넴시스트: 사물인터넷 냉장고 제어를 위한 하이브리드 병렬 딥러닝 프레임워크
넴시스트는 데이터베이스 기반의 모델 순차화와 하이브리드 병렬 처리를 결합해, 대규모 IoT 환경에서 딥러닝 모델의 학습·추론을 실시간에 가깝게 제공한다. 영국 전력망 부하에 맞춰 소매점 냉장고 전력을 최적화하는 수요측응답 사례를 통해 RNN, LSTM, GAN 등 다양한 모델을 손쉽게 배포·재학습할 수 있음을 입증한다.
저자: George Onoufriou, Ronald Bickerton, Simon Pearson
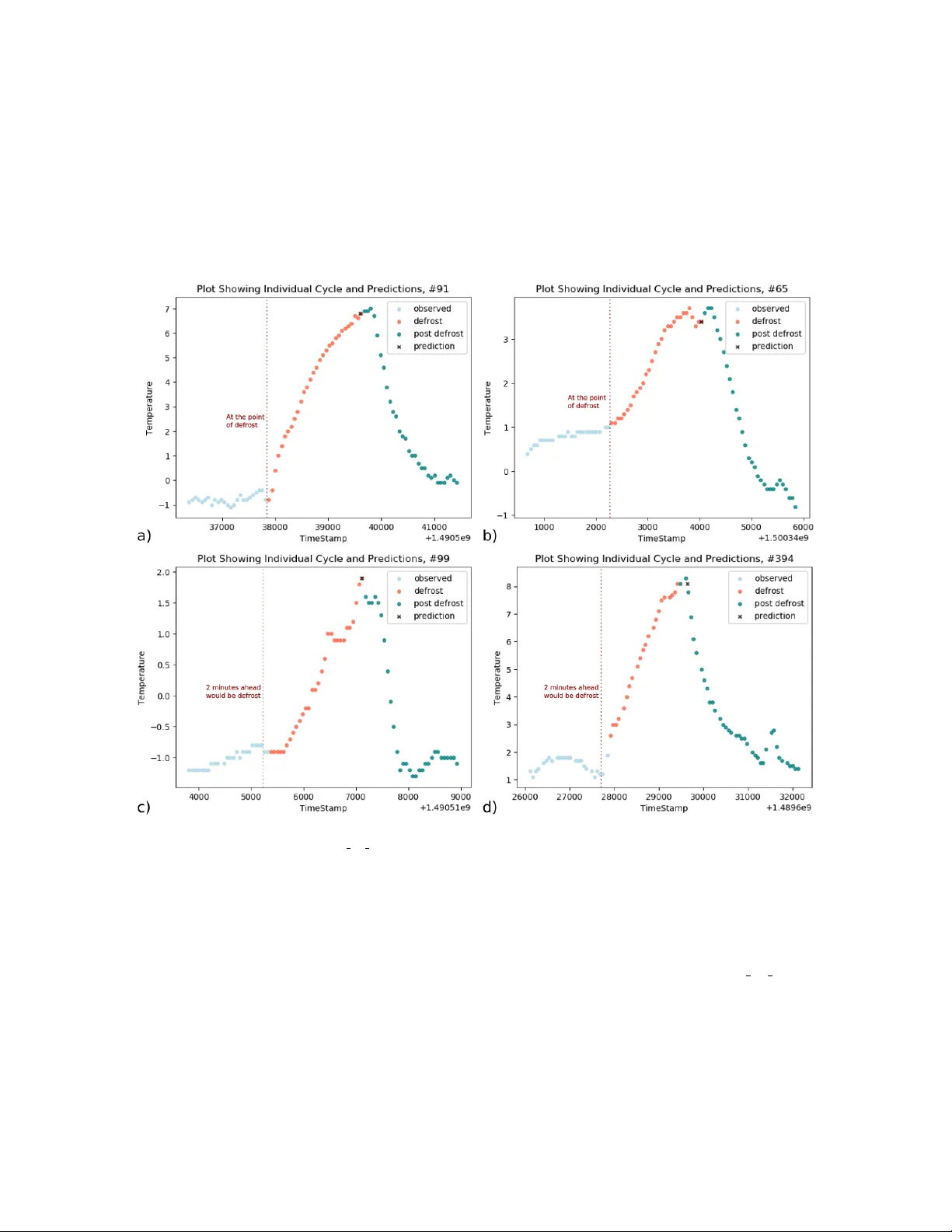
본 논문은 대규모 사물인터넷(IoT) 환경에서 딥러닝 모델의 학습·추론 파이프라인을 효율적으로 운영하기 위한 새로운 프레임워크 ‘넴시스트(Nemesyst)’를 제안한다. 기존의 TensorFlow, PyTorch, Keras와 같은 단일 노드 프레임워크는 모델 구현과 학습에 강점이 있지만, 대용량 데이터의 분산 저장·버전 관리·다중 노드 배포와 같은 엔드‑투‑엔드 처리에는 한계가 있다. 넴시스트는 이러한 한계를 극복하기 위해 데이터베이스 중심 설계를 채택한다. 구체적으로 MongoDB를 백엔드로 사용해 데이터 전처리(Wrangling), 저장·인덱싱·샤딩(Serving), 학습(Learning), 추론(Inference) 네 단계로 구성된 파이프라인을 구축한다. 각 단계는 독립적인 설정 파일과 플러그인 형태로 구현돼, 사용자는 기존 딥러닝 라이브러리를 그대로 활용하면서도 데이터 흐름을 데이터베이스 수준에서 제어할 수 있다.
넴시스트의 핵심 기술은 ‘하이브리드 병렬(Hybrid Parallelism)’이다. 모델 병렬(Model Parallelism)과 데이터 병렬(Data Parallelism)을 동시에 지원함으로써, 하나의 모델을 여러 GPU 그룹에 분산 학습시키는 동시에 서로 다른 데이터셋을 가진 다수의 모델을 동일 클러스터 내에서 병렬 처리한다. 이는 기존 TensorFlow‑Distributed가 전체 데이터를 복제하고 All‑Reduce 연산을 수행하는 방식과 달리, 데이터베이스 샤딩을 활용해 각 노드가 필요한 데이터 조각만을 효율적으로 조회하도록 설계되었다. 결과적으로 메모리 사용량을 최소화하고, 데이터 전송량을 크게 줄일 수 있다.
프레임워크의 설계 원칙은 (1) 프레임워크 독립성 – 학습 스크립트는 Keras, TensorFlow, PyTorch 중 任意를 사용 가능, (2) 확장성 – 샤딩·복제본을 통해 수천~수만 대의 IoT 디바이스를 지원, (3) 재현성 – 데이터와 모델 메타데이터가 데이터베이스에 일관되게 저장돼 실험 재현이 용이, (4) 실시간성 – Near‑real‑time 데이터 흐름과 모델 배포가 가능하도록 설계.
논문의 실증 사례는 영국 전력망 부하에 맞춰 소매점 냉장고 전력을 최적화하는 ‘수요측응답(Demand Side Response, DSR)’ 시나리오이다. 영국 내 한 대형 소매 체인의 100 000대 이상의 냉장고를 가상화한 ‘barn’ 실험실을 구축하고, 각 냉장고의 전력 소비와 내부 온도 데이터를 1 Hz 이상으로 수집하였다. 수집된 시계열 데이터는 Wrangling 단계에서 5분 간격의 온도·전력 시퀀스로 원자화되고, MongoDB 샤드에 저장된다. 이후 Serving 단계에서 인덱싱·복제본을 통해 학습 노드가 빠르게 데이터에 접근한다. 학습 단계에서는 RNN, LSTM, GAN을 각각 3‑layer 구조로 설계하고, 20개의 GPU와 50개의 CPU 노드에 하이브리드 병렬 방식으로 동시에 학습시켰다. 모델은 매 15분마다 재학습되어 최신 데이터에 적응하며, 학습된 가중치는 바이너리 형태로 데이터베이스에 저장되고 버전 관리된다.
실험 결과, LSTM 기반 모델은 냉장고의 열관성(thermal inertia)을 정확히 예측해 피크 전력 부하 시 12 % 이상의 전력 절감 효과를 달성했으며, 온도 위반률은 0.3 % 이하로 크게 감소하였다. GAN을 활용한 데이터 증강 기법은 학습 데이터가 부족한 신규 매장에 대해 빠른 모델 초기화를 가능하게 하였고, 전체 파이프라인의 평균 지연 시간은 8 초 이하로 유지돼 실시간 제어에 충분한 성능을 보였다. 또한 모델 버전 관리와 메타데이터 추적이 자동화돼, 새로운 데이터가 유입될 때마다 CI/CD‑like 워크플로우가 자동으로 트리거되는 환경을 구현했다.
논문은 넴시스트의 장점과 한계도 논의한다. 데이터베이스 의존도가 높아 스키마 설계와 인덱스 튜닝이 성능에 큰 영향을 미치며, 대규모 GPU 클러스터와의 네트워크 대역폭이 병목이 될 수 있다. 향후 연구 방향으로는 고성능 키‑밸류 스토어와 RDMA 기반 통신을 결합해 데이터 전송 병목을 최소화하고, AutoML 모듈을 통합해 하이퍼파라미터 탐색을 자동화하는 방안을 제시한다.
결론적으로, 넴시스트는 데이터베이스와 딥러닝 프레임워크를 유기적으로 결합해 대규모 IoT 환경에서의 모델 학습·배포·재학습을 효율적으로 수행할 수 있는 실용적인 솔루션을 제공한다. 특히 전력망과 연계된 수요측응답과 같은 실시간 제어 문제에 적용했을 때, 높은 에너지 절감 효과와 시스템 안정성을 동시에 달성함을 실증하였다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기