Nemesyst: A Hybrid Parallelism Deep Learning-Based Framework Applied for Internet of Things Enabled Food Retailing Refrigeration Systems
Deep Learning has attracted considerable attention across multiple application domains, including computer vision, signal processing and natural language processing. Although quite a few single node deep learning frameworks exist, such as tensorflow,…
Authors: George Onoufriou, Ronald Bickerton, Simon Pearson
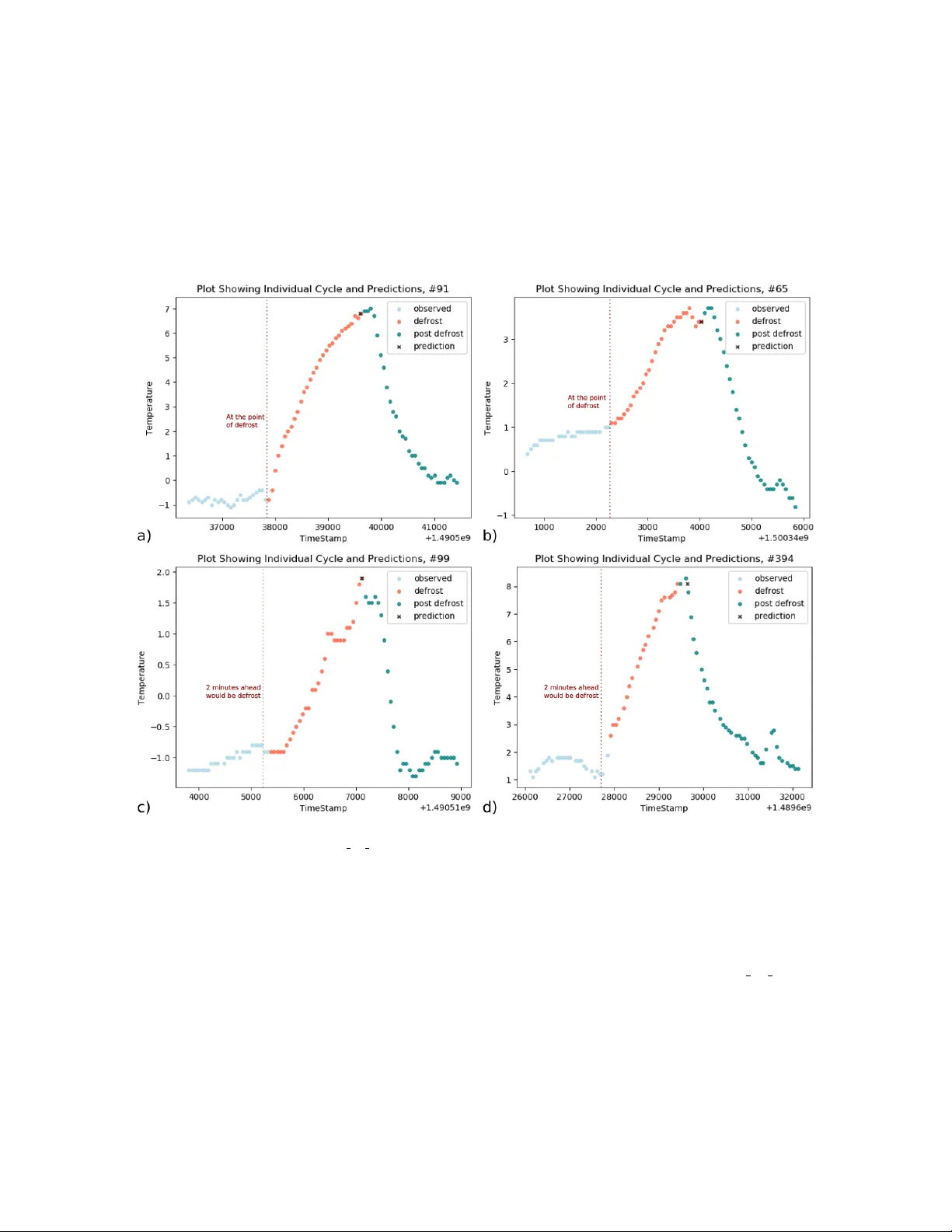
Nemesyst: A Hybrid P arallelism Deep Learning-Based F ramew ork Applied for In ternet of Things Enabled F o o d Retailing Refrigeration Systems George Onoufriou a , Ronald Bic kerton b , Simon P earson c , Georgios Leon tidis a, ∗ a Scho ol of Computer Scienc e, University of Linc oln, Br ayfor d Po ol Campus, LN67TS, Linc oln, UK b Scho ol of Engine ering, University of Linc oln, Br ayfor d Po ol Campus, LN67TS, Linc oln, UK c Linc oln Institute for A gri-F o o d T e chnolo gy, University of Lincoln, Br ayfor d Po ol Campus, LN67TS, Linc oln, UK Abstract Deep Learning has attracted considerable atten tion across multiple application domains, including computer vision, signal pro cessing and natural language pro cessing. Although quite a few single node deep learning frameworks exist, suc h as tensorflow, pytorc h and keras, we still lac k a complete pro cess- ing structure that can accommo date large scale data pro cessing, v ersion con trol, and deploymen t, all while staying agnostic of any specific single no de framework. T o bridge this gap, this pap er prop oses a new, higher level framework, i.e. Nemesyst, which uses databases along with mo del sequentialisation to allow pro cesses to b e fed unique and transformed data at the p oint of need. This facilitates near real-time application and mak es mo dels av ailable for further training or use at any no de that has access to the database sim ultaneously . Nemesyst is w ell suited as an application framew ork for internet of things aggregated control systems, deploying deep learning techniques to optimise individual machines in massive net works. T o demonstrate this framework, w e adopted a case study in a nov el domain; deplo ying deep learning to optimise the high sp eed con trol of electrical pow er consumed b y a massive in ternet of things netw ork of retail refrigeration systems in prop ortion to load av ailable on the UK Na- tional Grid (a demand side resp onse). The case study demonstrated for the first time in such a setting ho w deep learning models, such as Recurren t Neural Netw orks (v anilla and Long-Short-T erm Memory) and Generative Adversarial Net works paired with Nemesyst, ac hieve comp elling p erformance, whilst still b eing malleable to future adjustmen ts as b oth the data and requirements inevitably change o ver time. Keywor ds: Deep Learning, Databases, Distributed Computing, P arallel Computing, Demand Side Resp onse, Refrigeration, Internet of Things 1. In tro duction In telligence deriv ed from data has the potential to transform industrial productivity . Its application requires computational solutions that integrate database technologies, infrastructure and frameworks along with b espoke mac hine learning techniques to handle, pro cess, analyse, and recommend. Recen t adv ances in deep learning are accelerating application. Deep learning is a sub-field of machine learning that seeks to learn data represen tations, usually via a v ariant of artificial neural netw orks. Deep learning is concerned with t wo distinct tasks: • T raining; where the deep neural netw ork (DNN) learns the data representation through iterative metho ds, suc h as sto c hastic gradient descent. This is a very time consuming op eration that usually o ccurs at most on one no de, or a few CPU /GPU no des. ∗ Corresponding author. T el.:+44(0)7951053731 Email addr ess: gleontidis@lincoln.ac.uk (Georgios Leontidis) 1 • Inference; where the learned DNN can b e used in one form or another to make predictions, detection, localisation, etc. This is usually faster than training as it do es not require as man y op erations, but still requires a go o d p ortion of the same resources and time. [1] Both training and inference can b e impro ved b y the use of ’better’ hardw are, including faster and/or higher volume pro cessing via distributed/parallel systems, where parallel in this instance means any single system that according to Flyns taxonom y is using either: • single instruction, m ultiple data (SIMD) • m ultiple instruction, single data (MISD) • m ultiple instruction, multiple data (MIMD) This is separate from a distributed system, where each computing no de is a different netw orked com- puter, as opp osed to a single computer with m ultiple CPUs/GPUs for computation in parallelisation. Curren tly the ma jority of deep learning framew orks hav e matured in parallelisation, but they lac k or are still in their infancy with regard to distribution. Nov el solutions suc h as T ensorFlo w-distribute, or IBMs distributed deep learning are now emerging to resolve this issue [1]. The ability to share data b et w een distributed no des using deep learning frameworks is a critical b ottleneck, despite the prev a- lence of databases providing very mature and adv anced functionality , such as MongoDB’s aggregate pip eline. In addition, the unification of deep learning in terfaces to databases will aid repro ducibilit y , as it will standardise the message proto col in terface (MPI) and describ e what data in what manner is used for training and inference; in MongoDBs case, by using aggregate pip eline json files. The in tegration of deep learning in to database mo dels is crucial for any (near) real-time application, such as Netflix, Amazon, Go ogle, as ’rolling’ a b esp oke data managemen t system or MPI is costly and can result in inferior p erformance and capabilities. In this pap er, we prop ose a nov el end-to-end distributed framew ork that can handle an y t yp e of data, scales and distributes mo dels across v arious no des lo cally or on the cloud. W e demonstrate the approac h by developing a deep learning infrastructure to link the pow er con trol of a massiv e internet of things (IoT) enabled netw ork of fo o d retail refrigeration systems in prop ortion to the load av ailable on the UK National Grid (i.e. an optimised Demand Side Resp onse, DSR). The implementation utilises data from a large retail supermarket along with a purp ose-built demonstration/experimental store (the ’barn’) in our Riseholme Campus at the Univ ersity of Lincoln. 2. Bac kground 2.1. De ep L e arning F r ameworks Deep Learning, and its ability to learn complex abstract represen tations from high dimensional data, is transforming the application of artificial intelligence. Deep learning can learn a new task from scratc h, or adapt to p erform tasks in v arious domains b y transferring knowledge from one domain to another. Areas where deep learning, including Capsule Netw orks [2, 3], has pro duced state-of-the- art results – and why w e consider it here – are in particular; computer vision, and medical imaging [4, 5, 6, 7, 8]; signal, and natural language pro cessing [9, 10, 11, 12]; agriculture [13, 14, 15, 16]; and industry [17, 18, 19]. There are many p opular single no de deep learning framew orks currently av ailable [20, 21, 22, 23]. Ho wev er, there are fewer parallelisable deep learning frameworks [20, 24]. These can broadly b e categorised b y their parallelism strategies and capabilities, namely: [1] • Mo del parallelism (MP) (T ensorFlo w, Microsoft CNTK), where a single DNN mo del is trained using a group of hardw are instances, and a single data set. • Data parallelism (DP), where each hardware instance trains across different data (usually sepa- rate mo dels). 2 • Hybrid parallelism (HP) (Nemesyst), where a group of hardware trains a single mo del, but m ultiple groups can b e trained simultaneously with indep enden t data sets simultaneously . • Automatic selection (AP), where different parts of the training / inference pro cess are tiled, with differen t forms of parallelism b etw een tiles. Of note, T ensorFlow v1 uses a mo del parallelism strategy as it trains a single model ov er multiple GPUs on the same data. T ensorFlow has recently added functionality called T ensorFlow distribute whic h adds the ability to train on m ultiple machines connected by a netw ork [25] how ever this remains mo del parallelism as it requires that the entire set of mac hines broadcast replicas of the data, such that it do es not use different data in a single pro cess itself and instead requires that it b e run ov er multiple pro cesses externally or other such metho ds like parameter servers to sim ulate data parallelism. [25] Their curren t metho d for multi machine data broadcasting can b e seen in what T ensorFlo w distribute uses, what they call collective ops using metho ds suc h as all reduce as can b e seen in their source co de [26] whic h has limited functionality compared to a more sp ecialised to ol suc h as MongoDB. In con trast Nemesyst is a h ybrid parallelism framework as it can simultaneously wrangle, learn, and infer m ultiple mo dels, with multiple and distinct data sets, across a distributed/ wide system. In addition, Nemesyst can utilise existing single no de framew orks, suc h as Keras [23], T ensorFlo w, PyT orch, since training scripts are separate, distinct, and configurable. The Nemesyst co debase also includes examples and inbuilt functionality for multiple deep learning metho ds, such as RNN, LSTM, and GANs. Nemesyst’s dev elopment was inspired, tested, and accommo dated by the type of data and problems w e encoun tered through the handling of real data sets, including and not limited to: to o- large-to-fit data, requiring out-of-core pro cessing; Distributed p oints of need; requiring some metho d of near-real-time dissemination; Changing/ dynamic data, requiring dynamic data handling for ever c hanging scenarios, and scenario subsets such as some stores using C O 2 refrigerators vs water vs some other co olan t. All of which are not unusual circumstances for many large industries to face. 2.2. Case Study - Demand Side R esp onse Demonstr ation Here w e demonstrate Nemesyst by optimising the energy use and system op eration of a massiv e IoT netw ork of retail refrigeration systems. High demands for energy , along with future commitments to wards low carb on economies that include the generation of less predictable electrical loads (e.g. wind / solar renew ables) is placing National Grid infrastructure under increased strain. T o stabilise the Grid, fo cus is now placed on developing new approaches to manage load via the application of Demand Side Resp onse (DSR) measures. During DSR even ts individual electrical demand across massiv e aggregated netw orks of mac hines is adjusted in response to av ailable grid supply . Measures span financial incentiv es for commercial/industrial users to reduce demand during p eak times when there is low a v ailable p ow er and vice versa [27]. Man y DSR incentiv es require the control of large loads and the aggregation of multiple industrial pro cesses and mac hines [28, 29]. Standard static DSR mec hanisms includes Firm F requency Responses (FFR), where load is shed when the grid frequency drops to a predefined threshold. Figure 1 shows the tw o transitions typically encountered in a static FFR ev ent. In the first transition (also kno wn as primary FFR), industry has to shed load quickly (2 to 10s) and sustain this for 30 seconds; for the second transition the load can b e held off for 30 min utes (also kno wn as secondary FFR). Primary FFR’s aim is to arrest frequency deviations from the nominal v alue, whereas secondary FFR is p erformed to contain and partially reco ver the frequency [30]. The application of DSR to massive netw orks of machines requires exceptional levels of co ordinated con trol across individual devices. F o o d refrigeration systems can b e deploy ed within DSR even ts since the thermal inertia / mass of fo o d acts as a store of cold energy (effectively a battery). How ever, the thermal inertia in a retail refrigeration case will c hange as the fo o d is activ ely shopp ed b y con- sumers and then refilled, in addition ambien t temp erature can c hange, netw orks of stores can hav e m ultiple refrigeration systems and different fo o ds will need b esp ok e control. This complexity provides an excellent opportunity for Nemesyst since deep learning is required to mo del thousands of assets 3 Figure 1: (colour online) Firm F requency Resp onse ov erview (National Grid). sim ultaneously , with a need to contin uously retrain multiple thousands of mo dels / machine dynamics. The deplo yed control mo del must intelligen tly select whic h refrigerators to shed electrical load / turn off across a massive po ol; one UK retailer alone op erates > 100,000 devices. This requires an algorithm that can predict the thermal inertia in individual cases and therefore ho w long they can b e shut down (t ypically up to a maxim um of up to 30 min utes) before the fo od temperature breac hes a legally defined set p oint. Deep learning contin uously re learns the thermal inertia of each device. T o deliv er DSR, a sep erate candidacy algorithm selects whic h refrigerators can b e shut do wn across an aggregated p o ol and for how long. F or complian t DSR, a fixed electrical load, t ypically greater then 10MW, must b e shed across the en tire p o ol of machines for up to 30 min utes. More generally , the application of deep learning for refrigeration system control is limited, for ex- ample Hoang [31] purp orts gains of 7% in daily c hiller energy efficiency by using deep learning opposed to rote physical control mo dels. There ha ve also been some studies fo cussing on load forecasting for home appliances and energy disaggregation including refrigerators [32, 33, 34]. Although quite a few studies exist in related areas of research, such as demand resp onse algorithms for smart-grid ready residen tial buildings in [35] or demand resp onse strategies in autonomous micro-grids in [36], there has b een no studies sp ecifically deploying deep learning for DSR con trol in fo od retailing refrigeration systems. 3. Nemesyst F ramework The goal of this framework (figure 2) is to facilitate the use of deep learning on large distributed data sets in a distributable, accurate, and timely manner. As such, eac h stage must consider the follo wing criteria: • Handle data out-of-core as the incoming data ma y b e to o large to store in memory at any single instance • Retriev e necessary data from lo cations that may differ to where the lo cal framework pro cess exists • Disseminate mo dels to the agents that require them for inference. 4 Global Database Data offsite storage Data offsite storage Shard Shard refrigerator/ data source refrigerator/ data source refrigerator/ data source refrigerator/ data source refrigerator/ data source refrigerator/ data source refrigerator/ data source refrigerator/ data source refrigerator/ data source refrigerator/ data source Store Local Data Cleaner Data Data Live Data Local Database Machine CPU GPU NN Model Action Prediction data refrigerator/ data source refrigerator/ data source refrigerator/ data source refrigerator/ data source refrigerator/ data source refrigerator/ data source refrigerator/ data source refrigerator/ data source refrigerator/ data source refrigerator/ data source Store Local Data Cleaner Data Data Live Data Local Database Action Retrieving best model Retrieving best model Machine CPU GPU NN Model Prediction data Machine G PU C PU G PU GPU CPU Machine G PU C PU G PU GPU CPU Machine G PU C PU G PU GPU CPU Machine G PU C PU G PU GPU CPU Machine G PU C PU G PU GPU CPU Machine G PU C PU G PU GPU CPU Machine G PU C PU G PU GPU CPU Machine G PU C PU G PU GPU CPU T ensorflow Cluster Aggregate pipeline Machine G PU C PU G PU GPU CPU Pytorch Aggregate pipeline NN Model Outputting model Outputting model Storing every model Local Data Processing Atomizing examples Local on site database - shard of global database Local data processing and model transfer Database Layer Flexible Distributed Nemesyst Global Data Processing Invariant of deep learning backend Highly configurable Serialization of near- real-time and offline produced models. Scalable learning throughput Re-use of prior trained models Model tracking (what, how , when trained) MongoDB - Back-end deep learning framework Cloud Site/ local level/ single store data processing Global data processing Figure 2: (colour online) The literal representation of Nemesyst when applied to distributed refrigeration, in contrast to 3 which instead sho ws an abstraction of the Nemesyst framew ork. [37] Importing Wrangling Storage Learning Aggregation Dissemination Serving Data Config Config Config Cleaner Pipeline Infering Learner Config Inferer Pipeline Model Pipeline Figure 3: (colour online) The prop osed high lev el framework arc hitecture, in contrast to 2 whic h instead shows the literal representation of this abstraction. [37] T o ac hieve our goals and also be more agnostic and generalisable with respect to deep learning problems and techniques, we propose a new framework primarily consisting of four abstract core comp onen ts. While each comp onent is not new in of themselves combining them together as a formal framew ork 5 to enable distributed deep learning in a hybrid parallel manner, agnostic of deep learning back-end is (figure 3). 3.1. Wr angling W rangling; where the original data from a source is reformed in to individual atomised/single usable examples, whic h will later b e imported in to a database suc h as MongoDb. This stage seeks to filter out the un usable data and to clean the remaining data from artifacts and inconsistencies. As long as the data comprise single usable examples, e.g. in many-one sequence prediction m ultiple ro ws with a target column of a consisten t v alue, in many sequence generation m ultiple ro ws with m ultiple v alues in the target column, etc., the data can b e selectively chosen through MongoDB’s aggregation pip elines. This approach allows for maximal flexibilit y and also generalises well, since a single example can b e abstracted b y the implemen ter via custom config and cleaning scripts. Since databases are not tailored sp ecifically to deep learning and they are widely used, this forces us tow ards existing standards the b enefit of whic h is that we can then utilise already existing framew orks for databases like Amazons DynamoDB for MongoDB and then further exploit the capabilities of these framew orks to manage our databases for use with in-place encryption and transp ort lay er security (TLS). Data wrangling/ handling/ pre-pro cessing as a concept is not new as of itself, and is prev alent throughout the deep learning, mac hine learning, and statistics communities. 3.2. Serving Serving; where clean and atomised data exists and can be stored suc h that it is readily a v ailable for the learners to access at the p oint of need; and as a consequence of b eing stored in a database can no w b e prop erly indexed. Subsequently indexing the data using a database means w e are now free to utilise the adv anced functionality of these databases including the aggregation pip elines, sharding (critical to distribution), searching, sorting, filtering, finding/ querying, and replica sets (critical for up-time and a v ailability). When a database is used in this manner, i.e separate the data cleaning and data storage from any sp ecific learning script, the user creates a consistent in terface for the learning scrips. Unlike most deep learning scrips, our system is capable of branching many differen t and new algorithms as the serv er and learner are separate, this b ecomes the message passing interface (MPI). This stage also serv es any trained mo dels as learners are exp ected to return serialised binary ob jects of the learned weigh ts and arc hitecture. Serving is not a new concept in man y industries, but it is rarely a consideration in the deep learning comm unity , left more as an afterthought fo cusing more on absolute model p erformance ov er usability , and practicalit y . 3.3. L e arning Learning; where the aggregated data is fetched in rounds to train a learner in batches, at whic h p oin t the learner returns the training loss, v alidation loss, neural netw ork architecture (sequential and binarised) to the serving database for dissemination for further learning, and use. A t this stage it is p ossible and advisable to tak e adv antage of other frameworks such as tensorflo w, and p ossibly their distribute simultaneous training functionality on single machines. The learning stage should b e highly and completely configurable as it should not matter how a mo del is trained as long as it is returning all comp onen ts desired in future, such as the trained mo del, and/ or training parameters. 3.4. Inferring Inferring; where a trained serialised model stored in the database, and new data are aggregated and used to infer/ predict the target feature; What is represen ted b y the distribution of the data. Usually to ward some desired action or recommendation. 6 3.5. Ar chite ctur e Consider ation T owar ds Go als W e ha ve implemen ted a form of this framework, dubb ed: Nemesyst, [38] which incorporates deep learning tec hniques, such as RNNs, LSTMs, and GANs, and demonstrated its applicabilit y and impact on a large scale industrial application of high impact. W e ha ve also released the code for this framework implemen tation under a p ermissive licence and will contin ue to add to it at: h ttps://github.com/DreamingRa ven/Nemesyst. 4. Metho ds and T o ols F or the sake of b oth completeness and to maintain compactness this shall only b e a brief lo ok at the most imp ortan t to ols used. • Keras and T ensorflow;[23] De facto standard for production level deep learning, utilising graphics pro cessing unit (GPU) parallelisation to sp eed up computation. Both are free/ op en-source remo ving the need for exp ensive corp orate licensing • MongoDb; p erhaps the most p opular noSQL database type, b eing do cument oriented, scalable, ev entually consistent, and most imp ortantly free/ op en-source, and fast [39] 4.1. Par al lelism/ Multipr o c essing Stage: 2 (Infering) Wrangler Wrangler Wrangler Wrangler Current Running Processes Window maximum process pool size = 2 Learner Learner Learner Inferer Left->Right then T op-> Bottom Round: 0, Process: 0 Round: 0, Process: 1 Round: 1, Process: 0 Round: 1, Process: 1 Round: 2, Process: 0 Round: 2, Process: 1 Round: 3, Process: 0 Round: 4, Process: 0 Stage: 0 (Wrangling) Stage: 1 (Learning) Figure 4: (colour online) Shows the multi-process strategy of Nemesyst on any single mac hine after it has b een triggered. [37] Nemesyst uses pythons multiprocessing mo dule to implement parallelism through pro cess p o ols whic h can b e seen in figure 4. Python enforces what is called the global in terpreter lo ck (GIL), whic h means it is imp ossible to multi-thread python bytecodes as the GIL protects these bytecodes from access from m ultiple threads. In p ython the solution to this problem is to duplicate the to-b e- m ultithreaded co de and ob jects such that each process has its own independent copy whic h cannot affect the original or eac h other. This clearly inv olves ov erhead as ob jects must b e duplicated but it also means there is little ro om for race conditions as they also op erate completely indep endently . Eac h script/ algorithm provided to Nemesyst on a per-stage basis is run in parallel up to the maxim um n umber defined by the user for the process po ol size/ width. If more algorithms are pro vided than there are free processe s then the pro cess-windo w will slide across up on completion of the current 7 running algorithms. The pro cess windo w will not take algorithms from the next stages to fill an y free pro cesses as they could p oten tially dep end on the outcome of the user defined algorithm in the current or previous stages. Only once all algorithms of a given stage hav e completed will the pro cess p o ol mo ve to the next stage if the user has chosen for Nemesyst to do so. T o facilitate parallel op erations, each individual script is passed arguments to help it identify itself similar to how OpenCL’s processing elemen ts ha ve access to their processing element num b er, along with other helpful statistics such as how many other pro cessing elements of that round there are, ho w wide the windo w is, along with certain argumen ts b eing providable to each processing elemen t individually . 4.2. MongoDB In this framework we prop ose and use MongoDB as the data storage metho d. This comes with a plethora of consequences: • Distribution; utilising a clien t-server mo del through MongoDB affords the p ossibilit y to pro cess individual models for individual tasks from a central database of models and/or data. In this case training a broader mo del for all refrigerators, which is then re-trained/ fine tuned individually in a distributed manner for individual mac hines • Handling of large/ sharded data; Using a database allows muc h more complex data storage and represen tation to b e handled, sorted, and maintained • Querying; MongoDB is lik ely more effectiv e at querying than besp oke system, as it is established, widely used and prev alent, meaning more supp ort is av ailable from the communit y itself • In tegration; due to MongoDB b eing a popular database, it is likely that this framew ork’s Mon- goDB handling will b e able to integrate to existing systems • Complexit y; handling an y external and potentially changing framew ork can mean that the c hanges could cause unhandled exceptions, and temp orary do wn time, until the differences can b e adapted to • Securit y; MongoDB is more mature and has many more av ailable and used security implemen- tations, for a v ariety of different scenarios, as will likely b e the case up on application of this framew ork. This adaptability to the security need is an imp ortant part of the application of deep learning that is frequen tly ignored. Examples of suc h are in-place encryption, and trans- p ort lay er security integration. • Adaptabilit y; the MongoDB aggregate pip eline and its generic nature has b een included in this framew ork. This improv e the application breadth. W e note though that there must alwa ys be a target feature/ ground truth to b e predicted along with the data to use for prediction. 4.3. Time-Series Analysis Giv en the sequen tial nature of the signals w e are dealing with in this problem, it was intuitiv e to utilise Recurrent Neural Net works (RNN), such as Long-Short-T erm Memory (LSTM). Their cells can form ulate a non linear output a [ t ] based on b oth the input data x [ t ] at the current time step t , and the previous time-step activ ation a [ t − 1] , as describ ed in (1), where h (i.e. h yp erbolic tangent) is a non-linear activ ation function. a t = h ( x [ t ] , a [ t − 1] ) (1) LSTM is a v ery popular and successful RNN architecture comp osed of a memory cell, an input gate, an output gate and a forget gate. The cell is able to hold in memory v alues o ver arbitrary time interv als, whereas the three gates regulate the flow of information into and out of the cell. More sp ecifically a cell receiv es an input and stores it for a p eriod of time. In tuitively this is equiv alent to applying the 8 Model Binary Model Meta-Data MongoDB Document Epochs: Time Stamp: ... Loss Metric: Loss: 20 2018-10-24 16:1 1:04.047 ... MAE 0.01 Binary('gANja2V yYXMuZW5naW5lLnN lcXVlbnRpYWwKU2VxdWV udGlhbApx ACmBcQF9cQJYC...') Figure 5: (colour online) MongoDB do cumen t consecutively split in to abstraction hierarch y . iden tity function ( f ( x ) = x ) to the input. It is evident that the deriv ative of the identit y function is constan t; therefore when an LSTM mo del is trained with backpropagation through time the gradient do es not v anish. Bac kpropagation through time is a gradient-based tec hnique employ ed to train certain t yp es of RNN mo dels,suc h as LSTMs [40]. A ma jor problem that LSTMs circum ven ted o ver the traditional recurrent neural netw orks (RNN) has b een explo ding and v anishing gradients, which one encounters when training using hundreds of time steps. LSTMs are w ell suited to problems where preserving the memory of an ev ent that o ccurred man y time steps in the past is paramount for identifying patterns and hence informing b etter predictions. As outlined previously , the purp ose of the present study is not demonstrating or arguing the sup eriority of deep LSTM mo dels, but w e deploy the approach to evidence the impact that a state-of-the-art intelligen t system can hav e in retail refrigeration systems. This study is the first step to wards dev eloping a system that can work in the bac kground for thousands of refrigerator packs and pro vide candidates for DSR, whilst adhering to the requirements of the National Grid. As descirb ed an LSTM mo del was adopted due to its capability of learning long term dep endencies on data. The equations relativ e to LSTM netw orks follo w, and the reader is in vited to refer to the original pap er [40] for further details. e c [ t ] = tanh ( W ˜ c [ a [ t − 1] , x [ t ] ] + b ˜ c ) Γ u = σ ( W u [ a [ t − 1] , x [ t ] ] + b u ) Γ f = σ ( W f [ a [ t − 1] , x [ t ] ] + b f ) Γ o = σ ( W o [ a [ t − 1] , x [ t ] ] + b o ) c [ t ] = Γ u e c [ t ] + Γ f c [ t − 1] a [ t ] = Γ o tanh ( c [ t ] ) (2) In 2, c is the memory cell, Γ u , Γ f and Γ o are the up date, forget and output gates resp ectively; W denotes the mo del’s weigh ts, and b are bias vectors. These parameters are all jointly learned through bac kpropagation. Essentially , at each time-step, a candidate update of the memory cell is prop osed ( i.e. e c [ t ] ), and based on the gates Γ, e c [ t ] can b e utilised to up date the memory cell ( c [ t ] ), and subsequently pro vide a non-linear activ ation of the LSTM cell ( a [ t ] ). T o learn a meaningful representation of the signals, t wo LSTMs were stack ed, b oth with 400 neurons (figure 4). 4.4. Gener ative A dversarial Network Generativ e Adversarial Netw orks (GANs) prop osed by Go o dfellow [41] are: 9 Figure 6: (colour online) Recurrent neural netw ork architecture where: x = single input example of a defrost, x = the n th time step of this single example, ˆ y = is the output predictions (in this case only one per example), a [ n ] = activ ation v ector at lay er n, and no de/ time step m, T x = total n umber of time steps T for examples x • adv ersarial mo dels (comp eting/ co-op erating neural netw orks) • b oth trained simultaneously • a generator (G) neural netw ork which seeks to sim ulate the data distribution as clos ely as poss ible • a discriminator (D) neural net work whic h seeks to estimate the probabilit y that an y giv en sample came from the training data rather than sim ulated by G GANs (figure 5) were conceptualised through game theory of a minmax t wo play er game, where the generator and discriminator are trying to ac hieve what is called the Nash Equilibrium with resp ect to eac h other. In brief, the t wo comp onents of GANs, i.e. generator and discriminator, are improving themselv es by comp eting with eac h other. Generator starts with random noise as input; as the pro cess ev olves it arrives to a p oint where it has learned the underlying distribution of the input data, hence generating a very similar output. This pro cess contin ues up un til the generated data are indiscernible to the original ones. There hav e b een adv ancements in the techniques used to train GANs, such as p olicy gradien ts, and the ability to predict discreet features for things, such as natural language pro cessing or other sequence based tasks [42]. Using the v ariant of GANs called sequence-GAN or seqGAN, one could train these generativ e mo dels on this predominan tly sequence based/ time series prediction task. The principles of GANs are particularly relev ant to our studies, giv en that they are sim ultane- ously a type of generative and discriminative modelling compared to the soley discriminativ e nature of RNNs. As such GANs are very go o d at sim ulation, and provide the opportunity to expand further in to data correction, since the GAN mo del of learning seeks to mimic the data and its distribution, whic h w as a large hindrance using this dataset, having missing v alues, features (b etw een stores). Th us w ell p erforming GANs provide us in this case study sup erior accuracy , and ability to replace missing data realistically . On the other hand, their primary drawbac ks are that they tak e a more time to dev elop 10 Sample: 1 ... Sample: n Policy Gradient | Backpropagation Discriminator Neural Network Simulation: 1 ... Simulation: n Real Data Generated Data Real/Fake Generator Neural Network Data Wrangler Seeds/ Catalyst Data Real Data Initial Discriminator Training Initial Generator Training Frozen Weights Error Calculation at Both Stages Figure 7: (colour online) General architecture/ flow of real and sim ulated data through a GAN. and are not at least in their v anilla form compatible with sequence data. [42] 5. Nemesyst for Intelligen t refrigeration Systems 5.1. Case Study: Demand Side R esp onse R e c ommendation Demand side resp onse (DSR) even ts simply mo dify the p ow er demand load in prop ortion to av ail- able energym on the Grid [43, 44]. How ever, delivering DSR for sup ermark et refrigeration systems is complex, requiring high sp eed decisions on: • Where to displace load with an aggregated num b er of mac hines. This requires accurate predic- tions/ recommendations across large p ools of diverse machines • Pro visioning of data to train the algorithms for individual mac hines, in this instance the algorithm m ust learn the thermal inertia indirectly within eac h case to predict whether they can be safely sh ut down without a subsequent breec h of fo o d safety temp erature limits during a DSR ev ent; refrigerators with high thermal inertia can be sh ut down for a longer p eriod than those with low inertia. • Dealing with a large array of distributed assets, requiring a distributable algorithm or at least an algorithm that can handle database serv ers, whic h w ould likely b e the only non-local place this data could b e pro cessed at p oin t of need within tight time margins • Time b ound resp onse, whic h requires both sufficient computational pow er and efficient algorithms to exp edite the computation of this data to output within the required time-p erio d 11 5.1.1. Data Tw o sources of data w ere used to demonstrate Nemesyst, one from the exp erimen tal refrigeration researc h centre at at the Universit y of Lincoln (UoL; see for details [43, 44] and a second selected from a massive op erational netw ork (110,000 cases) of a national fo od retail company [43, 44]. Appendix B.1 sho ws the commercial stores’ refrigerator op erational data features, whereas App endix B.2 shows a sample of the data gathered at UoL, which represents a single fridge and all associated sensors in the con trolled test store. Figure 8: (colour online) Graph of air on temperature, against time, with ov erlay ed prediction and colour co ded sections for four fridges. Timestamp is simply the unix time since ep och. ”Observed” (light blue) here means what the neural netw ork is provided to learn from, ”defrost” (orange) is the ground truth; of which ”prediction” (x) is trying to predict the final ground truth (orange) v alue. The difference betw een the last ”observ ed” (light blue), and final ”defrost” (orange) v alue is the time (in seconds) that defrost can o ccur for b efore reaching the unsafe threshold of 8 ° c. Images a) and b) sho w the case where the prediction tak es place at the p oin t of defrost; whereas images c) and d) sho w the case where the prediction o ccurs 2 min utes in adv ance of defrost: taking place. Our ob jective w as to predict the time (in seconds) un til the refrigerator temperature (”air on temp erature”) rises from the p oint it is switc hed off until it breac hes a fo o d safety threshold. This duration v aries b et w een cases, for example the threshold is heuristically 8 ° c for high temperature refrigerators, and -183 ° c in lo w temp erature refrigerators (freezers), how ever since w e do not ha ve all the information ab out the threshold for each fridge or ev en a go o d w ay of iden tifying the fridge types we train the neural net work on the final p oint of defrost (see Fig 8) from the data as this is the most consisten t p oin t we can rely on. Subsequently the v ariation means a subset of fridges can be selected from the 12 p opulation whic h are capable of remaining co ol through a DSR even t. Th us knowing ho w long the refrigerators can remain off b efore reaching this threshold allows us to identify the b est candidates whic h reduce the p o wer consumption sufficien tly enough, while also minimising the total num b er of affected refrigerators, and p oten tially affected sto ck. This can b e visualised in figure 8 where the ligh t blue observed data set is used to predict the duration of the defrost section (orange) b efore it reac hes the unsafe threshold of 8 ° c (the difference b etw een last light blue to the last orange) giving us a single predicted duration p er refrigerator at an y given point in time. If we used longer time p erio ds we could p oten tially include information from previous defrosts but we found this unnecessary as the neural net work was already more than capable with the mere fluctuations prior to defrost for prediction/ In the data from the large chain foo d retailer, the only indicator av ailable on a consistent basis for how each fridge would act if it was switched off for DSR is its temperature response during a standard defrost cycle. T hese are routine and programmed 4 times a day for an y given fridge. During a defrost cycle – although dep ending on the refrigerator – the fridge is turned off un til it reac hes a giv en temp erature threshold. Case temp erature data during the defrost cycles were used to train the neural netw orks as this was the most readily av ailable information on refrigerator b eha viour when unp o w ered. In the commercial data set, we used 110,000 defrost examples from 935 refrigerators (90,000 train- ing, 10,000 v alidation, 10,000 testing), shared betw een 21 sup erstores after extraction. When optimised the data deplo yed by Nemesyst was 5.1KB p er data set, which results in a total data scale of 550MB. W e used only 3 mon ths of data (limitation imposed b y the data management pro cess), and only for a subset of the 3000+ av ailable stores i.e 21, while also eliminating redundancy and selecting certain p ortions of the av ailable sequences. This will b e significantly larger in practice, but is already to o large to b e visualised and trav erse easily , another adv antage of breaking this data do wn in to usable atomic examples. The extracted v alid sequences are on av erage 31.48 time-steps of c.1 min ute long (not including missing/ empty time steps). This means we hav e roughly 3,462,800 time steps, eac h with a minim um of 7 v alid data p oin ts per time step, resulting in 24,239,600 total data p oin ts processed for and subsequently used by a subset for any given neural net work pre ep och. Although it should b e noted an added difficult y in this scenario is that the ov erwhelming ma jority of the data is n ot sufficient in length or is problematic leaving on a subset that needs to b e extracted for use in training. Lastly if w e imagine this system will even tually b e used at all stores, a simple system isolated to one machine in one store will not b e sufficient to serve all stores and infer their data simultaneously . This shows the clear rationale for deploying distributing deep learning to internet of things systems, for b oth training and inference. Data quality for the commercial stores data set p osed significant problems, some of the these included: • Missing data (features and observ ations). Missing features are automatically remov ed b y Nemesyst, as they are easy to sp ot if the n umber of unique v alues of x are < = 1. Missing observ ations are dealt with in a customisable cleaner file in the wrangling stage as it may be desirable to maintain these observ ations in some form. • Inconsisten t data v alues, suc h as Y es, yes, y , YES etc, due to humans’ inconsistent input. These are automatically dealt with at the unifying stage of the customisable cleaner file. • Inconsisten t num b er of sensors b et ween stores and fridges, some having more and others having other inputs, making it more difficult to create a subset that share the same features/characteristics. This is dealt with in the customisable cleaner, as what is useful cannot be known and hence being able to deal with this automatically for all data. • Duplicate en tries, which is an exp ensive, time consuming op eration to fix, but dealt with in the customisable cleaner. • Extreme v alues, suc h as refrigerators at 50 . 0 ◦ C and b elow − 40 . 0 ◦ C, can b e dealt with by sigma clipping in the customisable cleaner. 13 M AE = n − 1 P i =0 | y i − ˆ y i | n (3) Mean Absolute Error (MAE), where: • y i is the i ’th target v alue, and ˆ y i is the corresp onding predicted v alue • | y i − ˆ y i | = | e i | , is the absolute difference b et ween the actual y i and predicted ˆ y i , otherwise kno wn as | e i | • n is the total n umber of ground truth target v alues, and the total num b er of predicted v alues. Nemesyst requires data to b e separated into single/ individual examples, so that they can b e imp orted in to the MongoDB database. It is then p ossible to use database functionality to b oth parallelise data handling, and unify the MPI of the system. As a side note, MongoDB has many to ols built around it, in particular helpful visualisation to ols that help sp eed up data exploration (figure A.1), and testing of aggregation pip elines (figure A.2). 5.1.2. Nemesyst Configur ation and Metho dolo gy In our public github rep ository , we show the implemen tation and source code of the RNNs, LSTMs, and GANs implemented in this study [45]. W e also sho w the asso ciated RNN architecture sho wn in figure 3, which can show the configurability of Nemesyst through simple adaptations in arguments to shift the en tire architecture. It has b een further extended to other techniques, suc h as GANs, which are included in our implementations. It can b e extended to any other nov el techniques due to the separation of the learner and Nemesyst core. In our test case, we split the 110,000 defrost examples suc h that c.10,000 w ere used for final testing c. 10,000 were randomly selected each time for v alidation (Monte Carlo with replacement). W e used a tw o-lay er RNN and LSTM, using MAE (3) as our error function and adam [46, 47] as our optimiser. W e chose MAE for this regression problem as the errors significance is equal, meaning we prefer to optimise the a verage case rather than p enalise extreme cases. W e chose the adam optimiser for our neural netw orks gradient descent as it is a light weigh t optimiser with a low er training cost than, AdaDelta, RMSProp, etc. The GAN contains a generator consisting of 3 la yers of RNN, leaky ReLU pairs [48], batc h normalisation [49], and 0.8 nesterov momentum [50, 51]. Batch normalisation is simply the normalisation of parameter up dates, betw een a group of examples, suc h as a group of size 32 will only result in a single parameter update that is some function of their constituen t errors. The sequence length we settled for led to the greatest predictive p o wer at 120 time-steps long. F or the purp oses of sp eed, w e utilised our hybrid parallelisation using 3 different machines to train different mo dels simultaneously , pro ducing mo dels in less than 2 minutes of training. 5.1.3. R esults and Discussion T able 1 shows the results ac hieved across the real and test stores, using all aforementioned mo dels (b earing in mind that the data flow at a granularit y of 1 minute). Single store refers to the store whic h returned the b est p erformance in terms of MAE whereas All stores is the global mo del using data from all the stores av ailable. It is imp ortant to note that the error is the mean absolute error (MAE) in seconds of predicted time un til unsafe temperature is reac hed. Assuming the ground truth v alue of the dep enden t v ariable time (to unsafe threshold) is 1800, then w e can rep ort that one can predict this time 1800 s ± 10 s . It is w orth p oin ting out that a normal defrosting cycle lasts b et ween 1800 and 2700 seconds. That helps with placing the p erformance – in terms of MAE – of the presented mo dels in T able 1 into p ersp ectiv e 14 Model Type Data Source Loss T rain MAE (Epo chs) Loss T est MAE Loss Ahead 2min (T est Set) T raining Data Poin ts T est Data Poin ts V anilla RNN T est Site 64 (20) 85 - 8640 8256 V anilla RNN Single Store 336 (23) 640 - 11040 8256 V anilla RNN All Stores 601 (3) 1418 - 84360 11520 LSTM T est Site < 10 (13) < 10 23 8640 8256 LSTM Single Store 87 (13) 119 224 11040 8256 LSTM All Stores 286 (2) 330 338 84360 11520 seqGAN T est Site < 10 (16) < 10 23 8640 8256 seqGAN Single Store < 10 (17) 33 33 11040 8256 seqGAN All Stores < 10 (13) 59 15 84360 11520 T able 1: T able showing results for Nemesyst applied to demand side response recommendation, error is seconds from no w until unsafe threshold is met. This table also sho ws the results for future prediction, i.e. 2 min utes ahead of p otential dsr even t. Figure 9: (colour online) Graph of air on temp erature, against time for a full day . As can b e seen an expected sup eriority in the p erformance of LSTM versus v anilla RNN o ccur, whic h is do wn to the long dep endencies on historical data, in particular since the data of an y single refrigerator has instances, denoting when they hav e b een turned off/defrosting b efore (example can b e seen in figure 9) . In table 1 we hav e also listed our future predictions with our developed LSTM, and GAN that sho w how predicting for a DSR even t tw o minutes ahead has a minimal impact on results. In table 2, single store p erformance (33 seconds in terms of MAE, using GAN) demonstrates clearly ho w feasible and plausible deploying suc h a system – error-wise – w ould b e. Even using a global mo del for all stores the p erformance of 128 seconds in terms of MAE, suggests that b eing able to predict with such a lo w MAE, at 60 seconds prior to a defrosting cycle kicking in is a promising indicator. T o this direction the p erformance we ac hieved in the barn store ( < 10 and 12 seconds in terms of MAE for in time and 2 min ahead predictions resp ectiv ely) is a goo d reference point of what the absolute p erformance under a controlled environmen t can b e. T able 1 clearly demonstrates that training mo dels on individual or a more tailored store sp ecific data sets provides sup erior p erformance compared to global ”all stores” data. This suggests that distributing the learning to more sp ecific learners w ould b e more b eneficial, in particular since to train 15 Figure 10: (colour online) Actual versus Predicted values plot, showing how close to the reference (diagonal) line the predictions are (barn, whole fleet and a random store highligh ted in a differen t colour). Any p oin ts falling on the diagonal line denote perfect predictions. It’s w orth p oin ting out that the predictions/dots in this plot (based on a subset of the test data) exceed the 200 ones; but many of them ov erlap with eac h other on the same sp ot. It is evident that the barn model p erforms better as can b e seen in 1, the reasons for this are explained in the main text. How ever, both mo dels visually demonstrate ho w promising the results are towards introducing an intelligen t system for DSR. a global ”all stores” mo del restricts the mo del to using only the subset of features shared b et ween all the stores, as opposed to the more av ailable data in one store that migh t not b e consisten t enough to use across all of them. Besides, each store exposes an underlying distinct b eha viour, suc h as num b er of visitors, preference in fresh v ersus other pro ducts, etc., whic h means that a b esp ok e individual mo del for eac h store – substantiated by the results provided as well – might be the answer. The results also sho w a significant difference b et ween the test site (barn) and the real sites (as evidenced b y figure 10 as well). Authors b elieve this could b e due to t wo reasons. First, the test site has some limitations in terms of how m uch real-life b eha viour and shopping patterns can b e captured, alb eit some interv en tions, suc h as op ening and closing the fridges, were incorp orated in the data utilised. Second and probably most imp ortantly , the av ailability of complete and reliable datasets allo w for a more concrete represen tation of the principles gov erning the op eration of the fridges, allowing long-term patterns to b e reliably identified and exploited. That is a very crucial message this pap er aims at conv eying, i.e. improving the av ailability of sensor data, inv esting on data science principles, such as data consistency/fidelity , establishing quality control pro cesses, flagging of in termittent transmission of information, and generating missing v alues in (near) real-time, are factors that will mak e a massive difference in the reliability and p erformance of intelligen t systems. T o the b est of our knowledge, this is the first study to show how an intelligen t system based on a b espoke framework that can automatically handle and pre-process data, coupled with deep learning tec hniques can b e incorp orated in the w orkflow of IoT mac hine optimisation This w as demonstrated for large retail sup ermark ets to optimise op erational pro cesses, decision-making process and subsequently reduce op erational energy costs. 16 6. Conclusions and F uture W ork This pap er prop osed a new deep learning-based framework, i.e. Nemesyst which can provide a solution and unification of deep learning techniques using a common interface, as w ell as allo wing h ybrid parallelisation and op erate within an IoT architecture. Nemesyst can store and retrieve generated mo dels (weigh ts, architecture), model data (train, test v alidation) and mo del metadata. As part of this w ork, the framework was applied to demand side resp onse recommendation. Our prop osed framework demonstrated state-of-the-art results on predicting time un til fridge temp erature rises to a set p oin t (in time and also 2 min utes ahead of defrosting cycle), whic h is directly applicable to demand side response recommendation in refrigeration systems. It has also b een shown via comparisons betw een the main fleet and the barn store how sligh t v ariations in data a v ailability and consistency can hav e a significant effect on the learning p erformance, suggesting a direct impro vemen t in predictive p erformance, should data a v ailability and fidelity b e improv ed in the future as part of the da y-to-da y data aggregation pro cess. This claim has b een substantiated by sev eral working examples using state-of-the-art mo dels, suc h as LSTMs and GANs, which demonstrated that such a framew ork and mo dels can b e deploy ed to improv e the scheduling of the defrosting cycles tow ards reacting to DSR. Lastly w e hav e introduced Nemesyst, and released it op enly as discussed previously so that others may use, and mo dify it freely , p oten tially con tributing and furthering the pro ject. Ac knowledgemen ts This research was supported by the Innov ate UK grant ”The developmen t of dynamic energy con trol mec hanisms for fo o d retailing refrigeration systems” with a reference n umber 102626. W e w ould also lik e to thank our partners Intelligen t Main tenance Systems Limited (IMS), the Grimsby Institute (GIFHE) and T esco Stores Limited for their supp ort throughout this pro ject. Conflicts of In terest Authors ha ve no conflict of interest to declare. References [1] Dhabalesw ar K DK Panda, Hari Subramoni, and Ammar Ahmad Awan. High p erformance dis- tributed deep learning: A b eginners guide. In Pr o c e e dings of the 24th Symp osium on Principles and Pr actic e of Par al lel Pr o gr amming , pages 452–454. ACM, 2019. [2] Sara Sab our, Nic holas F rosst, and Geoffrey E Hinton. Dynamic routing b etw een capsules. In A dvanc es in Neur al Information Pr o c essing Systems , pages 3856–3866, 2017. [3] F abio De Sousa Rib eiro, Georgios Leontidis, and Stefanos Kollias. Capsule routing via v ariational ba yes. arXiv pr eprint arXiv:1905.11455 , 2019. [4] Andre Estev a, Alexandre Robicquet, Bharath Ramsundar, V olodymyr Kuleshov, Mark DePristo, Katherine Chou, Claire Cui, Greg Corrado, Sebastian Thrun, and Jeff Dean. A guide to deep learning in healthcare. Natur e me dicine , 25(1):24, 2019. [5] Dimitrios Kollias, Miao Y u, Athanasios T agaris, Georgios Leontidis, Andreas Stafylopatis, and Stefanos Kollias. Adaptation and contextualization of deep neural netw ork mo dels. In 2017 IEEE Symp osium Series on Computational Intel ligenc e (SSCI) , pages 1–8. IEEE, 2017. [6] F abio De Sousa Rib eiro, Liyun Gong, F rancesco Caliv´ a, Mark Sw ainson, Kjartan Gudmundsson, Miao Y u, Georgios Leontidis, Xujiong Y e, and Stefanos Kollias. An end-to-end deep neural arc hitecture for optical character verification and recognition in retail fo o d pac k aging. In 2018 25th IEEE International Confer enc e on Image Pr o c essing (ICIP) , pages 2376–2380. IEEE, 2018. 17 [7] Siqi Nie, Meng Zheng, and Qiang Ji. The deep regression ba yesian netw ork and its applications: Probabilistic deep learning for computer vision. IEEE Signal Pr o c essing Magazine , 35(1):101–111, 2018. [8] F abio De Sousa Rib eiro, F rancesco Caliv´ a, Mark Swainson, Kjartan Gudm undsson, Georgios Leon tidis, and Stefanos Kollias. De ep bay esian self-training. Neur al Computing and Applic ations , Jul 2019. [9] Hao Y e, Geoffrey Y e Li, and Biing-Hwang Juang. Po wer of deep learning for channel estimation and signal detection in ofdm systems. IEEE Wir eless Communic ations L etters , 7(1):114–117, 2018. [10] Qingc hen Zhang, Laurence T Y ang, Zhikui Chen, and Peng Li. A survey on deep learning for big data. Information F usion , 42:146–157, 2018. [11] F abio De Sousa Rib eiro, F rancesco Caliv´ a, Dion ysios Chionis, Ab delhamid Dokhane, Antonios Mylonakis, Christophe Demaziere, Georgios Leontidis, and Stefanos Kollias. T ow ards a deep unified framework for nuclear reactor p erturbation analysis. In 2018 IEEE Symp osium Series on Computational Intel ligenc e (SSCI) , pages 120–127. IEEE, 2018. [12] T om Y oung, Dev amanyu Hazarik a, Soujany a Poria, and Erik Cambria. Recent trends in deep learning based natural language pro cessing. ie e e Computational intel ligenCe magazine , 13(3):55– 75, 2018. [13] Andreas Kamilaris and F rancesc X Prenafeta-Boldu. Deep learning in agriculture: A surv ey . Computers and Ele ctr onics in A gricultur e , 147:70–90, 2018. [14] Ja yme Garcia Arnal Barb edo. Plant disease identification from individual lesions and sp ots using deep learning. Biosystems Engine ering , 180:96–107, 2019. [15] Bashar Alhnaity , Simon P earson, Georgios Leontidis, and Stefanos Kollias. Using deep learning to predict plan t growth and yield in greenhouse environmen ts. arXiv pr eprint arXiv:1907.00624 , 2019. [16] John Ringland, Martha Bohm, and So-Ra Baek. Characterization of fo od cultiv ation along road- side transects with go ogle street view imagery and deep learning. Computers and Ele ctr onics in A gricultur e , 158:36–50, 2019. [17] Qingc hen Zhang, Laurence T Y ang, Zheng Y an, Zhikui Chen, and Peng Li. An efficien t deep learn- ing mo del to predict cloud workload for industry informatics. IEEE T r ansactions on Industrial Informatics , 14(7):3170–3178, 2018. [18] Liangzhi Li, Kaoru Ota, and Mianxiong Dong. Deep learning for smart industry: efficien t man- ufacture insp ection system with fog computing. IEEE T r ansactions on Industrial Informatics , 14(10):4665–4673, 2018. [19] Qingc hen Zhang, Laurence T Y ang, Zhikui Chen, and P eng Li. A tensor-train deep computa- tion mo del for industry informatics big data feature learning. IEEE T r ansactions on Industrial Informatics , 14(7):3197–3204, 2018. [20] Mart ´ ın Abadi, Ashish Agarwal, Paul Barham, Eugene Brevdo, Zhifeng Chen, Craig Citro, Greg S. Corrado, Andy Davis, Jeffrey Dean, Matthieu Devin, Sanjay Ghema wat, Ian Goo dfellow, Andrew Harp, Geoffrey Irving, Michael Isard, Y angqing Jia, Rafal Jozefo wicz, Luk asz Kaiser, Manjunath Kudlur, Josh Leven b erg, Dandelion Man ´ e, Ra jat Monga, Sherry Mo ore, Derek Murray , Chris Olah, Mik e Sc huster, Jonathon Shlens, Benoit Steiner, Ily a Sutskev er, Kunal T alwar, P aul T uck er, Vincen t V anhouck e, Vija y V asudev an, F ernanda Vi ´ egas, Oriol Vin yals, Pete W arden, Martin W attenberg, Martin Wick e, Y uan Y u, and Xiao qiang Zheng. T ensorFlo w: Large-scale mac hine learning on heterogeneous systems, 2015. Softw are av ailable from tensorflow.org. 18 [21] Y angqing Jia, Ev an Shelhamer, Jeff Donahue, Sergey Karay ev, Jonathan Long, Ross Girshick, Sergio Guadarrama, and T rev or Darrell. Caffe: Con volutional architecture for fast feature em- b edding. arXiv pr eprint arXiv:1408.5093 , 2014. [22] Adam Paszk e, Sam Gross, Soumith Chin tala, Gregory Chanan, Edward Y ang, Zac hary DeVito, Zeming Lin, Alban Desmaison, Luca An tiga, and Adam Lerer. Automatic differentiation in p ytorch. NIPS , 2017. [23] F ran¸ cois Chollet et al. Keras: The python deep learning library . Astr ophysics Sour c e Co de Libr ary , 2018. [24] F rank Seide and Amit Agarwal. Cn tk: Microsoft’s op en-source deep-learning to olkit. In Pr o- c e e dings of the 22nd A CM SIGKDD International Confer enc e on Know le dge Disc overy and Data Mining , pages 2135–2135. A CM, 2016. [25] Go ogle. T ensorflow distribute do cumen tation. https://www.tensorflow.org/guide/ distribute_strategy , 2019. [26] Go ogle. T ensorflo w distribute collective ops. https://github.com/tensorflow/tensorflow/ blob/master/tensorflow/python/ops/collective_ops.py , 2019. [27] P eter Bradley , Alexia Coke, and Matthew Leac h. Financial incentiv e approaches for reducing p eak electricity demand, exp erience from pilot trials with a uk energy pro vider. Ener gy Policy , 98:108–120, 2016. [28] Ramon Granell, Colin J Axon, David CH W allom, and Russell L Layberry . Po wer-use profile analysis of non-domestic consumers for electricit y tariff switching. Ener gy Efficiency , 9(3):825– 841, 2016. [29] Philipp Gr ¨ unewald and Jacop o T orriti. Demand resp onse from the non-domestic sector: Early uk exp eriences and future opp ortunities. Ener gy Policy , 61:423–429, 2013. [30] F ei T eng, Mark o Aunedi, Dann y Pudjian to, and Goran Strbac. Benefits of demand-side response in pro viding frequency response service in the future gb pow er system. F r ontiers in Ener gy R ese ar ch , 3:36, 2015. [31] Hoang Dung V u, Kok-Soon Chai, Bry an Keating, Nurislam T ursynbek, Boy an Xu, Kaige Y ang, Xiao yan Y ang, and Zhenjie Zhang. Data driven c hiller plan t energy optimization with domain kno wledge. CoRR , abs/1812.00679, 2018. [32] W eicong Kong, Zhao Y ang Dong, Da vid J Hill, F eng ji Luo, and Y an Xu. Short-term residential load forecasting based on resident b ehaviour learning. IEEE T r ansactions on Power Systems , 33(1):1087–1088, 2018. [33] P eiyang Guo, Jacqueline CK Lam, and Victor OK Li. Drivers of domestic electricit y users price resp onsiv eness: A nov el machine learning approac h. Applie d ener gy , 235:900–913, 2019. [34] Eklas Hossain, Imtia j Khan, F uad Un-No or, Sarder Shazali Sik ander, and Md Samiul Haque Sunn y . Application of big data and machine learning in smart grid, and asso ciated security concerns: A review. IEEE A c c ess , 7:13960–13988, 2019. [35] F abiano P allonetto, Mattia De Rosa, F ederico Milano, and Donal P Finn. Demand response algorithms for smart-grid ready residential buildings using mac hine learning mo dels. Applie d Ener gy , 239:1265–1282, 2019. [36] P araskev as Panagiotidis, Andrew Effraimis, and George A Xydis. An r-based forecasting ap- proac h for efficien t demand response strategies in autonomous micro-grids. Ener gy & Envir on- ment , 30(1):63–80, 2019. 19 [37] George Onoufriou. Nemesyst do cumen tation. http://nemesyst.readthedocs.io , 2019. [38] George Onoufriou. Nemesyst rep ository . https://github.com/DreamingRaven/nemesyst , 2019. [39] Elif Dede, Madh usudhan Go vindara ju, Daniel Gunter, Richard Shane Canon, and Lav any a Ra- makrishnan. P erformance ev aluation of a mongo db and hado op platform for scientific data anal- ysis. In Pr o c e e dings of the 4th A CM workshop on Scientific cloud c omputing , pages 13–20. ACM, 2013. [40] Sepp Ho chreiter and J ¨ urgen Sc hmidhuber. Long short-term memory . Neur al c omputation , 9(8):1735–1780, 1997. [41] Ian G oo dfellow, Jean P ouget-Abadie, Mehdi Mirza, Bing Xu, Da vid W arde-F arley , Sherjil Ozair, Aaron Courville, and Y oshua Bengio. Generative adversarial nets. In A dvanc es in neur al infor- mation pr o c essing systems , pages 2672–2680, 2014. [42] Lan tao Y u, W einan Zhang, Jun W ang, and Y ong Y u. Seqgan: Sequence generative adversarial nets with p olicy gradient. CoRR , abs/1609.05473, 2016. [43] Ibrahim Saleh, Andrey P ostniko v, Chris Bingham, Ronald Bic kerton, Argyrios Zolotas, Simon P earson, et al. Aggregated p o wer profile of a large netw ork of refrigeration compressors following ffr dsr ev ents. International Confer enc e on Ener gy Engine ering , 2018. [44] Ibrahim Saleh, Andrey P ostniko v, Corneliu Arsene, Argyrios Zolotas, Chris Bingham, Ronald Bic kerton, and Simon Pearson. Impact of demand side resp onse on a comme rcial retail refrigera- tion system. Ener gies , 11(2):371, 2018. [45] George Onoufriou. Nemesyst lstm. https://github.com/DreamingRaven/nemesyst/blob/ c6c8bb9b8f2f0e4e1aae85a7f5818312d0e4b8b3/examples/lstm.py , 2019. [46] Diederik P . Kingma and Jimmy Ba. Adam: A Method for Sto chastic Optimization. arXiv e-prints , page arXiv:1412.6980, Dec 2014. [47] Sashank J. Reddi, Saty en Kale, and Sanjiv Kumar. On the conv ergence of adam and b ey ond. In International Confer enc e on L e arning R epr esentations , 2018. [48] Alex Krizhevsky , Ilya Sutskev er, and Geoffrey E Hinton. Imagenet classification with deep conv o- lutional neural netw orks. In A dvanc es in neur al information pr o c essing systems , pages 1097–1105, 2012. [49] Sergey Ioffe and Christian Szegedy. Batch Normalization: Accelerating Deep Net work T raining b y Reducing Internal Cov ariate Shift. arXiv e-prints , page arXiv:1502.03167, F eb 2015. [50] Ily a Sutsk ever, James Martens, George Dahl, and Geoffrey Hinton. On the imp ortance of initial- ization and momen tum in deep learning. In International c onfer enc e on machine le arning , pages 1139–1147, 2013. [51] Timoth y Dozat. Incorp orating nesterov momentum into adam. 2016. 20 App endix A. Figures Figure Appendix A.1: This figure shows MongoDB compass automatically analysing the sc hema for data exploration, and highlighting areas of interest, in particular here extreme temp erature v alues that may need to either be explained or clipp ed. Figure Appendix A.2: This figure shows MongoDB compass automatically analysing the sc hema for data exploration, and highlighting areas of interest, in particular an in-balanced training set, whic h then had to be balanced. 21 Figure App endix A.3: Example image of MongoDB aggregate pipeline testing, and output. 22 App endix B. T ables F eature Barn Fleet defrost state 1 1 air on temp erature 1 1 air off temp erature 1 1 name 1 1 refrigeration case 1 1 class 1 1 sev erity 1 1 state 1 1 ip 0 1 store name 0 1 store n umber 0 1 timestamp 1 1 deriv ed shelfT emp 1 0 deriv ed fo o dT emp 1 0 ev ap orator in 1 0 ev ap orator out 1 0 ev ap orator v alve 1 0 do or state 1 0 date d d targetT emp on d d targetT emp on diff d d targetT emp off d d targetT emp off diff d d targetTime d d targetTime sec d d timestamp sec d d time diff sec d d T able App endix B.1: T able showing feature prev alence betw een data sets, where d is derived, 1 is present and 0 is absent. 23 TimeStamp air on air off fo o dTmp shelfTmp Def Ctrl dSP EvIn EvOut EvVlv Def1 Cln Door Lgt Is Is1 1488990480.0 3.8 1.7 3.8 2.5 17.2 1.7 -0.3 -9.4 3.5 100.0 0 0 0 1 1 0 1488990420.0 4.2 2.7 3.8 3.3 17.1 2.7 0.7 -9.0 3.7 100.0 0 0 0 1 1 0 1488990300.0 4.3 3.2 3.8 3.6 17.2 3.2 1.2 -7.2 3.5 100.0 0 0 0 1 1 1 1488990240.0 4.1 2.8 3.8 3.3 17.2 2.8 0.8 -3.9 3.2 0.0 0 0 0 1 0 0 1488990180.0 3.8 2.3 3.8 2.9 17.3 2.3 0.3 -5.0 3.0 0.0 0 0 0 1 0 0 1488990120.0 3.5 1.8 3.9 2.4 17.3 1.8 -0.2 -4.8 2.8 0.0 0 0 0 1 0 0 1488990060.0 3.3 1.1 3.9 1.9 17.3 1.1 -0.9 -6.0 2.7 0.0 0 0 0 1 0 0 1488989940.0 3.1 0.5 3.9 1.5 17.4 0.5 -1.5 -8.1 2.6 0.0 0 0 0 1 0 0 1488989880.0 3.0 0.1 3.9 1.2 17.5 0.1 -1.9 -7.3 2.6 0.0 0 0 0 1 0 0 1488989820.0 3.1 -0.1 4.0 1.1 17.5 -0.1 -2.1 -8.3 2.7 0.0 0 0 0 1 0 0 1488989760.0 3.5 0.8 4.0 1.8 17.4 0.8 -1.2 -8.6 3.2 0.0 0 0 0 1 0 0 1488989700.0 3.9 1.6 4.0 2.5 17.4 1.6 -0.4 -8.5 3.5 100.0 0 0 0 1 1 0 1488989580.0 4.3 2.4 4.0 3.1 17.3 2.4 0.4 -9.6 3.8 100.0 0 0 0 1 1 0 1488989520.0 4.5 3.1 4.1 3.6 17.4 3.1 1.1 -7.6 3.7 100.0 0 0 0 1 1 1 1488989460.0 4.3 2.9 4.1 3.4 17.2 2.9 0.9 -4.3 3.4 0.0 0 0 0 1 0 0 1488989400.0 4.0 2.4 4.1 3.0 17.1 2.4 0.4 -4.9 3.3 0.0 0 0 0 1 0 0 1488989340.0 3.7 1.6 4.1 2.4 16.8 1.6 -0.4 -5.7 3.0 0.0 0 0 0 1 0 0 T able App endix B.2: Sample of partially cleaned data from refrigerator op eration (BARN) 24 F eature Barn Fleet refrigeration case 0 1 store n umber 0 1 timestamp 0 1 fault name 0 1 T able Appendix B.3: T able showing feature prev alence b etw een data sets for work order faults, where d is derived, 1 is present and 0 is absent. 25
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment