r u b e the (close) ball of radius r around a point c P M , and let N p c, r q “ B p c, r q X P be the r -neighb orho o d of c in P . The size of the r -neigh b orho o d is n p c, r q “ | N p c, r q| . Definition 2.1 (F ANN). Given a data set P Ď M of n p oin ts and a parameter r , the goal is to prepro cess P suc h that for a given query q , one rep orts each point p P N p q , r q with probabilit y µ p where µ is an approximately uniform probabilit y distribution: P p q , r q{p 1 ` ε q ď µ p ď p 1 ` ε q P p q , r q , where P p q , r q “ 1 { n p q , r q . Definition 2.2 (F ANN with app roximate neighb orhoo d). Given a data set P Ď M of n points and a parameter r , the goal is to prepro cess them such that for a given query q , one rep orts eac h point p P S with probabilit y µ p where ϕ {p 1 ` ε q ď µ p ď p 1 ` ε q ϕ , where S is a point set suc h that N p q , r q Ď S Ď N p q , cr q , and ϕ “ 1 {| S | . 5 Set represen tation. Let U b e an underlying ground set of n ob jects (i.e., elements). In this pap er, we deal with sets of ob jects. Assume that suc h a set X Ď U is stored in some reasonable data-structure, where one can insert delete, or query an ob ject in constan t time. Querying for an ob ject o P U , requires deciding if o P X . Such a represen tation of a set is straigh tforward to implemen t using an arra y to store the ob jects, and a hash table. This represen tation allows random access to the elements in the set, or uniform sampling from the set. If hashing is not feasible, one can just use a standard dictionary data-structure – this w ould slow down the op erations b y a logarithmic factor. Subset size estimation. W e need the follo wing standard estimation to ol, [ BHR ` 17 , Lemma 2.8]. Lemma 2.3. Consider two sets B Ď U , wher e n “ | U | . L et ξ , γ P p 0 , 1 q b e p ar ameters, such that γ ă 1 { log n . Assume that one is given an ac c ess to a memb ership or acle that, given an element x P U , r eturns whether or not x P B . Then, one c an c ompute an estimate s , such that p 1 ´ ξ q | B | ď s ď p 1 ` ξ q | B | , and c omputing this estimates r e quir es O pp n { | B |q ξ ´ 2 log γ ´ 1 q or acle queries. The r eturne d estimate is c orr e ct with pr ob ability ě 1 ´ γ . W eigh ted sampling. W e need the follo wing standard data-structure for w eighted sampling. Lemma 2.4. Given a set of obje cts H “ t o 1 , . . . , o t u , with asso ciate d weights w 1 , . . . , w t , one c an pr epr o c ess them in O p t q time, such that one c an sample an obje ct out of H . The pr ob- ability of an obje ct o i to b e sample d is w i { ř t j “ 1 w j . In addition the data-structur e supp orts up dates to the weights. A n up date or sample op er ation takes O p log t q time. Pr o of: Build a balanced binary tree T , where the ob jects of G are stored in the lea v es. Every in ternal no de u of T , also maintains the total weigh t w p u q of the ob jects in its subtree. The tree T has height O p log t q , and weigh t up dates can b e carried out in O p log t q time, by up dating the path from the ro ot to the leaf storing the relev ant ob ject. Sampling is no w done as follows – w e start the trav ersal from the ro ot. A t each stage, when b eing at node u , the algorithm considers the tw o c hildren u 1 , u 2 . It con tinues to u 1 with probabilit y w p u 1 q{ w p u q , and otherwise it con tinues in to u 2 . The ob ject sampled is the one in the leaf that this tra versal ends up at. 3. Data-structure: Sampling from the union of sets The problem. Assume y ou are given a data-structure that con tains a large collection F of sets of ob jects. The sets in F are not necessarily disjoin t. The task is to prepro cess the data-structure, suc h that giv en a sub-collection G Ď F of the sets, one can quic kly pic k uniformly at random an ob ject from the set Ť G : “ Ť X P G X . Naiv e solution. The naive solution is to take the sets under consideration (in G ), compute their union, and sample directly from the union set Ť G . Our purp ose is to do (m uch) b etter 6 – in particular, the goal is to get a query time that dep ends logarithmically on the total size of all sets in G . 3.1. Prepro cessing F or each set X P F , w e build the set representation mentioned in the preliminaries section. In addition, w e assume that eac h set is stored in a data-structure that enables easy random access or uniform sampling on this set (for example, store eac h set in its o wn array). Th us, for eac h set X , and an element, we can decide if the element is in X in constan t time. 3.2. Uniform sampling via exact degree computation The query is a family G Ď F , and define m “ G : “ ř X P G | X | (whic h should b e distinguished from g “ | G | and from n “ | Ť G | ). The de gr e e of an elemen t x P Ť G , is the num b er of sets of G that con tains it – that is, d G p x q “ | D G p x q| , where D G p x q “ t X P G | x P X u . The algorithm repeatedly do es the following: (I) Pic ks one set from G with probabilities prop ortional to their sizes. That is, a set X P G is pic ked with probabilit y | X | { m . (I I) It pic ks an elemen t x P X uniformly at random. (I I I) Computes the degree d “ d G p x q . (IV) Outputs x and stop with probabilit y 1 { d . Otherwise, con tinues to the next iteration. Lemma 3.1. L et n “ | Ť G | and g “ | G | . The ab ove algorithm samples an element x P Ť G ac c or ding to the uniform distribution. The algorithm takes in exp e ctation O p g m { n q “ O p g 2 q time. The query time is takes O p g 2 log n q with high pr ob ability. Pr o of: Let m “ G . Observ e that an element x P Ť G is pick ed b y step (I I) with probabilit y α “ d p x q{ m . The element x is output with probabilit y β “ 1 { d p x q . As such, the probabilit y of x to b e output by the algorithm in this round is αβ “ 1 { G . This implies that the output distribution is uniform on all the elemen ts of Ť G . The probabilit y of success in a round is n { m , whic h implies that in expectation m { n rounds are used, and with high probability O pp m { n q log n q rounds. Computing the degree d G p x q takes O p| G |q time, which implies the first b ound on the running time. As for the second b ound, observ e that an elemen t can app ear only once in each set of G , whic h readily implies that d p y q ď | G | , for all y P Ť G . 3.3. Almost uniform sampling via degree appro ximation The b ottleneck in the ab o v e algorithm is computing the degree of an element. W e replace this b y an appro ximation. Definition 3.2. Giv en t wo positive real num b ers x and y , and a parameter ε P p 0 , 1 q , the n umbers x and y are ε -appr oximation of each other, denoted by x « ε y , if x {p 1 ` ε q ď y ď x p 1 ` ε q and y {p 1 ` ε q ď x ď y p 1 ` ε q . 7 In the approximate v ersion, given an item x P Ť G , we can approximate its degree and get an impro ved runtime for the algorithm. Lemma 3.3. The input is a family of sets F that one c an pr epr o c ess in line ar time. L et G Ď F b e a sub-family and let n “ | Ť G | , g “ | G | , and ε P p 0 , 1 q b e a p ar ameter. One c an sample an element x P Ť G with almost uniform pr ob ability distribution. Sp e cific al ly, the pr ob ability of an element to b e output is « ε 1 { n . After line ar time pr epr o c essing, the query time is O p g ε ´ 2 log n q , in exp e ctation, and the query suc c e e ds with high pr ob ability. Pr o of: Let m “ G . Since d p x q “ | D G p x q| , it follows that w e need to appro ximate the size of D G p x q in G . Given a set X P G , we can in constan t time chec k if x P X , and as suc h decide if X P D G p x q . It follows that we can apply the algorithm of Lemma 2.3 , whic h requires W p x q “ O ` g d p x q ε ´ 2 log n ˘ time, where the algorithm succeeds with high probabilit y . The query algorithm is the same as b efore, except that it uses the estimated degree. F or x P Ť G , let E x b e the even t that the elemen t x is pic ked for estimation in a round, and let E 1 x b e the ev ent that it was actually output in that round. Clearly , w e ha ve P r E 1 x | E x s “ 1 { d , where d is the degree estimate of x . Since d « ε d p x q (with high probabilit y), it follo ws that P r E 1 x | E x s « ε 1 { d p x q . Since there are d p x q copies of x in G , and the elemen t for estimation is pic k ed uniformly from the sets of G , it follo ws that the probability of an y elemen t x P Ť G to b e output in a round is P r E 1 x s “ P r E 1 x | E x s P r E x s “ P r E 1 x | E x s d p x q m « ε 1 { m, as E 1 x Ď E x . As suc h, the probability of the algorithm terminating in a round is α “ ř x P Ť G P r E 1 x s « ε n { m ě n { 2 m. As for the exp ected amoun t of work in eac h round, observe that it is prop ortional to W “ ÿ x P Ť G P r E x s W p x q “ ÿ x P Ť G d p x q m g ε 2 d p x q log n “ O ´ ng m ε ´ 2 log n ¯ . In tuitively , since the exp ected amount of w ork in each iteration is W , and the exp ected n umber of rounds is 1 { α , the exp ected running time is O p W { α q . This argumen t is not quite righ t, as the amoun t of work in eac h round effects the probability of the algorithm to terminate in the round (i.e., the tw o v ariables are not indep enden t). W e con tinue with a bit more care – let L i b e the running time in the i th round of the algorithm if it was to do an i th iteration (i.e., think about a version of the algorithm that skips the experiment in the end of the iteration to decide whether it is going to stop), and let Y i b e a random v ariable that is 1 if the (original) algorithm had not stopp ed at the end of the first i iterations of the algorithm. By the ab ov e, we ha ve that y i “ P r Y i “ 1 s “ P r Y i “ 1 | Y i ´ 1 “ 1 s P r Y i ´ 1 “ 1 s ď p 1 ´ α q y i ´ 1 ď p 1 ´ α q i , and E r L i s “ O p W q . Imp ortan tly , L i and Y i ´ 1 are indep enden t (while L i and Y i are dep endent). W e clearly ha v e that the running time of the algorithm is 8 O ` ř 8 i “ 1 Y i ´ 1 L i ˘ (here, we define Y 0 “ 1). Th us, the exp ected running time of the algo- rithm is prop ortional to E ” ÿ i Y i ´ 1 L i ı “ ÿ i E r Y i ´ 1 L i s “ ÿ i E r Y i ´ 1 s E r L i s ď W ÿ i y i ´ 1 ď W 8 ÿ i “ 1 p 1 ´ α q i ´ 1 “ W α “ O p g ε ´ 2 log n q , b ecause of linearit y of exp ectations, and since L i and Y i ´ 1 are independent. Rema rk 3.4. The query time of Lemma 3.3 deteriorates to O ` g ε ´ 2 log 2 n ˘ if one w an ts the b ound to hold with high probabilit y . This follo ws by restarting the query algorithm if the query time exceeds (say b y a factor of t wo) the exp ected running time. A standard application of Mark ov’s inequality implies that this pro cess would hav e to b e restarted at most O p log n q times, with high probabilit y . Rema rk 3.5. The sampling algorithm is indep endent of whether or not we fully kno w the underlying family F and the sub-family G . This means the past queries do not affect the sampled ob ject rep orted for the query G . Therefore, the almost uniform distribution prop erty holds in the presence of sev eral queries and indep enden tly for each of them. 3.4. Almost uniform sampling via sim ulation It turns out that one can av oid the degree appro ximation stage in the ab o ve algorithm, and ac hieve only a polylogarithmic dependence on ε ´ 1 . T o this end, let x be the element pic ked. W e need to sim ulate a pro cess that accepts x with probabilit y 1 { d p x q . W e start with the following natural idea for estimating d p x q – prob e the sets randomly (with replacemen t), and stop in the i th iteration if it is the first iteration where the probe found a set that contains x . If there are g sets, then the distribution of i is geometric, with probabilit y p “ d p x q{ g . In particular, in exp ectation, E r i s “ g { d p x q , whic h implies that d p x q “ g { E r i s . As suc h, it is natural to take g { i as an estimation for the degree of x . Thus, to simulate a pro cess that succeeds with probabilit y 1 { d p x q , it would b e natural to return 1 with probability i { g and 0 otherwise. Surprisingly , while this seems like a heuristic, it do es w ork, under the righ t interpretation, as testified b y the follo wing. Lemma 3.6. Assume we have g urns, and exactly d ą 0 of them, ar e non-empty. F urther- mor e, assume that we c an che ck if a sp e cific urn is empty in c onstant time. Then, ther e is a r andomize d algorithm, that outputs a numb er Y ě 0 , such that E r Y s “ 1 { d . The exp e cte d running time of the algorithm is O p g { d q . Pr o of: The algorithm repeatedly probes urns (uniformly at random), un til it finds a non- empt y urn. Assume it found a non-empt y urn in the i th prob e. The algorithm outputs the v alue i { g and stops. 9 Setting p “ d { g , and let Y b e the output of the algorithm. we hav e that E “ Y ‰ “ 8 ÿ i “ 1 i g p 1 ´ p q i ´ 1 p “ p g p 1 ´ p q 8 ÿ i “ 1 i p 1 ´ p q i “ p g p 1 ´ p q ¨ 1 ´ p p 2 “ 1 pg “ 1 d , using the formula ř 8 i “ 1 ix i “ x {p 1 ´ x q 2 . The exp ected n umber of prob es performed b y the algorithm un til it finds a non-empt y urn is 1 { p “ g { d , whic h implies that the exp ected running time of the algorithm is O p g { d q . The natural wa y to deploy Lemma 3.6 , is to run its algorithm to get a num b er y , and then return 1 with probability y . The problem is that y can b e strictly larger than 1, whic h is meaningless for probabilities. Instead, w e back off b y using the v alue y { ∆, for some parameter ∆. If the returned v alue is larger than 1, w e just treat it at zero. If the zeroing nev er happ ened, the algorithm would return one with probabilit y 1 {p d p x q ∆ q – whic h w e can use to our purposes via, essentially , amplification. Instead, the probabilit y of success is going to b e sligh tly smaller, but fortunately , the loss can b e made arbitrarily small by taking ∆ to b e sufficien tly large. Lemma 3.7. Ther e ar e g urns, and exactly d ą 0 of them ar e not empty. F urthermor e, assume one c an che ck if a sp e cific urn is empty in c onstant time. L et γ P p 0 , 1 q b e a p ar ameter. Then one c an output a numb er Z ě 0 , such that Z P r 0 , 1 s , and E r Z s P I “ “ 1 d ∆ ´ γ , 1 d ∆ ‰ , wher e ∆ “ r ln γ ´ 1 s ` 4 “ Θ p log γ ´ 1 q . The exp e cte d running time of the algorithm is O p g { d q . A lternatively, the algorithm c an output a bit X , such that P r X “ 1 s P I . Pr o of: W e mo dify the algorithm of Lemma 3.6 , so that it outputs i {p g ∆ q instead of i { g . If the algorithm do es not stop in the first g ∆ ` 1 iterations, then the algorithm stops and outputs 0. Observe that the probabilit y that the algorithm fails to stop in the first g ∆ iterations, for p “ d { g , is p 1 ´ p q g ∆ ď exp ´ ´ d g g ∆ ¯ ď exp p´ d ∆ q ď exp p´ ∆ q ! γ . Let Z be the random v ariable that is the n umber output b y the algorithm. Arguing as in Lemma 3.6 , we hav e that E r Z s ď 1 {p d ∆ q . More precisely , we ha v e E r Z s “ 1 d ∆ ´ ř 8 i “ g ∆ ` 1 i g ∆ p 1 ´ p q i ´ 1 p. Let g p j ` 1 q ÿ i “ g j ` 1 i g p 1 ´ p q i ´ 1 p ď p j ` 1 q g p j ` 1 q ÿ i “ g j ` 1 p 1 ´ p q i ´ 1 p “ p j ` 1 qp 1 ´ p q g j g ´ 1 ÿ i “ 0 p 1 ´ p q i p ď p j ` 1 qp 1 ´ p q g j ď p j ` 1 q ˆ 1 ´ d g ˙ g j ď p j ` 1 q exp p´ d j q . Let g p j q “ j ` 1 ∆ exp p´ d j q . W e hav e that E r Z s ě 1 d ∆ ´ β , where β “ ř 8 j “ ∆ g p j q . F urther- more, for j ě ∆, we hav e g p j ` 1 q g p j q “ p j ` 2 q exp p´ d p j ` 1 qq p j ` 1 q exp p´ d j q ď ˆ 1 ` 1 ∆ ˙ e ´ d ď 5 4 e ´ d ď 1 2 . 10 As suc h, w e ha ve that β “ 8 ÿ j “ ∆ g p j q ď 2 g p ∆ q ď 2 ∆ ` 1 ∆ exp p´ d ∆ q ď 4 exp p´ ∆ q ď γ , b y the choice of v alue for ∆. This implies that E r Z s ě 1 {p d ∆ q ´ β ě 1 {p d ∆ q ´ γ , as desired. The alternativ e algorithm takes the output Z , and returns 1 with probability Z , and zero otherwise. Lemma 3.8. The input is a family of sets F that one pr epr o c esses in line ar time. L et G Ď F b e a sub-family and let n “ | Ť G | , g “ | G | , and let ε P p 0 , 1 q b e a p ar ameter. One c an sample an element x P Ť G with almost uniform pr ob ability distribution. Sp e cific al ly, the pr ob ability of an element to b e output is « ε 1 { n . After line ar time pr epr o c essing, the query time is O p g log p g { ε qq , in exp e ctation, and the query suc c e e ds, with high pr ob ability (in g ). Pr o of: The algorithm rep eatedly samples an element x using steps (I) and (I I) of the algo- rithm of Section 3.2 . The algorithm returns x if the algorithm of Lemma 3.7 , inv oked with γ “ p ε { g q O p 1 q returns 1. W e hav e that ∆ “ Θ p log p g { ε qq . Let α “ 1 {p d p x q ∆ q . The algorithm returns x in this iteration with probability p , where p P r α ´ γ , α s . Observ e that α ě 1 {p g ∆ q , whic h implies that γ ! p ε { 4 q α , it follo ws that p « ε 1 {p d p x q ∆ q , as desired. The exp ected running time of each round is O p g { d p x qq . Arguing as in Lemma 3.3 , this implies that eac h round, in expectation tak es O p ng { m q time, where m “ G . Similarly , the exp ected n umber of rounds, in exp ectation, is O p ∆ m { n q . Again, arguing as in Lemma 3.3 , implies that the exp ected running time is O p g ∆ q “ O p g log p g { ε qq . Rema rk 3.9. Similar to Remark 3.4 , the query time of Lemma 3.8 can b e made to work with high probabilit y with an additional logarithmic factor. Th us with high probability , the query time is O p g log p g { ε q log n q . 3.5. Handling outliers Imagine a situation where w e hav e a mark ed set of outliers O . W e are in terested in sampling from Ť G z O . W e assume that the total degree of the outliers in the query is at most m O for some prespecified parameter m O . More precisely , we ha v e d G p O q “ ř x P O d G p x q ď m O . Lemma 3.10. The input is a family of sets F that one c an pr epr o c ess in line ar time. A query is a sub-family G Ď F , a set of outliers O , a p ar ameter m O , and a p ar ameter ε P p 0 , 1 q . One c an either (A) Sample an element x P Ť G z O with ε -appr oximate uniform distribution. Sp e cific al ly, the pr ob abilities of two elements to b e output is the same up to a factor of 1 ˘ ε . (B) A lternatively, r ep ort that d G p O q ą m O . The exp e cte d query time is O p m O ` g log p N { ε qq , and the query suc c e e ds with high pr ob ability, wher e g “ | G | , and N “ F . 11 Pr o of: The main mo dification of the algorithm of Lemma 3.8 , is that whenev er we encounter an outlier (the assumption is that one can c heck if an elemen t is an outlier in constan t time), then we delete it from the set X where it w as disco vered. If w e implemen t sets as arra ys, this can b e done by moving an outlier ob ject to the end of the activ e prefix of the arra y , and decreasing the count of the activ e arra y . W e also need to decrease the (activ e) size of the set. If the algorithm encoun ters more than m O outliers then it stops and rep orts that the n umber of outliers is to o large. Otherwise, the algorithm contin ues as b efore. The only difference is that once the query pro cess is done, the activ e coun t (i.e., size) of each set needs to b e restored to its original size, as is the size of the set. This clearly can be done in time prop ortional to the query time. 4. In the searc h for a fair near neigh b or In this section, we employ our data structure of Section 3 to show the tw o results on uniformly rep orting a neigh b or of a query p oint men tioned in Section 1.1 . First, let us briefly giv e some preliminaries on LSH . W e refer the reader to [ HIM12 ] for further details. Throughout the section, w e assume that our metric space, admits the LSH data structure. 4.1. Bac kground on LSH Lo calit y Sensitiv e Hashing ( LSH ). Let D denote the data structure constructed b y LSH , and let c denote the approximation parameter of LSH . The data-structure D consists of L hash functions g 1 , . . . , g L (e.g., L « n 1 { c for a c -appro ximate LSH ), whic h are chosen via a random process and each function hashes the points to a set of buc kets. F or a p oint p P M , let H i p p q b e the buck et that the p oin t p is hashed to using the hash function g i . The follo wing are standard guaran tees provided by the LSH data structure [ HIM12 ]. Lemma 4.1. F or a given query p oint q , let S “ Ť i H i p q q . Then for any p oint p P N p q , r q , we have that with a pr ob ability of le ast 1 ´ 1 { e ´ 1 { 3 , we have (i) p P S and (ii) | S z B p q , cr q| ď 3 L , i.e., the numb er of outliers is at most 3 L . Mor e over, the exp e cte d numb er of outliers in any single bucket H i p q q is at most 1 . Therefore, if w e tak e t “ O p log n q differen t data structures D 1 , . . . , D t with corresponding hash functions g j i to denote the i th hash function in the j th data structure, w e ha ve the follo wing lemma. Lemma 4.2. L et the query p oint b e q , and let p b e any p oint in N p q , r q . Then, with high pr ob ability, ther e exists a data structur e D j , such that p P S “ Ť i H j i p q q and | S z B p q , cr q| ď 3 L . By the ab ov e, the space used by LSH is S p n, c q “ r O p n ¨ L q and the query time is Q p n, c q “ r O p L q . 12 4.2. Appro ximate Neigh b orho o d F or t “ O p log n q , let D 1 , . . . , D t b e data structures constructed by LSH . Let F b e the set of all buck ets in all data structures, i.e., F “ H j i p p q ˇ ˇ i ď L, j ď t, p P P ( . F or a query p oint q , consider the family G of all buck ets con taining the query , i.e., G “ t H j i p q q | i ď L, j ď t u , and th us | G | “ O p L log n q . Moreo v er, we let O to b e the set of outliers, i.e., the p oin ts that are farther than cr from q . Note that as men tioned in Lemma 4.1 , the exp ected n um b er of outliers in each buc ket of LSH is at most 1. Therefore, by Lemma 3.10 , we immediately get the follo wing result. Lemma 4.3. Given a set P of n p oints and a p ar ameter r , we c an pr epr o c ess it such that given query q , one c an r ep ort a p oint p P S with pr ob ability µ p wher e ϕ {p 1 ` ε q ď µ p ď p 1 ` ε q ϕ , wher e S is a p oint set such that N p q , r q Ď S Ď N p q , cr q , and ϕ “ 1 {| S | . The algorithm uses sp ac e S p n, c q and its exp e cte d query time is r O p Q p n, c q ¨ log p 1 { ε qq . Pr o of: Let S “ Ť G z O ; b y Lemma 4.2 , w e kno w that N p q , r q Ď S Ď N p q , cr q , and moreo ver in exp ectation m O ď L “ | G | . W e apply the algorithm of Lemma 3.10 . The run time of the algorithm is in exp ectation r O p| G | log p 1 { ε qq “ r O p L ¨ log p 1 { ε qq “ r O p Q p n, c q ¨ log p 1 { ε qq , and the algorithm produces an almost uniform distribution o ver the p oin ts in S . Rema rk 4.4. F or the L 1 distance, the runtime of our algorithm is r O p n p 1 { c q` o p 1 q q and for the L 2 distance, the runtime of our algorithm is r O p n p 1 { c 2 q` o p 1 q q . These matc hes the run time of the standard LSH -based near neighbor algorithms up to p olylog factors. 4.3. Exact Neigh b orho o d As noted earlier, the result of the previous section only guarantees a query time which holds in exp ectation. Here, we pro vide an algorithm whose query time holds with high pr ob ability . Note that, here we cannot apply Lemma 3.10 directly , as the total num b er of outliers in our data structure migh t b e large with non-negligible probability (and thus w e cannot b ound m O ). How ev er, as noted in Lemma 4.2 , with high probabilit y , there exists a subset of these data structures J Ď r t s such that for each j P J , the n umber of outliers in S j “ Ť i H j i p q q is at most 3 L , and moreov er, we hav e that N p q , r q Ď Ť j P J S j . Therefore, on a high level, w e mak e a guess J 1 of J , which w e initialize it to J 1 “ r t s , and start by dra wing samples from G ; once w e encoun ter more than 3 L outliers from a certain data structure D j , w e infer that j R J , up date the v alue of J 1 “ J 1 zt j u , and set the weigh ts of the buck ets corresp onding to D j equal to 0, so that they will nev er participate in the sampling pro cess. As such, at any iteration of the algorithm we are effectiv ely sampling from G “ t H j i p q q | i ď L, j P J 1 u . Prepro cessing. W e k eep t “ O p log n q LSH data structures whic h w e refer to as D 1 , . . . , D t , and w e k eep the hashed p oints by the i th hash function of the j th data structure in the arra y denoted b y H j i . Moreov er, for each buck et in H j i , w e store its size | H j i | . Query Pro cessing. W e maintain the v ariables z j i sho wing the weigh ts of the buck et H j i p q q , whic h is initialized to | H j i p q q| that is stored in the prepro cessing stage. Moreo ver, w e k eep 13 the set of outliers detected from H j i p q q in O j i whic h is initially set to b e empt y . While running the algorithm, as we detect an outlier in H j i p q q , w e add it to O j i , and w e further decrease z j i b y one. Moreov er, in order to keep trac k of J 1 , for an y data structure D j , whenever ř i | O j i | exceeds 3 L , we will ignore all buc kets in D j , b y setting all corresp onding z j i to zero. A t eac h iteration, the algorithm pro ceeds by sampling a buck et H j i p q q proportional to its w eight z j i , but only among the set of buc kets from those data structures D j for whic h less than 3 L outliers are detected so far, i.e., j P J 1 . W e then sample a point uniformly at random from the p oints in the chosen buc k et that hav e not b een detected as an outlier, i.e., H j i p q qz O j i . If the sampled p oin t is an outlier, we up date our data structure accordingly . Otherwise, w e pro ceed as in Lemma 3.8 . Definition 4.5 (Active data structures and active buckets). Consider an iteration k of the algo- rithm. Let us define the set of active data structur es to b e the data structures from whom w e hav e seen less than 3 L outliers so far, and let us denote their indices b y J 1 k Ď r t s , i.e., J 1 k “ j ˇ ˇ ř i | O i j | ă 3 L ( . Moreo ver, let us define the active buckets to b e all buc kets con taining the query in these activ e data structures, i.e., G k “ t H j i p q q | i ď L, j P J 1 k u . Observ ation 4.6. L emma 4.2 implies that with high pr ob ability at any iter ation k of the algorithm N p q , r q Ď Ť G k . Definition 4.7 (active size). F or an activ e buc ket H j i p q q , w e define its activ e size to be z j i whic h sho ws the total n umber of p oin ts in the buc ket that ha ve not y et b een detected as an outlier, i.e., | H j i p q qz O j i | . Lemma 4.8. Given a set P of n p oints and a p ar ameter r , we c an pr epr o c ess it such that given a query q , one c an r ep ort a p oint p P P with pr ob ability µ p , so that ther e exists a value ρ P r 0 , 1 s wher e ‚ F or p P N p q , r q , we have ρ p 1 ` O p ε qq ď µ p ď p 1 ` O p ε qq ρ . ‚ F or p P N p q , cr qz N p q , r q , we have µ p ď p 1 ` O p ε qq ρ . ‚ F or p R N p q , cr q , we have µ p “ 0 . The sp ac e use d is r O p S p n, c qq and the query time is r O ` Q p n, c q ¨ log p 1 { ε qq with high pr ob ability. Pr o of: First note that the algorithm never outputs an outlier, and thus the third item is alw ays satisfied. Next, let K be a random v ariable showing the n umber of iterations of the algorithm, and for an iteration k , define the random v ariable M k “ N p q , cr q X Ť G k as the set of non-outlier p oin ts in the set of active buck ets. Conditioned on K “ k , b y Lemma 3.8 , we kno w that the distribution of the output is almost uniform on M k . Moreo v er, w e know that for all k w e hav e M k Ď M k ´ 1 , and that b y Observ ation 4.6 , N p q , r q Ď M k . Therefore, for all p oin ts in N p q , r q their probability of being rep orted as the final output of the algorithm is equal, and moreov er, for all points in N p q , cr qz N p q , r q , their probabilit y of b eing rep orted is lo wer (as at some iteration, some of these p oints might go out of the set of active buck ets). This pro ves the probabilit y condition. 14 T o b ound the query time, let us consider the iterations where the sampled p oin t p is an outlier, and not an outlier, separately . The total num b er of iterations where an outlier p oin t is sampled is at most 3 L ¨ t “ r O p L q “ r O p Q p n, c qq for whic h w e only pa y r O p 1 q cost. F or non-outlier points, their total cost can b e b ounded using Lemma 3.8 and Remark 3.9 by r O p| G 1 | log p 1 { ε qq “ r O p L ¨ log p 1 { ε qq “ r O p Q p n, c q ¨ log p 1 { ε qq . Lemma 4.9. Given a set P of n p oints and a p ar ameter r , we c an pr epr o c ess it such that given a query q , one c an r ep ort a p oint p P S with pr ob ability µ p wher e µ is an appr oximately uniform pr ob ability distribution: ϕ {p 1 ` ε q ď µ p ď ϕ p 1 ` ε q , wher e ϕ “ 1 {| N p q , r q| . The algorithm uses sp ac e S p n, c q and has query time of r O ` Q p n, c q ¨ | N p q,cr q| | N p q,r q| ¨ log p 1 { ε q ˘ with high pr ob ability. Pr o of: W e run Algorithm of Lemma 4.8 , and while its output is outside of N p q , r q , we ignore it and run the algorithm again. By Lemma 4.8 , the output is guaranteed to b e almost uniform on N p q , r q . Moreov er, b y Lemma 4.8 , and b ecause with high probabilit y , we only need to run the algorithm r O p | N p q,cr q| | N p q,r q| q times, we get the desired b ound on the query time. 5. Exp erimen ts In this section, we consider the task of retrieving a random p oin t from the neigh b orho o d of a giv en query p oin t, and ev aluate the effectiveness of our proposed algorithm empirically on real data sets. Data set and Queries. W e run our exp erimen ts on three datasets that are standard b enc hmarks in the context of Nearest Neigh b or algorithms (see [ ABF17 ]) (I) Our first data set con tains a random subset of 10K points in the MNIST training data set [ LBBH98 ] 3 . The full data set con tains 60K images of hand-written digits, where eac h image is of size 28 b y 28. F or the query , w e use a random subset of 100 (out of 10K) images of the MNIST test data set. Therefore, eac h of our points lie in a 784 dimensional Euclidean space and each co ordinate is in r 0 , 255 s . (I I) Second, w e tak e SIFT10K image descriptors that con tains 10K 128-dimensional p oints as data set and 100 p oin ts as queries 4 . (I I I) Finally , w e take a random subset of 10K w ords from the GloV e data set [ PSM14 ] and a random subset of 100 words as our query . GloV e is a data set of 1.2M w ord em b eddings in 100-dimensional space and we further normalize them to unit norm. W e use the L 2 Euclidean distance to measure the distance b et ween the p oints. LSH data structure and parameters. W e use the lo cality sensitiv e hashing data struc- ture for the L 2 Euclidean distance [ AI08 ]. That is, each of the L hash functions g i , is a concatenation of k unit hash functions h 1 i ‘ ¨ ¨ ¨ ‘ h k i . Each of the unit hash functions h j i 3 The dataset is av ailable here: http://y ann.lecun.com/exdb/mnist/ 4 The dataset if av ailable here: http://corpus-texmex.irisa.fr/ 15 is c hosen b y selecting a p oint in a random direction (b y c ho osing ev ery coordinate from a Gaussian distribution with parameters p 0 , 1 q ). Then all the p oints are pro jected on to this one dimensional direction. Then we put a randomly shifted one dimensional grid of length w along this direction. The cells of this grid are considered as buc k ets of the unit hash function. F or tuning the parameters of LSH , we follow the metho d describ ed in [ DI IM04 ], and the manual of E2LSH library [ And05 ], as follows. F or MNIST, the av erage distance of a query to its nearest neighbor in the our data set is around 4 . 5. Th us w e choose the near neigh b or radius r “ 5. Consequen tly , as w e observ e, the r -neighborho o d of at least half of the queries are non-empt y . As suggested in [ DI IM04 ] to set the v alue of w “ 4, we tune it b etw een 3 and 5 and set its v alue to w “ 3 . 1. W e tune k and L so that the false negativ e rate (the near p oints that are not retriev ed b y LSH ) is less than 10%, and moreov er the cost of hashing (prop ortional to L ) balances out the cost of scanning. W e thus get k “ 15 and L “ 100. This also agrees with the fact that L should b e roughly square ro ot of the total n umber of p oin ts. Note that we use a single LSH data structure as opp osed to taking t “ O p log n q instances. W e use the same metho d for the other t wo data sets. F or SIFT, we use R “ 255, w “ 4, k “ 15, L “ 100, and for GloV e w e use R “ 0 . 9, w “ 3 . 3, k “ 15, and L “ 100. Algorithms. Giv en a query p oint q , we retriev e all L buck ets corresp onding to the query . W e then implement the following algorithms and compare their p erformance in returning a neigh b or of the query p oint. ‚ Uniform/Uniform : Picks buc k et uniformly at random and pic ks a random p oin t in buc ket. ‚ W eigh ted/Uniform : Pic ks buc ket according to its size, and pic ks uniformly random p oin t inside buck et. ‚ Optimal : Picks buc ket according to size, and then pic ks uniformly random p oint p inside buc ket. Then it computes p ’s degree exactly and rejects p with probabilit y 1 ´ 1 { deg p p q . ‚ Degree appro ximation : Pic ks buc ket according to size, and pic ks uniformly random p oin t p inside buck et. It approximates p ’s degree and rejects p with probability 1 ´ 1 { deg 1 p p q . Degree appro ximation metho d. W e use the algorithm of Section 3.4 for the degree appro ximation: w e implement a v ariant of the sampling algorithm whic h rep eatedly samples a buc ket uniformly at random and c hecks whether p b elongs to the buc k et. If the first time this happens is at iteration i , then it outputs the estimate as deg 1 p p q “ L { i . Exp erimen t Setup. In order to compare the p erformance of different algorithms, for each query q , we compute M p q q : the set of neigh b ors of q whic h fall to the same buc k et as q by at least one of the L hash functions. Then for 100 | M p q q| times, w e dra w a sample from the neigh b orho o d of the query , using all four algorithms. W e compare the empirical distribution of the rep orted p oints on | M p q q| with the uniform distribution on it. More specifically , we compute the total v ariation distance (statistical distance) 5 to the uniform distribution. W e 5 F or t wo discrete distributions µ and ν on a finite set X , the total v ariation distance is 1 2 ř x P X | µ p x q´ ν p x q| . 16 rep eat each experiment 10 times and rep ort the av erage result of all 10 exp eriments o ver all 100 query p oin ts. Results. Figure 5.1 sho ws the comparison betw een all four algorithms. T o compare their p erformance, we compute the total v ariation distance of the empirical distribution of the algorithms to the uniform distribution. F or the tuned parameters ( k “ 15 , L “ 100), our results are as follo ws. F or MNIST, w e see that our proposed degree approximation based algorithm p erforms only 2 . 4 times w orse than the optimal algorithm, while w e see that other standard sampling metho ds p erform 6 . 6 times and 10 times w orse than the optimal algorithm. F or SIFT, our algorithm p erforms only 1 . 4 times w orse than the optimal while the other t wo p erform 6 . 1 and 9 . 7 times w orse. F or GloV e, our algorithm p erforms only 2 . 7 times worse while the other t wo p erform 6 . 5 and 13 . 1 times w orse than the optimal algorithm. Moreo ver, in order get a differen t range of degrees and sho w that our algorithm works w ell for those cases, w e further v ary the parameters k and L of LSH. More precisely , to get higher ranges of the degrees, first w e decrease k (the num b er of unit hash functions used in eac h of the L hash function); this will result in more collisions. Second, we increase L (the total n umber of hash functions). These are tw o w a ys to increase the degree of p oin ts. F or example for the MNIST data set, the ab ov e pro cedure increases the degree range from r 1 , 33 s to r 1 , 99 s . Query time discussion. As stated in the exp erimen t setup, in order to hav e a meaningful comparison b et ween distributions, in our co de, w e retrieve a random neigh b or of eac h query 100 m times, where m is the size of its neighborho o d (which itself can b e as large as 1000). W e further rep eat each exp erimen t 10 times. Th us, every query migh t b e asked upto 10 6 times. This is going to b e costly for the optimal algorithm that computes the degree exactly . Th us, we use the fact that we are asking the same query man y times and prepro cess the exact degrees for the optimal solution. Therefore, it is not meaningful to compare runtimes directly . Thus w e run the exp eriments on a smaller size dataset to compare the run times of all the four approaches: F or k “ 15 and L “ 100, our sampling approach is twice faster than the optimal algorithm, and almost five times slow er than the other tw o approac hes. Ho wev er, when the n umber of buc k ets (L) increases from 100 to 300, our algorithm is 4.3 times faster than the optimal algorithm, and almost 15 times slo w er than the other t wo approac hes. T rade-off of time and accuracy . W e can sho w a trade-off b et ween our prop osed sampling approac h and the optimal. F or the MNIST data set with tuned parameters ( k “ 15 and L “ 100), by asking twice more queries (for degree appro ximation), the solution of our approac h improv es from 2.4 to 1.6, and with three times more, it impro ves to 1.2, and with four times more, it improv es to 1.05. F or the SIFT data set (using the same parameters), using twice more queries, the solution impro ves from 1.4 to 1.16, and with three times more, it impro ves to 1.04, and with four times more, it improv es to 1.05. F or GloV e, using twice more queries, the solution improv es from 2.7 to 1.47, and with three times more, it impro ves to 1.14, and with four times more, it improv es to 1.01. 17 k D is t an c e Un ifo rm / Un ifo rm W e ig h t e d / Un ifo rm D eg r ee A p p r o x A l g . O p t im al A lg o rit h m 10 L _1 0. 232314 0. 12688 0. 033376 0. 0292465 11 L _1 0. 254682 0. 152997 0. 036595 0. 0289694 12 L _1 0. 270557 0. 155822 0. 0412464 0. 0295204 13 L _1 0. 29587 0. 181187 0. 0540551 0. 0294889 14 L _1 0. 265355 0. 164732 0. 0546907 0. 0283629 15 L _1 0. 270462 0. 179841 0. 0655905 0. 0271386 0 0.05 0.1 0.15 0.2 0.25 0.3 0.35 10 11 12 13 14 15 Statistical Distance Value of parameter k of LSH Statis tical Dist ance to Uniform Distrib ution Uniform/Uniform Weighted/Uniform Degree App rox Alg. Optimal Algorith m (a) MNIST, v arying the parameter k of LSH L D istan ce Un ifo rm / Un ifo rm We ig h te d / Un ifo rm D egree Ap p ro x Al g . Optim al A lg o rith m 100 L _1 0 .27 0 4 6 2 0 .17 9 8 4 1 0 .06 5 5 9 0 5 0 .02 7 1 3 8 6 200 L _1 0 .26 1 5 7 4 0 .18 1 6 8 7 0 .04 8 2 2 1 9 0 .02 8 8 5 9 6 300 L _1 0 .26 6 7 3 7 0 .19 2 7 4 8 0 .04 1 5 3 6 9 0 .03 0 0 1 4 0 0.05 0.1 0.15 0.2 0.25 0.3 100 200 300 Sta tis tical Dis ta n ce Valu e o f p ar ame ter L o f LSH St a tis tic al Dis t anc e t o Unif o rm Dis tribu tio n Un i fo rm/Un i fo r m W e i g h te d /Un i f o rm De g re e A p p ro x A l g . O p ti mal A l g o ri th m (b) MNIST, v arying the parameter L of LSH k D istan ce Un ifo rm / Un ifo rm We ig h te d / Un ifo rm D egree Ap p ro x Al g . Optim al A lg o rith m 10 L _1 0 .23 8 8 3 5 0 .12 1 1 1 5 0 .03 4 5 1 9 0 .03 2 5 8 3 7 11 L _1 0 .25 7 0 7 4 0 .13 6 0 3 5 0 .03 3 9 6 2 1 0 .03 1 9 1 8 5 12 L _1 0 .26 2 3 3 3 0 .14 7 0 8 8 0 .03 4 7 0 9 2 0 .03 1 1 5 0 3 13 L _1 0 .28 9 3 0 8 0 .16 1 9 8 4 0 .03 6 3 2 1 4 0 .03 0 4 2 7 1 14 L _1 0 .28 3 9 1 4 0 .16 8 4 5 5 0 .03 9 3 6 7 7 0 .03 0 7 0 6 9 15 L _1 0 .29 8 6 7 7 0 .18 6 7 6 0 .04 1 8 1 9 7 0 .03 0 8 0 1 3 0 0.05 0.1 0.15 0.2 0.25 0.3 0.35 10 11 12 13 14 15 Sta tis tical Dis ta n ce Valu e o f p ar amete r k o f L SH St a tis tic al Dis t anc e t o Unif o rm Dis tribu tio n Un i fo rm/Un i fo r m W e i g h te d /Un i f o rm De g re e A p p ro x A l g . O p ti mal A l g o ri th m (c) SIFT, v arying the parameter k of LSH L D istan ce Un ifo rm / Un ifo rm We ig h te d / Un ifo rm D egree Ap p ro x Al g . Optim al A lg o rith m 100 L _1 0 .29 8 6 7 7 0 .18 6 7 6 0 .04 1 8 1 9 7 0 .03 0 8 0 1 3 200 L _1 0 .27 2 1 2 2 0 .16 3 5 9 4 0 .03 5 4 2 7 8 0 .03 1 0 7 8 3 300 L _1 0 .25 7 7 6 9 0 .15 3 8 9 1 0 .03 3 4 0 6 1 0 .03 1 6 2 5 3 0 0.05 0.1 0.15 0.2 0.25 0.3 0.35 100 200 300 Sta tis tical Dis ta n ce Valu e o f p ar ame ter L o f LSH St a tis tic al Dis t anc e t o Unif o rm Dis tribu tio n Un i fo rm/Un i fo r m W e i g h te d /Un i f o rm De g re e A p p ro x A l g . O p ti mal A l g o ri th m (d) SIFT, v arying the parameter L of LSH k D istan ce Un ifo rm / Un ifo rm We ig h te d / Un ifo rm D egree Ap p ro x Al g . Optim al A lg o rith m 10 L _1 0 .18 5 4 8 0 .07 1 6 0 2 4 0 .02 7 6 4 0 5 0 .02 5 3 6 9 11 L _1 0 .16 6 1 3 1 0 .08 1 5 8 1 2 0 .03 1 8 2 7 1 0 .02 2 6 1 4 1 12 L _1 0 .20 5 1 4 8 0 .08 8 4 8 6 6 0 .02 6 7 9 8 9 0 .02 3 4 2 8 2 13 L _1 0 .22 2 3 2 7 0 .11 4 8 4 4 0 .03 9 9 7 2 1 0 .02 1 8 4 0 7 14 L _1 0 .21 8 1 0 1 0 .11 2 5 7 8 0 .03 7 1 8 6 3 0 .01 9 1 6 3 8 15 L _1 0 .26 0 5 2 7 0 .12 9 3 0 9 0 .05 2 9 8 8 9 0 .01 9 8 6 4 0 0.05 0.1 0.15 0.2 0.25 0.3 10 11 12 13 14 15 Sta tis tical Dis ta n ce Valu e o f p ar amete r k o f L SH St a tis tic al Dis t anc e t o Unif o rm Dis tribu tio n Un i fo rm/Un i fo r m W e i g h te d /Un i f o rm De g re e A p p ro x A l g . O p ti mal A l g o ri th m (e) GloV e, v arying the parameter k of LSH L D istan ce Un ifo rm / Un ifo rm We ig h te d / Un ifo rm D egree Ap p ro x Al g . Optim al A lg o rith m 100 L _1 0 .26 0 5 2 7 0 .12 9 3 0 9 0 .05 2 9 8 8 9 0 .01 9 8 6 4 200 L _1 0 .22 4 7 3 7 0 .13 4 6 0 5 0 .03 9 6 9 6 7 0 .01 9 6 1 0 3 300 L _1 0 .20 1 7 5 6 0 .10 2 2 2 2 8 0 .02 2 5 2 5 1 0 .02 1 8 1 7 6 0 0.05 0.1 0.15 0.2 0.25 0.3 100 200 300 Sta tis tical Dis ta n ce Valu e o f p ar ame ter L o f LSH St a tis tic al Dis t anc e t o Unif o rm Dis tribu tio n Un i fo rm/Un i fo r m W e i g h te d /Un i f o rm De g re e A p p ro x A l g . O p ti mal A l g o ri th m (f ) GloV e, v arying the parameter L of LSH Figure 5.1: Comparison of the p erformance of the four algorithms is measured by computing the statistical distance of their empirical distribution to the uniform distribution. 6. Ac kno wledgemen t The authors w ould lik e to thank Piotr Indyk for the helpful discussions ab out the mo deling and experimental sections of the pap er. 18 References [ABD ` 18] Alekh Agarwal, Alina Beygelzimer, Miroslav Dud ´ ık, John Langford, and Hanna M. W allac h. A reductions approach to fair classification. In Jennifer G. Dy and Andreas Krause, editors, Pr o c. 35th Int. Conf. Mach. L e arning (ICML), v olume 80 of Pr o c. of Mach. L e arn. R ese ar ch , pages 60–69. PMLR, 2018. [ABF17] M. Aum ¨ uller, E. Bernhardsson, and A. F aithfull. Ann-b enc hmarks: A b enc h- marking to ol for appro ximate nearest neigh b or algorithms. In International Confer enc e on Similarity Se ar ch and Applic ations , 2017. [Ada07] Eytan Adar. User 4xxxxx9: Anon ymizing query logs. App eared in the w orkshop Query L o g Analysis: So cial and T e chnolo gic al Chal lenges , in association with WWW 2007, 01 2007. [AI08] A. Andoni and P . Indyk. Near-optimal hashing algorithms for appro ximate nearest neigh b or in high dimensions. Commun. A CM , 51(1):117–122, 2008. [And05] Alexandr Andoni. E2lsh 0.1 user man ual. https://www.mit.e du/ an- doni/LSH/manual.p df , 2005. [AP19] P eyman Afshani and Jeff M. Phillips. Indep endent range sampling, revisited again. CoRR , abs/1903.08014, 2019. to app ear in SoCG 2019. [APS19] Martin Aum¨ uller, Rasm us P agh, and F rancesco Silv estri. F air near neigh- b or searc h: Indep endent range sampling in high dimensions. arXiv pr eprint arXiv:1906.01859 , 2019. [A W17] P eyman Afshani and Zhewei W ei. Indep endent range sampling, revisited. In Kirk Pruhs and Christian Sohler, editors, 25th A nnual Eur op e an Symp osium on A lgorithms, ESA 2017, Septemb er 4-6, 2017, Vienna, Austria , v olume 87 of LIPIcs , pages 3:1–3:14. Schloss Dagstuhl - Leibniz-Zen trum fuer Informatik, 2017. [BCN19] Suman K Bera, Deeparnab Chakrabart y , and Maryam Negah bani. F air algo- rithms for clustering. arXiv pr eprint , 2019. [BHR ` 17] P aul Beame, Sariel Har-P eled, Siv aramakrishnan Natara jan Ramamo orthy , Cyrus Rashtc hian, and Makrand Sinha. Edge estimation with indep endent set oracles. CoRR , abs/1711.07567, 2017. [BIO ` 19] Arturs Bac kurs, Piotr Indyk, Krzysztof Onak, Baruch Schieber, Ali V akilian, and T al W agner. Scalable fair clustering. arXiv pr eprint , 2019. 19 [Cho17] Alexandra Chouldecho v a. F air prediction with disparate impact: A study of bias in recidivism prediction instruments. Big data , 5(2):153–163, 2017. [CKL V17] Flavio Chieric hetti, Ra vi Kumar, Silvio Lattanzi, and Sergei V assilvitskii. F air clustering through fairlets. In A dvanc es in Neur al Information Pr o c essing Sys- tems , pages 5029–5037, 2017. [CKL V19] Flavio Chieric hetti, Ravi Kumar, Silvio Lattanzi, and Sergei V assilvtiskii. Ma- troids, matchings, and fairness. In Pr o c e e dings of Machine L e arning R ese ar ch , v olume 89 of Pr o c e e dings of Machine L e arning R ese ar ch , pages 2212–2220. PMLR, 2019. [DHP ` 12] Cyn thia Dw ork, Moritz Hardt, T oniann Pitassi, Omer Reingold, and Richard Zemel. F airness through aw areness. In Pr o c e e dings of the 3r d innovations in the or etic al c omputer scienc e c onfer enc e , pages 214–226. A CM, 2012. [DI IM04] M. Datar, N. Immorlica, P . Indyk, and V. S. Mirrokni. Lo calit y-sensitive hash- ing sc heme based on p -stable distributions. In Pr o c. 20th Annu. Symp os. Com- put. Ge om. (SoCG), pages 253–262, 2004. [DOBD ` 18] Mic hele Donini, Luca Oneto, Shai Ben-David, John S Sha we-T a ylor, and Mas- similiano Pon til. Empirical risk minimization under fairness constrain ts. In A dvanc es in Neur al Information Pr o c essing Systems , pages 2791–2801, 2018. [EJJ ` 19] Hadi Elza yn, Shahin Jabbari, Christopher Jung, Mic hael Kearns, Seth Neel, Aaron Roth, and Zachary Sc hutzman. F air algorithms for learning in allo cation problems. In Pr o c e e dings of the Confer enc e on F airness, A c c ountability, and T r ansp ar ency , pages 170–179. ACM, 2019. [ELL09] Brian S. Everitt, Sabine Landau, and Morven Leese. Cluster A nalysis . Wiley Publishing, 4th edition, 2009. [HAAA14] Ahmad Basheer Hassanat, Mohammad Ali Abbadi, Ghada Aw ad Altarawneh, and Ahmad Ali Alhasanat. Solving the problem of the K parameter in the KNN classifier using an ensemble learning approac h. CoRR , abs/1409.0919, 2014. [HGB ` 07] Jia yuan Huang, Arth ur Gretton, Karsten Borgwardt, Bernhard Sc h¨ olk opf, and Alex J Smola. Correcting sample selection bias b y unlab eled data. In A dvanc es in neur al information pr o c essing systems , pages 601–608, 2007. [HIM12] S. Har-Peled, P . Indyk, and R. Motw ani. Approximate nearest neigh b ors: T o- w ards removing the curse of dimensionalit y . The ory Comput. , 8:321–350, 2012. Sp ecial issue in honor of Ra jeev Motw ani. 20 [HK01] Da vid Harel and Y eh uda Koren. On clustering using random w alks. In Ramesh Hariharan, Madhav an Mukund, and V. Vinay , editors, FST TCS 2001: F oun- dations of Softwar e T e chnolo gy and The or etic al Computer Scienc e, 21st Con- fer enc e, Bangalor e, India, De c emb er 13-15, 2001, Pr o c e e dings , volume 2245 of L e ctur e Notes in Computer Scienc e , pages 18–41. Springer, 2001. [HPS16] Moritz Hardt, Eric Price, and Nati Srebro. Equalit y of opp ortunity in su- p ervised learning. In Daniel D. Lee, Masashi Sugiy ama, Ulrik e v on Luxburg, Isab elle Guyon, and Roman Garnett, editors, Neur al Info. Pr o c. Sys. (NIPS), pages 3315–3323, 2016. [HQT14] Xiao c heng Hu, Miao Qiao, and Y ufei T ao. Indep enden t range sampling. In Ric hard Hull and Martin Grohe, editors, Pr o c e e dings of the 33r d ACM SIGMOD-SIGA CT-SIGAR T Symp osium on Principles of Datab ase Systems, PODS’14, Snowbir d, UT, USA, June 22-27, 2014 , pages 246–255. ACM, 2014. [IM98] P . Indyk and R. Motw ani. Approximate nearest neighbors: T ow ards remo ving the curse of dimensionalit y . In Pr o c. 30th Annu. ACM Symp os. The ory Comput. (STOC), pages 604–613, 1998. [KE05] Matt J Keeling and Ken T.D Eames. Netw orks and epidemic mo dels. Journal of The R oyal So ciety Interfac e , 2(4):295–307, Septem b er 2005. [KLK12] Yi-Hung Kung, P ei-Sheng Lin, and Cheng-Hsiung Kao. An optimal k -nearest neigh b or for densit y estimation. Statistics & Pr ob ability L etters , 82(10):1786 – 1791, 2012. [KLL ` 17] Jon Klein b erg, Himabindu Lakk ara ju, Jure Lesk ov ec, Jens Ludwig, and Sendhil Mullainathan. Human decisions and machine predictions. The quarterly journal of e c onomics , 133(1):237–293, 2017. [KSAM19] Matth¨ aus Kleindessner, Samira Samadi, Pranjal Aw asthi, and Jamie Mor- genstern. Guaran tees for spectral clustering with fairness constraints. arXiv pr eprint , 2019. [LBBH98] Y ann LeCun, L´ eon Bottou, Y oshua Bengio, and Patric k Haffner. Gradien t- based learning applied to document recognition. Pr o c e e dings of the IEEE , 86(11):2278–2324, 1998. [MSP16] Cecilia Munoz, Megan Smith, and DJ P atil. Big Data: A R ep ort on Algorithmic Systems, Opp ortunity, and Civil Rights . Executive Office of the President and P enny Hill Press, 2016. [O A18] Matt Olfat and Anil Aswani. Con v ex form ulations for fair principal comp onent analysis. arXiv pr eprint , 2018. 21 [PR W ` 17] Geoff Pleiss, Manish Raghav an, F elix W u, Jon Kleinberg, and Kilian Q W ein- b erger. On fairness and calibration. In A dvanc es in Neur al Information Pr o- c essing Systems , pages 5680–5689, 2017. [PSM14] Jeffrey P ennington, Ric hard So c her, and Christopher Manning. Glo ve: Global v ectors for w ord representation. In Pr o c e e dings of the 2014 c onfer enc e on empir- ic al metho ds in natur al langu age pr o c essing (EMNLP) , pages 1532–1543, 2014. [QA08] Yinian Qi and Mikhail J. A tallah. Efficient priv acy-preserving k -nearest neigh- b or searc h. In 28th IEEE International Confer enc e on Distribute d Computing Systems (ICDCS 2008), 17-20 June 2008, Beijing, China , pages 311–319. IEEE Computer Society , 2008. [SDI06] Gregory Shakhnarovic h, T rev or Darrell, and Piotr Indyk. Ne ar est-neighb or metho ds in le arning and vision: the ory and pr actic e (neur al information pr o- c essing) . The MIT Press, 2006. [TE11] A. T orralba and A. A. Efros. Un biased look at dataset bias. In CVPR 2011 , pages 1521–1528, 2011. [ZV GRG17] Muhammad Bilal Zafar, Isab el V alera, Man uel Gomez Ro driguez, and Kr- ishna P Gummadi. F airness b ey ond disparate treatment & disparate impact: Learning classification without disparate mistreatmen t. In Pr o c e e dings of the 26th International Confer enc e on World Wide Web , pages 1171–1180, 2017. 22
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment