Privacy and Utility Preserving Sensor-Data Transformations
Sensitive inferences and user re-identification are major threats to privacy when raw sensor data from wearable or portable devices are shared with cloud-assisted applications. To mitigate these threats, we propose mechanisms to transform sensor data…
Authors: Mohammad Malekzadeh, Richard G. Clegg, Andrea Cavallaro
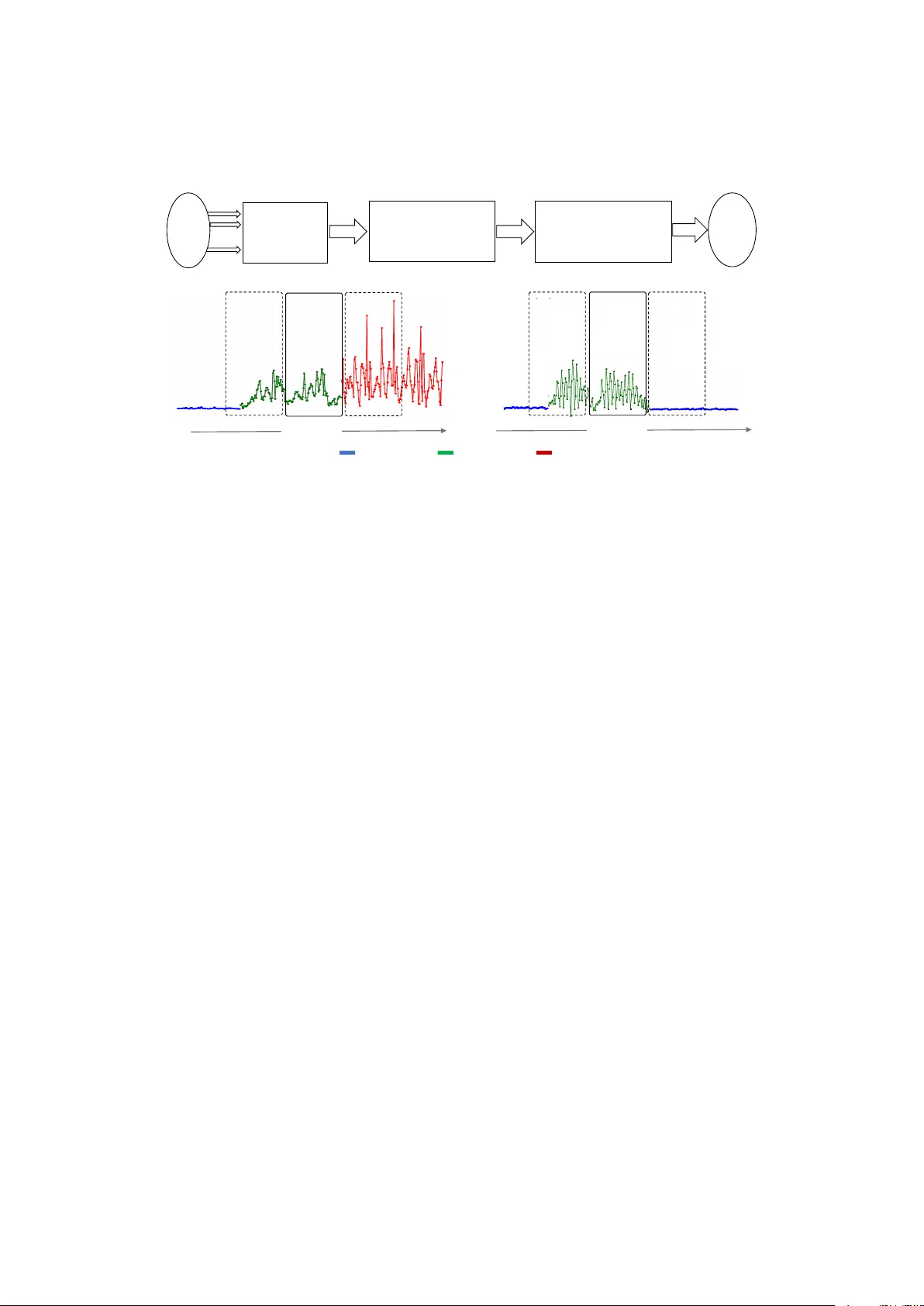
Priv acy and Utilit y Preserving Sensor-Data T ransformations 1 Mohammad Malekzadeh ∗ , Ric hard G. Clegg ∗ , Andrea Ca v allaro ∗ , Hamed Haddadi ∗∗ { m.malekzadeh, r.clegg, a.ca v allaro } @qm ul.ac.uk, h.haddadi@imp erial.ac.uk ∗ Queen Mary Univ ersity of London, ∗∗ Imp erial College London Abstract Sensitiv e inferences and user re-identifi cation are ma jor threats to priv acy when ra w sensor data from w earable or p ortable devices are shared with cloud-assisted applications. T o mitigate these threats, w e propose mec hanisms to transform sensor data b efore sharing them with applications running on users’ devices. These transformations aim at eliminating patterns that can b e used for user re- iden tification or for inferring p otentially sensitive activities, while introducing a minor utility loss for the target application (or task). W e show that, on gesture and activit y recognition tasks, w e can preven t inference of p otentially sensitive activities while k eeping the reduction in recognition accuracy of non-sensitive activities to less than 5 p ercen tage points. W e also sho w that w e can reduce the accuracy of user re-identification and of the p otential inference of gender to the level of a random guess, while k eeping the accuracy of activity recognition comparable to that obtained on the original data. 1. In tro duction Sensors such as accelerometer, gyroscop e, and magnetometer, em bedded in p ersonal smart devices generate data that can b e used to monitor users’ activities, in teractions, and moo d [1, 2, 3]. Applications (apps) installed on smart devices can get access to ra w sensor data to mak e r e quir e d ( i.e. desired) inferences for tasks such as gesture or activit y recognition. Ho wev er, sensor data can also facilitate some p oten tially sensitive ( i.e. undesired) inferences that a user might wish to keep priv ate, such as discov ering smoking habits [4] or revealing p ersonal attributes such as age and gender [5]. Some patterns in raw sensor data ma y also enable user re-iden tification [6]. Information priv acy can b e defined as “the right to sele ct what p ersonal in- formation ab out me is known to what p e ople” [7]. T o preserve priv acy , we need mec hanisms to control the t yp e and amount of information that pro viders of cloud-assisted apps can discov er from sensor data. The main ob jectiv e is to mov e 1 Accepted to app ear in P erv asiv e and Mobile computing (PMC) Journal, Elsevier. 1 … … … 𝑁𝑒𝑢𝑡𝑟𝑎𝑙 𝑅𝑒𝑞𝑢𝑖𝑟𝑒 𝑑 ,, , ,,,,,,,,,, 𝑆𝑒𝑛𝑠𝑖𝑡𝑖𝑣𝑒 Raw T ime -W indow … … 𝐗 𝐗′ 𝐗 ′′ Senso rs App Buffering a Time - Widow Transformation by 𝐴𝑛𝑜𝑛𝑦𝑚𝑖𝑧𝑖𝑛𝑔 𝐴𝑢𝑡𝑜𝑒𝑛𝑐𝑜𝑑𝑒𝑟 Transformation by 𝑅𝑒𝑝𝑙𝑎𝑐𝑒𝑚𝑒𝑛𝑡 𝐴𝑢𝑡𝑜𝑒𝑛𝑐𝑜𝑑𝑒𝑟 Time Time 𝐗 𝐗 ′′ Transformed Time - Window Figure 1: (T op) the data flo ws in the comp ound framework. At the test-time, first RAE auto- matically replaces sensitive time-windows with non-sensitive neutral data, while r e quir e d time- windo ws are passed with minimal distortions. Then, AEE transforms data to reduce the chance of user r e-identific ation . (Bottom) visual illustration of our transformation mechanism. Depicted signals show accelerometer data transformation for standing, walking, and jogging activities re- sp ectiv ely as neutr al , r e quir e d , and sensitive inferences (from exp eriment of Section 4.3). from the current binary setting of granting or not sensor p ermission to an app, to ward a mo del that allo ws users to grant each app p ermission ov er a controlled range of inferences according to the target task. The challenging task is to design a mechanism with an acceptable trade-off b etw een the protection of sensitive in- formation and the maintenance of the r e quir e d information for an inference [8]. T o this end, w e use neutr al inferences that are irrelev ant to the target task and not critical to the user’s priv acy . As sp ecific example of categorization of sensitive , r e quir e d , and neutr al in- formation, let us consider a smartw atc h step-coun ter app: r e quir e d information is essential for the app’s utilit y , such as walking or stair stepping; sensitive in- formation is ab out activities a user wishes to k eep priv ate, such as smoking or t yping on a keyboard, or information such as gender; whereas neutr al informa- tion leads to inferences that are neither r e quir e d nor sensitive , such as when the user sits or stands. Note that tw o types of information ( i.e. r e quir e d and sensitive , or neutr al and sensitive ) are sometimes en tangled in the data of the same temp oral window of sensor measurements. While lo cally differen tially pri- v ate mec hanisms [9] pro vide plausible deniabilit y guarantees when estimating, for example, the mean or frequency of a common v ariable among users [10], with m ulti-dimensional data released sequen tially a more practical priv acy mo del is in- fer ential privacy [11, 12, 13] that measures the difference b etw een an adv ersary’s b elief ab out sensitive inferences b efore and after observing the released data. W e assume the app pro vider is honest in stating its r e quir e d inferences that need to be made on the data, but it is also curious ab out making other unstated inferences that may rev eal sensitive information and th us violate priv acy . W e 2 define utility as the accuracy in making the r e quir e d inferences on the released data, and privacy loss as the accuracy in making sensitive inferences. W e define the app pro vider as adversary and quan tify the privacy loss as the improv emen t in the adv ersary’s p osterior b elief on making a sensitive inference by observing the data. Our prop osed mec hanisms aim to minimize the privacy loss while main taining the utility of the raw data. In this pap er, we present mec hanisms for transforming time-windows of sen- sor data to preserve priv acy and utility during information disclosure [14, 15, 16] to a honest-but-curious app running on users’ devices. Sp ecifically , we intro- duce a Replacemen t AutoEnco der (RAE) to protect sensitive inferences and an Anon ymizing AutoEnco der (AAE) to prev ent user r e-identific ation , as w ell as a comp ound architecture by cascading the RAE and AAE (see Figure 1). The RAE and AAE can b e deplo yed as in terface in to the devices’ op erating system to enable users to choose whether to share their sensor data with an app directly or after transformations. T o v alidate our mechanisms, in addition to using av ail- able datasets, w e collected a dataset of activit y recognition using smartphone sensors, which is made publicly a v ailable 2 . Exp erimen ts on gesture and activity recognition show that the RAE substantially reduces the privacy loss for sensi- tive gestures or activities while limiting the reduction in the utility of the r e quir e d and neutr al gestures or activities to less than 5 p ercentage p oints. F urthermore, results on an activity recognition dataset of 24 users show a promising trade-off, with the utility main tained ov er 92% and a reduction of the privacy loss in user re-iden tification to less than 7% , from an initial 96% on the raw data. W e also sho w that our mechanisms lead to mo dels that can generalize across datasets and can b e applied to new data of unseen users. 2. Related W ork Priv acy-preserving mechanisms for time-series data can b e implemented through p erturb ations , synthesis , filtering , or tr ansformations . Mec hanisms using p erturb ations hide sensitiv e patterns by adding a crafted noise to each time-windo w of the time-series. The ob jective is to preven t p er- turb ed data from including sufficien t information to accurately reconstruct the original data [17]. Because an indep enden t and identically distributed noise can b e easily remov ed from correlated time-series [18], to reduce the risk of infor- mation leak age, the correlation b etw een noise and original time-series should b e indistinguishable [19]. F or multi-dimensional sensor data, it is not easy to find a reliable mo del of correlation b et ween the original data and an adequate noise. Hence, when general time-series p erturbation approaches are extended to sen- sor data, effectiv ely hiding sensitive patterns without excessively p erturbing the non-sensitiv e ones is very challenging. 2 Co de and data are av ailable at: https://github.com/mmalekzadeh/motion- sense 3 T able 1: Priv acy-preserving mechanisms for sharing time series. Key - L o c al : applied on the user side (instead of b eing done globally b y a data curator); GesA ct : hides users’ sensitiv e gestures or activities; Identity : preven ts user re-identification; Sensors : ev aluated on sensor data; Unse en : can b e used for data of users who did not con tribute training data. Me chanism R efer enc e L o c al GesA ct Identity Sensor Unse en P erturbations [17, 18, 19] X X Syn thesis [22, 24, 25] X Filtering [26, 30, 33] X X [27] X X X T ransformations [12, 13] X X [11, 31] X X [29] X X X X Filtering & T ransformations Ours X X X X X Data can also b e synthesize d to maintain some required statistics of the orig- inal data without information that can b e used for re-iden tification. Adversarial learning enables one to appro ximate an underlying distribution to generate new data that are similar to the existing ones [20, 21]. T o pro vide a priv acy guaran tee, generators can b e trained under the constraint of differential priv acy [22, 23] or with constraints on the type of information that should b e unsynthesized in the data [24]. How ev er, these mechanisms are used for offline dataset publishing by a data aggregator [25], not for online data transformation at the user side. Filtering can b e used to remo v e un w anted comp onen ts only in temporal in ter- v als that include sensitive information. MaskIt [26] releases lo cation time-series when users are at a regular workplace and suppresses them when they are in a sensitiv e place, such as a hospital. A Marko v c hain built on a pre-defined set of conditions is employ ed for eac h user. A Dynamic Bay esian Netw ork mo del can b e used offline to replace sensitiv e time-windows that indicate users’ stress, while k eeping non-sensitive time-windows corresp onding to their walking p e rio ds [27]. T r ansformations can reduce the amount of sensitiv e information in the data b y reconstruction [12] or by pro jecting each data sample in to a lo wer dimensional laten t representation [13, 28]. The information bottleneck in the hidden la yers of neural netw orks helps to capture the main factors of v ariation in the data and to iden tify and obscure sensitive patterns in the latent representation [13], as well as during the reconstruction from the extracted lo w-dimensional repre- sen tation [29, 30]. Global mechanisms inv olv e a trusted data curator and, based on the information b ottleneck principle, compress sensor data to reduce sensitive information that is irrelev ant to the main task [11]. T able 1 compares methods related to our w ork. A priv acy-preserving mec h- anism can b e run globally or lo cally . Global mechanisms inv olv e a trusted data curator that has access to the original data and offer a data transformation service to remov e sensitiv e information b efore data publishing [11, 31, 32]. Lo cal mech- 4 T able 2: Main notation used in this pap er. x sj ∈ R reading from sensor comp onent s at sampling instant j ; X ∈ R M × W time-windo w of W samples from M sensors; X i , X o ⊆ R M × W input and output datasets, resp ectively , for training the RAE; X 0 , X 00 ∈ R M × W output of the RAE and the AAE, resp ectively; U ∈ { 0 , 1 } N N -dim vector representing the identit y of a user ( P N i =1 u i = 1); Y ∈ { 0 , 1 } B B -dim vector represen ting a gesture/activity ( P B i =1 y i = 1); I( · ; · ) m utual information function; d( · , · ) distance function b etw een tw o time-series ( e.g. Mean Squared Error). anisms, instead, manipulate data at the user side, without relying on a trusted curator [26, 29, 30]. Our mec hanisms run lo c al ly and can b e used b y users who did not con tribute training data ( unse en users). 3. Sensor-Data T ransformation W e first in tro duce the Replacemen t AutoEnco der (RAE) that protects sen- sitive inferences, then w e present the Anon ymizing AutoEnco der (AAE) that prev ents user r e-identific ation . The notations we use in this pap er are sho wn in T able 2. 3.1. R eplac ement AutoEnc o der Deep neural netw orks (DNNs) are p ow erful machine learning algorithms that progressiv ely learn hierarc hical and relev ant represen tations of their training data. Earlier lay ers of a DNN can encode generic low-lev el data patterns and later la yers can capture more sp ecific high-level features. Auto enco ders learn features from data through minimizing the differences ( e.g. mean squared error or cross en tropy) b et ween the input and its reconstruction. The information b ottlenec k [34] in the hidden la y ers forces an autoenco der to put more attention on the descriptiv e data patterns in order to generalize the mo del. Let a fixed-length time-windo w of sensor data, X = ( x sj ) ∈ R M × W , contain some sp ecific patterns that are utilized to recognize the gesture or activity of the user at that sp ecific time-p oin t. F or example, let us consider an smartw atch app whic h coun ts users’ daily steps. Users may wan t this app to only b e able to infer activities that are r e quir e d for step counting task, not other activities such as smoking or eating that may b e considered sensitive . The main idea of RAE is to automatically recognize and replace eac h time-widows that rev eals sensitive activities with a same dimension data that simulates a neutr al activit y , such as standing or sitting, whic h do es not affect the step counter utility . Let the training dataset include labeled sample time-windows, eac h belonging to one of the following categories: r e quir e d , sensitive , or neutr al . Let X i b e 5 Neutral ( Required ( 𝐗′ Training Sensitive ( Inference 𝐗 Time Time Figure 2: Circles represen t time-windo ws in the input ( X i ) and output ( X o ) datasets for training the RAE. W e first make a copy of the original input dataset and replace every sensitive time-windo w with a randomly c hosen neutr al one to prepare the output dataset for training the RAE. Then, the RAE is trained to transform each X i to the corresp onding X o . At inference time, RAE can replace unseen sensitive time-windows with data that simulates neutr al ones. the input dataset and X o b e the output dataset, with a one-to-one relationship b et ween each X i ∈ X i and an X o ∈ X o explained in Figure 2. Basically , data samples of sensitive classes in X i are randomly replaced with data samples from one of the neutr al classes to build X o . Therefore X o con tains only samples from the r e quir e d and neutr al classes. The RAE is then trained to transform eac h X i to the corresp onding X o , sub ject to a loss function, L R ( X i , X o ), which calculates the difference b etw een the input of the RAE and its corresp onding output. Let a replacemen t b e defined as privacy-pr eserving if its outcome remov es, or practically b ounds, the p ossibility of revealing sensitive inferences. If X r is a privacy-pr eserving replacemen t for sensitive data X , the RAE aims to implemen t the follo wing op eration: X 0 = RAE ( X ) = X r if X rev eals a sensitive inference, X otherwise, (1) where the privacy loss of the replaced data, X 0 , is equiv alen t to the amoun t of sensitiv e information it reveals. If R( X ; θ ) is an auto enco der with parameter set θ ∈ Θ, and L R ( · , · ) is the auto enco der’s loss function, we define the optimal parameter set for the RAE as θ ∗ = argmin θ ∈ Θ L R R X i ; θ , X o , (2) whic h can b e ac hieved through a neural netw ork optimization pro cess [35]. The implemen tation details of RAE are explained in Section 4. 3.2. Anonymization AutoEnc o der As time-windows that do not reveal sensitive inferences are supp osed to pass through the RAE with minim um distortion, they ma y b e used for other malicious purp oses such as user re-identification. As a motiv ational example, consider 6 participan ts in a study for a new treatment who share their daily sensor data with researchers [36]. These participants ma y wan t to minimize the risk of b eing re-iden tified b y those who will access their released data. Therefore, their sensor data should b e released in a w a y that the required information for the medical study , suc h as patients daily activities, can be accurately inferred, while other motion patterns that facilitate user re-iden tification are obscured. W e define the data with the user’s identifiable information obscured as the anon ymized sensor data, X 00 . Considering A( · ) as a potential data transformation function and X the data w e wan t to anonymize, we define the fitness function F( . ) as F A ( X ) = β i I U ; A ( X ) − β a I Y ; A ( X ) + β d d X , A ( X ) , (3) where the non-negative, real-v alued weigh ts β i , β a and β d determine the trade- off b et w een priv acy loss and utility . As it is discussed in Section 4, the desired trade-off is established through cross v alidation ov er the training dataset. Let the anon ymization function, A ( · ), that transforms X into X 00 b e A ( X ) = argmin A( X ) F A ( X ) . (4) The threefold ob jectiv e of Eq. (3) is to minimize I U ; A ( X ) , the m utual infor- mation b et w een the random v ariable that sp ecifies the iden tity of current user and the anonymized data; to maximize I Y ; A ( X ) , the mutual information b e- t ween the random v ariable that captures the user activity and the anonymized data ( i.e. to minimize its negativ e v alue); and, to av oid large data distortions by minimizing d X , A ( X ) , the distance b etw een raw and anonymized data. As we cannot practically search ov er all p ossible transformation functions, w e consider a DNN and look for the optimal parameter set through training. T o approximate the required mutual information terms, w e reformulate the op- timization problem in Eq. (4) as a DNN optimization problem. Let A( X ; θ ) b e a DNN, where θ is the parameter set of the DNN. The netw ork optimizer finds the optimal parameter set θ ∗ b y searching the space of all p ossible parameter sets, Θ, as: θ ∗ = argmin θ ∈ Θ β i I U ; A ( X ; θ ) − β a I Y ; A ( X ; θ ) + β d d X , A ( X ; θ ) , (5) where A ( · ; θ ∗ ) is the optimal data anonymizer for a general A ( · ) in Eq. (4). Again, w e can obtain θ ∗ using a sto chastic optimization algorithm [37]. A key con tributor to the AAE training is the following m ulti-ob jectiv e loss function, L A , whic h implements the fitness function F A ( x ) of Eq. (4): L A = β i L i − β a L a + β d L d , (6) where L a and L d are utility losses that can b e customized based on the target task requirements, whereas L i is a privacy loss that helps the AAE remov e user- sp ecific patterns that facilitate user re-identification. 7 Practically , the categorical cross-entrop y loss function for classification, L a = Y log( ˆ Y ), aims to preserv e activit y-sp ecific patterns, where ˆ Y , the output of a softmax function, is a B -dimensional v ector of probabilities for the prediction of the activity lab el. T o tune the desired priv acy-utilit y trade-off, the distance function that controls the amount of distortion, L d , forces X 00 to b e as similar as p ossible to the input X : L d = 1 M × W M X s =1 W X j =1 ( x sj − x 00 sj ) 2 . (7) Finally , the priv acy loss, L i , the most imp ortant term of our multi-ob jective loss function that aims to minimize sensitiv e information in the data, is defined as: L i = − U · log 1 N − ˆ U + log 1 − max ˆ U ! , (8) where N is the n umber of users in the training set, 1 N is the all-one column v ector of length N , U is the true identit y lab el for X , and ˆ U is the output of the softmax function, the N -dimensional v ector of probabilities learned b y the classifier ( i.e. the probability of eac h user lab el, given the input). U · log( 1 N − ˆ U ) is dot pro duct of row vectors. The goal of training AAE is to minimize the privacy loss by minimizing the amoun t of information leak age from U to X 00 . Hence, w e use adversarial training to approximate the mutual information by estimating the p osterior distribution of the sensitiv e data given the released data [38]. 4. Ev aluation T o ev aluate the RAE, we use four b enc hmark datasets of gesture and activit y recognition including at least 10 differen t labels: Opp ortunity [39], Sk oda [40], Hand-Gesture [41], and Ut wen te [42]. T o ev aluate the AAE, we need a dataset con taining sev eral users to sho w how w e can hide users’ gender or identit y . There- fore, w e use MotionSense [43] that con tains the collected data of 24 users in a range of gender, age, and height who p erformed 6 activities. W e also ev aluate the comp ound architecture (RAE+AAE) on a case study using the MotionSense dataset. Opp ortunit y [39] is comp osed of the collected data of 4 users and there are 18 gestures classes. Each record in this dataset comprises 113 sensory readings from v arious t yp es of b o dy-worn sensors like accelerometer, gyroscop e, magnetometer, and skin temp erature. Sk o da [40] is collected by an assem bly-line work er in a car pro duction company w earing 19 accelerometer sensors on his right and left arm and p erforming a set of pre-sp ecified exp eriments. 8 Hand-Gesture [41] includes data from accelerometer and gyroscope sensors attac hed to the upper and lo wer arm. There are t wo users p erforming 12 classes of hand mo vemen ts. Eac h record in this dataset has 15 real-v alued sensor readings. Ut wen te [42] includes the data of 6 participants p erforming several activities, including p oten tially sensitiv e smoking activit y , while wearing a smart-phone on their wrist. Accelerometer, gyroscope, and magnetometer data are collected. The whole dataset is publicly a v ailable in a single file with activity lab els only . MotionSense [43] is collected with a smart-phone kept in the users’ front p o ck et. A total of 24 users p erformed 6 activities in 15 trials in the same envi- ronmen t and conditions. It includes acceleration, rotation, gravit y , and attitude data. Each record in this dataset includes 12 real-v alued sensor readings. T able 3 summarizes the gesture/activity classes of the five datasets. F or Opp ortunit y , we use four trials as the training data, and consider the last trial as the testing data. F or other datasets, we consider 80% of the data as the training set and the rest as the testing set. The nul l class in the gesture datasets refers to data that cannot b e mapp ed to a kno wn b ehavior. All the gesture datasets are resampled to 30Hz sampling rate. 4.1. R eplac ement Let the B classes of inference, I = { I 1 , ..., I i , ..., I j , ..., I B } , be divided in to three categories: (i) R e quir e d , R = { I 1 , ..., I i } , (ii) Sensitive , S = { I i +1 , ..., I j } , and (iii) Neutr al , N = { I j +1 , ..., I B } . Considering a target app and its p oten tial users, w e assume S is the set of inferences that users wish to keep priv ate. W e assume these are sufficien tly sensitive that the user w ould wish to prev en t the app from making an y inferences within this set. Moreo v er, R is the set of r e quir e d inferences that users gain utility from if the app can accurately infer them. Fi- nally , N is the set of neutral inferences that are not sensitiv e to users that these inferences can be made by the app and it is also not useful for gaining utilit y . W e assume these lists are av ailable to the RAE for its training. 4.1.A. Gestur e Datasets Here, w e implemented RAE with the follo wing settings. Sev en fully-connected la yers with size (num ber of neurons) inp = ( M × W ), inp 2 , inp 8 , inp 16 , inp 8 , inp 2 , out = inp , resp ectively (except for the Hand-Gesture dataset with a lo wer di- mensionalit y that the three middle lay ers are inp 3 , inp 4 , inp 3 ). F or all datasets, w e consider 1 second time-window, W = 30. All the exp eriments are p erformed on 30 ep ochs with batc h size 128. The activ ation function for the output lay er is linear and for the input and all of the hidden la yers is Scaled Exp onential Linear Unit [44]. In our exp eriments, to retain the ov erall structure of the reconstructed data, w e set L R in Eq. (2) as the p oint-wise mean square error function. T o ev aluate the priv acy loss and utilit y of the RAE’s outcomes, b oth the ra w sensor data and the transformed data are giv en to a DNN classifier, as an en visioned app, and F 1 − scor e are calculated in T able 4, T able 5, and T able 6. Here w e use F 1 − scor e as ev aluation metric b ecause it takes b oth false p ositiv es 9 T able 3: Gesture/Activit y classes and prop erties of each dataset used for ev aluation. Gesture Datasets Activity Datasets # Opp ortunit y Sk o da HandGesture Ut w en te MotionSense 0 n ull n ull n ull — — 1 op en do or1 write notes op en window w alking standing 2 op en do or2 open hoo d close window jogging stairs-do wn 3 close do or1 close hoo d water a plant cycling stairs-up 4 close do or2 chec k front do or turn b o ok stairs-up w alking 5 op en fridge open left f door drink a bottle stairs-do wn jogging 6 close fridge close left f do or cut w/ knife sitting 7 op en washer close left do ors c hop w/ knife standing — 8 close washer chec k trunk stir in a b owl t yping — 9 op en draw er1 op en/close trunk forehand writing — 10 close draw er1 chec k wheels backhand eating — 11 op en draw er2 — smash smoking — 12 close draw er2 — — — — 13 op en draw er3 — — — — 14 close draw er3 — — — — 15 clean table — — — — 16 drink cup — — — — 17 toggle switch — — — — N 4 1 2 6 24 M 113 57 15 9 12 S.R. 30 Hz 30 Hz 30 Hz 50 Hz 50 Hz and false negatives into account. F or RAE, false p ositiv es ( i.e. recognizing R as S ) harm the utility and false negatives ( i.e. recognizing S as R or N ) harm priv acy . It should be noted that the classification accuracy metric also sho ws similar patterns 3 . The results show that utility is preserved for non-sensitive, R and N , classes while recognizing sensitiv e ones, S , is v ery unlik ely . Moreov er, Figure 3 sho ws that the mo del misclassifies all transformed sections corresponding to S into the N and therefore the false-p ositive rate on r e quir e d inferences is v ery lo w. F or instance, to see ho w RAE can establish a go o d utility priv acy trade-off, consider 3 Results av ailable at: https://github.com/mmalekzadeh/replacement- autoencoder 10 T able 4: Gesture recognition results ( F 1 − scor e ) by a pre-trained conv olutional neural netw ork on the Skoda dataset. # Set of Infer enc es X X 0 # Set of Inferences X X 0 R = { 4 , 8 , 9 , 10 } 97.9 96.3 R = { 1 , 4 , 10 } 97.6 95.0 1 S = { 1 , 5 , 6 , 7 } 96.2 0.0 3 S = { 2 , 3 , 8 , 9 } 98.0 0.0 N = { 0 , 2 , 3 } 94.3 93.4 N = { 0 , 5 , 6 , 7 } 92.3 88.2 R = { 2 , 3 , 5 , 6 , 7 , 9 } 96.5 93.2 R = { 2 , 3 , 5 , 6 , 7 , 9 } 95.8 91.1 2 S = { 4 , 8 , 10 } 97.9 0.0 4 S = { 4 , 8 , 10 } 97.4 0.0 N = { 0 , 1 } 93.9 94.8 N = { 0 , 1 } 94.3 92.4 T able 5: F 1 − scor e for the Hand-Gesture dataset. # Set of Inferences X X 0 R = { 1 , 2 , 3 , 4 , 9 , 10 , 11 } 94.1 90.1 1 S = { 5 , 6 , 7 , 8 } 95.7 0.3 N = { 0 } 95.0 96.5 R = { 1 , 3 , 4 , 5 , 6 , 7 } 95.2 90.4 2 S = { 2 , 8 , 9 , 10 , 11 } 94.5 0.6 N = { 0 } 95.0 97.5 R = { 1 , 3 , 4 , 5 , 6 , 7 , 8 } 97.2 93.3 3 S = { 2 , 9 , 10 , 11 } 92.5 0.7 N = { 0 } 95.9 97.5 R = { 2 , 3 , 5 , 6 , 7 , 9 } 96.1 92.1 4 S = { 4 , 8 , 10 } 97.0 0.5 N = { 0 , 1 } 95.7 97.6 T able 6: F 1 − scor e for the Opp ortunity dataset. # Set of Inferences X X 0 R = { 9,10,...,17 } 71.8 64.3 1 S = { 1,2,...,8 } 79.1 0.2 N = { 0 } 88.9 89.7 R = { 1,2,...,8,15,17 } 76.9 75.9 2 S = { 9,10,...,14 } 71.5 1.3 N = { 0,16 } 84.4 82.1 R = { 9,10,...,14,16 } 74.9 77.1 3 S = { 1,2,3,4,15,17 } 76.2 0.9 N = { 0,5,6,7,8 } 85.0 81.6 R = { 1,2,...,8,15,17 } 70.3 65.0 4 S = { 9,10,...,14,16 } 74.9 6.3 N = { 0,1 } 93.7 92.9 the results for the Skoda dataset in T able 4(#2). W e see that the gesture clas- sifier can effectiv ely recognize R gestures ( e.g. op ening and closing do ors), even when the app pro cesses the output of RAE instead of the raw data (with 93.2% accuracy). Ho w ever, S gestures ( e.g. chec king do ors) that can be recognized with high accuracy when app pro cesses the raw data (with 97.9% accuracy), are completely filtered out in the output of the RAE. Moreo ver, the corresp onding confusion matrix for this exp eriment in Figure 3 (Left-Bottom) shows that the utilit y of the r e quir e d inferences is preserv ed as the classifier wrongly infers all S gestures as some N gestures and not as one of R gestures. 11 Predicted Label Tru e L abe l 𝒮 ሺ 𝑅 ሻ ℛ ሺ 𝑅 ሻ 𝒩 ሺ 𝑅 ሻ 𝒩 𝒮 ሺ 𝑅 ሻ ℛ ሺ 𝑅 ሻ 𝒩 ሺ 𝑅 ሻ 𝒮 ℛ 𝒩 𝒮 ℛ 𝒩 𝒮 ℛ 𝒩 Skoda Hand -Gesture Opportunity Figure 3: Confusion Matrix for (top) original time-series, and (b ottom) transformed time-series b y RAE. After transformation almost all the sensitive gestures are recognized as neutr al ones. (Left) Results on the Skoda dataset in T able 4 (#2). (Middle) Hand-Gesture dataset in T able 5 (#1). (Right) Opp ortunity dataset in T able 6 (#2). 4.1.B. Utwente dataset Let S = { typing, writing, smoking, eating } b e the set of sensitive inferences, N = { sitting still, standing still } b e the set of neutral inferences, and R = { w alking, jogging, cycling, stairs-up, stairs-down } b e the set of required infer- ences. Considering a 2-second time-window ( W = 100), w e trained an RAE with 6 hidden lay ers: 4 Con v olutional-LSTM lay ers using hyp erb olic tangent as the activ ation function with 256, 128, 64 and 64 filters respectively , follo w ed by 2 Con volutional la yers using Scaled Exponential Linear Unit [44] as the activ ation function with 64 and 128 lay ers resp ectiv ely . W e also put a batc h-normalizer on the output of eac h hidden lay er to reduce the training time 4 . T o ev aluate the priv acy-utilit y trade-off, w e use a DNN classifier. As we see in T able 7, the av erage accuracy of the classifier on the raw data is more than 99%. How ev er, when w e feed the same classifier with the output of the RAE, all the S activities are recognized as sitting stil l , while the accuracy for R activities is almost equal to that of the raw data. W e observ e that for smoking there still is a 5% chance of recognition. Note that for some time-windows of the smoking the ra w data are similar to those of standing stil l . This effect can b e also seen 4 More implementation details and codes for reproducing the results can b e found at https: //github.com/mmalekzadeh/replacement- autoencoder 12 walking jogging cycling stairs-up stairs-down sitting standing t yping writing eating smoking walking 97.5 → 97.2 0.7 → 0.7 1.5 → 1.9 0.3 → 0.1 jogging 100 → 100 cycling 100 → 100 stairs-up 0.4 → 0.3 0.4 → 0.4 0.0 → 0.1 98.8 → 98.8 0.1 → 0.1 0.3 → 0.3 stairs-down 0.3 → 0.3 99.7 → 99.7 sitting 0.0 → 0.3 98.6 → 96.8 1.0 → 0.0 0.1 → 0.0 0.1 → 0.0 0.1 → 2.8 standing 0.0 → 0.3 99.4 → 98.2 0.6 → 1.5 typing 0.0 → 100 100 → 0.0 writing 0.0 → 0.7 0.0 → 99.3 99.9 → 0.0 0.1 → 0.0 eating 0.0 → 0.5 0.1 → 99.4 0.3 → 0.0 99.6 → 0.0 0.1 → 0.1 smoking 0.0 → 0.1 0.0 → 94.9 2.3 → 0.0 97.5 → 5.0 T able 7: Confusion Matrix of the results on the test data for Utw ente dataset. Ro ws show the true lab els and columns show the predicted lab els. In each cell, the left part shows the accuracy on the raw data, and the righ t part sho ws the accuracy after transformation. F or brevity , all the v alues are rounded to one decimal p oint. Empty cells show 0 . 0 → 0 . 0. in T able 7 (column smoking ). W e assume this is a lab eling error when the data curator lab els interv als b et w een cigarette drags as smoking b eha vior while user is standing. 4.2. Anonymization T o ev aluate the AAE as a data anonymizer, w e measure the extent to whic h the accuracy of activity recognition suffers from anon ymization compared to accessing the raw data. W e compare the trade-off b etw een recognizing users’ activit y v ersus their identit y , and compare with baseline metho ds for coarse- grain time-series data ( r esampling and singular sp e ctrum analysis ) and with the metho d in [13] that only considers the laten t represen tation b y the Enco der mo del (see Figure 4), without taking X 00 in to account. W e use resampling by F ast F ourier T ransform (FFT), whic h is desirable for p erio dic time-series, and this is t ypical with mobile sensor data for activit y recog- nition. Singular Spectrum Analysis (SSA) [45] is a mo del-free tec hnique that decomp oses time-series in to trend, p eriodic, and structureless (or noise) com- p onen ts using singular v alue decomp osition (SVD). In our case, we decomp ose X = { X 1 , X 2 , . . . , X D } such that the X i and X i +1 are arranged in descending order according to their corresp onding singular v alue and the original time-series can be reco vered as: X = P D i =1 X i . Thus, we test the idea of incr emental r e c onstruction b y SSA as a base-line transformation metho d. W e consider tw o metho ds of dividing the dataset into training and test sets, namely Subje ct and T rial . F or Subje ct , w e put all data of 4 of the users in the dataset, 2 females and 2 males, as testing data and the remaining 20 users as training. Hence, after training the AAE, w e ev aluate the mo del on a dataset of new unseen users. F or T rial , w e put one trial data of eac h user as testing data and the remaining trials of that user’s data as training. F or example, where we hav e three walking trials for ev ery user, we consider one trial as testing and the other t wo as training. In b oth cases, we put 20% of the training data for v alidation during the training phase. W e repeat eac h experiment 5 times and rep ort the 13 out inp (2, 12 8 ) (24) DecReg Model out inp (2, 32 ) (24) EncReg Model Input Layer (2, 128) out inp (2, 12 8 ) (2, 32) Encoder Model out inp (2, 32 ) (2, 128) Decoder Model out inp (2, 12 8 ) (4) ActReg Model Figure 4: Details of the training the AAE (Encoder and Deco der) for a dataset with 24 users and 4 activities. KEY – EncRe g and De cR e g : users’ identit y recognizers that monitors the output of the Enco der and Decoder, resp ectively , to reduce the priv acy loss; A ctR e g : a users’ activit y recognizer that monitors the output of the Deco der to increase the utilit y . mean and the standard deviation. F or all the exp eriments we use the magnitude v alue for b oth gyroscop e and acc elerometer. T o simplify the pro cess of enco ding data in to a lo w er-dimensional represen- tation and then deco ding it to the original dimension with con volutional filters, w e set W to b e a p ow er of 2. The larger W , the lo wer the possibility of taking adv antage of the correlation among the successiv e windows by adversaries [38]. But larger window sizes increase the dela y for real-time apps. W e set W = 128 ( i.e. 2.56 seconds). F or all the regularizers, EncR e g , De cR e g , and A ctR e g (see Figure 4), we use 2D con volutional neural netw orks. T o preven t o verfitting, we add a Drop out [46] la yer after eac h conv olution la yer. W e also use L2 regularization to p enalize large weigh ts. W e train the classifier on the original and the anon ymized training dataset, and then use it for inference on the test data. W e use the Sub ject setting, th us the test data includes data of new unseen users. T o measure the utility , w e train an activit y recognition classifier on b oth the ra w data and the output of each transformation metho d: R esampling , SSA , [13], and our AAE . Then, we use the trained mo del for inference on the corresp onding testing data. Here we use the Subje ct setting, th us the testing data include data of new unseen users. The second row of T able 8 (ACT) shows that the a verage accuracy for activity recognition for both Raw and AAE data is around 92%. Compared to other methods that decrease the utilit y of the data, w e can preserv e the utility and even sligh tly improv e it, on av erage, as the AAE shap es data suc h that an activity recognition classifier can learn b etter from the transformed data than from the ra w data. T o measure the priv acy loss, we assume that an adv ersary has access to the training dataset and we measure the ability of a pre-trained deep classifier on users ra w data in inferring the iden tity of the users when it receives the transformed data. W e train a classifier in the T rial setting o v er ra w data and then feed it differen t types of transformed data. The third row of T able 8 (ID) sho ws that do wnsampling data from 50Hz to 5Hz reveals more information than using the AAE output in the original frequency . These results sho w that the AAE can 14 T able 8: T rade-off b etw een utility (activity recognition) and priv acy (protecting iden tity). The forth row shows the K-NN rank b etw een 24 users (the lo wer the better). Key – ACT : activity recognition, ID : identit y recognition, ACC : accuracy , F1 : F 1 − scor e , DTW : Dynamic Time W arping as similarity measure, SSA : Singular Spectrum Analysis, AAE : Our metho d. Exp eriment Me asur e R aw Data R esampling SSA [13] AAE 50Hz 10Hz 5Hz 1+2 1 50Hz 50Hz ACT mean F1 92.5 91.1 88.0 88.6 87.4 91.5 92.9 xiance F1 2.1 0.6 1.8 0.9 0.9 0.9 0.37 ID mean ACC 96.2 31.1 13.5 34.1 16.1 15.9 7.0 mean F1 95.9 25.6 8.9 28.6 12.6 11.2 1.8 DTW mean Rank 0 7.2 9.3 6.8 9.5 10.7 6.6 v ariance Rank 0 5.7 5.8 5.6 5.4 5.5 4.7 effectiv ely obscure user-identifiable information so that even a mo del that has had access to the original data of the users cannot distinguish them after applying the transformation. Finally , to ev aluate the priv acy loss and efficiency of the anon ymization with an unsupervised mechanism, w e implemen t the k -Nearest Neighbors ( k -NN) with Dynamic Time W arping (DTW) [47]. Using DTW, w e measure the similarit y b et ween the transformed data of a target user k and the ra w data of eac h user l , X l , for all l ∈ { 1 , . . . , k , . . . , N } . Then we use this similarity measure to find the k nearest neigh b ors of user l and chec k their rank. The last ro w of T able 8 (DTW) shows that it is v ery difficult to find similarities b etw een the transformed and ra w data of the users as the p erformance of the AAE is very similar to the baseline metho ds and the constrain t in Eq. (5) main tain the data as similar as p ossible to the original data. This result shows that the utilit y-priv acy trade-off of AAE is preferable to that of the other metho ds. 4.3. Comp ound A r chite ctur e Here, w e ev aluate a setting where anonymization with the AEE follo ws re- placemen t using RAE. Considering MotionSense dataset, w e wan t an app to b e unable to infer gender or jogging activit y from motion data. Let S = { jo gging } b e the sensitive activity to be replaced with N = { standing stil l } as the neutr al activit y . W e also consider R = { walking, stairs-down, stairs-up } as the r e quir e d inferences. Let the time-window b e 2.56 seconds ( W = 128 samples) and M = 2, i.e. w e consider the magnitude of rotation and acceleration of the device. First, w e train tw o conv olutional neural netw orks as activit y and gender clas- sifiers on the original training dataset. Second, RAE is trained to replace the jogging time-windows while k eeping the r e quir e d time-windows unmodified in the RAE’s output, X 0 . Third, we use the RAE’s output, X 0 , as the AAE’s input and train the AEE to reduce the likelihoo d of the user’s gender b eing inferred from 15 T able 9: T rue-p ositive rate for eac h activity and gender classification accuracy (%) using a con volutional neural net w ork for each stage of the compound model on MotionSense [43] dataset. Infer enc e X : Original X 0 : R eplac ement X 00 : Anonymization β i = β a = β d β i = 1 2 β a = β d stairs-do wn 98.0 93.9 98.5 96.3 R stairs-up 96.4 97.8 92.3 96.3 w alking 99.7 94.8 89.4 94.8 S jogging 99.3 1.4 (92 as N ) .2 (92 as N ) .1 (84 as N ) N standing 99.9 99.9 100 99.9 Gender 98.9 97.1 45.0 39.0 the ultimate data that is shared with the app, X 00 . Finally , after training b oth auto enco ders, we feed the testing dataset into the comp ound mo del. T able 9 shows the activit y and gender classification results at each pro cess- ing stage. While X is highly informative for all inferences, after replacemen t jo gging interv als are not inferred in X 0 and they are classified as standing . How- ev er, gender can still b e inferred from X 0 . Inferring gender from X 00 ( i.e. after anon ymization) reaches the desired level of random guess while the inference of R is main tained close to the original accuracy . Imp ortan tly , the prop osed frame- w ork allo ws us to giv e differen t weigh ts on preserving the activity and hiding gender: the last column of T able 9 shows that a b etter accuracy can b e obtained if w e increase the risk of leaking more sensitiv e information. Notice that, the random guess is 50% accurate. Th us, the priv acy loss is larger when we hav e 39% accuracy for gender classifier than 45%. 5. Discussion While we b elieve the prop osed mechanisms establish effective utilit y-priv acy trade-offs for sensor data transformations, here w e discuss directions of this work that need more explorations. First, in the av ailable datasets, the activities/gestures that are categorized in to sensitive , r e quir e d , and neutr al are independent of eac h other and at eac h time-windo w only one of them is happ ening. How ev er, in the real-w orld situa- tions there might b e correlations among different activities that affect the pro- vided priv acy guarantees for some sensitive inferences. Similarly , correlations among consecutiv e time-windo ws of a sp ecific activity may incremen tally reveal information that facilitate user re-identification. T o assess this, w e w ould need access to m ulti-lab elled data collected ov er a muc h longer time p erio d as w ell as a large n umber of demographically different users. Second, to sho w that the prop osed mechanisms can generalize, w e p erformed ev aluations on several datasets collected from different t yp e of sensors located 16 in different part of users’ b o dy . Current public datasets of mobile and wearable sensor data do not simultaneously satisfy the requiremen ts of abundance and v ariety of activities and users. T o reduce the risk of o v erfitting, we performed our exp erimen ts on DNNs with small num b er of lay ers and small num b er of neurons in each la y er. With larger datasets, one can increase the learning capacit y of the RAE and AAE b y adding more lay ers to the neural net work or inv estigate v arious DNN architectures. Third, w e ha v e assumed the existence of a publicly av ailable dataset to train the RAE and the AAE. when such public dataset is not a v ailable, one option is to use priv acy-preserving mo del training without collecting p ersonal data [48], or training the required mo del through a federated learning [49]. Finally , we aim to in v estigate a priv acy-preserving mec hanism that trans- forms sensitive patterns in to a mixture of neutral activities rather than only one of them. Moreov er, w e aim to lo ok for, or to collect, larger datasets to conduct exp erimen ts on additional tasks, to deriv e statistical b ounds for the amount of priv acy achiev ed, and to measure the cost of running the prop osed lo cal trans- formations on user devices. 6. Conclusion In this pap er we show ed how to ac hieve a trade-off b et ween priv acy and util- it y for sensor data release with an appropriate learning pro cess. In particular, w e presented new wa ys to train deep auto enco ders for contin uous data trans- formations to preven t a honest-but-curious app from discov ering users’ sensitive information. Our mo del is general and can be applied to unseen data of new users, without need for re-training. Exp erimen ts conducted on v arious types of real-w orld sensor data show ed that our transformation mechanism eliminates the p ossibilit y of making sensitive inferences and obscures user-sp ecific motion pat- terns that enable user re-iden tification, in tro ducing a small utilit y loss for activit y and gesture recognition tasks. Ac kno wledgmen t The work w as supp orted by the Life Sciences Initiativ e at Queen Mary Univer- sit y of London and a Microsoft Azure for Research Award (CRM:0740917). An- drea Ca v allaro wishes to thank the Alan T uring Institute (EP/N510129/1), which is funded by the EPSRC, for its supp ort through the pro ject PRIMULA. Hamed Haddadi w as partially supp orted b y the EPSR C Datab ox grant (EP/N028260/1). References [1] K. Katev as, H. Haddadi, L. T ok arch uk, R. G. Clegg, W alking in sync: Two is company , three’s a crowd, in: Pro ceedings of the 2nd W orkshop on W orkshop on Physical Analytics, WP A ’15, Florence, Italy , ACM, 2015, pp. 25–29. 17 [2] K. H¨ ansel, K. Katev as, G. Orgs, D. C. Ric hardson, A. Alomainy , H. Haddadi, The potential of wearable tec hnology for monitoring so cial interactions based on in terp ersonal synchron y , in: Pro ceedings of the 4th ACM W orkshop on W earable Systems and Applications, A CM, 2018, pp. 45–47. [3] M. Irfan, L. T ok arch uk, L. Marcenaro, C. Regazzoni, Anomaly detection in crowds using m ulti sensory information, in: 15th IEEE In ternational Conference on Adv anced Video and Signal Based Surveillance (A VSS), IEEE, 2018, pp. 1–6. [4] P . M. Scholl, K. V an Laerhov en, A feasibility study of wrist-worn accelerometer based detection of smoking habits, in: 2012 Sixth International Conference on Innov ative Mobile and Internet Services in Ubiquitous Computing, IEEE, 2012, pp. 886–891. [5] Q. Riaz, A. V¨ ogele, B. Kr ¨ uger, A. W eber, One small step for a man: Estimation of gender, age and height from recordings of one step b y a single inertial sensor, Sensors 15 (12) (2015) 31999–32019. [6] N. Nevero v a, C. W olf, G. Lacey , L. F ridman, D. Chandra, B. Barb ello, G. T a ylor, Learning h uman identit y from motion patterns, IEEE Access 4 (2016) 1810–1820. [7] A. F. W estin, Priv acy and freedom, W ashington and Lee Law Review 25 (1) (1968) 166. [8] A. Ghosh, T. Roughgarden, M. Sundarara jan, Univ ersally utility-maximizing priv acy mech- anisms, SIAM Journal on Computing 41 (6) (2012) 1673–1693. [9] C. Dwork, A. Roth, The algorithmic foundations of differen tial priv acy , F oundations and T rends in Theoretical Computer Science 9 (3–4) (2014) 211–407. [10] A. Bittau, U. Erlingsson, P . Maniatis, I. Mironov, A. Raghunathan, D. Lie, M. Rudominer, U. Ko de, J. Tinnes, B. Seefeld, Pro chlo: Strong priv acy for analytics in the crowd, in: Pro ceedings of the 26th Symp osium on Op erating Systems Principles, A CM, 2017, pp. 441–459. [11] S. Menasria, J. W ang, M. Lu, The purpose driven priv acy preserv ation for accelerometer- based activity recognition, W orld Wide W eb 21 (6) (2018) 1773–1785. [12] C. Huang, P . Kairouz, X. Chen, L. Sank ar, R. Ra jagopal, Context-a ware generative adver- sarial priv acy , Entrop y 19 (12) (2017) 656. [13] H. Edwards, A. J. Storkey , Censoring representations with an adversary , in: 4th Interna- tional Conference on Learning Represen tations (ICLR), San Juan, Puerto Rico, Ma y 2-4, 2016. [14] G. Miklau, D. Suciu, A formal analysis of information disclosure in data exchange, Journal of Computer and System Sciences 73 (3) (2007) 507–534. [15] F. du Pin Calmon, N. F a w az, Priv acy against statistical inference, in: 50th Ann ual Allerton Conference on Communication, Control, and Computing (Allerton), 2012, pp. 1401–1408. [16] A. Ghosh, R. Kleinberg, Inferential Priv acy Guarantees for Differentially Priv ate Mecha- nisms, in: 8th Innov ations in Theoretical Computer Science Conference (ITCS), Dagstuhl, German y , 2017, pp. 9:1–9:3. [17] Y. Amar, H. Haddadi, R. Mortier, An information-theoretic approach to time-series data priv acy , in: Pro ceedings of the 1st W orkshop on Priv acy by Design in Distributed Systems, A CM, 2018, p. 3. [18] H. W ang, Z. Xu, CTS-DP: Publishing correlated time-series data via differential priv acy , Kno wledge-Based Systems 122 (2017) 167–179. [19] T. Zh u, P . Xiong, G. Li, W. Zhou, Correlated differential priv acy: hiding information in non-iid data set, IEEE T ransactions on Information F orensics and Security 10 (2) (2015) 229–242. [20] P . K. Diederik, M. W elling, et al., Auto-encoding v ariational bay es, in: Pro ceedings of the In ternational Conference on Learning Representations (ICLR), 2014. [21] I. Goo dfellow, J. P ouget-Abadie, M. Mirza, B. Xu, D. W arde-F arley , S. Ozair, A. Courville, Y. Bengio, Generativ e adv ersarial nets, in: Adv ances in neural information pro cessing systems, 2014, pp. 2672–2680. [22] B. K. Beaulieu-Jones, Z. S. W u, C. Williams, R. Lee, S. P . Bhavnani, J. B. Byrd, C. S. Greene, Priv acy-preserving generative deep neural netw orks supp ort clinical data sharing, Circulation: Cardiov ascular Qualit y and Outcomes 12 (7) (2019) e005122. 18 [23] G. Acs, L. Melis, C. Castelluccia, E. De Cristofaro, Differentially priv ate mixture of gen- erativ e neural netw orks, IEEE T ransactions on Knowledge and Data Engineering 31 (6) (2018) 1109–1121. [24] F. Laforet, E. Buc hmann, K. B¨ ohm, Individual priv acy constraints on time-series data, Information Systems 54 (2015) 74–91. [25] C. Esteban, S. L. Hyland, G. R¨ atsch, Real-v alued (medical) time series generation with recurren t conditional gans, arXiv preprint 1706.02633, 2017. [26] M. G¨ otz, S. Nath, J. Gehrk e, MaskIt: Priv ately releasing user con text streams for p er- sonalized mobile applications, in: Pro ceedings of the 2012 ACM SIGMOD In ternational Conference on Management of Data, SIGMOD ’12, ACM, 2012, pp. 289–300. [27] N. Saleheen, S. Chakrab orty , N. Ali, M. M. Rahman, S. M. Hossain, R. Bari, E. Buder, M. Sriv asta v a, S. Kumar, msieve: differential b ehavioral priv acy in time series of mobile sensor data, in: Pro ceedings of the 2016 ACM International Joint Conference on Perv asive and Ubiquitous Computing, 2016, pp. 706–717. [28] S. A. Osia, A. T aheri, A. S. Shamsabadi, M. Katev as, H. Haddadi, H. R. Rabiee, Deep priv ate-feature extraction, IEEE T ransactions on Knowledge and Data Engineering. [29] N. Rav al, A. Machana v a jjhala, J. Pan, Olympus: Sensor priv acy through utility a ware obfuscation, Pro ceedings on Priv acy Enhancing T echnologies 1 (2019) 21. [30] A. S. Shamsabadi, H. Haddadi, A. Cav allaro, Distributed one-class learning, in: 25th IEEE In ternational Conference on Image Pro cessing (ICIP), IEEE, 2018, pp. 4123–4127. [31] M. Lu, Y. Guo, D. Meng, C. Li, Y. Zhao, An information-aw are priv acy-preserving ac- celerometer data sharing, in: International conference of pioneering computer scientists, engineers and educators, Springer, Singap ore, 2017, pp. 425–432. [32] F. Xiao, M. Lu, Y. Zhao, S. Menasria, D. Meng, S. Xie, J. Li, C. Li, An information-aw are visualization for priv acy-preserving accelerometer data sharing, Human-cen tric Computing and Information Sciences 8 (1) (2018) 13. [33] I. Psychoula, E. Merdiv an, D. Singh, L. Chen, F. Chen, S. Hanke, J. Kropf, A. Holzinger, M. Geist, A deep learning approach for priv acy preserv ation in assisted living (2018) 710– 715. [34] Y. Bengio, A. Courville, P . Vincent, Represen tation learning: A review and new p er- sp ectiv es, IEEE transactions on pattern analysis and machine intelligence 35 (8) (2013) 1798–1828. [35] M. Malekzadeh, R. G. Clegg, H. Haddadi, Replacement autoenco der: A priv acy-preserving algorithm for sensory data analysis, in: 2018 IEEE/A CM Third International Conference on Internet-of-Things Design and Implementation (IoTDI), IEEE, 2018, pp. 165–176. [36] D. Ro driguez-Martin, C. Perez-Lopez, A. Sama, A. Catala, J. Moreno Arostegui, J. Cabestany , B. Mestre, S. Alcaine, A. Prats, M. Cruz Cresp o, A. Bay es, A waist-w orn inertial measurement unit for long-term monitoring of parkinsons disease patients, Sensors 17 (4) (2017) 827. [37] D. P . Kingma, B. J. Adam, A metho d for sto c hastic optimization. arxiv e-prints, 2014, in: The 3rd International Conference for Learning Represen tations, San Diego, 2015. [38] M. Malekzadeh, R. G. Clegg, A. Cav allaro, H. Haddadi, Mobile sensor data anonymiza- tion, in: Pro ceedings of the In ternational Conference on Internet of Things Design and Implemen tation (IoTDI), A CM, 2019, pp. 49–58. [39] R. Chav arriaga, H. Sagha, A. Calatroni, S. T. Digumarti, G. T r¨ oster, J. d. R. Mill´ an, D. Roggen, The opp ortunity challenge: A b enchmark database for on-b o dy sensor-based activit y recognition, P attern Recognition Letters 34 (15) (2013) 2033–2042. [40] P . Zappi, C. Lom briser, T. Stiefmeier, E. F arella, D. Roggen, L. Benini, G. T roster, Activity recognition from on-bo dy sensors: accuracy-p ow er trade-off by dynamic sensor selection, Lecture Notes in Computer Science 4913 (2008) 17. [41] A. Bulling, U. Blank e, B. Schiele, A tutorial on h uman activity recognition using b o dy-worn inertial sensors, ACM Computing Surveys 46 (3) (2014) 33:1–33:33. [42] M. Shoaib, S. Bosch, O. Incel, H. Scholten, P . Havinga, Complex human activity recognition using smartphone and wrist-w orn motion sensors, Sensors 16 (4) (2016) 426. 19 [43] M. Malekzadeh, R. G. Clegg, A. Cav allaro, H. Haddadi, Protecting sensory data against sensitiv e inferences, in: Proceedings of the 1st W orkshop on Priv acy by Design in Dis- tributed Systems, W-P2DS’18, A CM, 2018, pp. 2:1–2:6. [44] G. Klambauer, T. Unterthiner, A. Ma yr, S. Ho chreiter, Self-normalizing neural netw orks, in: Adv ances in Neural Information Pro cessing Systems, 2017, pp. 971–980. [45] D. S. Bro omhead, G. P . King, Extracting qualitative dynamics from exp erimental data, Ph ysica D: Nonlinear Phenomena 20 (2-3) (1986) 217–236. [46] N. Sriv astav a, G. Hinton, A. Krizhevsky , I. Sutsk ever, R. Salakhutdino v, Dropout: a simple w ay to preven t neural netw orks from ov erfitting, The Journal of Machine Learning Researc h 15 (1) (2014) 1929–1958. [47] S. Salv ador, P . Chan, T o ward accurate dynamic time warping in linear time and space, In telligent Data Analysis 11 (5) (2007) 561–580. [48] M. Abadi, A. Ch u, I. Go o dfellow, H. B. McMahan, I. Mirono v, K. T alwar, L. Zhang, Deep learning with differen tial priv acy , in: Pro ceedings of the 2016 ACM SIGSAC Conference on Computer and Comm unications Security , ACM, 2016, pp. 308–318. [49] K. Bonawitz, H. Eichner, W. Griesk amp, D. Huba, A. Ingerman, V. Iv ano v, C. Kiddon, J. Konecny , S. Mazzo cchi, H. B. McMahan, T. V an Overv eldt, D. Petrou, D. Ramage, J. Roselander, T ow ards federated learning at scale: System design, in: Pro ceedings of the 2nd SysML Conference, P alo Alto, CA, USA, 2019. 20
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment