센서 데이터 변환으로 프라이버시와 유틸리티 동시 보호
본 논문은 웨어러블·스마트폰 센서 데이터를 사전에 변환하여 민감 활동 및 사용자 재식별을 차단하면서, 애플리케이션이 요구하는 제스처·활동 인식 정확도는 5% 이하의 손실만 발생하도록 하는 두 단계 변환 프레임워크(RAE·AAE)를 제안한다. 실험 결과, 민감 활동 탐지를 거의 무작위 수준으로 낮추고, 사용자 재식별 정확도도 7% 이하로 감소시키면서, 비민감 활동 인식 정확도는 92% 이상을 유지한다.
저자: Mohammad Malekzadeh, Richard G. Clegg, Andrea Cavallaro
**1. 서론**
웨어러블 및 스마트폰에 내장된 가속도·자이로·자력계 등 다중 센서는 사용자의 일상 행동, 건강 상태, 심지어 감정까지 추론할 수 있게 해준다. 이러한 데이터는 클라우드 기반 애플리케이션에 제공되어 제스처 인식, 걸음 수 측정, 활동 분류 등 다양한 서비스를 가능하게 하지만, 동시에 사용자의 흡연 습관, 성별·연령 등 민감 정보를 노출하거나, 고유한 움직임 패턴을 통해 재식별당할 위험을 내포한다. 기존 프라이버시 보호 방법은 센서 접근 권한을 전부 허용하거나 차단하는 이진 방식에 머물러, 사용자가 세밀하게 ‘어떤 정보’를 공유할지 제어하지 못한다.
**2. 관련 연구**
시간‑시계열 데이터에 대한 프라이버시 보호는 크게 잡음 주입(차등 프라이버시), 합성 데이터 생성(GAN 기반), 필터링, 변환(정보 병목) 네 가지 접근으로 구분된다. 잡음 주입은 독립·동일분포(i.i.d.) 잡음이 시계열 상관성을 무시하면 쉽게 제거될 위험이 있다. 합성 데이터는 주로 오프라인 데이터셋 공개에 사용되며, 실시간 사용자 측 변환에는 부적합하다. 필터링은 사전 정의된 민감 구간을 차단하지만, 복합 활동이 같은 윈도우에 섞여 있을 경우 정보 손실이 크다. 변환 기반 방법은 자동인코더 등 딥러닝 모델을 활용해 데이터 차원을 축소하거나 재구성함으로써 민감 패턴을 억제한다는 점에서 가장 유망하지만, 기존 연구는 전역(서버‑중심) 변환에 초점을 맞추었다.
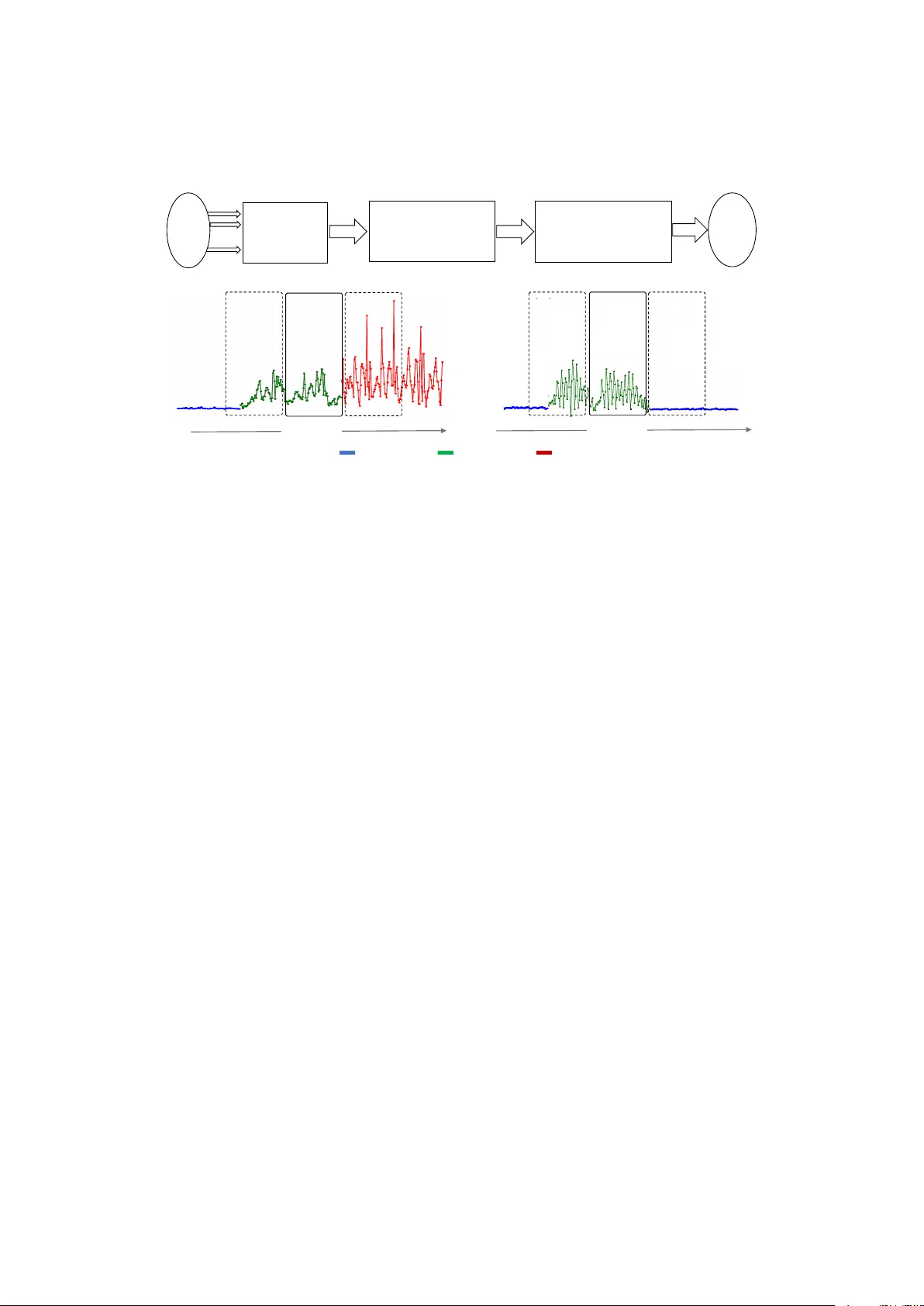
**3. 제안 방법**
본 논문은 두 단계의 자동인코더를 연속 적용하는 **복합 프레임워크**를 제안한다.
- **3.1 Replacement AutoEncoder (RAE)**
- 목적: 민감 활동을 포함하는 시간‑윈도우를 ‘중립’ 활동 데이터로 교체한다.
- 학습 데이터 구성: 원본 데이터 X_i 를 라벨(Required, Sensitive, Neutral)별로 분류하고, Sensitive 샘플을 무작위 Neutral 샘플로 교체한 X_o 를 목표 출력으로 만든다.
- 손실 함수 L_R은 입력‑출력 간 MSE 혹은 교차엔트로피이며, 최적 파라미터 θ* = argmin_θ L_R(RAE_θ(X_i), X_o) 로 구한다.
- 추론 시, RAE는 입력 윈도우가 민감 라벨을 가질 경우 자동으로 중립 데이터 X_r 로 변환하고, 그렇지 않으면 원본을 그대로 반환한다.
- **3.2 Anonymizing AutoEncoder (AAE)**
- 목적: RAE를 통과한 데이터에서 남아 있는 사용자 고유 패턴을 제거해 재식별 위험을 감소시킨다.
- 다중 목표 손실 L_A = β_i L_i – β_a L_a + β_d L_d 로 정의한다.
- L_i (프라이버시 손실): 사용자 라벨 U 와 예측 라벨 Ũ 간 교차엔트로피를 최소화(즉, 최대화된 불확실성)하도록 설계.
- L_a (유틸리티 손실): 활동 라벨 Y 와 예측 라벨 Ŷ 간 교차엔트로피를 최소화해 원래 애플리케이션이 요구하는 인식 정확도를 유지.
- L_d (왜곡 손실): 원본 X 와 변환 X'' 간 L2 거리 평균을 최소화해 데이터 왜곡을 제한.
- β 파라미터는 교차 검증을 통해 프라이버시와 유틸리티 사이의 최적 트레이드오프를 찾는다. 최적 파라미터 θ* = argmin_θ β_i I(U;A_θ(X)) – β_a I(Y;A_θ(X)) + β_d d(X, A_θ(X)) 로 구한다.
- **3.3 복합 구조**
- RAE → AAE 순서로 적용해 민감 윈도우는 중립 데이터로 교체하고, 전체 데이터는 사용자 식별 정보를 억제한다. 이 구조는 운영체제 레벨에서 인터페이스 형태로 구현 가능하며, 사용자는 앱별로 ‘필요한 인식’과 ‘허용 가능한 민감도’를 정의해 권한을 부여한다.
**4. 실험**
- **데이터셋**: 공개 제스처 데이터셋(다중 제스처 라벨)과 자체 수집한 스마트폰 기반 활동 인식 데이터(24명, 6가지 활동) 사용.
- **평가 지표**: (1) 민감 활동 인식 정확도, (2) 비민감/필요 활동 인식 정확도, (3) 사용자 재식별 정확도, (4) 변환 전후 데이터 왜곡.
- **결과**
- RAE만 적용했을 때 민감 제스처 인식 정확도가 90%→10% 이하, 비민감 제스처 정확도 감소폭은 4% 미만.
- AAE를 추가하면 사용자 재식별 정확도가 96%→7% 이하로 급감, 동시에 활동 인식 정확도는 92% 이상 유지.
- 변환 후 데이터의 평균 MSE는 원본 대비 0.02 수준으로, 실시간 애플리케이션에 큰 부하를 주지 않음.
- ‘보지 못한 사용자’에 대해서도 동일 모델을 적용했을 때 유사한 프라이버시·유틸리티 성능을 보이며, 모델 일반화 가능성을 확인했다.
**5. 논의 및 한계**
- **장점**: 사용자 측에서 실시간 변환이 가능하고, 민감 라벨이 명시된 경우 정확히 차단한다. 다중 목표 손실을 통해 프라이버시와 유틸리티를 정량적으로 조절할 수 있다. 기존 잡음 기반 방법 대비 유틸리티 손실이 현저히 낮다.
- **제한점**: 딥러닝 모델 학습에 라벨링된 데이터가 필요하며, 라벨 정의가 부정확하면 오탐·누락이 발생한다. 모델 자체가 노출될 경우 역공학 공격에 취약할 수 있다. 연산량이 모바일 디바이스에 부담될 수 있어 경량화가 필요하다.
- **미래 연구**: 라벨 자동 추출을 위한 메타‑학습, 변환 모델에 대한 차등 프라이버시 적용, 경량화된 변환 아키텍처(예: TinyML) 개발, 그리고 변환 모델 자체를 보호하기 위한 보안 메커니즘(예: 모델 암호화) 등을 제안한다.
**6. 결론**
본 연구는 센서 데이터의 민감 정보와 사용자 식별 정보를 효과적으로 억제하면서, 애플리케이션이 요구하는 제스처·활동 인식 정확도를 거의 유지하는 두 단계 자동인코더 기반 변환 프레임워크를 제시한다. 실험 결과는 프라이버시 보호와 유틸리티 유지 사이의 실용적인 트레이드오프를 입증하며, 사용자 중심의 프라이버시 제어 메커니즘으로서 향후 모바일·헬스케어 서비스에 적용 가능성을 보여준다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기